数据处理与建模流程-1演示教学

数据处理与建模流程:
1数据处理
1.1替换缺失值:
数据完整没有缺失值的情况基本不存在,我们的数据中,0点-5点的航班为0的情况
很多,所以数据缺失比较严重。时间序列分析要求时间周期完整,如果将缺失的数据只简单
地用其他所有数据的缺失值填充,误差较大。经过反复尝试,发现用临近两点均值填充,结果最为理想。
2时间序列的预处理
2.1时间序列平稳化
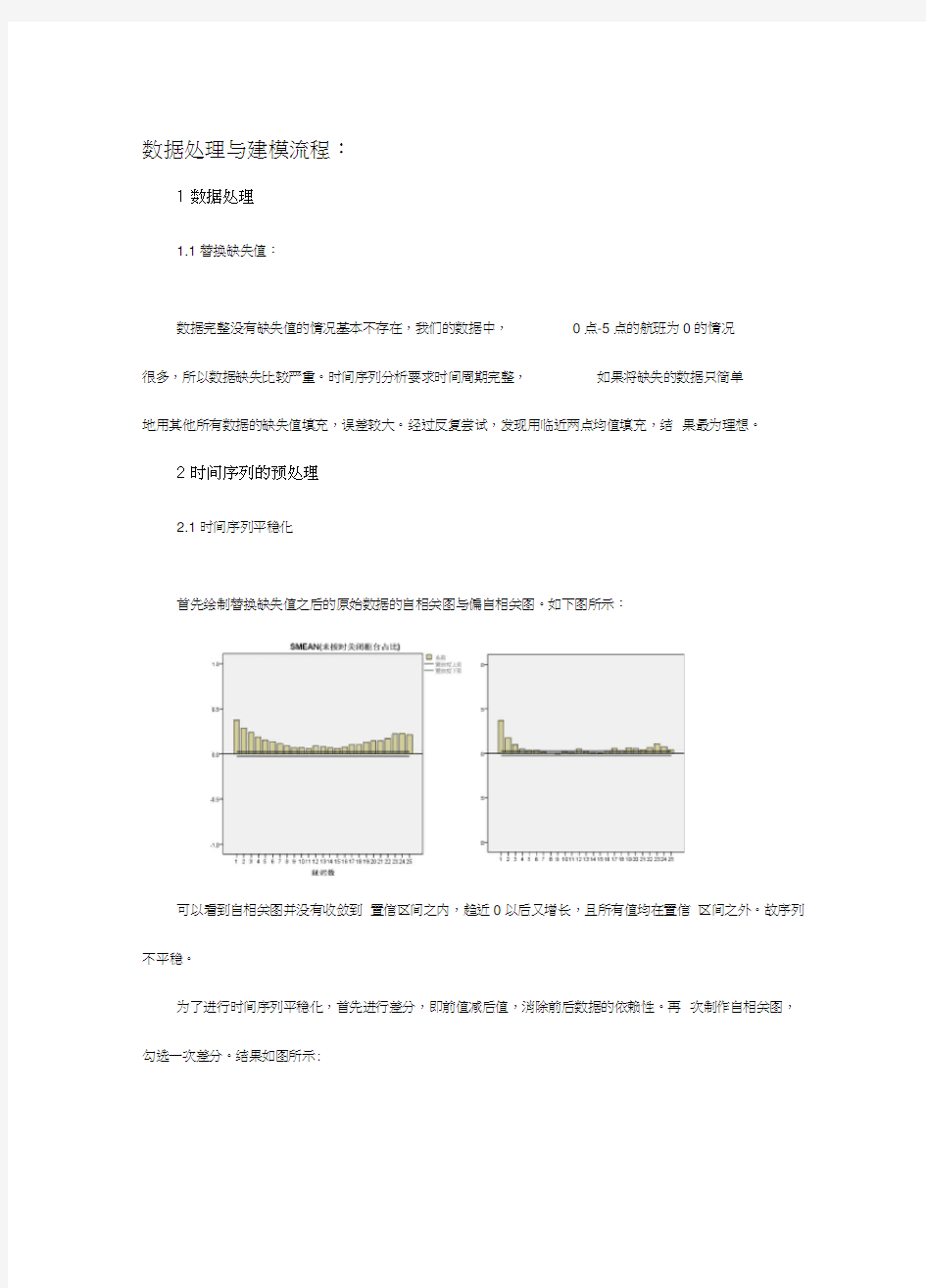
首先绘制替换缺失值之后的原始数据的自相关图与偏自相关图。如下图所示:
可以看到自相关图并没有收敛到置信区间之内,趋近0以后又增长,且所有值均在置信区间之外。故序列不平稳。
为了进行时间序列平稳化,首先进行差分,即前值减后值,消除前后数据的依赖性。再次制作自相关图,勾选一次差分。结果如图所示:
如图所示偏ACF 图仍然所有值均在置信区间之外。序列仍不平稳。勾选季节性差分再 次制作自相关图,后
一个周期相同位置的值减去前一个周期相同位置的值称为季节性差分。
结果如图所示:
从图中可知ACF 为截尾,PACF 为拖尾。序列已稳定。
故将原始序列先进行差分,后进行季节性差分。
22平稳序列的检验
为了考察单个序列是否的确已经转换为平稳的随机序列,制作自相关图( ACF )与偏相
关图(PACF )。此次将延迟拉大,观察相关图是否具有周期性:
口
'VL.IK hRI
然骤减。PACF 拖尾。根据下图,符合 MA(q),Seas.MA(Q) 模型。
事於.1各种4kMA?3J 的目冋归茶魏和價国归購锻虫忧趋勢
型
* R ( P )
- p 扁一霹醺
MA(f)
lair =w EfVlft
拖堆
AR? T S?. AH' Pi
拖珞
l 嗨 - p * M 尸 h ;曙 M
UA(v ),Sra fij ?A( fl )
(ACF 与PACF 怎么看:第一列数为 lag 值,第二列为相关系数的估计值, 第三列为标
准误差,其余为 Box-Ljung 检验结果。如果相关系数是突然收敛到置信区间之内, 95%的
值在置信区间之内,为截尾。如果相关系数像一条常常的尾巴, 95%的值在置信区间之外,
为拖尾。故,自相关图为截尾,偏相关图为拖尾。符合 MA 模型)
3指数平滑与ARIMA 的比较
指数平滑:
用序列过去值的加权均数来预测将来的值,
并给序列中近期的数据以较大的权重,
远期
的数据以较小的权重。理由是随着时间的流逝,过去值的影响逐渐减小。基本公式:
| L - ? ------------ b
1LJ
q+Sq 后仍
观察,发现其具有周期性,在
^1*1 It)
I 2 3 4
15 T B fl ID II I Z13U IS' Tlfl !9Z] :< 2II3Z1^?2131
:二 a 匕 + ( 1 一 U t () < a < 1
Ft 是t 时刻的预测值,Y 是t 时刻的实际值。指数平滑沿袭了修正的思想,
预测值是T 时刻的实际观测值对 T 时刻的预测值加以修正后得到的。展开式:
=a+ a (1 — a) _ j + a( 1 - a )2 + '" + or( 1 — a) 3 Y i
实际观测值对预测值的影响随着时间距离的增大而呈指数级数衰减,
这就是指数平滑的由来。
平沖的由来U 只走滅的建度由平滑系数欣決能,如黑仪-】,说叨r + 1吋刻的预刎"很由『时劉 的谨删價决定,而与卩时刻之前的任何数值Jt 天;半口權近1时?时Ml 庁列的衰减逢度非常快+预 測當只受彊近的儿牛现测値的比响.哽処处的影响禅少:芳(I 搖近。吋-即使迅处的观测佰也灯 当前的硕测有相沟的翻响力曲口果n = 0*说明序列非常螳宦嘔T 讨剧的观港值的霁咆’村由 听史数邮貴交,
根据指数平滑法的公式可以知道: 指数平滑法适合于影响随时间的消失呈下降的数据。
ARIMA 模型:
AR ( p )模型(Auto regression Model ) -------------自回归模型
刃=c + 0iXt-i + ^2Vt-2 + …+ 0p7t-p + e t
式中?”为时间序列第七时刻的观察值.即为因变呈或称被解释变註;y £_v y T -3.…,y?p 为时序片的淆后序列.这甲.作为自变帛戚称为解释变苗:內是融 机i 吴遼项:G 01 r 0“….0&为待估的门冋叽参数村
.4/ hg )模型:Moving Avemge MudeJ 移动平均税型
V 阶移动平均模型匕
£「乂十巧一坊空L _◎/;-_-一加Y
式中,H 为时间序列的平均数,但当輛}序列在0 I :卜变动时、显然#=0, 可删除此
项;%
s “ 为模型在第『期「第人I 期…初第 i 期
的课并,0]t 釦 z 0为待估的移副T 均卷数“
这里的d 是对原时序进行逐期差分的阶数,差分的目的是为了让某些非平稳(具有一
定趋势的)序列变换为平稳的,通常来说 d 的取值一般为0,1,2。对于具有趋势性非平稳时
序,不能直接建立 ARMA 模型,只能对经过平稳化处理,而后对新的平稳时序建立
ARMA (p,q )模型。这里的平稳化处理可以是差分处理,
也可以是对数变换,也可以是两者相 结合,先
对数变换再进行差分处理。
T+1时刻的
p 阶自回归模型:
对于具有季节性的非平稳时序(如冰箱的销售量,羽绒服的销售量)
,也同样需要进行
季节差分,从而得到平稳时序。这里的 D 即为进行季节差分的阶数; PQ 分别是季节性自回 归阶数和季节性移
动平均阶数; S 为季节周期的长度。
确定pqd,PQD 主要根据自相关图与偏自相关图。
4.建模
首先了解一下各个参数的意义:
R 方、平稳的R 方:R 方是使用原始序列计算出的模型决定系数,
用。平稳的R 方则是用模型的平稳部分计算出的决定系数, 当序列具有趋势或季
节波动时, 该指标优于普通 R 房。两者取值均为小于等于 1的任意数,负值表示该模型预测效果比只 用均数预
测还差。
RMSE :均方误差的平方根,表示模型预测因变量的精度,其值越小,精度越高。 MAE:平均绝对误差; MaxAE :最大绝对误差; MAPE:平均绝对误差百分比; MaxAPE:最大绝对误差百分比;
正态化的BIC :是基于均方误差的分数,包括模型中参数数量的罚分和序列长度。罚分
去除了具有更多参数的模型优势,从而可以容易地比较相同序列的不同模型的统计量。
其中百分比用来比较不同的模型,最大绝对误差与最大绝对误差百分比对于考虑预测最 坏情况很有用。
4.1指数平滑法建模
根据前面叙述,知道指数平滑法适用于影响随时间的消失呈下降的数据。
朋幽“忒和(疋'模型
自回归积分滑动平均模型
只能在序列平稳时使
对于我们的数
据可能不适用。但是保险起见,仍用指数平滑法进行建模。如图所示R方为负值,表示该模
型效果太差。故抛弃该方法。
4.2专家建模法选择合适模型
