差异性、优效性、等效性和非劣效性检验的区别

差异性、优效性、等效性和非劣效性检验的区别
在临床研究工作中,我想大部分临床研究者都听说过优效性、等效性和非劣效性检验等,有很多人也很明白,但也有人尚不太清楚它们之间的区别,本期我们将和大家一起来讨论这一问题。
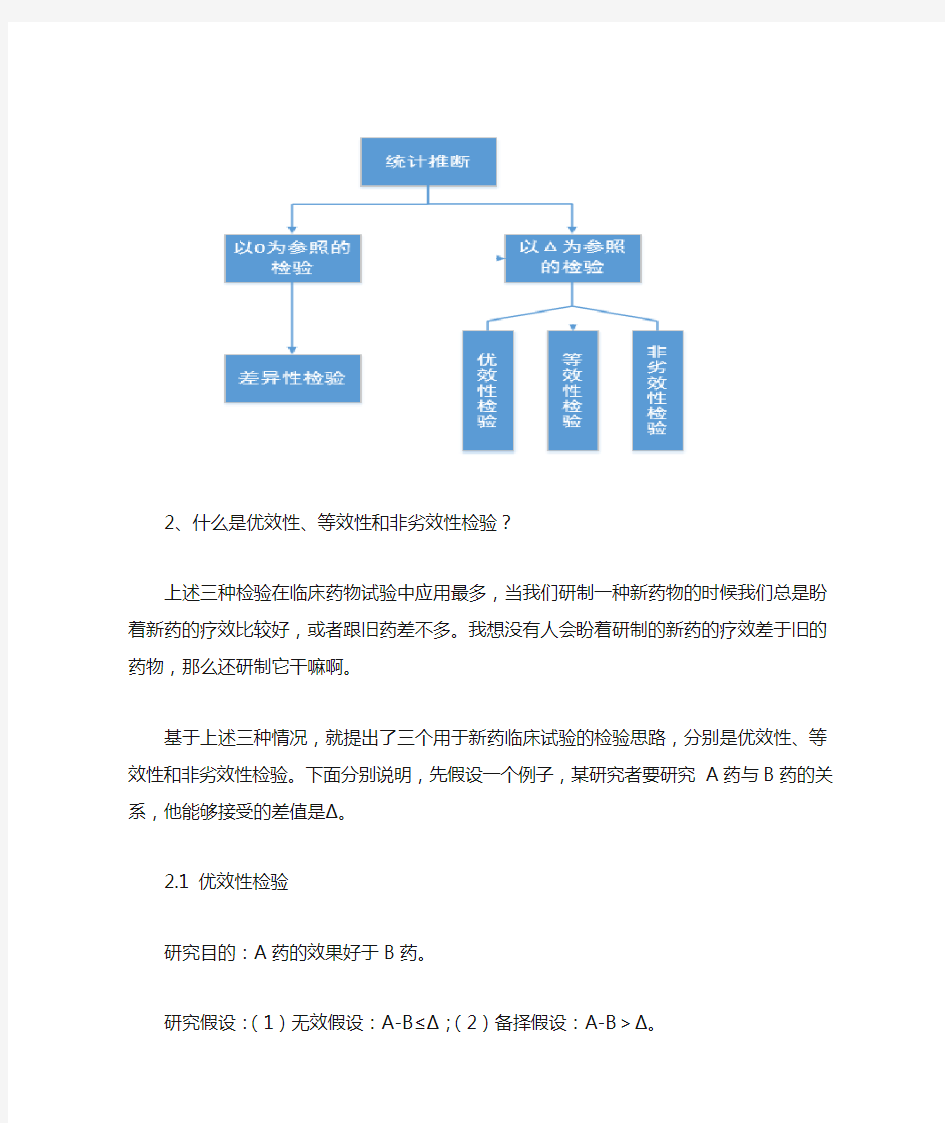
1、什么是差异性检验?
差异性检验,大家天天都在用,其实大家的论文里大部分用的都是差异性检验。比如独立样本t检验,两个可选的假设分别是A=B和A≠B。这就是差异性检验,或者叫不等的检验,意思就是A和B两组有差异、不相等。什么意思呢?就是检验A-B=0这一公式成立与否。
比如同一批病人,我们随机分成A和B组,然后检验A组和B组患者血红蛋白水平的高低,这就是差异性检验。即A组和B组之间有差异,什么叫有差异,就是两组间的差异不等于0。
跟上述内容相反的是,当我们将A组和B组之间的差异跟一个既定的值(Δ)比较时,就产生了一系列的检验,如优效性、等效性和非劣效性检验。
下面这个图可以先看一下:
2、什么是优效性、等效性和非劣效性检验?
上述三种检验在临床药物试验中应用最多,当我们研制一种新药物的时候我们总是盼着新药的疗效比较好,或者跟旧药差不多。我想没有人会盼着研制的新药的疗效差于旧的药物,那么还研制它干嘛啊。
基于上述三种情况,就提出了三个用于新药临床试验的检验思路,分别是优效性、等效性和非劣效性检验。下面分别说明,先假设一个例子,某研究者要研究A药与B药的关系,他能够接受的差值是Δ。
2.1 优效性检验
研究目的:A药的效果好于B药。
研究假设:(1)无效假设:A-B≤Δ;(2)备择假设:A-B>Δ。
备注:用来证实新药A的效果好于旧药B,来判断新药A上市的情况。它是一个单侧的检验。
2.2 等效性检验
研究目的:A药的效果等于B药。
研究假设:(1)无效假设:A-B≤-Δ或A-B≥Δ;(2)备择假设:-Δ<A-B <Δ。
备注:常用于同一活性成分的药物之间的疗效比较,证实的是A药和B药的疗效相当。它可以是单侧也可以是双侧的检验。
2.3 非劣效性检验
研究目的:A药的效果不差于于B药。
研究假设:(1)无效假设:A-B≤-Δ;(2)备择假设:A-B>-Δ。
备注:如果A药因给药方便、耐受性好等原因,只要A药的疗效不差于B药即可。非劣效性检验的样本量估算与等效性检验基本一致,不同是非劣效检验是单侧检验,而等效性检验单侧、双侧均可。
说了那么多大家来看个图吧,请注意该图是以研究目的来分类:
3、在优效、等效和非劣效检验中临界值Δ取多少合适?
