Oracle 12C优化器的巨大变化,上生产必读(上)

Oracle 12C优化器的巨大变化,上生产必读(上)
序言
优化器是Oracle数据库最吸引人的部件之一,因为它对每一个SQL语句的处理都必不可少。优化器为每个SQL语句确定最有效的执行计划,这是基于给定的查询的结构,可用的关于底层对象的统计信息,以及所有与优化器和执行相关的特性。
随着每个新版本的发布,优化器都会进化,利用新功能以及新的统计信息来生成更好的执行计划。随着对查询优化的新的自适应方法的引入,Oracle 12c数据库把这种进化更推上了一个台阶。
这份白皮书介绍了在Oracle 12c数据库中与优化器和统计相关的所有新特性并且提供了简单的,可再现的例子,使得你能够更容易地熟悉它们。它还概括了已有的功能是如何被增强以改善性能和易管理性。
优化器和统计信息新特性
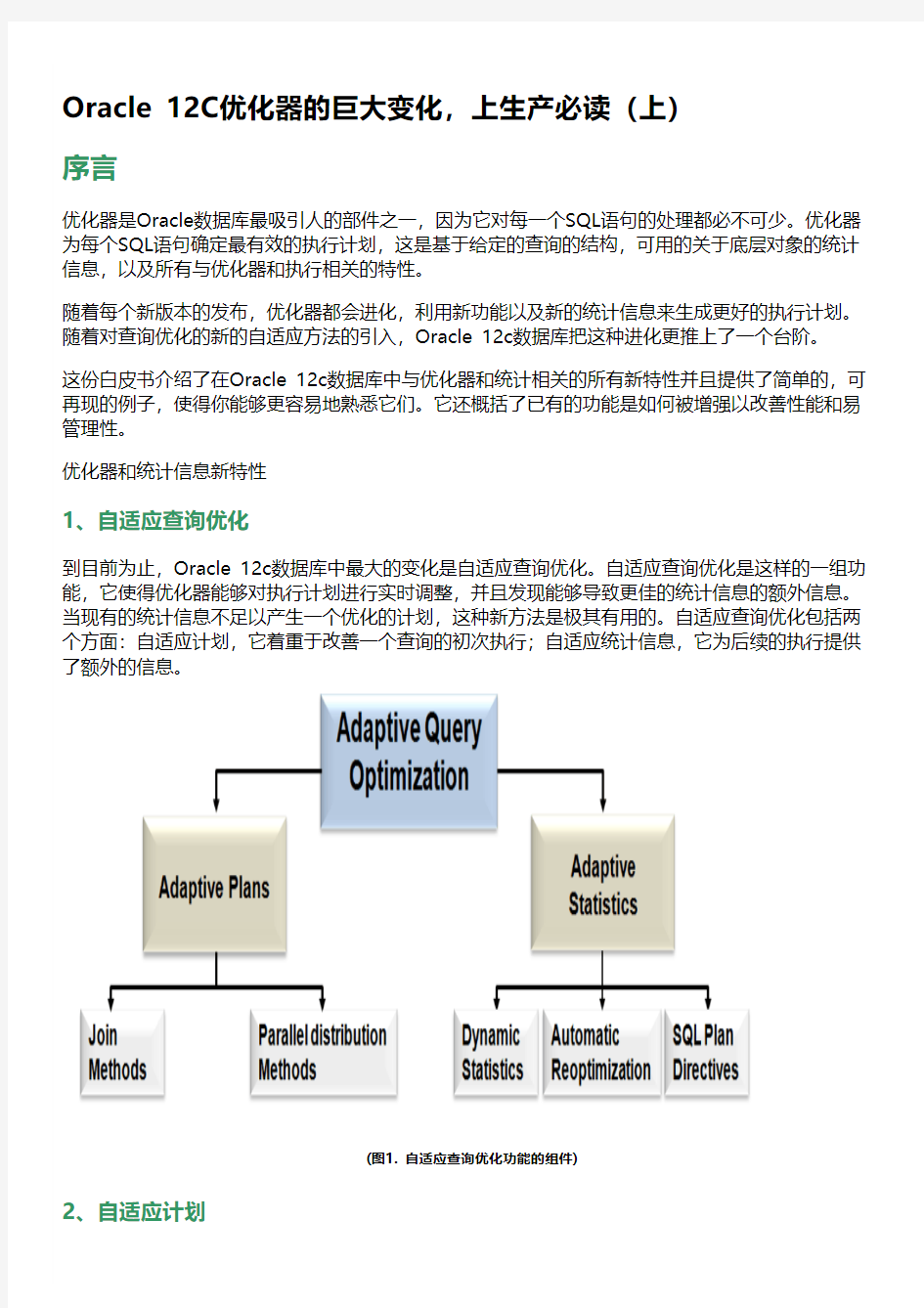
1、自适应查询优化
到目前为止,Oracle 12c数据库中最大的变化是自适应查询优化。自适应查询优化是这样的一组功能,它使得优化器能够对执行计划进行实时调整,并且发现能够导致更佳的统计信息的额外信息。当现有的统计信息不足以产生一个优化的计划,这种新方法是极其有用的。自适应查询优化包括两个方面:自适应计划,它着重于改善一个查询的初次执行;自适应统计信息,它为后续的执行提供了额外的信息。
(图1. 自适应查询优化功能的组件)
2、自适应计划
自适应计划使得优化器能够延迟产生一个语句的最终计划,直到执行的时候才决定。优化器在它所选择的计划(缺省计划)中植入统计收集器,从而在运行的时候,它能够判断自己的基数估算与计划的操作所实际看到的行数是否有很大的偏差。如果有显著的区别,那么这个计划或者计划的一部分在SQL语句的首次执行就能够被自动调整来避免不理想的性能。
3、自适应的连接方式
通过为计划中的某些分支预先确定多个子计划,优化器能够实时调整连接方式。例如,在图2中优化器的初始计划(缺省计划)为order_items 和 product_info 之间的连接选定的是嵌套循环连接,通过对product_info表的索引读取。另一个可选的子计划也同时被确定,它允许优化器将连接方式切换到哈希连接。在候选计划中product_info是通过全表扫描来读取的。
在执行的时候,统计收集器收集了关于这次执行的信息,并且将一部分进入到子计划的数据行缓存起来。在这个例子中,统计收集器监控并缓存了对order_items的全表扫描。基于它在统计收集器中看到的信息,优化器会最终确定采用哪个子计划。在这个例子中,哈希连接被选为最终计划,因为来自order_items表的行数大于优化器最初的估计。
在优化器选择了最终计划之后,统计收集器停止收集统计信息以及对数据行的缓存,而仅仅是传递数据。在子游标随后的执行中,优化器禁止了数据缓存,并且选择了同一个最终计划。目前的优化器能够从嵌套连接切换到哈希连接,反之亦然。可是,如果初始选中的连接方法是排序合并连接,则自适应不会发生。
(图2. 自适应执行计划确定Order_items 和 Prod_info 表之间的连接)
在缺省情况下,explain plan命令只会显示优化器选定的初始(缺省)计划。而
DBMS_XPLAN.DISPLAY_CURSOR只显示查询所用的最终计划。
(图3. Explain plan 和 DBMS_XPLAN.DISPLAY_CURSOR 为图2的查询例子所输出的计划)
为了看到自适应计划中所有的操作,包括统计收集器的位置,你必须在DBMS_XPLAN函数中指定额外的格式参数’+adaptive’。在这个模式下,id栏会出现一个额外的(-)记号,指明在计划中未被采用(非激活)的操作。在ORACLE企业管理器(OEM)中的SQL监控工具总是显示完整的自适应计划,但是并没有指明在计划中的哪些操作是非激活的。
(图4. 在DBMS_XPLAN.DISPLAY_CURSOR中使用’+adaptive’格式参数得到的完整自适应计划)
V$SQL中增加了一个新的列(IS_RESOLVED_ADAPTIVE_PLAN)来指明一个SQL语句是否有自适应计划,以及该计划是否已经完全被确定。如果IS_RESOLVED_ADAPTIVE_PLAN被设置为’Y’, 这意
味着计划不仅是自适应的,而且最终计划已被选定。可是,如果IS_RESOLVED_ADAPTIVE_PLAN 被设置为’N’, 这指明了选定的计划是自适应的,但是最终计划仍未被确认。’N’值仅仅在一个查询的初始执行阶段中可见,在此之后,自适应计划的这个值总是为’Y’。对于非自适应计划这个列被设置为NULL。
你也可以通过将初始化参数OPTIMIZER_ADAPTIVE_REPORTING_ONLY设置为TRUE(缺省值是FALSE),从而把自适应连接方式置于报告模式。在这个模式下,开启自适应连接方式所需的信息会被收集,但是改变计划的任何动作都不会发生。这意味着缺省计划总是会被采用,但是关于计划在“非报告”模式下会如何调整的信息将被收集。这个信息可以在自适应计划的报告中被查看,当你用额外的格式参数’+report’显示计划的时候就可以看到。
(图5. 在DBMS_XPLAN.DISPLAY_CURSOR中使用’+report’格式参数所显示的完整自适应报告)
4、自适应并行分配方法
当一个SQL语句以并行模式运行时,某些特定操作,例如排序,聚合和连接,它们要求在执行语句的并行服务进程之间重新分配数据。优化器所用的分配方法取决于操作类型,涉及到的并行服务进程数,以及预期的行数。如果优化器对行数估算不准确,那么选中的分配方法就可能不理想,结果某些并行服务进程就可能得不到充分利用。
随着新的自适应分配方法”混合型哈希”(HYBRID HASH)的引入,优化器可以将分配方法的确定延迟到执行的时候才确定,此时它对于涉及到的数据行数就有了更多的信息。一个统计收集器被插入到操作的前面,如果缓存的数据的实际行数比阈值小,则分配方法将从哈希(HASH)切换到广播(BROADCAST)。然而,如果缓冲的行数达到了阈值,则分配方法将会是哈希(HASH)。阈值的定义为并行度的两倍。
图6显示了SQL监控工具中的一个执行计划的例子,它是一个以并行模式执行的EMP和DEPT表之间的连接。一组并行服务进程(生产者,即粉红色图标)扫描两个表并且将数据送给另一组并行服务进程(消费者,即蓝色图标),该组进程是连接的真正执行者。优化器决定采用混合型哈希(HYBRID HASH)的分配方法。在这个连接中访问的第一个表是DEPT表。来自DEPT表的数据行被缓
存在统计收集器中,见计划的第六行,直至阈值被超越,或者最后一行被获取。在那时优化器将会决定采用何种分配方法。
(图6. SQL监控工具中的一个EMP和DEPT表之间的连接的执行计划,它使用了自适应分配方法)
