点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法

点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法。2009年06月03日下午 04:27
一.实验要求
编程实现中英文字符的显示。
二.实验目的
1.了解LED点阵显示的基本原理和实现方法。
2.掌握
三.实验电路及连线
点阵显示模块WTD3088的(红色)列输入线接至内部LED的阴极端,行输入线接至内部LED的阳极端(若阳极端输入为高电平,阴极端输入低电平,则该LED
点亮)。发光点的分布如图22-0所示。
Fig 22-0 WTD3088 LED分布
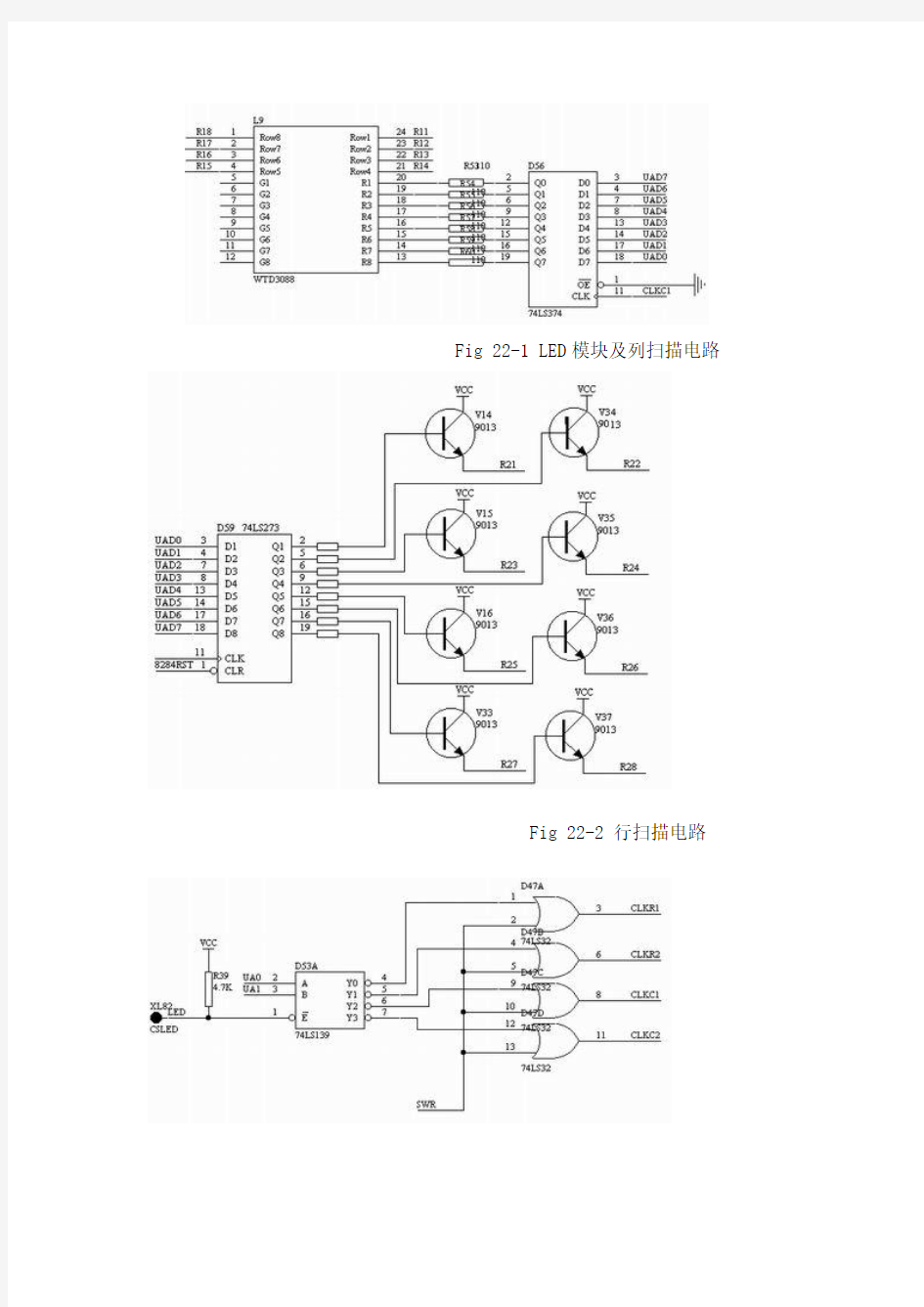
如图22-1示,本实验模块使用74LS374来控制列输入线的电平值。将74LS374的某输出置0,则对应的LED阴极端被置低。如图22-2示,本实验模块使用
74LS273来控制行输入线,并通过9013提供电流驱动。将74LS273的某输出置1,则对应的LED阳极端被置高。每次系统重新开启或总清后,74LS273输出为全0,LED显示被关闭。
通过编程控制各显示点对应LED阳极和阴极端的电平,就可以有效的控制各显示点的亮灭。
Fig 22-1 LED模块及列扫描电路
Fig 22-2 行扫描电路
Fig 22-3地址译码电路
本实验模块使用4块WTD3088组成16×16点阵,以满足汉字显示的要求。为了方便的控制四个单元,使用了一片74LS139译码,产生四个地址片选信号:CLKR1= CSLED,CLKR2= CSLED+1,用于行控制的两片74LS273;CLKC1= CSLED+2,CLKC2= CSLED+3,用于列控制的两片74LS374。
实验接线:按示例程序,模块的CSLED接51/96地址的8000H。
四.实验说明
使用高亮度LED发光管构成点阵,通过编程控制可以显示中英文字符、图形及视频动态图形。LED显示以其组构方式灵活、亮度高、技术成熟、成本低廉等特点在证券、运动场馆及各种室内/外显示场合得到广泛的应用。
所显示字符的点阵数据可以自行编写(即直接点阵画图),也可从标准字库(如ASC16、HZ16)中提取。后者需要正确掌握字库的编码方法和字符定位的计算。
实验盘片中“字符转换”子目录下提供的Basc16.exe,BHz16.exe可方便的将单个字符的码表从标准字库Asc16,Hzk16中提取出来。具体使用方法是运行上述可执行程序,根据提示输入所需字符(如是汉字还需要先启动dos下的汉字环境,如ucdos,pdos95等)。程序将该字符的码表提取出来,存放在该字符ASC或区位码为文件名称的.dat文件中。用户只需将该文件中内容拷贝、粘贴到自己的程序中即可。但需要注意字节排列顺序、字节中每一位与具体显示点的一一对应关系,必要时还要对码表稍作修改。同一目录下还提供了上述可执行程序的源文件,使用BC3.1编写,供用户参考。
五.实验程序框图
用户应留心其中行扫描的实现及码表的处理。
六.实验程序:
(一)提供LEDA51演示Asc16字符的简单点阵显示。
;*********LED 点阵显示示例程序*********************** ;** 该程序显示 Asc16字符 **
;** 为了简单起见,程序只显示一个字符 **
;** 该程序针对T598实验机的模块14 **
;****************************************************
CSLED EQU 8000H
CSR1 EQU CSLED ;行1 273
CSR2 EQU CSLED+1H ;行2 273
CSC1 EQU CSLED+2H ;列1 374
CSC2 EQU CSLED+3H ;列2 374
ORG 0000H
MOV SP,#60H
INIT: MOV A,#0H ;关闭行
MOV DPTR,#CSR1
MOVX @DPTR,A
MOV DPTR,#CSR2
MOVX @DPTR,A
MOV A,#0FFH ;关闭列
MOV DPTR,#CSC1
MOVX @DPTR,A
MOV DPTR,#CSC2
MOVX @DPTR,A
D: MOV R5,#00H
MOV R4,#01H ;每次为单行扫描
DISP:
MOV A,R5
MOV DPTR,#ASCE ;此处设定所要显示的字符
MOVC A,@A+DPTR
CPL ACC ;代码取反,决定显示的阴阳
MOV DPTR,#CSC2
MOVX @DPTR,A
MOV DPTR,#CSR1
MOV A,R4
MOVX @DPTR,A
RL ACC
MOV R4,ACC
INC R5
LCALL DELAY
CJNE R5,#8H,DISP
MOV A,#0H
MOVX @DPTR,A
MOV R5,#08H
MOV R4,#01H
DISP2:
MOV A,R5
MOV DPTR,#ASCE
MOVC A,@A+DPTR
CPL ACC
MOV DPTR,#CSC2
MOVX @DPTR,A
MOV DPTR,#CSR2
MOV A,R4
MOVX @DPTR,A
RL ACC
MOV R4,ACC
INC R5
LCALL DELAY
CJNE R5,#10H,DISP2
MOV A,#0H
MOVX @DPTR,A
SJMP D
;******** 延时子程序,协调字符显示速度 ************* DELAY: MOV R7,#1H
DL1: MOV R6,#00H
DL2: DJNZ R6,DL2
DJNZ R7,DL1
RET
;******** 字符点阵字库 ***************
; ASC16 字符编码排列
; 0
; 1
; |
; |
; 14
; 15
; 高位 D7--D0
; 请注意编码的排列次序和实际显示点阵分布的关系
ASCA:DB 00H,00H,10H,38H,6CH,0C6H,0C6H,0FEH
DB 0C6H,0C6H,0C6H,0C6H,00H,00H,00H,00H
ASCE:DB 00H,00H,0FEH,66H,62H,68H,78H,68H
DB 60H,62H,66H,0FEH,00H,00H,00H,00H
ASCD:DB 00H,00H,0F8H,6CH,66H,66H,66H,66H
DB 66H,66H,6CH,0F8H,00H,00H,00H,00H
ASCK:DB 00H,00H,0E6H,66H,66H,6CH,78H,78H
DB 6CH,66H,66H,0E6H,00H,00H,00H,00H
;**************************************************** END