临界值Δ的大小应该由临床专家来确定,一般是从专业角度反复论证并结合。不同的研究、不同科室的课题应该有自己的Δ,如有人提出[1]血压可取
Δ=5mmHg,胆固醇可取Δ=0.52mmol/L(20mg/dl),白细胞可取Δ=500个/mm3等,当Δ难以确定时,可酌情取1/5-1/2个标准差或对照组均数的1/10-1/5。
我觉得Δ的确定至关重要,最好还是要参考本领域的大部分研究以及专家学者的意见来确定。
非劣效性、等效性临床试验(优选内容)
优效性试验(superiority)—显示优效性的设计通过安慰剂对照试验显示优于安慰剂或优于阳性药,或由剂量反应关系证实疗效是最可信的。此类试验称为优效性试验。 非劣效性(non-inferiority)—试验/等效性(equivalence)试验—显示非劣效性或等效性的设计,以阳性药物为对照,试验的目标是显示试验药物的疗效与某种已知的阳性药物“不差”或“相当”,分别称为非劣效性试验和等效性试验 稳定性假设(constancy assumption)—指阳性对照药物在既往研究(对安慰剂)中的效应量在当前的非劣效性或等效性试验保持不变。 检测灵敏度(assay sensitivity)—分辨某种治疗与较差的治疗或无效的治疗之间差别的能力,对优效性试验、非劣效性试验与等效性试验具有不同的意义。优效性试验如果是成功的,即试验显示出试验药与安慰剂之间的差别,则检验灵敏度自然成立;对非劣效性和等效性试验而言,如果阳性药没有检测灵敏度,一个无效的试验药可能会因为非劣效性而错误地确认其疗效。{无效药如何得出非劣效性} 一、非劣效性/等效性试验中的样本含量估计 (一)决定非劣效性/等效性试验样本含量估计的要素 1. 非劣效性(non-inferiority)/等效性(equivalence)界值从临床
意义上确认药物的疗效,需要事先确认评价的界值。在优效性试验中,界值指试验药和对照药之间相差的临床上认可的最小值。在非劣效性试验中指临床上可接受的最大值。对非劣效性和等效性试验,它必须小于阳性对照药与安慰剂比较时的效应差值(如果已知,可取去1/3或1/2)。界值的确定需要由主要研究者从临床意义上和统计学专业人员才统计学意义上共同商定,而不是单独依赖于主要研究者或统计学专业人员。优效性试验和非劣效性试验仅用一个界值,用δ0表示;而等效性试验要用劣侧和优侧两个界值,分别用δ01和δ02表示,理论上两侧界值可以取不等距,但实际上有一般取等距。界值确定必须在实验设计阶段完成,并在试验方案中阐明,如有修订,必须在揭盲之前进行并阐述理由,一旦揭盲,不得修改。这一点很重要,若不遵守,则很容易陷入“数字游戏”的危险。 根据既往经验,对有些临床定量指标具有专业意义上的变化量,{血压实验组—血压对照组}可根据粗略的界值参考标准,例如血压可取为0.67kPa(5mmHg),胆固醇可取为0.52mmol/L(20mg/dl),白细胞可取为0.5x109/L(500个/mm3)。非劣效性/等效性试验经常是对变化量间的比较,相应的界值(指变化量之间的差值)应更小{血压变化值实验组—血压变化值对照值},例如血压变化值的等效界值可取为0.4kPa(3mmHg),胆固醇变化值的等效界值可取为0.26mmol/L(10mg/dl),白细胞变化值的等效界值可取为0.2x109/L(200个/mm3)。当难以确定时,可酌取1/5~1/2个标准差或参比组均数的1/10~1/5等。{变化值的标准差和变化值的
【科普】差异性、优效性、等效性和非劣效性检验的区别
【科普】差异性、优效性、等效性和非劣效性检验的区别差异性检验 在临床研究工作中,我想大部分临床研究者都听说过优效性、等效性和非劣效性检验等,但有很多人尚不太清楚它们之间的区别,本期我们将和大家一起来讨论这一问题。 1、什么是差异性检验? 差异性检验,大家天天都在用,其实大家的论文里大部分用的都是差异性检验。比如独立样本t检验,两个可选的假设分别是A=B 和A≠B。这就是差异性检验,或者叫不等的检验,意思就是A和B 两组有差异、不相等。什么意思呢?就是检验A-B=0这一公式成立与否。 比如同一批病人,我们随机分成A和B组,然后检验A组和B 组患者血红蛋白水平的高低,这就是差异性检验。即A组和B组之间有差异,什么叫有差异,就是两组间的差异不等于0。 跟上述内容相反的是,当我们将A组和B组之间的差异跟一个既定的值(Δ)比较时,就产生了一系列的检验,如优效性、等效性和非劣效性检验。 优效性、等效性和非劣效性检验1 跟上述内容相反的是,当我们将A组和B组之间的差异跟一个既定的值(Δ)比较时,就产生了一系列的检验,如优效性、等效性和非劣效性检验。 2、什么是优效性、等效性和非劣效性检验?
上述三种检验在临床药物试验中应用最多,当我们研制一种新药物的时候我们总是盼着新药的疗效比较好,或者跟旧药差不多。我想没有人会盼着研制的新药的疗效差于旧的药物,那么还研制它干嘛啊。基于上述三种情况,就提出了三个用于新药临床试验的检验思路,分别是优效性、等效性和非劣效性检验。下面分别说明,先假设一个例子,某研究者要研究A药与B药的关系,他能够接受的差值是Δ。 优效性、等效性和非劣效性检验2 2.1 优效性检验 研究目的:A药的效果好于B药。 研究假设:(1)无效假设:A-B≤Δ;(2)备择假设:A-B>Δ。 备注:用来证实新药A的效果好于旧药B,来判断新药A上市的情况。它是一个单侧的检验。 2.2 等效性检验 研究目的:A药的效果等于B药。 研究假设:(1)无效假设:A-B≤-Δ或A-B≥Δ;(2)备择假设:-Δ<A-B<Δ。 备注:常用于同一活性成分的药物之间的疗效比较,证实的是A 药和B药的疗效相当。它可以是单侧也可以是双侧的检验。 2.3 非劣效性检验 研究目的:A药的效果不差于于B药。 研究假设:(1)无效假设:A-B≤-Δ;(2)备择假设:A-B>-Δ。备注:如果A药因给药方便、耐受性好等原因,只要A药的疗效不
非劣效、等效性、优效性
非劣效、等效性、优效性
非劣效、等效和优效性检验及其适用范围 摘要:在对国内临床研究报告的审评中我们经常遇到以传统的显著性检验代替非劣效等设计的检验的情况,下文探讨了二者的区别及适用范围。 关键词:非劣效试验等效性试验优效性试验 一、传统检验和区间检验 药品的临床试验一般要求设计为随机、盲法和对照药物比较的研究,以判断和区别其实际的疗效如何,审评中我们常见到的错误是采用如下传统的假设检验: 无效假设H0: A药的疗效-B药的疗效=0 备择假设H1:A药的疗效≠B药的疗效 结论:如P>0.05,按α=0.05的检验水准不能拒绝H0假设,如P≤0.05,则接受H1假设。 目前已经公认这种传统的假设检验(又称显著性检验)用于临床试验判断药物的疗效是不合理的,它不能准确区分两药疗效差异的方向性和体现差异大小所揭示的临床实际意义,因此国际普遍采用非劣效、等效或优效性假设检验。 传统的假设检验之所以不合理,在于两个方面,一方面它所推断的是两个总体均数在统计学是否不相等,是纯粹的统计学意义,而