专家建模法默认两种建模方法均使用,因为手动计算合适参数较为复杂,专家建模器会为用户选择合适的模型与参数。如图所示,专家建模器选择的是ARIMA模型,并设置参数
为ARIMA(0,0,2)(0,0,1),根据前面分析可知”沁4八用「八弋;4";二:詞中p=0 ,d=0,q=2 ,
P=0,D=0,Q=1。结合数据的ACF图,说明ARIMA相对于指数平滑法更适合。
模型参数如下,图中R方与平稳的R方相等,该模型为非季节性模型。Ljung-Box Q 检验中白噪声未超过限定值,通过检验。
-VI fNm?E R-1询■暫■隣
■L^m
$ffl ?5 ?D
巧Y!R 1.flFJ sn ?Ti cn ?TJ 4T1 ,?71m 羽n-n H 7C-2?E fl https://www.360docs.net/doc/615651075.html, .90 fl?3 JT7Ed?珥RU5E ICi-HZD 1G.B:O1VJ94B H3JE3Q1C.BID 15.3-3C MJBSO ILQJD TCBIB lfli.EXi IWE LiOSf-KH 1.13GE*I4l.i 3?EH N2nm n>^4?汨|黑I14JP O43V 別胛13411叭胃1 . El - 1-1&05J0冋1C51□睞5J513 SJWS *■ V r I tt?Mff!? r>ft Ljirrgi-gra Uli #| 柿?“li W tfWH ■「「-■ 1?T3 1 :吓■-1fl nw Q 卜图为该模型预测的9月一天的数据。 ■wqEFIN 40 0. 20 0- ?0- =?nn- 申jtr - SD0-244 ?rj44 強 244也 — 244 23 顎 4 4.2调整模型参数 但是由前面进行的季节性分解分析可知,我们的数据具有周期性。由前面分析的图中所 示,ACF在1阶之后骤减,为截尾。进一步观察,发现其具有周期性,在q+Sq后仍然骤 减。PACF拖尾。根据下图,符合MA(q),Seas.MA(Q) 模型。 设置d=1,D=1,q=1 ,Q=1,设置p跟P均为0,建立模型如下。R方为负值表示该模型拟 合效果很差。需要进一步调整参数。 沖| . 4j 1 1E HK rir A-i niM 5TD 25sa FS M9£ 刊3册R ,.*T:m尿!■吟Rd VN-QBI Wl 厂心目 5 DM ■#?? an-m RHSE am ai?u 2*1 It 弭叭21 SMI ZBVI'I w Sl.tflft hrKFE 1 4iBE h H 1 di 1 4141 1 1 41VE*H 1 界■EMU 4咖屮E: 1 D5re+|iB i.wdE-*iia4 4 0?EE*1C 1 OflTE+HC4O9DE+1E ICB^E*^E NAE10.535 qBJVUE ivjaan■ B妙19刚;19 9W- IB 59■-1K QBS 1B3-B5 HiiAE IM.K3 13J.919i刖曲I13.BSS ■ra.M1E9.139 ll?P.盼1B1 flBb KBMb iritiL/ifecm 4.101 BJM1 viai 4 Ml 4.101 f.nr 0.BD1 t.iai tioi 9.M1 2p鱼■廿■Miq ■诩UEVHfill"晖*du rj 即=*■ rt-r. R p OF …苛 1 24>?V 1■慎B13'11 4 Si 1$ 故进一步调整模型参数。经过反复调整试验,模型参数设置为:ARIMA(2,1,1)(1,1,1)的时候, 模型具有最大的稳定R方值。如下图所示: 模型参数设置 建模的参数情况如下: Mt'lilrt ;v ■■ i 将预测值以及原始数据 将数据原始值与处理值以及两个模型预测值 (专家建模给出的参数与调整后的参数) 共 同绘制序列图如下: 干货&神图:数据分析师的完整流程与知识结构体系 【编者注】此图整理自微博分享,作者不详。一个完整的数据分析流程,应该包括以下几个方面,建议收藏此图仔细阅读。完整的数据分析流程:1、业务建模。2、经验分析。3、数据准备。 4、数据处理。 5、数据分析与展现。 6、专业报告。 7、持续验证与跟踪。 (注:图保存下来,查看更清晰) 作为数据分析师,无论最初的职业定位方向是技术还是业务,最终发到一定阶段后都会承担数据管理的角色。因此,一个具有较高层次的数据分析师需要具备完整的知识结构。 1. 数据采集 了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。这会帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时,对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。比如: Omniture中的Prop变量长度只有100个字符,在数据采集部署过程中就不能把含有大量中文描述的文字赋值给Prop变量(超过的字符会被截断)。 在Webtrekk323之前的Pixel版本,单条信息默认最多只能发送不超过2K的数据。当页面含有过多变量或变量长度有超出 限定的情况下,在保持数据收集的需求下,通常的解决方案是采用多个sendinfo方法分条发送;而在325之后的Pixel版本,单条信息默认最多可以发送7K数据量,非常方便的解决了代码部署中单条信息过载的问题。(Webtrekk基于请求量付费,请求量越少,费用越低)。 当用户在离线状态下使用APP时,数据由于无法联网而发出,导致正常时间内的数据统计分析延迟。直到该设备下次联网时,数据才能被发出并归入当时的时间。这就产生了不同时间看相同历史时间的数据时会发生数据有出入。 在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,如此才能更好的追本溯源。另外,这也能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。 2.数据存储 无论数据存储于云端还是本地,数据的存储不只是我们看到的数据库那么简单。比如: o数据存储系统是MySql、Oracle、SQL Server还是其他系统。 o数据仓库结构及各库表如何关联,星型、雪花型还是其他。 o生产数据库接收数据时是否有一定规则,比如只接收特定类型字段。 o生产数据库面对异常值如何处理,强制转换、留空还是返回错误。 大数据处理流程的主要环节 大数据处理流程主要包括数据收集、数据预处理、数据存储、数据处理与分析、数据展示/数据可视化、数据应用等环节,其中数据质量贯穿于整个大数据流程,每一个数据处理环节都会对大数据质量产生影响作用。通常,一个好的大数据产品要有大量的数据规模、快速的数据处理、精确的数据分析与预测、优秀的可视化图表以及简练易懂的结果解释,本节将基于以上环节分别分析不同阶段对大数据质量的影响及其关键影响因素。 一、数据收集 在数据收集过程中,数据源会影响大数据质量的真实性、完整性数据收集、一致性、准确性和安全性。