关于文本相似度计算-JaccardSimilarity和哈希签名函数.docx

关于文本相似度计算-J accar dSimilarity和
哈希签名函数
在目前这个信息过载的星球上,文本的相似度计算应用前景还是比较广泛的,他可以让人们过滤掉很多相似的新闻,比如在搜索引擎上,相似度太高的页面,只需要展示一个就行了,还有就是,考试的时候, 可以用这个来防作弊,同样的,论文的相似度检查也是一个检查论文是否抄袭的一个重要办法。
文本相似度计算的应用场景
?过滤相似度很高的新闻,或者网页去重
?考试防作弊系统
?论文抄袭检查
光第一项的应用就非常广泛。
文本相似度计算的基本方法
文本相似度计算的方法很多,主耍来说有两种,一是余弦定律,二是JaccardSimilarity方法,余弦定律不在木文的讨论范围之内,我们主要说一下JaccardSimilarity 方法。
JaccardSimilarity 方法
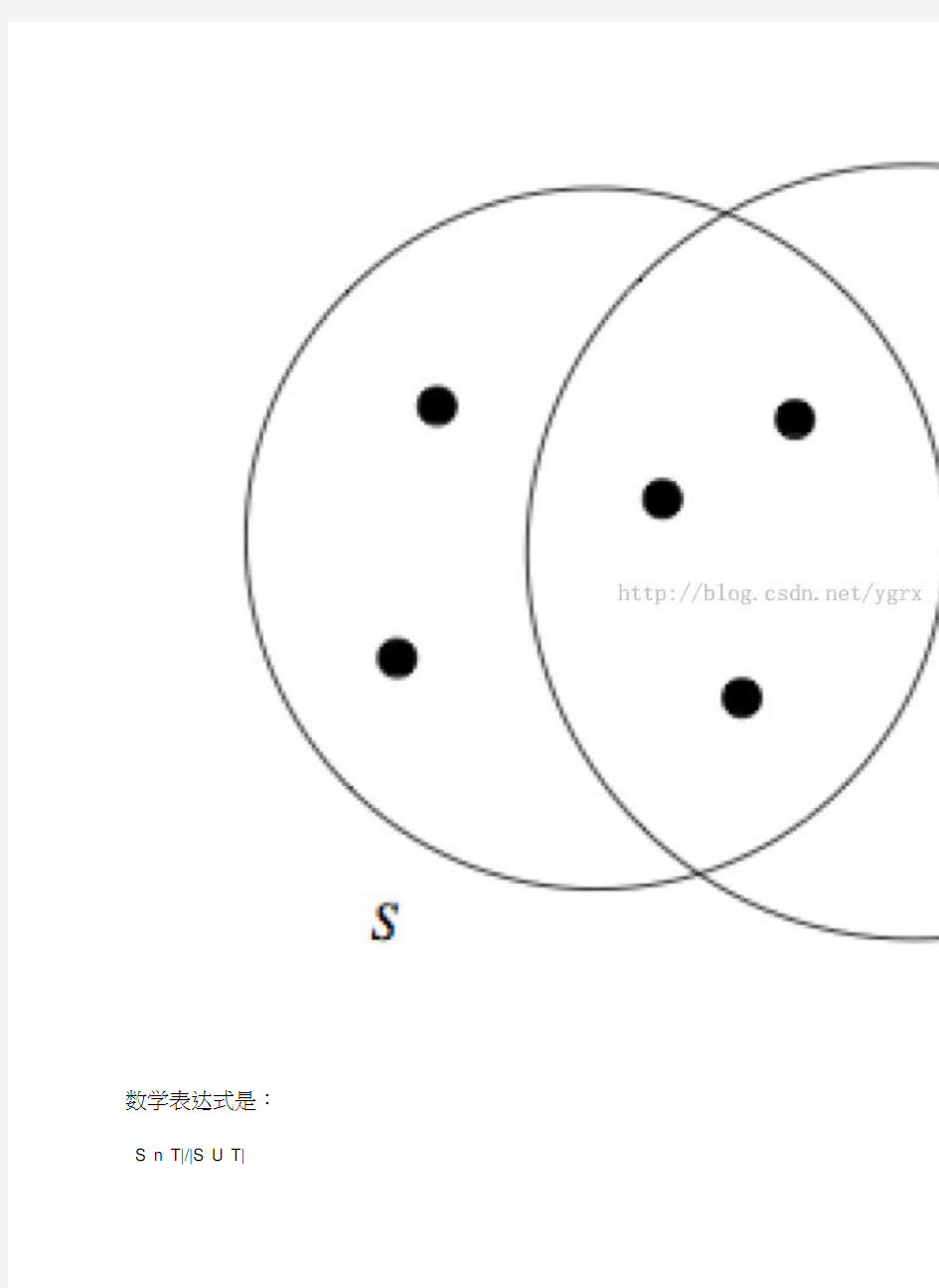
JaccardSimilarity说起来非常简单,容易实现,实际上就是两个集合
的交集除以两个集合的并集,所得的就是两个集合的相似度,直观的看就是下面这个图。
数学表达式是:S n T|/|S U T|
恩,基本的计算方法就是如此,而两个集合分别表示的是两个文本,集合中的元素实际上就是文本中出现的词语啦,我们需要做的就是把两个文本中的词语统计出来,然后按照上面的公式算一下就行了,其实很简单。
统计文本中的词语
关于统计文本中的词语,可以参考我的另外一篇博文一种没有语料字典的分词方法,文章中详细说明了如何从一篇文本中捉取有价值的词汇,感兴趣的童鞋可以看看。
当然,本篇博客主要是说计算相似度的,所以词语的统计使用的比较简单的算法k-shingle算法,k是一个变量,表示提取文本中的k个字符,这个k可以自己定义。
简单的说,该算法就是从头挨个扫描文本,然后依次把k个字符保存起來,比如有个文本,内容是abcdefg,k设为2,那得到的词语就是ab, be, cd, de, ef, fgo
得到这些词汇以后,然后统计每个词汇的数量,最后用上面的JaccardSimilarity算法来计算相似度。
具体的简单代码如下:
[python] view plaincopyprint?
name_list二["/Users/wuyinghao/Documents/testl.txt”,
2.'VUsers/wuyinghao/Documents/test2 3 ?"VUsers/wuyinghao/Documents/test3 4. hash_contents=[] 5? 6.#获取每个文本的词汇词频表 7.for file_name in file_name_list: 8 ?hash_contents?append([getHashlnfoFromFile(file_name,5 )J file_name]) 9. 10- 11> for indexl’vl in enumerate(hash_contents): 12.for index2,v2 in enumerate(hash_contents): 13.if(vl[l] != v2[l] and index2>indexl): 14?intersection=calclntersection(vl[0]v2[0]) # 计算交集 15 ?unio n_se t 二calcLI ni onSet (vl [0] ,v2[0] ’ in tersect ion) #计算并集 16. print vl[l]+ " | ||| | | H + v2[l] + " similarity is : " + str(calcSimilarity(intersection,union_set)) #计算 相似度 完整的代码可以看我的GitHub 如何优化 上述代码其实可以完成文本比较了,但是如果是大量文本或者单个文 本内容较大,比较的时候势必占用了大量的存储空间,因为一个词汇 表的存储空间大于文本本身的存储空间,这样,我们需要进行一下优化,如何优化呢,我们按照以下两个步骤来优化。 