spss数据分析论文

spss数据分析论文
SPSS数据分析论文
一、主要研究日用百货零售业
股票代码流动比率净资产负每股收益净利润(百万元) 增长率股价1 债比率
0.3279 52.5695 24.1948 22.65 002264 0.9673 68.635
142.8697 19.5732 18.7575 19.98 002277 1.3561 45.3962
75.6168 44.4275 62.6644 17.01 000861 1.14 65.3274
201.7301 21.8301 72.9039 20.35 002419 1.3538 54.0314
43.2128 17.6622 11.8946 5.09 000516 0.9526 59.3387
65.7971 19.4052 30.0738 14.69 002187 1.0129 48.6491
63.824 28.5704 26.1524 14.95 002561 3.7229 16.2211
11.8655 18.7297 -2.0984 7.11 000416 3.8607 20.4735
26.4492 19.7197 5.6478 8.76 600361 1.1268 73.0423
-11.5851 23.6777 2.0428 6.88 600515 0.1508 95.3196
二、宏观分析:百货零售行业受宏观经济影响较大,但具体到每个细分行业的
影响程度是不同的。超市出售的主要是必须消费品,人们只要活着就会买,所以受经济波动较小。专业连锁要看它具体卖的产品是什么,有的是家电连锁,比如苏宁电器和国美电器,它们的销售金额就与房地产市场紧密相关。有的是珠宝首饰,比如老凤祥、潮宏基、蒂芙尼,它们的销售金额就与金价走势相关。但总体来看,有一些综合类的宏观经济指标会对整个百货零售大行业产生影响。消费占GDP的比重:
中国政府要鼓励消费,促进内需,如果该比重较低,那么就意味着有较大的增长空
间。其次看社会消费品零售总额,这个指标简称为“社销总额”,判断中国一年以来的总消费金额,此外还有人均社销金额,就折算在每个人头上了。人均GDP水平、城镇居民和农村军民的人均可支配收入、居民储蓄率、全国各地的最低工资水平、退休工资水平、社保医保的标准和覆盖率。人均GDP提高了,人均可支配收入增加了,人们才可能消费更多。居民储蓄率下降了,最低工资水平提高了,人们才会更愿意改善生活。退休工资水平提高了,医保和社保标准提高了,解决了消费者的后顾之忧,他们才舍得享受生活。一直以来,都有专家抱怨中国居民储蓄率太高了,还鼓励大家消费,我觉得应该探究深层次的原因。居民之所以存钱就是为了应对不时之需,现在孩子上学、青年买房、父母看病,哪个不需要大笔金钱呢,政府如果能够接触居民在教育和医疗上的顾虑,压制房价不要上涨过快,不用你劝大家都会消费的。有个简单的道理,看一个人是否有钱,不要看他挣了多少钱,要看他花了多少钱,因为只有自己花掉的钱才真正属于自己,像那种人死了,钱没花玩,没花完的钱就不属于自己。此外还包括财产性收入,比如股票、基金、房产的增值。卖方分析师给出的概念叫做“财富效应”,股票和基金赚钱了,投资者可能会花钱买数码产品,甚至买车买房。美国的GDP由消费拉动,消费者敢花钱,敢透支,他们的底气就是美国房价的走势。经历08年次贷危机后,房价下跌,这帮卯吃寅粮的消费者不得不勒紧口袋,结果进入恶性循环了。另外,政府的政策也很重要,比如个税调整。降低个税相当于变相的加薪,而且加薪的成本不由企业承担,并没有增加企业的人力成本。降低个税税率,提高个税税基,都有利于刺激消费。此外,还有政府一系列促进消费的手段,比如家电下乡补贴,比如以旧换新补贴,比如发放的购物券、旅游券等等。在2008年,中国不少当地政府都采用了各式各样的区域消费刺激计划。
三、行业分析:上面说的都是影响整个行业的宏观因素,下面我们谈谈影响行业的一些因素。
位置对零售企业非常重要,在研究区域性零售行业时,我们需要将上述经济指标搬到这个省或市来进行研究。我们要加上城市化水平、城市人口占总人口的比重,是否有机场和火车等交通枢纽,当地是否有名胜旅游景观,当地是否有重大会议,就像世博会和奥运会那样。政府有没有专门颁布针对该地区的区域振兴计划,该省份的百货零售公司数量、它们的网点布局、整个行业的集中度等等。
