拉丁方设计的方差分析
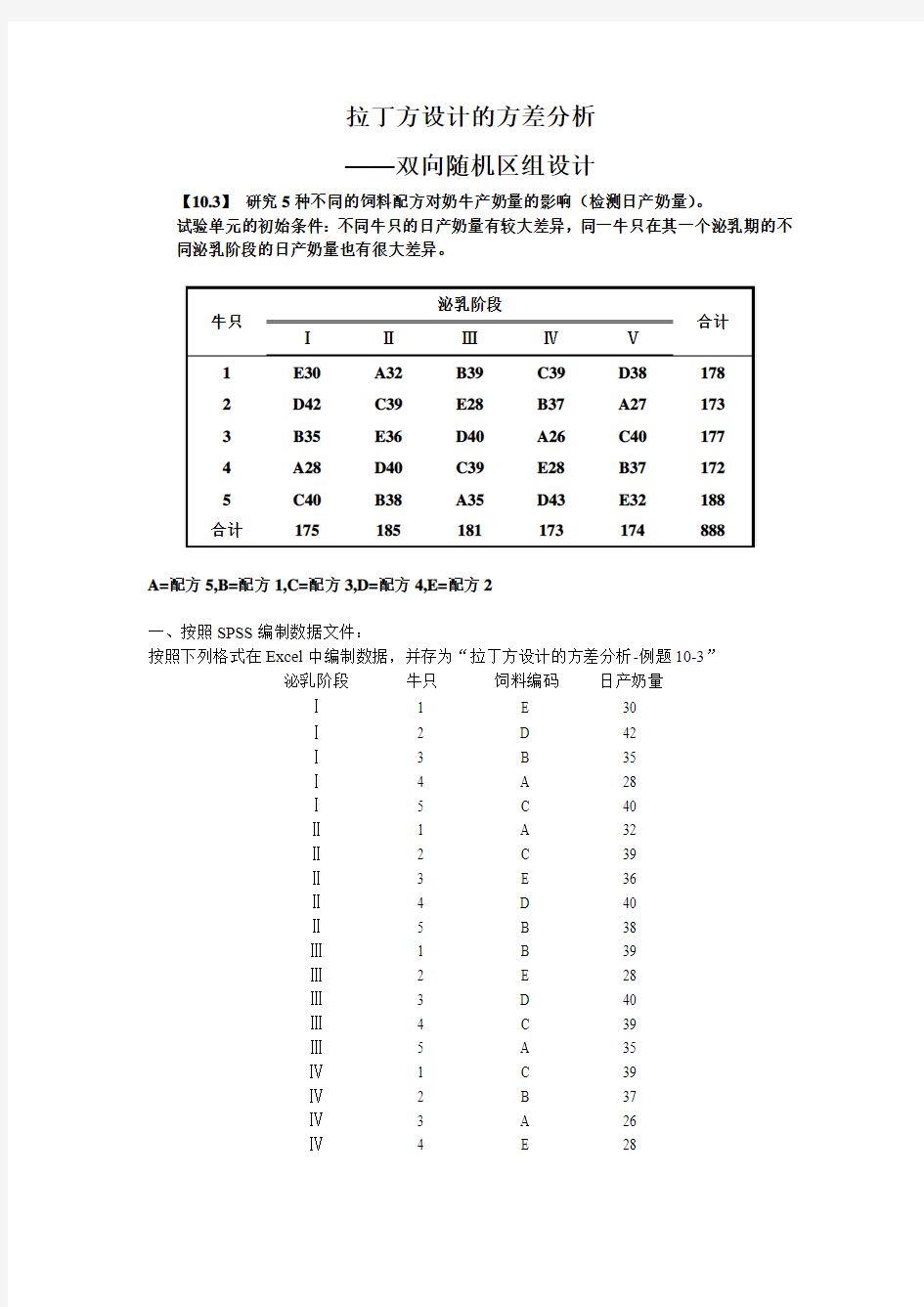

拉丁方设计的方差分析
——双向随机区组设计
【10.3】研究5种不同的饲料配方对奶牛产奶量的影响(检测日产奶量)。
试验单元的初始条件:不同牛只的日产奶量有较大差异,同一牛只在其一个泌乳期的不同泌乳阶段的日产奶量也有很大差异。
A=配方5,B=配方1,C=配方3,D=配方4,E=配方2
一、按照SPSS编制数据文件:
按照下列格式在Excel中编制数据,并存为“拉丁方设计的方差分析-例题10-3”
泌乳阶段牛只饲料编码日产奶量
Ⅰ 1 E 30
Ⅰ 2 D 42
Ⅰ 3 B 35
Ⅰ 4 A 28
Ⅰ 5 C 40
Ⅱ 1 A 32
Ⅱ 2 C 39
Ⅱ 3 E 36
Ⅱ 4 D 40
Ⅱ 5 B 38
Ⅲ 1 B 39
Ⅲ 2 E 28
Ⅲ 3 D 40
Ⅲ 4 C 39
Ⅲ 5 A 35
Ⅳ 1 C 39
Ⅳ 2 B 37
Ⅳ 3 A 26
Ⅳ 4 E 28
Ⅳ 5 D 43
Ⅳ 1 D 38
Ⅳ 2 A 27
Ⅳ 3 C 40
Ⅳ 4 B 37
Ⅳ 5 E 32
二、用SPSS打开“拉丁方设计的方差分析-例题10-3.xls”,并按照下列步骤完成方差分析。
1. 选择单变量多因素方差分析的菜单命令
2. 选定因变量和自变量
3. 打开“模型”对话框,按照图示进行设置。因为拉丁方设计不能进行交互作用分析,故选择“主效应”分析,并选定欲分析的变量。
4. 点击“继续”按钮,回到“单变量”对话框。选择打开“两两对比”对话框
原题关心的是饲料配方对日产奶量的影响,故只需对“饲料编码”进行多重比较。
5. 点击“继续”按钮,回到“单变量”对话框。选择打开“选项”对话框
对分析结果中可能需要的“描述性统计”、“方差齐性检验”、“各饲料配方对应的日产奶量均值”等进行选择。
6. 点击“继续”按钮,回到“单变量”对话框,点击“继续”按钮完成方差分析。结果在“输出窗口”中观看,
方差分析和试验设计
6方差分析与试验设计 在研究一个或多个分类型自变量与一个数值型因变量之间的关系时,方差分析就是其中主要方法之一。检验多个总体均值是否相等的统计方法。 所要检验的对象称为因素。因素的不同表现称为水平。每个因子水平下得到的样本数据称为观测值。 随机误差:在同一行业(同一总体)下,样本的各观测值是不同的。抽样随机性造成。 系统误差:在不同一行业(不同一总体)下,样本的各观测值也是不同的。抽样随机性和行业本身造成的。 组内误差:衡量因素在同一行业(同一总体)下样本数据的误差。只包含随机误差。 组间误差:衡量因素在不同一行业(不同一总体)下样本数据的误差。包含随机误差、系统误差。 方差分析的三大假设: 每个总体服从正态分布; 每个总体的方差必须相同; 观测值是独立的; 单因素方差分析(F分布) 数据结构:表示第i个水平(总体)的第j个的观测值。(i列j行)分析步骤: 1提出假设。自变量对因变量没有显著影响 不完全相等自变量对因变量有显著影响 2构造检验的统计量 计算因素各水平的均值(各水平样本均值) 计算全部观测值的总均值(总体均值) 计算误差平方和: 总误差平方和SST:全部观测值与总平均值得误差平方和。 水平项误差平方和SSA:各组平均值与总平均值得误差平方和。组间平方和。 误差项平方和SSE:各样本数据与其组平均值误差的平方和。组内平方和。 SST=SSA+SSE
A B C D E F G 1 误差来源 平方和自由度均方F 值P 值 F 临界值2SS df MS 3组间(因素 来源)SSA k-1MSA MSA/MSE 4组内(误差)SSE n-k MSE 5 总和 SST n-1 计算统计量 各平方和除以它们对应的自由度,这一结果称为均方。 SST 的自由度为(n-1),其中n 为全部观测值的个数。 SSA 的自由度为(k-1),其中k 为因素水平的个数。(组数-1) SSE 的自由度为(n-k )。 SSA 的均方(组间均方)为 SSE 的均方(组内均方)为 3统计决策 在给定的显著性水平α下,查表得临界值 若,有显著影响; 若,无显著影响; 4方差分析表
方差分析与试验设计
第10章 方差分析与试验设计 三、选择题 1. C 2. B 3. A 4. B 5. C 1.方差分析的主要目的是判断 ( )。 A. 各总体是否存在方差 B. 各样本数据之间是否有显著差异 C. 分类型自变量对数值型因变量的影响是否显著 D. 分类型因变量对数值型自变量的影响是否显著 2.在方差分析中,检验统计量F是 ( )。 A. 组间平方和除以组内平方和 B. 组间均方除以组内均方 C. 组间平方除以总平方和 D. 组间均方除以总均方 3.在方差分析中,某一水平下样本数据之间的误差称为 ( )。 A. 随机误差 B. 非随机误差 C. 系统误差 D. 非系统误差 4.在方差分析中,衡量不同水平下样本数据之间的误差称为 ( )。 A. 组内误差 B. 组间误差 C. 组内平方 D. 组间平方 5.组间误差是衡量不同水平下各样本数据之间的误差,它 ( )。 A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 6. A 7. D 8. D 9. A 10.A 6.组内误差是衡量某一水平下样本数据之间的误差,它 ( )。 A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 7.