我们假定这个例子中的并行度被设置为6, 从DEPT表扫描返回的行数是4, 阈值则是12行(2X6)。既然还未达到阈值,从DEPT表返回的4行将会被广播到负责完成连接的6个并行服务进程,结果计划中的分配步骤所处理的行数是是24行(4X6),见图7。
既然对于来自DEPT表的数据行采用了广播(BROADCAST)的分配方法,来自EMP表的数据行将会通过循环制(ROUND-ROBIN)的方法进行分配。这意味着来自EMP表的一行数据将会轮流发送给6个并行服务进程中的一个,直至所有的数据行都分配完毕。
(图7. 混合型哈希
分配法使用广播的分配方式,因为未达到阈值)
可是,如果这个例子的并行度被设置为2, 而扫描DEPT表返回的行数为4, 则阈值为4行(2X2)。既然已经达到了阈值,从DEPT表返回的4行数据将会以哈希(HASH)的方式分配到负责完成连接的2个并行服务进程, 结果计划中的分配步骤所处理的行数是是4行(见图8)。既然来自DEPT表的数据行采用了哈希(HASH)分配法,来自EMP表的数据也会以哈希(HASH)方法进行分配。
(图8. 混合型哈希
分配法使用哈希的分配方式,因为已达到阈值)
5、自适应统计信息
优化器所确定的执行计划的质量取决于可用的统计信息的质量。然而,有些查询谓词变得过于复杂,以至于无法单独依赖于基表的统计信息,而现在优化器能够用自适应统计信息来进行增补。
在一个SQL语句的编译过程中,优化器会判断已有的统计信息是否足以产生一个好的执行计划,或者它该考虑使用动态取样。动态取样是为了补偿缺失或者不充足的统计信息,如果不这么做,这样的信息可能导致非常糟糕的计划。在查询中的一个或者多个表的统计信息都缺失的情况下,优化器在优化语句之前就会在这些表上使用动态取样来收集基本的统计信息。这种情况下收集的统计信息在质量(因为是取样)和完整性上都不如使用DBMS_STATS包收集到的信息。
在Oracle 12c数据库中, 动态取样被强化为动态统计信息。动态统计信息允许优化器强化现有的统计信息以获取更加精确的基数估算,不仅仅是为单表的访问,而且也包含连接和分组(GROUP BY)谓词。初始化参数OPTIMIZER_DYNAMIC_SAMPLING引入了新的取样级别11。11级使得优化器能够自动为任何SQL语句使用动态统计信息,即使所有基本的表统计信息都已经存在。优化器做出使用动态统计的决定,是基于所用谓词的复杂性,和已经存在的基础统计信息,以及预期的SQL语句总执行时间。例如,之前的优化器在某些情况下会使用猜测的方法,比如带有LIKE谓词和模糊匹配的查询,而现在则会启用动态统计信息。
(图9. 当 OPTIMIZER_DYNAMIC_SAMPLING 被设为级别 11,动态取样会被使用,而不是猜测)
在这些新的条件下,当级别设置为11时,动态取样启用的频率很可能超过以往。这会增加语句的解析时间。为了将对性能的影响减到最低,动态取样查询的结果将会作为动态统计信息保留在缓存中,允许其他SQL语句来共享这些统计信息。SQL计划指令(下面将会更详细地讨论)也会利用这种级别的动态取样。
7、自动重优化
和自适应计划不同的是,在初次执行之后,自动重优化在随后的执行中修改计划。在一个SQL语句的初次执行结束之时,优化器利用初次执行期间收集到的信息来决定自动重优化是否值得。如果执行的信息和优化器原有的估计值有显著区别,则优化器会在下次执行寻求替换的计划。优化器会利用前一次执行收集到的信息来帮助确定这个替换计划。优化器可能将一个查询重新优化好几次,每次都学习并且进一步改善计划。Oracle 12c数据库支持多种不同形式的重优化。
统计信息反馈(以前称为基数反馈,cardinality feedback)是重优化的一种形式,它自动为那些反复执行的具有基数估算误差的查询改善计划。在一个SQL语句的首次执行期间,优化器生成了一个执行计划,并且决定是否应该为游标启动统计信息反馈监视器。统计信息反馈在如下的情形被启用:缺失统计信息的表,表上有多个合取或者析取谓词(指AND或者OR连接的谓词), 谓词包含有复杂操作,使得优化器不能准确估算基数。
在查询结束之时,优化器将它原来的基数估算和在执行期间观测到的实际基数进行比较,如果估算值和实际值有显著差异,它会将正确的值存储起来供后续使用。它还会创建一个SQL计划指令,使得其他的SQL语句也能受益于这次初始执行中学到的信息。如果查询再次执行,优化器会使用纠正过的基数估算值,而不是它原先的估算值,来确定执行计划。如果它发现初始的估算值是正确的,则不会采取任何额外的措施。在第一次执行之后,优化器关闭了统计信息反馈的监视。
图10显示了一个SQL语句受益于统计信息反馈的例子。在这个两表连接的初次执行中,由于customers表上有多个相关的单列谓词,优化器将基数低估了8倍。
(图10. 一个受益于自动重优化的统计信息反馈的SQL语句初次执行的情况)
在初次执行之后,优化器将它原来的基数估算和计划中的操作实际返回的行数进行比较。估计值和实际返回的行数有很大的差别,所以这个游标被标记为IS_REOPTIMIZIBLE(可重优化)并且不会被再次使用。IS_REOPTIMIZIBLE属性指明这个SQL语句应该在下一次执行的时候被硬解析,所以优化器能够使用在初次执行时记录下来的统计信息来确定一个更佳的执行计划。
(图11. 在初次执行的统计信息与原有的基数估算有显著差异之后,游标被标识为可重优化)
一个SQL计划指令同样被创建,这是为了确保下次如果在customers表使用了相似的谓词的SQL语句被执行,优化器会注意到这些列之间的相关性。
在第二次执行,优化器使用了来自初次执行的统计信息来确定一个具有不同连接顺序的新计划。在生成执行计划的过程中对统计信息反馈的使用情况被注明于执行计划下面的备注部分。
(图12. 新生成的计划使用来自初次执行的统计信息)
新计划没有标识为IS_REOPTIMIZIBLE,所以它将被这个SQL语句的所有后续执行所使用。
(图13. 新生成的计划标识为不可重优化)
9、性能反馈
重优化的另一种形式为性能反馈,当自动并行度(AutoDOP)在自适应模式下被启用,这会有助于改善重复执行的SQL语句的并行度的选择。(注:关于AutoDOP的更多信息请参照Oracle并行执行基础白皮书)当自动并行度(AutoDOP)在自适应模式下被启用,在一个SQL语句的首次执行过程中,优化器会决定语句是否应该在并行模式下执行;如果是,应该使用哪种并行度。并行度的选择是基于语句的预计性能表现。对于优化器决定并行执行的任何SQL语句,额外的性能监视器同样在初次执行的时候被打开。在初次执行结束时,优化器选择的并行度,和根据语句初次执行期间的实际性能统计信息(例如CPU时间)计算出来的并行度,被加以比较。如果两个值有显著差别,那么语句被标识为可重优化,初次执行的性能统计信息被作为反馈存储起来,以帮助为后续的执行计算出一个更加合适的并行度。如果性能反馈被用于一个SQL语句,它会在计划下方的备注部分被注明,如图14所示。注意:哪怕AutoDOP不在自适应模式下被启用,性能反馈也可能影响一个语句的并行度
