语法和语义分析器

实验二语法和语义分析器
一实验目的
1.掌握 Yacc 的基本用法,并能够根据语言给出语法规则的定义,最后生成语言的解析器;
2.使用Yacc实现一个高级计算器程序。
二实验内容
实现一个简单的表达式计算器,要求能进行加、减、乘、除、幂运算,注意优先级。求写出详细的步骤和相应的flex源程序。
三实验步骤
1.在linux中安装flex,使用如下命令:
Undo apt-lex install bison
2.实验源程序
%{
#define YYSTYPE double
#include
#include
#include
int yylex (void);
void yyerror (char const *);
%}
%token NUM
%left '-' '+'
%left '*' '/'
%%
input:
| input line
;
line: '\n'
| exp '\n' { printf ("\t%.10g\n", $1); }
| error '\n' {yyerrok;}
exp: NUM { $$ = $1; }
| exp '+' exp { $$ = $1 + $3; }
| exp '-' exp { $$ = $1 - $3; }
| exp '*' exp { $$ = $1 * $3; }
| exp '/' exp { $$ = $1 / $3; }
| '(' exp ')' { $$ = $2; }
;
%%
yylex ()
{
int c;
while ((c = getchar ()) == ' ' || c == '\t');
if (c == '.' || isdigit (c)) {
ungetc (c, stdin);
scanf ("%lf", &yylval);
return NUM;
}
if (c == EOF) return 0;
return c;
}
main ()
{
return yyparse ();
}
yyerror(char *msg)
{
printf("error %s encountered\n", msg);
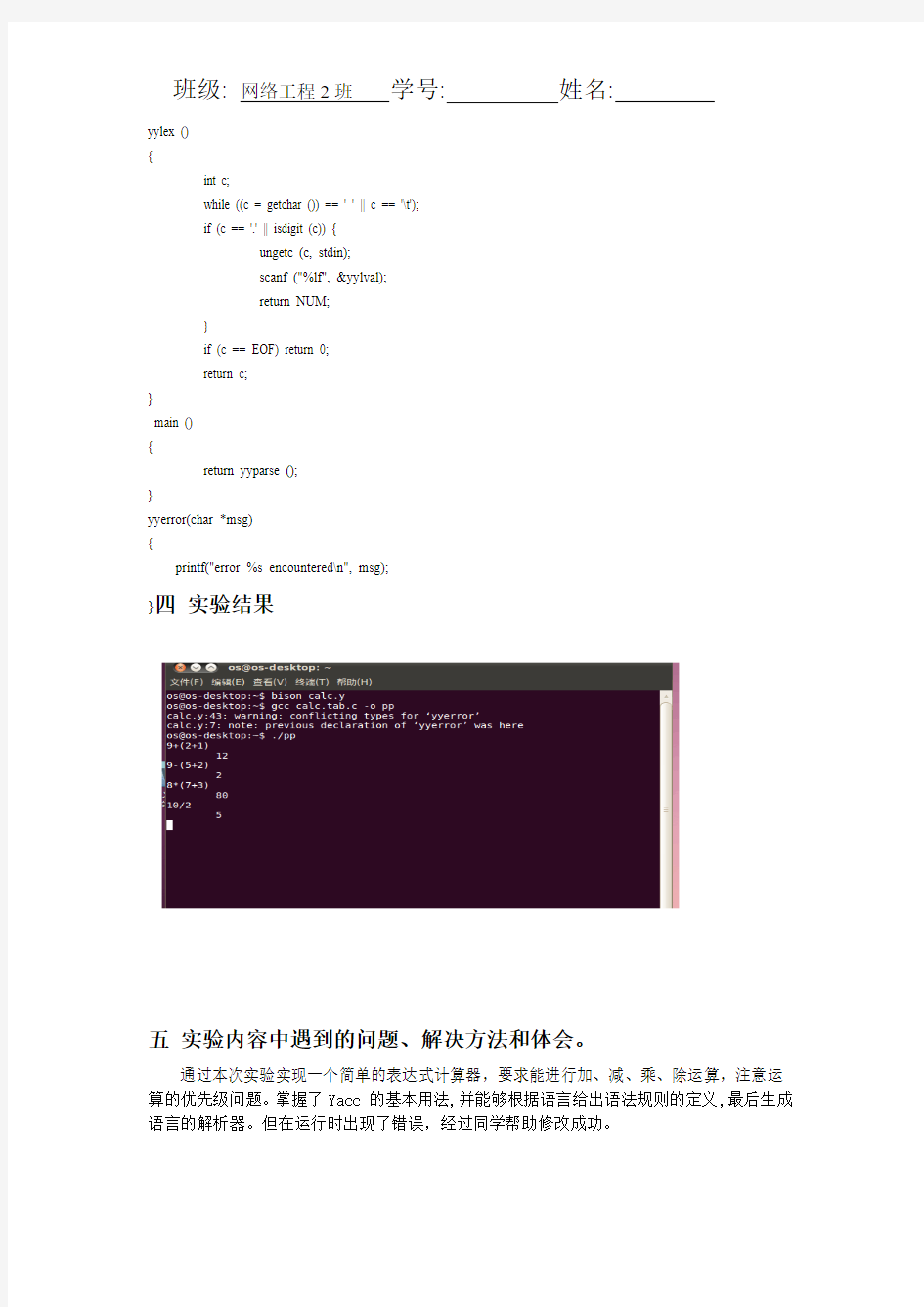
}四实验结果
五实验内容中遇到的问题、解决方法和体会。
通过本次实验实现一个简单的表达式计算器,要求能进行加、减、乘、除运算,注意运算的优先级问题。掌握了Yacc 的基本用法,并能够根据语言给出语法规则的定义,最后生成语言的解析器。但在运行时出现了错误,经过同学帮助修改成功。
编译原理课程设计-词法语法分析器
编译原理课程设计Course Design of Compiling (课程代码3273526) 半期题目:词法和语法分析器 实验学期:大三第二学期 学生班级:2014级软件四班 学生学号:2014112218 学生姓名:何华均 任课教师:丁光耀 信息科学与技术学院 2017.6
课程设计1-C语言词法分析器 1.题目 C语言词法分析 2.内容 选一个能正常运行的c语言程序,以该程序出现的字符作为单词符号集,不用处理c语言的所有单词符号。 将解析到的单词符号对应的二元组输出到文件中保存 可以将扫描缓冲区与输入缓冲区合成一个缓冲区,一次性输入源程序后就可以进行预处理了 3.设计目的 掌握词法分析算法,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解 4.设计环境(电脑语言环境) 语言环境:C语言 CPU:i7HQ6700 内存:8G 5.概要设计(单词符号表,状态转换图) 5.1词法分析器的结构 词法分析程序的功能:
输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 词法分析程序可以单独为一个程序;也可以作为整个编译程序的一个子程序,当需要一个单词时,就调用此法分析子程序返回一个单词. 为便于程序实现,假设每个单词间都有界符或运算符或空格隔开,并引入下面的全局变量及子程序: 1) ch 存放最新读进的源程序字符 2) strToken 存放构成单词符号的字符串 3) Buffer 字符缓冲区 4)struct keyType 存放保留字的符号和种别 5.2待分析的简单词法 (1)保留字 break、case、char、const、int、do、while… (2)运算符和界符 = 、+、-、* 、/、%、,、;、(、)、?、# 5.3各种单词符号对应的种别码