(二)LEDHZ51两个示例程序。和Hz16字符的简单点阵显示。;*********LED 点阵显示示例程序*********************** ;** 该程序显示 hz16字符 **
;** 为了简单起见,程序只显示一个字符 **
;** 该程序针对T598实验机的模块14 **
;****************************************************
CSLED EQU 8000H
CSR1 EQU CSLED ;行1 273
CSR2 EQU CSLED+1H ;行2 273
CSC1 EQU CSLED+2H ;列1 374
CSC2 EQU CSLED+3H ;列2 374
ORG 0000H
MOV SP,#60H
INIT: MOV A,#0H ;关闭LED显示
MOV DPTR,#CSR1
MOVX @DPTR,A
MOV DPTR,#CSR2
MOVX @DPTR,A
MOV A,#0FFH ;关闭LED显示
MOV DPTR,#CSC1
MOVX @DPTR,A
MOV DPTR,#CSC2
MOVX @DPTR,A
D: MOV R5,#00H
MOV R4,#01H DISP:
MOV A,R5
RL ACC
MOV DPTR,#HZAI MOVC A,@A+DPTR CPL ACC
MOV DPTR,#CSC2 MOVX @DPTR,A
MOV A,R5
RL ACC
INC ACC
MOV DPTR,#HZAI MOVC A,@A+DPTR CPL ACC
MOV DPTR,#CSC1 MOVX @DPTR,A
MOV DPTR,#CSR1 MOV A,R4
MOVX @DPTR,A
RL ACC
MOV R4,ACC
INC R5
LCALL DELAY
CJNE R5,#8H,DISP
MOV A,#0H
MOVX @DPTR,A
MOV R5,#08H
MOV R4,#01H
DISP2:
MOV A,R5
RL ACC
MOV DPTR,#HZAI MOVC A,@A+DPTR CPL ACC
MOV DPTR,#CSC2 MOVX @DPTR,A
MOV A,R5
RL ACC
INC ACC
MOV DPTR,#HZAI
MOVC A,@A+DPTR
CPL ACC
MOV DPTR,#CSC1
MOVX @DPTR,A
MOV DPTR,#CSR2
MOV A,R4
MOVX @DPTR,A
RL ACC
MOV R4,ACC
INC R5
LCALL DELAY
CJNE R5,#10H,DISP2
MOV A,#0H
MOVX @DPTR,A
SJMP D
;******** 延时子程序,协调字符显示速度 ************* DELAY: MOV R7,#1H
DL1: MOV R6,#00H
DL2: DJNZ R6,DL2
DJNZ R7,DL1
RET
;******** 字符点阵字库 ***************
; HZ16 字符编码排列
; 0 1
; 2 3
; |
; |
; 28 29
; 30 31
; 高位 D7--D0
HZAI:DB 00H,78H,3FH,80H,11H,10H,09H,20H
DB 7FH,0FEH,42H,02H,82H,04H,7FH,0F8H
DB 04H,00H,07H,0F0H,0AH,20H,09H,40H
DB 10H,80H,11H,60H,22H,1CH,0CH,08H
HZDI:DB 00H,80H,40H,80H,20H,88H,2FH,0FCH
DB 08H,88H,08H,88H,0E8H,88H,2FH,0F8H
DB 28H,88H,28H,88H,28H,88H,2FH,0F8H
DB 28H,08H,50H,06H,8FH,0FCH,00H,00H
HZKE:DB 01H,00H,01H,04H,0FFH,0FEH,01H,00H
DB 01H,10H,1FH,0F8H,10H,10H,10H,10H
DB 10H,10H,1FH,0F0H,14H,50H,04H,40H
DB 04H,40H,08H,42H,10H,42H,60H,3EH
;****************************************************
汉字编码
编码定义 用预先规定的方法将文字、数字或其他对象编成数码,或将信息、数据转换成规定的电脉冲信号。编码在电子计算机、电视、遥控和通讯等方面广泛使用。 编码是根据一定的协议或格式把模拟信息转换成比特流的过程。 在计算机硬件中,编码(coding)是在一个主题或单元上为数据存储,管理和分析的目的而转换信息为编码值(典型地如数字)的过程。在软件中,编码意味着逻辑地使用一个特定的语言如C或C++来执行一个程序。在密码学中,编码是指在编码或密码中写的行为。 将数据转换为代码或编码字符,并能译为原数据形式。是计算机书写指令的过程,程序设计中的一部分。在地图自动制图中,按一定规则用数字与字母表示地图内容的过程,通过编码,使计算机能识别地图的各地理要素。 n位二进制数可以组合成2的n次方个不同的信息,给每个信息规定一个具体码组,这种过程也叫编码。数字系统中常用的编码有两类,一类是二进制编码,另一类是二—十进制编码。 为什么要进行汉字编码 汉字编码Chinese character encoding为汉字设计的一种便于输入计算机的代码。由于电子计算机现有的输入键盘与英文打字机键盘完全兼容。因而如何输入非拉丁字母的文字(包括汉字)便成了多年来人们研究的课题。汉字信息处理系统一般包括编码、输入、存储、编辑、输出和传输。编码是关键。不解决这个问题,汉字就不能进入计算机。中国人本来是用一只手执笔杆,一笔一画写字的,现在却要统统改为用两只手十个指头击键写字。键符越过笔画,代表部件写字,在键盘上使用编码检出汉字,就是用编码写字,键盘就成为我们的笔杆了。这种以检字来使用汉字,提高信息交换速度,对中华民族的汉字来说,这是几千年来前所未有的一次翻天覆地的大变革。回顾汉字发展的历史,从甲骨文、金文、大篆、小篆、隶书,到现代汉字,它的变革,都只是笔势上的变革,而没有牵涉到它的结构。而这一次,却牵涉到它的结构——把汉字拆分为部件。因此,这次变革,不仅给我国人民将带来巨大的好处,还将使蒙辱一百多年的、背上“落后”黑锅的汉字,重新展现它的光辉。 途径 汉字进入计算机的三种途径分别为:
字模生成原理
