应用图像与计算

第二十讲应用图像与计算
图层混合模式是同一文件的相邻两个图层的混合,混合时两个图层的每个通道都参与其中,混合产生的结果使得合并图层发生变化。
Photoshop的应用图像可以实现来自同一文件或不同文件的图像与图像、图像与图层、图像与通道、图层与图层、图层与通道、通道与通道的混合,混合产生的结果直接改变当前图片。
如果我们把图像(刚打的开的只有背景的图像、合并的图层)、单个图层、通道(单个通道或复合通道)通称为图片,则可简述为:Photoshopd的应用图像操作可以实现来自同一文件或不同文件的两个图片的混合。显然,应用图像比图层混合应用范围更广。
Photoshop的计算操作只涉及来自同一文件或不同文件的通道间的混合,混合的结果并不改变参与混合的通道,而是生成蒙板或选区。
教程出自:CC视觉(https://www.360docs.net/doc/4218537449.html,)教程作者:疾舟
一、应用图像
1、打开方法:
以某一图片(注意图片的含义!)为当前图片,执行菜单:图像—应用图像,就会弹出一个应用图像对话框,弄清这个对话框就基本上掌握了应用图像的操作。
2、应用图像对话框解释
我们用实例来说明应用图像对话框的使用。
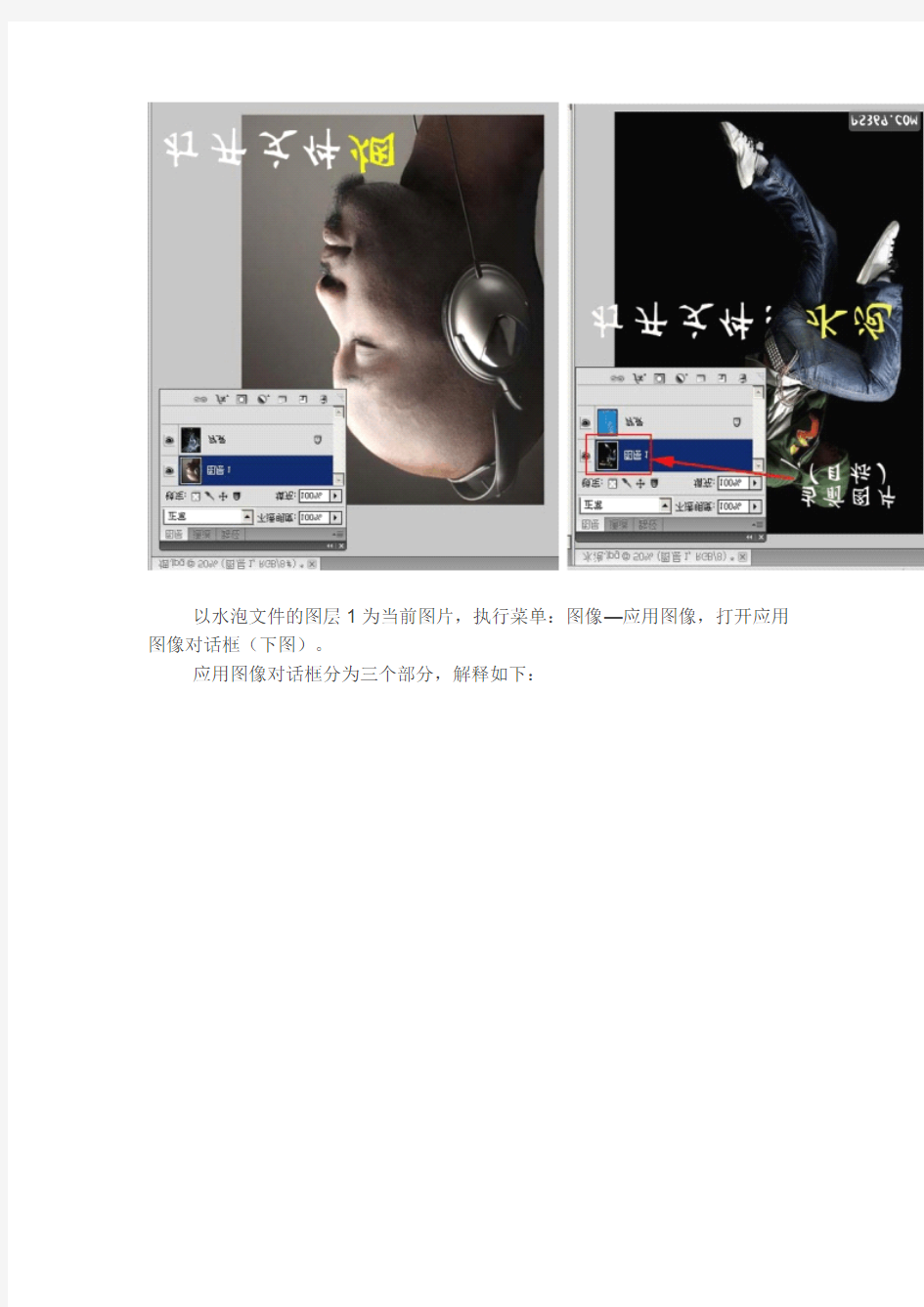
先打开了两个文件——烟和水泡,每个文件都有两个图层——背景和图层1。
以水泡文件的图层1为当前图片,执行菜单:图像—应用图像,打开应用图像对话框(下图)。
应用图像对话框分为三个部分,解释如下:
第1部分源
这部分给出了源文件名、源图层和源通道的选项栏,可以选择一个源图片作为基色来与当前图片混合。现在,我们选择了烟文件的背景图层的红通道作为源。
勾选通道选项栏旁的反相后,源通道经反相再与当前图片混合。
第2部分目标
目标就是我们打开应用图像时的当前图片,它作为混合色参加混合。一旦打开应用图像对话框,目标就不能更改。当源图片选定并点击确定后,作为目标的当前图片就被更改为结果色。
目标和源来自两个不同的文件时,两个文件的尺寸和分辨率必须完全相同。因此,烟和水泡文件的大小和分辨率必须是相同的。
第3部分混合模式、混合强度和混合范围
混合选项栏用于选择混合模式。应用图像的混合模式与图层混合方式基本相同,但增加了相加和减去模式。相加模式可将目标和源的像素相加,相加常用
于组合非重叠图片。减去模式是从目标中减去源的像素值。混合选项的下拉菜单如下:
上图表明,该例的混合模式选择了线性减淡。
混合模式选项栏下面的三个选项关系到混合强度和范围:
不透明度:这个值越小,混合的强度越弱。0%其实就是没有混合。
保留透明区域:图片中的透明区域不参与混合。
蒙版:勾选蒙版,会出现一个下拉菜单,在这个菜单里,你可以选择一个有蒙板的图片,其蒙板作为混合的蒙版;如果选择某个通道,该通道就作为蒙板。如果勾选反相,则所选蒙板反相以后再作为混合的蒙版。
混合加入蒙板后,由于蒙板黑色区域的遮挡,白色区域的显现,使得混合的范围得到控制,而蒙板的灰色区域又使混合强度受控。
下图示出了对实例的混合强度的选择:不透明度降为20%,并将烟文件背景图层的“灰”通道反相后作为混合的蒙版。
二、计算
计算是基于通道混合的操作。理解了应用图像后,理解计算就不难了。
1、打开方法:
我们仍用实例来说明。打开一个名为放飞的文件,这个文件的背景图层是个MM图片,而图层1是地球图案。
执行菜单:图像—计算,就会弹出一个计算对话框,弄清这个对话框,你就基本上掌握了计算的操作。至于用哪个通道作为当前通道来打开计算对话框,无关紧要,因为在对话框里要混合的两个源通道都是可以选择的。
2、计算对话框的解释:
1、源1:这个选择栏用于选择作为基色的源通道。
2、源2:这个选择栏用于选择作为混合色的源通道。
其中,源、图层、通道的含义与应用图像相同。两个源通道也可以来自不同的文件,前提是这些文件的尺寸和分辨率相同。另外,通道选择栏里没有复合通道(如RGB通道),这是因为复合通道其实就是图层,而计算只针对通道的混合。
3、混合模式:含义与应用图像相同。
4、不透明度:用于调整混合强度,含义与应用图像相同。
5、蒙板:勾选蒙板的含义与应用图像里的勾选蒙板相同。混合加入蒙板后,混合的范围和强度将受控于蒙板灰度的变化。
对于该例,我们选择了放飞文件的背景图层中的红通道为源1,选择放飞文件的背景图层中的蓝通道为源2,源1和源2用正片叠底模式合成,混合强度为80%(不透明度)。混合时,将放飞文件的图层1的红通道作为蒙板。
6、结果:从这个选择栏的菜单可知,源1和源2混合的结果(混合色)并不改变源通道,而是用于下面三种选择之一:
新建通道:混合的结果被存储在Alpha通道里。
选区:混合的结果生成选区(选择白色)。
新建文档:混合的结果生成一个黑白图像文件。
对于该例,下面三图示出了计算结果三种选择的效果:
通过对应用图像和计算对话框的认识,我们可以对它们的功能分别用一句话总结:
应用图像操作就是将两个图片按某种模式混合,混合的结果直接改变目标图片;
计算操作就是将两个通道按某种模式混合,混合的结果将生成选区或蒙板备用。
上面只是介绍了应用图像和计算的操作方法。要想有的放矢地自如应用这两种工具,还必须熟悉各个混合模式的原理及产生的效果。这就需要更多的学习和实践。
熟练使用应用图像和计算是PS应用的中高级阶段。它们在图像合成、调色、祛斑美容等PS领域有广泛的应用。当然,也可以用于抠图(见实例)。
实例:将云雾黄山变为彩霞黄山
素材:
效果:
步骤:
1、打开彩霞和黄山图片(同时显示),用移动工具将黄山拖入彩霞界面,生成图层1。
2、执行菜单:图像—计算,在弹出的计算对话框里,选择源1和源2均为图层1的蓝通道,混合模式为线性加深,结果选项选择新建通道。点击确定,生成Alpha1通道。
这一步的目的:产生黄山和天空的黑白蒙版备用。
3、以图层1为当前图层,执行菜单:图像—应用图像,应用图像对话框的选择如下图所示。
这一步的目的:在Alpha1通道作为蒙版的控制下,黄山图层(图层1)与彩霞图层(背景)作正片叠底混合,使黄山原来的云雾天空初步更换为彩霞天空。
4、仍以图层1为当前图层执行菜单:图像—应用图像,应用图像对话框的选择如下图所示。
这一步的目的:在Alpha1通道蒙版的控制下,已经初步更换为彩霞天空的黄山图层(图层1)与彩霞图层(背景)再次混合,这次,用强光模式修正图层1的彩霞天空,使之明亮。