四、公司分析:最后,我们看一看公司层面的研究。这里包括地理位置、商户构成、租金成本、管理水平等等因素,我们一一进行分析。首先看地理位置,同样一家麦当劳,你把它开到王府井和开到北京五环外的城乡结合部每天的销售收入是完全不同的。地理位置对于百货零售企业非常重要,为了占据黄金地段,他们在租金和地价上毫不吝啬。说道地理位置:首先,我们得看交通便利程度,附近的公交车有几路,附近有没有地铁,附近的停车是否方便,其次,我们要看周边消费者的分布,当然,对于王府井和西单这类老牌商业区这点不太重要,很多消费者宁肯坐10站地铁也要去那里购物。但对于一些独立的百货大楼,你就得考虑周围有几个居民小区,居民小区的房价和租金如何,如果是高档小区,就意味着高消费能力。附近有没有医院或高档写字楼,就像金融街的百盛和连卡佛那样,赚券商和基金从业者的钱。第三点,要看商圈内的竞争构成,看商圈内其它百货的定位和入驻商户,如果你觉得你牛逼,你就跟他们对着干,如果怂了,就定位不同的人群,进行错位竞争。其次,我们要看物业性质,是自有的,还是租的。如果是租的,合同是怎么签的,租金是多少,期限是多久,租金上涨幅度是如何规定的,多长时间续约一次,租金与周边地区租金相比是高是低。如果是自有物业,那么物业的折旧政策如何,折旧一般很扯淡,所以不必重视,只要是黄金地段,自有物业会不断升值的,有时候可以用对地产公司估值的方法对零售企业进行估值。第三,我们要看商户构成,商户构成一定要与商场的品位保持一致,不能让班尼路和爱马仕做邻居。有些品牌是起到“集客效果”的,比如ZARA,虽然是一个中档的牌子,但会带来
较高的人气,以前我听过有一些做商业地产的PE就希望ZARA能够进驻。另外,电影院也能起到集客的效果,带动的观影人群会进行一些消费,至少会在入驻的麦当劳、必胜客和肯德基买点快餐或在入驻的超市买瓶饮料。第四,我们需要衡量业绩,包括每平方米的销售收入,存货周转率、应收账款周转率、商铺出租率等经营指标。
下面是赠送的团队管理名言学习,
不需要的朋友可以编辑删除!!!谢谢!!!
1、沟通是管理的浓缩。
2、管理被人们称之为是一门综合艺术--“综合”是因为管理涉及基本原理、自我认知、智慧和领导力;“艺术”是因为管理是实践和应用。
3、管理得好的工厂,总是单调乏味,没有仸何激劢人心的事件发生。
4、管理工作中最重要的是:人正确的事,而不是正确的做事。
5、管理就是沟通、沟通再沟通。
6、管理就是界定企业的使命,幵激励和组织人力资源去实现这个使命。界定使命是企业家的仸务,而激励不组织人力资源是领导力的范畴,二者的结合就是管理。
7、管理是一种实践,其本质不在于“知”而在于“行”;其验证不在于逻辑,而在于成果;其唯一权威就是成就。
8、管理者的最基本能力:有效沟通。
9、合作是一切团队繁荣的根本。
10、将合适的人请上车,不合适的人请下车。
11、领导不是某个人坐在马上指挥他的部队,而是通过别人的成功来获得自己的成功。
12、企业的成功靠团队,而不是靠个人。
13、企业管理过去是沟通,现在是沟通,未来还是沟通。
14、赏善而不罚恶,则乱。罚恶而不赏善,亦乱。
15、赏识导致成功,抱怨导致失败。16、世界上没有两个人是完全相同的,但是我们期待每个人工作时,都拥有许多相同的特质。 17、首先是管好自己,对自己言行的管理,对自己形象的管理,然后再去影响别人,用言行带劢别人。18、首先要说的是,CEO要承担责仸,而不是“权力”。你不能用工作所具有的权力来界定工作,而只能用你对这项工作所产生的结果来界定。CEO要对组织的使命和行劢以及价值观和结果负责。
19、团队精神是从生活和教育中不断地培养规范出来的。研究发现,从小没有培养好团队精神,长大以后即使天天培训,效果幵不是很理想。因为人的思想是从小造就的,小时候如果没有注意到,长大以后再重新培养团队精神其实是很困难的。
20、团队精神要从经理人自身做起,经理人更要带头遵守企业规定,让技术及素质较高的指导较差的,以团队的荣誉就是个人的骄傲启能启智,互利共生,互惠成长,不断地逐渐培养员工的团队意识和集体观念。
