两独立样本T检验---SPSS操作详解

两独立样本T检验-SPSS操作详解
为了解某一新药降血压的效果,将28名高血压患者随机分为实验组和对照组,实验组采用新药,对照组采用常规药,测得治疗前后的血压变化,问新药是否优于常规药?
编号 1 2 3 4 5 6 7 8 9 10 11 新药前102 100 92 98 118 100 100 92 126 117 109 后90 90 85 90 114 95 86 88 102 92 98
编号 1 2 3 4 5 6 7 8 9 10 11 常规
前98 110 109 94 110 92 95 90 108 90 110 药
后100 103 105 98 109 95 94 88 104 85 110
变量1设置:name-group , decimals-0 , label-分组, value-(1=新药,2=常规药) 变量2设置:name-value , decimals-0 , label-血压下降值
2 输入数据---血压差=用药前血压-用药后血压
3 单击菜单栏analyze/compare means/independent-samples t test
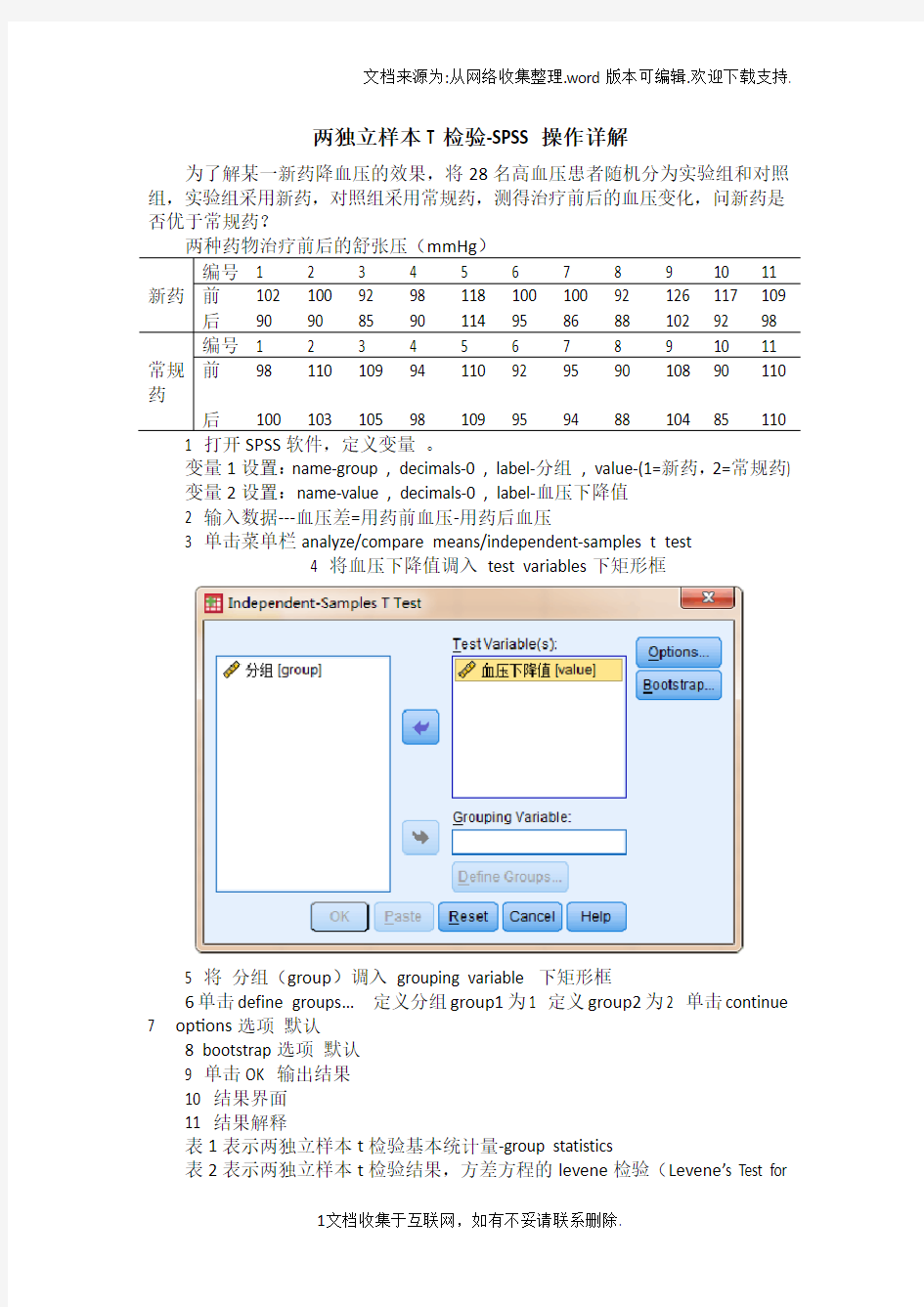
4 将血压下降值调入test variables下矩形框
5 将分组(group)调入grouping variable 下矩形框
6单击define groups…定义分组group1为1 定义group2为2 单击continue
7 options选项默认
8 bootstrap选项默认
9 单击OK 输出结果
10 结果界面
11 结果解释
表1表示两独立样本t检验基本统计量-group statistics
表2表示两独立样本t检验结果,方差方程的levene检验(Levene’s Test for
Equality of Variances 方差齐性检验)F=3.115,P=0.93,认为两样本来自的总体方差齐。T检验中t=3.18,P=0.005。按α=0.05水准拒绝H0
,差异有统计学意义。可认为新药组的降压效果优于常规药。
2017/06/06于深圳
随时交流:
两独立样本和配对样本T检验
两独立样本T检验 目的:利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异。 检验前提: 样本来自的总体应服从或近似服从正态分布; 两样本相互独立,样本数可以不等。 两独立样本T检验的基本步骤: 提出假设 原假设H_0:μ_1-μ_2=0 备择假设H_1:μ_1-μ_2≠0 建立检验统计量 如果两样本来自的总体分别服从N(μ_1,σ_1^2 )和N(μ_2,σ_2^2 ),则两样本均值差(x_1 ) ?-x ?_2应服从均值为μ_1-μ_2、方差为σ_12^2的正态分布。 第一种情况:当两总体方差未知且相等时,采用合并的方差作为两个总体方差的估计,为:s^2=((n_1-1) s_1^2+(n_2-1) s_2^2)/(n_1+n_2-2) 则两样本均值差的估计方差为: σ_12^2=s^2 (1/n_1 +1/n_2 ) 构建的两独立样本T检验的统计量为: t= ((x_1 ) ?-x ?_2)/√(s^2 (1/n_1 +1/n_2 ) ) 此时,T统计量服从自由度为n_1+n_2-2个自由度的t分布。 第二种情况:当两总体方差未知且不相等时,两样本均值差的估计方差为: σ_12^2=(s_1^2)/n_1 +(s_2^2)/n_2 构建的两独立样本T检验的统计量为: t= ((x_1 ) ?-x ?_2)/√((s_1^2)/n_1 +(s_2^2)/n_2 ) 此时,T统计量服从修正自由度的t分布,自由度为: f= ((s_1^2)/n_1 +(s_2^2)/n_2 )^2/(((s_1^2)/n_1 )^2/n_1 +((s_2^2)/n_2 )^2/n_2 ) 可见,两总体方差是否相等是决定t统计量的关键。所以在进行T检验之前,要先检验两总体方差是否相等。SPSS中使用方差齐性检验(Levene F检验)判断两样本方差是否相等近而间接推断两总体方差是否有显著差异。 三、计算检验统计量的观测值和p值 将样本数据代入,计算出t统计量的观测值和对应的概率p值。 四、在给定显著性水平上,做出决策 首先,利用F统计量判断两总体方差是否相等,Levene F检验的原假设为两独立总体方差相等。概率p<0.05时,有充分理由拒绝原假设,说明方差不齐;否则,两样本方差无显著性差异。 其次,将设定的显著性水平α与检验统计量的p值比较,如果t统计量的p值小于α,落入拒绝域内,则我们有充分理由拒绝原假设,认为两总体均值有显著差异。 SPSS实现过程: 菜单:Analyze -> Compare Means-> Independent Samples T test Test Variable(s):待检验的变量(一般是定距或定序变量) Grouping Variable :分组变量(只能比较两个样本)
SPSS—单样本T检验
