linux设备模型

一:前言
Linux设备模型是一个极其复杂的结构体系,在编写驱动程序的时候,通常不会用到这方面的东西,但是。理解这部份内容,对于我们理解linux设备驱动的结构是大有裨益的。我们不但可以在编写程序程序的时候知其然,亦知其所以然。又可以学习到一种极其精致的架构设计方法。由于之前已经详细分析了sysfs文件系统。所以本节的讨论主要集中在设备模型的底层实现上。上层的接口,如pci.,usb ,网络设备都可以看成是底层的封装。
二:kobject ,kset和ktype
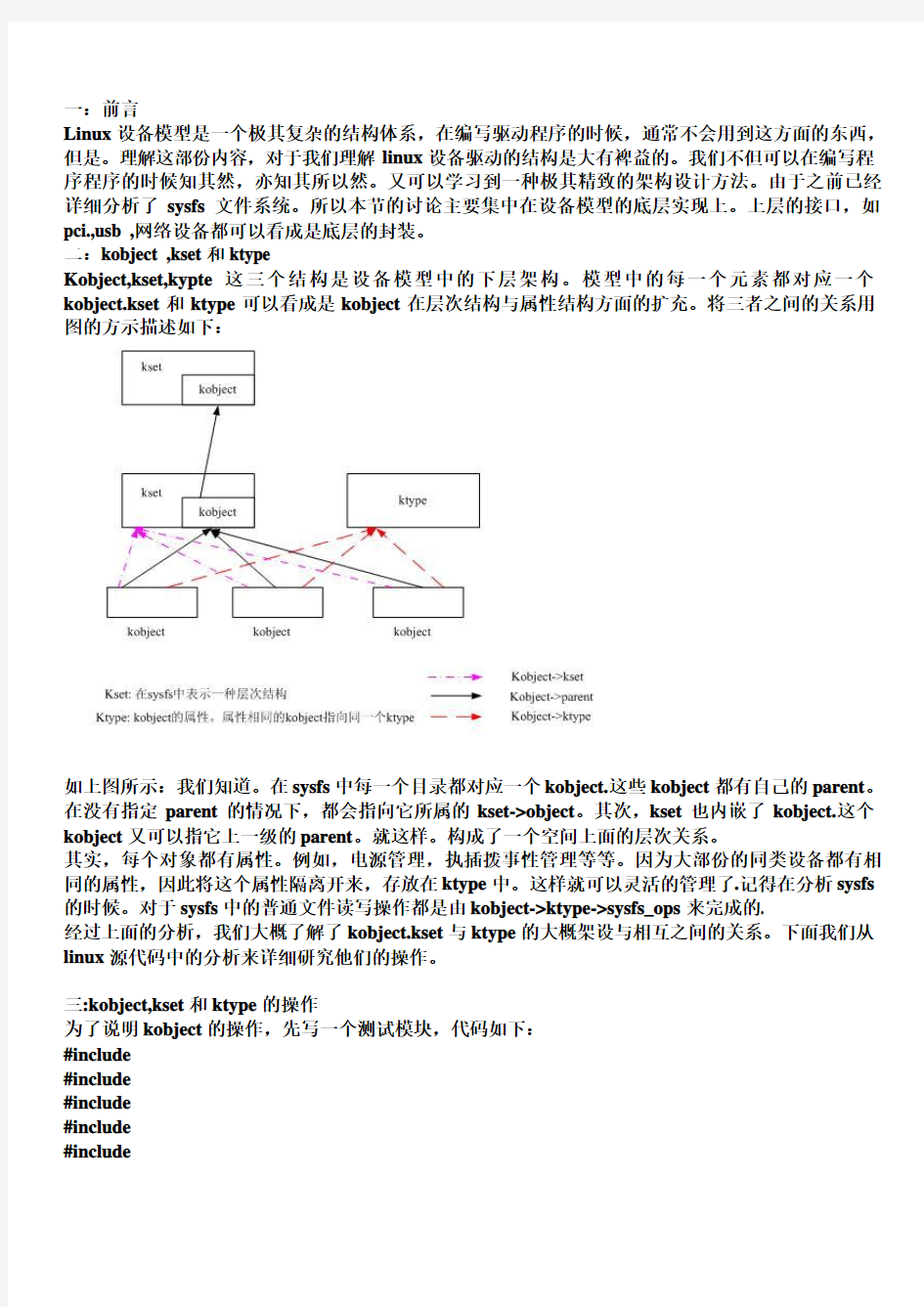
Kobject,kset,kypte这三个结构是设备模型中的下层架构。模型中的每一个元素都对应一个kobject.kset和ktype可以看成是kobject在层次结构与属性结构方面的扩充。将三者之间的关系用图的方示描述如下:
如上图所示:我们知道。在sysfs中每一个目录都对应一个kobject.这些kobject都有自己的parent。在没有指定parent的情况下,都会指向它所属的kset->object。其次,kset也内嵌了kobject.这个kobject又可以指它上一级的parent。就这样。构成了一个空间上面的层次关系。
其实,每个对象都有属性。例如,电源管理,执插拨事性管理等等。因为大部份的同类设备都有相同的属性,因此将这个属性隔离开来,存放在ktype中。这样就可以灵活的管理了.记得在分析sysfs 的时候。对于sysfs中的普通文件读写操作都是由kobject->ktype->sysfs_ops来完成的.
经过上面的分析,我们大概了解了kobject.kset与ktype的大概架设与相互之间的关系。下面我们从linux源代码中的分析来详细研究他们的操作。
三:kobject,kset和ktype的操作
为了说明kobject的操作,先写一个测试模块,代码如下:
#include
#include
#include
#include
#include
#include
#include
MODULE_AUTHOR("eric xiao");
MODULE_LICENSE("Dual BSD/GPL");
void obj_test_release(struct kobject *kobject);
ssize_t eric_test_show(struct kobject *kobject, struct attribute *attr,char *buf);
ssize_t eric_test_store(struct kobject *kobject,struct attribute *attr,const char *buf, size_t count); struct attribute test_attr = {
.name = "eric_xiao",
.mode = S_IRWXUGO,
};
static struct attribute *def_attrs[] = {
&test_attr,
NULL,
};
struct sysfs_ops obj_test_sysops =
{
.show = eric_test_show,
.store = eric_test_store,
};
struct kobj_type ktype =
{
.release = obj_test_release,
.sysfs_ops=&obj_test_sysops,
.default_attrs=def_attrs,
};
void obj_test_release(struct kobject *kobject)
{
printk("eric_test: release .\n");
}
ssize_t eric_test_show(struct kobject *kobject, struct attribute *attr,char *buf)
{
printk("have show.\n");
printk("attrname:%s.\n", attr->name);
sprintf(buf,"%s\n",attr->name);
return strlen(attr->name)+2;
}
ssize_t eric_test_store(struct kobject *kobject,struct attribute *attr,const char *buf, size_t count) {
printk("havestore\n");
printk("write: %s\n",buf);
return count;
}
struct kobject kobj;
static int kobject_test_init()
{
printk("kboject test init.\n");
kobject_init_and_add(&kobj,&ktype,NULL,"eric_test");
return 0;
}
static int kobject_test_exit()
{
printk("kobject test exit.\n");
kobject_del(&kobj);
return 0;
}
module_init(kobject_test_init);
module_exit(kobject_test_exit);
加载模块之后,会发现,在/sys下多了一个eric_test目录。该目录下有一个叫eric_xiao的文件。如下所示:
[root@localhost eric_test]# ls
eric_xiao
用cat察看此文件:
[root@localhost eric_test]# cat eric_xiao
eric_xiao
再用echo往里面写点东西;
[root@localhost eric_test]# echo hello > eric_xiao
Dmesg的输出如下:
have show.
attrname:eric_xiao.
havestore
write: hello
如上所示。我们看到了kobject的大概建立过程.我们来看一下kobject_init_and_add()的实现。在这个函数里,包含了对kobject的大部份操作。
int kobject_init_and_add(struct kobject *kobj, struct kobj_type *ktype,
struct kobject *parent, const char *fmt, ...)
{
va_list args;
int retval;
//初始化kobject
kobject_init(kobj, ktype);
va_start(args, fmt);
//为kobjcet设置名称,在sysfs中建立相关信息
retval = kobject_add_varg(kobj, parent, fmt, args);
va_end(args);
return retval;
}
上面的流程主要分为两部份。一部份是kobject的初始化。在这一部份,它将kobject与给定的ktype 关联起来。初始化kobject中的各项结构。另一部份是kobject的名称设置。空间层次关系的设置,具体表现在sysfs文件系统中.
