SPSS作业05
聚类分析、判别分析和因子分析
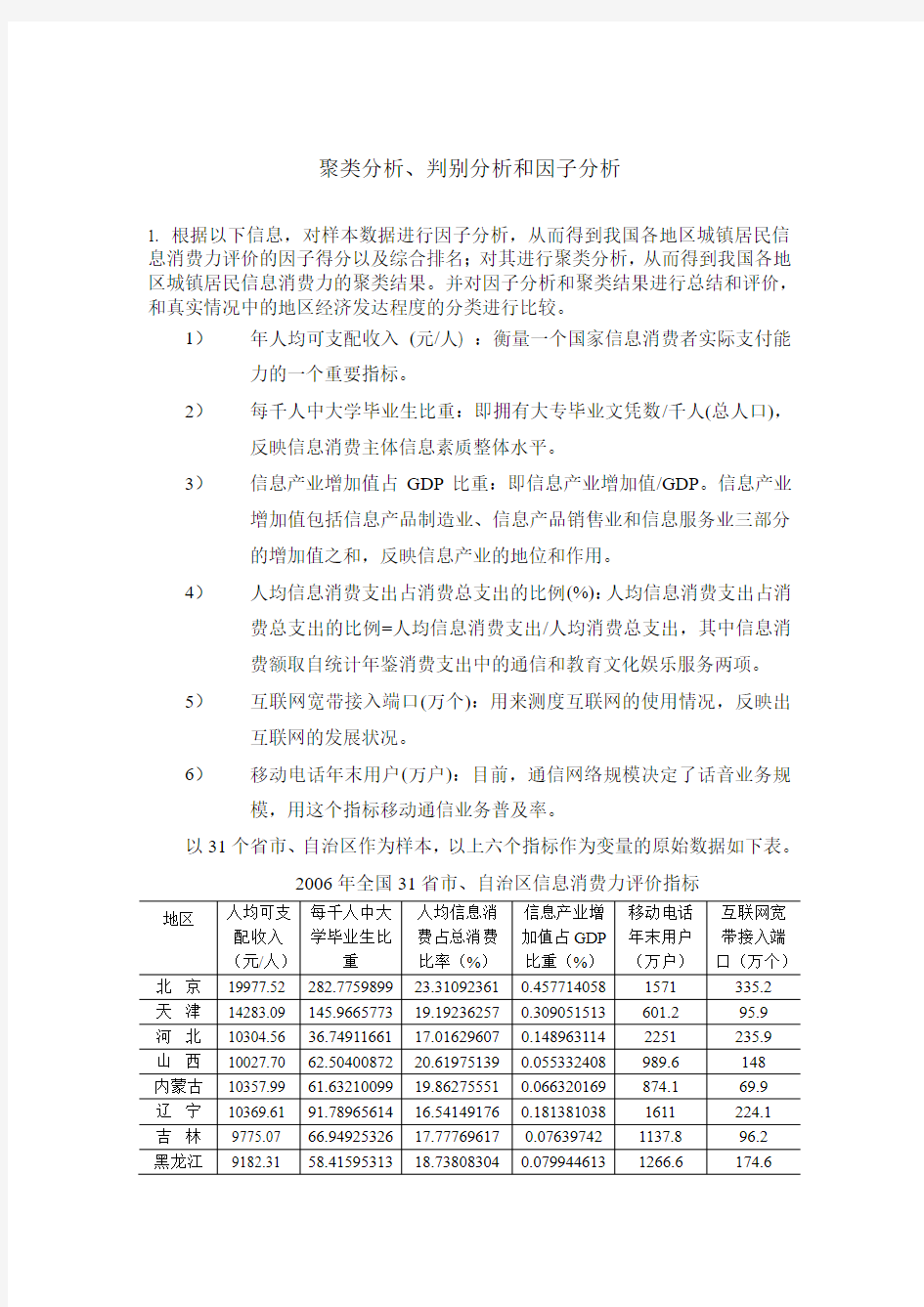
1. 根据以下信息,对样本数据进行因子分析,从而得到我国各地区城镇居民信息消费力评价的因子得分以及综合排名;对其进行聚类分析,从而得到我国各地区城镇居民信息消费力的聚类结果。并对因子分析和聚类结果进行总结和评价,和真实情况中的地区经济发达程度的分类进行比较。
1)年人均可支配收入(元/人) :衡量一个国家信息消费者实际支付能力的一个重要指标。
2)每千人中大学毕业生比重:即拥有大专毕业文凭数/千人(总人口),反映信息消费主体信息素质整体水平。
3)信息产业增加值占GDP比重:即信息产业增加值/GDP。信息产业增加值包括信息产品制造业、信息产品销售业和信息服务业三部分
的增加值之和,反映信息产业的地位和作用。
4)人均信息消费支出占消费总支出的比例(%):人均信息消费支出占消费总支出的比例=人均信息消费支出/人均消费总支出,其中信息消
费额取自统计年鉴消费支出中的通信和教育文化娱乐服务两项。
5)互联网宽带接入端口(万个):用来测度互联网的使用情况,反映出互联网的发展状况。
6)移动电话年末用户(万户):目前,通信网络规模决定了话音业务规模,用这个指标移动通信业务普及率。
以31个省市、自治区作为样本,以上六个指标作为变量的原始数据如下表。
2006年全国31省市、自治区信息消费力评价指标
地区人均可支
配收入
(元/人)每千人中大
学毕业生比
重
人均信息消
费占总消费
比率(%)
信息产业增
加值占GDP
比重(%)
移动电话
年末用户
(万户)
互联网宽
带接入端
口(万个)
北京19977.52 282.775989923.310923610.4577140581571335.2天津14283.09 145.966577319.192362570.309051513601.295.9河北10304.56 36.7491166117.016296070.1489631142251235.9山西10027.70 62.5040087220.619751390.0553********.6148内蒙古10357.99 61.6321009919.862755510.0663********.169.9辽宁10369.61 91.7896561416.541491760.1813810381611224.1吉林9775.07 66.9492532617.777696170.0763********.896.2黑龙江9182.31 58.4159531318.738083040.0799446131266.6174.6
上海20667.91 211.558245122.822700560.6344589971609.5421.3
江苏14084.26 69.004231819.97727601 1.1822299222873547.3
浙江18265.10 79.7618786121.050514250.5016669083012.3549.9
安徽9771.05 43.9345991618.751070980.1163507581216.7134.3
福建13753.28 54.5731243320.699837170.301155691538.9305.6
江西9551.12 42.9009957819.648215190.069971691933.3122.1
山东12192.24 53.8666480519.764182140.6753797512916433.8
河南9810.26 38.2083046620.190331450.187408422353.3230.8
湖北9802.65 73.2052006819.463265070.1588696441683.3221.7
湖南10504.67 47.2319074820.762978470.1464971511494.5207.9
广东16015.58 53.7032919521.03204416 1.6327897547117.5725.9
广西9898.75 42.021*******.970391420.0646414171204.1161.6
海南9395.13 50.1559251617.191775250.022*********.933.5
重庆11569.74 42.3764660622.225969790.1297333471064.6111.6
四川9350.11 42.4375032819.595179150.1960535161976.8244.4
贵州9116.61 24.9812496420.939958150.0556********.869.6
云南10069.89 28.6273846117.628773640.0689710791068.9113.7
西藏8941.08 9.71250971313.881474090.00491295660.5 4.8
陕西9267.70 70.7178804922.91600470.1510402131183.6134.8
甘肃8920.59 30.9428014420.949612930.033271527545.962.2
青海9000.35 55.06040818.506579520.007492733172.615.4
宁夏9177.26 66.799061218.002461980.012168577218.618.6
新疆8871.27 80.1884267418.436079590.054383961671.173.1
资料来源:《中国统计年鉴2007》《中国信息年鉴2007》
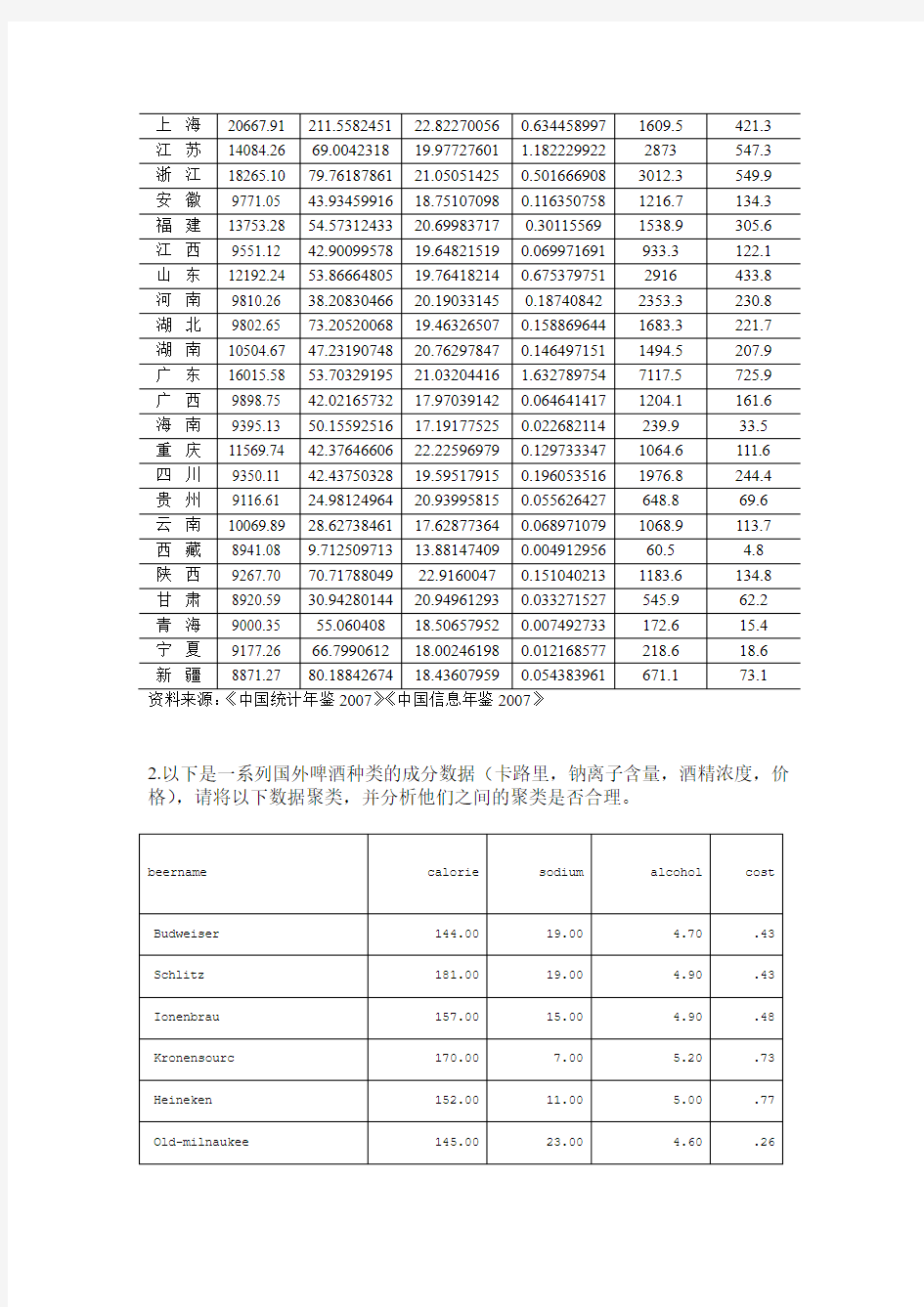
2.以下是一系列国外啤酒种类的成分数据(卡路里,钠离子含量,酒精浓度,价格),请将以下数据聚类,并分析他们之间的聚类是否合理。
beername calorie sodium alcohol cost Budweiser 144.00 19.00 4.70 .43 Schlitz 181.00 19.00 4.90 .43 Ionenbrau 157.00 15.00 4.90 .48 Kronensourc 170.00 7.00 5.20 .73 Heineken 152.00 11.00 5.00 .77 Old-milnaukee 145.00 23.00 4.60 .26
Aucsberger 175.00 24.00 5.50 .40
Strchs-bohemi 149.00 27.00 4.70 .42
Miller-lite 99.00 10.00 4.30 .43
Sudeiser-lich 113.00 6.00 3.70 .44
Coors 140.00 16.00 4.60 .44
Coorslicht 102.00 15.00 4.10 .46
Michelos-lich 135.00 11.00 4.20 .50
Secrs 150.00 19.00 4.70 .76
Kkirin 149.00 6.00 5.00 .79
Pabst-extra-l 68.00 15.00 2.30 .36
Hamms 136.00 19.00 4.40 .43
Heilemans-old 144.00 24.00 4.90 .43
Olympia-gold- 72.00 6.00 2.90 .46
Schlite-light 97.00 7.00 4.20 .47 3. 以下表格是一些上市公司的有关数据,通过建立判别分析函数,对表格最后五个公司的“是否有困难”字段,即上市公司是否可能发生财务困境进行判别。
name code type 是否有
困难
总自残负债
率