一、被调查学生对“云窗的打分值”总体平均值的推断: 1、以71个被调查学生为样本做T 检验 由表a 可知,71个观测的平均值为71.21,标准差为15,120,均值标准误为1.794。 表b 中,第二列是t 统计量的观测值为0.675,第三列是自由度n-1=70,第四列是t 统计量观测值的双尾概率p 值,第五列是样本均值与检验值的差(1.211),即t 统计量的分子部分,他除以表a 的均值标准误(1.794)后得到t 统计量的观测值0.675,第六列和第七列是总体均值与检验值差的95%的置信区间,为(67.63,74.79)。 对于研究的问题应采用双尾检验,因此比较 2α和2 p ,即比较α和p 。由于p 大于α(0.05),因此不能拒绝零假设,认为被调查学生对“云窗的打分值”总体平均值没有显著差异。有95%的把握认为总体均值在 67.63~74.79 分之间。70分包含在置信区间内,也证实了上述推断。
2、被调查学生对“云窗的打分值”的重抽样自举 表c Bootstrap 指定 采样方法简单箱图 样本数1000 置信区间度95.0% 置信区间类型百分位 由表c可知,自举过程执行1000次,随机数种子指定为默认值2000000,采样方法为简单箱图。 中均值的重抽样自举均值与实际样本均值的差为-0.12,1000个均值的标准差为1.82,由此得到的均值95%的置信区间为(67.18,74.46) 表e中没有给出双尾检验的概率p值,但是从检验的结果可知有95%的把握认为总体均值在 67.184~74.463之间。70包含在置信区间内。用更大的样本量再一次说明了被调查学生对“云窗的打分值”总体平均值没有显著差异。
6.3 两独立样本资料的t检验
第六章 假设检验基础 三、两独立样本资料的t 检验
概述 n两独立样本的t 检验 抽样:从同一对象群,随机抽取两组,各接受不同处理 或者从两个对象群,各随机抽取一组,接受相同处理 数据:两独立样本的资料 目的:检验两个总体均数是否相等 假定:两个总体均服从正态分布,方差相等(方差齐性)
例 1 某医师要观察两种药物对原发性高血压的疗效,将诊断为Ⅱ期高血压的 20名患者随机分为两组 (两组患者基线时血 压之间的差别没有统计学意义)? 一组用卡托普利治疗,另一组用尼莫地平治疗? 3 个月后观察舒张压下降的幅度(mm Hg) 结果如下: 卡托普利组(X1):12 17 13 8 4 10 9 12 10 7 尼莫地平组(X2):11 8 12 13 9 10 8 0 7 16 试比较两药平均降压效果有无差异。
经检验, 两组舒张压下降值均服从正态分布、方差齐性。 ) , ( N ~ X ), , ( N ~ X 2 2 2 2 1 1 s m s m 1. 建立检验假设,确定检验水准 H 0: 2 1 m m = , 或0 2 1 = -m m H 1: 2 1 m m 1 , 或0 2 1 1 -m m a =0.05
) n , ( N ~ X 1 2 1 1 s m ,) n , ( N X 2 2 2 2 s m ~ ,) n n , ( N X X 2 2 1 2 2 1 2 1 s s m m + - - ~ 检验统计量为: )1 1 ( 2 1 2 2 1 n n S X X t c + - = 2.计算统计量 2 c S 是利用两样本联合估计的方差,22 2 1122 12 (1)(1) 2 c n S n S S n n -+- = +- 已知,当 H 0 成立时,统计量服从自由度 2 2 1 - + = n n n 的 t 分布。
统计学两个独立样本T检验
《统计学》实验分析报告 实验完成者 罗雪清 班级 2014级1班 学号 201406240122 实验时间 2016 年5月12 日 一、实验名称 假设检验——两个独立样本T检验 二、实验目的 1、能够熟练使用SPSS进行两个彼此独立的来自正态分布总体的样本的T检验; 2、掌握利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异的方法; 3、运用SPSS分析检验。 三、实验步骤 1、打开SPSS,选择输入变量; 2、定义变量,输入数据。①点击“变量视图”定义变量工作表,用“name”命令定义变量“汽油价格”;②变量“月份”,1月份赋值为“1”,2月份赋值为“2”;③点击“数据视图”,按顺序将汽油价格输入,同时在月份中输入对应的月份; 3、设置分析变量。数据输入完后,点菜单栏:“分析”→“比较均值”→“独立样本T检验(T)”,将“汽油价格”移到检验变量列表中进行分析,将“月份”移到分组变量列表中进行分析,定义组:1月份为“1”,2月份为“2”;置信区间为95%,点击确定。
四、实验结果及分析 附件一:组统计量表,给出了各个样本的均值,标准差和均值的标准误;附件二:单个样本检验表,给出了各个样本的F值(F)t值(t)、自由度(df)、P值(Sig.双尾)、均值差值、差值的95%可信区间等。 通过F检验,得出概率p=0.100大于0.05,所以不能拒绝原假设,即认为两总体方差相等;再经T检验,得出概率0.283大于0.05,所以不能拒绝原假设,即认为方差相等,故:假说:“该地区1月份和2月份的汽油价格存在较大的变动”成立。 五、自评及问题 1、掌握了两个独立样本T检验的基本原理和运用SPSS分析检验; 2、熟悉SPSS软件操作和方法; 3、通过检验得出结论的真否,能够更快更简单的检验数据; 4、对数据的检验,让我很快的了解该数据的代表性。 六、成绩 七、指导教师 附件一、 附件二、
使用SPSS进行两组独立样本的t检验、F检验、显著性差异、计算p值
