AMOS结构方程模型解读

AMOS输出解读
惠顿研究
惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS 和LISREL。本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。AMOS同样能处理与时间有关的自相关回归。
惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。71疏离感的处理方式相同,使用1971年对应的两个量表的得分。第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI (邓肯的社会经济指数)确定。
步骤
解读
解读步骤
导入数据
数据。。
1.导入
数据
AMOS在文件ex06-a.amw中提供惠顿数据文件。使用File/Open,选择这个文件。在图形模式中,文件显示如下。虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型
2.模型识别
模型识别。。
潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。对误差项的处理也是一样。一旦做完这些处理,其它系数在模型中就可以被估计。在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。有了这些约束,模型就可以识别了。
注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。
模型。。
3.解释
解释模型
模型
模型设置完毕后,在图形模式中点击工具栏中计算估计
计算估计按钮运
计算估计
浏览文本按钮。输出如下。蓝色字体用于注解,不行分析。点击浏览文本
浏览文本
是AMOS输出的一部分。
Title
Title
Example 6, Model A: Exploratory analysis Stability of alienation, mediated by ses. Correlations, standard deviations and means from Wheaton et al. (1977).
以上是标题,全是英文,自己翻译去吧,没有什么价值,一堆垃圾。
Notes for Group (Group number 1)
Notes for Group (Group number 1)
The model is recursive.
Sample size = 932
各组注释各组注释::Group
number 1是模型内定的模型名称,因为你还没有给模型取名。它告诉你模型为递归模型,样本量为932。
Variable Summary (Group number 1)Variable Summary (Group number 1)
Your model contains the following variables (Group nu Your model contains the following variables (Group number 1)mber 1)mber 1)
Observed, endogenous variables
anomia67
powles67
anomia71
powles71
educatio
SEI
Unobserved, endogenous variables
71_alienation
67_alienation
Unobserved, exogenous variables
eps1
eps2
eps3
eps4
ses
delta1
zeta1
zeta2
delta2
变量汇总变量汇总::对模型中的变量作一些概括,内生观测变量内生观测变量内生观测变量::67无力感,67无价值感,71无力感,71无价值感,教育和SEI。内生非观测变量内生非观测变量内生非观测变量:67疏离感,71疏离感。外生非观测变量外生非观测变量
外生非观测变量:各种误差和社会经济地位。 注释注释::观测变量与非观测变量的区别:一个用方形表示,一个用椭圆表示。内生和外生的区别:箭头指向自己的就是内生,发送箭头的就是外生。注意区分测量模式和结构模式。
Variable counts (Group number 1)Variable counts (Group number 1)
Number of variables in your model: 17
Number of observed variables: 6
Number of unobserved variables: 11
Number of exogenous variables:
9 Number of endogenous variables: 8
变量计数变量计数::数数模型中的变量,变量总数为17,其中观测变量有6个,非观测变量有11个;外生变量有9个,内生变量有8个。
Parameter summary (Group number 1)Parameter summary (Group number 1) Weights Covariances Variances Means Intercepts Total Fixed 11 0 0 0 0 11 Labeled 0 0 0 0 0 0 Unlabeled 6 0 9 0 0 15 Total 17 0 9 0 0 26 模型的参数概括模型的参数概括::固定系数11个,就是模型识别中固定的11个1。还有6个自由的系数,9个方差对应着前面外生非观测变量。
Computation of degrees of freedom (Default model)Computation of degrees of freedom (Default model)
Number of distinct sample moments: 21
Number of distinct parameters to be estimated: 15
Degrees of freedom (21 - 15): 6
