Erdas基础教程数据预处理,校正、配准、镶嵌、裁剪

Erdas基础教程: 数据预处理
来源:陕西师范大学旅游与环境学院
在ERDAS中,数据预处理模块为Data preparation。图标面板工具条中,点击图标——Data Preparation菜单
1、图象几何校正
第一步:显示图象文件
在视窗中打开需要校正的Landsat TM图象:lanzhoucity.img.
第二步:启动几何校正模块
在Viewer#1的菜单条中,选择Raster|Geometric Correction
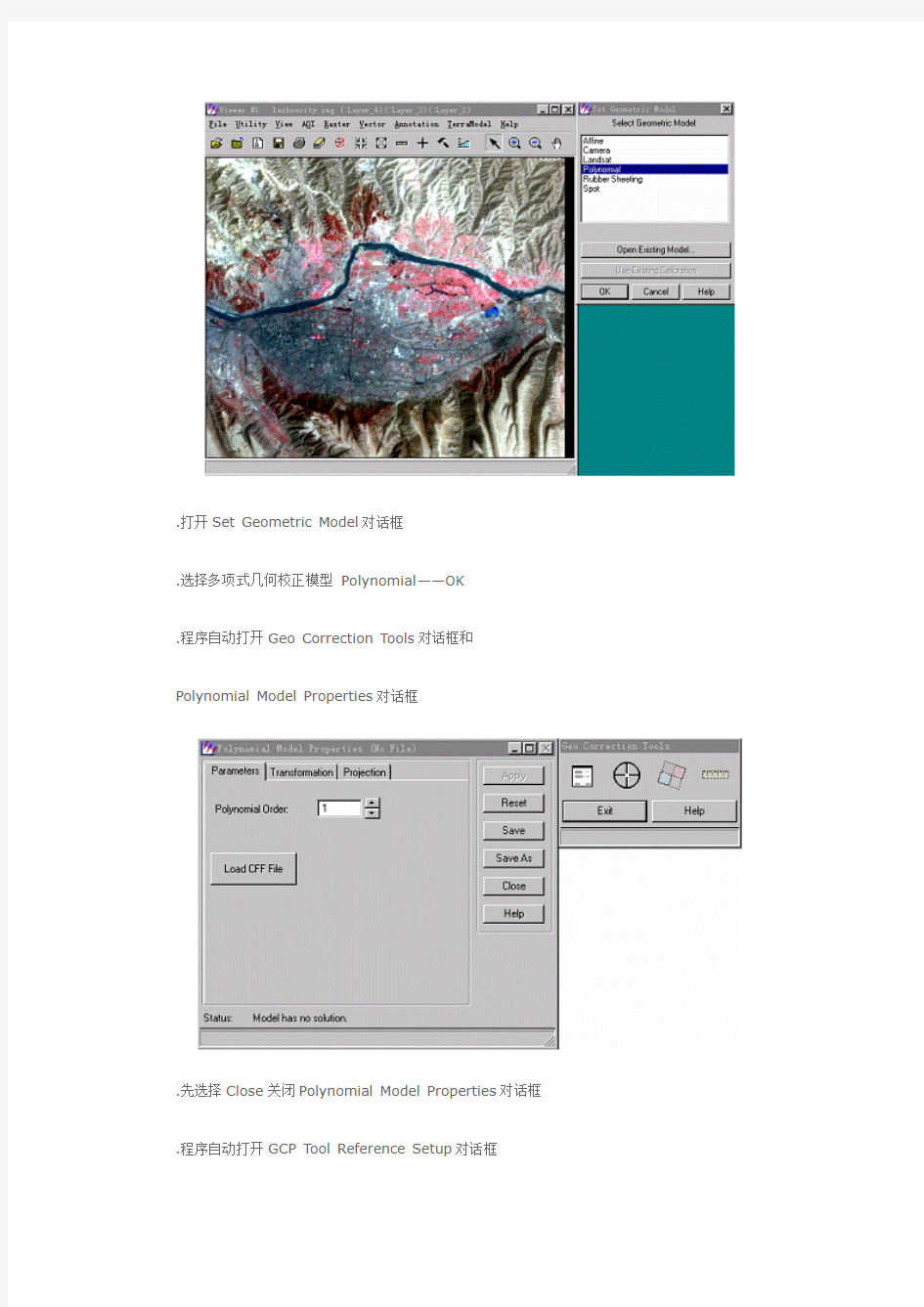
.打开Set Geometric Model对话框
.选择多项式几何校正模型Polynomial——OK
.程序自动打开Geo Correction Tools对话框和Polynomial Model Properties对话框
.先选择Close关闭Polynomial Model Properties对话框.程序自动打开GCP Tool Reference Setup对话框
.选择Keyboard Only
.OK
.程序自动打开Reference Map Information提示框。
.选择Map Units: Meters
.添加地图投影参数,如下图:
.选择OK 确定地图投影参数,并关闭上图。
.选择OK,确定Reference Map Information,并关闭提示框。
.并自动打开采集控制点对话框。
GCP的具体采集过程:
在图像几何校正过程中,采集控制点是一项非常重要和相当重要的工作,具体过程如下:.在GCP工具对话框中点select GCP 图标,进行GCP选择状态。
.在view#1中移动关联方框位置,寻找明显地物特征点,作为输入GCP。
.在GCP工具对话框中点击Great GCP图标,并在view#2中点击左键定点,GCP数据表将记录一个输入的GCP,包括编号、标识码、X、Y坐标。
.在GCP工具对话框中输入地图参数坐标X、Y。
.不断重复上述步骤,采集若干GCP,直到满足所选是的几何校正模型为止。
采集地面检查点
以上所采集的GCP为控制点,用于建立转换方模型及多项式方程,地面检查点,则用于检验所建立的转换方程的精度和实用性,具体过程如下:
.在GCP TOOL菜单条中选择GCP类型:Edit/Set Point Type —check。
.在GCP TOOL 菜单条中确定GCP匹配参数:Edit/Point matching —打开GCP Matching 对话框,并确定参数。
.确定地面检查点,其操作与选择控制点完全一样。
.计算检查点误差:在GCP TOOL工具条中,点击Compute Error 图标,检查点的误差就会显示在GCP TOOL 的上方(如下图),只有所有检查的误差小于一个像元时,才能进行以下的步骤。
.在Geo Correction Tools 对话框中选择Model Properties 图标打开
选择或检查参数,然后选择close关闭。
图像重采样
.在Geo Correction Tools 对话框中选择Image Resample 图标—打开Image Resample 对话框,并定义重采样参数。
.输出图像文件名(output file):rectify.img
.选择重采样方法(Resample Method):Nearest Neighbor
.定义输出图像在图与像元大小。
.设查输出统计中忽略零值。
.选择OK启动重采样进程,并关闭Image Resample 对话框。
2.图象拼接处理
本练习将同一区域机邻的三幅TM图象进行拼接。
其过程如下:
.启动图象拼接工具,在ERDAS图标面板工具条中,点击Dataprep/Data preparation/Mosaicc lmages—打开Mosaic Tool 视窗。
.加载Mosaic图像,在Mosaic Tool视窗菜单条中,Edit/Add images—打开Add Images for Mosaic 对话框。依次加载窗拼接的图像。
.在Mosaic Tool 视窗工具条中,点击set Input Mode 图标,进入设置图象模式的状态,利用所提供的编辑工具,进行图象叠置组合调查。
.图象匹配设置,点击Edit /Image Matching —打击Matching options 对话框,设置匹配方法:Overlap Areas。