选择。
(图14. 一个SQL语句的执行计划,性能反馈发现它串行执行会更好)
10、SQL计划指令
SQL计划指令是根据通过自动重优化学习到的信息所创建出来的。一个SQL计划指令是一些额外的信息, 优化器可用来生成一个更优的执行计划。例如,当发生连接的两个表在连接列有倾斜数据,SQL 计划指令可以指引优化器使用动态统计信息来获得更加精确的连接基数估算。SQL计划指令是在查询表达式之上创建的,而非语句级或者对象级,这样就可确保它们可被应用于多个SQL语句。在一个SQL语句上有多个SQL计划指令也是可能发生的。一个SQL语句所使用的SQL计划指令数目被显示于执行计划下方的备注部分(图15)。
(图15. 一个语句所使用的SQL计划指令数目被显示于执行计划下方的备注部分)
数据库自动维护SQL计划指令,并把它们存储在SYSAUX表空间。任何未被使用的SQL计划指令在53周之后会被自动清除。SQL计划指令也可以通过DBMS_SPD包手动管理。然而,你不可能手动创建一个SQL计划指令。SQL计划指令可以通过视图DBA_SQL_PLAN_DIRECTIVES和
DBA_SQL_PLAN_DIR_OBJECTS进行监控(见图16)。
如前所述,当图10所示的SQL语句被发现优化器的基数估算和计划中的操作所返回的实际行数有显著差异时,一个SQL计划指令就被创建。实际上,有两个SQL计划指令被自动创建。一个是为了纠正在customers表上由于多个单列谓词之间的相关性所导致的基数估算偏差,一个是为了纠正sales表上的基数估算偏差。
(图16. 查看根据
通过自动重优化学习到的信息所创建出来的SQL计划指令)
在目前仅有一种类型的SQL计划指令,即”动态取样(DYNAMIC_SAMPLING)”。这会告诉优化器,如果看到了这个特定的查询表达式(例如,在country_id, cust_city, 和 cust_state_province上一起使用的过滤谓词),它就应该使用动态取样来纠正基数估算的偏差。
SQL计划指令同样被ORACLE用来确定扩展统计信息(特别是列群组)是否缺失,是否基数估算偏差能被列群组所纠正。如果是这样的话,它会在下一次收集统计信息的时候自动在相应的表上创建那个列群组。于是如果可能的话,扩展信息就会取代SQL计划指令被使用在SQL计划中(等值谓词,group by分组等等)。如果SQL计划指令已经没必要存在,它会在53周后被自动清除。
(注:关于扩展统计信息的更多信息可见文章“理解优化器统计信息”)
举个例子,在前面的例子中,SQL计划指令16334867421200019996被创建于customers表。这个SQL计划指令被创建的原因是多个单列谓词之间的相关性。 一个CUST_CITY,
CUST_STATE_PROVINCE,和 COUNTRY_ID上的列群组就可以解决基数估算偏差。下一次收集customers表的统计信息的时候,这个列群组就会被自动创建。
(图17. 基于SQL计划指令自动创建的列群组)
下次这个SQL语句被执行的时候,列群组统计信息就会取代SQL计划指令被使用。
DBA_SQL_PLAN_DIRECTIVES中的state(状态)列指明了一个SQL计划指令在这个周期中目前处于哪个环节。
一旦单表的基数估算被解决,额外的SQL计划指令可能被创建于同样的语句来解决计划中的其他问题,例如连接和分组的基数估算偏差。
(图18. 随着时间推移,为图10中所见的SQL语句所创建的多个SQL计划指令)
11、优化器统计信息
优化器统计信息是描述数据库以及里面的对象的数据的集合。优化器利用这些统计信息来为每个SQL语句选择最佳的执行计划。对于任何一个Oracle系统,为了把性能维持在一个可接受的水平,及时收集适当的统计信息是至关重要的。随着每个新版本的发布,Oracle一直致力于自动提供必要的统计信息。
12、新型的直方图
直方图告诉优化器,数据在一个列中是如何分布的。在缺省情况下,优化器假定在一个列中,数据行是跨越不同的值均匀分布的, 在带有等值谓词查询中,基数的计算方法是将总行数除以等值谓词所用到的列中的不同值的个数。直方图的存在改变了优化器用来确定基数估算的公式,并且允许它生成更精确的估算值。在Oracle 12c之前,有两种类型的直方图:频度和等高直方图。现在多了两种额外的直方图,即顶级频度直方图和混合直方图。
13、顶级频度直方图
在过去,如果一个列有超过254个不同值而且指定的桶数为AUTO, 那么一个等高直方图就会被创建。但如果99%或者更多的数据所含有的不同值少于254个,会怎么样?如果等高直方图被创建,那么就存在这种风险,即不能将表中最频繁的值捕获为多个桶的端点值。因此有些频繁值就会被当作非频繁值处理,这会导致不理想的执行计划被选中。
在这种情况下,为了创建一个质量更加的直方图,更好的方法是在构成了表中数据的主体的那些极为频繁的值之上创建一个频度直方图,并且忽略那些非频繁值。一个频度直方图被创建于列中最频繁出现的那些值,当这些值出现在表中99%的数据或者更多。这允许列中所有频繁出现的值被当作频繁值来处理。仅当收集统计指令的ESTIMATE_PERCENT参数被设置为AUTO_SAMPLE_SIZE时,一个顶级频度直方图才会被创建,这是因为列中所有的值都必须被看到,才能确定是否达到必要的标准(99.6%的数据具有254个或者更少的不同的值)。
以PRODUCT_SALES表为例,这个表含有一个圣诞饰物公司的销售数据。表中有 1.78M 行,共有632个不同的TIME_ID。但是PRODUCT_SALES数据的主体含有少于254个不同的值,因为每年的圣诞饰物主要都在12月销售。为了让优化器知道列中的数据发生倾斜,有必要在TIME_ID列上创建一个直方图。在这个情况下,一个含有254个桶的顶级频度直方图被创建。
(图19. PRODUCT_SALES表中TIME_ID列数据的分布情况,以及之上所创建的顶级频度直方图)
14、混合直方图
在前一个版本,当一个列中不同值的个数大于254, 一个等高直方图就会被创建。在等高直方图中,只有在两个或两个以上的桶中作为端点出现的值才会被认为是频繁值。等高直方图的一个突出问题是,一个频度落在总群体的1/254和2/254之间的值可能会也可能不会作为一个频繁值出现。虽然它可能横跨两个桶,它可能只在一个桶中作为端点值出现。这样的值被认为是近似频繁值。等高直方图无法区分近似频繁值和真正非频繁值。