(内定模型内定模型))的自由度计算的自由度计算::21 "样本矩"是6个观测变量的6个样本方差加上15个协方差构成(也就是6中取2的组合数)。15个参数是模型的6个回归系数和9个被估计的方差。样本矩与估计参数的差为6个自由度。
(内定模型内定模型))迭代过程迭代过程::极大似然估计是一个迭代过程。这里给出迭代历史。这个输出是可选的,你不必直接使用它。 基本上没有什么用。 Result (Default model)Result (Default model)
Minimum was achieved
Chi-square = 71.544
Degrees of freedom = 6
Probability level = .000
卡方拟合指数卡方拟合指数::这是所有软件都使用的最普通的拟和检验。AMOS 和 LISREL 把它称为卡方统计量,其它软件称为卡方拟和优度 和 卡方拟和劣度 。卡方拟合指数检验选定的模型协方差矩阵与观察数据协方差矩阵相匹配的假设。原假设是模型协方差阵等于样本协方差阵。如果模型拟合的好,卡方值应该不显著。在这种情况下,数据拟和不好的模型被拒绝。卡方检验的问题是样本越大,越可能拒绝模型,越可能犯第一类错误。卡方拟和指数对违反多变量正态假设也是非常敏感。 这由卡方拟和指数的计算公式可以看出:
卡方统计量 = (N-1) x F
N 是样本量,F 是模型协方差阵和样本协方差阵的最小适配函数。这个函数比较复杂,也不知道是哪个天才搞出来的,它的计算公式中包含行列式,矩阵的迹,还要取对数,再经过一些加减运算把多维数据压缩为一个数值。
从卡方统计量的计算中可以看出,如果适配函数减少的速度没有样本量增加的速度快,即使模型协方差阵与样本协方差阵拟和的很好,但样本量的增加也会导致拒绝原假设。这种拒绝正确建议的行为就是犯了第一类错误。
如果不服从正态分布,卡方统计量会更多地拒绝真实模型。不过好在ML 估计比较稳健,所以即使违背了正态分布的假定,模型也能对付着用。
Maximum Likelihood Estimates Maximum Likelihood Estimates
SEM 使用最大似然法估计模型,而不是通常的最小二乘法。OLS 寻找
数据点到回归线距离的最小平方和。MLE 寻找最大的对数似然,它反映从自变量观测值预测因变量观测值的可能性有多大。
Regression Weights: (Group number 1 Regression Weights: (Group number 1 -- De Default model)fault model)fault model) Estimate
S.E. C.R. P Label 67_alienation <--- ses -.614
.056 -10.912 *** par_6 71_alienation <--- 67_alienation .705
.053 13.200 *** par_4 71_alienation <--- ses -.174
.054 -3.213 .001 par_5 powles71 <--- 71_alienation .849
.042 20.427 *** par_1 anomia71 <--- 71_alienation 1.000
powles67 <--- 67_alienation .888
.043 20.577 *** par_2 anomia67 <--- 67_alienation 1.000
educatio <--- ses 1.000
SEI <--- ses 5.331 .431 12.370 *** par_3 回归系数
回归系数是模型中带箭头的路径系数。为了识别模型,部分系数在模型识别中已固定为1 (例如,潜变量67疏离感到观测变量67无力感的路径)。也给出路径系数的标准误。"C.R." 是临界比,它是回归系数的估计值除以它的标准误(- 0.614 / 0.056 = - 10.912 )。临界比与原假设有关,在这个案例中对67疏离感和社会经济地位的原假设是回归系数为 0。如果我们处理近似标准正态分布的随机变量,在 0.05 的显著性水平上,临界比估计的绝对值大于 1.96 称之为显著。这样67疏离感和社会经济地位的回归系数 -10.912 的绝对值大于 1.96,可以说这个回归系数在 0.05 显著性水平上显著地不等于 0 。P 值给出检验原假设总体中参数是 0 的近似双尾概值。它表示67疏离感和社会经济地位的回归系数显著地不等于 0,p=0.001。P 值的计算假定参数估计是正态分布,它只是对大样本正确。
Variances: (Group number 1 Variances: (Group number 1 -- Default model) Default model)
Estimate
S.E. C.R. P Label ses 6.656
.641 10.379 *** par_7 zeta1 5.301
.483 10.967 *** par_8 zeta2 3.737
.388 9.623 *** par_9 eps1 4.010
.358 11.186 *** par_10 eps2 3.187
.284 11.242 *** par_11 eps3 3.696 .391 9.443 *** par_12
Estimate S.E. C.R. P Label
eps4 3.622 .304 11.915 *** par_13
delta1 2.944 .501 5.882 *** par_14
delta2 260.630 18.256 14.277 *** par_15
方差的估计,标准误和临界比和P 值的解释同上。
用表格看数据总是让人眼花缭乱,还是看图示舒服些,这是上面表格数字的图形显示。
Modification Indices (Group number 1 Modification Indices (Group number 1 -- Default model) Default model)