未体现实际的临床意义,虽然有单双侧之分,如单侧为H0:μ1-μ2=0,H1: μ1-μ2>0(或μ1-μ2<0),但它检验的依然是样本所代表的总体均数的统计学含义,而未将实际临床意义包含进来考虑。另一方面,对于传统检验的结论,如P>0.05,表示两药疗效的差别无统计学意义, 不拒绝H0假设,说明现有数据尚无法对两药疗效的总体均数是否不等的判断下结论,并不是当然的接受H0假设,并非认为H0假设必然成立而两药疗效的总体均数一定相等,此时有可能两药疗效的总体均数确实相似,也有可能是检验效能(把握度)不够,尚需更大样本量进行检验;如P≤0.05,两药疗效的差别有统计学意义,也就是说,两药疗效的总体均数确实不相等,但这种统计学意义的差异不一定具有实际的临床意义,也可能其临床意义却是优效、等效或非劣效的。 因此,临床试验的统计学家们提出了区间假设检验的方法,提出以临床意义的差异Δ来进行假设检验,这就是非劣效、等效和优效性检验的概念和方法。 非劣效性试验指主要研究目的是显示对试验药的反应在临床意义上不差于(非劣于)对照药的试验(ICH-E9的定义) 。如果治疗差异(A药的疗效-B药的疗效)>0,则试验药的疗效较好;治疗差异<0,则对照药疗效较好;如果我们允许A药疗效比B药疗效低一定范围,仍然认为两药疗效相当,即确定Δ表示临床意义上判断疗效不差所允许的最大差异值,则如果治疗差异>-Δ,便是试验药非劣效于对照药,此处的Δ称为非劣效试验的判断界值
如何确定非劣效试验的判断界值
如何确定非劣效试验的 判断界值 LG GROUP system office room 【LGA16H-LGYY-LGUA8Q8-LGA162】
发布日期 化药药物评价>>临床安全性和有效性评价 栏目 如何确定非劣效试验的判断界值 标题 黄钦 作者 部门 正文内容审评四部审评八室黄钦 摘要:非劣效试验中判断试验药和阳性对照药疗效相当的疗效差异至关重要,也比较复杂,下 文探讨了非劣效性试验界值确定的考虑要点及审评中的主要关注点。 关键词:非劣效性试验判断界值(margin) 非劣效、等效和优效性试验的区间检验与传统假设检验最大的不同是考虑了临床意义,以临 床意义的差异Δ来进行假设检验,那么,如何确定这个疗效差异的判断界值至关重要,若Δ 太大,将把疗效远不如对照药的药物判断为有效或等效;若Δ太小,则可能将本来可以推广 应用的有效药物误判为无效而得不到及时上市,并且所需的样本含量可能会大的不切实际,因 此Δ的确定应当合适,理论上应该是药效间具有临床意义的最大允许差异值。但实际确定起 来往往较为困难和复杂,需要根据已有的文献数据,设计类型及数据的分布类型,临床认识水 平及成本效益来综合考虑,是统计学推理和临床判断相结合的结果。没有哪本书或指导原则能 够给出一个精确无疑的算法。 非劣效试验的Δ值的确定最为复杂,通常参考阳性对照药与安慰剂间的疗效差异即阳性对照 药的绝对疗效来判定,需要达到两个目标(满足两个条件)才是适合的判断界值:使试验药物 (A)的疗效既要优于安慰剂(P)以保证药物的有效性(A-P>0),又要好到不差于阳性对照 药(B)(A-B>-Δ)。因此,ICH及EMEA等均推荐同时包括安慰剂对照和阳性对照药的三个试验 组设计的研究,试验药必须证明在统计学意义上优于安慰剂(试验产品与安慰剂差异的双侧 95%可信区间的下限必须大于0,如果试验药和参照药均未能显示在统计学意义上优于安慰剂,
非劣效、等效性、优效性
非劣效、等效和优效性检验及其适用范围 摘要:在对国内临床研究报告的审评中我们经常遇到以传统的显著性检验代替非劣效等设计的检验的情况,下文探讨了二者的区别及适用范围。 关键词:非劣效试验等效性试验优效性试验 一、传统检验和区间检验 药品的临床试验一般要求设计为随机、盲法和对照药物比较的研究,以判断和区别其实际的疗效如何,审评中我们常见到的错误是采用如下传统的假设检验: 无效假设 H0: A药的疗效-B药的疗效=0 备择假设 H1: A药的疗效≠B药的疗效 结论:如P>0.05,按α=0.05的检验水准不能拒绝H0假设,如P≤0.05,则接受H1假设。 目前已经公认这种传统的假设检验(又称显著性检验)用于临床试验判断药物的疗效是不合理的,它不能准确区分两药疗效差异的方向性和体现差异大小所揭示的临床实际意义,因此国际普遍采用非劣效、等效或优效性假设检验。 传统的假设检验之所以不合理,在于两个方面,一方面它所推断的是两个总体均数在统计学是否不相等,是纯粹的统计学意义,而未体现实际的临床意义,虽然有单双侧之分,如单侧为H0:μ1-μ2=0,H1: μ1-μ2>0(或μ1-μ2<0),但它检验的依然是样
本所代表的总体均数的统计学含义,而未将实际临床意义包含进来考虑。另一方面,对于传统检验的结论,如P>0.05,表示两药疗效的差别无统计学意义, 不拒绝H0假设,说明现有数据尚无法对两药疗效的总体均数是否不等的判断下结论,并不是当然的接受H0假设,并非认为H0假设必然成立而两药疗效的总体均数一定相等,此时有可能两药疗效的总体均数确实相似,也有可能是检验效能(把握度)不够,尚需更大样本量进行检验;如P≤0.05,两药疗效的差别有统计学意义,也就是说,两药疗效的总体均数确实不相等,但这种统计学意义的差异不一定具有实际的临床意义,也可能其临床意义却是优效、等效或非劣效的。 因此,临床试验的统计学家们提出了区间假设检验的方法,提出以临床意义的差异Δ来进行假设检验,这就是非劣效、等效和优效性检验的概念和方法。 非劣效性试验指主要研究目的是显示对试验药的反应在临床意义上不差于(非劣于)对照药的试验 (ICH-E9的定义) 。 如果治疗差异(A药的疗效-B药的疗效)>0,则试验药的疗效较好;治疗差异<0,则对照药疗效较好;如果我们允许A药疗效比B药疗效低一定范围,仍然认为两药疗效相当,即确定Δ表示临床意义上判断疗效不差所允许的最大差异值,则如果治疗差异>-Δ,便是试验药非劣效于对照药,此处的Δ称为非劣效试验的判断界值(margin)。非劣效试验的假设检验是 无效假设 H0: A药的疗效-B药的疗效≤-Δ
