《计量经济学》第5章数据#(精选.)

《计量经济学》各章数据
第5章自相关性
例5.3.1中国城乡居民储蓄存款模型(自相关性检验)。表5.3.1列出了我国城乡居民储蓄存款年底余额(单位:亿元)和GDP指数(1978年=100)的历年统计资料,试建立居民储蓄存款模型,并检验模型的自相关性。
表5.3.1 我国城乡居民储蓄存款与GDP指数统计资料
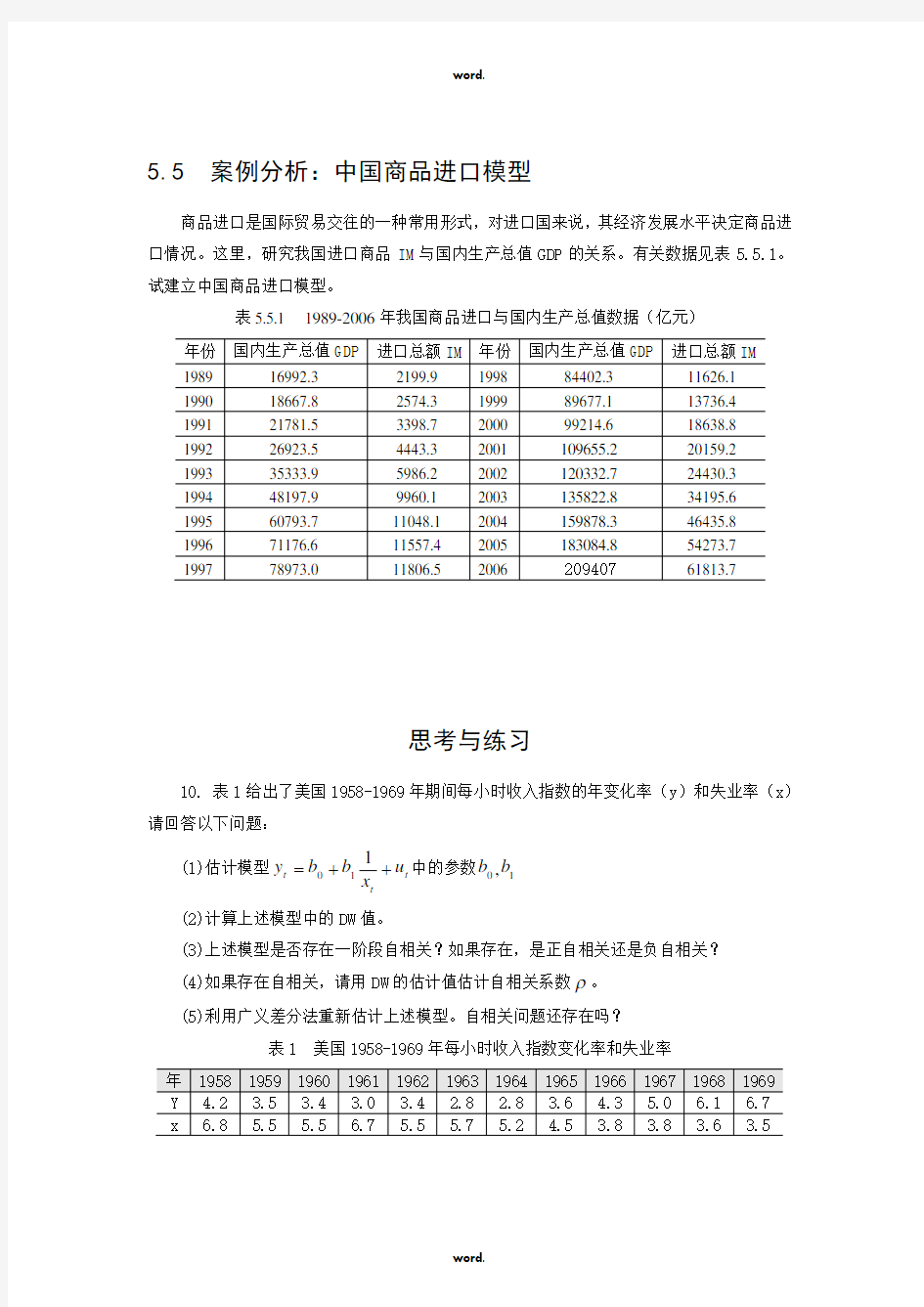
5.5 案例分析:中国商品进口模型
商品进口是国际贸易交往的一种常用形式,对进口国来说,其经济发展水平决定商品进口情况。这里,研究我国进口商品IM 与国内生产总值GDP 的关系。有关数据见表5.5.1。试建立中国商品进口模型。
表5.5.1 1989-2006年我国商品进口与国内生产总值数据(亿元)
思考与练习
10. 表1给出了美国1958-1969年期间每小时收入指数的年变化率(y )和失业率(x ) 请回答以下问题:
(1)估计模型t t
t u x b b y ++=1
1
0中的参数10,b b (2)计算上述模型中的DW 值。
(3)上述模型是否存在一阶段自相关?如果存在,是正自相关还是负自相关? (4)如果存在自相关,请用DW 的估计值估计自相关系数ρ。 (5)利用广义差分法重新估计上述模型。自相关问题还存在吗?