总资产周
转率
总自残
利润率
ST星源 5 综合类 1 0.43297 0.034 -0.0346 2
*ST石化A 13
批发和零售贸
易
1 0.69189 0.344 0.01615
ST鸿基40 综合类 1 0.45892 0.144 -0.0628
深万山49 房地产业 1 0.58581 0.164 0.00539 1
ST鑫光405 金属、非金属 1 0.44545 0.6 -0.1069
*ST四通409 机械、设备、
仪表
1 0.17246 0.228
-0.0789
8
ST五环412 综合类 1 0.59711 0.065 -0.2107 3
小天鹅A418
机械、设备、
仪表
1 0.39177 0.602
0.00784
4
丹东化纤498
石油、化学、
塑胶、塑料
1 0.67389 0.52
2 -0.0554
ST珠江505 房地产业 1 0.44233 0.121 -0.0533 3
ST美雅529 纺织、服装、
皮毛
1 0.45529 0.2
-0.1373
3
万家乐A533
机械、设备、
仪表
1 0.60231 0.336 0.00627
*ST戈德537 综合类 1 0.44677 0.152 -0.0288 6
白鸽股份544 金属、非金属 1 0.75773 0.489
0.00420
1
*ST长风552 机械、设备、
仪表
1 0.51843 0.132
-0.0993
2
*ST太光555 石油、化学、
塑胶、塑料
1 0.66906 0.522
0.01280
9
ST昆百大560
批发和零售贸
易
1 0.8387
2 0.633
-0.0702
3
*ST长岭561 机械、设备、
仪表
1 0.63047 0.407
-0.2432
8
海南海药566
医药、生物制
品
1 0.7644 0.195
-0.0610
7
海德股份567 综合类 1 0.63045 0.009
-0.0970
7
苏常柴A570
机械、设备、
仪表
1 0.56076 0.536
-0.1303
4
金盘股份572 综合类 1 0.71106 0.075
0.00095
7
ST威达603 机械、设备、
仪表
1 0.49471 0.137
0.00822
1
吉林化工618
石油、化学、
塑胶、塑料
1 0.67561 0.825
-0.0496
2
英力特635 石油、化学、
塑胶、塑料
1 0.66626 0.219
-0.3587
4
*ST南华660 综合类 1 0.71142 0.116 -0.0520 7
天发石油670
批发和零售贸
易
1 0.421
2 0.641 0.00112
ST寰岛691 综合类 1 0.26525 0.061 0.00160 1
滨海能源695
石油、化学、
塑胶、塑料
1 0.58369 0.224
-0.0323
6
ST佳纸699 造纸、印刷 1 0.68498 0.357 -0.0262 3
ST天仪710 机械、设备、
仪表
1 0.54805 0.148 -0.1241
*ST吉纸718 造纸、印刷 1 0.56765 0.308 0.00160 6
*ST环保730 建筑业 1 0.54719 0.121 -0.0044 5
南方摩托738
机械、设备、
仪表
1 0.46781 0.258
-0.0831
7
*ST华信765 批发和零售贸
易
1 0.60565 0.214
-0.0273
3
*ST通金766 医药、生物制
品
1 0.67938 0.107
0.01072
5
*ST大菲769 农、林、牧、
渔业
1 0.21886 0.008
-0.0301
3
ST湖山801 电子 1 0.33197 0.182 -0.1610 8
ST京西802 社会服务业 1 0.723 0.32 -0.0562 6
中汇医药809
纺织、服装、
皮毛
1 0.62977 0.765
-0.1388
5
*ST江力816 机械、设备、
仪表
1 0.4209 0.782
-0.0621
4
国投资源826
石油、化学、
塑胶、塑料
1 0.43045 0.249
-0.0517
9
*ST龙涤832 石油、化学、
塑胶、塑料
1 0.5565 0.664
-0.1437
8
高鸿股份851 金属、非金属 1 0.26013 0.288
-0.0340
2
一汽夏利927
机械、设备、
仪表
1 0.56573 0.467
-0.0118
5
*ST中科931 社会服务业 1 0.72549 0.11 -0.0254 2
中国重汽951
机械、设备、
仪表
1 0.63137 0.336
-0.0521
2
金马股份980
机械、设备、
仪表
1 0.53357 0.24
-0.0159
7
ST江纸6000
53
造纸、印刷 1 0.76125 0.236
-0.2052
2
夏新电子6000
57
电子 1 0.59762 0.762
-0.1348
6
ST长控6001
37
造纸、印刷 1 0.69786 0.301
0.02810
5
*ST鑫泰6001
56
纺织、服装、
皮毛
1 0.31035 0.466
-0.0961
3
桦林轮胎6001
82
石油、化学、
塑胶、塑料
1 0.6683 0.406
-0.0844
9
锦州港6001
90
交通运输、仓
储业
1 0.52404 0.109
0.01369
4
*ST福日6002
03
电子 1 0.64072 0.823
-0.0147
5
ST天龙6002
34
批发和零售贸
易
1 0.67584 0.247
-0.1006
6
仕奇实业6002
40
纺织、服装、
皮毛
1 0.10384 0.071
-0.0712
1
ST盛工6003
35
机械、设备、
仪表
1 0.54504 0.391
-0.0594
1
*ST永生6006
13
传播与文化产
业
1 0.3842
2 0.078
-0.1067
8
ST丰华6006
15
石油、化学、
塑胶、塑料
1 0.41781 0.213
-0.0381
8
*ST联华6006
17
石油、化学、
塑胶、塑料
1 0.4513 0.589
0.00199
8
嘉宝集团6006
22
综合类 1 0.37411 0.196
-0.0825
2
ST国嘉6006
46
传播与文化产
业
1 0.55665 0.247
0.05049
6
*ST花雕6006
59
综合类 1 0.63011 0.273
-0.0412
7
*ST华圣6006
72
农、林、牧、
渔业
1 0.39806 0.46
0.02201
6
ST万鸿6006
81
传播与文化产
业
1 0.60121 0.277
-0.0613
2
*ST林控6006
91
金属、非金属 1 0.64123 0.209
-0.0514
4
ST大江6006
95
食品、饮料 1 0.54933 0.841
-0.0702
6
*ST数码6007
00
综合类 1 0.69695 0.505
-0.0667
7
ST生态6007
09
农、林、牧、
渔业
1 0.23175 0.711
0.15210
8
大连国际881 综合类0 0.52397 0.744
0.03090
1
武汉石油668
批发和零售贸
易
0 0.60178 1.499
0.05267
9
粤宏远A573 综合类0 0.40299 0.108
0.00178
7
天创置业6007
91
房地产业0 0.55692 0.703
0.12527
2
海印股份861 金属、非金属0 0.48801 0.408
0.01180
3
力源液压6007
65
机械、设备、
仪表
0 0.2829 0.229
0.00537
6
建投能源600 综合类0 0.52783 0.209
