SAS第二次作业分析

第二次作业
习题7-3
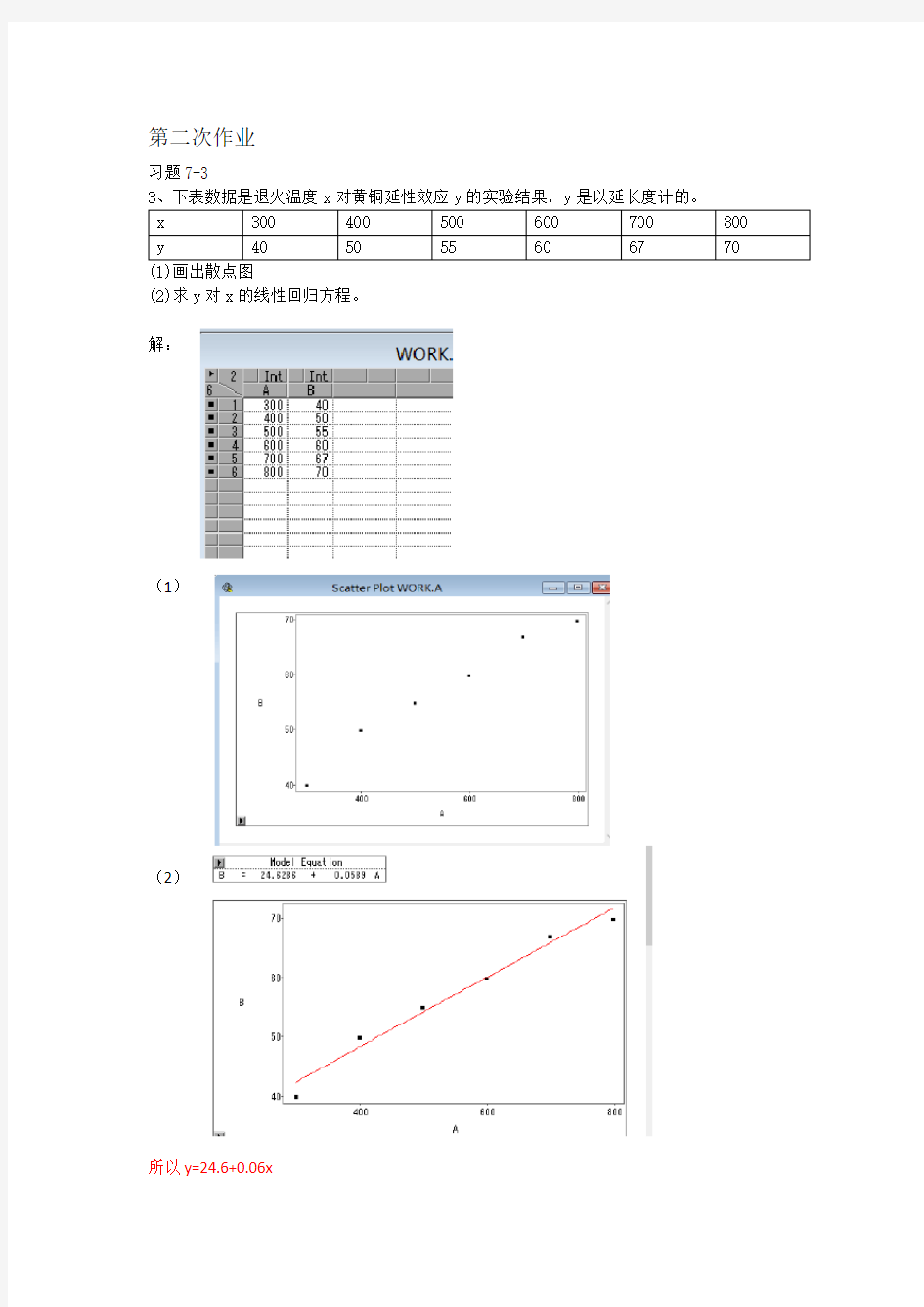
3、下表数据是退火温度x对黄铜延性效应y的实验结果,y是以延长度计的。
x 300 400 500 600 700 800 y 40 50 55 60 67 70
(1)画出散点图
(2)求y对x的线性回归方程。
解:
(1)
(2)
所以y=24.6+0.06x
(1)作散点图
(2)以模型y=b0+b1x+b2x2+ε,ε~N(0,σ2)拟合数据,其中b0,b1,b2,σ2与x无关,求回归方程y=b0+b1x+b2x2
解:
(1)
所以y=19.03+1.01x-0.02x2
3、钢包容积y和使用次数x的侵蚀数据如表所示:
(1)作散点图
(2)试作变量替换,化非线性回归模型为线性回归模型并讨论回归方程的显著性。解:
(1)
(2)程序
data data123;
input x y @@;
u=log(y);v=1/x;
cards;
2 106.42
3 108.20
4 109.58
5 109.50 7
110.00 8 109.93 10 110.49
11 110.59 14 110.60 15 110.90 16 110.76
18 111.00 19 111.20
;
proc reg;
model u=v;
run;
The REG Procedure
Model: MODEL1
Dependent Variable: u
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 1 0.00174 0.00174 410.17 <.0001 Error 11 0.00004672 0.00000425
Corrected Total 12 0.00179
Root MSE 0.00206 R-Square 0.9739
Dependent Mean 4.69983 Adj R-Sq 0.9715
Coeff Var 0.04385
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 4.71408 0.00090629 5201.49 <.0001
v 1 -0.09029 0.00446 -20.25 <.0001
所以lny=4.71+0.09(-1/x)
Pr<0.0001<0.01所以回归方程高度显著。
8.1
例一.有20例肝病患者的四项肝功能指标x1(转氨酶量SGPT),x2(肝大指数),x3(硫酸锌浊度ZnT)及x4(胎甲球AFP)的观察数据如表所示,试作这四项指标的主成分分析。
3 120 3.0 13 50
4 250 4.
