试验设计和数据分析第一次作业习题答案解析

习题答案
1.设用三种方法测定某溶液时,得到三组数据,其平均值如下:
试求它们的加权平均值。
解:根据数据的绝对误差计算权重:
, ,
因为
所以
2.试解释为什么不宜用量程较大的仪表来测量数值较小的物理量。
答:因为用量程较大的仪表来测量数值较小的物理量时,所产生的相对误差较大。如3.测得某种奶制品中蛋白质的含量为 ,试求其相对误差。
解:
4.在测定菠萝中维生素C含量的测试中,测得每100g菠萝中含有18.2mg维生素C,已知测量的相对误差为0.1%,试求每100g菠萝中含有维生素C的质量范围。
解: ,所以
所以m的范围为
或依据公式
5.今欲测量大约8kPa(表压)的空气压力,试验仪表用1)1.5级,量程0.2MPa 的弹簧管式压力表;2)标尺分度为1mm的U型管水银柱压差计;3)标尺分度为1mm的U形管水柱压差计。
求最大绝对误差和相对误差。
解:1)压力表的精度为1.5级,量程为0.2MPa,
则
2)1mm汞柱代表的大气压为0.133KPa,
所以
3)1mm水柱代表的大气压: ,其中 ,通常取
则
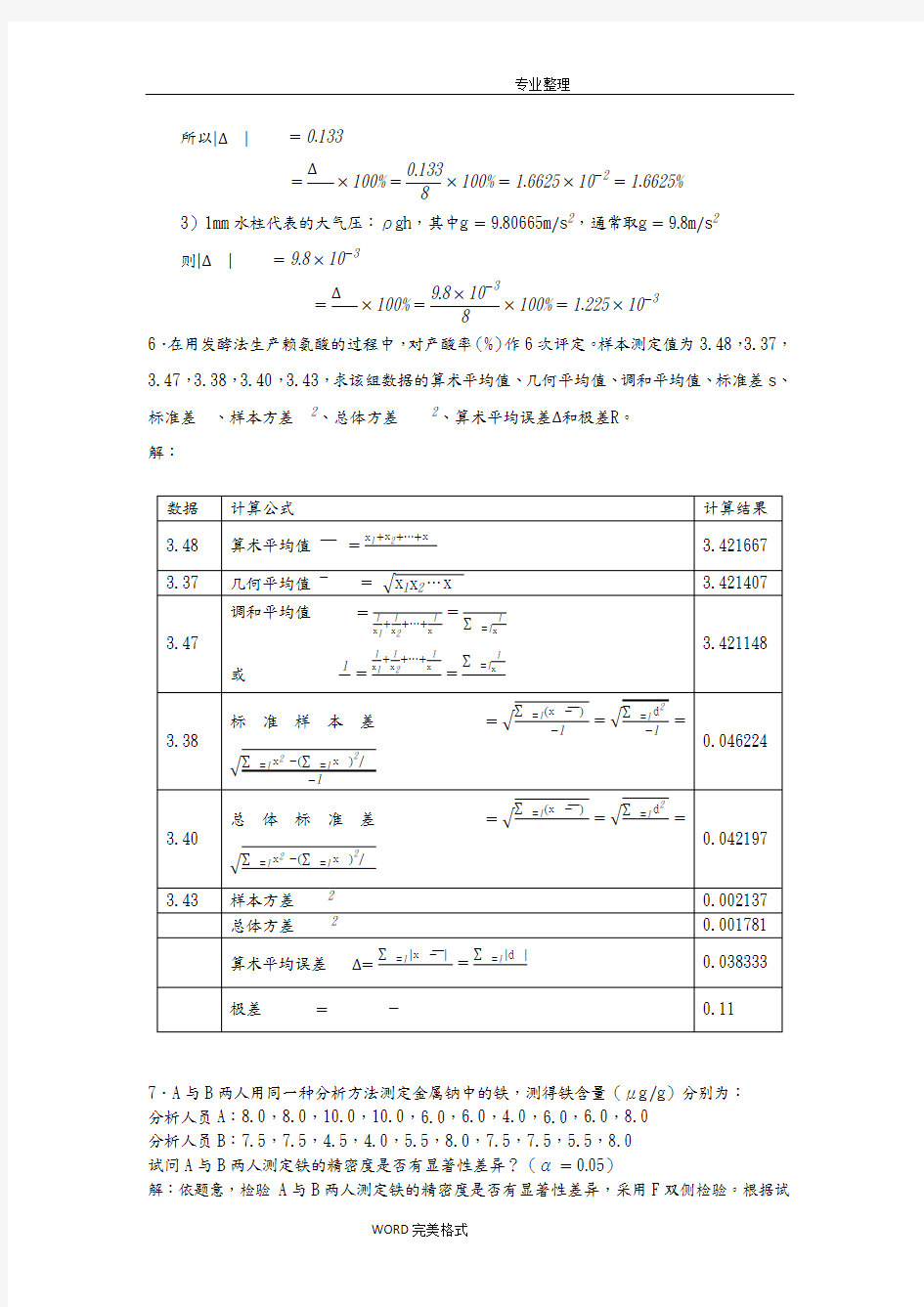
6.在用发酵法生产赖氨酸的过程中,对产酸率(%)作6次评定。样本测定值为3.48,3.37,3.47,3.38,3.40,3.43,求该组数据的算术平均值、几何平均值、调和平均值、标准差s、标准差、样本方差、总体方差、算术平均误差和极差 。
解:
7.A与B两人用同一种分析方法测定金属钠中的铁,测得铁含量( )分别为:
分析人员A:8.0,8.0,10.0,10.0,6.0,6.0,4.0,6.0,6.0,8.0
分析人员B:7.5,7.5,4.5,4.0,5.5,8.0,7.5,7.5,5.5,8.0
试问A与B两人测定铁的精密度是否有显著性差异?( )
解:依题意,检验A与B两人测定铁的精密度是否有显著性差异,采用F双侧检验。根据试验值计算出两种方法的方差以及F值:
,
根据显著性水平 , , 查F分布表得 , , , 。所以 , , ,A与B两人测定铁的方差没有显著差异,即两人测定铁的精密度没有显著性差异。
8.用新旧两种工艺冶炼某种金属材料,分别从两种冶炼工艺生产的产品中抽样,测定产品中的杂质含量(%),结果如下:
旧工艺(1):2.69,2.28,2.57,2.30,2.23,2.42,2.61,2.64,2.72,3.02,2.45,2.95,2.51;
新工艺(2):2.26,2.25,2.06,2.35,2.43,2.19,2.06,2.32,2.34
试问新冶炼工艺是否比旧工艺生产更稳定,并检验两种工艺之间是否存在系统误差?( )
解:工艺的稳定性可用精密度来表征,而精密度可由极差、标准差或方差等表征,这里依据方差来计算。 , ,由于,所以新的冶炼工艺比旧工艺生产更稳定。(依据极差:,,同样可以得到上述结论)(依据标准差, )
检验两种工艺之间是否存在系统误差,采用t检验法。
1)先判断两组数据的方差是否有显著性差异。根据试验数据计算出各自的平均值和方差:
,
,
故
已知n1=13,n2=9,则 , ,根据显著性水平 ,查F分布表得 , ,
,
2)进行异方差t检验
根据显著性水平 ,查单侧t分布表得 ,所以,则两种工艺的平均值存在差异,即两种工艺之间存在系统误差。
备注:
实验方差分析是单侧检验:因为方差分析不像差异显著检验,方差分析中关心的只是组间均方是否显著大于组内均方或误差均方。目的是为了区分组间差异是否比组内差异大的多,因为只有大得多,才能证明实验的控制条件是否造成了显著的差异,
方差齐性中F检验要用到双侧检验,因为要看的是否有显著性差异,而没有说是要看有差异时到底是谁大于谁,所以没有方向性。
9.用新旧两种方法测得某种液体的黏度( )如下:
新方法:0.73,0.91,0.84,0.77,0.98,0.81,0.79,0.87,0.85
旧方法:0.76,0.92,0.86,0.74,0.96,0.83,0.79,0.80,0.75
其中旧方法无系统误差。试在显著性水平( )时,检验新方法是否可行。
解:检验新方法是否可行,即检验新方法是否有系统误差,这里采用秩和检验。
先求出各数据的秩,如表所示。
此时,n1=9,n2=9,n=18,
对于 ,查秩和临界值表,得 ,,由于 ,故,两组数据无显著差异,新方法无系统误差,可行。
T检验成对数据的比较
对于 ,查表 ,所以,即两组数据无显著差异,新方法无系统误差,可行。
10.对同一铜合金,有10个分析人员分析进行分析,测得其中铜含量(%)的数据为:62.20,69.49,70.30,70.65,70.82,71.03,71.22,71.25,71.33,71.38(%)。问这些数据中哪个(些)数据应被舍去,试检验?( )
解:1)拉依达(Paǔta)检验法
○1检验62.20
计算包括62.20在内的平均值 及标准偏差
计算
比较和,,依据拉依达检验法,当 时,62.20应该舍去。
○2检验69.49
计算包括69.49在内的平均值 及标准偏差
计算
比较和,,依据拉依达检验法,当 时,69.49应该舍去。
○3检验70.30
计算包括70.30在内的平均值 及标准偏差
计算
比较和,,依据拉依达检验法,当 时,69.49不应该舍去。○4检验71.38
计算包括71.38在内的平均值 及标准偏差
计算
比较和,,依据拉依达检验法,当 时,71.38不应该舍去。2)格拉布斯(Grubbs)检验法
○1检验62.20
计算包括62.20在内的平均值 及标准偏差,查表得
计算
所以62.20应该舍去。
○2检验69.49
计算包括69.49在内的平均值 及标准偏差,查表得
,
计算
所以69.49应该舍去。
○3检验70.30
计算包括70.30在内的平均值 及标准偏差,查表得
计算
计算
69.49不应该舍去。
○4检验71.38
计算包括71.38在内的平均值 及标准偏差,查表得
计算
计算
当 时,71.38不应该舍去。
3)狄克逊(Dixon)检验法
应用狄克逊双侧情形检验:
○1对于62.20和71.38,,计算
当 ,对于双侧检验,查出临界值 ,由于,且,故最小值62.20应该被舍去。
