Excel轻松提取网上数据

网上信息采集工作,最头疼的便是从网页上一次次很枯燥地进行数据表格的复制,而且在复制过来之后还要进行很多修改,不但麻烦而且也很浪费时间,工作效率大打折扣。这时我们不妨用功能强大的Excel来试着解决一下问题。
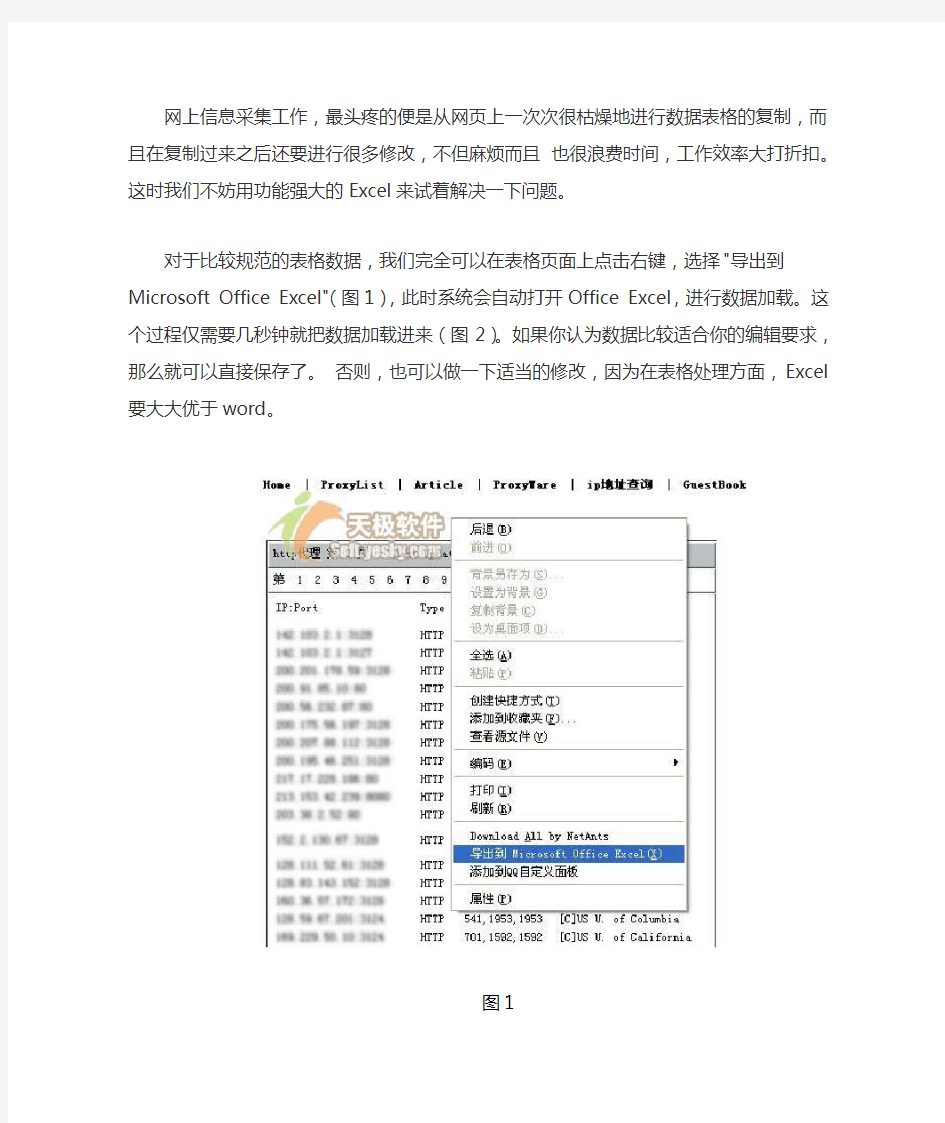
对于比较规范的表格数据,我们完全可以在表格页面上点击右键,选择"导出到Microsoft Office Excel"(图1),此时系统会自动打开Office Excel,进行数据加载。这个过程仅需要几秒钟就把数据加载进来(图2)。如果你认为数据比较适合你的编辑要求,那么就可以直接保存了。否则,也可以做一下适当的修改,因为在表格处理方面,Excel要大大优于word。
图1
在网上表格或数据采集这一点上,Excel往往是较为智能化的,它在进行数据采集与加载时,只加载表格固定区域内的数据,而不是把整个网页都加载进来。这一点我试过很多次,都是很听话的,请看图片2的效果。
图2
当然,在网页中也有一些不太规范的数据与表格,这样的数据,Excel处理起来,稍稍有一点难度,不过只要熟悉Excel 的操作功能的话,还是可以轻松搞定的。先看一下这个页面(图3),
图3
图3这种不规范的页面数据,如果让Excel处理起来就会出现这样的结果(图4),看着是不是感觉很乱,所有的东西都错位了,一般的人会感到速手无策的。主要原因就是多出了文件数据的开头与结尾。
图4
不过,只要我们删除文件上下两头的不规范的区域,剩下的这些数据不就变得好处理了吗?这时,我们再执行一下菜单:"数据――分列――下一步",这样就可以把不规范的数据变得规范了。这是处理之后的结果(图5)
图5
对于那些本来就比较规范的表格,就简单得多了,只要执行"导出加载――略修――保存"就可以了。
Excel数据分析统计
使用Excel可以完成很多专业软件才能完成的数据统计、分析工作,比如:直方图、相关系数、协方差、各种概率分布、抽样与动态模拟、总体均值判断,均值推断、线性、非线性回归、多元回归分析、时间序列等。本专题将教您完成几种最常用的专业数据分析工作。 注意:所有操作将通过Excel“分析数据库”工具完成,如果您没有安装这项功能,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项。 直方图 某班进行期中考试后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。 以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此表格为基础建立数据统计直方图。使用Excel可以直接完成此任务。 [具体方法] 描述统计 某班进行期中考试后,需要统计成绩的平均值、区间,并给出班级内部学生成绩差异的量化标准,借此来作为解决班与班之间学生成绩的参差不齐的依据。要求得到标准差等统计数值。 样本数据分布区间、标准差等都是描述样本数据范围及波动大小的统计量,统计标准差需要得到样本均值,计算较为繁琐。这些都是描述样本数据的常用变量,使用Excel 数据分析中的“描述统计”即可一次完成。[具体方法] 排位与百分比排位 某班级期中考试进行后,按照要求仅公布成绩,但学生及家长要求知道排名。故欲公布成绩排名,学生可以通过成绩查询到自己的排名,并同时得到该成绩位于班级百分比排名(即该同学是排名位于前“X%”的学生)。 排序操作是Excel的基本操作, Excel“数据分析”中的“排位与百分比排位”可以使这个工作简化,直接输出报表。[具体方法]
如何抓取网页数据,以抓取安居客举例
如何抓取网页数据,以抓取安居客举例 互联网时代,网页上有丰富的数据资源。我们在工作项目、学习过程或者学术研究等情况下,往往需要大量数据的支持。那么,该如何抓取这些所需的网页数据呢? 对于有编程基础的同学而言,可以写个爬虫程序,抓取网页数据。对于没有编程基础的同学而言,可以选择一款合适的爬虫工具,来抓取网页数据。 高度增长的抓取网页数据需求,推动了爬虫工具这一市场的成型与繁荣。目前,市面上有诸多爬虫工具可供选择(八爪鱼、集搜客、火车头、神箭手、造数等)。每个爬虫工具功能、定位、适宜人群不尽相同,大家可按需选择。本文使用的是操作简单、功能强大的八爪鱼采集器。以下是一个使用八爪鱼抓取网页数据的完整示例。示例中采集的是安居客-深圳-新房-全部楼盘的数据。 采集网站:https://https://www.360docs.net/doc/453762757.html,/loupan/all/p2/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
如何抓取网页数据,以抓取安居客举例图1 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
如何抓取网页数据,以抓取安居客举例图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,以建立一个翻页循环
如何抓取网页数据,以抓取安居客举例图3 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里的第一个楼盘信息区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