将词汇表进行hash 首先,我们将词汇表进行hash运算,把词汇表屮的每个词汇hash 成一个整数,这样存储空间就会大大降低了,至于hash的算法,网 上有很多,大家可以查查最小完美哈希,由于我这里只是为了验证整套算法的可行性,在python中,直接用了字典和数组,将每个词汇变成了一个整数。 比如上面说的abcdefg的词汇ab, be, cd, de, ef, fg,分别变成了 [0, 1,2,3, 4,5] 使用特征矩阵来描述相似度 何为文本相似度的特征矩阵,我们可以这么来定义 ? 一个特征矩阵的任何一行是全局所有元素中的一个元素,任何一列是一个集合。 ?若全局第i个元索出现在第j个集合里而,元素(i, j)为1,否则为0o 比如我们有world和could两个文本,设k为2通过k-shingle拆分以后,分别变成了[wo, or, rl, Id]和[co, ou, ul, Id]那么他们的特征矩阵就是 通过特征矩阵,我们很容易看出来,两个文本的相似性就是他们公共 的元素除以所有的元索,也就是1/7 在这个矩阵中,集合列上面不是0就是1,其实我们可以把特征矩阵稍微修改一下,列上面存储的是该集合屮词语出现的个数,我觉得可靠性更高一些。 至此,我们已经把一个简单的词汇表集合转换成上面的矩阵了,由于第一列的词汇表实际上是一个顺序的数列,所以我们需要存储的实际上只有后面的每一列的集合的数据了,而且也都是整数,这样存储空间就小多了。 继续优化特征矩阵,使用hash签名 对于保存上述特征矩阵,我们如果还嫌太浪费空间了,那么可以继续优化,如果能将每一列数据做成一个哈希签名,我们只需要比较签名的相似度就能大概的知道文本的 相似度就好了,注意,我这里用了大概,也就是说这种方法会丢失掉一部分信息,对相似度的精确性是有影响的,如果在大量需要处理的数据面前,丢失一部分精准度而提供处理速度是可以接受的。 那么,怎么来制作这个hash签名呢?我们这么来做 ?先找到一组自定义的哈希函数H1,H2...Hn ?将每一行的第一个元素,就是词汇表hash 得到的数字,分别于口定的哈希函数进行运算,得到一组新的数 ?建立一个集合(S1,S2...Sn)与哈希函数(H1,H2...Hn)的新矩阵 T,并将每个元素初始值定义为无穷大 ?对于任何一列的集合,如果T(Hi,Sj)为0,贝M十么都不做 ?对于任何一列的集合,如果T(Hi,Sj)不为0,则将T(Hi,Sj)和当前值比较,更新为较小的值。 还是上面那个矩阵,使用hash签名以后,我们得到一个新矩阵,我们使用了两个哈希函数:H1=(x+1)%7 H2=(3x+1)%7得到下面矩阵 然后,我们建立一个集合组T与哈希函数组H的新矩阵 接下來,按照上面的步骤來更新这个矩阵。 ?对于集合1,他对于H1来说,他存在的元素中,H1后最小的数是1,对于H2来说,最小的是0 ?对于集合2,他对于H1来说,他存在的元素屮,H1后最小的数是0,对于H2来说,最小的是2 所以,矩阵更新以后变成了 通过这个矩阵来计算相似度,只有当他们某一列完全相同的时候,我们才认为他们有交集,否则不认为他们有交集,所以根据上面这个矩阵,我们认为集合1和集合2 的相似度为0。这就是我刚刚说的大概的含义,他不能精确的表示两个文本的相似性,得到的只是一个近似值。 在编程的时候,上面那个矩阵其实并不需要完全保存在内存中,可以边使用边生成,所以,对于之前用整体矩阵来说,我们最后只需要有上面这个签名矩阵的存储空间就可以进行计算了,这只和集合的数量还有哈希函数的数量有关。 这部分的简单算法描述如下: [python] view plaincopyprint? 