5、a、以图层1为当前图层,点击图层调板下方的创建新的调整图层图标,在弹出的下拉菜单里选择色阶,建立色阶调整图层。
b、切换到通道面板,只让Alpha1通道显现。按Ctrl+I将其反相,按Ctrl+A 全选反相后的Alpha1通道,再按Ctrl+C将其拷贝到电脑剪贴板。
c、返回图层调板,按住Alt键点击色阶蒙版缩略图,使之成为大图(白色),再按Ctrl+V键,将反相后的Alpha1通道粘贴到色阶蒙版上。
这一步的目的:生成一个只让黄山显现的蒙版,为调整黄山作准备。
6、点击色阶调整图层左侧的图标,调出色阶调整面板,调整输入色阶,使得右侧的山体变暗。左侧山体已经很暗,可用黑色蒙版遮挡,避免调整。
超分辨率图像重建方法综述_苏衡
第39卷第8期自动化学报Vol.39,No.8 2013年8月ACTA AUTOMATICA SINICA August,2013 超分辨率图像重建方法综述 苏衡1,2周杰1张志浩1 摘要由于广泛的实用价值与理论价值,超分辨率图像重建(Super-resolution image reconstruction,SRIR或SR)技术成为计算机视觉与图像处理领域的一个研究热点,引起了研究者的广泛关注.本文将超分辨率图像重建问题按照不同的输入输出情况进行系统分类,将超分辨率问题分为基于重建的超分辨率、视频超分辨率、单帧图像超分辨率三大类.对于其中每一大类问题,分别全面综述了该问题的发展历史、常用算法的分类及当前的最新研究成果等各种相关问题,并对不同算法的特点进行了比较分析.本文随后讨论了各不同类别超分辨率算法的互相融合和图像视频质量评价的方法,最后给出了对这一领域未来发展的思考与展望. 关键词超分辨率图像重建,计算机视觉,图像处理,方法综述 引用格式苏衡,周杰,张志浩.超分辨率图像重建方法综述.自动化学报,2013,39(8):1202?1213 DOI10.3724/SP.J.1004.2013.01202 Survey of Super-resolution Image Reconstruction Methods SU Heng1,2ZHOU Jie1ZHANG Zhi-Hao1 Abstract Because of its extensive practical and theoretical values,the super-resolution image reconstruction(SRIR or SR)technique has become a hot topic in the areas of computer vision and image processing,attracting many researchers attentions.This paper categorizes the SR problems according to their input and output conditions into three main cat-egories:reconstruction-based SR,video SR and single image SR.For each category,the development history,common algorithm classes and state-of-the-art research achievements are reviewed comprehensively.We also analyze the charac-teristics of di?erent algorithms.Afterwards,we discuss the combination of di?erent super-resolution categories and the evaluation of image and video qualities.Thoughts and foresights of this?eld are given at the end of this paper. Key words Super-resolution image reconstruction,computer vision,image processing,survey Citation Su Heng,Zhou Jie,Zhang Zhi-Hao.Survey of super-resolution image reconstruction methods.Acta Auto-matica Sinica,2013,39(8):1202?1213 超分辨率图像重建(Super resolution image re-construction,SRIR或SR)是指用信号处理和图像处理的方法,通过软件算法的方式将已有的低分辨率(Low-resolution,LR)图像转换成高分辨率(High-resolution,HR)图像的技术.它在视频监控(Video surveillance)、图像打印(Image printing)、刑侦分析(Criminal investigation analysis)、医学图像处理(Medical image processing)、卫星成像(Satellite imaging)等领域有较广泛的应用. 收稿日期2011-08-31录用日期2013-01-29 Manuscript received August31,2011;accepted January29, 2013 国家自然科学基金重大国际(地区)合作研究项目(61020106004),国家自然科学基金(61005023,61021063),国家杰出青年科学基金项目(61225008),教育部博士点基金(20120002110033)资助 Supported by Key International(Regional)Joint Research Pro-gram of National Natural Science Foundation of China(6102010 6004),National Natural Science Foundation of China(61005023, 61021063),National Science Fund for Distinguished Young Scholars(61225008),and Ph.D.Programs Foundation of Min-istry of Education of China(20120002110033) 1.