如何抓取网页数据,以抓取安居客举例图4 2)系统会自动识别出页面中的其他同类元素,在操作提示框中,选择“选中全部”,以建立一个列表循环
如何利用excel做数据分析(上下)
网站分析中专业的工具除了Google Analytics, Adobe Sitecatalyst, Webtrends, 腾讯分析和百度统计等外,我想最常用的数据处理工具就是Excel了,Excel里头最基础的就是运算和图表的制作,稍微高级一点就是函数和数据透视表的使用了,当然你可能还会想到VBA和宏,但估计很少高手会使用这些高级的功能。 那对于高级的数据分析而言,也就是涉及统计学的专业分析方法和原理的时候,是不是就一定得求助于SPSS,SAS这类专业的分析工具呢?数据分析从低级到高级层次的跳跃过程中有没有可以起承接作用的工具呢?其实是有的,这就是Excel的数据分析功能。貌似最近比较火的两本Excel书籍《谁说菜鸟不会数据分析》和《让Excel飞》都没有涉及这部分的内容。高级的数据分析会涉及回归分析、方差分析和T检验等方法,不要看这些内容貌似跟日常工作毫无关系,其实往高处走,MBA的课程也是包含这些内容的,所以早学晚学都得学,干脆就提前了解吧,请查看以下内容。 在使用之前,首先得安装Excel的数据分析功能,默认情况下,Excel是没有安装这个扩展功能的,安装如下所示: 1)鼠标悬浮在Office按钮上,然后点击【Excel选项】: 2)找到【加载项】,在管理板块选择【Excel加载项】,然后点击【转到】:
3)选择【分析工具库】,点击【确定】: 4)安装完后,就可以【数据】板块看到【数据分析】功能,如下所示:
安装完后,首先来了解一下回归分析的内容。 一、回归分析 在详细进行回归分析之前,首先要理解什么叫回归?实际上,回归这种现象最早由英国生物统计学家高尔顿在研究父母亲和子女的遗传特性时所发现的一种有趣的现象:身高这种遗传特性表现出”高个子父母,其后代身高也高于平均身高;但不见得比其父母更高,到一定程度后会往平均身高方向发生’回归’”。这种效应被称为”趋中回归”。现在的回归分析则多半指源于高尔顿工作的那样一整套建立变量间的数量关系模型的方法和程序。这里的自变量是父母的身高,因变量是子女的身高。 百度百科对于回归分析的定义是: 回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛: 1)回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析; 2)按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。 这里举个电商的例子:电子商务的转换率是一定的,网站访问数一般正比对应于销售收入,现在要建立不同访问数情况下对应销售的标准曲线,用来预测搞活动时的销售收入,如下所示:
如何抓取网页数据
https://www.360docs.net/doc/453762757.html, 如何抓取网页数据 很多用户不懂爬虫代码,但是却对网页数据有迫切的需求。那么怎么抓取网页数据呢? 本文便教大家如何通过八爪鱼采集器来采集数据,八爪鱼是一款通用的网页数据采集器,可以在很短的时间内,轻松从各种不同的网站或者网页获取大量的规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑,规范化,摆脱对人工搜索及收集数据的依赖,从而降低获取信息的成本,提高效率。 本文示例以京东评论网站为例 京东评价采集采集数据字段:会员ID,会员级别,评价星级,评价内容,评价时间,点赞数,评论数,追评时间,追评内容,页面网址,页面标题,采集时间。 需要采集京东内容的,在网页简易模式界面里点击京东进去之后可以看到所有关于京东的规则信息,我们直接使用就可以的。
https://www.360docs.net/doc/453762757.html, 京东评价采集步骤1 采集京东商品评论(下图所示)即打开京东主页输入关键词进行搜索,采集搜索到的内容。 1、找到京东商品评论规则然后点击立即使用
https://www.360docs.net/doc/453762757.html, 京东评价采集步骤2 2、简易模式中京东商品评论的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为京东商品评论 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 商品评论URL列表:提供要采集的网页网址,即商品评论页的链接。每个商品的链接必须以#comment结束,这个链接可以在商品列表点评论数打开后进行复制。或者自己打开商品链接后手动添加,如果没有这个后缀可能会报错。多个商品评论输入多个商品网址即可。 将鼠标移动到?号图标可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
网页数据抓取方法详解
https://www.360docs.net/doc/453762757.html, 网页数据抓取方法详解 互联网时代,网络上有海量的信息,有时我们需要筛选找到我们需要的信息。很多朋友对于如何简单有效获取数据毫无头绪,今天给大家详解网页数据抓取方法,希望对大家有帮助。 八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。