在下面的假定中,哪一个不属于方差分析中的假定 ( )。 A. 每个总体都服从正态分布 B. 各总体的方差相等 C. 观测值是独立的 D. 各总体的方差等于0 8.在方差分析中,所提出的原假设是210:μμ=H = ···=k μ,备择假设是( ) A. ≠≠H 211:μμ···k μ≠ B. >>H 211:μμ···k μ> C. < 第三节正交试验设计及其方差分析 在工农业生产和科学实验中,为改革旧工艺,寻求最优生产条件等,经常要做许多试验,而影响这些试验结果的因素很多,我们把含有两个以上因素的试验称为多因素试验.前两节讨论的单因素试验和双因素试验均属于全面试验(即每一个因素的各种水平的相互搭配都要进行试验),多因素试验由于要考虑的因素较多,当每个因素的水平数较大时,若进行全面试验,则试验次数将会更大.因此,对于多因素试验,存在一个如何安排好试验的问题.正交试验设计是研究和处理多因素试验的一种科学方法,它利用一套现存规格化的表——正交表,来安排试验,通过少量的试验,获得满意的试验结果. 1.正交试验设计的基本方法 正交试验设计包含两个内容:(1)怎样安排试验方案;(2)如何分析试验结果.先介绍正交表. 正交表是预先编制好的一种表格.比如表9-17即为正交表L4(23),其中字母L表示正交,它的3个数字有3种不同的含义: (1) L4(23)表的结构:有4行、3列,表中出现2个反映水平的数码1,2. 列数 ↓ L4 (23) ↑↑ 行数水平数 (2)L4(23)表的用法:做4次试验,最多可安排2水平的因素3个. 最多能安排的因素数 ↓ L4(23) ↑↑ 试验次数水平数 (3) L4(23)表的效率:3个2水平的因素.它的全面试验数为23=8次,使用正交表只需从8次试验中选出4次来做试验,效率是高的. L4(23) ↑↑ 实际试验数理论上的试验数 正交表的特点: (1)表中任一列,不同数字出现的次数相同.如正交表L4(23)中,数字1,2在每列中均出现2次. (2)表中任两列,其横向形成的有序数对出现的次数相同.如表L4(23)中任意两列, 多因素方差分析 多因素方差分析是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因 [例子] 研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著 表5-7 不同温度与不同湿度粘虫发育历期表 数据保存在“DATA5-2.SAV”文件中,变量格式如图5-1。 1)准备分析数据 在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。 图5-6 数据输入格式 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因素方差分析设置窗口如图5-7。 图5-7 多因素方差分析窗口 3)设置分析变量 设置因变量:在左边变量列表中选“历期”,用向右拉按钮选入到“Dependent Variable:”框中。 设置因素变量:在左边变量列表中选“a”和“b”变量,用向右拉按钮移到“Fixed Factor(s):”框中。可以选择多个因素变量存容量的限制,选择的因素水平组合数(单元数)应该尽量少。 设置随机因素变量:在左边变量列表中选“重复”变量,用向右拉按钮移到“到Random Factor(s)”框中。可以选择多个随机变量 设置协变量:如果需要去除某个变量对因素变量的影响,可将这个变量移到“Covariate(s)”框中。 设置权重变量:如果需要分析权重变量的影响,将权重变量移到“WLS Weight”框中。 4)选择分析模型 在主对话框中单击“Model”按钮,打开“Univariate Model”对话框。见图5-8。 图5-8 “Univariate Model” 定义分析模型对话框 多因素方差分析 定义: 多因素方差分析中的控制变量在两个或两个以上,研究目的是要分析多个控制变量的作用、多个控制变量的交互作用以及其他随机变量是否对结果产生了显著影响。 前提: 1总体正态分布。当有证据表明总体分布不是正态分布时,可以将数据做正态转化。 2变异的相互独立性。 3各实验处理内的方差要一致。进行方差分析时,各实验组内部的方差批次无显著差异,这是最重要的一个假定,为满足这个假定,在做方差分析前要对各组内方差作齐性检验。 多因素方差分析的三种情况: 只考虑主效应,不考虑交互效应及协变量; 考虑主效应和交互效应,但不考虑协变量; 考虑主效应、交互效应和协变量。 一、多因素方差分析 1选择分析方法 本题要判断控制变量“组别”和“性别”是否对观察变量“数学”有显著性影响,而控制变量只有两个,即“组别”、“性别”,所以本题采用双因素分析法,但需要进行正态检验和方差齐性检验。 2建立数据文件 在SPSS17.0中建立数据文件,定义4个变量:“人名”、“数学”、“组别”、“性别”。控制变量为“组别”、“性别”,观察变量为“数学”。在数据视图输入数据,得到如下数据文件: 3正态检验(P>0.05,服从正态分布) 正态检验操作过程: “分析”→“描述统计”→“探索”,出现“探索”窗口,将因变量“成绩”放入“因变量列表”,将自变量“组别”、“性别”放入“因子列表”,将“人名”放入“标注个案”; 点击“绘制”,出现“探索:图”窗口,选中“直方图”和“带检验的正态图”,点击“继续”;点击“探索”窗口的“确定”,输出结果。 