SPSS与社会统计学逻辑回归分析Logistic课程
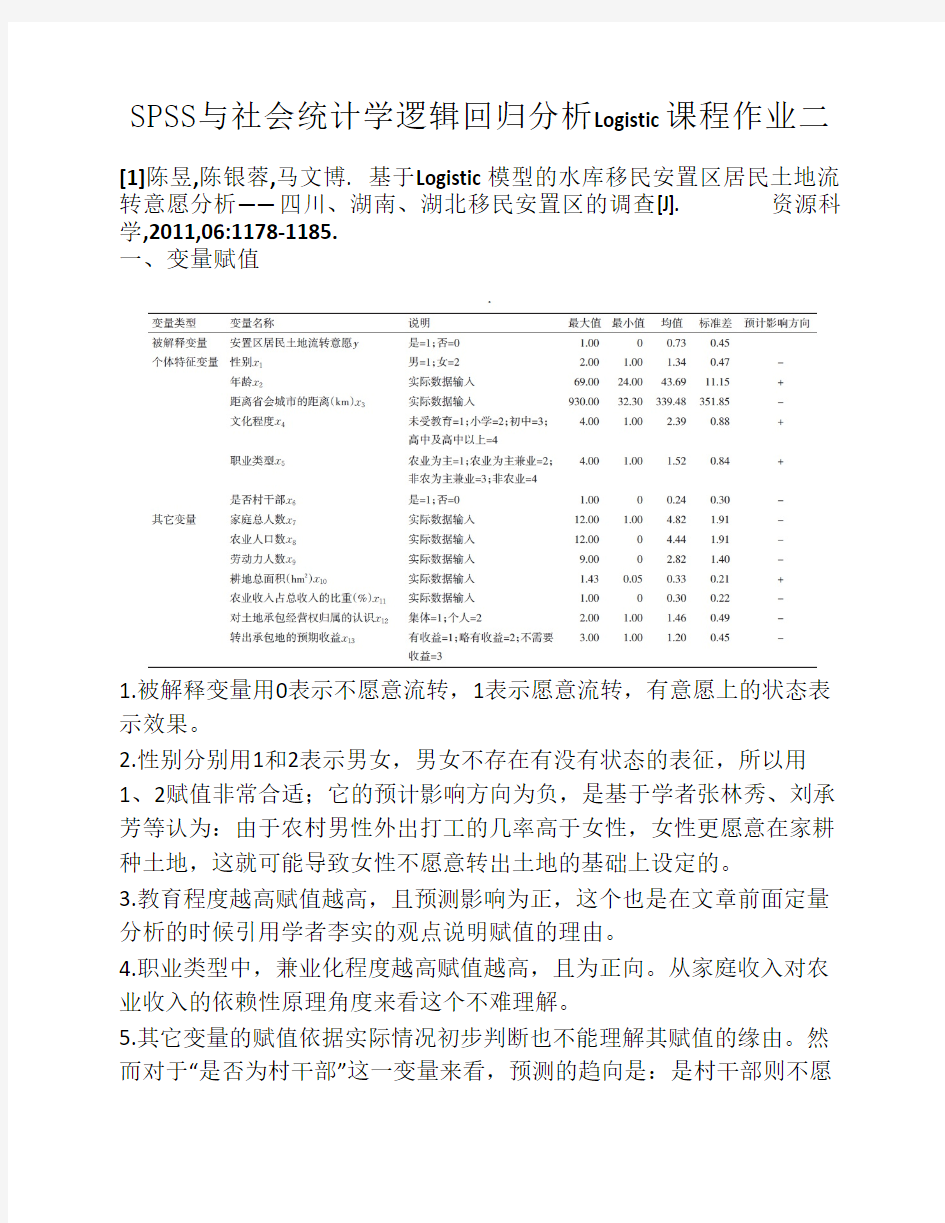
SPSS与社会统计学逻辑回归分析Logistic课程作业二[1]陈昱,陈银蓉,马文博. 基于Logistic模型的水库移民安置区居民土地流转意愿分析——四川、湖南、湖北移民安置区的调查[J]. 资源科学,2011,06:1178-1185.
