MPI安装与运行报告

MPI安装于运行报告
本机运行环境:
机器型号:联想G450
处理器:Pentium(R)Dual-Core CPU T4200 @ 2.00GHz
运行内存(RAM):2GB
操作系统:Windows 7(32位)
程序开发环境:Visual Studio 2008
MPI版本:
mpich2-1.3.2p1-win-ia32安装程序
详细安装步骤:
1、运行mpich2-1.3.2p1-win-ia32.msi。
安装过程中,会要求设置一个passphrase。我的机器上默认的passphrase是beHappy,很有意思的密码。设置这个东西很重要,一定要记住;下面会说到为什么。
2、安装完之后,不知道下一步怎么进行了。打开刚才安装的MPICH2
的快捷方式目录,发现了一个README文件。打开之后,发现了MPICH2的使用方法介绍,于是按照其中的指示,我进行了第一个MPI并行程序的编写。
我使用的是VC++2008。首先创建一个新的工程,取名为MPITest。
添加MPI库的支持:
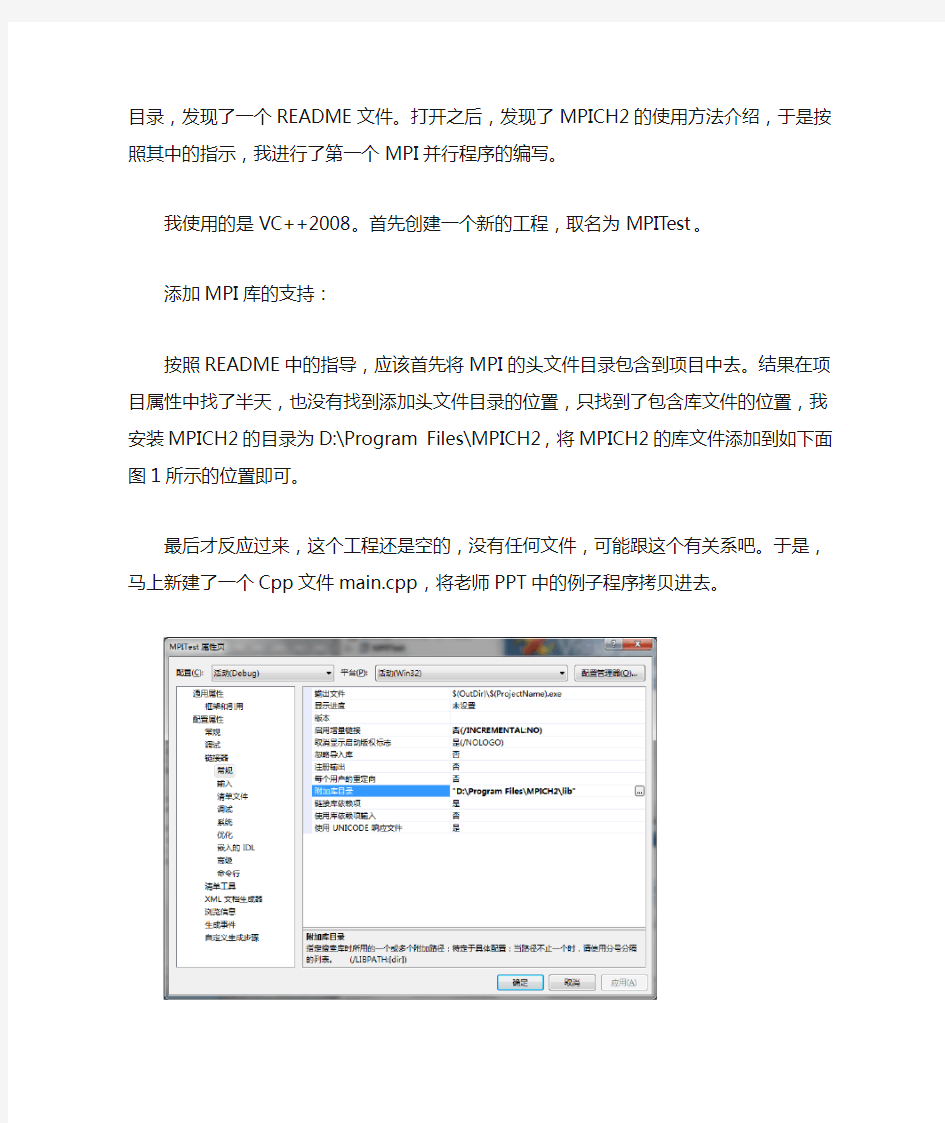
按照README中的指导,应该首先将MPI的头文件目录包含到项目中去。结果在项目属性中找了半天,也没有找到添加头文件目录的位置,只找到了包含库文件的位置,我安装MPICH2的目录为D:\Program
Files\MPICH2,将MPICH2的库文件添加到如下面图1所示的位置即可。
最后才反应过来,这个工程还是空的,没有任何文件,可能跟这个有关系吧。于是,马上新建了一个Cpp文件main.cpp,将老师PPT中的例子程序拷贝进去。
图 1
果然,新建了这个cpp文件之后,项目属性中多出了C/C++这样一项,于是,就可以在其中设置包含文件的目录了,相应的配置如下面图2所示。
图 2
设置好这些文件之后,编译程序,结果在连接的时候报错,类似于“main.obj : error LNK2019: 无法解析的外部符号_MPI_Finalize,该符号在函数
_main 中被引用”,这样的错误出现了六个。再看README文档,发现了这样一句话:
For C applications add mpi.lib to your target link command. 于是想到,可能需要在工程中显式添加mpi库的支持。在下面图3所示的位置设置响应的lib之后,重新编译、连接程序,顺利通过。
图 3
然后直接编译运行程序,出现了如下面图4所示的界面,表明该程序只在本机进行了运行,尚未真正并行执行。
图 4
安装完MPICH2之后,系统中应该会出现一个名为smpd的服务进程。在此情况下,运行并行程序时,会出现如下的错误提示:”Error: No smpd passphrase specified through the registry or .smpd file, exiting.”,如下面图5所示。
图 5
这个是需要用管理员账户,启动命令行(“以管理员身份”运行cmd.exe),然后输入smpd –install –phrase ******,星号部分就是你先前设置的passphrase。
再次用MPIEXEC wrapper来运行并行程序,出现正确结果,如下图所示。
图7
Ubuntu系统下mpich2的安装。
把老师给的“mpich2-1.3.2p1.tar.gz ”解压到我的用户目录下。此时已经是午夜12点了,白天还要去工作……
解压完之后,就在根目录下面发现了README文档,马上打开观看。参照其中Getting Started一章,我开始了新的探索。
一、首先进入解压后mpich2文件的根目录,运行配置操作:./configure
--prefix=/home/
下:
"No Fortran 77 compiler found. If you don't need to build any
Fortran programs, you can disable Fortran support using
--disable-f77 and --disable-fc. If you do want to build
Fortran programs, you need to install a Fortran compiler such
as gfortran or ifort before you can proceed."
于是按照提示修改命令,改为./configure --prefix=/home/east/mpich2-install --disable-f77 --disable-fc |& tee info.txt,结果又提示没有找到C++编译器:“configure: error: Aborting because C++ compiler does not work. If you do not
need a C++ compiler, configure with –disable-cxx”