对于Web数据,多采用网络爬虫方式进行收集,这需要对爬虫软件进行时间设置以保障收集到的数据时效性质量。比如可以利用八爪鱼爬虫软件的增值API设置,灵活控制采集任务的启动和停止。 二、数据预处理 大数据采集过程中通常有一个或多个数据源,这些数据源包括同构或异构的数据库、文件系统、服务接口等,易受到噪声数据、数据值缺失、数据冲突等影响,因此需首先对收集到的 大数据集合进行预处理,以保证大数据分析与预测结果的准确性与价值性。 大数据的预处理环节主要包括数据清理、数据集成、数据归约与数据转换等内容,可以大大提高大数据的总体质量,是大数据过程质量的体现。数据清理技术包括对数据的不一致检测、噪声数据的识别、数据过滤与修正等方面,有利于提高大数据的一致性、准确性、真实性和可用性等方面的质量; 数据集成则是将多个数据源的数据进行集成,从而形成集中、统一的数据库、数据立方体等,这一过程有利于提高大数据的完整性、一致性、安全性和可用性等方面质量; 数据归约是在不损害分析结果准确性的前提下降低数据集规模,使之简化,包括维归约、数据归约、数据抽样等技术,这一过程有利于提高大数据的价值密度,即提高大数据存储的价值性。 数据转换处理包括基于规则或元数据的转换、基于模型与学习的转换等技术,可通过转换实现数据统一,这一过程有利于提高大数据的一致性和可用性。 总之,数据预处理环节有利于提高大数据的一致性、准确性、真实性、可用性、完整性、安全性和价值性等方面质量,而大数据预处理中的相关技术是影响大数据过程质量的关键因素 大数据分析平台的需求报告 提供统一的数据导入工具,数据可视化工具、数据校验工具、数据导出工具和公共的数据查询接口服务管理工具是建立大数据分析平台的方向。 一、项目范围的界定 没有明确项目边界的项目是一个不可控的项目。基于大数据分析平台的需求,需要考虑的问题主要包括下面几个方面: (1)业务边界:有哪些业务系统的数据需要接入到大数据分析平台。 (2)数据边界:有哪些业务数据需要接入大数据分析平台,具体的包括哪些表,表结构如何,表间关系如何(区别于传统模式)。 (3)功能边界:提供哪些功能,不提供哪些功能,必须明确界定,该部分详见需求分析; 二、关键业务流程分析 业务流程主要考虑包括系统间数据交互的流程、传输模式和针对大数据平台本身涉及相关数据处理的流程两大部分。系统间的数据交互流程和模式,决定了大数据平台的架构和设计,因此必须进行专项分析。大数据平台本身需要考虑的问题包括以下几个方面: 2.1 历史数据导入流程 2.2 增量数据导入流程 2.3 数据完整性校验流程 2.4 数据批量导出流程 2.5 数据批量查询流程 三、功能性需求分析 3.1.历史数据导入3.1.1 XX系统数据3.1.1.1 数据清单 (3) 3.1.1.2 关联规则 (3) 3.1.1.3 界面 (3) 3.1.1.4 输入输出 (3) 3.1.1.5 处理逻辑 (3) 3.1.1.6 异常处理 (3) 3.2 增量数据导入3.3 数据校验 3.4 数据导出 3.5 数据查询 四、非功能性需求 4.1 性能 4.2 安全性 4.3 可用性 … 五、接口需求 5.1 数据查询接口 5.2 批量任务管理接口 5.3 数据导出接口 六、集群需求 大数据平台的技术特点,决定项目的实施必须考虑单独的开发环境和生产环境,否则在后续的项目实施过程中,必将面临测试不充分和性能无法测试的窘境,因此前期需求分析阶段,必须根据数据规模和性能需求,构建单独的开发环境和生产环境。 6.1开发环境 6.1.1 查询服务器 6.1.2 命名服务器 6.1.3 数据服务器 6.2 生产环境 6.2.1 查询服务器 数据分析方法、数据处理流程实战案例 大数据时代,我们人人都逐渐开始用数据的眼光来看待每一个事情、事物。确实,数据的直观明了传达出来的信息让人一下子就能领略且毫无疑点,不过前提是数据本身的真实性和准确度要有保证。今天就来和大家分享一下关于数据分析方法、数据处理流程的实战案例,让大家对于数据分析师这个岗位的工作内容有更多的理解和认识,让可以趁机了解了解咱们平时看似轻松便捷的数据可视化的背后都是 有多专业的流程在支撑着。 一、大数据思维 在2011年、2012年大数据概念火了之后,可以说这几年许多传统企业也好,互联网企业也好,都把自己的业务给大数据靠一靠,并且提的比较多的大数据思维。 那么大数据思维是怎么回事?我们来看两个例子: 案例1:输入法 首先,我们来看一下输入法的例子。 我2001年上大学,那时用的输入法比较多的是智能ABC,还有微软拼音,还有五笔。那时候的输入法比现在来说要慢的很多,许多时候输一个词都要选好几次,去选词还是调整才能把这个字打出来,效率是非常低的。 到了2002年,2003年出了一种新的输出法——紫光拼音,感觉真的很快,键盘没有按下去字就已经跳出来了。但是,后来很快发现紫光拼音输入法也有它的问题,比如当时互联网发展已经比较快了, 会经常出现一些新的词汇,这些词汇在它的词库里没有的话,就很难敲出来这个词。 在2006年左右,搜狗输入法出现了。搜狗输入法基于搜狗本身是一个搜索,它积累了一些用户输入的检索词这些数据,用户用输入法时候产生的这些词的信息,将它们进行统计分析,把一些新的词汇逐步添加到词库里去,通过云的方式进行管理。 比如,去年流行一个词叫“然并卵”,这样的一个词如果用传统的方式,因为它是一个重新构造的词,在输入法是没办法通过拼音“ran bing luan”直接把它找出来的。然而,在大数据思维下那就不一样了,换句话说,我们先不知道有这么一个词汇,但是我们发现有许多人在输入了这个词汇,于是,我们可以通过统计发现最近新出现的一个高频词汇,把它加到司库里面并更新给所有人,大家在使用的时候可以直接找到这个词了。 案例2:地图 大数据分析教程——制作数据报告的流程 上图中可以很清楚的看到,一个数据报告(副本)依据需求不同,有普通难度(蓝->橙->绿->红),也有英雄难度(蓝->橙->绿+黄->红),这次我们先讲普通难度的攻略,英雄难度放到下次讲。普通难度的数据报告要经历7个步骤:Step 1:目标确定 这一步在工作中通常是由你的客户/上级/其他部门同事/合作方提出来的,但第一次的数据报告中,需要你自己来提出并确定目标。 选择目标时,请注意以下几点: 1、选择一个你比较熟悉,或者比较感兴趣的领域/行业; 2、选择一个范围比较小的细分领域/细分行业作为切入点; 3、确定这个领域/行业有公开发表的数据/可以获取的UGC内容(论坛帖子,用户点评等)。 逐一分析上面三个注意点: 1、选择熟悉/感兴趣的领域/行业,是为了保证你在后续的分析过程中能够真正触及事情的本质——这一过程通常称为洞察——而不是就数字论数字; 2、选择细分领域/行业作为切入点,是为了保证你的报告能够有一条清晰的主线,而非单纯堆砌数据; 3、确定公开数据/UGC内容,是为了保证你有数据可以分析,可以做成报告,你说你是个军迷,要分析一下美国在伊拉克的军事行动与基地组织恐怖活动之间的关系……找到了数据麻烦告诉我一声,我叫你一声大神…… 不管用什么方法,你现在有了一个目标,那么就向下个阶段迈进吧。 