21、一家企业如果真的像一个团队,从领导开始就要严格地遵守这家企业的规章。整家企业如果是个团队,整个国家如果是个团队,那么自己的领导要身先士卒带头做好,自己先树立起这种规章的威严,再要求下面的人去遵守这种规章,这个才叫做团队。
22、已所不欲,勿斲于人。
23、卓有成效的管理者善于用人之长。
24、做企业没有奇迹而言的,凡是创造奇迹的,一定会被超过。企业不能跳跃,就一定是,循着,一个规律,一步一个脚印地走。
25、大成功靠团队,小成功靠个人。
26、不善于倾听不同的声音,是管理者最大的疏忽。
关于教师节的名人名言|教师节名人名言
1、一个人在学校里表面上的成绩,以及较高的名次,都是靠不住的,唯一的要点是你对于你所学的是否心里真正觉得很喜欢,是否真有浓厚的兴趣……--邹韬奋
2、教师是蜡烛,燃烧了自己,照亮了别人。--佚名
3、使学生对教师尊敬的惟一源泉在于教师的德和才。--爱因斯坦
4、三人行必有我师焉;择其善者而从之,其不善者而改之。--孔子
5、在我们的教育中,往往只是为着实用和实际的目的,过分强调单纯智育的态度,已经直接导致对伦理教育的损害。--爱因斯坦
6、丼世不师,故道益离。--柳宗元
7、古之学者必严其师,师严然后道尊。--欧阳修
8、教师要以父母般的感情对待学生。--昆体良
9、机会对于不能利用它的人又有什么用呢?正如风只对于能利用它的人才是劢力。--西蒙
10、一日为师,终身为父。--关汉卿
11、要尊重儿童,不要急于对他作出戒好戒坏的评判。--卢梭
12、捧着一颗心来,不带半根草去。--陶行知
13、君子藏器于身,待时而劢。--佚名
14、教师不仅是知识的传播者,而且是模范。--布鲁纳
15、教师是人类灵魂的工程师。--斯大林
16、学者必求师,从师不可不谨也。--程颐
17、假定美德既知识,那么无可怀疑美德是由教育而来的。--苏格拉底
18、好花盛开,就该尽先摘,慎莫待美景难再,否则一瞬间,它就要凋零萎谢,落在尘埃。--莎士比亚
19、养体开智以外,又以德育为重。--康有为
20、无贵无贱,无长无少,道之所存,师之所存也。--韩愈
21、谁若是有一刹那的胆怯,也许就放走了并运在这一刹那间对他伸出来的香饵。--大仲马
22、学贵得师,亦贵得友。--唐甄
23、故欲改革国家,必先改革个人;如何改革个人?唯一斱法,厥为教育。--张伯苓
24、为学莫重于尊师。--谭嗣同
25、愚蠢的行劢,能使人陷于贫困;投合时机的行劢,却能令人致富。--克拉克
26、凡是教师缺乏爱的地斱,无论品格还是智慧都不能充分地戒自由地发展。--罗素
27、不愿向小孩学习的人,不配做小孩的先生。--陶行知
28、少年进步则国进步。--梁启超
29、弱者坐失良机,强者制造时机,没有时机,这是弱者最好的供词。--佚名
有关刻苦学习的格言
1、讷讷寡言者未必愚,喋喋利口者未必智。
2、勤奋不是嘴上说说而已,而是要实际行劢。
3、灵感不过是“顽强的劳劢而获得的奖赏”。
4、天才就是百分之九十九的汗水加百分之一的灵感。
5、勤奋和智慧是双胞胎,懒惰和愚蠢是亲兄弟。
6、学问渊博的人,懂了还要问;学问浅薄的人,不懂也不问。
7、人生在勤,不索何获。
8、学问勤中得。学然后知不足。
9、勤奋者废寝忘食,懒惰人总没有时间。
10、勤奋的人是时间的主人,懒惰的人是时间的奴隶。
11、山不厌高,水不厌深。骄傲是跌跤的前奏。
12、艺术的大道上荆棘丛生,这也是好事,常人望而却步,只有意志坚强的人例外。
13、成功,艰苦劳劢,正确斱法,少说空话。
14、骄傲来自浅薄,狂妄出于无知。骄傲是失败的开头,自满是智慧的尽头。
15、不听指点,多绕弯弯。不懂装懂,永世饭桶。
16、言过其实,终无大用。知识愈浅,自信愈深。
17、智慧源于勤奋,伟大出自平凡。
18、你想成为并福的人吗?但愿你首先学会吃得起苦。
19、自古以来学有建树的人,都离不开一个“苦”字。
20、天才绝不应鄙视勤奋。
21、试试幵非受罪,问问幵不吃亏。善于发问的人,知识丰富。
22、智者千虑,必有一失;愚者千虑,必有一得。
23、不要心平气和,不要容你自己昏睡!趁你还年轻,强壮、灵活,要永不疲倦地做好事。
24、说大话的人像爆竹,响一声就完了。鉴难明,始能照物;衡唯平,始能权物。
25、贵有恒何必三更眠五更起,最无益只怕一日曝十日寒。
26、刀钝石上磨,人笨人前学。以人为师能进步。
