第10讲摄像机漫游分析解析

摄像机漫游
设置观察矩阵代码:
//建立并设置观察矩阵
D3DXVECTOR3 vEyePt( 0.0f,0.0f,-15.0f );
D3DXVECTOR3 vLookatPt( 0.0f, 0.0f, 0.0f );
D3DXVECTOR3 vUpV ec( 0.0f, 1.0f, 0.0f );
D3DXMA TRIX matView;
D3DXMatrixLookAtLH( &matView, &vEyePt, &vLookatPt, &vUpVec );
g_pd3dDevice->SetTransform( D3DTS_VIEW, &matView );
观察变换---摄像机属性
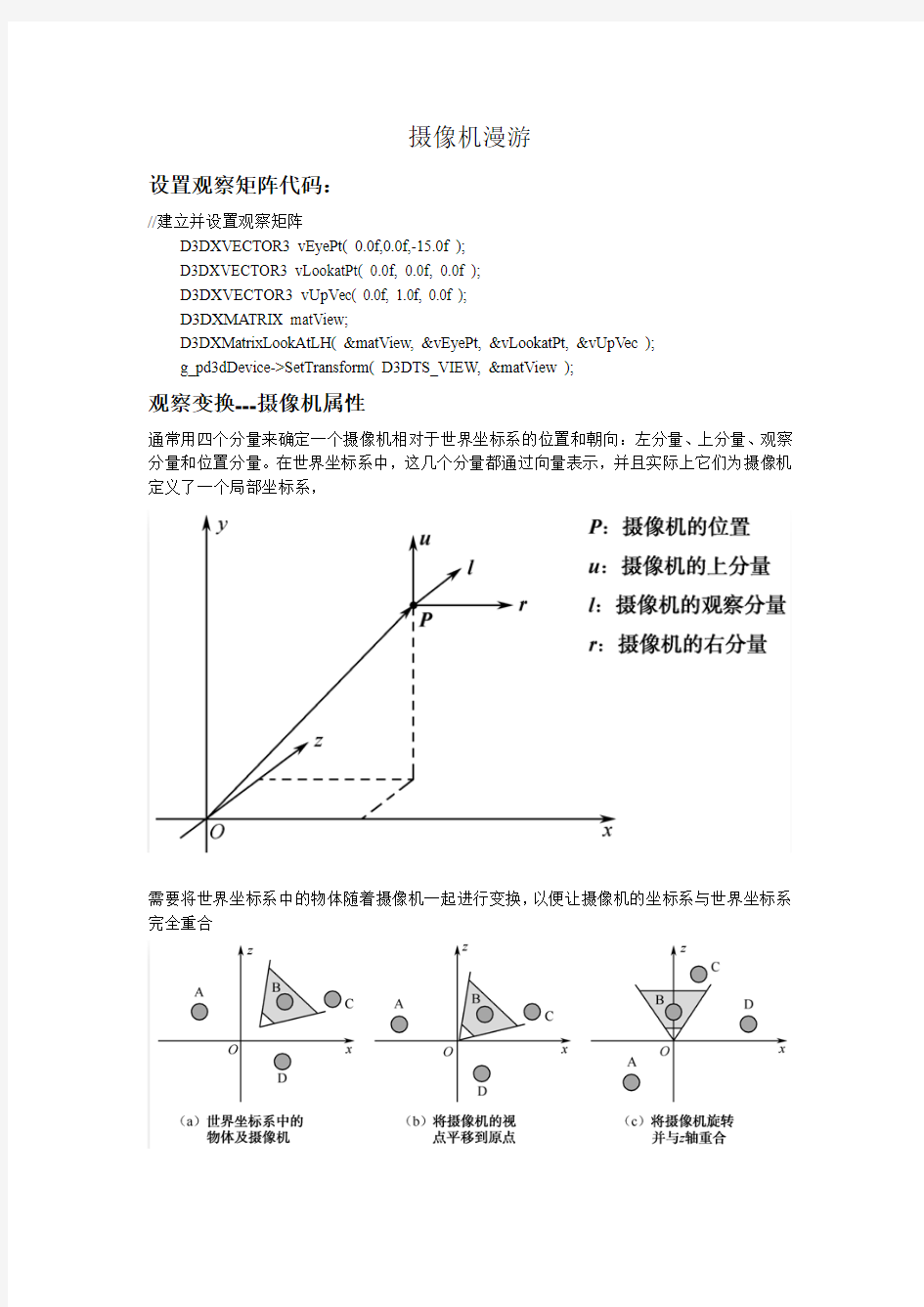
通常用四个分量来确定一个摄像机相对于世界坐标系的位置和朝向:左分量、上分量、观察分量和位置分量。在世界坐标系中,这几个分量都通过向量表示,并且实际上它们为摄像机定义了一个局部坐标系,
需要将世界坐标系中的物体随着摄像机一起进行变换,以便让摄像机的坐标系与世界坐标系完全重合
摄像机变换
1.沿各分量平移
由于摄像机包含向右、向上、观察三个分量,因此可以控制摄像机分别沿这三个分量进行平移。其中,沿右分量的平移称作扫视,沿上分量的平移称作升降,而沿观察分量的平移称作平动,如图所示
2.绕各分量旋转
摄像机的另一种变换是分别绕上分量、右分量和观察分量进行旋转。其中,绕上分量的旋转称作偏航,绕右分量的旋转称作俯仰,而绕观察分量的旋转称作滚动,如图所示
3.绕观察点旋转
摄像机的平移和旋转已经能够满足简单的应用,但是有时候还需要将观察点固定,并控制摄像机围绕该点做圆周运动,以便能够从不同角度观察同一物体。因此,还需要让摄像机绕某个点进行旋转,如图所示
以摄像机在y方向上绕点l=(l x,l y,l z)旋转为例,假设当前摄像机位于p点(观察点l与p点同在y平面内),那么当摄像机按逆时针方向旋转a 角度后应该位于p’点,如图所示。
//摄像机绕Y轴旋转fAngle角度
VOID CCamera::CircleRotationY(FLOAT fAngle)
{
D3DXMA TRIX R;
D3DXMatrixRotationAxis(&R, &m_vUpVec, fAngle);
D3DXVec3TransformCoord(&m_vRightVec, &m_vRightVec, &R);
D3DXVec3TransformCoord(&m_vLookVec, &m_vLookVec, &R);
float dx = m_vPosition.x - m_vLookat.x;
float dz = m_vPosition.z - m_vLookat.z;
m_vPosition.x = m_vLookat.x + dx * cosf(fAngle) - dz * sinf(fAngle);
m_vPosition.z = m_vLookat.z + dx * sinf(fAngle) + dz * cosf(fAngle);
ResetLookatPos(&m_vLookat);
}
根据上面介绍的内容,可以定义一个具有九个自由度的摄像机CCamera类,其中可以沿三个分量平移、绕三个分量旋转,以及在三个坐标方向上绕观察点旋转。
4.CCamera类定义
#pragma once
#include
#include
//--------------------------------------------------------------------------------------
// Name: class CCamera
// Desc: 虚拟摄像机平移、旋转
//--------------------------------------------------------------------------------------
class CCamera
{
private:
D3DXVECTOR3 m_vRightVec; // 摄像机右侧向量
D3DXVECTOR3 m_vUpVec; // 摄像机上方向量
D3DXVECTOR3 m_vLookVec; //摄像机视线方向
D3DXVECTOR3 m_vPosition; // 摄像机当前位置
D3DXMA TRIX m_matView; // 摄像机矩阵
D3DXMA TRIX m_matProj; // 投影矩阵
D3DXVECTOR3 m_vLookat; //摄像机视线位置
LPDIRECT3DDEVICE9 m_pd3dDevice;
public:
CCamera(IDirect3DDevice9 *pd3dDevice);
virtual ~CCamera(void);
public:
VOID GetViewMatrix(D3DXMA TRIX *pMatrix);//获取摄像机矩阵
VOID GetProjMatrix(D3DXMATRIX *pMatrix) { *pMatrix = m_matProj; }
VOID GetCameraPos(D3DXVECTOR3 *pVector) { *pVector = m_vPosition; }
VOID GetLookVector(D3DXVECTOR3 *pVector) { *pVector = m_vLookVec; }
VOID ResetLookatPos(D3DXVECTOR3 *pLookat = NULL);//设置视线位置
VOID ResetCameraPos(D3DXVECTOR3 *pVector = NULL);//设置摄像机位置
VOID ResetViewMatrix(D3DXMA TRIX *pMatrix = NULL);//设置摄像机(观察)矩阵
VOID ResetProjMatrix(D3DXMA TRIX *pMatrix = NULL);//设置投影矩阵
public:
// 沿各分量平移
VOID MoveAlongRightVec(FLOAT fUnits); // 沿right向量移动
VOID MoveAlongUpVec(FLOAT fUnits); // 沿up向量移动
VOID MoveAlongLookVec(FLOAT fUnits); // 沿look向量移动
// 绕各分量旋转
VOID RotationRightVec(FLOAT fAngle); // 绕right向量选择
VOID RotationUpVec(FLOAT fAngle); // 绕up向量旋转
VOID RotationLookVec(FLOAT fAngle); // 绕look向量旋转
// 绕空间点旋转
VOID CircleRotationX(FLOAT fAngle); // 在X方向上绕观察点旋转
VOID CircleRotationY(FLOAT fAngle); // 在Y方向上绕观察点旋转
VOID CircleRotationZ(FLOAT fAngle); // 在Z方向上绕观察点旋转
};
5、摄像机类CCamera类的实现
#include "Camera.h"
#include
CCamera::CCamera(IDirect3DDevice9 *pd3dDevice)
{
m_pd3dDevice = pd3dDevice;
m_vRightVec = D3DXVECTOR3(1.0f, 0.0f, 0.0f); // 默认右向量与X正半轴重合m_vUpVec = D3DXVECTOR3(0.0f, 1.0f, 0.0f); // 默认上向量与Y正半轴重合m_vLookVec = D3DXVECTOR3(0.0f, 0.0f, 1.0f); // 默认观察向量与Z正半轴重合m_vPosition = D3DXVECTOR3(0.0f, 0.0f, 0.0f); // 默认摄像机的位置为原点
m_vLookat = D3DXVECTOR3(0.0f, 0.0f, 0.0f);