5 18 0
5 120 3.5 9 50
6 10 1.5 12 50
7 40 1.0 19 40
8 270 4.0 13 60
9 280 3.5 11 60
10 170 3.0 9 60
11 180 3.5 14 40
12 130 2.0 30 50
13 220 1.5 17 20
14 160 1.5 35 60
15 220 2.5 14 30
16 140 2.0 20 20
17 220 2.0 14 10
18 40 1.0 10 0
19 20 1.0 12 60
20 120 2.0 20 0 解:
y1=0.99964z1+0.6898z2+0.0879z3+0.1628z4
y2=0.095z1-0.2836z2+0.9042z3+0.305z4
y3=-0.240049z1+0.0585z2-0.2703z3+0.9305z4
y4=-0.6659z1+0.6636z2+0.3189z3-0.1208z4
习题8-2
选拔职员对应聘人员测试6门科目:词汇,阅读,同义词,算数,代数,微积分,分别记为x1,x2,x3,x4,x5,x6,将所有应聘者的考试成绩做计算机处理,得样本相关阵,试对这六科成绩作因子分析,样本相关阵为
1 0.7
2 0.6
3 0.09 0.09 0.00
0.72 1 0.57 0.15 0.16 0.09
0.63 0.57 1 0.14 0.15 0.09
0.09 0.15 0.14 1 0.57 0.72
0.09 0.16 0.15 0.57 1 0.72
0.00 0.09 0.09 0.63 0.72 1
解:程序
data score(type=corr);
input name $ x1 x2 x3 x4 x5 x6;
cards;
x1 1 0.72 0.63 0.09 0.09 0.00
x2 0.72 1 0.57 0.15 0.16 0.09
x3 0.63 0.57 1 0.14 0.15 0.09
x4 0.09 0.15 0.14 1 0.57 0.63
x5 0.09 0.16 0.15 0.57 1 0.72
x6 0.00 0.09 0.09 0.63 0.72 1
;
proc factor data=score;
var x1 x2 x3 x4 x5 x6;
run;
结果:
因子1反映了考生的平均综合
能力,因子2反映了语文能力和
数学能力的差异。第一因子解差
的方差是2.601939,占信息量的
43.37%,是主要因子。→→→→
习题8-3
1、现有6个铅弹头,用“中子活化”方法测得7种微量元素的含量数据如下表所示,试用系统聚类法对6个弹头进行分类。
元素样品号Ag(银)
X1
Al(铝)
X2
Cu(铜)
X3
Ca(钙)
X4
Sb(锑)
X5
Bi(鉍)
X5
Sn(锡)
X7
1 0.05798 5.5150 347.10 21.910 8586 174
2 61.69
2 0.08441 3.9700 347.20 19.710 7947 2000 2440
3 0.07217 1.1530 54.58 3.052 3860 1445 9497
4 0.15010 1.7020 307.50 15.030 12290 1461 6480
5 5.7440 2.8540 229.60 9.657 8099 126
6 12520
6 0.21300 0.7058 240.30 13.910 8980 2820 4135
解:程序
data A;
input no x1-x7;
cards;
1 0.05789 5.5150 347.10 21.910 8586 174
2 61.69
2 0.08441 3.9700 347.20 19.710 7947 2000 2440
3 0.07217 1.1530 54.85 3.052 3860 1445 9497
4 0.15010 1.7020 307.50 15.030 12290 1461 6380
5 5.7440 2.8540 229.60 9.657 8099 126
6 12520
6 0.21300 0.7058 240.30 13.910 8980 2820 4135
;
proc cluster data = A method=sin outtree=out1; var x1-x7;
id no;
proc tree horizontal data=out1;
title'minimum distance';
run; 结果:
分为五类:{1}{2,6}{4}{3}{5}
分成四类:{1,2,6}{4}{3}{5}
分成三类:{1,2,6,4}{3}{5}
分成两类:{1,2,6,4,3}{5}
↓↓↓↓↓↓↓↓↓↓↓↓↓↓
sas统计分析报告
《统计软件》报告 聚类分析和方差分析 在统计学成绩分析中的应用 班级:精算0801班 姓名:张倪 学号:2008111500 报告时间:2011年11月 指导老师:郝际贵 成绩:
目录 一、背景及数据来源 (1) 二、描述性统计分析 (2) 三、聚类分析 (4) 四、方差分析 (6) 五、结果分析与结论 (8)
聚类分析和方差分析在统计学成绩分析中的应用 一、背景及数据来源 SAS 系统全称为Statistics Analysis System,最早由北卡罗来纳大学的两位生物统计学研究生编制,并于1976年成立了SAS软件研究所,正式推出了SAS 软件。SAS是用于决策支持的大型集成信息系统,但该软件系统最早的功能限于统计分析,至今,统计分析功能也仍是它的重要组成部分和核心功能。 SAS 系统是一个组合软件系统,它由多个功能模块组合而成,其基本部分是BASE SAS模块。BASE SAS模块是SAS系统的核心,承担着主要的数据管理任务,并管理用户使用环境,进行用户语言的处理,调用其他SAS模块和产品。也就是说,SAS系统的运行,首先必须启动BASE SAS模块,它除了本身所具有数据管理、程序设计及描述统计计算功能以外,还是SAS系统的中央调度室。它除可单独存在外,也可与其他产品或模块共同构成一个完整的系统。各模块的安装及更新都可通过其安装程序非常方便地进行。 本文利用SAS软件进行描述性统计、聚类分析等统计分析方法,将学生按照多指标综合考虑进行聚类。 数据来源:选取2010—2011第一学期统计学选教课成绩单,选取性别系别等变量进行考察。将中文名称改为英文。 数据类型如下所示: 当输入字符型的变量时,需要加上符号$在该变量的后面,用于区分数值型变量,所以用$来作为后缀。删除缺考错误分数等异常值。命名为2010stat.xls
