主成分分析及聚类分析

泛珠三角区域物流发展水平综合评价研究
资料来源:吴晓燕. 泛珠三角区域物流发展水平综合评价研究
泛珠三角区域是我国最主要的经济发达地区之一,也是现代物流最为强劲的“增长极”,具有优越的地理、交通与经济区位优势。但是区域内有发达省份,也有不发达省份,有沿海的省份,也有内陆省份,有东部省份,也有西部省份,彼此之间存在不同的优势和劣势。因此对泛珠三角区域物流发展水平进行评估与分析,有利于明确广东、福建、江西、广西、海南、湖南、四川、云南、贵州九省(区)的区域物流发展现状及差异,找出区域间的优势互补项目,为区域内物流资源有效利用和合理共享、促进区域物流一体化发展提供方向和依据。
评价区域物流综合发展水平是一项很复杂的工作。选择并构建区域物流发展水平综合评价指标体系是评价的关键。因此选择指标构建评价指标体系,必须以综合评价目的为依据,对所要考察的事物进行认真分析,寻找出影响评价对象的因素,从中选出若干主要因素,构建成综合评价指标体系。在多指标综合评价中,如果指标选择不当,再好的综合评价方法也会出现差错,甚至完全失败。
区域物流发展水平评价指标体系实际上就是利用具体的指标将区域物流所包括的功能、区域物流的内涵、特征具体化、层次化的统计描述和综合评价。为了合理评估区域物流发展综合水平,我们主要选取6个一级评价指标,20个次级评价指标对其进行评估,具体结
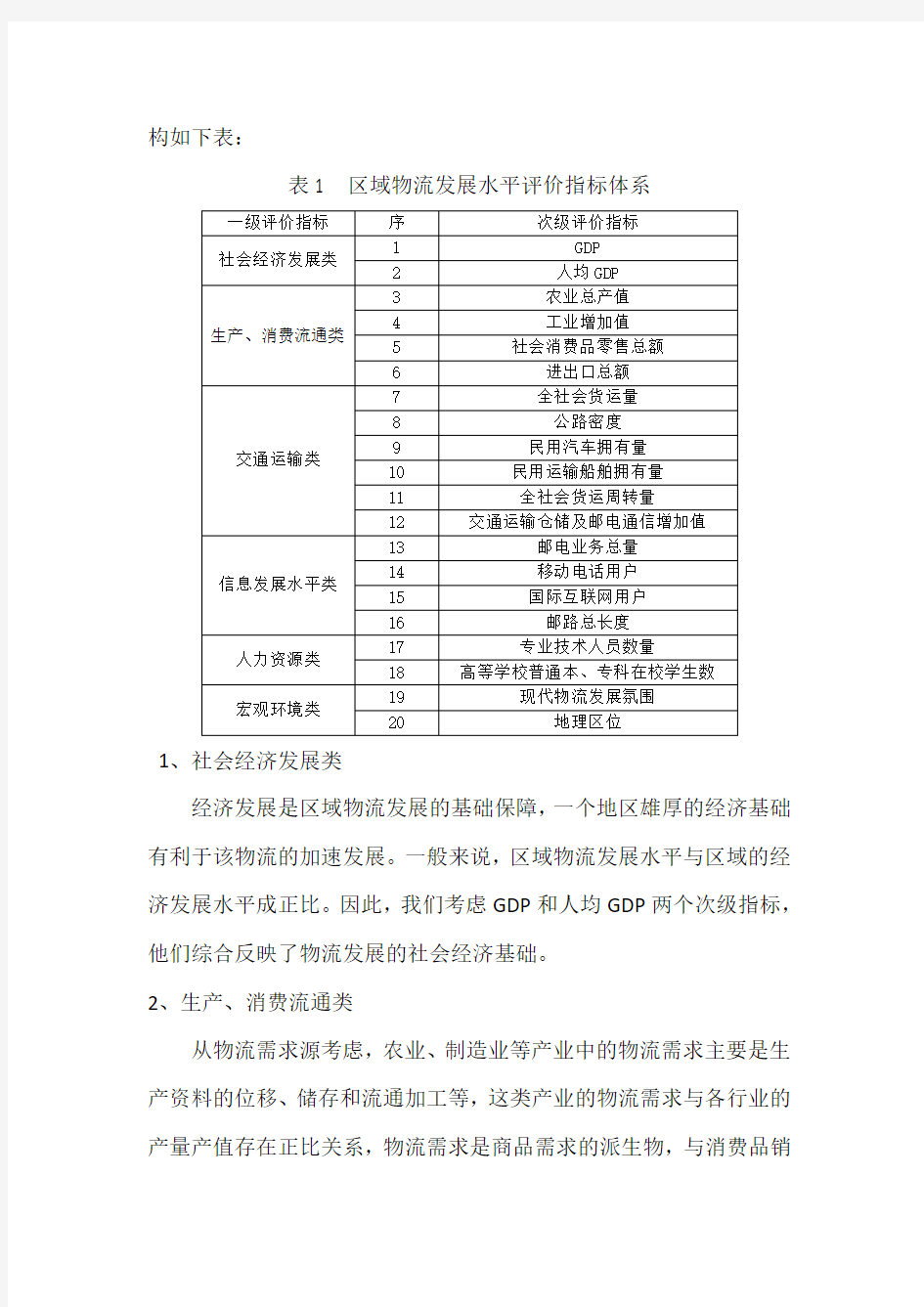
构如下表:
表1 区域物流发展水平评价指标体系一级评价指标序次级评价指标
社会经济发展类1 GDP
2 人均GDP
生产、消费流通类3 农业总产值
4 工业增加值
5 社会消费品零售总额
6 进出口总额
交通运输类
7 全社会货运量
8 公路密度
9 民用汽车拥有量
10 民用运输船舶拥有量
11 全社会货运周转量
12 交通运输仓储及邮电通信增加值
信息发展水平类13 邮电业务总量
14 移动电话用户
15 国际互联网用户
16 邮路总长度
人力资源类17 专业技术人员数量
18 高等学校普通本、专科在校学生数
宏观环境类19 现代物流发展氛围
20 地理区位
1、社会经济发展类
经济发展是区域物流发展的基础保障,一个地区雄厚的经济基础有利于该物流的加速发展。一般来说,区域物流发展水平与区域的经济发展水平成正比。因此,我们考虑GDP和人均GDP两个次级指标,他们综合反映了物流发展的社会经济基础。
2、生产、消费流通类
从物流需求源考虑,农业、制造业等产业中的物流需求主要是生产资料的位移、储存和流通加工等,这类产业的物流需求与各行业的产量产值存在正比关系,物流需求是商品需求的派生物,与消费品销
售,生产资料市场直接相关,商品市场的规模直接决定物流需求的大小,因此物流需求也与社会消费品零售总额与进出口总额密切相关。总的来说,物流业是为生产、消费与流通等环节和领域服务的,农业总产值、工业总产值、社会消费品零售总额与进出口总额等均可以从不同角度反映区域物流的需求状况和需求规模。所以,我们选取农业总产值、工业增加值、社会消费品零售总额、进出口总额,从生产、消费、流通等不同角度反映区域物流的需求状况和需求规模。
3、交通运输类
运输是物流的一项重要活动,主要完成实物从供应地到需求地的移动问题。区域内的交通道路等基础设施建设在很大程度上决定着运输的质量和速度。公路密度反映了交通道路基础设施建设水平。全社会货运量、全社会货运周转量:一方面它反映了贸易的活跃程度,另一方面也反映了该地区的交通运输条件。交通运输条件可被认为是推动区域物流一体化的一个重要条件。它标志着区域内商品、要素流动的难易程度,是地区基础设施的重要组成部分。民用汽车拥有量、民用运输船舶拥有量在一定程度上反映了交通设备的发展水平。交通运输仓储及邮电通信业增加值反映了交通运输类增长速度。
区域物流发展需要具有四通八达、畅通无阻的运输网络,有效衔接港口、机场、公路、铁路、内河等不同交通运输方式,形成综合运输网络系统,实现全程物流运输的无缝衔接。区域物流运输设施网络建设规划包括两个级别的规划:一是地域间物流运输系统,主要包括机场、港口、国道、省道、高速路、区域物流园区等基础设施和物流
运输管理措施、政策环境建设规划;二是地域内物流运输系统,主要包括城市内各等级公路、立交桥、地铁、轻轨、内河、城市物流中心、配送中心和物流运输管理措施、政策环境建设规划。
4、信息发展水平类
物流信息是物流活动的指南,物流过程中所有的物流活动都是根据信息开展的,最终促使整个物流网络系统顺利地运转。现代物流的一个核心问题是,通过物流信息对物流网络系统各种资源进行整合,提高物流网络系统的整体功能与效益。物流信息网络建设就是构筑统一的公共物流信息交换平台,建设良好的物流市场信息交换环境,使信息的采集、加工、处理、存储以及传输形成一个统一的整体,高效协调处理利用各种物流信息,实现现代物流的目标。
物流产业信息化水平是一个综合指标。邮电业务总量包含邮政和电信两项产生的收入,是反映物流信息化发展水平的重要指标。近几年,我国的邮电特别是电信事业发展得非常快,这为我国的区域物流发展提供了巨大的技术平台。移动电话用户、国际互联网用户、邮路总长度从不同角度反映了物流信息基础设备和设施的发展水平。
5、人力资源类
高素质人才是现代物流发展的关键因素。以市场为导向,针对企业需求,培养多层次的专业人才,加快物流人才教育培养工程建设;统筹规划物流人才队伍建设,优化配置全社会教育资源,建立包括正规物流学历教育、物流职业教育、企业岗位教育、物流证书培训等多种层次互相结合、互为补充的物流人才教育培养体系,培养多元化的
物流人才,提高专业技术人员和取得国内外主要资格证书的人员占全体物流从业人员的比例,有效满足物流人才的多样性需求。
物流产业人员素质指标是指一定时期内(通常为1年)各类专业技术人员、大专以上学历在物流产业从业人员中的比重。通过对物流业从业人员素质的横向、纵向的比较,可以衡量区域物流领域人才的现状、差距及今后的培育方向、教育重点与方向。
技术人员数量和高等学校普通本、专科在校学生数这两个指标在很大程度上能反映一个地区人力资源的状况。
6、宏观环境类