1- res=[] 2.for indexljvl in enumera_name_list): 3?for index2,v2 in enumera_name_list): 4?g_hash?clear() 5?g_val=0 6?hash_contents=[] 7?min_hashs=[] 8?if(vl != v2 and index2>indexl): 9?hash_contents?append(getHashlnfoFromFile( Vl)) #计算集合1的词汇表 10 ? hash_contents ? append(getHashInfoFromFile (v2)) #计算集合2的词汇表 adjContentList(hash_contents) #调整 hash a=[x for x in range(len(g_hash))] minhash_pares=[2>3J 5^7^11] #最小 hash 签名 for para in minhash_pares: min _hashs ? append(calcMinHash(para J le n(g_hash)^a)) #最小hash 签名函数生成 sig_list=calcSignatureMat(len(min_hashs) )#生成签名列表矩阵 17. for index,content in enumerate(hash_cont ents): 18? calcSignatures(content,min_hashs,sig _list,index) #计算最终签名矩阵 丄9? simalar=calcSimilarity(sig_list) #T| 算才目 似度 20? 21? 22? 同样,具体代码可以参考我的GitHub,代码没优化,只是做了算法 描述的实现,内存占用还是多,呵呵 口? 表长度 12? 函数参数 14? 15? 16. res ? append([vl,v2‘ simalar]) return res 1.信息检索中的重要发明TF-IDF 1.1TF Term frequency即关键词词频,是指一篇文章中关键词出现的频率,比如在一篇M个词的文章中有N个该关键词,则 (公式1.1-1) 为该关键词在这篇文章中的词频。 1.2IDF Inverse document frequency指逆向文本频率,是用于衡量关键词权重的指数,由公式 (公式1.2-1) 计算而得,其中D为文章总数,Dw为关键词出现过的文章数。2.基于空间向量的余弦算法 2.1算法步骤 预处理→文本特征项选择→加权→生成向量空间模型后计算余弦。 2.2步骤简介 2.2.1预处理 预处理主要是进行中文分词和去停用词,分词的开源代码有:ICTCLAS。 然后按照停用词表中的词语将语料中对文本内容识别意义不大但出 现频率很高的词、符号、标点及乱码等去掉。如“这,的,和,会,为”等词几乎出现在任何一篇中文文本中,但是它们对这个文本所表达的意思几乎没有任何贡献。使用停用词列表来剔除停用词的过程很简单,就是一个查询过程:对每一个词条,看其是否位于停用词列表中,如果是则将其从词条串中删除。 图2.2.1-1中文文本相似度算法预处理流程 2.2.2文本特征项选择与加权 过滤掉常用副词、助词等频度高的词之后,根据剩下词的频度确定若干关键词。频度计算参照TF公式。 加权是针对每个关键词对文本特征的体现效果大小不同而设置的机制,权值计算参照IDF公式。 2.2.3向量空间模型VSM及余弦计算 向量空间模型的基本思想是把文档简化为以特征项(关键词)的权重为分量的N维向量表示。 这个模型假设词与词间不相关(这个前提造成这个模型无法进行语义相关的判断,向量空间模型的缺点在于关键词之间的线性无关的假说前提),用向量来表示文本,从而简化了文本中的关键词之间的复杂关系,文档用十分简单的向量表示,使得模型具备了可计算性。 在向量空间模型中,文本泛指各种机器可读的记录。 