loadrunner基本使用流程及结果分析(图文).docx
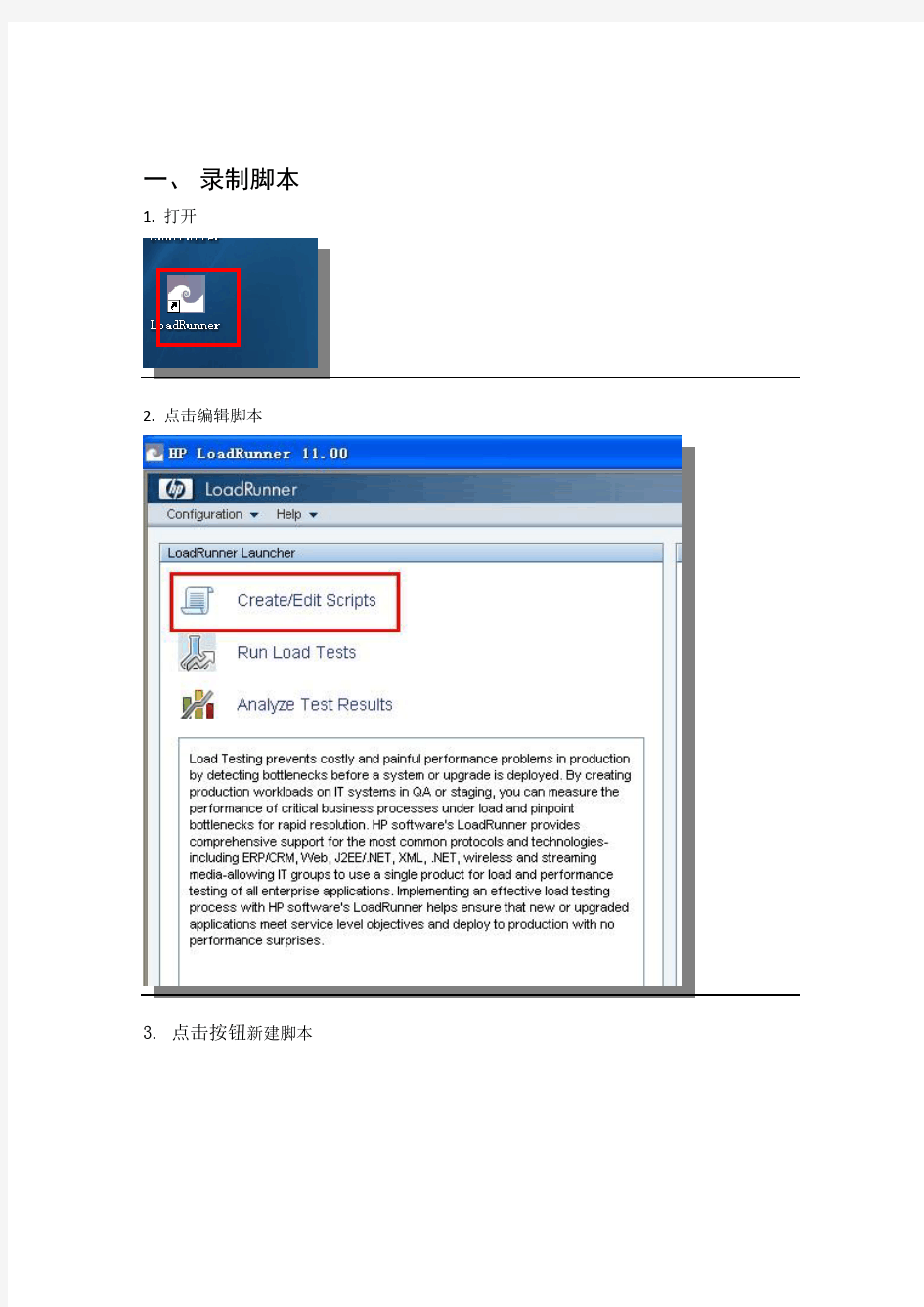

一、录制脚本
1. 打开
2. 点击编辑脚本
3. 点击按钮新建脚本
4. 弹出对话框,选着web(http/html)
5. 输入网址,点击ok
6. 录制脚本,录制结束后,点击一下按钮停止录制
7. 录制成功后,生成脚本
8. 点击如下按钮回放脚本
9. 点此按钮,可新增action
多元统计分析模拟考题及答案.docx
一、判断题 ( 对 ) 1 X ( X 1 , X 2 ,L , X p ) 的协差阵一定是对称的半正定阵 ( 对 ( ) 2 标准化随机向量的协差阵与原变量的相关系数阵相同。 对) 3 典型相关分析是识别并量化两组变量间的关系,将两组变量的相关关系 的研究转化为一组变量的线性组合与另一组变量的线性组合间的相关关系的研究。 ( 对 )4 多维标度法是以空间分布的形式在低维空间中再现研究对象间关系的数据 分析方法。 ( 错)5 X (X 1 , X 2 , , X p ) ~ N p ( , ) , X , S 分别是样本均值和样本离 差阵,则 X , S 分别是 , 的无偏估计。 n ( 对) 6 X ( X 1 , X 2 , , X p ) ~ N p ( , ) , X 作为样本均值 的估计,是 无偏的、有效的、一致的。 ( 错) 7 因子载荷经正交旋转后,各变量的共性方差和各因子的贡献都发生了变化 ( 对) 8 因子载荷阵 A ( ij ) ij 表示第 i 个变量在第 j 个公因子上 a 中的 a 的相对重要性。 ( 对 )9 判别分析中, 若两个总体的协差阵相等, 则 Fisher 判别与距离判别等价。 (对) 10 距离判别法要求两总体分布的协差阵相等, Fisher 判别法对总体的分布无特 定的要求。 二、填空题 1、多元统计中常用的统计量有:样本均值向量、样本协差阵、样本离差阵、 样本相关系数矩阵. 2、 设 是总体 的协方差阵, 的特征根 ( 1, , ) 与相应的单 X ( X 1,L , X m ) i i L m 位 正 交 化 特 征 向 量 i ( a i1, a i 2 ,L ,a im ) , 则 第 一 主 成 分 的 表 达 式 是 y 1 a 11 X 1 a 12 X 2 L a 1m X m ,方差为 1 。 3 设 是总体 X ( X 1, X 2 , X 3, X 4 ) 的协方差阵, 的特征根和标准正交特征向量分别 为: 1 2.920 U 1' (0.1485, 0.5735, 0.5577, 0.5814) 2 1.024 U 2' (0.9544, 0.0984,0.2695,0.0824) 3 0.049 U 3' (0.2516,0.7733, 0.5589, 0.1624) 4 0.007 U 4' ( 0.0612,0.2519,0.5513, 0.7930) ,则其第二个主成分的表达式是
LoadRunner教程
LoadRunner使用手册 测试中心刘艳会 1 LoadRunner概要介绍 LoadRunner? 是一种预测系统行为和性能的工业标准级负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner 能够对整个企业架构进行测试。通过使用LoadRunner ,企业能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。 目前企业的网络应用环境都必须支持大量用户,网络体系架构中含各类应用环境且由不同供应商提供软件和硬件产品。难以预知的用户负载和愈来愈复杂的应用环境使公司时时担心会发生用户响应速度过慢,系统崩溃等问题。这些都不可避免地导致公司收益的损失。