清华大学自动化系北京100084 2.北京葫芦软件技术开发有限公司北京100084 1.Department of Automation,Tsinghua University,Beijing 100084 2.Beijing Hulu Inc.,Beijing100084 超分辨率问题的解决涉及到许多图像处理(Im-age processing)、计算机视觉(Computer vision)、优化理论(Optimization problem)等领域中的基本问题[1],例如图像配准(Image registration)、图像分割(Image segmentation)、图像压缩(Image com-pression)、图像特征提取(Image feature extrac-tion)、图像质量评价(Image quality estimation)、机器学习(Machine learning)、最优化算法(Opti-mization algorithm)等,超分辨率是这些基本问题的一个具体应用领域,同时也对它们的研究进展起到了推动的作用.因此超分辨率问题本身的研究具有重要的理论意义.目前超分辨率问题已经成为相关研究领域的热点之一. 在上世纪80~90年代,就有人开始研究超分辨率图像重建的方法,1984年Tsai的论文[2]是最早提出这个问题的文献之一.在这之后有很多相关的研究对超分辨率的问题进行更加深入的讨论.有关超分辨率问题的研究成果,在计算机视觉、图像处理与信号处理领域的顶级会议和期刊都有大量收录. 1998年,Borman等[3]发表了一篇超分辨率图像重建的综述文章.2001年,Kluwer出版了一本详细介
被严重误导的“情感计算”
被严重误导的“情感计算” 一、前言 目前,人工智能呈现高速增长和全面扩张的态势,一方面人工智能不断朝更深层的智能方向发展:数学运算、逻辑推理、专家系统、模式识别、深度学习等;另一方面不断向社会的各个领域进行扩展:智能电视、智能手机、智能家居、智能交通、智能购物、智能城市、智能养老等。人工智能的下一个技术突破口必然是人工情感,只有实现了真正意义的人工情感,人工智能才会有更加广阔的发展空间,才会对社会生产力形成更加强大的推动力。 然而,当今的计算机从原理上讲主要是基于逻辑推理式系统,根本不存在任何情感能力,人工智能也只是逻辑推理能力的体现。让计算机和机器人具有人类式的情感,是许多科学家的梦想。与人工智能技术的高度发展相比,人工情感技术所取得的进展却是微乎其微,“情感”始终是横跨在人脑与电脑之间无法愈越的鸿沟。 “情感计算”的概念是在1997年由MIT媒体实验室Picard教授提出,从而在世界范围内拉开了人工智能走向人工情感的序幕,激发出人们对于人工情感研究的强大兴趣。然而,这一理论存在着严重的缺陷,并把人们引向一个重大误区,致使“情感计算”研究在一阵短暂的繁荣之后,紧接着出现了长达十多年的沉寂。 二、情感计算简介 对人的情感和认知的研究是人工智能的高级阶段,它的研究将会大大促进拟人控制理论、情感机器人、人性化的商品设计和市场开发等方面的进展,为最终营造一个人与人、人与机器和谐的社会环境做出贡献。
1.美国的情感计算 美国MIT媒体实验室Picard教授提出“情感计算”一词并给出了定义,即情感计算是关于情感、情感产生以及影响情感方面的计算。最近,美国加州Abyss Creations公司近日宣布,第一代性爱女机器人Harmony 已经成功研发出来,它具有学习能力,并且能与人类进行情感交流。 2.欧盟的情绪机器 欧盟国家也在积极地对情感信息处理技术(表情识别、情感信息测量、可穿戴计算等)进行研究。欧洲许多大学成立了情感与智能关系的研究小组。其中比较著名的有:日内瓦大学Klaus Soberer领导的情绪研究实验室。布鲁塞尔自由大学的D. Canamero领导的情绪机器人研究小组以及英国伯明翰大学的A. Sloman领导的Cognition and Affect Project。在市场应用方面,德国Mehrdad Jaladi-Soli等人在2001年提出了基于EMBASSI系统的多模型购物助手。EMBASSI是由德国教育及研究部(BMBF)资助并由20多个大学和公司共同参与的,以考虑消费者心理和环境需求为研究目标的网络型电子商务系统。英国科学家已研发出名为“灵犀机器人”(Heart Robot)的新型机器人,这是一种弹性塑胶玩偶,其左侧可以看到一个红色的“心”,而它的心脏跳动频率可以变化,通过程式设计的方式,让机器人可对声音、碰触与附近的移动产生反应。
并行计算综述
并行计算综述 姓名:尹航学号:S131020012 专业:计算机科学与技术摘要:本文对并行计算的基本概念和基本理论进行了分析和研究。主要内容有:并行计算提出的背景,目前国内外的研究现状,并行计算概念和并行计算机类型,并行计算的性能评价,并行计算模型,并行编程环境与并行编程语言。 关键词:并行计算;性能评价;并行计算模型;并行编程 1. 前言 网络并行计算是近几年国际上并行计算新出现的一个重要研究方向,也是热门课题。网络并行计算就是利用互联网上的计算机资源实现其它问题的计算,这种并行计算环境的显著优点是投资少、见效快、灵活性强等。由于科学计算的要求,越来越多的用户希望能具有并行计算的环境,但除了少数计算机大户(石油、天气预报等)外,很多用户由于工业资金的不足而不能使用并行计算机。一旦实现并行计算,就可以通过网络实现超级计算。这样,就不必要购买昂贵的并行计算机。 目前,国内一般的应用单位都具有局域网或广域网的结点,基本上具备网络计算的硬件环境。其次,网络并行计算的系统软件PVM是当前国际上公认的一种消息传递标准软件系统。有了该软件系统,可以在不具备并行机的情况下进行并行计算。该软件是美国国家基金资助的开放软件,没有版权问题。可以从国际互联网上获得其源代码及其相应的辅助工具程序。这无疑给人们对计算大问题带来了良好的机遇。这种计算环境特别适合我国国情。 近几年国内一些高校和科研院所投入了一些力量来进行并行计算软件的应用理论和方法的研究,并取得了可喜的成绩。到目前为止,网络并行计算已经在勘探地球物理、机械制造、计算数学、石油资源、数字模拟等许多应用领域开展研究。这将在计算机的应用的各应用领域科学开创一个崭新的环境。 2. 并行计算简介[1] 2.1并行计算与科学计算 并行计算(Parallel Computing),简单地讲,就是在并行计算机上所作的计算,它和常说的高性能计算(High Performance Computing)、超级计算(Super Computing)是同义词,因为任何高性能计算和超级计算都离不开并行技术。