使用SPSS 进行两组独立样本的t检验、F检验、显著性差异、计算p值 SPSS版本为SPSS 20. 如有以下两组独立的数据,名称分别为“111”,“222”。 111组:4、5、6、6、4 222组:1、2、3、7、7 首先打开SPSS,输入数据,命名分组,体重和组名要对应,111组的就不要输入到222组了。数据视图如下: 变量视图如下,名称可以改成“分组嗷嗷嗷”“体重喵喵喵”等
点击“分析”-“比较均值”-“独立样本T检验” 来到这里,分组变量为“分组嗷嗷嗷”,检验变量为“体重喵喵喵”。
【关键的一步】点击分组嗷嗷嗷,进行“定义组”
【关键的一步】输入对应的两组数据的组名:“ 111”和“222” 点击确定,可见数据与组名对应上了。
点击“确定”,生成T检验的报告,即将大功告成!
第一个表都知道什么回事就不缩了,excel都能实现的。 第二个表才是重点,不然用SPSS干嘛。 F检验:在两样本t检验中要用到F检验,F检验又叫方差齐性检验,用于判断两总体方差是否相等,即方差齐性。 如图:F旁边的 Sig的值为.007 即0.007, <0.01, 即两组数据的方差显著性差异! 看到“假设方差相等”和“假设方差不相等”了么? 此时由于F检验得出Sig <0.01,即认为假设方差不相等!因此只关注红框中的数据即可。 如图,红框内,Sig(双侧),为.490即0.490,也就是你们要求的P值啦, Sig ( 也就是P值 ) >0.05,所以两组数据无显著性差异。 PS:同理,如果F检验的Sig >.05(即>0.05),则认为两个样本的假设方差相等。 所以相应的t检验的结果就看上面那行。
spss 单样本t检验操作步骤
spss单样本t检验Analyze----compare Means----one sample T test 输入方式 实验数据 12 12 1 2 1 2 3 4 5 6 4 9 5 直接输入数据
Sig=0.000 差异显著
独立样本t检验(两组数据) Analyze-----compare Means----Independent-samples T test 输入方式 试验分组实验数据 1 12 1 13 1 12 1 12 1 1 1 1 2 2 2 2 2 2 2 2 2 两组数据个数可以不同
成组数据t检验 Analyze----compare Means-----paired-samples T test
单因素方差分析 Analyze---compare means----one-way ANOV A(analyze of variance)
Factor (因素)1 1 1 1 1 2 2 2 2 2 2 3 3 3 3(分组) Dependent List 试验数据 polynomial lines contrast---polynomial---Degree---linear post Hoc Multiple comparisons-----LSD(Duncan 邓肯检验) 先选方差齐性在结果中判断Sig 值?<0.05(差异显著)若不齐则进行数据转化。 数据输入 分组试验数据 1 12 1 13 1 13 1 1 2 2 2 2 2 2 3 3 3 3 3 3 4 4 4 4 4 4 双因素方差分析 Analyze-----General linear Model-----univariate Dependent Variable(因变因素)因别的数字变化而变化 Fixed Factor (固定因素) Random Factors(随机因素) Model-----custom-----Build Term---Interaction(交互作用)----Main effects(主因素) Contrast--- simple---first----change Plot Hoc----LSD (Duncan)
两独立样本T检验---SPSS操作详解
两独立样本T检验-SPSS操作详解 为了解某一新药降血压的效果,将28名高血压患者随机分为实验组和对照组,实验组采用新药,对照组采用常规药,测得治疗前后的血压变化,问新药是否优于常规药? 编号 1 2 3 4 5 6 7 8 9 10 11 新药前102 100 92 98 118 100 100 92 126 117 109 后90 90 85 90 114 95 86 88 102 92 98 编号 1 2 3 4 5 6 7 8 9 10 11 常规 前98 110 109 94 110 92 95 90 108 90 110 药 后100 103 105 98 109 95 94 88 104 85 110 变量1设置:name-group , decimals-0 , label-分组, value-(1=新药,2=常规药) 变量2设置:name-value , decimals-0 , label-血压下降值 2 输入数据---血压差=用药前血压-用药后血压 3 单击菜单栏analyze/compare means/independent-samples t test 4 将血压下降值调入test variables下矩形框 5 将分组(group)调入grouping variable 下矩形框 6单击define groups…定义分组group1为1 定义group2为2 单击continue 7 options选项默认 8 bootstrap选项默认 9 单击OK 输出结果 10 结果界面 11 结果解释 表1表示两独立样本t检验基本统计量-group statistics 表2表示两独立样本t检验结果,方差方程的levene检验(Levene’s Test for
