完整版逻辑回归模型分析见解

1.逻辑回归模型
1.1
逻辑回归模型
考虑具有p个独立变量的向量■',设条件概率卩;上二?丨门二广为根据观测
量相对于某事件发生的概率。逻辑回归模型可表示为
:「( 1.1)
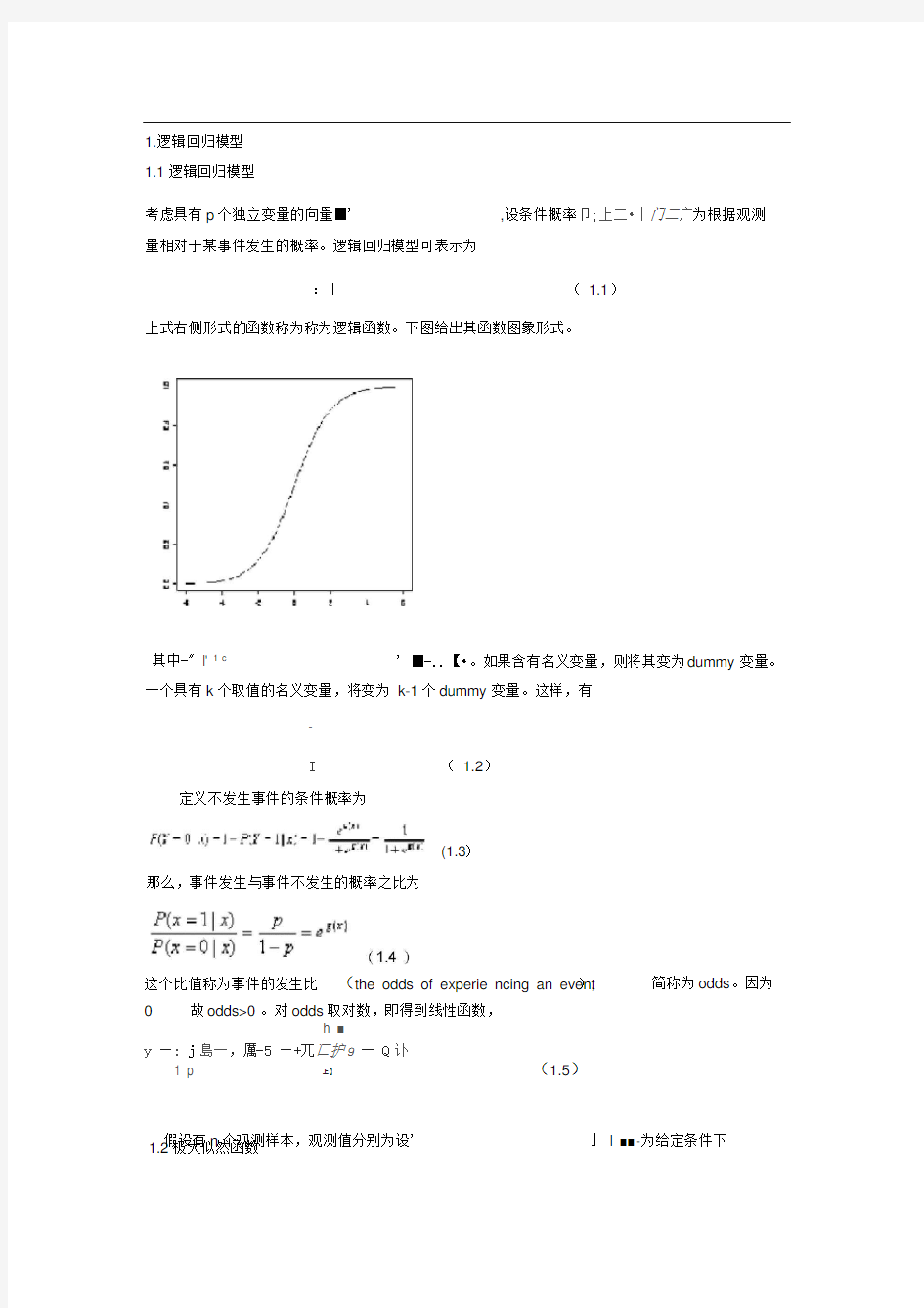
上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。
其中-" I' 1 c' ■-..【?。如果含有名义变量,则将其变为dummy 变量。一个具有k个取值的名义变量,将变为k-1个dummy 变量。这样,有
—
I ( 1.2)
这个比值称为事件的发生比(the odds of experie ncing an event),
0
h ■
y —: j島一,厲-5 —+兀匸护9一 Q讣
1 p 上】(1.5)
假设有n个观测样本,观测值分别为设' 」I ■■-为给定条件下
(1.3)
简称为odds。因为定义不发生事件的条件概率为
那么,事件发生与事件不发生的概率之比为
1.2极大似然函数
得到I 的概率。在同样条件下得到-- 的条件概率为丨:一"。
得到一个观测值的概率为
因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。
(1.7)
上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估
譏备心)(
」' (1.10 是,
◎ )*(1 ¥严(1.6 )
i-l
计。于是,最大似然估计的关键就是求出参数:- ,使上式取得最大值。
对上述函数求对数
— (1.8)
上式称为对数似然函数。为了估计能使亠取得最大的参数的值。
对此函数求导,得到p+1个似然方程。
Ei 片 n:—E L尹—心肿一时
(1.9 )
^叶切迄尸,j=1,2,..,p.