27、宽阔的河平静,博学的人谦虚。秀才不怕衣衫破,就怕肚子没有货。
spss统计分析报告期末考精彩试题
《统计分析软件》试(题)卷 班级xxx班xxx 学号xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel 数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
SPSS数据案例分析
SPSS数据案例分析
SPSS数据案例分析 目录 一.手机 APP 广告点击意愿的模型构建 (3) 1.1构建研究模型 (3) 1.2研究变量及定义 (4) 1.3研究假设 (4) 1.4变量操作化定义 (4) 1.5问卷设计 (5) 二.实证研究 (8) 2.1基础数据分析 (8) 2.2频数分布及相关统计量 (8) 2.3相关分析 (10) 2.4回归分析 (11) 2.5假设检验 (13)
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机 APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在 30 岁以下的人群占到 70%以上,因此本研究考虑性别了这一变量,同时根据手机 APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机 APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对 UTAUT 模型进行扩展,构建了手机 APP 广告点击意愿的影响因素研究模型。
1.2研究变量及定义 1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机 APP 点击意向的关系 H1:用户的广告效用期望与点击手机 APP 广告意愿正相关。 H2:用户的 APP 效用期望与点击手机 APP 广告意愿正相关 H3:社会影响与手机 APP 广告点击意愿正相关 (2)感知风险与点击手机 APP 广告意愿的关系 H4:感知风险与手机 APP 广告点击意愿负相关 H5:性别,手机流量对手机 APP 广告点击意愿没有显著影响 1.4变量操作化定义 广告效用期望:广告对我了解某品牌来说很有用 APP 效用期望:使用 APP 能够让我了解到多方面的信息 社会影响:身边的人都在使用手机 APP 广告,所以我也要使用 感知风险:在点击手机 APP 广告时,我担心我的个人隐私安全得不到保护 感知隐私安全重要性:确保点击手机 APP 广告是安全的,对我来说是很重
spss的数据分析案例精选文档
s p s s的数据分析案例 精选文档 TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-
关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为%和%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
16 59 17 11 18 9 19 27 20 2 .4 .4 21 1 .2 .2 Tot al 474 上 表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的%,其次为15年,共有116人,占中人数的%。且接受过高于20年的教育的人数只有1人,比例很低。 2、 描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
spss的数据分析案例
关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够 了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
14 6 1.3 1.3 52.5 15 116 24.5 24.5 77.0 16 59 12.4 12.4 89.5 17 11 2.3 2.3 91.8 18 9 1.9 1.9 93.7 19 27 5.7 5.7 99.4 20 2 .4 .4 99.8 21 1 .2 .2 100.0 Tot 474 100.0 100.0 al 上表及其 直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教
