ETL工具kettl实际中的一些应用说明

Kettle工具在实际中的一些应用说明
这里我就kettle工具在实际当中的一些应用做一些简单的说明,关于kettle工具的各个选项说明请参照以下文档。
一:资源库的设置
Kettle提供了两种资源库的选择方式:数据库存放、本地文件存放。
数据库
该方式是通过数据库连接直接在数据库里面创建kettle表,表里面记录着你所做的任何保存过的记录以及转换和任务。此方法是远程存放的方式,具有可多人共享一个资源库的优势,但是也存在资源库不稳定的缺点。
以下就数据库资源库具体怎么实现做一下介绍:
第一:
在tools选项下面有
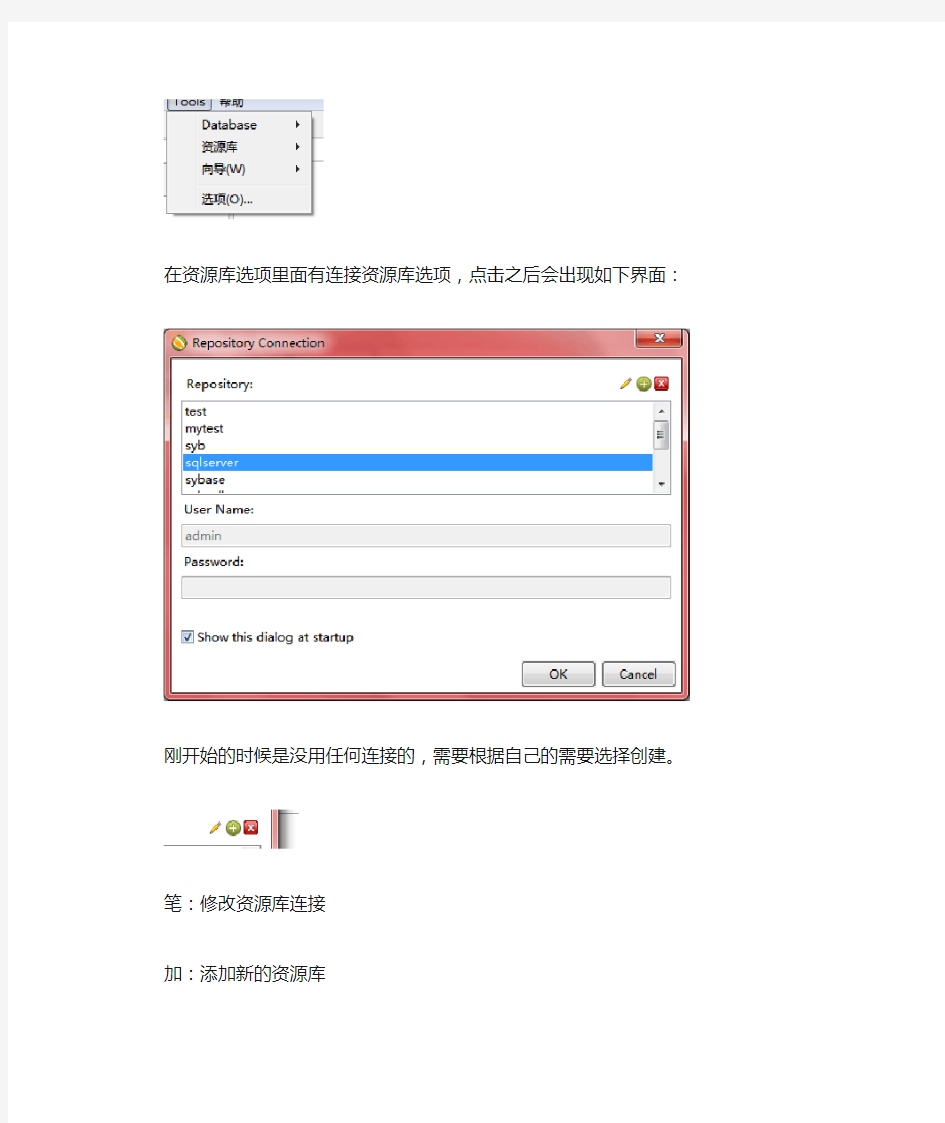
在资源库选项里面有连接资源库选项,点击之后会出现如下界面:
刚开始的时候是没用任何连接的,需要根据自己的需要选择创建。
笔:修改资源库连接
加:添加新的资源库
叉:删除选中资源库
点那个加号图标就可以进入到新建选项页面:
在中间的显示栏中:第一行代表着写入到数据库的资源库、第二行代表着保存到本地的资源库。
点击第一行进入如下界面:
点击新建按钮将会新建数据库连接,如果已经有你需要的数据库连接也可以选择你需要的。
上面就是新建数据库页面,根据你的需要选择具体的数据库连接方式,填写好完成之后点击一下测试按钮,就可以知道数据库连接是否成功。
到这里,资源库的连接已经做了一半了。接下来介绍另一半要做的事情。
回到这个页面,填写唯一的ID、名称,然后点击创建或更新按钮,之后会出现一些SQL语句,执行这些语句,如果成功的话就创建成功了,如果失败则要检查一下数据库。最后点击确定按钮就成功了。
这个时候就可以连接资源库了。
选择你创建的资源库,admin用户的默认密码是admin ,点击OK就行了。
本地
接下来简单介绍一下本地资源库,其实是很简单的。
选择第二行。将会看到如下页面:
这个就是本地的页面,比数据库简单多了,选择一下存放路径,给它一个ID号和名称,点击OK就可以了。
资源库建好之后就会进入到主页面了:
这个就是主页面了,表面上是空空如也的。
关于资源库的设置就就讲到这里了,关于更多的介绍请参照官方说明文档!