0.00559
3
广船国际6006
85
机械、设备、
仪表
0 0.72919 0.843
0.00357
7
青岛碱业6002
29
石油、化学、
塑胶、塑料
0 0.4882 0.589
0.04159
3
东华实业6003
93
房地产业0 0.46167 0.29
0.05993
9
青岛双星599
纺织、服装、
皮毛
0 0.58972 0.887 0.03203
鲁能泰山720
机械、设备、
仪表
0 0.46396 0.587
0.04837
5
交大南洋6006
61
综合类0 0.3415 0.596
0.03691
3
江泉实业6002
12
金属、非金属0 0.20615 0.766 0.07911
长春一东6001
48
机械、设备、
仪表
0 0.23992 0.606
0.03941
9
燕化高新609
石油、化学、
塑胶、塑料
0 0.09302 0.509
0.05507
9
西安民生564
批发和零售贸
易
0 0.45054 0.803
0.03449
1
京山轻机821
机械、设备、
仪表
0 0.3837 0.456
0.06329
6
天目药业6006
71
医药、生物制
品
0 0.38089 0.253
0.00612
2
博闻科技6008
83
综合类0 0.30214 0.319
0.05152
4
航天机电6001
51
机械、设备、
仪表
0 0.28509 0.494
0.04559
2
舒卡股份584 综合类0 0.57307 0.19
0.03056
6
四环药业605
机械、设备、
仪表
0 0.66093 0.185
0.00369
3
扬子石化866
石油、化学、
塑胶、塑料
0 0.51159 1.418
0.06109
5
广州浪奇523
石油、化学、
塑胶、塑料
0 0.32484 0.837 0.00607
创兴科技6001
93
综合类0 0.42332 0.219
0.03234
6
渤海物流889
批发和零售贸
易
0 0.52019 0.371
0.04321
6
长江投资6001
19
综合类0 0.47439 0.687
0.02823
6
武汉塑料665
石油、化学、
塑胶、塑料
0 0.37024 0.622
0.04026
2
美利纸业815 造纸、印刷0 0.48424 0.327
0.03974
1
力源液压6007
65
机械、设备、
仪表
0 0.2829 0.229
0.00537
6
华泰股份6003
08
造纸、印刷0 0.41667 0.285
0.04333
3
中色股份758 建筑业0 0.29647 0.15
-0.1049
1
一汽四环6007
42
机械、设备、
仪表
0 0.22466 0.889
0.08811
2
宝光药业593
批发和零售贸
易
0 0.42865 0.587
0.02237
8
华东医药963
医药、生物制
品
0 0.55665 1.582 0.03394
香梨股份6005
06
农、林、牧、
渔业
0 0.24523 0.13
0.04988
5
天通股份6003
30
电子0 0.21926 0.493
0.09809
7
华天酒店428 社会服务业0 0.34723 0.317
0.03456
6
远东股份681
纺织、服装、
皮毛
0 0.18343 0.76 0.03734
宁波富达6007
24
机械、设备、
仪表
0 0.52486 0.676
0.04806
6
力诺工业6008
85
石油、化学、
塑胶、塑料
0 0.68386 0.241
-0.0352
6
海螺型材619
石油、化学、
塑胶、塑料
0 0.16691 1.222
0.12588
6
海印股份861 金属、非金属0 0.48801 0.408
0.01180
3
青岛海尔6006
90
机械、设备、
仪表
0 0.2327 2.085
0.08899
5
山东基建6003
50
社会服务业0 0.18748 0.207
0.06526
3
宁波富达6007
24
机械、设备、
仪表
0 0.43217 0.901
0.07320
2
华夏建通6001
49
机械、设备、
仪表
0 0.44536 0.396
0.03596
4
民丰特纸6002
35
造纸、印刷0 0.51165 0.303
0.03923
4
超声电子823 电子0 0.3125 0.522
0.05478
4
界龙实业6008
36
造纸、印刷0 0.63932 0.587
0.01147
4
华纺股份6004
48
纺织、服装、
皮毛
0 0.41883 0.888
-0.0383
8
黑化股份6001
79
石油、化学、
塑胶、塑料
0 0.50631 0.741
0.01374
5
深赤湾A22
交通运输、仓
储业
0 0.3813 0.213 0.03905
联创光电6003
63
电子0 0.37303 0.63
0.03692
4
物华股份6002
47
批发和零售贸
易
0 0.29726 0.178
0.04512
2
望春花6006
45
纺织、服装、
皮毛
0 0.36938 0.462
-0.1101
7
上风高科967
机械、设备、
仪表
0 0.11859 0.301
0.02687
5
博瑞传播6008
80
传播与文化产
业
0 0.36579 0.719
0.07911
9
兴发集团6001
41
石油、化学、
塑胶、塑料
0 0.41501 0.515
0.04692
9
燕化高新609
石油、化学、
塑胶、塑料
0 0.09302 0.509
0.05507
9
舒卡股份584 综合类0 0.57307 0.19
0.03056
6
中视传媒6000
88
传播与文化产
业
0 0.11538 0.252
0.02956
5
阳光发展671 综合类0 0.57544 0.567
-0.0031
7
隆平高科998
农、林、牧、
渔业
0 0.15576 0.28
0.04095
1
博瑞传播6008
80
传播与文化产
业
0 0.3319 0.678
0.11645
2
鹏博士6008
04
金属、非金属0 0.47726 0.819
0.00976
4
广东甘化576 食品、饮料0 0.50602 0.47
0.01405
3
南方控股716 综合类0 0.475 0.076
-0.1340
4
罗牛山735 农、林、牧、
渔业
0 0.40409 0.204
0.06305
8
国投电力6008
86
电力、煤气及
水的生产和供
应业
0.05488 1.835
-0.0435
1
*ST秋林6008
91
批发和零售贸
易
0.3975 0.406
-0.0570
5
弘业股份6001
28
批发和零售贸
易
0.2946 1.738
0.01216
2
公用科技685 社会服务业0.23655 0.162
0.04745
9
桂林集琦750
医药、生物制
品
0.30746 0.18
0.00104
6
4. 根据给出的国家列表用判别分析求出空国家所属的类别并结合实际总结分析。
国名类别预期寿
命
成人识
字率
人均
GDP
美国 1 76.0 99.0 5,374
日本 1 79.5 99.0 5,359
瑞士 1 78.0 99.0 5,372
阿根廷 1 72.1 95.9 5,242
阿联酋 1 73.8 77.7 5,370
保加利亚 2 71.2 93.0 4,250
古巴 2 75.3 94.9 3,412
巴拉圭 2 70.0 91.2 3,390
格鲁吉亚 2 72.8 99.0 2,300
南非 2 62.9 80.6 3,799
中国68.5 79.3 1,950
罗马尼亚69.9 96.9 2,840
希腊77.6 93.8 5,233