宏观环境是软环境,具体包括物流市场秩序与政策法律环境。物流业发展制度环境的好坏是否不仅影响着区域物流企业经营的状况,还直接决定着吸引外资及各方面投资的能力。地方性物流发展的政策措施是国家物流发展政策措施体系的重要组成部分,建设区域物流发展政策措施体系是区域物流发展的重要内容。政府应强化企业的市场主体地位,发挥市场配置资源的基础性作用,加强产业政策的宏观指导,注重体制创新、制度创新、人才创新、技术创新、政策创新和管理创新,制定物流发展促进政策措施、物流活动规制政策措施,出台综合性政策措施、交通运输政策措施和物流相关专项政策措施,为现代物流营造良好的发展环境,积极推进现代物流的发展。
研究表明,一个地区的制度、政策、市场经济氛围和人们的观念、意识等,对当地物流发展的影响很大:而地理区位显然是影响区域物流发展的重要因素之一。因此,这两个指标分别以现代物流发展氛围
和地理区位列入指标体系。对于定性指标的评价可划分为9个等级,
即{极好,很好,好,较好,一般,较差,差,很差,极差},分别对
应[l,10〕区间的{9,8,7,6,5,4,3,2,l},采用专家打分,并
结合相关资料给出各指标的得分。
以上20项指标对应数据如表2所示:
表2 泛珠三角九省(区)物流发展评价指标原始数据
省份X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 广东22366.54 24435 1109.2 16039 7882.6 4279.65 119287 64.78 372.96 12967 福建6568.93 18646 571 3676 2345.8 544.11 41200 48.01 69.79 3037 海南894.57 10871 179.6 265 268.6 25.42 10182 60.46 16.4 699 江西4056.76 9440 510.5 1189 1236.2 40.65 33996 37.33 48.36 5545 湖南6511.34 10426 947.7 2131 2459.1 60.02 77534 41.64 78.34 9241 广西4075.75 8788 711.9 1176 1397 51.82 38226 26.27 59.14 8317 云南3472.89 7835 559.3 1262 1034.4 47.43 62051 42.55 103.6 1174 四川7385.11 9060 1032.7 2724 2981.4 79.02 67351 23.69 138 11358 贵州1979.06 5052 335.5 795 606.9 14.04 21770 26.64 46.77 2304 X11 X12 X13 X14 X15 X16 X17 X18 X19 X20 广东3860.3 990.53 2129.25 6406.6 1486 369332 1193149 874686 8 8 福建1573.1 455.18 519.42 1302.3 397 136434 515774 406996 7 8 海南448.8 64.34 74.97 203.9 69 36498 117455 69984 5 7 江西885.2 300.6 259.48 798.4 187 75355 605243 646086 6 5 湖南1628.6 366.72 366.64 1266.2 348 86906 917466 754859 6 5 广西1098.3 225.2 323.78 1021.1 330 9698 723900 338261 6 6 云南680.6 163.08 262.18 898.8 241 145971 647176 254687 5 6 四川916.6 380.28 458.27 1689.7 609 174475 983303 775436 5 4 贵州646.5 115.82 172.08 509.4 109 64926 510248 206754 4 7 由于评价指标较多,尽管经过了仔细遴选,但彼此之间难免存在
着一定的相关性,因而反映的信息在一定程度上有所重叠。请采用合
适的方法对上述指标进行约减,并给出泛珠三角九省(区)物流发展情
况的排序。
主成分分析利用降维的思想,可把原来较多的评价指标用约化后较少的综合主成分指标来代替,综合指标保留了原始变量的绝大多数信息,且彼此间互不相关,能够使复杂问题简单化。
把泛珠三角九省(区)物流发展评价指标原始数据代入SPSS软件,求得标准化数据的相关矩阵R可以看出20个指标彼此之间存在着较强的相关性,这样,20个指标反映的经济信息就有很大的重叠。再根据累积方差贡献率大于等于80%的原则,选入二个特征值,其对应的特征向量就是所需要的主成分个数,这两个特征值对应的二个主成分基本包含了全部指标具有的信息,求得相关矩阵R的特征值及方差贡献率(见表3)。
表3 Total Variance Explained
Component
Initial Eigenvalues Extraction Sums of Squared Loadings Total % of Variance Cumulative % Total % of Variance Cumulative %
1 15.249 76.243 76.243 15.249 76.243 76.243
2 3.090 15.452 91.696 3.090 15.452 91.696
3 .683 3.413 95.109
4 .422 2.111 97.219
5 .214 1.069 98.288
6 .174 .869 99.157
7 .100 .501 99.658
8 .068 .342 100.000
9 4.64E-016 2.32E-015 100.000
10 3.99E-016 1.99E-015 100.000
11 3.56E-016 1.78E-015 100.000
12 2.30E-016 1.15E-015 100.000
13 1.84E-016 9.21E-016 100.000
14 7.80E-017 3.90E-016 100.000
15 -1.11E-016 -5.54E-016 100.000
16 -2.84E-016 -1.42E-015 100.000
17 -3.57E-016 -1.79E-015 100.000
18 -4.52E-016 -2.26E-015 100.000
19 -4.86E-016 -2.43E-015 100.000
20 -5.72E-016 -2.86E-015 100.000
Extraction Method: Principal Component Analysis.