上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森
进行迭代求解。
(Newto n-Raphs on) 方法1.3 牛顿-拉斐森迭代法
对-八?求二阶偏导数,即Hessian矩阵为
如果写成矩阵形式,以H表示Hessian矩阵,X表示
(1.11 )
(2.1 )
得牛顿迭代法的形式为
对H 进行cholesky 分解。
最大似然估计的渐近方差(asymptotic 阵(information matrix )的逆矩阵估计出来。而信息矩阵实际上是匚…—二阶导数的负值,
表示为 。估计值的方差和协方差表示为 -'_
■',也就是说,估计值,二的 方差为矩阵I 的逆矩阵的对角线上的值,而估计值 ’】和厂的协方差为除了对角线以外的
值。然而在多数情况,我们将使用估计值
■〔的标准方差,表示为
2 .显著性检验
下面讨论在逻辑回归模型中自变量
?;[
是否与反应变量显著相关的显著性检验。零假设 ‘二
,:
■' = 0 (表示自变量 F 对事件发生可能性无影响作用)。如果零假设被拒绝, 说明事件发生
可能性依赖于"的变化。 2.1 Wald test
对回归系数进行显著性检验时,通常使用
Wald 检验,其公式为
r-
儿a-曹:
(i
(1.12 )
则H
=X T
VX 。再令 L 1
九■■■
“
然方程的矩阵形式。 >i -兀i >2 - %
■
丹■①」(注:前一个矩阵需转置),即似
(1.13 )
注意到上式中矩阵H 为对称正定的,求解
b'U 即为求解线性方程HX = U 中的矩阵X 。
varianee )和协方差(covarianee ) 可以由信息矩 for j=0,1,2. …,p (1.14 )
4
貝
A.
其中,■''匸?为二的标准误差。这个单变量
Wald 统计量服从自由度等于1的■-分布。
如果需要检验假设’'-
:
| :
I = 0,计算统计量
(2.2 )
4 宀
其中,厂为去掉'-所在的行和列的估计值,相应地, 准误差。这里, Wald 统计量服从自由度等于 p 的」分布。如果将上式写成矩阵形式,
^ = (QMQ^^)QT\QA) (2.3) 矩阵Q 是第一列为零的一常数矩阵。例如,如果检验
然而当回归系数的绝对值很大时,这一系数的估计标准误就会膨胀,于是会导致 统计值变得很小,以致第二类错误的概率增加。 也就是说,在实际上会导致应该拒绝零假设 时却未能拒绝。所以当发现回归系数的绝对值很大时, 就不再用 Wald 统计值来检验零假设, 而应该使用似然比检验来代替。 2.2
似然比(Likelihood ratio test )检验
在一个模型里面,含有变量①与不含变量山的对数似然值乘以-2的结果之差,服从
分布。这一检验统计量称为似然比
(likelihood ratio ) ,用式子表示为
L y 不纸似然、
G7哙科麝(2.4)
计算似然值采用公式(1.8 )。 倘若需要检验假设’‘一 :八一 -
4 = 0,计算统计量
讥『2>讣饵.“—"歸-十恥H m "HdfUWXl /cu 、
“ (2.5 )
上式中,"表示门=0的观测值的个数,而 匸表示门=1的观测值的个数,那么 n 就表示 所有观测值的个数了。实际上,上式的右端的右半部分
■■ 1_
'- ' "■ 一‘ ' 表示
只含有的似然值。统计量 G 服从自由度为p 的■「分布 2.3 Score 检验
在零假设"-'?
= 0下,设参数的估计值为'1 :
,即对应的 J = 0。计算Score 统 计量的公式为
A J TS
4
--为去掉’k 所在的行和列的标
Wald
5甩尸厂)(如刃(如〕
(2.6 )
上式中,’L-表示在=0下的对数似然函数(1.9 )的一价偏导数值,而''":■ :|
表示 在匚=0下的对数似然函数(1.9 )的二价偏导数值。Score 统计量服从自由度等于1的'■ 分布。 2.4
模型拟合信息
模型建立后,考虑和比较模型的拟合程度。有三个度量值可作为拟合的判断根据。 (1) -2LogLikelihood
】-乂 (2.7)
(2) Akaike 信息准则(Akaike In formation Criterio n. 血=_25亂+ 2住+小(28)
其中K 为模型中自变量的数目, S 为反应变量类别总数减1, 对于逻辑回归有 S=2-仁1 -2LogL 的值域为0至,其值越小说明拟合越好。当模型中的参数数量越大时,似然值也 就越大,-2LogL 就变小。因此,将2 (K+S )加到AIC 公式中以抵销参数数量产生的影响。 在其它条件不变的情况下,较小的 AIC 值表示拟合模型较好。
(3)Schwarz 准则
这一指标根据自变量数目和观测数量对 -2LogL 值进行另外一种调整。 SC 指标的定义
为 犯=-2比就+2也+心恤@)(2.9)
其中ln (n )是观测数量的自然对数。这一指标只能用于比较对同一数据所设的不同模型。在 其它条件相同时,一个模型的 AIC 或SC 值越小说明模型拟合越好。
3. 回归系数解释 3.1发生比
(1)连续自变量。对于自变量J j:
,每增加一个单位,odds ration 为
OR
(3.1)
简写为AIC )
odds=[p/(1-p)]
3
,即事件发生的概率与不发生的概率之比。而发生
比率(odds ration).
odds.