.在Mosaic Tool视窗菜单条中,点击Edit/set Overlap Function—打开set Overlap Function对话框
设置以下参数:
.设置相交关系(Intersection Method):No Cutline Exists。
.设置重叠图像元灰度计算(select Function):Average。
.Apply —close完成。
.运行Mosaic 工具在Mosaic Tool视窗菜单条中,点击Process/Run Mosaic —打开Run Mosaic 对话框。
设置下列参数:确定输出文件名:mosaic.img
确定输出图像区域:ALL
OK进行图像拼接。
3、图象分幅裁剪
在实际工作中,经常根据研究区的工作范围进行图像分幅裁剪,利用ERDAS 可实现两种图像分幅裁剪:规则分幅裁剪,不规则分幅裁剪。
1、规则分幅裁剪
即裁剪的边界范围为一矩形,其具体方法如下:
在ERDAS图标面板工具条中,点击DataPrep/Data preparation/subset Image—打开subset Image 对话框,并设置参数如下:
说明:裁剪范围输入:
①通过直接输入右上角、右下角的坐标值;
②先在图像视窗中放置查询框,然后在对话框中选择From Inquire Box
③先在图像视窗中绘制AOL区域,然后在对话框中选择AIO功能,利用此方法也可实现不规则裁剪。
2、不规则分幅裁剪
①用AOI区域裁剪,与上述的②的方法相同。
②用Arclnfo的多边形裁剪。
.将Arclnfo多边形转换成网格图象。
.ERDAS图标面板工具条中,点击Vector/vector to Raster—打开vector to Raster对话框,并设置参数,并实现转换。
.通过掩膜运算实现图像不规则裁剪。
.ERDAS 图标面板工具条中,点击Interpreter/Utilities /Mask--打开Mask对话框,并设置参数如下:
setup Recode设置裁剪区域内新值为1,区域外取0值。
如何对市场调研问卷的数据进行预处理
如何对市场调研问卷的数据进行预处理 市场调研问卷数据的预处理是整个市场调研工作的重要环节,如果预处理做得不好,就会使有问题的问卷进入后面的数据分析环节,对最终结果产生严重影响。 一、信度检验 1.信度分析简介 信度,即信任度,是指问卷数据的可信任程度。信度是保证问卷质量的重要手段,严谨的问卷分析通常会采用信度分析筛选部分数据。 α值是信度分析中的一个重要指标,它代指0~1的某个数值,如果α值小于0.7,该批次问卷就应当剔除或是进行处理;如果大于0.9,则说明信度很高,可以用于数据分析;如果位于0.7~0.9,则要根据具体情况进行判定。如表1所示。 α值意义 >0.9信度非常好 >0.8信度可以接受 >0.7需要重大修订但是可以接受 <0.7放弃 2.信度分析示例 操作过程 下面介绍的是一个信度分析的案例,其操作过程为:首先打开信度分析文件,可以看到该文件的结构很简单,一共包含10个题目,问卷的份数是102份。然后进入SPSS的“分析”模块,找到“度量”下面的“可靠性分析”,将这十个题目都选进去。 在接下来的统计量中,首先看平均值、方差和协方差等,为了消除这些变量的扰动,可以选择要或者不要这些相关的量,另外ANOVA(单音数方差分析)是分析两个变量之间有无关系的重要指标,一般选择要,但在这里可以不要,其他一些生僻的量值一般不要。描述性在多数情况下需要保留,因为模型的输出结果会有一些描述,因此应当选中项、度量和描述性,然后“确定”,这时SPSS输出的结果就会比较清楚。 结果解读 案例处理汇总后,SPSS输出的结果如图1所示。
图1 信度分析结果 由图1可知,案例中调查问卷的有效数据是102,已排除数是0,说明数据都是有效的,在这里如果某个问卷有缺失值,就会被模型自动删除,然后显示出已排除的问卷数。在信度分析中,可以看到Alpha值是0.881,根据前文的判定标准,这一数值接近0.9,可以通过。在图右下方部分有均值、方差、相关性等多个项目,这主要看最后的“项已删除的Alpha值”,该项目表示的是删除相应项目后整个问卷数据信度的变动情况,可以看出题目1、题目2和题目6对应的数值高于0.881,表明删除这三个题目后整个问卷的Alpha值会上升,为了确保整个调查的严谨性,应当将这三个题目删除。 二、剔除废卷 删除废卷大致有三种方法:根据缺失值剔除、根据重复选项剔除、根据逻辑关系剔除。 1.根据缺失值剔除 缺失值的成因 在市场调查中,即使有非常严格的质量控制,在问卷回收后仍然会出现缺项、漏项,这种情况在涉及敏感性问题的调查中尤其突出,缺失值的占比甚至会达到10%以上。之所以会出现这种现象,主要有以下原因:一是受访者对于疾病、收入等隐私问题选择跳过不答,二是受访者由于粗心大意而漏掉某些题目等。 缺失值的处理 在处理缺失值时,有些人会选择在SPSS或Excel中将其所在的行直接删除。事实上,不能简单地删除缺失值所在的行,否则会影响整个问卷的质量。这是因为在该行中除了缺失的数据以外,其他数据仍旧是有效的,包含许多有用信息,将其全部删除就等于损失了这部分信息。 在实际操作中,缺失值的处理主要有以下方式,如图2所示。
