霍夫曼编码

霍夫曼编码
四川大学计算机学院2009级戚辅光
【关键字】
霍夫曼编码原理霍夫曼译码原理霍夫曼树霍夫曼编码源代码霍夫曼编码分析霍夫曼编码的优化霍夫曼编码的应用
【摘要】
哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。uffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman 编码。哈夫曼压缩是个无损的压缩算法,一般用来压缩文本和程序文件。它属于可变代码长度算法一族。意思是个体符号(例如,文本文件中的字符)用一个特定长度的位序列替代。因此,在文件中出现频率高的符号,使用短的位序列,而那些很少出现的符号,则用较长的位序列。
【正文】
引言
哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。uffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman编码。
霍夫曼编码原理:
霍夫曼编码的基本思想:输入一个待编码的串,首先统计串中各字符出现的次数,称之为频次,假设统计频次的数组为count[],则霍夫曼编码每次找出count数组中的值最小的两个分别作为左右孩子,建立他们的父节点,循环这个操作2*n-1-n(n是不同的字符数)次,这样就把霍夫曼树建好了。建树的过程需要注意,首先把count数组里面的n个值初始化为霍夫曼树的n个叶子节点,他们的孩子节点的标号初始化为-1,父节点初始化为他本身的标号。接下来是编码,每次从霍夫曼树的叶子节点出发,依次向上找,假设当前的节点标号是i,那么他的父节点必然是myHuffmantree[i].parent,如果i是myHuffmantree[i].parent 的左节点,则该节点的路径为0,如果是右节点,则该节点的路径为1。当向上找到一个节点,他的父节点标号就是他本身,就停止(说明该节点已经是根节点)。还有一个需要注意的地方:在查找当前权值最小的两个节点时,那些父节点不是他本身的节点不能考虑进去,因为这些节点已经被处理过了。
霍夫曼树:
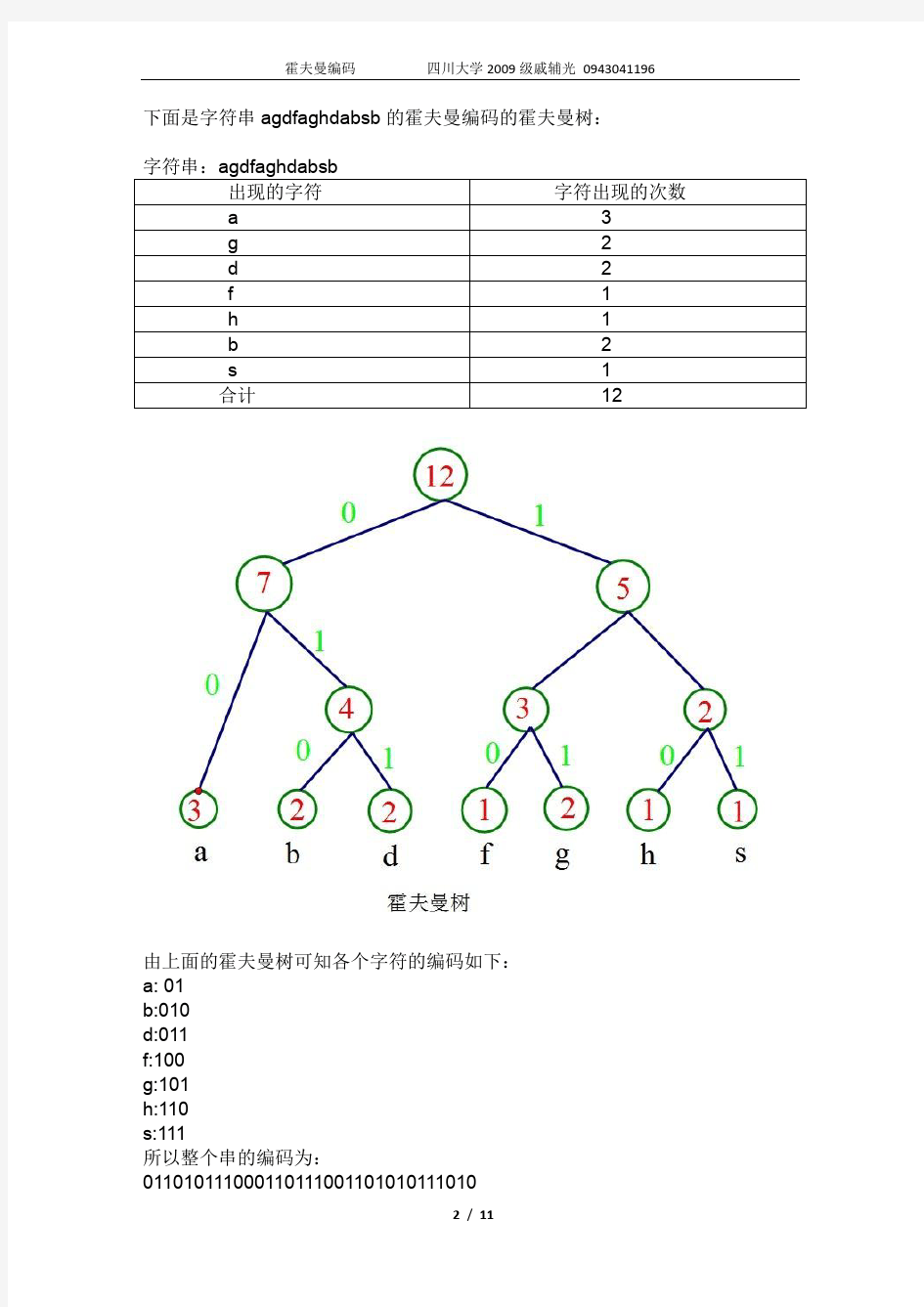
下面是字符串agdfaghdabsb的霍夫曼编码的霍夫曼树:
由上面的霍夫曼树可知各个字符的编码如下:
a: 01
b:010
d:011
f:100
g:101
h:110
s:111
所以整个串的编码为:011010111000110111001101010111010
霍夫曼译码原理:
对于霍夫曼的译码,可以肯定的是其译码结果是唯一的。
证明:因为霍夫曼编码是根据霍夫曼树来确定的,霍夫曼树是一棵二叉树,编码的时候是从树根一直往下走,直到走到叶子节点为止,在其经过的路径上,如果是树的左子树则为0,否则为1。因为每一次都要走到树的叶子节点,多以不可能存在两个编码a和b,使得a是b的前缀或者b是a的前缀。所以编码一定可以唯一确定。
根据上面的结论,我们可以很清楚地直到译码的方法:
定义两个指针p1,p2,P1指向当前编码的开始位置,P2指向当前编码的位置,如果P1-P2这一段编码能在编码库里面找到完全对应的编码结果,则译码成功,该段编码的译码结果就是与编码库里完全对应的编码的字符。循环次操作,直到译码结束!