Mercury Interactive 的 LoadRunner 能让企业保护自己的收入来源,无需购置额外硬件而最大限度地利用现有的IT 资源,并确保终端用户在应用系统的各个环节中对其测试应用的质量,可靠性和可扩展性都有良好的评价。 LoadRunner 是一种适用于各种体系架构的自动负载测试工具,它能预测系统行为并优化系统性能。LoadRunner 的测试对象是整个企业的系统,它通过模拟实际用户的操作行为和实行实时性能监测,来帮助您更快的查找和发现问题。此外,LoadRunner 能支持广范的协议和技术,为您的特殊环境提供特殊的解决方案。 1.1 轻松创建虚拟用户 使用LoadRunner 的Virtual User Generator,您能很简便地创立起系统负载。该引擎能够生成虚拟用户,以虚拟用户的方式模拟真实用户的业务操作行为。它先记录下业务流程(如下订单或机票预定),然后将其转化为测试脚本。利用虚拟用户,您可以在Windows ,UNIX 或Linux 机器上同时产生成千上万个用户访问。所以LoadRunner能极大的减少负载测试所需的硬件和人力资源。另外,LoadRunner 的TurboLoad 专利技术能提供很高的适应性。TurboLoad 使您可以产生每天几十万名在线用户和数以百万计的点击数的负载。 用Virtual User Generator 建立测试脚本后,您可以对其进行参数化操作,这一操作能让您利用几套不同的实际发生数据来测试您的应用程序,从而反映出本系统的负载能力。以一个订单输入过程为例,参数化操作可将记录中的固定数据,如订单号和客户名称,由可变值来代替。在这些变量内随意输入可能的订单号和客户名,来匹配多个实际用户的操作行为。 LoadRunner 通过它的Data Wizard 来自动实现其测试数据的参数化。Data Wizard 直接
web项目测试实战性能测试结果分析样章报告
5.4.2测试结果分析 LoadRunner性能测试结果分析是个复杂的过程,通常可以从结果摘要、并发数、平均事务响应时间、每秒点击数、业务成功率、系统资源、网页细分图、Web服务器资源、数据库服务器资源等几个方面分析,如图5- 1所示。性能测试结果分析的一个重要的原则是以性能测试的需求指标为导向。我们回顾一下本次性能测试的目的,正如错误!未找到引用源。所列的指标,本次测试的要求是验证在30分钟内完成2000次用户登录系统,然后进行考勤业务,最后退出,在业务操作过程中页面的响应时间不超过3秒,并且服务器的CPU 使用率、内存使用率分别不超过75%、70%,那么按照所示的流程,我们开始分析,看看本次测试是否达到了预期的性能指标,其中又有哪些性能隐患,该如何解决。 图5- 1性能测试结果分析流程图 结果摘要 LoadRunner进行场景测试结果收集后,首先显示的该结果的一个摘要信息,如图5- 2所示。概要中列出了场景执行情况、“Statistics Summary(统计信息摘要)”、“Transaction Summary(事务摘要)”以及“HTTP Responses Summary(HTTP响应摘要)”等。以简要的信息列出本次测试结果。 图5- 2性能测试结果摘要图
场景执行情况 该部分给出了本次测试场景的名称、结果存放路径及场景的持续时间,如图5- 3所示。从该图我们知道,本次测试从15:58:40开始,到16:29:42结束,共历时31分2秒。与我们场景执行计划中设计的时间基本吻合。 图5- 3场景执行情况描述图 Statistics Summary(统计信息摘要) 该部分给出了场景执行结束后并发数、总吞吐量、平均每秒吞吐量、总请求数、平均每秒请求数的统计值,如图5- 4所示。从该图我们得知,本次测试运行的最大并发数为7,总吞吐量为842,037,409字节,平均每秒的吞吐量为451,979字节,总的请求数为211,974,平均每秒的请求为113.781,对于吞吐量,单位时间内吞吐量越大,说明服务器的处理能越好,而请求数仅表示客户端向服务器发出的请求数,与吞吐量一般是成正比关系。 图5- 4统计信息摘要图 Transaction Summary(事务摘要) 该部分给出了场景执行结束后相关Action的平均响应时间、通过率等情况,如图5- 5所示。从该图我们得到每个Action的平均响应时间与业务成功率。