考虑到以后应该会用到g++,于是根据提示用“sudo apt-get i nstall g++”命令进行了安装。然后再次运行配置命令,终于成功完成。
二、运行make命令”make |& tee info.txt”,经过了漫长的等待,看到提
示”Make completed”的时候,终于松了一口气。
三、安装MPICH2,运行”make install |& tee info.txt”命令。很快,就“Make
completed”了。
四、将安装后MPICH2的bin目录“mpich2-install”添加到系统路径中,即添
加到启动脚本中,运行命令“PATH=/home/east/mpich2-install/bin:$PATH ;
export PATH”,或者直接修改系统配置文件/etc/profile,然后重启系统以使配置文件生效。然后运行which mpiexec,系统回显出mpiexec的路径,证明bin目录已经成功添加到系统路径中。
图8
为了节省时间,并确保程序的正确性,我就直接运行MPICH2安装文件中,example目录下自带的例子程序cpi了,这个程序是用来计算圆周率的。
用mpicc进行编译,mpiexec来运行程序。具体命令及运行结果如上面图8所示。
并行计算1
并行计算 实 验 报 告 学院名称计算机科学与技术学院专业计算机科学与技术 学生姓名 学号 年班级 2016年5 月20 日
一、实验内容 本次试验的主要内容为采用多线程的方法计算pi的值,熟悉linux下pthread 形式的多线程编程,对实验结果进行统计并分析以及加速比曲线分析,从而对并行计算有初步了解。 二、实验原理 本次实验利用中值积分定理计算pi的值 图1 中值定理计算pi 其中公式可以变换如下: 图2 积分计算pi公式的变形 当N足够大时,可以足够逼近pi,多线程的计算方法主要通过将for循环的计算过程分到几个线程中去,每次计算都要更新sum的值,为避免一个线程更新sum 值后,另一个线程仍读到旧的值,所以每个线程计算自己的部分,最后相加。三、程序流程图 程序主体部分流程图如下:
多线程执行函数流程图如下: 四、实验结果及分析
令线程数分别为1、2、5、10、20、30、40、50和100,并且对于每次实验重复十次求平均值。结果如下: 图5 时间随线程的变化 实验加速比曲线的计算公式类似于 结果如下: 图5 加速比曲线 实验结果与预期类似,当线程总数较少时,线程数的增多会对程序计算速度带来明显的提升,当线程总数增大到足够大时,由于物理节点的核心数是有限的,因此会给cpu带来较多的调度,线程的切换和最后结果的汇总带来的时间开销较大,所以线程数较大时,增加线程数不会带来明显的速度提升,甚至可能下降。 五、实验总结
本次试验的主要内容是多线程计算pi的实现,通过这次实验,我对并行计算有了进一步的理解。上学期的操作系统课程中,已经做过相似的题目,因此程序主体部分相似。不同的地方在于,首先本程序按照老师要求应在命令行提供参数,而非将数值写定在程序里,其次是程序不是在自己的电脑上运行,而是通过ssh和批处理脚本等登录到远程服务器提交任务执行。 在运行方面,因为对批处理任务不够熟悉,出现了提交任务无结果的情况,原因在于windows系统要采用换行的方式来表明结束。在实验过程中也遇到了其他问题,大多还是来自于经验的缺乏。 在分析实验结果方面,因为自己是第一次分析多线程程序的加速比,因此比较生疏,参考网上资料和ppt后分析得出结果。 从自己遇到的问题来看,自己对批处理的理解和认识还比较有限,经过本次实验,我对并行计算的理解有了进一步的提高,也意识到了自己存在的一些问题。 六、程序代码及部署 程序源代码见cpp文件 部署说明: 使用gcc编译即可,编译时加上-pthread参数,运行时任务提交到服务器上。 编译命令如下: gcc -pthread PI_3013216011.cpp -o pi pbs脚本(runPI.pbs)如下: #!/bin/bash #PBS -N pi #PBS -l nodes=1:ppn=8 #PBS -q AM016_queue #PBS -j oe cd $PBS_O_WORKDIR for ((i=1;i<=10;i++)) do ./pi num_threads N >> runPI.log
MPI编程环境配置与示例
目录 一、系统安装 (1) 1、下载地址 (1) 2、安装步骤 (1) 3、Visual Stdio设置 (1) 二、实验程序 (2) 1、简单得MPI编程示例 (2) 2、消息传递MPI编程示例1 (3) 3、消息传递MPI编程示例2 (4) 4、Monte Carlo方法计算圆周率 (6) 5、计算积分 (8) 三、心得体会 (9) 一.系统安装 1.下载地址 FTP匿名登陆,在pub/mpi/nt文件夹中 2.安装步骤 1)在安装有MPI得计算机上要建立一个有管理员权限得账户,不可以没有密 码; 2)双击exe文件,按默认设置安装MPI; 3)注册MPI账户,调用MPIRegister、exe,用户名与密码即为第一步中得账户。 3.Visual Stdio设置 为避免每新建一个项目都要设置一次,可以对它进行通用设置。 打开视图-其她窗口-属性管理器,点击Debug|Win32目录下得Microsoft、Cpp、Win32、user,在VC++目录下得包含目录中添加MPICH得Include路径,库目录中添加MPICH得Lib路径;在链接器-输入目录下得附加依赖项中添加mpich、lib、mpe、lib、mped、lib、mpichd、lib。