⑵二分类自变量的发生比率。变量的取值只能为0或1,称为dummy variable 。当取值为1,对于取值为0的发生比率为
- :' (3.2)
亦即对应系数的幕。
(3)分类自变量的发生比率。
如果一个分类变量包括m个类别,需要建立的dummy variable 的个数为m-1,所省略的
那个类别称作参照类(referenee category) 。设dummy variable 为八;:,其系数为,■,
对于参照类,其发生比率为丁、。
3.2逻辑回归系数的置信区间
对于置信度1 -二,参数「的100% (1 -「)的置信区间为
玄土益X曲並
" (3.3 )
上式中,亠为与正态曲线下的临界乙值(critical value ), =为系数估计的标
准误差,‘’和- '两值便分别是置信区间的下限和上限。当样本
较大时,匚=0.05水平的系数"的95%置信区间为
&±1,92 込
兀(3.4 )
4. 变量选择
4.1前向选择(forward selection ):在截距模型的基础上,将符合所定显著水平的自变量一次一个地加入模型。
具体选择程序如下
(1 )常数(即截距)进入模型。
(2 )根据公式(2.6 )计算待进入模型变量的Score检验值,并得到相应的P值。
(3)找出最小的p值,如果此p值小于显著性水平-,则此变量进入模型。如果此变量
是某个名义变量的单面化(dummy) 变量,则此名义变量的其它单面化变理同时也进入模
型。不然,表明没有变量可被选入模型。选择过程终止。
(4) 回到(2)继续下一次选择。
4.2后向选择(backward selection ):在模型包括所有候选变量的基础上,将不符合保留要求显著水平的自变量一次一个地删除。
具体选择程序如下
(1) 所有变量进入模型。
(2) 根据公式(2.1 )计算所有变量的Wald检验值,并得到相应的p值。
(3) 找出其中最大的p值,如果此P值大于显著性水平,则此变量被剔除。对于某个
名义变量的单面化变量,其最小p值大于显著性水平,则此名义变量的其它单面化变
量也被删除。不然,表明没有变量可被剔除,选择过程终止。
(4) 回到(2)进行下一轮剔除。
4.3 逐步回归(stepwise selection)
(1)基本思想:逐个引入自变量。每次引入对Y影响最显著的自变量,并对方程中的老变量
逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y
影响显著的变量,又不包含对Y影响不显著的变量。
⑵筛选的步骤:首先给出引入变量的显著性水平-和剔除变量的显著性水平J ,然后
按下图筛选变量。
Y亠―"I J厂巨二匸罠"J、、-i
I 乳I
J ______ _十
审谛丘至
(3)逐步筛选法的基本步骤
逐步筛选变量的过程主要包括两个基本步骤:一是从不在方程中的变量考虑引入新变量的步
骤;二是从回归方程中考虑剔除不显著变量的步骤。
假设有p个需要考虑引入回归方程的自变量.
①设仅有截距项的最大似然估计值为「。对p个自变量每个分别计算Score检验值,
设有最小p值的变量为'r-,且有2 " 1 ' J ^',对于单面化(dummy)变量,也如此。
逻辑回归模型分析见解
1.逻辑回归模型 1.1逻辑回归模型 考虑具有p个独立变量的向量,设条件概率为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为 (1.1) 上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。 其中。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有 (1.2) 定义不发生事件的条件概率为 (1.3) 那么,事件发生与事件不发生的概率之比为 (1.4) 这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。因为0
得到的概率。在同样条件下得到的条件概率为。于是,得到一个观测值的概率为 (1.6) 因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。 (1.7) 上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数,使上式取得最大值。 对上述函数求对数 (1.8) 上式称为对数似然函数。为了估计能使取得最大的参数的值。 对此函数求导,得到p+1个似然方程。 (1.9) ,j=1,2,..,p. 上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森(Newton-Raphson)方法进行迭代求解。 1.3牛顿-拉斐森迭代法 对求二阶偏导数,即Hessian矩阵为 (1.10) 如果写成矩阵形式,以H表示Hessian矩阵,X表示 (1.11) 令
回归模型分析
新疆财经大学 实验报告 课程名称:统计学 实验项目名称:回归模型分析 姓名: lili 学号: 20000000 班级:工商2011-2班 指导教师: 2014 年5 月
新疆财经大学实验报告
附:实验数据。
1、作散点图,加趋势线, 2、建立回归模型(用公式编辑器写),对模型进行统计检验。解释模型意义SUMMARY OUTPUT 回归统计 Multiple R 0.974111881 R Square 0.948893956 Adjusted R Square 0.947131679 标准误差527.4648386 观测值31 方差分析 df SS MS F Significance F 回归分析 1 149806425.5 149806426 538.4476 2.82E-20 残差29 8068355.522 278219.156 总计30 157874781.1 Coefficients 标准误差t Stat P-value Lower 95% Upper 95% Intercept 121.5246471 365.0193913 0.33292655 0.741585 -625.024 X Variable 1 1.270433698 0.054749518 23.2044728 2.82E-20 1.158458