○2舍去62.20后,对剩余的9个数据(n=9)进行狄克逊双侧检验:
当 ,对于双侧检验,查出临界值 ,由于,且,没有异常值。
单侧检验时,查表得到临界值 ,,没有异常值。
11.将下列数据保留4位有效数字:3.1459,136653,2.33050,2.7500,2.77447
解:3.146、1367×102、2.330、2.750、2.774
12.在容量分析中,计算组分含量的公式为,其中V是滴定时消耗滴定液的体积,c是滴定液的浓度。今用浓度为(1.000±0.001)mg/mL的标准溶液滴定某试液,滴定时消耗滴定液的体积为(20.00±0.02)mL,试求滴定结果的绝对误差和相对误差。
解:根据组分含量计算公式,各变量的误差传递系数分别为
,
所以组分含量的绝对误差为
(mg)
(mg)
最大相对误差为
13.在测定某溶液的密度 的试验中,需要测定液体的体积和质量,已知质量测定的相对误差≤0.02%,预使测定结果的相对误差≤0.1%,测量液体体积所允许的最大相对误差为多大?解:由公式,误差传递系数为
,
则绝对误差
相对误差
由于质量的相对误差 ,预使得,需要,即测量液体体积所允许的最大相对误差为0.08%。
实验设计与数据处理心得
实验设计与数据处理心得体会 刚开始选这门课的时候,我觉得这门课应该就是很难懂的课程,首先我们做过不少的实验了,当然任何自然科学都离不开实验,大多数学科(化工、化学、轻工、材料、环境、医药等)中的概念、原理与规律大多由实验推导与论证的,但我觉得每次到处理数据的时候都很困难,所以我觉得这就是门难懂的课程,却也就是很有必要去学的一门课程,它对于我们工科生来说也就是很有用途的,在以后我们实验的数据处理上有很重要的意义。 如何科学的设计实验,对实验所观测的数据进行分析与处理,获得研究观测对象的变化规律,就是每个需要进行实验的人员需要解决的问题。“实验设计与数据处理”课程就就是就是以概率论数理统计、专业技术知识与实践经验为基础,经济、科学地安排试验,并对试验数据进行计算分析,最终达到减少试验次数、缩短试验周期、迅速找到优化方案的一种科学计算方法。它主要应用于工农业生产与科学研究过程中的科学试验,就是产品设计、质量管理与科学研究的重要工具与方法,也就是一门关于科学实验中实验前的实验设计的理论、知识、方法、技能,以及实验后获得了实验结果,对实验数据进行科学处理的理论、知识、方法与技能的课程。 通过本课程的学习,我掌握了试验数据统计分析的基本原理,并能针对实际问题正确地运用,为将来从事专业科学的研究打下基础。这门课的安排很合理,由简单到复杂、由浅入深的思维发展规律,先讲单因素试验、双因素试验、正交试验、均匀试验设计等常用试验设计
方法及其常规数据处理方法、再讲误差理论、方差分析、回归分析等数据处理的理论知识,最后将得出的方差分析、回归分析等结论与处理方法直接应用到试验设计方法。 比如我对误差理论与误差分析的学习:在实验中,每次针对实验数据总会有误差分析,误差就是进行实验设计与数据评价最关键的一个概念,就是测量结果与真值的接近程度。任何物理量不可能测量的绝对准确,必然存在着测定误差。通过学习,我知道误差分为过失误差,系统误差与随机误差,并理解了她们的定义。另外还有对准确度与精密度的学习,了解了她们之间的关系以及提高准确度的方法等。对误差的学习更有意义的应该就是如何消除误差,首先消除系统误差,可以通过对照试验,空白试验,校准仪器以及对分析结果的校正等方法来消除;其次要减小随机误差,就就是要在消除系统误差的前提下,增加平行测定次数,可以提高平均值的精密度。 比如我对方差分析的理解:方差分析就是实验设计中的重要分析方法,应用非常广泛,它就是将不同因素、不同水平组合下试验数据作为不同总体的样本数据,进行统计分析,找出对实验指标影响大的因素及其影响程度。对于单因素实验的方差分析,主要步骤如下:建立线性统计模型,提出需要检验的假设;总离差平方与的分析与计算;统计分析,列出方差分析表。对于双因素实验的方差分析,分为两种,一种就是无交互作用的方差分析,另一种就是有交互作用的方差分析,对于这两种类型分别有各自的设计方法,但就是总体步骤都与单因素实验的方差分析一样。
EXCEL数据处理题库题目
E X C E L数据处理题库题 目 The pony was revised in January 2021
Excel数据处理 ==================================================题号:15053 注意:下面出现的所有文件都必须保存在考生文件夹下。 提示:[答题]按钮只会自动打开题中任意一个文件。 在[D:\exam\考生文件夹\Excel数据处理\1]下, 找到文件或文件: 1. 在考生文件夹下打开文件, (1)将Sheet1工作表的A1:E1单元格合并为一个单元格,内容水平居中; (2)在E4单元格内计算所有考生的平均分数 (利用AVERAGE函数,数值型,保留小数点后1位), 在E5和E6单元格内计算笔试人数和上机人数(利用COUNTIF函数), 在E7和E8单元格内计算笔试的平均分数和上机的平均分数 (先利用SUMIF函数分别求总分数,数值型,保留小数点后1位); (3)将工作表命名为:分数统计表
(4)选取"准考证号"和"分数"两列单元格区域的内容建立 "带数据标记的折线图",数据系列产生在"列", 在图表上方插入图表标题为"分数统计图",图例位置靠左, 为X坐标轴和Y坐标轴添加次要网格线, 将图表插入到当前工作表(分数统计表)内。 (5)保存工作簿文件。 2. 打开工作簿文件, 对工作表"图书销售情况表"内数据清单的内容按主要关键字 "图书名称"的升序次序和次要关键字"单价"的降序次序进行排序,对排序后的数据进行分类汇总,汇总结果显示在数据下方, 计算各类图书的平均单价,保存文件。 题号:15059 注意:下面出现的所有文件都必须保存在考生文件夹下。 提示:[答题]按钮只会自动打开题中任意一个文件。 在[.\考生文件夹\Excel数据处理\1]下,找到文件或exc文件:
实验设计与数据处理试题库