[数据分析] 教你一文掌握数据预处理
数据分析一定少不了数据预处理,预处理的好坏决定了后续的模型效果,今天我们就来看看预处理有哪些方法呢? 记录实战过程中在数据预处理环节用到的方法~ 主要从以下几个方面介绍: ?常用方法 ?N umpy部分 ?P andas部分 ?S klearn 部分 ?处理文本数据 一、常用方法 1、生成随机数序列 randIndex = random.sample(range(trainSize, len(trainData_copy)), 5*tra inSize) 2、计算某个值出现的次数 titleSet = set(titleData) for i in titleSet: count = titleData.count(i)
用文本出现的次数替换非空的地方。词袋模型 Word Count titleData = allData['title'] titleSet = set(list(titleData)) title_counts = titleData.value_counts() for i in titleSet: if isNaN(i): continue count = title_counts[i] titleData.replace(i, count, axis=0, inplace=True) title = pd.DataFrame(titleData) allData['title'] = title 3、判断值是否为NaN def isNaN(num): return num != num 4、 Matplotlib在jupyter中显示图像 %matplotlib inline 5、处理日期 birth = trainData['birth_date'] birthDate = pd.to_datetime(birth) end = pd.datetime(2020, 3, 5) # 计算天数birthDay = end - birthDate birthDay.astype('timedelta64[D]') # timedelta64 转到 int64 trainData['birth_date'] = birthDay.dt.days
《数据采集与预处理》教学教案—11用OpenRefine进行数据预处理
数据采集与预处理教案
通过API获取外部数据,增强电子表格中的内容。 二、任务实施; (1)在OpenRefine目录中使用“./refine”命令启动OpenRefine服务,如图4-8所示。 图4-8 启动OpenRefine服务 (2)进入其Web操作界面,单击“浏览…”按钮,选择bus_info.csv 文件,单击“打开”按钮,再单击“下一步”按钮,导入数据。 (3)进入一个新界面,在该界面中可以发现上传的CSV文件,如果文件出现乱码,则可以设置字符编码,应选择支持中文的编码,这里选择“GBK”编码,单击界面右上角的“新建项目”按钮。 (4)进入北京公交线路信息显示界面,在其“运行时间”列中有一些多余的信息,可将这些多余信息删除,以使数据更加简洁和直观,如图4-9所示。 图4-9 删除多余信息 (5)在“运行时间”下拉列表中选择“编辑单元格”中的“转换...”选项,启动转换功能。 (6)弹出“自定义文本转换于列运行时间”对话框,在“表达式”文本框中编写表达式,去除列中“运行时间:”多余信息,编写结束后,根据“预览”选项卡中的结果判断表达式编写是否正确。清洗结果满意后单击“确定”按钮,完成自定义文本转换操作。 (7)界面上方弹出一个黄色通知框,通知相关操作导致改变的单元格数,再次进行确认操作。在界面左边的“撤销/重做”选项卡中会显示刚刚的操作记录,如果不想进行相关操作,则可以单击界面左侧对应操作的上一步操作链接,以恢复操作。 同理,可以对其余几列执行类似操作。 (8)操作记录及结果如图4-45所示。 (9)下面将“公司”列中的“服务热线”信息抽取出来并使其独立成列。在“公司”下拉列表中选择“编辑列”中的“由此列派生新列...”选项。 (10)弹出“基于当前列添加列公司”对话框,设置“新列名称”和数据抽取的表达式。 (11)操作结束后,需要将预处理后的数据导出为文件。在界面右上