RESIDUAL OUTPUT 观测值预测 Y 残差标准残差 1 14252.56 -369.959 -0.71338 2 10116.66 196.2382 0.378401 3 7032.43 206.6701 0.398516 4 6607.597 412.4032 0.795225 5 7006.005 6.895144 0.013296 6 7843.094 -602.494 -1.16177 7 7098.874 -93.6736 -0.18063 8 6493.004 185.8963 0.358458 9 14147.49 720.0062 1.388367 10 8644.356 618.1438 1.191949 11 12461.12 717.8799 1.384267 12 6555.382 244.618 0.47169 13 9467.216 532.2839 1.026388 14 6365.198 536.2019 1.033943 15 7832.295 567.6051 1.094497 16 6399.5 526.5002 1.015235 17 7697.502 -375.502 -0.72407 18 7871.17 -171.17 -0.33006 19 12363.8 16.59511 0.032 20 7443.669 341.3307 0.658178 21 7111.959 147.341 0.284113 22 9164.599 -1070.9 -2.06498 23 7490.04 -448.14 -0.86414 24 6408.901 160.099 0.308714 25 7774.109 -130.509 -0.25166 26 10342.54 -1577.04 -3.04097 27 7362.997 -462.997 -0.89278 28 6852.282 -195.082 -0.37617 29 6982.121 -236.821 -0.45665 30 6893.317 -362.817 -0.69961 31 7260.6 -39.5998 -0.07636 y=β0+β1x y=121.225+1.27X 3、求相关系数与方向说明数意 根据以上的结果,0《r≤1,这表明x与y之间正线性相关,因为r=0.9741可视为高度相关;
回归模型结果分析
回归模型结果分析 为了提高回归模型的准确性,上文中我们分别按月份、颜色比、退偏振比三种情况进行回归建模,从以上的分析结果看来,按月份划分建立的回归模型反演效果较好。为了更好地对不同情况下得到的回归模型及反演结果进行对比,我们把相同情况下得到的所有反演结果表示在一张图上,并与相应的太阳光度计观测值进行对比分析。 (a)
(b) (c)
图4.1 图4.1中(a)、(b)、(c)三幅图为分别按月份、颜色比和退偏振比建立回归模型后得出的所有颗粒物体积浓度的反演结果与相应太阳光度计观测值的对比分析图。图(a)数据的样本容量为250,图(b)和图(c)的样本容量为150,虽然图(a)样本容量多,但是与图(b)和图(c)相比,图(a)中数据更为集中,大部分数据的反演结果与太阳光度计观测值接近,出现误差的数据少且误差小,图(c)的反演结果略优于图(b),总体来说按月份建立的颗粒物体积浓度的回归模型最准确,而按颜色比建立的回归模型准确性较差。 (a)
(b) (c)图4.2
图4.2中(a)、(b)、(c)三幅图为分别按月份、颜色比和退偏振比建立回归模型后得出的所有有效粒子半径的反演结果与相应太阳光度计观测值的对比分析图。图(a)样本容量较多且数据比较集中,但有一部分数据反演结果明显偏小,严重影响了回归模型的准确性,图(b)数据较离散,部分数据误差大,线性相关系数较小,图(c)个别数据误差大,虽然数据集中程度没有图(a)好。但是数据横纵坐标的差异比其他两幅图小。在确定最优样本容量时,我们发现随着样本容量的增加,线性相关系数减小,所以在无法统一样本容量且线性相关系数差异不大的情况下无法确定在哪种情况下建立的回归模型最准确。所以在建立有效粒子半径的回归模型时,我们可以按月份建立回归模型,也可以按退偏振比建立回归模型。
SPSS回归模型分析答案及解题思路
电视广告费用和报纸广告费用对公司营业收入 的回归模型分析 SPSS录入数据: 本研究关注的是电视广告费用和报纸广告费用对公司收入的影响。 公司收入样本总数为8,M=93.75,SD=1.909;电视广告费用(X1)M=3.19,SD=0.961;报纸广告费用(x2)M=2.48,SD=0.911。 通过皮尔逊相关性分析得出因变量与自变量x1和x2的相关系数分别为(r=0.8,p=0.008)和(r=-0.02,p=0.48),说明公司收入与电视广告费用呈显著性正相关,而公司收入与报纸广告费用相关不显著。 以电视广告费用和报纸广告费用分别作为自变量,以公司收入作为因变量,进行线性回归。具体结果见表1。结果发现,电视广告费用对公司收入存在显著的正向影响(β=0.808,B=1.604,t=3.357,p<0.05,R2=0.653),即电视广告费用的增长会提升公司收入,且该模型能够解释结果的65.3%;报纸广告费用对公司收入不存在显著的正向影响(β=-0.021,t=-0.05,p=0.96)。 表1:广告费用对公司收入的回归结果表 注: 表格中呈现了预测变量的非标准化系数, 括号内是标准误。
以电视广告费用和报纸广告费用同时作为自变量,以公司收入作为因变量,则两个费用对公司收入存在显著的正向影响(β电视=1.153,B电视=2.29,t=7.532,p<0.05;β报纸=0.621,B报纸=1.301,t=4.057,p<0.052, R2=0.919),即电视广告和报纸广告费用的同时增长会提升公司收入,且该模型能够解释结果的91.9%。共线性分析:VIF电视广告=1.448,VIF报纸广告=1.448,均小于5,说明电视广告和报纸广告之间共线性可能性较低。 思路及步骤: 1、公司收入样本总数为8,M=93.75,SD=1.909;电视广告费用M=3.19,SD=0.961; 报纸广告费用M=2.48,SD=0.911。 步骤:回归-线性,之后选择如下:【均值、标准差】
Logistic回归分析报告结果解读分析
L o g i s t i c回归分析报告结果解读分析 Company number:【0089WT-8898YT-W8CCB-BUUT-202108】
Logistic回归分析报告结果解读分析Logistic回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。比较常用的情形是分析危险因素与是否发生某疾病相关联。例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是”或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌感染等。自变量既可以是连续变量,也可以为分类变量。通过Logistic回归分析,就可以大致了解胃癌的危险因素。 Logistic回归与多元线性回归有很多相同之处,但最大的区别就在于他们的因变量不同。多元线性回归的因变量为连续变量;Logistic回归的因变量为二分类变量或多分类变量,但二分类变量更常用,也更加容易解释。 回归的用法 一般而言,Logistic回归有两大用途,首先是寻找危险因素,如上文的例子,找出与胃癌相关的危险因素;其次是用于预测,我们可以根据建立的Logistic回归模型,预测在不同的自变量情况下,发生某病或某种情况的概率(包括风险评分的建立)。 2.用Logistic回归估计危险度 所谓相对危险度(risk ratio,RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的 比值。Logistic回归给出的OR(odds ratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。如不同性别的胃癌发生危险不同,通过Logistic回归可以求出危险度的具体数值,例如,这样就表示,男性发生胃癌的风险是女性的倍。这里要注意估计的方向问题,以女性作为参照,男性患胃癌