哥伦比亚69.3 90.3 5,158
5.应用SPSS 对环境污染进行因子分析。
原始数据为我国各省、直辖市、自治区工业和生活污染物排放量见下表:
地区x1 x2 x3 x4 x5 x6 x7
北京53307 138423 112198 37586 152 3227 34047 天津22556 175554 29550 16790 1 1644 19328 河北53912 235387 191038 240328 269 9506 106431 山西52871 169977 319598 512995 1725 6316 47325 内蒙古20728 130964 159489 208286 115 4504 24005 辽宁96352 370781 240257 139654 437 8963 121941 吉林52464 257559 72242 95664 21 3008 38189
黑龙江56507 333727 78389 97804 1 4053 60750 上海118028 269138 97995 48926 0 4912 90020 江苏111239 402951 38850 15411 19 7318 198423 浙江67920 270760 35150 17621 32 5016 114690 安徽71688 283923 44474 32516 47 3647 61713 福建41947 153405 10018 10456 85 2007 52482 江西49641 279226 60825 8369 134 1743 45716 山东116979 489559 498827 133894 11 9089 11717 河南94270 307769 235035 36541 60 6618 91311 湖北114348 356399 77241 44248 52 5105 124177 湖南94280 261968 103332 39541 300 3452 131225 广东316432 588511 35692 17846 121 6344 117737 广西71255 244014 57382 33348 245 4152 86887 海南15514 57748 260 23 0 327 7515 重庆24652 133399 316659 143801 41 1713 33794 四川72562 310980 690014 359382 998 4606 102850 贵州32834 166487 1076400 198375 1188 3347 31113 云南28943 124331 53440 42237 571 1887 43317 西藏4067 36150 0 0 0 12 2392 陕西35861 156696 98884 40331 191 2497 34462 其中: X1 为生活污水排放量(万吨) , X2 为生活污水中化学需氧量排放量(吨) , X3 为生活二氧化硫放量(吨),X4 为生活烟尘排放量(吨) ,X5 为工业固体废物排放量(万吨) , X6 为工业废气排放总量(亿标立方米) , X7 为工业为水排放量(万吨) 。
一元线性回归spss作业
一元线性回归实验指导 一、使用spss进行线性回归相关计算 题目: 为研究医药企业销售收入与广告支出的关系,随机抽取了20家医药企业,得到它们的销售收入和广告支出的数据如下表(数据在‘广告.sav’中) 1.绘制散点图描述收入与广告支出的关系 结果:(散点图粘贴在下面) 从散点图可直观看出销售收入和广告支出(存在/不存在)线性关系 2.计算两个变量的相关系数r及其检验 相关性结果表格:(粘贴在下面)
从结果中可看出,销售收入与广告支出的相关系数为(),双侧检验的P值(),r在0.01显著性水平下(),表明销售收入与广告支出之间(存在/不存在)线性关系。 3.一元线性回归分析 计算回归分析;并输出标准化残差的pp图和直方图 分析输出的结果: 模型汇总表格:(粘贴在下面) 这个表格给出相关系数R=()以及标准估计的误差() 方差分析(ANOVA)表格:(粘贴在下面) 这个表格给出回归模型的方差分析表,包括回归平方和SSR、回归均方MSR、残差平方和SSE、残差均方MSE、总平方和SST和总均方MST,F值129.762以及P值(),此处p 值(),说明回归的线性关系(显著/不显著) 系数表格:(粘贴在下面) 上面这个表格给出的是参数估计和检验的有关内容,包括回归方程的常数项、非标准化回归系数、常数项和回归系数检验的统计量t和显著性水平sig,以及回归系数的%95置信区间从此表可以得出销售收入与广告支出的估计方程为()。回归系数()表示广告支出每变动1万元,销售收入平均变动()万元。
4.残差的检验 从上面的输出结果中可得到标准化残差的标准pp图和直方图(粘贴在下面) 同时在数据表格中出现残差以及估计值和区间的上下界,其中 PRE_1为点估计值; RES_1为非标准化残差; ZRE_1为标准化残差; LMCI_1和UMCI_1表示平均值的置信区间(均值的预测区间); LICI_1和UICI_1表示个别值的预测区间的上界和下界; 下面绘制非标转化残差图:(粘贴在下面) 从残差图上可以看出,各个残差随机分布于0轴两侧,没有任何固定模式,这表明在销售收入与广告支出的一元线性回归中,线性假定以及等方差的假定成立。 下面检验残差正态性: 做出标准化残差(ZRE_1)的散点图,并在图上画出0,2,-2三条y轴参考线(粘贴在下面)
数据分析spss作业
数据分析方法及软件应用 (作业) 题目:4、8、13、16题 指导教师: 学院:交通运输学院 姓名: 学号:
4、在某化工生产中为了提高收率,选了三种不同浓度,四种不同温度做试验。在同一浓度与温度组合下各做两次试验,其收率数据如下面计算表所列。试在α=0.05显著性水平下分析 (1)给出SPSS数据集的格式(列举前3个样本即可); (2)分析浓度对收率有无显著影响; (3)分析浓度、温度以及它们间的交互作用对收率有无显著影响。 解答:(1)分别定义分组变量浓度、温度、收率,在变量视图与数据视图中输入表格数据,具体如下图。 (2)思路:本问是研究一个控制变量即浓度的不同水平是否对观测变量收率产生了显著影响,因而应用单因素方差分析。假设:浓度对收率无显著影响。 步骤:【分析-比较均值-单因素】,将收率选入到因变量列表中,将浓度选入到因子框中,确定。 输出: 變異數分析 收率 平方和df 平均值平方 F 顯著性 群組之間39.083 2 19.542 5.074 .016 在群組內80.875 21 3.851 總計119.958 23 显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝原假设,认为浓度对收率有显著影响。