ENVI对SAR数据的预处理过程(详细版)资料
E N V I对S A R数据的预处理过程(详细版)
一、数据的导入: (1) 在 Toolbox 中,选择 SARscape ->Basic->Import Data->Standard Formats- >ALOS PALSAR。 (2) 在打开的面板中,数据类型(Data Type):JAXA-FBD Level 1.1。 注:这些信息可以从数据文件名中推导而来。 (3) 单击 Leader/Param file,选择 d1300816-005-ALPSRP246750820-H1.1__A\LED-ALPSRP246750820-H1.1__A文件。 (4) 点击 Data list,选择 d1300816-005-ALPSRP246750820-H1.1__A\IMG-HH-ALPSRP246750820- H1.1__A文件 (4) 单击 Output file,选择输出路径。 注:软件会在输入文件名的基础上增加几个标识字母,如这里增加“_SLC”(5) 单击 Start 执行,最后输出结果是 ENVI 的slc文件,sml格式的元数据文件,hdr格式的头文件等。 (6) 可在 ENVI 中打开导入生成的以slc为后缀的 SAR 图像文件。
二、多视 单视复数(SLC)SAR 图像产品包含很多的斑点噪声,为了得到最高空间分辨率的 SAR图像,SAR 信号处理器使用完整的合成孔径和所有的信号数据。多视处理是在图像的距离向和方位向上的分辨率做了平均,目的是为了抑制 SAR 图像的斑点噪声。多视的图像提高了辐射分辨率,降低了空间分辨率。 (1) 在 Toolbox 中,选择 SARscape->Basic ->Multilooking。 (2) 单击 Input file 按钮,选择一景 SLC 数据(前面导入生成的 ALOS PALSAR 数据)。 注意:文件选择框的文件类型默认是*_slc,就是文件名以_slc 结尾的文件,如不是,可选择*.*。 (3) 设置:方位向视数(Azimuth Looks):5,距离向视数(Range Looks):1 注:详细的计算方法如下所述。另外,单击 Look 按钮可以估算视数。
如何做好数据预处理(一)
数据分析中,需要先挖掘数据,然后对数据进行处理,而数据预处理的字面意思就是对于数据的预先处理,而数据预处理的作用是为了提高数据的质量以及使用数据分析软件,对于数据的预处理的具体步骤就是数据清洗、数据集成、数据变换、数据规范等工作,数据预处理是数据分析工作很重要的组成部分,所以大家一定要重视这个工作。 首先说一下数据清洗就是清理脏数据以及净化数据的环境,说到这里大家可能不知道什么是脏数据,一般来说,脏数据就是数据分析中数据存在乱码,无意义的字符,以及含有噪音的数据。脏数据具体表现在形式上和内容上的脏。就目前而言,脏数据在形式上就是缺失值和特殊符号,形式上的脏数据有缺失值、带有特殊符号的数据,内容上的脏数据上有异常值。 那么什么是缺失值呢?缺失值包括缺失值的识别和缺失值的处理。一般来说缺失值处理方法有删除、替换和插补。先来说说删除法吧。删除法根据删除的不同角度又可以分为删除观测样本和变量,删除观测样本,这就相当于减少样本量来换取信息的完整度,但当变量有较大缺失并且对研究目标影响不大时,可以直接删除。接着说一下替换法,所谓替换法就是将缺失值进行替换,根据变量的不同又有不同的替换规则,缺失值的所在变量是数值型用该变量下其他数的均值来替换缺失值;变量为非数值变量时则用该变量下其他观测值的中位数或众数替换。最后说说插补法,插补法分为回归插补和多重插补;回归插补指的是将插补的变量转变成替换法,然后根据替换法进行替换即可。
刚刚说到的缺失值,其实异常值也是需要处理的,那么什么是异常值呢?异常值跟缺失值一样,包括异常值的识别和异常值的处理。对于异常值的处理我们一般使用单变量散点图或箱形图来处理,在图形中,把远离正常范围的点当作异常值。异常值的的处理有删除含有异常值的观测、当作缺失值、平均值修正、不处理。在进行异常值处理时要先复习异常值出现的可能原因,再判断异常值是否应该舍弃。 大家在进行清洗数据的时候需要注意缺失数据的填补以及对异常数值的修正,这样才能够做好数据分析工作,由于篇幅的关系,如何做好数据预处理工作就给大家介绍到这里了,希望这篇文章能够给大家带来帮助。