对于第一部份,代码比较简单,这里不再赘述。跟踪第二部份,也就是kobject_add_varg()的实现. static int kobject_add_varg(struct kobject *kobj, struct kobject *parent,
const char *fmt, va_list vargs)
{
va_list aq;
int retval;
va_copy(aq, vargs);
//设置kobject的名字。即kobject的name成员
retval = kobject_set_name_vargs(kobj, fmt, aq);
va_end(aq);
if (retval) {
printk(KERN_ERR "kobject: can not set name properly!\n");
return retval;
}
//设置kobject的parent。在上面的例子中,我们没有给它指定父结点
kobj->parent = parent;
//在sysfs中添加kobjcet信息
return kobject_add_internal(kobj);
}
设置好kobject->name后,转入kobject_add_internal()。在sysfs中创建空间结构.代码如下:static int kobject_add_internal(struct kobject *kobj)
{
int error = 0;
struct kobject *parent;
if (!kobj)
return -ENOENT;
//如果kobject的名字为空.退出
if (!kobj->name || !kobj->name[0]) {
pr_debug("kobject: (%p): attempted to be registered with empty "
"name!\n", kobj);
WARN_ON(1);
return -EINV AL;
}
//取kobject的父结点
parent = kobject_get(kobj->parent);
//如果kobject的父结点没有指定,就将kset->kobject做为它的父结点/* join kset if set, use it as parent if we do not already have one */
if (kobj->kset) {
if (!parent)
parent = kobject_get(&kobj->kset->kobj);
kobj_kset_join(kobj);
kobj->parent = parent;
}
//调试用
pr_debug("kobject: '%s' (%p): %s: parent: '%s', set: '%s'\n",
kobject_name(kobj), kobj, __FUNCTION__,
parent ? kobject_name(parent) : "
kobj->kset ? kobject_name(&kobj->kset->kobj) : "
//在sysfs中创建kobject的相关元素
error = create_dir(kobj);
if (error) {
//v如果创建失败。减少相关的引用计数
kobj_kset_leave(kobj);
kobject_put(parent);
kobj->parent = NULL;
/* be noisy on error issues */
if (error == -EEXIST)
printk(KERN_ERR "%s failed for %s with "
"-EEXIST, don't try to register things with "
"the same name in the same directory.\n",
__FUNCTION__, kobject_name(kobj));
else
printk(KERN_ERR "%s failed for %s (%d)\n",
__FUNCTION__, kobject_name(kobj), error);
dump_stack();
} else
//如果创建成功。将state_in_sysfs建为1。表示该object已经在sysfs中了
kobj->state_in_sysfs = 1;
return error;
}
这段代码比较简单,它主要完成kobject父结点的判断和选定,然后再调用create_dir()在sysfs 创建相关信息。该函数代码如下:
static int create_dir(struct kobject *kobj)
{
int error = 0;
if (kobject_name(kobj)) {
//为kobject创建目录
error = sysfs_create_dir(kobj);
if (!error) {
//为kobject->ktype中的属性创建文件
error = populate_dir(kobj);
if (error)
sysfs_remove_dir(kobj);
}
}
return error;
}
我们在上面的示例中看到的/sys下的eric_test目录,以及该目录下面的eric_xiao的这个文件就是这里被创建的。我们先看一下kobject所表示的目录创建过程。这是在sysfs_create_dir()中完成的。代码如下:
int sysfs_create_dir(struct kobject * kobj)
{
struct sysfs_dirent *parent_sd, *sd;
int error = 0;
BUG_ON(!kobj);
/*如果kobject的parnet存在。就在目录点的目录下创建这个目录。如果没有父结点不存在,就在/sys下面创建结点。在上面的流程中,我们可能并没有为其指定父结点,也没有为其指定kset。*/
if (kobj->parent)
parent_sd = kobj->parent->sd;
else
parent_sd = &sysfs_root;
//在sysfs中创建目录
error = create_dir(kobj, parent_sd, kobject_name(kobj), &sd);
if (!error)
kobj->sd = sd;
return error;
}
在这里,我们就要联系之前分析过的sysfs文件系统的研究了。如果不太清楚的,可以在找到那篇文章仔细的研读一下。create_dir()就是在sysfs中创建目录的接口,在之前已经详细分析过了。这里不再讲述。
接着看为kobject->ktype中的属性创建文件。这是在populate_dir()中完成的。代码如下:static int populate_dir(struct kobject *kobj)
{
struct kobj_type *t = get_ktype(kobj);
struct attribute *attr;
int error = 0;
int i;
if (t && t->default_attrs) {
for (i = 0; (attr = t->default_attrs[i]) != NULL; i++) {
error = sysfs_create_file(kobj, attr);
if (error)
break;
}
}
return error;
}
这段代码比较简单。它遍历ktype中的属性。然后为其建立文件。请注意:文件的操作最后都会回溯到ktype->sysfs_ops的show和store这两个函数中.
Kobject的创建已经分析完了,接着分析怎么将一个kobject注销掉。注意过程是在kobject_del()中完成的。代码如下:
void kobject_del(struct kobject *kobj)
{
if (!kobj)
return;
sysfs_remove_dir(kobj);
kobj->state_in_sysfs = 0;
kobj_kset_leave(kobj);
kobject_put(kobj->parent);
kobj->parent = NULL;
}
该函数会将在sysfs中的kobject对应的目录删除。请注意,属性文件是建立在这个目录下面的。只需要将这个目录删除。属性文件也随之删除。
是后,减少相关的引用计数,如果kobject的引用计数为零。则将其所占空间释放.
//kset 中的kobject是独立的!!!
Kset的操作与kobject类似,因为kset中内嵌了一个kobject结构,所以,大部份操作都是集中在kset->kobject上.具体分析一下kset_create_and_add()这个接口,类似上面分析的kobject接口,这个接口也包括了kset的大部分操作.代码如下:
struct kset *kset_create_and_add(const char *name,
struct kset_uevent_ops *uevent_ops,
struct kobject *parent_kobj)
{
struct kset *kset;
int error;
//创建一个kset
kset = kset_create(name, uevent_ops, parent_kobj);
if (!kset)
return NULL;
//注册kset
error = kset_register(kset);
if (error) {
//如果注册失败,释放kset
kfree(kset);
return NULL;
}
return kset;
}
Kset_create()用来创建一个struct kset结构.代码如下:
static struct kset *kset_create(const char *name,
struct kset_uevent_ops *uevent_ops,
struct kobject *parent_kobj)
{
struct kset *kset;
kset = kzalloc(sizeof(*kset), GFP_KERNEL);
if (!kset)
return NULL;
kobject_set_name(&kset->kobj, name);
kset->uevent_ops = uevent_ops;
kset->kobj.parent = parent_kobj;
kset->kobj.ktype = &kset_ktype;
kset->kobj.kset = NULL;
return kset;
}
我们注意,在这里创建kset时.为其内嵌的kobject指定其ktype结构为kset_ktype.这个结构的定义如下:
static struct kobj_type kset_ktype = {
.sysfs_ops = &kobj_sysfs_ops,
.release = kset_release,
};
属性文件的读写操作全部都包含在sysfs_ops成员里.kobj_sysfs_ops的定义如下:
struct sysfs_ops kobj_sysfs_ops = {
.show = kobj_attr_show,
.store = kobj_attr_store,
};
Show,store成员对应的函数代码如下所示:
static ssize_t kobj_attr_show(struct kobject *kobj, struct attribute *attr,
char *buf)
{
struct kobj_attribute *kattr;
ssize_t ret = -EIO;
kattr = container_of(attr, struct kobj_attribute, attr);
if (kattr->show)
ret = kattr->show(kobj, kattr, buf);
return ret;
}
static ssize_t kobj_attr_store(struct kobject *kobj, struct attribute *attr,
const char *buf, size_t count)
{
struct kobj_attribute *kattr;
ssize_t ret = -EIO;
kattr = container_of(attr, struct kobj_attribute, attr);
if (kattr->store)
ret = kattr->store(kobj, kattr, buf, count);
return ret;
}
从上面的代码看以看出.会将struct attribute结构转换为struct kobj_attribte结构.也就是说struct kobj_attribte内嵌了一个struct attribute.实际上,这是和宏__ATTR配合在一起使用的.经常用于group中.在这里并不打算研究group.原理都是一样的.这里列出来只是做个说明而已.