实验三 自下而上语法分析及语义分析
实验三自下而上语法分析及语义分析 一、实验目的: 通过本实验掌握LR分析器的构造过程,并根据语法制导翻译,掌握属性文法的自下而上计算的过程。 二、实验学时: 4学时。 三、实验内容 根据给出的简单表达式的语法构成规则(见五),编制LR分析程序,要求能对用给定的语法规则书写的源程序进行语法分析和语义分析。 对于正确的表达式,给出表达式的值。 对于错误的表达式,给出出错位置。 四、实验方法 采用LR分析法。 首先给出S-属性文法的定义(为简便起见,每个文法符号只设置一个综合属性,即该文法符号所代表的表达式的值。属性文法的定义可参照书137页表6.1),并将其改造成用LR分析实现时的语义分析动作(可参照书145页表6.5)。 接下来给出LR分析表。 然后程序的具体实现: ●LR分析表可用二维数组(或其他)实现。 ●添加一个val栈作为语义分析实现的工具。 ●编写总控程序,实现语法分析和语义分析的过程。 注:对于整数的识别可以借助实验1。 五、文法定义 简单的表达式文法如下: E->E+T|E-T|T T->T*F|T/F|F F->(E)|i 上式中,i 为整数。 六、处理程序例 例1: 正确源程序例: 23+(45+4)* 40分析结果应为:正确的表达式。其值为:1983 例2: 错误源程序例: 5+(56+)-24 分析结果应为:错误的表达式:出错位置为)
附录:源程序 #include
编译原理词法分析器语法分析器实验报告
编译技术 班级网络0802 学号3080610052姓名叶晨舟 指导老师朱玉全2011年 7 月 4 日
一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为
TEST语言 -语法分析,词法分析实验报告
编译原理实验报告 实验名称:分析调试语义分析程序 TEST抽象机模拟器完整程序 保证能用!!!!! 一、实验目的 通过分析调试TEST语言的语义分析和中间代码生成程序,加深对语法制导翻译思想的理解,掌握将语法分析所识别的语法范畴变换为中间代码的语义翻译方法。 二、实验设计 程序流程图
extern int TESTScan(FILE *fin,FILE *fout); FILE *fin,*fout; //用于指定输入输出文件的指针 int main() { char szFinName[300]; char szFoutName[300]; printf("请输入源程序文件名(包括路径):"); scanf("%s",szFinName); printf("请输入词法分析输出文件名(包括路径):"); scanf("%s",szFoutName); if( (fin = fopen(szFinName,"r")) == NULL) { printf("\n打开词法分析输入文件出错!\n"); return 0; } if( (fout = fopen(szFoutName,"w")) == NULL) { printf("\n创建词法分析输出文件出错!\n"); return 0; } int es = TESTScan(fin,fout); fclose(fin); fclose(fout); if(es > 0) printf("词法分析有错,编译停止!共有%d个错误!\n",es); else if(es == 0) { printf("词法分析成功!\n"); int es = 0;
编译原理词法分析和语法分析报告 代码(C语言版)
词法分析 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 3.1 主程序示意图: 扫描子程序主要部分流程图 其他
