样本量与置信度对应表
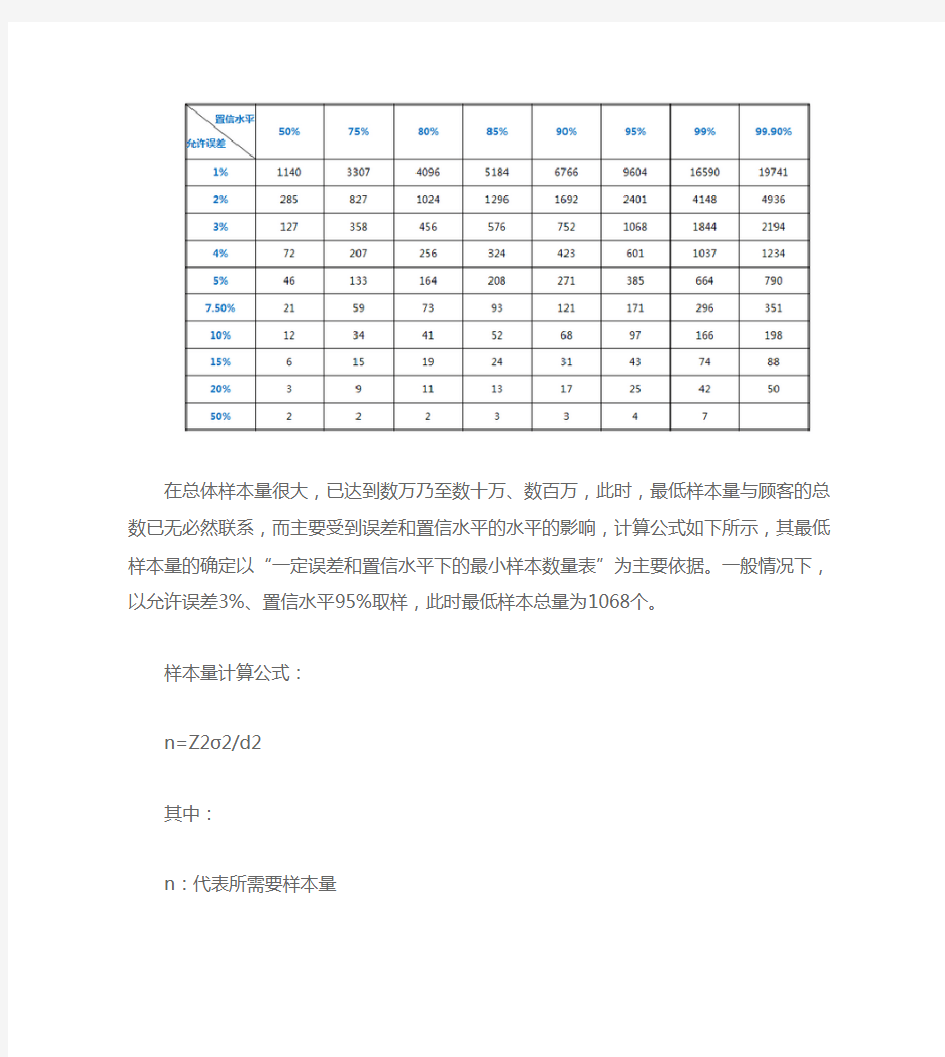

在总体样本量很大,已达到数万乃至数十万、数百万,此时,最低样本量与顾客的总数已无必然联系,而主要受到误差和置信水平的水平的影响,计算公式如下所示,其最低样本量的确定以“一定误差和置信水平下的最小样本数量表”为主要依据。一般情况下,以允许误差3%、置信水平95%取样,此时最低样本总量为1068个。
样本量计算公式:
n=Z2σ2/d2
其中:
n:代表所需要样本量
Z:置信水平的Z统计量,如95%置信水平的Z统计量为1.96,99%的Z 为2.68。
σ:总体的标准差,一般取0.5;
d:置信区间的1/2,在实际应用中就是容许误差,或者调查误差。
EXCEL显著性水平置信度置信区间
帮我通俗的解释下显著性水平和置信水平 这两个概念通俗的理解是咋样的啊,显著水平的0.05和0.01是什么意思,越高越好还是越低越好?除了0.05和0.01外还有别的值么?置信度和置信区间又是什么意思?置信度越高越好么? 回答:首先,置信水平和置信度应该是一样的,就是变量落在置信区间的可能性,“置信水平”就是相信变量在设定的置信区间的程度,是个0~1的数,用1-α表示。置信区间,就是变量的一个范围,变量落在这个范围的可能性是就是1-α。 显著性水平就是变量落在置信区间以外的可能性,“显著”就是与设想的置信区间不一样,用α表示。 显然,显著性水平与置信水平的和为1。 显著性水平为0.05时,α=0.05,1-α=0.95 如果置信区间为(-1,1),即代表变量x在(-1,1)之间的可能性为0.95。0.05和0.01是比较常用的,但换个数也是可以的,计算方法还是不变。 总之,置信度越高,显著性水平越低,代表假设的可靠性越高,越好。 置信度计算 现认为置信度在此算法中应该是用户指定一个即可。“In general,due to the weak (logarithmic)dependence on T,small settings for T(i.e.,less than 0.1)do not have a large effect on the overall window size”。 没找到较好的计算过程,先贴一段吧。 置信度: 置信度,是指特定个体对待特定命题真实性相信的程度,也就是概率是对个人信念合理性的量度。 对概率的置信度解释表明,事件本身并没有什么概率,事件之所以指派有概率只是指派概率的人头脑中所具有的信念证据。置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 置信度,也称为可靠度,或置信水平、置信系数,即在抽样对总体参数作出估计时,由于样本的随机性,其结论总是不确定的。因此,采用一种概率的陈述方法,也就是数理统计中的区间估计法,即估计值与总体参数在一定允许的误差范围以内,其相应的概率有多大,这个相应的概率称作置信度。 一般情况下,置信度是表明抽样指标和总体指标的误差不超过一定范围的概率保证度,用F(t)来表示,在大样本(n>30)条件下,置信度F(t)是概率度t函数,概率度越大,置信度越越大。假设我们指出测量结果的准确性有95%的可靠性,这个95%就称为置信度(P),又称为置信水平,它是指人们对测量结果判断的可信程度。 置信水平(Confidence level),是描述GIS中线元素与面元素的位置不确定性的重要指标之一。置信水平表示区间估计的把握程度,置信区间的跨度是置信水平的正函数,即要求的把握程度越大,势必得到一个较宽的置信区间,这就相应降低了估计的准确程度.