并行计算-练习题
2014年《并行计算系统》复习题 (15分)给出五种并行计算机体系结构的名称,并分别画出其典型结构。 ①并行向量处理机(PVP) ②对称多机系统(SMP) ③大规模并行处理机(MPP) ④分布式共享存储器多机系统(DSM) ⑤工作站机群(COW) (10分)给出五种典型的访存模型,并分别简要描述其特点。 ①均匀访存模型(UMA): 物理存储器被所有处理机均匀共享 所有处理机访存时间相同 适于通用的或分时的应用程序类型 ②非均匀访存模型(NUMA): 是所有处理机的本地存储器的集合 访问本地LM的访存时间较短 访问远程LM的访存时间较长 ③Cache一致性非均匀访存模型(CC-NUMA): DSM结构 ④全局Cache访存模型(COMA): 是NUMA的一种特例,是采用各处理机的Cache组成的全局地址空间 远程Cache的访问是由Cache目录支持的 ⑤非远程访存模型(NORMA): 在分布式存储器多机系统中,如果所有存储器都是专用的,而且只能被本地存储机访问,则这种访问模型称为NORAM 绝大多数的NUMA支持NORAM 在DSM中,NORAM的特性被隐匿的 3. (15分)对于如下的静态互连网络,给出其网络直径、节点的度数、对剖宽度,说明该网络是否是一个对称网络。 网络直径:8 节点的度数:2 对剖宽度:2 该网络是一个对称网络 4. (15分)设一个计算任务,在一个处理机上执行需10个小时完成,其中可并行化的部分为9个小时,不可并行化的部分为1个小时。问: (1)该程序的串行比例因子是多少,并行比例因子是多少? 串行比例因子:1/10
并行比例因子:9/10 如果有10个处理机并行执行该程序,可达到的加速比是多少? 10/(9/10 + 1) = 5.263 (3)如果有20个处理机并行执行该程序,可达到的加速比是多少? 10/(9/20 + 1)= 6.897 (15分)什么是并行计算系统的可扩放性?可放性包括哪些方面?可扩放性研究的目的是什么? 一个计算机系统(硬件、软件、算法、程序等)被称为可扩放的,是指其性能随处理机数目的增加而按比例提高。例如,工作负载能力和加速比都可随处理机的数目的增加而增加。可扩放性包括: 1.机器规模的可扩放性 系统性能是如何随着处理机数目的增加而改善的 2.问题规模的可扩放性 系统的性能是如何随着数据规模和负载规模的增加而改善 3.技术的可扩放性 系统的性能上如何随着技术的改变而改善 可扩放性研究的目的: 确定解决某类问题时何种并行算法与何种并行体系结构的组合,可以有效的利用大量的处理器; 对于运用于某种并行机上的某种算法,根据在小规模处理机的运行性能预测移植到大规模处理机上的运行性能; 对固定问题规模,确定最优处理机数和可获得的最大的加速比 (15分)给出五个基本的并行计算模型,并说明其各自的优缺点。 ①PRAM:SIMD-SM 优点: 适于表示和分析并行计算的复杂性; 隐匿了并行计算机的大部底层细节(如通信、同步),从而易于使用。 缺点: 不适于MIMD计算机,存在存储器竞争和通信延迟问题。 ②APRAM:MIMD-SM 优点: 保存了PRAM的简单性; 可编程性和可调试性(correctness)好; 易于进行程序复杂性分析。 缺点: 不适于具有分布式存储器的MIMD计算机。 ③BSP:MIMD-DM 优点: 把计算和通信分割开来; 使用hashing自动进行存储器和通信管理; 提供了一个编程环境。 缺点: 显式的同步机制限制并行计算机数据的增加; 在一个Superstep中最多只能传递h各报文。
超分辨率算法综述
超分辨率复原技术的发展 The Development of Super2Re solution Re storation from Image Sequence s 1、引言 在图像处理技术中,有一项重要的研究内容称为图像融合。通常的成像系统由于受到成像条件和成像方式的限制,只能从场景中获取部分信息,如何有效地弥 补观测图像上的有限信息量是一个需要解决的问题。图像融合技术的含义就是把相关性和互补性很强的多幅图像上的有用信息综合在一起,产生一幅(或多幅) 携带更多信息的图像,以便能够弥补原始观测图像承载信息的局限性。 (图象融合就是根据需要把相关性和互补性很强的多幅图象上的有用信息综合在一起,以供观察或进一步处理,以弥补原始单源观测图象承载信息的局限性,它是一门综合了传感器、图象处理、信号处理、计算机和人工智能等技术的现代高新技术,于20 世纪70 年代后期形成并发展起来的。由于图象融合具有突出的探测优越性,在国际上已经受到高度重视并取得了相当进展,在医学、遥感、计算机视觉、气象预报、军事等方面都取得了明显效益。从图象融合的目标来看,主要可将其归结为增强光谱信息的融合和增强几何信息的融合。增强光谱信息的融合是综合提取多种通道输入图象的信息,形成统一的图象或数据产品供后续处理或指导决策,目前在遥感、医学领域都得到了比较广泛的应用。增强几何信息的融合就是从一序列低分辨率图象重建出更高分辨率的图象(或图象序列) ,以提 高图象的空间分辨率。对图象空间分辨率进行增强的技术也叫超分辨率 (super2resolution) 技术,或亚像元分析技术。本文主要关注超分辨率(SR) 重建技术,对SR 技术中涉及到的相关问题进行描述。) (我们知道,在获取图像的过程中有许多因素会导致图像质量的下降即退化,如 光学系统的像差、大气扰动、运动、离焦和系统噪音,它们会造成图像的模糊和变形。图像复原的目的就是对退化图像进行处理,使其复原成没有退化前的理想图像。按照傅里叶光学的观点,光学成像系统是一个低通滤波器,由于受到光学衍射的影响,其传递函数在由衍射极限分辨率所决定的某个截止频率以上值均为零。显然,普通的图像复原技术如去卷积技术等只能将物体的频率复原到衍射极
关于图像超分辨率重构的现状研究