从临床试验实例看优效、等效和非劣效试验[1]
从临床试验实例看优效、等效和非劣效试验 - 结合一些临床试验的例子对优效、等效和非劣效试验再做一点阐述,权当加深理解吧。 让我们先看一个简单的例子(J Am Acad Dermatol 2003;48:535-41): 为了证实地氯雷他定对慢性荨麻疹的疗效和安全性,研究者设计了一项地氯雷他定对比安慰剂治疗慢性荨麻疹的随机对照双盲试验。本试验选择的主要终点是与基线相比搔痒评分的变化。假设标准差为 1.0分,每组需要100例病人在0.05的显著性水平上有90%的把握能检验出两组0.5分或更多的差别。最后结果地氯雷他定与基线相比搔痒评分的变化为 1.05,安慰剂组为0.52,p<0.001. 结论地氯雷他定可以有效治疗慢性荨麻疹。 以上这个例子就是一个最经典的优效性试验的例子,即通过安慰剂对照试验显示试验药物优于安慰剂,从而证实试验药物的疗效。这种安慰对照的优效性试验在临床试验的发展进程中起到了鼻祖的作用,以前对于某种疾病还没有治疗药物的时候,一种新药物的出现,往往会选择安慰剂对照来证实疗效,当然随着越来越多标准药物的出现,以及出于伦理等方面的考虑,现在安慰剂对照的试验也开始变少,但它在药物研发中的地位是决不能抹杀的。 随着医学的发展,现在各个疾病基本上都有自己有效的治疗药物,这时我们推出一种新药,往往在选择对照时,不得不选择那些已有的有效治疗药物,所以相比较安慰剂对照试验,阳性对照试验越来越多,而阳性对照试验最理想的情况是,你的药物优于阳性对照药物,这和上文中提及的安慰剂对照试验一样,是证实你的药物的疗效的最好的也是最有力的方法。这种阳性对照的优效性试验在现在我们的临床试验中发挥了很重要的作用,怎么说呢,一种新药的出现,如果它有突破性的进展,最大的证明就是你的疗效优于现在这种疾病的标准治疗药物,而此时阳性对照的优效性试验就是你证明你疗效的最理想的选择。 给大家介绍一个药物研发历史上一个很著名的阳性对照优效性试验的例子-EVIDENCE研究。 2003年3月8日,美国FDA正式批准瑞士雪兰诺公司的Rebif(干扰素beta-1a)治疗复发性多发性硬化。此次FDA批准Rebif上市,打破了另外一种干扰素类药物Avonex的市场专有状态,Avonex在1996年被批准用于多发性硬化的治疗。那么FDA为什么批准呢,其中最重要的依据就是一项Rebif与Avonex直接比较的研究-EVIDENCE研究,而Rebif的批准则说明了如果有另外一种药物比原有药物更有效或者更安全的话,那么就可以打破原有药物的市场专有状态。 那么现在我们来看一下EVIDENCE的研究设计和结果吧。EVIDENCE研究是一项比较Rebif与Avonex两种药物治疗复发性多发性硬化效果的大规模的研究,在美国、加拿大以及欧洲的多个中心进行。677名复发性多发性硬化病人被随机分配到Rebif和Avonex
非劣效性/等效性检验的样本含量估计及软件实现
非劣效性/等效性检验的样本含量估计及软件实现 【摘要】目的:以标准治疗为对照的非劣性/等效性检验中样本含量估计及软件实现。方法:采用PASS 11软件和相关计算公式,并通过实例分析计算两样本均数和两样本率比较时所需样本含量。结果:应用软件PASS 11和所给的公式计算中,两样本均数比较时结果相等,两样本率比较时非劣效性检验所需样本含量为111例,等效性检验所需样本含量为154例,与软件结果【Abstract】Objective:To realize sample size estimation and software implementation in non-inferiority/ equivalence tests with standard therapy for comparison. Methods:Using PASS 11 and related calculation formula calculate sample size of two sample means and two sample proportions by CaseStudy.Results: The two sample means were equal by using PASS 11 and the formula given. Comparing the two sample proportions, sample size required for non-inferiority tests was 111 cases, and sample size required for equivalence tests was 154 cases, which the result was very close to software等效性检验:其中为样本含量,、为单侧标准正态临界值,双侧标准正态临界值,是估计的共同标准差,是等效标准(界值) 。非劣性检验为单侧检验,因此为β单侧概率,等效性检验为双侧检验,因此β为双侧概率之和[2]。 1.2两样本率比较时,样本含量估算公式为: 非劣性检验:等效性检验:其中是平均有效率,其余指标含义同前。 2软件实现 2.1两样本均数比较时样本含量估算的PASS软件实现 【例1】一个新药AAA与对照药进行Ⅱ期临床检验,确认该新药不差于阳性药。根据以往的疗效和统计学的一般要求,取, ,等效标准,已知两组共同标准差,每组需要多少病例? 2.1.1非劣性检验参数设置,见图一。 图一非劣性检验参数设置 结果显示非劣效性检验所需样本含量为112例,见图二。 图二非劣效性检验样本含量估算结果
如何确定非劣效试验的判断界值
发布日期20061120 栏目化药药物评价>>临床安全性和有效性评价 标题如何确定非劣效试验的判断界值 作者黄钦 部门 正文内容 审评四部审评八室黄钦 摘要:非劣效试验中判断试验药和阳性对照药疗效相当的疗效差异至关重要,也比较 复杂,下文探讨了非劣效性试验界值确定的考虑要点及审评中的主要关注点。 关键词:非劣效性试验判断界值(margin) 非劣效、等效和优效性试验的区间检验与传统假设检验最大的不同是考虑了临床意义,以临床意义的差异Δ来进行假设检验,那么,如何确定这个疗效差异的判断界值 至关重要,若Δ太大,将把疗效远不如对照药的药物判断为有效或等效;若Δ太小, 则可能将本来可以推广应用的有效药物误判为无效而得不到及时上市,并且所需的样 本含量可能会大的不切实际,因此Δ的确定应当合适,理论上应该是药效间具有临床 意义的最大允许差异值。但实际确定起来往往较为困难和复杂,需要根据已有的文献 数据,设计类型及数据的分布类型,临床认识水平及成本效益来综合考虑,是统计学 推理和临床判断相结合的结果。没有哪本书或指导原则能够给出一个精确无疑的算