多元统计分析期末复习
第一章: 多元统计分析研究的内容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X 均值向量: 随机向量X 与Y 的协方差矩阵: 当X=Y 时Cov (X ,Y )=D (X );当Cov (X ,Y )=0 ,称X ,Y 不相关。 随机向量X 与Y 的相关系数矩阵: )',...,,(),,,(2121P p EX EX EX EX μμμ='=Λ)')((),cov(EY Y EX X E Y X --=q p ij r Y X ?=)(),(ρ
2、均值向量协方差矩阵的性质 (1).设X ,Y 为随机向量,A ,B 为常数矩阵 E (AX )=AE (X ); E (AXB )=AE (X )B; D(AX)=AD(X)A ’; Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变),(~∑μP N X μ∑μ p X X X ,,,21Λ),(~∑μP N X ) ,('A A d A N s ∑+μ)()1(,, n X X ΛX )',,,(21p X X X Λ)')(()()(1X X X X i i n i --∑=n 1 X μ∑μX )1,(~∑n N X P μ),1(∑-n W p X X
Loadrunner使用教程
LoadRunner使用教程 1. 了解LoadRunner 1.1 Loadrunner简介 LoadRunner 是一种预测系统行为和性能的工业标准级负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner 能够对整个企业架构进行测试。通过使用LoadRunner,企业能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。目前企业的网络应用环境都必须支持大量用户,网络体系架构中含各类应用环境且由不同供应商提供软件和硬件产品。难以预知的用户负载和愈来愈复杂的应用环境使公司时时担心会发生用户响应速度过慢、系统崩溃等问题。这些都不可避免地导致公司收益的损失。Mercury Interactive 的LoadRunner 能让企业保护自己的收入来源,无需购置额外硬件而最大限度地利用现有的IT 资源,并确保终端用户在应用系统的各个环节中对其测试应用的质量,可靠性和可扩展性都有良好的评价。LoadRunner 是一种适用于各种体系架构的自动负载测试工具,它能预测系统行为并优化系统性能。LoadRunner 的测试对象是整个企业的系统,它通过模拟实际用户的操作行为和实行实时性能监测,来帮助您更快的查找和发现问题。此外,LoadRunner 能支持广的协议和技术,为您的特殊环境提供特殊的解决方案。 1.2 为什么应进行自动性能测试? 自动性能测试是一项规,它利用有关产品、人员和过程的信息来减少应用程 序、升级程序或修补程序部署中的风险。自动性能测试的核心原理是通过将生产 时的工作量应用于预部署系统来衡量系统性能和最终用户体验。构造严密的性能 测试可回答如下问题: ?应用程序是否能够很快地响应用户的要求? ?应用程序是否能处理预期的用户负载并具有盈余能力? ?应用程序是否能处理业务所需的事务数量?