(3)思路:本问首先是研究两个控制变量浓度及温度的不同水平对观测变量收率的独立影响,然后分析两个这控制变量的交互作用能否对收率产生显著影响,因而应该采用多因素方差分析。假设,H01:浓度对收率无显著影响;H02:温度对收率无显著影响;H03:浓度与温度的交互作用对收率无显著影响。 步骤:【分析-一般线性模型-单变量】,把收率制定到因变量中,把浓度与温度制定到固定因子框中,确定。 输出: 主旨間效果檢定 因變數: 收率 來源第 III 類平方 和df 平均值平方 F 顯著性 修正的模型70.458a11 6.405 1.553 .230 截距2667.042 1 2667.042 646.556 .000 浓度39.083 2 19.542 4.737 .030 温度13.792 3 4.597 1.114 .382 浓度 * 温度17.583 6 2.931 .710 .648 錯誤49.500 12 4.125 總計2787.000 24 校正後總數119.958 23 a. R 平方 = .587(調整的 R 平方 = .209) 第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是均方;第五列是F检验统计量的观测值;第六列是检验统计量的概率p值。可以看到观测变量收率的总变差为119.958,由浓度不同引起的变差是39.083,由温度不同引起的变差为13.792,由浓度和温度的交互作用引起的变差为17.583,由随机因素引起的变差为49.500。浓度,温度和浓度*温度的概率p值分别为0.030,0.382和0.648。 浓度:显著性<0.05说明拒绝原假设(浓度对收率无显著影响),证明浓度对收率有显著影响;温度:显著性>0.05说明不拒绝原假设(温度对收率无显著影响),证明温度对收率无显著影响;浓度与温度: 显著性>0.05说明不拒绝原假设(浓度与温度的交互作用对收率无显著影响),证明温浓度与温度的交互作用对收率无显著影响。 8、以高校科研研究数据为例:以课题总数X5为被解释变量,解释变量为投入人年数X2、投入科研事业费X4、专著数X6、获奖数X8;建立多元线性回归模型,
SPSS大作业-环境保护
当代大学生对全球气候变化 认知程度的研究 摘要:随着我国经济建设的飞速发展,人们向大自然排放的有害物质与日俱增,环境问题日益严重。环境污染问题不仅影响我国人民的生存环境和生存质量,也危害人民的身体健康,在环境污染中城市环境污染已经成为制约社会发展的重要问题。本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷,采用SPSS statistics软件分析采样数据,得到频率表以及考虑性别的交叉表。本文考虑性别、城乡等差异,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究当代大学生对环境污染问题认知程度的差异。 关键字:性别;气候变化;差异;SPSS 一、研究背景 我国改革开放30多年的经济发展迅速,主要是以粗放式发展为主要模式。由此而带来的就是高增长、高能耗、高排放的三高企业,我国是发展中国家,在经济发展的过程中,政府对环境破坏的监管不力,睁一眼闭一眼,所以我国改革开放30年快速发展以牺牲能源、破坏环境为代价的,尤其我国的经济发展又极不平衡,主要是以城市主力军,这样城市的环境恶化就很严重。同样,农村人口环境保护意识淡薄,农村环境恶化也不可小觑,我国高速发展的近几十年来,环境的恶化程度逐年增加,应该引起政府环保部门的重视。 环境污染对人们的生活影响越来越严重,我们现在出门看到的最打眼的一景就是戴口罩的人越来越多,人们越来越感受到空气污染对
自己身心健康的威胁,据统计,世界儿童死亡80%是由于空气污染导致的,这个数字让人触目惊心。 环境污染很大因素是由于企业恣意排放污染物,但在日常生活中,民众的环保意识与环保行为对生活污染——尤其是随处可见的污染——有较大的影响。性别、年龄等不同,对气候变化认知程度也会存在差异。本文考虑到男女性别的差异、城乡区别,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究不同性别对环境污染问题认知程度的差异。 二、研究方法及样本描述 (一)研究方法 本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷调查的方法,与2014年5月在西安交通大学进行问卷调查。调查面向西安交大本科生以及研究生,最终获得有效问卷431份。 (二)样本特征描述 431位被访者中,女性209位,占48.5%;男性222位,占51.5%。如图1所示,样本主要来自大一、大二以及大三群体,总共381位,占88.4%;大四毕业生以及研究生占11.6%。被访者所读专业性质也有较大差别,文科生178位,占41.3%;工科生人数122位,占28.3%;理科生108位,占比25.1%,如表1所示。
SPSS作业
一、作业分析 案例背景:拟分析导致急救后颅脑损伤的主要影响因素,某省医院的外科 医生收集了2003-2005年间在该科室进行过急救治疗的脑外伤病例共201例。 研究目的:差异性比较 资料类型:本例根据是否出现迟发性脑损伤将数据分为两个独立样本。 本例的数据变量有性别、年龄、入院时血循环指标、入院时症状、入院时 意识程度、是否手术急救、其它治疗、是否出现迟发性脑损伤。在这些变量中 既有连续变量又有分类变量,所以在检验时需分成两种:定量检验与定性检验。 其中定量检验为:年龄、入院时血循环指标;定性检验为:性别、入院时 症状、入院时意识程度、是否手术急救、其它治疗。 二、数据描述 1 数量变量的描述 利用SPSS软件分析→描述统计→描述,将年龄、收缩压、舒张压、血小 板拖入,得到下表: 通过表格可以发现血小板的极差为372,标准差为63.568.极差和标准差都较大,通过求自然对数来减小标准差,所以我们改用血小板的自然对数为数据。得到下表:
2.分类变量的描述 利用SPSS软件分析→表→设定表,选中性别、脑挫伤、中线移位、脑肿胀、意识程度、手术、止血药、激素、脱水剂拖入框中,得到下表: 从表中可以大致看出,脑挫伤、手术、中线移位、意识程度、激素和脱水剂几个变量和是否发生脑损伤有关。但是,这些关联是否具有统计学意义还需要进行检验。 三、差异性比较 1数量变量的差异性比较
(1)年龄与迟发性脑损伤的关系 本案例为两独立样本,我们对其进行正态性检验。 利用SPSS软件分析→统计描述→探索,得到下表: 从表中,可得出年龄成正态性分布。 利用SPSS软件分析→比较均值→独立样本T检验,检验变量为年龄,分组变量为迟发性脑损伤,单击确定得到如下结果: 发生迟发性脑损伤与未发生迟发性脑损伤组中年龄均服从正态分布,两总体方差齐。 采用两独立样本的t检验:t=-1.038,df=199,P=0.300,可以得出,以 α=0.05为检验水准,年龄与是否发生迟发性脑损伤无明显差异。 (2)收缩压、舒张压与迟发性脑损伤的关系 与上述方式相同,对数据进行正态性检验,检验结果为:
spss期末作业
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
spss课后作业答案
SPSS课后作业 第一章 1-1、spss的运行方式有几种?分别是什么? 答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别? 答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。 第二章 2-1、在SPSS中可以使用那些方法输入数据? 答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。 2-2、对于缺失值,如何利用SPSS进行科学替代? 答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。最后选择合适的替代方式即可。 2-3、在计算数据的加权平均数时,如何对变量进行加权? 答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。 2-4、如何对变量进行自动赋值? 答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。从Recode Starting from框中有两个选项中选择一个,然后单击OK按钮,即可完成自动赋值运算。 3-1、一组数据的分布特征可以从哪几个方面进行测度? 答:一组数据的分布特征可以从平均数、中位数、众数、方差、百分位、频数、峰度、偏度等方面描述。 3-2、简述众数、中位数和均值的特点及应用场合。 答:均值是总体各单位某一数量标志的平均数。平均数可应用于任何场合,比如在简单时序预测中可用一定观察期内预测目标的时间序列的均值作为下一期的预测值。中位数是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。中位数的作用与算术平均数相近,也是作为所研究数据的代表值。在一个等差数列或一个正态分布数列中,中位数就等于算术平均数。在数列中出现了极端变量值的情况下,用中位数作为代表值要比用算术平均数更好,因为中位数不受极端变量值的影响。众数是指一组数据中出现次数最多的那个数据。它主要用于定类(品质标志)数据的集中趋势,当然也适用于作为定序(品质标志)数据以及定距和定比(数量标志)数据集中趋势的测度值。 3-3、
