基因BLAST及系统进化树构建操作步骤
基因BLAST及发育树构建操作步骤
整理--周志勤
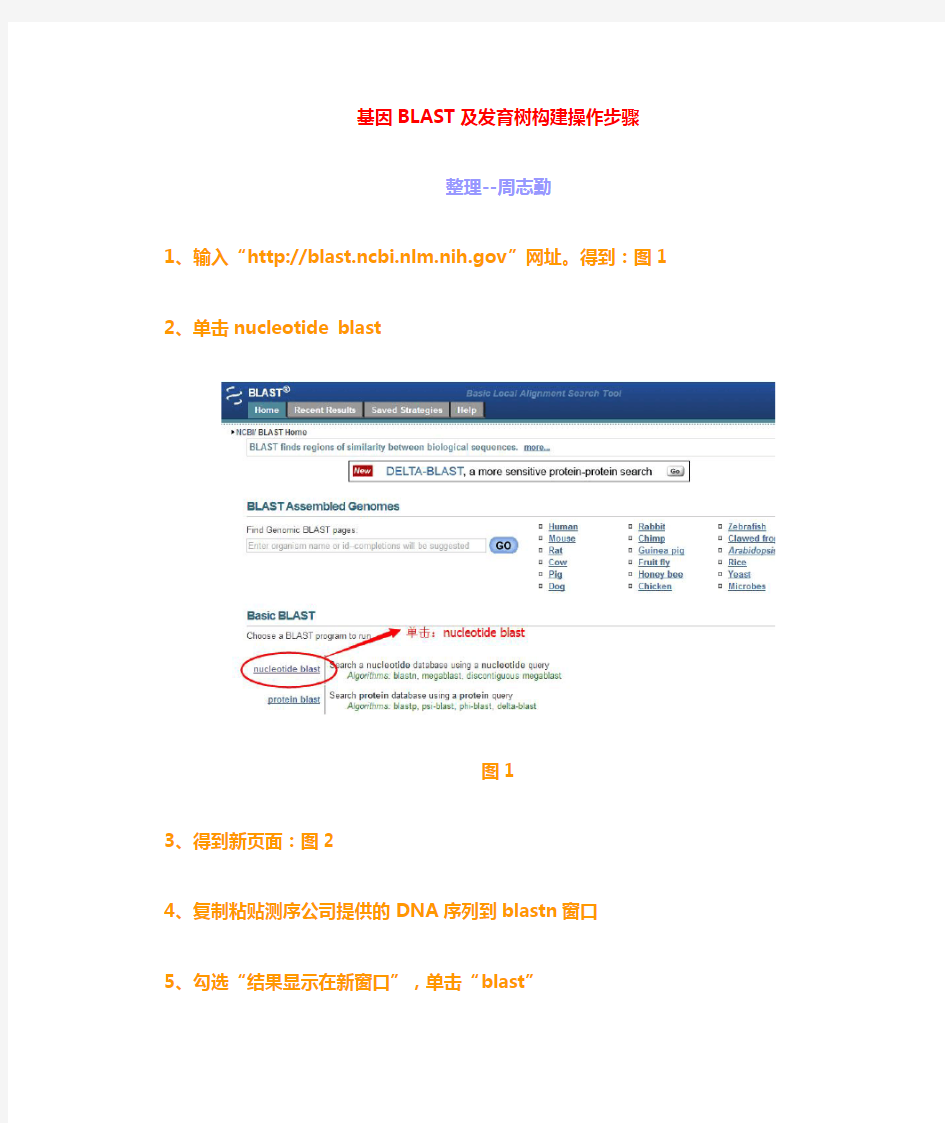
1、输入“https://www.360docs.net/doc/5611192912.html,”网址。得到:图1
2、单击nucleotide blast
图1
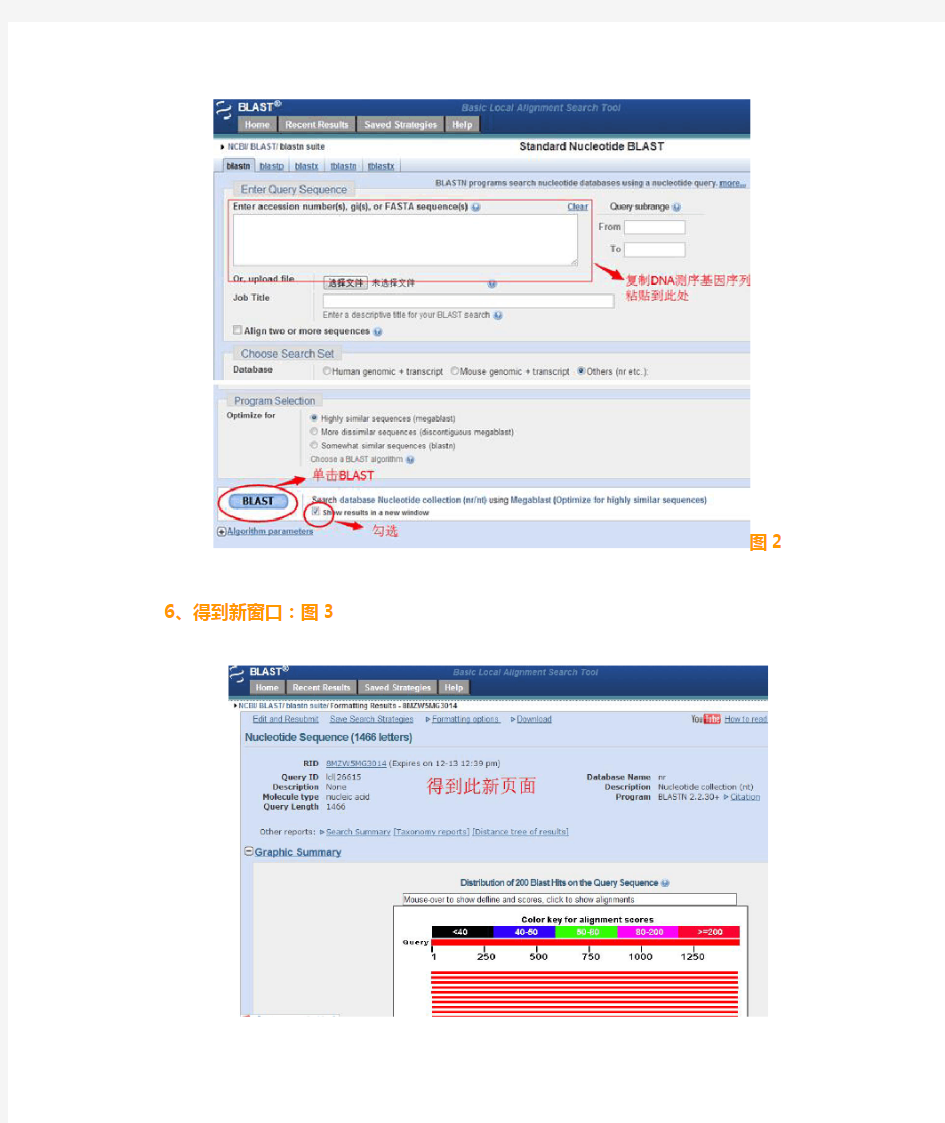
3、得到新页面:图2
4、复制粘贴测序公司提供的DNA序列到blastn窗口
5、勾选“结果显示在新窗口”,单击“blast”
图2 6、得到新窗口:图3
图3
7、下拉页面,如:图4
8、选择Accession下的基因编码。入选第一个“HQ711983.1”
图4
9、得到新窗口如:图5
10、单击FASTA
图5
11、得到如:图6
12、复制菌株种名跟16SrDNA序列,并粘贴到“.txt”文件中
图6
13、新建“.txt”文件,如:图7
14、把测序菌株16SrDNA序列和选取blast所得的匹配度高的菌株16SrDNA序列粘贴在“.txt”文件下,在菌株种名前
加“>”,每个序列后空一行
图7
15、复制“.txt”文件,改“.txt”文件为“.fasta”文件,如:图8
图8
16、用MEGA 4.0.2软件打开“.fasta”文件,如:图9
图9
17、单击Alignment里的Alinment Explorel/CLUSAC,如:
图10
图10
18、单击Alignment里的Align by clustalW,如:图11
图11
19、在弹出窗口中单击OK,如:图12
图12
19、在弹出窗口中单击OK,如:图13
图13
20、等待数据运算,如:图14
图14
21、运算结束,关闭当前窗口。如:图15
22、在弹出的第一个窗口单击NO
图15
23、在弹出的第一个窗口单击YES,如:图16
图16
24、将文件以“.meg”格式保存,如:图17
图17
25、关闭其余窗口,打开刚刚保存的“.meg”文件,如:图18
图18
26、选择phyloeny下的Bootsteap Test of phylogeng下的Neighbor-Joining...,如:图19
图19
27、在弹出窗口单击Compulte,如:图20
图20
28、单击树状图,得到系统发育树,建议截图保存,如:图21
图21
构建系统发育树需要注意的几个问题
构建系统发育树需要注意的几个问题 1 相似与同源的区别:只有当序列是从一个祖先进化分歧而来时,它们才是同源的。 2 序列和片段可能会彼此相似,但是有些相似却不是因为进化关系或者生物学功能相近的缘故,序列组成特异或者含有片段重复也许是最明显的例子;再就是非特异性序列相似。 3 系统发育树法:物种间的相似性和差异性可以被用来推断进化关系。 4 自然界中的分类系统是武断的,也就是说,没有一个标准的差异衡量方法来定义种、属、科或者目。 5 枝长可以用来表示类间的真实进化距离。 6 重要的是理解系统发育分析中的计算能力的限制。任何构树的实验目的基本上就是从许多不正确的树中挑选正确的树。 7 没有一种方法能够保证一颗系统发育树一定代表了真实进化途径。然而,有些方法可以检测系统发育树检测的可靠性。第一,如果用不同方法构建树能得到同样的结果,这可以很好的证明该树是可信的;第二,数据可以被重新取样(bootstrap),来检测他们统计上的重要性。 分子进化研究的基本方法 对于进化研究,主要通过构建系统发育过程有助于通过物种间隐含的种系关系揭示进化动力的实质。 表型的(phenetic)和遗传的(cladistic)数据有着明显差异。Sneath和Sokal(1973)将表型性关系定义为根据物体一组表型性状所获得的相似性,而遗传性关系含有祖先的信息,因而可用于研究进化的途径。这两种关系可用于系统进化树(phylogenetictree)或树状图(dendrogram)来表示。表型分枝图(phenogram)和进化分枝图(cladogram)两个术语已用于表示分别根据表型性的和遗传性的关系所建立的关系树。进化分枝图可以显示事件或类群间的进化时间,而表型分枝图则不需要时间概念。文献中,更多地是使用“系统进化树”一词来表示进化的途径,另外还有系统发育树、物种树(species tree)、基因树等等一些相同或含义略有差异的名称。 系统进化树分有根(rooted)和无根(unrooted)树。有根树反映了树上物种或基
如何做系统进化树