创建好了kset之后,会调用kset_register().这个函数就是kset操作的核心代码了.如下:
int kset_register(struct kset *k)
{
int err;
if (!k)
return -EINV AL;
kset_init(k);
err = kobject_add_internal(&k->kobj);
if (err)
return err;
kobject_uevent(&k->kobj, KOBJ_ADD);
return 0;
}
在kset_init()里会初始化kset中的其它字段.然后调用kobject_add_internal()为其内嵌的kobject结构建立空间层次结构.之后因为添加了kset.会产生一个事件.这个事件是通过用户空间的hotplug程序处理的.这就是kset明显不同于kobject的地方.详细研究一下这个函数.这对于我们研究hotplug的深层机理是很有帮助的.它的代码如下;
int kobject_uevent(struct kobject *kobj, enum kobject_action action)
{
return kobject_uevent_env(kobj, action, NULL);
}
之后,会调用kobject_uevent_env().这个函数中的三个参数含义分别为:引起事件的kobject.事件类型(add,remove,change,move,online,offline等).第三个参数是要添加的环境变量.
代码篇幅较长,我们效仿情景分析上面的做法.分段分析如下:
int kobject_uevent_env(struct kobject *kobj, enum kobject_action action,
char *envp_ext[])
{
struct kobj_uevent_env *env;
const char *action_string = kobject_actions[action];
const char *devpath = NULL;
const char *subsystem;
struct kobject *top_kobj;
struct kset *kset;
struct kset_uevent_ops *uevent_ops;
u64 seq;
int i = 0;
int retval = 0;
pr_debug("kobject: '%s' (%p): %s\n",
kobject_name(kobj), kobj, __FUNCTION__);
/* search the kset we belong to */
top_kobj = kobj;
while (!top_kobj->kset && top_kobj->parent)
top_kobj = top_kobj->parent;
if (!top_kobj->kset) {
pr_debug("kobject: '%s' (%p): %s: attempted to send uevent "
"without kset!\n", kobject_name(kobj), kobj,
__FUNCTION__);
return -EINV AL;
}
因为对事件的处理函数包含在kobject->kset-> uevent_ops中.要处理事件,就必须要找到上层的一个不为空的kset.上面的代码就是顺着kobject->parent找不到一个不为空的kset.如果不存在这样的kset.就退出
kset = top_kobj->kset;
uevent_ops = kset->uevent_ops;
/* skip the event, if the filter returns zero. */
if (uevent_ops && uevent_ops->filter)
if (!uevent_ops->filter(kset, kobj)) {
pr_debug("kobject: '%s' (%p): %s: filter function "
"caused the event to drop!\n",
kobject_name(kobj), kobj, __FUNCTION__);
return 0;
}
/* originating subsystem */
if (uevent_ops && uevent_ops->name)
subsystem = uevent_ops->name(kset, kobj);
else
subsystem = kobject_name(&kset->kobj);
if (!subsystem) {
pr_debug("kobject: '%s' (%p): %s: unset subsystem caused the "
"event to drop!\n", kobject_name(kobj), kobj,
__FUNCTION__);
return 0;
}
找到了不为空的kset.就跟kset-> uevent_ops->filter()匹配.看这个事件是否被过滤.如果没有被过滤掉.就会调用kset-> uevent_ops->name()得到子系统的名称,如果不存在kset-> uevent_ops->name().就会以kobject->name做为子系统名称.
/* environment buffer */
env = kzalloc(sizeof(struct kobj_uevent_env), GFP_KERNEL);
if (!env)
return -ENOMEM;
/* complete object path */
devpath = kobject_get_path(kobj, GFP_KERNEL);
if (!devpath) {
retval = -ENOENT;
goto exit;
/* default keys */
retval = add_uevent_var(env, "ACTION=%s", action_string);
if (retval)
goto exit;
retval = add_uevent_var(env, "DEVPATH=%s", devpath);
if (retval)
goto exit;
retval = add_uevent_var(env, "SUBSYSTEM=%s", subsystem);
if (retval)
goto exit;
/* keys passed in from the caller */
if (envp_ext) {
for (i = 0; envp_ext[i]; i++) {
retval = add_uevent_var(env, envp_ext[i]);
if (retval)
goto exit;
}
}
接下来,就应该设置为调用hotplug设置环境变量了.首先,分配一个struct kobj_uevent_env结构用来存放环境变量的值.然后调用kobject_get_path()用来获得引起事件的kobject在sysfs中的路径.再调用add_uevent_var()将动作代表的字串,kobject路径,子系统名称填充到struct kobj_uevent_env中,如果有指定环境变量,也将其添加进去. kobject_get_path()和add_uevent_var()都比较简单.这里不再详细分析了.请自行查看源代码
/* let the kset specific function add its stuff */
if (uevent_ops && uevent_ops->uevent) {
retval = uevent_ops->uevent(kset, kobj, env);
if (retval) {
pr_debug("kobject: '%s' (%p): %s: uevent() returned "
"%d\n", kobject_name(kobj), kobj,
__FUNCTION__, retval);
goto exit;
}
}
/*
* Mark "add" and "remove" events in the object to ensure proper
* events to userspace during automatic cleanup. If the object did
* send an "add" event, "remove" will automatically generated by
* the core, if not already done by the caller.
if (action == KOBJ_ADD)
kobj->state_add_uevent_sent = 1;
else if (action == KOBJ_REMOVE)
kobj->state_remove_uevent_sent = 1;
/* we will send an event, so request a new sequence number */
spin_lock(&sequence_lock);
seq = ++uevent_seqnum;
spin_unlock(&sequence_lock);
retval = add_uevent_var(env, "SEQNUM=%llu", (unsigned long long)seq);
if (retval)
goto exit;
在这里还会调用kobject->kset-> uevent_ops->uevent().让产生事件的kobject添加环境变量.最后将事件序列添加到环境变量中去.
#if defined(CONFIG_NET)
/* send netlink message */
if (uevent_sock) {
struct sk_buff *skb;
size_t len;
/* allocate message with the maximum possible size */
len = strlen(action_string) + strlen(devpath) + 2;
skb = alloc_skb(len + env->buflen, GFP_KERNEL);
if (skb) {
char *scratch;
/* add header */
scratch = skb_put(skb, len);
sprintf(scratch, "%s@%s", action_string, devpath);
/* copy keys to our continuous event payload buffer */
for (i = 0; i < env->envp_idx; i++) {
len = strlen(env->envp[i]) + 1;
scratch = skb_put(skb, len);
strcpy(scratch, env->envp[i]);
}
NETLINK_CB(skb).dst_group = 1;
netlink_broadcast(uevent_sock, skb, 0, 1, GFP_KERNEL);
}
}
#endif
/* call uevent_helper, usually only enabled during early boot */
if (uevent_helper[0]) {
char *argv [3];
argv [0] = uevent_helper;
argv [1] = (char *)subsystem;
argv [2] = NULL;
retval = add_uevent_var(env, "HOME=/");
if (retval)
goto exit;
retval = add_uevent_var(env,
"PATH=/sbin:/bin:/usr/sbin:/usr/bin");
if (retval)
goto exit;
call_usermodehelper(argv[0], argv, env->envp, UMH_WAIT_EXEC);
}
exit:
kfree(devpath);
kfree(env);
return retval;
}
忽略一段选择编译的代码.再后就是调用用户空间的hotplug了.添加最后两个环境变量.HOME和PATH.然后调用hotplug.以子系统名称为参数.
现在我们终于知道hotplug处理程序中的参数和环境变量是怎么来的了.^_^
使用完了kset.再调用kset_unregister()将其注销.这个函数很简单,请自行查阅代码.
为了印证一下上面的分析,写一个测试模块。如下:
#include
#include
#include
#include
#include
#include
#include
#include
MODULE_AUTHOR("eric xiao");
MODULE_LICENSE("Dual BSD/GPL");
int kset_filter(struct kset *kset, struct kobject *kobj);
const char *kset_name(struct kset *kset, struct kobject *kobj);
int kset_uevent(struct kset *kset, struct kobject *kobj,
struct kobj_uevent_env *env);
struct kset kset_p;
struct kset kset_c;
struct kset_uevent_ops uevent_ops =
{
.filter = kset_filter,
.name = kset_name,
.uevent = kset_uevent,
};
int kset_filter(struct kset *kset, struct kobject *kobj)
{
printk("UEVENT: filter. kobj %s.\n",kobj->name);
return 1;
}
const char *kset_name(struct kset *kset, struct kobject *kobj) {
static char buf[20];
printk("UEVENT: name. kobj %s.\n",kobj->name);
sprintf(buf,"%s","kset_test");
return buf;
}
int kset_uevent(struct kset *kset, struct kobject *kobj, struct kobj_uevent_env *env)
{
int i = 0;
printk("UEVENT: uevent. kobj %s.\n",kobj->name);
while( i< env->envp_idx){
printk("%s.\n",env->envp[i]);
i++;
}
return 0;
}
int kset_test_init()
{
printk("kset test init.\n");
kobject_set_name(&kset_p.kobj,"kset_p");
kset_p.uevent_ops = &uevent_ops;
kset_register(&kset_p);
kobject_set_name(&kset_c.kobj,"kset_c");
kset_c.kobj.kset = &kset_p;
kset_register(&kset_c);
return 0;
}
int kset_test_exit()
{
printk("kset test exit.\n");
kset_unregister(&kset_p);
kset_unregister(&kset_c);
return 0;
}
module_init(kset_test_init);
module_exit(kset_test_exit);
在这里,定义并注册了二个kset.第二个kset的kobj->kset域指向第一个kset.这样,当第二个kset 注册或者卸载的时候就会调用第一个kset中的uevent_ops的相关操作.
kset_p.uevent_ops->filter函数中,使其返回1.使其匹配成功。
在kset_p.uevent_ops->name中。使其返回的子系统名为引起事件的kobject的名称,即:kset_c. 最后在kset_p.uevent_ops->uevent中将环境变量全部打印出来。
下面是dmesg的输出结果:
kset test init.