SPSS调查报告期末作业
S P S S调查报告期末作业 Document serial number【LGGKGB-LGG98YT-LGGT8CB-LGUT-
---------------------------------------------装--------------------------------- --------- 订 ---------------------------------------- -线----------------------------------- -- - --
上表表明,5中不同年级形式下共有80个样本,大一的均值最高,大二的均值次之,接着,大四的均值排第三,而大三的均值是最低的。由于在录入数据当中,选择调查问卷中选项A“是”,身边有请人带过课的同学,则录为1:;选择调查问卷中选项B“否”,身边没有请人带过课的同学,则录为2。所以,均值的结果表明,数值越大,则身边出现代课同学越少,数值越小,则表明身边出现的代课同学越多。因此,大三中的代课同学是最多的,大四次之,大二次之,大一最少。 上表表明,不同年级下代课情况的方差齐性检验值为,概率为,。如果显着性水平为,由于概率值大于显着性水平,不应拒绝零假设,认为不同年级下代课情况的总体方差无显着差异,满足方差分析的前提要求。 上表分别显示了两两不同年级下代课情况均值检验的结果。通过两两比较,最终可以得出,大一的均值>大二的均值>大三的均值,大四的均值大小情况不能确定,基本上得出的结论与实际情况相符。 五、建议 在以上对数据的分析过程当中,我们提到了逃课现象严重,收费代课行为愈发普遍的原因,这里稍微再做一下总结。原因如下: a.一些专业课程,教学内容循规蹈矩,考试题目照本宣科,无法引起学生兴趣; b.学校管理有较大漏洞,上课学生中“替身”大量潜伏而不知; c.学生自身自制力不够,容易受到外界的影响,不能静心学习; d.社会就业压力大,导致学生青睐于早点实习; 针对以上这些导致收费代课产生的原因,我想提出几点建议: (一)学校在专业设置、教师的互动性教学、知识的创新性和灵活体现、教学管理体系建设等诸多方面,都应反思,并采取一定的措施。高校则应该实行自主办学措施,在课程设置、专业方向设置上应当有自我特色。与其大张旗鼓地对“收费代课”现象进行大力批判,还不如放开手来,从根本上指导学生如何学会自主学习,如何利用有限的学习时间。倘若不加以反思,做出课程设置、教师互动性教学的改进,而是纯粹地一味加强考勤管理,必然会扼杀一部分学生的学习积极性,“人在心不在”的上课状态恐怕也难以培养出符合时代需求的大学生。 (二)学生应该分清楚学习和工作的不同意义,学习是一种能力的提高过程。大学生应当学会对自己的现在以及未来负责。大学四年,是相当宝贵的青春年华。我们年轻,我们活动,但是这些都不应该成为我们虚度时间,不学习的理由。调查结果中显示,大三的收费代课现象是最为严重的,这样的结果确实应该引起学生的重视了。我们都知道,大三是专业学习的主要一年,很多的专业课都在大三进行安排。可是大三的同学的不认真学习专业课,选择请人代课,这不是明显浪费了学习专业课的机会吗所以,这里,我想提醒本部的同学们,要合理地定位自己的身份与任务,不要在该学习的阶段去实习或娱乐。另外,也要明确自己上大学的初衷,不要因为大学生活的闲适,而慢慢丢失了自己的理想。 (三)政府要给大学生提供公平的就业环境,打击不规范的就业行为,消除掉大学生的就业焦虑。为大学生就业,提供更加全面完整的服务系统,让大学生在大学期间安心学
SPSS作业
物流统计实验作业 <一>:试述聚类分析的基本思想以及SPSS操作的基本步骤? 系统聚类的基本思想是 聚类分析法又称集群分析法,它是研究样品或指标分类问题的一种多元统计方法。寻找一种能客观反应事物之间亲疏关系或合理评价事物性质相似程度的统计量,然后根据这种统计量和规定的分类准则把事物进行分类。 操作步骤: 1. 在SPSS窗口中选择Analyze→Classify→Hierachical Cluster,调出系统聚类分析主界面,并将变量移入Variables框中。在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。 2. 点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。这里我们选择系统默认值,点击Continue按钮,返回主界面。 3. 点击Plots,设置结果输出窗口给出的聚类分析统计图。选中Dendrogram复选框和Icicle栏中的None单选按钮,即只给出聚类树形图,而不给出冰柱图。单击Continue,返回主界面。 4. 点击Method,设置系统聚类的方法选项。Cluster Method下拉列表用于指定聚类的方法,包括组间连接法、组内连接法、最近距离法、最远距离法等;Measure栏用于选择对距离和相似性的测度方法;剩下的Transform Values和Transform Measures栏用于选择对原始数据进行标准化的方法。这里我们仍然均沿用系统默认选项。单击Continue,返回主界面。 5. 点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新变量。None表示不保存任何新变量;Single solution表示生成一个分类变量,在其后的矩形框中输入要分成的类数;Range of solutions表示生成多个分类变量。这里我们选择Range of solutions,并在后面的两个矩形框中分别输入2和4,即生成三个新的分类变量,分别表明将样品分为2类、3类和4类时的聚类结果。点击Continue,返回主界面。 6. 点击OK按钮,运行系统聚类过程。 <二>:利用2001年全国31个省自治区各类小康和现代化指数的数据,利用K-均值聚类方法对地区进行聚类分析。并且对SPSS分析的结果进行分析。文件名为“小康指数.sav”。 31个省市自治区小康和现代化指数的K-Means聚类分析结果(一) 这张表展示了3类的初始类中心点的情况。由表可知第二类各指数均是最优的,第一类次之,第三类各指数最不理想。 31个省市自治区小康和现代化指数的K-Means聚类分析结果(二)
SPSS调查报告 - 期末作业
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
SPSS调查报告期末作业
广东财经大学答题纸(格式二) 课程数据处理技术与SPSS 20 15 —20 16学年第1学期 成绩评阅人 评语: (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课” 现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面, 帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷, 回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