Step 2:数据获取 目标定下来了,接下来要去找相应的数据。如果你制定目标时完全遵循了第一步的三个注意点,那么你现在会很明确要找哪些数据。如果现在你还不确定自己需要哪些数据,那么……回到第一步重来吧。 下面我总结一下,在不依赖公司资源,不花钱买数据的情况下,获取目标数据的三类方法: 1、从一些有公开数据的网站上复制/下载,比如统计局网站,各类行业网站等,通过搜索引擎可以很容易找到这些网站。举例:要找汽车销量数据,在百度输入“汽车销量数据查询”关键字,结果如下: 昆明理工大学 空间数据库期末考察报告《简析大数据及其处理分析流程》 学院:国土资源工程学院 班级:测绘121 姓名:王易豪 学号:201210102179 任课教师:李刚 简析大数据及其处理分析流程 【摘要】大数据的规模和复杂度的增长超出了计算机软硬件能力增长的摩尔定律,对现有的IT架构以及计算能力带来了极大挑战,也为人们深度挖掘和充分利用大数据的大价值带来了巨大机遇。本文从大数据的概念特征、处理分析流程、大数据时代面临的挑战三个方面进行详细阐述,分析了大数据的产生背景,简述了大数据的基本概念。 【关键词】大数据;数据处理技术;数据分析 引言 大数据时代已经到来,而且数据量的增长趋势明显。据统计仅在2011 年,全球数据增量就达到了1.8ZB (即1.8 万亿GB)[1],相当于全世界每个人产生200GB 以上的数据,这些数据每天还在不断地产生。 而在中国,2013年中国产生的数据总量超过0.8ZB(相当于8亿TB),是2012年所产生的数据总量的2倍,相当于2009年全球的数据总量[2]。2014年中国所产生的数据则相当于2012 年产生数据总量的10倍,即超过8ZB,而全球产生的数据总量将超40ZB。数据量的爆发式增长督促我们快速迈入大数据时代。 全球知名的咨询公司麦肯锡(McKinsey)2011年6月份发布了一份关于大数据的详尽报告“Bigdata:The next frontier for innovation,competition,and productivity”[3],对大数据的影响、关键技术和应用领域等都进行了详尽的分析。进入2012年以来,大数据的关注度与日俱增。 数据分析程序流程图 数据分析程序 1 目的 确定收集和分析适当的数据,以证实质量管理体系的适宜性和有效性,评价和持续改进质量管理体系的有效性。 2 适用范围 本程序适用于烤烟生产服务全过程的数据分析。 3 工作职责 3.1 分管领导:负责数据分析结果的批准。 3.2 烟叶科:负责数据分析结果的审核。 3.3 相关部门:负责职责范围内数据的收集和分析。 4 工作程序 4.1 数据的分类 4.1.1 烟用物资采购发放数据:烟用物资盘点盘存、烟用物资需求、烟用物资采购、烟用物资发放、烟用物资分户发放、烟用物资供应商等相关数据。 4.1.2 烤烟生产收购销售数据。 4.1.3 烟叶挑选整理数据:烟叶挑选整理数据。 4.1.4 客户满意:烟厂(集团公司)和烟农满意度测量数据和其他反馈信息。 4.1.5 过程和质量监测数据:产购销过程各阶段检查数据及不合格项统计等。 4.1.6 持续改进数据。 4.2 数据的收集 4.2.1 烟用物资采购数据的收集 a) 烟草站于当年10月底对当年烟用物资使用情况进行收集,对库存情况进行盘点,并填写烟用物 资盘点情况统计表保存并送烟叶科; b) 储运科于当年10月底前将烟用物资库存情况进行盘点,送烟叶科; c) 储运站于当年挑选结束后对库存麻片、麻绳、缝口绳进行盘点,据次年生产需要,制定需求计 划表,送烟叶科。 d) 烟草站于当年10月底据次年生产需求填报烟用物资需求表,上报烟叶科,烟叶科据烟用物资需 求和库存盘点情况,拟定烟用物资需求计划,报公司烤烟生产分管领导批准; e) 烟叶科将物资采购情况形成汇总表,送财务科、报分管领导; f) 烟叶科形成烟用物资发放情况登记表,归档、备案; g) 烟草站形成烟用物资分户发放情况表,烟草站备案。 4.2.2 烤烟产购销数据的收集 a) 烟用物资采购数据收集完成后,由烟叶科填报《烟用物资采购情况汇总表》,于管理评审前上 报分管领导和经理。 b) 烤烟生产期间,烟草站每10天向烟叶科上报《烤烟生产情况统计表》,烟叶科汇总后定期上报 公司领导层。对所收集的进度报政府或上级部门时,必须由分管领导签字后才能送出。 业务流程图与数据流程图的比较 业务流程图与数据流程图的比较 一、业务流程图与数据流程图的区别 1. 描述对象不同 业务流程图的描述对象是某一具体的业务; 数据流程图的描述对象是数据流。 业务是指企业管理中必要且逻辑上相关的、为了完成某种管理功能的一系列相关的活动。在系统调研时, 通过了解组织结构和业务功能, 我们对系统的主要业务有了一个大概的认识。但由此我们得到的对业务的认识是静态的, 是由组织部门映射到业务的。而实际的业务是流动的, 我们称之为业务流程。一项完整的业务流程要涉及到多个部门和多项数据。例如, 生产业务要涉及从采购到财务, 到生产车间, 到库存等多个部门; 会产生从原料采购单, 应收付账款, 入库单等多项数据表单。因此, 在考察一项业务时我们应将该业务一系列的活动即整个过程为考察对象, 而不仅仅是某项单一的活动, 这样才能实现对业务的全面认识。将一项业务处理过程中的每一个步骤用图形来表示, 并把所有处理过程按一定的顺序都串起来就形成了业务流程图。如图 1 所示, 就是某公司物资管理的业务流程图。 数据流程图是对业务流程的进一步抽象与概括。抽象性表现在它完全舍去了具体的物质, 只剩下数据的流动、加工处理和存储; 概括性表现在它可以把各种不同业务处理过程联系起来,形成一个整体。从安东尼金字塔模型的角度来看, 业务流程图描述对象包括企业中的信息流、资金流和物流, 数据流程图则主要是对信息流的描述。此外, 数据流程图还要配合数据字典的说明, 对系统的逻辑模型进行完整和详细的描述。 2. 功能作用不同 业务流程图是一本用图形方式来反映实际业务处理过程的“流水帐”。绘制出这本流水帐对于开发者理顺和优化业务过程是很有帮助的。业务流程图的符号简单明了, 易于阅读和理解业务流程。绘制流程图的目的是为了分析业务流程, 在对现有业务流程进行分析的基础上进行业务流程重组, 产生新的更为合理的业务流程。通过除去不必要的、多余的业务环节; 合并重复的环节;增补缺少的必须的环节; 确定计算机系统要处理的环节等重要步骤, 在绘制流程图的过程中可以发现问题, 分析不足, 改进业务处理过程。 数据流程分析主要包括对信息的流动、传递、处理、存储等的分析。数据流程分析的目的就是要发现和解决数据流通中的问题, 这些问题有: 数据流程不畅, 前后数据不匹配, 数据处理过程不合理等。通过对这些问题的解决形成一个通畅的数据流程作为今后新系统的数据流程。