字模生成原理 本设计中因为使用汉字的点阵显示,需要提取汉字字模,因此我们首先来了解汉字点阵字模的提取方法。 汉字的点阵字模是从点阵字库文件中提取出来的。例如常用的16×16点阵HZK16文件,12×12点阵HZK12文件等等,这些文件包括了GB 2312字符集中的所有汉字。现在只要弄清汉字点阵在字库文件中的格式,就可以按照自己的意愿去显示汉字了。 下面以HZK16文件为例,分析取得汉字点阵字模的方法。 HZK16文件是按照GB 2312-80标准,也就是通常所说的国标码或区位码的标准排列的。国标码分为94 个区(Section),每个区94 个位(Position),所以也称为区位码。其中01~09 区为符号、数字区,16~87 区为汉字区。而10~15 区、88~94 区是空白区域。 如何取得汉字的区位码呢?在计算机处理汉字和ASCII字符时,使每个ASCII字符占用1个字节,而一个汉字占用两个字节,其值称为汉字的内码。其中第一个字节的值为区号加上32(20H),第二个字节的值为位号加上32(20H)。为了与ASCII字符区别开,表示汉字的两个字节的最高位都是1,也就是两个字节的值都又加上了128(80H)。这样,通过汉字的内码,就可以计算出汉字的区位码。 具体算式如下: qh=c1-32-128=c1-160 wh=c2-32-128=c2-160 或 qh=c1-0xa0 wh=c2-0xa0 qh,wh为汉字的区号和位号,c1,c2为汉字的第一字节和第二字节。 根据区号和位号可以得到汉字字模在文件中的位置: location=(94*(qh-1)+(wh-1))*一个点阵字模的字节数。 那么一个点阵字模究竟占用多少字节数呢?我们来分析一下汉字字模的具体排列方式。 例如下图中显示的“汉”字,使用16×16点阵。字模中每一点使用一个二进制位(Bit)表示,如果是1,则说明此处有点,若是0,则说明没有。这样,一个16×16点阵的汉字总共需要16*16/8=32个字节表示。字模的表示顺序为:先从左到右,再从上到下,也就是先画左上方的8个点,再是右上方的8个点,然后是第二行左边8个点,右边8个点,依此类推,画满16×16个点。 对于其它点阵字库文件,则也是使用类似的方法进行显示。例如HZK12,但是HZK12文件的格式有些特别,如果你将它的字模当作12*12位计算的话,根本无法正常显示汉字。因为字库设计者为了使用的方便,字模每行的位数均补齐为8的整数倍,于是实际该字库的位长度是16*12,每个字模大小为24字节,虽然每行都多出了4位,但这4位都是0(不显示),并不影响显示效果。还有UCDOS下的HZK24S(宋体)、HZK24K(楷体)或HZK24H(黑体)这些打印字库文件,每个字模占用24*24/8=72字节,不过这类大字模汉字库为了打印的方便,将字模都放倒了,所以在显示时要注意把横纵方向颠倒过来就可以了。 这样我们就完全清楚了如何得到汉字的点阵字模,这样就可以在程序中随意的显示汉字了。 5.7.2 字模提取程序 如果在程序中使用的汉字数目不多,也可以不必总是在程序里带上几百K的字库文件,也
GB2312GB_13000_GBKGB18030介绍讲解
1、GB231 2、GB 13000、GBK、GB18030 介绍 GB 2312:又称为GB 2312-80,是一个简体中文字符集的中国国家标准,于1980年由中国国家标准总局发布,1981年5月1日实施,全称为《信息交换用汉字编码字符集基本集》,规定了6763个汉字和682个非汉字图形。 GB 13000:为了便于多个文种的同时处理,国际标准化组织下属编码字符集工作组研制了新的编码字符集标准,ISO/IEC 10646。该标准第一次颁布是在1993年,当时只颁布了其第一部分,即ISO/IEC 10646.1: 1993,我国相应的国家标准是GB 13000.1-93《信息技术通用多八位编码字符集(UCS) 第一部分:体系结构与基本多文种平面》。 制定这个标准的目的是对世界上的所有文字统一编码,以实现世界上所有文字在计算机上的统一处理。 GBK:随着信息技术在各行业应用的深入,GB 2312 收录汉字数量不足的缺点已经初步显露出来。例如:"镕"字现在是高频率使用字,而GB 2312 却没有为它编码,因而,政府、新闻、出版、印刷等行业和部门在使用中感到十分不便。1995年,全世界大多数的PC 操作系统都实现了16/32 位。GB 13000.1 的实现出现了一线曙光。一方面为了对GB 2312 进行扩充,一方面顺应当时技术的发展向GB 13000.1 推进,同时兼顾当时最广泛采用GB 2312 内码系统。原电子部和原国家技术监督局联合颁布了指导性技术文件《汉字内码扩展规范》1.0版,即GBK 。 在GBK的内码系统中,GB 2312 汉字所在码位保持不便,这样,保证了GBK 对GB 2312 的完全兼容。同时,GBK 内码与GB 13000.1 代码一一对应,为GBK 向GB 13000.1 的转换提供了解决办法。 微软对GB 2312 的扩展,也就是CP936 字码表(Code Page 936)的扩展(原来的CP936 和GB 2312-80 一模一样),最初出现于Windows 95 简体中文版中。 注意GBK 并非国家正式标准,只是国家技术监督局标准化司、电子工业部科技与质量监督司发布的“技术规范指导性文件”。虽然GBK 收录了所有Unicode 1.1 及GB 13000.1-93 之中的汉字,但是编码方式与Unicode 1.1 及GB 13000.1-93 不同。仅仅是GB 2312 到GB 13000.1-93 之间的过渡方案。
国标(GB2312-80)汉字编码对照表
汉字编码简明对照表 说明: 1、下列汉字取自国标(GB 2312-80)中的分级与排列内容;包含所有的第一级汉字和第二级汉字中的常用部分。 2、第一级汉字(16—55区的汉字)以拼音字母为序进行排列,同音字以笔形顺序横、竖、撇、捺、折为序,起笔相同的按第二笔,依次类推;第二级汉字(56-87区的汉字)按部首为序进行排列。 3、对于多音字,仅在表中出现一次。如:柏,音(bai,bo),表中仅出现在“bai”中。 4、汉字区位码用阿拉伯数字表示,每个汉字对应4个数字。 5、本汉字代码表摘自《字符集和信息编码国家标准汇编》,(中国标准出版社,1998年编)。 a 啊 1601 阿 1602 吖 6325 嗄 6436 腌 7571 锕 7925 ai 埃 1603 挨 1604 哎 1605 唉 1606 哀 1607 皑 1608 癌 1609 蔼 1610 矮 1611 艾 1612 碍 1613 爱 1614 隘 1615 捱 6263 嗳 6440 嗌 6441 嫒 7040 瑷 7208 暧 7451 砹 7733 锿 7945 霭 8616 an 鞍 1616 氨 1617 安 1618 俺 1619 按 1620 暗 1621 岸 1622 胺 1623 案 1624 谙 5847 埯 5991 揞 6278 犴 6577 庵 6654 桉 7281 铵 7907 鹌 8038 黯 8786 ang 肮 1625 昂 1626 盎 1627 ao