线性回归模型的研究毕业论文
线性回归模型的研究毕业论文 1 引言 回归分析最早是由19世纪末期高尔顿(Sir Francis Galton)发展的。1855年,他发表了一篇文章名为“遗传的身高向平均数方向的回归”,分析父母与其孩子之间身高的关系,发现父母的身高越高或的其孩子也越高,反之则越矮。他把儿子跟父母身高这种现象拟合成一种线性关系。但是他还发现了个有趣的现象,高个子的人生出来的儿子往往比他父亲矮一点更趋向于平均身高,矮个子的人生出来的儿子通常比他父亲高一点也趋向于平均身高。高尔顿选用“回归”一词,把这一现象叫做“向平均数方向的回归”。于是“线形回归”的术语被沿用下来了。 回归分析中,当研究的因果关系只涉及因变量和一个自变量时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。此外,回归分析中,又依据描述自变量与因变量之间因果关系的函数表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。按照参数估计方法可以分为主成分回归、偏最小二乘回归、和岭回归。 一般采用线性回归分析,由自变量和规定因变量来确定变量之间的因果关系,从而建立线性回归模型。模型的各个参数可以根据实测数据解。接着评价回归模型能否够很好的拟合实际数据;如果不能够很好的拟合,则重新拟合;如果能很好的拟合,就可以根据自变量进行下一步推测。 回归分析是重要的统计推断方法。在实际应用中,医学、农业、生物、林业、金融、管理、经济、社会等诸多方面随着科学的发展都需要运用到这个方法。从而推动了回归分析的快速发展。 2 回归分析的概述 2.1 回归分析的定义 回归分析是应用极其广泛的数据分析方法之一。回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。 2.2 回归分析的主要容
Logistic回归分析报告结果解读分析
Logistic回归分析报告结果解读分析Logistic回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。比较常用的情形是分析危险因素与是否发生某疾病相关联。例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是”或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌感染等。自变量既可以是连续变量,也可以为分类变量。通过Logistic 回归分析,就可以大致了解胃癌的危险因素。 Logistic回归与多元线性回归有很多相同之处,但最大的区别就在于他们的因变量不同。多元线性回归的因变量为连续变量;Logistic回归的因变量为二分类变量或多分类变量,但二分类变量更常用,也更加容易解释。 回归的用法 一般而言,Logistic回归有两大用途,首先是寻找危险因素,如上文的例子,找出与胃癌相关的危险因素;其次是用于预测,我们可以根据建立的Logistic 回归模型,预测在不同的自变量情况下,发生某病或某种情况的概率(包括风险评分的建立)。 2.用Logistic回归估计危险度 所谓相对危险度(risk ratio,RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的 比值。Logistic回归给出的OR(odds ratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。如不同性别的胃癌发生危险不同,通过Logistic回归可以求出危险度的具体数值,例如,这样就表示,男性发生胃癌的风险是女性的倍。这里要注意估计的方向问题,以女性作为参照,男性患胃癌的OR是。如果以男性作为参照,算出的OR将会是(1/,表示女性发生胃癌的风险是男性的倍,或者说,是男性的%。撇开了参照组,相对危险度就没有意义了。
完整版逻辑回归模型分析见解
1.逻辑回归模型 1.1 逻辑回归模型 考虑具有p个独立变量的向量■',设条件概率卩;上二?丨门二广为根据观测 量相对于某事件发生的概率。逻辑回归模型可表示为 :「( 1.1) 上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。 其中-" I' 1 c' ■-..【?。如果含有名义变量,则将其变为dummy 变量。一个具有k个取值的名义变量,将变为k-1个dummy 变量。这样,有 — I ( 1.2) 这个比值称为事件的发生比(the odds of experie ncing an event), 0
得到I 的概率。在同样条件下得到-- 的条件概率为丨:一"。 得到一个观测值的概率为 因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。 (1.7) 上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估 譏备心)( 」' (1.10 是, ◎ )*(1 ¥严(1.6 ) i-l 计。于是,最大似然估计的关键就是求出参数:- ,使上式取得最大值。 对上述函数求对数 — (1.8) 上式称为对数似然函数。为了估计能使亠取得最大的参数的值。 对此函数求导,得到p+1个似然方程。 Ei 片 n:—E L尹—心肿一时 (1.9 ) ^叶切迄尸,j=1,2,..,p. 上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森 进行迭代求解。 (Newto n-Raphs on) 方法1.3 牛顿-拉斐森迭代法 对-八?求二阶偏导数,即Hessian矩阵为 如果写成矩阵形式,以H表示Hessian矩阵,X表示 (1.11 )
回归分析方法
回归分析方法Newly compiled on November 23, 2020