关于图像超分辨率重构的现状研究 摘要:图像超分辨率的重构技术是近20年来兴起的一门新的数字图像处理技术。随着计算机硬件技术和软件设计技术的不断发展,各种图像超分辨率重构算法被提出。综述超分辨率重构的相关研究,指出图像超分辨率重构技术近几年来的一些研究成果。 关键字:图像超分辨率;图像超分辨率重构;迭代法投影法 Abstract:Image super-resolution reconstruction technology is nearly 20 years the rise of a new digital image processing technology. With the continuous development of computer hardware and software design technology, all kinds of image super-resolution reconstruction algorithm was proposed. Of related studies on super-resolution reconstruction, and points out that the technology of image super-resolution reconstruction in recent years, some of the research. Keywords:image super-resolution; image super-resolution reconstruction; iterative projection method 1引言 超分辨率重构算法始于20世纪80年代,其目的在于恢复一些已丢失的频率分量。在成像过程中,由于受成像系统的物理性质和天气条件的影响,图像中存在着光学和运动模糊、采样不足和附加噪声等退化现象,图像空间分辨率较低。而在实际应用中,需要高分辨率的图像,如在遥感检测、军事侦查、交通及安全监控、医学诊断和模式识别等方面。在现有的传感器不作改变的情况下,人们希望利用信号处理的方法,通过一系列低分辨率图像来重构高分辨率图像。这种从同一场景的低分辨率图像序列中,通过信息融合来提高空间分辨率的方法通常被称为超分辨率重构。
超分辨率算法综述
图像超分辨率算法综述 摘要:介绍了图像超分辨率算法的概念和来源,通过回顾插值、重建和学习这3个层面的超分辨率算法,对图像超分辨率的方法进行了分类对比,着重讨论了各算法在还原质量、通用能力等方面所存在的问题,并对未来超分辨率技术的发展作了一些展望。 关键词:图像超分辨率;插值;重建;学习; Abstract:This paper introduced the conception and origin of image super resolu- tion technology. By reviewing these three kinds of methods(interpolation,reconstruct, study), it contrasted and classified the methods of image super-resolution,and at last, some perspectives of super-resolution are given. Key words: image super-resolution;interpolation;reconstruct;study;
1 引言 1.1 超分辨率的概念 图像超分辨率率(super resolution,SR)是指由一幅低分辨率图像(low resolution,LR)或图像序列恢复出高分辨率图像(high resolution, HR)。HR意味着图像具有高像素密度,可以提供更多的细节,这些细节往往在应用中起到关键作用。要获得高分辨率图像,最直接的办法是采用高分辨率图像传感器,但由于传感器和光学器件制造工艺和成本的限制[1],在很多场合和大规模部署中很难实现。因此,利用现有的设备,通过超分辨率技术获取HR图像(参见图1)具有重要的现实意义。 图1 图像超分辨率示意图 图像超分辨率技术分为超分辨率复原和超分辨率重建,许多文献中没有严格地区分这两个概念,甚至有许多文献中把超分辨率图像重建和超分辨率图像复原的概念等同起来,严格意义上讲二者是有本质区别的,超分辨率图像重建和超分辨率图像复原有一个共同点,就是把在获取图像时丢失或降低的高频信息恢复出来。然而它们丢失高频信息的原因不同,超分辨率复原在光学中是恢复出超过衍射级截止频率以外的信息,而超分辨率重建方法是在工程应用中试图恢复由混叠产生的高频成分。几何处理、图像增强、图像复原都是从图像到图像的处理,即输入的原始数据是图像,处理后输出的也是图像,而重建处理则是从数据到图像的处理。也就是说输入的是某种数据,而处理结果得到的是图像。但两者的目的是一致的,都是由低分辨率图像经过处理得到高分辨率图像。另外有些文献中对超分辨率的概念下定义的范围比较窄,只是指基于同一场景的图像序列和视频序列的超分辨处理,实际上,多幅图像的超分辨率大多数都是以单幅图像的超分辨率为基础的。在图像获取过程中有很多因素会导致图像质量下降,如传感器的形
网络社交媒体的情感认知与计算
本讲座选自清华大学电子工程系信息认知与系统智能研究所副所长黄永峰于2015年12月23日在清华RONGv2.0系列论坛之“社会关系网络与大数据技术”专场上所做的题为《网络社交媒体的情感认知与计算》的演讲。
黄永峰:各位老师、同学们,上午好!很荣幸有这个机会跟大家交流,我的题目是网络社交媒体的情感认知与计算。 下面我将从这三个方面为大家逐一介绍。
情感计算的历史是1997年由MIT的Picard教授提出的,她指出情感计算是与情感相关,来源于情感或能够对情感施加影响的计算。情感分为四类:情感识别、情感表示、情感建模、情感交互。今天我讲的更像是情感识别方面的研究。情感计算分为四个过程:情感信息采集、情感识别分析、情感理解认知、情感信息表达,这四个方面我们做得更多的是识别分析,理解认知是我们下一步想做的。
Picard提出这个计算的时候,最开始的想法是从一些图像的表情、语音的语调、姿态中采集数据,通过特征信息的抽取和分析,最后识别情感而今天我所做的情感是利用互联网这样一个平台来采集大量语言的信息或者语言数据来分析个体的情感。我们为什么要采集情感?首先情感的采集比别的更丰富,语言是人类思维的直接现实,是思想的传播载体,也是情感表达的媒介,通过采集语言数据分析情感是完全可能的。但是有没有难度?有个统计数据指出一个语言的情感信息10%来自于语言本身的内容,20%来自于语言的语调、语气,70%来自于表情。传统语言的语调、语气信号用于分析情感相对更容易,而我们基于语言内容来分析情感难度会大很多。