https://www.360docs.net/doc/453762757.html, 如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。 定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。 定时云采集的设置有两种方法: 方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。
https://www.360docs.net/doc/453762757.html, 第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。 第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
python抓取网页数据的常见方法
https://www.360docs.net/doc/453762757.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子:
https://www.360docs.net/doc/453762757.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.360docs.net/doc/453762757.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
谈用Excel做数据分析(doc 19页)
谈用Excel做数据分析(doc 19页)
用Excel做数据分析——回归分析 2006-12-04 14:02作者:大鸟原创出处:天极软件责任编辑:still 在数据分析中,对于成对成组数据的拟合是经常遇到的,涉及到的任务有线性描述,趋势预测和残差分析等等。很多专业读者遇见此类问题时往往寻求专业软件,比如在化工中经常用到的Origin和数学中常见的MATLAB等等。它们虽很专业,但其实使用Excel就完全够用了。我们已经知道在Excel自带的数据库中已有线性拟合工具,但是它还稍显单薄,今天我们来尝试使用较为专业的拟合工具来对此类数据进行处理。 点这里看专题:用Excel完成专业化数据统计、分析工作 注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘支持下加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项实例某溶液浓度正比对应于色谱仪器中的峰面积,现欲建立不同浓度下对应峰面积的标准曲线以供测试未知样品的实际浓度。已知8组对应数据,建立标准曲线,并且对此曲线进行评价,给出残差等分析数据。 这是一个很典型的线性拟合问题,手工计算就是采用最小二乘法求出拟合直线的待定参数,同时可以得出R的值,也就是相关系数的大小。在Excel中,可以采用先绘图再添加趋势线的方法完成前两步的要求。 选择成对的数据列,将它们使用“X、Y散点图”制成散点图。 在数据点上单击右键,选择“添加趋势线”-“线性”,并在选项标签中要求给出公式和相关系数等,可以得到拟合的直线。
在选项卡中显然详细多了,注意选择X、Y对应的数据列。“常数为零”就是指明该模型是严格的正比例模型,本例确实是这样,因为在浓度为零时相应峰面积肯定为零。先前得出的回归方程虽然拟合程度相当高,但是在x=0时,仍然有对应的数值,这显然是一个可笑的结论。所以我们选择“常数为零”。 “回归”工具为我们提供了三张图,分别是残差图、线性拟合图和正态概率图。重点来看残差图和线性拟合图。 在线性拟合图中可以看到,不但有根据要求生成的数据点,而且还有经过拟和处理的预测数据点,拟合直线的参数会在数据表格中详细显示。本实例旨在提供更多信息以起到抛砖引玉的作用,由于涉及到过多的专业术语,请各位读者根据实际,在具体使用中另行参考各项参数,此不再对更多细节作进一步解释。
网页内容如何批量提取
https://www.360docs.net/doc/453762757.html, 网页内容如何批量提取 网站上有许多优质的内容或者是文章,我们想批量采集下来慢慢研究,但内容太多,分布在不同的网站,这时如何才能高效、快速地把这些有价值的内容收集到一起呢? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集】,以【新浪博客】为例,教大家如何使用八爪鱼采集软件采集新浪博客文章内容的方法。 采集网站: https://www.360docs.net/doc/453762757.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/453762757.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/453762757.html, 步骤2:创建翻页循环