UEVENT: filter. kobj kset_c.
UEVENT: name. kobj kset_c.
UEVENT: uevent. kobj kset_c.
ACTION=add.
DEVPATH=/kset_p/kset_c.
SUBSYSTEM=kset_test.
输出结果跟我们的分析是吻合的.
在这里,值得我们注意的是。注册一个kobject不会产生事件,只有注册kset才会.
四:bus,device和device_driver
上面分析了kobject.kset,ktype.这三个结构联合起来一起构成了整个设备模型的基石.而bus.device.device_driver.则是基于kobject.kset.ktype之上的架构.在这里,总线,设备,驱动被有序的组和在一起.
Bus.device.device_driver三者之间的关系如下图所示:
如上图所示.struct bus_type的p->drivers_kset指向注册在上面的驱动程序.它的p->device_kset上挂着注册在上面的设备.每次有一个新的设备注册到上面,都会去匹配右边的驱动,看是否能匹配上.如果匹配成功,则将设备结构的is_registerd域置为0.然后将设备添加到驱动的p->klist_devices域.同理,每注册一个驱动,都会去匹配左边的设备,.如果匹配成功,将则设备加到驱动的p->klist_devices域.再将设备的is_registerd置为0/
这就是linux设备模型用来管理设备和驱动的基本架构. 我们来跟踪一下代码来看下详细的操作.
注册一个总线的接口为bus_register().我们照例分段分析:
int bus_register(struct bus_type *bus)
{
int retval;
struct bus_type_private *priv;
priv = kzalloc(sizeof(struct bus_type_private), GFP_KERNEL);
if (!priv)
return -ENOMEM;
priv->bus = bus;
bus->p = priv;
BLOCKING_INIT_NOTIFIER_HEAD(&priv->bus_notifier);
retval = kobject_set_name(&priv->subsys.kobj, "%s", bus->name);
if (retval)
goto out;
priv->subsys.kobj.kset = bus_kset;
priv->subsys.kobj.ktype = &bus_ktype;
priv->drivers_autoprobe = 1;
retval = kset_register(&priv->subsys);
if (retval)
goto out;
首先,先为struct bus_type的私有区分配空间,然后将其和struct bus_type关联起来.由于struct bus_type也要在sysfs文件中表示一个节点,因此,它也内嵌也一个kset的结构.这就是priv->subsys.
首先,它为这个kset的名称赋值为bus的名称,然后将priv->subsys.kobj.kset指向bus_kset. priv->subsys.kobj.ktype指向bus_ktype;然后调用kset_reqister()将priv->subsys注册.这里涉及到的接口都在之前分析过.注册过后,应该会在bus_kset所表示的目录下创建一个总线名称的目录.并且用户空间的hotplug应该会检测到一个add事件.我们来看一下bus_kset到底指向的是什么: bus_kset = kset_create_and_add("bus", &bus_uevent_ops, NULL);
从此可以看出.这个bus_kset在sysfs中的结点就是/sys/bus.在这里注册的struct bus_types就会在/sys/bus/下面出现.
retval = bus_create_file(bus, &bus_attr_uevent);
if (retval)
goto bus_uevent_fail;
bus_create_file()就是在priv->subsys.kobj的这个kobject上建立一个普通属性的文件.这个文件的属性对应在bus_attr_uevent.读写操作对应在priv->subsys.ktype中.我们到后面才统一分析bus注册时候的文件创建
priv->devices_kset = kset_create_and_add("devices", NULL,
&priv->subsys.kobj);
if (!priv->devices_kset) {
retval = -ENOMEM;
goto bus_devices_fail;
}
priv->drivers_kset = kset_create_and_add("drivers", NULL,
&priv->subsys.kobj);
if (!priv->drivers_kset) {
retval = -ENOMEM;
goto bus_drivers_fail;
}
klist_init(&priv->klist_devices, klist_devices_get, klist_devices_put);
klist_init(&priv->klist_drivers, NULL, NULL);
这段代码会在bus所在的目录下建立两个目录,分别为devices和drivers.并初始化挂载设备和驱动的链表
retval = add_probe_files(bus);
if (retval)
goto bus_probe_files_fail;
retval = bus_add_attrs(bus);
if (retval)
goto bus_attrs_fail;
pr_debug("bus: '%s': registered\n", bus->name);
return 0;
在这里,会为bus_attr_drivers_probe, bus_attr_drivers_autoprobe.注册bus_type中的属性建立文件bus_attrs_fail:
remove_probe_files(bus);
bus_probe_files_fail:
kset_unregister(bus->p->drivers_kset);
bus_drivers_fail:
kset_unregister(bus->p->devices_kset);
bus_devices_fail:
bus_remove_file(bus, &bus_attr_uevent);
bus_uevent_fail:
kset_unregister(&bus->p->subsys);
kfree(bus->p);
out:
return retval;
}
这段代码为出错处理
这段代码中比较繁锁的就是bus_type对应目录下的属性文件建立,为了直观的说明,将属性文件的建立统一放到一起分析
从上面的代码中可以看,创建属性文件对应的属性分别为:
bus_attr_uevent bus_attr_drivers_probe, bus_attr_drivers_autoprobe
分别定义如下:
static BUS_ATTR(uevent, S_IWUSR, NULL, bus_uevent_store);
static BUS_ATTR(drivers_probe, S_IWUSR, NULL, store_drivers_probe);
static BUS_ATTR(drivers_autoprobe, S_IWUSR | S_IRUGO,
show_drivers_autoprobe, store_drivers_autoprobe);
BUS_ATTR定义如下:
#define BUS_ATTR(_name, _mode, _show, _store) \
struct bus_attribute bus_attr_##_name = __ATTR(_name, _mode, _show, _store)
#define __ATTR(_name,_mode,_show,_store) { \
.attr = {.name = __stringify(_name), .mode = _mode }, \
.show = _show, \
.store = _store, \
}
由此可见.上面这三个属性对应的名称为别为uevent, drivers_probe, drivers_autoprobe.也就是说,会在bus_types目录下生成三个文件,分别为uevent,probe,autoprobe.
根据之前的分析,我们知道在sysfs文件系统中,对普通属性文件的读写都会回溯到kobject->ktype->sysfs_ops中.在这里,注意到有:
priv->subsys.kobj.kset = bus_kset;
priv->subsys.kobj.ktype = &bus_ktype;
显然,读写操作就回溯到了bus_ktype中.定义如下:
static struct kobj_type bus_ktype = {
.sysfs_ops = &bus_sysfs_ops,
};
static struct sysfs_ops bus_sysfs_ops = {
.show = bus_attr_show,
.store = bus_attr_store,
};
Show和store函数对应的代码为:
static ssize_t bus_attr_show(struct kobject *kobj, struct attribute *attr,
char *buf)
{
struct bus_attribute *bus_attr = to_bus_attr(attr);
struct bus_type_private *bus_priv = to_bus(kobj);
ssize_t ret = 0;
if (bus_attr->show)
ret = bus_attr->show(bus_priv->bus, buf);
return ret;
}
static ssize_t bus_attr_store(struct kobject *kobj, struct attribute *attr,
const char *buf, size_t count)
{
struct bus_attribute *bus_attr = to_bus_attr(attr);
struct bus_type_private *bus_priv = to_bus(kobj);
ssize_t ret = 0;
if (bus_attr->store)
ret = bus_attr->store(bus_priv->bus, buf, count);
return ret;
}
从代码可以看出.读写操作又会回溯到bus_attribute中的show和store中.在自定义结构里嵌入struct attribute,.然后再操作回溯到自定义结构中,这是一种比较高明的架构设计手法.