大家好: 我在此介绍几个进化树分析及其相关软件的使用和应用范围。这几个软件分别是PHYLIP、PUZZLE、PAUP、TREEVIEW、CLUSTALX和PHYLO-WIN (LINUX)。 在介绍软件之前,我先简要地叙述一下有关进化树分析的一些方法学问题。进化树也称种系树,英文名叫“Phyligenetic tree”。对于一个完整的进化树分析需要以下几个步骤:⑴要对所分析的多序列目标进行排列(To align sequences)。做ALIGNMENT的软件很多,最经常使用的有CLUSTALX和CLUSTALW,前者是在WINDOW下的而后者是在DOS下的。⑵要构建一个进化树(To reconstrut phyligenetic tree)。构建进化树的算法主要分为两类:独立元素法(discrete character methods)和距离依靠法(distance methods)。所谓独立元素法是指进化树的拓扑形状是由序列上的每个碱基/氨基酸的状态决定的(例如:一个序列上可能包含很多的酶切位点,而每个酶切位点的存在与否是由几个碱基的状态决定的,也就是说一个序列碱基的状态决定着它的酶切位点状态,当多个序列进行进化树分析时,进化树的拓扑形状也就由这些碱基的状态决定了)。而距离依靠法是指进化树的拓扑形状由两两序列的进化距离决定的。进化树枝条的长度代表着进化距离。独立元素法包括最大简约性法(Maximum Parsimony methods)和最大可能性法(Maximum Likelihood methods);距离依靠法包括除权配对法(UPGMAM)和邻位相连法(Neighbor-joining)。⑶对进化树进行评估。主要采用Bootstraping法。进化树的构建是一个统计学问题。我们所构建出来的进化树只是对真实的进化关系的评估或者模拟。如果我们采用了一个适当的方法,那么所构建的进化树就会接近真实的“进化树”。模拟的进化树需要一种数学方法来对其进行评估。不同的算法有不同的适用目标。一般来说,最大简约性法适用于符合以下条件的多序列:i 所要比较的序列的碱基差别小,ii 对于序列上的每一个碱基有近似相等的变异率,iii 没有过多的颠换/转换的倾向,iv 所检验的序列的碱基数目较多(大于几千个碱基);用最大可能性法分析序列则不需以上的诸多条件,但是此种方法计算极其耗时。如果分析的序列较多,有可能要花上几天的时间才能计算完毕。UPGMAM(Unweighted pair group method with arithmetic mean)假设在进化过程中所有核苷酸/氨基酸都有相同的变异率,也就
乳酸菌系统进化树
Lactobacillus.plantarum 204Lactobacillus.pentosus Lactobacillus.paraplantarum 575Lactobacillus.collinoides Lactobacillus.brevis Lactobacillus.farciminis Lactobacillus.alimentarius Lactobacillus.paralimentarius Lactobacillus.kimchii Lactobacillus.sanfranciscensis Lactobacillus.lindneri Lactobacillus.fructivorans Lactobacillus.hilgardii Lactobacillus.parakefiri Lactobacillus.buchneri Lactobacillus.parabuchneri Lactobacillus.kefiri Lactobacillus.kunkeei P.selangorensis Lactobacillus.perolens Lactobacillus.algidus Lactobacillus.mali Lactobacillus.nagelii Lactobacillus.murinus Lactobacillus.animalis Lactobacillus.ruminus Lactobacillus.equi Lactobacillus.agilis Lactobacillus.cypricasei Lactobacillus.acidipiscis Lactobacillus.salivarius Lactobacillus.salicinius Lactobacillus.aviarius Lactobacillus.araffinosus Lactobacillus.coryniformis Lactobacillus.bifermentans Lactobacillus.sakei