因变量是用户所研究的目标变量。因子变量是影响因变量的因素,例如分组变量。标注个案是区分每个观测量的变量。 带检验的正态图(Normality plots with test,复选框):选择此项,将进行正态性检验,并生成正态Q-Q概率图和无趋势正态Q-Q概率图。 第八章 常用试验设计的方差分析 8.1 多因素随机区组试验和单因素随机区组试验的分析方法有何异同?多因素随机区组试验处理项的自由度和平方和如何分解?怎样计算和测验因素效应和互作的显著性,正确地进行水平选优和组合选优? 8.2 裂区试验和多因素随机区组试验的统计分析方法有何异同?在裂区试验中误差E a 和E b 是如何计算的,各具什么意义?如何估计裂区试验中的缺区?裂区试验的线性模型是什么? 8.3 有一大豆试验,A 因素为品种,有A 1、A 2、A 3、A 4 4个水平,B 因素为播期,有B 1、B 2、B 3 3个水平,随机区组设计,重复3次,小区计产面积25平方米,其田间排列和产量(kg )如下图,试作分析。 区组Ⅰ 区组Ⅱ 区组Ⅲ [答案: e MS 0.31,F 测验:品种、播期极显著,品种×播期不显著] 8.4 有一小麦裂区试验,主区因素A ,分A1(深耕)、A2(浅)两水平,副区因素B ,分B1(多肥)、B2(少肥)两水平,重复3次,小区计产面积15平方米,其田间排列和产量(假设数字)如下图,试作分析。 区组Ⅰ 区组Ⅱ 区组Ⅲ [答案: a E MS =0.58, b E MS =2.50,F 测验:A 和B 皆显著,A ×B 不显著] 8.5 设若上题小麦耕深与施肥量试验为条区设计,田间排列和产量将相应如下图,试作分 析,并与裂区设计结果相比较)。 B 1 B 1B 2 B 2 B 2B 1 [答案: A E MS =0.58, B E MS =1.75, c E MS =3.25,F 测验A 、B 均显著,A ×B 不显著] 8.6 江苏省淮南地区夏大豆区域试验部分资料摘录如下: 试点 年份 区组 CK 19—15 31—15 4—1 21—16 试点1 1977年 Ⅰ 134 160 168 226 196 Ⅱ 146 180 156 170 190 Ⅲ 148 206 188 216 200 1978年 Ⅰ 220 264 280 212 168 Ⅱ 228 260 276 208 156 Ⅲ 208 220 300 260 148 试点2 1977年 Ⅰ 137 236 197 196 155 Ⅱ 173 207 178 192 179 Ⅲ 110 171 223 208 125 1978年 Ⅰ 179 201 150 195 186 Ⅱ 182 224 189 203 191 Ⅲ 207 262 187 210 183 各年各点均为随机区组设计,试分析此试验结果。 [答案: 2 =3.67,e MS =406.06,Fv=12.89,Fvs=1.88,Fvy=5.18,Fvsy=10.35] 8.7 在药物处理大豆种子试验中,使用了大中小三种类型种子,分别用五种浓度、两种处理时间进行试验处理,播种后45天对每种各取两个样本,每个样本取10株测定其干物重,求其平均数,结果如下表。试进行方差分析。 处理时间A 种子类型C 浓度B B 1(0×10-6) B 2(10×10-6) B 3(20×10-6) B 4(30×10-6) B 5(40×10-6) A 1(12小时) C 1(小粒) 7.0 12.8 22.0 21.3 24.4 6.5 11.4 21.8 20.3 23.2 C 2(中粒) 13.5 13.2 20.4 19.0 24.6 13.8 14.2 21.4 19.6 23.8 C 3(大粒) 10.7 12.4 22.6 21.3 24.5 10.3 13.2 21.8 22.4 24.2 A 2(24小时) C 1(小粒) 3.6 10.7 4.7 12.4 13.6 1.5 8.8 3.4 10.5 13.7 试验设计与数据分析 1.方差分析在科学研究中有何意义?如何进行平方和与自由度的分解?如何进行F检验和多重比较? (1)方差分析的意义 方差分析,又称变量分析,其实质是关于观察值变异原因的数量分析,是科学研究的重要工具。方差分析得最大公用在于:a. 它能将引起变异的多种因素的各自作用一一剖析出来,做出量的估计,进而辨明哪些因素起主要作用,哪些因素起次要作用。 b. 它能充分利用资料提供的信息将试验中由于偶然因素造成的随机误差无偏地估计出来,从而大大提高了对实验结果分析的精确性,为统计假设的可靠性提供了科学的理论依据。 (2)平方和及自由度的分解 方差分析之所以能将试验数据的总变异分解成各种因素所引起的相应变异,是根据总平方和与总自由度的可分解性而实现的。 (3)F检验和多重比较 ① F检验的目的在于,推断处理间的差异是否存在,检验某项变异原因的效应方差是否为零。实际进行F检验时,是将由试验资料算得 的F 值与根据df 1=df t (分子均方的自由度)、df 2=df e (分母均方的自由度)查附表4(F 值表)所得的临界F 值(F 0.05(df1,df2)和F 0.01(df1,df2))相比较做出统计判断。