数据采集和数据预处理
数据采集和数据预处理 3.2.1 数据采集 数据采集功能主要用于实现对DSM分析研究中所需的电力供需、相关政策法规等原始数据、信息的多种途径采集。数据采集为使用者提供定时数据采集、随机采集、终端主动上报数据等多种数据采集模式,支持手工输入、电子表格自动导入等多种导入方式,且能够对所采集的数据进行维护,包括添加、修改、删除等,并能进行自动定期备份。在需求侧管理专业化采集中,` 采集的数据根据结构特点,可以分为结构化数据和非结构化数据,其中,结构化数据包括生产报表、经营报表等具有关系特征的数据;非结构化数据,主要包括互联网网页( HTML)、格式文档( Word、PDF)、文本文件(Text)等文字性资料。这些数据目前可以通过关系数据库和专用的数据挖掘软件进行挖掘采集。特别是非结构化数据,如DSM相关的经济动态、政策法规、行业动态、企业动态等信息对DSM分析研究十分重要,综合运用定点采集、元搜索、主题搜索等搜索技术,对互联网和企业内网等数据源中符合要求的信息资料进行搜集,保证有价值信息发现和提供的及时性和有效性。DSM信息数据采集系统中数据采集类型如图2所示。在数据采集模块中,针对不同的数据源,设计针对性的采集模块,分别进行采集工作,主要有网络信息采集模块、关系数据库信息采集模块、文件系统资源采集模块和其他信息源数据的采集模块。 (1)网络信息采集模块。网络信息采集模块的主要功能是实时监控和采集目标网站的内容,对采集到的信息进行过滤和自动分类处理,对目标网站的信息进行实时监控,并把最新的网页及时采集到本地,形成目标站点网页的全部信息集合,完整记录每个网页的详细信息,包括网页名称、大小、日期、标题、文字内容及网页中的图片和表格信息等。 (2)关系数据库采集模块。该模块可以实现搜索引擎数据库与关系型数据库(包括Oracle、Sybase、DB2、SQL Server、MySQL等)之间的数据迁移、数据共享以及两者之间的双向数据迁移。可按照预设任务进行自动化的信息采集处理。 ( 3)文件系统资源采集模块。该模块可以实现对文件系统中各种文件资源(包括网页、XML文件、电子邮件、Office文件、PDF文件、图片、音视频多媒体文件、图表、公文、研究报告等)进行批量处理和信息抽取。 ( 4)其他信息源数据的采集。根据数据源接入方式,利用相应的采集工具进行信息获取、过滤等。 3.2.2 数据预处理 数据预处理的本质属于数据的“深度采集”,是信息数据的智能分析处理。利用网页内容分析、自动分类、自动聚类、自动排重、自动摘要/主题词抽取等智能化处理技术,对采集到的海量数据信息进行挖掘整合,最终按照统一规范的组织形式存储到DSM数据仓库,供图1 系统体系结构分析研究使用。数据预处理的工作质量很大程度上决定最终服务数据的质量,是DSM类项目(如,DSM项目全过程管理、有序用电方案评价等)深度分析的重要基础。在数据智能分析处理中,主要包括:1)自动分类,用于对采集内容的自动分类;2)自动摘要,用于对采集内容的自动摘要;3)自动排重,用于对采集内容的重复性判定。 ************************************** 电力数据采集与传输是电力系统分析和处理的一个重要环节。从采集被测点的各种信息,如母线电压,线路电压、电流、有功、无功,变压器的分接头位置,线路上的断路器、隔离开关及其它设备状态、报警、总有功功率、事件顺序等,对电力系统运行管理具有重要作用[ 1]。********************************** 电力信息的数据采集与集成 电力作为传统[业,其下属分系统众多,因而数据的种类也相当繁杂。数据类型包括工程
ENVI对SAR大数据地预处理过程(详细版)
一、数据的导入: (1) 在Toolbox 中,选择SARscape ->Basic->Import Data->Standard Formats->ALOS PALSAR。 (2) 在打开的面板中,数据类型(Data Type):JAXA-FBD Level 1.1。 注:这些信息可以从数据文件名中推导而来。 (3) 单击Leader/Param file,选择 d1300816-005-ALPSRP246750820-H1.1__A\LED-ALPSRP246750820-H1.1__A文件。 (4) 点击Data list,选择 d1300816-005-ALPSRP246750820-H1.1__A\IMG-HH-ALPSRP246750820-H1.1__A文件 (4) 单击Output file,选择输出路径。 注:软件会在输入文件名的基础上增加几个标识字母,如这里增加“_SLC” (5) 单击Start 执行,最后输出结果是ENVI 的slc文件,sml格式的元数据文件,hdr格式的头文件等。 (6) 可在ENVI 中打开导入生成的以slc为后缀的SAR 图像文件。