词法分析程序的C语言程序源代码: // 词法分析函数: void scan() // 数据传递: 形参fp接收指向文本文件头的文件指针; // 全局变量buffer与line对应保存源文件字符及其行号,char_num保存字符总数。 void scan() { char ch; int flag,j=0,i=-1; while(!feof(fp1)) { ch=fgetc(fp1); flag=judge(ch); printf("%c",ch);//显示打开的文件 if(flag==1||flag==2||flag==3) {i++;buffer[i]=ch;line[i]=row;} else if(flag==4) {i++;buffer[i]='?';line[i]=row;} else if(flag==5) {i++;buffer[i]='~';row++;} else if(flag==7) continue; else cout<<"\n请注意,第"< 仗剑独行编辑 为了能够在网络上进行更好的传输,首先将每幀图像划分为NAL单元,为了提高压缩率及错误处理能力提出了RBSP编码算法。 nal_unit(NumBytesInNALunit){//NumBytesInNALunit规定了NAL单元的大小forbidden_zero_bit nal_ref_idc//nal_ref_idc如果不为0,说明NAL单元的内容包含一个序列参数集或一个图像参数集,或一个参考图像条带,或一个参考图像的条带数据分割。 nal_unit_type//指明含在NAL单元中的RBSP数据结构的类型 NumBytesInRBSP=0 for(i=1;i 三、词法、语法、语义分析结合 一、实验目的与要求 在实现词法、语法分析程序的基础上,编写相应的语义子程序,进行语义处理,加深对语法制导翻译原理的理解,进一步掌握将语法分析所识别的语法范畴变换为某种中间代码(四元式)的语义分析方法,并完成相关语义分析器的代码开发。 二、实验内容 语法制导翻译模式是在语法分析的基础上,增加语义操作来实现的。对于给定文法中的每一产生式,编写相应的语义子程序。在语法分析过程中,每当用一个产生式进行推导或归约时,语法分析程序除执行相应的语法分析动作之外,还要调用相应的语义子程序,以便完成生成中间代码、查填有关表格、检查并报告源程序中的语义错误等工作。每个语义子程序需指明相应产生式中各个符号的具体含义,并规定使用该产生式进行分析时所应采取的语义动作。这样,语法制导翻译程序在对源程序从左到右进行的一遍扫描中,既完成语法分析任务,又完成语义分析和中间代码生成方面的工作。 输入:包含测试用例,如由无符号数和+、?、*、/、(、)构成的算术表达式的源程序文件。 输出:将源程序转换为中间代码形式表示,并将中间代码序列输出到文件中。若源程序中有错误,应指出错误信息。 三、实验设计 语法制导翻译模式实际上是对前后文无关文法的一种扩展。一般而言,首先需要根据进行的语义工作,完成对文法的必要拆分和语义动作的编写,从而为每个产生式都配备相应的语义子程序,以便在进行语法分析的同时进行语义解释。要求从编译器的整体设计出发,重点通过对实验二中语法分析程序的扩展,完成一个编译器前端程序的编写、调试和测试工作,形成一个将源程序翻译为中间代码序列的编译系统。 对文法G3[<算术表达式>]中的产生式添加语义处理子程序,完成无符号数的四则运算的计值处理,将输入的四则运算转换为四元式形式的中间代码。本实验只进行了算术表达式四元式的翻译。 四、源代码 1、在.h文件中添加了 //语义分析部分 #define PMAX 5//define 后面不加括号,定义产生式符号属性字符串的长度 int NXQ=0; /*全局变量NXQ用于指示所要产生的下一个四元式的编号*/ int NXTemp=1;//整型变量NXTemp指示临时变量的编号 int SentenceCount=1;//存放文件中句子的个数 struct QUATERNION /*四元式表的结构*/ { char op[PMAX]; /*操作符*/ char arg1[PMAX]; /*第一个操作数*/ char arg2[PMAX]; /*第二个操作数*/ char result[PMAX]; /*运算结果*/ }pQuad[256]; /*存放四元式的数组*/ char EBracket_Place[PMAX];//(E)的语义属性 TEST语言语法语义规则 程序中最后的声明必须是一个函数声明,名字为main。