康普顿散射虚拟仿真实验记录数据处理报告

康普顿散射实验
一、实验目的
(1)了解射线与物质的相互作用过程,熟悉常用的核辐射探测器的工作原理及特性,并掌握其使用方法;(2)利用闪烁体探测器谱仪测量γ能谱并学习能谱分析方法;
(3)了解γ射线在物质中的吸收规律,并测量不同能量γ射线在典型物质中的吸收系数;
(4)掌握康普顿效应光子的测量方法,验证康普顿散射的γ光子能量及微分截面与散射角的关系。
二、实验原理
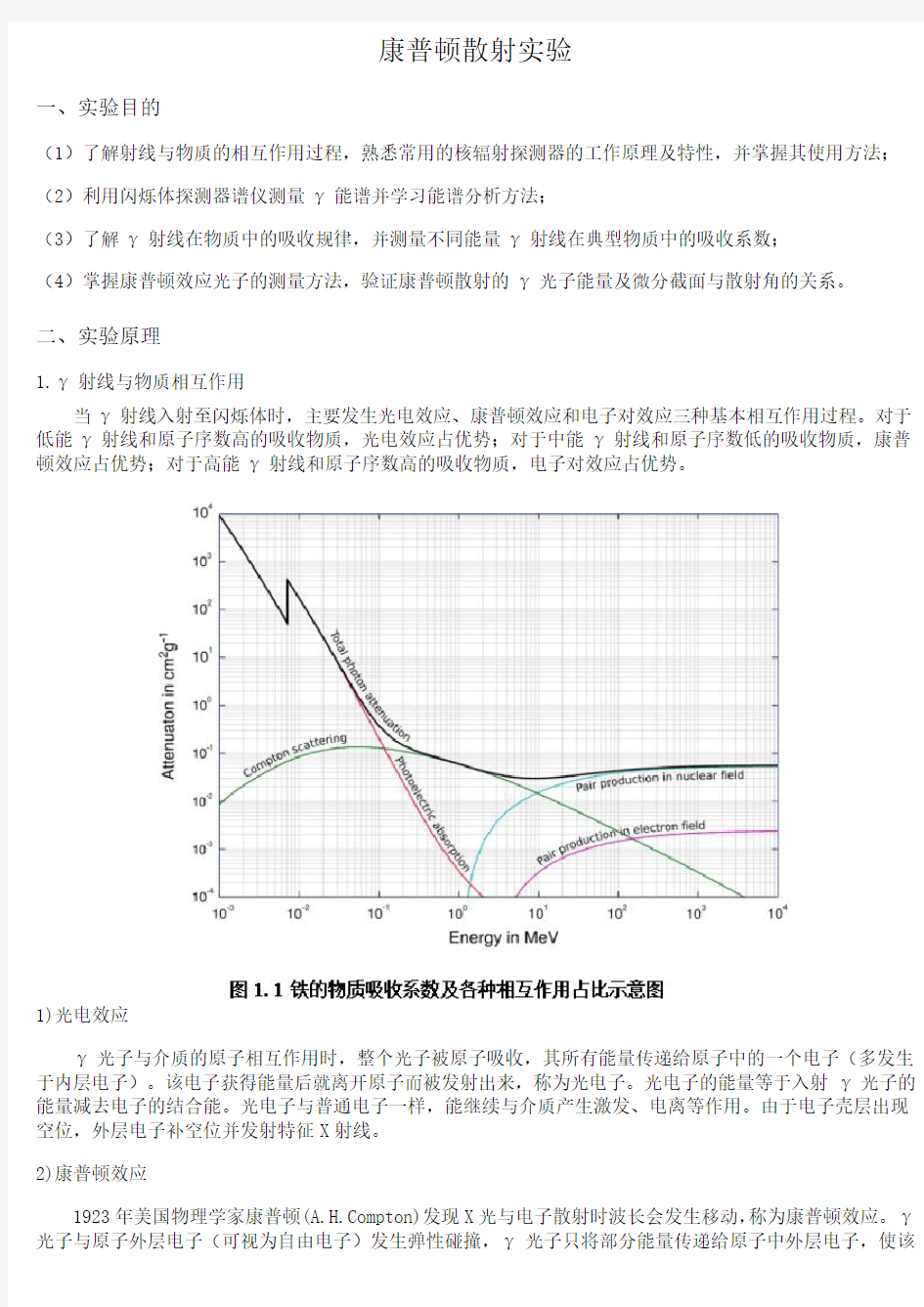
1.γ射线与物质相互作用
当γ射线入射至闪烁体时,主要发生光电效应、康普顿效应和电子对效应三种基本相互作用过程。对于低能γ射线和原子序数高的吸收物质,光电效应占优势;对于中能γ射线和原子序数低的吸收物质,康普顿效应占优势;对于高能γ射线和原子序数高的吸收物质,电子对效应占优势。
1)光电效应
γ光子与介质的原子相互作用时,整个光子被原子吸收,其所有能量传递给原子中的一个电子(多发生于内层电子)。该电子获得能量后就离开原子而被发射出来,称为光电子。光电子的能量等于入射γ光子的能量减去电子的结合能。光电子与普通电子一样,能继续与介质产生激发、电离等作用。由于电子壳层出现空位,外层电子补空位并发射特征X射线。
2)康普顿效应
1923年美国物理学家康普顿(https://www.360docs.net/doc/5114549964.html,pton)发现X光与电子散射时波长会发生移动,称为康普顿效应。γ光子与原子外层电子(可视为自由电子)发生弹性碰撞,γ光子只将部分能量传递给原子中外层电子,使该电子脱离核的束缚从原子中射出。光子本身改变运动方向。被发射出的电子称康普顿电子,能继续与介质发生相互相互作用。
散射光子与入射光子的方向间夹角称为散射角,一般记为θ。反冲电子反冲方向与入射光子的方向间夹角称为反冲角,一般记为φ。当散射角θ=0°,散射光子的能量为最大值,这时反冲电子的能量为0,光子能量没有损失;当散射角θ=180°时,入射光子和电子对头碰撞,沿相反方向散射回来,而反冲电子沿入射
3)电子对效应
能量大于1.022MeV的γ光子从原子核旁经过时,在原子核的库仑场作用下,γ光子转变成一个电子和一个正电子。光子的能量一部分转变成正负电子的静止能量(1.022MeV),其余就作为它们的动能。被发射出的电子还能继续与介质产生激发、电离等作用;正电子在损失能量之后,将于物质中的负电子相结合而变成γ射线,即湮没(annihilation),探测这种湮没辐射是判明正电子产生的可靠实验依据。
2.闪烁体及光电倍增管的工作原理
闪烁体探测器是利用电离辐射在某些物质中的闪光来进行探测的,也是应用最为广泛的电离辐射探测器之一。
1)闪烁体
入射辐射与闪烁体物质发生相互作用并沉积能量,引起闪烁体中原子(或分子)的电离激发,之后受激粒子退激释放出波长接近于可见光的闪烁光子。本实验采用的真实及虚拟探测器为NaI(Tl)闪烁体探测器,尺寸为50*50mm。
2)光电倍增管(Photomultiplier Tube, PMT)
它由光电阴极(PHOTOCATHODE)、打拿极(DYNODES)及阳极(ANODE)等密封在真空壳中组成。光电阴极是接受光子而放出光电子的电极,它是用光电效应较高,光电子逸出功小的特殊材料制成的。
闪烁光子通过光反射包装、光学耦合硅油等光导射入光电倍增管的光阴极并打出光电子,光电子受打拿极之间的强电场的作用加速运动并轰击下一打拿级,打出更多光电子,由此实现光电子的倍增,直到最终到
3.单道及多道分析仪的工作原理
单道幅度分析器(Single Channel Analyzer,SCA)简称单道分析器,当输入脉冲信号的峰值幅度在单道分析器的上、下阈值之间时,会输出一个逻辑脉冲。因此,它可以实现脉冲信号的幅度选择。
多道幅度分析器(Multichannel Analyzer,MCA)简称多道分析器,它使用高速ADC来检测并记录输入的脉冲信号,并根据其幅度大小对其进行计数统计。MCA是脉冲信号幅度分析的主要工具,它的脉冲幅度分析功能可以近似看作是多个上下阈值连续分布的单道分析器与计数器的组合结果,因此叫做多道分析器。
对于γ能谱仪来说,脉冲信号的幅度大小与入射粒子在探测器中沉积的能量成正比,因此对脉冲幅度的选择及分析就意味着对入射粒子沉积能量的分析。其中,求解输入信号的幅度大小与能量之间对应关系的过程就是谱仪的能量刻度。
4.多道分析器的能量刻度方法
能量刻度是确定入射粒子的能量与多道分析器的道数之间对应关系的实验工作。
能量线性指谱仪对入射γ射线的能量和它产生的脉冲幅度之间的对应关系。一般NaI(Tl)闪烁谱仪在较宽的能量范围内(100KeV到1300KeV)是近似线性的。这是利用该谱仪进行射线能量分析与判断未知放射性核素的重要依据。通常,在实验上利用系列γ标准源,在确定的实验条件下分别测量系列源γ谱。由已知γ射线能量全能峰峰位对相应的能量作图,这条曲线即能量刻度曲线。典型的能量刻度曲线为不通过原点的一条直线,即
式中xp为全能峰峰位;E0为直线截距;G为增益即每伏(或每道)相应的能量。能量刻度亦可选用标准137Cs(0.662MeV)和60Co(1.17、1.33MeV)来作,如图2-3所示。