用D(Document)表示文本,特征项(Term,用t表示)指出现在文档D中且能够代表该文档内容的基本语言单位,主要是由词或者短语构成,文本可以用特征项集表示为D(T1,T2,…,Tn),其中Tk是特征项,要求满足1<=k<=N。 下面是向量空间模型(特指权值向量空间)的解释。 假设一篇文档中有a、b、c、d四个特征项,那么这篇文档就可以表示为 D(a,b,c,d) 对于其它要与之比较的文本,也将遵从这个特征项顺序。对含有n 个特征项的文本而言,通常会给每个特征项赋予一定的权重表示其重要程度,即 D=D(T1,W1;T2,W2;…,Tn,Wn) 简记为 D=D(W1,W2,…,Wn) 我们把它叫做文本D的权值向量表示,其中Wk是Tk的权重, 计算文本相似度几种最常用的方法,并比较它们之间的性能 编者按:本文作者为Yves Peirsman,是NLP领域的专家。在这篇博文中,作者比较了各种计算句子相似度的方法,并了解它们是如何操作的。词嵌入(word embeddings)已经在自然语言处理领域广泛使用,它可以让我们轻易地计算两个词语之间的语义相似性,或者找出与目标词语最相似的词语。然而,人们关注更多的是两个句子或者短文之间的相似度。如果你对代码感兴趣,文中附有讲解细节的Jupyter Notebook地址。以下是论智的编译。 许多NLP应用需要计算两段短文之间的相似性。例如,搜索引擎需要建模,估计一份文本与提问问题之间的关联度,其中涉及到的并不只是看文字是否有重叠。与之相似的,类似Quora之类的问答网站也有这项需求,他们需要判断某一问题是否之前已出现过。要判断这类的文本相似性,首先要对两个短文本进行embedding,然后计算二者之间的余弦相似度(cosine similarity)。尽管word2vec和GloVe等词嵌入已经成为寻找单词间语义相似度的标准方法,但是对于句子嵌入应如何被计算仍存在不同的声音。接下来,我们将回顾一下几种最常用的方法,并比较它们之间的性能。 数据 我们将在两个被广泛使用的数据集上测试所有相似度计算方法,同时还与人类的判断作对比。两个数据集分别是: STS基准收集了2012年至2017年国际语义评测SemEval中所有的英语数据 SICK数据库包含了10000对英语句子,其中的标签说明了它们之间的语义关联和逻辑关系 下面的表格是STS数据集中的几个例子。可以看到,两句话之间的语义关系通常非常微小。例如第四个例子: A man is playing a harp. A man is playing a keyboard. 文本相似度算法 1.信息检索中的重要发明TF-IDF 1.1TF Term frequency即关键词词频,是指一篇文章中关键词出现的频率,比如在一篇M个词的文章中有N 个该关键词,则 (公式1.1-1) 为该关键词在这篇文章中的词频。 1.2IDF Inverse document frequency指逆向文本频率,是用于衡量关键词权重的指数,由公式 (公式1.2-1) 计算而得,其中D为文章总数,Dw为关键词出现过的文章数。 2.基于空间向量的余弦算法 2.1算法步骤 预处理→文本特征项选择→加权→生成向量空间模型后计算余弦。 2.2步骤简介 2.2.1预处理 预处理主要是进行中文分词和去停用词,分词的开源代码有:ICTCLAS。 然后按照停用词表中的词语将语料中对文本内容识别意义不大但出现频率很高的词、符号、标点及乱码等去掉。如“这,的,和,会,为”等词几乎出现在任何一篇中文文本中,但是它们对这个文本所表达的意思几乎没有任何贡献。使用停用词列表来剔除停用词的过程很简单,就是一个查询过程:对每一个词条,看其是否位于停用词列表中,如果是则将其从词条串中删除。 图2.2.1-1中文文本相似度算法预处理流程 2.2.2文本特征项选择与加权 过滤掉常用副词、助词等频度高的词之后,根据剩下词的频度确定若干关键词。频度计算参照TF公式。 加权是针对每个关键词对文本特征的体现效果大小不同而设置的机制,权值计算参照IDF公式。 