SPSS作业要求及答题格式
上机实习必做的练习题(留作业) 第一单元医学资料的统计描述 定量资料:习题1①②③,2,3 分类资料:习题4,5,6 第二单元定量资料的统计推断 t检验:习题1,3,4 方差分析:习题8,10 第三单元分类资料的统计推断 卡方检验:习题4,5,8 秩和检验:习题10,12,14 第四单元回归与相关 习题 1.①②③④⑤ 2.①② 3. 第五单元生存分析 习题2,3
附件: 作业、上机考试答题格式及评分标准 一、描述性题目 (一)集中趋势和离散趋势指标的计算 某卫生防疫站对30名麻疹易感儿童经气溶胶免疫一个月后,测得其血凝抑制抗体滴度资料如下:请计算平均滴度。 抗体滴度1:81:161:321:641:1281:2561:512合计例数2651042130 1.题意分析:这是抗体滴度资料,应该计算几何均数。(方法正确得10分) 2.计算结果(18分):经SPSS计算,得:G=48.5 3.答(5分):该30名麻疹易感儿童经气溶胶免疫一个月后血凝抑制抗体平均滴度为1:48.5 (二)医学参考值的计算 测得某地300名正常人尿汞值,其频数表如下。欲根据此资料制定95%正常值范围。 300例正常人尿汞值(ug/L)频数表 尿汞值例数尿汞值例数尿汞值例数0-4924-1648-3 4-4728-952-0 8-5832-956-2 12-4036-460-0 16-3540-564-0 20-2244-068-721 1.题意分析:本资料为偏态分布资料,应该用百分位数法制定。由于尿汞为有毒有害物质,应制定单侧上限即可,即计算P95。(方法正确得10分) 2.计算结果(18分):经SPSS计算得:P95=36.8(ug/L) 3.答(5分):该地正常人尿汞值95%正常值范围为<36.8(ug/L) (三)可信区间的计算(P426,习题1)
SPSS期末大作业_完整版
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,
确定。 (3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效 1 缺失0 百分位数 25 50.00 50 50.00 75 50.00 20~35岁 N 有效131 缺失0 百分位数 25 500.00 50 1000.00 75 5000.00 35~50岁 N 有效73 缺失0 百分位数 25 500.00 50 1000.00 75 4500.00 50岁以上 N 有效32 缺失0 百分位数 25 525.00 50 1000.00 75 2000.00 结果及结果描述:
spss作业
因子分析和聚类分析实验结果 实验三细分市场: 最终聚类中心 聚类 1 2 3 4 5 -.26315 -.30404 .14466 .44654 .05989 REGR factor score 1 for analysis 1 -.07182 .23828 -.26630 -.16127 .33259 REGR factor score 2 for analysis 1 -.19328 -.28719 .63660 -.02573 -.18672 REGR factor score 3 for analysis 1 .50829 -.00331 -.00021 -.34847 .11851 REGR factor score 4 for analysis 1 .40420 -.21962 -.11076 -.04081 .64739 REGR factor score 5 for analysis 1 -.30952 -.04110 .31218 -.10849 .13244 REGR factor score 6 for analysis 1 .10254 -.14466 -.45953 .38182 .64683 REGR factor score 7 for analysis 1 .26405 .22806 -.18056 -.42420 .29452 REGR factor score 8 for analysis 1 REGR factor score 9 for .79807 .18796 -.27608 -.03549 -1.28644 analysis 1 .19929 .31480 .22201 -.87975 .19295 REGR factor score 10 for analysis 1 -.25574 .37900 -.66646 .46458 -.57422 REGR factor score 11 for analysis 1 .37639 -.42108 -.22475 .55670 .17524 REGR factor score 12 for analysis 1 REGR factor score 13 for -.91613 .37980 -.04371 .18781 -.41194 analysis 1 -.33164 -.10366 .36184 -.09906 .26576 REGR factor score 14 for analysis 1 REGR factor score 15 for .09687 -.14233 .41251 .02394 -.80211 analysis 1 -.41177 .11759 -.37624 .09560 1.01041 REGR factor score 16 for analysis 1
spss统计软件期末课程考试题
《SPSS统计软件》课程作业 要求:数据计算题要求注明选用的统计分析模块和输出结果;并解释结果的意义。完成后将作业电子稿发送至 1. 某单位对100名女生测定血清总蛋白含量,数据如下: 计算样本均值、中位数、方差、标准差、最大值、最小值、极差、偏度和峰度,并给出均值的置信水平为95%的置信区间。 解: 描述 统计量标准误 血清总蛋白含量均值.39389 均值的 95% 置信区间下限 上限
5% 修整均值 中值 方差 标准差 极小值 极大值 范围 四分位距 偏度.054.241 峰度.037.478 样本均值为:;中位数为:;方差为:;标准差为:;最大值为:;最小值为:;极差为:;偏度为:;峰度为:;均值的置信水平为95%的置信区间为:【,】。 2. 绘出习题1所给数据的直方图、盒形图和QQ图,并判断该数据是否服从正态分布。解:
正态性检验 Kolmogorov-Smirnov a Shapiro-Wilk 统计量 df Sig. 统计量 df Sig. 血清总蛋白含量 .073 100 .200* .990 100 .671 a. Lilliefors 显著水平修正 *. 这是真实显著水平的下限。 表中显示了正态性检验结果,包括统计量、自由度及显著性水平,以K-S 方法的自由度sig.=,明显大于,故应接受原假设,认为数据服从正态分布。 3. 正常男子血小板计数均值为9 22510/L , 今测得20名男性油漆工作者的血小板计数值(单位:9 10/L )如下: 220 188 162 230 145 160 238 188 247 113
SPSS期末作业-因子分析