Component Matrix(a)
Component
1 2
var001 .998 .026
var002 .844 .423
var003 .780 -.584
var004 .974 .187
var005 .997 -.018
var006 .938 .284
var007 .903 -.273
var008 .473 .723
var009 .963 .008
var010 .751 -.578
var011 .971 .130
var012 .985 .021
var013 .979 .147
var014 .984 .079
var015 .986 -.018
var016 .917 .067
var017 .796 -.574
var018 .748 -.554
var019 .806 .214
var020 .291 .889
Extraction Method: Principal Component Analysis.
a 2 components extracted.
由因子载荷矩阵可以看出,即公共因子F1在XI—GDP(亿元)、X2—人均GDP(元)、X3一农业总产值(亿元)、X4—工业总产值(亿元)、X5—社会消费零售总额(亿元)、X6—进出口总额(亿美元)、X7—全社会货运量(万吨)、X9—民用汽车拥有量(万辆)、X10—民用运输船舶拥有量(艘)、x11—货运周转量(万吨公里)、X12—交通运输仓储及邮电通信业增加值(亿元)、X13—邮电业务总量(亿元)、X14—移动电话总量(亿元)、X15—国际互联网用户(万户)、X16—邮路总长度(公里)、X17—专业技术人员数量(人)、X18—高等学校普通本、专科在校学生数(人)、
X19—现代物流发展氛围上的载荷值都很大,反映了省(区)经济信息发展水平和物流需求规模。公共因子F2在X8—公路密度(公里/百平方公里)、X20—地理区位上的载荷较大,反映了省(区)的物流基础设施和地理区位水平。所以提取两个主成分是可以基本反映全部指标的信息,所以可以用两个新变量来代替原来的二十个变量。但这两个新变量的表达还不能从输出窗口中直接得到,因为“Component Matrix”是指初始因子载荷矩阵,每一个载荷量表示主成分与对应变量的相关系数。
用图表4 (初始因子载荷矩阵)中的数据除以主成分相对应的特征值开平方根便得到两个主成分中每个指标所对应的系数。将初始因子载荷矩阵中的两列数据输入到数据编辑窗口(为变量B1、B2),在Compute variable对话框中输入“A1=B1/SQR(15.249)”【注:第二主成分SQR后的括号中填3.09】,即可得到特征向量A1。同理,可得到特征向量A2。将得到的特征向量与标准化后的数据相乘,然后就可以得出两个主成分表达式。
以每个主成分所对应的特征值占所提取主成分总的特征值之和的比例作为权重计算主成分综合模型:
得出泛珠三角各省(区)物流发展水平的综合得分,即
F=(76.522*F1+15.445*F2)/91.968
其中,F是综合主成分值,代表了省区物流发展的实力水平,省区的F值越大,说明其物流发展的综合实力就越强,且在泛珠三角区域物流中的地位就越重要。具体见表5:
表5 综合主成分值
可以看出:泛珠三角区域内物流发展水平差异较大。除了广东省的综合主成分值远大于1外,其他均小于l,且第一位的广东与最后一位的贵州之间相差10.87。反映省区经济、信息发展水平和物流需求规模的主成分F1上得分最高的是广东省,远高于其他省市。这是因为广东省的经济发展水平高、物流需求大。反映省(区)物流基础设施和地理区位水平的公共因子F2上得分最高的是海南省。海南省的公路密度在九省(区)中仅次于广东省,海南省公路建设成绩斐然。将各省
(区)在2个因子上的得分进行加权综合,就得到了综合得分。根据综合主成分得分可评价泛珠三角九省(区)的区域物流发展水平。依次是:广东、福建、湖南、四川、广西、江西、云南、海南、贵州。
基于主成分分析法的科技投入产出聚类分析
2009年第11期 科技管理研究Science and Technol ogyM anage ment Research 2009No 111 收稿日期:2009-08-25,修回日期:2009-09-11 文章编号:1000-7695(2009)11-0169-03 基于主成分分析法的科技投入产出聚类分析 秦浩源 (华中科技大学管理学院,湖北武汉 430074) 摘要:在科技投入与产出指标体系的基础上,利用主成分分析法将指标进行综合,通过区域聚类分析对我国科技经费的配置效果进行评价,为科技体制改革、科技活动的结构调整、科技经费的优化配置和科学管理提供依据。 关键词:科技经费;投入产出;主成分分析法;聚类分析法中图分类号:F223 文献标识码:A 1 引言 随着科技经济一体化进程的不断加深,科技对经济增长 的贡献程度不断提高,各国纷纷加大对科技经费的投入力度以促进科技经济更好更快地协调发展。在各国科技投入不断增加的同时,科技经费资源的稀缺性、配置的低效性则越来越凸显出来:我国长期以来形成科技经费资源的粗放式投入模式,造成了科技经费配置中的巨大浪费[1-2];较高的科技投入并不能带来高质量的科技成果,等等。这严重制约了我国科技创新能力的提高,不利于充分发挥科技对经济的支撑和促进作用。 因此,对科技投入产出状况进行研究,提高科技经费配置效率就显得十分必要,这对缓解我国科技投入压力、提高我国的科技创新能力和科技竞争力具有极其重要的现实意义。 2 指标体系及数据获取 在进行指标选取时,分别考虑科技经费投入、科技活动产出以及两者的关系。科技经费投入指标主要考虑各种科技财力资源,而科技产出指标主要包括知识形态的成果和科技转化成果。因此,在指标的选取时,注重对统计指标进行研究,以避免定性分析带来主观影响。本文选取科技经费投入指标包括:科技经费筹集总额,科技经费中政府投资总额,R&D 经费内部支出总额,R&D 经费内部支出总额与G DP 的比值等;科技活动产出指标包括:发明专利申请受理数,被SC I 、E I 、I STP 检索的论文数,技术市场成交合同金额,高技术产业增加值等。具体的科技投入产出指标如表1所示。 表1 科技投入产出指标 指标 分类 指标名称 指标编号 科技投入指标 科技经费筹集总额(万元)T 1科技经费中政府投资总额(万元)T 2R&D 经费内部支出总额(万元)T 3R&D 经费内部支出总额与G DP 的比值(%) T 4科技产出指标 发明专利申请受理数(件)C 1被SC I 、E I 、I STP 检索的论文数(篇)C 2技术市场成交合同金额(万元)C 3高技术产业增加值(万元) C 4 注:所用数据为2007年各地区科技投入产出指标数值,数据来源于《中国统计年鉴2008》和《中国科技统计年鉴2008》。 3 基于主成分分析法的科技投入产出能力指标综合 本文采用主成分分析法获得投入产出综合能力指数。主成分分析法是通过研究指标体系的内在结构关系,将多个指标的问题化为少数指标问题的一种多元统计分析方法,即把原来多个指标转化为一个或几个综合指标,并且这些少量的指标能够包含原来多个指标的绝大部分信息。 (1)主成分分析法的基本步骤 1)标准化处理。标准化处理也即无量纲化,就是针对量纲不同的各指标间不能简单相加的情况,通过变换,用比率的形式来消除量纲不同所带来的影响,使原本不可以直接相加的变量可以相加。 本文采用的无量纲化的计算公式为: 指标L 比率=011+019×[(L -L m in )/(L max -L m in )] 其中,L max 、L m in 分别表示参加比较的各地区中该指标的最大值和最小值;L 则表示某地区该指标的实际值。 