表1 美国1958-1969年每小时收入指数变化率和失业率
11.考虑表2中所给数据:
表2 美国股票价格指数和GNP 数据
注:y-NYSE 10亿美元)
(1)利用OLS 估计模型:t t t u x b b y ++=10
(2)根据DW 统计量确定在数据中是否存在一阶自相关。
(3)如果存在一阶自相关,用DW 值来估计自相关系数ρ
?。 (4)利用估计的ρ
?值,用OLS 法估计广义差分方程: t t t t t v x x b b y y +-+-=---)?()?1(?1101ρρρ
(5)利用一阶差分法将模型变换成方程:
t t t t t v x x b y y +-=---)(111,或:t t t v x b y +?=?1
的形式,并对变换后的模型进行估计。比较(4)、(5)的回归结果,你能得出什么结论?在变换后的模型中还存在自相关吗?
12.中国1980-2000年投资总额x 与工业总产值x 的统计资料如表3所示。试问: (1)当模型设定为:t t t u x b b y ++=10时,是否存在自相关?如果存在自相关,利用
DW 求出ρ
?。 (2)若按一阶自相关假设t t t v u u +=-1ρ,试用Durbin 两步估计法与广义最小二乘法估计原模型。
(3)采用差分形式1*--=t t t y y y 与1*
--=t t t x x x 作为新数据,估计模型
t t t v x a a y ++=*10*
该模型是否存在序列相关?
表3 中国1980-2000年投资总额x 与工业总产值y 数据(亿元)
13.天津市城镇居民人均消费性支出(CONSUM ),人均可支配收入(INCOME ),以及消费价格指数(PRICE )见表4。定义人均实际消费性支出Y= CONSUM/ PRICE ,人均实际可支配收入X= INCOME / PRICE 。
表4 天津市城镇居民人均消费与人均可支配收入数据
(1)利用OLS 估计模型:t t t 10
(2)根据DW 检验法、LM 检验法检验模型是否存在自相关。
(3)如果存在一阶自相关,用DW 值来估计自相关系数ρ?。 (4)利用估计的ρ
?值,用OLS 法估计广义差分方程: t t t t t v x x b b y y +-+-=---)?()?1(?1101ρρρ
(5) 利用OLS 估计模型:t t t u x b b y ++=ln ln 10,检验此模型是否存在自相关,如何消除自相关?
最新文件 仅供参考 已改成word 文本 。 方便更改
计量经济学-李子奈-计算题整理集合
计算分析题(共3小题,每题15分,共计45分) 1、下表给出了一含有3个实解释变量的模型的回归结果: 方差来源 平方和(SS ) 自由度(d.f.) 来自回归65965 — 来自残差— — 总离差(TSS) 66056 43 (1)求样本容量n 、RSS 、ESS 的自由度、RSS 的自由度 (2)求可决系数)37.0(-和调整的可决系数2 R (3)在5%的显著性水平下检验1X 、2X 和3X 总体上对Y 的影响的显著性 (已知0.05(3,40) 2.84F =) (4)根据以上信息能否确定1X 、2X 和3X 各自对Y 的贡献?为什么? 1、 (1)样本容量n=43+1=44 (1分) RSS=TSS-ESS=66056-65965=91 (1分) ESS 的自由度为: 3 (1分) RSS 的自由度为: d.f.=44-3-1=40 (1分) (2)R 2=ESS/TSS=65965/66056=0.9986 (1分) 2R =1-(1- R 2)(n-1)/(n-k-1)=1-0.0014?43/40=0.9985 (2分) (3)H 0:1230βββ=== (1分) F=/65965/39665.2/(1)91/40 ESS k RSS n k ==-- (2分) F >0.05(3,40) 2.84F = 拒绝原假设 (2分) 所以,1X 、2X 和3X 总体上对Y 的影响显著 (1分) (4)不能。 (1分) 因为仅通过上述信息,可初步判断X 1,X 2,X 3联合起来 对Y 有线性影响,三者的变化解释了Y 变化的约99.9%。但由于 无法知道回归X 1,X 2,X 3前参数的具体估计值,因此还无法 判断它们各自对Y 的影响有多大。 2、以某地区22年的年度数据估计了如下工业就业模型 i i i i i X X X Y μββββ++++=3322110ln ln ln 回归方程如下: i i i i X X X Y 321ln 62.0ln 25.0ln 51.089.3?+-+-= (-0.56)(2.3) (-1.7) (5.8) 2 0.996R = 147.3=DW 式中,Y 为总就业量;X 1为总收入;X 2为平均月工资率;X 3为地方政府的
计量经济学名词解释
1、计量经济学 计量经济学是一门从数量上研究物质资料的生产、交换、分配、消费等经济关系和经济活动规律及其应用的科学。 2、数据质量 数据满足明确或隐含需求程度的指标 3、相关分析 主要研究变量之间的相互关联程度,用相关系数表示。包括简单相关和多重相关(复相关)。 4、回归分析(Regression Analysis) 研究一个变量(因变量)对于一个或多个其他变量(解释变量)的数量依存关系。其目的在于根据已知的解释变量的数值来估计或预测因变量的总体平均值。 5.内生变量 指由模型系统内决定的变量,取值在系统内决定 6、面板数据 时间序列数据和截面数据的混合 7.异方差: 总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差。如果这一假定不满足,则称线性回归模型存在异方差性。 8.自相关 自相关是在时间序列资料中按时间顺序排列的观测值之间的相关或在横截面资料中按空间顺序排列的观测值之间的相关