GetViewMatrix(&m_matView); // 取得取景变换矩阵
D3DXMatrixPerspectiveFovLH(&m_matProj, D3DX_PI / 4.0f, 1.0f, 1.0f, 2000.0f); // 投影变换矩阵
}
CCamera::~CCamera(void)
{
}
VOID CCamera::GetViewMatrix(D3DXMATRIX *pMatrix)
{
// 使各分量相互垂直
D3DXVec3Normalize(&m_vLookVec, &m_vLookVec);
D3DXVec3Cross(&m_vUpVec, &m_vLookVec, &m_vRightVec); // 上向量与观察向量垂直D3DXVec3Normalize(&m_vUpVec, &m_vUpVec); // 规格化上向量
D3DXVec3Cross(&m_vRightVec, &m_vUpVec, &m_vLookVec); // 右向量与上向量垂直//你能通过左手法则确定叉积返回的向量。按照第一个向量指向第二个向量弯曲你的左手,//这时拇指所指的方向就是叉积向量所指的方向。
D3DXVec3Normalize(&m_vRightVec, &m_vRightVec); // 规格化右向量
// 创建取景变换矩阵
pMatrix->_11 = m_vRightVec.x; // Rx
pMatrix->_12 = m_vUpVec.x; // Ux
pMatrix->_13 = m_vLookVec.x; // Lx
pMatrix->_14 = 0.0f;
pMatrix->_21 = m_vRightVec.y; // Ry
pMatrix->_22 = m_vUpVec.y; // Uy
pMatrix->_23 = m_vLookVec.y; // Ly
pMatrix->_24 = 0.0f;
pMatrix->_31 = m_vRightVec.z; // Rz
pMatrix->_32 = m_vUpVec.z; // Uz
pMatrix->_33 = m_vLookVec.z; // Lz
pMatrix->_34 = 0.0f;
pMatrix->_41 = -D3DXVec3Dot(&m_vRightVec, &m_vPosition); // -P*R
pMatrix->_42 = -D3DXVec3Dot(&m_vUpVec, &m_vPosition); // -P*U
pMatrix->_43 = -D3DXVec3Dot(&m_vLookVec, &m_vPosition); // -P*L
pMatrix->_44 = 1.0f;
}
VOID CCamera::ResetLookatPos(D3DXVECTOR3 *pLookat)
{
if (pLookat != NULL) m_vLookat = (*pLookat);
else m_vLookat = D3DXVECTOR3(0.0f, 0.0f, 1.0f);
m_vLookVec = m_vLookat - m_vPosition;
D3DXVec3Normalize(&m_vLookVec, &m_vLookVec);
D3DXVec3Cross(&m_vUpVec, &m_vLookVec, &m_vRightVec);
D3DXVec3Normalize(&m_vUpVec, &m_vUpVec);
D3DXVec3Cross(&m_vRightVec, &m_vUpVec, &m_vLookVec);
D3DXVec3Normalize(&m_vRightVec, &m_vRightVec);
}
VOID CCamera::ResetCameraPos(D3DXVECTOR3 *pVector)
{
D3DXVECTOR3 V = D3DXVECTOR3(0.0f, 0.0f, 0.0f);
m_vPosition = pVector ? (*pVector) : V;
}
VOID CCamera::ResetViewMatrix(D3DXMA TRIX *pMatrix)
{
if (pMatrix) m_matView = *pMatrix;
else GetViewMatrix(&m_matView);
m_pd3dDevice->SetTransform(D3DTS_VIEW, &m_matView);
m_vRightVec = D3DXVECTOR3(m_matView._11, m_matView._12, m_matView._13);
m_vUpVec = D3DXVECTOR3(m_matView._21, m_matView._22, m_matView._23);
m_vLookVec = D3DXVECTOR3(m_matView._31, m_matView._32, m_matView._33); }
VOID CCamera::ResetProjMatrix(D3DXMA TRIX *pMatrix)
{
if (pMatrix != NULL) m_matProj = *pMatrix;
else D3DXMatrixPerspectiveFovLH(&m_matProj, D3DX_PI / 4.0f, 1.0f, 1.0f, 1000.0f);
m_pd3dDevice->SetTransform(D3DTS_PROJECTION, &m_matProj);
}
// 沿右向量平移fUnits个单位
VOID CCamera::MoveAlongRightVec(FLOAT fUnits)
{
m_vPosition += m_vRightVec * fUnits;
m_vLookat += m_vRightVec * fUnits;
}
// 沿上向量平移fUnits个单位
VOID CCamera::MoveAlongUpVec(FLOAT fUnits)
{
m_vPosition += m_vUpVec * fUnits;
m_vLookat += m_vUpVec * fUnits;
}
// 沿观察向量平移fUnits个单位
VOID CCamera::MoveAlongLookVec(FLOAT fUnits)
{
m_vPosition += m_vLookVec * fUnits;
m_vLookat += m_vLookVec * fUnits;
}
//旋转使用D3DXMatrixRotationAxis函数实现,绕right\up\look方向旋转的实现方法:VOID CCamera::RotationRightVec(FLOAT fAngle)
{
D3DXMA TRIX R;
D3DXMatrixRotationAxis(&R, &m_vRightVec, fAngle);
D3DXVec3TransformCoord(&m_vUpVec, &m_vPosition, &R);
D3DXVec3TransformCoord(&m_vLookVec, &m_vLookVec, &R);
m_vLookat = m_vLookVec * D3DXVec3Length(&m_vPosition);
}
/*D3DXVec3TransformCoord
用矩阵变换3-D向量,并且用w = 1投影结果。
定义:
D3DXVECTOR3 *WINAPI D3DXVec3TransformCoord(
D3DXVECTOR3 *pOut,
CONST D3DXVECTOR3 *pV,
CONST D3DXMATRIX *pM
);
Parameters
pOut: [in, out] 指向 D3DXVECTOR3 结构的操作结果。
pV: [in] 指向 D3DXVECTOR3 结构的向量。
pM: [in] 指向 D3DXMATRIX 结构的变换矩阵。
Return Value
指向 D3DXVECTOR3 结构的变换后的向量。
说明:
这个函数用矩阵pM变换3-D向量pV (x, y, z, 1),并且用w = 1投影结果。
函数返回值跟pOut 参数返回值是一样的。这样可以让函数
D3DXVec3TransformCoord作为其它函数的参数使用。
*/
VOID CCamera::RotationUpVec(FLOAT fAngle)
{
D3DXMA TRIX R;
D3DXMatrixRotationAxis(&R, &m_vUpVec, fAngle);
D3DXVec3TransformCoord(&m_vRightVec, &m_vRightVec, &R);
D3DXVec3TransformCoord(&m_vLookVec, &m_vLookVec, &R);
m_vLookat = m_vLookVec * D3DXVec3Length(&m_vPosition);
D3DXVECTOR3 vNormal;
D3DXVec3Normalize(&vNormal, &m_vLookat);
}
VOID CCamera::RotationLookVec(FLOAT fAngle)
{
D3DXMA TRIX R;
D3DXMatrixRotationAxis(&R, &m_vLookVec, fAngle);
D3DXVec3TransformCoord(&m_vRightVec, &m_vRightVec, &R);
D3DXVec3TransformCoord(&m_vUpVec, &m_vUpVec, &R);
m_vLookat = m_vLookVec * D3DXVec3Length(&m_vPosition);
}
//摄像机绕X轴旋转fAngle角度
VOID CCamera::CircleRotationX(FLOAT fAngle)
{
D3DXMA TRIX R;
D3DXMatrixRotationAxis(&R, &m_vRightVec, fAngle);
D3DXVec3TransformCoord(&m_vUpVec, &m_vUpVec, &R);
D3DXVec3TransformCoord(&m_vLookVec, &m_vLookVec, &R);
float dy = m_vPosition.y - m_vLookat.y;
float dz = m_vPosition.z - m_vLookat.z;
m_vPosition.y = m_vLookat.y + dy * cosf(fAngle) - dz * sinf(fAngle);
m_vPosition.z = m_vLookat.z + dy * sinf(fAngle) + dz * cosf(fAngle);
ResetLookatPos(&m_vLookat);
}
//摄像机绕Y轴旋转fAngle角度
VOID CCamera::CircleRotationY(FLOAT fAngle)
{
D3DXMA TRIX R;
D3DXMatrixRotationAxis(&R, &m_vUpVec, fAngle);
D3DXVec3TransformCoord(&m_vRightVec, &m_vRightVec, &R);
D3DXVec3TransformCoord(&m_vLookVec, &m_vLookVec, &R);
float dx = m_vPosition.x - m_vLookat.x;
float dz = m_vPosition.z - m_vLookat.z;
m_vPosition.x = m_vLookat.x + dx * cosf(fAngle) - dz * sinf(fAngle);
m_vPosition.z = m_vLookat.z + dx * sinf(fAngle) + dz * cosf(fAngle);
ResetLookatPos(&m_vLookat);
}
VOID CCamera::CircleRotationZ(FLOAT fAngle)
{
D3DXMA TRIX R;
D3DXMatrixRotationAxis(&R, &m_vLookVec, fAngle);
D3DXVec3TransformCoord(&m_vRightVec, &m_vRightVec, &R);
D3DXVec3TransformCoord(&m_vUpVec, &m_vUpVec, &R);
float dx = m_vPosition.x - m_vLookat.x;
float dy = m_vPosition.y - m_vLookat.y;
m_vPosition.x = m_vLookat.x + dx * cosf(fAngle) + dy * sinf(fAngle);
m_vPosition.y = m_vLookat.y - dx * sinf(fAngle) + dy * cosf(fAngle);
ResetLookatPos(&m_vLookat);
}
第10章-简单线性回归分析思考与练习参考答案
第10章 简单线性回归分析 思考与练习参考答案 一、最佳选择题 1.如果两样本的相关系数21r r =,样本量21n n =,那么( D )。 A. 回归系数21b b = B .回归系数12b b < C. 回归系数21b b > D .t 统计量11r b t t = E. 以上均错 2.如果相关系数r =1,则一定有( C )。 A .总SS =残差SS B .残差SS =回归 SS C .总SS =回归SS D .总SS >回归SS E. 回归MS =残差MS 3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )正确。 A .ρ=0时,r =0 B .|r |>0时,b >0 C .r >0时,b <0 D .r <0时,b <0 E. |r |=1时,b =1 4.如果相关系数r =0,则一定有( D )。 A .简单线性回归的截距等于0 B .简单线性回归的截距等于Y 或X C .简单线性回归的残差SS 等于0 D .简单线性回归的残差SS 等于SS 总 E .简单线性回归的总SS 等于0 5.用最小二乘法确定直线回归方程的含义是( B )。 A .各观测点距直线的纵向距离相等 B .各观测点距直线的纵向距离平方和最小 C .各观测点距直线的垂直距离相等 D .各观测点距直线的垂直距离平方和最小
E .各观测点距直线的纵向距离等于零 二、思考题 1.简述简单线性回归分析的基本步骤。 答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。 2.简述线性回归分析与线性相关的区别与联系。 答:区别: (1)资料要求上,进行直线回归分析的两变量,若X 为可精确测量和严格控制的变量,则对应于每个X 的Y 值要求服从正态分布;若X 、Y 都是随机变量,则要求X 、Y 服从双变量正态分布。直线相关分析只适用于双变量正态分布资料。 (2)应用上,说明两变量线性依存的数量关系用回归(定量分析),说明两变量的相关关系用相关(定性分析)。 (3)两个系数的意义不同。r 说明具有直线关系的两变量间相互关系的方向与密切程度,b 表示X 每变化一个单位所导致Y 的平均变化量。 (4)两个系数的取值范围不同:-1≤r ≤1,∞<<∞-b 。 (5)两个系数的单位不同:r 没有单位,b 有单位。 联系: (1)对同一双变量资料,回归系数b 与相关系数r 的正负号一致。b >0时,r >0,均表示两变量X 、Y 同向变化;b <0时,r <0,均表示两变量X 、Y 反向变化。 (2)回归系数b 与相关系数r 的假设检验等价,即对同一双变量资料,r b t t =。由于相关系数r 的假设检验较回归系数b 的假设检验简单,故在实际应用中常以r 的假设检验代替b 的假设检验。 (3)用回归解释相关:由于决定系数2 R =SS 回 /SS 总 ,当总平方和固定时,回归平方 和的大小决定了相关的密切程度。回归平方和越接近总平方和,则2 R 越接近1,说明引入相关的效果越好。例如当r =0.20,n =100时,可按检验水准0.05拒绝H 0,接受H 1,认为两变量有相关关系。但2 R =(0.20)2=0.04,表示回归平方和在总平方和中仅占4%,说明
第十章 spss教程之分类分析
第十章分类分析 第一节 K-Means Cluster过程 10.1.1 主要功能 10.1.2 实例操作 第二节 Hierarchical Cluster过程 10.2.1 主要功能 10.2.2 实例操作 第三节 Discriminant过程 10.3.1 主要功能 10.3.2 实例操作 人们认识事物时往往先把被认识的对象进行分类,以便寻找其中同与不同的特征,因而分类学是人们认识世界的基础科学。在医学实践中也经常需要做分类的工作,如根据病人的一系列症状、体征和生化检查的结果,判断病人所患疾病的类型;或对一系列检查方法及其结果,将之划分成某几种方法适合用于甲类病的检查,另几种方法适合用于乙类病的检查;等等。统计学中常用的分类统计方法主要是聚类分析与判别分析。 聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。判别分析则先根据已知类别的事物的性质,利用某种技术建立函数式,然后对未知类别的新事物进行判断以将之归入已知的类别中。聚类分析与判别分析有很大的不同,聚类分析事先并不知道对象类别的面貌,甚至连共有几个类别也不确定;判别分析事先已知对象的类别和类别数,它正是从这样的情形下总结出分类方法,用于对新对象的分类。 第一节 K-Means Cluster过程 10.1.1 主要功能 调用此过程可完成由用户指定类别数的大样本资料的逐步聚类分析。所谓逐步聚类分析就是先把被聚对象进行初始分类,然后逐步调整,得到最终分类。
返回目录返回全书目录 10.1.2 实例操作 [例10.1]为研究儿童生长发育的分期,调查1253名1月至7岁儿童的身高(cm)、体重(kg)、胸围(cm)和坐高(cm)资料。资料作如下整理:先把1月至7岁划成19个月份段,分月份算出各指标的平均值,将第1月的各指标平均值与出生时的各指标平均值比较,求出月平均增长率(%),然后第2月起的各月份指标平均值均与前一月比较,亦求出月平均增长率(%),结果见下表。欲将儿童生长发育分为四期,故指定聚类的类别数为4,请通过聚类分析确定四个儿童生长发育期的起止区间。 10.1.2.1 数据准备 激活数据管理窗口,定义变量名:虽然月份分组不作分析变量,但为了更直观地了解聚类结果,也将之输入数据库,其变量名为month;身高、体重、胸围和坐高的变量名分别为x1、x2、x3和x4,输入原始数额。 10.1.2.2 统计分析 激活Statistics菜单选Classify中的K-Means Cluster...项,弹出K-Means Cluster Analysis
统计学习题集第五章相关与回归分析(0)
所属章节: 第五章相关分析与回归分析 1■在线性相关中,若两个变量的变动方向相反,一个变量的数值增加,另一个变量数值随之减少,或一个变量的数值减少,另一个变量的数值随之增加,则称为()。 答案: 负相关。干扰项: 正相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答: 本题的正确答案为: 负相关。 2■在线性相关中,若两个变量的变动方向相同,一个变量的数值增加,另一个变量数值随之增加,或一个变量的数值减少,另一个变量的数值随之减少,则称为()。 答案: 正相关。干扰项: 负相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答:
本题的正确答案为: 正相关。 3■下面的xx中哪一个是错误的()。 答案: 相关系数不会取负值。干扰项: 相关系数是度量两个变量之间线性关系强度的统计量。干扰项: 相关系数是一个随机变量。干扰项: 相关系数的绝对值不会大于1。 提示与解答: 本题的正确答案为: 相关系数不会取负值。 4■下面的xx中哪一个是错误的()。 答案: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 干扰项: 相关系数显著性检验的原假设是: 总体中两个变量不存在相关关系。 干扰项: 回归分析中回归系数的显著性检验的原假设是:
所检验的回归系数的真值为0。 干扰项: 回归分析中多元线性回归方程的整体显著性检验的原假设是: 自变量前的偏回归系数的真值同时为0。 提示与解答: 本题的正确答案为: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 5■根据你的判断,下面的相关系数值哪一个是错误的()。 答案: 1.25。干扰项:-0.86。干扰项: 0.78。干扰项:0。 提示与解答: 本题的正确答案为: 1.25。 6■下面关于相关系数的陈述中哪一个是错误的()。 答案: 数值越大说明两个变量之间的关系越强,数值越小说明两个变量之间的关系越弱。 干扰项:
《统计分析与SPSS的应用(第五版)》课后练习答案(第10章)
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第10章SPSS的聚类分析 1、根据“高校科研研究.sav”数据,利用层次聚类分析对各省市的高校科研情况进行层次聚类分析。要求: 1)根据凝聚状态表利用碎石图对聚类类数进行研究。 2)绘制聚类树形图,说明哪些省市聚在一起。 3)绘制各类的科研指标的均值对比图。 4)利用方差分析方法分析各类在哪些科研指标上存在显著差异。 采用欧氏距离,组间平均链锁法 利用凝聚状态表中的组间距离和对应的组数,回归散点图,得到碎石图。大约聚成4类。步骤:分析分类系统聚类按如下方式设置……
结果: 凝聚计划 阶段 组合的集群 系数 首次出现阶段集群 下一个阶段集群1集群2集群1集群2 12630002 22629107 32025005 44120015 5820036 6816509 724260210 87110011 9580622 1024317022 11270816 1222280019 136230017 1410190025 154214021 162311021 1761313020 189180025 19142201224 2061517023 2124161526 2252491024 2362720026 24514221928 25910181427 2626212328 2791725029 2825262429 2929282730 30120290
将系数复制下来后,在EXCEL中建立工作表。选中数据列,点击“插入”菜单拆线图……
碎石图: 由图可知,北京自成一类,江苏、广东、上海、湖南、湖北聚成一类。其他略。 接下来,添加一个变量CLU4_1,其值为类别值。(1、2、3、4),再数据汇总设置……确定。
第十章直线相关与回归
第十章 直线相关与回归 一、教学大纲要求 (一) 掌握内容 ⒈ 直线相关与回归的基本概念。 ⒉ 相关系数与回归系数的意义及计算。 ⒊ 相关系数与回归系数相互的区别与联系。 (二)熟悉内容 ⒈ 相关系数与回归系数的假设检验。 ⒉ 直线回归方程的应用。 ⒊ 秩相关与秩回归的意义。 (三)了解内容 曲线直线化。 二、 学内容精要 (一) 直线回归 1. 基本概念 直线回归(linear regression)建立一个描述应变量依自变量变化而变化的直线方程,并要求各点与该直线纵向距离的平方和为最小。直线回归是回归分析中最基本、最简单的一种,故又称简单回归(simple regression )。 直线回归方程bX a Y +=?中,a 、b 是决定直线的两个系数,见表10-1。 表10-1 直线回归方程a 、b 两系数对比 a b 含义 回归直线在Y 轴上的截距(intercept )。 表示X 为零时,Y 的平均水平的估计值。 回归系数(regression coefficient ),即直线的斜率。表示X 每变化一个单位时,Y 的平均变化量的估计值。 系数>0 a >0表示直线与纵轴的交点在原点的上方 b >0,表示直线从左下方走向右上方,即Y 随X 增大而增大 系数<0 a <0表示直线与纵轴的交点在原点的下方 b <0,表示直线从左上方走向右下方,即Y 随X 增大而减小 系数=0 a =0表示回归直线通过原点 b =0,表示直线与X 轴平行,即Y 不随X 的变化而变化 计算公式 X b Y a -= XX XY l l X X Y Y X X b =---= ∑∑2 )())(( 2. 样本回归系数b 的假设检验 (1)方差分析; (2)t 检验。
第十章_logit回归
第十章 logitic 回归 本章导读: Logitic 回归模型是离散选择模型之一,属于多重变数分析范畴,是社会学、生物统计学、临床、数量心理学、市场营销、会计与财务等实证分析的常用方法。 10.1 logit 模型和原理 Logistic 回归分析是对因变量为定性变量的回归分析。它是一种非线性模型。其基本特点是:因变量必须是二分类变量,若令因变量为y ,则常用y=1表示“yes ”,y=0表示“no ”。 [在发放股利与不发放股利的研究中,分别表示发放和不发放股利的公司]。自变量可以为虚拟变量也可以为连续变量。从模型的角度出发,不妨把事件发生的情况定义为y=1,事件未发生的情况定义为0,这样取值为0、1的因变量可以写作: ???===事情未发生 事情发生01y 我们可以采用多种方法对取值为0、1的因变量进行分析。通常以P 表示事件发生的概率(事件未发生的概率为1-P ),并把P 看作自变量x 的线性函数。由于y 是0-1型Bernoulli 分布,因此有如下分布: P=P (y=1|x ):自变量为x 时y=1的概率,即发放现金股利公司的概率 1-P=P (y=0|x ):自变量为x 时y=0的概率,即不发放现金股利公司的概率 事件发生和不发生的概率比成为发生比,即相对风险,表现为P P odds -= 1.因为是以 对数形式出现的,故该发生比为对数发生比(log odds ),表现为)1ln(P P odds -=。对数发生比也是事件发生概率P 的一个特定函数,通过logistic 转换,该函数可以写成logistic 回归的logit 模型: )1(log )(log P P P it e -= Logit 一方面表达出它是事件发生概率P 的转换单位;另一方面,它作为回归的因变量就可以自己与自变量之间的依存关系保持传统回归模式。 根据离散型随即变量期望值的定义,可得: E(y)=1(P)+0(1-P)=P 进而得到x P y E 10)(ββ+== 因此,从以上分析可以看出,当因变量的取值为0、1时,均值x y E 10)(ββ+=总是代表给定自变量时y=1的概率。虽然这是从简单线性回归分析而得,但也适合复杂的多元回归函数情况。 k k x x x itP y E ββββ++++==Λ22110log )( β0为常数项,β1,β2,…,βk 分别为k 个自变量的回归系数。 因此,logistic 模型为:
管理决策-决策分析
管理决策
无概率决策问题 无概率决策问题(不确定型决策问题),这类决策问题的特点是:决策人面临多种决策方案,对每个决策方案对应的几个不同决策状态无法估计其出现概率的大小,仅凭个人的主观倾向和偏好进行方案选择。
无概率决策问题——基本问题 例某公司打算生产一种新产品。该厂考虑了三种方案: (1)新建一条生产线(A1); (2)改造原有的生产线(A2); (3)从市场上采购部分零件进行组装(A3)。 产品投放市场后,可能有需求量较高(N1)、需求量一般(N2)和需求量较低(N3)三种状态。由于缺乏信息,无法对状态的概率作出估计,但可以估计出各方案的年收益,收益值如表所示。 但由于缺乏资料,无法估计状态发生的概率,所以这是一个典型的无概率决策问题。这类问题的决策主要取决于决策者的经验和素质。
无概率决策问题——决策的基本准则 典型的无概率决策准则主要包括乐观准则、悲观准则、折中准则、等可能准则和最小后悔值准则。 这些决策准则有时会产生相同的决策,但通常会产生不同的决策。决策者必须选择最适合自己需要的决策准则或决策准则组合。 为描述方便,作如下假定: 假设无概率决策问题的备选方案集为A={A1,A2, …, Am},自然状 态集为N={N1, N2, …, Nn},方案A i 在状态N j 下的收益值为b ij 。
无概率决策问题——决策的基本准则 乐观准则 特点:决策者在情况不明时,对自然状态抱最乐观的态度,从最好的自然状态出发,先从各方案中挑选最大收益值,然后再从这些最大收益值中挑选出最优决策方案。 公式 则Al 是乐观准则下的最优决策方案。 乐观准则是一种比较冒险的决策方法,实际中很少采用。 … …
第十章战略管理会计
第十三章战略管理会计 第一节现代企业面临的挑战与传统管理会计的局限 一、现代企业面临的挑战 现代企业正处于一个错综复杂、瞬息万变的外部环境之中。 (一)市场全球化使企业面对更激烈的竞争 随着近年来自由贸易的发展和企业经营的国际化,企业间的竞争日趋激烈。企业要在激烈的竞争中生存,不仅要保持住现有顾客,还要不断发展新的顾客群体,企业面临的市场已从过去的已知顾客群转向包括潜在顾客在内的多样化的顾客群体。为满足多样化顾客的不同需求,企业的生产组织必须从传统的、以追求规模经济为目标的大批量生产方式转变为能对顾客不同需求迅速作出反应的“顾客化生产”。所谓“顾客化生产”就是以顾客为中心,以顾客的满意程度作为产品质量的判别依据,在对顾客需要进行动态掌握的基础上,尽可能按照顾客的要求,在较短的时间内完成从产品设计、制造到投放市场的全过程。而要使企业能对顾客的特定需求经常保持快速反应的能力,其生产组织必须具有高度的灵活性,能灵活地变化生产线,在不追加或追加有限成本的条件下,生产出更多样化的产品,这就要求企业的内部组织从产品设计、制造,到销售各环节高度灵活,共同协作。只有这样,企业才能发挥整体优势,在激烈的全球市场竞争中立于不败之地。 (二)科学技术的迅猛发展给企业提出丁新的机遇和挑战 本世纪70年代,第三次技术革命在电子技术革命的基础上形成了生产高度电脑化、自动化。电子数控机床和机器人、电脑辅助设计、电脑辅助工程、电脑辅助制造的广泛应用,以及电脑一体化制造系统的形成和应用,从产品订货,到设计、制造、销售等阶段,把所使用的各种自动化系统综合成一个整体,由电脑中心统—进行调控。这种高度的电脑化、自动化,可以协助设计人员取得新产品的功能、形状、成本构成的最佳组合。在实际投产以前,利用计算机模拟生产,从而实现新产品技术先进性和经济可行性的统一,这不仅为企业进行灵活多样的“顾客化生产”提供了技术上的可能,而且提高了劳动生产率和产品的市场竞争力。 二、传统管理会计的局限 (一)成本计算 传统管理会计以成本性态作为研究的起点,按照成本与产量的关系把成本划分为固定成本和变动成本,并推崇变动成本法,认为产品成本只包括变动成本(即直接材料、直接人工和变动性制造费用),而固定成本(包括固定性制造费用)作为期间费用不计入产品成本。在使用传统的生产技术进行生产,以追求“规模经济”为目标的大批量生产方式下,由于直接材料和直接人工成本在产品成本中所占比重较大,且直接材料和直接人工的消耗 一般与产量有较为密切的关系,这种成本计算方法可使利润的实现建立在产品销售实现的基础上,具有较大的现实性。 然而,现代企业生产是建立在高度自动化基础上的技术密集型生产技术含量越高,制造费用所占比重越大,而制造费用的发生在“顾客化生产”方式下是由多因素驱动,与产
第十章 凯恩斯模型 答案
第十章凯恩斯模型 宏观经济学的核心问题是研究什么因素决定一国的国民收入水平。凯恩斯对古典宏观经济模型的前提和内容做了全面的批判,开创了现代宏观经济学的新篇章。国民收入决定理论所要研究的问题是收入与产出之间相互作用的关系;IS一LM模型将产品市场货币市场联系起来,考察两个市场相互作用的情况,IS一LM模型是短期宏观经济学的核心,是宏观经济分析的基本工具。 本章重点: (1)消费函数和储蓄函数以及二者的关系 (2)投资、乘数和加速数 (3)二、三、四部门均衡国民收入的决定 (4)IS一LM模型 习题 1、名词解释 萨伊定律、边际消费倾向、边际储蓄倾向、乘数效应、投资乘数、资本边际效率、投资边际效率、加速原理、摩擦失业、非自愿失业、IS曲线、LM曲线、 2、单项选择题 (1)边际消费倾向与边际储蓄倾向之和等于( D ) A.大于1的正数B.小于1的正数C.零D.等于1 (2)平均消费倾向与平均储蓄倾向之和等于( D )。 A.大于1的正数B.小于1的正数C.零D.等于1 (3)根据消费函数,引起消费增加的因素是( B )。 A.价格水平下降B.收入增加C.储蓄增加D.利率提高。 (4)消费函数的斜率取决于(A ) A.边际消费倾向B.与可支配收入无关的消费的总量 C.平均消费倾向D.由于收入变化而引起的投资总量 (5)如果与可支配收入无关的消费为300亿元,投资为400亿元,边际储蓄倾向为0.1,那么,在两部门经济中,均衡收入水平为( D )。(300+400)*(1/0.1)=7000 A.770亿元B.4300亿元C.3400亿元D.7000亿元。 (6)以下四种情况中,投资乘数最大的是( A )。 A.边际消费倾向为0.6B.边际消费倾向为0.1 C.边际消费倾向为0.4D.边际消费倾向为0.3 (7)如果投资增加150亿元,边际消费倾向为0.8,那么收入水平将增加( C )。150*[1/(1-0.8)]=750 A.150亿元B.600亿元C.750亿元D.450亿元 (8)已知某个经济充分就业的收入是4000亿元,实际均衡收入是3800亿元。假定边际储蓄倾向为25%,增加100亿元投资将使经济( C )。100*(1/0.25)=400, 400-(4000-3800)=200 A.达到充分就业的均衡B.出现50亿元的通货膨胀缺口 C.出现200亿元的通货膨胀缺口D.出现50亿元的紧缩缺口 (9)消费者储蓄增加而消费支出减少则( C)。 A.储蓄上升,但GDP下降B.储蓄保持不变,GDP下降
第10章相关分析与回归分析
第八章相关与回归分析 一、本章重点 1.相关系数的概念及相关系数的种类。事物之间的依存关系,可以分为函数关系和相关关系。相关关系又有单向因果关系和互为因果关系;单相关和复相关;线性相关和非线性相关;不相关、不完全相关和完全相关;正相关和负相关等类型。 2.相关分析,着重掌握如何画相关表、相关图,如何测定相关系数、测定系数以及进行相关系数的推断。相关表和相关图是变量间相关关系的生动表示,对于未分组资料和分组资料计算相关系数的方法是不同的,一元线性回归中相关系数和测定系数有着密切的关系,得到样本相关系数后还要对总体相关系数进行科学推断。 3.回归分析,着重掌握一元回归的基本原理方法,一元回归是线性回归的基础,多元线性回归和非线性回归都是以此为基础的。用最小平方法估计回归参数,回归参数的性质和显著性检验,随机项方差的估计,回归方程的显著性检验,利用回归方程进行预测是回归分析的主要内容。 4.应用相关与回归分析应注意的问题。相关与回归分析都有它们的应用范围,必须知道在什么情况下能用,什么情况下不能用。相关分析和回归分析必须以定性分析为前提,否则可能会闹出笑话,在进行预测时选取的样本要尽量分散,以减少预测误差,在进行预测时只有在现有条件不变的情况下才能进行,如果条件发生了变化,原来的方程也就失去了效用。 二、难点释疑 本章难点在于计算公式多,不容易记忆,所以更要注重计算的练习。为了掌握基本计算的内容,起码应认真理解书上的例题,做完本指导书上的全部计算题。初学者可能会感到本章公式多且复杂,难于记忆,其实只要抓住Lxx、Lxy、Lyy 这三个记号,记住它们的展开式,几个主要的公式就不难记忆了。如果能自己把这些公式推证一下,搞清其关系,那就更容易记住了。 三、练习题 (一)填空题 1事物之间的依存关系,根据其相互依存和制约的程度不同,可以分为()和()两种。 2.相关关系按相关关系的情况可分为()和();按自变量的多少分()和();按相关的表现形式分()和();按相关关系的
第10章 聚类分析
第十章聚类分析 教学目的:掌握快速聚类和层次聚类的操作,了解各种距离,掌握其结果的阅读。 教学重点:重点考察K-means cluster、hierarchial cluster过程 教学时数:讲授2学时,操作2学时 教学方法:讲授与演示结合 聚类分析(Cluster Analysis)是研究将个体或变量进行分类的一种多元统计方法。是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。 属于一种探索性分析,不同研究者对于同一组数据进行聚类分析,由于所使用的方法不同,常会得出不同的结论。 聚类分析方法根据统计方法的不同分为层次聚类和快速聚类 根据分类对象的不同分为两类:一类是对样本所作的分类,即Q-型聚类,一类是对变量所作的分类,即R-型聚类。聚类分析的基本思想是,据已知数据,计算各观察个体或变量之间亲疏关系的统计量(距离或相关系数)。根据某种准则(最短距离法、最长距离法、中间距离法),使同一类内的差别较小,而类与类之间的差别较大,最终将观察个体或变量分为若干类。分类过程是一个逐步减少类别的过程,在每一个聚类层次,必须满足“类内差异小,类间差异大”原则,直至归为一类。 例: 不同地区城镇居民收入和消费状况的分类研究 区域经济及社会发展水平的分析及全国区域经济综合评价 在儿童生长发育研究中,把以形态学为主的指标归于一类,以机能为主的指标归于另一类 研究样品间的关系常用距离,研究指标间的关系常用相似系数。 1、距离 (1)欧式(Euclidian )距离 假使每个样品有p个变量,则每个样品都可以看成p维空间中的一个点,n个样品就是p维空间中的n 个点,则第i样品与第j样品之间的距离记为dij (2)欧式距离平方(系统默认) 2、相似系数 相似系数常用的有:夹角余弦与相关系数 3、类间距离 最近距离、最远距离、类间平均法等 10.1 层次聚类分析(系统聚类) 10.1.1基本概念与方法 其原理是将n个变量(观察量)看成不同的n类,然后将性质最接近的两类合并为一类,再从这n-1类中找到最接近的两类加以合并,依此类推,直到所有的变量(观察量)被合为一类。得到该结果后,使用者再根据具体的问题和聚类结果来决定应当分为几类。 其优点:可以对变量进行聚类(R型聚类),也可对观察量进行聚类(Q型聚类);变量可以是连续性变量,也可是分类变量。计算距离的方法也较丰富。 其缺点:需反复计算距离,观察量太大或变量较多时,速度较慢。 10.1.2实例1 一、例题与数据E10-1a.sav(将北京地区18区县按中等职业教育发展水平的9个指标进行聚类,)
(决策管理)决策分析内容
决策理论和方法(章节目录) Decision Theory and Technology 引言 第一章决策的基本概念 §1-1引论 一、决策与决策分析的定义 1. Decision的本义:(牛津词典) 2.苏联大百科全书 3.<现代科学技术辞典> 4. <美国大百科全书>的“Decision Theory”条: 5.美国现代经济词典 6.哈佛管理丛书: 7.决策的政治含义 二、发展简史 三、地位(与其他学科的关系) 1.是运筹学的一支 2. 控制论的延伸 3.管理科学的重要组成部分 4.系统工程中的重要部分 5.是社会科学与自然科学的交叉,典型的软科学 §1-2决策问题的基本特点与要素 一、特点 二、要素 §1-3决策问题的分类 一、按容易区分的因素划分 二、按涉及面的宽窄 三、个人事务决策与公务决策 §1-4 决策人与决策分析人 一、问题的复杂性: 二、微观经济学和决策论关于经济人的假定: 三、决策人和决策分析人的分工 §1-5 分析方法和步骤
一、决策树与抽奖 二、分析步骤 习题 进一步阅读的文献 第二章主观概率和先验分布 Subjective Probability and Prior Distribution §2-1 基本概念 一、概率(probability) . 频率Laplace在《概率的理论分析》(1812)中的定公理化定义 二、主观概率(subjective probability, likelihood) 1. 为什么引入主观概率 2.主观概率定义 三、概率的数学定义 四、主客观概率的比较 §2-2 先验分布(Prior distribution)及其设定 一、设定先验分布时的几点假设 二、离散型随机变量先验分布的设定 三、连续型RV的先验分布的设定 1.直方图法 2.相对似然率法 3.区间对分法 4.与给定形式的分布函数相匹配 5. 概率盘法(dart) §2-3 无信息先验分布 一、为什么要研究无信息先验 二、如何设定无信息先验分布 §2.4 利用过去的数据设定先验分布 一、有θ的统计数据 二、状态θ不能直接观察时 习题 进一步阅读的文献
第10章 聚类分析
第 10 章 聚类分析 “物以类聚,人以群分”。对事物进行分类,是人们认识事物的出发点,也是人们认识世界的一种重要方法。因此,分类学已成为人们认识世界的一门基础科学。 在生物、经济、社会、人口等领域的研究中,存在着大量量化分类研究。例如:在生物学中,为了研究生物的演变,生物学家需要根据各种生物不同的特征对生物进行分类。在经济研究中,为了研究不同地区城镇居民生活中的收入和消费情况,往往需要划分不同的类型去研究。在地质学中,为了研究矿物勘探,需要根据各种矿石的化学和物理性质和所含化学成分把它们归于不同的矿石类。在人口学研究中,需要构造人口生育分类模式、人口死亡分类状况,以此来研究人口的生育和死亡规律。但历史上这些分类方法多半是人们主要依靠经验作定性分类,致使许多分类带有主观性和任意性,不能很好地揭示客观事物内在的本质差别与联系;特别是对于多因素、多指标的分类问题,定性分类的准确性不好把握。为了克服定性分类存在的不足,人们把数学方法引入分类中,形成了数值分类学。后来随着多元统计分析的发展,从数值分类学中逐渐分离出了聚类分析方法。随着计算机技术的不断发展,利用数学方法研究分类不仅非常必要而且完全可能,因此近年来,聚类分析的理论和应用得到了迅速的发展。 聚类分析就是分析如何对样品(或变量)进行量化分类的问题。根据聚类对象的不同,聚类分析分为Q 型聚类和R 型聚类。Q 型聚类是对样品进行分类处理,R 型聚类是对变量进行分类处理。根据聚类方法的不同,聚类分析又可以分为系统聚类法、K -均值聚类法、有序样品聚类法、模糊聚类法等。本书将仅针对系统聚类法和K -均值聚类法进行介绍。 10.1 系统聚类法的理论与方法 10.1.1 系统聚类的基本思想 系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。系统聚类过程是:假设总共有个样品(或变量),第一步将每个样品(或变量)独自聚成一类,共有类;第二步根据所确定的样品(或变量)“距离”公式,把距离较近的两个样品(或变量)聚合为一类,其它的样品(或变量)仍各自聚为一类,这样,形成1n n n ?类;第三步1? 个类中“距离”最近的两个类进一步聚成一类,这样,形2n 将n 成?类;……。 以上步骤一直进行下去,最后将所有的样品(或变量)全聚成一类。为了直观地反映以上的系统聚类过程,可以把整个分类系统画成一张谱系图,所以,系统聚类有时也称为谱系分析。 10.1.2 个体之间距离的度量方法 进行聚类分析首先要建立在各个样品(或变量)之间“距离”的精确度量的基础之上。根据变量类型的不同,“距离”的度量方式也不相同,下面分别叙述: 1. 针对连续变量的距离测度 欧氏距离(Euclidean distance ): 两个体p 个变量值之差平方和的平方根
第十章 多元线性回归与曲线拟合
第十章多元线性回归与曲线拟合―― Regression菜单详解(上) 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。 §10.1Linear过程 10.1.1 简单操作入门 调用此过程可完成二元或多元的线性回归分析。在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。 例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响? 显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。 回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。 这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。 10.1.1.1 界面详解 在菜单中选择Regression==>liner,系统弹出线性回归对话框如下:
除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。 【Dependent框】 用于选入回归分析的应变量。 【Block按钮组】 由Previous和Next两个按钮组成,用于将下面Independent框中选入的自变量分组。由于多元回归分析中自变量的选入方式有前进、后退、逐步等方法,如果对不同的自变量选入的方法不同,则用该按钮组将自变量分组选入即可。下面的例子会讲解其用法。 【Independent框】 用于选入回归分析的自变量。 【Method下拉列表】 用于选择对自变量的选入方法,有Enter(强行进入法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)五种。该选项对当前Independent框中的所有变量均有效。
第11章 决策分析
第11章决策分析 一、选择 1. 在实际中,要求完美信息价值(EVPI)( C )调查预测费用才有实际经济价值。 A 小于 B 等于 C 大于 D 无关 2.完整的决策过程:一是确定目标,二是收集信息,三是提出方案,四是( A ),五是实 施。 A 方案选优 B 分析决策 C 决策环境调查 D 检查 3. 乐观主义决策准则又称为(B ) A max min决策准则 B max max决策准则 C min max决策准则 D Laplace决策准则 4. 决策按问题的性质和条件,可分为四种,下面不属于该类的决策是(D ) A、确定型 B、不确定型 C风险型 D、战略决策 5.乐观主义决策准则又称为(B ) A、max min决策准则 B、max max决策准则 C、min max决策准则 D、Laplace决策准则 6.决策的五要素:决策者,可供选择的方案,客观环境,可测知方案的结果,(C ) A 决策目标 B信息收集 C 衡量结果的评价标准 D 预测 7. 悲观主义决策准则又称为(a ) A、max min决策准则 B、max max决策准则 C、min max决策准则 D、Laplace决策准则 8. 最大收益期望值(EMV)决策准则中各事件的发生概率是( B ) A不可估算的 B 是可以估算的 C是相等的概率 D 1 9.在决策树中,决策点用(A )表示。 A □ B ○ C △ D ◇ 10.在决策树中,事件点用(B )表示 A □ B ○ C △ D ◇ 二、填空 1.等可能性决策准则又称(拉普拉斯准则)。 2.决策按内容和层次,可分为(战略决策)和(战术决策)。 3.决策按重复程度,可分为(程序决策)和(非程序决策) 4.决策按问题性质和条件,可分为(确定型)、(不确定型)、(风险型)和(竞争型决策)。 5.决策按时间可划分为(长期决策)、(中期决策)和(短期决策)。 6.决策按达到的目标分(单目标决策)、(多目标决策) 7.决策按阶段分为(单阶段决策)和(多阶段决策) 8.决策按决策人参与情况分为(个人决策)和(群体决策)。
第十章-一元线性回归说课材料