二、多视 单视复数(SLC)SAR 图像产品包含很多的斑点噪声,为了得到最高空间分辨率的SAR图像,SAR 信号处理器使用完整的合成孔径和所有的信号数据。多视处理是在图像的距离向和方位向上的分辨率做了平均,目的是为了抑制SAR 图像的斑点噪声。多视的图像提高了辐射分辨率,降低了空间分辨率。 (1) 在Toolbox 中,选择SARscape->Basic ->Multilooking。 (2) 单击Input file 按钮,选择一景SLC 数据(前面导入生成的ALOS PALSAR 数据)。 注意:文件选择框的文件类型默认是*_slc,就是文件名以_slc 结尾的文件,如不是,可选择*.*。 (3) 设置:方位向视数(Azimuth Looks):5,距离向视数(Range Looks):1 注:详细的计算方法如下所述。另外,单击Look 按钮可以估算视数。 (4) Border Resize 选项,选择此项,会对检测结果边缘中的无效值,进而重新计算输出图像的大小。这里不选择。 (5) 输出路径会依据软件默认参数设置自动添加或自行修改,单击Start 按钮执行。 (6) 计算完之后在Display 中显示结果,可以看到图像的斑点噪声得到的抑制,但是降低了空间分辨率
数据导入和预处理系统设计与实现
数据导入和预处理系统设计与实现 传统数据仓库随着Hadoop技术的发展受到巨大挑战,Hadoop从最初解决海量数据的存储难题,到现在被越来越多的企业用来解决大数据处理问题,其应用广泛性越来越高。本文主要研究基于Hadoop系统对传统数据库数据和文本数据进行迁移,帮助传统数据仓库解决在大数据存储处理等方面遇到的难题,同时依靠Hadoop的扩展性提升数据存储和处理的性能。论文中系统根据现今传统数据仓库的应用情况及Hadoop大数据平台的前景预测,针对传统数据仓库已无法满足用户需求的问题,设计出传统数据仓库与基于Hadoop的hdfs文件系统协作进行数据存储与处理的架构,同时解决企业用户数据控制权限的要求。系统分为四个部分,数据管理、数据预处理、系统管理和发布管理提供从数据导入到数据控制,数据预处理最终实现数据发布共享的功能。 系统的主要功能是采集数据和对采集到的数据进行预处理,系统设计成能够对多种类型的数据进行采集和预处理,同时系统能够实现很好的扩展功能,为系统中增加机器学习算法节点对数据进一步挖掘处理提供了可能。系统采用当下流行的Hadoop基本架构,同时结合Haddoop生态圈中的数据仓库Hive和数据迁移工具Sqoop进行数据的迁移和处理。在一定程度上能够满足企业的基本需求。系统以Web系统的方式实现,方便用户使用,在实现Web系统时采用成熟的ssm框架进行开发,保证系统的稳定性。 系统从企业的实际需求出发,同时充分考虑传统数据库在企业中的应用,设计实现基于Hadoop的数据管理平台原型,为企业提供实际应用指导。本论文从系统实现的背景、系统系统需求、系统设计、系统实现以及系统测试五大模块对系统进行了全面详细的论述,全面阐述了系统实现的意义,有一定的实际应用指导意义。
大数据分析和处理的方法步骤
大数据处理数据时代理念的三大转变:要全体不要抽样,要效率不要绝对精确,要相关不要因果。具体的大数据处理方法其实有很多,但是根据长时间的实践,天互数据总结了一个基本的大数据处理流程,并且这个流程应该能够对大家理顺大数据的处理有所帮助。整个处理流程可以概括为四步,分别是采集、导入和预处理、统计和分析,以及挖掘。 采集 大数据的采集是指利用多个数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除此之外,Redis和MongoDB 这样的NoSQL数据库也常用于数据的采集。 在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。 统计/分析 统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL 的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。 导入/预处理 虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使用来自Twitter的Storm来对数据进行流式计算,来满足