应用多元统计分析SAS作业审批稿
应用多元统计分析S A S 作业 YKK standardization office【 YKK5AB- YKK08- YKK2C- YKK18】
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为2.95,2.15和1.54,试判断该标本是含矿还是不含矿? 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 2.58 0.9 0.95 1 2.9 1.23 1 1 3.55 1.15 1 1 2.35 1.15 0.79 1 3.54 1.85 0.79 1 2.7 2.23 1.3 1 2.7 1.7 0.48 2 2.25 1.98 1.06 2 2.16 1.8 1.06 2 2.3 3 1.7 4 1.1 2 1.96 1.48 1.04
2 1.94 1.4 1 2 3 1.3 1 2 2.78 1.7 1.48 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=3.19774。还可知两个三元总体均值相等的检验结果:D =3.19774,F =3.10891,p =0.0756<0.10,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值2.95、2.15、1.54分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
SAS作业(1)详解
SAS作业(1)详解 By 乔兴龙P57 13.下表分别给出两个文学家马克吐温(Mark Twain)的8篇小品文以及斯诺特格拉斯(Snodgrass)的10篇小品文中由3个字母组成的词的比例: 马克 0.225 0.262 0.217 0.240 0.230 0.229 0.235 0.217 吐温 斯诺 0.209 0.205 0.196 0.210 0.202 0.207 0.224 0.223 0.220 0.201 特格 拉斯 设两组数据分别来自正态总体,且两个总体方差相等,两个样本相互独立。问两个作家所写的小品文中包含由3个字母组成的词的比例是否有显著的差异(取α=)? 0.05 分析:检验是否有差异,即检验u1-u2=0,方差相等且未知,因此要用t检验法,置信区间a=0.05 操作: 在program editor 中输入 Data P59Q13; input x y @@; card; 0.225 0.209 0.262 0.205 0.217 0.196 0.240 0.210 0.230 0.202 0.229 0.207 0.235 0.224 0.217 0.223 . 0.220 . 0.201 proc print; run; 点击运行一次。 Solutions—analysis—analyst File—open by sas name—work—p59q13—OK Statistics—hypothesis tests—two sample t test for means 选中two variables,x—group 1,y—group 2,mean1-mean2=0,alternative选择第一个,test—confidence intervals选择interval,95.0% OK—OK 所得结果: Two Sample t-test for the Means of x and y 8 09:29 Wednesday, October 7, 2011 Sample Statistics
应用多元统计分析SAS作业
应用多元统计分析S A S作 业 Prepared on 22 November 2020
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为,和,试判断该标本是含矿还是不含矿 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 1 1 1 1 1 1 1 1 2 2
2 2 2 1 2 3 1 2 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=。还可知两个三元总体均值相等的检验结果:D =,F =,p =<,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值、、分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
SAS作业
1. Homework1数据集是我国农产品进口排名前10的国家,请对进口额进行描述性统计分析(要求计算均值,标准差,最大,最小,中位数)。 程序及运行结果: /*读入数据文件*/ procimport datafile='C:\Users\Administer\Desktop\SAS\第一次作业 \Homework1.csv'out=homework1; run; procprint data=homework1; run; 上述读取数据的运行结果如下: /*描述性统计*/ procmeans data=homework1 meanstdmaxminmedian ; var VAR3; outputout=result; run; means过程指定输出平均值,标准差,最大值,最小值和中位数的描述性统计结果如下图。
2. Homework2 数据集是对成人每天摄入蛋白质含量的调查数据,利用univariate 过程对调查数据进行描述分析,进一步按照性别分组分析。 (1)读入数据 procimport datafile='C:\Users\Administer\Desktop\SAS\第一次作业 \Homework2.txt'out=homework2; run; procprint data=homework2; run; 打印数据: (2)利用univariate过程对调查数据进行描述分析 procunivariate data=homework2; var VAR3 VAR4 ; run; VAR3变量运行结果(VAR4同理,结果不再列出)如下。其中位置检验表明t检验,符号检验和符号秩和检验都显著,即拒绝原假设。