闲言少叙.我们对应看一下上面三个文件对应的最终操作:
Uevent对应的读写操作为:NULL, bus_uevent_store.对于这个文件没有读操作,只有写操作.用cat 命令去查看这个文件的时候,可能会返回”设备不存在”的错误.bus_uevent_store()代码如下:
static ssize_t bus_uevent_store(struct bus_type *bus,
const char *buf, size_t count)
{
enum kobject_action action;
if (kobject_action_type(buf, count, &action) == 0)
kobject_uevent(&bus->p->subsys.kobj, action);
return count;
}
Linux设备驱动程序举例
Linux设备驱动程序设计实例2007-03-03 23:09 Linux系统中,设备驱动程序是操作系统内核的重要组成部分,在与硬件设备之间 建立了标准的抽象接口。通过这个接口,用户可以像处理普通文件一样,对硬件设 备进行打开(open)、关闭(close)、读写(read/write)等操作。通过分析和设计设 备驱动程序,可以深入理解Linux系统和进行系统开发。本文通过一个简单的例子 来说明设备驱动程序的设计。 1、程序清单 //MyDev.c 2000年2月7日编写 #ifndef __KERNEL__ #define __KERNEL__//按内核模块编译 #endif #ifndef MODULE #define MODULE//设备驱动程序模块编译 #endif #define DEVICE_NAME "MyDev" #define OPENSPK 1 #define CLOSESPK 2 //必要的头文件 #include
一个简单的演示用的Linux字符设备驱动程序.
实现如下的功能: --字符设备驱动程序的结构及驱动程序需要实现的系统调用 --可以使用cat命令或者自编的readtest命令读出"设备"里的内容 --以8139网卡为例,演示了I/O端口和I/O内存的使用 本文中的大部分内容在Linux Device Driver这本书中都可以找到, 这本书是Linux驱动开发者的唯一圣经。 ================================================== ===== 先来看看整个驱动程序的入口,是char8139_init(这个函数 如果不指定MODULE_LICENSE("GPL", 在模块插入内核的 时候会出错,因为将非"GPL"的模块插入内核就沾污了内核的 "GPL"属性。 module_init(char8139_init; module_exit(char8139_exit; MODULE_LICENSE("GPL"; MODULE_AUTHOR("ypixunil"; MODULE_DESCRIPTION("Wierd char device driver for Realtek 8139 NIC"; 接着往下看char8139_init( static int __init char8139_init(void {
int result; PDBG("hello. init.\n"; /* register our char device */ result=register_chrdev(char8139_major, "char8139", &char8139_fops; if(result<0 { PDBG("Cannot allocate major device number!\n"; return result; } /* register_chrdev( will assign a major device number and return if it called * with "major" parameter set to 0 */ if(char8139_major == 0 char8139_major=result; /* allocate some kernel memory we need */ buffer=(unsigned char*(kmalloc(CHAR8139_BUFFER_SIZE, GFP_KERNEL; if(!buffer { PDBG("Cannot allocate memory!\n"; result= -ENOMEM;
Linux设备驱动程序学习(18)-USB 驱动程序(三)
Linux设备驱动程序学习(18)-USB 驱动程序(三) (2009-07-14 11:45) 分类:Linux设备驱动程序 USB urb (USB request block) 内核使用2.6.29.4 USB 设备驱动代码通过urb和所有的 USB 设备通讯。urb用 struct urb 结构描述(include/linux/usb.h )。 urb以一种异步的方式同一个特定USB设备的特定端点发送或接受数据。一个USB 设备驱动可根据驱动的需要,分配多个 urb 给一个端点或重用单个 urb 给多个不同的端点。设备中的每个端点都处理一个 urb 队列, 所以多个 urb 可在队列清空之前被发送到相同的端点。 一个 urb 的典型生命循环如下: (1)被创建; (2)被分配给一个特定 USB 设备的特定端点; (3)被提交给 USB 核心; (4)被 USB 核心提交给特定设备的特定 USB 主机控制器驱动; (5)被 USB 主机控制器驱动处理, 并传送到设备; (6)以上操作完成后,USB主机控制器驱动通知 USB 设备驱动。 urb 也可被提交它的驱动在任何时间取消;如果设备被移除,urb 可以被USB 核心取消。urb 被动态创建并包含一个内部引用计数,使它们可以在最后一个用户释放它们时被自动释放。 struct urb
struct list_head urb_list;/* list head for use by the urb's * current owner */ struct list_head anchor_list;/* the URB may be anchored */ struct usb_anchor *anchor; struct usb_device *dev;/* 指向这个 urb 要发送的目标 struct usb_device 的指针,这个变量必须在这个 urb 被发送到 USB 核心之前被USB 驱动初始化.*/ struct usb_host_endpoint *ep;/* (internal) pointer to endpoint */ unsigned int pipe;/* 这个 urb 所要发送到的特定struct usb_device 的端点消息,这个变量必须在这个 urb 被发送到 USB 核心之前被 USB 驱动初始化.必须由下面的函数生成*/ int status;/*当 urb开始由 USB 核心处理或处理结束, 这个变量被设置为 urb 的当前状态. USB 驱动可安全访问这个变量的唯一时间是在 urb 结束处理例程函数中. 这个限制是为防止竞态. 对于等时 urb, 在这个变量中成功值(0)只表示这个 urb 是否已被去链. 为获得等时 urb 的详细状态, 应当检查 iso_frame_desc 变量. */ unsigned int transfer_flags;/* 传输设置*/ void*transfer_buffer;/* 指向用于发送数据到设备(OUT urb)或者从设备接收数据(IN urb)的缓冲区指针。为了主机控制器驱动正确访问这个缓冲, 它必须使用 kmalloc 调用来创建, 不是在堆栈或者静态内存中。对控制端点, 这个缓冲区用于数据中转*/ dma_addr_t transfer_dma;/* 用于以 DMA 方式传送数据到 USB 设备的缓冲区*/ int transfer_buffer_length;/* transfer_buffer 或者 transfer_dma 变量指向的缓冲区大小。如果这是 0, 传送缓冲没有被 USB 核心所使用。对于一个 OUT 端点, 如果这个端点大小比这个变量指定的值小, 对这个USB 设备的传输将被分成更小的块,以正确地传送数据。这种大的传送以连续的 USB 帧进行。在一个 urb 中提交一个大块数据, 并且使 USB 主机控制器去划分为更小的块, 比以连续地顺序发送小缓冲的速度快得多*/
linux设备驱动中常用函数
Linux2.6设备驱动常用的接口函数(一) ----字符设备 刚开始,学习linux驱动,觉得linux驱动很难,有字符设备,块设备,网络设备,针对每一种设备其接口函数,驱动的架构都不一样。这么多函数,要每一个的熟悉,那可多难啦!可后来发现linux驱动有很多规律可循,驱动的基本框架都差不多,再就是一些通用的模块。 基本的架构里包括:加载,卸载,常用的读写,打开,关闭,这是那种那基本的咯。利用这些基本的功能,当然无法实现一个系统。比方说:当多个执行单元对资源进行访问时,会引发竞态;当执行单元获取不到资源时,它是阻塞还是非阻塞?当突然间来了中断,该怎么办?还有内存管理,异步通知。而linux 针对这些问题提供了一系列的接口函数和模板框架。这样,在实际驱动设计中,根据具体的要求,选择不同的模块来实现其功能需求。 觉得能熟练理解,运用这些函数,是写号linux设备驱动的第一步。因为是设备驱动,是与最底层的设备打交道,就必须要熟悉底层设备的一些特性,例如字符设备,块设备等。系统提供的接口函数,功能模块就像是工具,能够根据不同的底层设备的的一些特性,选择不同的工具,方能在linux驱动中游刃有余。 最后就是调试,这可是最头疼的事。在调试过程中,总会遇到这样,那样的问题。怎样能更快,更好的发现并解决这些问题,就是一个人的道行咯!我个人觉得: 发现问题比解决问题更难! 时好时坏的东西,最纠结! 看得见的错误比看不见的错误好解决! 一:Fops结构体中函数: ①ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); 用来从设备中获取数据. 在这个位置的一个空指针导致 read 系统调用以-EINVAL("Invalid argument") 失败. 一个非负返回值代表了成功读取的字节数( 返回值是一个 "signed size" 类型, 常常是目标平台本地的整数类型). ②ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); 发送数据给设备. 如果 NULL, -EINVAL 返回给调用 write 系统调用的程序. 如果非负, 返回值代表成功写的字节数 ③loff_t (*llseek) (struct file *, loff_t, int); llseek 方法用作改变文件中的当前读/写位置, 并且新位置作为(正的)返回值. loff_t 参数是一个"long offset", 并且就算在 32位平台上也至少 64 位宽. 错误由一个负返回值指示. 如果这个函数指针是 NULL, seek 调用会以潜在地无法预知的方式修改 file 结构中的位置计数器( 在"file 结构" 一节中描述). ④int (*open) (struct inode *, struct file *);
Linux设备模型(文档翻译)_(整理文档)