第四节正态总体的置信区间
第四节 正态总体的置信区间 与其他总体相比, 正态总体参数的置信区间是最完善的,应用也最广泛。在构造正态总体参数的置信区间的过程中,t 分布、2χ分布、F 分布以及标准正态分布)1,0(N 扮演了重要角色. 本节介绍正态总体的置信区间,讨论下列情形: 1. 单正态总体均值(方差已知)的置信区间; 2. 单正态总体均值(方差未知)的置信区间; 3. 单正态总体方差的置信区间; 4. 双正态总体均值差(方差已知)的置信区间; 5. 双正态总体均值差(方差未知但相等)的置信区间; 6. 双正态总体方差比的置信区间. 注: 由于正态分布具有对称性, 利用双侧分位数来计算未知参数的置信度为α-1的置信区间, 其区间长度在所有这类区间中是最短的. 分布图示 ★ 引言 ★ 单正态总体均值(方差已知)的置信区间 ★ 例1 ★ 例2 ★ 单正态总体均值(方差未知)的置信区间 ★ 例3 ★ 例4 ★ 单正态总体方差的置信区间 ★ 例5 ★ 双正态总体均值差(方差已知)的置信区间 ★ 例6 ★ 双正态总体均值差(方差未知)的置信区间 ★ 例7 ★ 例8 ★ 双正态总体方差比的置信区间 ★ 例9 ★ 内容小结 ★ 课堂练习 ★ 习题6-4 内容要点 一、单正态总体均值的置信区间(1) 设总体),,(~2σμN X 其中2σ已知, 而μ为未知参数, n X X X ,,,21 是取自总体X 的一个样本. 对给定的置信水平α-1, 由上节例1已经得到μ的置信区间 ,,2/2/???? ? ??+?-n u X n u X σσαα 二、单正态总体均值的置信区间(2) 设总体),,(~2σμN X 其中μ,2σ未知, n X X X ,,,21 是取自总体X 的一个样本. 此时可用2σ的无偏估计2S 代替2σ, 构造统计量 n S X T /μ-=, 从第五章第三节的定理知).1(~/--= n t n S X T μ 对给定的置信水平α-1, 由 αμαα-=? ?????-<-<--1)1(/)1(2/2/n t n S X n t P ,
置信区间与置信水平样本量的关系
置信区间与置信水平、样本量的关系 置信区间与置信水平、样本量的关系(2008-10-28 08:39:39)标签:置信区间与置信水平教育分类:数学相关 置信水平Confidence level 置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 一、置信区间的概念 置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。置信区间是按下列三步计算出来的: 第一步:求一个样本的均值 第二步:计算出抽样误差。 人们经过实践,通常认为调查: 100个样本的抽样误差为±10% 500个样本的抽样误差为±5% 1,200个样本时的抽样误差为±3% 第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点。 