怎样提取图片中的文字

怎样提取图片中的文字
使用电脑过程中,需要抓取文字的地方很多,如提示框、对话框、菜单、图片、PDF、视频等等位置的文字,有时还需批量获取大量文件的文件名,以方便修改名称。这些需求如何快速实现呢,笔者将这方面的技巧总结出来,与朋友们共享。
一、抓取对话框、菜单上文字
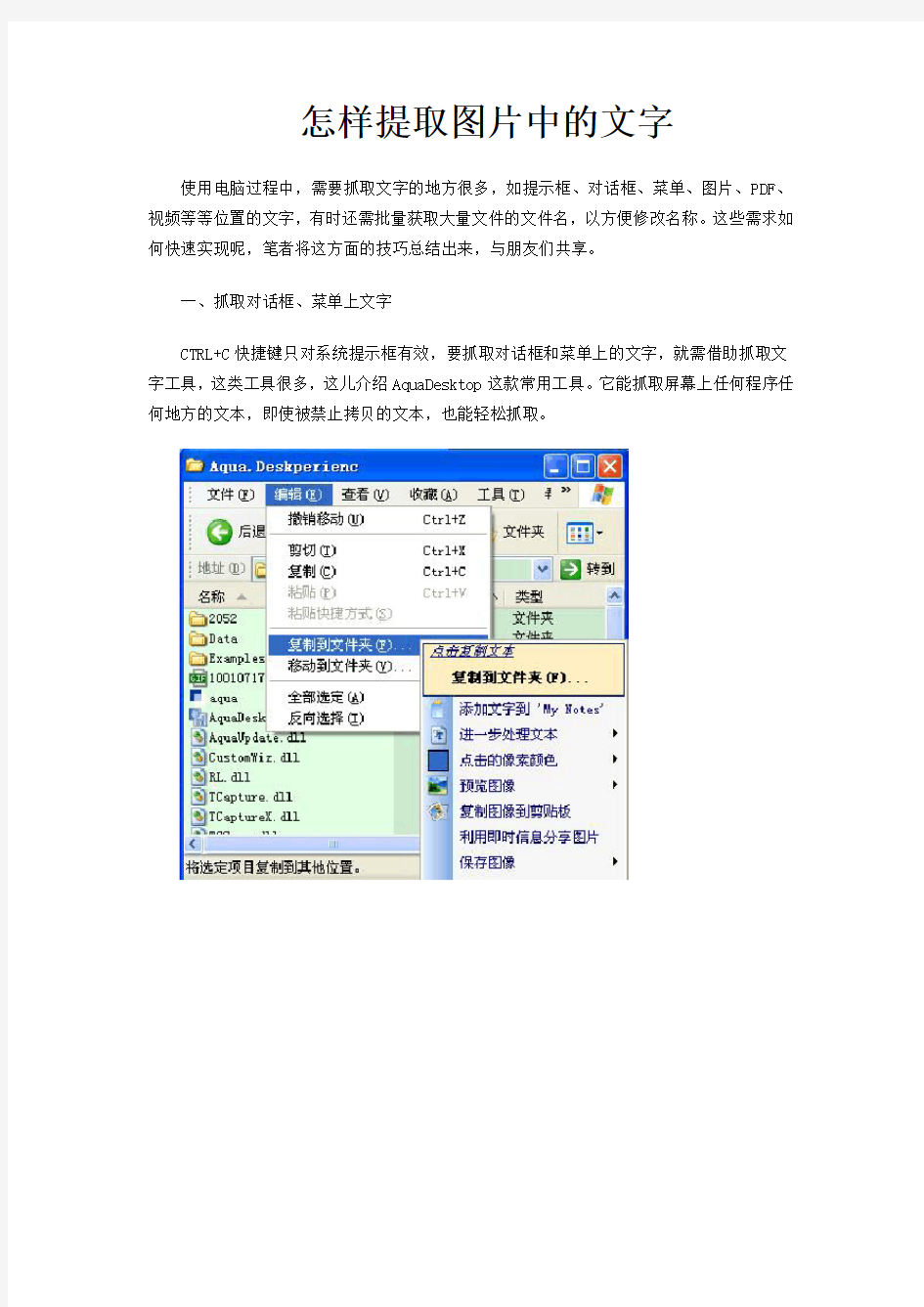
CTRL+C快捷键只对系统提示框有效,要抓取对话框和菜单上的文字,就需借助抓取文字工具,这类工具很多,这儿介绍AquaDesktop这款常用工具。它能抓取屏幕上任何程序任何地方的文本,即使被禁止拷贝的文本,也能轻松抓取。
从https://www.360docs.net/doc/7d11641200.html,/soft/28432.html下载AquaDesktop V1.5.0.29绿色版,解压运行后,打开需要抓取文字的菜单,按下CTRL键,再在需要的菜单项的空白处点击鼠标右键,就将该菜单文字抓取,并在弹出菜单中显示,点击菜单上的“点击复制文本”项,将抓取的文字复制到剪切板,随后粘贴到需要的位置即可。该工具也能抓取对话框文字,同时按住CTRL+SHIFT键,再按住鼠标左键拖选需要抓取的文字区域,松开鼠标左键,抓取的文字显示在菜单中(图2)。
二、抓取图片和视频文字
由于工作需要,经常要从扫描或相机拍摄图片上获取文字,甚至要从视频中获得文字,进行二次编辑再使用。可是图片和视频上的文字不能复制,如何解决将图片和视频上文字转换成编辑的文本这一难题呢?