Lactobacillus.curvatus Lactobacillus.sharpeae Lactobacillus.manihotivorans Lactobacillus.rhamnosus Lactobacillus.zeae Lactobacillus.casei Lactobacillus.panis Lactobacillus.frumenti Lactobacillus.oris Lactobacillus.vaginalis Lactobacillus.pontis Lactobacillus.reuteri Lactobacillus.colehominis Lactobacillus.mucosae Lactobacillus.fermentum Lactobacillus.amylophilus Lactobacillus.johnsonii Lactobacillus.gasseri Lactobacillus.iners Lactobacillus.jensenii Lactobacillus.fornicalis Lactobacillus.psittaci https://www.360docs.net/doc/5611192912.html,ctis Lactobacillus.delbrueckii Lactobacillus.bulgaricus Lactobacillus.acetotolerans Lactobacillus.hamsteri Lactobacillus.amylolyticus Lactobacillus.intestinalis Lactobacillus.gallinarum Lactobacillus.helveticus Lactobacillus.acidophilus Lactobacillus.crispatus Lactobacillus.amylovorus Lactobacillus.fructosus B.subtilis 99579999 99 704924 98 90 79 999999859996949999 9955 99 85746473999985 999445 404332 67 89 7599 998475999972 6599 5799 52 4798 92 97 91853836481621 59 49 3943 358829 37 12 16 0.01
基因工程的基本操作程序教案
一、教材分析 《基因工程的基本操作程序》是专题1《基因工程》的第二节,也是《基因工程》的核心,上承《DNA重组技术的基本工具》,下接《基因工程的应用》。本节课主要介绍了基因工程的基本操作程序的四个步骤,教学内容多,难点多,最好化整为零、各个击破。 二、教学目标 1.知识目标: 简述基因工程原理及基本操作程序。 2.能力目标: 尝试设计某一转基因生物的研制过程。 3.情感、态度和价值观目标: (1)关注基因工程的发展。 (2)认同基因工程的诞生和发展离不开理论研究和技术创新。 三、教学重点和难点 1、教学重点 基因工程基本操作程序的四个步骤。 2、教学难点 (1)从基因文库中获取目的基因 (2)利用PCR技术扩增目的基因 四、学情分析 本节课内容较多,难点较多,学生学习起来有一定困难,所以之前应该要求学生做好预习,尽量采用化整为零、各个击破的教学策略。 五、教学方法 1、学案导学:见学案。 2、新授课教学基本环节:预习检查、总结疑惑→情境导入、展示目标→合作探究、精讲点拨→反思总结、当堂检测→发导学案、布置预习 六、课前准备 1.学生的学习准备:预习《基因工程的基本操作程序》,初步把握基因工程原理及基本操作程序。 2.教师的教学准备:多媒体课件制作,课前预习学案,课内探究学案,课后延伸拓展学案。 七、课时安排:2课时 八、教学过程 (一)预习检查、总结疑惑 检查学生落实预习的情况并了解学生的疑惑,使教学具有针对性。 (二)情境导入、展示目标 教师首先提问: (1)什么是基因工程?(基因工程的概念) (2)DNA重组技术的基本工具有哪些?(限制酶、DNA连接酶、载体) (3)运载体需要具备哪些条件?(有一个或多个限制酶切割位点;有标记基因;能在受体细胞中稳定存在并自我复制或者整合到受体细胞染色体DNA上随染色体DNA的复制而同步复制) 上节课我们学习了DNA重组技术的基本工具,本节课我们将继续学习《基因工程》的核心内容——基因工程的基本操作程序。我们来看本节课的学习目标。(多媒体展示学习目标,强调重难点) (三)合作探究、精讲点拨
运用mega5构建系统发生进化树.
