(完整版)EViews计量经济学实验报告-异方差的诊断及修正模板

姓名 学号
实验题目 异方差的诊断与修正
一、实验目的与要求:
要求目的:1、用图示法初步判断是否存在异方差,再用White 检验异方差;
2、用加权最小二乘法修正异方差。
二、实验内容
根据1998年我国重要制造业的销售利润与销售收入数据,运用EV 软件,做回归分析,用图示法,White 检验模型是否存在异方差,如果存在异方差,运用加权最小二乘法修正异方差。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)
(一) 模型设定
为了研究我国重要制造业的销售利润与销售收入是否有关,假定销售利润与销售收入之间满足线性约束,则理论模型设定为:
i Y =1β+2βi X +i μ
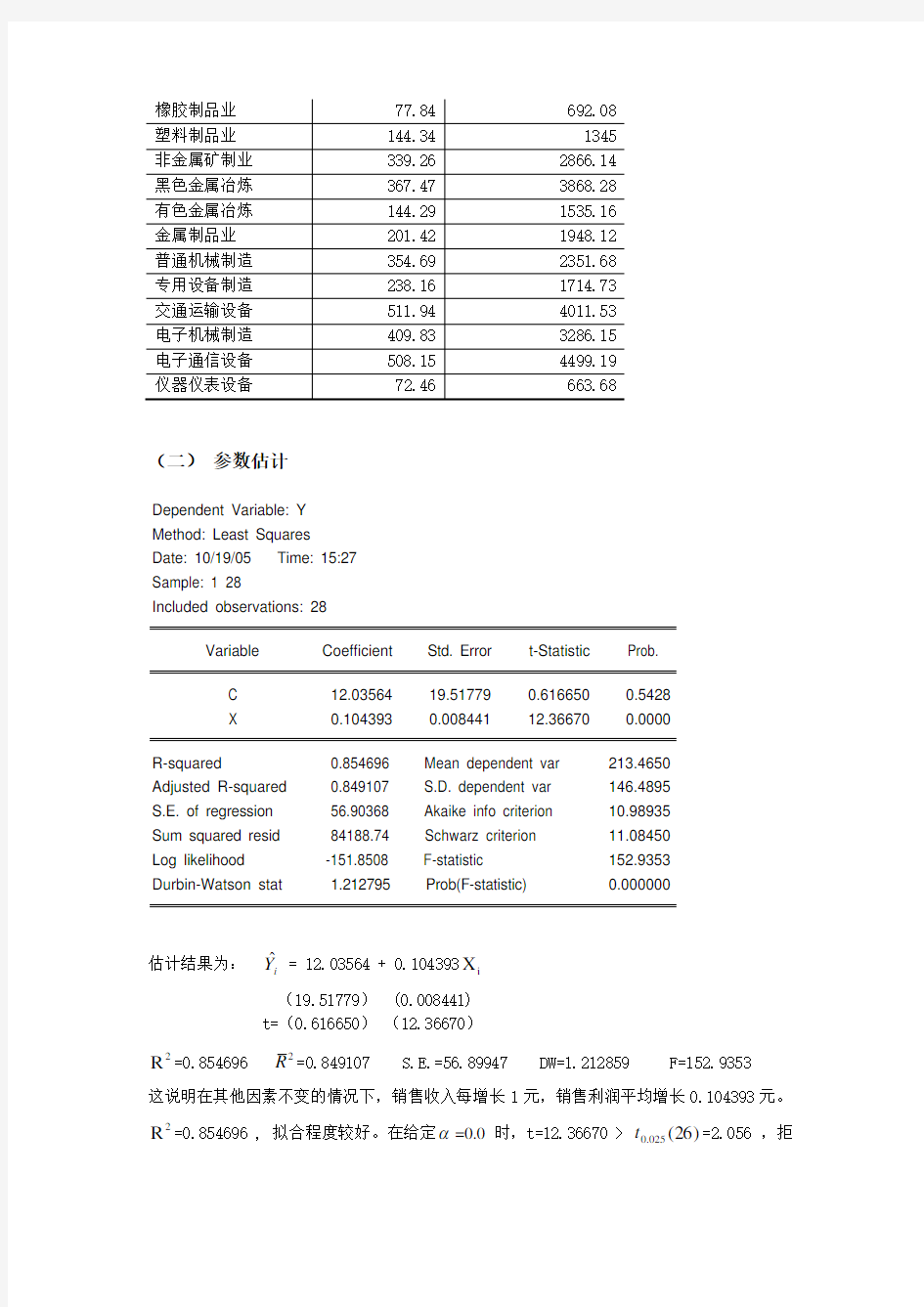
其中,i Y 表示销售利润,i X 表示销售收入。由1998年我国重要制造业的销售收入与销售利润的数据,如图1:
1988年我国重要制造业销售收入与销售利润的数据 (单位:亿元)
(二) 参数估计
Dependent Variable: Y Method: Least Squares Date: 10/19/05 Time: 15:27 Sample: 1 28
Included observations: 28
Variable Coefficient Std. Error t-Statistic Prob. C 12.03564 19.51779 0.616650 0.5428 X
0.104393
0.008441 12.36670
0.0000
R-squared 0.854696 Mean dependent var 213.4650 Adjusted R-squared 0.849107 S.D. dependent var 146.4895 S.E. of regression 56.90368 Akaike info criterion 10.98935 Sum squared resid 84188.74 Schwarz criterion 11.08450 Log likelihood -151.8508 F-statistic 152.9353 Durbin-Watson stat
1.212795 Prob(F-statistic)
0.000000
估计结果为: i
Y ? = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670)
2R =0.854696 2R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353
这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。
2R =0.854696 , 拟合程度较好。在给定 =0.0时,t=12.36670 > )26(025.0t =2.056 ,拒
绝原假设,说明销售收入对销售利润有显著性影响。F=152.9353 > )6,21(F 05.0= 4.23 ,表明方程整体显著。
(三) 检验模型的异方差
※(一)图形法
6、判断
由图3可以看出,被解释变量Y 随着解释变量X 的增大而逐渐分散,离散程度越来越大; 同样,由图4可以看出,残差平方2
i e 对解释变量X 的散点图主要分布在图形中的下三角部分,大致看出残差平方2
i e 随i X 的变动呈增大趋势。因此,模型很可能存在异方差。但是否
确实存在异方差还应该通过更近一步的检验。
※ (二)White 检验
White 检验结果
White Heteroskedasticity Test:
F-statistic 3.607218 Probability 0.042036 Obs*R-squared
6.270612 Probability
0.043486
Test Equation:
Dependent Variable: RESID^2 Method: Least Squares Date: 10/19/05 Time: 15:29 Sample: 1 28
Included observations: 28
Variable Coefficient Std. Error t-Statistic Prob. C -3279.779 2857.117 -1.147933 0.2619 X 5.670634 3.109363 1.823728 0.0802 X^2
-0.000871
0.000653 -1.334000
0.1942
R-squared 0.223950 Mean dependent var 3006.741 Adjusted R-squared 0.161866 S.D. dependent var 5144.470 S.E. of regression 4709.744 Akaike info criterion 19.85361 Sum squared resid 5.55E+08 Schwarz criterion 19.99635 Log likelihood -274.9506 F-statistic 3.607218 Durbin-Watson stat 1.479908 Prob(F-statistic)