凹 1628 敖 1629 熬 1630 翱 1631 袄 1632 傲 1633 奥 1634 懊 1635 澳 1636 坳 5974 拗 6254 嗷 6427 岙 6514 廒 6658 遨 6959 媪 7033 骜 7081 獒 7365 聱 8190 螯 8292 鏊 8643 鳌 8701 鏖 8773 ba 芭 1637 捌 1638 扒 1639 叭 1640 吧 1641 笆 1642 八 1643 疤 1644 巴 1645 拔 1646 跋 1647 靶 1648 把 1649 耙 1650 坝 1651 霸 1652 罢 1653 爸 1654 茇 6056 菝 6135 岜 6517 灞 6917 钯 7857 粑 8446 鲅 8649 魃 8741 bai 白 1655 柏 1656 百 1657 摆 1658 佰 1659 败 1660 拜 1661 稗 1662 捭 6267 呗 6334 掰 7494 ban 斑 1663 班 1664 搬 1665 扳 1666 般 1667 颁 1668 板 1669 版 1670 扮 1671 拌 1672 伴 1673 瓣 1674 半 1675 办 1676 绊 1677 阪 5870 坂 5964 钣 7851 瘢 8103 癍 8113 舨 8418 bang 邦 1678 帮 1679 梆 1680 榜 1681 膀 1682 绑 1683 棒 1684 磅 1685 蚌 1686 镑 1687 傍 1688 谤 1689 蒡 6182 浜 6826 bao 苞 1690 胞 1691 包 1692 褒 1693 剥 1694 薄 1701 雹 1702 保 1703 堡 1704 饱 1705 宝 1706 抱 1707 报 1708 暴 1709 豹 1710 鲍 1711 爆 1712 葆 6165 孢 7063 煲 7650 鸨 8017 褓 8157 趵 8532 龅 8621 bei 杯 1713 碑 1714 悲 1715 卑 1716 北 1717 辈 1718 背 1719 贝 1720 钡 1721 倍 1722 狈 1723 备 1724 惫 1725 焙 1726 被 1727 孛 5635 陂 5873 邶 5893 蓓 6177 悖 6703 碚 7753 鹎 8039 褙 8156 鐾 8645 鞴 8725 ben 奔 1728 苯 1729 本 1730 笨 1731 畚 5946 坌 5948 贲 7458 锛 7928 beng 崩 1732 绷 1733 甭 1734 泵 1735 蹦 1736 迸 1737 嘣 6452 甏 7420 bi
点阵字库的原理
点阵字库的原理 2010-12-06 17:12:46 分类: 点阵字库的原理(引文) 所有的汉字或者英文都是下面的原理, 由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。 生成的字库说明:(以12×12例子) 一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。 编码排序A0A0→A0FE A1A0→A2FE依次排列。 以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。 其他的类推即可。 英文点阵也是如此推理。 在DOS程序中使用点阵字库的方法 首先需要理解的是点阵字库是一个数据文件,在这个数据文件里面保存了所有文字的点阵数据.至于什么是点阵,我想我不讲大家都知道的,使用过"文曲星"之类的电子辞典吧,那个的液晶显示器上面显示的汉子就能够明显的看出"点阵"的痕迹.在PC 机上也是如此,文字也是由点阵来组成了,不同的是,PC机显示器的显示分辨率更高,高到了我们肉眼无法区分的地步,因此"点阵"的痕迹也就不那么明显了. 点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词.点阵从本质上讲就是单色位图,他使用一个比特来表示一个点,如果这个比特为0,表示某个位置没有点,如果为1表示某个位置有点.矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是一个二维的阵列.位图就是这种二维的阵列,这个阵列中的(x,y) 位置上的数据代表的就是对原始图形进行采样量化后的颜色值.但是,另一方面,我们要面对的问题是,计算机中数据的存放都是一维的,线性的.因此,我们需要将二维的数据线性化到一维里面去.通常的做法就是将二维数据按行顺序的存放,这样就线性化到了一维. 那么点阵字的数据存放细节到底是怎么样的呢.其实也十分的简单,举个例子最能说明问题.比如说16*16 的点阵,也就是说每一行有16个点,由于一个点使用一个比特来表示,如果这个比特的值为1,则表示这个位置有点,如果这个比特的值为0,则表示这个位置没有点,那么一行也就需要16个比特,而8个比特就是一个字节,也就是说,这个点阵中,一行的数据需要两个字节来存放.第一行的前八个点的数据存放在点阵数据的第一个字节里面,第一行的后面八个点的数据存放在点阵数据的第二个字节里面,第二行的前八个点的数据存放在点阵数据的
常用字符集介绍和编码转换原理
常用字符集介绍和编码转换原理 目录 1. GB2312编码介绍 (2) 1.1 基本信息 (2) 1.2 GB标准 (2) 1.3 分区表示 (2) 1.4 字节结构 (2) 2. 通用字符集UCS (3) 2.1 定义 (3) 2.2 概要 (3) 2.3 实现级别 (3) 2.4 与UNICODE的兼容关系 (3) 3. unicode编码介绍 (3) 3.1 基本简介 (4) 3.2 编码实现 (4) 3.2.1 编码方式 (4) 3.2.2 实现方式 (5) 4. UTF-8介绍 (5) 4.1 基本介绍 (5) 4.2 编码原理 (5) 4. 转换原理 (7)
1. GB2312编码介绍 1.1 基本信息 1.2 GB标准 GB2312或GB2312-80是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集·基本集》,又称为GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。 GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。 GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。 对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB18030汉字字符集的出现。 1.3 分区表示 GB 2312中对所收汉字进行了―分区‖处理,每区含有94个汉字/符号。这种表示方式也称为区位码。 01-09区为特殊符号。 16-55区为一级汉字,按拼音排序。 56-87区为二级汉字,按部首/笔画排序。 10-15区及88-94区则未有编码。 举例来说,―啊‖字是GB2312之中的第一个汉字,它的区位码就是1601。 1.4 字节结构