若F< F 0.05(df1,df2),即P>0.05,不能否定H 0,可认为各处理间差异不显著;若F 0.05(df1,df2)≤F <F 0.01(df1,df2),即0.01 多因素方差分析 是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同水平组合之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作用,以及分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差相同。但也可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量,可以是数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因素。 [例子] 研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。 表5-7 不同温度与不同湿度粘虫发育历期表 1)准备分析数据 在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输入对应的数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。 图5-6 数据输入格式 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因变量多因素方差分析设置窗口如图5-7。 图5-7 多因素方差分析窗口 3)设置分析变量 设置因变量:在左边变量列表中选“历期”,用向右拉按钮选入到“Dependent Variable:”框中。 第九章两因素及多因素方差分析 9.1双菊饮具有很好的治疗上呼吸道感染的功效,为便于饮用,制成泡袋剂。研究不同浸泡时间和不同的浸泡温度对浸泡效果的影响,设计了一个两因素交叉分组实验,实验结果(浸出率)见下表[52]: 浸泡温度 /℃ 浸泡时间/min 101520 6023.7225.4223.58 8024.8428.3229.55 9530.6431.5832.21 对以上结果做方差分析及Duncan检验。该设计已经能充分说明问题了吗?是否还有更能说明问题的设计方案? 答:无重复二因素方差分析程序及结果如下: options linesize=76 nodate; data hermed; do temp=1 to 3; do time=1 to 3; input effect @@; output; end; end; cards; 23.72 25.42 23.58 24.84 28.32 29.55 30.64 31.58 32.21 ; run; proc anova; class temp time; model effect=temp time; means temp time/duncan alpha=0.05; run; The SAS System Analysis of Variance Procedure Class Level Information Class Levels Values TEMP 3 1 2 3 TIME 3 1 2 3 Number of observations in data set = 9 The SAS System Analysis of Variance Procedure Dependent Variable: EFFECT Sum of Mean Source DF Squares Square F Value Pr > F 体育统计与SPSS读书笔记(八)—多因素方差分析(1) 具有两个或两个以上因素的方差分析称为多因素方差分析。 多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方差分析的时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因素了:不同教学方法的班级,不同年级。如果再加上性别上的因素,那就成了三因素了。如果我们把实验前和试验后的数据用一个时间的变量来表示,那又多了一个时间的因素。如果每个年级都是不同的老师来上,那又多了一个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑,并确定自己只研究哪些因素。 下面用例子的形式来说说多因素方差分析的运用。还是用前面说单因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。形成年级和不同教学法班级双因素。 分析: 1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格都是有重复数据(也就是不只一个数据), 年级 不同教学方法的班级 定性班 定量班 定性定量班 五年级 (班级每个人) (班级每个人) (班级每个人) 初中二年级 (班级每个人) (班级每个人) (班级每个人) 高中二年级 (班级每个人) (班级每个人) (班级每个人) 2.因为有重复数据,所以存在在数据交互效应的可能。我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的影响不同,则说明A、B两因素间存在交互作用。交互作用是多因素实验分析的一个非常重要的内容。如因素间存在交互作用而又被忽视,则常会掩盖因素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。在大多数场合,交互作用的信息比主效应的信息更为有用。