第八章回归分析方法 当人们对研究对象的内在特性和各因素间的关系有比较充分的认识时,一般用机理分析方法建立数学模型。如果由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型,那么通常的办法是搜集大量数据,基于对数据的统计分析去建立模型。本章讨论其中用途非常广泛的一类模型——统计回归模型。回归模型常用来解决预测、控制、生产工艺优化等问题。 变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来。例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。回归分析就是处理变量之间的相关关系的一种数学方法。其解决问题的大致方法、步骤如下: (1)收集一组包含因变量和自变量的数据; (2)选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数; (3)利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型; (4)判断得到的模型是否适合于这组数据; (5)利用模型对因变量作出预测或解释。 应用统计分析特别是多元统计分析方法一般都要处理大量数据,工作量非常大,所以在计算机普及以前,这些方法大都是停留在理论研究上。运用一般计算语言编程也要
占用大量时间,而对于经济管理及社会学等对高级编程语言了解不深的人来说要应用这些统计方法更是不可能。MATLAB 等软件的开发和普及大大减少了对计算机编程的要求,使数据分析方法的广泛应用成为可能。MATLAB 统计工具箱几乎包括了数理统计方面主要的概念、理论、方法和算法。运用MATLAB 统计工具箱,我们可以十分方便地在计算机上进行计算,从而进一步加深理解,同时,其强大的图形功能使得概念、过程和结果可以直观地展现在我们面前。本章内容通常先介绍有关回归分析的数学原理,主要说明建模过程中要做的工作及理由,如模型的假设检验、参数估计等,为了把主要精力集中在应用上,我们略去详细而繁杂的理论。在此基础上再介绍在建模过程中如何有效地使用MATLAB 软件。没有学过这部分数学知识的读者可以不深究其数学原理,只要知道回归分析的目的,按照相应方法通过软件显示的图形或计算所得结果表示什么意思,那么,仍然可以学到用回归模型解决实际问题的基本方法。包括:一元线性回归、多元线性回归、非线性回归、逐步回归等方法以及如何利用MATLAB 软件建立初步的数学模型,如何透过输出结果对模型进行分析和改进,回归模型的应用等。 8.1 一元线性回归分析 回归模型可分为线性回归模型和非线性回归模型。非线性回归模型是回归函数关于未知参数具有非线性结构的回归模型。某些非线性回归模型可以化为线性回归模型处理;如果知道函数形式只是要确定其中的参数则是拟合问题,可以使用MATLAB 软件的curvefit 命令或nlinfit 命令拟合得到参数的估计并进行统计分析。本节主要考察线性回归模型。 一元线性回归模型的建立及其MATLAB 实现 其中01ββ,是待定系数,对于不同的,x y 是相互独立的随机变量。
多元线性回归模型案例分析报告
多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据
设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用 EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024
【原创】r语言收入逻辑回归分析报告附代码数据
逻辑回归对收入进行预测 1逻辑回归模型 回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。 最简单的回归是线性回归,在此借用Andrew NG的讲义,有如图1.a所示,X为数据点——肿瘤的大小,Y为观测值——是否是恶性肿瘤。通过构建线性回归模型,如h θ (x)所示,构建线性回归模型后,即可以根据肿瘤大小,预测是否为恶性肿瘤h θ(x)≥.05为恶性,h θ (x)<0.5为良性。 Zi=ln(Pi1?Pi)=β0+β1x1+..+βnxn Zi=ln(Pi1?Pi)=β0+β1x1+..+βnxn 2数据描述 该数据从美国人口普查数据库抽取而来,可以用来预测居民收入是否超过50K$/year。该数据集类变量为年收入是否超过50k$,属性变量包含年龄,工种,学历,职业,人种等重要信息,值得一提的是,14个属性变量中有7个类别型变量。 3问题描述 其实对于收入预测,主要是思考收入由哪些因素推动,再对每个因素做预测,最后得出收入预测。这其实不是一个财务问题,是一个业务问题。 对于某企业新用户,会利用大数据来分析该用户的信息来确定是否为付费用户,弄清楚用户属性,提高运营人员的办事效率。 流失预测。这方面会偏向于大额付费用户,提取额特征向量运用到应用场景的用户流失和预测里面去。 我们尝试并预测个人是否可以根据数据中可用的人口统计学变量使用逻辑回归预测收入是否超过$ 50K的资金。在这个过程中,我们将: 1.导入数据 2.检查类别偏差 3.创建训练和测试样本 4.建立logit模型并预测测试数据 5.模型诊断
二元logistic逻辑回归分析1
二元logistic逻辑回归分析1 SPSS与社会统计学课程作业二 [1]陈昱,陈银蓉,马文博. 基于Logistic模型的水库移民安置区居民土地流转意愿分析——四川、湖南、湖北移民安置区的调查[J]. 资源科学,2011,06:1178-1185. 一、变量赋值 1.被解释变量用0表示不愿意流转,1表示愿意流转,有意愿上的状态表示效果。 2.性别分别用1和2表示男女,男女不存在有没有状态的表征,所以用1、2赋值非常合适;它的预计影响方向为负,是基于学者张林秀、刘承芳等认为:由于农村男性外出打工的几率高于女性,女性更愿意在家耕种土地,这就可能导致女性不愿意转出土地的基础上设定的。 3.教育程度越高赋值越高,且预测影响为正,这个也是在文章前面定量分析的时候引用学者李实的观点说明赋值的理由。
4.职业类型中,兼业化程度越高赋值越高,且为正向。从家庭收入对农业收入的依赖性原理角度来看这个不难理解。 5.其它变量的赋值依据实际情况初步判断也不能理解其赋值的缘由。然而对于“是否为村干部”这一变量来看,预测的趋向是:是村干部则不愿意流转,前面的分析并没有说明为什么会是这样。虽然这知识一种预判,但是若能够给出预判的一丁点理由就更好了。二、系数解读 1. 标准化系数中,x1,x3,x7,x9,x11,x12系数为付,意味着性别是男、与市中心距离 越近、家庭人口和劳动力人数越少、农业收入占比越少、认为土地经营权权属则土地流 转的意愿越强; 2. 其中X3(与市中心距离),x9(劳动力人数)影响系数绝对值较大,分别为 0.815,0.322。 在显著性检验方面,x3、x9、x11分别通过了15%、1%、5%的显著性检验。也就是说, 土地不愿意流转与劳动力人数多有显著相关性,与农业收入占比高有较显著的相关,与 市中心距离近相关性不显著。
逻辑回归模型分析见解
逻辑回归模型分析见解
1.逻辑回归模型 1.1逻辑回归模型 考虑具有P个独立变量的向量*=(Xl,X2,”q),设条件概率= 为根据观测量相对于某事件发生 的概率。逻辑回归模型可表示为 1 L十严 上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。 其中。如果含有名义变量,则将其变为dummy 变量。一个具有k个取值的名义变量,将变为k-1个dummy 变量。这样,有 定义不发生事件的条件概率为 (1.1) (1.2)