二:实现增量更新的方法
Kettle工具并没有提供增量更新的选项,这个是要根据你的策略来实现的。基本的策略是根据时间字段来做增量更新。接下来我们就如何根据时间字段做增量更新。
要实现增量更新的前提必须是原表必须要有一个时间字段,然后目标表根据这个时间字段来做查询和更新。(具体思想请参照开源ETL工具之增量更新设计技巧文档)
如图:
我将一一解释一下各个选项的具体作用。
第一个表输入:
这个是要获取目标表要做增量更新的时间字段的最大值,这个值将会传递给下一个表输入。此查询必须要保证只能传送一个值。
第二个表输入:
这个就是对原表的查询,要注意SQL语句里面的where子句。Where子句里面的判断字段就是做增量更新的时间字段,值就是前面一个表输入传递过来的。此时判断的值要用?来代
替,这两个选项要这样设置。
表输出:
这里就是要进行更新的目标表了,也就是第一个表输入的表。里面具体的一些选项请参照kettle工具说明手册。
以上就是增量更新的实现方法。
三:JOB定时的实现方法
我们在实际应用当中往往要实现定时的功能,kettle提供了定时的功能,这个只能在任务里面实现定时的功能。
见如下图:
在JOB里面的start选项里面提供了定时机制,可以根据你的需求来选择你需要的定时类型
这里要注意一下,要定时的时候一定要把重复的按钮给勾选上。
这里是通过kettle提供的机制来进行定时的,另一种定时的机制是依靠写脚本语句来定时调用kettle脚本。(这种我们在后面会在脚本调用介绍到)
四:kettle变量的设置与获取
变量在kettle里面使用的比较频繁,这里我就做一下简单的介绍,具体的变量设置请根据实际情况来设置。我这里的案例是获取系统时间,然后分别设置四个变量,这四个变量分别代表着“年”、“月”、“日”、“时”。
如下图:
变量的相关选项在转换里面中的作业里面。
我获取的是系统信息是:系统日期(关于这个选项请参看kettle手册)
为了达到我之前的需求,我在这里运用了kettle另一个功能。
中的javascript脚本选项。
这个步骤是讲系统时间认为的分割为四个字段。这四个字段将会作为变量的值传递到下一个步骤。(关于这个选项请参看kettle手册)
接下来就是到设置变量这个环节了。
后可以用变量名调用变量),第三是变量的活动类型(一般选择是作为全局变量)
第四列是给变量设置默认值。
以上就是变量设置的相关介绍,变量在使用之前必须先执行这个变量设置的转换,这样在后面才能实现对变量的调用。
关于变量的获取,这个在选项中只要有
这个标志的都是可以用变量的,变量的获取可以使用CTRL+ALT+SPACE快捷键来选择你所需要的变量名。
五:通过shell脚本调用kettle文件
在部署有kettle工具的机器上可以通过写脚本文件来调用kettle文件,这样就能实现不打开kettle工具而后台实现kettle文件的运行。
在kettle工具的文件下有这样两个文件
一下就是我在linux系统下写的一个脚本调用的案例:
#!/bin/sh
. /etc/profile
sh /sybase/data-integration/kitchen.sh -rep=111 -user=admin -pass=admin -job=EXCL -dir="/EXCL/" -level=basic>/sybase/pdi/EXCLlog.txt
~
就关于几个参数做一下介绍。
sh /sybase/data-integration/kitchen.sh ——调用kettle文件下的kitchen.sh文件
-rep=111 ——资源库ID
-user=admin ——资源库登陆用户
-pass=admin ——登陆密码
-job=EXCL ——调用JOB的名称
-dir="/EXCL/" ——JOB的存放路径
-level=basic>/sybase/pdi/EXCLlog.txt ——kettle日志写入到文件中
相关的一些参数的详细说明如下:
Options:
-rep = Repository name
-user = Repository username
-pass = Repository password
-job = The name of the job to launch
-dir = The directory (dont forget the leading /)
-file = The filename (Job XML) to launch
-level = The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing)
-logfile = The logging file to write to
-listdir = List the directories in the repository
-listjobs = List the jobs in the specified directory
-listrep = List the available repositories
-norep = Do not log into the repository
-version = show the version, revision and build date
-param = Set a named parameter
-export = Exports all linked resources of the specified job. The argument is the name of a ZIP file.
-maxloglines = The maximum number of log lines that are kept internally by Kettle. Set to 0 to keep all rows (default)
-maxlogtimeout = The maximum age (in minutes) of a log line while being kept internally by Kettle. Set to 0 to keep all rows indefinitely (default)
在linux系统中可以使用crontab命令来做定时,下面就简单介绍一下这个命令。
crontab命令的功能是在一定的时间间隔调度一些命令的执行。在/etc目录下有一个crontab 文件,这里存放有系统运行的一些调度程序。每个用户可以建立自己的调度crontab。
crontab命令有三种形式的命令行结构:
crontab [-u user] [file]
crontab [-u user] [-e|-l|-r]
crontab -l -u [-e|-l|-r] 第一个命令行中,file是命令文件的名字。如果在命令行中指定了这个文件,那么执行crontab命令,则将这个文件拷贝到crontabs目录下;如果在命令行中没有制定这个文件,crontab命令将接受标准输入(键盘)上键入的命令,并将他们也存放在crontab 目录下。
命令行中-r选项的作用是从/usr/spool/cron/crontabs目录下删除用户定义的文件crontab;命令行中-l选项的作用是显示用户crontab文件的内容。
使用命令crontab -u user -e命令编辑用户user的cron(c)作业。用户通过编辑文件来增加或修
改任何作业请求。
执行命令crontab -u user -r即可删除当前用户的所有的cron作业。
作业与它们预定的时间储存在文件/usr/spool/cron/crontabs/username里。username使用户名,在相应的文件中存放着该用户所要运行的命令。命令执行的结果,无论是标准输出还是错误输出,都将以邮件形式发给用户。文件里的每一个请求必须包含以spaces和tabs分割的六个域。前五个字段可以取整数值,指定何时开始工作,第六个域是字符串,称为命令字段,其中包括了crontab调度执行的命令。