一、名词解释:(20分) 1. 准确度和精确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度 2. 重复和区组:试验中同一处理的试验单元数将试验空间按照变异大小分成若干个相对均匀的局部,每个局部 就叫一个区组 3回归分析和相关分析:对能够明确区分自变数和因变数的两变数的相关关系的统计方法: 对不能够明确区分自变数和因变数的两变数的相关关系的统计方法 4?总体和样本:具有共同性质的个体组成的集合从总体中随机抽取的若干个个体做成的总体 5. 试验单元和试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间 二、填空:(20分) 1. 资料常见的特征数有:(3空)算术平均数方差变异系数 2. 划分数量性状因子的水平时,常用的方法:等差法等比法随机法(3空) 3. 方差分析的三个基本假定是(3空)可加性正态性同质性 4. 要使试验方案具有严密的可比性,必须(2空)遵循“单一差异”原则设置对照 5. 减小难控误差的原则是(3空)设置重复随机排列局部控制 6. 在顺序排列法中,为了避免同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用(2空)逆向式 阶梯式 7. 正确的取样技术主要包括:()确定合适的样本容量采用正确的取样方法 8. 在直线相关分析中,用(相关系数)表示相关的性质,用(决定系数)表示相关的程度。 三、选择:(20分) 1试验因素对试验指标所引起的增加或者减少的作用,称作(C) A、主要效应 B、交互效应 C、试验效应 D、简单效应 2. 统计推断的目的是用(A) A、样本推总体 B、总体推样本 C、样本推样本 D、总体推总体 3. 变异系数的计算方法是(B) 4. 样本平均数分布的的方差分布等于(A) 5. t检验法最多可检验(C)个平均数间的差异显著性。 6. 对成数或者百分数资料进行方差分析之前,须先对数据进行(B) A、对数 B、反正弦 C、平方根 D、立方根 7. 进行回归分析时,一组变量同时可用多个数学模型进行模拟,型的数据统计学标准是(B) A、相关系数 B、决定性系数 C、回归系数 D、变异系数 8. 进行两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进行单尾检验,u0.05=(A) 9. 进行多重比较时,几种方法的严格程度(LSD\SSR\Q)B 10. 自变量X与因变量Y之间的相关系数为0.9054,则Y的总变异中可由X与Y的回归关系解释的比例为(C) A、0.9054 B、0.0946 C、0.8197 D、0.0089 四、简答题:(15分) 1. 回归分析和相关分析的基本内容是什么?(6分)配置回归方程,对回归方程进行检验,分析多个自变量的主次 效益,利用回归方程进行预测预报: 计算相关系数,对相关系数进行检验 2. 一个品种比较试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复(区组),各重复内均随机排列。请画出田间排列示意图。(2分) 3. 田间试验中,难控误差有哪些?(4分)土壤肥力,小气候,相邻群体间的竞争差异,同一群体内个体间的竞争 差异。 4随即取样法包括哪几种方式?(3分)简单随机取样法分层随机取样法整群简单随机取样法 五、计算题(25分) 1. 研究变数x与y之间的关系,测得30组数据,经计算得出:x均值=10,y均值=20,l xy =60, l yy=300,r=0.6。根
定性数据分析第二章课后答案(供参考)
第二章课后作业 【第1题】 解:由题可知消费者对糖果颜色的偏好情况(即糖果颜色的概率分布),调查者 取500块糖果作为研究对象,则以消费者对糖果颜色的偏好作为依据,500块糖果的颜色分布如下表1.1所示: 表1.1 理论上糖果的各颜色数 由题知r=6,n=500,我们假设这些数据与消费者对糖果颜色的偏好分布是相符,所以我们进行以下假设: 原假设::0H 类i A 所占的比例为)6,...,1(0==i p p i i 其中i A 为对应的糖果颜色,)6,...,1(0=i p i 已知,16 10=∑=i i p 则2χ检验的计算过程如下表所示: 在这里6=r 。检验的p 值等于自由度为5的2χ变量大于等于18.0567的概率。在Excel 中输入“)5,0567.18(chidist =”,得出对应的p 值为05.00028762.0<<=p ,故拒绝原假设,即这些数据与消费者对糖果颜色的偏好分布不相符。 【第2题】 解:由题可知 ,r=3,n=200,假设顾客对这三种肉食的喜好程度相同,即顾客 选择这三种肉食的概率是相同的。所以我们可以进行以下假设:
原假设 )3,2,1(3 1 :0==i p H i 则2χ检验的计算过程如下表所示: 在这里3=r 。检验的p 值等于自由度为2的2χ变量大于等于15.72921的概率。在Excel 中输入“)2,72921.15(chidist =”,得出对应的p 值为 05.00003841.0<<=p ,故拒绝原假设,即认为顾客对这三种肉食的喜好程度是 不相同的。 【第3题】 解:由题可知 ,r=10,n=800,假设学生对这些课程的选择没有倾向性,即选 各门课的人数的比例相同,则十门课程每门课程被选择的概率都相等。所以我们可以进行以下假设: 原假设)10,...,2,1(1.0:0==i p H i 则2χ检验的计算过程如下表所示: 在这里10=r 。检验的p 值等于自由度为9的2χ变量大于等于5.125的概率。在Excel 中输入“)9,125.5(chidist =”,得出对应的p 值为05.0823278349.0>>=p ,
实验设计与数据处理
《实验设计与数据处理》大作业 班级:环境17研 姓名: 学号: 1、 用Excel (或Origin )做出下表数据带数据点的折线散点图 余浊(N T U ) 加量药(mL) 总氮T N (m g /L ) 加量药(mL ) 图1 加药量与剩余浊度变化关系图 图2 加药量与总氮TN 变化关系图 总磷T P (m g /L ) 加量药(mL) C O D C r (m g /L ) 加量药(mL) 图3 加药量与总磷TN 变化关系图 图4 加药量与COD Cr 变化关系图 去除率(%) 加药量(mL)