Covariances: (Group number 1 Covariances: (Group number 1 -- Default model) Default model) M.I. Par Change
eps2 <--> delta1 5.905 -.424
eps2 <--> eps4 26.545 .825
eps2 <--> eps3 32.071 -.988
eps1 <--> delta1 4.609 .421
M.I. Par Change
eps1 <--> eps4 35.367 -1.069
eps1 <--> eps3 40.911 1.253
Variances: (Group number 1 Variances: (Group number 1 -- Default model) Default model)
M.I. Par Change
Regression Weights: (Group number 1 Regression Weights: (Group number 1 -- Default model) Default model) M.I. Par Change
powles71 <--- powles67 5.457 .057
powles71 <--- anomia67 9.006 -.065
anomia71 <--- powles67 6.775 -.069
anomia71 <--- anomia67 10.352 .076
powles67 <--- powles71 5.612 .054
powles67 <--- anomia71 7.278 -.054
anomia67 <--- powles71 7.706 -.070
anomia67 <--- anomia71 9.065 .068
修正指数(MI)。拟合的改进是用卡方统计量的减少来测量, 它能发现使卡方拟合指数减少的有意义的信息。对每个固定和约束参数(系数),如果固定参数或等价约束通过去掉它的路径从模型中排除,模型被重新估计,修正指数预测卡方统计量的减少。"Par Change",表示参数的改变,它提供系数会改变多少的实际估计。
对协方差的修正指数,如果两个误差项变量允许相关,MI 与卡方统计量减少有关。对估计回归系数的修正指数,如果去掉两个变量间的路径,在模型中不再要求估计去掉路径的系数,MI 与卡方统计量的减少有关。常用的方法是去掉最大MI 的参数,通过卡方拟合指数看看测量效果。自然地,去掉路径或允许误差项变量相关只有当它有实际意义并且统计感觉也是这样时才能执行。LISREL 和AMOS 都计算修正指数。
既然这样, 最大的 MI 是 40.911 ,位于eps1 (67无力感误差项) 和eps3 (71无力感误差项) 间。建议去掉两个误差项相关系数为 0 的约束,即,允许相关将使卡方统计量的估计至少减少40.911。惠顿数据是纵向数据,在时间序列中,两个不同时间点(1967和1971)相同测量(无力感)的自相关很相似,所以去掉这个约束在理论上有一个合理的理由。相同的
逻辑用于去掉 eps2 和 eps4 (分别为1967和1971无价值感的误差变量)间零相关的约束, 它使卡方统计量的估计减少26.545。
然而,在这个输出中,我们没有用这种方式重新设置模型。要看见改变设置的效果,见AMOS 自带文件 ex06-b.amw 。
Model Fit Summary
CMIN CMIN Model NPAR CMIN DF P CMIN/DF
Default model 15 71.544 6 .000 11.924
Saturated model 21 .000 0
Independence model 6 2131.790 15 .000 142.119
模型拟合汇总模型拟合汇总::AMOS 输出大量可替换的拟合模式测量。每个测量用三种模式计算。"内定模式" 是由你自己设定的模式。"独立模式" 是指模型中所有变量完全的独立,所以如果“内地模式”拟合的比“独立模式”差,那么应该拒绝内地模式。"饱和模式"是没有约束,总是完美拟合数据的模式,所以通常内地模式的拟合度量在独立模式和饱和模式之间。
NPAR 是模型中被估计的参数个数,不是拟合测量。
P(CMIN) 处理最小样本差异 。如果 P(CMIN) 小于 0.05,我们拒绝数据完全拟合模型的原假设。对大样本,原假设非常可能被拒绝。按照这个标准,这个模型作为完整拟合被拒绝。
CMIN/DF 是最小样本差异除以自由度。被称之为相对卡方或规范卡方。有些人允许这个值达到5作为适当的拟合,但是当相对卡方大于2或3时,保守的使用就需要拒绝模型。按照此标准,这个模型应被拒绝。 RMR, GFI RMR, GFI
Model RMR GFI AGFI PGFI
Default model .284 .975 .913 .279
Saturated model .000 1.000
Independence model 12.342 .494 .292 .353
RMR 是残差均方根。RMR 是样本方差和协方差减去对应估计的方差和协方差的平方和,再取平均值的平方根,估计假定内地模型是正确的。RMR越小,拟合越好。
GFI 是拟合优度指数,范围在0和1间,但理论上能产生没有意义的负数。按照约定,要接受模型,GFI 应该等于或大于0.90。按照此标准,这个模型可接受。
AGFI 是调整拟合优度指数,利用自由度和变量个数的比例来调整GFI,它的变化范围也是0和1间,但理论上能产生没有意义的负数。AGFI 也应该至少大于0 .90。按照此标准,这个模型可接受。
PGFI 是简效拟合优度指数。它是独立模式的自由度与内定模式的自由度的比率乘以GFI。
Baseline Comparisons
Baseline Comparisons
Model
NFI
Delta1
RFI
rho1
IFI
Delta2
TLI
rho2
CFI
Default model .966 .916 .969 .923 .969
Saturated model 1.000 1.000 1.000
Independence model .000 .000 .000 .000 .000