上证A股房地产行业盈利能力因子分析 摘要:本文选取了上证A股房地产行业70家公司2014年度的财务数据,通过SPSS 19.0因子分析模型,对我国房地产行业的盈利能力进行了简单的实证分析。得出各房地产公司综合得分和排名情况,并以各公司综合得分作为其盈利能力综合指标。 关键字:盈利能力;房地产行业;因子分析; 一.引言 20 年来,房地产业蓬勃发展,已经成为我国国民经济的支柱产业之一,在经济建设中扮演着越来越重要的作用。然而,2008 年全球性金融危机以及政府一系列宏观调控政策使得我国房地产市场发生了深刻变化,中国房地产市场进入深度调整期。当前中国的房地产企业,普遍存在着企业规模小、资产负债率高、资信不高、整体盈利水平低等问题,企业的生存和发展面临巨大压力。在此背景下,房地产企业要想在不断变化的市场上获得生存和发展的空间,必须积极增强自己的盈利能力,因此研究房地产上市公司盈利能力,对于规范房地产市场合理健康、持续发展有一定现实意义和指导意义。 要研究房地产上市公司的盈利能力状况,就要充分了解影响盈利水平的各种因素。一般来说,影响公司盈利能力的因素很多,分为外部和内部两大类。其中外部因素包括经济环境、市场环境和法律环境等等,例如经济发展水平、产品市场状况、产业发展规模、行业准则及税收法律等等。这些外部因素是公司不能改变的,因此,提高企业的竞争力和综合实力只有改变内部的自身条件,资产利用合理化的前提下,再充分利用外部环境,才能提高企业自身综合能力,逐步扩大市场占有率。在这种情况下,本文基于房地产公司的财务指标-盈利能力建立因子分析模型,并最后得出公司的综合得分和排名就有了重要意义。 二.变量选取 由于本文选取的数据主要是基于财务方面的数据,因此在选取衡量公司盈利能力指标方面侧重于财务方面的指标,为此我们主要从生产经营盈利能力、资产盈利能力和所有者投资盈利能力选取以下6个指标:营业毛利率、主营业务收入
SPSS统计软件期末作业
统计软件及应用期末作业 完成作业:3、5、11、12题 第3题:基本统计分析3 利用居民储蓄调查数据,从中随机选取85%的样本,进行分析,实现以下目标: 1、分析不同职业储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格; 2、分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度;分析储户一次存款金额的分布,并对不同年龄段的储户进行比较。 基本思路: 首先通过随机抽样中的近似抽样方式,对居民储蓄调查数据进行抽样。 操作步骤:选择菜单数据→选择个案→随机个案样本,样本尺寸填大约所有个案85%。 1、题目:分析不同职业储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格。 基本思路:首先进行多选项分析,定义名为X的多选项变量集,其中包括a7_1、a7_2、a7_3三个变量,然后对多选项变量集进行频数分析;对不同职业储户储蓄目的进行分析,采用多选项交叉分组下的频数分析。 操作步骤:
分析:从折线图看出,储户中商业服务业的人数最多,总体上所有职业储户的正常生活零用所占的百分比最大,买证券及单位集资的人较少,说明大部分人群还没有这方面的意识。 2、分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度。 基本思路:该问题列联表的行变量为户口,列变量为未来收入状况,在列联表中输出各种百分比、期望频数、剩余、标准化剩余,显示各交叉分组下频数分布柱形图,并利用卡方检验方法,对城镇和农村储户对该问题的态度是否一致进行分析。 操作步骤:分析→描述统计→交叉表,显示复式条形图前打勾,行选择户口,列选择未来收入情况,统计量选择卡方,点击单元格,在观察值、期望值、行、列、总计、四舍五入单元格计数前打勾,最后确认。
SPSS作业
统计软件应用第一次作业 金融102班1005010259 于闯一.现有1992年-2006年国家财政收入和国内生产总值的数据如下表所示,请研究国家财政收入和国内生产总值之间的线性关系。 1.根据数据并作出散点图可以得知1992年-2006年国家财政收入和国内生产总值两 个变量之间具有一元线性关系。我们利用SPSS软件作出散点图,步骤如下:依次选择菜单“图形→旧对话框→散点/点状→简单分布”,具体操作如图所示: 并将“国内生产总值”作为x轴,“财政收入”作为y轴,得到如下所示图形。
图一:散点图 可以看出两变量具有较强的线性关系,可以用一元线性回归来拟合两变量。 2.为了便于数据分析所以定义三个变量,分别为“year”(年份)、“x”(国内生产总值)、“y”(财政收入)。 3.选择菜单“分析→回归→线性”,打开“线性回归”对话框,将变量“财政收入”作为因变量,“国内生产总值”作为自变量。 4.打开“统计量”对话框,选上“估计”和“模型拟合度”。单击“绘制(T)…”按钮,打开“线性回归:图”对话框,选用DEPENDENT作为y轴,*ZPRED为x轴作图。并且选择“直方图”和“正态概率图”作相应的保存选项设置,如预测值、残差和距离等。
○1变量输入和移去表
表中显示回归模型编号、进入模型的变量、移出模型的变量和变量的筛选方法。可以看出,进入模型的自变量为“国内生产总值” ○2模型综述表 R=0.989,说明自变量与因变量之间的相关性很强。R方(R2) =0.979,说明自变量“国内生产总值”可以解释因变量“财政收入”的97.9%的差异性。 ○3方差分析表 表中显示因变量的方差来源、方差平方和、自由度、均方、F检验统计量的观测值和显著性水平。方差来源有回归、残差。从表中可以看出,F统计量的观测值为592.25,显著性概率为0.000,即检验假设“H0:回归系数B = 0”成立的概率为0.000,从而应拒绝原假设,说明因变量和自变量的线性关系是非常显著的,可建立线性模型。 ○4回归系数表 表中显示回归模型的常数项、非标准化的回归系数B值及其标准误差、标准化的回归系数值、统计量t值以及显著性水平(Sig.)。从表中可看出,回归模型的常数项为-4993.281,自变量“国内生产总值”的回归系数为0.197。因此,可以得出回归方程:财政收入=-4993.281 + 0.197 ×国内生产总值。 回归系数的显著性水平为0.000,明显小于0.05,故应拒绝T检验的原假设,这也说明了回
SPSS统计软件期末作业
完成作业:3、5、11、12题 第3题:基本统计分析3 利用居民储蓄调查数据,从中随机选取85%的样本,进行分析,实现以下目标: 1、分析不同职业储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格; 2、分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度;分析储户一次存款金额的分布,并对不同年龄段的储户进行比较。 基本思路: 首先通过随机抽样中的近似抽样方式,对居民储蓄调查数据进行抽样。 操作步骤:选择菜单数据→选择个案→随机个案样本,样本尺寸填大约所有个案85%。 1、题目:分析不同职业储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格。 基本思路:首先进行多选项分析,定义名为X的多选项变量集,其中包括a7_1、a7_2、a7_3三个变量,然后对多选项变量集进行频数分析;对不同职业储户储蓄目的进行分析,采用多选项交叉分组下的频数分析。 操作步骤: 分析:从折线图看出,储户中商业服务业的人数最多,总体上所有职业储户的正常生活零用所占的百分比最大,买证券及单位集资的人较少,说明大部分人群还没有这方面的意识。 2、分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度。 基本思路:该问题列联表的行变量为户口,列变量为未来收入状况,在列联表中输出各种百分比、期望频数、剩余、标准化剩余,显示各交叉分组下频数分布柱形图,并利用卡方检验方法,对城镇和农村储户对该问题的态度是否一致进行分析。 操作步骤:分析→描述统计→交叉表,显示复式条形图前打勾,行选择户口,列选择未来收入情况,统计量选择卡方,点击单元格,在观察值、期望值、行、列、总计、四舍五入单元格计数前打勾,最后确认。