图5 加药量与各指标去除率变化关系图
2、对离心泵性能进行测试的实验中,得到流量Q v 、压头H 和效率η的数据如表所示,绘制离心泵特性曲线。将扬程曲线和效率曲线均拟合成多项式(要求作双Y 轴图)。 η H (m ) Q v (m 3 /h) 图6 离心泵特性曲线 扬程曲线方程为:H=效率曲线方程为:η=+、列出一元线性回归方程,求出相关系数,并绘制出工作曲线图。 (1) 表1 相关系数的计算 Y 吸光度(A ) X X-3B 浓度(mg/L ) i x x - i y y - l xy l xx l yy R 10 -30 2800 20 -20 30 -10 40 ()() i i x x y y l R --= = ∑
50 10 60 20 70 30 平均值 40 吸光度 X-3B浓度(mg/L) 图7 水中染料活性艳红(X-3B )工作曲线 一元线性回归方程为:y=+ 相关系数为:R 2= (2) 代入数据可知: 样品一:x=样品二:x=、试找出某伴生金属c 与含量距离x 之间的关系(要求有分析过程、计算表格以及回归图形)。 表2 某伴生金属c 与含量距离x 之间的关系分析计算表 序号 x c lgx 1/x 1/c 1 2 2 3 3 4 4 5 5 7 6 8 7 10 1
数据挖掘考试题库【最新】
一、填空题 1.Web挖掘可分为、和3大类。 2.数据仓库需要统一数据源,包括统一、统一、统一和统一数据特征 4个方面。 3.数据分割通常按时间、、、以及组合方法进行。 4.噪声数据处理的方法主要有、和。 5.数值归约的常用方法有、、、和对数模型等。 6.评价关联规则的2个主要指标是和。 7.多维数据集通常采用或雪花型架构,以表为中心,连接多个表。 8.决策树是用作为结点,用作为分支的树结构。 9.关联可分为简单关联、和。 10.B P神经网络的作用函数通常为区间的。 11.数据挖掘的过程主要包括确定业务对象、、、及知识同化等几个步 骤。 12.数据挖掘技术主要涉及、和3个技术领域。 13.数据挖掘的主要功能包括、、、、趋势分析、孤立点分析和偏 差分析7个方面。 14.人工神经网络具有和等特点,其结构模型包括、和自组织网络 3种。 15.数据仓库数据的4个基本特征是、、非易失、随时间变化。 16.数据仓库的数据通常划分为、、和等几个级别。 17.数据预处理的主要内容(方法)包括、、和数据归约等。 18.平滑分箱数据的方法主要有、和。 19.数据挖掘发现知识的类型主要有广义知识、、、和偏差型知识五种。 20.O LAP的数据组织方式主要有和两种。 21.常见的OLAP多维数据分析包括、、和旋转等操作。 22.传统的决策支持系统是以和驱动,而新决策支持系统则是以、建 立在和技术之上。 23.O LAP的数据组织方式主要有和2种。 24.S QL Server2000的OLAP组件叫,OLAP操作窗口叫。 25.B P神经网络由、以及一或多个结点组成。 26.遗传算法包括、、3个基本算子。 27.聚类分析的数据通常可分为区间标度变量、、、、序数型以及混合 类型等。 28.聚类分析中最常用的距离计算公式有、、等。 29.基于划分的聚类算法有和。
试验设计与数据处理
试验设计与数据处理方法总述及总结 王亚丽 (数学与信息科学学院 08统计1班 081120132) 摘要:实验设计与数据处理是一门非常有用的学科,是研究如何经济合理安排 试验可以解决社会中存在的生产问题等,对现实生产有很重要的指导意义。因此本文根据试验设计与数据处理进行了总述与总结,以期达到学习、理解、掌握的以及灵活运用的目的。 1 试验设计与数据处理基本知识总述 1.1试验设计与数据处理的基本思想 试验设计与数据处理是数理统计学中的一个重要分支。它是以概率论、数理统计及线性代数为理论基础,结合一定的专业知识和实践经验,研究如何经济、合理地安排实验方案以及系统、科学地分析处理试验结果的一项科学技术,从而解决了长期以来在试验领域中,传统的试验方法对于多因素试验往往只能被动地处理试验数据,而对试验方案的设计及试验过程的控制显得无能为力这一问题。 1.2试验设计与数据处理的作用 (1)有助于研究者掌握试验因素对试验考察指标影响的规律性,即各因素的水平改变时指标的变化情况。 (2)有助于分清试验因素对试验考察指标影响的大小顺序,找出主要因素。(3)有助于反映试验因素之间的相互影响情况,即因素间是否存在交互作用。(4)能正确估计和有效控制试验误差,提高试验的精度。 (5)能较为迅速地优选出最佳工艺条件(或称最优方案),并能预估或控制一定条件下的试验指标值及其波动范围。 (6)根据试验因素对试验考察指标影响规律的分析,可以深入揭示事物内在规律,明确进一步试验研究的方向。
1.3试验设计与数据处理应遵循的原则 (1)重复原则:重可复试验是减少和估计随机误差的的基本手段。 (2)随机化原则:随机化原则可有效排除非试验因素的干扰,从而可正确、无偏地估计试验误差,并可保证试验数据的独立性和随机性。 (3)局部控制原则:局部控制是指在试验时采取一定的技术措施方法减少非试验因素对试验结果的影响。用图形表示如下: 2试验设计与数据处理方法总述和总结 2.1方差分析 (1)概念:方差分析是用来检验两个或两个以上样本的平均值差异的显著程度。并由此判断样本究竟是否抽自具有同一均值的总体。 (2)优点:方差分析对于比较不同生产工艺或设备条件下产量、质量的差异,分析不同计划方案效果的好坏和比较不同地区、不同人员有关的数量指标差异是否显著时,是非常有用的。 (3)缺点:对所检验的假设会发生错判的情况,比如第一类错误或第二类错误的发生。 (4)基本原理:方差分析的基本思路是一方面确定因素的不同水平下均值之间的方差,把它作为对由所有试验数据所组成的全部总体的方差的第一个估计值;另一方面再考虑在同一水平下不同试验数据对于这一水平的均值的方差,由此计算出对由所有试验数据所组成的全部数据的总体方差的第 二个估计值。比较上述两个估计值,如果这两个方差的估计值比较接近就说明因素的不同水平下的均值间的差异并不大,就接受零假设;否则,说明因素的不同水平下的均值间的差异比较大。
实验设计与数据处理试题库