多元统计分析实验报告,计算协方差矩阵,相关矩阵,SAS
院系:数学与统计学学院 专业:__统计学 年级:2009 级 课程名称:统计分析 ____ 学号:____________ 姓名:_________________ 指导教师:____________ 2012年4月28日 (一)实验名称 1. 编程计算样本协方差矩阵和相关系数矩阵;
2. 多元方差分析MANOVA。 (二)实验目的 1. 学习编制sas程序计算样本协方差矩阵和相关系数矩阵; 2. 对数据进行多元方差分析。 (三)实验数据 第一题: 第二题:
(四)实验内容 1. 打开SAS软件并导入数据; 2. 编制程序计算样本协方差矩阵和相关系数矩阵; 3. 编制sas程序对数据进行多元方差分析; 4. 根据实验结果解决问题,并撰写实验报告; (五)实验体会(结论、评价与建议等) 第一题: 程序如下: proc corr data=sasuser.sha n cov; proc corr data=sasuser.sha n no simple cov; with x3 x4; partial x1 x2; run; 结果如下: (1)协方差矩阵 $AS亲坯 曲;15 Friday, Apr: I SB,沙DO COUR过程 x4 目由度=30 Xi x2x3x4x5X? -10.I9B4944-0.45E2GJ5I.3347097-G.1193E48-£0.e75?GS
-ID. 188494669,36&Q3?9-7.22IO&OS1J5692043I5.49ee^91S.Oa97SM -8.45S2645■7,221050829.S78&S46-6.372E47I-15.3084183-21.7352376-11.5674785 1.3841097 1.G5S2M7t.3726171IJ24?17B 4.e093011 4.4C12473 2.B747CM -G. I1S3S49 1.GS92043-is.soul aa 4.B09B01I68.7978495劣』S670971S.57ai1B3 -IH.05l6l?a15.43S6569-J1.73S2376孔耶124TB27.0387097105.103225&S7.3505S7E: -2D K5752??319-11337204-1L55M7S52r9747?3i19,573118337.3S0&87E33.3SQ6452 (2) 相关系数矩阵 Pearson相关系数” N =引 当HO: Rho=0 时.Prob > |r| Xi Xi xl 1.QQ000 x2 -C.23954 0.2061 x3 -0,30459 0.0957 x4 0.18975 Q.3092 x5 '0.14157 0.4475 x6 -0.83787 0.0630 -0.49292 0.0150 x2-0.23354 1.00000-0.162750.143510.022700.181520.24438 x20.20C10.31:1?0.441?0.90350.32640.1761 x3-0.30459-0.16275 1.00000-0.06219-0.34641-0.^797-0.23674 x30.095?0.381?<.00010.0563o.oses0 JS97 x40.1S8760.14351-0.86219L000000.400540,313650.22610 x40.30920.4412<.0001 D.02EG Q.085S0.2213 x5-0J 41570.02270-0.946410.40054 1.000000.317370.26750 x50.4J750.90350.0G68Q.025&0.08130 + 1620 x6-0.33?e?0.1S162-0.397970.813650.31787LOOOOO0.82976 x60.0S300.32840.02660.08580.0813C0001辺-0.432920.24938-0.288740.22810 D.267600.92976 1.00000 x70,01500J7610.19970.22130JG20<.0001 第二题: 程序如下: proc anova data=sasuser.hua ng; class kind; model x1-x4=k ind; manova h=k ind; run; 结果如下: (1)分组水平信息 The ANNA Procedure Cla^s Level Informat ion Class Level?Values kind 3 123 Number of observatIons CO (2) x1、x2、x3、x4的方差分析
SAS统计分析教程方法总结
对定量结果进行差异性分析 1.单因素设计一元定量资料差异性分析 1.1.单因素设计一元定量资料t检验与符号秩和检验 T检验前提条件:定量资料满足独立性和正态分布,若不满足则进行单因素设计一元定量资料符号秩和检验。 1.2.配对设计一元定量资料t检验与符号秩和检验 配对设计:整个资料涉及一个试验因素的两个水平,并且在这两个水平作用下获得的相同指标是成对出现的,每一对中的两个数据来自于同一个个体或条件相近的两个个体。 1.3.成组设计一元定量资料t检验 成组设计定义: 设试验因素A有A1,A2个水平,将全部n(n最好是偶数)个受试对象随机地均分成2组,分别接受A1,A2,2种处理。再设每种处理下观测的定量指标数为k,当k=1时,属于一元分析的问题;当k≥2时,属于多元分析的问题。 在成组设计中,因2组受试对象之间未按重要的非处理因素进行两两配对,无法消除个体差异对观测结果的影响,因此,其试验效率低于配对设计。 T检验分析前提条件:
独立性、正态性和方差齐性。 1.4.成组设计一元定量资料Wil coxon秩和检验 不符合参数检验的前提条件,故选用非参数检验法,即秩和检验。1.5.单因素k(k>=3)水平设计定量资料一元方差分析 方差分析是用来研究一个控制变量的不同水平是否对观测变量产生了显著影响。这里,由于仅研究单个因素对观测变量的影响,因此称为单因素方差分析。 方差分析的假定条件为: (1)各处理条件下的样本是随机的。 (2)各处理条件下的样本是相互独立的,否则可能出现无法解析的输出结果。 (3)各处理条件下的样本分别来自正态分布总体,否则使用非参数分析。(4)各处理条件下的样本方差相同,即具有齐效性。 1.6.单因素k(k>=3)水平设计定量资料一元协方差分析 协方差分析(Analysis of Covariance)是将回归分析与方差分析结合起来使用的一种分析方法。在这种分析中,先将定量的影响因素(即难以控制的因素)看作自变量,或称为协变量(Covariate),建立因变量随自变量变化的回归方程,这样就可以利用回归方程把因变量的变化中受不易控制的定量因素的影响扣除掉,从而,能够较合理地比较定性的影响因素处在不同水平下,经过回归分析手段修正以后的因变量的样本均数之间的差别是否有统计学意义,这就是协方差分析解决问题的基本计算原理。
时间序列分析,sas各种模型,作业神器
实验一分析太阳黑子数序列 一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。 二、实验内容:分析太阳黑子数序列。 三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。 四、实验时间:2小时。 五、实验软件:SAS系统。 六、实验步骤 1、开机进入SAS系统。 2、创建名为exp1的SAS数据集,即在窗中输入下列语句: 3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问 后就可以把这段程序保存下来即可)。 4、绘数据与时间的关系图,初步识别序列,输入下列程序: ods html; ods listing close; 5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。 7、提交程序,观察输出结果。初步识别序列为AR(2)模型。 8、估计和诊断。输入如下程序: 9、提交程序,观察输出结果。假设通过了白噪声检验,且模型合理,则进行预测。 10、进行预测,输入如下程序: 11、提交程序,观察输出结果。
12、退出SAS系统,关闭计算机。总程序: data exp1; infile "D:\"; input a1 @@;
year=intnx('year','1jan1742'd,_n_-1); format year year4.; ; proc print;run; ods html; ods listing close; proc gplot data=exp1 ; symbol i=spline v=dot h=1 cv=red ci=green w=1; plot a1*year/autovref lvref=2 cframe=yellow cvref=black ; title "太阳黑子数序列"; run; proc arima data=exp1; identify var=a1 nlag=24 minic p=(0:5) q=(0:5); estimate p=3; forecast lead=6 interval=year id=year out=out; run; proc print data=out; run; 选取拟合模型的规则: 1.模型显著有效(残差检验为白噪声)
数据分析SAS报告
90-08年人民消费能力分析 一、问题提出 改革开放以来中国经济飞速发展,GDP连续超过德国、日本,现以成为世界上第二大经济体,人民生活水平不断提高,但受金融危机的影响,近几年来物价持续上涨,本月CPI创历史新高,人民的消费能力是否随着GDP的增加而增加呢?本文以中国经济年鉴中的“人民消费支出构成”的数据为依据利用统计软件SAS 进行了相关分析。数据如下 食品衣着居住家庭设备用品及服务交通通讯文教娱乐用品及服务医疗保健其他商品及服务 1990 58.8000 7.7700 17.3400 5.2900 1.4400 5.3700 3.2500 0.7400 1995 58.6200 6.8500 13.9100 5.2300 2.5800 7.8100 3.2400 1.7600 2000 49.1300 5.7500 15.4700 4.5200 5.5800 11.1800 5.2400 3.1400 2005 45.4800 5.8100 14.4900 4.3600 9.5900 11.5600 6.5800 2.1300 2007 43.0800 6.0000 17.8000 4.6300 10.1900 9.4800 6.5200 2.3000 2008 43.6700 5.7900 18.5400 4.7500 9.8400 8.5900 6.7200 2.0900 二、问题分析 1、通过对消费种类进行主成分分析判断人民的消费情况。 2、对主成分标准化后在分析各年的消费能力排名。 三、解决问题 3.1 SAS程序: data examp4_4; input id x1-x8; cards; 1990 58.8000 7.7700 17.3400 5.2900 1.4400 5.3700 3.2500 0.7400 1995 58.6200 6.8500 13.9100 5.2300 2.5800 7.8100 3.2400 1.7600 2000 49.1300 5.7500 15.4700 4.5200 5.5800 11.1800 5.2400 3.1400 2005 45.4800 5.8100 14.4900 4.3600 9.5900 11.5600 6.5800 2.1300 2007 43.0800 6.0000 17.8000 4.6300 10.1900 9.4800 6.5200 2.3000 2008 43.6700 5.7900 18.5400 4.7500 9.8400 8.5900 6.7200 2.0900 ; run; proc corr cov nosimple data=examp4_4; var x1-x8; run; proc princomp data=examp4_4 out=bb; var x1-x8; run; data score1; /*以下程序是对各年按第一主成分得分进行排名并打印结果*/ set bb; keep id prin1;
sas第一次作业