点阵式汉字LED显示屏的原理与制作(精)
单片机应用 电子报 /2004年 /08月 /08日 /第 011版 / 点阵式汉字 L ED 显示屏的原理与制作 深圳石学军 本文介绍一种实用汉字显示屏的制作。该显示屏使用 256只高亮度发光二极管组成 16×16点阵。为降低制作难度 , 此处仅作了一个字的轮流显示。 每个字由 16×16点阵组成 , 每点为一个像素 , 每个字的字形为一幅图像 , 故此屏既可以显示汉字 , 也可以显示 256像素范围内的任何图形。下面以显示“大” 字为例说明其扫描原理。 在 UCDOS 宋体字库中 , 每个字由 16×16, , 一个字要拆分为上、下两部分 , 由两个 8×16 部分 , 即第 0列的 P00~, 时 , 只有 P05点亮 , 即 04H 。 , 即从 P27向 P20方向扫描 , 这一 , , , 依照这个方法 , 扫描 32个 8位 , 得出汉字“大” :04H、 00H 、 04H 、 02H 、 04H 、 02H 、 04H 、 04H 、 04H 、 08H 、 04H 、 30H 、 05H 、0C0H 、 0FEH 、 00H 、 05H 、 80H 、 04H 、 60H 、 04H 、 10H 、 04H 、 08H 、 04H 、 04H 、 0CH 、 06H 、 04H 、 04H 、 00H 、 00H 。 无论显示何种字体或图像 , 都可以用这个方法分析扫描代码。目前有很多现成的汉字字模生成软件 , 软件打开后输入汉字 , 点“检取” 键 , 即可自动生成十六进制汉字代码。此例使用 4-16线译码器 74L S154完成列显示 , 行的 16条线接 P0口和 P2口。源程序清单如下 : OR G 00H LOOP :MOVA , #0FFH ; 初始化
点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法
点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法。2009年06月03日下午 04:27 一.实验要求 编程实现中英文字符的显示。 二.实验目的 1.了解LED点阵显示的基本原理和实现方法。 2.掌握 三.实验电路及连线 点阵显示模块WTD3088的(红色)列输入线接至内部LED的阴极端,行输入线接至内部LED的阳极端(若阳极端输入为高电平,阴极端输入低电平,则该LED 点亮)。发光点的分布如图22-0所示。
Fig 22-0 WTD3088 LED分布 如图22-1示,本实验模块使用74LS374来控制列输入线的电平值。将74LS374的某输出置0,则对应的LED阴极端被置低。如图22-2示,本实验模块使用 74LS273来控制行输入线,并通过9013提供电流驱动。将74LS273的某输出置1,则对应的LED阳极端被置高。每次系统重新开启或总清后,74LS273输出为全0,LED显示被关闭。 通过编程控制各显示点对应LED阳极和阴极端的电平,就可以有效的控制各显示点的亮灭。 Fig 22-1 LED模块及列扫描电路
Fig 22-2 行扫描电路 Fig 22-3地址译码电路
本实验模块使用4块WTD3088组成16×16点阵,以满足汉字显示的要求。为了方便的控制四个单元,使用了一片74LS139译码,产生四个地址片选信号:CLKR1= CSLED,CLKR2= CSLED+1,用于行控制的两片74LS273;CLKC1= CSLED+2,CLKC2= CSLED+3,用于列控制的两片74LS374。 实验接线:按示例程序,模块的CSLED接51/96地址的8000H。 四.实验说明 使用高亮度LED发光管构成点阵,通过编程控制可以显示中英文字符、图形及视频动态图形。LED显示以其组构方式灵活、亮度高、技术成熟、成本低廉等特点在证券、运动场馆及各种室内/外显示场合得到广泛的应用。 所显示字符的点阵数据可以自行编写(即直接点阵画图),也可从标准字库(如ASC16、HZ16)中提取。后者需要正确掌握字库的编码方法和字符定位的计算。 实验盘片中“字符转换”子目录下提供的,可方便的将单个字符的码表从标准字库Asc16,Hzk16中提取出来。具体使用方法是运行上述可执行程序,根据提示输入所需字符(如是汉字还需要先启动dos下的汉字环境,如ucdos,pdos95等)。程序将该字符的码表提取出来,存放在该字符ASC或区位码为文件名称的.dat 文件中。用户只需将该文件中内容拷贝、粘贴到自己的程序中即可。但需要注意字节排列顺序、字节中每一位与具体显示点的一一对应关系,必要时还要对码表
汉字编码
汉字编码 上海市洋泾中学沈文艳 一、教学目标: 1.知识与技能: (1)理解汉字字形码、机内码及输入码的作用及特点 (2)了解计算机处理汉字的一般过程 2.过程与方法: (1)通过ViewChr软件观察汉字点阵图,探究汉字在屏幕上的显示方式,认识字形码。(2)通过WinHex软件观察汉字内码,探究汉字在计算机内部的存储方式,认识机内码。3.情感、态度与价值观: 通过简介我国科学家王选及汉字全息编码发明少年杜冰蟾的事例,弘扬爱国主义精神及民族自豪感,激发创新意识。认识取得成功必须要有坚韧不拔的毅力和科学严谨的治学态度。 二、教学重点难点 教学重点:汉字输入码、机内码及字形码的作用及特点 教学难点: (1)对汉字三种编码作用及相互关系的理解 (2)汉字字形码存储容量的计算方法。 三、教学过程:
《汉字编码》导学案 班级:姓名:学号: 【学习目标】 1.学习目标 (1)理解汉字字形码、机内码及输入码的作用及特点 (2)了解计算机处理汉字的一般过程 2.重点难点 (1)对汉字三种编码作用及相互关系的理解 (2)汉字字形码存储容量的计算方法。 【活动探究】 活动1:汉字在屏幕上是怎样显示的 步骤: (1)打开ViewChr软件,输入不同的汉字,观察汉字的显示方式, 通过观察,可以很容易地看出,每个汉字是通过一些点的组合来显示的。汉字中有笔画的部分,点是_____(有/无)颜色的,没笔画的部分,点是_____(有/无)颜色的。也就是说屏幕上的每个点既可以有颜色,也可以无颜色,所以,每个点在颜色的显示上最多有_____种状态。 (2)在ViewChr软件中输入汉字“上”,你能否根据软件的显示结果,在下面的16×16的方格图内用二进制数码来描述这个汉字 因为每一个点有两种颜色状态,又因为一个二进制位 可以表示_____种信息,所以,要表示图中的每一个点需要