举例说明: 美国Gallup(盖洛普)公司就消费者对美国产品质量的看法,对美国、德国和日本三国共计3,500名消费者(每个国家约1,200名)分别进行了调查,调查结果:有55%的美国人认为美国产品质量好,而只有26%的德国人和17%的日本人持同样看法。抽样误差为±3%,置信水平为95%。则这三个国家消费者的置信区间分别为: 国别样本均值抽样误差置信区间 美国55% ±3% 52%-58% 德国26% ±3%23%-29% 日本17% ±3%14%-20% 二、关于置信区间的宽窄 窄的置信区间比宽的置信区间能提供更多的有关总体参数的信息。 假设全班考试的平均分数为65分,则 置信区间间隔宽窄度表达的意思 0-100分100 宽等于什么也没告诉你 30-80分50 较窄你能估出大概的平均分了(55分) 60-70分10 窄你几乎能判定全班的平均分了(65分)
抽样调查样本量确定
抽样调查样本量的确定 在贸易统计中, 对于限额以下批零餐饮企业普遍采用抽样调查方法进行解决。然而,由于当前市场经济情况的多样性,经济发展的不均衡性,以及地域宽广性,导致情况多种多样;实际情况的复杂,决定了方案的复杂性,增加了具体抽样的难度。经过多年的探讨,区域二相抽样调查比较符合当前我国的实际情况,我们在这里根据试点所掌握的情况针对采用区域二相抽样调查的贸易抽样方案中如何确定样本量进行分析。 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。
样本量的确定
样本量的确定 北京广播学院新闻传播学院 调查统计研究所 二零零一年五月 沈浩 本讲主要内容 如何计算简单随机抽样的样本量确定 如何实现分层抽样中各层样本单位数的分配样本容量的确定 样本量=费用+精度 (函数) 确定样本容量,需要处理好预定的精度与现有经费,同时也要考虑资源和时间等限 制条件,最终的样本量确定是在上述因素之间的权衡关系。分层抽样分配样本的标准 总的样本容量事先确定 估计值要求达到的精度预先给定 影响调查样本容量的因素 调查估计值所希望达到的精度 调查估计值所能允许的误差。 估计量的抽样方差较小,估计值是精确的 估计值的精度越高,所需的样本容量就越大 影响精度的因素也同样影响着样本容量的大小 所研究指标在总体中的变异程度 总体的大小
样本设计和所使用的估计量 无回答率 客户提供的经费能支持多大容量的样本 整个调查持续的时间有多长 调查需要多少访员 能招聘到的访员有多少 除了估计值的精度以外,调查实际操作的限制条件也许是影响样本容量的最大因 素。 11>(给定精度水平下样本容量的确定样本容量的大小与调查估计值所要求的精度紧密相关 数据是通过抽样而不是普查收集的,就会产生抽样误差。 精度是由抽样方差来测量的。 随着样本容量的增加,调查估计值的精度也会不断提高。标准误差 误差界限 变异系数 抽样方差的几种计量方法 抽样调查中样本容量的确定,也经常会使用一种或多种这样的计量方法来对精度进 行说明。 非抽样误差 非抽样误差会对调查估计值的精度产生显著的影响 非抽样误差的大小与样本容量的大小却没有很大的关系 确定样本容量,就不必将这些误差作为影响因素加以考虑
样本量的确定方法.