SAS 第二次作业 光科1201 梁修业 7-4-2一种合金在某种添加剂的不同浓度之下,各做三次实验,得数据如下表: 浓度x 10.0 15.0 20.0 25.0 30.0 抗压强度y 25.2 27.3 28.7 29.8 31.1 27.8 31.2 32.6 29.7 31.7 30.1 32.3 29.4 30.8 32.8 (1)作散点图; (2)以模型y=b 0+b1x+b2x+ ε ,2~0N εσ(,),拟合数据,其中b0,b1,b2,2σ与x 无 关,求回归方程2012????y b b x b x =++。 解:(1) (2)将x 看成x1,x^2 看成x2,在表格中增加变量x2,此题即转化为多元线性回归 所以2?19.0333 1.00860.0204y x x =+-。
7-4-3对§7.4例3的钢包容积y和使用次数x的数据,假定 b x y ae-=。 (1)画散点图; (2)试分别作变量替换,化非线性回归模型为线性回归模型并讨论回归方程的显著性。 解: (1) (2)利用Insight模块求解。增加两个变量,u=lny,v=-1/x, 说明:方程为 1 ? ln 4.71410.0903() y x =+-,方差分析表中p-值小于0.0001,说明 了回归方程高度显著。
7-4-4槲寄生是一种寄生在大树上部树枝上的寄生植物,它喜欢寄生在年轻的大树上,下表给出在一定条件下完成的实验中采集的数据。 x 3 4 9 15 40 y 28 33 22 10 36 24 15 22 10 6 14 9 1 1 (1)作出(x i ,y i )的散点图, (2)令z i =lny i ,作出(x i ,z i )的散点图 (3)以模型2 ,ln~(0,) bx y ae N εεσ =拟合数据,其中a,b,2σ与x无关,试求曲线回归方程?bx ? ?y=ae。 解:(1) (2)Insight模块。增加变量z=lny
SAS作业
使用SAS软件完成下列任务: 1.对数据集sashelp.class中的身高和体重进行描述性统计分析,计算基本统计量,并给出分析结论。 身高: 结论:身高数据共19个,最大值为72,最小值为51.3,相差20.7。55-65之间的数据最多。中位数为62.8,平均数为62.3。数据的标准差为5.1271,方差为26.2869
体重: 结论:体重数据共19个,最大值为150,最小值为50,相差99.5。中位数为99.5,平均数为100.026。数据的标准差为22.7739,方差为518.652 2.对数据集中的男生和女生分别进行问题1中的基本统计量的计算,并写出结论 身高:
结论:男生身高数据共10个,平均数为63.91。数据的标准差为4.9379,方差为24.3832,对男生身高95%的可能集中于60.3776到67.4424之间。 女生身高数据共9个,平均数为60.5889。数据的标准差为5.0183,方差为25.1836,对女生身高预测95%的可能集中于56.7315到64.4463之间。 男生的身高相较于女生而言更集中。男生身高也普遍比女生高一些。 体重: 结论:男生体重数据共10个,平均数为108.95。数据的标准差为22.7272,方差为516.525,对男生身高95%的可能集中于92.692到125.208之间。 女生体重数据共9个,平均数为90.1111。数据的标准差为19.3839,方差为375.7361,对女生身高预测95%的可能集中于75.2113到105.0109之间。 女生的体重相较于男生而言更集中。女生体重也普遍比男生轻一些。
应用多元统计分析SAS作业第三章
3-8假定人体尺寸有这样的一般规律,身高(X 1),胸围(X 2)和上半臂围(X 3)的平均尺寸比例是6:4:1,假设()()1,,X n αα=L 为来自总体()123=,,X X X X '的随机样本,并设()~,X N μ∑。试利用表3.4中男婴这一数据来检验其身高、胸围和上半臂围这三个尺寸变量是否符合这一规律(写出假设H 0,并导出检验统计量)。 解:设32,~(,),~(,)Y CX X N Y N C C C μμ'=∑∑。 121231233106,,,,,014C X X X μμμμμμμ??-?? ? == ? ?-?? ? ??其中,分别为 的样本均值。则检验三个变量是否符合规律的假设为 0212:,:H C O H C O μμ=≠。 检验统计量为 2 1(1)1~(1,1) (3,6)(1)(1) n p F T F p n p p n n p ---+= --+==--, 由样本值计算得:=(82,60.2,14.5)X ',及 15840.2 2.5=40.215.86 6.552.5 6.559.5A ?? ? ? ??? , 2-1(1)()()()=47.1434T n n CX CAC CX ''=-,
221(1)12 =18.8574(1)(1)5 n p F T T n p ---+= ?=--, 对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值: p =P {F ≥18.8574}=0.0091948。 因为p 值=0.0091948<0.05,故否定0H ,即认为这组男婴数据与人类的一般规律不一致。在这种情况下,可能犯第一类错误·且犯第一类错误的概率为0.05。 SAS 程序及结果如下: prociml ; n=6;p=3; x={7860.616.5, 7658.112.5, 9263.214.5, 815914, 8160.815.5, 8459.514 }; m0={00,00}; c={10 -6,01 -4}; ln={[6]1}; x0=(ln*x)`/n; print x0; mm=i(6)-j(6,6,1)/n; a=x`*mm*x; a1=inv(c*a*c`); a2=c*x0; dd=a2`*a1*a2; d2=dd*(n-1); t2=n*d2; f=(n+1-p)*t2/((n-1)*(p-1)); print x0 a d2 t2 f; p0=1-probf(f,p-1,n-p+1); fa=finv(0.95,2,4); print p0; run ;
SAS统计分析