9.多重共线性 解释变量之间存在完全的线性关系或近似的线性关系。解释变量存在完全的线性关系叫完全多重共线;解释变量之间存在近似的线性关系叫不完全多重共线。 10.虚拟变量 虚拟变量:在建立模型时,有一些影响经济变量的因素无法定量描述 构造只取“0”或“1”的人工变量,通常称为虚拟变量,记为D 11.平稳序列 是指时间序列的统计规律不会随着时间的推移而发生变化。 12.伪回归 所谓“伪回归”,是指变量间本来不存在相依关系,但回归结果却得出存在相依关系的错误结论。 13.协整 所谓协整,是指多个非平稳变量的某种线性组合是平稳的 14.前定变量 所有的外生变量和滞后的内生变量。前定变量=外生变量+滞后内生变量+滞后外生变量 15.恰好识别 恰好识别:能够唯一地估计出结构参数值。 16.结构式模型 体现经济理论中经济变量之间的关系结构的联立方程模型,称为结构式模型17.过度识别
计量经济学
名词解释 1、 因果效应:在理想化随机对照实验中得到的,某一给定的行为或处理对结果的影响 2、 实验数据:来源于为评价某种处理(某项政策)抑或某种因果效应而设计的实验 3、 观测数据:通过观察实验之外的实际行为而获得的数据 4、 截面数据:对不同个体如工人、消费者、公司或政府机关等在某一特定时间段内收集到的数据 5、 时间序列数据:对同一个体(个人、公司、国家等)在多个时期内收集到的数据 6、 面板数据:即纵向数据,是多个个体分别在两个或多个时期内观测到的数据 7、 离散型随机变量:一些随机变量是离散的 连续型随机变量:一些随机变量是连续的 8、 期望值:随机变量经过多次重复实验出现的长期平均值,记作E (Y ) 9、 期望:Y 的长期平均值,记作μY 10、方差:是Y 距离其均值的偏差平方的期望值,记作var (Y ) 11、标准差:方差的平方根来表示偏差程度,记作σY 12、独立性:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息 13、标准正态分布:指那些均值102==σμ、方差的正态分布,记作N (0,1) 14、简单随机抽样:n 个对象从总体中抽取,且总体中的每一个个体都有相等的可能性被选入样本 15、独立分布:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息,那么这两个变量X 和Y 独立分布 16、偏差:设Y Y E Y Y μμμμ-??)(为的一个估计量,则偏差是; 一致性:当样本容量增大时,Y μ ?落入真实值Y μ的微小领域区间内的概率接近于1,即Y Y μμ与?是一致的 有效性:如果Y μ ?的方差比Y μ~更小,那么可以说Y Y μμ~?比更有效 17、最小二乘估计量:21)(m i n i -Y ∑ =最小化误差m -i Y 平方和的估计量m 18、P 值:即显著性概率,指原假设为真的情况下,抽取到的统计量与原假设之间的差异程度至少等于样本计算值与 原假设之间差异程度的概率 19、第一类错误:拒绝了实际上为真的原假设 20、一元线性回归模型:i i 10i μββ+X +=Y ;1β代表1X 变化一个单位所导致Y 的变化量 21、普通最小二乘(OLS )估:选择使得估计的回归线与观测数据尽可能接近的回归系数,其中近似程度用给定X 时预 测Y 的误差的平方和来度量 22、回归2R :可以由i X 解释(或预测)的i Y 样本方差的比例,即TSS SSR TSS ESS R -==12 23、最小二乘假设:①给定i X 时误差项i μ的条件均值为零:0)(i i =X μE ; ②从联合总体中抽取的, ,,,),,(n ...21i i i =Y X 满足独立同分布; ③大异常值不存在:即i i Y X 和具有非零有限的四阶距 24、1β置信区间:以95%的概率包含1β真值的区间,即在所有可能随机抽取的样本中有95%包含了1β的真值 25、同方差:若对于任意i=1,2,...,n ,给定) (条件分布的方差时χμμ=X X i i i i var 为常数且不依赖于χ,则 称误差项i μ是同方差
计量经济学分析计算题Word版
计量经济学分析计算题(每小题10分) 1.下表为日本的汇率与汽车出口数量数据, X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3= ,Y 554.2=,2 X X 4432.1∑ (-)=,2 Y Y 68113.6∑(-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义 是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。
问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2 Y Y 68113.6∑ (-)=, 求判定系数和相关系数。 5.有如下表数据 日本物价上涨率与失业率的关系 (1)设横轴是U ,纵轴是P ,画出散点图。根据图形判断,物价上涨率与失业率之间是什么样的关系?拟合什么样的模型比较合适? (2)根据以上数据,分别拟合了以下两个模型: 模型一:1 6.3219.14 P U =-+ 模型二:8.64 2.87P U =- 分别求两个模型的样本决定系数。 7.根据容量n=30的样本观测值数据计算得到下列数据:XY 146.5= ,X 12.6=,Y 11.3=,2X 164.2=,2Y =134.6,试估计Y 对X 的回归直线。 8.下表中的数据是从某个行业5个不同的工厂收集的,请回答以下问题:
计量经济学的概念
计量经济学是经济科学领域内的一门应用科学,以一定的经济理论和实际统计资料为基础,运用数学、统计方法与计算机技术,以建立经济计量模型为主要手段,定量分析研究具有随机特性的经济变量关系。 2、数理经济模型与计量经济模型的区别。 数理:揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 计量:揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述。 3、经典计量经济学模型的一般形式。 4、计量经济学的数据类型。 时间序列数据:按时间先后排列的统计数据。 截面数据:一个或多个变量在某一时点上的数据集合。 合并数据(平行数据):既包含时间序列数据又有截面 数据。 5、建立计量经济学模型的步骤。 1) 模型的数学形式。③拟定模型中待估计参数的理论期望 值。 2)样本数据的收集: 差项产生序列相关。②截面数据易引起模型随机误差项 产生异方差。③样本数据的质量:完整性、准确性、可 比性、一致性。 3)模型参数的估计。 4 度检验、变量的显着性检验、方程的显着性检验。③计 量经济学检验:序列相关、异方差法(随机误差项)、 多重共线性(解释变量)④模型预测检验。 6、计量经济学模型的应用。 1)结构分析;2)经济预测;3)政策评价;4)检验与发展经济理论。 7、如何正确选择解释变量。 作为“变量”的原因:1 2)考虑数据的可得性;3)考虑入选变量之间的关系。 8、回归分析的目的。 1)根据自变量的取值,估计应变量的均值;2)检验建立在经济理论基础上的假设;3) 值,预测应变量的均值。 9、总体回归函数(PRF)和样本回归函数(SRF)各变量系数名称及函数方程。 10、随机误差项(Ui)的性质或主要内容。