0.042036
2、因为本例为一元函数,没有交叉乘积项,则辅助函数为 2t σ=0α+1αt x +2α2
t x +t ν 从上表可以看出,n 2R =6.270612 ,有White 检验知,在α=0,05下,查2
χ分布表,得临界值5.002
χ
(2)
=5.99147。比较计算的2χ统计量与临界值,因为n 2R = 6.270612 > 5
.002
χ(2)=5.99147 ,所以拒绝原假设,不拒绝备择假设,这表明模型存在异方差。
(四) 异方差的修正
在运用加权最小二乘法估计过程中,分别选用了权数t 1ω=1/t X ,t 2ω=1/2
t X ,t 3ω=1/t X 。
ω的结果
用权数
t1
Dependent Variable: Y
Method: Least Squares
Date: 10/22/10 Time: 00:13
Sample: 1 28
Included observations: 28
Weighting series: W1
Variable Coefficient Std. Error t-Statistic Prob.
C 5.988351 6.403392 0.935184 0.3583
X 0.108606 0.008155 13.31734 0.0000
Weighted Statistics
R-squared 0.032543 Mean dependent var 123.4060 Adjusted R-squared -0.004667 S.D. dependent var 31.99659 S.E. of regression 32.07117 Akaike info criterion 9.842541 Sum squared resid 26742.56 Schwarz criterion 9.937699 Log likelihood -135.7956 F-statistic 177.3515 Durbin-Watson stat 1.465148 Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.853095 Mean dependent var 213.4650 Adjusted R-squared 0.847445 S.D. dependent var 146.4895 S.E. of regression 57.21632 Sum squared resid 85116.40 Durbin-Watson stat 1.261469
ω的结果
用权数
t2
Dependent Variable: Y
Method: Least Squares
Date: 10/22/10 Time: 00:16
Sample: 1 28
Included observations: 28
Weighting series: W2
Variable Coefficient Std. Error t-Statistic Prob.
C 6.496703 3.486526 1.863374 0.0737
X 0.106892 0.010991 9.725260 0.0000
Weighted Statistics
R-squared 0.922715 Mean dependent var 67.92129 Adjusted R-squared 0.919743 S.D. dependent var 75.51929 S.E. of regression 21.39439 Akaike info criterion 9.032884 Sum squared resid 11900.72 Schwarz criterion 9.128041 Log likelihood -124.4604 F-statistic 94.58068 Durbin-Watson stat 1.905670 Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.854182 Mean dependent var 213.4650 Adjusted R-squared 0.848573 S.D. dependent var 146.4895 S.E. of regression 57.00434 Sum squared resid 84486.88 Durbin-Watson stat 1.242212
:
的结果
用权数
t3
Dependent Variable: Y
Method: Least Squares
Date: 10/22/10 Time: 00:17
Sample: 1 28
Included observations: 28
Weighting series: W3
Variable Coefficient Std. Error t-Statistic Prob.