那就使用“文通慧视”这款绿色版工具来抓取其上的文字吧,这款工具对于能看到的文字,它就能抓取。同时支持图片、PDF和视频上的文字抓取,效率和效果都很出色。
1、抓取图片上文字
从https://www.360docs.net/doc/7d11641200.html,/soft/sort001/sort0370/down-72973.html下载“文通慧视”后,解压到英文目录下,执行其中的注册表文件WtSign32.reg进行注册,随后再执行“文字识别.exe”启动软件,运行后软件的工具条出现在屏幕的上方,默认工具条是自动隐藏的,也可以进行锁定,操作起来非常简单,就像QQ面板一样。
使用图片浏览工具打开要获取文字的图片,从“文通慧视”工具条上点选“慧视屏幕”,这时鼠标变成十字型,按下鼠标左键选取图片上要转换的文字区域,从弹出的“屏幕识别”对话框中,内容下选择“文本”,背景选择“自动”,语种选择“简体”,点击“确定”,软件自动识别选择区域中的文字,很快文字被识别出来,并自动打开记事本将识别的文字显示出来,识别率相当高(图3)。
2、抓取视频中文字
“文通慧视”还能抓取视频播放窗口中的文字。使用播放软件播放到需要抓取文字的视频画面暂停,操作与抓取图片文字相似,只是在“屏幕识别”中勾选下方的“视频识别”项,再框选视频播放窗口的文字区域,单击“识别”,很快就抓取到播放画面中的文字。该工具对字幕中的文字识别率较高,视频中的文字识别率不是很高。
小提示:该软件非常适合抓取相机拍摄照片上的文字。它不但能识别中文,还能识别日语、韩语外文等,操作选择相应语种就可以了,识别率也极高。
三、批量抓取图片、PDF上文字
如果需要对大量图片和图片型PDF文档中的文字抓取,“文通慧视”执行效率就不高了,它每次操作都需要选择抓取文字范围区域,只能一张一张进行,不能批量抓取多张图片、PDF
等文档的文字。这时就可使用“ABBYY FineReader”这款世界排名第一的OCR文字识别工具,它识别精度达到99%,能批量将图片、图片型PDF转换成可编辑的文本,操作时只需选择文件,而无需选择区域。更难能可贵的是转换得到的WORD文档与原图片、PDF文档版式保持一致。
从https://www.360docs.net/doc/7d11641200.html,/soft/9316.html下载“ABBYY FineReader 10.102.185中文绿色版”,它是一款半绿色软件,将其解压到硬盘的任意位置,双击运行解压得到的“!)FineReaderPorable.exe”文件完成软件的初始化,在出现的窗口中点击“安装”按钮,完成该软件的初始化操作。然后执行主程序FineReader.exe,打开它的操作界面。这儿以批量抓取PDF文档文字为例说明操作方法。点击工具栏上的“新建任务”按钮,在弹出的“新建任务”对话框的“公共”中,选择“将PDF/图像转换为Microsoft Word”项(图4)。
从弹出的“打开图像”对话框中选择需要识别的PDF文件,软件首先打开图片型PDF 的每一个页面,自动进行识别,并给出识别进度提示,识别工作完成后,自动打开WORD文档,将识别内容显示出来,不但将文字、图片识别出来,版式也与原PDF一个样。在软件右侧“文本”窗格中,也显示识别出的相应页面的内容(图5)。
个别文字没有正确识别时,在“页面”窗格中点选相应页面,再在“图像”中拖选整个页面的文字区域。点击工具栏上的“读取”按钮,这时软件重新读取识别文字,很快完成后,在“文本”窗格中显示识别出的文字,这下识别率就更高了。点击窗口下方的“单击此外可查看缩放的图像(Ctrl键+F5)”,将选择的PDF页面放大显示在下方,在“文本”窗格中,选择软件标记出的识别不确定文字,此时下方窗格会自动切换到相应位置,对照修改,修改完成后,点击工具栏“保存”按钮旁边的下箭头,从中选择需要保存的文档格式,将其保存成Word等格式文件方便编辑(图6)。