没有原型说明, 约定:主调函数的定义必须在被调函数的定义之前。 1. 一.实验目的 ●了解编译器的词法分析器的作用。其作用是源程序转化为便于编译程序其余部分进行处 理的内部格式。 ●了解词法分析器的任务。识别出源程序中的各个基本语法单位;删除无用的空白字符, 回车以及其他与输入介质相关的非实质性的字符,以及注释等。 一.实验说明 ●词法分析程序:词法分析程序完成的是编译第一阶段的工作。词法分析工作可以是独立 的一遍,把字符流的源程序变为单词序列,输出在一个中间文件上,这个文件做为语法分析程序的输入而继续编译过程。然而,更一般的情况,是将词法分析程序设计成一个子程序,每当语法分析程序需要一个单词时,则调用该子程序。词法分析程序每得到一次调用,便从源程序文件中读入一些字符,直到识别出一个单词,或说直到下一单词的第一个字符为止。 ●词法分析程序的主要功能是从字符流的源程序中识别单词,它要从左至右逐个字符地扫 描源程序,因此它还可完成其它一些任务。比如,滤掉源程序中的注释和空白(由空格,制表或回车换行字符引起的空白);又比如,为了使编译程序能将发现的错误信息与源程序的出错位置联系起来,词法分析程序负责记录新读入的字符行的行号,以便行号与出错信息相联;再有,在支持宏处理功能的源语言中,可以由词法分析程序完成其预处理等等。 ●以下是五种单词符号: - 保留字,关键字 - 标识符 - 常数(量) - 运算符 - 界符 ●词法分析程序所输出的单词符号常常采用以下二元式表示:(单词种别,单词自身的值)。 单词的种别是语法分析需要的信息,而单词自身的值则是编译其它阶段需要的信息。比如在PASCAL的语句const i=25, yes=1;中的单词25和1的种别都是常数,常数的值25和1对于代码生成来说,是必不可少的。有时,对某些单词来说,不仅仅需要它的值,还需要其它一些信息以便编译的进行。比如,对于标识符来说,还需要记载它的类别、层次还有其它属性,如果这些属性统统收集在符号表中,那么可以将单词的二元式表示设计成如下形式(标识符,指向该标识符所在符号表中位置的指针),如上述语句中 语法、语义、语用三个平面的区别与联系 2004年北京语言大学对外汉语专业的考研题 近年来,国内外有些语言学家在语法研究中注意到区别三个不同的平面,即句法平面、语义平面和语用平面,这是语法研究方法上的新进展,有助于语法学科的精密化、系统化和实用化。但这样研究语法还仅仅是开始。如何在语法分析中,特别是在汉语的语法分析中全面地、系统地把句法分析、语义分析和语用分析既界限分明地区别开来,又互相兼顾地结合起来,这是摆在语法研究工作者面前的新课题,是值得进行深入探索的。 (一)语法研究中的句法平面,是指对句子进行句法分析。句中词语与词语(即符号与符号)之间有一定的关系,这种关系是属于句法的(Syntactic)。词语与词语按照一定的方式组合起来,构成一定的句法结构,对句法结构进行分析,就是句法分析。对句子进行句法分析,主要从两方面进行。 一方面,对句法结构内部的词语与词语之间的关系进行成分分析,也就是着眼于句子成分的确定和结构方式的判别。传统语法学进行语法分析时,总要把句子分为若干成分,如主语、谓语、宾语、定语、状语、补语等等,这些都是句法分析的术语。传统语法学分析一个句子,就是要分析句子里各类实词(包括名词、动词、形容词、数词、代词、副词等)充当什么句子成分。比如“张三批评了李四”,就得分析成主谓句,其中“张三”是主语,“批评了李四”是谓语,“批评”是谓语动词,“李四”是宾语。假如说成“李四被张三批评了”,也得分析成主谓句, 但这句里“李四”是主语,“被张三批评了”是谓语,“被张三”是介词短语作状语,“张三”是介词“被”的宾语,“批评”是谓语动词。这样的成分分析,讲什么词充当什么句子成分,都是着眼于句子结构分析出来的。