C 8.640341 11.18733 0.772333 0.4469
X 0.106153 0.007746 13.70473 0.0000
Weighted Statistics
R-squared 0.611552 Mean dependent var 165.8420 Adjusted R-squared 0.596612 S.D. dependent var 67.13044 S.E. of regression 42.63646 Akaike info criterion 10.41205 Sum squared resid 47264.56 Schwarz criterion 10.50720 Log likelihood -143.7686 F-statistic 187.8197 Durbin-Watson stat 1.275429 Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.854453 Mean dependent var 213.4650 Adjusted R-squared 0.848855 S.D. dependent var 146.4895 S.E. of regression 56.95121 Sum squared resid 84329.44 Durbin-Watson stat 1.233545
经估计检验,发现用权数t 1ω,t 3ω的结果,其可决系数反而减小;只有用权数t 2ω的效果最好,可决系数增大。
用权数t 2ω的结果
Dependent Variable: Y Method: Least Squares Date: 10/22/10 Time: 00:16 Sample: 1 28
Included observations: 28 Weighting series: W2
Variable Coefficient Std. Error t-Statistic Prob. C 6.496703 3.486526 1.863374 0.0737 X 0.106892
0.010991 9.725260 0.0000
Weighted Statistics
R-squared 0.922715 Mean dependent var 67.92129 Adjusted R-squared 0.919743 S.D. dependent var 75.51929 S.E. of regression 21.39439 Akaike info criterion 9.032884 Sum squared resid 11900.72 Schwarz criterion 9.128041 Log likelihood -124.4604 F-statistic 94.58068 Durbin-Watson stat
1.905670 Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.854182 Mean dependent var 213.4650 Adjusted R-squared 0.848573 S.D. dependent var 146.4895 S.E. of regression 57.00434 Sum squared resid 84486.88
Durbin-Watson stat
1.242212
用权数t 2ω的估计结果为: i
Y ?= 6.496703 + 0.106892i X (1.863374) (9.725260)
2R =0.922715 DW=1.905670 F=94.58068
括号中的数据为t 统计量值。
由上可以看出,运用加权最小二乘法消除了异方差后,参数2β的t 检验显著,可决系数提高了不少,F 检验也显著,并说明销售收入每增长1元,销售利润平均增长0.106892元。
四、实践结果报告:
1、用图示法初步判断是否存在异方差:被解释变量Y 随着解释变量X 的增大而逐渐分散,离散程度越来越大;同样的,残差平方2
i e 对解释变量X 的散点图主要分布在图形中的下三角部分,大致看出残差平方2
i e 随i X 的变动呈增大趋势。因此,模型很可能存在异方差。但是否确实存在异方差还应该通过更近一步的检验。 再用White 检验异方差:因为n 2R = 6.270612 > 5.002
χ(2)=5.99147 ,所以拒绝原假设,
不拒绝备择假设,这表明模型存在异方差。
2、用加权最小二乘法修正异方差:
发现用权数t 2ω的效果最好,则估计结果为:
i
Y ?= 6.496703 + 0.106892i X (1.863374) (9.725260)
2R =0.922715 DW=1.905670 F=94.58068
括号中的数据为t 统计量值。
由上可以看出,2R =0.922715,拟合程度较好。在给定α=0.0时,t=9.725260 >
)26(025.0t =2.056 ,拒绝原假设,说明销售收入对销售利润有显著性影响。
F=94.58068 > )6,21(F 05.0= 4.23 , 表明方程整体显著。
运用加权最小二乘法后,参数2β的t 检验显著,可决系数提高了不少,F 检验也显著,并说明销售收入每增长1元,销售利润平均增长0.106892元。
3、再用White 检验修正后的模型是否还存在异方差:
White 检验结果
White Heteroskedasticity Test:
F-statistic 3.144597 Probability 0.060509 Obs*R-squared
5.628058 Probability
0.059963
Test Equation:
Dependent Variable: STD_RESID^2 Method: Least Squares Date: 10/22/10 Time: 00:17 Sample: 1 28