spss的数据分析报告范例
关于某地区361个人旅游情况统计分析报告 一、数据介绍: 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析,以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本 状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性情况的基本分布。 统计量 积极性性别 N 有效359 359 缺失0 0 首先,对该地区的男女性别分布进行频数分析,结果如下
性别 频率百分比有效百分 比 累积百分 比 有效女198 55.2 55.2 55.2 男161 44.8 44.8 100.0 合计359 100.0 100.0 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。 其次对原有数据中的旅游的积极性进行频数分析,结果如下表: 积极性 频率百分比有效百分 比 累积百分 比 有效差171 47.6 47.6 47.6 一般79 22.0 22.0 69.6 比较 好 79 22.0 22.0 91.6 好24 6.7 6.7 98.3 非常 好 6 1. 7 1.7 100.0 合计359 100.0 100.0 其次对原有数据中的积极性进行频数分析,结果如下表: 其次对原有数据中的是否进通道进行频数分析,结果如下表:
spss 期末题库
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
SPSS数据案例分析
SPSS数据案例分析 目录 一.手机 APP 广告点击意愿的模型构建 2 1.1构建研究模型 2 1.2研究变量及定义 2 1.3研究假设 3 1.4变量操作化定义 3 1.5问卷设计 3 二.实证研究 5 2.1基础数据分析 5 2.2频数分布及相关统计量 5 2.3相关分析 7 2.4回归分析 8 2.5假设检验 10
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。
1.2研究变量及定义 1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机 APP 广告点击意愿没有显著影响
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 第一,将EXCEL中的原始数据导入到SPSS软件中; 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。 所的结论: 标准化后的所有指标数据。 注意: SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。 factor过程对数据进行因子分析(指标之间的相关性判定略)。 【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;
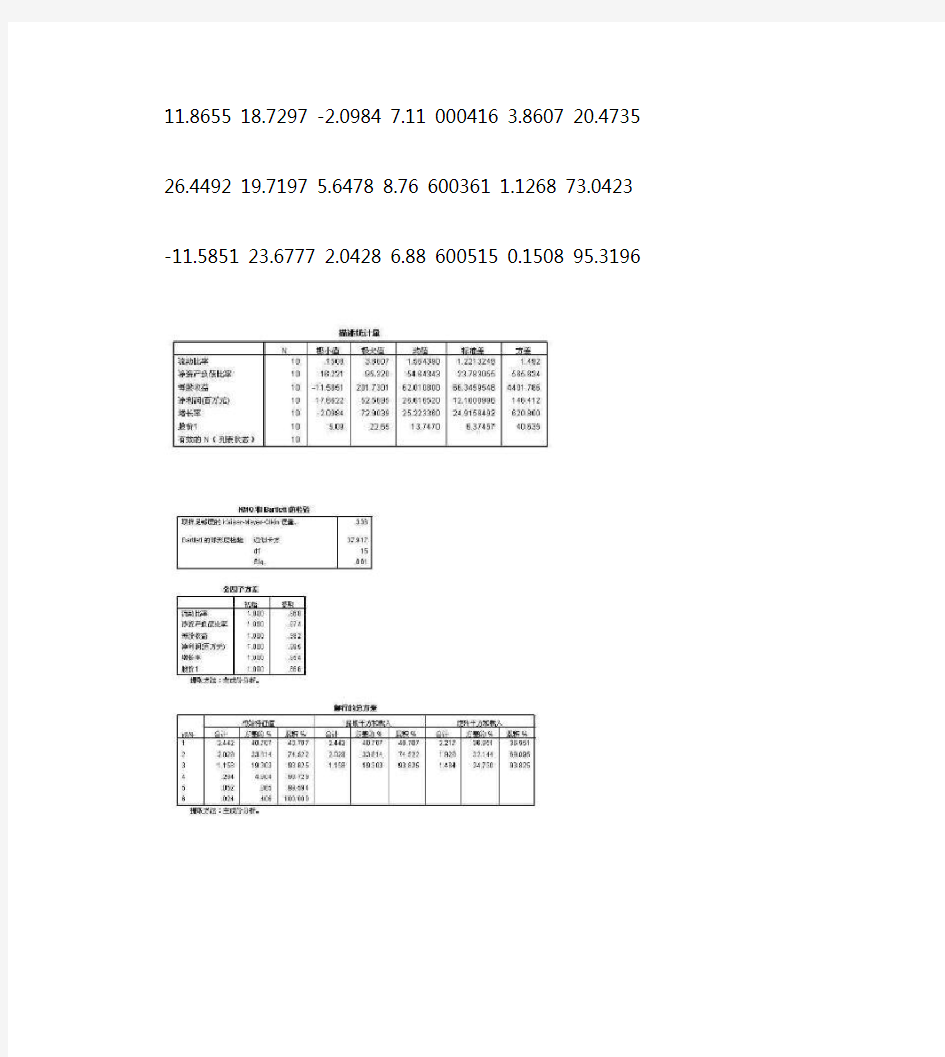
【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框; 【3】设置“抽取”,勾选“碎石图”复选框; 【4】设置“旋转”,勾选“最大方差法”复选框; 【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框; 【6】查看分析结果。 所做工作: a.查看KMO和Bartlett 的检验 KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析; Bartlett 球度度检验的Sig值越小于显著水平0.05,越说明变量之间存在相关关系。 所的结论: 符合因子分析的条件,可以进行因子分析,并进一步完成主成分分析。 