2.2.3向量空间模型VSM及余弦计算 向量空间模型的基本思想是把文档简化为以特征项(关键词)的权重为分量的N维向量表示。 这个模型假设词与词间不相关(这个前提造成这个模型无法进行语义相关的判断,向量空间模型的缺点在于关键词之间的线性无关的假说前提),用向量来表示文本,从而简化了文本中的关键词之间的复杂关系,文档用十分简单的向量表示,使得模型具备了可计算性。 在向量空间模型中,文本泛指各种机器可读的记录。 用D(Document)表示文本,特征项(Term,用t表示)指出现在文档D中且能够代表该文档内容的基本语言单位,主要是由词或者短语构成,文本可以用特征项集表示为D(T1,T2,…,Tn),其中Tk 是特征项,要求满足1<=k<=N。 下面是向量空间模型(特指权值向量空间)的解释。 假设一篇文档中有a、b、c、d四个特征项,那么这篇文档就可以表示为 D(a,b,c,d) 对于其它要与之比较的文本,也将遵从这个特征项顺序。对含有n个特征项的文本而言,通常会给每个特征项赋予一定的权重表示其重要程度,即 D=D(T1,W1;T2,W2;…,Tn,Wn) 1文本相似度算法基本原理 1.1文本相似度含义 文本相似度来自于相似度概念,相似度问题是一个最基本的问题,是信息科学中绕不过去的概念,在不同的应用方向其含义有所不同,但基本的内涵表示了一个信息结构与另外一个信息结构的一致程度,从某个角度研究时特征量之间的距离大小[10]。比如,在机器翻译方面是指词这个基本单位的可替代性,在信息检索方面是指检索结果与检索内容的一致性,在自动问答方面是指搜索的结果与输入的问题的匹配程度。这充分表明文本相似度研究和应用领域十分广泛,所表达的含义也十分不同。从本文研究的角度来看,文本相似度可以描述为:有A、B两个对象,二者之间的公共区域越多、共性越大,则相似程度越高;若二者没有关联关系,则相似程度低。在文本相似度研究方面,一个层次是研究文档中以篇章、句子、词语衡量相似程度,这不同层次衡量算法也不同,研究的标准和依据也不同,算法的复杂程度也不同。从这个意义上,可以运用在新闻领域对新闻稿件进行归档,按照新闻的领域分门别类的存放在一起;也可以运用在信息检索进行信息查询,作为一个文本与另一个文本之间相似程度测量的基本方法。 1.2文本相似度计算方法分类 当前研究文本相似度都是以计算机作为计算工具,即利用计算机算法对文本进行分类,在各个领域应用十分广泛,比如包括网页文本分类、数据智能挖掘、信息识别检索、自动问答系统、论文查重分析和机器自主学习等领域,其中起最关键作用的是文本相似度计算算法,在信息检索、数据挖掘、机器翻译、文档复制检测等领域有着广泛的应用。 特别是随着智能算法、深度学习的发展,文本相似度计算方法已经逐渐不再是基于关键词匹配的传统方法,而转向深度学习,目前结合向量表示的深度学习使用较多,因此度量文本相似度从方法论和算法设计全局的角度看,一是基于关键词匹配的传统方法,如N-gram相似度;二是将文本映射到向量空间,再利用余弦相似度等方法,三是运用机器学习算法的深度学习的方法,如基于用户点击数据的深度学习语义匹配模型DSSM,基于卷积神经网络的ConvNet和LSTM 等方法。 本文研究的重点是对电子作业检查等各类电子文档对比,在对两个电子文档是否相同,相似比例为多少这一问题探究中需要比较文档的相似度,而文档的相似度又可分成段落相似度、句子相似度来进行考虑,所以课题的关键是如何定义 文本相似度的设计与实现 摘要:本文主要设计并实现了一个文本相似度系统,该系统主要功能计算文档之间的相似度,通过使用向量空间模型(VSM, Vector Space Model)及余弦相似度计算公式计算文档之间的相似度,数据预处理过程中加入word2vec模型进行语义扩充,从而能够匹配到更多相关文档。 1.向量空间模型 向量空间模型(VSM, Vector Space Model)由Salton等人于20世纪70年代年提出[1,2]。向量空间模型的主要思想是将文本内容的处理简化为向量空间中的向量运算,这样将空间上的相似度转化为语义上的相似度。