二.实验程序 1.简单得MPI编程示例 1)源代码 #include
MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &num); MPI_Comm_rank(MPI_COMM_WORLD, &rk); printf("Hello world from Process %d of %d\n", rk, num); MPI_Finalize(); return 0; } 2)运行截图 2.消息传递MPI编程示例1 1)源代码 #include
并行计算实验报告一
江苏科技大学 计算机科学与工程学院 实验报告 实验名称:Java多线程编程 学号:姓名:班级: 完成日期:2014年04月22日
1.1 实验目的 (1) 掌握多线程编程的特点; (2) 了解线程的调度和执行过程; (3)掌握资源共享访问的实现方法。 1.2 知识要点 1.2.1线程的概念 (1)线程是程序中的一个执行流,多线程则指多个执行流; (2)线程是比进程更小的执行单位,一个进程包括多个线程; (3)Java语言中线程包括3部分:虚拟CPU、该CPU执行的代码及代码所操作的数据。 (4)Java代码可以为不同线程共享,数据也可以为不同线程共享; 1.2.2 线程的创建 (1) 方式1:实现Runnable接口 Thread类使用一个实现Runnable接口的实例对象作为其构造方法的参数,该对象提供了run方法,启动Thread将执行该run方法; (2)方式2:继承Thread类 重写Thread类的run方法; 1.2.3 线程的调度 (1) 线程的优先级 ●取值范围1~10,在Thread类提供了3个常量,MIN_PRIORITY=1、MAX_ PRIORITY=10、NORM_PRIORITY=5; ●用setPriority()设置线程优先级,用getPriority()获取线程优先级; ●子线程继承父线程的优先级,主线程具有正常优先级。 (2) 线程的调度:采用抢占式调度策略,高优先级的线程优先执行,在Java中,系统按照优先级的级别设置不同的等待队列。 1.2.4 线程的状态与生命周期
说明:新创建的线程处于“新建状态”,必须通过执行start()方法,让其进入到“就绪状态”,处于就绪状态的线程才有机会得到调度执行。线程在运行时也可能因资源等待或主动睡眠而放弃运行,进入“阻塞状态”,线程执行完毕,或主动执行stop方法将进入“终止状态”。 1.2.5 线程的同步--解决资源访问冲突问题 (1) 对象的加锁 所有被共享访问的数据及访问代码必须作为临界区,用synchronized加锁。对象的同步代码的执行过程如图14-2所示。 synchronized关键字的使用方法有两种: ●用在对象前面限制一段代码的执行,表示执行该段代码必须取得对象锁。 ●在方法前面,表示该方法为同步方法,执行该方法必须取得对象锁。 (2) wait()和notify()方法 用于解决多线程中对资源的访问控制问题。 ●wait()方法:释放对象锁,将线程进入等待唤醒队列; ●notify()方法:唤醒等待资源锁的线程,让其进入对象锁的获取等待队列。 (3)避免死锁 指多个线程相互等待对方释放持有的锁,并且在得到对方锁之前不会释放自己的锁。 1.3 上机测试下列程序 样例1:利用多线程编程编写一个龟兔赛跑程序。 乌龟:速度慢,休息时间短;
计算方法上机实验报告
《计算方法》上机实验报告 班级:XXXXXX 小组成员:XXXXXXX XXXXXXX XXXXXXX XXXXXXX 任课教师:XXX 二〇一八年五月二十五日
前言 通过进行多次的上机实验,我们结合课本上的内容以及老师对我们的指导,能够较为熟练地掌握Newton 迭代法、Jacobi 迭代法、Gauss-Seidel 迭代法、Newton 插值法、Lagrange 插值法和Gauss 求积公式等六种算法的原理和使用方法,并参考课本例题进行了MATLAB 程序的编写。 以下为本次上机实验报告,按照实验内容共分为六部分。 实验一: 一、实验名称及题目: Newton 迭代法 例2.7(P38):应用Newton 迭代法求 在 附近的数值解 ,并使其满足 . 二、解题思路: 设'x 是0)(=x f 的根,选取0x 作为'x 初始近似值,过点())(,00x f x 做曲线)(x f y =的切线L ,L 的方程为))((')(000x x x f x f y -+=,求出L 与x 轴交点的横坐标) (') (0001x f x f x x - =,称1x 为'x 的一次近似值,过点))(,(11x f x 做曲线)(x f y =的切线,求该切线与x 轴的横坐标) (') (1112x f x f x x - =称2x 为'x