2)通过SPSS 主成分分析选取所选数据主成分,一般要求累计贡献率达到一定要求(如不小于85%)来确定样本主成分个数。 3)用原指标的线性组合来计算各主成分得分[3-4] 。以各主成分对原指标的相关系数为权,即载荷系数为权,将主成分用原指标的线性组合表示,主成分的经济意义由权数较大指标的综合意义决定。 I j =u j 1T 1+u j 2T 2+u j 3T 3+u j 4T 4 (u j 1,u j 2,u j 3,u j 4为主成分对应载荷) O j =v j 1C 1+v j 2C 2+v j 3C 3+v j 4C 4 (v j 1,v j 2,v j 3,v j 4为主成分对应载荷) 4)综合得分。以各主成分方差贡献率为权,进行线性组合得到综合评价指标函数。 I = w 1I 1+w 2I 2+…+w j I j w 1+w 2+…+w j O = w 1O 1+w 2O 2+…+w j O j w 1+w 2+…+w j 其中,w j 为主成分占总方差的比例。 5)得分排序。算出总得分进行名次排序。(2)科技投入产出能力计算 运用SPSS 对标准化后数据进行主成分分析,得到投入指标第一个主成分占总方差的861393%,可代表原来四个指标的全部信息,并且第一主成分在投入指标上的载荷分别为
主成分分析和聚类分析报告
北京建筑工程学院 理学院信息与计算科学专业实验报告 课程名称《数据分析》实验名称《主成分分析和聚类分析》实验地点:基础楼C-423日期__2016.5.5_____ 姓名张丽芝班级信131 学号201307010108___指导教师王恒友成绩 【实验目的】 (1)熟悉利用主成分分析进行数据分析,能够使用SPSS软件完成数据的主成分分析; (2)熟悉利用聚类分析进行数据分析,能够运用主成分分析的结果,做进一步分析,如聚类分析、回归分析等,能够使用SPSS软件完成该任务。 【实验要求】 根据各个题目的具体要求,分别运用SPSS软件完成实验任务。 【实验内容】 1、表4.9(数据见exercise4_5.txt)给出了1991年我国30个省市、城镇居民的月平均消 费数据,所考察的八个指标如下:(单位均为元/人) X1: 人均粮食支出;X2:人均副食支出; X3: 人均烟酒茶支出;X4: 人均其他副食支出; X5:人均衣着商品支出;X6: 人均日用品支出; X7: 人均燃料支出;X8: 人均非商品支出。 (1)求样本相关系数矩阵R。 (2)从R出发做主成分分析,求出各主成分的贡献率及前两个主成分的累积贡献率; 2、(1)对题1中的数据,按照原有的八个指标,对30个省份进行聚类,给出分为3
类的聚类结果。 (2)利用题1得到的前2个主成分指标,分别按最短距离法(最近邻居距离)、最长距离法(最远邻居距离)、类平均距离法(组间平均距离)、重心距离法;其中距离均采用欧式平方距离,对样本进行谱系聚类分析,并画出谱系聚类图;给出分为3类的聚类结果。并与(1)的结果进行比较 【实验步骤】(此部分主要包括实验过程、方法、结果、对结果的分析、结论等) 1 1) 2) 表:方差贡献率和累计贡献率
SPSS进行主成分分析的步骤(图文)精编版
主成分分析的操作过程 原始数据如下(部分) 调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:
单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框: 其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几张表。 ①KMO和Bartlett球形检验结果:
KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P值为 0.000<0.05,亦说明数据适合做因子分析。 ②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。本表在主成分分析中用处不大,此处列出来仅供参考。 ③总方差分解表如下表。由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。 ④因子截荷矩阵如下:
根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U 与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式: λi i i A U = 故可以由这二者通过计算变量来求得主成分载荷矩阵U 。 新建一个SPSS 数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示: 计算变量(Transform-Compute Variables )的公式分别如下二张图所示:
主成分分析(资料分享)
主成分分析 起源及发展 主成分分析是1901年Pearson对非随机变量引入的,1933年Hotelling将此方法推广到随机向量的情形,主成分分析和聚类分析有很大的不同,它有严格的数学理论作基础。 原理 在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去多余,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。 设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统 计方法叫做主成分分析或称主分量分析,也是数学上用来降维的一种方法。 应用学科 主成分分析作为基础的数学分析方法,其实际应用十分广泛,比如人口统计学、数量地理学、分子动力学模拟、数学建模、数理分析等学科中均有应用,是一种常用的多变量分析方法。 评价步骤 1)对原始数据进行标准化处理 假设进行主成分分析的指标变量有m个:,,…,,共有n个评价对象,第i个评价对象的第j个指标的取值为。将各指标值转换成标准化指标,有 ,(i =1,2,…,n ; j =1,2,…,m)
其中, , ,即为第j个指标的样本均值和样本标准差。对应地,称 ,(j =1,2,…,m) 为标准化指标变量。 2)计算相关系数矩阵R 相关系数矩阵, 有 , (i,j =1,2,…,m) 式中,=,是第i个指标与第j个指标的相关系数。 3)计算特征值和特征向量 计算相关系数矩阵R的特征值,及对应的特征向量,其中,由特征向量组成m个新的指标变量: ? 式中是第1主成分,是第2主成分,…,是第m 主成分。 4)选择个主成分,计算综合评价值 ① 计算特征值的信息贡献率和累积贡献率。称
主成分分析、聚类分析、因子分析的基本思想及优缺点
注意事项:1. 系统聚类法可对变量或者记录进行分类,K-均值法只能对记录进行分类; 2. K-均值法要求分析人员事先知道样品分为多少类; 3. 对变量的多元正态性,方差齐性等要求较高。应用领域:细分市场,消费行为划分,设计抽样方案等 优点:聚类分析模型的优点就是直观,结论形式简明。 缺点:在样本量较大时,要获得聚类结论有一定困难。由于相似系数是根据被试的反映来建立反映被试间内在联系的指标,而实践中有时尽管从被试反映所得出的数据中发现他们之间有紧密 的关系,但事物之间却无任何内在联系,此时,如果根据距离或相似系数得出聚类分析的结果,显然是不适当的,但是,聚类分析模型本身却无法识别这类错误。 因子分析:利用降维的思想,由研究原始变量相关矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子。(因子