与确定句子成分有联系的,就是结构类型的判别。结构类型决定于结构成分之间的关系,也就是决定于结构方式。比如“鸟飞”“身体健康”,是由主语和谓语两成分组成的,通常称为主谓结构;“飞鸟”“健康的身体”,是由定语和它的中心语两成分组成的,通常称为偏正结构;“读书”“建设祖国”,是由动词和它的宾语两成分组成的,通常称为动宾结构。研究一个组合体是什么结构,也是句法分析的重要内容。另一方面,对句法结构内部的词语与词语之间的层次关系进行分析,也就是着眼于句法结构的层次切分。这种层次分析,要求把句法结构中词语之间的关系分为直接关系和间接关系、内部关系和外部关系,也就是要句法结构的直接成分和间接成分以及内部成分和外部成分区别开来。例如“干大事的人”,这个句法结构里“干大事”和“人”之间是直接关系,“干”和“大事”之间也是直接关系,但“干”和“人”之间以及“大事”和“人”之间都是间接关系。又如“张三的哥哥批评了李四的弟弟”这个句子,进行层次分析,词语间的直接关系可图示如下: 三的哥哥批评了四的弟弟 直接关系直接关系 直接关系 直接关系 这个句子里“张三”与“批评”之间、“李四”与“批评”之间、“哥哥”与“李 编译原理课程设计(词法分析,语法分析,语义分析,代码 生成) #include char left;// string right;// int len;// }; ivan css[20];// 20 struct pank// action { char sr;// int state;// }; pank action[46][18];//action int go_to[46][11];// go_to struct ike// { ike *pre; int num;// int word;// ike *next; }; ike *stack_head,*stack_tail;// struct L// { int k; string op;// string op1;// string op2;// string result;// L *next;// L *Ltrue;//true L *Lfalse;//false }; 语法、语义、语用的区别 (2012-12-23 22:38:32) 汉语是缺乏形态标志的语言,注重意合是汉语语法的一个主要特点。汉语的语序对语义的制约性很强,句法成分之间存在着较复杂的语义关系,在许多情况下仅对语法形式进行句法结构分析是解释不了句子的内部规律的。教学实践表明,让外国学生按照教材上所展示的句法结构模式去造句,他们有时会造出许多符合句法但不合情理也不能使用的句子来,究其原因,正是错在句子语义搭配和语用选择上。 句法、语义和语用这三个平面既有联系又有区别。句法是基础,语义和语用都要通过句法结构才能表现。句法结构中构成成分之间存在着诸如主谓、动宾、动补、偏正等句法关系意义,同时也存在着诸如动作与施事、受事、处所、工具等语义关系意义,还存在着诸如陈述、话题、焦点和预设、已知信息与新信息等语用意义。但是,句法、语义和语用实际上又处于不同平面上,它们之间并没有严格的对应。例如:“写文章”、“写毛笔”、“写黑板”,句法结构完全相同(动宾),但分别表达了“动作与结果”、“动作与工具”、“动作与处所”不同的语义关系;又如:“客人来了”与“来了客人”,两个句法结构的语义关系基本相同,“客人”与“来”都是“施事”与“动作”的关系,但句法关系分别是主谓和动宾。语用意义也不相同,前一个结构的“客人”是定指,表达已知信息,后一个结构的“客人”是非定指,表达新信息。更复杂一点的结构,如:①“床上躺着一个人”;②“那个人在床上躺着”;③“那个人躺在床上”;④“床上的那个人躺着”,这几个句子的句法结构关系各不相同,但语义关系基本相同,“人”、“床上”、“躺”之间都是“施事”、“处所”与“动作”的关系。 语法教学中进行语义分析,除了上述指出的句法成分间的语义规定性,即施事(主体)、受事与事(客体)、对象、处所、时间、结果、原因、目的、方式等之外,主要还是对语义指向的分析。由于汉语句法上的结合关系与语义的结合关系存在着不一致的现象,语义指向分析对理解句子的语义结构显得尤其重要。