的二次近似值,重复以上过程,得'x 的近似值序列{}n x ,把 ) (') (1n n n n x f x f x x - =+称为'x 的1+n 次近似值,这种求解方法就是牛顿迭代法。 三、Matlab 程序代码: function newton_iteration(x0,tol) syms z %定义自变量 format long %定义精度 f=z*z*z-z-1; f1=diff(f);%求导 y=subs(f,z,x0); y1=subs(f1,z,x0);%向函数中代值 x1=x0-y/y1; k=1; while abs(x1-x0)>=tol x0=x1; y=subs(f,z,x0); y1=subs(f1,z,x0); x1=x0-y/y1;k=k+1; end x=double(x1) K 四、运行结果: 实验二:
MPI安装与运行报告
MPI 安装于运行报告 本机运行环境: 机器型号:联想G450 处理器:Pentium(R)Dual-Core CPU T4200 @ 2.00GHz 运行内存 (RAM):2GB 操作系统:Windows 7(32 位) 程序开发环境:Visual Studio 2008 MPI 版本: mpich2-1.3.2p1-win-ia32 安装程序 详细安装步骤: 1、运行mpich2-1.3.2p1-win-ia32.msi。 安装过程中,会要求设置一个passphrase我的机器上默认的passphrase是beHappy,很有意思的密码。设置这个东西很重要,一定要记住;下面会说到为什么。 2、安装完之后,不知道下一步怎么进行了。打开刚才安装的MPICH2 的快捷方式目录,发现了一个README文件。打开之后,发现了MPICH2的使用方法介绍,于是按照其中的指示,我进行了第一个MPI 并行程序的编写。 我使用的是VC++2008首先创建一个新的工程,取名为MPITes。 添加MPI 库的支持: 按照README中的指导,应该首先将MPI的头文件目录包含到项目中去。结果在项目属性中找了半天,也没有找到添加头文件目录的位置,只找到了包含库文件的位置,我安装MPICH2的目录为D:\Program Files\MPICH2将MPICH2的库文件添加到如下面图1所示的位置即可。 最后才反应过来,这个工程还是空的,没有任何文件,可能跟这个有关系吧。 于是,马上新建了一个Cpp文件main.cpp,将老师PPT中的例子程序拷贝进去。
图1 果然,新建了这个cpp文件之后,项目属性中多出了C/C++这样一项, 于是,就可以在其中设置包含文件的目录了,相应的配置如下面图2所示 图2 设置好这些文件之后,编译程序,结果在连接的时候报错,类似于 main.obj : error LNK2019:无法解析的外部符号_MPI_Finalize,该符号在函数_main中被引用”这样的错误出现了六个。再看READM文档,发现了这样? 句话:
进程管理实验报告
进程的控制 1 .实验目的 通过进程的创建、撤消和运行加深对进程概念和进程并发执行的理解,明确进程与程序之间的区别。 【答:进程概念和程序概念最大的不同之处在于: (1)进程是动态的,而程序是静态的。 (2)进程有一定的生命期,而程序是指令的集合,本身无“运动”的含义。没有建立进程的程序不能作为1个独立单位得到操作系统的认可。 (3)1个程序可以对应多个进程,但1个进程只能对应1个程序。进程和程序的关系犹如演出和剧本的关系。 (4)进程和程序的组成不同。从静态角度看,进程由程序、数据和进程控制块(PCB)三部分组成。而程序是一组有序的指令集合。】2 .实验内容 (1) 了解系统调用fork()、execvp()和wait()的功能和实现过程。 (2) 编写一段程序,使用系统调用fork()来创建两个子进程,并由父进程重复显示字符串“parent:”和自己的标识数,而子进程则重复显示字符串“child:”和自己的标识数。 (3) 编写一段程序,使用系统调用fork()来创建一个子进程。子进程通过系统调用execvp()更换自己的执行代码,新的代码显示“new
program.”。而父进程则调用wait()等待子进程结束,并在子进程结束后显示子进程的标识符,然后正常结束。 3 .实验步骤 (1)gedit创建进程1.c (2)使用gcc 1.c -o 1编译并./1运行程序1.c #include
多核编程与并行计算实验报告 (1)
(此文档为word格式,下载后您可任意编辑修改!) 多核编程与并行计算实验报告 姓名: 日期:2014年 4月20日