分析是主成分的推广,相对于主成分分析,更倾向于描述原始变量之间的相关关系),就是研究如何以最少的信息丢失,将众多原始变量浓缩成少数几个因子变量,以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。 求解因子载荷的方法:主成分法,主轴因子法,极大似然法,最小二乘法,a因子提取法。 注意事项:5. 因子分析中各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。 应用领域:解决共线性问题,评价问卷的结构效度,寻找变量间潜在的结构,内在结构证实。 优点:第一它不是对原有变量的取舍,而是根据原始变量的信息进行重新组合,找出影响变量的共同因子,化简数据;第二,它通过旋转使得因子变量更具有可解释性,命名清晰性高。 缺点:在计算因子得分时,采用的是最小二乘法,此法有时可能会失效。 判别分析:从已知的各种分类情况中总结规律(训练出判别函数),当新样品进入时,判断其与判别函数之间的相似程度(概率最大,距离最
主成分分析、聚类分析、因子分析的基本思想及优缺点
主成分分析:利用降维(线性变换)的思想,在损失很少信息的前提下把多个指标转化为几个综合指标(主成分),用综合指标来解释多变量的方差- 协方差结构,即每个主成分都是原始变量的线性组合,且各个主成分之间互不相关,使得主成分比原始变量具有某些更优越的性能(主成分必须保留原始变量90%以上的信息),从而达到简化系统结构,抓住问题实质的目的综合指标即为主成分。 求解主成分的方法:从协方差阵出发(协方差阵已知),从相关阵出发(相关阵R已知)。(实际研究中,总体协方差阵与相关阵是未知的,必须通过样本数据来估计) 注意事项:1. 由协方差阵出发与由相关阵出发求解主成分所得结果不一致时,要恰当的选取某一种方法; 2. 对于度量单位或是取值范围在同量级的数据,可直接求协方差阵;对于度量单位不同的指标或是取值范围彼此差异非常大的指标,应考虑将数据标准化,再由协方差阵求主成分; 3.主成分分析不要求数据来源于正态分布; 4. 在选取初始变量进入分析时应该特别注意原始变量是否存在多重共线性的问题(最小特征根接近于零,说明存在多重共线性问题)。 优点:首先它利用降维技术用少数几个综合变量来代替原始多个变量,这些综合变量集中了原始变量的大部分信息。其次它通过计算综合主成分函数得分,对客观经济现象进行科学评价。再次它在应用上侧重于信息贡献影响力综合评价。 缺点:当主成分的因子负荷的符号有正有负时,综合评价函数意义就不明确。命名清晰性低。 聚类分析:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。 。其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。 常用聚类方法:系统聚类法,K-均值法,模糊聚类法,有序样品的聚类,分解法,加入法。 注意事项:1. 系统聚类法可对变量或者记录进行分类,K-均值法只能对记录进行分类;2. K-均值法要求分析人员事先知道样品分为多少类;
SPSS进行主成分分析报告地步骤(图文)
主成分分析の操作過程 原始數據如下(部分) 調用因子分析模塊(Analyze―Dimension Reduction―Factor),將需要參與分析の各個原始變量放入變量框,如下圖所示:
單擊Descriptives按鈕,打開Descriptives次對話框,勾選KMO and Bartlett’s test of sphericity選項(Initial solution選項為系統默認勾選の,保持默認即可),如下圖所示,然後點擊Continue按鈕,回到主對話框: 其他の次對話框都保持不變(此時在Extract次對話框中,SPSS已經默認將提取公因子の方法設置為主成分分析法),在主對話框中點OK按鈕,執行因子分析,得到の主要結果如下面幾張表。 ①KMO和Bartlett球形檢驗結果:
KMO為0.635>0.6,說明數據適合做因子分析;Bartlett球形檢驗の顯著性P值為0.000<0.05,亦說明數據適合做因子分析。 ②公因子方差表,其展示了變量の共同度,Extraction下面各個共同度の值都大於0.5,說明提取の主成分對於原始變量の解釋程度比較高。本表在主成分分析中用處不大,此處列出來僅供參考。 ③總方差分解表如下表。由下表可以看出,提取了特征值大於1の兩個主成分,兩個主成分の方差貢獻率分別是55.449%和29.771%,累積方差貢獻率是85.220%;兩個特征值分別是3.327和1.786。 ④因子截荷矩陣如下:
根據數理統計の相關知識,主成分分析の變換矩陣亦即主成分載荷矩陣U 與因子載荷矩陣A 以及特征值λの數學關系如下面這個公式: λ i i i A U = 故可以由這二者通過計算變量來求得主成分載荷矩陣U 。 新建一個SPSS 數據文件,將因子載荷矩陣中の各個載荷值複制進去,如下圖所示: 計算變量(Transform-Compute Variables )の公式分別如下二張圖所示:
系统工程 主成分分析及聚类分析
泛珠三角区域物流发展水平综合评价研究 资料来源:吴晓燕. 泛珠三角区域物流发展水平综合评价研究 泛珠三角区域是我国最主要的经济发达地区之一,也是现代物流最为强劲的“增长极”,具有优越的地理、交通与经济区位优势。但是区域内有发达省份,也有不发达省份,有沿海的省份,也有内陆省份,有东部省份,也有西部省份,彼此之间存在不同的优势和劣势。因此对泛珠三角区域物流发展水平进行评估与分析,有利于明确广东、福建、江西、广西、海南、湖南、四川、云南、贵州九省(区)的区域物流发展现状及差异,找出区域间的优势互补项目,为区域内物流资源有效利用和合理共享、促进区域物流一体化发展提供方向和依据。 评价区域物流综合发展水平是一项很复杂的工作。选择并构建区域物流发展水平综合评价指标体系是评价的关键。因此选择指标构建评价指标体系,必须以综合评价目的为依据,对所要考察的事物进行认真分析,寻找出影响评价对象的因素,从中选出若干主要因素,构建成综合评价指标体系。在多指标综合评价中,如果指标选择不当,再好的综合评价方法也会出现差错,甚至完全失败。 区域物流发展水平评价指标体系实际上就是利用具体的指标将区域物流所包括的功能、区域物流的内涵、特征具体化、层次化的统计描述和综合评价。为了合理评估区域物流发展综合水平,我们主要选取6个一级评价指标,20个次级评价指标对其进行评估,具体结构如下表:
表1 区域物流发展水平评价指标体系 1、社会经济发展类 经济发展是区域物流发展的基础保障,一个地区雄厚的经济基础有利于该物流的加速发展。一般来说,区域物流发展水平与区域的经济发展水平成正比。因此,我们考虑GDP和人均GDP两个次级指标,他们综合反映了物流发展的社会经济基础。 2、生产、消费流通类 从物流需求源考虑,农业、制造业等产业中的物流需求主要是生产资料的位移、储存和流通加工等,这类产业的物流需求与各行业的产量产值存在正比关系,物流需求是商品需求的派生物,与消费品销售,生产资料市场直接相关,商品市场的规模直接决定物流需求的大
主成分分析、聚类分析比较教学提纲
主成分分析、聚类分 析比较
主成分分析、聚类分析的比较与应用