尸wmx 十各-占 (1.3 ) 那么,事件发生与事件不发生的概率之比为 F (H =1|幻—P “曲 = Q | x ) \-p 这个比值称为事件 的发生比 (the odds of experie ncing an eve nt), 简称为 odds 。 因为0
于是,最大似然估计的关键就是求出参数 ,使上式取得 最大值。 对上述函数求对数 山应?*的?召仙恥区;]丨门丫」訓:叩丄】 (i 8 ) 上式称为对数似然函数。为了估计能使 £(旳取得 最大的参数的值。 对此函数求导,得到p+1个似然方程。 纠片-v 相严纠# _ ]新.站卄”和丸 (i 9 ) 圣屮.『;-* 几-百工 一 f Ji' j=1 2 p 上式称为似然方程。为了解上述非线性方程,应 用牛顿一拉斐森 (Newto n-Raphso n ) 方法 进行迭代求解。 亦占二址(1-隔) 兰丝二-S 耳赳兀(1-花) 阴阴处心“ (1.10 ) 如果写成矩阵形式,以H 表示 Hessian 矩阵, X 表示 1.3 牛顿-拉斐森迭代法 对心;求二阶偏导数,即Hessian 矩阵为 护 M - i-l
回归模型的残差分析
回归模型的残差分析 山东 胡大波 判断回归模型的拟合效果是回归分析的重要内容,在回归分析中,通常用残差分析来判断回归模型的拟合效果。下面具体分析残差分析的途径及具体例子。 一、残差分析的两种方法 1、差分析的基本方法是由回归方程作出残差图,通过观测残差图,以分析和发现观测数据中可能出现的错误以及所选用的回归模型是否恰当;在残差图中,残差点比较均匀地落在水平区域中,说明选用的模型比较合适,这样的带状区域的宽度越窄,说明模型的拟合精度越高,回归方程的预报精度越高。 2、可以进一步通过相关指数∑∑==--- =n i i n i i i y y y y R 1 2 1 2 ^ 2 )()(1来衡量回归模型的拟合效果,一般 规律是2 R 越大,残差平方和就越小,从而回归模型的拟合效果越好。 二、典例分析: 例1、某运动员训练次数与运动成绩之间的数据关系如下: 试预测该运动员训练47次以及55次的成绩。 解答:(1)作出该运动员训练次数x 与成绩y 之间的散点图,如图1所示,由散点图可 知,它们之间具有线性相关关系。
由上表可求得875.40,25.39==y x , 126568 1 2=∑=i i x ,137318 1 2=∑=i i y , 131808 1 =∑=i i i y x ,所以∑∑==---= 8 1 2 8 1 )() )((i i i i i x x y y x x β.0415.188 1 2 28 1≈--= ∑∑==i i i i i x x y x y x 00302.0-≈-=x y βα,所以回归直线方程为.00302 .00415.1^ -=x y (3)计算相关系数 将上述数据代入∑∑∑===---= 8 1 8 1 2 22 2 8 1 ) 8)(8(8i i i i i i i y y x x y x y x r 得992704 .0=r ,查表可知 707.005.0=r ,而05.0r r >,故y 与x 之间存在显著的相关关系。 (4)残差分析: 作残差图如图2,由图可知,残差点比较均匀地分布在水平带状区域中,说明选用的模型比较合适。 计算残差的方差得884113.02 =σ ,说明预报的精度较高。 (5)计算相关指数2 R 计算相关指数2 R =0.9855.说明该运动员的成绩的差异有98.55%是由训练次数引起的。 (6)做出预报 由上述分析可知,我们可用回归方程.00302.00415.1^ -=x y 作为该运动员成绩的预报值。 将x =47和x =55分别代入该方程可得y =49和y =57, 故预测运动员训练47次和55次的成绩分别为49和57. 点评:一般地,建立回归模型的基本步骤为:
二元logistic逻辑回归分析8)
《应用二分类Logistic回归模型分析浅表淋巴结良恶性的超声诊断结果》文中把与恶性相关的指标赋值记录为1,与良性相关的指标赋值记录为0:单发(记 为0),多发(记为1)。测量淋巴结最大切面的长径和短径,计算长短径比值,大于等于2 记为0,小于2记为1。边界以淋巴结周围亮线样回声完整为清晰(记为0),回声不完整或与其他淋巴结融合为不清晰(记为1)。内部回声及分布主要分析皮质回声,低于髓质为低回声(记为0),高于髓质为高回声(记为1);分布均匀一致(记为1),内部回声混杂多样(记 为0)。如果淋巴结内存在无回声区则为透声(记为0),否则为无透声(记为1)。淋巴结门结构主要分析髓质,以中心高回声带存在为清晰(记为0),消失为不清晰(记为1)。肿大淋巴结彼此孤立为不融合(记为0),不同肿大淋巴结不能区分开为相互融合(记为1)。淋巴结血供以清晰显示多条血管状血流信号为丰富(记为1),无明显血流或只有少量点状血流信号为不丰富(记为0)。其血流信号类型为无血流型(0 型),血流信号沿淋巴门分布为淋巴门型血流(1 型),淋巴结内有血流信号但无规则分布为中心型血流(2 型),淋巴门处无血流信号而血流信号主要分布在淋巴结周围为周边型血流(3 型),淋巴结内部及周边均有血流为混合型血流(4 型)。 本文以超声检查淋巴结的各观察值为自变量,以淋巴结的良恶性为因变量,构建二分类Logistic回归模型,采用偏最大似然估计前进法进行对因变量逐步回归,对模型的拟合优度进行Hosmer-Lemeshow(HL)检验,并采用2x检验,自由度为8,P=(>),证明模型拟合得较好,说明当前数据中的信息以及被充分提取,并且可以排除混杂因素的影响。模型判断恶性淋巴结概率预测值的ROC曲线中,得到AUC为±,P<,95%可信区间为(,),证明该模型的拟合效果较好,用于预测淋巴结的良恶性效果也很好。另外,血流类型亚变量分析结果显示,均以无血流信号型血流为参照水平,淋巴门型血流的OR值小于1,提示支持良性诊断,中心型血流的OR 值大于1,提示支持恶性诊断,但两组P值均大于,无显著统计学意义。而与无血流信号型相比,周边型血流和混合型血流的OR值均大于1,支持恶性诊断,且P值均小于,有非常显著的统计学意义。 在良恶性淋巴结超声诊断指标的对比结果中,其中边界是否清晰、内部回声是否均匀、有无淋巴门结构、血流是否丰富、是否有透声区以及长短径比值的赋值在良恶性淋巴结比较中P 值均小于,说明有显著统计学差异。血流类型的统计结果显示,淋巴结的良恶性与血流类型的P值小于,表示有非常显著统计学相关性。 因此,二分类Logistic 回归多元分析模型能够很好地描述和分析良恶性淋巴结的超声鉴别
回归分析方法