Linux 内核文档翻译- driver-model/bus.txt Bus Types 总线类型 Definition 定义 ~~~~~~~~~~ See the kerneldoc for the struct bus_type. intbus_register(struct bus_type * bus); Declaration 声明 ~~~~~~~~~~~ Each bus type in the kernel (PCI, USB, etc) should declare one static object of this type. They must initialize the name field, and may optionally initialize the match callback. 内核中每个总线类型(PCI、USB 等等)都应该声明一个此类型的静态对象。它们必须初始化该对象的name 字段,然后可选的初始化match 回调函数。 structbus_typepci_bus_type = { .name = "pci", .match = pci_bus_match, }; The structure should be exported to drivers in a header file: 这个结构体应该在头文件中向驱动程序导出: extern struct bus_typepci_bus_type; Registration 注册 ~~~~~~~~~~~~ When a bus driver is initialized, it calls bus_register. This initializes the rest of the fields in the bus object and inserts it into a global list of bus types. Once the bus object is registered, the fields in it are usable by the bus driver. 当初始化一个总线驱动时,将会调用bus_register。这时这个总线对象剩下的字段将被初始化,然后这个对象会被插入到总线类型的一个全局列表里去。一旦完成一个总线对象的注册,那么对于总线驱动来说它里面的字段就已经可用了。
Linux设备驱动模型之platform总线深入浅出
Linux设备驱动模型之platform总线深入浅出 在Linux2.6以后的设备驱动模型中,需关心总线,设备和驱动这三种实体,总线将设备和驱动绑定。在系统每注册一个设备的时候,会寻找与之匹配的驱动;相反,在系统每注册一个驱动的时候,会寻找与之匹配的设备,而匹配由总线完成。 对于依附在USB、PCI、I2C、SPI等物理总线来这些都不是问题。但是在嵌入式系统里面,在Soc系统中集成的独立外设控制器,挂接在Soc内存空间的外设等却不依附在此类总线。基于这一背景,Linux发明了一种总线,称为platform。相对于USB、PCI、I2C、SPI等物理总线来说,platform总线是一种虚拟、抽象出来的总线,实际中并不存在这样的总线。 platform总线相关代码:driver\base\platform.c 文件相关结构体定义:include\linux\platform_device.h 文件中 platform总线管理下最重要的两个结构体是platform_device和platform_driver 分别表示设备和驱动在Linux中的定义如下一:platform_driver //include\linux\platform_device.h struct platform_driver { int (*probe)(struct platform_device *); //探测函数,在注册平台设备时被调用int (*remove)(struct platform_device *); //删除函数,在注销平台设备时被调用void (*shutdown)(struct platform_device *); int (*suspend)(struct platform_device *, pm_message_t state); //挂起函数,在关机被调用int (*suspend_late)(struct platform_device *, pm_message_t state); int (*resume_early)(struct platform_device *); int (*resume)(struct platform_device *);//恢复函数,在开机时被调用struct device_driver driver;//设备驱动结构}; 1 2 3 4 5 6 7 8
11个常见的linux基础面试题
11个常见的linux面试题 Q.1: Linux 操作系统的核心是什么? Shell Kernel Command Script Terminal 答: 内核(Kernel)是Linux 操作系统的核心。Shell是一个命令行解释器,命令(Command)是针对计算机的指令,脚本(Script)是存储在文件中的命令的集合,终端(Termial)是命令行接口。 Q.2: Linus Torvalds 都创建过什么东东? Fedora Slackware Debian Gentoo Linux 答: Linux Torvalds 创建了Linux,Linux是所有上述操作系统的核心,同样也是其他一些Linux 操作系统的核心。 Q.3: Torvalds,使用C++语言编写了Linux内核的大部分代码,是这样吗? 答: 不! Linux内核包含了12,020,528行代码,其中注释占去了2,151,595 行。因此剩下的9,868,933 行就是纯代码了。而其中7,896,318行都是用C语言写的。 剩下的1,972,615行则是使用C++,汇编,Perl, Shell Script, Python, Bash Script, HTML, awk, yacc, lex, sed等。 注:代码行数每天都在变动,平均每天超过3,509行代码添加到内核。 Q.4: 起初,Linux 是为Intel X86 架构编写的,但是后来比其他操作系统移植的硬件平台都多,是这样吗? 答: 是的,我同意。Linux那时候是为x86机器写的,而且现已移至到所有类型的平台。今天超过90%的超级计算机都在使用Linux。Linux在移动手机和平板电脑领域前景广阔。事实上我们被Linux包围着,远程遥控,太空科学,研究,Web,桌面计算等等,举之不尽。 Q.5: 编辑Linux 内核合法吗? 答: 是的,内核基于GPL发布,任何人都可以基于GPL允许的权限随意编辑内核。Linux 内核属于免费开源软件(FOSS)。
linux系统及编程基础课后答案
第1章习题答案 1. 什么是Linux? 答:Linux是一款优秀的操作系统,支持多用户、多进程、多线程,实时性好,功能强大且稳定。同时,它又具有良好的兼容性和可移植性,被广泛应用于各种计算机平台上。作为Internet的产物,Linux操作系统由全世界的许多计算机爱好者共同合作开发,是一个自由的操作系统。 2. Linux的主要特点是什么? 答:Linux具有UNIX的所有特性并且具有自己独特的魅力,主要表现在以下几个方面: 开放性 多用户 多任务 出色的稳定性能 良好的用户界面:Linux向用户提供了两种界面:用户界面和系统调用界面。 设备独立性:设备独立性是指操作系统把所有外部设备统一当作文件来看,只要安装它们的驱动程序,任何用户都可以像使用文件那样操作并使用这些设备,而不必知道它们的具体存在形式。 丰富的网络功能:完善的内置网络是Linux的一大特点,Linux在通信和网络 功能方面优于其他操作系统。其他操作系统不包含如此紧密的内核结合在一起的联接网络的能力,也没有内置这些联网特性的灵活性。而Linux为用户提供了完善的、强大的网络功能。
可靠的安全性 良好的可移植性:可移植性是指将操作系统从一个平台转移到另一个平台,使它仍然能按其自身的方式运行的能力。 3. Linux的主要组成包括什么? 答:Linux主要组成为: Linux内核(Kernel):内核(Kernel)是系统的心脏,是运行程序和管理硬件设备的内核程序,决定着系统的性能和稳定性,实现操作系统的基本功能。 Linux的Shell:Shell是系统的用户界面,提供用户与内核进行交互操作的一种接口。Shell是一个命令解释器,它解释由用户输入的命令并且把他们送到内核执行。Shell编程语言具有普通编程语言的很多特点,用这种编程语言编写shell程序与其他应用程序具有同样的效果。 Linux 文件系统:文件系统是文件存放在磁盘等存储设备上的组织方法。通常是按照目录层次的方式进行组织,用户能够从一个目录切换到另一个目录,而且可以设置目录和文件的权限、文件的共享程度。 Linux 实用程序(utilities)和应用程序(Applications):标准的Linux系统都有一套成为应用程序的程序集,包括文本编辑器、编程语言、X Window、办公套件、Internet工具、数据库等。 4. Linux与Windows的主要区别是什么? 答:主要区别: (1)Linux的应用目标是网络 Linux的设计定位于网络操作系统。虽然现在已经实现Linux操作系统的图形界面,但仍然没有舍弃文本命令行。由于纯文本可以非常好地跨越网络进行工作,所以Linux
Linux设备驱动程序学习(20)-内存映射和DMA-基本概念
Linux设备驱动程序学习(20)-内存映射和DMA-基本概念 (2011-09-25 15:47) 标签: 虚拟内存设备驱动程序Linux技术分类:Linux设备驱动程序 这部分主要研究 Linux 内存管理的基础知识, 重点在于对设备驱动有用的技术. 因为许多驱动编程需要一些对于虚拟内存(VM)子系统原理的理解。 而这些知识主要分为三个部分: 1、 mmap系统调用的实现原理:它允许设备内存直接映射到一个用户进程地址 空间. 这样做对一些设备来说可显著地提高性能. 2、与mmap的功能相反的应用原理:内核态代码如何跨过边界直接存取用户空间的内存页. 虽然较少驱动需要这个能力. 但是了解如何映射用户空间内存到内 核(使用 get_user_pages)会有用. 3、直接内存存取( DMA ) I/O 操作, 它提供给外设对系统内存的直接存取. 但所有这些技术需要理解 Linux 内存管理的基本原理, 因此我将先学习VM子 系统的基本原理. 一、Linux的内存管理 这里重点是 Linux 内存管理实现的主要特点,而不是描述操作系统的内存管理理论。Linux虚拟内存管理非常的复杂,要写可以写一本书:《深入理解Linux 虚拟内存管理》。学习驱动无须如此深入, 但是对它的工作原理的基本了解是必要的. 解了必要的背景知识后,才可以学习内核管理内存的数据结构. Linux是一个虚拟内存系统(但是在没有MMU的CPU中跑的ucLinux除外), 意味着在内核启动了MMU 之后所有使用的地址不直接对应于硬件使用的物理地址,这些地址(称之为虚拟地址)都经过了MMU转换为物理地址之后再从CPU的内存总线中发出,读取/写入数据. 这样 VM 就引入了一个间接层, 它是许多操作成为可能: 1、系统中运行的程序可以分配远多于物理内存的内存空间,即便单个进程都可拥有一个大于系统的物理内存的虚拟地址空间. 2、虚拟内存也允许程序对进程的地址空间运用多种技巧, 包括映射程序的内存到设备内存.等等~~~ 1、地址类型 Linux 系统处理几种类型的地址, 每个有它自己的含义: 用户虚拟地址:User virtual addresses,用户程序见到的常规地址. 用户地址在长度上是 32 位或者 64 位, 依赖底层的硬件结构, 并且每个进程有它自己 的虚拟地址空间.