一、名词解释:(20分) 1.准确度和精确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度 2.重复和区组:试验中同一处理的试验单元数将试验空间按照变异大小分成若干个相对均匀的局部,每个局部就叫一个区组 3回归分析和相关分析:对能够明确区分自变数和因变数的两变数的相关关系的统计方法: 对不能够明确区分自变数和因变数的两变数的相关关系的统计方法 4.总体和样本:具有共同性质的个体组成的集合从总体中随机抽取的若干个个体做成的总体 5.试验单元和试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间 二、填空:(20分) 1.资料常见的特征数有:(3空)算术平均数方差变异系数 2.划分数量性状因子的水平时,常用的方法:等差法等比法随机法(3空) 3.方差分析的三个基本假定是(3空)可加性正态性同质性 4.要使试验方案具有严密的可比性,必须(2空)遵循“单一差异”原则设置对照 5.减小难控误差的原则是(3空)设置重复随机排列局部控制 6.在顺序排列法中,为了避免同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用(2空)逆向式阶梯式 7.正确的取样技术主要包括:()确定合适的样本容量采用正确的取样方法 8.在直线相关分析中,用(相关系数)表示相关的性质,用(决定系数)表示相关的程度。 三、选择:(20分) 1试验因素对试验指标所引起的增加或者减少的作用,称作(C) A、主要效应 B、交互效应 C、试验效应 D、简单效应 2.统计推断的目的是用(A) A、样本推总体 B、总体推样本 C、样本推样本 D、总体推总体 3.变异系数的计算方法是(B) 4.样本平均数分布的的方差分布等于(A) 5.t检验法最多可检验(C)个平均数间的差异显著性。 6.对成数或者百分数资料进行方差分析之前,须先对数据进行(B) A、对数 B、反正弦 C、平方根 D、立方根 7.进行回归分析时,一组变量同时可用多个数学模型进行模拟,型的数据统计学标准是(B) A、相关系数 B、决定性系数 C、回归系数 D、变异系数 8.进行两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进行单尾检验,u0.05=(A) 9.进行多重比较时,几种方法的严格程度(LSD\SSR\Q)B 10.自变量X与因变量Y之间的相关系数为0.9054,则Y的总变异中可由X与Y的回归关系解释的比例为(C) A、0.9054 B、0.0946 C、0.8197 D、0.0089 四、简答题:(15分) 1.回归分析和相关分析的基本内容是什么?(6分)配置回归方程,对回归方程进行检验,分析多个自变量的主次效益,利用回归方程进行预测预报: 计算相关系数,对相关系数进行检验 2.一个品种比较试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复(区组),各重复内均随机排列。请画出田间排列示意图。(2分) 3.田间试验中,难控误差有哪些?(4分)土壤肥力,小气候,相邻群体间的竞争差异,同一群体内个体间的竞争差异。 4随即取样法包括哪几种方式?(3分)简单随机取样法分层随机取样法整群简单随机取样法 五、计算题(25分) 1.研究变数x与y之间的关系,测得30组数据,经计算得出:x均值=10,y均值=20,l xy=60, l yy=300,r=0.6。根据所得数据建立直线回归方程。(5分)a=2 b=1.8 y=2+1.8 x 2.完成下列方差分析表,计算出用LSR法进行多重比较时各类数据填下表:
数据分析经典测试题含答案解析
数据分析经典测试题含答案解析 一、选择题 1.某校九年级数学模拟测试中,六名学生的数学成绩如下表所示,下列关于这组数据描述正确的是() A.众数是110 B.方差是16 C.平均数是109.5 D.中位数是109 【答案】A 【解析】 【分析】 根据众数、中位数的概念求出众数和中位数,根据平均数和方差的计算公式求出平均数和方差. 【详解】 解:这组数据的众数是110,A正确; 1 6 x=×(110+106+109+111+108+110)=109,C错误; 21 S 6 = [(110﹣109)2+(106﹣109)2+(109﹣109)2+(111﹣109)2+(108﹣109)2+ (110﹣109)2]=8 3 ,B错误; 中位数是109.5,D错误; 故选A. 【点睛】 本题考查的是众数、平均数、方差、中位数,掌握它们的概念和计算公式是解题的关键. 2.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5,
则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 3.如图,是根据九年级某班50名同学一周的锻炼情况绘制的条形统计图,下面关于该班50名同学一周锻炼时间的说法错误的是() A.平均数是6 B.中位数是6.5 C.众数是7 D.平均每周锻炼超过6小时的人数占该班人数的一半 【答案】A 【解析】 【分析】 根据中位数、众数和平均数的概念分别求得这组数据的中位数、众数和平均数,由图可知锻炼时间超过6小时的有20+5=25人.即可判断四个选项的正确与否. 【详解】 A、平均数为1 50 ×(5×7+18×6+20×7+5×8)=6.46,故本选项错误,符合题意; B、∵一共有50个数据, ∴按从小到大排列,第25,26个数据的平均值是中位数, ∴中位数是6.5,故此选项正确,不合题意; C、因为7出现了20次,出现的次数最多,所以众数为:7,故此选项正确,不合题意; D、由图可知锻炼时间超过6小时的有20+5=25人,故平均每周锻炼超过6小时的人占总数的一半,故此选项正确,不合题意; 故选A. 【点睛】 此题考查了中位数、众数和平均数的概念等知识,中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(最中间两个数的平均数),叫做这组数据的中位数,如果中位数的概念掌握得不好,不把数据按要求重新排列,就会错误地将这组数据最中间的那个数当作中位数.