数据预处理实验1
重庆交通大学信息科学与工程学院 实验报告 班级:曙光1701班 姓名学号: 实验项目名称:数据导入与预处理实验一 实验项目性质:验证性、设计性 实验所属课程:《数据导入与预处理》实验室(中心):语音楼八楼 指导教师: 实验完成时间: 2019 年 11 月 1 日
一.实验目的 1.了解和掌握数据库的恢复,数据库数据的变换,数据的统计以及可视化;掌握Json数据集的API下载方法,数据提取,以及导入其他数据结构的方法。 2.了解和掌握不同数据格式之间的转换方法;掌握用计算机编程语言实现数据的格式转换以及数据信息的提取。 二.实验要求 1.安装Mysql数据库,以及mysql workbench客户端, 2.下载对公众开放的安然(Enron)公司的电子邮件数据集。 下载地址: 3.在mysql中恢复Enron数据库。 4.数据统计每一天和每一周发邮件的数量,并用可视化软件实现可视化。 5.采用iTunes API做个小实验,利用关键词来生成JSON数据结果集。iTunes是由Apple公司提供的一个音乐服务,任何人都可以利用iTunes服务来查找歌曲、艺术家和专辑。在查找的时候需要把搜索关键词添加到iTunes API URL的后面。URL中,=后面的是搜索关键词,是一个乐队的名字,the Growlers。注意:URL中用+代替空格字符,URL不允许包含空格字符。
iTunes API 会根据提供的关键词从音乐库中返回50个结果。整个结果集形成一个JSON文件,每一条音乐信息中的元素,以名字-值的格式存放在JSON文件中。 The Growlers Apple iTunes的开发文档: 6.使用一种熟悉的语言,编写程序,将下载下来的the Growlers的所有音乐的歌名提取出来,并可视化显示。 三、需求分析 1.提取出安然公司数据集中的每天的阅读量和每周的阅读量,并画出趋势图 2.提取出iTunes中的trackname数据 四、实验过程 1.安装好Mysql和Mysql Workbench
数据预处理在什么情况下采取哪种方法最合适
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。 数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。 数据无量纲化处理主要解决数据的可比性。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。 数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化 这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。 用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。 步骤如下: 1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; 2.进行标准化处理:
05-数据的产生、导入与预处理测试试卷
测试试卷 模块1:单选题 1 大数据的数据仓库工具是(C) A MapReduce B HDFS C HIVE D Spark 2 目前国内外大数据对实时计算和挖掘分析的流行工具(D) A MapReduce B HDFS C HIVE D Spark 3 下列哪一项是华为的大数据解决方案产品(D) A CDH B MapR Hadoop C Apache Hadoop D FusionInsight Hadoop 4 通过将以下什么工具与Hadoop集群整合后,可以查看Hadoop集群中每个Master/Slave节点的运行状态(A) A Ganglia B Zookeeper C HIVE D Spark 5 用来将Hadoop和关系型数据库中的数据相互转移的工具是(B) A Zookeeper B Sqoop C HIVE D Spark 6. 在sql的查询语句中,用于分组查询的语句是( C )。 a)order by b)where c)group by d)having 7、在“学生情况”表中,查询计算机专业、助学金大于40元的学生的姓名,正确的语句是( C )。 a)select 姓名from 学生情况where 计算机.and.助学金<40 b)select 姓名from 学生情况where 专业=“计算机”.or.助学金>40 c)select 姓名from 学生情况where 专业=“计算机”.and.助学金>40 d)select 姓名from 学生情况where 专业=“计算机”.and.助学金<40