通径分析的SAS实现方法 任红松,吕新,曹连莆,袁继勇 (石河子大学新疆作物高产研究中心,新疆石河子832003) 摘要:本文以小麦丰产3号主要农艺性状的相关及通径分析为例,阐明其SAS实施过程。并通过标准化回归系数的方法计算通径系数,最后在各性状与产量的相关系数分解为直接通径系数和间接通径系数之和的基础上对通径分析结果作全面解释。 关键词:线性回归;相关系数;通径分析;sAs程序 【中图分类号】S126【文献标识码】B【文章编号】1007—6581(2003)04一o0017一03 通径分析作为一种衡量自变量(性状)相对重要性的方法,已在众多领域得到广泛应用。但由于其样本量之大,计算过程复杂,使得一些分析难以进行,计算结果不够准确。如何利用sAs统计软件实现其计算过程的自动化,笔者就此进行了论述,旨在方便读者处理各种类型有关通径分析的资料。 1材料与方法 1.1材料来源 分析数据来自文献【1】多元回归部分。具体数值见以下所编sAs程序部分。 1.2分析方法 以小麦丰产3号单株籽粒产量为因变量y,每株穗数为自变量x。,每穗结实小穗数为自变量X2,百粒重为自变量X3,株高为自变量】(4,利用SAs拟合因变量关于自变量的线性回归方程。然后通过标准化回归系数方法计算各自变量对因变量的通径系数。最后将各自变量(农艺性状)与因变量(株产)的相关系数进行分解,并对通径分析结果作出全面解释。 2结果与分析 2.1SAS程序 (1ata】dao栅: inputyx卜x4@@; cards: 15.710233.611314.59203.610617.510223.711122.513213.710915.510223.611016.910233.51038.68233.310017.010243.411413.710203.4104 13.410213.411020.310233.910410.28213.51097.462331211411.68213.711312.39223.6105 ' proccorr; varyx1一x4; ptocte舀 modely=x1一x4/Stb; rUn:2.2参数估计及检验 参数估计部分给出了截距和偏回归系数的估计值及标准误差和显著性检验结果(表1) 寰1参数估计 变量自由度参数估计标准◆数估计标准误差t值P值 截距1—51.∞2066O.∞000∞013.35181742—3.蚰70.∞30 X112.026l∞0.7鼹30213O.272042477.448O.O∞l X210.653997O.19319217O.3027∞792.1610.056l X317.7969380.339939042.332814503.3420∞75 x4l0.049697n05304790n082鲫779晚5鲫O.5626 由表1可得多重线性回归方程: y =一51.902066+2.02618x1+0.653997x2+7.796938x3+0.049697x4 对截距一51.902066检验结果,t=一3.887,p≤0.003;各偏回归系数显著性检验结果为x,X3达极显著水平,X2接近显著水平,x4不显著.说明除株高外,截距和其它三项偏回归系数与0之间差别显著,可认为所求的直线回归方程成立。 2.3方差分析 方差分析的目的是为了检验所求的线性回归方程是否显著。从表2可以看出,F=30.063,p≤O.0001,多元决定系数R2=0.9232,校正多元决定系数R2=0.8925,残差标准差的估计值为1.35711,这些都说明所求的线性回归方程非常显著,作y关于x。X2X3)【I的通径分析是有意义的。 模型 误差 总和 均方根 因变量均值 变异系数 221.47175 18.41758 239.88933 舻 校正R2 2.4通径系数的计算及显著性检验 根据通径系数为标准的偏回归系数回,可求得各自变量)d关于因变量y的通径系数分别为 pyl20.75830213py220.19319217py320.33993904py420.05304790
SAS入门教程
第一章SAS系统概况 SAS(Statistic Analysis System)系统是世界领先的信息系统,它由最初的用于统计分析经不断发展和完善而成为大型集成应用软件系统;具有完备的数据存取、管理、分析和显示功能。在数据处理和统计分析领域,SAS系统被誉为国际上的标准软件系统。 SAS系统是一个模块化的集成软件系统。SAS系统提供的二十多个模块(产品)可完成各方面的实际问题,功能非常齐全,用户根据需要可灵活的选择使用。 ●Base SAS Base SAS软件是SAS系统的核心。主要功能是数据管理和数据加工处理,并有报表生成和描述统计的功能。Base SAS软件可以单独使用,也可以同其他软件产品一起组成一个用户化的SAS系统。 ●SAS/AF 这是一个应用开发工具。利用SAS/AF的屏幕设计能力及SCL语言的处理能力可快速开发各种功能强大的应用系统。SAS/AF采用先进的OOP(面向对象编程)的技术,是用户可方便快速的实现各类具有图形用户界面(GUI)的应用系统。 ●SAS/EIS 该软件是SAS系统种采用OOP(面向对象编程)技术的又一个开发工具。该产品也称为行政信息系统或每个人的信息系统。利用该软件可以创建多维数据库(MDDB),并能生成多维报表和图形。 ●SAS/INTRNET ●SAS/ACCESS 该软件是对目前许多流行数据库的接口组成的接口集,它提供的与外部数据库的接口是透明和动态的。 第二章Base SAS软件 第一节SAS编程基础 SAS语言的编程规则与其它过程语言基本相同。 SAS语句 一个SAS语句是有SAS关键词、SAS名字、特殊字符和运算符组成的字符串,并以分号(;)结尾。 注释语句的形式为:/*注释内容*/ 或*注释内容。 二、SAS程序 一序列SAS语句组成一个SAS程序。SAS程序中的语句可分为两类步骤:DA TA步和
SAS 作业
课程作业报告 课程名称:数据统计分析软件 班级:环科1401 学号:A03140377 姓名:沈晶晶 教师:郭微 成绩: P61 例5.1.1(1) data eg51;
input name $ sex $ age salary educa $; label name="姓名" sex="性别" age="年龄"; label salary="工资"educa="受教育情况"; cards ; 李斯 男 20 1200 初 王老五 女 25 1260 初 赵柳 女 28 1350 中 史奇 男 27 1350 高 朱巴 男 30 1290 中 刘久 男 35 1400 中 康实 女 32 1410 高 申山 男 31 1410 高 ;; proc gchart data =eg51; vbar sex; run ; P61 例5.1.1(2) data eg51; input name $ sex $ age salary educa $; label name="姓名" sex="性别" age="年龄"; label salary="工资"educa="受教育情况"; cards ; 李斯 男 20 1200 初 王老五 女 25 1260 初 赵柳 女 28 1350 中 史奇 男 27 1350 高 朱巴 男 30 1290 中