一、变量赋值
1.被解释变量用0表示不愿意流转,1表示愿意流转,有意愿上的状态表示效果。
2.性别分别用1和2表示男女,男女不存在有没有状态的表征,所以用1、2赋值非常合适;它的预计影响方向为负,是基于学者张林秀、刘承芳等认为:由于农村男性外出打工的几率高于女性,女性更愿意在家耕种土地,这就可能导致女性不愿意转出土地的基础上设定的。
3.教育程度越高赋值越高,且预测影响为正,这个也是在文章前面定量分析的时候引用学者李实的观点说明赋值的理由。
4.职业类型中,兼业化程度越高赋值越高,且为正向。从家庭收入对农业收入的依赖性原理角度来看这个不难理解。
5.其它变量的赋值依据实际情况初步判断也不能理解其赋值的缘由。然而对于“是否为村干部”这一变量来看,预测的趋向是:是村干部则不愿
意流转,前面的分析并没有说明为什么会是这样。虽然这知识一种预判,但是若能够给出预判的一丁点理由就更好了。
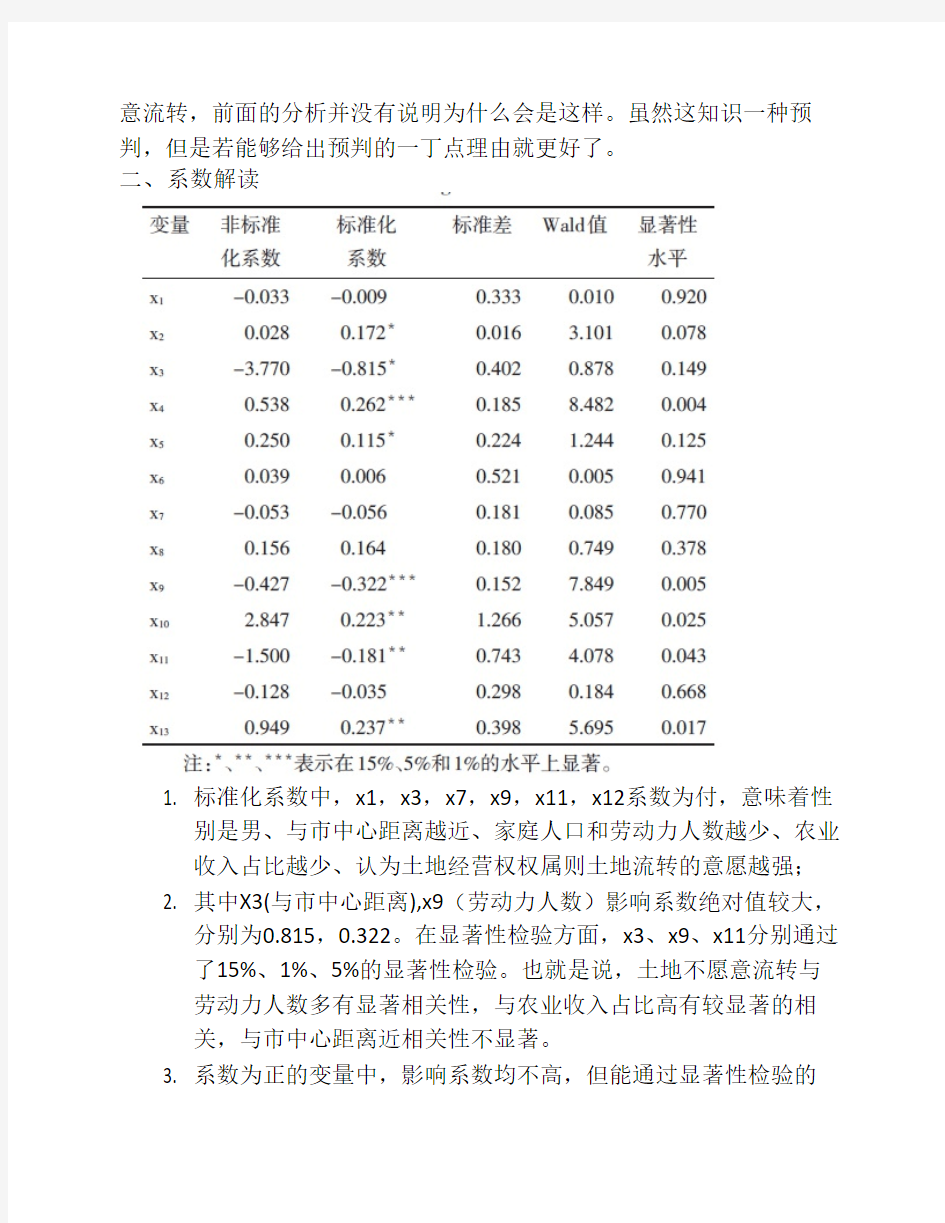
二、系数解读
1. 标准化系数中,x1,x3,x7,x9,x11,x12系数为付,意味着性
别是男、与市中心距离越近、家庭人口和劳动力人数越少、农业
收入占比越少、认为土地经营权权属则土地流转的意愿越强;
2. 其中X3(与市中心距离),x9(劳动力人数)影响系数绝对值较大,
分别为0.815,0.322。在显著性检验方面,x3、x9、x11分别通过
了15%、1%、5%的显著性检验。也就是说,土地不愿意流转与
劳动力人数多有显著相关性,与农业收入占比高有较显著的相
关,与市中心距离近相关性不显著。
3. 系数为正的变量中,影响系数均不高,但能通过显著性检验的
有:x2、x5(15%);x10、x13(5%);x4(1%)。说明文化程
度高对愿意流转的影响是非常显著的,而且在系数为正的变量
中,x4的系数为最大,说明x4与y(1)显著相关。
三、模型检验
这篇文章主要是对模型的拟合优度进行检验。检验方法选取Hosmerand Lemeshow 检验和Omnibus 检验。H-L 检验和Omnibus检验结果如上表4和表5所示:由表4可知,模型的卡方值为4.302,显著性水平为0.829,不能拒绝原假设,认为模型拟合程度较好。而表5显示,模型以0.01的显著性水平通过检验,说明模型中至少有一个自变量与因变量显著相
关。结合H-L检验和Omnibus检验可知,选择的模型以及回归结果可以较好的反映水库移民安置区农户土地转出的意愿。
[2]叶男. 农民的土地流转意愿及其影响因素研究[J]. 统计与决策,2013,09:99-101.