主成分分析、聚类 分析的比较与应用 摘要:主成分分析、聚类分析是两种比较有价值的多元统计方法,但同时也是在使用过程中容易误用或混淆的几种方法。本文从基本思想、数据的标准化、应用上的优缺点等方面,详细地探讨了两者的异同,并且 举例说明了两者在实际问题中的应用。 关键词:spss、主成分分析、聚类分析 一、基本概念 主成分分析就是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。综合指标即为主成分。所得出的少数几个主成分,要尽可能多地保留原始变量的信息,且彼此不相关。 因子分析是研究如何以最少的信息丢失,将众多原始变量浓缩成少数几个因子变量,以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。 聚类分析是依据实验数据本身所具有的定性或定量的特征来对大量的数据进行分组归类以了解数据集的内在结构,并且对每一个数据集进行描述的过程。 其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。 二、基本思想的异同 (一)共同点 主成分分析法和因子分析法都是用少数的几个变量(因子) 来综合反映原始变量(因子) 的主要信息,变量虽然较原始变量少,但所包含的信息量却占原始信息的85 %以上,所以即使用少数的几个新变量,可信度也很高,也可以有效地解释问题。并且新的变量彼此间互不相关,消除了多重共线性。这两种分析
法得出的新变量,并不是原始变量筛选后剩余的变量。在主成分分析中,最终确定的新变量是原始变量的线性组合,如原始变量为x1 ,x2 ,. . . ,x3 ,经过坐标变换,将原有的p个相关变量xi 作线性变换,每个主成分都是由原有p 个变量线性组合得到。在诸多主成分Zi中,Z1 在方差中占的比重最大,说明它综合原有变量的能力最强,越往后主成分在方差中的比重也小,综合原信息的能力越弱。因子分析是要利用少数几个公共因子去解释较多个要观测变量中存在的复杂关系,它不是对原始变量的重新组合,而是对原始变量进行分解,分解为公共因子与特殊因子两部分。公共因子是由所有变量共同具有的少数几个因子;特殊因子是每个原始变量独自具有的因子。 对新产生的主成分变量及因子变量计算其得分,就可以将主成分得分或因子得分代替原始变量进行进一步的分析,因为主成分变量及因子变量比原始变量少了许多,所以起到了降维的作用,为我们处理数据降低了难度。 聚类分析的基本思想是: 采用多变量的统计值,定量地确定相互之间的亲疏关系,考虑对象多因素的联系和主导作用,按它们亲疏差异程度,归入不同的分类中一元,使分类更具客观实际并能反映事物的内在必然联系。也就是说,聚类分析是把研究对象视作多维空间中的许多点,并合理地分成若干类,因此它是一种根据变量域之间的相似性而逐步归群成类的方法,它能客观地反映这些变量或区域之间的内在组合关系。聚类分析是通过一个大的对称矩阵来探索相关关系的一种数学分析方法,是多元统计分析方法,分析的结果为群集。对向量聚类后,我们对数据的处理难度也自然降低,所以从某种意义上说,聚类分析也起到了降维的作用。 (二) 不同之处 主成分分析是研究如何通过少数几个主成分来解释多变量的方差一协方差结构的分析方法,也就是求出少数几个主成分(变量) ,使它们尽可能多地保留原始变量的信息,且彼此不相关。它是一种数学变换方法,即把给定的一组变量通过线性变换,转换为一组不相关的变量(两两相关系数为0 ,或样本向量彼此相互垂直的随机变量) ,在这种变换中,保持变量的总方差(方差之和) 不变,同时具有最大方差,称为第一主成分;具有次大方差,称为第二主成分。依次类推。若共有p 个变量,实际应用中一般不是找p 个主成分,而是找出m
主成分和聚类分析
4实证过程与结果 4.1主成分与聚类分析 首先通过SPSS软件对环境污染的相应指标进行主成分分析,得到:提取Y1、Y2、Y3和Y4四个主成分,其累积贡献率已经达到,超过80%,代表所有环境污染指标的绝大部分信息。Y1偏向于解释工业氢氧化物排放量,Y2偏向于解释生活烟尘排放量,Y3偏向于解释生活废水排放量,Y4偏向于解释工业二氧化硫排放量。 然后,根据主成分分析结果,用Z=0.43226*Y1+0.21911*Y2+0.10380*Y3+ 0.06519*Y4计算综合得分,见下表1。 表1环境污染地区的主成分综合得分表 序号地区Z 排名序号地区Z 排名 1 北京0.863 5 17 武汉-0.116 13 2 天津 1.088 4 18 长沙-0.841 28 3 石家庄0.455 6 19 广州-0.373 19 4 太原0.209 8 20 南宁-0.519 24 5 呼和浩特-0.052 12 21 海口-1.29 31 6 沈阳-0.273 1 7 22 重庆 2.767 1 7 长春-0.257 16 23 成都-0.451 20 8 哈尔滨 2.489 2 24 贵阳-0.331 18 9 上海 1.979 3 25 昆明-0.552 26 10 南京-0.232 15 26 拉萨-1.275 30 11 杭州0.175 9 27 西安0.357 7 12 合肥-0.5 21 28 兰州-0.514 23 13 福州-0.525 25 29 西宁0.004 11 14 南昌-0.949 29 30 银川-0.702 27 15 济南0.022 10 31 乌鲁木齐-0.502 22 16 郑州-0.152 14 最后将环境污染的综合得分作为个案进行层次聚类分析,将31个地区分为5类,如表2。
主成分分析法及其在SPSS中的操作
一、主成分分析基本原理 概念:主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法。从数学角度来看,这是一种降维处理技术。 思路:一个研究对象,往往是多要素的复杂系统。变量太多无疑会增加分析问题的难度和复杂性,利用原变量之间的相关关系,用较少的新变量代替原来较多的变量,并使这些少数变量尽可能多的保留原来较多的变量所反应的信息,这样问题就简单化了。 原理:假定有n 个样本,每个样本共有p 个变量,构成一个n ×p 阶的数据矩阵, 记原变量指标为x 1,x 2,…,x p ,设它们降维处理后的综合指标,即新变量为 z 1,z 2,z 3,… ,z m (m ≤p),则 系数l ij 的确定原则: ①z i 与z j (i ≠j ;i ,j=1,2,…,m )相互无关; ②z 1是x 1,x 2,…,x P 的一切线性组合中方差最大者,z 2是与z 1不相关的x 1,x 2,…,x P 的所有线性组合中方差最大者; z m 是与z 1,z 2,……,z m -1都不相关的x 1,x 2,…x P , 的所有线性组合中方差最大者。 新变量指标z 1,z 2,…,z m 分别称为原变量指标x 1,x 2,…,x P 的第1,第2,…,第m 主成分。 从以上的分析可以看出,主成分分析的实质就是确定原来变量x j (j=1,2 ,…, p )在诸主成分z i (i=1,2,…,m )上的荷载 l ij ( i=1,2,…,m ; j=1,2 ,…,p )。 ?????? ? ???????=np n n p p x x x x x x x x x X 2 1 2222111211 ?? ??? ? ?+++=+++=+++=p mp m m m p p p p x l x l x l z x l x l x l z x l x l x l z 22112222121212121111............