什么叫情感?首先要对情感的模型有一个理解。Plutchik提出了一个最典型的情绪模型,他把人的情感分为八个类别、四个种类,分别用锥形模型和展开后的模型描述。从这两个模型我们能够看出情感的描述有很多方法,目前用得最普遍的是三维模型,把情感用强度划分为三个等级,这八个类别相对的是不同极性情感,相邻的情感区域的情感是很相似的,即情感的第3维,相似性。我们后面展开的情感研究主要是对这24类情感研究的一个简单的量化,情感很复杂,我们的研究从两个方面进行量化,第一个是强度,第二个是把相似性和极性合到一起研究。
图像超分辨率重建
收稿日期:2008唱08唱21;修回日期:2008唱10唱28 作者简介:王培东(1953唱),男,黑龙江哈尔滨人,教授,硕导,CCF会员,主要研究方向为计算机控制、计算机网络、嵌入式应用技术;吴显伟(1982唱),男(回族),河南南阳人,硕士,主要研究方向为计算机控制技术(wu_xianwei@126.com). 一种自适应的嵌入式协议栈缓冲区管理机制 王培东,吴显伟 (哈尔滨理工大学计算机科学与技术学院,哈尔滨150080) 摘 要:为避免创建缓冲区过程中必须指定大小和多次释放而导致可能的内存泄露和代码崩溃的弊端,提出一种自适应的嵌入式协议栈的缓冲区管理机制AutoBuf。它是基于抽象缓冲区接口而设计的,具有自适应性,支持动态内存的自动分配与回收,同时实现了嵌入式TCP/IP协议栈各层之间的零拷贝通信。在基于研究平台S3C44B0X的Webserver网络数据监控系统上的测试结果表明,该缓冲区的设计满足嵌入式系统网络通信的应用需求,是一种高效、可靠的缓冲区管理机制。 关键词:嵌入式协议栈;抽象缓冲区;零拷贝;内存分配 中图分类号:TP316 文献标志码:A 文章编号:1001唱3695(2009)06唱2254唱03doi:10.3969/j.issn.1001唱3695.2009.06.077 Designandimplementationofadaptivebufferforembeddedprotocolstack WANGPei唱dong,WUXian唱wei (CollegeofComputerScience&Technology,HarbinUniversityofScience&Technology,Harbin150080,China) Abstract:Toavoidtraditionalmethodofcreatingbuffer,whichmusthavethesizeofbufferandfreememoryformanytimes,whichwillresultinmemoryleaksandcodescrash.ThispaperproposedaflexiblebuffermanagementmechanismAutoBufforembeddednetworkprotocolstack.Itwasadaptiveandscalableandbasedonanabstractbufferinterface,supporteddynamicme唱moryallocationandbackup.ByusingtheAutoBufbuffermanagementmechanismwithdatazerocopytechnology,itimplementedtotransferdatathroughtheembeddednetworkprotocolstack.ThemanagementmechanismhadbeenappliedtotheWebserversystembaseonS3C44b0Xplatformsuccessfully.Theresultsinrealnetworkconditionshowthatthesystemprovidesagoodper唱formanceandmeetsthenecessaryofembeddednetworksystem.Keywords:embeddedstack;abstractbuffer;zero唱copy;memoryallocation 随着网络技术的快速发展,主机间的通信速率已经提高到了千兆数量级,同时多媒体应用还要求网络协议支持实时业务。嵌入式设备网络化已经深入到日常生活中,而将嵌入式设备接入到互联网需要网络协议栈的支持。通过分析Linux系统中TCP/IP协议栈的实现过程,可以看出在协议栈中要有大量数据不断输入输出,而管理这些即时数据的关键是协议栈中的缓冲区管理机制,因此对嵌入式协议栈的缓冲区管理将直接影响到数据的传输速率和安全。通用以太网的缓冲区管理机制,例如4.4BSDmbuf [1] 和现行Linux系统中的sk_buf [2] 多是在大内存、 高处理速率的基础上设计的,非常庞大复杂。由于嵌入式设备的硬件资源有限,特别是可用物理内存的限制,通用的协议栈必然不适用于嵌入式设备,在应用时要对标准的TCP/IP协议进行裁剪 [3] 和重新设计缓冲区管理机制。 1 缓冲区管理机制的性能需求分析 缓冲区管理 [4] 是对内存提供一种统一的管理手段,通过该 手段能够对可用内存提供分配、回收、数据操作等行为。内存的分配操作是根据一定的内存分配策略从缓冲区中获得相应大小的内存空间;缓冲区的数据操作主要是向缓冲区写数据,从缓冲区读数据,在缓冲区中删除数据,对空闲的内存块进行合并等行为;内存的回收就是将已空闲的内存重新变为可用内存,以供存 储其他新的数据。 为了满足长度不一的即时数据的需求,缓冲区对内存的操作主要集中在不断地分配、回收、合并空闲的内存块等操作。因为网络中的数据包小到几个字节大到几千个字节,不同长度的数据对内存的需求必然不同。现存嵌入式设备中的内存多是以物理内存,即实模式形式存在的,没有虚拟内存的形式,对内存的操作实际是操作真实的物理内存,所以对内存操作要特别谨慎。在传统使用动态分配的缓冲区(通过调用malloc()/free())在函数之间传递数据。尽管该方法提供了灵活性,但它也带来了一些性能影响。首先考虑对缓冲区的管理(分配和释放内存块)。如果分配和释放不能在相同的代码位置进行,那么必须确保在某个内存块不再需要时,释放一次(且仅释放一次)该内存块是很重要的,否则就会导致内存泄露。其次是必须确定缓冲区的大小才能分配该内存块。然而,确定数据大小并非那么容易,传统做法是采用最大的数据尺寸的保守估计。而采用保守估计预分配的内存大小总是远超过实际需要的大小,而且没有一定的范围标准,这样难免会导致资源的严重浪费。 随着数据在协议栈中的不断流动,内存块的多次释放和多次分配是难以避免的,而保守估计对于有限的资源来说又是一种浪费的策略。因此为了能有效地利用资源,设计一种可自控的、不用预判断大小的数据缓冲区接口就势在必行。 第26卷第6期2009年6月 计算机应用研究 ApplicationResearchofComputers Vol.26No.6Jun.2009