SPSS-比较均值-独立样本T检验_案例解析
SPSS-比较均值-独立样本T检验案例解析 2011-08-26 14:55 在使用SPSS进行单样本T检验时,很多人都会问,如果数据不符合正太分布,那还能够进行T检验吗?而大样本,我们一般会认为它是符合正太分布的,在鈡型图看来,正太分布,基本左右是对称的,一般具备两个参数,数学期望和标准方差,即:N(p, Q) 如果你的样本数非常少,一般需要进行正太分布检验,检验的方法网上很多,我就不说了 下面以“雄性老鼠和雌性老鼠分别注射了某种毒素,经过观察分析,进行随机取样,查看最终老鼠是否活着。 问题:很多人认为,雄性老鼠和雌性老鼠分别注射毒液后,雌性老鼠存活下来的数量会比雄性老鼠多? 我们将通过进行统计分析来认证这个假设是否成立。 下面进行参数设置:a 代表:雄性老鼠 b代表:雌性老鼠 tim 代表:生存时间,即指经过多长时间后,去查看结果 0 代表:结果死亡 1 代表:结果活着 随机抽取的样本,如下所示:
打开SPSS- 分析---检验均值---独立样本T检验,如下图所示:
将你要分析的变量,移入右边的框内,再将你要进行分组的变量移入“分组变量”框内,“组别group()里面的两个参数,不能够随意设置,必须要跟样本里面的数字一致 点击确定后,分析结果,如下所示: 从组统计量可以看出,雄性老鼠的存活下来的均值为0.73,但是雌性老鼠存活下来的均值为1.00,很明显,雌性老是存活下来的个数明显比雄性老鼠多,但是一般我们不看这个结果,为什么?因为样本不够大,如果将样本升至10000个?也许这个均值将会发生变化,不具备统计学意义, 我们一般只看独立样本检验的结果。 独立样本检验,提供了两种方法:levene检验和均值T检验两种方法 Levene检验主要用来检验原假设条件是否成立,(即:假设方差相等和方差不相等两种情况)如果SIG>0.05,证明假设成立,不能够拒绝原假设,如果 SIG<0.05,证明假设不成立,拒绝原假设。 进行levene检验结果判断是第一步,从上图,可以看出 sig<0.05 方差相等的假设不成立,所以看第二行,方差不相等的情况 sig=0.082>0.05 即说明 P 值大于显著性水平,不应该拒绝原假设:即指:雌性老鼠和雄性老鼠在注射毒液后,存活下来的个数没有显著的差异
用SPSS19进行单样本T检验 截屏
用SPSS19进行单样本T检验(One -Sample T Test) 作者:邀月来源:博客园发布时间:2010-10-14 00:13 阅读:305 次原文链接[收藏] 在《0-1总体分布下的参数假设检验示例一(SPSS实现)》中,我们简要介绍了用SPSS 检验二项分布的参数。今天我们继续看看如何用SPSS进行单样本T检验(One -Sample T Test)。看例子: 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 分析:此检验的假设是: H0:该市五年级学生的400米平均成绩是仍为100秒。 H1:该市五年级学生的400米平均成绩是不为100秒。 打开SPSS,读入数据
从结果中可以判断: 1、p=0.287>0.05,在5%的显著性水平上,不能拒绝假设H0。 2、95%的置信区间端点一正一负,必然覆盖总体均值。应该接受零假设(假设H0)。 这个结论出乎很多人的意料,因为样本均值明显下降了,105.38500000000003。实际上,那是因为有一个样本值为400秒,从而造成错觉的缘故。 再看一个更有趣的例子。 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高B.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 同上,打开SPSS,读入数据,结果:
独立样本的T检验08022
独立样本的T检验 (independent-samples T Test) 对于相互独立的两个来自正态总体的样本,利用独立样本的T 检验来检验这两个样本的均值和方差是否来源于同一总体。在SPSS 中,独立样本的T检验由“Independent-Sample T Test”过程来完成。 例:双语教师的英语水平有高低之分,他们(她们)所教的学生对双语教学的态度是否有显著差异? 例题分析: ——研究目的:寻找差异 ——自变量:双语教师的英语水平(ordinal data等级变量),有两个水平:;level1低水平,level2 高水平 ——因变量:学生的双语教学态度(interval data等距变量) SPSS操作步骤 ·Analyze→Compare Means→Independent Samples T Test ·Click the 双语教学态度to the column of “Test Variable(s)” and the 教师英语水平分组to the column of “Grouping variable” ·Click the button of “Define Groups…” and put the group numbers “1” and “3” into Group 1 and Group 2, and “Continue” back, then “OK”.