数据处理与实验设计小论文
上海大学2014~2015学年秋季学期研究生课程考试课程名称:数据处理与实验设计课程编号:11S009003论文题目:正交实验在锂离子电极材料制备中的应用 研究生姓名:李艳峰学号:14722191 论文评语: 成绩:任课教师: 评阅日期:
正交实验在锂离子电极材料制备中的应用 李艳峰 (上海大学环境与化学工程学院,上海200444) 摘要:锂源、反应温度、反应时间和锂钛摩尔比是影响锂离子电极负极材料Li4Ti5O12制备的重要因素,本文利用正交实验L9 (34)的方法对液相法制备Li4Ti5O12的各种影响因素进行进一步优化,从而得到最优水平组合,并对各种影响因素进行权重分析。最后,利用正交实验确定了液相法制备Li4Ti5O12的最佳工艺:烧结温度为750℃,烧结时间为8h,LiOH·H2O 为锂源,原料中锂钛摩尔比为0.85。 关键词:正交实验设计;液相法;影响因素; 中图分类号:O242.1文献标识码:A The application of orthogonal experimental design on liquid method in the production of Lithium-ion electrode materials Yanfeng Li (School of Environmental and Chemical Engineering, Shanghai University, Shanghai 200444, China) Abstract:lithium source, reaction temperature, reaction time and lithium titanium molar ratio are important factors for the preparation of Li4Ti5O12 conditions of liquid method. Based on the single factor experiment, this study use L9 (34) orthogonal experiments to optimized the removal of the preparation of Li4Ti5O12 of liquid method. The optimal technological parameters of solution method determined by the orthogonal experiment were as follows: sintering temperature was 750℃, sintering time was 8 h, the lithium resource was LiOH·H2O and the mole ration of Li to Ti was 0.85. Key words: Orthogonal experimental design;Liquid method; Factors;
第四章 数据分析(梅长林)习题答案
第四章 习题 一、习题4.4 解:(1)通过SAS 的proc princomp 过程对相关系数矩阵R 做主成分分析,得到个主成分的贡献率以及累计贡献率如表1所 表 1 从表中可以得到特征值向量为: ]0.2429 0.4515 0.5396 0.8091 2.8567[=*λ 第一主成分贡献率为:57.13 % 第二主成分贡献率为:16.18 % 第三主成分贡献率为: 10.79% 第四主成分贡献率为:9.03 % 第五主成分贡献率为:6.86 % 进一步得到各主成分分析结果如表2所示: 表 2
(2)由(1)中得到的结果可知前两个主成分的累积贡献率为73.32%,得到第一主成分、第二主成分为: 54212.044215.034702.024571.014636.01x x x x x Y ++++=* 55820.045257.032604.025093.012404.02x x x x x Y ++---=* 由于1*Y 是五个标准化指标的加权和,由此第一主成分更能代表三种化工股票和两种石油股票周反弹率的综合作用效果,1*Y 越大表示各股票的综合周反弹率越大。* 2Y 中关于三种化工股票的周反弹率系数为 负,而关于两种石油的系数为正,它放映了两种石油周反弹率和三种化工股票周反弹率的对比,* 2Y 的绝对值越大, 表明两种石油周反弹率和三种化工股票周反弹率的差距越大。 二、习题4.5 解:(1)利用SAS 的proc corr 过程求得相关系数矩阵如表3: 表 3 (2)从相关系数矩阵出发,通过proc princomp 过程对其进行主成分分析,表4给出了各主成分的贡献率以及累积贡献率:
试验设计与数据处理课程论文
课 程 论 文 课程名称试验设计与数据处理 专业2012级网络工程 学生姓名孙贵凡 学号201210420136 指导教师潘声旺职称副教授
成绩 科学研究与数据处理 学院信息科学与技术学院专业网络工程姓名孙贵凡学号:201210420136 摘要:《实验设计与数据处理》这门课程列举典型实例介绍了一些常用的实验设计及实验数据处理方法在科学研究和工业生产中的实际应用,重点介绍了多因素优化实验设计——正交设计、回归分析方法以对目标函数进行模型化处理。其适于工艺、工程类本科生使用,尤其适用于化学化工、矿物加工、医学和环境学等学科的本科生使用。其对行实验设计可提供很大的帮助,也可供广大分析化学工作者应用。关键字:优化实验设计; 标函数进行模型化处理; 正交设计; 回归分析方法 1 引言 实验是一切自然科学的基础,科学界中大多数公式定理是由试验反复验证而推导出来的。只有经得起试验验证的定理规律才具有普遍实用性。而科学的试验设计是利用自己已有的专业学科知识,以大量的实践经验为基础而得出的既能减少试验次数,又能缩短试验周期,从而迅速找到优化方案的一种科学计算方法,就必然涉及到数据处理,也只有对试验得出的数据做出科学合理的选择,才能使实验结果更具说服力。实验设计与数据处理在水处理中发挥着不可估量的作用,通过科学合理的实验设计过程加上严谨规范的数据处理方法,可以使水处理原理,内在规律性被很好的发现,从而更好的应用于生产实践。 2 材料与方法 2.1 供试材料 1. 论文所围绕的目标和假设 研究的目标就是实验的目的,我们设计了这个实验是想来做什么以及想得到什么样的结论。要正确的识别问题和陈述问题,这些需要专业知识和大量的阅读文献综述等方法来获得我们所要提出的问题。需要对某一个具体的问题,并且对这个具体的问题提出假设。如水处理中混凝剂的最佳投加量,混凝剂的最佳投加量有一个适宜的PH值范围。
大数据技术及应用题库