一、变量赋值
1. 对性别的赋值这里是赋为女(0),男(1),作为定类变量,
虽然这样赋值没多大错误,但是按我们的习惯似乎赋予1,2这样
的值更令我们可以接受。
2. 文化程度同样是越高数值越大,而健康状况则越好赋值越少。职
业类型中,非农就业全部赋值为0,务农全部赋值为1,没有依
赖度上的区分。兼业化程度从农户的视角来分析,变量选取上似
乎比较粗糙,难以定量;比如说,如何界定农业兼业户与非农兼
业户。而且很有可能与变量“职业类型”存在共线性的问题。土地
依赖性越高赋值越小,离县城越远赋值越大,所在村越穷赋值越
大。在地形地貌上,平原赋值为1,山区丘陵赋值为0.有新农保
赋值1,没有则为0.
二、系数解读(以转出意愿模型为例)
在这篇文章中,我们主要来解读Exp(B)。对于系数为负的变量,我们以年龄作为一个解读例子。年龄越高,可能受恋土情结等因素的影响,土地流出意愿越弱,且在0.01的显著性水平上通过了检验,说明年龄对土地流出意愿有显著影响。发生比为0.953,即在其它条件不变的情况下,年龄每增加1,土地流出意愿比将是原来的0.953倍,土地流出的概率比原来减少了0.047。对于系数为正的变量,我们以土地依赖性为例。土地依赖性越低,土地流出的意愿越高。且在0.01的显著性水平上通过了检验,说明土地依赖性对土地流出意愿有显著影响。发生比为2.548,即在其它条件不变的情况下,依赖程度每降一级(变量值增加1),土地流出意愿比将是原来的2.548倍,土地流出的概率比原来扩大了1.548倍。
三、模型检验(以转出意愿模型为例)
-2 Loglikelihood=365.95;Cox & Snell RSquare=0.269;Nagelkerke R Square=0.363;Sig. =0.000来看,模型拟合较好,因为-2 Loglikelihood足够大,而且非常显著,具有较好的解释力。后两个R2是伪决定值,所以不能用作判断。
感想:发现很难找到把所有的模型检验的指标都在文章中体现的文献,选择性的把指标给出,能体现作者的无奈之举。
参考文献:
[1]陈昱,陈银蓉,马文博. 基于Logistic模型的水库移民安置区居民土地流转意愿分析——四川、湖南、湖北移民安置区的调查[J]. 资源科学,2011,06:1178-1185.
[2]叶男. 农民的土地流转意愿及其影响因素研究[J]. 统计与决策,2013,09:99-101.