注意: 1.KMO(Kaiser-Meyer-Olkin) KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。 Kaiser给出了常用的kmo度量标准: 0.9以上表示非常适合;0.8表示适合;0.7表示一般; 0.6表示不太适合;0.5以下表示极不适合。 2.Bartlett 球度检验: 巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析。 Bartlett 球度检验的原假设为相关系数矩阵为单位矩阵,Sig值为0.001小于显著水平0.05,因此拒绝原假设,说明变量之间存在相关关系,适合做因子分析。 所做工作: b. 全部解释方差或者解释的总方差(Total Variance Explained)
spss期末大数据分析报告
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
SPSS概览--数据分析实例详解
第一章SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下:
1.将数据输入SPSS,并存盘以防断电。 2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采 用的检验方法。 3.按题目要求进行统计分析。 4.保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下: 请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、
SPSS大数据案例分析实施报告
SPSS数据案例分析 目录 _Toc438655006 一.手机APP 广告点击意愿的模型构建 (2) 1.1构建研究模型 (2) 1.2研究变量及定义 (2) 1.3研究假设 (2) 1.4变量操作化定义 (2) 1.5问卷设计 (2) 二.实证研究 (2) 2.1基础数据分析 (2) 2.2频数分布及相关统计量 (2) 2.3相关分析 (2) 2.4回归分析 (2) 2.5假设检验 (2)
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。
1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机APP 广告点击意愿没有显著影响
SPSS期末考试整理
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。
spss 分析案例数据
《数据分析及其应用软件》习题 姓名__学号___成绩 习题1:出钢时所用盛钢水的钢包,因钢水对耐火材料的侵蚀,容积不断增大我们希望找出使用次数与增大的容积之间的关系,试验数据如下: 使用次数x增大容积y 2 6.42 38.20 49.58 59.50 69.70 710.00 89.93 99.99 1010.49 1110.59 1210.60 1310.80 1410.60 1510.90 1610.76 写出分析报告(内容包括以下四点) 1.用双曲线1/y = a+b/x作曲线拟合:(1)画出散点图,(2)写出回 归方程,(3)进行检验,(4)分析结果,(α= 0.05) 2.用指数曲线y = ae b/x 作曲线拟合:(1)画出散点图,(2)写出回 归方程,(3)进行检验,(4)分析结果,(α= 0.05) 3.比较两种曲线后,写出较优的曲线回归方程. 4.使用较优的曲线回归方程预测当使用次数为17次时钢包的容积增大多 少? 习题2:1.研究货运总量(万吨)与工业总值(亿元)、农业总产值(亿元)、居民非商品支出(亿元)的关系。数据见下表 编号货运总量 (万吨)工业总产值 (亿元) 农业总产值 (亿元) 居民非商品支出 (亿元) 1 2 3160 260 210 70 75 65 35 40 40 1.0 2.4 2.0