第一道第五个字段的整数取值范围及意义是:
0~59 表示分
1~23 表示小时
1~31 表示日
1~12 表示月份
0~6 表示星期(其中0表示星期日)
/usr/lib/cron/cron.allow表示谁能使用crontab命令。如果它是一个空文件表明没有一个用户能安排作业。如果这个文件不存在,而有另外一个文件/usr/lib/cron/cron.deny,则只有不包括在这个文件中的用户才可以使用crontab命令。如果它是一个空文件表明任何用户都可安排作业。两个文件同时存在时cron.allow优先,如果都不存在,只有超级用户可以安排作业。第1列分钟1~59
第2列小时1~23(0表示子夜)
第3列日1~31
第4列月1~12
第5列星期0~6(0表示星期天)
第6列要运行的命令
下面是crontab的格式:
分时日月星期要运行的命令
这里有crontab文件条目的一些例子:
30 21 * * * /usr/local/apache/bin/apachectl restart
上面的例子表示每晚的21:30重启apache。
45 4 1,10,22 * * /usr/local/apache/bin/apachectl restart
上面的例子表示每月1、10、22日的4 : 45重启apache。
10 1 * * 6,0 /usr/local/apache/bin/apachectl restart
上面的例子表示每周六、周日的1 : 10重启apache。
0,30 18-23 * * * /usr/local/apache/bin/apachectl restart
上面的例子表示在每天18 : 00至23 : 00之间每隔30分钟重启apache。
0 23 * * 6 /usr/local/apache/bin/apachectl restart
上面的例子表示每星期六的11 : 00 pm重启apache。
* */1 * * * /usr/local/apache/bin/apachectl restart
每一小时重启apache
* 23-7/1 * * * /usr/local/apache/bin/apachectl restart
晚上11点到早上7点之间,每隔一小时重启apache
0 11 4 * mon-wed /usr/local/apache/bin/apachectl restart
每月的4号与每周一到周三的11点重启apache
0 4 1 jan * /usr/local/apache/bin/apachectl restart
一月一号的4点重启apache
以上就是一些在实际应用中常用的一些技巧,接下来我们就根据具体的实例来做具体的分析和讲解。
六:实例讲解
1从FTP服务器上下载文件
这个是JOB实现的是每隔一个小时从FTP服务器上下载当前时段的一个文件。此JOB要实现的核心在于时间变量的设置,同时还需要根据你要下载的文件编写相应的正则表达式。
首先我们来看变量是如何设置的:
第一:获取使用获取系统信息选项,此选项在装换当中的输入文件夹下面。
打开此选项我们可以看到有如下一些选择:
这里根据我们的需求选择“系统日期(可变)”,这个是第一步,接下来就要使用到另一个重要的选项“javascript”。
第二:javascript选项来提取我们需要的时间格式
这里我们是要分别提取系统时间的“年”、“月”、“日”、“时”四个时段的值。这个选项提供一些相应的方法来实现这个功能,我使用的是date2str(var,var)方法,此方法的说明如下:
var dValue = new Date();
Alert(date2str(dValue));
Alert(date2str(dValue,"dd.MM.yyyy"));
Alert(date2str(dValue,"dd.MM.yyyy HH:mm:ss"));
Alert(date2str(dValue,"E.MMM.yyyy","DE"));
Alert(date2str(dValue,"dd.MM.yyyy HH:mm:ss","EN"));
Alert(date2str(dValue,"dd.MM.yyyy HH:mm:ss","EN", "EST"));
这个是选项中现成提供的一个,里面还有很多。这里不单可以使用选项本身带有的,还可以自己编写相应的javascript脚本语句。
以下就我获取不同时段的代码:
years=date2str(sysdate,"yyyy");
mons=date2str(sysdate,"MM");
days=date2str(sysdate,"dd");
hous=date2str(sysdate,"HH");
这里一共有四个字段,这意味我们在后面要分别设置四个变量。
好,接下来就让我们来看看最后一步:变量的设置
第三:变量设置
如图:
我设置了四个变量:分别是“年”、“月”、“日”、“时”,全部设置为全局变量。
好,到这里我们的定时下载FTP已经完成了第一步,这个为什么要设置四个变量呢?接下来就会知道了。
然后就是FTP选项的相关设置
如图:
第一个页面是填写相关的FTP服务的信息。填写正确之后有个“TEST CONNECTION”按钮可
以测试服务器是否连接成功。在看下面有一个控制编码选项,这个选项是选择相应的文件编码格式,特别是文件在不同系统之间传输最容易导致乱码问题。这里手动指定相应的编码格式可以有效避免乱码问题。
第二个页面如下:
这里有两点需要注意一下,第一就是通配符选项。此选项是用来写相应的正则表达式来提取相应的文件。我们之前设置的变量也就是在这里使用。
我下载的是EXCL文件,文件名格式“广东电信C网拨测系统-服务质量支撑及管理系统-指标数据(2011年11月25日12点)”。我们要实现动态提取当前文件就得根据文件名当中哪些是变化的,这里明显可以看出文件名当中的时间是变化的,但是此时间不是标准的时间格式,所以我们使用了四个变量也就是如此了。
相应的正则表达式如下:
.*(${years}.*${mons}.*${days}.*${hous}.*).xls
另一个需要注意的地方就是:
此选项可以实现相应的文件操作,比如跳过、覆盖等等一些。
以上就是从FTP服务器下载的整个JOB 的流程,这个根据自己的需求还可以做很多变化,具体的有哪些变化,就交给大家去实践中体验了。
2从EXCL文件读取数据入库
上次我们讲到了从FTP下载文件,这次我们了解一下我们如何将EXCL文件导入到数据库当中。
Kettle工具提供了一个选项,此选项的功能是把excl文件的数据提取出来。
在使用这个选项的时候,必须EXCL文件格式是标准的表模式。(表模式—头一行是字段名,下面是数据行。)
我们就来看看详细的配置:
大数据分析的六大工具介绍