混合直方图类似于传统的等高直方图,因为它只在列中不同值的个数大于254的时候才会被创建。可是,相似性也仅限于此。在混合直方图中,没有任何一个值会出现在多个桶的端点,这就允许直方图包含更多的端点值,实际上也就是比等高直方图具有更多的桶数。那么,混合直方图是如何标识频繁值的?每个端点的频度被记录下来(在一个新的名为endpoint_repeat_count的列中),这样就为每个端点值提供了更精确的指示。
以CUSTOMERS表的CUST_CITY_ID列为例。CUSTOMERS表中有55,500行数据,CUST_CITY_ID列有620个不同的值。在这种情况下频度直方图和顶级频度直方图都不合适。在Oracle 11g数据库中,一个等高直方图将会被创建在这个列上。这个等高直方图有213个桶但是只代表了42个频繁值(出现在2个或更多的桶的端点的值)。CUST_CITY_ID列中实际的频繁值个数是54(即,出现频度大于总行数/桶数=55500/254的那些值有54个)。
在Oracle 12c数据库中,一个混合直方图会被创建。混合直方图有254个桶,并且代表了所有54个频繁值。实际上混合直方图将63个值当作频繁值。这意味着在Oracle 11g数据库中被当作近似频繁值(只在一个桶中作为端点值)现在被处理为频繁值,并且将会有更精确的基数估算。图20显示了一个例子,在Oracle 11g数据库中的一个近似频繁值(52114)如何在Oracle 12c数据库中得到更佳的基数估算。
在 CUST_CITY_ID=52114的数据总共有227行:
(图 20. 混合直方图使得那些Oracle 11g数据库中被当作近似频繁值的值得到更精确的基数估算)
15、统计信息在线收集
当一个索引被创建,全表扫描是必不可少的,Oracle顺便加上统计信息的收集,将自动收集优化器统计信息作为索引创建任务的一部分。现在,同样的技术也被应用于直接路径操作,例如create table as select (CTAS)和insert as select(IAS)操作。将统计信息收集搭载为数据加载操作的一部分,意味着在数据加载结束之后,不需要额外的全表扫描就可以立即拥有统计信息。
(图21. 统计信息在线收集为新创建的SALES2表同时提供了表统计和列统计信息)
统计信息在线收集并不包括收集直方图或者索引统计,因为这些类型的统计信息需要额外的扫描,这可能会对数据加载的性能造成很大的影响。为了收集必要的直方图和索引统计,而无需重新收集基础列统计信息,请使用DBMS_STATS.GATHER_TABLE_STATS过程并将options参数设置为新的GATHER AUTO选项。
(图22. 将 options 设为 GATHER AUTO 在SALES2表上创建了直方图而无需收集基础统计信息)
备注列中的“HISTOGRAM_ONLY”指明直方图在没有重新收集基础列统计的情况下被收集。GATHER AUTO选项仅在统计信息的在线收集发生之后被推荐使用。
有两种方法可以确定统计信息的在线收集是否发生:检查执行计划,看看新的数据源OPTIMIZER STATISTICS GATHERING是否在计划中出现,或者查看USER_TAB_COL_STATISTICS表的新的NOTES列,看看是否有状态值STATS_ON_LOAD。
(图23. 统计信息在线收集操作的执行计划)
根据设计,统计信息在线收集对直接路径操作的性能影响要最小化,因此它只能发生于空对象的数据加载。在向一张现有的表的新的分区中加载数据的时候,为了确保统计信息在线收集能够发生,请使用扩展的语法来显式指定分区。在这种情况下,分区级别的统计信息会被创建,但是全局(表级别)统计信息不会被修改。如果增量统计信息在分区表上被打开,一份纲要也会作为数据加载的一部分被创建。(译注: 纲要(synopsis)是在表分区级别收集的辅助统计信息,包含这个分区的某个列的不同值(NDV)的清单,根据这个信息可以推算出全表的不同值)
(图24. 在往现有分区表插入操作时发生了统计信息在线收集)
注意,在语句级别指定提示NO_GATHER_OPTIMIZER_STATISTICS可以关闭统计信息在线收集。
ASPEN PLUS 反应器模拟教程
简介 什么是Process Flowsheet Process Flowsheet(流程图)可以简单理解为设备或其一部分的蓝图.它确定了所有的给料流,单元操作,连接单元操作的流动以及产物流.其包含的操作条件和技术细节取决于Flowsheet 的细节级别.这个级别可从粗糙的草图到非常精细的复杂装置的设计细节. 对于稳态操作,任何流程图都会产生有限个代数方程。例如,只有一个反应器和适当的给料和产物,方程数量可通过手工计算或者简单的计算机应用来控制。但是,当流程图复杂程度提高,且带有很多清洗流和循环流的蒸馏塔、换热器、吸收器等加入流程图时,方程数量很容易就成千上万了。这种情况下,解这一系列代数方程就成为一个挑战。然而,叫做流程图模拟的电脑应用专门解决这种大的方程组,Aspen PlusTM,ChemCadTM,PRO/IITM。这些产品高度精炼了用户界面和网上组分数据库。他们被用于在真是世界应用中,从实验室数据到大型工厂设备。 流程模拟的优点 在设备的三个阶段都很有用:研究&发展,设计,生产。在研究&发展阶段,可用来节省实验室实验和设备试运行;设计阶段可通过与不同方案的对比加速发展;生产阶段可用来对各种假设情况做无风险分析。 流程模拟缺点 人工解决问题通常会让人对问题思考的更深,找到新颖的解决方式,对假设的评估和重新评估更深入。流程模拟的缺点就是缺乏与问题详细的交互作用。这是一把双刃剑,一方面可以隐藏问题的复杂性使你专注于手边的真正问题,另一方面隐藏的问题可能使你失去对问题的深度理解。 历史 AspenPlusTM在密西根大学 界面基础 启动AspenPlus,一个新的AspenPlus对象有三个选项,可以Open an Existing Simulation,从Template开始,或者用BlankSimulation创建你的工作表。这里选择blank simulation。
大型ORACLE数据库优化设计方案