如对你有帮助,请购买下载打赏,谢谢!样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。
置信度的计算
案例:置信度的计算(大数定律) 应用背景:数字通信系统中的许多元件都必须满足一项有关误码率()(εP )的最低规范。对于一个给定系统,在输入端送入某种预定形式的比特流,然后检测其输出,通过与输入相 比较可以估测出()(εP ) 。输出与输入之间的任何一个差错均视为一次误码。检测到的错误位数(ε)与已经传送的总位数(n )之比即为误码率(),其表示是真实误码率()(?εP )(εP )的估计,估计的准确度随传送位数的增加而改进。由大数定律,其关系可表示为: )()(?εε εP n P n ??→?=+∞ → [1] 重要的是,必须传送、测试足够数目的比特数才能保证是)(?εP )(εP 的合理近似,所以,对于合理限制的测试时间,我们有必要知道完成一个统计有效的测试所需的最少位数。 分析: 在许多场合,我们仅仅需要验证)(εP 是否好于某预定标准。换句话说,只要证明)(εP 比某一上限低即可。例如,许多通信系统要求)(εP 达到或更好(上限为)。统计学中有关加以上限的置信度概念可以用来推测,在某个量化的可信度前提下,真实1010?1010?)(εP 低于规定上限。这种方法带来的主要好处,就是容许你在测试时间和测试精度之间进行折衷。 问题的解决: (1)统计置信度的定义 统计置信度定义为,经过一系列试验,某事件的实际概率优于规定水平的几率(该定义中的实际概率是指,有限次测量所得概率在试验次数趋向无限时的极限值)。应用于)(εP 估计,统计置信度可重新阐述为,(基于n 位传送中检测到ε个错误)真实)(εP 优于规定水平γ(如)的概率。用数学语言表示为: 1010? },|)({n P P CL εγε<= 其中,CL 为置信度。由定义,CL 为概率,因此其在 取值。 ]1,0[计算出统计置信度之后就可以讲,我们有百分之CL 的把握相信,)(εP 优于γ。另外一种表达,如果我们多次重复测量误码率,并对每个测量周期重复计算n P εε=)(?,那么可以预 测,有百分之CL 的优于)(?εP γ。
置信区间的解释及求取
置信区间的解释及求取-学习了解 95%置信区间(Confidence Interval,CI):当给出某个估计值的95%置信区间为【a,b】时,可以理解为我们有95%的信心(Confidence)可以说样本的平均值介于a到b之间,而发生错误的概率为5%。 有时也会说90%,99%的置信区间,具体含义可参考95%置信区间。 置信区间具体计算方式为: (1) 知道样本均值(M)和标准差(ST)时: 置信区间下限:a=M - n*ST; 置信区间上限:a=M + n*ST; 当求取90% 置信区间时n=1.645 当求取95% 置信区间时n=1.96 当求取99% 置信区间时n=2.576 (2) 通过利用蒙特卡洛(Monte Carlo)方法获得估计值分布时: 先对所有估计值样本进行排序,置信区间下限:a为排序后第lower%百分位值; 置信区间上限:b为排序后第upper%百分位值. 当求取90% 置信区间时 lower=5 upper=95; 当求取95% 置信区间时lower=2.5 upper=97.5 当求取99% 置信区间时lower=0.5 upper=99.5 当样本足够大时,(1)和(2)获取的结果基本相等。 参考资料:http://140.116.72.80/~smallko/ns2/confidence_interval.htm Confidence Limits: The range of confidence interval 附MATLAB 求取置信区间源码: %%% 置信区间的定义90%,95%,99%-------Liumin 2010.04.28 clear clc sampledata=randn(10000,1); a=0.01; %0.01 对应99%置信区间,0.05 对应95%置信区间,0.1 对应90%置信区间 if a==0.01 n=2.576; % 2.576 对应99%置信区间,1.96 对应95%置信区间,1.645 对应90%置信区间 elseif a==0.05 n=1.96; elseif a==0.1 n=1.645; end %计算对应百分位值 meana=mean(sampledata); stda=std(sampledata); sorta=sort(sampledata); %对数据从小到大排序 leng=size(sampledata,1); CIa(1:2,1)=[sorta(leng*a/2);sorta(leng*(1-a/2))]; %利用公式计算置信区间 CIf(1:2,1)=[meana-n*stda;meana+n*stda];
样本量的确定方法