当文档被表示为文档空间的向量时,便可通过计算向量之间的相似性来度量文档间的相似性。文本处理中最常用的相似性度量方式是余弦距离。 向量空间模型的基本思想: 给定一篇文档D=D(T1,T2,…T i,…,T n),若T i在文档中既可以重复出现又存在先后次序,因此分析起来会较为困难。针对上述情况,暂不考虑T i的顺序,并要求T i互异,此时可将T1,T2,…T i,…,T n看作n维坐标,每一维对应相应值W i,因此D(W1,W2,…,W i,…,W n)便可以看作一个n维向量。 例如:有一篇文档D={大家好,才是真的好},首先进行分词后转换为D={大家/好/才是/真的/好},之后提取出公因词D={大家,好,才是,真的},最后通过向量空间模型将文档转换为对应的向量D={1,2,1,1}。 向量空间模型只是将文档转换为方便计算的格式,若进行相似度计算,还需使用相似度计算公式进行计算。本文使用余弦相似度计算公式。 2.余弦相似度 余弦相似度计算公式广泛应用于文本数据之间的相似度计算过程中。其数学表达如下: 计算过程如下: 例如,有2个文档D1={大家好},D2={才是真的好},首先将D1、D2分词后,D1={大家/好},D2={才是/真的/好},其次提取出公因词D={大家,好,才是,真的},然后通过向量空间模型转换成向量表达,D1={1,1,0,0},D2={0,1,1,1},最后进行相似度计算 Score== 3.文本相似度系统 本文主要使用向量空间模型及余弦相似度距离公式进行文本相似度计算任务,系统的基本架构如下图1所示: 几种相似度计算方法作对比 句子相似度的计算在自然语言处理具有很重要的地位,如基于实例的机器翻译(Example Based Ma-chine Translation,EBMT)、自动问答技术、句子模糊匹配等.通过对术语之间的语义相似度计算,能够为术语语义识别[1]、术语聚类[2]、文本聚类[3]、本体自动匹配[4]等多项任务的开展提供重要支持。在已有的术语相似度计算方法中,基于搜索引擎的术语相似度算法以其计算 简便、计算性能较高、不受特定领域语料库规模和质量制约等优点而越来越受到重视[1]。 相似度计算方法总述: 1 《向量空间模型信息检索技术讨论》,刘斌,陈桦发表于计算机学报,2007 相似度S(Similarity):指两个文档内容相关程度的大小,当文档以向量来表示时,可 以使用向量文档向量间的距离来衡量,一般使用内积或夹角0的余弦来计算,两者夹角越小说明似度越高。由于查询也可以在同一空间里表示为一个查询向量(见图1),可以通过相似度计算公式计算出每个档向量与查询向量的相似度,排序这个结果后与设立的阈值进行比较。如果大于阈值则页面与查询相关,保留该页面查询结果;如果小于则不相关,过滤此页。这 样就可以控制查询结果的数量,加快查询速度。 2 《相似度计算方法综述》 相似度计算用于衡量对象之间的相似程度,在数据挖掘、自然语言处理中是一个基础性计算。其中的关键技术主要是两个部分,对象的特征表示,特征集合之间的相似关系。在信息检索、网页判重、推荐系统等,都涉及到对象之间或者对象和对象集合的相似性的计算。而针对不同的应用场景,受限于数据规模、时空开销等的限制,相似度计算方法的选择又会有所区别和不同。下面章节会针对不同特点的应用,进行一些常用的相似度计算方法进行介绍。 内积表示法: 1 《基于语义理解的文本相似度算法》,金博,史彦君发表于大连理工大学学报,2007 在中文信息处理中,文本相似度的计算广泛应用于信息检索、机器翻译、自动问答系统、文本挖掘等领域,是一个非常基础而关键的问题,长期以来一直是人们研究的热点和难点。计算机对于中文的处理相对于对于西文的处理存在更大的难度,集中体现在对文本分词的处理上。分词是中文文本相似度计算的基础和前提,采用高效的分词算法能够极大地提高文本相似度计算结果的准确性。