loadrunner学习总结
Loadrunner学习总结 LoadRunner,是一种预测系统行为和性能的负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner 能够对整个企业架构进行测试。企业使用LoadRunner能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。 LoadRunner可适用于各种体架构的自动负载测试,能预测系统行为并评估系统性能。操作流程如下: 1.录制脚本: 选择适当的协议,web服务器一般选择http协议。 录制方式一般选择HTML-based Script,但有下列情况选择URL-based Script:不是基于浏览器的应用程序,应用程序中包含javaScript脚本且产生了请求,基于浏览器的应用程序使用了https协议
默认设置记录的浏览器为IE,不要使用其他浏览器 在录制过程中不要后退页面 2.录制结束后点绿色方块按钮结束录制,系统会自动生成录制脚本。
3.录制完之后就是对脚本的回放处理,可以在运行时设置界面设置回放的设置, 如:迭代(重复次数)、步(开始新迭代时候的时间设置)、思考时间(录制时间的停留时间)等,设置好之后就开始回放。 4.回放结束后,回放的情况会显示出来,没有错误表示录制的进程没有问题。 5.负载测试运行
选择录制的脚本添加,然后确认。
可以在场景计划 可以在场景计划这里设置要测试的参数,比如开始用户数,持续时间,停止方式等。 如果想测定某个操作的响应时间,可以在脚本中插入事务,使用事务把该操作包装起来。分析执行结果的时候可以查看到该事务的响应时间。 插入集合点,可以使多个用户并发进行同一操作,提高操作的并发程度,以对服务器增加负载,测试并发能力。 在Run-Time Setting设置中,设置网络带宽以模拟不同带宽的网络;设置block、action的迭代次数。 对脚本进行参数化,设置参数变更方式
(完整word版)实用多元统计分析相关习题
练习题 一、填空题 1.人们通过各种实践,发现变量之间的相互关系可以分成(相关)和(不相关)两种类型。多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相关系数。 2.总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。3.回归方程显著性检验时通常采用的统计量是(S R/p)/[S E/(n-p-1)]。 4.偏相关系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的)的相关系数。 5.Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。 6.主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求(降维)的一种方法。 7.主成分分析的基本思想是(设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来替代原来的指标)。 8.主成分表达式的系数向量是(相关系数矩阵)的特征向量。 9.样本主成分的总方差等于(1)。 10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。主成分的协方差矩阵为(对称)矩阵。主成分表达式的系数向量是(相关矩阵特征值)的特征向量。 11.SPSS中主成分分析采用(analyze—data reduction—facyor)命令过程。 12.因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部分为(特殊因子)。 13.变量共同度是指因子载荷矩阵中(第i行元素的平方和)。 14.公共因子方差与特殊因子方差之和为(1)。 15.聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏程度)进行科学的分类。 16.Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。 17.Q型聚类统计量是(距离),而R型聚类统计量通常采用(相关系数)。 18.六种Q型聚类方法分别为(最长距离法)、(最短距离法)、(中间距离法)、(类平均法)、(重心法)、(离差平方和法)。 19.快速聚类在SPSS中由(k-均值聚类(analyze—classify—k means cluster))过程实现。 20.判别分析是要解决在研究对象已(已分成若干类)的情况下,确定新的观测数据属于已知类别中哪一类的多元统计方法。 21.用判别分析方法处理问题时,通常以(判别函数)作为衡量新样本点与各已知组别接近程度的指标。 22.进行判别分析时,通常指定一种判别规则,用来判定新样本的归属,常见的判别准则有(Fisher准则)、(贝叶斯准则)。 23.类内样本点接近,类间样本点疏远的性质,可以通过(类与类之间的距离)与(类内样本的距离)的大小差异表现出来,而两者的比值能把不同的类区别开来。这个比值越大,说明类与类间的差异越(类与类之间的距离越大),分类效果越(好)。24.Fisher判别法就是要找一个由p个变量组成的(线性判别函数),使得各自组内点的
软件测试实验报告LoadRunner的使用
南昌大学软件学院 实验报告 实验名称 LoadRunner的使用 实验地点 实验日期 指导教师 学生班级 学生姓名 学生学号 提交日期 LoadRunner简介: LoadRunner 是一种适用于各种体系架构的自动负载测试工具,它能预测系统行为并优化系统性能。LoadRunner 的测试对象是整个企业的系统,它通过模拟实际用户的操作行为和实行实时性能监测,来帮助您更快的查找和发现问题。此外,LoadRunner 能支持广范的协议和技术,为您的特殊环境提供特殊的解决方案。LoadRunner是目前应用最为广泛的性能测试工具之一。 一、实验目的