Included observations: 28
Variable Coefficient Std. Error t-Statistic Prob. C 1927.346 675.2246 2.854378 0.0085 X -1.456613 0.734838 -1.982223 0.0585 X^2
0.000245
0.000154
1.586342
0.1252
R-squared 0.201002 Mean dependent var 425.0258 Adjusted R-squared 0.137082 S.D. dependent var 1198.210 S.E. of regression 1113.057 Akaike info criterion 16.96857 Sum squared resid 30972414 Schwarz criterion 17.11130 Log likelihood -234.5599 F-statistic 3.144597 Durbin-Watson stat
2.559506 Prob(F-statistic)
0.060509
由上看出,n 2
R = 5.628058 ,由White 检验知,在α=0,05下,查2
χ分布表,得临界值:
5.002χ(2)=5.99147。
比较计算的2
χ统计量与临界值,因为n 2R = 5.628058 < 5
.002
χ(2)=5.99147 ,所以接
受原假设,这说明修正后的模型不存在异方差。
spss实验报告---方差分析
实验报告 ——(方差分析) 一、实验目的 熟练使用SPSS软件进行方差分析。学会通过方差分析分析不同水平的控制变量是否对结果产生显著影响。 二、实验内容 1、某职业病防治院对31名石棉矿工中的石棉肺患者、可疑患者及非患者进行了用力肺活量(L)测定,问三组石棉矿工的用力肺活量有无差别?(自建数据集) 石棉肺患者可疑患者非患者 1.8 2.3 2.9 1.4 2.1 3.2 1.5 2.1 2.7 2.1 2.1 2.8 1.9 2.6 2.7 1.7 2.5 3.0 1.8 2.3 3.4 1.9 2.4 3.0 1.8 2.4 3.4 1.8 3.3 2.0 3.5 SPSS计算结果: 在建立数据集时定义group1为石棉肺患者,group2为可疑患者,group3为非患者。 零假设:各水平下总体方差没有显著差异。 相伴概率为0.075,大于0.05,可以认为各个组的方差是相等的,可以进行方差检验。
从上表可以看出3个组之间的相伴概率都小于显著性水平0.05,拒绝零假设,说明3个组之间都存在显著差别。 2、某汽车经销商在不同城市进行调查汽车的销售量数据分析工作,每个城市分别处于不同的区域:东部、西部和中部,而且汽车经销商在不同城市投放不同类型的广告,调查数据放置于附件中数据文件“汽车销量调查.sav”。 (1)试分析不同区域与不同广告类型是否对汽车的销量产生显著性的影响?(2)如果考虑到不同城市人均收入具有差异度时,再思考不同区域和不同广告类型对汽车销量产生的影响差异是否改变,这说明什么问题? SPSS计算结果: (1)此为多因素方差分析 相伴概率为0.054大于0.05,可以认为各个组总体方差相等可以进行方差检验。
异方差实验报告
附件二:实验报告格式(首页) 山东轻工业学院实验报告成绩 课程名称计量经济学指导教师实验日期 2013.5.18 院(系)商学院会计系专业班级会计实验地点实验楼二机房 学生姓名学号同组人无 实验项目名称异方差的检验 一、实验目的和要求 1、理解异方差的含义后果、 2、学会异方差的检验与加权最小二乘法要求熟悉基本操作步骤,读懂各项上机榆出结果 的含义并进行分析 3、掌握异方差性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操 作方法 4、练习检查和克服模型的异方差的操作方法。 5、掌握异方差性的检验及处理方法 6、用图示法、斯皮尔曼法、戈德菲尔德、white验证法,验证该模型是否存在异方差 二、实验原理 1、异方差的检验出消除方法 2、运用EVIEWS软件及普通最小二乘法进行模型估计 3、检验模型的异方差性并对其进行调整 三、主要仪器设备、试剂或材料 Eviews软件、课本教材、电脑 四、实验方法与步骤 一、准备工作。建立工作文件,并输入数据,用普通最小二乘法估计方程(操作步骤 与方法同前),得到残差序列。 1、CREATE U 1 31 回车 2、DATA Y X 回车 输入数据
obs Y X 1 264 8777 2 105 9210 3 90 9954 4 131 10508 5 122 10979 6 10 7 11912 7 406 12747 8 503 13499 9 431 14269 10 588 15522 11 898 16730 12 950 17663 13 779 18575 14 819 19635 15 1222 21163 16 1702 22880 17 1578 24127 18 1654 25604 19 1400 26500 20 1829 26760 21 2200 28300 22 2017 27430 23 2105 29560 24 1600 28150 25 2250 32100 26 2420 32500 27 2570 35250 28 1720 33500 29 1900 36000 30 2100 36200 31 2800 38200 3、LS Y C X 回车 用最小二乘法进行估计出现 Dependent Variable: Y Method: Least Squares Date: 05/18/13 Time: 11:19 Sample: 1 31 Included observations: 31 Variable Coefficien t Std. Error t-Statistic Prob.