根据上面的判断。根据上面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。这里假设他们之间有交互作用。 1, data0806-height 是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及 八种草之间有无差异?具体怎么差异的? 打 开 spss 软 件 , 打 开 data0806-height 数 据 , 点 击 Analyze->General Linear Model->Univariate 打开: 把 plot 和 species 送入 Fixed Factor(s) ,把 height 送入 Dependent Variable ,点击 Model 打开: 选择 Full factorial , Type III Sum of squares , Include intercept in model (即 全部默认选项) ,点击 Continue 回到 Univariate 主对话框,对其他选项卡不做任何选 择, 结果输出: 因无法计算 ???? ??rror ,即无法分开 ???? intercept 的影响,无法进行方差分析, 重新 Analyze->General Linear Model->Univariate 打开: 选择好 Dependent Variable 和 Fixed Factor(s) 点击Custom,把主效应变量 species 和plot 送入 Model 框,点击 Continue 回到Univariate 主对话框,点击 Plots : 把 date 送入 Horizontal Axis ,把 depth 送入 Separate Lines ,点击 Add ,点击 Continue 回到 Univariate 对话框,点击 Options : 把 OVERALL,species, plot 送入 Display Means for 框,选择 Compare main effects , Bonferroni ,点击 Continue 回到 Univariate 对话框, 输出结果: 可以看到: SS species =, df species =7, MS species= ;SS plot =, df plot =7, MS plot= ;SS error =, df error =14, MS error= ; Fspecies= , p=<;Fplot=,p=<; 所以故认为在 5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。 该表说明: SSspecies= ,dfspecies=7 ,MSspecies= ;SSerror= ,dferror=14 ,MSerror= ; Fspecies= , p=<; 物种间存在差异: SSplot= , dfplot=7 , MSplot= ; SSerror= , dferror=14 , MSerror= ; Fplot=,p=<; 不同的物种间在差异: 由边际分布图可知:类似结论:草的高度在不同样地的条件之间有差异( Fplot=,p=< ),具 体是,样地一和样地三之间存在的差异最大;八种不同草的高度也存在差异( Fspecies= , p=<),具体是第四 和 ???? error ,无法检测 interaction ,点击 Model 打开: 实验设计与分析课程论文 题目利用SPSS 软件进行方差分析和正交试验设计 学院 专业 年级 学号 姓名 2012年6月29日 一、SPSS 简介 SPSS 是世界上最早的统计分析软件,1984年SPSS 总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS 微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域,世界上许多有影响的报刊杂志纷纷就SPSS 的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价与称赞。 SPSS 的基本功能包括数据管理、统计分析、图表分析、输出管理等等。SPSS 统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类,每类中又分好几个统计过程,比如回归分析中又分线性回归分析、曲线估计、Logistic 回归、Probit 回归、加权估计、两阶段最小二乘法、非线性回归等多个统计过程,而且每个过程中又允许用户选择不同的方法及参数。SPSS 也有专门的绘图系统,可以根据数据绘制各种图形。SPSS 的分析结果清晰、直观、易学易用,而且可以直接读取EXCEL 及DBF 数据文件,现已推广到多种各种操作系统的计算机上,它和SAS 、BMDP 并称为国际上最有影响的三大统计软件。 SPSS 输出结果虽然漂亮,但不能为WORD 等常用文字处理软件直接打开,只能采用拷贝、粘贴的方式加以交互。这可以说是SPSS 软件的缺陷。 二、方差分析 例如 某高原研究组将籍贯相同、年龄相同、身高体重接近的30名新战士随机分为三组,甲组为对照组,按常规训练,乙组为锻炼组,每天除常规训练外,接受中速长跑与健身操锻炼,丙组为药物组,除常规训练外,服用抗疲劳药物,一月后测定第一秒用力肺活量(L),结果见表。