SPSS实验报告_线性回归_曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
实验7相关及回归分析SPSS应用
实验7 相关与回归分析 7.1实验目的 熟练掌握一元线性回归分析的SPSS应用技能,掌握一元非线性回归分析的SPSS应用技能,对实验结果做出解释。 7.2相关知识(略) 7.3实验内容 7.3.1一元线性回归分析的SPSS实验 7.3.2一元非线性回归分析的SPSS实验 7.4实验要求 7.4.1准备实验数据 1.线性回归分析数据 (The Wall 美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》 Street Journal Almanac 1999)上。航班正点到达的比率和每10万名乘客投诉 的次数的数据,见表7-1所示。 表7-1 美国航空公司航空正点率与乘客投诉次数资料 2.非线性回归分析数据 1992~2013年某国保费收入与国内生产总值的数据,试研究保费收入与国内生产
总值的关系的数据,见表7-2所示。 表7-2 1992~2013年某国保费收入与国内生产总值数据 单位:万元 7.4.2完成一元线性回归分析的SPSS 实验,对实验结果作出简要分析。 7.4.3完成一元非线性回归分析的SPSS 实验,对实验结果作出简要分析。 7.5实验步骤 7.5.1 完成一元线性回归分析的SPSS 实验步骤 1.运用SPSS 绘制散点图散点图。 第一步:在excel 中输入数据 图7-1 第二步:将excel 数据导入spss 单击打开数据文档按钮(或选择菜单文件→打开)→选择文件航空公司航班
正点率与投诉率.xls 图7-2 第三步:选择菜单图形→旧对话框→散点/点状,在散点图/点图对话框中, 选择简单分布按钮 图7-3 第三步:在简单散点图对话框中,将候选变量框中的投诉率添加到Y轴,航班正点率添加到X轴,点击确定:
多元线性回归SPSS实验报告
回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
spss软件分析异常值检验实验报告
实验五:残差分析 【实验目的】 (1)通过残差检验,掌握残差分析的方法 (2)异常值检验 【仪器设备】 计算机、spss软件、何晓群《实用回归分析》表和表的数据 【实验内容、步骤和结果】 对何晓群《实用回归分析》表的数据进行残差分析 原始数据如表1,其中y表示货运总量(亿吨)x1表示工业总产值(亿元)x2表示农业总产值(亿元)x3表示居民非商业支出(亿元) 表1. 对表1数据用spss软件进行分析得以下各表
由上表可知复相关系数R=,决定系数R方=,由决定系数看出回归方程的显著性不高,接下来看方差分析表3 由表3知F值为较小,说明x1、x2、x3整体上对y的影响不太显著。 表4系数 模型非标准化系数标准系数 t Sig. B标准误差试用版 1(常量).096 x1.385.100 x2.535.049 x3.277.284
表4系数 模型 非标准化系数 标准系数 t Sig. B 标准 误差 试用版 1 (常量) .096 x1 .385 .100 x2 .535 .049 x3 .277 .284 回归方程为 123348.280 3.7547.10112.447y x x x =-+++
图1.学生化残差
差 残差: 对数据用spss进行分析得 表6异常值的诊断分析
数据不存在异常值.绝对值最大的删除学生化残差为SDR=,因而根据学生化删除残差诊断认为第6个数据为异常值.其中中心化杠杆值,cook距离为位于第一大.因此第6个数据为异常值. 对何晓群《实用回归分析》表的数据进行残差分析 原始数据为 : 表个啤酒品牌的广告费用和销售量
回归分析实验报告
实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日
一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1)
图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏
5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。
相关分析与回归分析SPSS实现
相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS 软件进行相关分析和回归分析,具体包括: (1) 皮尔逊pearson 简单相关系数的计算与分析 (2) 学会在SPSS 上实现一元及多元回归模型的计算与检验。 (3) 学会回归模型的散点图与样本方程图形。 (4) 学会对所计算结果进行统计分析说明。 (5) 要求试验前,了解回归分析的如下内容。 ? 参数α、β的估计 ? 回归模型的检验方法:回归系数β的显著性检验(t -检验);回归 方程显著性检验(F -检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson 简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进行检验和判断,并进行预测等。 线性回归数学模型如下: i ik k i i i x x x y εββββ+++++= 22110 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: i ik k i i i e x x x y +++++=ββββ????22110 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量
SPSS软件应用于相关分析与回归分析