实验中欲得到较理想的线性,还需要注意对放大器及单道分析器甄别阈的线性进行必要的检验与调整。此外,实验条件变化时应重新进行刻度。
5.γ能谱的构成及分析
在物理学中,粒子能谱是指粒子的计数或粒子束流的强度随粒子能量的分布。通过对谱仪进行能量刻度之后,就可以得到当前环境下粒子在探测器中的沉积能量的分布情况,就是对粒子能谱的一种定量分析。
一般情况下,γ射线的能谱主要包含以下一些主要结构:
●全能峰
全能峰是指当γ粒子的全部能量都沉积在探测器内时贡献的信号形成的峰。它理论上应该是一条单能谱线,但由于谱仪有限的能量分辨能力,这条谱线就被展宽成了一个高斯形状的峰。一般情况下,寻峰操作意味着针对这类峰进行高斯拟合。全能峰的主要贡献者是发生了光电效应的那些γ入射事例,因此其又常被称为光电峰。
全能峰的峰位能量应该为Eγ,其中,Eγ是入射的γ光子的能量。
●康普顿平台
康普顿平台是一个能量从零开始的连续区域,其主要贡献者是发生了康普顿效应的那些γ入射事例。因此其能量的最大值应该是电子在康普顿散射中所能得到的最大能量,也就是康普顿散射角度在180°时的示例。
在真实情况下,有一些γ光子可能在进入探测器之前已经经历过一次或者多次康普顿散射过程,这种现象在能谱上会形成一个峰结构,这个峰的峰计数大多是由一些经过约180°散射后的γ光子贡献的,因此被称为背散射峰。其峰位大致位于全能峰减去康普顿边界的能量。
●单、双逃逸峰
对于入射γ光子能量大于两倍电子静质量(1.022MeV)的时候,电子对效应就可能发生,这时候正负电子湮灭后产生的两个511keV的次级γ可能:
◆都把全部能量沉积在探测器中
◆其中一个逃离了探测器,而另一个能量全部沉积在探测器中,此时将在能谱中产生一个峰位为Eγ-511keV 的峰,即单逃逸峰
◆两个都逃离了探测器,此时将在能谱中产生一个峰位为Eγ-2*511keV的峰,即双逃逸峰
6.物质对γ射线的吸收规律
当γ射线穿过物质时,与物质作用发生光电效应、康普顿效应和电子对效应(当γ能量大于人1.022MeV 时才产生),γ射线损失其能量。γ射线与物质的原子一旦发生三种相互作用,原来为Eγ的光子就消失,或散射后能量改变并偏离原来的入射方向。通常把通过物质的未经过相互作用的光子所组成的射线束称为窄束γ射线(也称为良好的几何条件下的射线束)。γ射线通过物质时其强度会逐渐减弱,这种现象称为γ射线吸收,单能束γ射线强度的衰减,遵循指数规律,即
其中I0、I分别是通过物质前、后γ射线强度,x是γ射线通过物质的厚度(单位为cm),σγ是三种效应(光电效应、康普顿效应和电子对效应)截面之和,N是吸收物质单位体积中的原子数,μ是物质的线性吸收系数(μ=σγN(单位为cm-1)。显然μ的大小反映了物质吸收γ射线能力的大小。
由于在相同的实验条件下,某一时刻的计数率n总是与该时刻的γ射线强度I成正比,因此I与x的关系也可以用n与x的关系来代替。由上式可以得到
可见,如果在半对数坐标图上绘制吸收曲线,那么这条曲线就是一条直线(如图7-1),该直线斜率的绝对值就是线性吸收系数μ。
7.微分散射截面
根据微分散射截面的定义,当有N0个光子入射时,与样品中Ne个电子发生作用,在忽略多次散射自吸
收的情况下,散射到θ方向Ω立体角里的光子数N(θ)应为,式中?是散射样品的自吸收因子,闪烁谱仪测量各散射角的散射γ光子能谱,用光电峰峰位及光电峰面积得出散
射γ光子能量,并计算出微分截面的相对值(详见实验指导讲义),通过测量不同角度散射的光子数,验证康普顿散射的γ光子相对微分截面与散射角的关系。
8.康普顿散射效应验证
康普顿效应是入射光子与物质原子中的核外电子产生非弹性碰撞而被散射的现象。碰撞时,入射光子把部分能量转移给电子,使它脱离原子成为反冲电子,而散射光子的能量和运动方向发生变化。如图8-1所示。
1)散射γ光子能量与入射γ光子能量、散射角的关系:
2)康普顿散射的微分截面的意义是:
一个能量为hv的入射γ光子与原子中的一个核外电子作用后被散射到θ方向单位立体角里的几率(记作,单位:cm2/单位立体角)为:
式中r0=2.818×10-13cm,是电子的经典半径,此式通常称为“克来茵一仁科”公式,此式所描述的就是微分截面与入射γ光子能量及散射角的关系。
在实验中,不同散射角度下,散射探测器测量到的能谱计数率,不光与当时的康普顿散射微分截面有关,也与散射探测器针对中心探测器张开的立体角、散射探测器对入射γ射线的本征探测效率有关。由于散射探测器是围绕中心探测器做圆周运动的,因此其立体角是固定的,那么可以得到归一化的康普顿散射微分截面公式如下:
ε可以根据物质对于γ射线的吸收规律得到,如果已知探测器材料及厚度大小(本实验中探测散射γ光子的探测器材料为NaI,厚度为5cm),那么只要实验测量得到其吸收系数,就可以得到探测器的本征效率如下:
其中,μ为NaI材料针对特定能量γ射线的吸收系数,单位为cm-1,E为在某个特定角度下的散射γ射线的能量,t为NaI闪烁体的厚度,对于本实验来说,t即为5cm。
本实验提供了具有多种γ射线能量的放射源,可以用于拟合μ(E)曲线,对于不同角度下的特定能量的散射γ射线来说,只需要利用插值法求得其对应的吸收系数即可。