大数据分析的六大工具介绍 2016年12月 一、概述 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分学在大数据处理分析过程中六大最好用的工具。 我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设il?的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式, 相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 二.第一种工具:Hadoop Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop是 以一种可黑、高效、可伸缩的方式进行处理的。Hadoop是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop还是可伸缩的,能够处理PB级数据。此外,Hadoop依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地 在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下儿个优点: ,高可黑性。Hadoop按位存储和处理数据的能力值得人们信赖。,高扩展性。Hadoop是 在可用的计?算机集簇间分配数据并完成讣算任务 的,这些集簇可以方便地扩展到数以千计的节点中。 ,高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动 态平衡,因此处理速度非常快。 ,高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败 的任务重新分配。 ,Hadoop带有用Java语言编写的框架,因此运行在Linux生产平台上是非 常理想的。Hadoop上的应用程序也可以使用其他语言编写,比如C++。 第二种工具:HPCC HPCC, High Performance Computing and Communications(高性能计?算与通信)的缩写° 1993年,山美国科学、工程、技术联邦协调理事会向国会提交了“重大挑战项 U:高性能计算与通信”的报告,也就是被称为HPCC计划的报告,即美国总统科学战略项U ,其U的是通过加强研究与开发解决一批重要的科学与技术挑战 问题。HPCC是美国实施信息高速公路而上实施的计?划,该计划的实施将耗资百亿 美元,其主要U标要达到:开发可扩展的计算系统及相关软件,以支持太位级网络 传输性能,开发千兆比特网络技术,扩展研究和教育机构及网络连接能力。
东方通ETL工具软件TI-ETL v2 产品白皮书
T ongT ech? TI-ETL v2 产品白皮书 北京东方通科技公司 2015年
目录 1 前言 (1) 2 为什么要用ETL (1) 2.1 业务需求 (1) 2.2 IT需求 (2) 2.3 IT与业务一致性要求 (2) 3 TI-ETL v2简介 (3) 3.1 产品组成结构 (3) 3.1.1 集成开发工具 (4) 3.1.2 服务器 (5) 3.1.3 资源库 (5) 3.1.4 统一管理平台 (6) 3.2 产品结构关系 (7) 3.3 转换流程和任务流程 (8) 3.3.1 转换流程 (8) 3.3.2 任务流程 (9) 4 主要功能和特点 (10) 4.1 大数据适配 (10) 4.2 强健的ETL引擎 (10) 4.3 丰富的系统适配 (11) 4.4 资源统一存储 (11) 4.5 丰富的处理组件 (11) 4.6 多种数据抽取模式 (11) 4.7 图形化操作/调试/预览能力 (11) 4.8 高效数据处理 (12) 4.9 异常恢复和数据一致性 (12) 4.10 强大的监控管理功能 (12) 4.11 插件式组件管理和可扩展性 (12) 4.12 国产环境支持 (13) 5 成功案例 (13)
1前言 随着IT应用建设的发展,数据成为了最重要的资源,无论是接地气的业务系统、应用软件、数据中心或是高大上的云/物/移/大/智,均是以数据资源为核心,依托发挥数据价值而存在和发展。 目前,虽然各行业IT发展成熟度不一致,但基本已经度过了大批量业务系统建设阶段,业务系统也经过了几年的运转,积累了不同量级的数据资源。但因早起IT业务系统的很少跨部门、跨单位、跨层级的统一规划和建设,导致业务系统处于分散、独立的状况,业务间数据资源不仅处于烟囱状态,数据资源的一致性和互用性较差,数据资源的价值无法充分发挥。 此外,各行业自身业务也在逐渐多元化和复杂化,业务产生和所需使用的数据也就具有不确定和频繁变动性,导致一旦应用发生变化、新增系统或物理数据变动,一旦无法借助某些手段适应变化,整个应用和数据体系均有较大可能不得不随之修改。 数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,通过应用间的数据有效流通和流通的管理从而达到集成,主要解决数据的分布性、异构性、有效性和及时性的问题。此外,数据集成是个长期不断持续的过程,需要有易用的工具、长期可靠的运行环境、全面有效的监控管理共同支撑,而非仅通过工具可以一次性解决的。 ETL是数据集成领域的落地技术,区别与传统数据交换,ETL在可完成基本数据交换(抽取、传输、装载)的前提下,对数据的转换(即数据的按需加工处理)提供更易用和更强大的支持,使数据在不同业务之间流动的同时,各业务获取到的数据确实是可有准确、及时、有效应用的。 TI-ETL是从传统数据交换产品继续发展的产物,有着多年的数据集成领域产品研制的积淀,已在大交通(海/陆/空)、大政府、国防工业、企业等行业核心系统中成功应用,辅助众多行业和用户逐渐发挥出了数据的价值,提升了IT支撑业务的有效性。 2为什么要用ETL 2.1业务需求 IT建设随业务发展,业务过程以数据贯穿,即业务有效性的基础是数据,且有效性又包含可获得性、及时性、准确性和一致性。在信息化早起,因信息系统较少、业务关系复杂度较低,对数据关注度也较低。随着各单位自身的发展,内部组织机构、多级组织机构建设愈发全
ETL工具kettle
概览 Kettle也叫PDI(全称是Pentaho Data Integeration),是一款开源的ETL工具,项目开始于2003年,2006年加入了开源的BI 组织Pentaho, 正式命名为PDI。官方网站:https://www.360docs.net/doc/8717967162.html,/ 术语 1.Transformation 转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。然后最终输出到某一个地方,文件或者数据库等。 2.Job 作业,可以调度设计好的转换,也可以执行一些文件处理(比较,删除等),还可以ftp上传,下载文件,发送邮件,执行shell命令等, 3.Hop连接转换步骤或者连接Job(实际上就是执行顺序) 的连线 Transformation hop:主要表示数据的流向。从输入,过滤等转换操作,到输出。 Job hop:可设置执行条件: 1,无条件执行 2,当上一个Job执行结果为true时执行 3,当上一个Job执行结果为false时执行
Kettle,etl设计及运行1.Kettle整体结构图 Kettle整体结构图 2.转换设计样例图绿色线条为hop,流水线
转换设计样例 3.运行方式 使用java web start 方式运行的配置方法 命令行方式 1)Windows下执行kitchen.bat,多个参数之间以“/”分隔,Key和value以”:”分隔例如: kitchen.bat /file:F:\samples\demo-table2table.ktr /level:Basic /log:test123.log /file:指定转换文件的路径 /level:执行日志执行级别 /log: 执行日志文件路径 2)Linux下执行kitchen.sh,多个参数之间以“-”分隔,Key和value以”=”分隔kitchen.sh -file=/home/updateWarehouse.kjb -level=Minimal 如果设计的转换,Job是保存在数据库中,则命令如下: Kitchen.bat /rep:资源库名称/user:admin /pass:admin /job:job名 4.Xml保存转换,job流程 设计用户定义的作业可以保存在(xml格式)中或某一个特定的数据库中 转换的设计文件以.ktr结尾(xml文格式),保存所有配置好的数据库连接,文件相对路径,
ETL 设计实现