情感计算综述
情感计算综述 控制工程1102班李晓宇 2111103172 摘要:情感计算是人工智能的一个分支。情感计算的目的是通过赋予计算机识别、理解、表达和适应人的情感的能力来建立和谐人机环境,并使计算机具有更高的、全面的智能。本文分别从情感计算的研究历史、应用前景、研究内容和理论框架来阐述情感计算,以便使更多的人了解情感计算。 关键字: 情感计算;情感识别;情感理论框架 Summary of Affective Computing Abstract:Affective computing is a branch of artificial intelligence. The aim of affective computing is to give computers to recognize, understand, adapt to people's emotional expression and the ability to establish harmonious human environment, and to have higher computer, full of intelligence.This paper explain affective computing through the study of history of affective computing ,applications in the future, research content and theoretical framework, so that more people understand the affective computing. Key word: Affective computing; emotion recognition; the theoretical framework of emotional 1、引言 情感计算的概念是在1997年由MIT媒体实验室Picard教授提出,她指出情感计算是与情感相关,来源于情感或能够对情感施加影响的计算。中国科学院自动化研究所的胡包刚等人也通过自己的研究,提出了对情感计算的定义:“情感计算的目的是通过赋予计算机识别、理解、表达和适应人的情感的能力来建立和谐人机环境,并使计算机具有更高的、全面的智能”。 在较长一段时期内,情感一直位于认知科学研究者的视线以外。直到20世纪末期,情感作为认知过程重要组成部分的身份才得到了学术界的普遍认同。当代的认知科学家们把情感与知觉、学习、记忆、言语等经典认知过程相提并论,关于情感本身及情感与其他认知过程间相互作用的研究成为当代认知科学的研究热点,情感计算( affective computing )也成为一个新兴研究领域。 众所周知,人随时随地都会有喜怒哀乐等情感的起伏变化。那么在人与计算机交互过程中,计算机是否能够体会人的喜怒哀乐,并见机行事呢?情感计算研究就是试图创建一种能感知、识别和理解人的情感,并能针对人的情感做出智能、灵敏、友好反应的计算系统,即赋予计算机像人一样的观察、理解和生成各种情感特征的能力。 2、研究现状 让计算机具有情感能力首先是由美国MIT大学Minsky教授(人工智能创始人之一)提出的。他在1985年的专著《The Society of Mind》中指出,问题不在于智能机器能否有任何情感,而在于机器实现智能时怎么能够没有情感。从此,赋予计算机情感能力并让计算机能够理解和表达情感的研究、探讨引起了计算机界许多人士的兴趣。这方面的工作首推美国MIT 媒体实验室Picard教授领导研究小组的工作。情感计算一词也首先由Picard教授于1997年出版的专著《Affective Computing》中提出并给出了定义,即情感计算是关于情感、情感产生以
蒙特卡罗方法并行计算
Monte Carlo Methods in Parallel Computing Chuanyi Ding ding@https://www.360docs.net/doc/4218537449.html, Eric Haskin haskin@https://www.360docs.net/doc/4218537449.html, Copyright by UNM/ARC November 1995 Outline What Is Monte Carlo? Example 1 - Monte Carlo Integration To Estimate Pi Example 2 - Monte Carlo solutions of Poisson's Equation Example 3 - Monte Carlo Estimates of Thermodynamic Properties General Remarks on Parallel Monte Carlo What is Monte Carlo? ? A powerful method that can be applied to otherwise intractable problems ? A game of chance devised so that the outcome from a large number of plays is the value of the quantity sought ?On computers random number generators let us play the game ?The game of chance can be a direct analog of the process being studied or artificial ?Different games can often be devised to solve the same problem ?The art of Monte Carlo is in devising a suitably efficient game.