数据流程图比起业务流程图更为抽象, 它舍弃了业务流程图中的一些物理实体, 更接近于信息系统的逻辑模型。对于较简单的业务, 我们可以省略其业务流程图直接绘制数据流程图。 3. 基本符号不同 (1)业务流程图的常用的基本符号有以下六种, 见图 2 所示。 (2)数据流程图的基本符号见图 3 所示 大数据分析的流程浅析之一:大数据采集过程分析 数据采集,就是使用某种技术或手段,将数据收集起来并存储在某种设备上,这种设备可以是磁盘或磁带。区别于普通的数据分析,大数据分析的数据采集在数据收集和存储技术上都是不同的。具体情况如下: 1.大数据收集过程 在收集阶段,大数据分析在时空两个方面都有显著的不同。在时间维度上,为了获取更多的数据,大数据收集的时间频度大一些,有时也叫数据采集的深度。在空间维度上,为了获取更准确的数据,数据采集点设置得会更密一些。 以收集一个面积为100 平方米的葡萄园的平均温度 为例。小数据时代,由于成 本的原因,葡萄园主只能在 葡萄园的中央设置一个温度 计用来计算温度,而且每一 小时观测一次,这样一天就 只有24个数据。而在大数据 时代,在空间维度上,可以 设置100个温度计,即每个 1平方米一个温度计;在时间维度上,每隔1分钟就观测一次,这 样一天就有144000个数据,是原来的6000倍。 有了大量的数据,我们就可以更准确地知道葡萄园的平均温度,如果加上时间刻度的话,还可以得出一个时间序列的曲线,结果看起来使人很神往。 2.大数据的存储技术 通过增加数据采集的深度和广度,数据量越来越大,数据存储问题就凸现。原来1TB的数据,可以使用一块硬盘就可以实现数据的存储,而现在变成了6000TB,也就是需要6000块硬盘来存放数据,而且这个数据是每天都是增加的。这个时候计算机技术中的分布式计算开始发挥优势,它可以将6000台甚至更多的计算机组合在一起,让它们的硬盘组合成一块巨大的硬盘,这样人们就不用再害怕大数据了,大数据再大,增加计算机就可以了。实现分布式计算的软件有很多,名气最大的,目前市场上应用最广的,就是hadoop技术了,更精确地说应该是叫hadoop框架。 hadoop框架由多种功能性软件组成,其自身只是搭建一个和操作系统打交道的平台。其中最核心的软件有两个,一个是hdfs分布式文件系统,另一个是mapreduce分布式计算。hdfs分布式文件系统完成的功能就是将6000台计算机组合在一起,使它们的硬盘组合成一块巨大的硬盘,至于数据如何在硬盘上存放和读取,这件事由hadoop和hdfs共同完成,不用我们操心,这就如我们在使用一台计算机时只管往硬盘上存放数据,而数据存放在硬盘上的哪个磁道,我们是不用关心的。 【采购】采购数据分析的8个流程与常用7 个思路 在采购过程中,数据分析具有极其重要的战略意义,是优化供应链和采购决策的核心大脑。因此做好数据分析,是采购过程中最重要的环节之一。 那么如何做好数据分析呢?以下梳理出数据分析的8步流程,以及常见的7种分析思路。在启动数据分析前,最好跟主管或数据经验较丰富的童鞋确认每一步的分析流程。 一、数据分析八流程: 1、为什么分析? 首先,你得知道为什么分析?弄清楚此次数据分析的目的。比如,什么类型的 客户交货期总是拖延。你所有的分析都的围绕这个为什么来回答。避免不符合 目标反复返工,这个过程会很痛苦。 2、分析目标是谁? 要牢记清楚的分析因子,统计维度是金额,还是产品,还是供应商行业竞争趋势,还是供应商规模等等。避免把金额当产品算,把产品当金额算,算出的结 果是差别非常大的。 3、想达到什么效果? 通过分析各个维度产品类型,公司采购周期,采购条款,找到真正的问题。例 如这次分析的薄弱环节供应商,全部集中采购,和保持现状,都不符合利益最 大化原则。通过分析,找到真正的问题根源,发现精细化采购管理已经非常必 要了。 4、需要哪些数据? 采购过程涉及的数据,很多,需要哪些源数据?采购总额?零部件行业竞争度?货款周期?采购频次?库存备货数?客户地域因子?客户规模?等等列一个表。避免不断增加新的因子。 5、如何采集? 数据库中供应商信息采集,平时供应商各种信息录入,产品特性录入等,做数据分析一定要有原料,否则巧妇难为无米之炊。 6、如何整理? 整理数据是门技术活。不得不承认EXCEL是个强大工具,数据透视表的熟练使 用和技巧,作为支付数据分析必不可少,各种函数和公式也需要略懂一二,避 免低效率的数据整理。Spss也是一个非常优秀的数据处理工具,特别在数据量 比较大,而且当字段由特殊字符的时候,比较好用。 7、如何分析? 整理完毕,如何对数据进行综合分析,相关分析?这个是很考验逻辑思维和推 理能力的。同时分析推理过程中,需要对产品了如指掌,对供应商很了解,对 采购流程很熟悉。看似一个简单的数据分析,其实是各方面能力的体现。首先 是技术层面,对数据来源的抽取-转换-载入原理的理解和认识;其实是全局观,对季节性、公司等层面的业务有清晰的了解;最后是专业度,对业务的流程、设计等了如指掌。练就数据分析的洪荒之力并非一朝一夕之功,而是在实 践中不断成长和升华。一个好的数据分析应该以价值为导向,放眼全局、立足 业务,用数据来驱动增长。 8、如何展现和输出? 数据分析师的完整流程与知识结构体系 ————————————————————————————————作者:————————————————————————————————日期: 1.数据采集 了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。这会帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时,对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。比如:Omniture中的Prop变量长度只有100个字符,在数据采集部署过程中就不能把含有大量中文描述的文字赋值给Prop变量(超过的字符会被截断)。 在Webtrekk323之前的Pixel版本,单条信息默认最多只能发送不超过2K的数据。当页面含有过多变量或变量长度有超出限定的情况下,在保持数据收集的需求下,通常的解决方案是采用多个sendinfo方法分条发送;而在325之后的Pixel 版本,单条信息默认最多可以发送7K数据量,非常方便的解决了代码部署中单条信息过载的问题。(Webtrekk基于请求量付费,请求量越少,费用越低)。 当用户在离线状态下使用APP时,数据由于无法联网而发出,导致正常时间内的数据统计分析延迟。直到该设备下次联网时,数据才能被发出并归入当时的时间。这就产生了不同时间看相同历史时间的数据时会发生数据有出入。 在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,如此才能更好的追本溯源。另外,这也能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。 