这是比较内定模式与独立模式拟合的一组拟合优度测量。因为独立模式通常很糟糕,内定模式与它做比较将使内定模式看起来良好但不能用于研究目的。标题DELTA 和RHO 是这些测量的可选名称。
NFI 是规范拟合指数,变化范围在0和1间,1 = 完全拟合。按照约定,NFI 小于0.90 表示需要重新设置模型。
RFI 是相对拟合指数,它不保证其值的变化范围在0和1间。RFI 接近1表示拟合良好。
IFI 是增值拟合指数,它不保证其值的变化范围在0和1间。IFI接近1表示拟合良好,大于0.90为可接受拟合。
TLI 是Tucker-Lewis 系数,也叫做Bentler-Bonett 非规范拟合指数(NNFI)。TLI不保证其值的变化范围在0和1间。TLI接近1表示拟合良好。
CFI 是比较拟合指数,其值位于0和1之间。CFI 接近1表示拟合非常好,其值大于0.90表示模型可接受。
Parsimony Parsimony--Adjusted Measures Adjusted Measures Model PRATIO PNFI PCFI
Default model .400 .387 .388
Saturated model .000 .000 .000
Independence model 1.000 .000 .000
PRATIO 是简效比率,它是内定模式的自由度与独立模式自由度的比率。 PRATIO 自身不是拟合优度检验,但在拟合优度中用于测量惩罚简效模型的PNFI 和PCFI (用相对较少的参数模型去估计与模型有关的变量数和关系。)
PNFI 是简效规范拟合指数,等于PRATIO 乘以 NFI 。
PCFI 是简效比较拟合指数,等于PRATIO 乘以 CFI 。
NCP NCP Model NCP LO 90 HI 90
Default model 65.544 41.936 96.603
Saturated model .000 .000 .000
Independence model 2116.790 1968.786 2272.133
FMIN FMIN Model FMIN F0 LO 90 HI 90
Default model .077 .070 .045 .104
Saturated model .000 .000 .000 .000
Independence model 2.290 2.274 2.115 2.441
RMSEA RMSEA
Model RMSEA LO 90 HI 90 PCLOSE
Default model .108 .087 .132 .000
Independence model .389 .375 .403 .000
NCP 是非中心参数。它和 F0 在计算 RMSEA (近似误差均方根)中
使用,它合并差异函数准则(比较观测协方差矩阵与预测协方差矩阵) 和简效准则(见上面)。对每一项,LO 90 和HI 90 表示系数上90% 置信限制。按照惯例,如果RMSEA 小于或等于0.05,模型拟合的好。如果RMSEA 小于0.08,有适当的模型拟合。按照此标准,这个模型应该被拒绝因为RMSEA 是0.108。PCLOSE 检验RMSEA 不大于0.05的原假设。因为PCLOSE 近似为0,我们拒绝原假设,得出结论RMSEA 大于0.05,表示没有紧密的拟合。
AIC
AIC
Model AIC BCC BIC CAIC
Default model 101.544 101.771 174.104 189.104
Saturated model 42.000 42.318 143.584 164.584 Independence model 2143.790 2143.881 2172.814 2178.814
ECVI
ECVI
Model ECVI LO 90 HI 90 MECVI
Default model .109 .084 .142 .109
Saturated model .045 .045 .045 .045
Independence model 2.303 2.144 2.470 2.303
这是一组基于信息理论的测量。当使用极大似然方法估计比较模型时,适合用这组准则。
AIC 是赤池信息准则。
BCC 是Browne-Cudeck 准则。
BIC 是贝耶斯信息准则,也是知名的赤池贝耶斯信息准则(ABIC)。
CAIC 是一致AIC 准则。
ECVI 是AIC 的另一种变体。
MECVI 是BCC的变体。
HOELTER
HOELTER
Model HOELTER
.05
HOELTER
.01
Default model 164 219
Independence model 11 14
这是Hoelter 的临界数N,是在0.05或0.01水平上接受模型的最大样本量。它使你知道所使用的样本量是否足够用来估计模型的参数和模型的拟合。既然这样,这个模型的实际样本量是932 ,并且模型被拒绝。如果样本量只有164,在0.05水平上接受模型。
Execution time summary
Execution time summary
Minimization: .090
Miscellaneous: 1.312
Bootstrap: .000
Total: 1.402
估计模型的计算时间。计算这个模型总共用了1.402秒。
AMOS结构方程模型分析
A M O S结构方程模型分 析 文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]