计量经济学异方差的检验与修正
《计量经济学》实训报告 实训项目名称异方差模型的检验与处理 实训时间 2012-01-02 实训地点实验楼308 班级 学号 姓名
实 训 (实 践 ) 报 告 实 训 名 称 异方差模型的检验与处理 一、 实训目的 掌握异方差性的检验及处理方法。 二 、实训要求 1.求销售利润与销售收入的样本回归函数,并对模型进行经济意义检验和统计检验; 2.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 3.如果模型存在异方差,选用适当的方法对异方差进行修正,消除或减小异方差对模型的影响。 三、实训内容 建立并检验我国制造业利润函数模型,检验异方差性,并选用适当方法对其进行修正,消除或不同) 四、实训步骤 1.建立一元线性回归方程; 2.建立Workfile 和对象,录入数据; 3.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 4.对所估计的模型再进行White 检验,观察异方差的调整情况,从而消除或减小异方差对模型的影响。 五、实训分析、总结 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料。假设销售利润与销售收入之间满足线性约束,则理论模型设定为: 12i i i Y X u ββ=++ 其中i Y 表示销售利润,i X 表示销售收入。
表1 我国制造工业1998年销售利润与销售收入情况 行业名称销售利润Y 销售收入X 行业名称销售利润销售收入 食品加工业187.25 3180.44 医药制造业238.71 1264.1 食品制造业111.42 1119.88 化学纤维制品81.57 779.46 饮料制造业205.42 1489.89 橡胶制品业77.84 692.08 烟草加工业183.87 1328.59 塑料制品业144.34 1345 纺织业316.79 3862.9 非金属矿制品339.26 2866.14 服装制品业157.7 1779.1 黑色金属冶炼367.47 3868.28 皮革羽绒制品81.7 1081.77 有色金属冶炼144.29 1535.16 木材加工业35.67 443.74 金属制品业201.42 1948.12 家具制造业31.06 226.78 普通机械制造354.69 2351.68 造纸及纸品业134.4 1124.94 专用设备制造238.16 1714.73 印刷业90.12 499.83 交通运输设备511.94 4011.53 文教体育用品54.4 504.44 电子机械制造409.83 3286.15 石油加工业194.45 2363.8 电子通讯设备508.15 4499.19 化学原料纸品502.61 4195.22 仪器仪表设备72.46 663.68 1.建立Workfile和对象,录入销售收入X和销售利润Y: 图1 销售收入X和销售利润Y的录入 2.图形法检验 ⑴观察销售利润Y与销售收入X的相关图:在群对象窗口工具栏中点击
方差分析实验报告
非参数检验 实验报告 方差分析 学院: 参赛队员: 参赛队员: 参赛队员: 指导老师:
目录 一、实验目的 (1) 1.了解方差分析的基本内容; (1) 2.了解单因素方差分析; (1) 3.了解多因素方差分析; (1) 4.学会运用spss软件求解问题; (1) 5.加深理论与实践相结合的能力。 (1) 二、实验环境 (1) 三、实验方法 (1) 1. 单因素方差分析; (1) 2. 多因素方差分析。 (1) 四、实验过程 (1) 问题一: (1) 1.1实验过程 (1) 1.1.1输入数据,数据处理; (1) 1.1.2单因素方差分析 (1) 1.2输出结果 (3) 1.3结果分析 (3) 1.3.1描述 (3) 1.3.2方差性检验 (4) 1.3.3单因素方差分析 (4) 问题二: (4) 2.1实验步骤 (5) 2.1.1命名变量 (5) 2.1.2导入数据 (5) 2.1.3单因素方差分析 (5) 2.1.4输出结果 (7) 2.2结果分析 (7) 2.2.1描述 (7) 2.2.2方差性检验 (8)
2.2.3单因素方差分析 (8) 问题三: (8) 3.1提出假设 (8) 3.2实验步骤 (8) 3.2.1数据分组编号 (8) 3.2.2多因素方差分析 (9) 3.2.3输出结果 (13) 3.3结果分析 (14) 五、实验总结 (14)
方差分析 一、实验目的 1.了解方差分析的基本内容; 2.了解单因素方差分析; 3.了解多因素方差分析; 4.学会运用spss软件求解问题; 5.加深理论与实践相结合的能力。 二、实验环境 Spss、office 三、实验方法 1.单因素方差分析; 2.多因素方差分析。 四、实验过程 问题一: 1.1.1输入数据,数据处理; 1.1.2单因素方差分析 选择:分析→比较均值→单因素AVONA;
实验报告 单因素方差分析
5.1、实验步骤: 1.建立数据文件。 定义2个变量:PWK和DCGJSL,分别表示排污口和大肠杆菌数量。 2. 选择菜单“分析→比较均值→单因素”,弹出“单因素方差分析”对话框。在对话 框左侧的变量列表中,选择变量“DCGJSL”进入“因变量”列表框,选择变量“PWK”进入“因子”列表框。
3.单击“确定”按钮,得到输出结果。 结果解读: 由以上结果可以看到,观测变量大肠杆菌数量的总离差平方和为460.438;如果仅考虑“排污口”单个因素的影响,则大肠杆菌数量总变差中,排污口可解释的变差为308.188,抽样误差引起的变差为152.250,它们的方差(平均变差)分别为102.729和12.688,相除所得的F统计量的观测值为8.097,对应的概率P值为0.003。在显著性水平α为0.05的情况下。由于概率P值小于显著性水平α,则应拒绝零假设,认为不同的排污口对大肠杆菌数量产生了显著影响,它对大肠杆菌数量的影响效应不全为0。 因此,可判断各个排污口的大肠杆菌数量是有差别的。 5.2、实验步骤: 1.建立数据文件。 定义2个变量:Branch和Turnover,分别表示分店和日营业额。将Branch的值定义为1=第一分店,2=第二分店,3=第三分店,4=第四分店,5=第五分店。 2. 选择菜单“分析→比较均值→单因素”,弹出“单因素方差分析”对话框。在对话 框左侧的变量列表中,选择变量“Turnover”进入“因变量”列表框,选择变量“Branch”进入“因子”列表框。
3.单击“确定”按钮,得到输出结果。
结果解读: 由以上结果可以看到,观测变量日营业额的总离差平方和为1187668.733;如果仅考虑“分店”单个因素的影响,则日营业额总变差中,分店可解释的变差为366120.900,抽样误差引起的变差为821547.833,它们的方差(平均变差)分别为91530.225和14937.233,相除所得的F统计量的观测值为6.128,对应的概率P值近似为0。在显著性水平α为0.05的情况下,由于概率P值小于显著性水平α,则应拒绝零假设,认为不同的分店对日营业额产生了显著影响,它对日营业额的影响效应不全为0。 因此,在α=0.05的显著性水平下,“这五个分店的日营业额相同”这一假设不成立。 5.3、实验步骤: 1.建立数据文件。 定义3个变量:weight和method,分别表示幼苗干重(mg)和处理方式。将method 的值定义为1=HCI,2=丙酸,3=丁酸,4=对照。 2. 选择菜单“分析→比较均值→单因素”,弹出“单因素方差分析”对话框。在对话 框左侧的变量列表中,选择变量“,method”进入“因变量”列表框,选择变量“weight”进入“因子”列表框。在“两两比较”选项中选择LSD、Bonferroni 和Scheffe方法。
计量经济学异方差实验报告材料二
实验报告2 实验目的:掌握异方差的检验及处理方法。 实验容:检验家庭人均纯收入与家庭生活消费支出可能存在的异方差性。有关数据如下:其中,收入为X,家庭生活消费支出为Y。 地区家庭人均 纯收入 家庭生活 消费支出地区 家庭人均 纯收入 家庭生活 消费支出 北京9439.63 6399.27 湖北3997.48 3090 天津7010.06 3538.31 湖南3904.2 3377.38 河北4293.43 2786.77 广东5624.04 4202.32 山西3665.66 2682.57 广西3224.05 2747.47 3953.1 3256.15 海南3791.37 2556.56 辽宁4773.43 3368.16 重庆3509.29 2526.7 吉林4191.34 3065.44 四川3546.69 2747.27 4132.29 3117.44 贵州2373.99 1913.71 上海10144.62 8844.88 云南2634.09 2637.18 江苏6561.01 4786.15 西藏2788.2 2217.62 浙江8265.15 6801.6 陕西2644.69 2559.59 安徽3556.27 2754.04 甘肃2328.92 2017.21 福建5467.08 4053.47 青海2683.78 2446.5 江西4044.7 2994.49 宁夏3180.84 2528.76 山东4985.34 3621.57 新疆3182.97 2350.58 河南3851.6 2676.41 实验步骤如下: 一、建立有关模型分析异方差检验如下。 方法一、图示法。(两种) (一)、x y 相关分析 从图中可以看出,随着收入的增加,家庭生活消费支出不断的提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 建立模型: 1、从图中可以看出,x y不是简单的线性关系。建立线性回归方程如下, LS Y C X
方差分析与假设检验实验报告
云南大学滇池学院 方差分析与假设检验实验报告二 学生姓名:方炜学号:20092123080 专业:软件工程 一、实验目的和要求: 1、初步了解SPSS的基本命令; 2、掌握方差分析和假设检验。 二、实验内容: 1、为比较5中品牌的合成木板的耐久性,对每个品牌取4个样本作摩擦试验测量磨损量,得以下数据: (1)它们的耐久性有无明显差异? (2)有选择的作两品牌的比较,能得出什么结果?