实验一 // exa1.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 实验二 // exa2.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include MPI 并行环境的搭建 1、在计算机中,安装两个CentOS系统 2、[root@node1 etc]# ifconfig #查看ip 192.168.241.128 [root@node2 etc]# ifconfig 192.168.241.129 3、互ping [root@node1 etc]# ping 192.168.241.129 #测试网络是否联通 [root@node2 etc]# ping 192.168.241.128 4、修改/etc/hosts文件,在节点设置节点名称 192.168.241.128 node1 192.168.241.129 node2 [root@node1 etc]# source /etc/hosts [root@node2 etc]# source /etc/hosts 5、各个节点是否互通 [root@node1 etc]# ping node2 #测试主机名修改是否成功 [root@node2 etc]# ping node1 6、关闭iptables防火墙 [root@node1 etc]# serviceiptables stop [root@node2 etc]# serviceiptables stop 在各个节点设置iptables 防火墙开机关闭 [root@node1 usr]# chkconfigiptables off #设置iptables开机关闭 [root@node2 usr]# chkconfigiptables off #设置iptables开机关闭7、在各个节点创建共享目录 [root@node1 etc]#mkdir /usr/cluster [root@node2 etc]#mkdir /usr/cluster 在node1上修改/usr/cluster为777 [root@node1 etc]#chmod –R 777 /usr/cluster 8、挂在nfs文件系统 /etc/exports文件配置 在node1(主节点)节点配置 [root@node1 etc]# vi /etc/exports usr/cluster 192.168.241.128(rw) /usr/cluster 192.168.241.129(rw) 启动nfs服务 在node1节点执行 [root@node1 usr]# yum install nfs-utilsrpcbind #安装nfs [root@node1 usr]# service rpcbind start #启动rpc [root@node1 usr]# service nfs start #启动nfs服务 [root@node1 usr]# chkconfigrpcbind on #设置rpcbind开机启动[root@node1 usr]# chkconfignfs on #设置nfs开机启动 在node2节点执行 单片机并行口实验报告 实验二并行口实验报告 班级: 学号: 姓名: 教师: 一、实验目的 通过实验了解8051并行口输入方式和输出方式的工作原理及编程方法。 二、实验内容 1、输出实验 如图4-1所示。以8031的P2口为输出口。通过程序控制发光二极管的亮灭。 2、输入实验 如图4-1所示。以8031的P1口为输入口。用开关向P1.0~P1.3输入不同的状态,控制P2口P2.4~P2.7发光二极管的亮灭。 3、查询输入输出实验 如图1-1所示。以8051的P1.6或P1.0为输入位,以P2口为输出,二进制计数记录按键的次数。 图1-1 三、编程提示 1、输出实验程序 (1)设计一组显示花样,编程使得P2口按照设计的花样重复显示。 (2)为了便于观察,每一状态加入延时程序。 2、输入实验程序 开关打开,则输入为1;开关闭合,则输入为0。读取P1.0~ P1.3的状态,并将它们输出到P2.4~ P2.7,驱动发光二极管。所以发光二极管L1~L4的亮灭应与开关P1.0~ P1.3的设置相吻合。 3、查询输入输出程序 (1)编程计数P1.0按键次数,按键不去抖动。 (2)编程计数P1.6按键次数,按键不去抖动。 (3)编程计数P1.0按键次数,按键软件延时去抖动。 观察(1)、(2)、(3)、的结果。 四、实验器材 计算机,目标系统实验板 五、实验步骤 1、在KEILC中按要求编好程序,编译,软件调试,生成.HEX文件。 2、断开电源,按图1-1所示,连好开关及发光二极管电路。 3、下载程序。 4、调试运行程序,观察发光二极管状态。 六、C源程序清单 1、#include 并行计算上机实验报告题目:多线程计算Pi值 学生姓名 学院名称计算机学院 专业计算机科学与技术时间 一. 实验目的 1、掌握集群任务提交方式; 2、掌握多线程编程。 二.