法。 非劣效试验的Δ值的确定最为复杂,通常参考阳性对照药与安慰剂间的疗效差异即阳性对照药的绝对疗效来判定,需要达到两个目标(满足两个条件)才是适合的判断界值:使试验药物(A)的疗效既要优于安慰剂(P)以保证药物的有效性(A-P>0),又要好到不差于阳性对照药(B)(A-B>-Δ)。因此,ICH及EMEA等均推荐同时包括安慰剂对照和阳性对照药的三个试验组设计的研究,试验药必须证明在统计学意义上优于安慰剂(试验产品与安慰剂差异的双侧95%可信区间的下限必须大于0,如果试验药和参照药均未能显示在统计学意义上优于安慰剂,可能提示试验不灵敏或者是测定方法不灵敏),然后要用临床判断来评价所观察到的与安慰剂的差异是否具有临床意义。因为有阳性药参照组,可有助于做出这一判断,如果参照药是经注册管理部门批准的药物,并且已知在同类型的试验中通常能得到具有临床意义的效果,那么这一试验中所见的参照药与安慰剂之间的差异有助于评价安慰剂与试验药品之间差异的 临床意义。例如,如果试验中试验组的表现优于参照组,则断定试验产品具有临床意义是合理的。 但是国内研究设计中更多见的是仅为试验药组和阳性对照组,而没有安慰剂对照组的二试验组研究,而且阳性对照药的绝对疗效常常不易确定,这时就要检索充分的文献,参考历史数据,并进行荟萃分析等以找出所采用的阳性对照药和安慰剂进行比较的同类研究,估计在目标患者人群中阳性对照药物和安慰剂之间的差异,确定药效灵敏度(Sensitivity to Drug Effects)。关于对照药的选择原则及其优缺点的考虑请参见ICH-E10的详细阐述。需要注意的是,药效灵敏度和试验的检测灵敏度(Assay Sensitivity)是不同的,很多情况下药效灵敏度难以维持恒定不变,由于临床实践可
非劣效、等效和优效性检验及其适用范围
非劣效、等效和优效性检验及其适用范围 审评四部审评八室黄钦 摘要:在对国内临床研究报告的审评中我们经常遇到以传统的显著性检验代替非劣效等设计的检验的情况,下文探讨了二者的区别及适用范围。 关键词:非劣效试验等效性试验优效性试验 一、传统检验和区间检验 药品的临床试验一般要求设计为随机、盲法和对照药物比较的研究,以判断和区别其实际的疗效如何,审评中我们常见到的错误是采用如下传统的假设检验: 无效假设H0: A药的疗效-B药的疗效=0 备择假设H1:A药的疗效≠B药的疗效 结论:如P>0.05,按α=0.05的检验水准不能拒绝H0假设,如P≤0.05,则接受H1假设。 目前已经公认这种传统的假设检验(又称显著性检验)用于临床试验判断药物的疗效是不合理的,它不能准确区分两药疗效差异的方向性和体现差异大小所揭示的临床实际意义,因此国际普遍采用非劣效、等效或优效性假设检验。 传统的假设检验之所以不合理,在于两个方面,一方面它所推断的是两个总体均数在统计学是否不相等,是纯粹的统计学意义,而未体现实际的临床意义,虽然有单双侧之分,如单侧为H0:μ1-μ2=0,H1: μ1-μ2>0(或μ1-μ2<0),但它检验的依然是样本所代表的总体均数的统计学含义,而未将实际临床意义包含进来考虑。另一方面,对于传统检验的结论,如P>0.05,表示两药疗效的差别无统计学意义, 不拒绝H0假设,说明现有数据尚无法对两药疗效的总体均数是否不等的判断下结论,并不是当然的接受H0假设,并非认为H0假设必然成立而两药疗效的总体均数一定相等,此时有可能两药疗效的总体均数确实相似,也有可能是检验效能(把握度)不够,尚需更大样本量进行检验;如P≤0.05,两药疗效的差别有统计学意义,也就是说,两药疗效的总体均数确实不相等,但这种统计学意义的差异不一定具有实际的临床意义,也可能其临床意义却是优效、等效或非劣效的。 因此,临床试验的统计学家们提出了区间假设检验的方法,提出以临床意义的差异Δ来进行假设检验,这就是非劣效、等效和优效性检验的概念和方法。 非劣效性试验指主要研究目的是显示对试验药的反应在临床意义上不差于(非劣于)对照药的试验(ICH-E9的定义) 。 如果治疗差异(A药的疗效-B药的疗效)>0,则试验药的疗效较好;治疗差异<0,则对照药
EMEA发布的《非劣效性界值选择的指导原则》
发布日期20070405 栏目化药药物评价>>临床安全性和有效性评价 标题EMEA发布的《非劣效性界值选择的指导原则》 作者黄钦 部门 正文内容 审评四部审评八室黄钦审校 伦敦,2005年7月27日索引:EMEA/CPMP/EWP/2158/99 人用药品委员会(CHMP) 生效日期2006年1月 目录 前言 1.背景 2.一般考虑 3.证明疗效
3.1 三个组的试验:试验产品、参照品和安慰剂 3.2 两个组的试验:试验产品和对照产品 3.3 不能肯定优于安慰剂的情况 4.确定与活性对照药相比可接受的疗效 5. 难以证明有合理非劣效性界值的情况 5.1使用显著性水平升高的优效性 5.2在另一方面有优势的产品 6.结论 前言 许多将一种试验产品与一种活性对照药物进行比较的临床试验被设计为非劣效性试验。目前“非劣效性”这一术语已得到普遍认可,但如果从字面上来理解可能会产生误导。非劣效性试验的目的往往声明为了证实试验产品不亚于对照药物。但只有优效性试验才能证实这一点。事实上非劣效性试验的目的是为了证实试验产品不如对照产品的程度,不超过事先指定的一个较小的量。这个量被称为非劣效性界值(non-inferiority margin),或称为Δ。 在许多情况下,可能进行非劣效性试验而不做优效性试验,或者除了做优效性试验,另外再做劣效性试验。这些情况包括: l 在某些情况下不可能进行生物等效性研究时(例如缓释产品或局部用制剂),根据基本上相似的情况提出的申请;