Amos模型设定操作 在使用AMOS进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties,为潜变量命名。 2.为潜变量设置可测变量及相应的残差变量 使用绘制。在可测变量上点击右键选择Object Properties为可测变量命名。其中Variable Name对应的是数据的变量名,在残差变量上右键选择Object Properties为残差变量命名。 3.配置数据文件,读入数据 File——Data Files——File Name——OK。 4.模型拟合 View——Analysis Properties——Estimation——Maximum Likelihood。 5.标准化系数 Analysis Properties——Output——Standardized Estimates——因子载荷标准化系数。 6.参数估计结果 Analyze——Calculate Estimates。红色框架部分是模型运算基本结果信息,点击View the Output Path Diagram查看参数估计结果图。 7.模型评价 点击查看AMOS路径系数或载荷系数以及拟合指标评价。 路径系数/载荷系数的显着性 模型评价首先需要对路径系数或载荷系数进行统计显着性检验。 模型拟合指数 模型拟合指数是考察理论结构模型对数据拟合程度的统计指标。拟合指数的作用是考察理论模型与数据的适配程度,并不能作为判断模型是否成立的唯一依据。拟合优度高的模型只能作为参考,还需要根据所研究问题的背景知识进行模型合理性讨论。 指数名称评价标准1 绝对拟合指2 (卡方)越小越好
Amos_验证性因子分析步步教程
应用案例1 第一节模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。 表 2.1、顾客满意模型中各因素的具体范畴 参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。 1关于该案例的操作也可结合书上第七章的相关内容来看。 2本案例是在Amos7中完成的。 3见spss数据文件“处理后的数据.sav”。
表
三、关于顾客满意调查数据的收集 本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。问卷内容包括7个潜变量因子,24项可测指标,7个人口变量,量表采用了Likert10级量度,如对 四、缺失值的处理 采用表列删除法,即在一条记录中,只要存在一项缺失,则删除该记录。最终得到401条数据,基于这部分数据做分析。 五、数据的的信度和效度检验 1.数据的信度检验 4正向的,采用Likert10级量度从“非常低”到“非常高”
AMOS结构方程模型分析
Amos 模型设定操作 在使用 AMOS 进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图, 并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties,为潜变量命名。 2.为潜变量设置可测变量及相应的残差变量 使用绘制。在可测变量上点击右键选择对应的是数据的变量名,在残差变量上右键选择Object Properties为可测变量命名。其中 Object Properties为残差变量命名。 Variable Name
3.配置数据文件,读入数据 File—— Data Files—— File Name—— OK。 4.模型拟合 View—— Analysis Properties—— Estimation—— Maximum Likelihood 。 5.标准化系数 Analysis Properties—— Output—— Standardized Estimates——因子载荷标准化系数。
6.参数估计结果 Analyze—— Calculate Estimates。红色框架部分是模型运算基本结果信息,点击 View the Output Path Diagram查看参数估计结果图。 7.模型评价 点击查看 AMOS 路径系数或载荷系数以及拟合指标评价。 路径系数 /载荷系数的显著性 模型评价首先需要对路径系数或载荷系数进行统计显著性检验。 模型拟合指数 模型拟合指数是考察理论结构模型对数据拟合程度的统计指标。拟合指数的作用是考察理论模型与数据的适配程度,并不能作为判断模型是否成立的唯一依据。拟合优度高的模型只能作为参考,还需要根据所研究问题的背景知识进行模型合理性讨论。
AMOS解释结构方程模型
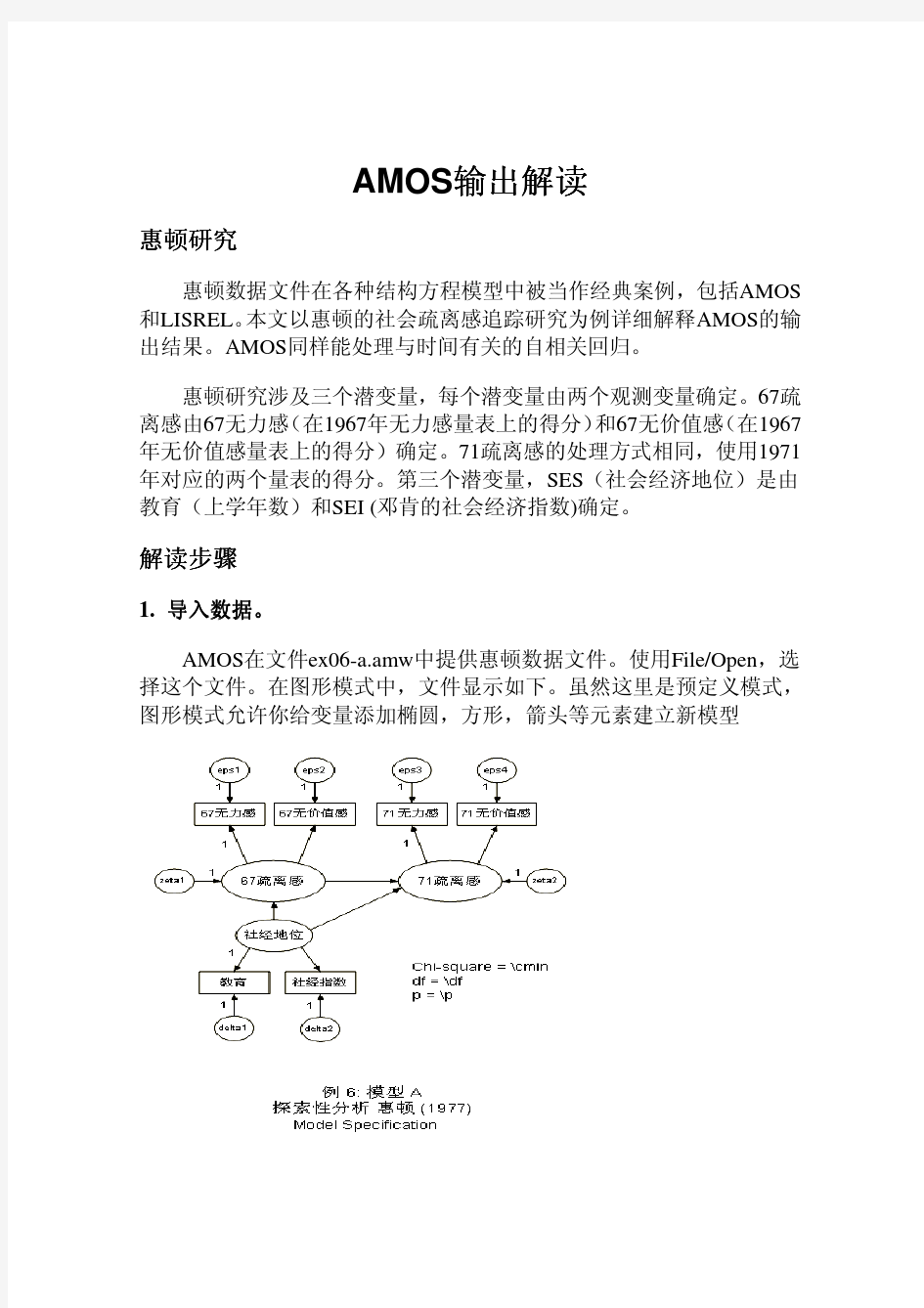
AMOS输出解读 惠顿研究 惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS 和LISREL。本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。AMOS同样能处理与时间有关的自相关回归。 惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。71疏离感的处理方式相同,使用1971年对应的两个量表的得分。第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI (邓肯的社会经济指数)确定。 解读步骤 1.导入数据。 AMOS在文件ex06-a.amw中提供惠顿数据文件。使用File/Open,选择这个文件。在图形模式中,文件显示如下。虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型
2.模型识别。 潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。对误差项的处理也是一样。一旦做完这些处理,其它系数在模型中就可以被估计。在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。有了这些约束,模型就可以识别了。 注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。 3.解释模型。 模型设置完毕后,在图形模式中点击工具栏中计算估计按钮 。输出如下。蓝色字体用于注解,不是AMOS输出的一部分。 Title Example 6, Model A: Exploratory analysis Stability of alienation, mediated by ses. Correlations, standard deviations and means from Wheaton et al. (1977). 以上是标题,全是英文,自己翻译去吧。 Notes for Group (Group number 1) The model is recursive. Sample size = 932 各组注释:它告诉你模型为递归模型,样本量为932。