点阵汉字的原理及应用
点阵汉字原理与应用 一.汉字的编码 由于在电脑中,所有的数据都是以0和1保存的。因此,想要用计算机来显示汉字前提就是要将汉字以二进制,即0和1形式进行编码。 GBK内码 在英文的显示操作中,一个字母、数字及字符均由1个ASCII码表示,并且由于英文字符种类相对较少,故其ASCII码是小于等于127的。而汉字由于种类繁多,每个汉字有2个ASCII码构成,这两个ASCII码称为汉字的GBK内码,通常用十六进制表示。例如,“啊”的GBK内码=B0 A1。汉字的GBK内码一定大于A0H,即160,目的是为了防止与英文的ASCII码产生冲突。 区位码 为了使每一个汉字有一个全国统一的代码,1980年,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。由于国标码是四位十六进制,如汉字的GBK内码,为了便于交流,大家常用的是四位十进制的区位码。所有的国标汉字与符号组成一个94×94的矩阵(见图1所示)。在此方阵中,每一行称为一个"区",每一列称为一个"位",因此,这个方阵实际上组成了一个有94个区(区号分别为0 1到94)、每个区内有94个位(位号分别为01到94)的汉字字符集。一个汉字所在的区号和位号简单地组合在一起就构成了该汉字的"区位码"。区位码和GBK内码之间可以相互转换,区位码=GBK内码-A0H。例如:“啊”的GBK内码=B0 A1,则其区码=B0-A0=10H=16,而其位码=A1-A0=01,所以“啊”的区位码=16 01,为4位十进制码。 在区位码中,01-09区为682个特殊字符,16~87区为汉字区,包含6763个汉字。其中16-55区为一级汉字(3755个最常用的汉字,按拼音字母的次序排列),56-87区为二级汉字(3008个汉字,按部首次序排列)。因此利用区位码便可实现对6000多个汉字的提取。 图1汉字的区位码表
12点阵汉字在HD系列机型中的应用-汉字点阵字库原理
汉字点阵字库原理 一、汉字编码 1.区位码 在国标GD2312—80中规定,所有的国标汉字及符号分配在一个94行、94列的方阵中,方阵的每一行称为一个“区”,编号为01区到94区,每一列称为一个“位”,编号为01位到94位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的“区位码”。区位码的前两位是它的区号,后两位是它的位号。用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。汉字“母”字的区位码是3624,表明它在方阵的36区24位,问号“?”的区位码为0331,则它在03区3l位。 2.机内码 汉字的机内码是指在计算机中表示一个汉字的编码。机内码与区位码稍有区别。如上所述,汉字区位码的区码和位码的取值均在1~94之间,如直接用区位码作为机内码,就会与基本ASCII码混淆。为了避免机内码与基本ASCII码的冲突,需要避开基本ASCII码中的控制码(00H~1FH),还需与基本ASCII码中的字符相区别。为了实现这两点,可以先在区码和位码分别加上20H,在此基础上再加80H(此处“H”表示前两位数字为十六进制数)。经过这些处理,用机内码表示一个汉字需要占两个字节,分别称为高位字节和低位字节,这两位字节的机内码按如下规则表示: 高位字节=区码+20H+80H(或区码+A0H) 低位字节=位码+20H+80H(或位码+AOH) 由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的01~94),所以汉字的高位字节与低位字节的取值范围则为A1H~FEH(即十进制的161~254)。 例如,汉字“啊”的区位码为1601,区码和位码分别用十六进制表示即为1001H,它的机内码的高位字节为B0H,低位字节为A1H,机内码就是B0A1H。
E-mail三种编码标准
E-mail传送中的三种编码标准 一、编码的必要性 E-mail只能传送ASCII码(美国国家标准信息交换码)格式的文字信息,ASCII码是7位代码,非ASCII码格式的文件在传送过程中就需要,先编成7位的ASCII代码,然后才能通过E-mail进行传送;如果不经过编码,则在传送过程中会因为ASCII码7位的限制而被分解,分解之后只会让收信方看到一堆杂乱的ASCII字符。经过编码后的文件,在传送过程中可顺利传送,不会有“被截掉一位”的危险。但是收信方必须具有相应的解码程序,将这份经过编码的东西还原,才能看到发信人要传送的信息是什么。 有一点要注意:大部分的人认为“文本文件不需要编码”,但我们的中文是属于8位代码的文字,并不是标准的ASCII码格式,由于在国内中文是通行的文字,所以大部分的邮件服务器都已能够处理GB内码的文件,因而不需要做这种编码/解码的操作,可以直接传送。但如果要送中文邮件到国外,就需要经过这种转换才能传送,因为国外的邮件服务器是无法辨认中文内码的。中文码在经过一些不支持中文内码的传递主机时,依然会被截掉一位,造成文件支离破碎无法读取。而经过编码的中文邮件,收信人收到后将文件解码还原,也需要有中文系统才能看所写的中文信息。 二、常见的三种编码标准 ●UU编码(Unix-to-Unix encoding) uuencode和uudecode原来是unix系统中使用的编码和解码程序,后来被改写成为在DOS中亦可执行的程序。在早期传送非ASCII码的文件时,最常用的便是这种UU 编码方式。 使用的方法是:发邮件前,在DOS下先用uuencod e exe程序将原文件编码成ASCII码文件,然后将邮件发出。收信人收到邮件后,用uudecode exe程序将文件还原。 基于Windows的类似程序有wincode和winzip等。wincode的使用原理和DOS 下的uuencode和uudecode没什么两样,只是在Windows的界面下操作更为简便。wincode除支持UU编码外也支持MIME、Binhex等编码格式,应用范围颇为广泛。 以上介绍的UU编码并非只能编中文文字。任何你要寄送的文件包括exe等二进制文件都可以按照编码→发送→收信方收信→解码还原的步骤传送。 ●MIME标准(Multipurpose Internet Mail Exte ntions) UU编码解决了E-mail只能传送ASCII文件的问题。但这种方式其实并不是很方便,因而又发展出一种新的编码标准,其全名是Multipurpose Internet Mail Exten tions,一般译作“多媒体邮件传送模式”。顾名思义,它可以传送多媒体文件,在一封电子邮件中附加各种格式文件一起送出。 MIME标准现已成为Internet电子邮件的主流。它的好处是以物件作为包装方式,可将多种不同文件一起打包后传送。发信人只要将要传送的文件选好,它在传送时即时编码,收信人的软件收到也是即时解码还原,完全自动化,非常方便。当然先决条件是双方的软件都必须具有这种功能,要不然发信人很方便地把信送出去了,但收信人的软件如果没有这种功能,无法把它还原,看到的也就是一大堆乱码了。使用这种方式,用户根本不需要知道它是如何编码/解码的。即使只是用文字写的信,一样是打好包便寄出。如果是要寄多媒体文件,只要做选文件的动作,选完后寄出,其余的工作由电子邮件软件自动完成。由于MIME的方便