如:①“这些书我都看过了”;②“这本书我们都看过了”;③“这些书我们都看过了”。这三个句子中的“都”在句法上均与动词“看”结合,构成偏正关系,在语义上“都”的语义指向分别是①“这些书”(受事),②“我们”(施事),③在没有特定语境时,“都”所涉及的可以是“我们”,也可以是“这些书”,还可以是“我们”和“这些书”。再如:①“饭吃多了”。②“饭吃饱了”;③“饭吃快了”; ④“饭吃完了”。以上几例按照句法分析,它们的层次构造完全一样,但分析其语义指向,“多”指“吃的饭”多了,“饱”指吃饭的人“饱”了,“快”说明的是“吃”这一动作行为,而“完”既可以说明“饭”完了(即“饭吃光了”),也可以说明吃饭这一动作行为的结束。以上几个句法结构体,“多”“饱”“快”“完”都与“吃”是句法上的直接成分(动补),但语义结构上却有区别。④ 语法教学中的语用分析,是对语言现象的动态分析,指明其使用的条件和语境,以利于学生恰当地使用学过的句子去交际。⑤比如动词重叠式,主要表示“短时、尝试、轻微、少量”的意义,但在具体语言环境中,意义又有所侧重,有着不同的表达功能和限定条件。如为什么我们可以说“讨论这个问题”,但不能说“讨论讨论一个问题”呢?这是因为后一句违背了“动词重叠后,其宾语前带数量词作定语时,数量词须为确定的。”这样一条语用规则。 ⑥其他如:动词带补语时,不用重叠形式,所以不能说“我想想清楚再说”,“请把房间收拾收拾整齐。”又如,否定式陈述句不用动词重叠式,不能说“我不想去唱唱歌”。(但可以说“你怎么不去唱唱歌?”);动词做修饰限制语的成分时,也不能用重叠式,不能说“你试试的那件衣服很合身。”等等。类似这样的各种条件限制,对汉语为母语的人来说,一般 词法分析 一、实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 2.1 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2.2 各种单词符号对应的种别码: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 3.1 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 3.2 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。 词法、语法、语义分析结合 一、实验目的与要求 在实现词法、语法分析程序的基础上,编写相应的语义子程序,进行语义处理,加深对语法制导翻译原理的理解,进一步掌握将语法分析所识别的语法范畴变换为某种中间代码(四元式)的语义分析方法,并完成相关语义分析器的代码开发。 二、实验内容 语法制导翻译模式是在语法分析的基础上,增加语义操作来实现的。对于给定文法中的每一产生式,编写相应的语义子程序。在语法分析过程中,每当用一个产生式进行推导或归约时,语法分析程序除执行相应的语法分析动作之外,还要调用相应的语义子程序,以便完成生成中间代码、查填有关表格、检查并报告源程序中的语义错误等工作。每个语义子程序需指明相应产生式中各个符号的具体含义,并规定使用该产生式进行分析时所应采取的语义动作。这样,语法制导翻译程序在对源程序从左到右进行的一遍扫描中,既完成语法分析任务,又完成语义分析和中间代码生成方面的工作。 输入:包含测试用例,如由无符号数和+、?、*、/、(、)构成的算术表达式的源程序文件。 输出:将源程序转换为中间代码形式表示,并将中间代码序列输出到文件中。若源程序中有错误,应指出错误信息。 三、一般实现方法 语法制导翻译模式实际上是对前后文无关文法的一种扩展。一般而言,首先需要根据进行的语义工作,完成对文法的必要拆分和语义动作的编写,从而为每个产生式都配备相应的语义子程序,以便在进行语法分析的同时进行语义解释。要求从编译器的整体设计出发,重点通过对实验二中语法分析程序的扩展,完成一个编译器前端程序的编写、调试和测试工作,形成一个将源程序翻译为中间代码序列的编译系统。 四、基本实验题目 题目:对文法G3[<算术表达式>]中的产生式添加语义处理子程序,完成无符号数的四则运算的计值处理,将输入的四则运算转换为四元式形式的中间代码。