大型ORACLE数据库优化设计方案 本文主要从大型数据库ORACLE环境四个不同级别的调整分析入手,分析ORACLE的系统结构和工作机理,从九个不同方面较全面地总结了ORACLE数据库的优化调整方案。 对于ORACLE数据库的数据存取,主要有四个不同的调整级别,第一级调整是操作系统级 包括硬件平台,第二级调整是ORACLE RDBMS级的调整,第三级是数据库设计级的调整,最后一个调整级是SQL级。通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。下面从九个不 同方面介绍ORACLE数据库优化设计方案。 一.数据库优化自由结构OFA(Optimal flexible Architecture) 数据库的逻辑配置对数据库性能有很大的影响,为此,ORACLE公司对表空间设计提出了一种优化结构OFA。使用这种结构进行设计会大大简化物理设计中的数据管理。优化自由结构OFA,简单地讲就是在数据库中可以高效自由地分布逻辑数据对象,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。数据库逻辑设计的结果应当符合下面的准则:(1)把以同样方式使用的段类型存储在一起; (2)按照标准使用来设计系统;(3)存在用于例外的分离区域;(4)最小化表空间冲突;(5)将数 据字典分离。 二、充分利用系统全局区域SGA(SYSTEM GLOBAL AREA) SGA是oracle数据库的心脏。用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。正确的SGA大小对数据库的性能至关重要。SGA 包括以下几个部分: 1、数据块缓冲区(data block buffer cache)是SGA中的一块高速缓存,占整个数据库大小 的1%-2%,用来存储从数据库重读取的数据块(表、索引、簇等),因此采用least recently used (LRU,最近最少使用)的方法进行空间管理。 2、字典缓冲区。该缓冲区内的信息包括用户账号数据、数据文件名、段名、盘区位置、表 说明和权限,它也采用LRU方式管理。 3、重做日志缓冲区。该缓冲区保存为数据库恢复过程中用于前滚操作。 4、SQL共享池。保存执行计划和运行数据库的SQL语句的语法分析树。也采用LRU算法 管理。如果设置过小,语句将被连续不断地再装入到库缓存,影响系统性能。 另外,SGA还包括大池、JAVA池、多缓冲池。但是主要是由上面4种缓冲区构成。对这
OracleSQL性能优化方法
OracleSQL性能优化方法 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访咨询Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访咨询数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访咨询 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14运算记录条数 (9) 15用Where子句替换HA VING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11) 18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及储备参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存体会,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用咨询题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建立分区一样以关键字为分区的标志,也能够以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时能够进行讲明: create table TABLENAME(
技术研究总结报告-最终版
《高频数据线缆偏心在线检测装置技术的研究》 技术研究开发总结报告 东莞岳丰电子科技有限公司 电子科技大学 2013年9月
目录 1.采用的详细技术路线,技术原理及主要技术特征 (3) 1.1 非接触式高精度偏心在线检测技术 (3) 1.2 测试原理研究 (4) 1.2.1 激励源DDS信号发生器 (5) 1.2.2 系统的硬件设计 (7) 1.2.3 系统的软件设计 (7) 1.3 生产信息数字化传输技术 (8) 1.4 信号滤波处理技术 (8) 2.项目研究的目的及意义 (10) 3.主要技术经济指标 (11) 1)项目预期实现的技术指标 (11) 4.技术创新点,技术的新颖性、先进性、实用性和成熟度,主要技术指标与国内外同类技术先进水平的比较,对社会经济发展和科技进步的作用意义 (12) 4.1生产过程的偏心在线实时检测 (12) 4.2线缆制造过程监控管理 (14) 5.成果转化和推广应用的条件及前景 (16) 6.存在的主要问题、改进意见及进一步深入研究的设想等 (17)
1.采用的详细技术路线,技术原理及主要技术特征 项目以需求为研发导向,重点突破面向制造装备的可重组的开放式数字化平台的检测、控制及设计技术,开发满足特殊工艺要求的关键技术(在线检测工艺流程示意如图1所示),使之能适应各类生产制造装备的检测与控制,进而实现数字化线缆生产线的技术升级。 上位机 张力监测速度检测 外径检测 外径检测 偏心检测图1 生产过程在线实时检测工艺流程 1.1 非接触式高精度偏心在线检测技术 目前高频数据线缆生产中除了开机初期可以靠熟练工人采用人工剥切凭经验检测外,其他时段则只有无损检测方法可行。这种方法就是对线缆成品进行切割,在线缆截面上通过千分尺测量和人的肉眼观察的方法判断线缆是否发生了偏心。这种检测方法的缺点在于无法实现线缆偏心度的在线实时检测,检测精度较低,而且属于破坏性检验,造成了材料的浪费。本项目提出了一种基于电涡流非接触式检测方法。电涡流产生的磁场与检测线圈产生的交变磁场相互作用,导致
( O管理)ORACLESL性能优化(内部培训资料)
(O管理)ORACLESL性能优化(内部培训资料)
ORACLESQL性能优化系列(一) 1.选用适合的ORACLE优化器 ORACLE的优化器共有3种: a.RULE(基于规则) b.COST(基于成本) c.CHOOSE(选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS.你当然也在SQL句级或是会话(session)级对其进行覆盖. 为了使用基于成本的优化器(CBO,Cost-BasedOptimizer),你必须经常运行analyze命令,以增加数据库中的对象统计信息(objectstatistics)的准确性. 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关.如果table已经被analyze过,优化器模式将自动成为CBO,反之,数据库将采用RULE形式的优化器. 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(fulltablescan),你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器.