本实验采用符合测量技术来验证康普顿散射中的公式。其中,中心探测器采用的是塑料闪烁体,用来与入射γ射线发生康普顿效应。并散射出次级γ,因为其材质是由碳氢氧组成,原子量Z偏低,所以其发生康普顿散射的相对概率高,而光电效应的相对概率低。而旋转探测器采用的是NaI(Tl)闪烁体,用来测量被散射的次级γ射线。其能量分辨较好,并且探测效率较高。
闪烁谱仪测量各散射角的散射γ光子能谱,用光电峰峰位及光电峰面积得出散射γ光子能量hv,并计
算出微分截面的相对值。
9.符合测量技术
在核探测技术中,符合测量是一种非常重要的工具,它常被用来提高系统信噪比或者检测微弱信号。
符合测量技术是利用电子学方法,把有时间关联性的两个或多个探测器信号挑选出来。很多核物理过程在单次事例中都会产生两个或者多个次级粒子,因此假如能同时,或者在一定的延迟之内探测到这些次级粒子,就对于挑选这类事例起到很好的抑制噪声信号的作用。
例如康普顿效应的验证实验中,一次康普顿散射会产生一个反冲电子与一个散射光子。如果不使用符合测量技术,那么散射探测器上将接收大量的事例,它们可能是真事例,也就是从中心探测器上发生康普顿散射,而散射光子被散射探测器吸收;也可能是噪声事例,即由放射源直接入射的γ事例,或者是由其他物质上产生的散射事例等。如果使用符合测量,则大量噪声事例将被剔除,信噪比也会大幅提高。
三、实验仪器设备
1.软件平台
“康普顿散射虚拟仿真实验”虚拟仿真实验教学软件和管理平台。
2.虚拟仿真软件中的数字化实验仪器设备
(1)放射源库:137Cs、60Co、22Na、152Eu、54Mn
(2)吸收片库:Fe、Al、Cu、Pb、NaI
(3)探测器库:NaI(Tl)闪烁体探测器、塑料闪烁体探测器等
(4)高压电源
(5)线性脉冲放大器
(6)单道分析器
(7)多道分析器
(8)康普顿散射旋转平台
(9)移动式γ谱仪
四、实验材料
1.放射源表
2.吸收片表
3.其它参数
(1)探测器类型:碘化钠闪烁体探测器、塑料闪烁体探测器(2)工作电压:
碘化钠闪烁体探测器的推荐工作电压:1000V;
碘化钠闪烁体探测器的最大工作电压:1500V;
塑料闪烁体探测器的推荐工作电压:800V;
塑料闪烁体探测器的最大工作电压:1200V;
(3)放射源活度:50μCi - 50 mCi;
(4)放射源与探测器距离:400mm;
(5)放大器增益:20-1500;
(6)多道分析器总道数:8192。
五、实验数据
一、谱仪的能量刻度
全能峰对应能量(keV)峰位道址半高全宽
662 3480 25.94
1173 6173 41.38
1333 7012 44.62
谱仪的能量分辨率:dE/E*1003.918 % @ 662keV 二、不同能量下γ射线吸收系数的测量
能量(keV)全能峰原始计数
率1cm NaI 计数率2cm NaI 计数率3cm NaI 计数率4cm NaI 计数率5cm NaI 计数率
NaI材料的吸收
系数(cm-1)
152Eu 122 7648 998 908 907 886 882 4.18 152Eu 245 1871 1075 706 557 496 442 0.806
1000
200030004000500060007000
8000B
A
图11 用软件求出全能峰能量122keV 时NaI 材料的吸收系数
400
60080010001200
1400160018002000B
A
图12 用软件求出全能峰能量245keV 时NaI 材料的吸收系数
500
10001500200025003000
3500400045005000B
A
图13用软件求出全能峰能量344keV 时NaI 材料的吸收系数
2000
4000600080001000012000
14000160001800020000B
A
图14用软件求出全能峰能量511keV 时
NaI 材料的吸收系数
4000
60008000100001200014000160001800020000B
A
图15用软件求出全能峰能量662keV 时NaI 材料的吸收系数
500
600700800
900
1000
1100
B
A
图16用软件求出全能峰能量779keV 时NaI 材料的吸收系数
4000
600080001000012000
140001600018000B
A
图16用软件求出全能峰能量835keV 时NaI 材料的吸收系数
1
2
3
4
B
A
图16用软件求出NaI 材料的吸收系数与能量的曲线公式u=0.29545+27.0877e-0.0159E
三、康普顿散射的验证
θ/°光电峰峰位能量
(keV)
NaI材料的吸收系数u
(cm-1)5cm NaI探测效率
()E
ε
20 609 0.297138 0.77365389 u=0.29545+27.0877e-0.0159E 40 505 0.30427276 0.781586189
60 398 0.34380816 0.820762
80 316 0.473566 0.9063162
100 259.53 0.7326138 0.974346339
120 221.20 1.1256422 0.9964049989
θ/°总计数测量时间/s总计数率Na(?)