本文在对常用的中文分词算法分析比较的基础上,提出了一种改进的正向最大匹配切分(MM)算法及歧义消除策略,对分词词典的建立方式、分词步骤及歧义字段的处理提出了新的改进方法,提高了分词的完整性和准确性。随后分析比较了现有的文本相似度计算方法,利用基于向量空间模型的TF-IDF方法结合前面提出的分词算法,给出了中文文本分词及相似度计算的计算机系统实现过程,并以科技文本为例进行了测试,对所用方 文本相似度计算系统 摘要 在中文信息处理中,文本相似度的计算广泛应用于信息检索、机器翻译、自动问答系统、文本挖掘等领域,是一个非常基础而关键的问题,长期以来一直是人们研究的热点和难点。本次毕设的设计目标就是用两种方法来实现文本相似度的计算。 本文采用传统的设计方法,第一种是余弦算法。余弦算法是一种易于理解且结果易于观察的算法。通过余弦算法可以快捷的计算出文本间相似度,并通过余弦算法的结果(0、1之间)判断出相似度的大小。由于余弦计算是在空间向量模型的基础上,所以说要想用余弦算法来完成本次系统,那么必须要将文本转化成空间向量模型。而完成空间向量模型的转换则要用到加权。在空间向量模型实现之前,必须要进行文本的去停用词处理和特征选择的处理。第二种算法是BM25算法,本文将采用最基础的循环来完成,目的是观察余弦算法中使用倒排索引效率是否提高有多大提高。 本次文本相似度计算系统的主要工作是去除停用词、文本特征选择、加权,在加权之后用余弦算法计算文本的相似度。在文本特征选择之后用BM25计算相似度。由于为了使系统的效率提高,在程序设计中应用了大量的容器知识以及内积、倒排算法。 关键词:文本相似度;余弦;BM25;容器 Text Similarity Algorithm Research Abstract In Chinese information processing,text similarity computation is widely used in the area of information retrieval,machine translation,automatic question—answering,text mining and etc.It is a very essential and important issue that people study as a hotspot and difficulty for a long time.Currently,most text similarity algorithms are based on vector space model(VSM).However,these methods will cause problems of high dimension and sparseness.Moreover,these methods do not effectively solve natural language problems existed in text data.These natural language problems are synonym and polyseme.These problems sidturb the efficiency and accuracy of text similarity algorithms and make the performance of text similarity computation decline. This paper uses a new thought which gets semantic simirality computation into traditional text similarity computation to prove the performance of text similarity algorithms.This paper deeply discusses the existing text