实验五 SPSS软件应用于 相关分析与回归分析 学院:动物科技学院 班级:动科101 姓名:李貌 学号:2010020407
实验五SPSS软件应用于相关分析与回归分析 一、实验目的: 1、理解线性相关分析和回归分析的意义及应用并对有关数据进行分析。 2、熟悉SPSS软件应用于相关分析和回归分析的操作和步骤。 3、进一步掌握运用SPSS软件处理数据和分析数据的能力。 二、实验内容: 玉米在盐胁迫后的萎焉程度(R)与根中蛋白(R)、叶中蛋白(L)、脯氨酸(pro)之间关系如下,试进行变量间的相关分析、回归分析。 萎焉度(Y)/% 根中蛋白(R)/% 叶中蛋白(L)/% 脯氨酸(pro)/% 0.9300 0.79 0.98 0.093 0.9547 0.99 1.02 0.105 0.9661 0.91 1.58 0.119 0.9678 1.01 1.47 0.155 0.9725 1.14 1.89 0.234 0.9735 1.36 1.32 0.251 0.9856 1.36 1.76 0.217 1.0032 1.19 2.61 0.271 1.0045 1.21 2.33 0.227 1.0075 1.06 2.88 0.270 1.0186 1.58 2.40 0.282 1.0201 1.30 2.40 0.557 1.0245 1.81 2.37 0.650 1.0260 1.88 2.59 0.622 1.0283 1.46 3.10 0.611 1.0364 1.68 3.36 0.657 三、实验步骤: (一、线性回归分析) 1、启动SPSS,进行变量定义和数据录入,如(图1、2)。
相关分析和一元线性回归分析SPSS报告
用下面的数据做相关分析和一元线性回归分析: 选用普通高等学校毕业生数和高等学校发表科技论文数量做相关分析和一元线性回归分析。 一、相关分析 1.作散点图
普通高等学校毕业生数和高等学校发表科技论文数量的相关图 从散点图可以看出:普通高等学校毕业生数和高等学校发表科技论文数量的相关性很大。 2.求普通高等学校毕业生数和高等学校发表科技论文数量的相关系 数
把要求的两个相关变量移至变量中,因为都是定距数据,选择相关系数中的Pearson,点击确定,可以得到下面的结果:
Correlations 普通高等学校毕业生数(万人)高等学校发表科技论文数量(篇) 普通高等学校毕业生数(万人)Pearson Correlation1.998** Sig. (2-tailed).000 N1414 高等学校发表科技论文数量(篇)Pearson Correlation.998**1 Sig. (2-tailed).000 N1414 **. Correlation is significant at the 0.01 level (2-tailed). 两相关变量的Pearson相关系数=0.0998,表示呈高度正相关;相关系数检验对应的概率P值=0.000,小于显著性水平0.05,应拒绝原假设(两变量之间不具有相关性),即毕业生人数好发表科技论文数之间的相关性显著。 3.求两变量之间的相关性 选择相关系数中的全部,点击确定:
Correlations (万人)(篇) Kendall's tau_b(万人)Correlation Coefficient 1.000 1.000** Sig. (2-tailed).. N1414 (篇)Correlation Coefficient 1.000** 1.000 Sig. (2-tailed).. N1414 Spearman's rho(万人)Correlation Coefficient 1.000 1.000** Sig. (2-tailed).. N1414 (篇)Correlation Coefficient 1.000** 1.000 Sig. (2-tailed).. N1414 **. Correlation is significant at the 0.01 level (2-tailed). 注解:两相关变量(毕业生数和发表论文数)的Kendall相关系数=1.000,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。 两相关变量(毕业生数和发表论文数)的Spearman相关系数=1.000,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。 4.普通高等学校毕业生数和高等学校发表科技论文数量的相关系数
SPSS实验报告材料91487
CENTRAL SOUTH UNIVERSITY SPSS实验报告 学生王强 学号4303110516 指导教师邵留国 学院商学院 专业工商1101
实验一、数据集 实验目的:掌握基本的统计学理论,学会使用SPSS录入数据,建立SPSS数据集。 实验容: 1.3:三十名儿童身高、体重样本数据如下表所示。建立SPSS数据集。 三十名儿童身高、体重样本数据
13 14 15 男 男 男 14 14 14 168.0 164.5 153.0 50.0 44.0 58.0 28 29 30 女 女 女 15 15 15 158.0 158.6 169.0 44.3 42.8 51.1 实验步骤: 步骤一:启动SPSS。 步骤二:选择文件,新建,数据,如图。 步骤三:切换到变量视图,定义变量。其中,性别变量需要设置值标签。如图所 示。 步骤四:切换到数据视图,按照次序依次输入数据。 步骤五:保存数据。
实验结果:
实验二:统计量描述 实验目的: (1)结合图表描述掌握各种描述性统计量的构造原理及其应用。 (2)熟练掌握运用SPSS进行统计描述的基本技能。 实验容:大学生在校期间的各门课程考试成绩,尽管在学生与学生之间、院系之间、男女生之间以及不同的课程之间,都存在着各种各样的差异,但整体上的分布状况还是有规律可循的。今有两个学院共1040名男女生的统计学和经济学期末考试成绩数据,储存在SPSS数据文件中,文件名:lytjcj.sav。试运用图表描述与统计量描述的方法,对此数据展开尽可能全面和深入的描述与分析。 实验步骤: 步骤一:打开SPSS数据,文件名:lytjcj.sav。如图。