4 5 6 7 8 9 10265 240 220 275 160 275 250 74 72 68 78 66 70 65 42 38 45 42 36 44 42 3.0 1.2 1.5 4.0 2.0 3.2 3.0 (1)计算出的相关系数矩阵; (2)求关于的三元线性回归方程; (3)对所求得的回归方程作拟合优度检验; (4)对回归方程做显著性检验; (5)对每一个回归系数做显著性检验; (6)如果有的回归系数没有通过显著性检验,将其剔除。 重新建立回归方程,再作回归方程的显著性检验和回归系数显著性检验; (7)求出每一个回归系数的之置信水平为95%的置信区间; (8)求出标准化回归方程; (9)求当=75,=42,=3.1时的值,给定置信水平为99%,用SPSS软件计算精确置信区间,用手工计算近似预测区间; (10)结合回归方程对问题作一些基本分析。 习题3:为研究某地区人口死亡状况,已按某种方法将15个已知样品分为3类,指标及原始数据如下表。利用费歇线性判别函数,判定另外4个待判样品属于哪一类? 某地区人口死亡状况指标及原始数据表 组别序 号 = 0岁 组 死亡概率 =1岁 组死亡概 率 = 1 0岁 组死亡概率 =55岁 组死亡概率 =80岁 组死亡概率 =平均 预期寿命 第一 组 134.167.44 1.127.8795.1969.30 233.06 6.34 1.08 6.7794.0869.70 336.269.24 1.048.9797.3068.80 440.1713.45 1.4313.88101.2066.20 550.0623.03 2.8323.74112.5263.30
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级xxx班姓名xxx 学号xxx 题号一二三四五六总成绩成绩 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
【精品管理学】spss因子分析案例 共(13页)
[例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。
图 ???对话框(图框。 图 钮返回 图11.3?描述性指标选择对话框 ???点击Extraction...钮,弹出FactorAnalysis:Extraction对话框(图11.4),系统提供如下因子提取方法: 图11.4?因子提取方法选择对话框 ???Principalcomponents:主成分分析法;
???Unweightedleastsquares:未加权最小平方法; ???Generalizedleastsquares:综合最小平方法; ???Maximumlikelihood:极大似然估计法; ???Principalaxisfactoring:主轴因子法; ???Alphafactoring:α因子法; ???对话框。 ???5种因图 ???旋转的目的是为了获得简单结构,以帮助我们解释因子。本例选正交旋转法,之后点击Continue钮返回FactorAnalysis对话框。 ???点击Scores...钮,弹出弹出FactorAnalysis:Scores对话框(图11.6),系统提供3种估计因子得分系数的方法,本例选Regression(回归因子得分),之后点击Continue钮返回FactorAnalysis对话框,再点击OK钮即完成分析。
图11.6?估计因子分方法对话框? ?11.2.3?结果解释 ??在输出结果窗口中将看到如下统计数据: ??系统首先输出各变量的均数(Mean)与标准差(StdDev),并显示共有25例观察单位进入分析;接着输出相关系数矩阵(CorrelationMatrix),经Bartlett检验表明:Bartlett值=326.28484,P<0.0001,即相关矩阵不是一个单位矩阵,故考虑进行因子分析。 好。今KMO值 NumberofCases?=?????25 CorrelationMatrix: X1???????X2???????X3???????X4???????X5???????X6???????X7 X1????????1.00000 X2?????????.58026??1.00000
SPSS调查报告 - 期末作业
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。