样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。
置信区间与置信水平、样本量的关系
置信水平Confidence level 置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 一、置信区间的概念 置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。置信区间是按下列三步计算出来的:第一步:求一个样本的均值 第二步:计算出抽样误差。 人们经过实践,通常认为调查: 100个样本的抽样误差为±10% 500个样本的抽样误差为±5% 1,200个样本时的抽样误差为±3% 第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点。 举例说明: 美国Gallup(盖洛普)公司就消费者对美国产品质量的看法,对美国、德国和日本三国共计3,500名消费者(每个国家约1,200名)分别进行了调查,调查结果:有55%的美国人认为美国产品质量好,而只有26%的德国人和17%的日本人持同样看法。抽样误差为±3%,置信水平为95%。则这三个国家消费者的置信区间分别为: 国别样本均值抽样误差置信区间
美国55% ±3% 52%-58% 德国26% ±3%23%-29% 日本17% ±3%14%-20% 二、关于置信区间的宽窄 窄的置信区间比宽的置信区间能提供更多的有关总体参数的信息。 假设全班考试的平均分数为65分,则 置信区间间隔宽窄度表达的意思 0-100分100 宽等于什么也没告诉你 30-80分50 较窄你能估出大概的平均分了(55分) 60-70分10 窄你几乎能判定全班的平均分了(65分) 三、样本量对置信区间的影响 影响:在置信水平固定的情况下,样本量越多,置信区间越窄。 下面是经过实践计算的样本量与置信区间关系的变化表(假设置信水平相同):样本量置信区间间隔宽窄度 100 50%—70% 20 宽 800 56.2%-63.2% 7 较窄 1,600 57.5%—63% 5.5 较窄 3,200 58.5%—62% 3.5 更窄 由上表得出: 1、在置信水平相同的情况下,样本量越多,置信区间越窄。
样本量的确定方法
样本量的确定方法 The pony was revised in January 2021
样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城
部门间满意度评估表经理
部门间满意度评估表经理 Jenny was compiled in January 2021
内部客户满意度调查问卷 <部门经理用> 各位同志: 大家好! 为了更好地实现集团公司总部的绩效管理的工作,促进集团公司总部职能管理部门的工作质量的提高,人力资源部需要对职能管理部门进行客户满意度调查。 填写问卷大概需要占用您20分钟,您所提供的信息对我们、对公司非常有价值! 您的答案人力资源部将给予严格保密,每一个环节都有严格的保密控制! 期望您积极参与、客观评价,支持我们的工作。 一、行政后勤部 1.总体上,您对行政后勤部新财年的工作是否满意12345 2.您如何评价行政后勤部在新财年的工作表现 (1)有进步(2)无变化(3)有退步 3.具体有哪些变化 4.下面我们想了解一下您对该部门的看法,请您对以下选项分别进行满意度评 价 12345(2)问题解决12345(1)部门创新意 识 12345(4)工作效率12345(3)工作流程有 序 12345(6)实现承诺12345(5)持续改进服 务 (7)客户界面12345 5.您对行政后勤部的以下具体业务的满意情况如何12345 (1)在制度建设和管理政策制订上12345(2)公司物业环境的规模和建设12345
6.在问题中,如果您选择了的答案,烦请您具体说明原因,以便 具体工作的改进。 7.下季度,行政后勤部应重点加强哪些薄弱环节的工作 二、财务部 1.总体上,您对财务部新财年的工作是否满意12345 2.您如何评价财务部在新财年的工作表现 (1)有进步(2)无变化(3)有退步 3.具体有哪些变化 4.下面我们想了解一下您对该部门的看法,请您对以下选项分别进行满意度评 价 12345(2)问题解决12345(1)部门创新意 识 12345(4)工作效率12345(3)工作流程有 序 12345(6)实现承诺12345(5)持续改进服 务 (7)客户界面12345 5.您对财务部的以下具体业务的满意情况如何 (1)在制度建设和管理政策制订上12345(2)对各部门和下属企业的业务指导和支持12345 6.对财务报表工作的满意度12345 在哪些方面存在不足: (1)提供及时性(2)数据准确性(3)数据全面性 (4)其他 7.对公司经营分析工作的满意度12345 在哪些方面存在不足:
案例:置信度的计算(二项分布)