SPSS相关分析实验报告.doc
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R 值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。
(1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。 b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.000<0.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.8665<0.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操
SPSS对主成分回归实验报告
《多元统计分析分析》实验报告 2012 年月日学院经贸学院姓名学号 实验 实验成绩名称 一、实验目的 (一)利用SPSS对主成分回归进行计算机实现. (二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释. 二、实验内容 以教材例题为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用 三、实验步骤(以文字列出软件操作过程并附上操作截图) 1、数据文件的输入或建立:(文件名以学号或姓名命名) 将表数据输入spss:点击“文件”下“新建”——“数据”见图1: 图1 点击左下角“变量视图”首先定义变量名称及类型:见图2: 图2: 然后点击“数据视图”进行数据输入(图3): 图3
完成数据输入 2、具体操作分析过程: (1)首先做因变量Y与自变量X1-X3的普通线性回归: 在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4): 图4 将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5): 然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9) 其他选项按软件默认。最后点击“确定”,运行线性回归,输出相关结果(见表1-3)
应用回归分析实验报告
实验报告一、步骤: 本实验运用的是spss19.0中文版。 1.输入数据 2.画散点图
输出结果为: 3.回归分析
二、输出结果: 表一描述性统计量 均值 标准 偏差 N y 2.850 1.4347 10 x 762.00 379.746 10
表二相关性 y x Pearson 相关性y 1.000 .949 x .949 1.000 Sig. (单侧)y . .000 x .000 . N y 10 10 x 10 10 由上表可得 x与y的相关系数为0.949,在置性水平为0.05下,y与x显著相关。 表三输入/移去的变量b 模型输入的变量移去的变量方法 1 x a. 输入 a. 已输入所有请求的变量。 b. 因变量: y 表四模型汇总 模型R R 方调整 R 方标准估计的误 差 1 .949a.900 .888 .4800 a. 预测变量: (常量), x。 由上图知该回归方程的标准误差是0.4800 由图中的R 方知决定系数是0.900 表五Anova b 模型平方和df 均方 F Sig. 1 回归16.68 2 1 16.682 72.396 .000a 残差 1.843 8 .230 总计18.525 9 a. 预测变量: (常量), x。 b. 因变量: y 由ANOVA方差分析图知,此模型的回归平方和是16.682,残差平方和是1.843,总平方和是18.525;三者自由度分别为:1,8,9;回归平方和与残差平方和的平
均平方和依次为16.682,0.23;此模型的F 检验值为72.396. 表六系数a 模型 非标准化系数 标准系数 t Sig. B 的 95.0% 置信区间 B 标准 误差 试用版 下限 上限 1 (常量) .118 .355 .333 .748 -.701 .937 x .004 .000 .949 8.509 .000 .003 .005 a. 因变量: y 由上图知 (1).回归方程为0.1180.004y x ∧∧ =+ (2).回归系数的区间估计,在置信度为95%下,01ββ∧ ∧ 和的置信区间分别为(-0.701,0.937),(0.003,0.005)。 (3).10.004β∧ =,其标准误差为0,t 检验值是8.509,在显著性检验下看出y 与x 是显著相关的。 三、残差图 将spss 输出的残差作出相应的散点图如下: 从残差图上看出,残差是围绕0e =随机波动,从而模型的基本假设是满足的。
应用回归分析实验报告
重庆交通大学学生实验报告 实验课程名称应用回归分析 开课实验室数学实验室 学院理学院年级专业班 学生姓名学号 开课时间2013 至2014 学年第2 学期 评分细则评分 报告表述的清晰程度和完整性(20分) 程序设计的正确性(40分) 实验结果的分析(30分) 实验方法的创新性(10分) 总成绩 教师签名邹昌文