计算机常见编码
计算机常见编码 一.有关编码的基础知识 1. 位 bit 最小的单元 字节 byte 机器语言的单位 1byte=8bits 1KB=1024byte 1MB=1024KB 1GB=1024MB 2. 二进制 binary 八进制 octal 十进制 decimal 十六进制 hex 3. 字符:是各种文字和符号的总称,包括各个国家的文字,标点符号,图形符号,数字等。 字符集:字符集是多个符号的集合,每个字符集包含的字符个数不同。 字符编码:字符集只是规定了有哪些字符,而最终决定采用哪些字符,每一 个字符用多少字节表示等问题,则是由编码来决定的。计算机要 准确的处理各种字符集文字,需要进行字符编码,以便计算机能 够识别和存储各种文字。 二.常见字符集的编码介绍: 常见的字符集有:ASCII 字符集,GB2312 字符集,BIG5 字符集,GB18030 字符集,Unicode 字符集,下面一一介绍: 1. ASCII 字符集: 定义: 美国信息互换标准代码,是基于罗马字母表的一套电脑编码系统,主要显示 英语和一些西欧语言,是现今最通用的单字节编码系统。 包含内容: 控制字符(回车键,退格,换行键等) 可显示字符(英文大小写,阿拉伯数字,西文符号) 扩展字符集(表格符号,计算符号,希腊字母,拉丁符号) 编码方式: 第 0-31 号及 127 号是控制字符或通讯专用字符; 第 32-126 号是字符,其中 48-57 号为 0-9 十个阿拉伯数字,65-90 号为 26 个大写英文字母,97-122 号为 26 个英文小写字母,其余为一些标点符号,运 算符号等。 在计算机存储单元中,一个 ASCII 码值占一个字节(8 个二进制位),最高位 是用作奇偶检验位。【奇偶校验是指:在代码传送的过程中,用来检验是否 出错的一种方法。】奇偶校验分为奇校验和偶校验。奇校验规定:正确的代 码一个字节中 1 的个数必须是奇数,若非奇数,则在最高位添 1;偶校验规 定:正确的代码一个字节中 1 的个数必须是奇数,若非奇数,则在最高位添 1。
汉字点阵字库原理
一、汉字编码 1. 区位码 在国标GD2312—80中规定,所有的国标汉字及符号分配在一个94行、94列的方阵中,方阵的每一行称为一个―区‖,编号为01区到94区,每一列称为一个―位‖,编号为01位到94位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的―区位码‖。区位码的前两位是它的区号,后两位是它的位号。用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。汉字―母‖字的区位码是3624,表明它在方阵的36区24位,问号―?‖的区位码 为0331,则它在03区3l位。 2. 机内码 汉字的机内码是指在计算机中表示一个汉字的编码。机内码与区位码稍有区别。如上所述,汉字区位码的区码和位码的取值均在1~94之间,如直接用区位码作为机内码,就会与基本ASCII码混淆。为了避免机内码与基本ASCII码的冲突,需要避开基本ASCII码中的控制码(00H~1FH),还需与基本ASCII码中的字符相区别。为了实现这两点,可以先在区码和位码分别加上20H,在此基础上再加80H(此处―H‖表示前两位数字为十六进制数)。经过这些处理,用机内码表示一个汉字需要占两个字节,分别称为高位字节和低 位字节,这两位字节的机内码按如下规则表示: 高位字节= 区码+ 20H + 80H(或区码+ A0H) 低位字节= 位码+ 20H + 80H(或位码+ AOH) 由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的01~94),所以汉字的高位字节与低位字节的取值范围则为A1H~FEH(即十进制的161~254)。 例如,汉字―啊‖的区位码为1601,区码和位码分别用十六进制表示即为1001H,它的机内码的高位字节为 B0H,低位字节为A1H,机内码就是B0A1H。 二、点阵字库结构 1. 点阵字库存储 在汉字的点阵字库中,每个字节的每个位都代表一个汉字的一个点,每个汉字都是由一个矩形的点阵组成,0代表没有,1代表有点,将0和1分别用不同颜色画出,就形成了一个汉字,常用的点阵矩阵有12*12, 14*14, 16*16三种字库。 字库根据字节所表示点的不同有分为横向矩阵和纵向矩阵,目前多数的字库都是横向矩阵的存储方式(用得最多的应该是早期UCDOS字库),纵向矩阵一般是因为有某些液晶是采用纵向扫描显示法,为了提高显示速度,于是便把字库矩阵做成纵向,省得在显示时还要做矩阵转换。我们接下去所描述的都是指横向矩阵 字库。 2. 16*16点阵字库 对于16*16的矩阵来说,它所需要的位数共是16*16=256个位,每个字节为8位,因此,每个汉字都需 要用256/8=32个字节来表示。 即每两个字节代表一行的16个点,共需要16行,显示汉字时,只需一次性读取32个字节,并将每两个 字节为一行打印出来,即可形成一个汉字。 点阵结构如下图所示:
16-16点阵LED显示汉字汇编语言
LED16X16点阵显示课程设计报告 学院 专业 班级 学生 指导老师