案例:置信度的计算(二项分布) 应用背景:数字通信系统中的许多元件都必须满足一项有关误码率()(εP )的最低规范。对于一个给定系统,在输入端送入某种预定形式的比特流,然后检测其输出,通过与输入相 比较可以估测出()(εP ) 。输出与输入之间的任何一个差错均视为一次误码。检测到的错误位数(ε)与已经传送的总位数(n )之比即为误码率(),其表示是真实误码率()(?εP )(εP )的估计,估计的准确度随传送位数的增加而改进。其关系可表示为: )()(?εε εP n P n ??→?=+∞ → [1] 重要的是,必须传送、测试足够数目的比特数才能保证是)(?εP )(εP 的合理近似,所以,对于合理限制的测试时间,我们有必要知道完成一个统计有效的测试所需的最少位数。 分析: 在许多场合,我们仅仅需要验证)(εP 是否好于某预定标准。换句话说,只要证明)(εP 比某一上限低即可。例如,许多通信系统要求)(εP 达到或更好(上限为)。统计学中有关加以上限的置信度概念可以用来推测,在某个量化的可信度前提下,真实1010?1010?)(εP 低于规定上限。这种方法带来的主要好处,就是容许你在测试时间和测试精度之间进行折衷。 问题的解决: (1)统计置信度的定义 统计置信度定义为,经过一系列试验,某事件的实际概率优于规定水平的几率(该定义中的实际概率是指,有限次测量所得概率在试验次数趋向无限时的极限值)。应用于)(εP 估计,统计置信度可重新阐述为,(基于n 位传送中检测到ε个错误)真实)(εP 优于规定水平γ(如)的概率。用数学语言表示为: 1010? },|)({n P P CL εγε<= 其中,CL 为置信度。由定义,CL 为概率,因此其在 取值。 ]1,0[计算出统计置信度之后就可以讲,我们有百分之CL 的把握相信,)(εP 优于γ。另外一种表达,如果我们多次重复测量误码率,并对每个测量周期重复计算n P εε=)(?,那么可以预 测,有百分之CL 的优于)(?εP γ。
部门间满意度调查评估表
<部门经理用> 1. 1 总体上,您对行政后勤部新财年的工作是否满意? 2. 2 您如何评价行政后勤部在新财年的工作表现? (1). 1 有进步 (2).2无变化 (3). 3 有退步 3. 3 具体有哪些变化? 4. 4 下面我们想了解一下您对行政后勤部的看法,请您对以下选项分别进行满 意度评价 (1). 1 矩阵式管理模式的贯彻和落实 (2). 2 部门创新意识 (3). 3 工作流程有序 (4). 4 以客户为导向持续改进服务 (5). 5 客户界面 (6). 6 问题解决 (7).7 工作效率 (8).8 实现承诺 您对行政后勤部的以下具体业务的满意情况如何? 5. 5 在制度建设和管理政策制订上 6. 6 公司物业环境的规模和建设
7.7 对事业部和大区行政后勤的指导和帮助 8.8 在问题1-7中,如果您选择了1-3的答案,烦请您具体说明原因,以便 具体工作的改进。 9.9 下季度,行政后勤部应重点加强哪些薄弱环节的工作? 1. 1 总体上,您对财务部新财年的工作是否满意? 2. 2 您如何评价财务部在新财年的工作表现? (1). 1 有进步 (2). 2 无变化 (3). 3 有退步 3. 3 具体有哪些变化? 4. 4 下面我们想了解一下您对财务部的看法,请您对以下选项分别进行满意度 评价 (1). 1 矩阵式管理模式的贯彻和落实 (2). 2 部门创新意识 (3). 3 工作流程有序 (4). 4 以客户为导向持续改进服务
(5). 5 客户界面 (6). 6 问题解决 (7).7 工作效率 (8).8 实现承诺 您对财务部的以下具体业务的满意情况如何? 5. 5 在制度建设和管理政策制订上 6. 6 对各事业部和大区专港的业务指导和支持 7.7 对财务报表工作的满意度 在哪些方面存在不足: (1).1提供及时性 (2).2 数据准确性 (3).3 数据全面性 (4).4 其他 8.8 对公司经营分析工作的满意度 在哪些方面存在不足: (1).1报告及时性 (2).2数据准确性 (3).3内容适用性 (4).4分析深入 (5).5熟悉业务 (6).6其他
置信度和置信区间
首先我们要弄清楚两个概念,置信度和置信区间 置信度:以测量值为中心,在一定范围内,真值出现在该范围内的几率。一般设定在2σ,也就是95%,95%是通常情况下置信度(置信水平)的设定值。 置信区间:在某一置信度下,以测量值为中心,真值出现的范围。 我们在论文里经常看到CI,CI是置信区间,一定概率下真值得取值范围(可靠范围)称为置信区间。其概率称为置信概率或置信度(置信水平) 真实数据往往是实际上不能获知的,我们只能进行估计,估计的结果是给出一对数据,比如从1到1.5,真实的值落在1到1.5之间的可能性是95%(也有5%的可能性在这区间之外的)。区间是由抽样的数据根据大样定律结合查表得来的。区间越小精度越高,区间越大置信度越高。打个比方,我们猜张燕燕的年龄,你给出区间是25-35,这个区间很小置信度很低但精度就很高,你说在8岁到80岁之间,那是百分百的置信度了不过精度太低毫无意义。的确99%准确度高于95%,但是它的精度(精密度)就低于95%。95%的置信度是一般通用的。