linux设备模型介绍
第一节基本概念 在设备模型里面,所有的东西都是kobject,这也是linux建立设备设计模型的目的(对比2.4之前),实现了统一的实体;我们理解上,却可以分为两个层次,一个是kobject,一个是管理kobject的kobject(可以把它叫做kset虽然有点绕,但是没有办法了,毕竟就像那个“世界上先有鸡还是先有蛋的哲学问题一下”); kobject结构
1)前面两个顾名思义,就是name了,为什么会有两个呢?k_name就是指向name的,如何知道呢,呵呵,看一下代码 2)kref就是一个内核的原子计数结构,因为涉及内核的操作基本都需要是原子性的,为了大家的方便,kobject就把它包括进来了,所以大家就不必要各自定义自己的计数了(一般情况下:),poll也是类似,把等待队列包括进来; 3)entry 这个名字比较让人误解,其实看它的类型知道是list成员,它就是加入到kset的list 的那个零部件; 4)ktpye 要理解这个成员就稍微麻烦些了,先看一下定义 Default_attrs就是一种比较简单的设置属性文件的方法,它其实跟我们自己调用sysfs_create_file没有什么区别,呵呵,看一下代码就知道了,所以大家基本上可以把它忽略掉:),调用关系为kobject_add->create_dir->populate_dir 把一个忽略掉,剩下的两个就比较重要了;每个对象一般都有多个属性,用面向对象的角度来看,我们可以把对属性的操作抽象为show和store这一对方法,那么多个属性就会有多对show和store的方法;那么,为了实现对这些方法的统一调用,就利用ktype中的sysfs_ops 实现了多态;这样一来,对于sysfs中的普通文件读写操作都是由kobject->ktype->sysfs_ops
Linux入门教程(精华基础版)
第一章Linux入门教程 Linux,在今天的广大电脑爱好者心中已经不再是那个遥不可及的新东西了,如果说几年前的Linux是星星之火的话,如今Linux不仅在服务器领域的应用取得较大进展,而且在桌面应用领域也有越来越多的人选择使用。Linux的开放性和灵活性使它得以在实验室和其它研究机构中被用于创新性技术变革的前沿,现在Linux已经真正地向广大的电脑爱好者们敞开了大门。 只要你对Linux感兴趣,想要学习Linux,那么本教程将带你走进Linux的世界。 第一章初识Linux 在学习使用之前我们还是先来了解一下Linux吧。 Linux是什么?按照Linux开发者的说法,Linux是一个遵循POSIX(标准操作系统界面)标准的免费操作系统,具有BSD和SYSV的扩展特性(表明其在外表和性能上同常见的UNIX非常相象,但是所有系统核心代码已经全部被重新编写了)。它的版权所有者是芬兰籍的Linus B.Torvalds先生。 1991年8月这位来自芬兰赫尔辛基大学的年轻人Linus Benedict Torvalds,对外发布了一套全新的操作系统。 最开始的Linux版本是被放置到一个FTP服务器上供大家自由下载的,FTP服务器的管理员认为这是Linus的Minix,因而就建了一个Linux目录来存放这些文件,于是Linux这个名字就传开了,如今已经成了约定俗成的名称了。 下图就是Linux的吉祥物,一只可爱的小企鹅(起因是因为Linus是芬兰人,因而挑选企鹅作为吉祥物): Linux的吉祥物 闲话少叙进入正题。我们主要的学习方向有如下几点:
1.熟练掌握基本命令。每个系统都有自己特定的语言环境,Linux也不例外,只有熟悉并熟练掌握Linux的常用基础命令才可以深入学习。 2.系统管理及运用。系统的管理包括启动、用户、进程以及安全管理等等。大体上都是通过命令来进行配置文件及脚本文件的。 3.源码的学习和研究。由于内核的相似,Linux同UNIX一样都是由C语言开发而成的,所以了解UNIX的朋友学习起来相对容易。 4.内核开发。现在的很多服务器系统,网络设备,安全防护软件以及手机系统和掌上PDA 的操作管理系统都是由Linux编程开发而成的,所以内核的开发学习当然必不可少。 5.数据库及服务器领域。如今Linux做的服务器在市场中占有率第一的位置无可动摇,其中包括:WWW服务器,FTP服务器,mail服务器,数据库服务器等等多种服务器。 了解了学习的目的和方向后,下面以Red Hat9.0为例来介绍Linux的安装过程。 第一步:设置电脑的第一启动驱动器为光盘驱动器,插入Linux系统光盘启动计算机。 第二步:系统会自动进入到Linux安装初始画面,第一要选择安装的方式,其中如果要选择文本界面安装需要在引导命令处输入命令linux text,如果要选择图形界面安装的话直接安回车Enter。笔者使用的是图形安装。 第三步:选择完安装方式后便出现了光盘检测界面,出现这个对话框的意思就是在安装之前确定系统盘是否有损坏,如果确定没有损坏选择“Skip”直接跳过检测进入下个环节。如果选择“OK”则自动转到光盘检测程序自动检测光盘。对于初次接触Linux的朋友,还是建议您在安装之前先检测下系统安装光盘,省去在安装过程中所带来的不便。 第四步:检测完光盘后会出现Linux的软件介绍说明以及选择系统语言的对话框,选择“简体中文”,当然如果你精通别的语言也是可以选择其他语言进行安装和使用的。 第五步:键盘以及鼠标设置。在选项中提供了多种型号,品牌,接口和语言的键盘和鼠标,根据你现所用的键鼠进行对应选择。选择完毕后单击“下一步” 第六步:安装类型。其中包括“个人桌面”,“工作站”,“服务器”,“定制”。四种类型名称不同,内容大同小异。由于篇幅所限这个会在日后的讲座中给大家详细介绍。 第七步:磁盘分区设置。其中包括两个选项,“自动”和“手动”。自动分区会将所有的整个硬盘按照容量大小平均分区格式化,适合没有装任何资料的新电脑,但如果你在这之前装有其他系统,或是其他分区中存在的数据的话,建议您还是“手动分区”,这样不会丢失您原来的文件数据。 第八步:新建分区。在图形界面下比较直观,一般都会显示出你硬盘的容量,厂商等相关信息。直接点击“新建”来创建新的分区。
Linux设备驱动程序简介
第一章Linux设备驱动程序简介 Linux Kernel 系统架构图 一、驱动程序的特点 ?是应用和硬件设备之间的一个软件层。 ?这个软件层一般在内核中实现 ?设备驱动程序的作用在于提供机制,而不是提供策略,编写访问硬件的内核代码时不要给用户强加任何策略 o机制:驱动程序能实现什么功能。 o策略:用户如何使用这些功能。 二、设备驱动分类和内核模块 ?设备驱动类型。Linux 系统将设备驱动分成三种类型 o字符设备 o块设备 o网络设备 ?内核模块:内核模块是内核提供的一种可以动态加载功能单元来扩展内核功能的机制,类似于软件中的插件机制。这种功能单元叫内核模块。 ?通常为每个驱动创建一个不同的模块,而不在一个模块中实现多个设备驱动,从而实现良好的伸缩性和扩展性。 三、字符设备 ?字符设备是个能够象字节流<比如文件)一样访问的设备,由字符设备驱动程序来实现这种特性。通过/dev下的字符设备文件来访问。字符设备驱动程序通常至少需要实现 open、close、read 和 write 等系统调用 所对应的对该硬件进行操作的功能函数。 ?应用程序调用system call<系统调用),例如:read、write,将会导致操作系统执行上层功能组件的代码,这些代码会处理内核的一些内部 事务,为操作硬件做好准备,然后就会调用驱动程序中实现的对硬件进 行物理操作的函数,从而完成对硬件的驱动,然后返回操作系统上层功 能组件的代码,做好内核内部的善后事务,最后返回应用程序。 ?由于应用程序必须使用/dev目录下的设备文件<参见open调用的第1个参数),所以该设备文件必须事先创建。谁创建设备文件呢? ?大多数字符设备是个只能顺序访问的数据通道,不能前后移动访问指针,这点和文件不同。比如串口驱动,只能顺序的读写设备。然而,也 存在和数据区或者文件特性类似的字符设备,访问它们时可前后移动访
Linux应用基础模拟试题