并行计算环境搭建
并行计算环境搭建 一.搭建并调试并行计算环境MPI的详细过程。 1.首先,我们选择在Windows XP平台下安装MPICH。第一步确保Windows平台下安装上了.net框架。 2.在并行环境的每台机子上创建相同的用户名和密码,并使该平台下的各台主机在相同的工作组中。 3.登陆到新创建的帐号下,安装MPICH软件,在选择安装路径时,每台机子的安装路径要确保一致。安装过程中,需要输入一致的passphrase,也即本机的用户名。 4.安装好软件后,要对并行环境进行配置(分为两步): 第一步:注册。在每台机器上运行wmpiregister,按照提示输入帐号和密码,即 本机的登录用户名和密码。 第二步:配置主机。在并行环境下,我们只有一台主机,其他机子作为端结点。 运行主机上的wmpiconfig,在界面左侧栏目中选择TNP工作组,点击“select”按 钮,此时主机会在网络中搜索配置好并行环境的其他机子。配置好并行环境的其他 机子会出现绿色状态,点击“apply”按钮,最后点击“OK”按钮。 5.在并行环境下运行的必须是.exe文件,所以我们必须要对并行程序进行编译并生成.exe文件。为此我们选择Visual C++6.0编译器对我们的C语言程序进行编译, 在编译过程中,主要要配置编译器环境: (1)在编译器环境下选择“工程”,在“link”选项卡的“object/library modules” 中输入mpi.lib,然后点击“OK”按钮。 (2)选择“选项”,点击“路径”选项卡,在“show directories for”下选择“Include files”,在“Directories”中输入MPICH软件中“Include”文件夹的路径; 在“show directories for”下选择“Library files”,在“Directories”中输入 MPICH软件中Library文件夹的路径,点击“OK”。 (3)对并行程序进行编译、链接,并生成.exe文件。 6.将生成的.exe文件拷贝到并行环境下的各台机子上,并确保每台机子的存放路径要相同。 7.在主机上运行“wmpiexec”,在Application中选择生成的.exe文件;输入要执行此程序的进程数,选中“more options”选项卡,在“host”栏中输入主机和各个端结 点的计算机名,点击“execute”执行程序。 二.搭建并调试并行计算环境MPI的详细过程。 1.以管理员身份登录每台计算机,在所有连接的计算机上建立一个同样的工作组,命名为Mshome,并在该工作组下建立相同的帐户,名为GM,密码为GM。 2.安装文件Microsoft NET Framwork1.1,将.NET框架安装到每台计算机上,再安装MPI到每台主机。在安装MPI的过程中,必须输入相同的passphrase,在此输 入之前已建好的帐户名GM。 3.安装好MPI后,再对每台计算机进行注册和配置,其中注册必须每台计算机都要进行,配置只在主控计算机进行: (1)注册:将先前在每台计算机上申请的帐号和密码注册到MPI中去,这样
联想网御的多核并行计算网络安全平台
龙源期刊网 https://www.360docs.net/doc/4218537449.html, 联想网御的多核并行计算网络安全平台 作者:李江力王智民 来源:《中国计算机报》2008年第44期 随着网络带宽的不断发展,网络如何安全、高效地运行逐渐成为人们关注的焦点。上期文章《多核技术开创万兆时代》指出,经过多年不断的努力探索,在历经了高主频CPU、FPGA、ASIC、NP后,我们迎来了多核时代。是不是有了多核,就能够满足当前人们对网络安全处理能力的需求呢?答案也许并非那么简单。 本文将从多核处理器带来的机遇与挑战、多核编程的困境、联想网御的解决方案三个方面来详细阐述多核并行计算相关的技术问题。 多核处理器带来机遇与挑战 通常我们所说的多核处理器是指CMP(ChipMulti-processors)的芯片结构。CMP是由美国斯坦福大学提出的,其思想是将大规模并行处理器中的SMP(Symmetric Multi-processors,对称多处理器)集成到同一芯片内,各个处理器并行执行,在同一个时刻同时有多条指令在执行。 多核处理器的出现使得人们从以前的单纯靠提高CPU主频的“死胡同”走了出来,同时又使得软件开发人员能够采用高级语言进行编程,看似是一个比较完美的技术方案,但同时我们也应该看到多核处理器也给业界带来了一系列的挑战。 同构与异构 CMP的构成分成同构和异构两类,同构是指内部核的结构是相同的,而异构是指内部的核结构是不同的。核内是同构还是异构,对不同的应用,带来的性能影响是不同的。 核间通信 多核处理器各个核之间通信是必然的事情,高效的核间通信机制将是多核处理器性能的重要保障。目前主流的芯片内部高效通信机制有两种,一种是基于总线共享的Cache结构,一种是基于片上的互连结构。采用第一种还是第二种,也是设计多核处理器的时候必须考虑的问题。 并行编程