P值指的是比较的两者的差别是由机遇所致的可能性大小。P值越小,越有理由认为对比事物间存在差异。例如,P<0.05,就是说结果显示的差别是由机遇所致的可能性不足5%,或者说,别人在同样的条件下重复同样的研究,得出相反结论的可能性不足5%。P>0.05称“不显著”;P<=0.05称“显著”,P<=0.01称“非常显著”。 由于常用“显著”来表示P值大小,所以P值最常见的误用是把统计学上的显著与临床或实际中的显著差异相混淆,即混淆“差异具有显著性”和“具有显著差异”二者的意思。其实,前者指的是p<=0.05,即说明有充分的理由认为比较的二者来自同一总体的可能性不足5%,因而认为二者确实有差异,下这个结论出错的可能性<=5%。而后者的意思是二者的差别确实很大。举例来说,4和40的差别很大,因而可以说是“有显著差异”,而4和4.2差别不大,但如果计算得到的P值<=0.05,则认为二者“差别有显著性”,但是不能说“有显著差异”。
正态总体参数的区间估计
第19讲 正态总体参数的区间估计 教学目的:理解区间估计的概念,掌握各种条件下对一个正态总体的均值和方差进行 区间估计的方法。 教学重点:置信区间的确定。 教学难点:对置信区间的理解。 教学时数: 2学时。 教学过程: 第六章 参数估计 §6.3正态总体参数的区间估计 1. 区间估计的概念 我们已经讨论了参数的点估计,但是对于一个估计量,人们在测量或计算时,常不以得到近似值为满足,还需估计误差,即要求知道近似值的精确程度。因此,对于未知参数θ,除了求出它的点估计?θ外,我们还希望估计出一个范围,并希望知道这个范围包含参数θ真值的可信程度。 设?θ为未知参数θ的估计量,其误差小于某个正数ε的概率为1(01)αα-<<,即 ?{||}1P θθεα -<=- 或 αεθθεθ-=+<<-1)??(P 这表明,随机区间)?,?(εθεθ+-包含参数θ真值的概率(可信程度)为1α-,则这个区间)?,?(εθεθ+-就称为置信区间,1α-称为置信水平。 定义 设总体X 的分布中含有一个未知参数θ。若对于给定的概率1(01)αα-<<,存在两个统计量1112(,,,)n X X X θθ= 与2212(,,,)n X X X θθ= ,使得 12{}1P θθθα <<=-
则随机区间12(,)θθ称为参数θ的置信水平为1α-的置信区间,1θ称为置信下限,2θ称为置信上限,1α-称为置信水平。 注(1)置信区间的含义:若反复抽样多次(各次的样本容量相等,均为n ),每一组样本值确定一个区间12(,)θθ,每个这样的区间要么包含θ的真值,要么不包含θ的真值。按伯努利大数定理,在这么多的区间中,包含θ真值的约占100(1)%α-,不包含θ真值的约仅占100%α。例如:若0.01α=,反复抽样1000次,则得到的1000个区间中,不包含θ真值的约为10个。 (2)置信区间的长度表示估计结果的精确性,而置信水平表示估计结果的可靠性。对于置信水平为1α-的置信区间12(,)θθ,一方面置信水平1α-越大,估计的可靠性越高;另一方面区间12(,)θθ的长度(2)ε越小,估计的精确性越好。但这两方面通常是矛盾的,提高可靠性通常会使精确性下降(区间长度变大),而提高精确性通常会使可靠性下降(1α-变小),所以要找两方面的平衡点。 在学习区间估计方法之前,我们先介绍标准正态分布的α分位点概念。 设 () ~0,1X N ,若 z α 满足条件 { },01 P X z α αα>=<<,则称点z α为标准正态分布的α分位点。例如求0.01z 。按照α分位点定义,我们有 {}0.010.01P X z >=,则{}0.010.99P X z ≤=,即0.01()0.99z φ=。查表可得0.01 2.327z =. 又 由()x ?图形的对称性知1z z αα-=-。下面列出了几个常用的z α值: 2. 正态总体均值μ的区间估计 设已给定置信水平为1α-,总体()2~,X N μσ,12,,,n X X X 为一个样本,2 ,X S 分别是样本均值和样本方差。
置信区间与置信水平
“置信区间与置信水平、样本量的关系 置信水平Confidence level 置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 一、置信区间的概念 置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。置信区间是按下列三步计算出来的: 第一步:求一个样本的均值 第二步:计算出抽样误差。 人们经过实践,通常认为调查: 100个样本的抽样误差为±10% 500个样本的抽样误差为±5% 1,200个样本时的抽样误差为±3% 第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点。 