本实验只进行了算术表达式四元式的翻译。 五、源代码 *****************************词法分析.h文件 # include 上海电力学院 编译原理 课程实验报告 实验名称:实验三自下而上语法分析及语义分析 院系:计算机科学和技术学院 专业年级: 学生姓名:学号: 指导老师: 实验日期: 实验三自上而下的语法分析 一、实验目的: 通过本实验掌握LR分析器的构造过程,并根据语法制导翻译,掌握属性文法的自下而上计算的过程。 二、实验学时: 4学时。 三、实验内容 根据给出的简单表达式的语法构成规则(见五),编制LR分析程序,要求能对用给定的语法规则书写的源程序进行语法分析和语义分析。 对于正确的表达式,给出表达式的值。 对于错误的表达式,给出出错位置。 四、实验方法 采用LR分析法。 首先给出S-属性文法的定义(为简便起见,每个文法符号只设置一个综合属性,即该文法符号所代表的表达式的值。属性文法的定义可参照书137页表6.1),并将其改造成用LR分析实现时的语义分析动作(可参照书145页表6.5)。 接下来给出LR分析表。 然后程序的具体实现: ● LR分析表可用二维数组(或其他)实现。 ●添加一个val栈作为语义分析实现的工具。 ●编写总控程序,实现语法分析和语义分析的过程。 注:对于整数的识别可以借助实验1。 五、文法定义 简单的表达式文法如下: (1)E->E+T (2)E->E-T (3)E->T (4)T->T*F (5)T->T/F (6)T->F (7)F->(E) (8)F->i 状态ACTION(动作)GOTO(转换) i + - * / ( ) # E T F 0 S5 S4 1 2 3 1 S6 S1 2 acc 2 R 3 R3 S7 S13 R3 R3 3 R6 R6 R6 R6 R6 R6 4 S 5 S4 8 2 3 5 R8 R8 R8 R8 R8 R8 6 S5 S4 9 3 7 S5 S4 10 8 S6 R12 S11 9 R1 R1 S7 S13 R1 R1 10 R4 R4 R4 R4 R4 R4 11 R7 R7 R7 R7 R7 R7 12 S5 S4 14 3 13 S5 S4 15 14 R2 R2 S7 S13 R2 R2 15 R5 R5 R5 R5 R5 R5 五、处理程序例和处理结果例 示例1:20133191*(20133191+3191)+ 3191# 语义语法与翻译表达 在影响翻译表达的诸多因素中,首先遇到的莫过于对句中词汇意思的、对句子结构的分析,也就是语义和语法这两个方面。在翻译过程中这两个方面的问题解决得好,那么翻译的东西可以说基本上达到了"信"和"达"。至于"雅"的问题,它与译者的文笔修养及其他一些因素等联系甚紧,本文无意谈及。笔者只想从语义和语法的角度对翻译表达中出现的一些问题用实例加以分析,旨在证明语义和语法这两个因素在翻译表达中的重要性。 一、语义理解应准确 符号学的观点认为,一门语言就是一个系统,表达概念的词可以看作是系统中的实体,这些实体只有在系统中才有意义。这就是说词汇是静态的,句子是动态的。词汇只有置于句子才有意义,而只有根据句子乃至语篇来确定某个词汇的准确含义,才能真正达到翻译便是译意的目的。所以,语义的理解应力求准确。不仅要突出文字的表层意思,有的还必须译出其深层的涵义。这样译文表达才可能正确无误。可见理解准确是翻译准确的前提,否则便会译不达意,贻笑大方。现就语义理解的重要性以若干实例加以说明: 1. Health is above wealth, for this cannot give so much happiness as that. 译文:健康比财富更重要,因为财富不能像健康那样给人们带来幸福。 原句中this代替就近的名词,即wealth(财富),that代替较远的名词,即health(健康)。要把两个代词翻译成所代之名词才说得通。如果把this和that拘泥于表面原意译成"这个"和"那个",这样指代很不明确,放到译文中则让人不知所云。