数据集成(ETL)工具的设计与构建 陈小菲 经过几十年来快速不断的IT创新造就了大批综合性的、分布式的且不断变化的应用系统,这些系统跨越了从大型机到Web的多种平台,因此不同系统的互连成了亟待解决的问题。如何发挥这些系统中各种数据的作用,将不同应用系统的数据进行提炼、整合,并充分利用已有的技术及应用资源,建成一个完整的、可持续发展的集成系统,数据集成工具成为一种重要的技术,面对多种技术环境开发的基础业务系统,把业务数据迁移到综合业务系统和决策分析系统,并进行有效整合。 数据集成工具主要包括以下几个过程:抽取、清洗、转换和加载等,本文中数据集成工具简称为ETL工具。在实际项目中,本ETL工具已开始实现研发和试用,本文将对ETL工具的设计思想与功能实现等内容进行讨论。 一、ETL工具的功能目标 本ETL工具以各种技术环境开发的基础业务系统为基础,把业务数据迁移到综合业务系统和决策分析系统,并进行有效整合,建成一个完整的集成数据库系统,因此在企业应用集成(EAI)系统中,ETL工具扮演着相当关键的角色,以下是EAI数据集成模型图,箭头表示的数据迁移过程需要通过ETL工具实现。 图 1 数据集成模型 1、主要功能 ETL工具主要功能可分为两部分:数据集成配置和数据集成服务,具体如下: (1)数据集成配置:提供一个GUI界面,使得用户能够通过界面的互动,比较容易地实现数据集成的流程、规则的定义;同时提供相应的解析功能,实现将配置规则进行解析,
并对数据进行集成。最后能够定义并执行相应的抽取计划。 (2)数据集成服务:提供相应的解析功能,实现对集成规则的解析,服务读取这些规则,生成集成任务,在后台进行运行数据集成。并且把这些集成信息发布出来,可以让其它集成工具进行信息共享。 2、特点 (1)易用性:数据集成工具进行抽取任务配置时,比较繁锁,而本ETL工具在进行抽取任务配置时可以做到简单易学,易用;同时配置操作也流程化,易于理解。 (2)稳定性:本ETL工具进行任务执行,保证抽取任务的正常进行。运行稳定,不轻易发生系统错误,不轻易发生程序死机。 (3)可靠性:本ETL工具进行任务抽取时,能可靠地完成抽取,源数据到目标数据的抽取误差低于0.01%,对于因特殊情况无法进行抽取的,或中途停止无法抽取的系统将记录详细信息。 (4)执行效率:本ETL工具对大数据量进行数据抽取,可以保证对大数据量的抽取在正常情况下能较好地执行,在一定时间内完成对大数据量的抽取。 二、ETL工具的总体架构设计 图 2 ETL工具总体架构 如图2所示,ETL工具主要包括配置工具和抽取服务两个部分内容。
5大可视化BI工具选型对比分析
2018年5大可视化BI工具选型对比分析 如今,有大量功能强大的可视化工具和BI工具能快速的实现数据可视化,帮助业务分析推动决策。 在本文中,5类BI可视化工具(QlikView、Tableau、Power BI、帆软FineBI 和Google Data Studio)的特性、优点和缺点。主要比较它们的关键参数,包括可用性、设置、价格、支持、维护、自助服务功能、不同数据类型的支持等。 一、QlikView QlikView是一种将用户作为数据接收者的解决方案。它允许用户在工作流程中探索和发现数据,这与开发人员在处理数据时的工作方式类似。为了保持数据探索和可视化方法的灵活性,该软件致力于维护数据之间的关联。这可以帮助最终用户发现您的数据,即使这些搜索项目的来源是令人难以置信的,这些数据也会提醒您检索相关项目。 QlikView比较灵活,展示样式多样。它允许设置和调整每个对象的每个小方面,并自定义可视化和仪表板的外观。QlikView数据文件(QVD文件)概念的引入,一定程度上取代了ETL工具的功能,拥有可集成的ETL(提取,转换,加载)引擎,能够执行普通的数据清理操作,但是这可能会很昂贵。 1.产品差异化
Qlikview的设计是在avant-garde预构建的仪表板应用程序和联想仪表板的基础上开发的,这些应用程序既创新又直观易用。由于具有先进的搜索功能,它还提供了避免使用数据仓库和使用关联仪表板在存中提取数据的功能。 2.特征 Qlikview的独特性和灵活性的完美结合使其在其他BI供应商中占有一席之地,并为各行各业处理了大量不同规模的业务提供各种有用的应用程序。 其中一个特点是QlikView能够自动关联数据:识别集合中各种数据项之间的关系,无需手动建模。 另一个特性,Qlikview处理数据输入,是将其保存在多个用户的存中,即保存在服务器的RAM中。这样可以加快查询速度,从而加快数据探索速度,并改善用户在运行中计算的聚合体验,而不是基于存储的计算。由于Qlikview保留了存中的数据,因此根据需要计算聚合要快得多,而不是查询预先计算的聚合值。又有点也有缺点,存型的BI工具,数据处理速度很大程度上依赖存大小,对硬件要求较高,一般企业的配置,数据处理起来较慢,而且Qlikview对于复杂业务需求,必须写qlikview的脚本。 3.可用性 QlikView的仪表板和报告很容易浏览,但是对于构建报表可能有点挑战,因为它需要高水平的开发人员技能,熟悉默认SQL以及使用Qlikview的专有查询语言(qlikview脚本)进行训练以构建数据库交互。
开源ETL工具kettle系列之常见问题
开源ETL工具kettle系列之常见问题 kettle, ETL, 工具, 开源 1. Join 我得到A 数据流(不管是基于文件或数据库),A包含field1 , field2 , field3 字段,然后我还有一个B 数据流,B包含field4 , field5 , field6 , 我现在想把它们‘加’ 起来, 应该怎么样做.这是新手最容易犯错的一个地方,A数据流跟B数据流能够Join,肯定是它们包含join key ,join key 可以是一个字段也可以是多个字段。如果两个数据流没有join key ,那么它们就是在做笛卡尔积,一般很少会这样。比如你现在需要列出一个员工的姓名和他所在部门的姓名,如果这是在同一个数据库,大家都知道会在一个sql 里面加上where 限定条件,但是如果员工表和部门表在两个不同的数据流里面,尤其是数据源的来源是多个数据库的情况,我们一般是要使用Database Join 操作,然后用两个database table input 来表示输入流,一个输入是部门表的姓名,另一个是员工表的姓名,然后我们认为这两个表就可以”Join” 了,我们需要的输出的确是这两个字段,但是这两个字段的输出并不代表只需要这两个字段的输入,它们之间肯定是需要一个约束关系存在的。另外,无论是在做 Join , Merge , Update , Delete 这些常规操作的时候,都是先需要做一个compare 操作的,这个compare 操作都是针对compare key 的,无论两个表结构是不是一样的,比如employee 表和department 表,它们比较的依据就是employee 的外键department_id , 没有这个compare key 这两个表是不可能连接的起来的.. 对于两个表可能还有人知道是直接sql 来做连接,如果是多个输入数据源,然后是三个表,有人就开始迷茫了,A表一个字段,B表一个字段,C表一个字段,然后就连Join操作都没有,直接 database table output , 然后开始报错,报完错就到处找高手问,他们的数据库原理老师已经在吐血了。如果是三个表连接,一个sql 不能搞定,就需要先两个表两个表的连接,通过两次compare key 连接之后得到你的输出,记住,你的输出并不能代表你的输入. 下面总结一下: 1. 单数据源输入,直接用sql 做连接 2. 多数据源输入,(可能是文本或是两个以上源数据库),用database join 操作. 3. 三个表以上的多字段输出. 2. Kettle的数据库连接模式 Kettle的数据库连接是一个步骤里面控制一个单数据库连接,所以kettle的连接有数据库连接池,你可以在指定的数据库连接里面指定一开始连接池里面放多少个数据库连接,在创建数据库连接的时候就有Pooling 选项卡,里面可以指定最大连接数和初始连接数,这可以一定程度上提高速度. 3. transaction 我想在步骤A执行一个操作(更新或者插入),然后在经过若干个步骤之后,如果我发现某一个条件成立,我就提交所有的操作,如果失败,我就回滚,kettle提供这种事务性的操作吗? Kettle 里面是没有所谓事务的概念的,每个步骤都是自己管理自己的连接的,在这个步骤开始的时候打开数据库连接,在结束的时候关闭数据库连接,一个步骤是肯定不会跨session的(数据库里面的session), 另外,由于kettle 页脚内容1