()
()
Na
E
θ
εθ相对微分截面
00
()
()/()
()/()()
/Na
d d Na
d d E E
θ
σθθ
σθεθεθ
Ω
Ω
=
20 5699 9 633 818.195 1
40 4446 11 404 0.6317535
60 4467 18 248 0.36929856369
80 4345 25 174 0.2346457455
100 4158 28 148 0.185648539
120 4209 29 145 0.177858769
四、心得体会
感谢武汉大学吴奕初老师团队提供这么先进的实验平台,您们通过采用先进的虚拟放射源和数字化多道等技术开发3D仿真实验,不仅解决了放射源辐射安全的难题,而且利用虚拟放射源不受放射源种类和强度的限制,引入符合测量技术,拓展了传统实验教学内容的广度和深度。我通过本实验快速全面地熟悉了基本的核电子学设备,掌握了其实验原理、过程以及数据处理方法。提高了科学思维方法、科学素质和科学实验综合能力,学会了康普顿散射效应的测量技术,验证了康普顿散射的光子及反冲电子的能量与散射角的关系,理解了康普顿散射的微分截面的意义, 学会了求微分截面的相对值, 掌握了对谱仪进行能量刻度, 测量不同散射角时的散射光子能谱,观察了微分散射截面和散射峰能量随散射角的变化。
γ射线的测量题目
? 1. γ与物质最常见的三种相互作用不包含哪一种:
? A. 光电效应
? B. 康普顿散射效应
? C. 电子对效应
? D. 指数衰减效应
? 2. 在光电效应中,与γ射线发生相互作用的主要是:
? A. 内层电子
? B. 外层电子
? C. 所有电子
? D. 原子核
? 3. 在康普顿散射效应中,与γ射线发生相互作用的主要是:
? A. 内层电子
? B. 外层电子
? C. 所有电子
误差理论与数据处理实验报告
误差理论与数据处理 实验报告 姓名:小叶9101 学号:小叶9101 班级:小叶9101 指导老师:小叶
目录 实验一误差的基本概念 实验二误差的基本性质与处理 实验三误差的合成与分配 实验四线性参数的最小二乘法处理实验五回归分析 实验心得体会
实验一误差的基本概念 一、实验目的 通过实验了解误差的定义及表示法、熟悉误差的来源、误差分类以及有效数字与数据运算。 二、实验原理 1、误差的基本概念:所谓误差就是测量值与真实值之间的差,可以用下式表示 误差=测得值-真值 1、绝对误差:某量值的测得值和真值之差为绝对误差,通常简称为误差。 绝对误差=测得值-真值 2、相对误差:绝对误差与被测量的真值之比称为相对误差,因测得值与 真值接近,故也可以近似用绝对误差与测得值之比值作为相对误差。 相对误差=绝对误差/真值≈绝对误差/测得值 2、精度 反映测量结果与真值接近程度的量,称为精度,它与误差大小相对应,因此可以用误差大小来表示精度的高低,误差小则精度高,误差大则精度低。 3、有效数字与数据运算 含有误差的任何近似数,如果其绝对误差界是最末位数的半个单位,那么从这个近似数左方起的第一个非零的数字,称为第一位有效数字。从第一位有效数字起到最末一位数字止的所有数字,不论是零或非零的数字,都叫有效数字。 数字舍入规则如下: ①若舍入部分的数值,大于保留部分的末位的半个单位,则末位加1。 ②若舍去部分的数值,小于保留部分的末位的半个单位,则末位加1。 ③若舍去部分的数值,等于保留部分的末位的半个单位,则末位凑成偶数。即当末位为偶数时则末位不变,当末位为奇数时则末位加1。 三、实验内容 1、用自己熟悉的语言编程实现对绝对误差和相对误差的求解。 2、按照数字舍入规则,用自己熟悉的语言编程实现对下面数据保留四位有效数字进行凑整。 原有数据 3.14159 2.71729 4.51050 3.21551 6.378501 舍入后数据
数据分析实验报告
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
核型分析实验报告
核型分析 摘要植物核型分析是指对植物细胞染色体的数目、形态、长度、带型和着丝粒位置等内容的分析研究,是植物分类和遗传研究的重要手段。本实验利用Photoshop软件,对栽培四棱大麦的染色体进行核型分析。本方法主要是物理分析法,在本试验中,我们先对大麦的染色体进行配对,再利用Photoshop软件对染色体进行分析,并测量了大麦染色体的臂长和随体长。 1.引言 核型指染色体组在有丝分裂中期的表型,包括染色体数目、大小、形态特征的总和。一个体细胞中的全部染色体,按其大小、形态特征(着丝粒的位置)顺序排列所构成的图像就称为核型。将待测细胞的核型进行染色体数目、形态特性的分析,确定其是否与正常核型完全一致,称为核型分析。以目前的技术水平,已实现使用计算机自动完成核型分析,我们学生也可以利用Adobe Photoshop 很容易地完成染色体的测量、排序等工作,再利用Excel 表格和Photoshop结合做出核型模式图。 2.实验材料 2.1实验材料 栽培四棱大麦的分散良好的有丝分裂中期细胞的显微照片、Adobe Photoshop等软件2.2实验方法 2.2.1绘制核型图 在Photoshop中对照片进行必要的处理。首先是剪裁照片,用套索工具将每条染色体分离出来,对染色体进行配对并将每条染色体的着丝点排在一条线上,并对染色体进行适当的旋转变换。其次是利用标尺工具测量每条染色体的臂长、随体长。再根据测量结果计算出染色体的臂比,总长,随体长,相对长度等数据。 2.2.2写出核型公式 根据上面的测量结果写出四棱大麦的核型公式。 2.2.3画核型模式图 将所测并经过计算后的数据在Excel表格中绘制成堆积柱形图,并在Photoshop里切出着丝点和次缢痕。除此之外,还需将整个图像转换成黑白。 3.结果与讨论 3.1染色体核型分析图 图1 染色体核型分析图
数据库上机实验报告
数据库实验 (第三次) 题目1 实验内容: 1. 检索上海产的零件的工程名称; 2. 检索供应工程J1零件P1的供应商号SNO; 3. 检索供应工程J1零件为红色的供应商号SNO; 4. 检索没有使用天津生产的红色零件的工程号JNO; 5. 检索至少用了供应商S1所供应的全部零件的工程号JNO; 6. 检索购买了零件P1的工程项目号JNO及数量QTY,并要求对查询的结果按数 量QTY降序排列。
1 select jname from j where jno in (select jno from spj where sno in (select sno from s where city ='上海' ) ); 2 select sno from spj where jno ='j1'and pno ='p1' 3