2、将土质基本相同的一块耕地分成5块,每块又分成均等的4小块。在每块地内把4个品 种的小麦分钟在4小块内,每小块的播种量相同,测得收获量如下: 考察地块和品种对小麦的收获量有无显著影响?并在必要时作进一步比较。 3、为了研究合成纤维收缩率和拉伸倍数对纤维弹性的影响进行了一些试验。收缩率取0,4, 8,12四个水平;拉伸倍数取460,520,580,640四个水平,对二者的每个组合重复作两次试验,所得数据如下:
(1)收缩率,拉伸倍数及其交互作用对弹性有无显著影响? (2)使弹性达到最大的生产条件是什么? 三、实验结果与分析: 1、运行结果截图: 1、结果分析: (1)、Sig<0.05,耐久性有明显差异 (2)、由样本分析,品牌3分为一类;品牌1,2,5分为一类;品牌4分为一类。而品牌3和品牌4差距最大,品牌3的耐久性最差,品牌4的耐久性最好。 2、运行结果截图:
2、结果分析: (1)、地块(A组)Sig>0.05对小麦的收获量无显著影响,品种(B组)Sig<0.05对小麦的收获量有显著影响。 (2)、由图得,地块4最适合种小麦,地块1最不适合种小麦;而品种2的小麦收获量最大,品种4的小麦收获量最小。 3、运行结果截图:
异方差性的检验和补救
异方差性的检验和补救 一、研究目的和要求 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型,检验其是否存在异方差,并加以补救。 表1 我国制造工业1998年销售利润与销售收入情况 二、参数估计 EVIEWS 软件估计参数结果如下
Dependent Variable: Y Method: Least Squares Date: 06/01/16 Time: 20:16 Sample: 1 28 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 12.03349 19.51809 0.616530 0.5429 X 0.104394 0.008442 12.36658 0.0000 R-squared 0.854694 Mean dependent var 213.4639 Adjusted R-squared 0.849105 S.D. dependent var 146.4905 S.E. of regression 56.90455 Akaike info criterion 10.98938 Sum squared resid 84191.34 Schwarz criterion 11.08453 Log likelihood -151.8513 Hannan-Quinn criter. 11.01847 F-statistic 152.9322 Durbin-Watson stat 1.212781 Prob(F-statistic) 0.000000 用规范的形式将参数估计和检验结果写下 2?12.033490.104394(19.51809)(0.008442) =(0.616530) (12.36658)0.854694152.9322 i Y X t R F =+ = = 三、 检验模型的异方差 (一) 图形法 1. 相关关系图 X Y X Y 相关关系图
计量经济学多元线性回归、多重共线性、异方差实验报告概要
计量经济学实验报告
多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到30.0亿人次,同比增长13.6%,国内旅游收入2.3万亿元,同比增长19.1%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β1X 1 +β2X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元
方差分析实验报告
实验报告 方差分析 学院: 参赛队员: 参赛队员: 参赛队员: 指导老师:
目录 一、实验目的 (4) 1.了解方差分析的基本内容; (4) 2.了解单因素方差分析; (4) 3.了解多因素方差分析; (4) 4.学会运用spss软件求解问题; (4) 5.加深理论与实践相结合的能力。 (4) 二、实验环境 (4) 三、实验方法 (4) 1. 单因素方差分析; (4) 2. 多因素方差分析。 (4) 四、实验过程 (4) 问题一: (4) 1.1实验过程 (4) 1.1.1输入数据,数据处理; (4) 1.1.2单因素方差分析 (4) 1.2输出结果 (6) 1.3结果分析 (6) 1.3.1描述 (6) 1.3.2方差性检验 (7) 1.3.3单因素方差分析 (7) 问题二: (7) 2.1实验步骤 (8) 2.1.1命名变量 (8) 2.1.2导入数据 (8) 2.1.3单因素方差分析 (8) 2.1.4输出结果 (10) 2.2结果分析 (10) 2.2.1描述 (10) 2.2.2方差性检验 (11) 2.2.3单因素方差分析 (11)
问题三: (11) 3.1提出假设 (11) 3.2实验步骤 (11) 3.2.1数据分组编号 (11) 3.2.2多因素方差分析 (12) 3.2.3输出结果 (16) 3.3结果分析 (17) 五、实验总结 (17) 方差分析
一、实验目的 1.了解方差分析的基本内容; 2.了解单因素方差分析; 3.了解多因素方差分析; 4.学会运用spss软件求解问题; 5.加深理论与实践相结合的能力。 二、实验环境 Spss、office 三、实验方法 1. 单因素方差分析; 2. 多因素方差分析。 四、实验过程 问题一: 1.1.1输入数据,数据处理; 1.1.2单因素方差分析 选择:分析→比较均值→单因素AVONA;
异方差检验
七、 异方差与自相关 一、背景 我们讨论如果古典假定中的同方差和无自相关假定不能得到满足,会引起什么样的估计问题呢?另一方面,如何发现问题,也就是发现和检验异方差以及自相关的存在性也是一个重要的方面,这个部分就是就这个问题进行讨论。 二、知识要点 1、引起异方差的原因及其对参数估计的影响 2、异方差的检验(发现异方差) 3、异方差问题的解决办法 4、引起自相关的原因及其对参数估计的影响 5、自相关的检验(发现自相关) 6、自相关问题的解决办法 (时间序列部分讲解) 三、要点细纲 1、引起异方差的原因及其对参数估计的影响 原因:引起异方差的众多原因中,我们讨论两个主要的原因,一是模型的设定偏误,主要指的是遗漏变量的影响。这样,遗漏的变量就进入了模型的残差项中。当省略的变量与回归方程中的变量有相关关系的时候,不仅会引起内生性问题,还会引起异方差。二是截面数据中总体各单位的差异。 后果:异方差对参数估计的影响主要是对参数估计有效性的影响。在存在异方差的情况下,OLS 方法得到的参数估计仍然是无偏的,但是已经不具备最小方差性质。一般而言,异方差会引起真实方差的低估,从而夸大参数估计的显著性,即是参数估计的t 统计量偏大,使得本应该被接受的原假设被错误的拒绝。 2、异方差的检验 (1)图示检验法 由于异方差通常被认为是由于残差的大小随自变量的大小而变化,因此,可以通过散点图的方式来简单的判断是否存在异方差。具体的做法是,以回归的残差的平方2i e 为纵坐标,回归式中的某个解释变量i x 为横坐标,画散点图。如果散点图表现出一定的趋势,则可以判断存在异方差。 (2)Goldfeld-Quandt 检验