计量经济学计算题解法汇总
计量经济学:部分计算题解法汇总 1、求判别系数——R^2 已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2Y Y 68113.6∑(-)=, 2、置信区间 有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y Adjusted R-squared F-statistic Durbin-Watson (1(2)在95%的置信度下检验参数的显著性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在90%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其中29.3x =,2()992.1x x - =∑) 答:(1)回归模型的R 2 =,表明在消费Y 的总变差中,由回归直线解释的部分占到90%以上,回归直线的代表性及解释能力较好。(2分) 家庭收入对消费有显著影响。(2分)对于截距项,
检验。(2分) (3)Y f =+×45=(2分) 90%置信区间为(,+),即(,)。(2分) 注意:a 水平下的t 统计量的的重要性水平,由于是双边检验,应当减半 3、求SSE 、SST 、R^2等 已知相关系数r =,估计标准误差?8σ=,样本容量n=62。 求:(1)剩余变差;(2)决定系数;(3)总变差。 (2)2220.60.36R r ===(2分) 4、联系相关系数与方差(标准差),注意是n-1 在相关和回归分析中,已知下列资料: 222X Y i 1610n=20r=0.9(Y -Y)=2000σσ∑=,=,,,。 (1)计算Y 对X 的回归直线的斜率系数。(2)计算回归变差和剩余变差。(3) (2)R 2=r 2==, 总变差:TSS =RSS/(1-R 2)=2000/=(2分)
斯托克,沃森计量经济学第七章实证练习stata
E7.2 E7.3 E7.4
-------------------------------------------- (1) (2) ahe ahe -------------------------------------------- age 0.605*** 0.585*** (15.02) (16.02) female -3.664*** (-17.65) bachelor 8.083*** (38.00) _cons 1.082 -0.636 (0.93) (-0.59) (表2)Robust ci in parentheses *** p<0.01, ** p<0.05, * p<0.1 -------------------------------------------- N 7711 7711 -------------------------------------------- t statistics in parentheses * p<0.10, ** p<0.05, *** p<0.01 (表1) (1) 建立ahe 对age 的回归。截距估计值是1.082,斜率估计值是0.605。 (2) ①建立ahe 对age ,female 和bachelor 的回归。Age 对收入的效应的估计值是0.585。 ② age 回归系数的95%置信区间: (0.514,0.657) (3) 设H 0:βa,(2)-βa,(1)=0 H1:βa,(2)-βa (1)≠0 由表3,得SE ,SE(βa,(2)-βa,(1))=√(0.0403)2+(0.0365)2=0.054 t=(0.605-0.585)/0.054=0.37<1.96 所以不拒绝原假设,即在5%显著水平下age 对ahe 的效应估计没有显著差异,所以(1)中的回归没有遭遇遗漏变量偏差。 (4) B ob’s predicted ahe=0.585×26-3.664×0+8.083×0-0.636=$14.574 Alexis ’s predicted ahe=0.585×30-3.664×1+8.083×1-0.636=$21.333 VARIABLES ahe age 0.585*** (0.514 - 0.657) female -3.664*** (-4.071 - -3.257) bachelor 8.083*** (7.666 - 8.500) Constant -0.636 (-2.759 - 1.487) Observations 7,711 R-squared 0.200
计量经济学计算题
1、某农产品试验产量Y (公斤/亩)和施肥量X (公斤/亩)7块地的数据资料汇总如下: ∑=255i X ∑=3050i Y ∑=71.12172i x ∑=429.83712i y ∑=857.3122i i y x 后来发现遗漏的第八块地的数据:208=X ,4008=Y 。 要求汇总全部8块地数据后进行以下各项计算,并对计算结果的经济意义和统计意义做简要的解释。 (1)该农产品试验产量对施肥量X (公斤/亩)回归模型Y a bX u =++进行估计; (2)对回归系数(斜率)进行统计假设检验,信度为; (3)估计可决系数并进行统计假设检验,信度为。 解:首先汇总全部8块地数据: 871 81 X X X i i i i +=∑∑== =255+20 =275 n X X i i ∑==8 1 )8(375.348 275 == 2) 7(7 127 127X x X i i i i +=∑∑== =+7?2 7255?? ? ??