2.访问Table的方式 ORACLE采用两种访问表中记录的方式: a.全表扫描 全表扫描就是顺序地访问表中每条记录.ORACLE采用一次读入多个数据块(databaseblock)的方式优化全表扫描. b.通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,,ROWID包含了表中记录的物理位置信息..ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系.通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高. 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中.这块位于系统全局区域SGA(systemglobalarea)的共享池(sharedbufferpool)中的内存可以被所有的数据库用户共享.因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路
oracle数据库优化报告
o r a c l e数据库优化报告公司内部编号:(GOOD-TMMT-MMUT-UUPTY-UUYY-DTTI-
oracle数据库 优化报告 目录 1、概述 随着应用软件用户负载的增加和愈来愈复杂的应用环境,操作系统的各项性能参数、数据库的使用效率、用户的响应速度、系统的安全运行等性能问题逐渐成为系统必须考虑的指标之一。性能测试以及优化通常通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试,用来检测系统是否达到用户提出的性能指标,及时发现系统中存在的瓶颈,最后起到优化系统的目的。
随着需求不断增加,特别是复杂逻辑的需求,一旦出现高并发量时,也将可能导致数据库主机无法承载,因此数据库优化亟待解决。 2、数据库优化部分 从2018年1月份开始跟踪及分析,发现托管区数据库在环境、设计及SQL 三方面,都存在不少问题。在SQL类优化中,本地化代码编写和设计不良,是比较明显的问题。下面将分成环境、设计、SQL优化三类进行持续分析,并给出相关建议、整改方案、整改进度。 、环境优化 被关闭 zonghe托管区数据库统计信息未自动收集,如果未打开收集,会对系统性能造成较大的影响。 需要开启统计信息 开启方法如下: --执行 BEGIN (client_name => 'auto optimizer statscollection', operation => NULL, window_name =>NULL); END;
部分索引失效 需要将索引进行删除。删除命令参考如下: drop index index_name; 、设计优化 设计类问题概述 设计类问题优化建议 1、对于表的创建开发人员需要与业务人员确认后再定义 2、经常与其他表进行连接的表,在连接字段上应该建立索引 3、索引应该建在选择性高的字段上。例如:表示性别的数据列,由于只有男女两种值,就属于选择性低
ORACLE 性能优化
ORACLE 数据库性能优化 参考书目: 《ORACLE 9i Database Performance Tuning Guide and Reference》《ORACLE 9i Database Reference》 《ORACLE 9i SQL Reference》 《ORACLE 9i Database Administrator’s Guide》
一、数据库实例创建过程参数确定 在创建数据库实例过程中,需要确定以下几个参数: 1. 数据块大小(DB_BLOCK_SIZE) 该参数指明了ORACLE所处理的数据存贮于数据文档以及SGA内存中的数据块大小。 该参数的可选择的范围为:4k,8k,16k,32k,64k。对于OLTP系统而言,取值可以为4K或8K,对于DSS系统而言,则可以取较大的数据,如32K或64K 建议统一取8K(即8192) 说明 DB_BLOCK_SIZE的大小将影响创建表时的EXTENT的大小。例如指定db_block_size=16K,某表空间的EXTENT MANAGEMENT 为local autoallocate,则其系统将extent的大小最小指定为1M.所以将可能导致空间的浪费。 2. 字符集(Character set) 该参数确定数据库以何种字符集来存贮CHAR以及V ARCHAR、V ARCHAR2等字符类型的值。对于ORACLE数据字典中的字符(如表及字段的COMMENT 内容)具有同样的作用。因此需要考虑如字符集的使用。对于国际项目,因为数据库中的comment内容(包括表及字符、存贮过程中的中文字符等内容)可能性需要以中文存贮,而用户业务数据使用的字符可能性是使用本地的语言,基于此,该参数需要选择支持UNICODE的字符编码的字符集。目前ORACLE9i支持以下二种UNICODE字符集: ?UTF8 ?AL32UTF8 建议统一取AL32UTF8
优化设计实验指导书(完整版)
优化设计实验指导书 潍坊学院机电工程学院 2008年10月 目录
实验一黄金分割法 (2) 实验二二次插值法 (5) 实验三 Powell法 (8) 实验四复合形法 (12) 实验五惩罚函数法 (19)
实验一黄金分割法 一、实验目的 1、加深对黄金分割法的基本理论和算法框图及步骤的理解。 2、培养学生独立编制、调试黄金分割法C语言程序的能力。 3、掌握常用优化方法程序的使用方法。 4、培养学生灵活运用优化设计方法解决工程实际问题的能力。 二、实验内容 1、编制调试黄金分割法C语言程序。 2、利用调试好的C语言程序进行实例计算。 3、根据实验结果写实验报告 三、实验设备及工作原理 1、设备简介 装有Windows系统及C语言系统程序的微型计算机,每人一台。 2、黄金分割法(0.618法)原理 0.618法适用于区间上任何单峰函数求极小点的问题。对函数除“单峰”外不作 其它要求,甚至可以不连续。因此此法适用面相当广。 0.618法采用了区间消去法的基本原理,在搜索区间内适当插入两点和,它们把 分为三段,通过比较和点处的函数值,就可以消去最左段或最右段,即完成一次迭代。 然后再在保留下来的区间上作同样处理,反复迭代,可将极小点所在区间无限缩小。 现在的问题是:在每次迭代中如何设置插入点的位置,才能保证简捷而迅速地找到极小点。 在0.618法中,每次迭代后留下区间内包含一个插入点,该点函数值已计算过,因此以后的每次迭代只需插入一个新点,计算出新点的函数值就可以进行比较。 设初始区间[a,b]的长为L。为了迅速缩短区间,应考虑下述两个原则:(1)等比收缩原理——使区间每一项的缩小率不变,用表示(0<λ<1)。 (2)对称原理——使两插入点x1和x2,在[a,b]中位置对称,即消去任何一边区间[a,x1]或[x2,b],都剩下等长区间。 即有 ax1=x2b 如图4-7所示,这里用ax1表示区间的长,余类同。若第一次收缩,如消去[x2,b]区间,则有:λ=(ax2)/(ab)=λL/L 若第二次收缩,插入新点x3,如消去区间[x1,x2],则有λ=(ax1)/(ax2)=(1-λ)L/λL
Oracle SQL性能优化方法研究
Oracle SQL性能优化方法探讨 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访问Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访问数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访问 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14计算记录条数 (9) 15用Where子句替换HAVING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11)
18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建
大型ORACLE数据库优化设计方案
大型ORACLE数据库优化设计方案 摘要主要从大型数据库ORACLE环境四个不同级别的调整分析入手,分析ORACLE的系统结构和工作机理,从九个不同方面较全面地总结了ORACLE数据库的优化调整方案。 关键词ORACLE数据库环境调整优化设计方案 对于ORACLE数据库的数据存取,主要有四个不同的调整级别,第一级调整是操作系统级包括硬件平台,第二级调整是ORACLERDBMS级的调整,第三级是数据库设计级的调整,最后一个调整级是SQL级。通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。下面从九个不同
方面介绍ORACLE数据库优化设计方案。 一.数据库优化自由结构OFA(OptimalflexibleArchitecture) 数据库的逻辑配置对数据库性能有很大的影响,为此,ORACLE公司对表空间设计提出了一种优化结构OFA。使用这种结构进行设计会大大简化物理设计中的数据管理。优化自由结构OFA,简单地讲就是在数据库中可以高效自由地分布逻辑数据对象,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。 二、充分利用系统全局区域SGA (SYSTEMGLOBALAREA) SGA是oracle数据库的心脏。用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。正确的SGA大小对数据库