P100 例6.1 title'6种施肥法的小麦植株含氮量的方差分析'; data mp97; input treat nitrogen @@; cards; 1 2.9 2 4.0 3 2.6 4 0. 5 5 4. 6 6 4.0 1 2.3 2 3.8 3 3.2 4 0.8 5 4. 6 6 3.3 1 2. 2 2 3.8 3 3. 4 4 0.7 5 4.4 6 3.7 1 2.5 2 3.6 3 3. 4 4 0.8 5 4.4 6 3.5 1 2.7 2 3.6 3 3.0 4 0. 5 5 4.4 6 3.7 ; proc anova; class treat; model nitrogen=treat; means treat/duncan; run; 6种施肥法的小麦植株含氮量的方差分析 The ANOVA Procedure Class Level Information Class Levels Values treat 6 1 2 3 4 5 6
sas期末考试作业
Computer Software Application on Aquaculture Your grade depends on: 1. Correctness of programming upon the requests in the questions, 2. Syntax error, 3. Structure and notes on the programming, e.g., sub-setting, comments, designation of variables, titles, etc., and 4. Interpretation of the printouts. Attached your answer in two files: 1. a SAS program file, 2. a word file of the answers to the questions by its order. Submit it to my box (yhchien@https://www.360docs.net/doc/7c16312.html,.tw) before 17:00 of June 26 (Thu.) _____________________________________________________________ I. (10%) The following data are the number of fish caught by a standardized sampling gear (an indication of fish survived) in each of the 9-week experiment period. A decaying exponential equation or survival model is used to present the survival condition over the whole experiment period. Fit the given data to the equation: Nt = No x exp (-z x t), where Nt is the number of fish survived at week t, No the number of fish at stocking, z the weekly instantaneous mortality coefficient, by using 1.Direct fitting method, and 2.Log-transform to linear method. Provide the following answers: (1) What are the estimates of No and z? (2) A plot showing the observed and the predicted and a plot for residual distribution. (Data for question I is on attached file Q1data) II. (20%) This question is to test your ability how to reorganize data sets, differentiate some parameters expressing variability, and examine relationships between two (2) Get the summary statistics: mean, standard deviation (std), standard error (stderr), and coefficient of variation (cv) of both height (ht) and weight (wt) and show me and prove to me the mathematical relationships: a. between standard deviation and standard error, b. between cv and mean; (3) Compare the variation between ht and wt; (4) Plot out: (a) an overlay plot of both ht and wt versus age and (b) a plot of wt versus ht; and (5) Fit the data into a weight-length(height) equation: wt=a*ht**b by: (a) Non-linear direct fitting and (b) log-transformed linear fitting (hint: log(wt)=log(a)+b*log(ht). (Data for question II is on attached file Q2 data)