selectdistinct sno from spj where pno in (select pno from p where color='红'and pno in (select pno from spj where jno ='j1' ) ); 4 selectdistinct jno from spj where pno notin (select pno from p where color ='红'and pno in (select pno from spj where sno in (select sno from s where city ='天津' ) ) )
5 select jno from spj where sno ='s1' 6 select jno,qty from spj where pno ='p1' orderby qty desc 四﹑思考题 1.如何提高数据查询和连接速度。 建立视图 2. 试比较连接查询和嵌套查询 有些嵌套查询是可以用连接来代替的,而且使用连接的方式,性能要比 嵌套查询高出很多 当查询涉及多个关系时,用嵌套查询逐步求解结构层次清楚,易于构造,具有结构化程序设计的优点。但是相比于连接运算,目前商用关系数据库管理系统对嵌套查询的优化做的还不够完善,所以在实际应用中,能够用连接运算表达的查询尽可能采用连接运算。
2.基尔霍夫定律和叠加原理的验证(实验报告答案)含数据处理
实验二 基尔霍夫定律和叠加原理的验证 一、实验目的 1. 验证基尔霍夫定律的正确性,加深对基尔霍夫定律的理解。 2. 验证线性电路中叠加原理的正确性及其适用范围,加深对线性电路的叠加 性和齐次性的认识和理解。 3. 进一步掌握仪器仪表的使用方法。 二、实验原理 1.基尔霍夫定律 基尔霍夫定律是电路的基本定律。它包括基尔霍夫电流定律(KCL)和基尔霍 夫电压定律(KVL)。 (1)基尔霍夫电流定律(KCL) 在电路中,对任一结点,各支路电流的代数和恒等于零,即 ΣI =0。 (2)基尔霍夫电压定律(KVL) 在电路中,对任一回路,所有支路电压的代数和恒等于零,即 ΣU =0。 基尔霍夫定律表达式中的电流和电压都是代数量,运用时,必须预先任意假 定电流和电压的参考方向。当电流和电压的实际方向与参考方向相同时,取值为 正;相反时,取值为负。 基尔霍夫定律与各支路元件的性质无关,无论是线性的或非线性的电路,还 是含源的或无源的电路,它都是普遍适用的。 2.叠加原理 在线性电路中,有多个电源同时作用时,任一支路的电流或电压都是电路中 每个独立电源单独作用时在该支路中所产生的电流或电压的代数和。某独立源单 独作用时,其它独立源均需置零。(电压源用短路代替,电流源用开路代替。) 线性电路的齐次性(又称比例性),是指当激励信号(某独立源的值)增加 或减小 K 倍时,电路的响应(即在电路其它各电阻元件上所产生的电流和电压 值)也将增加或减小 K 倍。 三、实验设备与器件 1. 直流稳压电源 1 2. 直流数字电压表 1 3. 直流数字毫安表 1 4. 万用表 1 5. 实验电路板 1 四、实验内容 1.基尔霍夫定律实验 按图 2-1 接线。 台块 块 块块
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/5114549964.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/5114549964.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
C上机实验报告实验四
实验四数组、指针与字符串 1.实验目的 1.学习使用数组 2.学习字符串数据的组织和处理 3.学习标准C++库的使用 4.掌握指针的使用方法 5.练习通过Debug观察指针的内容及其所指的对象的内容 6.联系通过动态内存分配实现动态数组,并体会指针在其中的作用 7.分别使用字符数组和标准C++库练习处理字符串的方法 2.实验要求 1.编写并测试3*3矩阵转置函数,使用数组保存3*3矩阵。 2.使用动态内存分配生成动态数组来重新完成上题,使用指针实现函数的功能。 3.编程实现两字符串的连接。要求使用字符数组保存字符串,不要使用系统函数。 4.使用string类定义字符串对象,重新实现上一小题。 5.定义一个Employee类,其中包括姓名、街道地址、城市和邮编等属性,以及change_name()和display()等函数。Display()显示姓名、街道地址、城市和邮编等属性,change_name()改变对象的姓名属性。实现并测试这个类。 6.定义包含5个元素的对象数组,每个元素都是Employee类型的对象。 7. (选做)修改实验4中的选做实验中的people(人员)类。具有的属性如下:姓名char name[11]、编号char number[7]、性别char sex[3]、生日birthday、身份证号char id[16]。其中“出生日期”定义为一个“日期”类内嵌对象。用成员函数实现对人员信息的录入和显示。要求包括:构造函数和析构函数、拷贝构造函数、内联成员函数、聚集。在测试程序中定义people类的对象数组,录入数据并显示。 3.实验内容及实验步骤 1.编写矩阵转置函数,输入参数为3*3整形数组,使用循环语句实现矩阵元素的行列对调,注意在循环语句中究竟需要对哪些元素进行操作,编写main()函数实现输入、输出。程序名:lab6_1.cpp。 2.改写矩阵转置函数,参数为整型指针,使用指针对数组元素进行操作,在main()函数中使用new操作符分配内存生成动态数组。通过Debug观察指针的内容及其所指的对象中的内容。程序名:lab6_2.cpp。 3.编程实现两字符串的连接。定义字符数组保存字符串,在程序中提示用户输入两个字符串,实现两个字符串的连接,最后用cout语句显示输出。程序名:lab6_3.cpp。用cin实现输入,注意,字符串的结束标志是ASCII码0,使用循环语句进行字符串间的字符拷贝。 4.使用string类定义字符串对象,编程实现两字符串的连接。在string类中已重载了运算符“+=”实现字符串的连接,可以使用这个功能。程序名:lab6_4.cpp。 5.在employee.h文件中定义Employee类。Employee类具有姓名、街道地址、城市和邮编等私有数据成员,在成员函数中,构造函数用来初始化所有数据成员;display()中使用cout显示
误差理论与数据处理 实验报告
《误差理论与数据处理》实验指导书 姓名 学号 机械工程学院 2016年05月