的性能至关重要。SGA包括以下几个部分: 2、字典缓冲区。该缓冲区内的信息包括用户账号数据、数据文件名、段名、盘区位置、表说明和权限,它也采用LRU 方式管理。 3、重做日志缓冲区。该缓冲区保存为数据库恢复过程中用于前滚操作。 4、SQL共享池。保存执行计划和运行数据库的SQL语句的语法分析树。也采用LRU算法管理。如果设置过小,语句将被连续不断地再装入到库缓存,影响系统性能。 另外,SGA还包括大池、JA V A池、多缓冲池。但是主要是由上面4种缓冲区构成。对这些内存缓冲区的合理设置,可以大大加快数据查询速度,一个足够大的内存区可以把绝大多数数据存储在内存中,只有那些不怎么频繁使用的数据,才从磁盘读取,这样就可以大大提高内存区的命中率。三、规范与反规范设计数据库
ORACLE性能优化31条
1.ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO,Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze 命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE 形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,ROWID包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的内存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大大地提高了SQL 的执行性能并节省了内存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 当你向ORACLE提交一个SQL语句,ORACLE会首先在这块内存中查找相同的语句。这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等)。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 共享的语句必须满足三个条件: A、字符级的比较:当前被执行的语句和共享池中的语句必须完全相同。 B、两个语句所指的对象必须完全相同: C、两个SQL语句中必须使用相同的名字的绑定变量(bind variables)。 4.选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表driving table)将被最先处理。在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。当ORACLE处理多个表时,会运用排序及合并的方式连接它们。首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并。 如果有3个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指
机械优化设计复习总结.doc
1. 优化设计问题的求解方法:解析解法和数值近似解法。解析解法是指优化对象用数学方程(数学模型)描述,用 数学 解析方法的求解方法。解析法的局限性:数学描述复杂,不便于或不可能用解析方法求解。数值解法:优 化对象无法用数学方程描述,只能通过大量的试验数据或拟合方法构造近似函数式,求其优化解;以数学原理 为指导,通过试验逐步改进得到优化解。数值解法可用于复杂函数的优化解,也可用于没有数学解析表达式的 优化问题。但不能把所有设计参数都完全考虑并表达,只是一个近似的数学描述。数值解法的基本思路:先确 定极小点所在的搜索区间,然后根据区间消去原理不断缩小此区间,从而获得极小点的数值近似解。 2. 优化的数学模型包含的三个基本要素:设计变量、约束条件(等式约束和不等式约束)、目标函数(一般使得目 标 函数达到极小值)。 3. 机械优化设计中,两类设计方法:优化准则法和数学规划法。 优化准则法:x ;+, = c k x k (为一对角矩阵) 数学规划法:X k+x =x k a k d k {a k \d k 分别为适当步长\某一搜索方向一一数学规划法的核心) 4. 机械优化设计问题一般是非线性规划问题,实质上是多元非线性函数的极小化问题。重点知识点:等式约束优 化问 题的极值问题和不等式约束优化问题的极值条件。 5. 对于二元以上的函数,方向导数为某一方向的偏导数。 函数沿某一方向的方向导数等于函数在该点处的梯度与这一方向单位向量的内积。梯度方向是函数值变化最快的方 向(最速上升方向),建议用单位向暈表示,而梯度的模是函数变化率的最大值。 6. 多元函数的泰勒展开。 7. 极值条件是指目标函数取得极小值吋极值点应满足的条件。某点取得极值,在此点函数的一阶导数为零,极值 点的 必要条件:极值点必在驻点处取得。用函数的二阶倒数来检验驻点是否为极值点。二阶倒数大于冬,取得 极小值。二阶导数等于零时,判断开始不为零的导数阶数如果是偶次,则为极值点,奇次则为拐点。二元函数 在某点取得极值的充分条件是在该点岀的海赛矩阵正定。极值点反映函数在某点附近的局部性质。 8. 凸集、凸函数、凸规划。凸规划问题的任何局部最优解也就是全局最优点。凸集是指一个点集或一个区域内, 连接 英中任意两点的线段上的所有元素都包含在该集合内。性质:凸集乘上某实数、两凸集相加、两凸集的交 集仍是凸集。凸函数:连接凸集定义域内任意两点的线段上,函数值总小于或等于用任意两点函数值做线性内 插所得的值。数学表达:/[^+(l-a )x 2] 1 目录 第 1 章反应器设计 (1) 1.1 反应器设计概述 (1) 1.2 反应器的选型 (1) 第 2 章催化剂 (3) 2.1 催化剂的选择 (3) 2.2 催化剂失活的原因 (3) 2.3 催化剂再生的方法 (3) 第 3 章丙烷脱氢反应器 (4) 3.1 主反应及副反应方程式 (4) 3.2 反应机理 (4) 3.3 动力学方程 (4) 3.3.1 催化反应动力学模型 (4) 3.3.2 失活动力学 (5) 3.4 反应器设计思路说明 (6) 3.4.1 反应条件 (6) 3.4.2 反应器类型的选择 (7) 3.4.3 反应器数学模拟 (7) 3.4.4 反应器体积的计算 (7) 3.5 催化剂设计 (11) 3.5.1 催化剂用量 (11) 3.5.2 催化剂来源 (11) 3.5.3 催化剂的装填 (11) 3.6 反应器内部结构设计 (11) 3.6.1 催化剂床层开孔 (11) 3.6.2 催化剂分布器 (12) 3.6.3 气体分布器 (12) 2 3.7 反应器管口计算 (12) 3.7.1 进料管(以第一台反应器为例) (12) 3.7.2 出料管 (13) 3.7.3 吹扫空气入口 (13) 3.7.4 催化剂进料口 (13) 3.7.5 催化剂出口 (13) 3.7.6 排净口 (13) 3.7.7 人孔 (14) 3.7.8 催化剂床层固定钢 (14) 3.8 加热炉 (14) 3.9 机械强度的计算和校核 (14) 3.9.1 反应器材料的选择 (14) 3.9.2 反应器筒体厚度的选择 (14) 3.9.3 反应器封头厚度的计算 (15) 3.9.4 液压试验校核 (16) 3.9.5 反应器强度校核 (16) 3.9.6 反应器封头的选择 (25) 3.10 设计结果总结(以第一台反应器为例) (26) 第 4 章乙炔选择性加氢反应器 (26) 4.1 概述 (26) 4.2 反应方程式 (27) 4.3 催化剂的选用 (27) 4.4 设计简述 (27) 4.5 在Polymath中的模拟与优化 (29) 4.6 选择性加氢反应器总结 (30) 第 5 章参考文献 (30) 3 ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO, Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率, ROWID 包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同, ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大提高了SQL的执行性能并节省了存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。 公路线形优化设计总结 公路线形是车辆运行的直接载体,一旦确定,无论优劣,都很难改变,高速公路尤其如此。这就要求公路设计者应特别重视线形设计质量,任何一个不安全的指标、一个不良的组合设计都可能形成交通安全隐患,设计者必须认识到所绘制的每条线不仅是几何线,还是经济线、能源线、环境线,更是生命线。 以往,我们已经认识到长直线接小半径等不利线形组合是车辆运行安全的隐患,但受设计车速体系制约,该问题一直无法定量化。运行车速理论提供了解释和解决该类问题的方法。