一、设计目的 本次课程设计目的剖析试验箱,利用微机接口芯片8255,并行控制LED点阵显示;其次就是掌握8088微机系统与LED点阵显示模块之间接口电路设计及编程,了解LED点阵显示的基本原理和如何来实现汉字的的循环左移显示。 二、设计容 利用598H试验系统扩展接口CZ7座,在控制板MC1上以并行通信的方式控制LED点阵显示。要求自建字库,编制程序实现点阵循环左移显示汉字,并要求通过protues仿真软件画出电路图,运行程序。 三、硬件电路设计 整个电路由8088CPU,两片8255,1个74ls373,1个74LS138,1个16×16的LED,5个7407。该电路可静态显示1个16*16位的汉字,也可循环显示。 1、8255 Intel8255A是一种通用的可编程序并行I/O接口芯片,又称“可编程外设接口芯片”,是为Intel8080/8085系列微处理据设计的,也可用于其它系列的微机系统。可由程序来改变其功能,通用性强、使用灵活。通过8255A,CPU可直接同外设相连接,是应用最广的并行I/O接口芯片。其中含3个独立的8位并行输入/输出端口,各端口均具有数据的控制和锁存能力。可通过编程设置各端口的工作方式和数据传送方向(入/出/双向)。 2、138译码器 译码器是组合逻辑电路的一个重要的器件,74LS138的输出是低电平有效,故实现逻辑功能时,输出端不可接或门及或非门,74LS138与前面不同,其有使能端,故使能端必须加以处理,否则无法实现需要的逻辑功能。发光二极管点亮只须使其正向导通即可,根据LED的公共极是阳极还是阴极分为两类译码器,即针对共阳极的低电平有效的译码器;针对共阴极LED的高电平输出有效的译码器。 3、373锁存器 74LS373是低功耗肖特基TTL8D锁存器,有8个相同的D型(三态同相)锁存器,由两个控制端(11脚G或EN;1脚OUT、CONT、OE)控制。当OE接地时,若G为高电平,74LS373接收由PPU输出的地址信号;如果G为低电平,则将地址信号锁存。工作原理:74LS373的输出端O0—O7可直接与总线相连。当三态允许控制端OE为低电平时,O0—O7为正常逻辑状态,可用来驱动负载或总线。当OE为高电平时,O0—O7呈高阻态,即不驱动总线,也不为总线的负载,但锁存器部的逻辑操作不受影响。当锁存允许端LE为高电平时,O随数据D而变。当LE为低电平时,O被锁存在已建立的数据电平。 4、LED 动态显示原理 LED点阵显示系统中各模块的显示方式:有静态和动态显示两种。静态显示原理简单、控制方便,但硬件接线复杂,在实际应用中一般采用动态显示方式,动态显示采用扫描的方式工作,由峰值较大的窄脉冲电压驱动,从上到下逐次不断地对显示屏的各行进行选通,同时又向各列送出表示图形或文字信息的列数据信号,反复循环以上操作,就可显示各种图形或文字信息。 点阵式LED绝大部分是采用动态扫描显示方式,这种显示方式巧妙地利用了人眼的视
点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法
点阵L E D显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法 -CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN
点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法。2009年06月03日下午 04:27 一.实验要求 编程实现中英文字符的显示。 二.实验目的 1.了解LED点阵显示的基本原理和实现方法。 2.掌握 三.实验电路及连线 点阵显示模块WTD3088的(红色)列输入线接至内部LED的阴极端,行输入线接至内部LED的阳极端(若阳极端输入为高电平,阴极端输入低电平,则该LED点亮)。发光点的分布如图22-0所示。 Fig 22-0 WTD3088 LED分布 如图22-1示,本实验模块使用74LS374来控制列输入线的电平值。将74LS374的某输出置0,则对应的LED阴极端被置低。如图22-2示,本实验模块使用74LS273来控制行输入线,并通过9013提供电流驱动。将74LS273的某输出置1,则对应的LED阳极端被置高。每次系统重新开启或总清后,74LS273输出为全0,LED显示被关闭。 通过编程控制各显示点对应LED阳极和阴极端的电平,就可以有效的控制各显示点的亮灭。
Fig 22-1 LED模块及列扫描电路 Fig 22-2 行扫描电路
Fig 22-3地址译码电路 本实验模块使用4块WTD3088组成16×16点阵,以满足汉字显示的要求。为了方便的控制四个单元,使用了一片74LS139译码,产生四个地址片选信号:CLKR1= CSLED,CLKR2= CSLED+1,用于行控制的两片74LS273;CLKC1= CSLED+2,CLKC2= CSLED+3,用于列控制的两片74LS374。 实验接线:按示例程序,模块的CSLED接51/96地址的8000H。 四.实验说明 使用高亮度LED发光管构成点阵,通过编程控制可以显示中英文字符、图形及视频动态图形。LED显示以其组构方式灵活、亮度高、技术成熟、成本低廉等特点在证券、运动场馆及各种室内/外显示场合得到广泛的应用。 所显示字符的点阵数据可以自行编写(即直接点阵画图),也可从标准字库(如ASC16、HZ16)中提取。后者需要正确掌握字库的编码方法和字符定位的计算。 实验盘片中“字符转换”子目录下提供的,可方便的将单个字符的码表从标准字库Asc16,Hzk16中提取出来。具体使用方法是运行上述可执行程序,根据提示输入所需字符(如是汉字还需要先启动dos下的汉字环境,如ucdos,pdos95等)。程序将该字符的码表提取出来,存放在该字符ASC或区位码为文件名称的.dat文件中。用户只需将该文件中内容拷贝、粘贴到自己的程序中即可。但需要注意字节排列顺序、字节中每一位与具体显示点的一一对应关系,必要时还要对码表稍作修改。同一目录下还提供了上述可执行程序的源文件,使用编写,供用户参考。 五.实验程序框图
一般汉字的编码规则
一般汉字的编码规则 一般汉字就是除了上述两类汉字之外的所有汉字,这部分汉字也称合体汉字,这是五笔字型需要处理的绝大部分汉字。 为了能正常对这些汉字进行编码,五笔字型同时规定了字根码和识别码。 1、字根码: 五笔字型的每一个字根都位于某一个键上,这个键的编码就是字根码。任何字根,只要位于同一个键上,则它们的字根码都相同。 2、识别码: 一个汉字的识别码就是这个汉字的最后一笔的代码与 该汉字的字型结构代码相组合而成。 ⑴、汉字的最后一笔代码: 汉字的最后一笔可分为五种笔画,其为横、竖、撇、捺、折,分别用代码1、2、3、4、5来表示。 ⑵、汉字的字型结构代码: 五笔字型把汉字分为三种字型结构,即左右结构、上下结构和混合结构,分别用代码1、2和3来表示。 如从汉字的组成明显能分成左右两部分,则这类汉字就为左右结构型。如从汉字的组成明显能分成上下两部分,则这类汉字就为上下结构型。除左右结构和上下结构包括汉字
的其余汉字均为混合结构型。 例如:陈、汉、江、语、码为左右结构代码为1 字、笔、定、案、要为上下结构代码为2 虎、运、未、图、包为混合结构代码为3 ⑶、汉字的识别码: 汉字识别码=汉字最后一笔代码+汉字字型结构码。 汉字识别码的示例见下表4-6。 表4-6 汉字识别码示例表 例字最后一笔代码字型结构代码识别码 陈捺 4 左右 1 41 识捺 4 左右 1 41 最捺 4 上下 2 42 数捺 4 左右 1 41 字横 1 上下 2 12 案捺 4 上下 2 42 问横 1 混合 3 13 包折 5 混合 3 53 虎折 5 混合 3 53 未捺 4 混合 3 43