8、下列sql语句中,修改表结构的是( A )。 a)alter b)create c)desc d)rename 9、已知职工表emp有工号e_no和工资e_sal两个字段。从职工关系中检索所有工资值,要求在输出结果中没有重复的工资值,则sql的命令语句能实现上述功能的是( B )。 a)select all e_sal from emp b)select distinct e_sal from emp c)select e_sal from emp d)select e_sal where emp 10、请选出属于dml的选项(C )---数据操纵语言(Data Manipulation Language, DML) a) truncate b)creat c)delete d)commit 11 数据仓库是随着时间变化的,下面的描述不正确的是(C) A. 数据仓库随时间的变化不断增加新的数据内容; B. 捕捉到的新数据会覆盖原来的快照; C. 数据仓库随事件变化不断删去旧的数据内容; D. 数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合. 12. 关于基本数据的元数据是指: (D) A. 基本元数据与数据源,数据仓库,数据集市和应用程序等结构相关的信息; B. 基本元数据包括与企业相关的管理方面的数据和信息; C. 基本元数据包括日志文件和简历执行处理的时序调度信息; D. 基本元数据包括关于装载和更新处理,分析处理以及管理方面的信息. 13. 下面关于数据粒度的描述不正确的是: (C) A. 粒度是指数据仓库小数据单元的详细程度和级别; B. 数据越详细,粒度就越小,级别也就越高; C. 数据综合度越高,粒度也就越大,级别也就越高; D. 粒度的具体划分将直接影响数据仓库中的数据量以及查询质量. 14. 有关数据仓库的开发特点,不正确的描述是: (A) A. 数据仓库开发要从数据出发; B. 数据仓库使用的需求在开发出去就要明确; C. 数据仓库的开发是一个不断循环的过程,是启发式的开发; D. 在数据仓库环境中,并不存在操作型环境中所固定的和较确切的处理流,数据仓库中数据分析和处理更灵活,且没有固定的模式 15. OLAP技术的核心是: (D) ----OLAP联机分析处理 A. 在线性; B. 对用户的快速响应; C. 互操作性. D. 多维分析;
数据挖掘:数据探索和预处理方法
目录CONTENTS 0102 数据探索 ?数据质量分析 ?数据特征分析数据预处理 ?数据抽样?数据清洗?数据变换
目录CONTENTS01数据探索数据质量分析 数据探索 ?数据质量分析 ?数据特征分析 数据预处理 ?数据抽样 ?数据清洗 ?数据变换
1)缺失值的属性有哪些2)属性的缺失数3)缺失率 数据质量分析包括很多内容,这里我们主要介绍缺失值分析和异常值分析 1)简单统计量分析2)三倍标准差原则3)箱型图分析 数据质量分析 缺失值分析内容异常值分析方法
titanic.csv是数据挖掘的典型案例,对其进行缺失值分析 A B 1=file("D:/KDD/titanic.csv").import@qtc() / 导入xls 数据2=A1.fname()/数据的属性 3=A2.((y=~,A1.align@a([true,false],!eval(y))))/按照是否缺失分组 3=A2.new(~:col,A3(#)(1).len():null_no,A3(#)(2).len():no_null,round(null_no/A1.len(),3):null_rate) 4/统计属性的缺失数,未缺失数,缺失率。 A4 A1 A2A3 缺失值分析
箱形图 A B 1=file("D:/KDD/catering_sale.csv").import@tc() 2=A1.(sales).median(:4)/返回数据分4份的各分位点 3=A2(3)-A2(1)/四分位距 4=A2(1)-1.5*A3/下四分位数 5=A2(3)+1.5*A3/上四分位数 6=A1.select(sales