l 与标准治疗相比安全性方面可能有优势的产品需要与标准治疗进行疗效比较,以便进行风险-受益评价; l 需要直接与活性对照进行比较以协助风险受益评价的情况; l 与活性对照相比疗效没有显著降低可以接受的情况; l 不能用安慰剂组,要用活性对照试验以证实试验产品疗效的某些疾病。 在以上最后4种情况下,如果能显示优于参照产品则不一定要做非劣效性试验。 为证实非劣效性,推荐的方法是在方案中事先指定一个非劣效性的界值。研究完成后,计算出两种药物真正差异的双侧95%可信区间(或单侧97.5%可信区间)。这一区间应当完全在非劣效性界值(non-inferiority margin)的有利一侧。Δ的选择在临床上和统计学方面一定要合理。一定要根据特定的临床情况而具体制定,没有适用于各种情况的统一规则。但某些原则可作为一般指导。 以下法规性的指南可供参考用于选择非劣效性或等效性界值。这些指南要与本指南结合起来看。 l ICH指南E9的注释(临床试验的统计学原理)(ICH Note for Guidance E9 (Statistical Principles for Clinical Trials);
差异性、优效性、等效性和非劣效性检验的区别
差异性、优效性、等效性和非劣效性检验的区别 在临床研究工作中,我想大部分临床研究者都听说过优效性、等效性和非劣效性检验等,有很多人也很明白,但也有人尚不太清楚它们之间的区别,本期我们将和大家一起来讨论这一问题。 1、什么是差异性检验 差异性检验,大家天天都在用,其实大家的论文里大部分用的都是差异性检验。比如独立样本t检验,两个可选的假设分别是A=B和A≠B。这就是差异性检验,或者叫不等的检验,意思就是A和B两组有差异、不相等。什么意思呢就是检验A-B=0这一公式成立与否。 比如同一批病人,我们随机分成A和B组,然后检验A组和B组患者血红蛋白水平的高低,这就是差异性检验。即A组和B组之间有差异,什么叫有差异,就是两组间的差异不等于0。 跟上述内容相反的是,当我们将A组和B组之间的差异跟一个既定的值(Δ)比较时,就产生了一系列的检验,如优效性、等效性和非劣效性检验。 下面这个图可以先看一下: 2、什么是优效性、等效性和非劣效性检验
上述三种检验在临床药物试验中应用最多,当我们研制一种新药物的时候我们总是盼着新药的疗效比较好,或者跟旧药差不多。我想没有人会盼着研制的新药的疗效差于旧的药物,那么还研制它干嘛啊。 基于上述三种情况,就提出了三个用于新药临床试验的检验思路,分别是优效性、等效性和非劣效性检验。下面分别说明,先假设一个例子,某研究者要研究A药与B药的关系,他能够接受的差值是Δ。 , 优效性检验 研究目的:A药的效果好于B药。 研究假设:(1)无效假设:A-B≤Δ;(2)备择假设:A-B>Δ。 备注:用来证实新药A的效果好于旧药B,来判断新药A上市的情况。它是一个单侧的检验。 等效性检验 研究目的:A药的效果等于B药。 研究假设:(1)无效假设:A-B≤-Δ或A-B≥Δ;(2)备择假设:-Δ<A-B <Δ。 备注:常用于同一活性成分的药物之间的疗效比较,证实的是A药和B药的疗效相当。它可以是单侧也可以是双侧的检验。 非劣效性检验 研究目的:A药的效果不差于于B药。 研究假设:(1)无效假设:A-B≤-Δ;(2)备择假设:A-B>-Δ。 | 备注:如果A药因给药方便、耐受性好等原因,只要A药的疗效不差于B药即可。非劣效性检验的样本量估算与等效性检验基本一致,不同是非劣效检验是单侧检验,而等效性检验单侧、双侧均可。 说了那么多大家来看个图吧,请注意该图是以研究目的来分类: 3、在优效、等效和非劣效检验中临界值Δ取多少合适
临床非劣效性与等效性评价的统计学方法二
临床非劣效性与等效性评价的统计学方法二 第一步:非劣效性评价 单侧假设检验:z=(2+3)/1.033=4.84>1.645(z0.95),P<0.05 单侧95%可信区间下限:CL=2-1.645×1.033=0.301>-3 两种方法均显示,在抗高血压效果方面新药AII拮抗剂与标准药ACE抑制剂相比具有非劣效性。 第二步:优效性评价 单侧假设检验:z=2/1.033=1.936>1.645,P<0.05 单侧95%可信区间下限:CL=0.301>0结果表明,新药AII拮抗剂比标准药ACE 抑制剂的抗高血压效果具有统计学意义优效性。 ICHE9指导原则中的建议[1]更保守些,若按α取0.025的标准判断,非劣效性评价的z=4.84>1.96(z0.975),P<0.025,可下非劣效性结论。但是,因优效性评价的z=1.936<1.96,P>0.025,尚不能认为具有统计学优效性,更达不到临床意义上的优效性。 有一种情况值得注意,即求得的可信区间的下限大于-δ,但上限却比0小,管理当局比如美国的FDA可能仍然把试验药看作和标准药不等效,甚至比标准药还差,尽管非劣效性的标准已经达到了。这一额外增加的标准之严格,似乎并不是从统计学意义上考虑的。事实上,这对很高效地完成试验而出现了窄小的CI可能是不公正的。 4非劣效性/等效性试验样本含量估计及检验效能 对服从正态分布的数据(定量指标)和服从二项分布的数据(率指标)分别介绍。 4.1定量指标 4.1.1非劣效性试验按照单侧的检验水准α,要求允许的二类误差概率不超过β,在T=S的条件下,非劣效性试验每组需要的样本含量为: n=2[(Z1-α+z1-β)(s/δ)]2 检验效能为: 1-β=Ф[δ(2s2/n)-1/2-z1-α]
抗菌药物非劣效临床试验设计技术指导原则
附件13: 抗菌药物非劣效临床试验设计技术指导原则 一、概述 (一)抗菌药物的定义 抗菌药物(antibacterial agents)是指具有杀菌或抑菌阳性、主要供全身应用(含口服、肌注、静注、静滴等,部分也可用于局部)的各种抗生素、磺胺药、异烟肼、吡咯类、硝咪唑类、喹诺酮类、呋喃类等化学药物。本指导原则所涉及的抗菌药物仅指具有抗细菌作用的抗菌药物,且符合《药品注册管理办法》(国家食品药品监督管理局令第28号)规定的创新药物。 (二)抗菌药物的临床试验 抗菌药物临床试验遵循药物研究和开发的基本规律,遵循GCP 的相关要求,探索目标适应证和给药方案,包括单次给药剂量、给药频率和治疗持续时间的优化,最终确认药物的安全性和有效性,并为药物注册、临床应用以及说明书的撰写提供依据。简而言之,抗菌药物临床试验包含了临床药理学研究、探索性临床治疗试验和确证性临床治疗试验,并以确定产品上市的有效性为最终研究目的。 抗菌药物临床试验遵循《抗菌药物临床试验技术指导原则》的基本要求,但并不完全局限于这些要求。目前,有良好随机对照并能充分说明产品有效性的临床试验已经成为产品上市的前提条件。临床试验中统计学假设检验的选择也是确保良好临床试验的关键,目前常用的统计学假设检验类型包括优效性检验、等效性检验和非劣效性检验,其中非劣效性检验的目的是以试验药物的治疗效果在临床上不劣于阳性对照药物的形式证实试验药物的有效性。基于抗菌药物的特点和伦理学考虑,以阳性药物为对照的非劣效性统计假设已