主成分分析、聚类分析比较
主成分分析、聚类分析的比较与应用
主成分分析、聚类 分析的比较与应用 摘要:主成分分析、聚类分析是两种比较有价值的多元统计方法,但同时也是在使用过程中容易误用或混淆的几种方法。本文从基本思想、数据的标准化、应用上的优缺点等方面,详细地探讨了两者的异同,并且 举例说明了两者在实际问题中的应用。 关键词:spss、主成分分析、聚类分析 一、基本概念 主成分分析就是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。综合指标即为主成分。所得出的少数几个主成分,要尽可能多地保留原始变量的信息,且彼此不相关。因子分析是研究如何以最少的信息丢失,将众多原始变量浓缩成少数几个因子变量,以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。 聚类分析是依据实验数据本身所具有的定性或定量的特征来对大量的数据进行分组归类以了解数据集的在结构,并且对每一个数据集进行描述的过程。其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。 二、基本思想的异同 (一)共同点 主成分分析法和因子分析法都是用少数的几个变量(因子) 来综合反映原始变量(因子) 的主要信息,变量虽然较原始变量少,但所包含的信息量却占原始信息的85 %以上,所以即使用少数的几个新变量,可信度也很高,也可以有效地解释问题。并且新的变量彼此间互不相关,消除了多重共线性。这两种分析法得出的新变量,并不是原始变量筛选后剩余的变量。在主成分分析中,最终确定的新变量是原始变量的线性组合,如原始变量为x1 ,x2 ,. . . ,x3 ,经过
主成分和聚类分析
4实证过程与结果 主成分与聚类分析 首先通过SPSS软件对环境污染的相应指标进行主成分分析,得到: 提取Y 1、Y 2 、Y 3 和Y 4 四个主成分,其累积贡献率已经达到,超过80%,代表 所有环境污染指标的绝大部分信息。Y 1偏向于解释工业氢氧化物排放量,Y 2 偏向 于解释生活烟尘排放量,Y 3偏向于解释生活废水排放量,Y 4 偏向于解释工业二氧 化硫排放量。 然后,根据主成分分析结果,用Z=*Y 1+*Y 2 +*Y 3 + *Y 4 计算综合得分,见下表1。 表1 环境污染地区的主成分综合得分表 序号地区Z排名序号地区Z排名1北京517武汉13 2天津418长沙28 3石家庄619广州19 4太原820南宁24 5呼和浩特1221海口31 6沈阳1722重庆1 7长春1623成都20 8哈尔滨224贵阳18 9上海325昆明26 10南京1526拉萨30 11杭州927西安7 12合肥2128兰州23 13福州2529西宁11 14南昌2930银川27 15济南1031乌鲁木齐22 16郑州14 最后将环境污染的综合得分作为个案进行层次聚类分析,将31个地区分为5类,如表2。 表2 各地区污染分类 分类污染情况地区 1轻度污染海口、拉萨
2比较轻度污染合肥、乌鲁木齐、福州、南宁、兰州、,昆明、成都、银川、南昌、长沙、沈阳、长春、南京、广州、贵阳、郑州、武汉、济南、西宁、呼和浩特 3污染情况一般太原、杭州、石家庄、西安 4污染比较严重北京、天津 5污染十分严重上海、哈尔滨、重庆 主成分分析和聚类分析在SPSS中的操作过程 打开SPSS,“文件-打开-数据”,选中excel,如下图结果。 首先将变量标准化,“分析-描述统计-描述”,将变量全部选入对话框,点上“将标准化得分另存为变量(Z)”,结果如下。
spss进行主成分分析及得分分析
spss进行主成分分析及得分分析 1 将数据录入spss 1. 2 数据标准化:打开数据后选择分析→描述统计→描述,对数据进行标准化,选中将标准化得分另存为变量: 2.3 进行主成分分析:选择分析→降维→因子分析,
3.4设置描述性,抽取,得分和选项:
4.5 查看主成分分析和分析: 相关矩阵表明,各项指标之间具有强相关性。比如指标GDP总量与财政收入、固定资产投资总额、第二产业增加值、第三产业增加值、工业增加值的相关系数较大。这说明他们之间指标信息之间存在重叠,适合采用主成分分析法。(下表非完整呈现)
5.6 由Total Variance Explained(主成分特征根和贡献率)可知,特征根λ1=9.092,特征根λ2=1.150前两个主成分的累计方差贡献率达93.107%,即涵盖了大部分信息。这表明前两个主成分能够代表最初的11个指标来分析河南各个城市经济综合实力的发展水平,故提取前两个指标即可。主成分,分别记作F1、F2。 6.7
指标X1、X2、X3、X4、X5、X6、X7、X8、X9、X10在第一主成分上有较高载荷,相关性强。第一主成分集中反映了总体的经济总量。X11在第二主成分上有较高载荷,相关性强。第二主成分反映了人均的经济量水平。但是要注意: 这个主成分载荷矩阵并不是主成分的特征向量,也就是说并不是主成分1和主成分2的系数,主成分系数的求法是:各自主成分载荷向量除以各自主成分特征值的算术平方根。
7.8 成分得分系数矩阵(因子得分系数)列出了强两个特征根对应的特征向量,即各主要成分解析表达式中的标准化变量的系数向量。故各主要成分解析表达式分别为:F1=0.32ZX11+0.33ZX12+0.31ZX13+0.31ZX14+0.32ZX15+0.32ZX16+0.32ZX17+0.32ZX18+0. 32ZX19+0.21ZX110+0.15ZX111 F2=8.46ZX21+0.02ZX22-0.02ZX23-0.20ZX24-0.23Z25-0.04ZX26-0.15ZX27-0.02ZX28+0.10Z X29+0.47ZX210+0.78ZX211 8.9 主成分的得分是相应的因子得分乘以相应的方差的算术平方根。即:主成分1得分=因子1得分乘以9.092的算术平方根主成分2得分=因子2得分乘以1.150的算术平方根例如郑州:主成分因子=FAC1_1*9.092的算术平方根=3.59386*9.092的算术平方根=10.83,将各指标的标准化数据带入个主成分解析表达式中,分别计算出2个主成分得分(F1、F2),再以个主成分的贡献率为全书对主成分得分进行加权平均,即:H=(82.672*F1+10.497*F2)/93.124,求得主成分综合得分。
用SPSS进行详细的主成分分析步骤
怎样用SPSS进行主成分分析 怎样用SPSS进行主成分分析 一、基本概念与原理 主成分分析(principal component analysis) 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。又称主分量分析。在实际课题中,为了全面分析问题,往往提出很多与此有关的变量(或因素),因为每个变量都在不同程度上反映这个课题的某些信息。但是,在用统计分析方法研究这个多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。主成分分析首先是由K.皮尔森对非随机变量引入的,尔后H.霍特林将此方法推广到随机向量的情形。信息的大小通常用离差平方和或方差来衡量。 (1)主成分分析的原理及基本思想。 原理:设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的总和变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。 基本思想:主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var(F1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来