similarity algorithms and samentic text computation and gives a Chinese text similarity algorithm which is based on semantic similarity.There is an online information management system which is used to manage students’graduate design papers.Those papers ale used to calculate similarity by that the algorithm to validate that algorithm. This text similarity computing system's main job is to stop word removal, text feature selection, weighting, after weighting using cosine algorithm to calculate the 相似度计算方面 Jaccard相似度:集合之间的Jaccard相似度等于交集大小与并集大小的比例。适合的应用包括文档文本相似度以及顾客购物习惯的相似度计算等。 Shingling:k-shingle是指文档中连续出现的任意k个字符。如果将文档表示成其k-shingle集合,那么就可以基于集合之间的Jaccard相似度来计算文档之间的文本相似度。有时,将shingle哈希成更短的位串非常有用,可以基于这些哈希值的集合来表示文档。 最小哈希:集合上的最小哈希函数基于全集上的排序转换来定义。给定任意一个排列转换,集合的最小哈希值为在排列转换次序下出现的第一个集合元素。 最小哈希签名:可以选出多个排列转换,然后在每个排列转换下计算集合的最小哈希值,这些最小哈希值序列构成集合的最小哈希签名。给定两个集合,产生相同哈希值的排列转换所占的期望比率正好等于集合之间的Jaccard相似度。 高效最小哈希:由于实际不可能产生随机的排列转换,因此通常会通过下列方法模拟一个排列转换:选择一个随机哈希函数,利用该函数对集合中所有的元素进行哈希操作,其中得到的最小值看成是集合的最小哈希值。 签名的局部敏感哈希:该技术可以允许我们避免计算所有集合对或其最小哈希签名对之间的相似度。给定集合的签名,我们可以将它们划分成行条,然后仅仅计算至少有一个行条相等的集合对之间的相似度。通过合理选择行条大小,可以消除不满足相似度阈值的大部分集合对之间的比较。 向量空间距离方面 欧式距离:n维空间下的欧式距离,是两个点在各维上差值的平方和的算数平方根。适合欧式空间的另一个距离是曼哈顿距离,指两个点各维度的差的绝对值之和。 Jaccard距离:1减去Jaccard相似度也是一个距离测度。 余弦距离:向量空间下两个向量的夹角大小。 编辑距离:该距离测度应用于字符串,指的是通过需要的插入、删除操作将一个字符串处理成另一个字符串的操作次数。编辑距离还可以通过两个字符串长度之和减去两者最长公共子序列长度的两倍来计算。 海明距离:应用于向量空间。两个向量之间的海明距离计算的是它们之间不相同的位置个数。 索引辅助方面 字符索引:如果将集合表示成字符串,且需要达到的相似度阈值接近1。那么就可以将每个字符串按照其头部的一小部分字母建立索引。需要索引的前缀的长度大概等于整个字符串的长度乘以给定的最大的Jaccard距离。 位置索引:我们不仅可以给出索引字符串前缀中的字符,也可以索引其在前缀中的位置。如果两个字符串共有的一个字符并不出现在双方的第一个位置,那么我们就知道要么存在某些前面的字文本相似度算法
计算文本相似度几种最常用的方法,并比较它们之间的性能
文本相似度算法
文本相似度算法基本原理
文本相似度的设计与实现
信息检索几种相似度计算方法作对比
文本相似度计算
文本相似度的计算方法