2.数据存储 无论数据存储于云端还是本地,数据的存储不只是我们看到的数据库那么简单。比如: 数据存储系统是MySql、Oracle、SQL Server还是其他系统。 数据仓库结构及各库表如何关联,星型、雪花型还是其他。 生产数据库接收数据时是否有一定规则,比如只接收特定类型字段。 生产数据库面对异常值如何处理,强制转换、留空还是返回错误。 生产数据库及数据仓库系统如何存储数据,名称、含义、类型、长度、精度、是否可为空、是否唯一、字符编码、约束条件规则是什么。 接触到的数据是原始数据还是ETL后的数据,ETL规则是什么。 数据仓库数据的更新更新机制是什么,全量更新还是增量更新。 不同数据库和库表之间的同步规则是什么,哪些因素会造成数据差异,如何处理差异的。 大数据处理培训:大数据处理流程 生活在数据裸奔的时代,普通人在喊着如何保护自己的隐私数据,黑心人在策划着如何出售个人信息,而有心人则在思考如何处理大数据,数据的处理分几个步骤,全部完成之后才能获得大智慧。 大数据处理流程完成的智慧之路: 第一个步骤叫数据的收集。 首先得有数据,数据的收集有两个方式: 第一个方式是拿,专业点的说法叫抓取或者爬取。例如搜索引擎就是这么做的:它把网上的所有的信息都下载到它的数据中心,然后你一搜才能搜出来。比如你去搜索的时候,结果会是一个列表,这个列表为什么会在搜索引擎的公司里面?就是因为他把数据都拿下来了,但是你一点链接,点出来这个网站就不在搜索引擎它们公司了。比如说新浪有个新闻,你拿百度搜出来,你不点的时候,那一页在百度数据中心,一点出来的网页就是在新浪的数据中心了。 第二个方式是推送,有很多终端可以帮我收集数据。比如说小米手环,可以 将你每天跑步的数据,心跳的数据,睡眠的数据都上传到数据中心里面。 第二个步骤是数据的传输。 一般会通过队列方式进行,因为数据量实在是太大了,数据必须经过处理才会有用。可系统处理不过来,只好排好队,慢慢处理。 第三个步骤是数据的存储。 现在数据就是金钱,掌握了数据就相当于掌握了钱。要不然网站怎么知道你想买什么?就是因为它有你历史的交易的数据,这个信息可不能给别人,十分宝贵,所以需要存储下来。 第四个步骤是数据的处理和分析。 上面存储的数据是原始数据,原始数据多是杂乱无章的,有很多垃圾数据在里面,因而需要清洗和过滤,得到一些高质量的数据。对于高质量的数据,就可以进行分析,从而对数据进行分类,或者发现数据之间的相互关系,得到知识。 比如盛传的沃尔玛超市的啤酒和尿布的故事,就是通过对人们的购买数据进行分析,发现了男人一般买尿布的时候,会同时购买啤酒,这样就发现了啤酒和尿布之间的相互关系,获得知识,然后应用到实践中,将啤酒和尿布的柜台弄的很近,就获得了智慧。 第五个步骤是对于数据的检索和挖掘。 检索就是搜索,所谓外事不决问Google,内事不决问百度。内外两大搜索引擎都是将分析后的数据放入搜索引擎,因此人们想寻找信息的时候,一搜就有了。 另外就是挖掘,仅仅搜索出来已经不能满足人们的要求了,还需要从信息中挖掘出相互的关系。比如财经搜索,当搜索某个公司股票的时候,该公司的高管 新手学习:一张图看懂数据分析流程? 1.数据采集 ? 2.数据存储 ? 3.数据提取 ? 4.数据挖掘 ? 5.数据分析 ? 6.数据展现 ? 7.数据应用 一个完整的数据分析流程,应该包括以下几个方面,建议收藏此图仔细阅读。完整的数据分析流程: 1、业务建模。 2、经验分析。 3、数据准备。 4、数据处理。 5、数据分析与展现。 6、专业报告。 7、持续验证与跟踪。 作为数据分析师,无论最初的职业定位方向是技术还是业务,最终发到一定阶段后都会承担数据管理的角色。因此,一个具有较高层次的数据分析师需要具备完整的知识结构。 1.数据采集 了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。这会帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时,对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。比如:Omniture中的P rop变量长度只有100个字符,在数据采集部署过程中就不能把含有大量中文描述的文字赋值给Prop变量(超过的字符会被截断)。 在Webtrekk323之前的Pixel版本,单条信息默认最多只能发送不超过2K的数据。当页面含有过多变量或变量长度有超出限定的情况下,在保持数据收集的需求下,通常的解决方案是采用多个sendinfo方法分条发送;而在325之后的Pixel版本,单条信息默认最多可以发送7K数据量,非常方便的解决了代码部署中单条信息过载的问题。(W ebtrekk基于请求量付费,请求量越少,费用越低)。 当用户在离线状态下使用APP时,数据由于无法联网而发出,导致正常时间内的数据统计分析延迟。直到该设备下次联网时,数据才能被发出并归入当时的时间。这就产生了不同时间看相同历史时间的数据时会发生数据有出入。 在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,如此才能更好的追本溯源。另外,这也能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。 2.数据存储 无论数据存储于云端还是本地,数据的存储不只是我们看到的数据库那么简单。比如: 数据存储系统是MySql、Oracle、SQL Server还是其他系统。 数据仓库结构及各库表如何关联,星型、雪花型还是其他。 生产数据库接收数据时是否有一定规则,比如只接收特定类型字段。 生产数据库面对异常值如何处理,强制转换、留空还是返回错误。 生产数据库及数据仓库系统如何存储数据,名称、含义、类型、长度、精度、是否可为空、是否唯一、字符编码、约束条件规则是什么。 接触到的数据是原始数据还是ETL后的数据,ETL规则是什么。 数据仓库数据的更新更新机制是什么,全量更新还是增量更新。 大数据处理数据时代理念的三大转变:要全体不要抽样,要效率不要绝对精确,要相关不要因果。具体的大数据处理方法其实有很多,但是根据长时间的实践,天互数据总结了一个基本的大数据处理流程,并且这个流程应该能够对大家理顺大数据的处理有所帮助。整个处理流程可以概括为四步,分别是采集、导入和预处理、统计和分析,以及挖掘。 采集 大数据的采集是指利用多个数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除此之外,Redis和MongoDB 这样的NoSQL数据库也常用于数据的采集。 在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。 