举例说明: 美国Gallup(盖洛普)公司就消费者对美国产品质量的看法,对美国、德国和日本三国共计3,500名消费者(每个国家约1,200名)分别进行了调查,调查结果:有55%的美国人认为美国产品质量好,而只有26%的德国人和17%的日本人持同样看法。抽样误差为±3%,置信水平为95%。则这三个国家消费者的置信区间分别为: 国别样本均值抽样误差置信区间 美国55% ±3% 52%-58% 德国26% ±3% 23%-29% 日本17% ±3% 14%-20% 二、关于置信区间的宽窄 窄的置信区间比宽的置信区间能提供更多的有关总体参数的信息。 假设全班考试的平均分数为65分,则 置信区间间隔宽窄度表达的意思 0-100分 100 宽等于什么也没告诉你 30-80分50 较窄你能估出大概的平均分了(55分) 60-70分10 窄你几乎能判定全班的平均分了(65分) 三、样本量对置信区间的影响 影响:在置信水平固定的情况下,样本量越多,置信区间越窄。 下面是经过实践计算的样本量与置信区间关系的变化表(假设置信水平相同): 样本量置信区间间隔宽窄度 100 50%—70% 20 宽 800 56.2%-63.2% 7 较窄 1,600 57.5%—63% 5.5 较窄 3,200 58.5%—62% 3.5 更窄 由上表得出: 1、在置信水平相同的情况下,样本量越多,置信区间越窄。
抽样调查样本量确定.
抽样调查样本量确定.
抽样调查样本量的确定 在贸易统计中, 对于限额以下批零餐饮企业普遍采用抽样调查方法进行解决。然而,由于当前市场经济情况的多样性,经济发展的不均衡性,以及地域宽广性,导致情况多种多样;实际情况的复杂,决定了方案的复杂性,增加了具体抽样的难度。经过多年的探讨,区域二相抽样调查比较符合当前我国的实际情况,我们在这里根据试点所掌握的情况针对采用区域二相抽样调查的贸易抽样方案中如何确定样本量进行分析。 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1研究对象的变化程度,即变异程度; (2要求和允许的误差大小,即精度要求; (3要求推断的置信度,一般情况下,置信度取为95%; (4总体的大小; (5抽样的方法。
也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样 本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算 样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根 据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。 1.简单随机抽样确定样本量主要有两种类型: (1对于平均数类型的变量 对于已知数据为绝对数,我们一般根据下列步骤来计算所需要的样本量。已知期望调查 结果的精度(E, 期望调查结果的置信度(L,以及总体的标准差估计值σ的具体数据,总体
样本量的确定方法
样本量的确定方法 (2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,
培训满意度评估表
亲爱的同事: 培训效果反馈评估表 欢迎您参加本次培训。为有效了解您在此次课程中的收获、评估本次课程、讲师以及组织工作的专业水平,收集您对培训的意见和建议,请填写以下表格,以利于我们改进工作,为您提供更优质的培训。 请用“”标示您选择的项目。 一、培训内容信息/请填写(可事先录入,一并打印) 培训项目名称开课时间培训地点主讲 全民经纪人操作流程及后台操作 二、您对培训课程的评价 请打分,1 分最低,10 分最高(6 分为及格)12345678910 1.课程内容与需求的符合程度 2.课程内容对工作的帮助程度 3.课程体系设计(重点/条理/深 4.时间安排合理程度 5.教学方法(练习/案例)的有效程度 三、您对培训讲师的评价 请打分,1 分最低,10 分最高(6 分为及格)12345678910 6.专业水平高且课程准备充分 7.良好的表达能力、讲解清晰 8.善于安排课堂活动,促进互动 9.鼓励学员参与,有效回答问题 10.时间把握及现场控制良好 11.为人师表、富有激情和热忱 四、您对培训组织服务的评价 请打分,1 分最低,10 分最高(6 分为及格)12345678910 12.对培训场地、布置的满意度 13.对培训系列准备的满意度 14.视频培训音像质量的满意度 五、您的总体评价 15.您在本培训中的收获:□5 很多□4较多□3 还可以□2 较少□1几乎没有□不好说 16.对本培训的满意度:□ 100% □ 90% □80% □70% □60% □50% □ 40% □30% □20% □10% 六、您的心得与建议 17.本次培训收获最大的两点是:18.本次培训最需要改进的两点是: 19.您最迫切需要但本次培训没有涉及到的是: