spss统计学第一次实验作业答案
实验作业
1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D. 较差;E.差。调查结果见book3.01.xls。
要求:
(1)根据Excel文件中提供的数据,建立SPSS数据文件,简述操作步骤。
(2)指出上述数据属于什么类型?
(3)制作一张频数分布表;
(4)绘制一张条形图,反映评价等级的分布。
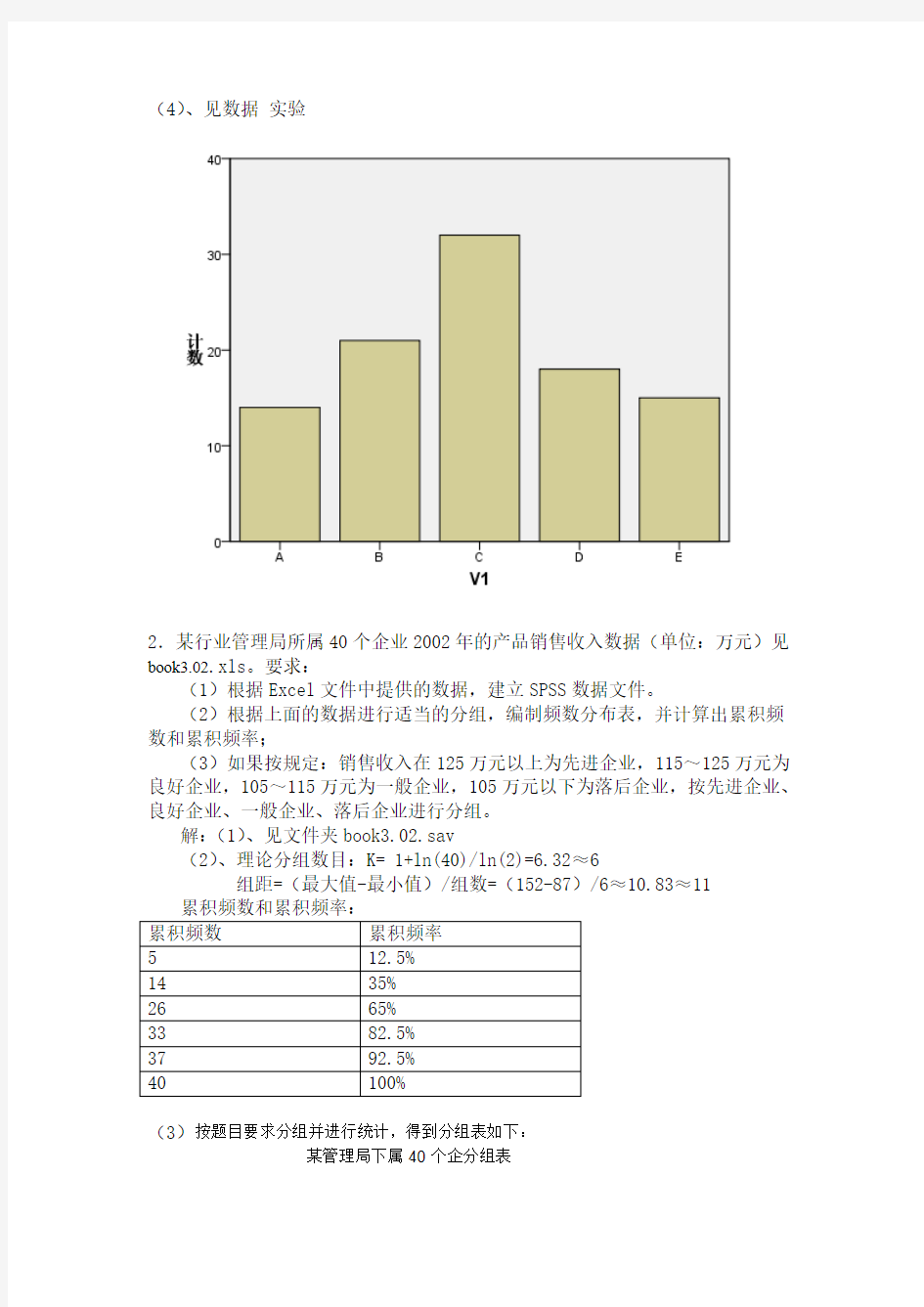
解:(1)、①【文件】—【打开】—【数据】
②将【文件类型】改为“所有文件”,找到【文件】book3.01.xls -【打开】
③取消“从第一行数据读取变量名”。----单击【确定】
(2)、字符型数据。
(4)、见数据实验
2.某行业管理局所属40个企业2002年的产品销售收入数据(单位:万元)见book3.02.xls。要求:
(1)根据Excel文件中提供的数据,建立SPSS数据文件。
(2)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;
(3)如果按规定:销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
解:(1)、见文件夹book3.02.sav
(2)、理论分组数目:K= 1+ln(40)/ln(2)=6.32≈6
组距=(最大值-最小值)/组数=(152-87)/6≈10.83≈11
(3)按题目要求分组并进行统计,得到分组表如下:
某管理局下属40个企分组表
按销售收入分组(万元)企业数(个)频率(%)
先进企业良好企业一般企业落后企业11
11
9
9
27.5
27.5
22.5
22.5
合计40 100.0
3.为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果见book3.04.xls。
(1)根据Excel文件中提供的数据,建立SPSS数据文件。
(2)利用计算机对上面的数据进行排序;
(3)以组距为10进行等距分组,整理成频数分布表,并绘制直方图。
(4)制作茎叶图,并与直方图作比较。
解:
(2)排序:移动数据到同一列,点击:数据→排序→确定,即完成数据排序的工作。
(3
)
(4)茎叶图
制作茎叶图:以十位以上数作为茎,填入表格的首列,将百、十位数相同的数据的个位数按由小到大的顺序填入相应行中,即成为叶,
得到茎叶图如下:
茎叶图与直方图比较:
两图整体比较相似,茎叶图表达出的信息相对更多。
统计学第一次作业+参考答案
《统计学》第一次作业 一、单选题(共10个) 1.统计工作的成果是( C )。 A. 统计学 B. 统计工作 C. 统计资料 D. 统计分析和预测 2. 社会经济统计的研究对象是( C )。 A. 抽象的数量关系 B. 社会经济现象的规律性 C. 社会经济现象的数量特征和数量关系 D. 社会经济统计认识过程的规律和方法 3. 对某地区的全部产业依据产业构成分为第一产业、第二产业和第三产业,这里所使用的计量尺 度是( A )。 A. 定类尺度 B. 定序尺度 C. 定距尺度 D. 定比尺度 4.某城市工业企业未安装设备普查,总体单位是( D )。 A. 工业企业全部未安装设备 B. 工业企业每一台未安装设备 C. 每个工业企业的未安装设备 D. 每一个工业企业 5.统计总体的同质性是指( B )。 A. 总体各单位具有某一共同的品质标志或数量标志 B. 总体各单位具有某一共同的品质标志属性或数量标志值 C. 总体各单位具有若干互不相同的品质标志或数量标志 D. 总体各单位具有若干互不相同的品质标志属性或数量标志值 6.下列调查中,调查单位与填报单位一致的是(D ) A. 企业设备调查 B. 人口普查 C. 农村耕地调查 D. 工业企业现状调查 7.某灯泡厂为了掌握该厂的产品质量,拟进行一次全厂的质量大检查,这种检查应当选择( D) A. 统计报表 B. 重点调查 C. 全面调查 D. 抽样调查 8.重点调查中重点单位是指(A ) A. 标志总量在总体中占有很大比重的单位 B. 具有典型意义或代表性的单位 C. 那些具有反映事物属性差异的品质标志的单位 D. 能用以推算总体标志总量的单位 9.书籍某分组数列最后一组是500以上,该组频数为10,又知其相邻组为400-450,则最后一组 的频数密度为( A)
统计学实验报告汇总
本科生实验报告 实验课程统计学 学院名称商学院 专业名称会计学 学生姓名苑蕊 学生学号0113 指导教师刘后平 实验地点成都理工大学南校区 实验成绩 二〇一五年十月二〇一五年十月
依据上述资料编制组距变量数列,并用次数分布表列出各组的频数和频率,以及向上、向下累计的频数和频率, 并绘制直方图、折线图。 学生 实验 心得
2.已知2001-2012年我国的国内生产总值数据如表2-16所示。 学生 实验 心得 要求:(1)依据2001-2012年的国内生产总值数据,利用Excel软件绘制线图和条形图。
(2)依据2012年的国内生产总值及其构成数据,绘制环形图和圆形图。 学生 实验 心得 3.计算以下数据的指标数据 1100 1200 1200 1400 1500 1500 1700 1700 1700 1800 1800 1900 1900 2100 2100 2200 2200 2200 2300 2300 2300 2300 2400 2400 2500 2500 2500 2500 2600 2600 2600 2700 2700 2800 2800 2800 2900 2900 2900 3100 3100 3100 3100 3200 3200 3300 3300 3400 3400 3400 3500 3500 3500 3600 3600 3600 3800 3800 3800 4200
4.一家食品公司,每天大约生产袋装食品若干,按规定每袋的重量应为100g。为对产品质量进行检测,该企业质检部门采用抽样技术,每天抽取一定数量的食品,以分析每袋重量是否符合质量要求。现从某一天生产的一批食品8000袋中随机抽取了25袋(不重复抽样),测得它们的重量分别为: 学生实验心得 101 103 102 95 100 102 105 已知产品重量服从正态分布,且总体方差为100g。试估计该批产品平均重量的置信区间,置信水平为95%.
教育统计学与SPSS课后作业答案祥解题目
教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1
第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果
3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤:
统计分析及SPSS的应用课后练习答案解析
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第4章SPSS基本统计分析 1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。 分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。 Statistics 户口所在 地 职业年龄 N Valid282282282 Missing000 户口所在地 Frequency Percent Valid Percent Cumulative Percent Valid 中心城市200 边远郊区82 Total282 职业 Frequency Percent Valid Percent Cumulative Percent Valid 国家机关24商业服务业54文教卫生18公交建筑业15经营性公司18学校15一般农户35种粮棉专业 户 4
种 果菜专业 户 10 工商运专业 户 34 退役人员17 金融机构35 现役军人3 Total282 年龄 Frequency Percent Valid Percent Cumulative Percent Valid 20岁以下4 20~35岁146 35~50岁91 50岁以上41 Total282
分析:本次调查的有效样本为282份。常住地的分布状况是:在中心城市的人最多,有200人,而在边远郊区只有82人;职业的分布状况是:在商业服务业的人最多,其次是一般农户和金融机构;年龄方面:在35-50岁的人最多。由于变量中无缺失数据,因此频数分布表中的百分比相同。 2、利用第2章第7题数据,从数据的集中趋势、离散程度以及分布形状等角度,分析被调查者本次存款金额的基本特征,并与标准正态分布曲线进行对比。进一步,对不同常住地储户存款金额的基本特征进行对比分析。 分析——描述统计——描述,选择存款金额到变量中。点击选项,勾选均值、标准差、方差、最小值、最大值、范围、偏度、峰度、按变量列表,点击继续——确定。 分析:由表中可以看出,有效样本为282份,存(取)款金额的均值是,标准差为,峰度系数为,偏度系数为。与标准正态分布曲线进行对比,由峰度系数可以看出,此表的存款金额的数据分布比标准正态分布更陡峭;由偏度系数可以看出,此表的存款金额的数据为右偏分布,表明此表的存款金额均值对平均水平的测度偏大。
北邮大统计学基础第一次阶段作业
一、单项选择题(共10道小题,共100.0分) 1.在下列调查中.调查单位与填报单位一致的是( )。 A.公司设备调查 B.农村耕地调查 C.学生学习情况调查 D.汽车养护情况调查 知识点: 第二章 学生答 案: [C;] 得分: [10] 试题分 值: 10.0 提示: 2.通过调查鞍钢、武钢等几个钢铁基地,了解我国钢铁生产的基本情况,这 种调查方式是( )。 A.典型调查 B.重点调查 C.抽样调查 D.普查 知识点: 第二章 学生答 案: [B;] 得分: [10] 试题分 值: 10.0 提示:
3.进行百货商店工作人员普查,调查对象是( )。 A.各百货商店 B.各百货商店全体工作人员 C.一个百货商店 D.每位工作人员 知识点: 第二章 学生答 [B;] 案:
得分: [10] 试题分 值: 10.0 提示: 4.变量数列中各组频率之和是( )。 A.不等于l B.大于1 C.小于1 D.等于l 知识点: 第三章 学生答 案: [D;] 得分: [10] 试题分 值: 10.0 提示: 5.统计表的结构,从其外形看,是由( )。 A.标题和数字资料两部分构成 B.标题、横行、纵栏标目三部分构成 C.横行和纵栏数字资料构成 D.标题、横纵、纵栏、数字资料等部分构成 知识点: 第三章 学生答 案: [D;] 得分: [10] 试题分 值: 10.0 提示: 6.在全距一定的情况下,组距的大小与组数多少( )。
A.成正比 B.成反比 C.无比例关系 D.有时成正比,有时成反比 知识点: 第三章 学生答 案: [B;] 得分: [10] 试题分 值: 10.0
教育统计学与SPSS名解总结
第一章导论(阅览前必读:书上每个章节后的名解我全都列出来了,黑色字体的都是书上原文,量多,但有些不重要的名解没必要背,你挑着背不要被吓到。绿色是章节题目,红色的就是我的一些说明、补充、吐槽,一个人打字很无聊啊有木有!一直自言自语啊有木有!并非书上的名词解释,看看就好,可删。这段紫色的也删了哈。接下来……正文,走你!) 统计学(statistics):即研究统计原理与方法的科学。 教育统计学(educational statistics):是专门研究如何搜集、整理、分析在心理和教育方面有实验或调查所获得的数字资料,如何根据这些资料所传递的信息,进行数学推论,找出客观规律的一门学科。简言之,教育统计学是运用统计学的一般原理和方法研究教育科学领域数量关系的一门科学。 描述统计(descriptiive statistics):是实验或调查所获得的数据加以整理(如制表、绘图),并计算其各种代表量数(如集中量数、差异量数、相关量数等),其基本思想是平均。 Or:是研究如何整理心理与教育科学实验或调查得来的大量数据,描述一组数据的全貌,表达一件事物的性质的一种统计方法。 推断统计(inferencial statistics):又称抽样统计,它是根据对部分个体进行观测所得到的信息,通过概括性的分析、论证,在一定可靠程度上去推测相应的团体。 Or:是研究如何通过局部数据所提供的信息,运用概率的理论进行分析论证,在一定可靠程度上推论总体或全局情形的统计方法。这是统计学中的主要内容。 实验设计(experimental statistics):是研究如何更加合理、有效的获得观测资料,如何更正确、更经济、更有效的达到实验目的,以揭示实验中各种变量关系的实验计划。 Or:实验者为了揭示实验中自变量与因变量的关系,在实验之前所制定的实验计划,称为实验设计。他是研究如何科学地、经济地以及更有效地进行实验。 统计常态法则:从总体中随机抽取一部分个体所组成的样本,差不多可以保持总体的特征。 小数永存法则:从总体中抽取的第一个样本中所表现的特性,在其他样本中也会存在。 大量惰性原则:某一事物的某一性质或状态,在反复观察或试验中是保持不变的。 有效数字:是指能影响测量准确性的数字。 随机变量(random variable):在统计学中把在取值之前不能预料到取什么值的量称为变量(随机变量)。 数据(data):如果一旦某个数值被取定了,成这个数值为随机变量的一个观察值,即数据。 总体(population):指客观存在的,并在同一性质的基础上结合起来的许多个别单位的整体,即具有某一特性的一类事物的全体,又叫母体或全域。 个体(individual): 构成总体的基本单位或单元,又称元素或个案。 样本(sample):从总体中抽取的一部分个体。 参数(parameter):表示总体特征的量数。 统计量(statistic):是直接从样本计算出的量数,代表样本的特征。
川大2019《统计学》第一次作业-答案.docx
你的得分:100.0 完成日期:2019年07月28日14点47分 说明:每道小题选项旁的标识是标准答案。 一、单项选择题。本大题共20个小题,每小题2.5 分,共50.0分。在每小题给出的选项中,只有一项是符合题目要求的。 1.一个研究者应用有关车祸的统计数据估计在车祸中死亡的人数,在这个例子中使用的统计属于()。 A.推断统计学 B.描述统计学 C.既是描述统计学,又是推断统计学 D.既不是描述统计学,有不是推断统计学 2.某研究部门准备在全市200万个家庭中抽取2000个家庭,推断该城市所有职工家庭的年人均收入。这项 研究的总体是()。 A.2000个家庭 B.200万个家庭 C.2000个家庭的年人均收入 D.200万个家庭的总收入 3.对某地区5000个企业的企业注册类型、产值和利润总额等调查数据进行分析,下列说法中正确的是 ()。 A.企业注册类型是定序变量 B.利润总额是品质标志 C.产值是定类变量 D.产值和利润总额都是连续变量 4.为了了解居民对小区物业服务的意见和看法,管理人员随机抽取了50户居民,上门通过问卷进行调查。这 种数据收集方法称为()。 A.面访式问卷调查 B.实验调查 C.观察式调查 D.自填式问卷调查 5.对同一总体选择两个或两个以上标志重叠起来进行分组,称为()。 A.简单分组 B.平行分组 C.一次性分组 D.复合分组 6.统计表的横行标题表明()。 A.全部统计资料的内容 B.研究总体及其组成部分 C.总体特征的统计指标的名称 D.现象的具体数值 7.下列指标属于比例相对指标的是()。 A.2000年北京市失业人员再就业率为73% B.三项社会保险统筹基金收缴率95% C.北京人口性别比为103 D.北京每百户居民拥有电脑32台 8.一组数据排序后处于25%和75%的位置上的值称为()。 A.众数 B.中位数 C.四分位数
《统计分析与SPSS的应用(第五版)》课后练习标准答案(第2章)
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第2章SPSS数据文件的建立和管理 1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么? SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。 ●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的 统计指标。 ●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总 后的数据。 2、什么是SPSS的个案?什么SPSS的变量? 个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。 变量:数据编辑器窗口中的一列。 3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明? 默认的变量名:VAR------;默认的变量类型:数值型。 变量名标签和变量值标签可增强统计分析结果的可读性。 4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料? 产品类型体重变化情况 明显减轻无明显变化 第一种产品2719 第二种产品20 33 问:在SPSS中应如何组织该数据? 数据文件如图所示: 5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值? 缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing
Value)。用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“?”。在变量视图中定义。 6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。如何在SPSS中指定变量的计算尺度? 变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。在变量视图中定义。 7、有一份关于居民储蓄调查的模拟数据存储在Excel中,文件名为“居民储蓄调查数据.xls”。该数据的第一行是变量名,格式如下图所示。请将该份数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签。(该份数据的具体含义见Excel文件的后半部分) 【文件(F)】→【打开(O)】→【数据(A)】→文件类型选“Excel(*.xls,…)”,文件名选“居民储蓄调查数据.xls”→【打开】→选中“从第一行数据读取变量名”,在“范围” 中输入“A1:Q283”→【确定】→在“变量视图”窗口,调整A1变量的宽度,输入变量名标签和变量值标签→在主菜单窗口选定【文件(F)】→【保存】→选择保存路径,保存类型为“sav”,文件名为“居民储蓄调查数据”→【保存】. 8、现有股民投资状况调查的文本数据,文件名为“股民投资数据.txt”。其中各变量的含义和编码见文件“股民投资数据.xls”。请将该文本数据读入SPSS,并定义变量名标签和变量值标签。其中各变量取值为9的均为用户缺失值,请加以定义说明。(注:本调查问卷中涉及多选项问题,以及多选项问题的编码等,可先忽略。) 【文件(F)】→【打开文本数据(D)】→【数据(A)】→文件类型选“Text(*.txt,…)”,文件名选“股民投资数据.txt”,【打开】→在“您的文本文件与预定义的格式匹配吗?”中选“否”,【下一步】→在“变量名称是否包括在文件的顶部”中选“是”,【下一步】→在“第一个数据个案从哪个行号开始”中输入“2”,其他默认,【下一步】→【下一步】→在“数据格式”中输入“字符串”,接着在弹出的窗口输入“4”,【下一步】→默认各选项,【完成】→在主菜单窗口选定【文件(F)】→【保存】→选择保存路径,保存类型为“sav”,文件名为“股民投资数据”→【保存】.
川大2019《统计学》第一次作业 答案
您得得分: 100、0 完成日期:2019年07月28日14点47分 说明:每道小题选项旁得标识就是标准答案。 一、单项选择题。本大题共20个小题,每小题2、5 分,共50、0分。在每小题给出得选项中,只有一项就是符合题目要求得。 1.一个研究者应用有关车祸得统计数据估计在车祸中死亡得人数,在这个例子中使用得统计属于( )。 A.推断统计学 B.描述统计学 C.既就是描述统计学,又就是推断统计学 D.既不就是描述统计学,有不就是推断统计学 2.某研究部门准备在全市200万个家庭中抽取2000个家庭,推断该城市所有职工家庭得年人均收入。这项研 究得总体就是( )。 A.2000个家庭 B.200万个家庭 C.2000个家庭得年人均收入 D.200万个家庭得总收入 3.对某地区5000个企业得企业注册类型、产值与利润总额等调查数据进行分析,下列说法中正确得就是( )。 A.企业注册类型就是定序变量 B.利润总额就是品质标志 C.产值就是定类变量 D.产值与利润总额都就是连续变量 4.为了了解居民对小区物业服务得意见与瞧法,管理人员随机抽取了50户居民,上门通过问卷进行调查。这种 数据收集方法称为( )。 A.面访式问卷调查 B.实验调查 C.观察式调查 D.自填式问卷调查 5.对同一总体选择两个或两个以上标志重叠起来进行分组,称为( )。 A.简单分组 B.平行分组 C.一次性分组 D.复合分组 6.统计表得横行标题表明( )。 A.全部统计资料得内容 B.研究总体及其组成部分 C.总体特征得统计指标得名称 D.现象得具体数值 7.下列指标属于比例相对指标得就是( )。 A.2000年北京市失业人员再就业率为73% B.三项社会保险统筹基金收缴率95% C.北京人口性别比为103 D.北京每百户居民拥有电脑32台 8.一组数据排序后处于25%与75%得位置上得值称为( )。 A.众数 B.中位数 C.四分位数 D.算术平均数
统计学 SPSS作业
频率 统计量 XB性别MRC月消费金额 N 有效126 126 缺失0 0 频率表 XB性别 频率百分比有效百分比累积百分比 有效 A.男65 51.6 51.6 51.6 A.女61 48.4 48.4 100.0 合计126 100.0 100.0 MRC月消费金额 频率百分比有效百分比累积百分比 有效 A.300元-400元 1 .8 .8 .8 B.401元-600元9 7.1 7.1 7.9 C.601元-1000元77 61.1 61.1 69.0 D.1000元以上39 31.0 31.0 100.0 合计126 100.0 100.0
通过以上交叉表可知,男性日常用品花费在41-60元和61-100元这两个区间所占比 游程检验 2 XB性别NL年龄 检验值a 1.48 19.59 案例 < 检验值65 70 案例 >= 检验值61 56 案例总数126 126 Runs 数8 35 Z -10.017 -5.112 渐近显著性(双侧) .000 .000 a. 均值 从上图中可以知道图中显示性别的分割点分别为1和1.48,,SPSS计算出游程数分别共有1和8,表格中年龄所使用的分割点为均数19和19.59,而不是原先的中位数20,导致游程增加到46和35.
可见在年龄为21时样本的信心指数均值为1.8556,低于基线水平100.样本均数抽样误差为0.13216 由上面的检验结果t=-742.635 p=0 由于p值小于检验水准0.05。因此拒绝H0,所以样本所在的均值与假设的在总体均值相同。
分析结果的第一部分为Levene’s方差齐性检验,用于判别两总体方差是否为齐性方差,这里的检测结果为F=10.975,P=0.006,因此拒绝Ho,认为本例中两个样本所在总体的方差是不齐的。 相关性 控制变量NL年龄YY MRC月消费金额NL年龄相关性 1.000 . 显著性(双侧). . df 0 15 YY 相关性. 1.000 显著性(双侧). . df 15 0 在控制了月消费金额之后计算出的年龄和总指数的偏相关矩阵,可见两者的偏相关系数为1。 G图
统计学基础第一次作业
统计学基础第一次作业 一、填空题 1、按照所采用的计量尺度不同,可以将统计数据分为_分类数据_、_顺序数据_和_数值型 数据_。 2、按照数据的收集方法的不同,可将统计数据分为_观测数据_和__实验数据_。 3、按照被描述的对象与时间的关系,可将统计数据分为_截面数据__和_时间序列数 4、体重的数据类型是:clear all。 5、民族的数据类型是:CHAR。 6、空调销量的数据类型是:电器。 7、支付方式(购买商品)的数据类型是:分类变量。 8、学生对教学改革的态度(赞同、中立、反对)的数据类型是:顺序数据。 9、从总体中抽出的一部分元素的集合,称为___样本_____。 10、参数是用来描述_总体特征_______的概括性数字度量;而用来描述样本特征的概括 性数字度量,称为___统计量_____。 11、参数是用来描述_总体特征_的概括性数字度量;而用来描述样本特征的概括性数字 度量,称为_统计量_。 12、统计数据有两种不同来源:一是_直接来源__,二是__间接来源___。 13、统计数据的误差有两种类型,即__抽样误差_和_非抽样误差。 14、统计表由_数据__、__表头__、___行标题_和__列标题__四个部分组成。 15、统计分组应遵循“不____重_____不__漏_______”、“___上限______不在组内”的 原则。 16、按取值的不同,数值型变量可分为_离散型变量__和_连续型变量_。 17、在数据分组中,_离散型变量_______可以进行单变量值分组,也可以进行组距分组, 而___连续型变量_____只能进行组距式分组。 18、组距分组中,向上累积频数是指某组_上限以下_的频数之和。 19、将某地区100个工厂按产值多少分组而编制的频数分布中,频数是_各组的工厂数 __。 20、频数分布中,靠近中间的变量值分布的频数少,靠近两端的变量值分布频数多,这
统计学实验报告1
统计学实验报告1 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
实验报告
二、打开文件“数据 3.XLS”中“城市住房状况评价”工作表,完成以下操作。 1)通过函数,计算出各频率以及向上累计次数和向下累计次数;2)根据两城市频数分布数据,绘制出两城市满意度评价的环形图三、打开文件“数据 3.XLS”中“期末统计成绩”工作表,完成以下操作。 1)要求根据数据绘制出雷达图,比较两个班考试成绩的相似情况。 实验过程: 实验任务一: 1)利用函数frequency制作一张频数分布表 步骤1:打开文件“数据 3. XLS”中“某公司4个月电脑销售情况”工作表 步骤 2.在“频率(%)”的右侧加入一列“分组上限”,因统计分组采用“上限不在内”,故每组数据的上限都比真正的上限值小0.1,例如:“140-150”该组的上限实际值应为“150”,但我们为了计算接下来的频数取“149.9”. 步骤3.选定C20:C29,再选择“插入函数”按钮 3 步骤 4.选择类别“统计”—选择函数“FREQUENCY”
步骤5.在“data_array”对话框中输入“A2:I13”,在“bins_array”对话框中输入“E20:E29 该函数的第一个参数指定用于编制分布数列的原始数据,第二个参数指定每一组的上限. 步骤6.选定C20:C30区域,再按“自动求和” 按钮,即可得到频数的合计
步骤7.在D20中输入“=(C20/$C$30)*1OO” 步骤8:再将该公式复制到D21:D29中,并按“自动求和”按钮计算得出所有频率的合计。
教育统计学 SPSS练习题
1.某学校初中一年级80名学生的数学考试成绩如下,制作频数分布表和图形并作频数分布分析。 某校初一年级80名学生的数学考试成绩 88,89,90,72,89,88,84,83,92,86 90,86,76,87,91,90,90,74,85,84 90,85,89,76,77,85,93,91,81,84 91,83,80,85,87,86,87,84,89,91 84,89,88,84,83,95,85,89,89,89 80,95,83,91,86,87,92,93,89,73 95,82,87,89,80,70,85,85,68,83 82,89,88,85,90,89,80,90,77,72 2.将第1题中的80名学生的数学考试成绩分成0-60,60-70,70-80,80-90,90-100五段,进行分段频数统计,并绘制频数分布条形图 3.某班学生政治面貌分布情况为:党员21人,团员35人,群众43人,请绘制统计图。 4.某班学生政治面貌分布情况为:党员21人(其中男生11人,女生10人),团员35人(其中男生15人,女生20人),群众43人(其中男生23人,女生20人),请绘制统计图。 5.某职业技术学院2000年对其240名学生家长的职业调查结果如下:公务员58人,医生26人,军人15人,工人90人,个体工商业主45人,教师6人,请据此绘制一个圆形图。 6.对15名初三学生用一套初中数学水平测验试卷进行测试,其测验得分如下,另以这些学生的校内数学期末考试成绩为效标,试计算初中数学水平测验的效标关联效度系数。 学生序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 水平测验得分56 73 65 78 64 77 90 61 54 75 45 72 88 95 61 期末成绩63 65 70 74 68 85 92 64 59 70 50 79 90 91 65 7.某大学一年级12名学生的英语阅读理解能力测验成绩与其平时阅读作业成绩如下表所列,试计算阅读理解能力测验的效标关联效度系数。 学生序号 1 2 3 4 5 6 7 8 9 10 11 12 测验得分32 33 34 34 36 37 38 39 40 41 43 45 作业成绩(等级)6 4 2 7 5 9 1 3 11 12 10 8 8. 从某班学生中随机抽取15名,测得他们的数学成绩如下: 65,77,80,78,89,90,74,73,89,95,83,56,68,92,82 (1)试对该班学生的数学平均成绩和成绩的离散程度作出估计。 (2)试求该班成绩均值的95%和99%的置信区间。 9.已知某年级学生的语文成绩服从正态分布,其中总体平均数为76.9,标准差未知。现从该年级某班随机抽取16名学生的语文成绩,数据如下: 75,88,73,93,85,76,68,90,61,58,78,89,95,77,60,74,问该班学生的平均语文成绩是否也是76.9?(α=0.01)
四川大学《应用统计学》第一次作业答案
首页-我的作业列表- 欢迎你, 你的得分:94.0 完成日期: 2018年06月12日09点20分 说明:每道小题选项旁的标识是标准答 一、单项选择题。本大题共20个小题,每小题4.0分,共80.0分。在每小题给出的选项中,只有一项是符合题目要求的。 1. 要了解某企业职工的文化水平情况,则总体单位是() A. 该企业的全部职工 B. 该企业每一个职工的文化程度 C. 该企业的每一个职工 D. 该企业全部职工的平均文化程度 2. 属于品质标志的是() A. 变量 B. 指标 C. 标志 D.变异 3. 从标志角度看,变量是指() A. 可变的数量标志 B. 可变的数量标志值 C. 可变的品质标志 D. 可变的属性标志值 4. 某工人月工资150元,则“工资”是() A. 数量标志 B. 品质标志 C. 质量标志 《应用统计学》第一次作业答案
5. 标志与指标的区别之一是() A. 标志是说明总体特征的;指标是说明总体单位的特征 B. 指标是说明总体特征的;标志是说明总体单位的特征。 C. 指标是说明有限总体特征的;标志是说明无限总体特征 的。 D. 指标是说明无限总体特征的;标志是说明有限总体特征 的。 6. 乡镇企业局为总结推广先进生产管理经验,选择几个先进乡镇企业进行调查,这种调查属于 ()。 A. 抽样调查 B. 典型调查 C. 重点调查 D. 普查 7. 下列各项中属于全面调查的是() A. 抽样调查 B. 重点调查 C. 典型调查 D. 快速普查 8. 人口普查规定统一的时间是为了() A. 避免登记的重复和遗漏 B. 具体确定调查单位 C. 确定调查对象的范围 D. 为了统一调查时间,一起行动 9. 调查鞍钢、武钢、宝钢等十几个大型钢铁公司就可以了解我国钢铁生产的基本情况。这种调 查方式是()。 A. 典型调查 B. 重点调查 C. 抽样调查
《统计分析与SPSS的应用(第五版)》课后练习答案解析(第4章)
WORD 格式整理 《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第 4 章 SPSS基本统计分析 1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。 分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。 Statistics 户口所在职业年龄 地 Valid282282282 N Missing 000 户口所在地 Frequency Percent Valid Cumulative Percent Percent 中心城市20070.970.970.9 Valid 边远郊区8229.129.1100.0 Total282100.0100.0 职业 Frequency Percent Valid Cumulative Percent Percent 国家机关248.58.58.5 商业服务业5419.119.127.7 文教卫生18 6.4 6.434.0 公交建筑业15 5.3 5.339.4 Valid 经营性公司18 6.4 6.445.7学校15 5.3 5.351.1 一般农户3512.412.463.5 种粮棉专业 4 1.4 1.464.9 户
WORD 格式整理 种果菜专业 10 3.5 3.568.4 户 工商运专业 3412.112.180.5户 退役人员17 6.0 6.086.5 金融机构3512.412.498.9 现役军人3 1.1 1.1100.0 Total282100.0100.0 年龄 Frequency Percent Valid Cumulative Percent Percent 20 岁以下4 1.4 1.4 1.4 20~35 岁14651.851.853.2 Valid 35~50 岁9132.332.385.5 50 岁以上4114.514.5100.0 Total282100.0100.0
卫生统计学第一次作业及参考答案
卫生统计学第一次作业 及参考答案 Company Document number:WTUT-WT88Y-W8BBGB-BWYTT-19998
【补充选择题】A型题 1.统计资料的类型可以分为 A定量资料和等级资料B分类资料和等级资料 C正态分布资料和离散分布的资料D定量资料和分类资料 E二项分布资料和有序分类资料 2.下列符号中表示参数的为 A S B u C D t E X 3.统计学上所说的随机事件发生的概率P,其取值范围为 A P≤1 B P≥1 C P≥0 D1≥P≥0E1>P>0 4.小概率事件在统计学上的含义是 A指的是发生概率P≤的随机事件 B指一次实验或者观察中绝对不发生的事件 C在一次实验或者观察中发生的可能性很小的事件,一般指P≤ D以上说法均不正确 EA和C正确 5.描述定量资料集中趋势的指标有 A均数、几何均数、变异系数B均数、几何均数、四分位数间距 C均数、变异系数、几何均数D均数、四分位数间距、变异系数 E均数、几何均数、中位数 6.关于频数表的说法正确的是 A都分为10个组段
B每一个组段必须组距相等 C从频数表中可以初步看出资料的频数分布类型 D不是连续型的资料没有办法编制频数表 E频数表中的每一个组段不一定是半开半闭的区间,可以任意指定 7.关于偏态分布资料说法不正确的是 A正偏态资料的频数分布集中位置偏向数值大的一侧 B负偏态资料的频数分布集中位置偏向数值大的一侧 C偏态分布资料频数分布左右不对称 D不宜用均数描述其集中趋势 E不宜用变异系数来描述其离散程度 8.对于一个两端都没有确切值的资料,宜用下列哪个指标来描述其集中趋势A几何均数B均数C方差 D中位数E四分位数间距 9.下列关于标准差的说法中哪种是错误的 A对于同一个资料,其标准差一定小于均数 B标准差一定大于0 C同一个资料的标准差可能大于均数,也可能小于均数 D标准差可以用来描述正态分布资料的离散程度 E如果资料中观察值是有单位的,那么标准差一定有相同单位 10.下列关于标准差S和样本含量n的说法,正确的是 A同一个资料,其他条件固定不变,随着n增大,S一定减小 B同一个资料,即使其他条件固定不变,随着n增大,也不能确定S一定减小C同一个资料,其他条件固定不变,随着n增大,S一定增大
统计学实验报告【最新】
统计学实验报告 一、实验主题:大学生专业与实习工作的关系 二、实验背景: 二十一世纪的今天大学生已是一个普遍的社会群体,高校毕业人数日益增加,社会、企业所提供的职位日益紧张,大学生就业问题是当今社会关注的焦点。面对日益沉重的就业压力,越来越多的大学毕业生选择了企业需求的职业,而这种职业与自己在校所学专业根本“无关”或相去甚远,大学毕业生就业专业不对口的现象非常严重。专业对口是个广义的概念,就是说你所学的专业与你所作的工作相关,比如你专业是会计,工作后你到了一个企业做会计,或者到银行做柜员,这都是与经济相关的,这就是对口。如果你学机械设计,但工作后却做了统计员,业务员等于你所学专业无关的工作,这就叫专业不对口。专业不对口导致毕业生所学知识没有用武之地,所以这是一种人力资源的浪费。 三、实验目的: 大学生就业专业不对口是客观存在的问题,我们研究此问题有这几点目的:①了解当代大学生实习工作与专业是否对口的情况,当代大学生对工作与专业不对口现象的态度。②分析大学生就业结构和
专业对口问题,了解当今大学生专业对口情况,为以后大学生选择专业、选择工作岗位提供有效的信息和借鉴。③寻找导致专业不对口的原因,以减少社会普遍存在的人力资源的浪费。 四、实验要求:就相关问题收集一定数量的数据,用EXCEL进行如下 分析:1进行数据筛选、排序、分组;2、制作饼图并进行简要解释;3、制作频数分布图,直方图等并进行简要解释。 五、实验设备及材料:计算机,手机,EXCEL软件,WORD软件。 六、实验过程: (一)制作并发放调查问卷。 (二)收回并统计原始数据:收回了102名大学生填写的调查问卷,并对相关数据进行统计。 (三)筛选与实验相关问题: 1.您的性别( ): A. 男B.女
统计学模拟实验spss 实验报告
(此文档为word格式,下载后您可任意编辑修改!) 目录 第一章数据介绍 (3) 1.1研究问题的提出 (3) 1.2数据的来源 (3) 第二章基本统计分析 (4) 2.1 基本统计分析 (4) 2.1.1 全部变量的频数分析 (4) 2.1.3变量的交差分析 (9) 2.1.5 异常值的检验 (12) 2.2 参数检验 (13) 2.2.1 单样本T检验 (13) 2.2.2 两独立样本T检验 (14) 2.3 相关分析 (14) 2.4 多元线性回归分析 (15) 第三章总结和建议 (21) 3.1 存在的问题 (21) 3.2 如何改进这些不足 (21) 附录A22 附录B22
摘要 当前的消费市场中,大学生作为一个特殊的消费群体正受到越来越大的关注。由于大学生年纪较轻,群体较特别,有着不同于社会其他消费群体的消费心理和行为。一方面,他们有着旺盛的消费需求,另一方面,他们尚未获得经济上的独立,消费受到很大的制约。消费观念的超前和消费实力的滞后,都对他们的消费有很大影响。社会大众对大学生的消费存在种种争议,认为他们出手阔绰。本文从我校大学生消费状况,消费的行为、消费结构、消费倾向和消费观念等方面来分析大学生的消费特征以及怎样提高他们的消费观念和理财能力,引导在校大学生树立正确的消费观。 关键词:大学生消费观;理性;问题;改进;数据分析
第一章数据介绍 1.1研究问题的提出 大学生消费问题日渐成为一个社会广为关注的问题,大学生作为一个特殊的群体,处于校园与社会交界处,脱离了父母,开始经济独立,独自生活。大学是一个精彩的世界,社会生活又是充满诱惑的,对大学生的消费都存在着很大的影响。同时也不免回存在一些非理性的消费问题,导致社会群众对大学生消费状况的批评。为了弄清大学生的消费问题的真实问题本小组成员进行了该项调查主要想弄清楚大学生们平时把钱花在哪里,花多少,影响他们消费的因素有哪些,以及他们在消费中有那些问题,应该怎样的去改造这些问题。 1.2数据的来源 本次分析的数据来源于我校90名不同专业和年级的同学消费情况调查。Spss数据中共包含十一变量,分别是:性别,户口状况,家庭年总收入,月生活费,伙食费占生活费的比例,娱乐占生活费的比列,生活费的来源,消费习惯,消费倾向,消费商品是注重,生活费盈余的处理,消费状况是否满意。通过运用spss统计软件,对变量进行基本统计分析、参数检验、相关分析、回归分析,以了解我校同学在上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 第二章基本统计分析 2.1 基本统计分析 2.1.1 全部变量的频数分析 户口情况频数分析(表一) 频率百分比有效百分比累积百分比 有效城镇17 18.9 18.9 18.9 农村73 81.1 81.1 100.0 合计90 100.0 100.0 从表一中可知被调查的同学中有73人来自农村占总人数的81%,只有17个同学来自城镇占总人数的19%。说明我校学生户口大多数分布在农村,生活水平较低。 性别状况的频数分析(表二) 频率百分比有效百分比累积百分比
《统计分析与SPSS的应用(第五版)》课后练习答案.doc (1)
《统计分析与SPSS的应用(第五版)》课后练习答案 第一章练习题答案 1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案) 英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions) 2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。 ●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据; ●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。 3、SPSS的数据集: ●SPSS运行时可同时打开多个数据编辑器窗口。每个数据编辑器窗口分别显示不同 的数据集合(简称数据集)。 ●活动数据集:其中只有一个数据集为当前数据集。SPSS只对某时刻的当前数据集 中的数据进行分析。 4、SPSS的三种基本运行方式: ●完全窗口菜单方式、程序运行方式、混合运行方式。 ●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按 钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简 洁和直观。 ●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工 编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。该方式适用 于大规模的统计分析工作。 ●混合运行方式:是前两者的综合。 5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名 .spv是结果查看器窗口中的SPSS分析结果文件的扩展名 .sps是语法窗口中的SPSS程序 6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。 7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。概率抽样包括简单随机抽样、系统抽样(等距抽样)、分层抽样(类型抽样)、整群抽样、多阶段抽样等。 ●简单随机抽样(simple random sampling):从包括总体N个单位的抽样框中随机地 抽取n个单位作为样本,每个单位抽入样本的概率是相等的。是最基本的抽样方法,是其它抽样方法的基础。优点:简单、直观,在抽样框完整时,可直接从中抽取样 本,用样本统计量对总体参数进行估计比较方便。局限性:当N很大时,不易构造 抽样框,抽出的单位很分散,给实施调查增加了困难。 ●分层抽样(stratified sampling):将抽样单位按某种特征或某种规则划分为不同 的层,然后从不同的层中独立、随机地抽取样本。优点:保证样本的结构与总体的 结构比较相近,从而提高估计的精度,组织实施调查方便(当层是以行业或行政区 划分时),既可以对总体参数进行估计,也可以对各层的参数进行估计。 ●整群抽样(cluster sampling):将总体中若干个单位合并为组(群),抽样时直接抽 取群,然后对选中群中的所有单位全部实施调查。优点:抽样时只需群的抽样框, 可简化工作量;调查的地点相对集中,节省调查费用,方便调查的实施。缺点:估