AMOS操作
Amos软件操作 1.模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos软件进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 2.模型构建的思路 根据构建的理论模型,通过设计问卷对留学生学习汉语的学习动机、学习策略和焦虑调查得到实际数据,然后利用对缺失值进行处理后的数据进行分析,并对文中提出的模型进行拟合、修正和解释。 3.潜变量和可测变量的设定 模型中共包含2个因素(潜变量):学习动机、学习策略,7个可测变量:融入型动机、工具型动机、焦虑、记忆策略、认知策略、情感策略和社交策略。 4.关于调查数据的收集 本次问卷调研的对象为不同国家的留学生 5.缺失值的处理 采用表列删除法,即在一条记录中,只要存在一项缺失,则删除该记录。数据的的信度和效度检验 1).数据的信度检验 信度(reliability)指测量结果(数据)一致性或稳定性的程度。一致性主要反映的是测验内部题目之间的关系,考察测验的各个题目是否测量了相同的内容或特质。稳定性是指用一种测量工具(譬如同一份问卷)对同一群受试者进行不同时间上的重复测量结果间的可靠系数。如果问卷设计合理,重复测量的结果间应该高度相关。由于本案例并没有进行多次重复测量,所以主要采用反映内部一致性的指标来测量数据的信度。 Cronbach在1951年提出了一种新的方法(Cronbach's Alpha系数),这种方法将测量工具中任一条目结果同其他所有条目作比较,对量表进行内部一致性估计。
Amos实现 一、Amos模型设定操作 1.模型的绘制 在使用Amos进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。相关软件操作如下: 第一步,使用建模区域绘制模型中的2个潜变量。为了保持图形的美观,可以使用先绘制一个潜变量,再使用复制工具绘制其他潜变量,以保证潜变量大小一致。在潜变量上点击右键选择Object Properties,为潜变量命名。绘制好的潜变量图形。 第二步设置潜变量之间的关系。使用来设置变量间的因果关系,使用 来设置变量间的相关关系。绘制好的潜变量关系图。 第三步为潜变量设置可测变量及相应的残差变量(一定要设置残差),可以使用绘制,也可以使用和自行绘制。在可测变量上点击右键选择Object Properties,为可测变量命名。其中Variable Name一项对应的是数据中的变量名,在残差变量上右键选择Object Properties为残差变量命名。最终绘制完成模型结果。 2.数据文件的配置 Amos可以处理多种数据格式,如文本文档(*.txt),表格文档(*.xls、*.wk1),数据库文档(*.dbf、*.mdb),SPSS文档(*.sav)等。 为了配置数据文件,选择File菜单中的Data Files,出现对话框,然后点击File name按钮,会再出现一个对话框,找到需要读入的数据文件“处理后的数据.sav”,双击文件名或点击下面的“打开”按钮,最后点击对话框中“ok”按钮就读入数据了。 二、模型拟合 1.参数估计方法选择 模型运算是使用软件进行模型参数估计的过程。Amos提供了多种模型运算方法供选择。可以通过点击View菜单在Analysis Properties(或点击工具栏的 )中的Estimation项选择相应的估计方法。
AMOS结构方程模型修正经典案例
AMOS结构方程模型修正经典案例 第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解 释四个步骤。下面以一个研究实例作为说明,使用 Amos7 软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承 ASCI 模型核心概念的基础上,对模型作了一些改进,在模型中 增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素 (潜变量 ):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素 是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍, 2000)。 表 7-1设计的结构路径图和基本路径假设 设计的结构路径图基本路径假设 超市形象 顾客抱怨质量期望 感知价值 顾客满意 质量感知 顾客忠诚超市形象对质量期望有路径影响 质量期望对质量感知有路径影响 质量感知对感知价格有路径影响 质量期望对感知价格有路径影响 感知价格对顾客满意有路径影响 顾客满意对顾客忠诚有路径影响 超市形象对顾客满意有路径影响 超市形象对顾客忠诚有路径影响 2.1 、顾客满意模型中各因素的具体范畴 1本案例是在Amos7 中完成的。 2见 spss数据文件“处理后的数据 .sav”。
手把手教AMOS结构方程模型
宋锋华编辑制作——更多内容请访问“统计之都”
AMOS 的使用
?
第一部分: 介绍
o o o o
关于文挡 访问 AMOS 文挡 获得 AMOS 帮助 SEM 概述 SEM 术语 为什么使用 SEM? 合理的样本量 连续和正态内生变量 模型识别(识别方程) 完整数据或缺失数据的适当处理 模型规范和因果关系的理论基础 结构方程——多重回归关系的说明 使用 AG 绘制模型 将数据读入到 AMOS 中 选择 AMOS 分析选项和运行模型 评估整体模型拟合 绝对拟合检验 相对拟合检验 修改模型获得较好的拟合优度 浏览路径图 独立参数的显著性检验
?
第二部分 : SEM 基础
o o o
?
第三部分: SEM 假设
o o o o o
?
第四部分: 使用 AG 建立和检验模型
o o o o
?
第五部分: AMOS 输出解释
o o o o o o
?