1.准备序列文件 准备fasta格式序列文件(fasta格式:大于号>后紧跟序列名,换行后是序列。举例如下)。每条序列可以单独为一个文件,也可以把所有序列放在同一文件内。 核酸序列: >sequence1_name CCTGGCTCAGGATGAACGCT 氨基酸序列: >sequence2_name MQSPINSFKKALAEGRTQIGF 2.多序列比对 打开MEGA 5,点击Align,选择Edit/Build Alignment,选择Create a new alignment,点击OK。
这时需要选择序列类型,核酸(DNA)或氨基酸(Protein)。 选择之后,在弹出的窗口中直接Ctrl + V粘贴序列(如果所有序列在同一个文件中,即可全选序列,复制)。也可以:点击Edit,选择Insert Sequence From File,选择序列文件(可多选)。
序列文件加载之后,呈蓝色背景(为选中状态)。点击按钮,选择Align DNA (如果是氨基酸序列,则会出现Align Protein)。弹出的窗口中设置比对参数,一般都是采用默认参数即可。点击OK,开始多序列比对。
比对完成后,呈现以下状态。 这时需要截齐两端含有---的序列:选中含有---的序列,按键Delete删除(注意:两端都需要截齐)。截齐之后,保存文件为:filename.mas
3.构建系统进化树 多序列比对窗口,点击Data,选择Phylogenetic Analysis,弹出窗口询问:所用序列是否编码蛋白质,根据实际情况选择Yes或No。此时,多序列比对文件就激活了,可以返回MEGA 5主界面建树了。
基因工程的基本过程
基因工程的基本过程 基因工程主要包括几个过程: 1、目的基因的制备; 2、选择合适的载体,将目的基因与载体相连接生成重组DNA分子; 3、将重组DNA片段导入受体; 4、选择目的基因; 5、目的基因的表达。 对于整个基因过程来讲,目的基因的获取是关键,它直接涉及到产物,而且还影响到产物的量。很多在基因操作过程中,目的基因是很难获得的,所以通常采取先生成基因文库的方法,然后从基因文库中筛选。如果目的基因的序列以及它的调控等信息很清楚,可以直接通过PCR或cDNA获取,这样就大大减少了选择目的基因的盲目性,可以将整个过程简化为以下步骤: 图10-3-8 基因工程过程
(1)目的基因的分离和制备 目的基因是指准备导入受体细胞内的,以研究或应用为目的所需要的外源基因称目的基因。获得目的基因的方法很多,但也是十分困难的一步。目前获得目的基因有4条途径: 1.从生物基因组群体中分离目的基因 原核生物基因组较小,基因容易定位,用限制性内切酶将基因组切成若干段后,用带有标记的核酸探针,从中选出目的基因。真核生物一般通过基因组文库的方法获得目的基因。 图10-3-1 限制性内切酶
限制性内切酶(restrictive enzyme)是20世纪60年代末在细菌中发现的,能水解DNA分子骨架的磷酸二酯键,使一个完整的DNA分子切成若干段,每一种限制酶,都有自己特定的作用位点,而且切口或切下来的序列,往往是回文结构(palindromes)。例如Eco RI把GAATTC在GA之间切开,形成粘性末端。也有一些限制酶作用的结果产生不含粘性末端的平整末端,如HapI。多在原核生物中存在,能识别4~6个特苷酸特定的碱基序列。限制酶对细菌有保护作用,某些入侵的噬菌体可因DNA链被限制性酶切断而不能在细菌中繁殖,“限制”因此而得名。限制酶不能切开细菌本身的DNA,这是因为细菌DNA的腺嘌呤和胞嘧啶甲基化(-CH3)而受到保护之故。 这样就可以用限制性内切酶把一个基因组DNA分成很多片段,对于原核生物比较小的基因组来说,可以直接用标记地探针来获取在通过特定的方法,对于比较大的基因组,可以先制作基因文库,然后钓取所需要的带有目的基因的片段。 2.人工合成目的基因DNA片段 人工合成目的基因DNA片段有化学合成和酶促合成法两条途径。一般是采用DNA合成仪来合成长度不是很大的DNA片段。 3.PCR反应合成DNA 聚合酶链式反应(PCR)是以DNA变性、复制的某些特性为原理设计的。通过PCR技术获取所需要的特异DNA片段在实际应用用得非常多,但是前提条件是必须对目的基因有一定的了解,需要设计引物。PCR技术的原理如下:
Mega的使用以及进化树的绘制
1.MEGA构建系统进化树的步骤 2.CLUSTALX进行序列比对 1.MEGA构建系统进化树的步骤 1. 将要用于构建系统进化树的所有序列合并到同一个fasta格式文件,注意:所有序列的方向都要保持一致( 5’-3’)。如图: 2. 打开MEGA软件,选择"Alignment" - "Alignment Explorer/CLUSTAL",在对话框中选择Retrieve sequences from a file, 然后点OK,找到准备好的序列文件并打开,如图: 。 3. 在打开的窗口中选择”Alignment”-“Align by ClustalX” 进行对齐,对齐过程需要一段时间,对齐完成后,最好将序列两端切齐,选择两端不齐的部分,
单击右键,选择delete即可,如图: 。 4. 关闭当前窗口,关闭的时候会提示两次否保存,第一次无所谓,保存不保存都可以,第二次一定要保存,保存的文件格式是.meg。根据提示输入Title,然后会出现一个对话框询问是否是Protein-coding nucleotide sequence data, 根据情况选择Yes或No。最后出现一个对话框询问是否打开,选择Yes,如图: 。 5. 回到MEGA主窗口,在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” -“Neighbor-joining”,打开一个窗口,里面有很多参数可以设
置,如何设置这些参数请参考详细的MEGA说明书,不会设置就暂且使用默认值,不要修改,点击下面的Compute按钮,系统进化树就画出来了,如图: 在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“Minimun-evolution”,如图: 在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“Maximun-parsimony”,如图: 在菜单栏中选择”Phylogeny”-“Bootstrap Test of Phylogeny” –“UPGMA”,