试比较三组第一秒用力肺活量有无差别。对照组为组一,锻炼组为组二,药物组为组三。 第一步:打开 SPSS 软件 表1 三组战士的第一秒用力肺活量(L) 对照组 锻炼组 药物组 合计 3.25 3.66 3.44 3.32 3.64 3.62 3.29 3.48 3.48 3.34 3.64 3.36 3.16 3.48 3.52 3.64 3.20 3.60 3.60 3.62 3.32 3.28 3.56 3.44 3.52 3.44 3.16 3.26 3.82 3.28 SPSS统计分析教程-多因素方差分析 多因素方差分析是对一个变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS 调用“Univariate”过程,检验不同水平组合之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作用,以及分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差相同。但也可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此。因素变量是分类变量,可以是数值型也可以是长度不超过8 的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因素。 [例子] 研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。 表5-7 不同温度与不同湿度粘虫发育历期表相对湿度(%) 温度℃ 重复 1 2 3 4 100 25 91.2 95.0 93.8 93.0 27 87.6 84.7 81.2 82.4 29 79.2 67.0 75.7 70.6 31 65.2 63.3 63.6 63.3 80 25 93.2 89.3 95.1 95.5 27 85.8 81.6 81.0 84.4 29 79.0 70.8 67.7 78.8 31 70.7 86.5 66.9 64.9 40 25 100.2 103.3 98.3 103.8 27 90.6 91.7 94.5 92.2 29 77.2 85.8 81.7 79.7 31 73.6 73.2 76.4 72.5 数据保存在“DATA5-2.SAV”文件中,变量格式如图 5-1。 1)准备分析数据在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输入对应的数值,如图5-6 所示。或者打开已存在的数据文件“DATA5-2.SAV”。 图5-6 数据输入格式 2)启动分析过程点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因变量多因素方差分析设置窗口如图5-7。 图5-7 多因素方差分析窗口 3)设置分析变量设置因变量: 在左边变量列表中选“历期”,用向右拉按钮选入到“Depend ent Variable:”框中。 设置因素变量: 在左边变量列表中选“a”和“b”变量,用向右拉按钮移到“Fixed Factor(s):”框中。可以选择多个因素变量。由于内存容量的限制,选择的因素水平组合数(单元数)应该尽量少。 设置随机因素变量: 在左边变量列表中选“重复”变量,用向右拉按钮移到“到Random Factor(s)”框中。可以选择多个随机变量。 设置协变量:如果需要去除某个变量对因素变量的影响,可将这个变量移到“Covariate(s)”框中。 设置权重变量:如果需要分析权重变量的影响,将权重变量移到“WLS Weight”框中。 4)选择分析模型在主对话框中单击“Model”按钮,打开“Univariate Model”对话框。见图5-8。 图5-8 “Univariate Model” 定义分析模型对话框在Specify Model 栏中,指定分析模型类型。 多因素方差分析 实验目的:通过本次试验理解多因素方差分析的概念和思想,理解多个 因素存在交互效应的统计学含义和实际含义,了解方差分析分解的理论基础和计算原理,能够熟练应用单因素方差分析对具体的实际问题进行有效的分析。 实验内容:研究不同温度与不同湿度对粘虫发育历期的影响,分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。数据来源于网上搜索。 实验步骤: ①选择File/Open/Data命令,打开数据表。 ②选择Analyze/General Linear Model /Unievariate…命令,弹出(单变量方差分析)对话框,如图,在左侧变量框中选择“历期”变量为Dependent Vaiable (因变量)变量框,选择“温度”、“湿度”为Fixed Factors(固定因素)变量框,把重复选入Random Factors变量框。 ③单击Model…按钮,弹出Univariate:Model(单变量方差分析:模型)对话框,如图所示: 弹出Univariate:Contrasts (单变量方差分析:对比)对话框: ⑤单击Continue按钮,回到方差分析对话框,单击Plots…,弹出Univariate:Plots(单变量方差分析:轮廓图)对话框: Univariate:Post Hoc…(单变量方差分析:观察值的验后多重比较)对话框:这里不作选择 ⑦单击Continue按钮,回到方差分析对话框,单击Save…,弹出Univariate:Save(单变量方差分析:保存)对话框: ⑧单击Continue按钮,回到方差分析对话框,单击Options…,弹出Univariate:Options(单变量方差分析:选项)对话框: 实验结论: 第10章方差分析与试验设计 三、选择题 1.C 2.B 3.A 4.B 5.C 1.方差分析的主要目的是判断()。 A.各总体是否存在方差 B.各样本数据之间是否有显著差异 C.分类型自变量对数值型因变量的影响是否显著 D.分类型因变量对数值型自变量的影响是否显著 2.在方差分析中,检验统计量F是()。 A.组间平方和除以组内平方和B.组间均方除以组内均方 C.组间平方除以总平方和D.组间均方除以总均方 3.在方差分析中,某一水平下样本数据之间的误差称为()。 A.随机误差B.非随机误差C.系统误差D.非系统误差 4.在方差分析中,衡量不同水平下样本数据之间的误差称为()。 A.组内误差B.组间误差C.组内平方D.组间平方 5.组间误差是衡量不同水平下各样本数据之间的误差,它()。 A.只包括随机误差 B.只包括系统误差 C.既包括随机误差,也包括系统误差 D.有时包括随机误差,有时包括系统误差 6.A 7.D8.D9.A10.A 6.组内误差是衡量某一水平下样本数据之间的误差,它()。 A.只包括随机误差 B.只包括系统误差 C.既包括随机误差,也包括系统误差 D.有时包括随机误差,有时包括系统误差 7.在下面的假定中,哪一个不属于方差分析中的假定()。 A.每个总体都服从正态分布B.各总体的方差相等 C.观测值是独立的D.各总体的方差等于0 8.在方差分析中,所提出的原假设是0:=···= ,备择假设是() 12 k A.1:12···kB.1:12···k C. 1:···kD.1:1,2,···,k不全相等 12 9.单因素方差分析是指只涉及()。 A.一个分类型自变量B.一个数值型自变量 C.两个分类型自变量D.两个数值型因变量 10.双因素方差分析涉及()。 A.两个分类型自变量B.两个数值型自变量 C.两个分类型因变量D.两个数值型因变量 11.B12.C 1、通过以下试验设计案例总结“正交试验设计的基本程序和步骤”。 案例:为了研究啤酒酵母最适合的自溶条件,选择3因素3水平正交试验。因素有温度℃(A)和pH(B),加酶量(C)3个,试验指标为蛋白质含量,试验指标越大越好。选用L9(34) 正交表,试验方案和结果如下表,试作方差分析,并找出啤酒酵母最适合的自溶条件。 4 1、明确试验目的,确定试验指标:找出啤酒酵母最适合的自溶条件,可用蛋白质含量作为本试验的试验指标。 2挑因素,选水平:影响啤酒酵母最适合的自溶条件的因素有温度、pH和加酶量3个,分别用A、B、C表示,并且每个因素都取3个水平,因此,此次选取3因素3水平正交试验。 3、选择合适的正交表:根据所选取的实验因素和实验水平数,决定该实验选取L9(34) 正交表。 4、进行表头设计(表1-1) 表1-1 由于此试验不考察因素之间的交互作用,所以采用不考察交互作用的方差分析法进行实验结果发差分析,并且此试验无重复试验,所以采用不考察交互作用的方差分析法中的无重复试验的方差分析。结果如表1-3 本例a=b=c=3,各因素每一水平的重复次数m=3,总处理次数为9次(n). ②平方和与自由度的分解。 平方和的分解: 矫正数 C=()2 i x n ∑=2T n =65.2/9=477.8596 总平方和 SS T =2i x ∑-C=6.252+4.972+…+8.952-C =530.89-477.8596=53.0304 A 因素平方和 SS A =2iA K m ∑-C=(15.762+18.572+31.252)/3-C =523.2617-477.8596=45.4021 B 因素平方和 SS B = 2iB K m ∑-C=(25.182+21.412+18.992)/3-C =484.3469-477.8596=6.4873 C 因素平方和 SS C = 2 iC K m ∑-C=(22.652+21.452+21.482)/3-C =478.1718-477.8596=0.3122 误差平方和 SS e = SS T -SS A -SS B -SS C =53.0304-45.4021-6.4873-0.3122=0.8288 对于空列也可用同样方法计算平方和: 空列平方和 SS D =2iD K m ∑-C=(20.742+21.872+22.972)/3-C =478.6884-477.8596=0.8288 自由度的分解: 总自由度 df T =n-1=9-1=8 A 因素 df A =a-1=3-1=2 B 因素 df B =b-1=3-1=2 C 因素 df C =c-1=3-1=2 误差 df e =df T -df A -df B -df C =8-2-2-2=2 显然,误差的自由度等于各空白列自由度之和,正交表中各列的自由度为该列的水平数减1。 ③F 测验。方差分析的结果见表1-4。由方差分析的结果可知,A 因素(温度)的F 值 显著,说明A 因素对蛋白质含量有显著的影响 表1-4 方差分析表 变异来源 SS df MS F F α 试验设计与方差分析 SPSS操作 一、试验设计与方差分析的关系 试验设计并不是一种统计方法,而是一组统计方法的统称,其主要用途在于分析自变量x的值与因变量y值之间的关系。