实验一误差的基本性质与处理 一、实验内容 1.对某一轴径等精度测量8次,得到下表数据,求测量结果。 Matlab程序: l=[24.674,24.675,24.673,24.676,24.671,24.678,24.672,24.674];%已知测量值 x1=mean(l);%用mean函数求算数平均值 disp(['1.算术平均值为:',num2str(x1)]); v=l-x1;%求解残余误差 disp(['2.残余误差为:',num2str(v)]); a=sum(v);%求残差和 ah=abs(a);%用abs函数求解残差和绝对值 bh=ah-(8/2)*0.001;%校核算术平均值及其残余误差,残差和绝对值小于n/2*A,bh<0,故以上计算正确 if bh<0 disp('3.经校核算术平均值及计算正确'); else disp('算术平均值及误差计算有误'); end xt=sum(v(1:4))-sum(v(5:8));%判断系统误差(算得差值较小,故不存在系统误差) if xt<0.1 disp(['4.用残余误差法校核,差值为:',num2str(x1),'较小,故不存在系统误差']); else disp('存在系统误差'); end bz=sqrt((sum(v.^2)/7));%单次测量的标准差 disp(['5.单次测量的标准差',num2str(bz)]);
p=sort(l);%用格罗布斯准则判断粗大误差,先将测量值按大小顺序重新排列 g0=2.03;%查表g(8,0.05)的值 g1=(x1-p(1))/bz; g8=(p(8)-x1)/bz;%将g1与g8与g0值比较,g1和g8都小于g0,故判断暂不存在粗大误差if g1 篇一:大学物理实验1误差分析 云南大学软件学院实验报告 课程:大学物理实验学期: - 学年第一学期任课教师: 专业: 学号: 姓名: 成绩: 实验1 误差分析 一、实验目的 1. 测量数据的误差分析及其处理。 二、实验内容 1.推导出满足测量要求的表达式,即 0? (?)的表达式; 0= (( * )/ (2*θ)) 2.选择初速度A,从[10,80]的角度范围内选定十个不同的发射角,测量对应的射程, 记入下表中: 3.根据上表计算出字母A 对应的发射初速,注意数据结果的误差表示。 将上表数据保存为A. ,利用以下程序计算A对应的发射初速度,结果为100.1 a =9.8 _ =0 =[] _ = ("A. "," ") _ = _ . ad ()[:-1] = _ [:]. ('\ ') _ = _ . ad ()[:-1] = _ [:]. ('\ ') a (0,10): .a d( a . ( a ( [ ])* / a . (2.0* a ( [ ])* a . /180.0))) _ += [ ] 0= _ /10.0 0 4.选择速度B、C、D、重复上述实验。 B C 6.实验小结 (1) 对实验结果进行误差分析。 将B表中的数据保存为B. ,利用以下程序对B组数据进行误差分析,结果为 -2.84217094304 -13 a =9.8 _ =0 1=0 =[] _ = ("B. "," ") _ = _ . ad ()[:-1] = _ [:]. ('\ ') _ = _ . ad ()[:-1] = _ [:]. ('\ ') a (0,10): .a d( a . ( a ( [ ])* / a . (2.0* a ( [ ])* a . /180.0))) _ += [ ] 0= _ /10.0 a (0,10): 1+= [ ]- 0 1/10.0 1 (2) 举例说明“精密度”、“正确度”“精确度”的概念。 1. 精密度 计量精密度指相同条件测量进行反复测量测值间致(符合)程度测量误差角度说精密度所 反映测值随机误差精密度高定确度(见)高说测值随机误差定其系统误差亦。 2. 正确度 计量正确度系指测量测值与其真值接近程度测量误差角度说正确度所反映测值系统误差 正确度高定精密度高说测值系统误差定其随机误差亦。 3. 精确度 计量精确度亦称准确度指测量测值间致程度及与其真值接近程度即精密度确度综合概念 测量误差角度说精确度(准确度)测值随机误差系统误差综合反映。 比如说系统误差就是秤有问题,称一斤的东西少2两。这个一直恒定的存在,谁来都是 这样的。这就是系统的误差。随机的误差就是在使用秤的方法。 篇二:数据处理及误差分析 物理实验课的基本程序 《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布? 数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 测量刚体的转动惯量实验报告及数据处理 Company number:【0089WT-8898YT-W8CCB-BUUT-202108】 实验讲义补充: 1.刚体概念:刚体是指在运动中和受力作用后,形状和大小不变,而且内部各点的相对位置不 变的物体。 2.转动惯量概念:转动惯量是刚体转动中惯性大小的量度。它取决于刚体的总质量,质量分 布、形状大小和转轴位置 3.转动定律:合外力矩=转动惯量×角加速度 4.转动惯量叠加: 空盘:(1)阻力矩(2)阻力矩+砝码外力→J1 空盘+被测物体:(1)阻力矩(2)阻力矩+砝码外力→J2 被测物体:J3=J2-J1 5.转动惯量理论公式:圆盘&圆环J=0.5mr2,J=0.5m(r12+r12) 6.转动惯量实验仪器:水准仪;线水平;线与孔不产生摩擦;塔轮选小的半径;至少3个塔轮 半径,3组砝码质量 7.计数器:遮光板半圈π;单电门,多脉冲;空盘15圈,20个值;加上被测物体,8个值; 8.泡沫垫板 9.重力加速度:s^2 10.质量:1次读数,包括砝码,圆盘,圆环,以及两圆柱体; 11.游标卡尺:6次读数,包括圆盘半径,圆环内外半径,塔轮半径,转盘上孔的内外半径(求 平均值) 12.实验目的:测量值与理论值对比 实验计算补充说明: 1.有效数字:质量,故有效数字为3位 2.游标卡尺:,读数最后一位肯定为偶数; 3.误差&不确定度: (1)理论公式计算的误差: 圆盘:J=0.5mR2(注意:直接测量的是直径) 质量m=±;(保留4位有效数字) um=*100%=% 半径R=± 若测6次,x1,x2,x3,x4,x5,x6,i=6,计算x平均值 , 取n=6时的 ,我们处理为0 C=,仪器允差,δB= 总误差:,ux= m 《数据库技术与应用》上机实验报告 姓名:谢优贤 学号:020******* 专业班级:安全工程1003班 通过这次上机实验,我做了学生信息管理系统数据库,通过创建表、查询、窗体、报表和宏对输入数据库中的学生的基本信息进行整理和操作,以便得到我们想要的信息。