第六部分:摘要:结论的实质性解释
1
第一部分:介绍
关于文档
SEM=Structural Equation Modeling Amos=Analysis of Moment Structures
本课程使用 AMOS(距结构分析)软件对结构方程进行简单的介绍和概述。结构方程模型 (SEM) 包括多种统计技术,如路径分析,验证性因子分析,带潜变量的因果关系模型,甚 至方差分析和多重线性回归。 课程介绍 SEM 的逻辑,SEM 的假设和输入需求,怎样使用 AMOS 执行 SEM 分析。 到课程结束,能够使用 AMOS 拟合 SEM。也能给出 SEM 适合研究问题的评价和 SEM 方 法基本假设的概述。
You must do it
应该已经知道使用 SAS,SPSS 或类似统计软件怎样产生多重线性回归分析。也应该理解 怎样解释多重线性回归分析的输出。最后,应该理解基本微软视窗导航操作:打开文件和文 件夹,保存文件,重新调用先前保存过的文件,等等。
访问 AMOS
可以用下列三种方法访问 AMOS: 1. 个人计算机用户须从 SPSS 公司(SPSS 许可版本)或者 Smallwaters 公司(独立版本) 获得许可密码 2. 德克萨斯大学的教师,学生和职员经由 STATS 视窗终端服务器访问 AMOS。要使 用终端服务器,必须获得 ITS 计算机账号(或分类账号) ,然后在 NT 服务器上验证 账号。接下来下载和配置客户端软件使个人计算机,Macintosh,或 UNIX 工作站 能连接终端服务器。最后连接服务器,通过双击位于 STATS 终端服务组中 AMOS 程序肖像登陆 AMOS。如何获得 ITS 计算机账号的细节,账号使用的变更,下载客 户端软件和配置指导可以在 General FAQ #30: Connecting to published statistical applications on the ITS Windows Terminal Server. 中找到。 3. 从 AMOS development website 网站下载免费 AMOS 学生版到个人计算机上。 如果模型比较小,免费演示版能充分满足需求。对大型模型,需要购买 AMOS 软件 或通过校园网络访问 ITS 共享的软件副本。特别是如果决定利用服务器访问其它程 序软件(例如,SAS,SPSS,HLM,Mplus 等等) ,后一项选择最有效。
文档
2
amos结构方程模型分析
Amos模型设定操作 在使用AMOS进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties,为潜变量命名。 2.为潜变量设置可测变量及相应的残差变量 使用绘制。在可测变量上点击右键选择Object Properties为可测变量命名。其中Variable Name对应的是数据的变量名,在残差变量上右键选择Object Properties为残差变量命名。
3.配置数据文件,读入数据 File——Data Files——File Name——OK。 4.模型拟合 View——Analysis Properties——Estimation——Maximum Likelihood。 5.标准化系数 Analysis Properties——Output——Standardized Estimates——因子载荷标准化系数。
6.参数估计结果 Analyze——Calculate Estimates。红色框架部分是模型运算基本结果信息,点击View the Output Path Diagram查看参数估计结果图。 7.模型评价 点击查看AMOS路径系数或载荷系数以及拟合指标评价。 路径系数/载荷系数的显着性 模型评价首先需要对路径系数或载荷系数进行统计显着性检验。 模型拟合指数 模型拟合指数是考察理论结构模型对数据拟合程度的统计指标。拟合指数的作用是考察理论模型与数据的适配程度,并不能作为判断模型是否成立的唯一依据。拟合优度高的模型只能作为参考,还需要根据所研究问题的背景知识进行模型合理性讨论。
IBM SPSS AMOS 结构方程模型教程
表
一、关于顾客满意调查数据的收集 本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。问卷内容包括7个潜变量因子,24项可测指标,7个人口变量,量表采用了Likert10级量度,如对 1正向的,采用Likert10级量度从“非常低”到“非常高”
二、缺失值的处理 采用表列删除法,即在一条记录中,只要存在一项缺失,则删除该记录。最终得到401条数据,基于这部分数据做分析。 三、数据的的信度和效度检验 1.数据的信度检验 信度(reliability)指测量结果(数据)一致性或稳定性的程度。一致性主要反映的是测验内部题目之间的关系,考察测验的各个题目是否测量了相同的内容或特质。稳定性是指用一种测量工具(譬如同一份问卷)对同一群受试者进行不同时间上的重复测量结果间的可靠系数。如果问卷设计合理,重复测量的结果间应该高度相关。由于本案例并没有进行多次重复测量,所以主要采用反映内部一致性的指标来测量数据的信度。 折半信度(split-half reliability)是将测量工具中的条目按奇偶数或前后分成两半,采用Spearman-brown公式估计相关系数,相关系数高提示内部一致性好。然而,折半信度系数是建立在两半问题条目分数的方差相等这一假设基础上的,但实际数据并不一定满足这一假定,因此信度往往被低估。Cronbach在1951年提出了一种新的方法(Cronbach's Alpha系数),这种方法将测量工具中任一条目结果同其他所有条目作比较,对量表内部一致性估计更为慎重,因此克服了折半信度的缺点。本章采用SPSS16.0研究数据的内部一致性。在Analyze菜单中选择Scale下的Reliability Analysis(如图7-1),将数据中在左边方框中待分析的24个题目一 一选中,然后点击,左边方框中待分析的24个题目进入右边的items方框中,使用Alpha 模型(默认),得到图7-2,然后点击ok即可得到如表7-3的结果,显示Cronbach's Alpha系数为0.892,说明案例所使用数据具有较好的信度。 图7-1 信度分析的选择
★结构方程模型要点
★结构方程模型要点 一、结构方程模型的模型构成 1、变量 观测变量:能够观测到的变量(路径图中以长方形表示) 潜在变量:难以直接观测到的抽象概念,由观测变量推估出来的变量(路径图中以椭圆形表示) 内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图会受 外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量;路 中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他变量影响,还可能对其他变量产生影响。 内生潜在变量:潜变量作为内生变量 内生观测变量:内生潜在变量的观测变量 外生潜在变量:潜变量作为外生变量 外生观测变量:外生潜在变量的观测变量 中介潜变量:潜变量作为中介变量 中介观测变量:中介潜在变量的观测变量 2、参数(“未知”和“估计”) 潜在变量自身:总体的平均数或方差 变量之间关系:因素载荷,路径系数,协方差 参数类型:自由参数、固定参数 自由参数:参数大小必须通过统计程序加以估计 固定参数:模型拟合过程中无须估计 (1)为潜在变量设定的测量尺度 ①将潜在变量下的各观测变量的残差项方差设置为1 ②将潜在变量下的各观测变量的因子负荷固定为1 (2)为提高模型识别度人为设定 限定参数:多样本间比较(半自由参数) 3、路径图 (1)含义:路径分析的最有用的一个工具,用图形形式表示变量之间的各种线性关系,包括直接的和间接的关系。 (2)常用记号: ①矩形框表示观测变量 ②圆或椭圆表示潜在变量 ③小的圆或椭圆,或无任何框,表示方程或测量的误差 单向箭头指向指标或观测变量,表示测量误差 单向箭头指向因子或潜在变量,表示内生变量未能被外生潜在变量解释的部分,是方程的误差 ④单向箭头连接的两个变量表示假定有因果关系,箭头由原因(外生)变量指向结果(内生)变量