第八章 回归分析方法 当人们对研究对象的内在特性和各因素间的关系有比较充分的认识时,一般用机理分析方法建立数学模型。如果由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型,那么通常的办法是搜集大量数据,基于对数据的统计分析去建立模型。本章讨论其中用途非常广泛的一类模型——统计回归模型。回归模型常用来解决预测、控制、生产工艺优化等问题。 变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来。例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。回归分析就是处理变量之间的相关关系的一种数学方法。其解决问题的大致方法、步骤如下: (1)收集一组包含因变量和自变量的数据; (2)选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数; (3)利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型; (4)判断得到的模型是否适合于这组数据; (5)利用模型对因变量作出预测或解释。 应用统计分析特别是多元统计分析方法一般都要处理大量数据,工作量非常大,所以在计算机普及以前,这些方法大都是停留在理论研究上。运用一般计算语言编程也要占用大量时间,而对于经济管理及社会学等对高级编程语言了解不深的人来说要应用这些统计方法更是不可能。MA TLAB 等软件的开发和普及大大减少了对计算机编程的要求,使数据分析方法的广泛应用成为可能。MATLAB 统计工具箱几乎包括了数理统计方面主要的概念、理论、方法和算法。运用MA TLAB 统计工具箱,我们可以十分方便地在计算机上进行计算,从而进一步加深理解,同时,其强大的图形功能使得概念、过程和结果可以直观地展现在我们面前。本章内容通常先介绍有关回归分析的数学原理,主要说明建模过程中要做的工作及理由,如模型的假设检验、参数估计等,为了把主要精力集中在应用上,我们略去详细而繁杂的理论。在此基础上再介绍在建模过程中如何有效地使用MA TLAB 软件。没有学过这部分数学知识的读者可以不深究其数学原理,只要知道回归分析的目的,按照相应方法通过软件显示的图形或计算所得结果表示什么意思,那么,仍然可以学到用回归模型解决实际问题的基本方法。包括:一元线性回归、多元线性回归、非线性回归、逐步回归等方法以及如何利用MATLAB 软件建立初步的数学模型,如何透过输出结果对模型进行分析和改进,回归模型的应用等。 8.1 一元线性回归分析 回归模型可分为线性回归模型和非线性回归模型。非线性回归模型是回归函数关于未知参数具有非线性结构的回归模型。某些非线性回归模型可以化为线性回归模型处理;如果知道函数形式只是要确定其中的参数则是拟合问题,可以使用MATLAB 软件的curvefit 命令或nlinfit 命令拟合得到参数的估计并进行统计分析。本节主要考察线性回归模型。 8.1.1 一元线性回归模型的建立及其MATLAB 实现 01y x ββε=++ 2~(0,)N εσ 其中01ββ,是待定系数,对于不同的,x y 是相互独立的随机变量。
SPSS与社会统计学逻辑回归分析Logistic课程
SPSS与社会统计学逻辑回归分析Logistic课程作业二 [1]陈昱,陈银蓉,马文博. 基于Logistic模型的水库移民安置区居民土地流转意愿分析——四川、湖南、湖北移民安置区的调查[J]. 资源科学,2011,06:1178-1185. 一、变量赋值 1.被解释变量用0表示不愿意流转,1表示愿意流转,有意愿上的状态表示效果。 2.性别分别用1和2表示男女,男女不存在有没有状态的表征,所以用1、2赋值非常合适;它的预计影响方向为负,是基于学者张林秀、刘承芳等认为:由于农村男性外出打工的几率高于女性,女性更愿意在家耕种土地,这就可能导致女性不愿意转出土地的基础上设定的。 3.教育程度越高赋值越高,且预测影响为正,这个也是在文章前面定量分析的时候引用学者李实的观点说明赋值的理由。 4.职业类型中,兼业化程度越高赋值越高,且为正向。从家庭收入对农业收入的依赖性原理角度来看这个不难理解。 5.其它变量的赋值依据实际情况初步判断也不能理解其赋值的缘由。然而对于“是否为村干部”这一变量来看,预测的趋向是:是村干部则不愿意流转,前面的分析并没有说明为什么会是这样。虽然这知识一种预判,但是若能够给出预判的一丁点理由就更好了。 二、系数解读
1.标准化系数中,x1,x3,x7,x9,x11,x12系数为付,意味着性别是男、与市中心距离 越近、家庭人口和劳动力人数越少、农业收入占比越少、认为土地经营权权属则土地流转的意愿越强; 2.其中X3(与市中心距离),x9(劳动力人数)影响系数绝对值较大,分别为0.815,0.322。 在显著性检验方面,x3、x9、x11分别通过了15%、1%、5%的显著性检验。也就是说,土地不愿意流转与劳动力人数多有显著相关性,与农业收入占比高有较显著的相关,与市中心距离近相关性不显著。 3.系数为正的变量中,影响系数均不高,但能通过显著性检验的有:x2、x5(15%);x10、 x13(5%);x4(1%)。说明文化程度高对愿意流转的影响是非常显著的,而且在系数为正的变量中,x4的系数为最大,说明x4与y(1)显著相关。 三、模型检验
二项logistic回归案列分析
二项logistic回归案列分析 第九组成员:曹克强张铭牛孝龙张昕鑫 1、实验分析目标:建立客户购买的预测模型,分析影响因素 2、操作步骤: 第一步:选择选项“分析”-“回归”-“二项Logistic回归”,出现窗口 第二步:在“方法”中选择解释变量的筛选策略选择默认方法 在“选项”项中,可以指定输出内容和设置建模中的某些参数。如下图所示:
在“保存”项中,可以将预测结果、残差依据强影响点的探测值等保存到数据编辑窗口,如下图所示: 在“分类”选项设置性别、收入分类变量对比为指示符、以第一个为参考类别。
3、结果分析: 下图为初始阶段(方程中只有常数项时)的混淆矩阵 可以看到,269人实际没购买且模型预测正确,正确率为100%,162人实际购买了但模型预测错误,正确率为0,模型的总的预测正确率为62.4%。 方程中常量的显著性检验p值小于0.05所以拒绝原假设说明常数量对模型影响是显著地 从上表统计量p值可以看出年龄的统计量p 值大于0.05所以接受原假设,年龄对是否购买影响不显著。
下图为当前模型时的混淆矩阵 在实际没购买的269人中,模型正确识别了236人,错误识别了33人,正确率为87.7%。在实际购买的162中,模型正确识别了31人,错误识别了131人,正确率为19.1%,模型的总的预测正确率为62.9%。 下图为Hosmer-Lemeshow检验的结果 在最终模型中,Hosmer-Lemeshow统计量为8.749,P值为0.364,大于显著性水平,因此,不拒绝原假设,认为观测频数的分布与预测频数的分布无显著差异,那么模型拟合效果较好 从上表中可以看出年龄的统计量p值大于0.05、接受原假设,所以在模型中年龄对是否购买影响不显著,可以不用考虑年龄。 根据上表所示拟合方程为: P=-0.814-0.511gender(1) P=-0.814-0.787income(1) P=-0.814-0.686income(2)