实验内容 1、通过下图中的近似公式,使用多线程编程实现pi的计算; 2、通过控制变量N的数值以及线程的数量,观察程序的执行效率。 三.实现方法 1. 下载配置SSH客户端 2. 用多线程编写pi代码 3. 通过文件传输界面,将文件上传到集群上 4.将命令行目录切换至data,对.c文件进行编译 5.编写PBS脚本,提交作业 6.实验代码如下: #include #include 关于在vc++6.0中安装配置MPI 1、下载安装MPICH,安装过程中最好把密码设置为自己的开机密码 关于安装完成后设置 对MPICH2的wmpiregister.exe 设置用户名密码,是计算机名和开机密码 可以来个简单的测试,打开wmpirexec.exe 在application中添加Program Files (x86)\MPICH2\examples中例子,选中“run in an separate window”然后点击execute…(如果有问题,有可能是wmpiregister.exe用户名设置的问题) 现在设置vc++6.0------------------------------------------------------------------ 2、打开vc++6.0 在(工具-选项-目录)把mpich相对应的include和lib添加到include files/library files 3、新建一个工程,可以写mpitest.cpp,为了避免宏定义冲突,在#include”mpi.h”之前要加入#include MPICH_SKIP_MPICXX(这样就可以通过编译) 4、编译通过了,但是链接仍然会出错继续设置 (在工程—>设置->链接中的对象/库模板块后加入mpi.lib)上图 这样就可以通过链接了(每次建工程都要加入mpi.lib的操作) 再贴一个简单的例子吧 #define MPICH_SKIP_MPICXX #include "mpi.h" #include 华中科技大学 课程名称并行处理 实验名称矩阵乘法的实现及加速比分析考生姓名李佩佩 考生学号 M201372734 系、年级计算机软件与理论2013级类别硕士研究生 考试日期 2014年1月3日 一. 实验目的 1) 学会如何使用集群 2) 掌握怎么用并行或分布式的方式编程 3) 掌握如何以并行的角度分析一个特定的问题 二. 实验环境 1) 硬件环境:4核CPU、2GB内存计算机; 2) 软件环境:Windows XP、MPICH2、VS2010、Xmanager Enterprise3; 3) 集群登录方式:通过远程桌面连接211.69.198.2,用户名:pppusr,密码:AE2Q3P0。 三. 实验内容 1. 实验代码 编写四个.c文件,分别为DenseMulMatrixMPI.c、DenseMulMatrixSerial.c、SparseMulMatrixMPI.c和SparseMulMatrixSerial.c,用于比较并行和串行矩阵乘法的加速比,以及稀疏矩阵和稠密矩阵的加速比。这里需要说明一下,一开始的时候我是把串、并行放在一个程序中,那么就只有两个.c文件DenseMulMatrix.c 和SparseMulMatrix.c,把串行计算矩阵乘的部分放到了主进程中,即procsID=0的进程,但是结果发现执行完串行后,再执行并行就特别的慢。另外,对于稀疏矩阵的处理方面可能不太好,在生成稀疏矩阵的过程中非0元素位置的生成做到了随机化,但是在进行稀疏矩阵乘法时没有对矩阵压缩,所以跟稠密矩阵乘法在计算时间上没多大区别。 方阵A和B的初始值是利用rand()和srand()函数随机生成的。根据稀疏矩阵和稠密矩阵的定义,对于稀疏矩阵和稠密矩阵的初始化方法InitMatrix(int *M,int *N,int len)会有所不同。这里需要说明一下,一开始对于矩阵A和B的初始化是两次调用InitMatrix(int *M ,int len),生成A和B矩阵,但是随后我发现,由于两次调用方法InitMatrix的时间间隔非常短,又由于srand()函数的特点,导致生成的矩阵A和B完全一样;然后,我就在两次调用之间加入了语句“Sleep(1000);”,加入头文件“#include 北京科技大学计算机与通信工程学院 实验报告 实验名称: 学生姓名: 专业: 班级: 学号: 指导教师: 实验成绩:________________________________ 实验地点: 实验时间:2015年05月 一、实验目的与实验要求 1、实验目的 1对比矩阵乘法的串行和并行算法,查看运行时间,得出相应的结论;2观察并行算法不同进程数运行结果,分析得出结论; 2、实验要求 1编写矩阵乘法的串行程序,多次运行得到结果汇总; 2编写基于MPI,分别实现矩阵乘法的并行化。对实现的并行程序进行正确性测试和性能测试,并对测试结果进行分析。 二、实验设备(环境)及要求 《VS2013》C++语言 MPICH2 三、实验内容与步骤 实验1,矩阵乘法的串行实验 (1)实验内容 编写串行程序,运行汇总结果。 (2)主要步骤 按照正常的矩阵乘法计算方法,在《VS2013》上编写矩阵乘法的串行程序,编译后多次运行,得到结果汇总。 实验2矩阵乘法的并行化实验 3个总进程 5个总进程 7个总进程 9个进程 16个进程 四:实验结果与分析(一)矩阵乘法并行化 矩阵并行化算法分析: 并行策略:1间隔行带划分法 算法描述:将C=A*B中的A矩阵按行划分,从进程分得其中的几行后同时进行计算,最后通信将从进程的结果合并的主进程的C矩阵中 对于矩阵A*B 如图:进程1:矩阵A第一行 进程2:矩阵A第二行 进程3:矩阵A第三行 进程1:矩阵A第四行 时间复杂度分析: f(n) =6+2+8+k*n+k*n+k*n+3+10+n+k*n+k*n+n+2 (k为从进程分到的行数) 因此O(n)=(n); 空间复杂度分析: 从进程的存储空间不共用,f(n)=n; 因此O(n)=(n); 2间隔行带划分法 算法描述:将C=A*B中的A矩阵按行划分,从进程分得其中的几行后同时进行计算,最后通信将从进程的结果合并的主进程的C矩阵中 对于矩阵A*B 如图:进程1:矩阵A第一行 进程2:矩阵A第二行 进程3:矩阵A第三行 进程3:矩阵A第四行 时间复杂度分析: f(n) =6+2+8+k*n+k*n+k*n+3+10+n+k*n+k*n+n+2 (k为从进程分到的行数) 因此O(n)=(n); 空间复杂度分析: 从进程的存储空间不共用,f(n)=n; 因此T(n)=O(n); 多核编程与并行计算实验报告 姓名: 日期:2014年 4月20日 实验一 // exa1.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 实验二 // exa2.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include MPI并行计算环境的建立 一、配置前的准备工作 假设机群是3个节点。 1.安装Linux(CentOS 5.2)系统,并保证每个节点的sshd服务能正常启动。 笔者并没采用真实的3台机器,而是利用虚拟机(VMware Workstation6.5)在一台装有XP系统的机器上安装多个Linux系统进行模拟。 注意事项: (1)因为笔者采用mpich2-1.3.2p1.tar.gz,此版本对gcc、autoconf等软件包版本要求较高,为避免出错,尽量安装最新的Linux系统。 (2)在用VMware Workstation安装Linux系统时可能会遇到磁盘类型不兼容的问题,笔者采用的版本就出现了这样的问题,解决要点如下: a.启动Workstation选择创建定制的虚拟机; b.SCSI适配器类型选LSI Logic (Linux内核在2.4以下的选择BusLogic); c.选择虚拟磁盘类型(IDE)。 (3)安装VMware Workstation tools。 Linux系统启动后,选择菜单栏——虚拟机——安装VMware tools,按照提示将相应的安装包复制到你想要的目录下,执行命令: tar zxvf vmware-tools.tar.gz cd vmware-tools(进入解压目录) ./install.pl(因版本不同,名字不一定相同,读者注意,执行名字类似的即可) 2.为每个节点分配IP地址,IP地址最好连续分配,如192.168.1.2、192.168.1.3、192.168.1.4、......。(不要分配192.168.1.1) 3.配置/etc/hosts文件,该文件可以实现IP地址和机器的对应解析,所有节点的该文件均要按下面的内容修改: 192.168.1.2 node1 192.168.1.3 node2 192.168.1.4 node3 8255并行口实验实验报告 作者: 一、实验目的 掌握8255A的编程原理。 二、实验设备 CPU挂箱、8086CPU模块。 三、实验内容 8255A的A口作为输入口,与逻辑电平开关相连。8255A的B口作为输出口,与发光二极管相连。编写程序,使得逻辑电平开关的变化在发光二极管上显示出来。 四、实验原理介绍 本实验用到两部分电路:开关量输入输出电路和8255可编程并口电路。 五、实验步骤 1、实验接线 CS0?CS8255; PA0~PA7?平推开关的输出K1~K8; PB0~PB7?发光二极管的输入LED1~LED8。 2、编程并全速或单步运行。 3、全速运行时拨动开关,观察发光二极管的变化。当开关某位置于L 时,对应的发光二极管点亮,置于H时熄灭。 六、实验提示 实验也是如此。实验中,8255A工作于基本8255A是比较常用的一种并行接口芯片,其特点在许多教科书中均有介绍。8255A有三个8位的输入输出端口,通常将A端口作为输入用,B端口作为输出用,C端口作为辅助控制用,本输入输出方式(方式0)。 七、实验结果 程序全速运行后,逻辑电平开关的状态改变应能在LED上显示出来。例如:K2置于L位置,则对应的LED2应该点亮。 