2.15 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经过10周时间,收集了每周加班工作时间的数据和签发新保单数目,x 为每周签发的新保单数目,y 为每周加班工作时间(小时)。 表2.7 y 3.5 1 4 2 1 3 4.5 1.5 3 5 x 825 215 1070 550 480 920 1350 325 670 1215 (1)画散点图; (2)x 与y 之间是否大致呈线性关系? (3)用最小二乘估计求出回归方程; (4)求回归标准误差?σ ; (5)给出0?β、1 ?β的置信度为95%的区间估计; (6)计算x 与y 的决定系数; (7)对回归方程做方差分析; (8)做回归系数1 ?β显著性检验; (9)做相关系数的显著性检验; (10)对回归方程做残差图并作相应的分析; (11)该公司预计下一周签发新保单01000x =张,需要的加班时间是多少? (12)给出0y 的置信水平为95%的精确预测区间和近视预测区间。 (13)给出0()E y 置信水平为95%的区间估计。 (1)将数据输入到SPSS 中,画出散点图如下:
(2)由下表可知x与y的相关系数高达0.949,大于0.8,所以x与y之间线性相关性显著。 相关性 y x Pearson 相关性y 1.000 .949 x .949 1.000 Sig. (单侧)y . .000 x .000 . N y 10 10 x 10 10
相关分析和回归分析SPSS实现
相关分析和回归分析 S P S S实现 TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-
相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS软件进行相关分析与回归分析,具体包括: (1)皮尔逊pearson简单相关系数的计算与分析 (2)学会在SPSS上实现一元及多元回归模型的计算与检验。 (3)学会回归模型的散点图与样本方程图形。 (4)学会对所计算结果进行统计分析说明。 (5)要求试验前,了解回归分析的如下内容。 参数α、β的估计 回归模型的检验方法:回归系数β的显着性检验(t-检验);回归 方程显着性检验(F-检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数与模型进行检验与判断,并进行预测等。 线性回归数学模型如下: 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量与解释变量及其函数形式,或者对数据进行加工整理之后再次估计参数。回归模型的检验包括一级检验与二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟与优度
多元回归分析实验报告
多元回归分析实验报告 【实验环境】SPSS 23.0 【实验名称】多元回归分析 【实验目的】 (1)掌握应用SPSS软件执行简单的多元回归分析,并根据统计输出结果整理报表 (2)熟悉按Enter和Stepwise等不同的方法把自变量置入回归模型,分析并报告结果 【实验内容】 1.分析前期的虚拟变量处理准备。利用“回归分析数据”执行统计分析,以便探讨主管品德、 主管工作能力、主管人际能力三个因素对员工离职倾向的影响。其中,为了排除员工性别(1=男,2=女)和组织类型(1=政府机关;2=事业单位;3=国有企业;4=非国有企业)两个因素对分析结果的干扰,通常需要把员工性别和组织类型作为控制变量建立分析模型。并且,由于上述两个控制变量均为分类变量,不宜直接置入回归模型,应将其应用重新编码为不同变量,分别将它们转换为取值为0或者1的虚拟变量。在进行虚拟变量转换时,可以把“男”作为性别的参照组,而把“政府机关”作为组织类型的参照组,以此进行转换(可以参照实验结果中的表1加以理解)。 2.按照Enter法置入解释变量执行回归分析。把主管品德、主管工作能力、主管人际能力三 个因素,以及经过上一步经过转换得到并用作控制变量的虚拟变量,同时置入模型作为IV (Independent Variable),同时注意勾选方差变化量及多重共线性检验,执行统计分析,并根据输出结果按表1要求的信息制作报表。 3.按照stepwise法置入解释变量执行回归分析。把主管品德、主管工作能力、主管人际能力 三个因素,以及经过上一步经过转换得到并用作控制变量的虚拟变量,同时置入模型作为IV(Independent Variable),同时注意勾选方法为Stepwise(步进,或译为逐步)及多重共线性检验,执行统计分析,并根据输出结果按表2要求的信息制作报表。 【实验过程】
管理统计学相关分析和回归分析的SPSS实现实验报告
相关分析和回归分析的SPSS实现 一、实验目的与要求 1.掌握t检验的SPSS实现方法。 2.熟悉单因素方差分析的SPSS实现方法。 3.了解卡方检验的SPSS的实现方法。 二、实验内容提要 1.某医生研究婴儿出生体重和双顶径的数量关系,收集了婴儿出生体重(X,g)和双顶径 (Y,mm)数据,分析两者的数量关系。 X 273 299 226 315 294 260 383 273 234 329 302 357 Y 94 88 91 99 93 87 94 93 81 94 94 91 2.某专门面向年轻人制作肖像的公司计划在国内再开设几家分店,收集了目前已开设的分 店的销售数据(Y,万元)及分店所在城市的16岁以下人数(X1,万人)、人均可支配收入(X2, 元),数据见reg.sav。试进行统计分析,并预测当X1为5,X2为2000时,Y的值是多少。 三、实验步骤 针对实验内容提要1: 步骤: 1.绘制散点图 选着分析→图表构建程序,选择简单散点图,将其拖入画布中,将双顶径拖到y轴,将 体重拖入到x轴,点击确定。 2.分析双重量相关
选着分析-相关,选择双变量,将体重和双顶径添加到变量中,点击确定。 相关性 X Y X Pearson 相关 性 1 .500 显著性(双侧) .098 N 12 12 Y Pearson 相关 性 .500 1 显著性(双侧) .098 N 12 12 从散点图上看它们比较散乱,不能认为它们有关系,因为P 值为0.98>0.05,所以认为它们的关联性不大。 针对内容提要2. 选着分析-回归-线性,点击保存,选取未标准化,点击确定