有关研究显示,大量的公路交通事故是由相邻路段较大的运行车速差导致,当相邻路段运行车速差超过某一限值时,路段存在运行安全隐患,而运行车速理论的核心就是通过改善相邻路段指标组合,降低容许运行车速差,从而消除安全隐患。 运行速度作为公路安全设计的主要指标,将指导我国公路设计工作更加关注“以人为本,注重安全”等新理念,以期在设计阶段就消除隐含的一些安全隐患,体现动态设计、考虑驾驶行为。所以根据基本的平、纵、横设计数据,进行运行速度测算分析;以分析结果指导路线设计与优化,将逐渐成为我国公路设计工作(流程)中不可或缺的重要一环。 01 运行速度的定义及路段划分 运行车速是在单元路段上车辆的实际行驶速度。因不同车辆在行驶过程中可能采用不同车速,通常按统计学中测定的从高速到低速排列第85个百分点对应的车辆行驶速度作为运行车速。有别于设计车速的人为规定,运行车速是一个统计学指标,是单元路段车辆实际行驶速度。因此,运行速度的定义:是指在特定路段(无横向干扰等)上,在干净、潮湿条件下,在自由流的情况下,85%的驾驶员行车不会超过的行驶速度,简称V85。 运行车速计算之前,首先要对路线进行单元路段划分,通过《公路项目安全性评价指南》中的预测模型公式计算出单元路段 ),然后根据各单元路段特征点的运行速特征点的运行速度(v 85 )进行评价,最后按评价结果指导路线线形最优设度之差(△v 85 计。 路线单元路段通常划分为直线段、纵坡段、小半径组合段、弯坡组合段、短直线段等路段类型。 直线段是指路线纵坡小于3%的直线段或曲线半径大于1000m 且纵坡小于3%的曲线段。 小半径组合段是指曲线半径小于等于1000m且纵坡小于3%的曲线段。 纵坡段是指路线纵坡大于等于3%的直线段或曲线半径大于1000m且纵坡大于等于3%的曲线段。 弯坡组合段是指路线曲线半径小于等于1000m且纵坡大于等于3%的曲线段。 Oracle SQL的优化 标签:oraclesql优化date数据库subquery 2009-10-14 21:18 18149人阅读评论(21) 收藏举报分类: Oracle Basic Knowledge(208) SQL的优化应该从5个方面进行调整: 1.去掉不必要的大型表的全表扫描 2.缓存小型表的全表扫描 3.检验优化索引的使用 4.检验优化的连接技术 5.尽可能减少执行计划的Cost SQL语句: 是对数据库(数据)进行操作的惟一途径; 消耗了70%~90%的数据库资源;独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低; 可以有不同的写法;易学,难精通。 SQL优化: 固定的SQL书写习惯,相同的查询尽量保持相同,存储过程的效率较高。 应该编写与其格式一致的语句,包括字母的大小写、标点符号、换行的位置等都要一致 ORACLE优化器: 在任何可能的时候都会对表达式进行评估,并且把特定的语法结构转换成等价的结构,这么做的原因是 要么结果表达式能够比源表达式具有更快的速度 要么源表达式只是结果表达式的一个等价语义结构 不同的SQL结构有时具有同样的操作(例如: = ANY (subquery) and IN (subquery)),ORACLE会把他们映射到一个单一的语义结构。 1 常量优化: 常量的计算是在语句被优化时一次性完成,而不是在每次执行时。下面是检索月薪大于2000的的表达式: sal > 24000/12 sal > 2000 sal*12 > 24000 如果SQL语句包括第一种情况,优化器会简单地把它转变成第二种。 优化器不会简化跨越比较符的表达式,例如第三条语句,鉴于此,应尽量写用常量跟字段比较检索的表达式,而不要将字段置于表达式当中。否则没有办法优化,比如如果sal上有索引,第一和第二就可以使用,第三就难以使用。 2 操作符优化: 优化器把使用LIKE操作符和一个没有通配符的表达式组成的检索表达式转换为一个“=”操作符表达式。 例如:优化器会把表达式ename LIKE 'SMITH'转换为ename = 'SMITH' 优化器只能转换涉及到可变长数据类型的表达式,前一个例子中,如果ENAME 字段的类型是CHAR(10),那么优化器将不做任何转换。 一般来讲LIKE比较难以优化。 其中: ~~IN 操作符优化: 优化器把使用IN比较符的检索表达式替换为等价的使用“=”和“OR”操作符的检索表达式。 例如,优化器会把表达式ename IN ('SMITH','KING','JONES')替换为 ename = 'SMITH' OR ename = 'KING' OR ename = 'JONES‘ oracle 会将in 后面的东西生成一存中的临时表。然后进行查询。 如何编写高效的SQL: 当然要考虑sql常量的优化和操作符的优化啦,另外,还需要: 1 合理的索引设计: 例:表record有620000行,试看在不同的索引下,下面几个SQL的运行情况:语句A SELECT count(*) FROM record WHERE date >'19991201' and date <'19991214‘and amount >2000 语句B y物理模型CheckList (Oracle,性能) 1. 系统级优化 数据库参数配置 合理分配SGA及其内部参数(经验值如下): SGA=phy*(60%-80%) Share pool=SAG*45% DB Cache=SGA*45% Log Buffer: 1~3M 注:Oracle9i在Windows下有bug,是由Windows下的SGA最大 值有2G的限制造成的 注意调整process和open cursor参数,这两个参数直接影响 数据库的session量 分离表和索引:将表和索引建立在不同的表空间,决不要将 不属于Oracle内部系统的对象存放到SYSTEM表空间。同 时,确保数据表空间和索引表空间置于不同的硬盘,减少I/O 竞争; 如果是企业版数据库,大表可以考虑采取分区存储措施,提 高系统的性能; 优化Export和Import工作:使用较大的BUFFER(比如10MB , 10,240,000)可以提高EXPORT和IMPORT的速度 定期分析查询计划,提高数据库的性能; 2. 索引相关 要对经常查询的字段建立索引,但是由于索引管理的开销, 在增删改操作频繁的情况下避免建立不必要的索引; 对于只读或者接近只读的场合,如数据仓库,对于势值比较 小的列可以考虑使用bitmap索引; 如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 3. SQL相关 Oracle的From子句表的顺序:记录越多的表放在越前面 (左); Oracle的where子句表达式的顺序:过滤掉最大数目记录的条 件放到where子句的末尾; Select子句中避免使用‘*’,增加了查询表的列的开销; 在执行结果等效的情况下,使用Truncate代替Delete; 为了在查询过程中要尽量使用索引,对于like语句避免使用 右匹配或者中间匹配的模糊查询; 将过滤条件尽可能放到Where子句中,而不是放到Having子 句中; 在SQL语句中,要减少对表的查询,特别是在含有子查询的 SQL子句中; 使用表的别名可以减少解析的时间并避免引起歧义; 使用exists替代in; 用NOT EXISTS替代NOT IN; 通常情况下,采用表连接的方式比exists更有效率; 当提交一个包含一对多表信息(比如部门表和雇员表)的查询 目前购物中心停车位主要分为机械式立体车库、屋顶停车场、停车楼、地下停车场、地面停车场。其中,购物中心采取地下停车场方式较多。本文就以地下停车场为例,具体分析购物中心停车场该如何优化。 1停车位 停车位的大小需根据车型的不同尺寸,最大限度的利用有效的面积设计最多的停车位。 据调查,不同车型的外廓尺寸如下: 经济型、中档车的宽度约为1750~1800mm,长度约4500-4800mm; 中高档车宽度超过1800mm,长度超过5000mm; 小型车的外廊尺寸为4800*1800mm。 一般小型车垂直车位的尺寸为5300m*2400m。 三种停车方式所占面积平均值: 1、垂直式停车:长24m,宽5.3m的空地,可以停放10辆小型机动车,平均占地12.7㎡/辆。 垂直停车可以从两个方向进、出车,停放较方便,在几个停车方式中所占面积最小,但转弯半径要求较大,行车通道较宽。 2、斜列式停车:长24m,宽5.3m的空地,可以停放7辆小型机动车,平均占地20.2㎡/辆。 3、平行式停车:长24m,宽2.5m的空地,可以停放4辆小型机动车,平均占地15㎡/辆。 平行停车方式车辆进、出车位更方便、安全,但每辆车因进出需要而占用的面积较大。 综上所述,垂直停车所占车位面积最小。 2柱网 根据规范,停3辆车的柱间净宽应为7200mm,若采用600×600的柱子,停3辆车的柱网轴线间宽度至少为7800mm,若一边有墙则为8100mm。 对柱网进行优化改进,可以优化地下停车库,增加停车位数量。 ①调整柱网尺度,增加停车位数量。 以双行道6米,单行道3米标准,结合不同柱网尺寸,本项目采用11*8.4M的柱距较为经济,可增加29个车位。(完整)反应器初步设计说明书
Oracle性能优化
公路线形优化设计总结
Oracle SQL地优化
Oracle性能优化
商业区停车位优化设计数据总结