学生信息管理系统可以实现对学生的基本信息:学号、姓名、联系方式、性别、成绩等的查询,还有对教师的情况进行比较了解从而可以帮助学生更好地选课和学习,省去了纸质档案管理不方便的方面。 通过窗体的创建和美化,使我们在操作数据时有一个简洁明了美观的窗口,简化了用户的操作程序,方便用户的使用。报表的创建可以使用户想要的数据很好地呈现在纸上。使用宏命令还使数据库有了设置密码的功能,很好的保护了数据的使用权限;也可以使用宏命令打开我们希望打开的窗口。 一、主要上机内容 1. 数据库的创建: 我使用自行创建数据库的方式进行创建,数据库文件名为学生信息管理系统。数据库要实现的主要功能:学生基本信息及学习成绩情况的统计,通过窗体进行学生信息的查询、学生信息及成绩的普通查询、打印学生信息报表等。 2. 表的创建: 基本表为学生信息表、学生成绩表、教师信息表、课程信息表等均使用设计器创建表学生信息表的记录: 学生信息表结构: 在学生信息表中设置了学号为主键,为了方便输入又在学号字段中设置了掩码(如下图) 学生年龄一般不会太大或太小,于是为了防止填写信息时出错,添加了有效性规则 性别只有男和女之分,于是为了方便,选择了查询向导 同样在入学日期和电话字段也设置了输入掩码 头像属于图片类型,其数据类型为“OLE对象”,所得荣誉和自我介绍选择了“备注”类 数据库实验报告姓名学号 目录 一.实验标题:2 二.实验目的:2 三.实验内容:2 四.上机软件:3 五.实验步骤:3 (一)SQL Server 2016简介3(二)创建数据库 4 (三)创建数据库表 7(四)添加数据17 六.分析与讨论: 19 一.实验标题: 创建数据库和数据表 二.实验目的: 1.理解数据库、数据表、约束等相关概念; 2.掌握创建数据库的T-SQL命令; 3.掌握创建和修改数据表的T-SQL命令; 4.掌握创建数据表中约束的T-SQL命令和方法; 5.掌握向数据表中添加数据的T-SQL命令和方法三.实验内容: 1.打开“我的电脑”或“资源管理器”,在磁盘空间以自己的姓名或学号建立文件夹; 2.在SQL Server Management Studio中,使用create database命令建立“学生-选课”数据库,数据库文件存储在步骤1建立的文件夹下,数据库文件名称自由定义; 3.在建立的“学生-选课”数据库中建立学生、课程和选课三张表,其结构及约束条件如表所示,要求为属性选择合适的数据长度; 4.添加具体数据; 四.上机软件: SQL Server 2016 五.实验步骤: (一)SQL Server 2016简介 1.SQL Server 2016的界面 2.启动和退出SQL Server 2016 1)双击图标,即出现SQL Server2016的初始界 2)选择“文件”菜单中的“退出”命令,或单击控制按钮中的“×”即可 注意事项: 1.在退出SQL Server 2016之前,应先将已经打开的数据库进行保存, 2.如果没有执行保存命令,系统会自动出现保存提示框,根据需要选择相应的操作 《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (2) 1.1数据挖掘 (2) 1.1.1数据挖掘的概念 (2) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (3) 1.2.1关联规则的概念 (3) 1.2.2关联规则的实现——Apriori算法 (4) 2.用Matlab实现关联规则 (6) 2.1Matlab概述 (6) 2.2基于Matlab的Apriori算法 (7) 3.用java实现关联规则 (11) 3.1java界面描述 (11) 3.2java关键代码描述 (14) 4、实验总结 (19) 4.1实验的不足和改进 (19) 4.2实验心得 (20) 1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下:·数据清理(消除噪声和删除不一致的数据) ·数据集成(多种数据源可以组合在一起) ·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。 神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art模型、koholon模型为代表的,用于聚类的自组织映射方法。神经网络方法的缺点是"黑箱"性,人们难以理解网络的学习和决策过程。 遗传算法:遗传算法是一种基于生物自然选择与遗传机理的随机搜索算法,是一种仿生全局优化方法。遗传算法具有的隐含并行性、易于和其它模型结合等性质使得它在数据挖掘中被加以应用。sunil已成功地开发了一个基于遗传算法的数据挖掘工具,利用该工具对两个飞机失事的真实数据库进行了数据挖掘实验,结果表明遗传算法是进行数据挖掘的有效方法之一。遗传算法的应用还体现在与神经网络、粗糙集等技术的结合上。如利用遗传算法优化神经网络结构,在不增加错误率的前提下,删除多余的连接和隐层单元;用遗传算法和bp算法结合训练神经网络,然后从网络提取规则等。但遗传算法的算法较复杂,收敛于局部极小的较早收敛问题尚未解决。 决策树方法:决策树是一种常用于预测模型的算法,它通过将大量数据有目的分类,从 创作编号: GB8878185555334563BT9125XW 创作者:凤呜大王* 叠加原理实验报告范文 一、实验目的 验证线性电路叠加原理的正确性,加深对线性电路的叠加性和齐次性的认识和理解。 二、原理说明 叠加原理指出:在有多个独立源共同作用下的线性电路中,通过每一个元件的电流或其两端的电压,可以看成是由每一个独立源单独作用时在该元件上所产生的电流或电压的代数和。 线性电路的齐次性是指当激励信号(某独立源的值)增加或减小K倍时,电路的响应(即在电路中各电阻元件上所建立的电流和电压值)也将增加或减小K倍。 三、实验设备 高性能电工技术实验装置DGJ-01:直流稳压电压、直流数字电压表、直流数字电流表、叠加原理实验电路板DGJ-03。 四、实验步骤 1.用实验装置上的DGJ-03线路,按照实验指导书上的图3-1,将两路稳压电源的输出分别调节为12V和6V,接入图中的U1和U2处。 2.通过调节开关K1和K2,分别将电源同时作用和单独作用在电路中,完成如下表格。 表3-1 3.将U2的数值调到12V,重复以上测量,并记录在表3-1的最后一行中。 4.将R3(330 )换成二极管IN4007,继续测量并填入表3-2中。 