经成为抗菌药物确证性临床试验中常用的比较方法,用以证明产品的有效性,但并不拒绝其他可行的方法。 (三)本指导原则的目的及应用范围 本指导原则旨在为药品注册申请人和临床试验研究者在进行抗菌药物的非劣效临床试验设计、实施、数据管理和分析时,提供必要的技术指导,降低研发风险,使安全有效的抗菌药物更好更早地用于临床治疗。 本指导原则仅适用于抗菌药物有效性的确证性临床治疗试验设计,不适用于各种探索性临床治疗试验设计。 本指导原则主要适用于全身用药的创新抗菌药物的临床试验。局部用药等其他创新抗菌药物的临床试验也可参照执行。 二、非劣效临床试验应用条件 以阳性药物为对照的非劣效临床试验为确证性临床试验中常用的比较方法,用以证明产品的有效性。其应用前提包括了如下要求:已经进行并基本完成了全面的药学研究、非临床安全有效性研究,质量可控性有一定基础,临床试验有一定的安全性保证,并已经获得药品监督管理机构的临床试验许可; 已经进行并基本完成了比较全面的临床药效学研究,人体耐受范围确定,人体药代动力学信息基本全面,量效关系清晰; 已经基本完成了探索性临床治疗试验,可以初步对目标病种、单次给药剂量、给药频率和治疗持续时间进行判定,但需要进一步进行确证。 三、非劣效临床试验技术要求 (一)非劣效临床试验目的 非劣效性试验的目的是证明试验药物的有效性,通过在确证性临床治疗试验中试验药物的治疗效果在临床上不劣于阳性对照药物
非劣效界值的确定
1)非劣效性界值为15%的确定依据 非劣效性界值可理解为在非劣效性试验中,试验组与对照组疗效差别的临床上可接受的最大值,通常用Δ来表示。界值的确定需要由主要研究者从临床意义上和统计学专业人员从统计学意义上共同审慎的商定,要考虑到临床特性、同类产品的临床疗效、安全性、安慰剂效应等因素。欧洲药物评审组织(EMEA)发布的《非劣效界值选择的指导原则》1(索引号:EMEA/CPMP/EWP/2158/99),以及人用药品注册技术要求国际协调会(ICH)发布的E9、E10指导原则对非劣效性界值的设置提供了基本的指导,但因该值的确定需建立在具体疾病特征、临床意义、风险/效益分析等要素基础上,所以一直缺乏具体的方法和标准。我国学者发表的文章、著作中对该问题的阐释极少,基本为对上面两个指导原则的理解,无具体方法及实例。而对于无法实施安慰剂效应的医疗器械产品,该如何采用以上两指导原则,仍然是临床研究中的盲区。 由于EMEA和ICH指导原则强调确定非劣效界值时不能忽略安慰剂效应,难以适用无“安慰器械”的医疗器械产品。故本临床试验采用美国FDA对抗感染药物临床试验推荐的递减方程(Step-down function)的方法,当同类产品疗效反应率(有效率)分别为90%、<90%但≥80%、<80%但≥70%时,推荐Δ值分别为10%、15%、20%。查询近年来椎间融合术临床疗效相关文献,得到:
结合调查数据可知,我国近年来应用椎间融合器治疗脊柱损伤、退行性病变类手术的有效率能达到80%以上,未见有效率低于80%的报道。本临床试验相关研究者认为,学术研究更多关注于某一集中症状人群的术后疗效评价,从而在研究样本中剔除了复杂的危重病例样本。而鉴于我国实际国情,就诊患者大多为危重病例,故将实际临床中的同类产品的临床有效率定为80%~90%之间更为保守稳妥,可一定程度消除研究者的偏倚性认识。根据以上结论,北京大学人民医院、中国人民解放军总医院第一附属医院主要研究者以及相关统计人员研究后认为将该项目的非劣效界值定为15%比较恰当,该值所体现的临床意义及统计学意义都比较明显。
EMEA发布的《非劣效性界值选择的指导原则》
发布日期 栏目化药药物评价>>临床安全性和有效性评价 标题EMEA发布的《非劣效性界值选择的指导原则》作者黄钦 部门 正文内容 审评四部审评八室? 黄钦审校 伦敦,2005年7月27日?? 索引:EMEA/CPMP/EWP/2158/99? 人用药品委员会(CHMP) 生效日期 2006年1月 ????????????? 目录 前言? 1.背景? 2.一般考虑? 3.证明疗效?
三个组的试验:试验产品、参照品和安慰剂? 两个组的试验:试验产品和对照产品? 不能肯定优于安慰剂的情况? 4.确定与活性对照药相比可接受的疗效? 5. 难以证明有合理非劣效性界值的情况? 使用显着性水平升高的优效性? 在另一方面有优势的产品? 6.结论? 前言 许多将一种试验产品与一种活性对照药物进行比较的临床试验被设计为非劣效性试验。目前“非劣效性”这一术语已得到普遍认可,但如果从字面上来理解可能会产生误导。非劣效性试验的目的往往声明为了证实试验产品不亚于对照药物。但只有优效性试验才能证实这一点。事实上非劣效性试验的目的是为了证实试验产品不如对照产品的程度,不超过事先指定的一个较小的量。这个量被称为非劣效性界值(non-inferiority margin),或称为Δ。 在许多情况下,可能进行非劣效性试验而不做优效性试验,或者除了做优效性试验,另外再做劣效性试验。这些情况包括: l?在某些情况下不可能进行生物等效性研究时(例如缓释产品或局部用制剂),根据基本上相似的情况提出的申请;
l?与标准治疗相比安全性方面可能有优势的产品需要与标准治疗进行疗效比较,以便进行风险-受益评价; l?需要直接与活性对照进行比较以协助风险受益评价的情况; l?与活性对照相比疗效没有显着降低可以接受的情况; l?不能用安慰剂组,要用活性对照试验以证实试验产品疗效的某些疾病。 在以上最后4种情况下,如果能显示优于参照产品则不一定要做非劣效性试验。 为证实非劣效性,推荐的方法是在方案中事先指定一个非劣效性的界值。研究完成后,计算出两种药物真正差异的双侧95%可信区间(或单侧%可信区间)。这一区间应当完全在非劣效性界值(non-inferiority margin)的有利一侧。Δ的选择在临床上和统计学方面一定要合理。一定要根据特定的临床情况而具体制定,没有适用于各种情况的统一规则。但某些原则可作为一般指导。 以下法规性的指南可供参考用于选择非劣效性或等效性界值。这些指南要与本指南结合起来看。 l?ICH指南E9的注释(临床试验的统计学原理)(ICH Note for Guidance E9 (Statistical Principles for Clinical Trials); l?ICH指南E10的注释(对照组的选择)(ICH Note for Guidance E10 (Choice
EMEA发布的非劣效性界值选择的指导原则