统计/分析 统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL 的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。 导入/预处理 虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使用来自Twitter的Storm来对数据进行流式计算,来满足 业务流程图与数据流程图的比较 一、业务流程图与数据流程图的区别 1. 描述对象不同 业务流程图的描述对象是某一具体的业务; 数据流程图的描述对象是数据流。 业务是指企业管理中必要且逻辑上相关的、为了完成某种管理功能的一系列相关的活动。在系统调研时, 通过了解组织结构和业务功能, 我们对系统的主要业务有了一个大概的认识。但由此我们得到的对业务的认识是静态的, 是由组织部门映射到业务的。而实际的业务是流动的, 我们称之为业务流程。一项完整的业务流程要涉及到多个部门和多项数据。例如, 生产业务要涉及从采购到财务, 到生产车间, 到库存等多个部门; 会产生从原料采购单, 应收付账款, 入库单等多项数据表单。因此, 在考察一项业务时我们应将该业务一系列的活动即整个过程为考察对象, 而不仅仅是某项单一的活动, 这样才能实现对业务的全面认识。将一项业务处理过程中的每一个步骤用图形来表示, 并把所有处理过程按一定的顺序都串起来就形成了业务流程图。如图 1 所示, 就是某公司物资管理的业务流程图。 数据流程图是对业务流程的进一步抽象与概括。抽象性表现在它完全舍去了具体的物 质, 只剩下数据的流动、加工处理和存储; 概括性表现在它可以把各种不同业务处理过程联系起来,形成一个整体。从安东尼金字塔模型的角度来看, 业务流程图描述对象包括企业中的信息流、资金流和物流, 数据流程图则主要是对信息流的描述。此外, 数据流程图还要配合数据字典的说明, 对系统的逻辑模型进行完整和详细的描述。 2. 功能作用不同 业务流程图是一本用图形方式来反映实际业务处理过程的“流水帐”。绘制出这本流水帐对于开发者理顺和优化业务过程是很有帮助的。业务流程图的符号简单明了, 易于阅读和理解业务流程。绘制流程图的目的是为了分析业务流程, 在对现有业务流程进行分析的基础上进行业务流程重组, 产生新的更为合理的业务流程。通过除去不必要的、多余的业务环节; 合并重复的环节;增补缺少的必须的环节; 确定计算机系统要处理的环节等重要步骤, 在绘制流程图的过程中可以发现问题, 分析不足, 改进业务处理过程。 数据流程分析主要包括对信息的流动、传递、处理、存储等的分析。数据流程分析的目的就是要发现和解决数据流通中的问题, 这些问题有: 数据流程不畅, 前后数据不匹配, 数据处理过程不合理等。通过对这些问题的解决形成一个通畅的数据流程作为今后新系统的数据流程。数据流程图比起业务流程图更为抽象, 它舍弃了业务流程图中的一些物理实体, 更接近于信息系统的逻辑模型。对于较简单的业务, 我们可以省略其业务流程图直接绘制数据流程图。 3. 基本符号不同 (1)业务流程图的常用的基本符号有以下六种, 见图 2 所示。 (2)数据流程图的基本符号见图 3 所示 对数据流程图的基本符号解释如下: 外部实体表示数据流的始发点或终止点。原则上讲, 它不属于数据流程图的核心部分, 只是数据流程图的外围环境部分。在实际问题中它可能是人员、计算机外设、系统外部的文件等。 大数据处理:技术与流程 文章来源:ECP大数据时间:2013/5/22 11:28:34发布者:ECP大数据(关注:848) 标签: “大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。特点是:数据量大(Volume)、数据种类多样(Variety)、要求实时性强(Velocity)。对它关注也是因为它蕴藏的商业价值大(Value)。也是大数据的4V特性。符合这些特性的,叫大数据。 大数据会更多的体现数据的价值。各行业的数据都越来越多,在大数据情况下,如何保障业务的顺畅,有效的管理分析数据,能让领导层做出最有利的决策。这是关注大数据的原因。也是大数据处理技术要解决的问题。 大数据处理技术 大数据时代的超大数据体量和占相当比例的半结构化和非结构化数据的存在,已经超越了传统数据库的管理能力,大数据技术将是IT领域新一代的技术与架构,它将帮助人们存储管理好大数据并从大体量、高复杂的数据中提取价值,相关的技术、产品将不断涌现,将有可能给IT行业开拓一个新的黄金时代。 大数据本质也是数据,其关键的技术依然逃不脱:1)大数据存储和管理;2)大数据检索使用(包括数据挖掘和智能分析)。围绕大数据,一批新兴的数据挖掘、数据存储、数据处理与分析技术将不断涌现,让我们处理海量数据更加容易、更加便宜和迅速,成为企业业务经营的好助手,甚至可以改变许多行业的经营方式。 大数据的商业模式与架构----云计算及其分布式结构是重要途径 1)大数据处理技术正在改变目前计算机的运行模式,正在改变着这个世界:它能处理几乎各种类型的海量数据,无论是微博、文章、电子邮件、文档、音频、视频,还是其它形态的数据;它工作的速度非常快速:实际上几乎实时;它具有普及性:因为它所用的都是最普通低成本的硬件,而云计算它将计算任务分布在大量计算机构成的资源池上,使用户能够按需获取计算力、存储空间和信息服务。云计算及其技术给了人们廉价获取巨量计算和存储的能力,云计算分布式架构能够很好地支持大数据存储和处理需求。这样的低成本硬件+低成本软件+低成本运维,更加经济和实用,使得大数据处理和利用成为可能。 方法、数据处理流程实战案例时代,我们人人都逐渐开始用数据的眼光来看待每一个事情、事物。确实,数据的直观明了传达出来的信息让人一下子就能领略且毫无疑点,不过前提是数据本身的真实性和准确度要有保证。今天就来和大家分享一下关于方法、数据处理流程的实战案例,让大家对于这个岗位的工作内容有更多的理解和认识,让可以趁机了解了解咱们平时看似轻松便捷的数据可视化的背后都是有多专业的流程在支撑着。 一、大数据思维 在2011年、2012年大数据概念火了之后,可以说这几年许多传统企业也好,互联网企业也好,都把自己的业务给大数据靠一靠,并且提的比较多的大数据思维。 那么大数据思维是怎么回事?我们来看两个例子: 案例1:输入法 首先,我们来看一下输入法的例子。 我2001年上大学,那时用的输入法比较多的是智能ABC,还有微软拼音,还有五笔。那时候的输入法比现在来说要慢的很多,许多时候输一个词都要选好几次,去选词还是调整才能把这个字打出来,效率是非常低的。 到了2002年,2003年出了一种新的输出法——紫光拼音,感觉真的很快,键盘没有按下去字就已经跳出来了。但是,后来很快发现紫光拼音输入法也有它的问题,比如当时互联网发展已经比较快了,会经常出现一些新的词汇,这些词汇在它的词库里没有的话,就很难敲出来这个词。 在2006年左右,搜狗输入法出现了。