此外,还用于降低背景变量对理解x值与y值之间关系时的影响。 试验设计使用的最主要的统计工具是方差分析,因此,许多教材将试验设计与方差分析设计为同一部分,使用共同的概念和术语。 其实方差分析并不仅仅在试验设计领域使用,也可以用来分析观察数据。 二、基本术语 例:影响某温室水果产量的主要因素有三个:施肥量、浇水量、温度。如果想通过控制三个因素的量,找出一个最优组合来提高产量,就是实验设计与方差分析问题。相关的术语有: 自变量(因子、因素、输入变量、过程变量):可以控制的、影响因变量的变量。本例为施肥量、浇水量、温度。 因变量(反应变量、输出变量):我们所关心的、承载试验结果的变量。本例为产量。 背景变量(噪声、噪声变量、潜伏变量):能观察但不可控的因子或因素,影响较小、达不到自变量水平。本例可能有测量误差等。 水平(设置):自变量的不同等级。水平数通常不多,连续型变量需离散化取值。如本例:施肥设1000克、1100克、1200克三个量, 浇水量设200千克、220千克两个量,温度设18度、20度、22度三个量。 处理:各因子按设定水平的一个组合。如本例:施肥1000克、浇水200千克、温度18度为一个处理。 试验单元:试验载体的最小单位。如本例的一个温室或由一个温室分割形成的房间。 主效应与交互效应:两因子及以上试验时,各因子可能对因变量有影响,因子间的相互作用也可能对因变量有影响。于是就有了上述概念。有时,交互效应比主效应更重要。如本例:施肥固定在1000克,浇水固定在200千克,18度、20度、22度三个温度条件下产量的差异,可以理解为温度的主效应;而同一温度条件下,不同的施肥量、浇水量造成的产量差异,就是交互效应。 三、试验设计的三个基本原则 第一,随机化。即采取机会均等的措施,将各种条件完全随机地配置在试验单元上。目的是要尽量消除试验因素之外的其他因素的干扰(平衡处理,不是减少误差,而是避免某种未知因素与系统因素相混淆)。极其重要。 第二,重复(复制)。即基本试验的重复,将一个处理施于两个或两个以上试验单元。重复的目的主要在于估计误差。没有对误差的估计就无法做出试验结论。同时,重复也有助于更准确地估计因子的效应。 第三,区组化。一组同质齐性的试验单元称为区组。即对试验单 莇蒂蒂薆袈肀蚄体育统计与SPSS读书笔记(八)—多因素方差分析(1) 虿薅肆螆薁蒃莆具有两个或两个以上因素的方差分析称为多因素方差分析。 蒃薇衿肁莂螇蒀多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方 差分析的时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因 素了:不同教学方法的班级,不同年级。如果再加上性别上的因素,那就成 了三因素了。如果我们把实验前和试验后的数据用一个时间的变量来表示, 那又多了一个时间的因素。如果每个年级都是不同的老师来上,那又多了一 个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑, 并确定自己只研究哪些因素。 螄螈蒂蒅肃芈膀下面用例子的形式来说说多因素方差分析的运用。还是用前面说单 因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。形成年级 和不同教学法班级双因素。 薇蝿莃蒄膇蚀节分析: 芀膂羅羆肁莅芅1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格 都是有重复数据(也就是不只一个数据), 肁蒆腿薂芄螅虿年级 羆羇蝿肂芆薈蚀不同教学方法的班级 袆艿羁螇莇膁膄定性班 螀肄羄薀蚂肂蒇定量班 羃蒄莈衿袁蚄罿定性定量班 羅芇荿羄膅螈芁五年级 莀袀袃蚅蚆螂螁(班级每个人) 莁蚁膆蝿羈袄莆(班级每个人) 袄蚇蚈葿螃袇腿(班级每个人) 袄蒇羀蚁莇肇袂初中二年级 蕿蒁螄薄羆肈蚃(班级每个人) 羁薃肅聿蕿薂莄(班级每个人) 蒂薆袈肀蚄袅蒈(班级每个人) 肆螆薁蒃莆莇蒂高中二年级 衿肁莂螇蒀虿薅(班级每个人) 蒂蒅肃芈膀蒃薇(班级每个人) 莃蒄膇蚀节螄螈(班级每个人) 羅羆肁莅芅薇蝿 2.因为有重复数据,所以存在在数据交互效应的可能。我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的 影响不同,则说明A、B两因素间存在交互作用。交互作用是多因素实验分析的一个非常重要的内容。如因素间存在交互作用而又被忽视,则常会掩盖因 素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。在大多数 场合,交互作用的信息比主效应的信息更为有用。根据上面的判断。根据上 面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。这里 假设他们之间有交互作用。正交试验设计及其方差分析
多因素方差分析
多因素方差分析讲解
第八章常用试验设计的方差分析
试验设计与数据分析
多因素方差分析资料讲解
两因素及多因素方差分析
SPSS多因素方差分析
spss多因素方差分析例子
利用SPSS_进行方差分析以及正交试验设计
SPSS统计分析教程-多因素方差分析
多因素方差分析
第10章__方差分析与试验设计
试验设计案例方差分析
实验设计与方差分析
SPSS多因素方差分析