1. 熟练LoadRunner的工具组成和工具原理。 2. 熟练使用LoadRunner进行Web系统测试和压力负载测试。 3. 掌握LoadRunner测试流程。 二、实验设备 PC机:清华同方电脑 操作系统:windows 7 实用工具:WPS Office,LoadRunner8.0工具,IE9 三、实验内容 (1)、熟悉LoadRunner的工具组成和工具原理 1.LoadRunner工具组成 虚拟用户脚本生成器:捕获最终用户业务流程和创建自动性能测试脚本,即我们在以后说的产生测试脚本; 压力产生器:通过运行虚拟用户产生实际的负载; 用户代理:协调不同负载机上虚拟用户,产生步调一致的虚拟用户;压力调度:根据用户对场景的设置,设置不同脚本的虚拟用户数量;监视系统:监控主要的性能计数器; 压力结果分析工具:本身不能代替分析人员,但是可以辅助测试结果的分析。 2.LoadRunner工具原理 代理(Proxy)是客户端和服务器端之间的中介人,LoadRunner 就是通过代理方式截获客户端和服务器之间交互的数据流。 ①虚拟用户脚本生成器通过代理方式接收客户端发送的数据包,
应用多元统计分析试题及答案
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
实用多元统计分析相关习题学习资料
实用多元统计分析相 尖习题 练习题 一、填空题 1?人们通过各种实践,发现变量之间的相互矢系可以分成(相尖)和(不相尖)两种 类型。多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相尖系数。 2?总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。 3 ?回归方程显著性检验时通常采用的统计量是(S R/P)/[S E/ (n-p-1) ]O 4?偏相尖系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的) 的相尖系数。 5. Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。
6 ?主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求 (降维)的一种方法。 7 ?主成分分析的基本思想是(设法将原来众多具有一定相尖性(比如P个指标),重 新组合成一组新的互相无矢的综合指标来替代原来的指标)。 8 ?主成分表达式的系数向量是(相尖系数矩阵)的特征向量。 9 ?样本主成分的总方差等于(1)。 10 ?在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。主成分的协方差矩阵为(对称)矩阵。主成分表达式的系数向量是(相尖矩阵特征值)的特征向量。 11. SPSS 中主成分分析采用(analyze—data reduction — facyor)命令过程。 12?因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部
分为(特殊因子)。 13 ?变量共同度是指因子载荷矩阵中(第i行元素的平方和)。 14 ?公共因子方差与特殊因子方差之和为(1) o 15 ?聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏 程度)进行科学的分类。 16. Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。 17. Q型聚类统计量是(距离),而R型聚类统计量通常采用(相尖系数)。 18. 六种Q型聚类方法分别为(最长距离法)、(最短距离法)、(中间距离法)、(类平均法)、(重心法)、(离差平方和法)。 19?快速聚类在SPSS中由(k■均值聚类(analyze— classify— k means cluste))过程实 现。 20. 判别分析是要解决在研究对象已(已分成若干类)的情况下,确定新的观测数据属于已知类别中哪一类的多元统计方法。 21. 用判别分析方法处理问题时,通常以(判别函数)作为衡量新样本点与各已知组别接近程度的指标。 22. 进行判别分析时,通常指定一种判别规则,用来判定新样本的归属,常见的判别准则有 (Fisher准则)、(贝叶斯准则)。 23. 类内样本点接近,类间样本点疏
《LoadRunner中文使用手册完全版》
LoadRunner操作入门 案例介绍: 测试Tomcat自带的一个jsp提交表单的性能。 测试页面如下: 输入一个数字后,点击提交,执行程序后返回页面:
测试步骤 第一步:录制脚本 从程序菜单中启动“LoadRunner”->“Visual User Generator” 在协议选择框中选择“Web(HTTP/HTML)”协议,进入主界面。 在工具条上选择“Start Record”,弹出启动“Start Recording”对话框。 在URL输入框中输入上述要测试的第一个页面的URL,即输入表单的页面。 同时注意,请让“Record the application startup”选择框失效,以便手工控制录制开始的时间,跳过刚开始的输入页面。 点击“OK”,这是LoadRunner会启动浏览器,并指向第一个输入页面,同时在浏览器窗口上方将出现一个“Recording Suspended…”的工具条窗口。 等待输入页面显示完全以后,点击工具条窗口中的“Record”按钮,进入录制状态,从现在 开始,在打开的浏览器上的所有操作将被录制成测试的脚本。