=10507 287 1 28 1 2X X X i i i i +=∑∑== =10507+202 = 10907 2) 8(8 1 28 1 28X X x i i i i +=∑∑== = 10907-8?2 8275?? ? ??= 87 1 81 Y Y Y i i i i +=∑∑===3050+400=3450 25.4318 3450 8 1 )8(== =∑=n Y Y i i 2) 7(7 1 2 712 7Y y Y i i i i +=∑∑== =+7?2 73050??? ??=1337300 287 1 2 81 2Y Y Y i i i i +=∑∑== =1337300+4002 = 1497300 2)8(8 1 28128Y Y y i i i i +=∑∑== =1497300 -8?( 8 3450)2 == ) 7()7(7 1 7 17Y X y x Y X i i i i i i +=∑∑== ==+7??? ??7255??? ? ??73050 =114230 887 1 81 Y X Y X Y X i i i i i i +=∑∑== =114230+20?400 =122230
计量经济学范本
第八章 虚拟变量 一、单选题: 1、虚拟变量模型i i i D Y μβα++=中,i Y 为居民的年可支配收入,i D 为虚拟解释变量, i D =1代表城镇居民,i D =0代表非城镇居民。当i μ满足古典假设时,则α ==)0|(i i D Y E 表示( B ) A 、城镇居民的年平均收入, B 、非城镇居民的年平均收入, C 、所有居民的年平均收入, D 、其他; 2、虚拟变量模型i i i D Y μβα++=中,i Y 为居民的年可支配收入,i D 为虚拟解释变量, i D =1代表城镇居民,i D =0代表非城镇居民。当i μ满足古典假设时,则βα+==)1|(i i D Y E 表示( A ) A 、城镇居民的年平均收入, B 、非城镇居民的年平均收入, C 、所有居民的年平均收入, D 、其它; 3、在没有定量解释变量的情形下,以加法形式引入虚拟解释变量,主要用于( C )。 A 、共线性分析, B 、自相关分析, C 、方差分析 , D 、其它 4、如果你有连续几年的月度数据,如果只有2、4、6、8、10、12月表现季节类型,则需要引入虚拟变量的个数是( B )。 A 、模型中有截距项时,引入12个, B 、模型中有截距项时,引入5个 C 、模型中没有截距项时,引入11个, D 、模型中没有截距项时,引入12个 5、下列不属于常用的虚拟变量模型是( D ); A 、解释变量中只包含虚拟变量, B 、解释变量中既含定量变量又含虚拟变量, C 、被解释变量本身为虚拟变量的模型, D 、解释变量和被解释变量中不含虚拟变量。 6、考虑虚拟变量模型:i i i X D D D Y μβαααα+++++=3322110,其中 ???=其他一季度011D ???=其他二季度012D ???=其他 三季度013D , 当其随机扰动项服从古典假定时,则下列回归方程中表示一季度的是:( B ) A 、i i i X D D D X Y E βαα++====)()0,1,|(20312 B 、i i i X D D D X Y E βαα++====)()0,1,|(10321 C 、i i i X D D D X Y E βαα++====)()0,1,|(30213 D 、i i i X D D D X Y E βα+====0321)0,|( 7、在含有截距项的分段线性回归分析中,如果只有一个属性变量,且其有三种类型,则引入虚拟变量个数应为( B ) A 、 1个, B 、 2个, C 、3个, D 、4个; 8、某商品需求函数为 u x b b y i i i ++=10,其中y 为需求量,x 为价格。为了考虑“地
计量经济学计算题
计量经济学计算题例题 0626 一元线性回归模型相关例题 1.假定在家计调查中得出一个关于 家庭年收入X 和每年生活必须品综合支出 Y 的横截面样 根据表中数据: (1) 用普通最小二乘法估计线性模型 Y t 0 1 X t u t (2) 用G — Q 检验法进行异方差性检验 (3) 用加权最小二乘法对模型加以改进 答案:(1)丫=+( 2)存在异方差(3)丫=+ 2 ?已知某公司的广告费用 X 与销售额(Y )的统计数据如下表所示: (1) 估计销售额关于广告费用的一元线性回归模型 (2) 说明参数的经济意义 (3) 在 0.05的显著水平下对参数的显著性进行 t 检验 答案: (1) 一元线性回归模型 Y t 319.086 4 185X i (2) 参数经济意义:当广告费用每增加 1万元,销售额平均增加万元
(3)t=> t o.025(10),广告费对销售额有显著影响
3. : 根据表中数据: (1) 求Y 对X 的线性回归方程; (2) 用t 检验法对回归系数进行显著性检验(a =) ; (3) 求样本相关系数r; 答案:Y =+ 用t 检验法对回归系数进行显著性检验(a =); 答案:显著 2 2 假设y 对x 的回归模型为% b o biX u ,,且Var (uJ x ,,试用适当的 方法估计此回归模型。 2 2 解:原模型: y b 0 b 1x 1 U i , Var (u ,) 为模型存在异方差性 为消除异方差性,模型两边同除以 X ,, 得: bo — a u._ (2分) X , X x , * y , * 1 u , 令: y ,x , ■,v , x x X , 得: * y , * b box ' (2分)
计量经济学重点知识整理