Group Statistics 教师英语水平分组 N Mean Std. Deviation Std. Error Mean 双语教学态度 低水平组 33 3.0606 .91291 .15892 高水平组 41 3.7100 .78248 .12220 结果在论文中的呈现方式 独立样本T 检验结果显示,双语教师的英语水平不同,其所教学生对双语教学的态度有显著差异(t=-3,249, df=72, p<0.05)。双语教师英语水平较低所教的学生,他们对双语教学态度的得分也显著低于英语水平较高的双语教师所教的学生(MD=-0.65)。这可能是因为…… 练习:文科生和理科生对双语教学的态度是否有显著差异? 配对样本T 检验(Paired-samples T Test ) 配对样本T 检验,用于检验两个相关的样本(配对资料)是否来自具有相同均值的总体。 例:本次调查中,学生对自己英语能力水平和英语知识水平的评价之间是否有显著差异? 例题分析: ——研究目的:寻找差异 ——自变量:学生的评价对象(norminal data 定类数据),有两个水平:level1对自身英语能力水平的评价,level2对自身英语知识水平的评价。 ——因变量:学生自身英语能力和知识的评价分数 Independent Samples Test Levene's Test for Equality of Variances t-test for Equality of Means 95% Confidence Interval of the Difference F Sig. t df Sig. (2-tailed) Mean Difference Std. Error Difference Lower Upper 双语教学态度 Equal variances assumed .000 .985 -3.294 72 .002 -.64942 .19714 -1.04240 -.25644 Equal variances not assumed -3.239 63.321 .002 -.64942 .20047 -1.04999 -.24885
spss操作独立样本T检验模板
例题:对某地区的山地和平原土壤中的磷含量的背景值各取了10个样品,数据如下所示: (单位:10-6),问山地与平原土壤中磷含量是否有显著性差异。( 25分) 1、本题中自变量个数等于2,且不是来自于同一组样本,故采用独立样本T检验 2、打开spss,在变量视图内定义变量,由题目可知,磷含量为“计量资料”,归类为“度量变量”,地形为计数资料,归类为“名义变量”,并对地形进行赋值,如图输入: 3、在数据视图内如下图输入数据: 4、独立样本T检验进行的假设: (1)数据必须为连续性数据; 2 2 ⑵方差齐性(可偏不齐,即(T 1 / (T 2 <3); (3)每组数据均服从正态分布 5、进行验证: (1)由题目可以看出,数据为连续型数据,满足; (2)此检验可于结果中查看; (3)首先,新建spss视图,重新输入变量进行探索队列,如下图所示:
将“山地”“平原”选入因变量列表,并于“绘图(T) ”中勾选“带检验的正态图”,操作步骤如下图所示: 根据正态性检验表的“ K-S检验”结果,由于样本内数据数量<30,故看Shapiro-Wilk 结果, 由于两者的sig均大于,故满足正态分布 *. a. Lilliefors 显著性校正 6、进行独立样本T检验: (1)依次点击“分析”-“比较平均值”-“独立样本T检验”,调出独立样本T检验对话框: ⑵将“磷含量”选入检验变量(T),将“地形”选入分组变量,然后定义组,于主页面中点 击“确定”,输出结果: 7、结果分析:
根据独立样本检验表的方差方程的Levene检验,F统计量的sig值<,否认方差相等的假设,认为方差不齐性,故参考第二行的t检验结果; 第二行t检验的双侧sig=>,即可认为在的显著性水平上,山地与平原土壤中磷含量
独立样本的T检验
独立样本的T检验 对于相互独立的两个来自正态总体的样本,利用独立样本的T检验来检验这两个样本的均值和方差是否来源于同一总体。在SPSS中,独立样本的T检验由“Independent-Sample T Test”过程来完成。 实例 在有小麦丛矮病的麦田里,调查了13株病株和11株健株的植株高度,分析健株高度是否高于病株。其调查数据如下: 健株 26.0 32.4 37.3 37.3 43.2 47.3 51.8 55.8 57.8 64.0 65.3 病株 16.7 19.8 19.8 23.3 23.4 25.0 36.0 37.3 41.4 41.7 45.7 48.2 57.8 该数据保存在“DATA4-3.SA V”文件中,变量格式如图4-6,状态变量中:1表示病株,2表示健株。 图4-6 1)准备分析数据 在数据编辑窗口输入分析的数据,如图4-6所示。或者打开需要分析的数据文件“DATA4-3.SA V”。 2)启动分析过程 在主菜单选中“Analyze”中的“Compare Means”,在下拉菜单中选中“Independent -Sample T Test”命令。出现图4-7设置对话框。。 图4-7 独立样本T检验窗口 3)设置分析变量