ETL浅谈
ETL浅谈 ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。 ETL是BI项目重要的一个环节。通常情况下,在BI项目中ETL会花掉整个项目至少 1/3的时间,ETL设计的好坏直接关接到BI项目的成败。 ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。在设计ETL的时候我们也是从这三部分出发。数据的抽取是从各个不同的数据源抽取到ODS(Operational Data Store,操作型数据存储)中——这个过程也可以做一些数据的清洗和转换),在抽取的过程中需要挑选不同的抽取方法,尽可能的提高ETL的运行效率。ETL三个部分中,花费时间最长的是“T”(Transform,清洗、转换)的部分,一般情况下这部分工作量是整个ETL的2/3。数据的加载一般在数据清洗完了之后直接写入DW(Data Warehousing,数据仓库)中去。 ETL的实现有多种方法,常用的有三种。一种是借助ETL工具(如Oracle的OWB、SQL Server 2000的DTS、SQL Server2005的SSIS服务、Informatic等)实现,一种是SQL方式实现,另外一种是ETL工具和SQL相结合。前两种方法各有各的优缺点,借助工具可以快速的建立起ETL工程,屏蔽了复杂的编码任务,提高了速度,降低了难度,但是缺少灵活性。SQL的方法优点是灵活,提高ETL运行效率,但是编码复杂,对技术要求比较高。第三种是综合了前面二种的优点,会极大地提高ETL的开发速度和效率。 一、数据的抽取(Extract) 这一部分需要在调研阶段做大量的工作,首先要搞清楚数据是从几个业务系统中来,各个业务系统的数据库服务器运行什么DBMS,是否存在手工数据,手工数据量有多大,是否存在非结构化的数据等等,当收集完这些信息之后才可以进行数据抽取的设计。 1、对于与存放DW的数据库系统相同的数据源处理方法 这一类数据源在设计上比较容易。一般情况下,DBMS(SQLServer、Oracle)都会提供数据库链接功能,在DW数据库服务器和原业务系统之间建立直接的链接关系就可以写Select 语句直接访问。 2、对于与DW数据库系统不同的数据源的处理方法 对于这一类数据源,一般情况下也可以通过ODBC的方式建立数据库链接——如SQL Server和Oracle之间。如果不能建立数据库链接,可以有两种方式完成,一种是通过工具将源数据导出成.txt或者是.xls文件,然后再将这些源系统文件导入到ODS 中。另外一种方法是通过程序接口来完成。 3、对于文件类型数据源(.txt,.xls),可以培训业务人员利用数据库工具将这些数据导入到指定的数据库,然后从指定的数据库中抽取。或者还可以借助工具实现。 4、增量更新的问题 对于数据量大的系统,必须考虑增量抽取。一般情况下,业务系统会记录业务发生的时间,我们可以用来做增量的标志,每次抽取之前首先判断ODS中记录最大的时间,然后根据这个时间去业务系统取大于这个时间所有的记录。利用业务系统的时间戳,一般情况下,业务系统没有或者部分有时间戳。 二、数据的清洗转换(Cleaning、Transform)
主流ETL工具选型
主流ETL工具选型 ETL(extract, transform and load)产品乍看起来似乎并不起眼,单就此项技术本身而言,几乎也没什么特别深奥之处,但是在实际项目中,却常常在这个环节耗费太多的人力,而在后续的维护工作中,更是往往让人伤透脑筋。之所以出现这种状况,恰恰与项目初期没有正确估计ETL工作、没有认真考虑其工具支撑有很大关系。 做ETL产品的选型,仍然需要从以前说的四点(即成本、人员经验、案例和技术支持)来考量。在此,主要列举三种主流ETL产品: Ascential公司的Datastage、 Informatica公司的Powercenter、 NCR Teradata公司的ETL Automation、 Oracel 公司的ODI、 国产udis睿智ETL、 其中,ETL Automation相对其他两种有些特别之处,放在后面评述。 旗鼓相当:Datastage与Powercenter: 就Datastage和Powercenter而言,这两者目前占据了国内市场绝大部分的份额,在成本上看水平相当,虽然市面上还有诸如Business Objects公司的Data Integrator、Cognos公司的DecisionStream,但尚属星星之火,未成燎原之势。 谈Datastage和Powercenter,如果有人说这个就是比那个好,那听者就要小心一点了。在这种情况下有两种可能:他或者是其中一个厂商的员工,或者就是在某个产品上有很多经验而在另一产品上经验缺乏的开发者。为什么得出这一结论?一个很简单的事实是,从网络上大家对它们的讨论和争执来看,基本上是各有千秋,都有着相当数量的成功案例和实施高手。确实,工具是死的,人才是活的。在两大ETL工具技术的比对上,可以从对ETL流程的支持、对元数据的支持、对数据质量的支持、维护的方便性、定制开发功能的支持等方面考虑。 一个项目中,从数据源到最终目标表,多则上百个ETL过程,少则也有十几个。这些过程之间的依赖关系、出错控制以及恢复的流程处理,都是工具需要重点考虑。在这一方面,Datastage的早期版本对流程就缺乏考虑,而在6版本则加入Job Sequence的特性,可以将Job、shell脚本用流程图的方式表示出来,依赖关系、串行或是并行都可以一目了然,就直
ETL工具-BeeDI6.0技术白皮书
北京灵蜂纵横软件有限公司
BeeDI 6.0 技术白皮书
https://www.360docs.net/doc/8717967162.html, [2010]
BeeDI 6.0 技术白皮书
2010 年 5 月 4 日
目录
1. 2. 3. 4. 产品背景................................................................................................................................... 2 产品概述................................................................................................................................... 2 产品架构................................................................................................................................... 3 产品功能................................................................................................................................... 4 4.1 