表3-2 五、实验数据处理和分析 对图3-1的线性电路进行理论分析,利用回路电流法或节点电压法列出电路方程,借助计算机进行方程求解,或直接用EWB软件对电路分析计算,得出的电压、电流的数据与测量值基本相符。验证了测量数据的准确性。电压表和电流表的测量有一定的误差,都在可允许的误差范围内。 验证叠加定理:以I1为例,U1单独作用时,I1a=8.693mA,,U2单独作用时, I1b=-1.198mA,I1a+I1b=7.495mA,U1和U2共同作用时,测量值为7.556mA,因此叠加性得以验证。2U2单独作用时,测量值为-2.395mA,而2*I1b=-2.396mA,因此齐次性得以验证。其他的支路电流和电压也可类似验证叠加定理的准确性。 对于含有二极管的非线性电路,表2中的数据不符合叠加性和齐次性。 核磁共振实验报告及数据核磁共振实验报告及数据 2011年04月20日核磁共振1了解核磁共振的基本原理教学目的2学习利用核磁共振校准磁场和测量g因子的方法3理解驰豫过程并计算出驰豫时间。重难点1核磁共振的基本原理2磁场强度和驰豫时间的计算。教学方法讲授、讨论、实验演示相结合。学时3个学时一、前言核磁共振是重要的物理现象。核磁共振技术在物理、化学、生物、医学和临床诊断、计量科学、石油分析与勘探等许多领域得到重要应用。自旋角动量P不为零的原子核具有相应的磁距μ而且其中称为原子核的旋磁比是表征原子核的重要物理量之一。当存在外磁场B时核磁矩和外磁场的相互作用使磁能级发生塞曼分裂相邻能级的能量差为其中hh/2πh为普朗克常数。如果在与B垂直的平面内加一个频率为ν的射频场当时就发生共振现象。通常称y/2π为原子核的回旋频率一些核素的回旋频率数值见附录。核磁共振实验是理科高等学校近代物理实验课程中的必做实验之一如今许多理科 院校的非物理类专业和许多工科、医学院校的基础物理实验课程也安排了核磁共振实验或演示实验。利用本装置和用户自备的通用示波器可以用扫场的方式观察核磁共振现象 并测量共振频率适合于高等学校近代物理实验基础实验教 学使用。二、实验仪器永久磁铁含扫场线圈、可调变阻器、探头两个样品分别为、和、数字频率计、示波器。三、实 验原理一核磁共振的稳态吸收核磁共振是重要的物理现象核磁共振实验技术在物理、化学、生物、临床诊断、计量科学和石油分析勘探等许多领域得到重要应用。1945年发现核磁共振现象的美国科学家Purcell和Bloch1952年获诺贝尔物理学奖。在改进核磁共振技术方面作出重要贡献的瑞士科学家Ernst1991年获得诺贝尔化学奖。大家知道氢原子中电子的能量不能连续变化只能取分立的数值在微观世界中物理量只能取分立数值的现象很普通本实验涉及到的原子核自旋角动量也不能连续变化只能取分立值其中I称为自旋量子数只能取0123?6?7等整数值或1/23/25/2?6?7等半整数值公式中的h/2π而h为普朗克常数对不同的核素I分别有不同的确定数值本实验涉及质子和氟核F19的自旋量子数I 都等于1/2类似地原子核的自旋角动量在空间某一方向例如z方向的分量也不能连续变化只能取分立的数值Pzm 。其中量子数m只能取II-1?6?7-II-I等2I1个数值。自旋角动量不为零的原子核具有与之相联系的核自旋磁矩其大小为 1 其中e为质子的电荷M为质子的质量g是一个由原子核结构决定的因子对不同种类的原子核g的数值不同g称为原子核的g因子值得注意的是g可能是正数也可能是负数因此核磁矩的方向可能与核自旋动量方向相同也可能相反。由于核自旋角动量在任意给定z方向只能取2I1个分立的数值因此核磁矩在z方向也只能取2I1个分立的数值。2 原子核的磁 数据分析与挖掘实验报告 《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30) 1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数 据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组 大连海事大学实验报告 专业班级:环境工程2011-1 学号:2220113199 姓名:陈凡 课程名称:数据采集与处理技术 实验时间:6月18号 指导教师:刘明(电航101) 实验名称:实验三 金属箔式应变片——全桥性能实验 一、实验目的:了解全桥测量电路的优点。 二、基本原理:全桥测量电路中,将受力方向相同的两应变片接入电桥对边,相反的应变片接入电桥邻边。当应变片初始阻值:R 1=R 2=R 3=R 4,其变化值ΔR 1=ΔR 2=ΔR 3=ΔR 4时,其桥路输出电压U 03=KEε。其输出灵敏度比半桥又提高了一倍,非线性误差和温度误差均得到改善。 三、需用器件和单元:同实验二。 四、实验步骤: 1、将托盘安装到应变传感器的托盘支点上。将实验模板差动放大器调零:用导线将实验模板上的±15v 、⊥插口与主机箱电源±15v 、⊥分别相连,再将实验模板中的放大器的两输入口短接(V i =0);调节放大器的增益电位器R W3大约到中间位置(先逆时针旋转到底,再顺时针旋转2圈);将主机箱电压表的量程切换开关打到2V 档,合上主机箱电源开关;调节实验模板放大器的调零电位器R W4,使电压表显示为零。 图3—1 全桥性能实验接线图 2、2、拆去放大器输入端口的短接线,根据图3—1接线。实验方法与实验二相同,将实验数据填入 表3画出实验曲线;进行灵敏度和非线性误差计算。实验完毕,关闭电源。 表2 五、实验数据处理 1、根据表2画出实验U-W 曲线 取图中点(20,0.015)、(200,0.157)得曲线斜K=S 2=ΔU/ΔW=(0.157-0.015)/(200-20)=0.000789v/g Δm 在点(60,0.047)处取得,Δm=0.001,δ=Δm/y FS ×100%=0.001/200×100%=0.0005% 六、思考题: 1、测量中,当两组对边(R 1、R 3为对边)电阻值R 相同时,即R 1=R 3,R 2=R 4,而R 1≠R 2时,是否可以组成全桥:(1)可以(2)不可以。 2、某工程技术人员在进行材料拉力测试时在棒材上贴了两组应变片,如图3—2,如何利用这四片应变片组成电桥,是否需要外加电阻。 图3-2应变式传感器受拉时传感器圆周面展开图大学物理实验报告数据处理及误差分析
数据分析实验报告
数据分析实验报告
测量刚体的转动惯量实验报告及数据处理
数据库上机实验报告
(完整版)数据库实验报告
【最全最详细】数据分析与挖掘实验报告
叠加原理 实验报告范文(含数据处理)
核磁共振实验报告及数据
数据分析与挖掘实验报告
数据采集与处理实验报告3