计量经济学重点知识整理 1一般性定义 计量经济学是以经济理论和经济数据的事实为依据,运用数学和统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。 研究的主体(出发点、归宿、核心): 经济现象及数量变化规律 研究的工具(手段): 模型数学和统计方法 必须明确: 方法手段要服从研究对象的本质特征(与数学不同),方法是为经济问题服务 2注意:计量经济研究的三个方面 理论:即说明所研究对象经济行为的经济理论——计量经济研究的基础 数据:对所研究对象经济行为观测所得到的信息——计量经济研究的原料或依据 方法:模型的方法与估计、检验、分析的方法——计量经济研究的工具与手段 三者缺一不可 3计量经济学的学科类型 ●理论计量经济学 研究经济计量的理论和方法 ●应用计量经济学:应用计量经济方法研究某些领域的具体经济问题 4区别: ●经济理论重在定性分析,并不对经济关系提供数量上的具体度量 ●计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容 5计量经济学与经济统计学的关系 联系: ●经济统计侧重于对社会经济现象的描述性计量 ●经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据 ●经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据 6计量经济学与数理统计学的关系 联系: ●数理统计学是计量经济学的方法论基础 区别: ●数理统计学是在标准假定条件下抽象地研究一 般的随机变量的统计规律性; ●计量经济学是从经济模型出发,研究模型参数 的估计和推断,参数有特定的经济意义,标准 假定条件经常不能满足,需要建立一些专门的 经济计量方法 3、计量经济学的特点:
计量经济学计算题汇总
计量经济学计算题汇总
————————————————————————————————作者:————————————————————————————————日期:
计量经济学计算题总结1、表中所列数据是关于某种商品的市场供给量Y和价格水平X的观察值: ①用OLS法拟合回归直线; ②计算拟合优度R2; ③确定β1是否与零有区别。 2、求下列模型的参数估计量,
3、设某商品需求函数的估计结果为(n=18) : 解:(1)4
5、 模型式下括号中的数字为相应回归系数估计量的标准误。又由t分布表和F分布表得知:t0.025(5)=2.57,t0.025(6)=2.45;F0.05(3,6)=4.76,F0.05(4,5)=5.19, 试根据上述资料,对所给出的两个模型进行检验,并选择出一个合适的模型。
解: (1)总离差平方和的自由度为n-1,所以样本容量为 35。 (2) (3) 7.某商品的需求函数为 其中,Y 为需求量,X1为消费者收入,X2为该商品价格。 (1)解释参数的经济意义。 (2)若价格上涨10%将导致需求如何变化? (3)在价格上涨10%情况下,收入增加多少才能保持需求不变。 (4)解释模型中各个统计量的含义。 2 20.61143841 26783/(1) 10.587/(1) ESS R TSS RSS n k R TSS n ===--=-=-ESS/k 解:(1)由样本方程的形式可知,X1的参数为此商品的收 入弹性,表示X2的参数为此商品的价格弹性。 (2)由弹性的定义知,如果其它条件不变,价格上涨10%,那么对此商品的需求量将下降1.8%。 8、 现有X 和Y 的样本观察值如下表: X 2 5 10 4 10 Y 4 7 4 5 9 假设Y 对X 的回归模型为: 试用适当的方法估计此回归模型。
计量经济学
一、 1、列举计量经济分析过程的几个要素:1、数据; 2、计量模型。 3、解释变量; 4、被解释变量; 5、相关影响。 2、计量经济分析过程基本围绕着四类值。例如要预测一个硬币被抛1000次出现正面的次数,第一步: 从理论上研究,出现正面的概率是1/2, 这个概率是真值;第二步:做实验,例如抛硬币100次,观察出现正面的次数,那么这个次数为观察值;第三步:估计概率,用观察的次数除以100作为概率的估计值;第四步:用估计的概率乘以1000作为硬币被抛1000次出现正面的预测值。 3、估计量一般都采用哪三种评选标准:1、无偏性;2、有效性;3、一致性. 4、无偏估计量的概念:若估计量的数学期望存在且等于其对应 真值,即 ()E θ θ=。 4估计量的有效性:设 1 θ 与 2 θ均为θ的无偏估计量,若对于任意θ,有 1 θ 的方差小于等于 2 θ的方差,则 1 θ较 2 θ有效。 5、列举计量经济分析的三种数据类型:1、横截面数据;2、时间序列数据;3、面板数据。 6、虚拟变量即一种二值变量,是对解释变量的一种定性描述。 二、: 1、简述多元线性回归中('i i i y x βε=+)的高斯-马科夫假设(Gauss – Markov assumption )?若要求得到无偏估计量需满足其中的哪(些)项? 112 {}0,1,2,...,{,...,}{,...,}{}1,2,...,{,}0 i N N i i j E i N x x V i N C ov εεεεσεε=====与相互独立,
若想得到无偏估计量,需满足{}0,1,2,...,i E i N ε==,和1 1 {,...,}{,...,}N N x x εε与相互独立 某种元件的寿命X(以小时计)服从正态分布N(),均未知.现测得16只元件的寿命如下(已知 t 0.05(15) =1.7531) : 159 280 101 212 224 379 179 264 222 362 168 250 149 260 485 170 问是否有理由认为元件的平均寿命大于225(小时)? 2:解 按题意需检验 : =225, : 取a =0.05.此检验问题的拒绝域为 t= t a (n-1). 现在n=16, t 0.05(15) =1.7531.又根据 ,s= 算得 =241.5, s=98.7259,即有 t ==0.6685 1.7531. t 没有落在拒绝域中,故接受,即认为元件的平均寿命不大于 225小时. 3、在平炉上进行一项试验以确定改变操作方法的建议是否会增加钢的得率,试验是在同一只平炉上进行的,每炼一炉钢时除操作方法外,其他条件都尽可能做到相同.先用标准方法炼一炉,然后用建议的方法炼一炉,以后交替进行,各炼成了10炉,其得率分别为 (1) 标准方法 78.1 72.4 76.2 74.3 77.4 78.4
斯托克、沃森着《计量经济学》第九章