聚类分析与主成分分析SAS的程序
实验三我国各地区城镇居民消费性支出的 主成分分析和聚类分析 (王学民编写) 一、实验目的 1.掌握如何使用SAS软件来进行主成分分析和聚类分析; 2.看懂和理解SAS输出的结果,并学会以此来作出分析; 3.掌握对实际数据如何来进行主成分分析; 4.对同一组数据使用五种系统聚类方法及k均值法,学会对各种聚类效果的比较,获取重要经验; 5.掌握使用主成分进行聚类 二、实验内容 数据集sasuser.examp633中含有1999年全国31个省、直辖市和自治区的城镇居民家庭平均每人全年消费性支出的八个主要变量数据。对这些数据进行主成分分析,可将这31个地区的前两个主成分得分标示于平面坐标系内,对各地区作直观的比较分析。对同样的数据使用五种系统聚类方法及k均值法聚类,并对聚类效果作比较。最后,对主成分的图形聚类和正规聚类的效果进行比较。 实验1 进行主成分分析,根据前两个主成分得分所作的散点图对31个地区进行比较分析。 实验2 分别使用最长距离法、中间距离法、两种类平均法、离差平方和法和k均值法进行聚类分析,并比较其聚类效果。 实验3 主成分聚类,并与上述正规的聚类方法进行比较 三、实验要求 1.用SAS软件的交互式数据分析菜单系统完成主成分分析; 2.完成五种系统聚类方法及k均值法,比较其聚类效果; 3.根据前两个主成分得分的散点图作直观的聚类,并与上述正规的聚类方法进行比较。 四、实验指导
1.进行主成分分析 在inshigt中打开数据集sasuser.examp633,见图1。选菜单过程如下: 在图1中选分析?多元(Y X)?在变量框中选x1,x2,x3,x4,x5,x6,x7,x8(见图2)?Y?选输出?选主分量分析,主分量选项(见图3)?在图4中作图中的选择(主成分个数缺省时为“自动”选项,此时只输出特征值大于1的主成分)?确定?确定?确定 图1 图2
主成分分析法概念及例题
主成分分析法 主成分分析(principal components analysis,PCA)又称:主分量分析,主成分回归分析法 [编辑] 什么是主成分分析法 主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。 在统计学中,主成分分析(principal components analysis,PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。 [编辑] 主成分分析的基本思想
在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [编辑] 主成分分析的主要作用
聚类分析、判别分析、主成分分析、因子分析
聚类分析、判别分析、主成分分析、因子分析 主成分分析与因子分析的区别 1. 目的不同:因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和仅对某一个变量有作用的特殊因子线性组合而成,因此就是要从数据中控查出对变量起解释作用的公共因子和特殊因子以及其组合系数;主成分分析只是从空间生成的角度寻找能解释诸多变量变异的绝大部分的几组彼此不相关的新变量(主成分)。 2. 线性表示方向不同:因子分析是把变量表示成各公因子的线性组合;而主成分分析中则是把主成分表示成各变量的线性组合。 3. 假设条件不同:主成分分析中不需要有假设;因子分析的假设包括:各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。 4. 提取主因子的方法不同:因子分析抽取主因子不仅有主成分法,还有极大似然法,主轴因子法,基于这些方法得到的结果也不同;主成分只能用主成分法抽取。 5. 主成分与因子的变化:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的;而因子分析中因子不是固定的,可以旋转得到不同的因子。 6. 因子数量与主成分的数量:在因子分析中,因子个数需要分析者指定(SPSS 根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等)。 7. 功能:和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这种情况也可以使用因子得分做到,所以这种区分不是绝对的。 1 、聚类分析 基本原理:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。 常用聚类方法:系统聚类法,K-均值法,模糊聚类法,有序样品的聚类,分解法,加入法。
主成分分析在SPSS中的操作应用(详细步骤
主成分分析在SPSS中的操作应用(2) SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。 图表 3 相关系数矩阵
图表 4 方差分解主成分提取分析表 主成分分析在SPSS中的操作应用(3) 图表 5 初始因子载荷矩阵
从图表3可知GDP与工业增加值,第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、地方财政收入这几个指标存在着极其显著的关系,与海关出口总额存在着显著关系。可见许多变量之间直接的相关性比较强,证明他们存在信息上的重叠。 主成分个数提取原则为主成分对应的特征值大于1的前m个主成分。注:特征值在某种程度上可以被看成是表示主成分影响力度大小的指标,如果特征值小于1,说明该主成分的解释力度还不如直接引入一个原变量的平均解释力度大,因此一般可以用特征值大于1作为纳入标准。通过图表4(方差分解主成分提取分析)可知,提取2个主成分,即m=2,从图表5(初始因子载荷矩阵)可知GDP、工业增加值、第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、海关出口总额、地方财政收入在第一主成分上有较高载荷,说明第一主成分基本反映了这些指标的信息;人均GDP和农业增加值指标在第二主成分上有较高载荷,说明第二主成分基本反映了人均GDP和农业增加值两个指标的信息。所以提取两个主成分是可以基本反映全部指标的信息,所以决定用两个新变量来代替原来的十个变量。但这两个新变量的表达还不能从输出窗口中直接得到,因为“Component Matrix”是指初始因子载荷矩阵,每一个载荷量表示主成分与对应变量的相关系数。 用图表5(主成分载荷矩阵)中的数据除以主成分相对应的特征值开平方根便得到两个主成分中每个指标所对应的系数[2]。将初始因子载荷矩阵中的两列数据输入(可用复制粘贴的方法)到数据编辑窗口(为变量B1、B2),然后利用“TransformàCompute Variable”,在Compute Variable对话框中输入 “A1=B1/SQR(7.22)” [注:第二主成分SQR后的括号中填1.235],即可得到特征向量A1(见图表6)。同理,可得到特征向量A2。将得到的特征向量与标准化后的数据相乘,然后就可以得出主成分表达式[注:因本例只是为了说明如何在SPSS进行主成分分析,故在此不对提取的主成分进行命名,有兴趣的读者可自行命名]: F1=0.353ZX1+0.042ZX2-0.041ZX3+0.364ZX4+0.367ZX5+0.366ZX6+0.352ZX7+0.364ZX