大数据技术及应用题库单选题: 1 从大量数据中提取知识的过程通常称为(A)。 a. . 数据挖掘 b. . 人工智能 c. . 数据清洗 d. . 数据仓库 2 下列论据中,能够支撑“大数据无所不能”的观点的是( A )。 A、互联网金融打破了传统的观念和行为 B、大数据存在泡沫 C、大数据具有非常高的成本 D、个人隐私泄露与信息安全担忧 3 数据仓库的最终目的是(D)。 a. . 收集业务需求 b. . 建立数据仓库逻辑模型 c. . 开发数据仓库的应用分析 d. . 为用户和业务部门提供决策支持 4 大数据处理技术和传统的数据挖掘技术最大的区别是(A)。 a. . 处理速度快(秒级定律)
b. . 算法种类更多 c. . 精度更高 d. . 更加智能化 5 大数据的起源是( C )。 a. . 金融 b. . 电信 c. . 互联网 d. . 公共管理 6 大数据不是要教机器像人一样思考。相反,它是( A )。 a. . 把数学算法运用到海量的数据上来预测事情发生的可能性 b. . 被视为人工智能的一部 c. . 被视为一种机器学习 d. . 预测与惩罚 7 人与人之间沟通信息、传递信息的技术,这指的是(D)。 a. . 感测技术 b. . 微电子技术 c. . 计算机技术 d. . 通信技术
8 数据清洗的方法不包括(D)。 a. . 缺失值处理 b. . 噪声数据清除 c. . 一致性检查 d. . 重复数据记录处理 9. 下列关于舍恩伯格对大数据特点的说法中,错误的是(D) A. 数据规模大 B. 数据类型多样 C. 数据处理速度快 D. 数据价值密度高 10规模巨大且复杂,用现有的数据处理工具难以获取、整理、管理以及处理的数据,这指 的是(D)。 a. . 富数据 b. . 贫数据 c. . 繁数据 d. . 大数据 1大数据正快速发展为对数量巨大、来源分散、格式多样的数据进行采集、存储和关联分 析,从中发现新知识、创造新价值、提升新能力的(D)。 a. . 新一代信息技术 b. . 新一代服务业态 c. . 新一代技术平台 d. . 新一代信息技术和服务业态
实验设计与数据处理
试验设计与数据处理 学院 班级 学号 学生姓名 指导老师
第一章 4、 相对误差18.20.1%0.0182x mg mg ?=?= 故100g 中维生素C 的质量范围为:±。 5、1)、压力表的精度为级,量程为, 则 max 0.2 1.5%0.00333 0.375 8 R x MPa KPa x E x ?=?==?=== 2)、1mm 的汞柱代表的大气压为, 所以 max 2 0.1330.133 1.662510 8 R x KPa x E x -?=?===? 3)、1mm 水柱代表的大气压为gh ρ,其中2 9.8/g m s = 则: 3max 33 9.8109.810 1.22510 8 R x KPa x E x ---?=???===? 6. 样本测定值 算数平均值 几何平均值 调和平均值 标准差s 标准差σ 样本方差S 2 总体方差σ2 算术平均误差△ 极差R 7、S ?2=,S ?2= F =S ?2/ S ?2== 而F ()=,= 所以F ()< F < 两个人测量值没有显著性差异,即两个人的测量方法的精密度没有显著性差异。 |||69.947|7.747 6.06 p p d x =-=>
分析人员A分析人员B 8样本方差1 8样本方差2 10Fa值 104F值 6 68 4705 6 6 88 8.旧工艺新工艺 %% %% %% %% %% %% %% %% %% % % % % t-检验: 双样本异方差假设 变量 1变量 2 平均 方差 观测值139假设平均差0 df8 t Stat-38. P(T<=t) 单尾0 t 单尾临界 P(T<=t) 双尾0 t 双尾临界 F-检验双样本方差分析
测绘数据处理与数字成图复习题
复习思考题 1.与传统模拟测图相比较,数字测图具有哪些特点? 答:数字测图的实质是全解析、机助成图。 a、使大比例尺测图走向自动化 b、数字测图使得大比例尺测图走向数字化 c、提高了测图精度 d、数字测图促进了大比例尺的发展、更新 1. 大比例尺测图自动化:野外测量自动记录、自动结算处理,自动成图、绘图,并提供可供处理的数字地图。效率高、劳动强度小。 2. 大比例尺测图的数字化:数字地形信息可以传输、处理和多用户共享;可自动提取点位坐标、距离、方位、面积等;可供工程CAD(计算机辅助设计)使用;可供GIS建库使用,可绘制各类专题地图;可进行局部更新,保持地图的现势性。 3.模拟测方法的比例尺精度决定了图的最高精度。数字地形图无损地体现了外业测量的精度。 4. 地面数字测图的图根控制测量与碎部测量可同时进行。 5. 地面数字测图在测区内可不受图幅的限制。 6. 地面数字测图必须有足够的特征点坐标才能绘制地物符号。 2.根据空间数据来源以及采用仪器的不同,目前数字测图的主要作业方法有哪些?各适用于什么情况?并谈谈你对各种作业方法未来发展的展望? 答:(1)全站仪地面数据采集,适用于城市大比例尺数字测图 (2)既有模拟地形图数字化。这种方法适用于计算机存档、图纸更新、修测,任意比例尺地形图的测制 (3)数字摄影测量。适合大面积中、大比例尺地形图测制和更新,也将是城市GIS数据获取的主要方法。 (4)GPS、RTK地面数据采集。适合大比例尺地形图的测制。 3.什么是数字测图系统?试根据你的认识绘出数字测图系统生产工艺流程框图? 答:依托计算机系统,在外连输入输出设备软、硬件的支持下,以数字测图软件为核心对地形空间数据进行采集、输入、编辑、成图、管理、输出的测绘系统。 4.什么是数字地形图?与纸质模拟地形图相比较,数字地形图具有哪些特点? 答:数字地形图是根据地形图制图表示的要求,将地形要素进行计算机处理后,以矢量或栅格数据结构组织、储存并可以图形方式输出的数字产品。 特点:(1)真实三维坐标数字化存储在磁介质中 (2)地形要素分层组织与管理 (3)突破图纸大小限制,可以自然界线分区存储 (4)易于复制分发 5.有同学说:“在数字地形图中地形要素的空间数据是以真实坐标存储的,因而进入数字测图时代不再存在比例尺和比例尺精度的概念了。”试谈谈你对这句话的看法? 答:数字测图也离不开比例尺,测图过程中地物的取舍就必须考虑比例尺,不同的比例尺地面表达的程度不一样,只是说在室内成图时比例尺比较容易修改而已。 6.有同学说:“进入数字测图时代,再大测区范围的地形信息都可以存储在一个数字地形图中,因而不再需要地形图的分幅与编号了。”试谈谈你对这句话的看法? 答:为了不重测、漏测,就需要将地面按一定的规律分成若干块,为了科学的反映各种比例尺地形图之间的关系和相同比例尺地图的拼接关系,为了能迅速查找到所需的某地区某种比例尺的地图,需要将地形图按一定规律进行编号。 7.地形要素具有哪些基本特征?在数字地形图中是如何存储和组织这些特征信息的? 答:空间位置、属性关系、连接关系。 8.什么是图层?对数字地形图分层的目的和作用是什么?结合你的认识制定一套1:500、1:1000和1:2000数字地形图分层方案? 答:图层:在电子地图中,图层是地形特征相似的地形要素组成的逻辑或物理集合。 作用:(1)图形数据库图形组织与管理的一种技术,通过控制图层的特性来控制图形对象的显示、输出,以提高图形处理的效率 (2)更重要的是适应数据管理的需要。 9.对地形要素进行编码的目的和作用是什么?编码设计时应遵循哪些原则?在基于CAD的数字测图软件中实现编码管理的方案有哪些? 答:编码的目的:便于数字测图软件及GIS软件识别与处理(采集、检索、分析、输出和数据交换)。 原则:规范性,适用性,唯一性,稳定性,可扩展性。