从“Test Variable(s):”从左边的变量列表中选中变量后,点击右拉按钮后,这个变量就进入到检验分析“Test Variable(s):”框里,用户可以从左边变量列表里选择一个或多个。本例选择“小麦丛矮病[株高]”。 “Grouping Variable(s):”栏是分组变量栏。从左边的变量列表中选中分组变量后,按 右拉按钮,这个变量就进入到“Grouping Variable(s):”框里。本例选择“状态”变量。 “Define Groups”按钮是定义分组变量的分组值。当该按钮可用时,出现图4-8对话框。 图4-8 定义分组值对话框 如果分组变量是离散型数值变量应选择“Use specified values”项,该项下面的“Group 1”和“Group 2”栏用于输入分组 变量值;字符型数据输入相应分组字符。若分组变量是连续型变量,应选择“Cut point”项,分组变量会按该项输入值分为大于和小于两组。 本例选择“Use specified values”项,在“Group 1”栏输入1;在“Group 2”栏输入2。按“Continue”按钮退回上一级对话框。 4)设置其他参数 点击“Options”按钮,打开设置检验的置信度和缺失值对话框。在“Confidence Interval:”框输入置信度水平,系统默认为95%;“Missing Values”框里的“Exclude cases analysis by analysis”栏,是只排除分析变量为缺失值的选择项,“Exclude cases listwise”是排除任何含有缺失值的选择项。 5)提交执行 输入完成后,在过程主窗口中单击“OK”按钮,SPSS输出分析结果如表4-5和表4-6。 6)结果与分析 结果 表4-5 分组统计量列表 Group Statistics 表4-6 独立样本的检验结果 Independent Samples Test
SPSS两独立样本T检验结果解析
定量分析之两独立样本T检验 (2007-04-01 22:26:38) 由输出结果可以看出: 样本中区域编号为1(即苏南地区)的城市有5个。其地区生产总值的平均值为1928.3540亿元,标准差为1059.98148,均值标准误差为474.03813。人均GDP的平均值为40953.40元,标准差为13391.301,均值标准误差为5988.772。 样本中区域编号为2(即苏中地区)的城市有3个。其地区生产总值的平均值为906.4633 亿元,标准差为279.86759,均值标准误差为161.58163。人均GDP的平均值为15726.33元,标准差为1673.922,均值标准误差为966.440。 由输出结果可以看到: 对于地区生产总值来说,F值为2.574,相伴概率为0.160,大于显著性水平0.05,不能拒绝方差相等的假设,可以认为苏南和苏中的地区生产总值方差无显著差异;然后看方差相等
时T检验的结果,T统计量的相伴概率为0.167,大于显著性水平0.05,不能拒绝T检验的零假设,也就是说,苏南和苏中两个地区城市生产总值平均值不存在显著差异。另外从样本的均值差的95%置信区间看,区间跨0,这也说明两个地区生城市生产总值的平均值无显著差异。 对于人均GDP来说,F值为24.266,相伴概率为0.003,小于显著性水平0.05,拒绝方差相等的假设,可以认为苏南和苏中地区城市人均GDP方差存在显著差异;然后看方差不相等时T检验的结果,T统计量的相伴概率为0.013小于显著性水平0.05,拒绝T检验的零假设,也就是说,苏南和苏中两个地区城市人均GDP平均值存在显著差异。另外从样本的均值差的95%置信区间看,区间没有跨0,这也说明两个地区城市人均GDP平均值存在显著差异。
SPSS两独立样本t检验
两个独立样本t检验分析步骤: 1.如图,进入两个样本t检验的分析。 2.将检验变量选到对应的框内。如图。 3.定义两个总体的标识值。如图。
Group Statistics 282521.725812.17539.22907168 26.7165 18.96748 1.46337 户口状况本市户口外地户口 人均面积 N Mean Std. Deviation Std. E rror Mean Independent Samples Test 65.469 .000 -4.9682991.000-4.99069 1.00466-6.96057-3.02080-3.369 175.278 .001 -4.99069 1.48119 -7.91396 -2.06742 Equal variances assumed Equal variances not assumed 人均面积 F Sig.Levene's Test for Equality of Variances t df Sig. (2-tailed) Mean Difference Std. Error Difference Low er Upper 95% Confidence Interval of the Difference t-test for Equality of Means 分析: 上表即是分析结果的呈现。 从上表可以看出, 1. 总体方差的检验F 对应的概率P-为0.00小于显著性水平a=0.05。所以,两总体方差有显著性差异。 2. 、由于从上一步得出,两总体方差有显著差异。所以,在 栏目中要看第二行。 在第二行中,t 统计量对应的双尾概率p-值为0.001小于显著性差异a=0.05。因此,两总体的均值有显著差异,即
两独立样本和配对样本T检验
两独立样本T 检验 目的:利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异。 检验前提: 样本来自的总体应服从或近似服从正态分布; 两样本相互独立,样本数可以不等。 两独立样本T 检验的基本步骤: 提出假设 原假设H_0:「1-「2=0 备择假设H_1:叮-卩_2工0 建立检验统计量 如果两样本来自的总体分别服从N(^_1,c_1A2)和N(「2, q_2A2),则两样本均值差(x_1 ) ?-x ?_2应服从均值为Q-匸2、方差为c_12A2的正态分布。 第一种情况:当两总体方差未知且相等时,采用合并的方差作为两个总体方差的估计,为: sA2=((n_1-1) s_1A2+(n_2-1) s_2A2)/(n_1+n_2-2) 则两样本均值差的估计方差为: c_12A2=sA2 (1/n_1 +1/n_2 ) 构建的两独立样本T检验的统计量为: t= ((x_1 ) ?-x ?_2/ V (sA2 (1/n_1 +1/n_2 )) 此时,T统计量服从自由度为n_1+n_2-2个自由度的t分布。 第二种情况:当两总体方差未知且不相等时,两样本均值差的估计方差 为: (T _12A2=(s_1A2)/n_1 +(s_2八2)/n_2