执行预定的表单提交动作,等结果页面显示完整以后,点击工具条上的黑色方框按钮,停止录制,回到Visual User Generator的主窗口,此时可以看到脚本已经录制成功。 选择“File”->“Save”,把当前的脚本保存下来 第二步:生成测试场景 选择菜单“Tools”->“Create Controller Scenario”,弹出“Create Scenario”对话框,保持缺省值不变,直接点击“OK”,唯一可能需要该的就是测试结果文件生成的路径。 这时,将启动LoadRunner的另一个工具“Controller”,这是执行压力测试的环境。 Controller的主界面有“Design”和“Run”两个Tab组成,可以随时切换,首先进入的是Design界面,在这里可以调整运行场景的各种参数,如果只是作强度测试,唯一需要调整 就是并发用户数,如下图所示:
利用loadrunner分析场景、监视图表
7 分析以及监视场景 在运行过程中,可以监视各个服务器的运行情况(DataBase Server、Web Server 等)。 监视场景通过添加性能计数器来实现。这一章非常的重要,确定系统瓶颈全靠它了。 下面重点讲讲需要添加那些计数器,以及那些计数器代表什么意思。 由于Win2000 Professional、Server 以及Advanced Server 提供的计数器不完全相同,这 里我们讨论将以Server 为基准。 监视场景需要在Run 视图中设置 然后,出现添加计数器的对话框 其他的操作就和控制面板“性能”中添加性能计数器的操作一样,这里不再详细说明。本章主要说明一下各个系统计数器的含义(数据库的计数器不做重点,只是拿SQL Server2000 作为例子进行说明。因为数据库各个版本之间差异比较大,请参考您使用的数据
库系统的帮助)。 8 分析实时监视图表 这一章仅仅介绍几个最重要的图表。 Q1 事务响应时间是否在可接受的时间内?哪个事务用的时间最长? 看Transaction Response Time 图,可以判断每个事务完成用的时间,从而可以判断出那个事 务用的时间最长,那些事务用的时间超出预定的可接受时间。 下图可以看出,随着用户数的不断增加,login 事务的响应时间增长的最快! Q2 网络带宽是否足够? “Throughput”图显示在场景运行期间的每一秒钟,从Web Server 上接受到的数据量的值。拿这个值和网络带宽比较,可以确定目前的网络带宽是否是瓶颈。 如果该图的曲线随着用户数的增加,没有随着增加,而是呈比较平的直线,说明目前的 网络速度不能够满足目前的系统流量。 Q3 硬件和操作系统能否处理高负载? “Windows Resources”图实时地显示了Web Server 系统资源的使用情况。利用该图提供的数据,可以把瓶颈定位到特定机器的某个部件。
loadrunner使用步骤说明
一、LoadRunner的下载,安装与破解 .ddooo./softdown/61971.htm https://www.360docs.net/doc/5a8115963.html,/softjc/71256.html// 这是安装篇 二、LoadRunner在Web项目上的使用 1.新建一个Web(HTTP/HTML):File---->new New single Protocol Script :选择一个协议 New Multiple Protocol Script :选择多个协议 New Script recent Protocol :选择最近使用的协议 2.点击Start Record开始录制
Application type :选择程序类型。包含两个选项,Internet Applications 一般指B/S的系统,也就是通过浏览器访问的系统;Win32 Applications 一般C/S 的系统,也就是本地的应用程序,如QQ Program to record :选择启动程序的路径,如果是本地程序(C/S),就找到程序的启动程序。(这个暂时没有使用过) 如果是B/S的体统找到IE浏览器的安装路径。如: C:\Program Files (x86)\Internet Explorer\iexplore.exe 。 默认为Microsoft Internet Explorer,最好手动指定IE浏览器的安装路径。 URL Address :如果是B/S的系统,请输入要访问的网址(如果访问本机,要用127.0.0.1代替localhost,如127.0.0.1:8080/ssh)。如果是C/S则为空。 Working directory :工具目录,也就是分析信息的保存路径。Record into Action :将录制结果放到Action里面 3.点击Options
loadrunner结果分析论文(标准版)
Loadrunner 结果分析论文 指导老师:高小雷 作者:闵光辉 学校:东莞理工学院 班级:08计算机科学与技术2班 邮箱:mingh168@https://www.360docs.net/doc/5a8115963.html, Loadrunner性能测试的目的: 自动性能测试是一项规范,它利用有关产品、人员和过程的信息来减少应用程 序、升级程序或修补程序部署中的风险。自动性能测试的核心原理是通过将生产 时的工作量应用于预部署系统来衡量系统性能和最终用户体验。构造严密的性能 测试可回答如下问题: ?应用程序是否能够很快地响应用户的要求? ?应用程序是否能处理预期的用户负载并具有盈余能力? ?应用程序是否能处理业务所需的事务数量? ?在预期和非预期的用户负载下,应用程序是否稳定? ?是否能确保用户在真正使用软件时获得积极的体验? 通过回答以上问题,自动性能测试可以量化更改业务指标所产生的影响。进而可 以说明部署的风险。有效的自动性能测试过程将有助于您做出更明智的发行决 策,并防止系统出现故障和解决可用性问题。 LoadRunner 包含下列组件: ?虚拟用户生成器用于捕获最终用户业务流程和创建自动性能测试脚本(也称为虚拟用户脚本)。 ?Controller 用于组织、驱动、管理和监控负载测试。 ?负载生成器用于通过运行虚拟用户生成负载。 ?Analysis 有助于您查看、分析和比较性能结果。 ?Launcher 为访问所有LoadRunner 组件的统一界面。 负载测试流程: 负载测试通常由五个阶段组成:计划、脚本创建、场景定义、场景执行和结果 分析。 计划负载测试:定义性能测试要求,例如并发用户的数量、典型业务流程和所需 响应时间。 创建Vuser 脚本:将最终用户活动捕获到自动脚本中。 定义场景:使用LoadRunner Controller 设置负载测试环境。 运行场景:通过LoadRunner Controller 驱动、管理和监控负载测试。 分析结果:使用LoadRunner Analysis 创建图和报告并评估性能。Loadrunner测试结果分析如下:
LoadRunner压力测试结果分析探讨
LoadRunner 压力测试结果分析探讨 分析原则: 1.具体问题具体分析(这是由于不同的应用系统,不同的 测试目的,不同 的性能关注点) 2. 查找瓶颈时按以下顺序,由易到难。 服务器硬件瓶颈 网络瓶颈(对局域网,可以不考虑) 服务器操作系统 瓶颈(参数配置) 中间件瓶颈(参数配置,数据库,web 服务器等) 瓶颈(SQL 语句、数据库设计、业务逻辑、算法等) 分析的信息来源: 1.根据场景运行过程中的错误提示信息 2.根据测试结果收集到的监控指标数据 .错误提示分析 分析实例: 1. Error: Failed to connect to server Connection 分析: A 应用服务死掉。 (小用户时:程序上的问题。程序上处理数据库的问题,实际测试中多半是 服务器链接的配置问题) B 、应用服务没有死 (应用服务参数设置问题) 应用 “172.17.7.230 〃 : [10060] Error: timed out Error: Server conn ecti on p rematurely “172.17.7.230 〃 has shut down the
对应的Apache 和tomcat 的最大链接数需要修改,如果连接时收到 connection refused 消息,说明应提高相应的服务器最大连接的设置,增加幅 度要根据实际情况和服务器硬件的情况来定,建议每次增加 25%! C 数据库的连接 (数据库启动的最大连接数(跟硬件的内存有关) ) D 我们的应用程序spring 控制的最大链接数太低 2. Error: Page download timeout (120 seconds) has expired 分析: 实际测试时有些资源需要请求外网,而我们的测试环境是局域网环境 3. Error “http://172.17.7.230/Home.do 分析: A 脚本设计错误,造成页面异常。服务器有响应! B 、并发数过大,造成服务器响应延迟。 4. Error page “text=xxxxx ” 分析: A 脚本设计问题,例如,前一脚本修改了某些内容,造成后面的脚本访问 异常。 B 、不确定因素,有时候回放正常的脚本,一放到场景中就出现这样的错误。 只能反复修改脚本! .监控指标数据分析 1.Vusers 数 A 、 应用服务参数设置太大导致服务器的瓶颈 B 、 页面中图片太多 C 、 在程序处理表的时候检查字段太大多 D 、
多元统计分析简答题..
1、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设H0和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2/21exp 2np n e tr n λ????=-?? ?????S S 00p H =≠ΣΣI : /2/2**1exp 2np n e tr n λ????=-?? ????? S S 检验12k ===ΣΣΣ012k H ===ΣΣΣ: 统计量/2/2/2/211i i k k n n pn np k i i i i n n λ===∏∏S S 2. 针对一个总体均值向量的检验而言,在协差阵已知和未知的两种情形下,如何分别构造的统计量? 3. 作多元线性回归分析时,自变量与因变量之间的影响关系一定是线性形式的吗?多元线性回归分析中的线性关系是指什么变量之间存在线性关系? 答:作多元线性回归分析时,自变量与因变量之间的影响关系不一定是线性形式。当自变量与因变量是非线性关系时可以通过某种变量代换,将其变为线性关系,然后再做回归分析。 多元线性回归分析的线性关系指的是随机变量间的关系,因变量y 与回归系数βi 间存在线性关系。 多元线性回归的条件是: (1)各自变量间不存在多重共线性; (2)各自变量与残差独立; (3)各残差间相互独立并服从正态分布; (4)Y 与每一自变量X 有线性关系。 4.回归分析的基本思想与步骤 基本思想:
LoadRunner性能测试软件的基本使用步骤
LoadRunner性能测试软件的基本使用步骤 一. 1、测试脚本录制 1.1录制前准备工作 在录制脚本前需检查压测环境的整体功能是否正确,待测部分的功能是否正确,只有确定功能正确后才可进行压测。 1.2录制及调试脚本 在准备工作OK后,进行脚本的录制,具体过程如下: 打开“开始>程序>MercuryLoadRunner>MercuryLoadRunner”测试脚本录制; 2、点击“Create/EdirScripts”,也可在“File”下选择New 新建。 3、选择Web(HTTP/HTML)协议,我们测试的是B/S模式,采用的是Web协议,选择后点【OK】按钮。 4、点击界面中的录制按钮,这个表示开始录制脚本点。 录制前,如果已经打开待测页面的话,建议关闭该页面。点【OK】后,同时会出现这表示现在已经开始录制。 5、所有操作完成后,点击中停止按钮,停止录制,页面将自动关闭,返回到loadrunner录制界面,将在界面中显示录制脚本代码,保存录制的脚本。 6、调试代码并进行参数化 录制后的代码需要进行调试才可用于压测,调试的办法就是进行