MEGA构建系统进化树的步骤(以MEGA7为例)
MEGA构建系统进化树的步骤(以MEGA7为例) 本文是看中国慕课山东大学生物信息学课程总结出来的 分子进化的研究对象是核酸和蛋白质序列。研究某个基因的进化,是用它的DNA序列,还是翻译后的蛋白质序列呢?序列的选取要遵循以下原则:1)如果DNA序列的两两间的一致度≥70%,选用DNA 序列。因为,如果DNA序列都如此相似,它的蛋白质会相似到看不出区别,这对构建系统发生树是不利的。所以这种情况下应该选用DNA序列,而不选蛋白质序列。2)如果DNA序列的两两间的一致度≤70%,DNA序列和蛋白质序列都可以选用。 1. 将要用于构建系统进化树的所有序列合并到同一个fasta格式文件,注意:所有序列的方向都要保持一致( 5’-3’)。 想要做系统发生树先要做多序列比对,然后把多序列比对的结果提交给建树软件进行建树,所以在用MEGA建树时可以输入一个已经比对好的多序列比对,也可以输入一条原始序列,让MEGA先来做多序列比对,再建树(一般我们都是原始序列)。所以我们以后者为例。 2.打开MEGA软件,选择主窗口的”File”→“Open A File”→找到并打开fasta文件,这时会询问以何种方式打开,我们是原始序列,需要先进行多序列比对,所以选择“Align”。如果是比对好的多序列比对可以直接选择“Analyze”。 3.在打开的Alignment Explorer窗口中选择”Alignment”-“Align by ClustalW”进行多序列比对(MEGA提供了ClustalW和Muscle两种多序列比对方法,这里选择熟悉的ClustalW),弹出窗口询问“Nothing selected for alignment,Select all?”选择“OK”。 4. 之后,弹出多序列比对参数设置窗口。这个窗口和EMBL在线多序列比对一样,可以设置替换记分矩阵、不同的空位罚分(罚分填写的是正数,计算时按负数计算)等参数。MEGA的所有默认参数都是经过反复考量设置的,这保证了MEGA傻瓜机全自动档的品质,所以当你无从下手,或者没有什么特别要求的时候,直接点击“OK”,接受这些默认参数,开始多序列比对。
基因工程基本过程
基因工程基本过程 基因工程(genetic engineering),也叫基因操作、遗传工程,或重组体DNA 技术。它是一项将生物的某个基因通过基因载体运送到另一种生物的活性细胞中,并使之无性繁殖(称之为"克隆")和行使正常功能(称之为"表达"),从而 创造生物新品种或新物种的遗传学技术。一般说来,基因工程是专指用生物化学的方法,在体外将各种来源的遗传物质(同源的或异源的、原核的或真核的、天 然的或人工合成的DNA片段)与载体系统(病毒、细菌质粒或噬菌体)的DNA 结合成一个复制子。这样形成的杂合分子可以在复制子所在的宿主生物或细胞中复制,继而通过转化或转染宿主细胞、生长和筛选转化子,无性繁殖使之成为克隆。然后直接利用转化子,或者将克隆的分子自转化子分离后再导入适当的表达体系,使重组基因在细胞内表达,产生特定的基因产物。 常用的工具酶 限制性内切酶—主要用于DNA分子的特异切割 DNA甲基化酶—用于DNA分子的甲基化 核酸连接酶—用于DNA和RNA的连接 核酸聚合酶—用于DNA和RNA的合成 核酸酶—用于DNA和RNA的非特异性切割 核酸末端修饰酶—用于DNA和RNA的末端修饰 其它酶类--用于生物细胞的破壁、转化、核酸纯化、检测等。 主要过程有为四步: 一.获得目的基因 有多种方法可获得目得基因 1.构建cDNA文库分离目的基因 过程: (1)从真核细胞中提取mRNA,以其为模板,在反转录酶的作用下合成cDNA的第一条链。 (2)以第一条链为模板,以反转录酶或DNA聚合酶I作用下合成cDNA的
第二条链。 (3)在甲基化酶作用下使cDNA甲基化。 (4)接头或衔接子连接。 (5)凝胶过滤分离cDNA。 (6)通过核酸探针法或免疫反应法从cDNA文库中分离特异cDNA克隆。 2.人工化学合成法 适于已知的核苷酸序列且校小的DNA片断合成,常用方法有磷酸二酯法、磷酸三酯法、亚磷酸三酯法、固相合成法、自动化合成法等。 过程:先用以上方法合成基因DNA不同部位的两条链的寡核苷短片段,再退火成为两端形成粘性末端的DNA双链片段。然后将这些DNA片段按正确的次序进行退火连接起来形较长的DNA片段,再用连接酶连接成完整的基因。 3.利用PCR技术直接扩增目的基因 PCR(Polymerase Chain Reaction)法,又称为聚合酶链反应或PCR扩增技术,已知待扩增目的基因或DNA片段两侧的序列,根据该序列化学合成聚合反应必需的双引物,类似于DNA的天然复制过程,用PCR法进行扩增,特异地合成目的cDNA链,用于重组、克隆。 二.载体的选择与制备 1.载体的选择(以质粒为例) ⑴载体必须是复制子。 ⑵具有合适的筛选标记,便于重组子的筛选。 ⑶具备多克隆位点(MCS),便于外源基因插入。 ⑷自身分子量较小,拷贝数高。 ⑸在宿主细胞内稳定性高。 (6)应具有很强的启动子,能为大肠杆菌的RNA聚合酶所识别 (7)应具有阻遏子,使启动子受到控制,只有当诱导时才能进行转录。 (8)应具有很强的终止子,以便使RNA聚合酶集中力量转录克隆的外源基因,而不转录其他无关的基因,且所产生的mRNA较为稳定。
构建系统进化树的方法步骤
构建系统进化树的方法步骤 1. 建树前的准备工作 1.1 相似序列的获得——BLAST BLAST是目前常用的数据库搜索程序,它是Basic Local Alignment Search Tool的缩写,意为“基本局部相似性比对搜索工具”(Altschul et al.,1990[62];1997[63])。国际著名生物信息中心都提供基于Web的BLAST服务器。BLAST算法的基本思路是首先找出检测序列和目标序列之间相似性程度最高的片段,并作为内核向两端延伸,以找出尽可能长的相似序列片段。 首先登录到提供BLAST服务的常用网站,比如国内的CBI、美国的NCBI、欧洲的EBI和日本的DDBJ。这些网站提供的BLAST服务在界面上差不多,但所用的程序有所差异。它们都有一个大的文本框,用于粘贴需要搜索的序列。把序列以FASTA格式(即第一行为说明行,以“>”符号开始,后面是序列的名称、说明等,其中“>”是必需的,名称及说明等可以是任意形式,换行之后是序列)粘贴到那个大的文本框,选择合适的BLAST程序和数据库,就可以开始搜索了。如果是DNA序列,一般选择BLASTN搜索DNA数据库。 这里以NCBI为例。登录NCBI主页-点击BLAST-点击Nucleotide-nucleotide BLAST (blastn)-在Search文本框中粘贴检测序列-点击BLAST!-点击Format-得到result of BLAST。 BLASTN结果如何分析(参数意义): >gi|28171832|gb|AY155203.1| Nocardia sp. ATCC 49872 16S ribosomal RNA gene, complete sequence Score = 2020 bits (1019), Expect = 0.0 Identities = 1382/1497 (92%), Gaps = 8/1497 (0%) Strand = Plus / Plus Query: 1 gacgaacgctggcggcgtgcttaacacatgcaagtcgagcggaaaggccctttcgggggt 60 |||||||||||||||||||||||||||||||||||||||||| ||||||||| ||||| Sbjct: 1 gacgaacgctggcggcgtgcttaacacatgcaagtcgagcggtaaggcccttc--ggggt 58 Query: 61 actcgagcggcgaacgggtgagtaacacgtgggtaacctgccttcagctctgggataagc 120 || ||||||||||||||||||||||||||||||| | |||||| ||||||||||||| Sbjct: 59 acacgagcggcgaacgggtgagtaacacgtgggtgatctgcctcgtactctgggataagc 118 Score :指的是提交的序列和搜索出的序列之间的分值,越高说明越相似;
基因工程的基本操作步骤
水寨中学生物自主探究学案 内容:基因工程的基本操作程序课时:2课时年级:高二编号64 一、教学目标 1.知识目标: 了解基因工程原理及基本操作程序。 2.能力目标: 尝试设计某一转基因生物的研制过程。 3.情感、态度和价值观目标: (1)了解基因工程的发展。 (2)认同基因工程的诞生和发展离不开理论研究和技术创新。 二、教学重点和难点 1、教学重点 基因工程基本操作程序的四个步骤。 2、教学难点 (1)从基因文库中获取目的基因 (2)利用PCR技术扩增目的基因 第一课时 三、教学过程 (一)复习上节内容 1、什么是基因工程?DNA重组技术的基本工具有哪些?运载体需要具备哪些条件? 以上问题可以不展示 (二)讲授新课 1、基因工程的基本步骤包括那四步? 2、第一步:目的基因的获取 (1)为什么要有目的基因的获取这一步骤? (2)目的基因的获取方法有哪些? (3)为什么要建立基因文库?怎么建立的?
(4)如何从基因文库中获取目的基因? (5)为什么要建立cDNA文库?如何获取cDNA? (5)PCR技术的原理是什么?利用PCR技术扩增目的基因的前提是什么? (6)如何获取引物? (7)请你用文字和箭头描述PCR技术扩增的过程? 3、第二步:基因表达载体的构建(基因工程的核心步骤) (1)在基因工程的操作过程中,为什么要构建基因表达载体?单独的DNA片段能不能稳定遗传? (2)参考课本P11页图1—10基因表达载体模式图,在学案上绘出基因表达载体的模式图,并标出其组成部分。并了解什么是启动子、终止子?他们位于哪里?有什么作用?标记基因的作用是什么?
思考:1、作为基因工程的表达载体,只需含有目的基因就可以完成任务吗?为什么 2、完成教材P11页的“寻根问底” 第二课时 4、第三步:将目的基因导入受体细胞 (1)为什么要把目的基因导入受体细胞而不是在外界培养让其维持稳定和表达?(2)什么是转化? (3)将目的基因导入植物细胞的方法有哪些?最常用的方法是哪种?(结合示意图,了解农杆菌转化法的基本过程) (4)将目的基因导入动物细胞的基本操作程序是怎样的?要用到什么技术? (5)早期的基因工程为什么选择原核生物作为受体细胞?大肠杆菌细胞最常用的转化方法是?
MEGA构建系统进化树的步骤(以MEGA7为例)教学文案
M E G A构建系统进化树的步骤(以M E G A7为 例)
MEGA构建系统进化树的步骤(以MEGA7为例) 本文是看中国慕课山东大学生物信息学课程总结出来的 分子进化的研究对象是核酸和蛋白质序列。研究某个基因的进化,是用它的DNA序列,还是翻译后的蛋白质序列呢?序列的选取要遵循以下原则:1)如果DNA序列的两两间的一致度≥70%,选用DNA序列。因为,如果DNA序列都如此相似,它的蛋白质会相似到看不出区别,这对构建系统发生树是不利的。所以这种情况下应该选用DNA序列,而不选蛋白质序列。2)如果DNA 序列的两两间的一致度≤70%,DNA序列和蛋白质序列都可以选用。 1. 将要用于构建系统进化树的所有序列合并到同一个fasta格式文件,注意:所有序列的方向都要保持一致 ( 5’-3’)。 想要做系统发生树先要做多序列比对,然后把多序列比对的结果提交给建树软件进行建树,所以在用MEGA建树时可以输入一个已经比对好的多序列比对,也可以输入一条原始序列,让MEGA先来做多序列比对,再建树(一般我们都是原始序列)。所以我们以后者为例。 2.打开MEGA软件,选择主窗口的”File”→“Open A File”→找到并打开fasta文件,这时会询问以何种方式打开,我们是原始序列,需要先进行多序列比对,所以选择“Align”。如果是比对好的多序列比对可以直接选择“Analyze”。 3.在打开的Alignment Explorer窗口中选择”Alignment”-“Align by ClustalW”进行多序列比对(MEGA提供了ClustalW和Muscle两种多序列比对方法,这
一步一步教你如何做系统进化树