例一:
假设有一段字符含有a,,c,d三个字符,经过编码之后三个字符对应的编码结果分别为:
a:01
c:010
d:011
现在给你一段编码0110101,要求将其译码!
按照上面介绍的方法我们可以直到:
编码的前三个字符是且仅是d的编码,所以011译码为d,依次译码可得整串的译码结果为daa
霍夫曼编码源代码:
#include
#include
#include
#include
using namespace std;
#define INF 0x7fffffff //无穷大
structHuffmantree //霍夫曼树的节点
{
int weight;
intparent,ld,rd;
};
structmyNode
{
charch;
intnum;
};
structmycode //字符和其对应的编码
{
char ch; //字符
int s[50]; //ch的编码
intlen; //编码长度
};
intnNode; //叶子节点数目
inttotalNode; //霍夫曼树的总节点个数
char toCode[100000] ; //待编码的字符串
myNodemyToCode[100000]; //待编码的字符串和权值
intweightOfToCode[100000] ; //字符串的权值!
HuffmantreemyHuffmantree[1000000]; //霍夫曼树(数组模拟)
char allchar[1000000]; //所哟出现过的字符
mycode coder[1000000]; //字符与对应的编码
int Len; //待编码的字符的总长度
int Coding[100000]; //译码之后的01串
intlenOfCoding ; //01串的长度
void build(int n); //建立霍夫曼树
void select(int&a,int&b); //选择两个权值最小的节点
void Code(); //编码
void printCode(); //打印编码
void deCode(); //译码
int match(intl,int h);
int main()
{
int i;
cout<<"\n=============================霍夫曼编码程序=============================";
cout<<"\n 作者:戚辅光"< cout<<" 时间:2010-11-23"< while(1) { printf("请输入待编码的字符串\n"); int flag=0; gets(toCode); intlen=strlen(toCode); if(len==1) { flag=1; } Len=len; map for(i=0;i { myMap[toCode[i]]++; } map int h=1; for(iter=myMap.begin();iter!=myMap.end();iter++) { myToCode[h].ch=iter->first; allchar[h]=iter->first; weightOfToCode[h]=iter->second; myToCode[h++].num=iter->second; } nNode=h-1; //叶子节点个数 cout<<"----------------------字符统计如下--------------------------------------"< cout<<" 字符次数"< for(i=1;i { cout<<" "< } cout< totalNode=nNode; //totalNode初始值为nNode cout<<"-----------霍夫曼树节点信息如下(子节点为-1表示是叶子节点)---------------"< build(nNode); cout< Code(); cout<<"\n-------------------------字符串的编码结果如下--------------------------\n"; printCode(); cout<<"\n-------------------------01串的译码结果如下-----------------------------\n"; deCode(); cout<<"\n是否继续?(Y/N)\n"; char con[10]; cin>>con; char fang=toupper(con[0]); if(fang=='N') { break; } getchar(); } return 0; } void build(int n) //建立霍夫曼树 { int i; int m=2*n-1; //n个叶子节点的霍夫曼树总节点数为2*n-1 for(i=1;i<=n;i++) //初始化霍夫曼数组 { myHuffmantree[i].weight=weightOfToCode[i]; //叶子节点权值为字符出现次数 myHuffmantree[i].ld=-1; //叶子节点没有左孩子 myHuffmantree[i].rd=-1; //叶子节点没有右孩子 myHuffmantree[i].parent=i; //叶子节点父节点先初始化为他本身 } for(i=n+1;i<=m;i++) { inta,b; select(a,b); myHuffmantree[a].parent=i; myHuffmantree[b].parent=i; myHuffmantree[i].ld=a; myHuffmantree[i].rd=b; myHuffmantree[i].weight=myHuffmantree[a].weight+myHuffmantree[b].weight; myHuffmantree[i].parent=i; } for(i=1;i<=totalNode;i++) { printf("节点:%3d 权值:%3d 左节点:%3d 右节点:%3d 父节点:%3d \n",i,myHuffmantree[i].weight,myHuffmantree[i].ld,myHuffmantree[i].rd,myHuffmantree[i].pare nt); } } void Code() //编码 { inti,j; intnumOfCode[100000]; cout<<"--------------------------各字符编码结果如下----------------------------"< if(Len==1) { cout< return ; } for(i=1;i<=nNode;i++) { j=i; int h=0; while(myHuffmantree[j].parent!