https://www.360docs.net/doc/453762757.html, 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。) 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax加载数据”,超时时间设置为5秒,点击“确定”。
https://www.360docs.net/doc/453762757.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。 2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。
利用R从网站上抓数据
Webscraping using readLines and RCurl There is a massive amount of data available on the web. Some of it is in the form of precompiled, downloadable datasets which are easy to access. But the majority of online data exists as web content such as blogs, news stories and cooking recipes. With precompiled files, accessing the data is fairly straightforward; just download the file, unzip if necessary, and import into R. For “wild” data however, getting the data into an analyzeable format is more difficult. Acce ssing online data of this sort is sometimes reffered to as “webscraping”. Two R facilities, readLines() from the base package and getURL() from the RCurl package make this task possible. readLines For basic webscraping tasks the readLines() function will usually suffice. readLines() allows simple access to webpage source data on non-secure servers. In its simplest form, readLines() takes a single argument – the URL of the web page to be read: web_page <- readLines("https://www.360docs.net/doc/453762757.html,") As an example of a (somewhat) practical use of webscraping, imagine a scenario in which we wanted to know the 10 most frequent posters to the R-help listserve for January 2009. Because the listserve is on a secure site (e.g. it has https:// rather than http:// in the URL) we can't easily access the live version with readLines(). So for this example, I've posted a local copy of the list archives on the this site. One note, by itself readLines() can only acquire the data. You'll need to use grep(), gsub() or equivalents to parse the data and keep what you need. # Get the page's source web_page <- readLines("https://www.360docs.net/doc/453762757.html,/jan09rlist.html") # Pull out the appropriate line author_lines <- web_page[grep("", web_page)] # Delete unwanted characters in the lines we pulled out authors <- gsub("", "", author_lines, fixed = TRUE) # Present only the ten most frequent posters author_counts <- sort(table(authors), decreasing = TRUE) author_counts[1:10]
1.怎样定义抓取网页数据的规则
1 怎样定义抓取网页数据的规则 MetaSeeker工具的用处是定义抓取网页数据的规则,就像首 页所说,手工编写抓取网 页数据的规则容易出错,MetaSeeker能够自动生成抓取规则,使用直观的图形化界面,将人为编码错误的可能降到最 小,而且能够用极短的时间定义一套新的信息提取规则。 与其它网页数据抓取工具不同,MetaSeeker首先引导用户为目标网页定义语义结构(我们称之为信息结构), 并且存储到信息结构描述文件中,这一步看似多余,实际上意义重大,因为目标网站的页面结构可能随着时间进行改变,例如,网站软件进行升级等,原先定义的抓 取网页数据的规则可能会部分失效,需要针对最新页面结构进行调整,调整信息结 构要比直接调整抓取规则直观的多,因为信息结构直接对应网页内容的语义结构, 加上图 形化用户界面(GUI)的便利性,锁定目标网站信息结构变化很容易。 另外,定义信息结构,而不是直接对网页在浏览器上的展现形式或者HTML源代码文 档进行分析,网站更换界面风格(称为皮肤,skin或者 theme)或者修改HTML文档中各内容块的位置和顺序不会导致原先定义的网页数据抓取规则失效。 定义信息结构还有更重大的意义,将网页数据抓取演进到语义网络时代的内容格式化和结构化数据(data sets)管理,抓取下来的结构化网页数据由于包含语义元数据,既可以很 容易的集成到Web 2.0的服务器系统中,例如,垂直搜索、SNS、商品比价服务、商业情报(智能)分析等等,又可以顺利地向Web 3.0(语义网络)时代演进,例如,建设异构数据 对象搜索、结构化数据对象的多形式展现(例如,手机搜索或者手机mashup混搭)等。 与其它网页数据抓取工具的另外一个重大区别是:MetaSeeker工具包将生成抓取网页数据规则和使用抓取规则进行数据抽取的工作分到两个软件工 具上,即MetaStudio 和DataScraper, 是一种高度模块化设计,而且增加了部署的灵活性。实际上,生成网页数据 抓取规则和爬行网络提取信息是两个泾渭分明的任务,分别用不同的模块实现可以最恰当 的贴合软件运行逻辑,例如,DataScraper采用了工作流框架,既确保软件执行效率又确保系统的扩展性,如果想增强DataScraper爬行网络 的能力,只需要扩展工作流的处理节点即可,关于DataScraper的特点和分析留待《DataScraper 使用手册》详述。 MetaStudio生成的抓取网页数据的规则存储在信息提取指令文件中,即数据提取指令 文件和线索提取指令文件,顾名思义,这两个文件命令DataScraper连续不断地从目标网站 上抓取页面数据和网页上的超链接。
php获取网页内容方法
1.file_get_contents获取网页内容 2.curl获取网页内容 3.fopen->fread->fclose获取网页内容
JAVA通过url获取网页内容
import java.io.*; import https://www.360docs.net/doc/453762757.html,.URL; import https://www.360docs.net/doc/453762757.html,.URLConnection; public class TestURL { public static void main(String[] args) throws IOException { test4(); test3(); test2(); test(); } /** * 获取URL指定的资源。 * * @throws IOException */ public static void test4() throws IOException { URL url = new URL("https://www.360docs.net/doc/453762757.html,/attachment/200811/200811271227767778082.jpg"); //获得此URL 的内容。 Object obj = url.getContent(); System.out.println(obj.getClass().getName()); } /** * 获取URL指定的资源 * * @throws IOException */ public static void test3() throws IOException { URL url = new URL("https://www.360docs.net/doc/453762757.html,/down/soft/45.htm"); //返回一个URLConnection 对象,它表示到URL 所引用的远程对象的连接。 URLConnection uc = url.openConnection(); //打开的连接读取的输入流。 InputStream in = uc.getInputStream(); int c; while ((c = in.read()) != -1) System.out.print(c); in.close(); } /** * 读取URL指定的网页内容
利用Excel实现的数据分析方法
利用Excel实现的数据分析方法 利用Excel实现的数据分析方法 随着客服中心的规范化、精细化管理成为行业发展方向,数据分析在运营管理及决策支撑中扮演了越来越重要的角色,很多客服中心认识到数据分析的重要性并积极开始追求各种复杂数据分析技术的应用,但效果往往不佳。其实,笔者认为就国内客服中心运营管理的发展状态而言,能够熟练运用基础的数据分析方法就能够解决运营管理中的大部分问题。分析方法的优劣不在于数学复杂度或者理论高度,而应该注意的是能否科学有效地达到分析目的。 说到分析工具的选择,笔者认为有两点原则需要分析人员注意。第一条原则是选择能够达到分析效果的最简单工具,第二条原则是选择最能够清晰展现分析结果的工具。在目前服务运营分析中出现最多的工具就是Excel,Excel的好处是操作简单,不像SAS、MATLAB需要输入代码命令,对于没有统计分析基础的人来说使用Excel是再好不过的选择。但这是有前提的,就是数据分析人员必须对业务有深刻的了解,因为数据是属于业务的,一个不了解业务的分析人员分析出来的结果往往会偏离现实,不会对管理层的决策与执行层的实施起到任何帮助。下面就介绍一些利用Excel就可以实现的简单有效的数据分析方法。 1、对比分析法 对比分析是客服中心运营分析中运用最多的基础方法,对比分析适用于指标间的横纵向比较、时间序列的比较分析、不同业务或不同人员的比较。
举个例子,拿中国移动某省客服中心接通率数据来看,从时间的维度上分析,我们可以看到品牌A、品牌B与品牌C三个品牌之间接通率随时间的变化趋势,了解在此期间哪个品牌的接通率相对较高,趋势比较稳定。再例如我们分析各品牌话务量情况,首先可以从单一品牌做分析(如图1),各年份话务量基本保持在一致的水平上,但2009年11月份与12月份相对于其他年份话务量明显过高,这可能是由于某些突发事件导致。其次还可以从某一时间点上做分析(如图2),整体上来看,2011年的话务量相对于前两个年份显著降低了很多,这就需要进一步挖掘原因了,一方面可能是已经有一部分客户流失,需要我们找出客户流失的原因并马上制定出客户挽留计划,防止客户继续流失;另一方面就是我们在日常运营时通过有效的方法对话务做分流处理,缓解了一线的话务压力。 图1
如何抓取网页数据
网页源码中规则数据的获取过程: 第一步:获取网页源码。 第二步:使用正则表达式匹配抽取所需要的数据。 第三步:将结果进行保存。 这里只介绍第一步。 https://www.360docs.net/doc/453762757.html,.HttpWebRequest; https://www.360docs.net/doc/453762757.html,.HttpWebResponse; System.IO.Stream; System.IO.StreamReader; System.IO.FileStream; 通过C#程序来获取访问页面的内容(网页源代码)并实现将内容保存到本机的文件中。 方法一是通过https://www.360docs.net/doc/453762757.html,的两个关键的类 https://www.360docs.net/doc/453762757.html,.HttpWebRequest; https://www.360docs.net/doc/453762757.html,.HttpWebResponse; 来实现的。 具体代码如下 方案0:网上的代码,看明白这个就可以用方案一和方案二了 HttpWebRequest httpReq; HttpWebResponse httpResp; string strBuff = ""; char[] cbuffer = new char[256]; int byteRead = 0; string filename = @"c:\log.txt"; ///定义写入流操作 public void WriteStream() { Uri httpURL = new Uri(txtURL.Text); ///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest 的Creat方法建立,并进行强制的类型转换 httpReq = (HttpWebRequest)WebRequest.Create(httpURL); ///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换 httpResp = (HttpWebResponse) httpReq.GetResponse(); ///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生 ProtoclViolationException错误。在此正确的做法应将以下的代码放到一个try块中处理。这里简单处理 Stream respStream = httpResp.GetResponseStream(); ///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容,并以StreamReader类的Read方法依次读取网页源程序代码每一行的内容,直至行尾(读取的编码格式:UTF8) StreamReader respStreamReader = new StreamReader(respStream,Encoding.UTF8); byteRead = respStreamReader.Read(cbuffer,0,256);
活用excel超简单网页列表数据手动抓取法
思路:将直接复制下来的列表信息,通过对各种符号的批量替换,最终使其能在excel文档里,自动排列为A、B、C等不同列,最终通过excel公式,批量生成sql查询语句,直接执行查询,数据入库; 例: https://www.360docs.net/doc/453762757.html,/search.aspx?ctl00$ContentPlaceHolder1$cboPrevio=%E5% 8C%97%E4%BA%AC 1.直接把列表信息复制进新建的txt文档,格式非自动换行,如下图:
2.再把txt里的数据复制进新建的word文档,如图: (注:此处先复制进txt再复制进word的原因是,从网上拿下来的数据直接放入word会包含自身的列表结构甚至是图片,那些都是不需要的东西) 3. ctrl+H打开搜索替换,通过观察,我们在搜索中输入“回车+空格”,即“^p ”,替换中输入“空格”,即“”,如图:
4.全部替换,如图: 5.搜索替换,搜索中输入两个空格“”,替换中输入一个空格“”,疯狂的全部替换,一直到再也搜不到双空格,最终把所有有间隔的地方,变成了一个空格,如图所示:
6.将数据全选复制到新建excel文件的A列,选中A列,数据,分列,如图: 7.选分隔符号,下一步,空格,完成分列,(有连续识别符作为单个处理的选项,可以节省步骤5,但是我为了保险,还是没省略),如图:
8.手动修改例如第三行的,奇葩的、不合群的数据: 9.在此特殊例中,由于每四个电话号码出现一个空格,导致了分列,可用一个简单公式:在E1中输入“=C1&D1”,回车,然后在E1单元格的右下角下拉公式至最后一行,合并如图:
如何运用EXCEL进行数据分析答案
如何运用E X C E L进行 数据分析答案 Document number【980KGB-6898YT-769T8CB-246UT-18GG08】
如何运用EXCEL进行数据分析 课后测试 如果您对课程内容还没有完全掌握,可以点击这里再次观看。 观看课程 测试成绩:90.0分。恭喜您顺利通过考试! 单选题 1. 人力资源专员希望统计表能够自动将合同快要到期的员工姓名突出显示出来,以免耽误续签,这时需要用到EXCEL工具中的:√ A 条件格式 B 排序法 C 数据透视图 D 数据透视表 正确答案:A 2. 在OFFICE2003版本中,EXCEL条件格式中的条件按钮最多有:√ A 1个 B 3个 C 10个 D 无限个 正确答案:B 3. 对比办公软件的不同版本,2007及以上版本相对于2003版本在条件格式中的优势不包括:× A 可以做条形图或色阶 B 自动提供大于、小于等条件的选择 C 可以添加个性化出错警告 D 自动根据文本界定更改颜色 正确答案:C 4. 在EXCEL中,数据透视表的作用可以归纳为:√ A 排序筛选 B 数据统计
C 逻辑运算 D 分类汇总 正确答案:D 5. 数据透视表的所有操作可以概括为:√ A 拖拽、左键 B 拖拽、右键 C 复制、粘贴 D 双击、右键 正确答案:B 6. 使用数据透视表表示公司各部门中员工的平均年龄、平均工资时,分类是(),汇总是()。√ A 部门年龄、工资 B 部门、年龄工资 C 年龄、工资部门 D 年龄工资、部门 正确答案:A 判断题 7. 数据分析的实质是将结论转化为结果,将简单的问题复杂化。此种说法:√ 正确 错误 正确答案:错误 8. 在EXCEL中,做排序和筛选之前必须先选中想要操作的列。此种说法:√ 正确 错误 正确答案:错误 9. EXCEL不仅能够针对数值排序,还能对文本排序。此种说法:√ 正确 错误 正确答案:正确 10. 在数据透视表制作过程中,选区内原始数据标题没有重名、没有合并、没有阿拉伯数字的叫做字段表。此种说法:√ 正确
js 爬虫如何实现网页数据抓取
https://www.360docs.net/doc/453762757.html, js 爬虫如何实现网页数据抓取 互联网Web 就是一个巨大无比的数据库,但是这个数据库没有一个像SQL 语言可以直接获取里面的数据,因为更多时候Web 是供肉眼阅读和操作的。如果要让机器在Web 取得数据,那往往就是我们所说的“爬虫”了。有很多语言可以写爬虫,本文就和大家聊聊如何用js实现网页数据的抓取。 Js抓取网页数据主要思路和原理 在根节点document中监听所有需要抓取的事件 在元素事件传递中,捕获阶段获取事件信息,进行埋点 通过getBoundingClientRect() 方法可获取元素的大小和位置 通过stopPropagation() 方法禁止事件继续传递,控制触发元素事件 在冒泡阶段获取数据,保存数据 通过settimeout异步执行数据统计获取,避免影响页面原有内容 Js抓取流程图如下
https://www.360docs.net/doc/453762757.html, 第一步:分析要爬的网站:包括是否需要登陆、点击下一页的网址变化、下拉刷新的网址变化等等 第二步:根据第一步的分析,想好爬这个网站的思路 第三步:爬好所需的内容保存 爬虫过程中用到的一些包:
https://www.360docs.net/doc/453762757.html, (1)const request = require('superagent'); // 处理get post put delete head 请求轻量接http请求库,模仿浏览器登陆 (2)const cheerio = require('cheerio'); // 加载html (3)const fs = require('fs'); // 加载文件系统模块将数据存到一个文件中的时候会用到 fs.writeFile('saveFiles/zybl.txt', content, (error1) => { // 将文件存起来文件路径要存的内容错误 if (error1) throw error1; // console.log(' text save '); }); this.files = fs.mkdir('saveFiles/simuwang/xlsx/第' + this.page + '页/', (e rror) => { if (error) throw error; }); //创建新的文件夹 //向新的文件夹里面创建新的文件 const writeStream = fs.createWriteStream('saveFiles/simuwang/xlsx/'
用Excel做数据分析——直方图
用Excel做数据分析——直方图 使用Excel自带的数据分析功能可以完成很多专业软件才有的数据统计、分析,这其中包括:直方图、相关系数、协方差、各种概率分布、抽样与动态模拟、总体均值判断,均值推断、线性、非线性回归、多元回归分析、时间序列等内容。下面将对以上功能逐一作使用介绍,方便各位普通读者和相关专业人员参考使用。 注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项。 某班级期中考试进行后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。
以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此表格为基础建立数据统计直方图。使用Excel中的“数据分析”功能可以直接完成此任务。 操作步骤 1.打开原始数据表格,制作本实例的原始数据要求单列,确认数据的范围。本实例为化学成绩,故数据范围确定为0-100。 2.在右侧输入数据接受序列。所谓“数据接受序列”,就是分段统计的数据间隔,该区域包含一组可选的用来定义接收区域的边界值。这些值应当按升序排列。在本实例中,就是以多少分数段作为统计的单元。可采用拖动的方法生成,也可以按照需要自行设置。本实例采用10分一个分数统计单元。 3.选择“工具”-“数据分析”-“直方图”后,出现属性设置框,依次选择:
输入区域:原始数据区域; 接受区域:数据接受序列; 如果选择“输出区域”,则新对象直接插入当前表格中; 若选择“累计百分率”,则会在直方图上叠加累计频率曲线; 4.输入完毕后,则可立即生成相应的直方图,这张图还需要比较大的调整。
网站数据抓取能抓取哪些数据
https://www.360docs.net/doc/453762757.html, 网站数据抓取能抓取哪些数据 互联网数据爆发式增长,且这些数据大多是开放的。通过在线的方式,所有人均可访问和获取这些数据,即网页上直接可见的数据,99%都是可以抓取的。 详细到具体网站,可抓取IT橘子和36Kr的各公司的投融资数据;可抓取知乎/微博/微信等平台的内容;可抓取天猫/淘宝/京东/淘宝等电商的评论及销售数据;可抓取58同城/安居客/Q房网/搜房网上的房源信息;可抓取大众点评/美团网等网站的用户消费和评价;可抓取拉勾网/中华英才/智联招聘/大街网的职位信息...... 网站数据是为我们的需要服务的,先确定好自己的需求,然后选择目标网站,通过写代码/网站数据抓取工具的方式,抓取数据即可。以下是一个八爪鱼采集今日头条网站的完整示例。示例中采集的是今日头条-热点下的新闻标题、新闻来源、发布时间。 采集网站: https://https://www.360docs.net/doc/453762757.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式”
https://www.360docs.net/doc/453762757.html, 网站数据抓取能抓取哪些数据图1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站数据抓取能抓取哪些数据图2
https://www.360docs.net/doc/453762757.html, 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容 网站数据抓取能抓取哪些数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.360docs.net/doc/453762757.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 网站数据抓取能抓取哪些数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量