搜狗输入法基于搜狗本身是一个搜索,它积累了一些用户输入的检索词这些数据,用户用输入法时候产生的这些词的信息,将它们进行统计分析,把一些新的词汇逐步添加到词库里去,通过云的方式进行管理。 比如,去年流行一个词叫“然并卵”,这样的一个词如果用传统的方式,因为它是一个重新构造的词,在输入法是没办法通过拼音“ran bing luan”直接把它找出来的。然而,在大数据思维下那就不一样了,换句话说,我们先不知道有这么一个词汇,但是我们发现有许多人在输入了这个词汇,于是,我们可以通过统计发现最近新出现的一个高频词汇,把它加到司库里面并更新给所有人,大家在使用的时候可以直接找到这个词了。 案例2:地图 再来看一个地图的案例,在这种电脑地图、手机地图出现之前,我们都是用纸质的地图。这种地图差不多就是一年要换一版,因为许多地址可能变了,并且在纸质地图上肯定是看不出来,从一个地方到另外一个地方怎么走是最好的?中间是不是堵车?这些都是有需要有经验的各种司机才能判断出来。 在有了百度地图这样的产品就要好很多,比如:它能告诉你这条路当前是不是堵的?或者说能告诉你半个小时之后它是不是堵的?它是不是可以预测路况情况? 此外,你去一个地方它可以给你规划另一条路线,这些就是因为它采集到许多数据。比如:大家在用百度地图的时候,有GPS地位信息,基于你这个位置的移动信息,就可以知道路的拥堵情况。另外,他可以收集到很多 网络竞价人员工作职责流程以及数据分析方法 竞价日常工作内容和流程: 1.检查网站,商务通,是否存在打不开。弹窗不弹出等情况。 2.打开商盾查看恶点拦截情况,该否的IP手动否定。 3. 查看昨天工作日志,确定今天日常工作安排是否需要做出调整,遗留问题是否解决 4.调整排名,每天用来抢排名的关键词首先要保证质量度、匹配是否对应,调整过程中,分析竞争对手的排名,竞价策略,上下浮预,估算出大概的比例/价格,有无虚高等情况.(如果使用刷价软件,务必规划好刷价模式,精度,手调词) 5.记录每个时段展现.消费,点击,咨询的记录,有无异常消费。 6.定时做搜索词,消费大致为否定不相关消费词,高价匹配低价词,每日消费词有无的异 7.质量度记录(深入了解每个户每日质量度的变化) 8.撰写创意-优先攥写消费高,展现高的优化.每日条数依照工作量多少限定 9.账户创意/关键词,包含不宜推广,待审核,空单元,空创意.添加/修改/删除 10.每日平均排名的关注,是否因出价/匹配模式的更改导致匹配词排名下降 11.抽空和同行交流,多了解市场状况; 每周工作内容 1.每周一次拓词.搜索词/商务通流量/对话词,加词,须经2次拓词. 2.每周一次商务通ip分析。商务通否定恶性点击Ip段. 3.质量的为灰色一星词删除重新添加.或者单独建立一词一单元 4.每周一次账户着陆页排查,剔除404,文章与关键词不对应等情况. 5.关于物料违规:百度上传,图片,关键词,创意,溪径,及其相关产品的培训。 基本要求: 每月工作内容(含周) 1.每月页面分析一份 2.每月病种分析一份 3.每月投放时段分析一份 4.每月关键词效果分析一份 5.每月地区投放分析一份 6.各个账户效果统筹分析一份 (每个数据分析,找出亮点与问题,并且根据这些数据进行针对性调整) 百度竞价基本工作=百度计划-百度单元-关键词-创意-网站着陆页面+关键词排位调价 竞价日常数据分析总结 1,配合百度/站长统计,分析搜索,展现词进入站长统计的情况。分析站长统计每小时的流量是否与竞价的点击成正比,差别在哪里?高点击关键词与站长统计关键词是否成正比 1.有展现没点击 2. 有展现有点击没咨询 3.高展现高点击没咨询 4.高展现高点击高咨询低(无)预约 5. 转化率高(重点词)(预约或者有效咨询) 6.有展现高展现无点击少点击品牌词流量词(流量词的一个作用是提高曝光率,提高品牌词的知名度,流量词创意可以以医院包装为主) 数据分析中常用的10种图表 1折线图 折线图可以显示随时间(根据常用比例设置)而变化的连续数据,因此非常适用于显示在相等时间间隔下数据的趋势。 表1家用电器前半年销售量 图1 数点折线图 图2堆积折线图 图3百分比堆积折线图 2柱型图 柱状图主要用来表示各组数据之间的差别。主要有二维柱形图、三维柱形图、圆柱图、圆锥图和棱锥图。 图4二维圆柱图 3堆积柱形图 堆积柱形图不仅可以显示同类别中每种数据的大小还可以显示总量的大小。 图5堆积柱形图 图6百分比堆积柱形图 百分比堆积柱形图主要用于比较类别柱上每个数值占总数的百分比,该图的目的是强调每个数据系列的比例。 4线-柱图 图7线-柱图 这种类型的图不仅可以显示出同类别的比较,更可以显示出平均销售量的趋势情况。 5两轴线-柱图 1月58501200048.75% 2月58401500038.93% 3月44502000022.25% 4月65001000065.00% 5月52001800028.89% 6月55003000018.33% 图8两轴线-柱图 操作步骤:01 绘制成一样的柱形图,如下表所示: 图1 操作步骤02: 左键单击要更改的数据,划红线部分所示,单击右键选择【设置数据系列格式】,打开盖对话框,将【系列选项】中的【系统绘制在】更改为“次坐标轴”,得到图4的展示结果。 图2 图3 图4 操作步骤03: 选中上图4中的绿色柱子,更改图表类型,选择折线图即可,得到图5的展示 结果。 图5 主次坐标柱分别表示了收入情况和占比情况,对比更加明显,同时在一个图表中反映,易于分析。 6条形图 图9条形图 条形图类似于横向的柱状图,和柱状图的展示效果相同,只是表现形式不同。 主要用于各项类的比较,例如,各省的GDP的比较或者就针对我们的客户来说:主要是各个地级市的各种资源储量的比较或者各物料类型的客户数量的比较7三维饼图 以1月份3种家用电器的销售量占比为例,具体饼图如下所示: 图10 三维饼图 主要用于显示三种电器销售量的占比情况。有分离和组合两种形式。 8复合饼图 根据电话拜访结果展示出的信息状态。可以使有效信息得到充分展示,展示效果更佳,利于下一步分析的进行。 9母子饼图 母子饼图可直观地分析项目的组成结构与比重。 蔬菜白菜10萝卜20土豆30黄瓜5[数据分析] 神图 数据分析师的完整流程与知识结构体系
大数据处理流程的主要环节
大数据分析平台的需求报告模板
华为大数据数据分析方法数据处理流程实战案例
大数据分析教程——制作数据报告的流程
简析大数据及其处理分析流程
数据分析程序
业务流程图与数据流程图的比较知识讲解
大数据分析的流程浅析之一:大数据采集过程分析
采购数据分析的8个流程与常用7个思路
数据分析师的完整流程与知识结构体系
大数据处理培训:大数据处理流程
新手学习-一张图看懂数据分析流程
大数据分析和处理的方法步骤
业务流程图与数据流程图的比较(1)
大数据处理:技术与流程
大数据数据分析方法 数据处理流程实战案例
竞价专员日常工作流程和数据分析总结
大数据分析报告中常用地10种图表及制作过程