EMEA发布的《非劣效性界值选择的指导原则》 审评四部审评八室黄钦审校 伦敦,2005年7月27日索引:EMEA/CPMP/EWP/2158/99 人用药品委员会(CHMP) 生效日期 2006年1月 目录 前言 1.背景 2.一般考虑 3.证明疗效 3.1 三个组的试验:试验产品、参照品和安慰剂 3.2 两个组的试验:试验产品和对照产品 3.3 不能肯定优于安慰剂的情况 4.确定与活性对照药相比可接受的疗效 5. 难以证明有合理非劣效性界值的情况 5.1使用显著性水平升高的优效性 5.2在另一方面有优势的产品 6.结论 前言 许多将一种试验产品与一种活性对照药物进行比较的临床试验被设计为非劣效性试验。目前“非劣效性”这一术语已得到普遍认可,但如果从字面上来理解可能会产生误导。非劣效性试验的目的往往声明为了证实试验产品不亚于对照药物。但只有优效性试验才能证实这一点。事实上非劣效性试验的目的是为了证实试验产品不如对照产品的程度,不超过事先指定的一个较小的量。这个量被称为非劣效性界值(non-inferiority margin),或称为Δ。 在许多情况下,可能进行非劣效性试验而不做优效性试验,或者除了做优效性试验,另外再做劣效性试验。这些情况包括: l 在某些情况下不可能进行生物等效性研究时(例如缓释产品或局部用制剂),根据基本上相似的情况提出的申请; l 与标准治疗相比安全性方面可能有优势的产品需要与标准治疗进行疗效比较,以便进行风险-受益评价;
l 需要直接与活性对照进行比较以协助风险受益评价的情况; l 与活性对照相比疗效没有显著降低可以接受的情况; l 不能用安慰剂组,要用活性对照试验以证实试验产品疗效的某些疾病。 在以上最后4种情况下,如果能显示优于参照产品则不一定要做非劣效性试验。 为证实非劣效性,推荐的方法是在方案中事先指定一个非劣效性的界值。研究完成后,计算出两种药物真正差异的双侧95%可信区间(或单侧97.5%可信区间)。这一区间应当完全在非劣效性界值(non-inferiority margin)的有利一侧。Δ的选择在临床上和统计学方面一定要合理。一定要根据特定的临床情况而具体制定,没有适用于各种情况的统一规则。但某些原则可作为一般指导。 以下法规性的指南可供参考用于选择非劣效性或等效性界值。这些指南要与本指南结合起来看。 l ICH指南E9的注释(临床试验的统计学原理)(ICH Note for Guidance E9 (Statistical Principles for Clinical Trials); l ICH指南E10的注释(对照组的选择)(ICH Note for Guidance E10 (Choice of Control Group); l CPMP优效性和非劣效性转换的考虑要点(CPMP Points to Consider on Switching Between Superiority and Non-inferiority) 这些文件中,有关如何选择非劣效性界值的讨论有限。但它们确实就非劣效性研究的设计和操作作了详细的讨论。这些问题极为重要,如果试验的开展没有达到足够高的标准,那么Δ的选择就毫无意义。 本文件讨论两种类型的非劣效性试验:2个组的试验即试验产品和对照品;3个组的试验,即试验产品、活性对照药和安慰剂。 试验产品的表现有许多方面需要考虑。这些大致与疗效和安全性有关,但这些方面的每一项都可以针对每个产品细分为许多关注点。一项临床试验或临床计划可能是为了显示某些变量的非劣效性,而其他一些变量可能需要证明优效性。这份文件中“非劣效性”和“优效性”用于指单个终点而不是整个产品的特点。 始终假定治疗效果可以测定,并且测量值可以区分期望的(正面)与不期望的(负面)作用。再进一步假定所测变量的正面数值越大,则正面作用越大。
非劣效性试验
临床非劣效性与等效性评价的统计学方法 临床非劣效性与等效性评价的统计学方法 以安慰剂作为对照的随机双盲临床试验一直被视为药物开发中的金标准,它在确认新的试验药物的疗效优于安慰剂方面发挥着重要的作用。然而,如果有现成的疗效肯定的药物,仍用安慰剂对照做临床试验,会面临伦理上的困难。随着愈来愈多可供应用的有效药物的出现,疗效有突破的新药愈来愈少,因而药物临床研究的目的发生了转变。在阳性对照试验中,更多的情形是探求新药与标准的有效药物相比其疗效是否不差或疗效相等(严格地说,疗效相等应该是既不比标准药差,也不比标准药好),而并不一定要知道新药是否优于标准药,由此而提出了非劣效性/等效性试验(noninfer_iority/equivalencetrials)。 非劣效性/等效性试验与通常意义下的优效性试验(superioritytrials)在设计和统计分析上是有区别的。近年来,尽管对设计和分析该类试验已给予强调,但遗憾的是,许多非劣效性/等效性临床试验的评价缺少针对性,仍仿照安慰剂对照试验的方式进行,因而导致了非劣效性/等效性试验的样本含量估计、无效假设和备选假设确定、统计学分析和结论推断等方面的不够合理,难以达到设想的目的。 本文拟主要介绍有关非劣效性/等效性试验中涉及的统计学分析方面的一些具体问题,至于在设计时还必须考虑的有关对照的选定等问题可参考文献及ICH文件E10:“临床试验对照的选择”。 1非劣效性/等效性界值 从临床上讲,一种新药的药效不比标准对照药差,到底临床上可接受的最大允许的范围是多少呢?或者说,新药比对照药最低到多大程度才能算“非劣效(noninferiority)”呢?类似地,新药和对照药的疗效相比,最低不能低于多少以及最高不能超过多少才可认为是“等效(equivalence)”呢?这就涉及到临床非劣效性/等效性界值(nonferiority/equivalencemargin)的问题。为叙述方便,我们统一用δ表示界值,并以-δ表示劣侧界值,以δ表示优侧界值。显然,非劣效性试验仅用-δ一个界值,而等效性试验要用-δ和δ两个界值。δ是一个有临床意义的值,该值的选定至关重要。若δ选大了,将把药效达不到要求的药物判断为非劣效或等效而推向市场;若δ选小了,则可能会埋没一些本可推广使用的药物。这一数值不应大于安慰剂对照的优效性试验确认有效的效应差值△。一般来说,δ的决定应该由临床学家和统计学家商讨联合做出,而不是单独地依赖统计学家。注意,选定δ时一定要从临床药效角度,结合以往的试验结果,必要时进行成本效益分析等诸多方面反复论证。δ界值必须在试验的设计阶段决定并在试验方案中阐明,一旦确定,事后不得随意更改。除非发现新的δ界值比原先选定的δ界值更合理,在揭盲之前可作更正,并在修订方案中