回放操作,如果回放过程无错误,运行结果也正确的话,则可用于压测。 二.设计测试场景 在脚本录制完成,调试通过后,可以进行测试场景的设计。 1.打开“开始>程序>MercuryLoadRunner >MercuryLoadRunner” 2.点击的RunLoadTests;在新建场景的窗口,选择一种场景类型。 3.选择要进行场景设计的脚本,若没有出现需要对应的脚本,可点击Browse查找后添加进来,选择好脚本后,点add则可加入到右边的窗口中然后点【OK】。 4.显示的是脚本的路径与并发数个数,根据测试方案中的并发 数可更改此处的并发数。 Eg:假如我们设计的场景是每15秒增加2个,所有并发数增加完后持续运行5分钟,5分钟运行结束后,每30秒减少5个并发。 5.再点击页面右下角的“Run-timeSettings” 。 6.一切设置OK后,点击运行测试场景。 三.测试结果分析 1.场景执行结束后可以,使用loadrunner自带的分析工具进行结果分析。 2.在菜单栏中选择打开,找到要分析的场景执行结果,点【打开】即可,还可以直接在场景运行结束后,点击Controller菜单栏
具体实例教你如何做LoadRunner结果分析
具体实例教你如何做LoadRunner结果分析 文本Tag:测试工具性能测试LoadRunner 【IT168 技术文档】1.前言: LoadRunner 最重要也是最难理解的地方--测试结果的分析.其余的录制和加压测试等设置对于我们来讲通过几次操作就可以轻松掌握了.针对Results Analysis 我用图片加文字做了一个例子,希望通过例子能给大家更多的帮助.这个例子主要讲述的是多个用户同时接管任务,测试系统的响应能力,确定系统瓶颈所在.客户要求响应时间是1 个人接管的时间在5S 内. 2.系统资源: 2.1 硬件环境: CPU:奔四2.8E 硬盘:100G 网络环境:100Mbps 2.2 软件环境: 操作系统:英文windowsXP 服务器:tomcat 服务 浏览器:IE6.0 系统结构:B/S 结构 3.添加监视资源
下面要讲述的例子添加了我们平常测试中最常用到的 一些资源参数.另外有些特殊的资源暂时在这里不做讲解了.我会在以后相继补充进来。 Mercury Loadrunner Analysis 中最常用的5 种资源. 1. Vuser 2. Transactions 3. Web Resources 4. Web Page Breakdown 5. System Resources 在Analysis 中选择“Add graph”或“New graph”就可以看到这几个资源了.还有其他没有数据的资源,我们没有让它显示. 如果想查看更多的资源,可以将左下角的display only graphs containing data 置为不选.然后选中相应的点“open graph”即可. 打开Analysis 首先可以看的是Summary Report.这里显示了测试的分析摘要.应有尽有.但是我们并不需要每个都要仔细去看.下面介绍一下部分的含义: Duration(持续时间):了解该测试过程持续时间.测试人员本身要对这个时期内系统一共做了多少的事有大致的熟 悉了解.以确定下次增加更多的任务条件下测试的持续时间。
应用多元统计分析习题解答_因子分析
第七章 因子分析 7.1 试述因子分析与主成分分析的联系与区别。 答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、简化数据的技术。②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。因子分析可以说是主成分分析的姐妹篇,将主成分分析向前推进一步便导致因子分析。因子分析也可以说成是主成分分析的逆问题。如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。 因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标变换到变异程度大的方向上为止,突出数据变异的方向,归纳重要信息。而因子分析是从显在变量去提炼潜在因子的过程。此外,主成分分析不需要构造分析模型而因子分析要构造因子模型。 7.2 因子分析主要可应用于哪些方面? 答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。具体来说,①因子分析可以用于分类。如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对空气的优劣予以分类等等②因子分析可以用于探索潜在因素。即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。对我们进一步研究与探讨指示方向。在社会调查分析中十分常用。③因子分析的另一个作用是用于时空分解。如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判断各自的影响和变化规律。 7.3 简述因子模型中载荷矩阵A 的统计意义。 答:对于因子模型 1122i i i ij j im m i X a F a F a F a F ε=++ ++ ++ 1,2, ,i p = 因子载荷阵为1112 121 22212 12 (,, ,)m m m p p pm a a a a a a A A A a a a ????? ?==?????? ? ?A i X 与j F 的协方差为: 1Cov(,)Cov(,)m i j ik k i j k X F a F F ε==+∑ =1 Cov( ,)Cov(,)m ik k j i j k a F F F ε=+∑ =ij a 若对i X 作标准化处理,=ij a ,因此 ij a 一方面表示i X 对j F 的依赖程度;另一方面也反映了