=j) { int x=j; j=myHuffmantree[j].parent; if(myHuffmantree[j].ld==x) { numOfCode[h++]=0; } else if(myHuffmantree[j].rd==x) { numOfCode[h++]=1; } } cout<<" "< int x=0; coder[i].len=h; coder[i].ch=allchar[i]; for(int k=h-1;k>=0;k--) { coder[i].s[x++]=numOfCode[k]; printf("%d",numOfCode[k]); } cout< } } void select(int&a,int&b) //选择两个权值最小的节点 { int i; int min1=INF; int min2=INF; int sign1=1; //最小值的下标 int sign2=2; //次小值的下标 for(i=1;i<=totalNode;i++) { if(myHuffmantree[i].parent==i) //说明其是已经更新过的节点 { if(myHuffmantree[i].weight { min1=myHuffmantree[i].weight; sign1=i; } } } for(i=1;i<=totalNode;i++) { if(myHuffmantree[i].parent==i) //说明其是已经更新过的节点 { if(myHuffmantree[i].weight { min2=myHuffmantree[i].weight; sign2=i; } } } a=sign1; b=sign2; totalNode++; //总节点数加1 } void printCode() //打印编码结果! { int i; if(Len==1) //长度为1的时候特殊考虑 { cout<<"0\n"; return ; } int h=0; for(i=0;i { for(int j=1;j<=nNode;j++) { if(toCode[i]==coder[j].ch) { for(int k=0;k { printf("%d",coder[j].s[k]); Coding[h++]=coder[j].s[k]; } } } } lenOfCoding=h; cout< } void deCode() //译码 { inti,j; int begin=0; for(i=0;i { if(match(begin,i)!=-1) { int x=match(begin,i); printf("%c",coder[x].ch); begin=i+1; } } printf("\n"); } int match(intl,int h) //译码的辅助函数(寻找匹配){ inti,j,k; int flag=0; for(i=1;i<=nNode;i++) { if(coder[i].len!=h-l+1) { continue; } k=l; for(j=0;j { if(Coding[k]!=coder[i].s[j]) { break; } if(j==coder[i].len-1) { flag=1; goto ok; } k++; } } ok:; if(flag==1) //查找成功返回对应的下表 { return i; } else //查找不成功返回-1; { return -1; } } 霍夫曼编码代码分析: 1.运行环境:win7操作系统,Inter(R) Core(TM) Duo t6600 @ 2.20GHz 2.20GHz 内存:2.00GB,32位操作系统 2.程序运行结果: 3. 程序功能模块分析: 整个程序包含6个函数: A.void build(int n); B.void select(int&a,int&b); C.void Code(); D.void printCode(); E.void deCode(); F.int match(intl,int h); 其中A是用来建立霍夫曼树,B是在A中调用的一个辅助函数,用来查找两个权值最小的节点的下标,C是对字符串编码,D是现实编码结果,E是译码01串,F是E的辅助函数,用来寻找编码的匹配。 包含3个结构体: A.structHuffmantree //霍夫曼树的节点 { int weight; intparent,ld,rd; }; B.structmyNode//字符和其权值 { char ch; //字符 intnum; //权值 }; C.structmycode //字符和其对应的编码 { char ch; //字符 int s[50]; //ch的编码 intlen; //编码长度 }; 各结构功能如注释! 4. 程序效率分析: 该程序几乎都是用“暴力”的手段完成编码与译码的,所以当要编码的字符比较长,达到10^8长度时运行就会很慢,主要原因在于在建树时每次选择权值最小的两个是用暴力枚举的,还有译码时每次都要在编码库里面去一一匹配,假设编码之后的01串长度为10^7,而其中出现的不同字符数为200,在最坏情况下,译码的时候就需要200*10^7的时间,在这种情况下程序运行就会比较慢,当然,这只是最坏估计,实际上是不可能达到这么高的时间复杂度的,因为不可能每次寻找编码匹配时都要遍历到最后才找到! 5.程序的优化: 既然用“暴力”的方法有时效率会很低,那么有没有什么优化方法呢?答案是肯定的!在建树的时候可以用一个优先队列将个节点信息存在队列里面,优先队列按照节点的权值从小到大排序,所以每次只需取出队列的前两个节点就是权值最小的两个节点,而不需遍历所有节点来选择最小的。优先队列里面是右堆来排序的,时间复杂度很低,为lg(n),所以用有限队列能大幅度降低程序建树的时间复杂度! 霍夫曼编码的应用: 随着信息技术的飞速发展,各种各样的信息需要传输,传输信息就要得先经过编码,然后再译码,可见编码技术的提高对整个信息产业有着举足轻重的作用。霍夫曼编码是一种可变的无损压缩方法,其效率也比较高,所以在当今网络传输中意义重大。霍夫曼树是一棵最有二叉树,在各种程序设计中都用到它来降低程序运行的时间复杂度。 附录二 表1. 传真用的修正霍夫曼编码表 构造码 64 11011 0000001111 960 011010100 0000001110011 128 10010 000011001000 1024 011010101 0000001110100 192 010111 000011001001 1088 011010110 0000001110101 256 0110111 000001011011 1152 011010111 0000001110110 320 00110110 000000110011 1216 011011000 0000001110111 384 00110111 000000110100 1280 011011001 0000001010010 448 01100100 000000110101 1344 011011010 0000001010011 512 01100101 0000001101100 1448 011011011 0000001010100 576 01101000 0000001101101 1472 010011000 0000001010101 640 01100111 0000001001010 1536 010011001 0000001011010 704 011001100 0000001001011 1600 010011010 0000001011011 768 011001101 0000001001100 1664 011000 0000001100100 832 011010010 0000001001101 1728 010011011 0000001100101 896 011010011 0000001110010 EOL 000000000001 000000000001 结尾码 游程长度 白游程编码 黑游程编码 游程长度白游程编码 黑游程编码 0 00110101 0000110111 32 000111011 000001101010 1 000111 010 33 00010010 000001101011 2 0111 11 34 00010011 000011010010 3 1000 10 35 00010100 000011010011 4 1011 011 36 00010101 000011010100 5 1100 0011 37 00010110 000011010101 6 1110 0010 38 00010111 000011010110 7 1111 00011 39 00101000 000011010111 8 10011 000101 40 00101001 000001101100 9 10100 000100 41 00101010 000001101101 10 00111 0000100 42 00101011 000011011010 11 01000 0000101 43 00101100 000011011011 12 001000 0000111 44 00101101 000001010100 13 000011 00000100 45 00000100 000001010101 14 110100 00000111 46 00000101 000001010110 15 110101 000011000 47 00001010 000001010111 16 101010 0000010111 48 00001011 000001100100 17 101011 0000011000 49 01010010 000001100101 18 0100111 0000001000 50 01010011 000001010010 19 0001100 00001100111 51 01010100 000001010011 20 0001000 00001101000 52 01010101 000000100100 21 0010111 00001101100 53 00100100 000000110111 22 0000011 00000110111 54 00100101 000000111000 23 0000100 00000101000 55 01011000 000000100111 24 0101000 00000010111 56 01011001 000000101000 25 0101011 00000011000 57 01011010 000001011000 26 0010011 000011001010 58 01011011 000001011001 27 0100100 000011001011 59 01001010 000000101011 28 0011000 000011001100 60 01001011 000000101100 29 00000010 000011001101 61 00110010 000001011010 30 00000011 000001101000 62 00110011 000001100110 31 00011010 000001101001 63 00110100 000001100111 205 三进制霍夫曼编码 Prepared on 22 November 2020 题目:将霍夫曼编码推广至三进制编码,并证明它能产生最优编码。 ※将霍夫曼编码推广至三进制编码 设一个数据文件包含Q个字符:A1,A2,……,Aq,每个字符出现的频度对应为P:P1,P2,……,Pq。 1.将字符按频度从大到小顺序排列,记此时的排列为排列1。 2.用一个新的符号(设为S1)代替排列1中频度值最小的Q-2k(k为(Q-1)/2取整)个字符,并记其频度值为排列1中最小的Q-2k个频度值相加,再重新按频度从大到小顺序排列字符,记为排列2。(注:若Q-2k=0,则取其值为2,若Q-2k=1,则取其值为 3.) 3.对排列2重复上述步骤2,直至最后剩下3个概率值。 4.从最后一个排列开始编码,根据3个概率大小,分别赋予与3个字符对应的值:0、1、2,如此得到最后一个排列3个频度的一位编码。 5.此时的3个频度中有一个频度是由前一个排列的3个相加而来,这3个频度就取它的一位编码后面再延长一位编码,得到二位编码,其它不变。 6.如此一直往前,直到排列1所有的频度值都被编码为止。 举例说明如下(假设Q=9): 频度中的黑体为前一频度列表中斜体频度相加而得。编码后字符A1~A9的码字依次为:2,00,02,10,11,12,010,011,012。 构造三进制霍夫曼编码伪码程序如下: HUFFMAN(C) 1 n ←∣C ∣ 2 Q ← C 3 for i ← 1 to n-1 4 do allocate a new node s 5 left[s] ← x ← EXTRACT-MIN(Q) 6 middle[s] ← y ← EXTRACT-MIN(Q) 7 right[s] ← z ← EXTRACT-MIN(Q) 8 f[s] ← f[x]+f[y]+f[z] 9 INSERT(Q,z) 10 return EXTRACT-MIN(Q) ※霍夫曼编码(三进制)最优性证明 在二进制霍夫曼编码中,文件的最优编码由一棵满二叉树表示,树中每个非叶子结点都有两个子结点。在此与之相对应,构造一棵满三叉树来表示三进制的霍夫曼编码,树中每个非叶子结点都有三个子结点。对文件中A中的每个字符a,设f(a)表示a在文件中出现的频度,d T(a)表示字符a的编码长度,亦即a 的叶子在树中的深度。这样,编码一个文件所需的位数就是 B(T)=∑f(a)d T(a) 设A为一给定文件,其中每个字符都定义有频度f[a]。设x,y和z是A中具有最低频度的两个字符。并设A'为文件A中移去x,y和z,再加上新的字符s后的文件,亦即A'=A-{x,y,z}∪{s};如A一样为A'定义f,其中f[s]=f[x]+f[y]+f[z]。设T'为文件A'上最优 霍夫曼编码 霍夫曼编码(Huffman Coding)是一种编码方法,霍夫曼编码是可变字长编码(VLC)的一种。1952年,David A. Huffman在麻省理工攻读博士时所提出一种编码方法,并发表于《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)一文。 该方法完全依据字符出现概率来构造异字头的平均长度最短的 码字,有时称之为最佳编码,一般就叫作Huffman编码。 在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。1951年,霍夫曼和他 在MIT信息论的同学需要选择是完成学期报告还是期末考试。 导师Robert M. Fano给他们的学期报告的题目是,查找最有效的二进制编码。由于无法证明哪个已有编码是最有效的,霍夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的想法,并很快证明了这个方法是最有效的。由于这个算法,学生终于青出于蓝,超过了他那曾经和信息论创立者克劳德·香农共同研究过类似编码的导师。霍夫曼使用自底向上的方法构建二叉树,避免了次优算法Shannon-Fano编码的最大弊端──自顶向下构建树。 霍夫曼(Huffman)编码是一种统计编码。属于无损(lossless)压缩编码。 以霍夫曼树─即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。 ←根据给定数据集中各元素所出现的频率来压缩数据的 一种统计压缩编码方法。这些元素(如字母)出现的次数越 多,其编码的位数就越少。 ←广泛用在JPEG, MPEG, H.2X等各种信息编码标准中。霍夫曼编码的步骤 霍夫曼编码的具体步骤如下: 1)将信源符号的概率按减小的顺序排队。 2)把两个最小的概率相加,并继续这一步骤,始终将较高的概率分支放在上部,直到最后变成概率1。 3)将每对组合的上边一个指定为1,下边一个指定为0(或相反)。4)画出由概率1处到每个信源符号的路径,顺序记下沿路径的0和1,所得就是该符号的霍夫曼码字。 信源熵的定义: 概率空间中每个事件所含有的自信息量的数学期望称信源熵或简称熵(entropy),记为: 例:现有一个由5个不同符号组成的30个符号的字 符串:BABACACADADABBCBABEBEDDABEEEBB 计算 (1) 该字符串的霍夫曼码 (2) 该字符串的熵 (3) 该字符串的平均码长 哈夫曼编码步骤: 一、对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F= {T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。(为方便在计算机上实现算法,一般还要求以Ti的权值Wi的升序排列。) 二、在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。 三、从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。 四、重复二和三两步,直到集合F中只有一棵二叉树为止。 /*------------------------------------------------------------------------- * Name: 哈夫曼编码源代码。 * Date: 2011.04.16 * Author: Jeffrey Hill+Jezze(解码部分) * 在Win-TC 下测试通过 * 实现过程:着先通过HuffmanTree() 函数构造哈夫曼树,然后在主函数main()中 * 自底向上开始(也就是从数组序号为零的结点开始)向上层层判断,若在 * 父结点左侧,则置码为0,若在右侧,则置码为1。最后输出生成的编码。*------------------------------------------------------------------------*/ #include #include"stdafx.h" #include"stdio.h" #include"conio.h" #include 霍夫曼编码的matlab实现 一、实验内容: 用Matlab语言编程实现霍夫曼(Huffman)编码。 二、实验原理及编码步骤: 霍夫曼(Huffman)编码算法是满足前缀条件的平均二进制码长最短的编-源输出符号,而将较短的编码码字分配给较大概率的信源输出。算法是:在信源符号集合中,首先将两个最小概率的信源输出合并为新的输出,其概率是两个相应输出符号概率之和。这一过程重复下去,直到只剩下一个合并输出为止,这个最后的合并输出符号的概率为1。这样就得到了一张树图,从树根开始,将编码符号1 和0 分配在同一节点的任意两分支上,这一分配过程重复直到树叶。从树根到树叶途经支路上的编码最后就构成了一组异前置码,就是霍夫曼编码输出。以本教材P74例题3-18信源为例: 信源: X x1 x2 x3 x4 x5 q(X) = 0.4 0.2 0.2 0.1 0.1 解: 通过上表的对信源缩减合并过程,从而完成了对信源的霍夫曼编码。 特点:霍夫曼编码在三种编码方法中编码效率最高 基本步骤:p72 三、实验程序及运行结果 (见附录6) 程序流程图:XXXXXXXXXXXX 四 分析结果 由程序运行结果可知: 方法一(概率之和往上排): 码字:11 01 00 101 100 编码效率: %4.962 .212 .21log 2 .22.038.0212 .2)(log ) (log )(log n 5 11≈= ==?+?==-= = ∑ηη所以:) (D n X H D n xm q xm q D X H 码长均值:2.22.038.02n 1=?+?= 码长均方差:{}16.02.0)2.23(8.0)2.22()2221=?-+?-=-n n E ( 方法二(概率之和往下排): 码字:0 10 111 1101 1100 编码效率: %4.962 .212 .21log 2.22.042.032.024.0112.2)(log ) (log )(log n 5 12≈= ==?+?+?+?==-= =∑ηη所以:) (D n X H D n xm q xm q D X H 码长均值:2.22.042.032.024.01n 2=?+?+?+?= 码长均方差: { }36 .12.02.2-42.02.2-32.0)2.22(4.0)2.21()2 2222 22=?+?+?-+?-=-)()((n n E 比较方法一和方法二可知:两张编码方法平均码长相等,但方法二均方差较大,一般取均方 差小的编码方法,这样译码会更简单。 1.哈夫曼编码的方法 编码过程如下: (1) 将信源符号按概率递减顺序排列; (2) 把两个最小的概率加起来, 作为新符号的概率; (3) 重复步骤(1) 、(2), 直到概率和达到1 为止; (4) 在每次合并消息时,将被合并的消息赋以1和0或0和1; (5) 寻找从每个信源符号到概率为1处的路径,记录下路径上的1和0; (6) 对每个符号写出"1"、"0"序列(从码数的根到终节点)。 2.哈夫曼编码的特点 ①哈夫曼方法构造出来的码不是唯一的。 原因 ·在给两个分支赋值时, 可以是左支( 或上支) 为0, 也可以是右支( 或下支) 为0, 造成编码的不唯一。 ·当两个消息的概率相等时, 谁前谁后也是随机的, 构造出来的码字就不是唯一的。 ②哈夫曼编码码字字长参差不齐, 因此硬件实现起来不大方便。 ③哈夫曼编码对不同的信源的编码效率是不同的。 ·当信源概率是2 的负幂时, 哈夫曼码的编码效率达到100%; ·当信源概率相等时, 其编码效率最低。 ·只有在概率分布很不均匀时, 哈夫曼编码才会收到显著的效果, 而在信源分布均匀的情况下, 一般不使用哈夫曼编码。 ④对信源进行哈夫曼编码后, 形成了一个哈夫曼编码表。解码时, 必须参照这一哈夫编码表才能正确译码。 ·在信源的存储与传输过程中必须首先存储或传输这一哈夫曼编码表在实际计算压缩效果时, 必须考虑哈夫曼编码表占有的比特数。在某些应用场合, 信源概率服从于某一分布或存在一定规律 使用缺省的哈夫曼编码表有 解:为了进行哈夫曼编码, 先把这组数据由大到小排列, 再按上方法处理 (1)将信源符号按概率递减顺序排列。 (2)首先将概率最小的两个符号的概率相加,合成一个新的数值。 (3)把合成的数值看成是一个新的组合符号概率,重复上述操作,直到剩下最后两个符号。 5.4.2 Shannon-Famo编码 Shannon-Famo(S-F) 编码方法与Huffman 的编码方法略有区别, 但有时也能编 出最佳码。 1.S-F码主要准则 符合即时码条件; 在码字中,1 和0 是独立的, 而且是( 或差不多是)等概率的。 这样的准则一方面能保证无需用间隔区分码字,同时又保证每一位码字几乎有 1位的信息量。 2.S-F码的编码过程 信源符号按概率递减顺序排列; 把符号集分成两个子集, 每个子集的概率和相等或近似相等; 霍夫曼编码 四川大学计算机学院2009级戚辅光 【关键字】 霍夫曼编码原理霍夫曼译码原理霍夫曼树霍夫曼编码源代码霍夫曼编码分析霍夫曼编码的优化霍夫曼编码的应用 【摘要】 哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。uffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman 编码。哈夫曼压缩是个无损的压缩算法,一般用来压缩文本和程序文件。它属于可变代码长度算法一族。意思是个体符号(例如,文本文件中的字符)用一个特定长度的位序列替代。因此,在文件中出现频率高的符号,使用短的位序列,而那些很少出现的符号,则用较长的位序列。 【正文】 引言 哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。uffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman编码。 霍夫曼编码原理: 霍夫曼编码的基本思想:输入一个待编码的串,首先统计串中各字符出现的次数,称之为频次,假设统计频次的数组为count[],则霍夫曼编码每次找出count数组中的值最小的两个分别作为左右孩子,建立他们的父节点,循环这个操作2*n-1-n(n是不同的字符数)次,这样就把霍夫曼树建好了。建树的过程需要注意,首先把count数组里面的n个值初始化为霍夫曼树的n个叶子节点,他们的孩子节点的标号初始化为-1,父节点初始化为他本身的标号。接下来是编码,每次从霍夫曼树的叶子节点出发,依次向上找,假设当前的节点标号是i,那么他的父节点必然是myHuffmantree[i].parent,如果i是myHuffmantree[i].parent 的左节点,则该节点的路径为0,如果是右节点,则该节点的路径为1。当向上找到一个节点,他的父节点标号就是他本身,就停止(说明该节点已经是根节点)。还有一个需要注意的地方:在查找当前权值最小的两个节点时,那些父节点不是他本身的节点不能考虑进去,因为这些节点已经被处理过了。 霍夫曼树: 题目:将霍夫曼编码推广至三进制编码,并证明它能产生最优编码。 ※将霍夫曼编码推广至三进制编码 设一个数据文件包含Q个字符:A1,A2,……,Aq,每个字符出现的频度对应为P:P1,P2,……,Pq。 1.将字符按频度从大到小顺序排列,记此时的排列为排列1。 2.用一个新的符号(设为S1)代替排列1中频度值最小的Q-2k(k为(Q-1)/2取整)个字符,并记其频度值为排列1中最小的Q-2k个频度值相加,再重新按频度从大到小顺序排列字符,记为排列2。(注:若Q-2k=0,则取其值为2,若Q-2k=1,则取其值为 3.) 3.对排列2重复上述步骤2,直至最后剩下3个概率值。 4.从最后一个排列开始编码,根据3个概率大小,分别赋予与3个字符对应的值:0、1、2,如此得到最后一个排列3个频度的一位编码。 5.此时的3个频度中有一个频度是由前一个排列的3个相加而来,这3个频度就取它的一位编码后面再延长一位编码,得到二位编码,其它不变。 6.如此一直往前,直到排列1所有的频度值都被编码为止。 举例说明如下(假设Q=9): 字符A1 A2 A3 A4 A5 A6 A7 A8 A9 频度0.22 0.18 0.15 0.13 0.10 0.07 0.07 0.05 0.03 字符频度编码频度编码频度编码频度编码A1 0.22 2 0.22 2 0.30 1 0.480 A2 0.18 00 0.18 00 0.22 2 0.30 1 A3 0.15 02 0.1501 0.18 00 0.22 2 A4 0.13 10 0.15 02 0.15 01 A5 0.10 11 0.13 10 0.15 02 A6 0.07 12 0.10 11 A7 0.07 010 0.07 12 A8 0.05 011 A9 0.03 012 频度中的黑体为前一频度列表中斜体频度相加而得。编码后字符A1~A9的码字依次为:2,00,02,10,11,12,010,011,012。 构造三进制霍夫曼编码伪码程序如下: HUFFMAN(C) 1 n ←∣C ∣ 2 Q ← C 3for i ←1 to n-1 4 do allocate a new node s 以下是Huffman编码原理简介: 霍夫曼(Huffman)编码是1952年为文本文件而建立,是一种统计编码。属于无损压缩编码。霍夫曼编码的码长是变化的,对于出现频率高的信息,编码的长度较短;而对于出现频率低的信息,编码长度较长。这样,处理全部信息的总码长一定小于实际信息的符号长度。 对于学多媒体的同学来说,需要知道Huffman编码过程的几个步骤: l)将信号源的符号按照出现概率递减的顺序排列。(注意,一定要递减) 2)将最下面的两个最小出现概率进行合并相加,得到的结果作为新符号的出现概率。 3)重复进行步骤1和2直到概率相加的结果等于1为止。 4)在合并运算时,概率大的符号用编码0表示,概率小的符号用编码1表示。 5)记录下概率为1处到当前信号源符号之间的0,l序列,从而得到每个符号的编码。 下面我举个简单例子: 一串信号源S={s1,s2,s3,s4,s5}对应概率为p={40,30,15,10,5},(百分率) 按照递减的格式排列概率后,根据第二步,会得到一个新的概率列表,依然按照递减排列,注意:如果遇到相同概率,合并后的概率放在下面! 最后概率最大的编码为0,最小的编码为1。如图所示: 所以,编码结果为 s1=1 s2=00 s3=010 s4=0110 s5=0111 霍夫曼编码具有如下特点: 1) 编出来的码都是异字头码,保证了码的唯一可译性。 2) 由于编码长度可变。因此译码时间较长,使得霍夫曼编码的压缩与还原相当费时。 3) 编码长度不统一,硬件实现有难度。 4) 对不同信号源的编码效率不同,当信号源的符号概率为2的负幂次方时,达到100%的编码效率;若信号源符号的概率相等,则编码效率最低。 5) 由于0与1的指定是任意的,故由上述过程编出的最佳码不是唯一的,但其平均码长是一样的,故不影响编码效率与数据压缩性能。 重庆交通大学信息科学与工程学院综合性设计性实验报告 专业班级:通信工程2012级2班 学号:631206040217 姓名:雷勇 实验所属课程:信息论与编码 实验室(中心):软件与通信实验中心 指导教师:黄大荣 2015年4月 教师评阅意见: 签名:年月日实验成绩: 霍夫曼编码的matlab实现 一、实验目的和要求 1回顾霍夫曼编码的原理。 2用Matlab语言编程实现霍夫曼(Huffman)编码。 二、实验原理 1 霍夫曼编码介绍 霍夫曼编码(Huffman Coding)是一种熵编码编码压缩方式,霍夫曼编码是可变字长编码(VLC)的一种。霍夫曼压缩是个无损的压缩算法,一般用来压缩文本和程序文件。哈夫曼压缩属于可变代码长度算法一族。意思是不同符号(例如,文本文件中的字符)用一个特定长度的位序列替代。因此,在文件中出现频率高的符号,使用短的位序列,而那些很少出现的符号,则用较长的位序列。 霍夫曼编码的码长是变化的,对于出现频率高的信息,编码的长度较短;而对于出现频率低的信息,编码长度较长。这样,处理全部信息的总码长一定小于实际信息的符号长度。霍夫曼编码是一种根据字母的使用频率而设计的变长码,能提高信息的传输效率,至今仍有广泛的应用。霍夫曼编码方法的具体过程是:首先把信源的各个输出符号序列按概率递降的顺序排列起来,求其中概率最小的两个序列的概率之和,并把这个概率之和看做是一个符号序列的概率,再与其他序列依概率递降顺序排列(参与求概率之和的这两个序列不再出现在新的排列之中)。然后,对参与概率求和的两个符号序列分别赋予二进制数字0和1。继续这样的操作,直到剩下一个以1为概率的符号序列。最后,按照与编码过程相反的顺序读出各个符号序列所对应的二进制数字组,就可分别得到各该符号序列的码字霍夫曼编码(Huffman Coding)是一种编码方式,是一种用于无损数据压缩的熵编码(权编码)算法。1952年,David A. Huffman在麻省理工攻读博士时所发明的,并发表于《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)一文。 在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一 %哈夫曼编码的 MATLAB 实现(基于 0、1 编码):clc; clear; A=[0.3,0.2,0.1,0.2,0.2];A=fliplr(sort(A));% T=A;信源消息的概率序列按降序排列 [m,n]=size(A); B=zeros(n,n-1);% 空的编码表(矩阵)for i=1:n B(i,1)=T(i);% end 生成编码表的第一列 r=B(i,1)+B(i-1,1);% 最后两个元素相加T(n-1)=r; T(n)=0; T=fliplr(sort(T) );t=n-1; for j=2:n-1% 生成编码表的其他各列for i=1:t B(i,j)=T(i) ;end K=find(T==r); B(n,j)=K(end);% %该列的位置 从第二列开始,每列的最后一个元素记录特征元素在r=(B(t- 1,j)+B(t,j));% T(t-1)=r;最后两个元素相加T(t)=0; T=fliplr(sort(T) ); t=t-1; end B;%输出编码表 END1=sym('[0,1]');% 给最后一列的元素编码END=END1; t=3; d=1; for j=n-2:-1:1% 从倒数第二列开始依次对各列元素编码for i=1:t-2 if i>1 & B(i,j)==B(i- 1,j)d=d+1; else d=1;end B(B(n,j+1),j+1)=-1; temp=B(:,j+1); x=find(temp==B(i,j)); END(i)=END1(x(d)); end y=B(n,j+1); END(t-1)=[char(END1(y)),'0']; END(t)=[char(END1(y)),'1']; t=t+1; END1=END; end A% 排序后的原概率序列 END% 编码结果 for i=1:n [a,b]=size(char(END(i))) ; L(i)=b; end avlen=sum(L.*A)% 平均码长 H1=log2(A); H=-A*(H1')% 熵 P=H/avlen%编码效率 2 实验六图像的霍夫曼编码 一、实验目的: 1)理解并熟练对图像进行霍夫曼编码的算法; 2)进一步加深对所学数字图像处理内容的认识; 3)能够利用各种软件对算法加以实现。 二、实验内容: 1)对数字图像进行哈弗曼编码 2)对数字图像进行算术编码 3)分析所得到的结果。 三、实验原理 哈夫曼(Huffman)编码是一种常用的压缩编码方法,是Huffman于1952年为压缩文本文件建立的。它的基本原理是频繁使用的数据用较短的代码代替,较少使用的数据用较长的代码代替,每个数据的代码各不相同。这些代码都是二进制码,且码的长度是可变的。具体算法如下: 1)首先统计出每个符号出现的频率,上例S0到S7的出现频率分别为4/14,3/14, 2/14,1/14,1/14,1/14,1/14,1/14。 2)从左到右把上述频率按从小到大的顺序排列。 3)每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根 节点,这两个叶子节点不再参与比较,新的根节点参与比较。 4)重复(3),直到最后得到和为1的根节点。 5)将形成的二叉树的左节点标0,右节点标1。把从最上面的根节点到最下面 的叶子节点途中遇到的0,1序列串起来,就得到了各个符号的编码。 四、实验过程 1)实验流程图 霍夫曼编码示意图如下: 2)实验代码 见实验报告附页。 五、实验结果 1)打开要进行编码的图片,如下图所示: 2)对图片进行霍夫曼编码,得到如下结果: 六、实验总结 1)通过本实验,进一步加深了对霍夫曼编码的实验原理和算法的理解和认识; 2)加强了分析问题和解决问题的能力; 3)熟练了软件的使用能力,提高了利用软件对数字图像进行处理的能力。 附页: 实验代码: unsigned int PcxBytesPerLine; BOOL LoadPcxFile (HWND hWnd,char *PcxFileName) { FILE *PCXfp; PCXHEAD header; LOGPALETTE *pPal; 编号: 题目名称图像编码——霍夫曼编码 学生姓名学号 学院信息科学与工程学院 专业年级 2009级通信一班 指导教师职称老师 填写时间2012年10月27日 摘要 进入21世纪,人类已步入信息社会,新信息技术革命使人类被日益增多的多媒体信息所包围,这也正好迎合了人类对要示提高视觉信息的需求。多媒体信息主要有三种形式:文本、声音和图像。从信息传输的发展史(电报、电话、传真、收音机、电视机直至现在的网络)可以看出,人们逐渐将信息传输的重点从声音转向图像,然而图像是三种信息形式中数据量最大的,这给图像的传输和存储带来了极大的困难。对于巨大的数字图像数据量,如果不经过压缩,不仅超出了计算机的存储和处理能力,而且在现有的通信信道的传输速率下,是无法完成大量多媒体信息实时传输的,数字图像高速传输和存贮所需要的巨大容量已成为推广数字图像通信和最大障碍。因此,为了存储、处理和传输这些数据,必须进行压缩。 图像压缩之所以能够进行压缩是因为原始图像数据是高度相关的,存在很大的数据冗余。数字图像包含的冗余信息一般有以下几种:空间冗余、时间冗余、信息熵冗余、统计冗余、结构冗余、视觉冗余以及知识冗余等。图像压缩算法就是要在保证图像一定的重建质量的同时,尽可能多的去除这些冗余信息,以达到对图像压缩的目的。 关键词:图像处理,图像压缩,压缩算法,图像编码,霍夫曼编码 1.图像数据压缩原理 对数字图像进行压缩通常利用两个基本原理:一是数字图像的相关性。在图像的同一行相邻象素之间,相邻象素之间,活动图像的相邻帧的对应象素之间往往存在很强的相关性,去除或减少这些相关性,也即去除或减少图像信息中的冗余度也就实现了对数字图像的压缩。帧内象素的相关称做空域相关性。相邻帧间对应象素之间的相关性称做时域相关性。二是人的视觉心理特征。人的视觉对于边缘急剧变化不敏感(视觉掩盖效应),对颜色分辨力弱,利用这些特征可以在相应部分适当降低编码精度而使人从视觉上并不感觉到图像质量的下降,从而达到对数字图像压缩的目的。 图像数据压缩的目的是在满足一定图像质量的条件下,用尽可能少的比特数来表示原始图像,以提高图像传输的效率和减少图像存储的容量,在信息论中称为信源编码。图像压缩是通过删除图像数据中冗余的或者不必要的部分来减小图像数据量的技术,压缩过程就是编码过程,解压缩过程就是解码过程。压缩技术分为无损压缩和有损压缩两大类,前者在解码时可以精确地恢复原图像,没有任何损失;后者在解码时只能近似原 霍夫曼编码 080212418高延邦 摘要:霍夫曼编码是一种常用的无损编码,他基于不同符号的概率分布,在信息源中出现概率越大的符号,相应的码越短;出现概率越小的符号,其码越长,从而达到用尽可能少的码符号表示源数据。本文首先介绍了信息论中的信息量,信息量是信息多少的量度。然后介绍了霍夫曼编码的应用,原理,具体步骤和特点。本文主要特色是结合实例十分详细地介绍了霍夫曼编码的原理,霍夫曼编码的方法,霍夫曼树的生成过程,霍夫曼编码的产生,霍夫曼表的构建,霍夫曼编码的结果以及怎么用计算机实现霍夫曼编码。 关键字:霍夫曼编码霍夫曼树最优二叉树无损压缩霍夫曼编码源代码 引言 霍夫曼编码(Huffman Coding)是一种编码方式,是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码。 一、霍夫曼编码理论基础 什么是信息量?信息量是信息多少的量度。1928年R.V.L.霍特莱首先提出信息定量化的初步设想,他将消息数的对数定义为信息量。若信源有m种消息,且每个消息是以相等可能产生的,则该信源的信息量可表示为I=-log(m)。 一个事件集合x1,x2,……x n,处于一个基本概率空间,其相应概率为p1,p2,……p n,且p1,p2,……p n 之和为1,每一个事件的信息量为I(x k)=-log n(p k),如定义在空间中的每一事件的概率不相等的平均不肯定程度或平均信息量叫做H,则H=E{I(x k)}=∑p k I(x k)=- ∑p k log a(p k)。 对于图像来说,n=2m个灰度级xi,则p(xi)为各灰度级出现的概率,熵即表示平均信息量为多少比特,换句话说,熵是编码所需比特数的下限,即编码所需的最少比特。编码一定要用不比熵少的比特数编码才能完全保持原图像的信息,这是图像压缩的下限。当a=2是,H的单位是比特。 二、霍夫曼编码简介 霍夫曼编码是1952年为文本文件而建立,是一种统计编码。霍夫曼编码是常用的无损编码方法,广泛应用于图像压缩技术。JPEG标准中的基准模式采用的就是霍夫曼编码。霍夫曼编码是不定长编码,即代表各元素的码字长度不等。该编码是基于不同符号的概率分布,在信息源中出现概率越大的符号,相应的码越短;出现概率越小的符号,其码越长,从而达到用尽可能少的码符号表示源数据。它在变长编码中是最佳的。在计算机信息处理中,“霍夫曼编码”是一种一致性编码法(又称"熵编码法")。 哈夫曼编码: 哈夫曼编码,又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码。 发展历史: 1951年,哈夫曼和他在MIT信息论的同学需要选择是完成学期报告还是期末考试。导师Robert M. Fano给他们的学期报告的题目是,寻找最有效的二进制编码。由于无法证明哪个已有编码是最有效的,哈夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的想法,并很快证明了这个方法是最有效的。由于这个算法,学生终于青出于蓝,超过了他那曾经和信息论创立者香农共同研究过类似编码的导师。 1952年,David A. Huffman在麻省理工攻读博士时发表了《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)一文,它一般就叫做Huffman编码。 Huffman在1952年根据香农(Shannon)在1948年和范若(Fano)在1949年阐述的这种编码思想提出了一种不定长编码的方法,也称霍夫曼(Huffman)编码。霍夫曼编码的基本方法是先对图像数据扫描一遍,计算出各种像素出现的概率,按概率的大小指定不同长度的唯一码字,由此得到一张该图像的霍夫曼码表。编码后的 图像数据记录的是每个像素的码字,而码字与实际像素值的对应关系记录在码表中。 赫夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就称Huffman 编码。下面引证一个定理,该定理保证了按字符出现概率分配码长,可使平均码长最短。 我们设置一个结构数组HuffNode 保存哈夫曼树中各结点的信息。根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n-1 个结点,所以数组HuffNode 的大小设置为2n-1 。HuffNode 结构中有weight, lchild, rchild 和parent 域。其中,weight 域保存结点的权值, lchild 和rchild 分别保存该结点的左、右孩子的结点在数组HuffNode 中的序号,从而建立起结点之间的关系。为了判定一个结点是否已加入到要建立的哈夫曼树中,可通过parent 域的值来确定。初始时parent 的值为-1。当结点加入到树中去时,该结点parent 的值为其父结点在数组HuffNode 中的序号,而不会是-1 了。 求叶结点的编码: 该过程实质上就是在已建立的哈夫曼树中,从叶结点开始,沿结点的双亲链域回退到根结点,每回退一步,就走过了哈夫曼树的一个分支,从而得到一位哈夫曼码值。由于一个字符的哈夫曼编码是从根结点到相应叶结点所经过的路径上各分支所组成的0、1 序列,因此先得到的分支代码为所求编码的低位,后得到的分支代码为所求编码的高位码。我们可以设置一个结构数组HuffCode 用来存放各字符的哈夫曼编码信息,数组元素的结构中有两个域:bit 和start。其中,域bit 为一维数组,用来保存字符的哈夫曼编码,start 表示该编码在数组bit 中的开始位置。所以,对于第i 个字符,它的哈夫曼编码存放在H uffCode[i].bit 中的从HuffCode[i].start 到n 的bit 位中。 /*------------------------------------------------------------------------- * Name: 哈夫曼编码源代码。 * Date: 2011.04.16 * Author: Jeffrey Hill * 在Win-TC 下测试通过 * 实现过程:着先通过HuffmanTree() 函数构造哈夫曼树,然后在主函数mai n()中 * 自底向上开始(也就是从数组序号为零的结点开始)向上层层判断,若在 * 父结点左侧,则置码为0,若在右侧,则置码为1。最后输出生成的编码。 *------------------------------------------------------------------------*/ #include 霍夫曼编码表
三进制霍夫曼编码
霍夫曼编码
哈夫曼编码步骤
哈夫曼树的编码和译码
霍夫曼编码
哈夫曼编码的方法
霍夫曼编码原理
三进制霍夫曼编码
霍夫曼编码
霍夫曼编码
霍夫曼编码的MATLAB实现(完整版).pdf
图像的霍夫曼编码
图像编码——霍夫曼编码
霍夫曼编码
哈夫曼编码实验报告
哈夫曼编码方法