第十一章 一元线性回归 一、填空题 1、对回归系数的显著性检验,通常采用的是 检验。 2、若回归方程的判定系数R 2=0.81,则两个变量x 与y 之间的相关系数r 为_________________。 3、若变量x 与y 之间的相关系数r=0.8,则回归方程的判定系数R 2为____________。 4、对于直线趋势方程bx a y c +=,已知 ∑=,0x ∑=130xy ,n=9,1692=∑x , a=b ,则趋势 方程中的b=______。 5、回归直线方程bx a y c +=中的参数b 是_____________。估计待定参数a 和 b 常用的方法是-_________________。 6、相关系数的取值范围_______________。 7、在回归分析中,描述因变量y 如何依赖于自变量x 和误差项的方程称为 。 8、在回归分析中,根据样本数据求出的方程称为 。 9、在回归模型εββ++=x y 10中的ε反映的是 。 10、在回归分析中,F 检验主要用来检验 。 11、说明回归方程拟合优度检验的统计量称为 。 二、单选题 1、年劳动生产率(x :千元)和工人工资(y :元)之间的回归方程为1070y x =+,这意味着年劳动生产率没提高1千元,工人工资平均( ) A 、 增加70元 B 、 减少70元 C 、增加80元 D 、 减少80元 2、两变量具有线形相关,其相关系数r=-0.9,则两变量之间( )。 A 、强相关 B 、弱相关 C 、不相关 D 、负的弱相关关系 3、变量的线性相关关系为0,表明两变量之间( )。 A 、完全相关 B 、无关系 C 、不完全相关 D 、不存在线性关系 4、相关关系与函数关系之间的联系体现在( )。 A 、相关关系普遍存在,函数关系是相关关系的特例 B 、函数关系普遍存在,相关关系是函数关系的特例 C 、相关关系与函数关系是两种完全独立的现象 D 、相关关系与函数关系没有区别 5、已知x 和y 两变量之间存在线形关系,且δx =10, δy =8, δxy 2=-7,n=100,则x 和y 存在着( )。 A 、显著正相关 B 、低度正相关 C 、显著负相关 D 、低度负相关 6、对某地区前5年粮食产量进行直线趋势估计为:80.5 5.5y t =+? 这5年的时间代码分别是:-2,-1,0,1,2,据此预测今年的粮食产量是( )。 A 、107 B 、102.5 C 、108 D 、113.5 7、两变量的线性相关关系为-1,表明两变量之间( )。 A 、完全相关 B 、无关系 C 、不完全相关 D 、不存在线性关系 8、已知x 和y 两变量之间存在线形关系,且δx =10, δy =8, δxy 2 =-7,n=100,则x 和y 存在着( )。 A 、显著正相关 B 、低度正相关 C 、显著负相关 D 、低度负相关
聚类分析
聚类分析(Cluster Analysis ) 一、简介 聚类分析也是一种分类技术。与多元分析的其他方法相比,该方法较为粗糙,理论上还不完善,但应用方面取得了很大成功。与回归分析、判别分析一起被称为多元分析的三大方法。 1. 聚类的目的 根据已知数据,计算各观察个体或变量之间亲疏关系的统计量(距离或相关系数)。根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最终将观察个体或变量分为若干类。 2. 聚类分析的应用例子 同一种疾病(如肝炎),根据临床表现等将病人分成若干类(甲、乙、丙、丁、戊型 肝炎) 根据疾病的若干临床表现,将病人分成轻、中、重三型 在儿童生长发育研究中,把以形态学为主的指标归于一类,以机能为主的指标归于 另一类 3. 聚类的种类 根据分类的原理可将聚类分析分为: ?系统聚类与快速聚类 根据分类的对象可将聚类分析分为: ?系统Q型与R型(即样品聚类clustering for individuals 与指标聚类clustering for variables) 4. 聚类分析数据格式 5. 判别分析数据格式
6. 聚类分析与判别分析间的联系 先采用聚类分析获得各个个体的类别(classification );然后采用判别分析建立判别函数,对新个体进行类型识别((identification ) 二、图示法聚类分析 1. 散点图(Scatter diagrams) 2. 轮廓图(Profile diagram)
三、距离与相似系数 (一)距离 假使每个样品有p个变量,则每个样品都可以看成p维空间中的一个点,n个样品就是p维空间中的n个点,则第i样品与第j样品之间的距离记为dij 1. 欧式(Euclidian )距离 1.1 二维空间欧式距离 1.2 欧式距离的平方 2. 明氏(Minkowski )距离
第7讲 决策分析
第7讲决策分析 §1 决策分析的基本问题 一、概述 决策是人们在政、经、技等中一种选择方案的行为.赫伯特.亚历山大.西蒙(1978年度的诺贝尔经济学奖)名言: 管理就是决策. 管理的核心就是决策, 决策的失误是最大的失误. 研究内容: 决策的基本原理, 信息, 方法, 风险等.
涉及方面: 社会学, 心理学, 行为学, 行政学等. 研究分支: 单目标决策、多目标决策, 群决策等. 【 1.决策的分类 (1) 按决策的长远性分类 战略决策,战术决策 i) 战略决策: 全局性, 长远的, 如选择厂址, 确定新产品, 新市场, 选择原料地等ii) 战术决策: 中短期的,如企业产品规格的选择, 工艺方案等注: 划分是相对的. (2) 按决策环境分类
确定型决策: 环境条件确定, 决策结果明确; 风险型决策: 环境有随机因素, 但发生概率已知; 不确定型决策:随机因素的发生概率未知,主观决策. (3) 按定量和定性分类 , i) 定量决策: 依照数据指标决策; ii) 定性决策: 按照全局性的指标决策. (4) 按决策过程的阶段性分类 单项决策:整个决策过程只作一个决策就得到结果.序贯决策: 一系列的决策组成. (5) 按重复度分类
i) 程序决策: 有章可循, 可重复. ii) 非程序决策: 主要凭经验直觉, 一次性的特点. 2.决策原则 ) 信息原则,预测原则,可行性原则,系统原则,反馈原则
另外也可分为如单目标和多目标决策; 3. 决策的程序 (1) 形成决策问题; (2) 对各方案出现不同结果的可能性进行判断; (3) 利用各方案结果的度量值, 给出一个倾向性; (4) 综合, 给出决策, (有时作一个灵敏度分析) ? 4. 决策模型要素 (1) 决策者, 主要是责任人, 领导们; (2) 可供选择的方案(替代方案), 行动或策略;
管理学课后练习第十章知识分享
三、名词解释 1.管理幅度 2.变量依据法 3.直线职权 4.越级授权 四、简述题 1.组织结构设计程序的主要步骤 2.管理层次与管理幅度的关系 3.简述影响分权程度的因素 4.简述划分部门的常用方法 五、论述题 1.试述职权的类型及其相互关系 2.授权应遵循的原则 三、名词解释 1.管理幅度 管理幅度是指一名主管人员有效地管理直接下属的人数。 2.变量依据法
变量依据法是美国洛克希德导弹与航空公司研究出的一种方法。该方法是通过找出影响中层管理人员管理宽度的六个关键变量,把这些变量按困难程度排成五级,并加权使之反映重要程度,最后加以修正,提出建议的管辖人数标准值。 3.直线职权 直线职权是一种完整的职权,拥有直线职权的人有权作出决策,有权进行指挥,有权发布命令。 4.越级授权 越级授权是上层领导者把本来属于中间领导层的权力直接授予下级。 四、简述题 1. 组织结构的设计程序一般包括以下几个步骤: ⑴确定组织目标。组织目标是进行组织设计的基本出发点。任何组织都是实现其一定目标的工具,没有明确的目标,组织就失去了存在的意义。因此,管理组织设计的第一步,就是要在综合分析组织外部环境和内部条件的基础上,合理确定组织的总目标及各种具体的派生目标。
⑵确定业务内容。根据组织目标的要求,确定为实现组织目标所必须进行的业务管理工作项目,并按其性质适当分类,如市场研究、经营决策、产品开发、质量管理、营销管理、劳动人事等。明确各类活动的范围和大概工作量,进行业务流程的总体设计,使总体业务流程优化。 ⑶确定组织结构。根据组织规模、生产技术特点、地域分布、市场环境、职工素质及各类管理业务工作量的大小,参考同类其他组织设计的经验和教训,确定应采取什么样的管理组织形式,需要设计哪些单位和部门,并把性质相同或相近的管理业务工作分归适当的单位和部门负责,形成层次化、部门化的结构。 ⑷配备职务人员。根据各单位和部门所分管的业务工作的性质和对职务人员素质的要求,挑选和配备称职的职务人员及其行政负责人,并明确其职务和职称。 ⑸规定职责权限。根据组织目标的要求,明确规定各单位和部门及其负责人对管理业务工作应负的责任以及评价工作成绩的标准。同时,还要根据搞好业务工作的实际需要,授予各单位和部门及其负责人以相应的职权。 ⑹联成一体。这是组织设计的最后一步,即通过明确规定各单位、各部门之间的相互关系,以及它们之间在信