AMOS-结构方程模型分析
Amos 模型设定操作 在使用AMOS进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用H建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties为潜变量命名。 真:Object Properties 2.为潜变量设置可测变量及相应的残差变量 使用 对应的是数据的变量名,在残差变量上右键选择Object Properties为残差变量命名。 "J绘制。在可测变量上点击右键选择Object Properties为可测变量命名。其中Variable Name | Visitulity | Font size Font style Farajietcis | Colors | Fornat Text Variable label
File Edit View Dia^r^m A.n? lyz^ Taols Pkrginw Help New New wi th Template— Open,.. Retrieve Backup... Ctrl+S Gave As... Sa^e As Template,.. P K.st imat e Jieans :and int ercepnts 标准化系数 An alysis Properties---- Output ----- Sta ndardized Estimate—因子载荷标准化系数。 3. 险abj#rt Proom rrX Tmrt |Parsji?^6r3 Cclois || Fsntal | Visibility F^ozit size fon^ style 3 Rogulir □01 label 為t gfauLt A—— 耳3D旣响 Undo □a 配置数据文件,读入数据 File Data Files ---- File Name OK。 Save Ill D心td Fil亡父Ctrl+D 4. 模型拟合 View ----- An alysis Properties----- Estimati on Maximum Likelihood 钿Interne Properties.., HR Rrtjptrtie^■■“ Ctrl-hl Ctrl+A NumeriLcal Bias | Output Boot strap Peraurt at ions |R^iidoin #Title r+irun ■ 匸包lA khia/—I" Dmnqr+;a£ Discr&pEuacy Est liRsrt: ion 5.
AMOS结构方程模型分析
A M O S结构方程模型分析 IM B standardization office【IMB 5AB- IMBK 08- IMB 2C】
A m o s模型设定操作 在使用AMOS进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties,为潜变量命名。 2.为潜变量设置可测变量及相应的残差变量 使用绘制。在可测变量上点击右键选择Object Properties为可测变量命名。其中Variable Name对应的是数据的变量名,在残差变量上右键选择Object Properties 为残差变量命名。 3.配置数据文件,读入数据 File——Data Files——File Name——OK。 4.模型拟合 View——Analysis Properties——Estimation——Maximum Likelihood。 5.标准化系数 Analysis Properties——Output——Standardized Estimates——因子载荷标准化系数。 6.参数估计结果 Analyze——Calculate Estimates。红色框架部分是模型运算基本结果信息,点击View the Output Path Diagram查看参数估计结果图。 7.模型评价 点击查看AMOS路径系数或载荷系数以及拟合指标评价。 路径系数/载荷系数的显着性 模型评价首先需要对路径系数或载荷系数进行统计显着性检验。 模型拟合指数 模型拟合指数是考察理论结构模型对数据拟合程度的统计指标。拟合指数的作用是考察理论模型与数据的适配程度,并不能作为判断模型是否成立的唯一依据。拟合优度高的模型只能作为参考,还需要根据所研究问题的背景知识进行模型合理性讨论。
AMOS结构方程模型分析
Amos 模型设定操作 在使用AMO 进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图, 并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用H 建模区域绘制模型中的潜变量,在潜变量上点击右键选择 Object Properties ,为潜变量 命名。 2.为潜变量设置可测变量及相应的残差变量 使用绘制。在可测变量上点击右键选择 Object Properties 为可测变量命名。其中Variable Name 对应的是数据的变量名,在残差变量上右键选择 Object Properties 为残差变量命名。 囲:Object Propenes Text Paraiet ers a ▼ Variable label 3 F 匚ivt style I Regular 1ST T Variable Unco 珪鑼旨買政启
3. 4. 5. 配置数据文件,读入数据 File Name ----------- O K File 模型拟合 Data Files f^1 f1 rsTi ) - CH 口丁 View ------- An alysis Properties Estimati on Maximum Likelihood Dia g rarm Analyze Tools Plu-gins Help Interface Properties.- B > Ctrl- hl 需Anol戸is Properties”Ctrl A r+rij.n b 匕(A khiiciy~t Dircmqr1*;m£ 标准化系数 An alysis Properties Output --------- S tan dardized Estimates 因子载荷标准化系数。