Chapter 9. Assessing Studies Based on Multiple Regression 9.1 Internal and External Validity Multiple regression has some key virtues: ?It provides an estimate of the effect on Y of arbitrary changes ΔX. ?It resolves the problem of omitted variable bias, if an omitted variable can be measured and included. ?It can handle nonlinear relations (effects that vary with the X’s)
Still, OLS might yield a biased estimator of the true causal effect. A Framework for Assessing Statistical Studies Internal and External Validity ?Internal validity: The statistical inferences about causal effects are valid for the population being studied.
?External validity: The statistical inferences can be generalized from the population and setting studied to other populations and settings, where the “setting” refers to the legal, policy, and physical environment and related salient features.
计量经济学题库(超完整版)及答案.详解
计量经济学题库 计算与分析题(每小题10分) 1.下表为日本的汇率与汽车出口数量数据, X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3=,Y 554.2=,2X X 4432.1∑(-)=,2 Y Y 68113.6∑ (-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 R 2= F= 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2= 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 ()() n=19 R 2= 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。 问:(1)利用t 值检验参数β的显著性(α=);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2 Y Y 68113.6∑(-)=, 求判定系数和相关系数。
计量经济学
第六章 6.1 解释概念 (1)双对数模型 (2)对数-线性模型 (3)线性-对数模型 (4)多项式回归 (5)标准化变量 (6)边际效应 (7)弹性 (8)瞬时增长率 答:(1)双对数模型是一种广泛应用的函数形式,模型中的因变量和自变量都以对数度量,比如设定一个双对数模型12ln ln Y X u ββ=++ (2)对数线性模型是指因变量取对数、解释变量为原有形式的模型。比如: 12log()wage educ u ββ=++。 (3)线性对数模型是指因变量为原有形式,解释变量取对数的模型。比如: 12ln Y X u ββ=++ (4)多项式回归模型中解释变量并不都是以线性的形式出现,多项式是由常数和一个或多个解释变量及其正整数次幂构成的表达式。多项式回归模型的一般函数形式表示为 21123k k Y X X X u ββββ-=+++++L (5)标准化变量是标准化变量就是将变量减去其均值并除以其标准差。 (6)边际效应是指一单位变量X 的变化所引起的变量Y 的单位变化。 (7)弹性是指一个变量变动的百分比相应于另一变量变动的百分比来反应变量之间的变动的灵敏程度。 (8)瞬时增长率是指仅当时间变动很小时,才近似等于因变量的相对变化。 6.2 考虑双对数模型 12ln ln Y X u ββ=++ 分别描绘出21β=,21β>,201β<<,21β=-,21β<-,210β-<<时表现Y 与X 之间关系的曲线。 答:当21β=时,Y 和X 对应的是曲线是:
当21β>时,对应的曲线是: 201β<<时: 21β=-时,Y 和X 对应的图形为:
21β <-时,对应的函数为: 210β-<<时,Y 和X 的曲线为: 6.3 在研究生产函数时,我们得到如下结果
斯托克计量经济学课后习题实证答案
P ART T WO Solutions to Empirical Exercises
Chapter 3 Review of Statistics Solutions to Empirical Exercises 1. (a) Average Hourly Earnings, Nominal $’s Mean SE(Mean) 95% Confidence Interval AHE199211.63 0.064 11.50 11.75 AHE200416.77 0.098 16.58 16.96 Difference SE(Difference) 95% Confidence Interval AHE2004 AHE1992 5.14 0.117 4.91 5.37 (b) Average Hourly Earnings, Real $2004 Mean SE(Mean) 95% Confidence Interval AHE199215.66 0.086 15.49 15.82 AHE200416.77 0.098 16.58 16.96 Difference SE(Difference) 95% Confidence Interval AHE2004 AHE1992 1.11 0.130 0.85 1.37 (c) The results from part (b) adjust for changes in purchasing power. These results should be used. (d) Average Hourly Earnings in 2004 Mean SE(Mean) 95% Confidence Interval High School13.81 0.102 13.61 14.01 College20.31 0.158 20.00 20.62 Difference SE(Difference) 95% Confidence Interval College High School 6.50 0.188 6.13 6.87