数据转换.......................................................................................................................... 4 4.2 数据联邦.......................................................................................................................... 6 4.3 数据同步.......................................................................................................................... 7 4.4 工作流调度...................................................................................................................... 8 4.5 WebService ...................................................................................................................... 9 4.6 脚本调试.......................................................................................................................... 9 4.7 作业调度........................................................................................................................ 11 4.8 远程调度........................................................................................................................ 12 4.9 数据安全........................................................................................................................ 13 4.10 日志记录........................................................................................................................ 14 4.11 统计分析........................................................................................................................ 15 安装实施................................................................................................................................. 16 5.1 硬件环境........................................................................................................................ 16 5.2 软件环境........................................................................................................................ 17 运营维护................................................................................................................................. 17 产品优势................................................................................................................................. 18 产品应用................................................................................................................................. 18
5.
6. 7. 8.
1
ETL工具介绍
a ETL工具介绍 2020年6月14日
目录 1. 引言 (3) 1.1 编写目的 (3) 1.2 文档背景 (3) 1.3 预期读者 (3) 1.4 参考资料 (3) 2. ETL 基本概念 (4) 2.1 ETL 的定义 (4) 2.2 ETL 的作用 (4) 2.3 ETL 工具的功能 (5) 2.3.1 对平台的支持 (5) 2.3.2 对数据源的支持 (5) 2.3.3 数据转换功能 (6) 2.3.4 管理和调度功能 (6) 2.3.5 集成和开放性 (6) 2.3.6 对元数据的管理 (7) 3. 主流的ETL 工具 (7) 3.1 一类是专业ETL 厂商的产品 (7) 3.2 另一类是整体数据仓库方案供应商 (8) 3.3 还有一类是由开源提供的软件 (8) 4. 报表工具简介 (8) 5. 前端展现 (9) 6. 建行RIDE 报表工具介绍 (9) 6.1 RIDE 介绍 (9) 6.2 RIDE 的应用 (10) 6.3 RIDE 功能 (10)
1. 引言 1.1编写目的 本文介绍ETL的基本感念和功能,以及ETL目前主流工具,并对BI/DW架构的最后一个环节报表展示,给予介绍。 1.2文档背景 1.3预期读者 对数据挖掘感兴趣的人员 1.4参考资料 1.5修改记录
2. ETL 基本概念 2.1 ETL 的定义 ETL分别是“ Extract、“ Transform、” “ Load三个单词的首字母缩写也就是抽取”、“转换”、“装载”,但我们日常往往简称其为数据抽取。ETL 是BI/DW (商务智能/数据仓库)的核心和灵魂,按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。ETL 包含了三方面,首 先是“抽取”:将数据从各种原始的业务系统中读取出来,这是所有工作的前提。其次“转换”:按照预先设计好的规则将抽取得数据进行转换,使本来异构的数据格式能统一起来。最后“装载”:将转换完的数据按计划增量或全部导入到数据仓库中。 2.2 ETL 的作用 ETL 所完成的工作主要包括三方面:首先,在数据仓库和业务系统之间搭建起一座桥梁,确保新的业务数据源源不断地进入数据仓库; 其次,用户的分析和应用也能反映出最新的业务动态,虽然ETL 在数据仓库架构的三部分中技术含量并不算高,但其涉及到大量的业务逻辑和异构环境,因此在一般的数据仓库项目中ETL 部分往往也是牵扯精力最多的; 第三,如果从整体角度来看,ETL 主要作用在于屏蔽了复杂的业务逻辑,从而为各种基于数据仓库的分析和应用提供了统一的数据接口,这也是构建数据仓库最重要的意义所在 整个BI/DW 系统由三大部分组成:数据集成、数据仓库和数据集市、多维数据分析。通常,商务智能运作所依靠的信息系统是一个由传统系统、不兼容数据源、数据库与应用所共同构成的复杂数据集合,各个部分之间不能彼此交流。从这个层面看:目前运行的应用系统是用户花费了很大精力和财力构建的、不可替代的系统,特别是系统的数据。而新建的商务智能系统目的就是要通过数据分析来辅助用户决策,恰恰这些数据 的来源、格式不一样,导致了系统实施、数据整合的难度。此时,非常希望有一个全面 的解决方案来解决用户的困境,解决数据一致性与集成化问题,使用户能够从已有传统 环境与平台中采集数据,并利用一个单一解决方案对其进行高效的转换。这个解决方案就是ETL 。 ETL 是BI/DW 的核心和灵魂,按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。如果说数据仓库的模型设计是一座大厦的设计蓝图,数据是砖瓦的