再如: There are two classes of people: the selfish and the selfless; these are respected, while those are looked down upon. 此句中的these指前面靠近的the selfless(忘我的人),those指较远的the selfish(自私的人)。所以全句应译成: 世上有两种人:自私者和忘我者;忘我的有受到尊敬,而自私的人则遭鄙视。 2. Men and nations working apart created these problems, men and nations working together must solve them. 译文:人与人之间以及国与国之间离心离德产生了这些问题:人与人之间以及国与国之间同心同德必定能解决这些问题。 句中men和nations都是复数。如果简单地译成"人们"和"国家"但不合原意,甚至被理解为人同国家之间离心离德和同心同德。故此,应在"人"和"国家"之后加上"之间",使句子不仅准确地表达了men和nations两个词在句中的深层含义,而且读起来也通顺。 3.He was astounded but highly pleased that the man who presided over the destinies of the mighty British Empire should come pleading to him. 译文:他又惊又喜,那位掌握着大英帝国命运的人居然来向他央求。 Should作为情态动词有"应该"的意思,但是当句子中有pity, surprise, shame, shock等表达说话人感情色彩的词时,从句中的should就往往被译成"居然","竟然"等,把说话人的同情、吃惊、羞怯、不满、赞叹、怀疑等感情表达出来。原文中有astounded和pleased表示惊喜的词,所以should应译民"居然",如果译成"应该",就错了。 4. Hairless Yunus has a few marbles missing because he is a wrestler. 译文:秃头尤诺斯是个角力士,他缺几个心眼。 实验二语法和语义分析器 一实验目的 1.掌握 Yacc 的基本用法,并能够根据语言给出语法规则的定义,最后生成语言的解析器; 2.使用Yacc实现一个高级计算器程序。 二实验内容 实现一个简单的表达式计算器,要求能进行加、减、乘、除、幂运算,注意优先级。求写出详细的步骤和相应的flex源程序。 三实验步骤 1.在linux中安装flex,使用如下命令: Undo apt-lex install bison 2.实验源程序 %{ #define YYSTYPE double #include yylex () { int c; while ((c = getchar ()) == ' ' || c == '\t'); if (c == '.' || isdigit (c)) { ungetc (c, stdin); scanf ("%lf", &yylval); return NUM; } if (c == EOF) return 0; return c; } main () { return yyparse (); } yyerror(char *msg) { printf("error %s encountered\n", msg); }四实验结果 五实验内容中遇到的问题、解决方法和体会。 通过本次实验实现一个简单的表达式计算器,要求能进行加、减、乘、除运算,注意运算的优先级问题。掌握了Yacc 的基本用法,并能够根据语言给出语法规则的定义,最后生成语言的解析器。但在运行时出现了错误,经过同学帮助修改成功。语义语法
语义分析
TEST语法语义规则
编译器的词法分析器
语法、语义和语用三个平面的联系与区别
编译原理课程设计(词法分析,语法分析,语义分析,代码生成)
语法、语义、语用
编译原理词法分析和语法分析报告+代码(C语言版)
词法、语法、语义分析结合
编译原理实验三-自下而上语法分析及语义分析.docx
语义语法与翻译表达
语法和语义分析器