八、程序框图(实验程序名:t8255.asm) 开始 设置8255工作方式 读A口 输出至B口 结束 九、程序源代码清单: assume cs:code code segment public org 100h start: mov dx,04a6h ;控制寄存器地址 mov ax,90h ;设 置为A口输入,B口输出 out dx,ax mov al,0feh start1:mov dx,04a2h 芯片的 入口地址 out dx,al mov bl,al mov dx ,04a0h in al,dx test ax,01h jz strat2 mov al ,bl rol al,1 流水灯循环左移 mov bl,al mov cx,3000h 设置cx为灯闪烁时间对应的循环次数 add: loop add jmp start1 无条件跳转至start1 strat2:mov al,bl mov dx,04a2h out dx,al ror al,1 流水灯循环左移 mov bl, al mov cx,3000h add1: loop add jmp start 无条件跳转至start code ends end start 十、实验总结 通过该实验,掌握了8255A的编程原理,学会了用汇编语言来编写程序控制8255A进行流水灯的操作实验。 深圳大学 实验报告 课程名称:并行计算 实验名称:矩阵乘法的OpenMP实现及性能分析姓名: 学号: 班级: 实验日期:2011年10月21日、11月4日 一. 实验目的 1) 用OpenMP 实现最基本的数值算法“矩阵乘法” 2) 掌握for 编译制导语句 3) 对并行程序进行简单的性能 二. 实验环境 1) 硬件环境:32核CPU 、32G 存计算机; 2) 软件环境:Linux 、Win2003、GCC 、MPICH 、VS2008; 4) Windows 登录方式:通过远程桌面连接192.168.150.197,用户名和初始密码都是自己的学号。 三. 实验容 1. 用OpenMP 编写两个n 阶的方阵a 和b 的相乘程序,结果存放在方阵c 中,其中乘法用for 编译制导语句实现并行化操作,并调节for 编译制导中schedule 的参数,使得执行时间最短,写出代码。 方阵a 和b 的初始值如下: ????????? ? ??????????-++++=12,...,2,1,..2,...,5,4,31,...,4,3,2,...,3,2,1n n n n n n n a ???????? ? ???????????= 1,...,1,1,1..1,...,1,1,11,...,1,1,11,..., 1,1,1b 输入: 方阵的阶n 、并行域的线程数 输出: c 中所有元素之和、程序的执行时间 提示: a,b,c 的元素定义为int 型,c 中所有元素之各定义为long long 型。 Windows 计时: 用 Win7/win8系统下visual studio+intel visual fortran 的安装 & windows 下mpi配置 第一部分所需组件: 虚拟光驱daemon tools(免费的lite版就可以)或者Ultra iso Visual studio 2012.iso 安装文件更新补丁文件patch_KB2781514.exe,没有补丁,装完Visual Studio之后点击更新程序提示进行更新也可以。 Intel visual fortran composer XE 2013 及注册.lic文件 Mpi实现(32位机和64位机选用) 第二部分软件安装 先安装Visual studio 2012再安装Intel visual fortran,最后安装mpich2。Visual studio 2012的安装, 1、安装虚拟光驱daemon tools 图略。 2、载入VisualStudio2012镜像 3、载入之后再磁盘窗口可以看到下图 4、点击进入,双击运行安装程序 5、接下来就是30分钟左右的等待时间(vs的确很庞大。。) 6、安装完vs2012之后,在开始菜单找到程序运行,第一次运行默 认环境设置选择C++,如图 7、这时,右下角会出现更新提示,点击进行更新 8、这两个更新是比较慢的,可以省略这一步,直接安装前面提到 的补丁patch_KB2781514.exe 直接双击安装,大概5分钟装完。 9、至此VS2012安装完毕,注意补丁是必须的。 IVF的安装 1、直接双击安装文件安装, 2、下一步,下一步,直到Activation,选择choose alternative activationMPI环境搭建
单片机并行口实验报告
并行计算第一次实验报告
关于vc++6.0安装配置MPI
并行处理实验报告:用MPI实现的矩阵乘法的加速比分析
矩阵乘法的并行化 实验报告
多核编程与并行计算实验报告 (1)
MPI并行计算环境的建立
并行口实验实验报告
并行计算-实验二-矩阵乘法的OpenMP实现及性能分析
win7下vs+ivf+mpi配置