国际三大主流ETL工具分析
国际三大主流ETL工具选型分析 摘要:做ETL产品的选型,仍然需要从以前说的四点(即成本、人员经验、案例和技术支持)来考量。在此,主要列举三种主流ETL产品:Ascential公司的Datastage、Informatica公司的 Powercenter、NCR Teradata公司的ETL Automation ETL(extract, transform and load)产品乍看起来似乎并不起眼,单就此项技术本身而言,几乎也没什么特别深奥之处,但是在实际项目中,却常常在这个环节耗费太多的人力,而在后续的维护工作中,更是往往让人伤透脑筋。之所以出现这种状况,恰恰与项目初期没有正确估计ETL工作、没有认真考虑其工具支撑有很大关系。 做ETL产品的选型,仍然需要从以前说的四点(即成本、人员经验、案例和技术支持)来考量。在此,主要列举三种主流ETL产品:Ascential公司的Datastage、Informatica公司的Powercenter、 NCR Teradata 公司的ETL Automation。其中,ETL Automation相对其他两种有些特别之处,放在后面评述。 旗鼓相当:Datastage与Powercenter 就Datastage和Powercenter而言,这两者目前占据了国内市场绝大部分的份额,在成本上看水平相当,虽然市面上还有诸如Business Objects公司的Data Integrator、Cognos公司的DecisionStream,但尚属星星之火,未成燎原之势。 谈Datastage和Powercenter,如果有人说这个就是比那个好,那听者就要小心一点了。在这种情况下有两种可能:他或者是其中一个厂商的员工,或者就是在某个产品上有很多经验而在另一产品上经验缺乏的开发者。为什么得出这一结论?一个很简单的事实是,从网络上大家对它们的讨论和争执来看,基本上是各有千秋,都有着相当数量的成功案例和实施高手。确实,工具是死的,人才是活的。 在两大ETL工具技术的比对上,可以从对ETL流程的支持、对元数据的支持、对数据质量的支持、维护的方便性、定制开发功能的支持等方面考虑。 一个项目中,从数据源到最终目标表,多则上百个ETL过程,少则也有十几个。这些过程之间的依赖关系、出错控制以及恢复的流程处理,都是工具需要重点考虑。在这一方面,Datastage的早期版本对流程就缺乏考虑,而在6版本则加入Job Sequence的特性,可以将Job、shell脚本用流程图的方式表示出来,依赖关系、串行或是并行都可以一目了然,就直观多了。Powercenter有Workflow的概念,也同样可以将Session串联起来,这和Datastage Sequence大同小异。 ETL的元数据包括数据源、目标数据的结构、转换规则以及过程的依赖关系等。在这方面,Datastage 和Powercenter从功能上看可谓不分伯仲,只是后者的元数据更加开放,存放在关系数据库中,可以很容易被访问。此外,这两个厂家又同时提供专门的元数据管理工具,Ascential有Metastage,而Informatica 拥有Superglue。你看,就不给你全部功能,变着法子从你口袋里面多掏点钱。 数据质量方面,两种产品都采用同样的策略——独立出ETL产品之外,另外有专门的数据质量管理产品。例如和Datastage配套用的有ProfileStage和QualityStage,而Informatica最近也索性收购了原先OEM的数据质量管理产品FirstLogic。而在它们的ETL产品中,只是在Job或是Session前后留下接口,所谓前过程、后过程,虽然不是专为数据质量预留的接口,不过至少可以利用它外挂一些数据质量控制的模块。 在具体实现上看,Datastage通过Job实现一个ETL过程,运行时可以通过指定不同参数运行多个实例。Powercenter通过Mapping表示一个ETL过程,运行时为Session,绑定了具体的物理数据文件或表。在修改维护上,这两个工具都是提供图形化界面。这样的好处是直观、傻瓜式的;不好的地方就是改动还
01ETL工具介绍
ETL基本概念 1.1 ETL的定义ETL分别是“Extract”、“ Transform” 、“Load”三个单词的首字母缩写也就是“抽取”、“转换”、“装载”,但我们日常往往简称其为数据抽取。ETL是BI/DW(商务智能/数据仓库)的核心和灵魂,按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。ETL包含了三方面,首先是“抽取”:将数据从各种原始的业务系统中读取出来,这是所有工作的前提。其次“转换”:按照预先设计好的规则将抽取得数据进行转换,使本来异构的数据格式能统一起来。最后“装载”:将转换完的数据按计划增量或全部导入到数据仓库中。 1.2 ETL的作用整个BI/DW系统由三大部分组成:数据集成、数据仓库和数据集市、多维数据分析。通常,商务智能运作所依靠的信息系统是一个由传统系统、不兼容数据源、数据库与应用所共同构成的复杂数据集合,各个部分之间不能彼此交流。从这个层面看:目前运行的应用系统是用户花费了很大精力和财力构建的、不可替代的系统,特别是系统的数据。而新建的商务智能系统目的就是要通过数据分析来辅助用户决策,恰恰这些数据的来源、格式不一样,导致了系统实施、数据整合的难度。此时,非常希望有一个全面的解决方案来解决用户的困境,解决数据一致性与集成化问题,使用户能够从已有传统环境与平台中采集数据,并利用一个单一解决方案对其进行高效的转换。这个解决方案就是ETL。ETL是BI/DW 的核心和灵魂,按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。如果说数据仓库的模型设计是一座大厦的设计蓝图,数据是砖瓦的话,那么ETL就是建设大厦的过程。在整个项目中最难部分是用户需求分析和模型设计,而ETL规则设计和实施则是工作量最大的,其工作量要占整个项目的60%-80%,这是国内外专家从众多实践中得到的普遍共识。ETL在BI/DW中的作用如图1-1所示。图1-1 ETL在BI/DW中的作用通常,用户的数据源分布在各个子系统和节点中,利用ETL将各个子系统上的数据,通过自动化FTP或手动控制传到UNIX或NT服务器上,进行抽取、清洗和转化处理,然后加载到数据仓库。因为现有业务数据源多,保证数据的一致性,真正理解数据的业务含义,跨越多平台、多系统整合数据,最大可能提高数据的质量,迎合业务需求不断变化的特性,是ETL技术处理的关键。 1.3 ETL工具的功能对平台的支持随着各种应用系统数据量的飞速增长和对业务可靠性的要求不断提高,数据抽取工具面对的要求往往是将几十上百个GB的数据在有限的几个小