数据分析课后习题答案
数据分析第一次上机实验报告 班级:信计091 学号:200900901023 姓名:李骏 习题一 1.1 某小学60位学生(11岁)的身高(单位:cm)数据如下: (数据略) (1)计算均值、方差、标准差、变异系数、偏度、峰度; (2)计算中位数,上、下四分位数,四分位极差,三均值; (3)做出直方图; (4)做出茎叶图; 解:(1)使用软件计算得到 变异系数=标准差/均值=5.08% (2)部分答案在解(1) 四分位极差=Q3-Q1=144.75-135=9.75 三均值=0.25*Q1+0.5*M+0.25*Q3=139.4375 (3)使用软件画图得到
(4)使用软件画图得到 身高 Stem-and-Leaf Plot Frequency Stem & Leaf 1.00 Extremes (=<120) 1.00 12 . 3 5.00 12 . 67889 7.00 13 . 1122244 18.00 13 . 555677777888899999 13.00 14 . 0112222223344 13.00 14 . 5566677778999 2.00 15 . 01 Stem width: 10.00 Each leaf: 1 case(s)
1.8 对20名中年人测量6个指标,其中3个生理指标:体重(x1)、腰围(x2)、脉搏(x3);3个训练指标:引体向上(x4)、直坐次数(x5)、跳跃次数(x6)。数据如下表 (表格略) (1)计算协方差矩阵,Pearson相关矩阵; (2)计算Spearman相关矩阵; (3)分析各指标间的相关性。 解: (1)使用软件得到下表
实验设计与数据处理课后答案
《试验设计与数据处理》 专业:机械工程班级:机械11级专硕学号:S110805035 姓名:赵龙 第三章:统计推断 3-13 解:取假设H0:u1-u2≤0和假设H1:u1-u2>0用sas分析结果如下:Sample Statistics Group N Mean Std. Dev. Std. Error ---------------------------------------------------- x 8 0.231875 0.0146 0.0051 y 10 0.2097 0.0097 0.0031 Hypothesis Test Null hypothesis: Mean 1 - Mean 2 = 0 Alternative: Mean 1 - Mean 2 ^= 0 If Variances Are t statistic Df Pr > t ---------------------------------------------------- Equal 3.878 16 0.0013 Not Equal 3.704 11.67 0.0032 由此可见p值远小于0.05,可认为拒绝原假设,即认为2个作家所写的小品文中由3个字母组成的词的比例均值差异显著。 3-14 解:用sas分析如下: Hypothesis Test Null hypothesis: Variance 1 / Variance 2 = 1 Alternative: Variance 1 / Variance 2 ^= 1 - Degrees of Freedom - F Numer. Denom. Pr > F ---------------------------------------------- 2.27 7 9 0.2501 由p值为0.2501>0.05(显著性水平),所以接受原假设,两方差无显著差异 第四章:方差分析和协方差分析 4-1 解: Sas分析结果如下: Dependent Variable: y Sum of Source DF Squares Mean Square F Value Pr > F
数据的试题及答案
数据的试题及答案 1、当前大数据技术的基础是由(C)首先提出的;A:微软B:百度C:谷歌D:阿里巴巴; 2、大数据的起源是(C);A:金融B:电信C:互联网D:公共管理; 3、根据不同的业务需求来建立数据模型,抽取最有意;A:数据管理人员B:数据分析员C:研究科学家D:; 4、(D)反映数据的精细化程度,越细化的数据,价;A:规模B:活性C:关联度D:颗粒度; 5、数据清洗的方法不包 1、当前大数据技术的基础是由( C)首先提出的。(单选题,本题2分) A:微软 B:百度 C:谷歌 D:阿里巴巴 2、大数据的起源是(C )。(单选题,本题2分) A:金融 B:电信 C:互联网 D:公共管理 3、根据不同的业务需求来建立数据模型,抽取最有意义的向量,决定选取哪种方法的数据分析角色人员是( C)。(单选题,本题2分) A:数据管理人员 B:数据分析员 C:研究科学家 D:软件开发工程师 4、(D )反映数据的精细化程度,越细化的数据,价值越高。(单选题,本题2分) A:规模 B:活性 C:关联度 D:颗粒度 5、数据清洗的方法不包括( D)。(单选题,本题2
A:缺失值处理 B:噪声数据清除 C:一致性检查 D:重复数据记录处理 6、智能健康手环的应用开发,体现了( D)的数据采集技术的应用。(单选题,本题2分) A:统计报表 B:网络爬虫 C:API接口 D:传感器 7、下列关于数据重组的说法中,错误的是( A)。(单选题,本题2分) A:数据重组是数据的重新生产和重新采集 B:数据重组能够使数据焕发新的光芒 C:数据重组实现的关键在于多源数据融合和数据集成D:数据重组有利于实现新颖的数据模式创新 8、智慧城市的构建,不包含( C)。(单选题,本题2分) A:数字城市 B:物联网 C:联网监控 D:云计算 9、大数据的最显著特征是( A)。(单选题,本题2分) A:数据规模大 B:数据类型多样 C:数据处理速度快 D:数据价值密度高 10、美国海军军官莫里通过对前人航海日志的分析,绘制了新的航海路线图,标明了大风与洋流可能发生的地点。这体现了大数据分析理念中的(B )。(单选题,本题