构建的两独立样本T 检验的统计量为: t= ((x_1 ) ?x ?_2)/ V ((s_1A2)/n_1 +(s_2A2)/n_2 ) 此时,T 统计量服从修正自由度的t 分布,自由度为: f= ((s_1A2)/n_1 +(s_2A2)/n_2 )A2/(((s_1A2)/n_1 )A2/n_1 +((s_2A2)/n_2 )A2/n_2 ) 可见,两总体方差是否相等是决定t 统计量的关键。所以在进行T 检验之前,要先检验两总体方差是否相等。SPS芽使用方差齐性检验(Levene F检 验)判断两样本方差是否相等近而间接推断两总体方差是否有显著差异。 三、计算检验统计量的观测值和p 值 将样本数据代入,计算出t 统计量的观测值和对应的概率p 值。 四、在给定显著性水平上,做出决策 首先,利用F统计量判断两总体方差是否相等,Levene F检验的原假设为两独立总体方差相等。概率p<0.05 时,有充分理由拒绝原假设,说明方差不齐;否则,两样本方差无显著性差异。 其次,将设定的显著性水平a与检验统计量的p值比较,如果t统计量的p 值小于a,落入拒绝域内,则我们有充分理由拒绝原假设,认为两总体均值有显著差异。 SPSS实现过程: 菜单:Analyze -> Compare Means-> Independent Samples T test Test Variable(s):待检验的变量(一般是定距或定序变量) Grouping Variable :分组变量(只能比较两个样本) 结果中比较有用的值:方差齐次性检验F统计量对应的P值和方差相等或 不相等T统计量对应的P值。 例:利用pkustedu.sav 数据,检验不同性别学生的平均月生活费是否存在差异。 扩展案例:
独立样本T检验的步骤-2
独立样本T检验的步骤 步骤1:生成变量 1.打开SPSS。 2.点击变量视图标签。 在SPSS中生成四个变量,一个是不同微课形式的组别,将变量命名为微课形式,另外三个分别是记忆测验、匹配测验和迁移测验的分数,变量各自命名为记忆测验、匹配测验和迁移测验。 3. 在数据视图窗口的前四行分别输入四个变量的名称。 4.为变量微课形式建立变量标签,1=“实验组”,2=“对照组”。
步骤2:输入数据 1.点击数据视图标签。变量微课形式、记忆测验、匹配测验和迁移测验出现在数据视图窗口的前四列。(微课形式一列中的1代表实验组,对照组的分数粘贴于实验组的下方,第一列数值为2) 2.输入每个参与者四个变量的数据。如第一行为组别和学生的三组测试成绩,数值为1、0.72、0.86、0.67。依次输入78位参与者的数据。如已做好Excel 表格,则可直接复制粘贴,注意粘贴顺序。 步骤3:分析数据 1.从菜单栏中选择分析——比较均值——独立样本T检验。
打开独立样本T检验对话框,变量微课形式、记忆测验、匹配测验和迁移测验出现在对话框的左边。 2.选择因变量记忆测验分数、匹配测验分数和迁移测验分数,点击向右箭头按钮,把变量移到“检验变量”框。 3.选择自变量微课形式,点击向右箭头按钮,把变量移到“分组变量”框中。 在分组变量框中,变量右侧括号内出现两个问号,它们分别表示样本的实验组和对照组(也就是1,2),这些数字需要通过点击“定义组”来输入。
4.点击“定义组”。 5.定义组对话框打开,在组1(表示实验组)的右边输入1,组2(表示对照组)输入2。 6.点击“继续”。 7.点击“确定”。
独立样本T检验
独立样本T检验 This manuscript was revised on November 28, 2020
独立样本T检验 要求被比较的两个样本彼此独立,既没有配对关系,要求两个样本均来自正态分布,要求均值是对于检验有意义的描述统计量。 例如:男性和女性的工资均值比较 分析——比较均值——独立样本T检验。 分析身高大于等于155厘米与身高小于155的两组男生的体重和肺活量均值之间是否有显着性差异。 基本信息的描述 方差齐次性检验(详见下面第二个例题)和T检验的计算结果。从sig(双侧)栏数据可以看出,无论两组体重还是肺活量,方差均是齐的,均选择假设方差相等一行数据进行分析得出结论。 体重T检验结果,sig(双侧)=,小于,拒绝原假设。两组均值之差的99%上、下限均为正值,也说明两组体重均值之差与0的差异显着。由此可以得出结论,按身高分组的两组体重均值差异,在统计学上高度显着。 肺活量T检验的结果,sig(双侧)=,大于,。两组均值之差的上下限为一个正值,一个负值,也说明差值的99%上下限与0的差异不显着。由此可以得出结论,按身高分组烦人两组肺活量均值差异在99%水平上不显着,均值差异是由抽样误差引起的。 以性别作为分组变量,比较当前工资salary变量的均值 方差齐性检验(levene检验)结果,F值为,显着性概率为p<,因此结论是两组方差差异显着,及方差不齐。在下面的T 检验结果中应该选择假设方
差不相等一行的数据作为本例的T检验的结果数据,另一航是假设方差相等的T检验的据算数据,不取这个结果。 T的值 sig 两组均值差异为.平均现工资女的低于男的. 差值的标准误为 差分的95%的置信区间在-18003~-12816之间,不包括0,也说明两组均值之差与0有显着差异。 结论:从T 检验的P的值为<,和均值之差值的95%置信区间不包括0都能得出,女雇员现工资明显低于男雇员,茶差异有统计学意义。