Linux应用基础模拟试题二 一、单项选择题(每小题分,共40题,计60分) BCDBD CAAAC DAADD BBCDA BBDBA CBADC DABAC ABBDB 1、ldconfig的配置文件是( B )。 A、 /lib/lD、so B、 /etc/LD、 C、 /etc/l D、 D、 /etc/ 2、下面哪个命令可以压缩部分文件( C )。 A、 tar -dzvf * B、 tar -tzvf * C、 tar -czvf * D、 tar -xzvf * 3、网络服务的daemon是( D )。 A、 lpd B、 netd C、 httpd D、 inetd 4、Linux与windows 95的网上领居互联,需要提供什么daemon( B ) A、 bind B、 smbd C、 nmbd D、 shard 5、对于Apache服务器,提供的子进程的缺省的用户是( D )。 A、 root B、 apached C、 httpd D、 nobody 6、sendmail中缺省的未发出信件的存放位置是( C )。 A、 /var/mail/ B、 /var/spool/mail/ C、 /var/spool/mqueue/ D、 /var/mail/deliver/ 7、apache的主配置文件是( A )。 A、 httpD、conf B、 httpD、cfg C、 D、 8、关于可装载的模块,装载时的参数,如I/O地址等的存放位置是( A )。 A、 /etc/ B、 /etc/ C、 /boot/ D、 /etc/sysconfig 9、在 Linux 中,如何关闭邮件提示( A ) A、 biff n B、 mesg n C、 notify off D、 set notify=off 10、在 bash shell 环境下,当一命令正在执行时,按下 control-Z 会( C )。 A、中止前台任务 B、给当前文件加上 EOF. C、将前台任务转入后台 D、注销当前用户 11、定义bash环境的用户文件是( D )。 A、 bash & .bashrc B、 bashrc & .bash_conf C、 bashrc & bash_profile D、 .bashrc & .bash_profile 12、下面哪条命令用来显示一个程序所使用的库文件( A ) A、 ldd B、 ld so C、 modprobe D、 ldconfig
如何实现Linux设备驱动模型
文库资料?2017 Guangzhou ZHIYUAN Electronics Stock Co., Ltd. 如何实现Linux 设备驱动模型 设备驱动模型,对系统的所有设备和驱动进行了抽象,形成了复杂的设备树型结构,采用面向对象的方法,抽象出了device 设备、driver 驱动、bus 总线和class 类等概念,所有已经注册的设备和驱动都挂在总线上,总线来完成设备和驱动之间的匹配。总线、设备、驱动以及类之间的关系错综复杂,在Linux 内核中通过kobject 、kset 和subsys 来进行管理,驱动编写可以忽略这些管理机制的具体实现。 设备驱动模型的内部结构还在不停的发生改变,如device 、driver 、bus 等数据结构在不同版本都有差异,但是基于设备驱动模型编程的结构基本还是统一的。 Linux 设备驱动模型是Linux 驱动编程的高级内容,这一节只对device 、driver 等这些基本概念作介绍,便于阅读和理解内核中的代码。实际上,具体驱动也不会孤立的使用这些概念,这些概念都融合在更高层的驱动子系统中。对于大多数读者可以忽略这一节内容。 1.1.1 设备 在Linux 设备驱动模型中,底层用device 结构来描述所管理的设备。device 结构在文件
Linux设备模型 热插拔、mdev 与 firmware
Linux设备驱动程序学习(15) -Linux设备模型(热插拔、mdev 与firmware) 热插拔 有2 个不同角度来看待热插拔: 从内核角度看,热插拔是在硬件、内核和内核驱动之间的交互。 从用户角度看,热插拔是内核和用户空间之间,通过调用用户空间程序(如hotplug、udev 和mdev)的交互。当需要通知用户内核发生了某种热插拔事件时,内核才调用这个用户空间程序。 现在的计算机系统,要求Linux 内核能够在硬件从系统中增删时,可靠稳定地运行。这就对设备驱动作 者增加了压力,因为在他们必须处理一个毫无征兆地突然出现或消失的设备。 热插拔工具 当用户向系统添加或删除设备时,内核会产生一个热插拔事件,并在/proc/sys/kernel/hotplug文件里查找处理设备连接的用户空间程序。这个用户空间程序主要有 hotplug:这个程序是一个典型的bash 脚本,只传递执行权给一系列位于/etc/hot-plug.d/ 目录树的程序。hotplug 脚本搜索所有的有 .hotplug 后缀的可能对这个事件进行处理的程序并调用它们, 并传递给它们许多不同的已经被内核设置的环境变量。(基本已被淘汰,具体内容请参阅《LDD3》) udev :用于linux2.6.13或更高版本的内核上,为用户空间提供使用固定设备名的动态/dev目录的解 决方案。它通过在sysfs 的/class/ 和/block/ 目录树中查找一个称为dev 的文件,以确定所创建的 设备节点文件的主次设备号。所以要使用udev,驱动必须为设备在sysfs中创建类接口及其dev属性文件,方法和sculld模块中创建dev属性相同。udev的资料网上十分丰富,我就不在这废话了,给出以 下链接有兴趣的自己研究:
linux基础知识总结
linux基础知识总结 1 linux 概述 1.1 linux 结构 1.1.1 linux的四部分 可以把Linux系统看作由四部分构成:内核、用户界面、文件结构和实用工具 /bin 普通用户的可执行文件,系统的任何用户都可以执行该目录中的命令 /boot 存放Linux操作系统启动时所需要的文件 /dev 系统中所有设备文件 /etc 系统中的配置文件 /home 普通用户的宿主目录,每个用户在该目下都有一个于用户名同名的目录。 /mnt 中的子目录用于系统中可移动设备的挂载点 /root 超级用户root的宿主目录 /sbin 系统中的管理命令,普通用户不能执行 /tmp 系统的临时目录 /usr 系统应用程序的相关文件 /var 系统中经常变化的文件如日志文件和用户邮件 / / \ / \ etc home
/ / / / profilexiaoming / \ 配置系统 .bash_profile 环境变量配置用户的环境变量 环境变量:配置.bashrc文件可以指定某些程序在用户登录的时候就自动启动 系统环境变量设置:在root目录下 Vi .bash_profile 修改PATH=$PATH:$HOME/bin :/安装目录/bin 需要退出(quit),重新登陆 当希望临时加入某个环境变量:用export PATH =$PATH : $HOME /bin:/root/test/t1 已定义好的环境变量: SHELL:默认的shell PATH:路径 USER:当前登录用户的用户名 显示变量内容:echo $PATH echo $USER echo $SHELL 也可以使用env命令显示环境变量 通配符: * 代表多个字母或数字 ?一个 别名: 命令:alias显示系统当前定义的所有alias aliascp ='cp-i' aliasll='ls -l --color = tty' 2. linux 基本命令 2.0 重启 shutdown - h now 立刻关机 shutdown - r now 重启 reboot 重启 2.1 文件查看和连接命令 cat cat[选项]
Linux设备驱动程序学习(10)-时间、延迟及延缓操作
Linux设备驱动程序学习(10)-时间、延迟及延缓操作 Linux设备驱动程序学习(10) -时间、延迟及延缓操作 度量时间差 时钟中断由系统定时硬件以周期性的间隔产生,这个间隔由内核根据HZ 值来设定,HZ 是一个体系依赖的值,在
的.config文件中定义,并没有在make menuconfig的配置选项中出现。Linux的\arch\arm\configs\s3c2410_defconfig文件中的定义为: 所以正常情况下s3c24x0的HZ为200。这一数值在后面的实验中可以证实。 每次发生一个时钟中断,内核内部计数器的值就加一。这个计数器在系统启动时初始化为0,因此它代表本次系统启动以来的时钟嘀哒数。这个计数器是一个64-位变量( 即便在32-位的体系上)并且称为“jiffies_64”。但是驱动通常访问jiffies 变量(unsigned long)(根据体系结构的不同:可能是jiffies_64 ,可能是jiffies_64 的低32位)。使用jiffies 是首选,因为它访问更快,且无需在所有的体系上实现原子地访问64-位的jiffies_64 值。 使用jiffies 计数器 这个计数器和用来读取它的工具函数包含在