计量经济学计算题题库
五、简答题: 1.给定一元线性回归模型: (1)叙述模型的基本假定;(2)写出参数0β和1β的最小二乘估计公式; (3)说明满足基本假定的最小二乘估计量的统计性质; (4)写出随机扰动项方差的无偏估计公式。 2.对于多元线性计量经济学模型: (1)该模型的矩阵形式及各矩阵的含义; (2)对应的样本线性回归模型的矩阵形式; (3)模型的最小二乘参数估计量。 6.线性回归模型的基本假设。违背基本假设的计量经济模型是否可以估计 五、简答题: 1.答:(1)零均值,同方差,无自相关,解释变量与随机误差项相互独立(或者解释变量为非随机变量) (2)∑∑===n t t n t t t x y x 121 1?β,X Y 1 0??ββ-= (3)线性即,无偏性即,有效性即 (4)2?122-=∑=n e n t t σ ,其中∑∑∑∑∑=====-=-=n t t t n t t n t t n t t n t t y x y x y e 111212211212??ββ 2. 答: (1)N XB Y +=; (2)E B X Y +=?; (3)()Y X X X B ''=-1?。 6.答: (1)随机误差项具有零均值。即 E(i μ)=0 i=1,2,…n (2)随机误差项具有同方差。即 Var(i μ)=2μσ i=1,2,…n (3)随机误差项在不同样本点之间是独立的,不存在序列相关。即 Cov(j i μμ,)=0 i≠j i,j=1,2,…n (4)解释变量k X X X ,,,21 是确定性变量,不是随机变量,随机误差项与解释变量之间不相关。即
Cov(i ji X μ,)=0 j=1,2,…k i=1,2,…n (5)解释变量之间不存在严重的多重共线性。 (6)随机误差项服从零均值、同方差的正态分布。即 i μ~N(0,2μσ) i=1,2,…n 六、一元计算题 某农产品试验产量Y (公斤/亩)和施肥量 X (公斤/亩)7块地的数据资料汇总如下: 后来发现遗漏的第八块地的数据:208=X ,4008=Y 。 要求汇总全部8块地数据后分别用小代数解法和矩阵解法进行以下各项计算,并对计算结果的经济意义和统计意义做简要的解释。 1.该农产品试验产量对施肥量X (公斤/亩)回归模型u bX a Y ++=进行估计。 2.对回归系数(斜率)进行统计假设检验,信度为0.05。 3.估计可决系数并进行统计假设检验,信度为0.05。 4.计算施肥量对该农产品产量的平均弹性。 5.令施肥量等于50公斤/亩,对农产品试验亩产量进行预测,信度为0.05。 6.令施肥量等于30公斤/亩,对农产品试验平均亩产量进行预测,信度为0.01。 所需临界值在以下简表中选取: t 0.025,6 = 2.447 t 0.025,7 = 2.365 t 0.025,8 = 2.306 t 0.005,6 = 3.707 t 0.005,7 = 3.499 t 0.005,8 = 3.355 F 0.05,1,7 = 5.59 F 0.05,2,7 = 4.74 F 0.05,3,7 = 4.35 F 0.05,1,6 = 5.99 F 0.05,2,6 = 5.14 F 0.05,3,6 = 4.76 首先汇总全部8块地数据: 87181X X X i i i i +=∑∑== =255+20 =275 2)7(71271 27X x X i i i i +=∑∑== =1217.71+7?27255?? ? ??=10507 2871 2812X X X i i i i +=∑∑== =10507+202 = 10907 2)8(8128128X X x i i i i +=∑∑== = 10907-8?28275??? ??=1453.88
斯托克,沃森计量经济学第四章实证练习stata操作及答案
E4.1 E4.2 E4.3 E4.4
E4.1 VARIABLES ahe age 0.605 (0.0245) Constant 1.082 (0.688) Observations 7,711 R-squared 0.029 Robust standard errors in parentheses *** p<0.01, ** p<0.05, * p<0.1 1. ① 截距估计值estimated intercept: 1.082 ② 斜率估计值estimated slope: 0.605 回归方程:ahe= 1.082+0.605*age ③ 当工人年长 1 岁,平均每小时工资增加0.605 美元。 2. Bob: 0.605*26+1.082=16.812 (美元) Alexis: 0.605*30+1.082=19.232 (美元) 答:预测Bob 的收入为每小时16.812美元,Alexis为19.232 美元。 3. 年龄不能解释不同个体收入变化的大部分。因为R-squared 反映了因变量的 全部变化能通过回归关系被自变量充分解释的比例,而分析得R-squared 的值为0.029,解释度低,说明年龄不能解释不同个体收入变化的大部分
E4.1 (0.0449) Observations 463 R-squared 0.036 Robust standard errors in parentheses *** p<0.01, ** p<0.05, * p<0.1 ① 截距估计值: 3.998 斜率估计值: 0.133 回归方程: Course_Eval=3.998+0.133*beauty lave_esruo 0a u ty a e 1. 答:两者看上去有微弱的正相关关系 2. VARIABLES course eval beauty Constant 0.133 (0.0550) 3.998