一步一步教你如何做系统进化树 在此介绍几个进化树分析及其相关软件的使用和应用范围。这几个软件分别是PHYLIP 、PUZZLE 、PAUP 、TREEVIEW 、CLUSTALX 和PHYLO-WIN (LINUX )。 在介绍软件之前,我先简要地叙述一下有关进化树分析的一些方法学问题。 进化树也称种系树,英文名叫“Phyligenetic tree ”。对于一个完整的进化树分析需要以下几个步骤:⑴ 要对所分析的多序列目标进行排列(To align sequences )。做ALIGNMENT 的软件很多,最经常使用的有CLUSTALX 和CLUSTALW ,前者是在WINDOW 下的而后者是在DOS 下的。⑵ 要构建一个进化树(To reconstrut phyligenetic tree )。构建进化树的算法主要分为两类:独立元素法(discrete character methods )和距离依靠法(distance methods )。所谓独立元素法是指进化树的拓扑形状是由序列上的每个碱基/氨基酸的状态决定的(例如:一个序列上可能包含很多的酶切位点,而每个酶切位点的存在与否是由几个碱基的状态决定的,也就是说一个序列碱基的状态决定着它的酶切位点状态,当多个序列进行进化树分析时,进化树的拓扑形状也就由这些碱基的状态决定了)。而距离依靠法是指进化树的拓扑形状由两两序列的进化距离决定的。进化树枝条的长度代表着进化距离。独立元素法包括最大简约性法(Maximum Parsimony methods )和最大可能性法(Maximum Likelihood methods );距离依靠法包括除权配对法(UPGMAM )和邻位相连法(Neighbor-joining )。⑶ 对进化树进行评估。主要采用Bootstraping 法。进化树的构建是一个统计学问题。我们所构建出来的进化树只是对真实的进化关系的评估或者模拟。如果我们采用了一个适当的方法,那么所构建的进化树就会接近真实的“进化树”。模拟的进化树需要一种数学方法来对其进行评估。不同的算法有不同的适用目标。一般来说,最大简约性法适用于符合以下条件的多序列:i 所要比较的序列的碱基差别小,ii 对于序列上的每一个碱基有近似相等的变异率,iii 没有过多的颠换/转换的倾向,iv 所检验的序列的碱基数目较多(大于几千个碱基);用最大可能性法分析序列则不需以上的诸多条件,但是此种方法计算极其耗时。如果分析的序列较多,有可能要花上几天的时间才能计算完毕。UPGMAM (Unweighted pair group method with arithmetic mean )假设在进化过程中所有核苷酸/氨基酸都有相同的变异率,也就是存在着一个分子钟。这种算法得到的进化树相对来说不是很准确,现在已经很少使用。邻位相连法是一个经常被使用的算法,它构建的进化树相对准确,而且计算快捷。其缺点是序列上的所有位点都被同等对待,而且,所分析的序列的进化距离不能太大。另外,需要特别指出的是对于一些特定多序列对象来说可能没有任何一个现存算法非常适合它。最好是我们来发展一个更好的算法来解决它。但无疑这是非常难的。我想如果有人能建立这样一个算法的话,那他(她)完全可以在 生 物秀-专心做生物 w w w .b b i o o .c o m
人教版《基因工程的基本操作程序》教学设计
“基因工程的基本操作程序”一节的教学设计 1 教材分析 《基因工程的基本操作程序》是人教版选修3专题1基因工程中第2节内容,本节是《基因工程》专题的核心,上承《DNA重组技术的基本工具》一节,下接《基因工程的应用》。 对于基因工程,学生接触得很少,文字描述中会感到抽象,为此,教材中采用形象化得呈现方式简述了基因工程基本操作程序的四个步骤。例如,基因文库中把基因组文库比作国家图书馆,而把cDNA文库比作某市图书馆,这样便于学生理解和掌握。此外,在教材处理中还呈现主干,割舍枝杈,将非主干内容以《生物技术资料卡》、《拓展视野》等方式呈现,做到有主有次。【1】 2 学情分析 学生经过上一节的学习已经掌握DNA重组技术所需三种基本工具的作用及基因工程载体所需条件等知识,具备学习基因工程的基本操作程序一节的基础;而且经过一年必修教材的学习,学生的生物基础知识较扎实,思维的目的性、连续性和逻辑性已初步建立。但基因工程一节对学生来说难点较多,如果处理不好,会变成简单的死记硬背。因此在教学过程中,应在教师引导下适时加强学生解决问题和运用概念图等生物学语言归纳结论等方面的能力。 3 教学目标 3.1 知识目标 ⑴简述基础理论研究和技术进步催化了基因工程 ⑵简述基因工程的原理和基本步骤 3.2 能力目标 ⑴学会运用概念图总结基因工程的基本步骤及方法 ⑵尝试运用基因工程原理,提出解决某一实际问题的方案 3.3 情感态度与价值观 ⑴关注基因工程的发展 ⑵认同基因工程的应用促进生产力的提高 4 教学重点与难点 4.1 教学重点基因工程基本操作程序的四个步骤 4.2 教学难点 ⑴从基因文库中获取目的基因 ⑵利用PCR技术扩增目的基因 5 教学整体思路 采用从“整体-部分-整体”的教学思路,首先引用基因工程案例使学生从整体上了解基因工程的四个步骤,其次采用分步探究的形式帮助学生理解各个步骤的原理、方法和过程,最后教师引导学生用概念图将所学的知识从整体上再次整合。【2】 6 教学过程 教学环节教师行为 学生 活动 导入新课1)出示我国有知识 产权的转基因抗 虫棉的培育图解 2)质疑:转基因抗 看图并回 答:首先
构建系统进化树的详细步骤
构建系统进化树的详细步骤 1. 建树前的准备工作 1.1 相似序列的获得——BLAST BLAST是目前常用的数据库搜索程序,它是Basic Local Alignment Search Tool 的缩写,意 为“基本局部相似性比对搜索工具”(Altschul et al.,1990[62];1997[63])。国际著名生物信息中心 都提供基于Web的BLAST服务器。BLAST算法的基本思路是首先找出检测序列和目标序 列之间相似性程度最高的片段,并作为核向两端延伸,以找出尽可能长的相似序列片段。 首先登录到提供BLAST服务的常用,比如国的CBI、美国的NCBI、欧洲的EBI和日本的DDBJ。这些提供的BLAST服务在界面上差不多,但所用的程序有所差异。它 们都有一个大的文本框,用于粘贴需要搜索的序列。把序列以FASTA格式(即第一行为说明 行,以“>”符号开始,后面是序列的名称、说明等,其中“>”是必需的,名称及说明等可以是 任意形式,换行之后是序列)粘贴到那个大的文本框,选择合适的BLAST程序和数据库,就 可以开始搜索了。如果是DNA序列,一般选择BLASTN搜索DNA数据库。 这里以NCBI为例。登录NCBI主页-点击BLAST-点击Nucleotide-nucleotide BLAST (blastn)-在Search文本框中粘贴检测序列-点击BLAST!-点击Format-得到result of BLAST。 BLASTN结果如何分析(参数意义): >gi|28171832|gb|AY155203.1| Nocardia sp. ATCC 49872 16S ribosomal RNA gene, complete sequence Score = 2020 bits (1019), Expect = 0.0 Identities = 1382/1497 (92%), Gaps = 8/1497 (0%) Strand = Plus / Plus