第六章 spss相关分析和回归分析
第六章 SPSS相关分析与回归分析 6.1 相关分析和回归分析概述 客观事物之间的关系大致可归纳为两大类,即 ●函数关系:指两事物之间的一种一一对应的关系,如商品的销售额和销售量之间的 关系。 ●相关关系(统计关系):指两事物之间的一种非一一对应的关系,例如家庭收入和 支出、子女身高和父母身高之间的关系等。相关关系又分为线性相关和非线性相关。 相关分析和回归分析都是分析客观事物之间相关关系的数量分析方法。 6.2 相关分析 相关分析通过图形和数值两种方式,有效地揭示事物之间相关关系的强弱程度和形式。 6.2.1 散点图 它将数据以点的的形式画在直角坐标系上,通过观察散点图能够直观的发现变量间的相关关系及他们的强弱程度和方向。 6.2.2 相关系数 利用相关系数进行变量间线性关系的分析通常需要完成以下两个步骤: 第一,计算样本相关系数r; ●相关系数r的取值在-1~+1之间 ●R>0表示两变量存在正的线性相关关系;r<0表示两变量存在负的线性相关关 系 ●R=1表示两变量存在完全正相关;r=-1表示两变量存在完全负相关;r=0表 示两变量不相关 ●|r|>0.8表示两变量有较强的线性关系;|r|<0.3表示两变量之间的线性关系较 弱 第二,对样本来自的两总体是否存在显著的线性关系进行推断。 对不同类型的变量应采用不同的相关系数来度量,常用的相关系数主要有Pearson简单相关系数、Spearman等级相关系数和Kendall τ相关系数等。 6.2.2.1 Pearson简单相关系数(适用于两个变量都是数值型的数据) Pearson简单相关系数的检验统计量为: 6.2.2.2 Spearman等级相关系数 Spearman等级相关系数用来度量定序变量间的线性相关关系,设计思想与Pearson简 x y,而是利单相关系数相同,只是数据为非定距的,故计算时并不直接采用原始数据(,) i i
回归分析实验报告模板及范例
填写说明 1、填写实验报告须字迹工整,使用黑色钢笔或签字笔填写。 2、课程编号和课程名称必须和教务系统中保持一致,实验项目名称填写须完整规范,不能省略或使用简称。 3、每个实验项目应填写一份实验报告。如同一个实验项目分多次进行,可在实验报告中写明。
实验目录及成绩登记 说明:实验项目顺序和名称由学生填写,必须前后保持一致;实验成绩以百分制计,由实验指导教师填写并签名;实验报告部分最终成绩为所有实验项目成绩的平均值。
实验报告 实验日期: 2020 年 4 月 15日星期三
4.点击“分析”——“相关”——“双变量”,弹出双变量相关性对话框,如下图2所示,选中IQ、语文成绩和数学成绩作为我们研究的变量;因为变量都是等距变量,选中系统默认的”皮尔逊(N)”这一相关系数,选中系统默认的“双侧检验(T)”;勾选”标记显著性相关(F)”以便于在导出的结果中将具有统计学意义的数据标记出来。 表2
5.在双变量相关性对话框中,点击“选项”,弹出对话框,如下图3所示,选中“平均值和标准差(M)、叉积偏差和协方差(C)”就可以在输出的数据中,显示上述三个变量的这两种的统计情况;在缺失值中,勾选系统默认的“成对排除个案(P)”,这样在我们分析过程中,遇到缺失值,就会成对排除在数据之外。 表3 6.点击“确定”,自动导出数据 CORRELATIONS /VARIABLES=IQ 语文成绩数学成绩 /PRINT=TWOTAIL NOSIG /STATISTICS DESCRIPTIVES XPROD /MISSING=PAIRWISE. 相关性 (1)描述性统计量表,如下表a; (2)相关性表,如下表b。 (二)第六章第四题——简单线性回归分析 1、课程了解学习 回归分析则是研究分析某一变量受别的变量影响的分析方法,它以被影响变量为因变量,以影响变
统计分析软件SPSS实验报告.docx
实验报告课程名称:统计分析软件(SPSS)
学生实验报告一、实验目的及要求 二、实验描述及实验过程
(一)、利用SPSS绘制统计图 1、打开“职工数据.sav”,调用Graphs 菜单的Bar功能,绘制直条图。直条图用直条的长短来表示非连续性资料的数量大小。弹出Bar Chart定义选项。 2、在定义选项框的下方有一数据类型栏,大多数情形下,统计图都是以组为单位的形式来体现数据的。在定义选项框的上方有3种直条图可选:Simple为单一直条图、Clustered 为复式直条图、Stacked为堆积式直条图,本实验选单一直条图。 3、点击Define钮,弹出Define Clustered Bar: Summaries for groups of cases对话框,在左侧的变量列表中选基本工资点击按钮使之进入Bars Represent栏的Other summary function选项的Variable框,选性别/文化程度/职称点击按钮使之进入Category Axis框。
4、点击Titles钮,弹出Titles对话框,在Title栏内输入“不同性别的基本工资状况”/“不同职称的基本工资状况”/“不同文化程度的基本工资状况”,点击Continue钮返回Define Clustered Chart: Summaries for groups of cases对话框,再点击OK钮即完成。(二)、用SPSS求描述性统计量 1.点击analyze中的Descriptive Statistics选择frequencies,弹出一个frequencies对话框,选中基本工资和年龄拖入Variable(s)列 2.点击statistics选择相应的统计量(例如:Mean,.median,mode等)