独立样本t检验
独立样本T检验 要求被比较的两个样本彼此独立,既没有配对关系,要求两个样本均来自正态分布,要求均值是对于检验有意义的描述统计量。 例如:男性和女性的工资均值比较 分析——比较均值——独立样本T检验。 分析身高大于等于155厘米与身高小于155的两组男生的体重和肺活量均值之间是否有显着性差异。
基本信息的描述 方差齐次性检验(详见下面第二个例题)和T检验的计算结果。从sig(双侧)栏数据可以看出,无论两组体重还是肺活量,方差均是齐的,均选择假设方差相等一行数据进行分析得出结论。 体重T检验结果,sig(双侧)=0.000,小于0.01,拒绝原假设。两组均值之差的99%上、下限均为正值,也说明两组体重均值之差与0的差异显着。由此可以得出结论,按身高155.0分组的两组体重均值差异,在统计学上高度显着。 肺活量T检验的结果,sig(双侧)=0.018,大于0.01,。两组均值之差的上下限为一个正值,一个负值,也说明差值的99%上下限与0的差异不显着。由此可以得出结论,按身高155.0分组烦人两组肺活量均值差异在99%水平上不显着,均值差异是由抽样误差引起的。 以性别作为分组变量,比较当前工资salary变量的均值 方差齐性检验(levene检验)结果,F值为119.669,显着性概率为p<0.001,因此结论是两组方差差异显着,及方差不齐。在下面的T 检验结果中应该选择假设方差不相等一行的
数据作为本例的T检验的结果数据,另一航是假设方差相等的T检验的据算数据,不取这个结果。 T的值 sig 两组均值差异为15409.9.平均现工资女的低于男的15409.9. 差值的标准误为1318.40 差分的95%的置信区间在-18003~-12816之间,不包括0,也说明两组均值之差与0有显着差异。 结论:从T 检验的P的值为0.000<0.01,和均值之差值的95%置信区间不包括0都能得出,女雇员现工资明显低于男雇员,茶差异有统计学意义。
SPSS统计分析教程独立样本T检验
独立样本T检验 下面我们要用SPSS来做成组设计两样本均数比较的t检验,选择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下: 将变量X选入test框内,变量 group选入grouping框内,注意这时 下面的Define Groups按钮变黑,表示 该按钮可用,单击它,系统弹出比较组 定义对话框如右图所示: 该对话框用于定义是哪两组相比,在两 个group框内分别输入1和2,表明是 变量group取值为1和2的两组相比。 然后单击Continue按钮,再单击OK 按钮,系统经过计算后会弹出结果浏览 窗口,首先给出的是两组的基本情况描 述,如样本量、均数等(糟糕,刚才的 半天工夫白费了),然后是t检验的结 果如下: Levene's Test for Equality of Variances t-test for Equality of Means F Sig. t df Sig. (2-tailed) Mean Difference Std. Error Difference 95% Confidence Interval of the Difference Lower Upper X Equal variances .032 .860 2.524 22 .019 .4363 .1729 7.777E-02 .7948
差是否齐,这里的戒严结果为F = 0.032,p = 0.860,可见在本例中方差是齐的;第二部分则分别给出两组所在总体方差齐和方差不齐时的t检验结果,由于前面的方差齐性检验结果为方差齐,第二部分就应选用方差齐时的t检验结果,即上面一行列出的t= 2.524,ν=22,p=0.019。从而最终的统计结论为按α=0.05水准,拒绝H0,认为克山病患者与健康人的血磷值不同,从样本均数来看,可认为克山病患者的血磷值较高。
用SPSS进行单样本T检验(One -Sample T Test)
用SPSS进行单样本T检验(One -Sample T Test) 在《0-1总体分布下的参数假设检验示例一(SPSS实现)》中,我们简要介绍了用SPSS 检验二项分布的参数。今天我们继续看看如何用SPSS进行单样本T检验(One -Sample T Test)。看例子: 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 分析:此检验的假设是: H0:该市五年级学生的400米平均成绩是仍为100秒。 H1:该市五年级学生的400米平均成绩是不为100秒。 打开SPSS,读入数据
从结果中可以判断: 1、p=0.287>0.05,在5%的显著性水平上,不能拒绝假设H0。 2、95%的置信区间端点一正一负,必然覆盖总体均值。应该接受零假设(假设H0)。 这个结论出乎很多人的意料,因为样本均值明显下降了,105.38500000000003。实际上,那是因为有一个样本值为400秒,从而造成错觉的缘故。 再看一个更有趣的例子。 例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高B.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)? 同上,打开SPSS,读入数据,结果: 从结果中判断: t统计值的显著性概率为0.005小于1%,在1%犯错误的水平上拒绝零假设。可以认为,今年该市五年级学生的400米平均成绩明显下降了。