基因工程的基本操作程序教案
基因工程的基本操作程序 教案 Last revision on 21 December 2020
专题一基因工程的基本操作程序 一、教材分析 《基因工程的基本操作程序》是专题1《基因工程》的第二节,也是《基因工程》的核心,上承《DNA重组技术的基本工具》,下接《基因工程的应用》。本节课主要介绍了基因工程的基本操作程序的四个步骤,教学内容多,难点多,最好化整为零、各个击破。 二、教学目标 1.知识目标: 简述基因工程原理及基本操作程序。 2.能力目标: 尝试设计某一转基因生物的研制过程。 3.情感、态度和价值观目标: (1)关注基因工程的发展。 (2)认同基因工程的诞生和发展离不开理论研究和技术创新。 三、教学重点和难点 1、教学重点 基因工程基本操作程序的四个步骤。 2、教学难点 (1)从基因文库中获取目的基因 (2)利用PCR技术扩增目的基因 四、学情分析
本节课内容较多,难点较多,学生学习起来有一定困难,所以之前应该要求学生做好预习,尽量采用化整为零、各个击破的教学策略。 五、教学方法 1、学案导学:见学案。 2、新授课教学基本环节:预习检查、总结疑惑→情境导入、展示目标→合作探究、精讲点拨→反思总结、当堂检测→发导学案、布置预习 六、课前准备 1.学生的学习准备:预习《基因工程的基本操作程序》,初步把握基因工程原理及基本操作程序。 2.教师的教学准备:多媒体课件制作,课前预习学案,课内探究学案,课后延伸拓展学案。 七、课时安排:2课时 八、教学过程 (一)预习检查、总结疑惑 检查学生落实预习的情况并了解学生的疑惑,使教学具有针对性。 (二)情境导入、展示目标 教师首先提问: (1)什么是基因工程(基因工程的概念) (2)DNA重组技术的基本工具有哪些(限制酶、DNA连接酶、载体) (3)运载体需要具备哪些条件(有一个或多个限制酶切割位点;有标记基因;能在受体细胞中稳定存在并自我复制或者整合到受体细胞染色体DNA上随染色体DNA的复制而同步复制)
系统进化树视频教程-多序列比对教程等
所有视频内容和编号: 001-1系统进化树构建序列文件格式说明(1080P) 001-2 MEGA软件构建邻接树(NJ树) (1080P) 001-3 MEGA软件构建最大简约树(MP树) (1080P) 001-4 MEGA软件构建最大似然树(ML树) (1080P) 001-5 MEGA软件构建UPGMA树(1080P) 001-6 MEGA软件计算遗传距离和导出Excel(1080P) 001-7 MEGA软件分析序列特征-信息位点变异位点等(1080P) 001-8 MEGA软件对序列饱和性检验和作图(1080P) 001-9 MEGA软件最序列分组并计算组间和组内遗传距离(1080P) 001-10 MEGA软件对树图置根修改字体和字号等(1080P) 002-1 贝叶斯法Mrbayes构建系统进化树教程视频(1080P) 002-2 PAUP软件构建最大似然(ML)树教程 002-3 Mrbayes贝叶斯建树(MrMTgui模型计算)视频教程(1080P) 002-4 贝叶斯不收敛问题的解决办法(1080P) 002-5 PAUP软件构建最大似然(ML)树教程(1080P) 002-6 PAUP软件构建简约树(MP)树教程(1080P) 002-7 PAUP软件构建邻接树(NJ)树教程(1080P) 003-1 MAFFT多序列比对教程 003-2 Jmodeltest模型计算方法与说明 003-3 primer5引物设计 003-4 Photoshop图片排版(期刊格式) 003-4 primer5引物设计(加酶切位点)(1080P) 004-1 多基因序列快速联合(拼接)与格式转换-软件SequenceMatrix(1080P) 004-2 多基因序列快速联合(拼接)详细版-SequenceMatrix(1080P) 004-3 贝叶斯多基因片段联合分区建树(分区设定模型)(1080P) 005-1 MEGA软件美化树图置根等内容补充 005-2 如何编辑贝叶斯或PAUP(ML)树图(PDF格式)的名称、字体、分枝等并输出图片格式 005-3 MEGA软件修改树图标尺显示分枝长度自举值显示方式等设置(1080P)
系统进化树的这些知识
系统进化树的这些知识,你都Get了吗? 系统进化树(Phylogenetic tree,又称为系统发生树/系统发育树/系统演化树/进化树等),是用来表示物种间亲缘关系远近的树状结构图。在系统进化树中,物种按照亲缘关系远近被安放在树状结构的不同位置,因而,进化树可以简单地表示生物的进化过程和亲缘关系。 自达尔文时期,很多生物学家就希望用一棵树的形式描述地球上所有生命的进化历程。早期的系统发育研究主要基于生物的表型特征,通过表型比较来研究物种之间的进化关系,然而,利用表型特征进行系统发育分析存在很大的局限性,1965[1]年,Linus Pauling等提出了分子进化理论,基于分子特性(DNA、RNA和蛋白质分子),推断物种之间的系统发生关系,由于核苷酸和氨基酸序列中含有生物进化历史的全部信息,因此利用该方法构建的系统进化树更为准确。 图1 系统进化树 理论上,一个DNA序列在物种形成或者基因复制时,会分成两个子序列,因而系统进化树是一般是二叉树,由许多节点和分支构成。根据位置的不同,节点分为外部节点和内部节点,外部节点代表最终分类,可以是物种、群体,或者DNA、RAN、蛋白质等,内部节点表示该分支可能的祖先节点,不同节点间的连线则称为分支。 根据是否指定根节点,将系统发育树分为有根树和无根树。有根树绘制过程中需要引入外群,因而具有一个根节点,作为树中所有物种(样本)的共同祖先节点,可以判断演化方向,反映分类单元间的进化关系,外群与进化树中其他物种(样本)的亲缘关系不宜太近,也不能太远,一般构建种内不同品种/亚种间的进化树,外群应选择同属内其他物种,构建属内不同种间的进化树,外群应选择科内其他属物种。无根树绘制过程中并未引入外群,因而没有根节点,无法判断演化方向,只能表明不同单元之间的分类关系。