方差分析实验报告
篇一:spss的方差分析实验报告 实 验 报告 篇二:方差分析实验报告 方差分析实验报告 学生姓名:琚锦涛学号:091230126 一.实验目的 根据方差分析的相关方法,利用excel中的相关工具,将数据收集,整理,从而了解方差分析的特点和性质。 二.实验内容 1.单因素方差分析 利用以下数据进行单因素方差分析,判断不同产地的原材料是否显著影响产品的质量指标; 2.双因素方差分析 利用以下数据进行双因素方差分析,检验因素a与因素b搭配下是否对其有显著差异,交互作用是否显著; 三.实验结果分析 1.单因素方差分析由以上数据可知,p-value=0.2318>0.05,因此可得出:原材料产地的这一质量指标无显著影响。 2.双因素方差分析 样本、列及交互的p-value远小于0.05,由此可得出燃料和推进器两因素对于火箭影响显著。数据来源:《应用统计学》第二版;篇三:单因素方差分析实验报告 天水师范学院数学与统计学院 实验报告 实验项目名称单因素方差分析所属课程名称实验类型设计型实验日期2011.11.22 班级 09统计一班学号 291050146 姓名成绩 【实验目的】 通过测量数据研究各个因素对总体的影响效果,判定因素在总变异中的重要程度 【实验原理】 比较因素a的r个水平的差异归结为比较这r个总体的均值.即检验假设 ho : μ1 = μ2 = … = μr, h1 : μ1, μ2, … , μr 不全相等给定显著水平α,用p 值检验法, 当p值大于α时,接受原假设ho,否则拒绝原假设ho 【实验环境】 r 2.13.1 pentinu(r)dual-core cpu e6700 3.20ghz 3.19ghz,2.00gb的内存【实验方案】 准备数据,查找相关r程序代码并进行编写运行得出结果进行分析总结 【实验过程】(实验步骤、记录、数据、分析) 1.根据四种不同配方下的元件寿命数据 材料使用寿命 a1 1600 1610 1650 1680 1700 1700 1780 a2 1500 1640 1400 1700 1750 a3 1640 1550 1600 1620 1640 1600 1740 1800 a4 1510 1520 1530 1570 1640 1600 2.利用主函数aov()编写该数据的方差分析r程序 3.运行得出结果 df sum sq mean sq f value pr(>f) a3 49212 16404 2.1659 0.1208 residuals 22 166622 7574
多元线性回归实验报告
实验题目:多元线性回归、异方差、多重共线性 实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。 实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。 实验步骤: 1.建立出口货物总额计量经济模型: 错误!未找到引用源。(3.1) 1.1建立工作文件并录入数据,得到图1 图1 在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据 表。点”view/graph/line/ok”,形成线性图2。 图2 1.2对(3.1)采用OLS估计参数 在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3 根据图3中的数据,得到模型(3.1)的估计结果为 (8638.216)(0.012799)(9.776181) t=(-2.110573) (10.58454) (1.928512) 错误!未找到引用源。错误!未找到引用源。F=522.0976 从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。但当错误!未找到引用源。=0.05时,错误!未找到引用源。=错误!未找到引用源。2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。 2.多重共线性模型的识别 2.1计算解释变量x2、x3的简单相关系数矩阵。 点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。 相关系数矩阵 图4 由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。 2.2多重共线性模型的修正
异方差的检验及修正
异方差问题的检验与修正 【实验目的】 1、深刻理解异方差性的实质、异方差出现的原因、异方差的出现对模型的不良影响(即异方差的后果),掌握估计和检验异方差性的基本思想和修正异方差的若干方法。 2、能够运用所学的知识处理模型中的出现的异方差问题,并要求初步掌握用Eviews处理异方差的基本操作方法。 【实验原理】 1、最小二乘估计。 2、异方差。 3、最小二乘残差图解释异方差。 4、Breusch-Pagan检验(B-P检验)和White检验(怀特检验)检验特定方差函数的异方差性。 5、稳健标准差和加权最小二乘法对特定方差函数的异方差性的修正。 【实验软件】 Eviews6.0 【实验步骤】 一、设定模型 首先将实验数据导入软件之中。(注:本实验报告正文部分只显示软件统计结果,导入数据这一步骤参见附A) 本次实验的数据主要是Big Andy店的食品销售收入数据与食品价格数据,共采用了75组。 实验数据来源于课本中的例题,由老师提供。如下表: 表Big Andy店月销售收入和价格的观测值
sales price sales price sales price sales price 73.2 5.6975.7 5.5978.1 5.773.7671.8 6.4974.4 6.2288 5.2271.2 6.3762.4 5.6368.7 6.4180.4 5.0584.7 5.3367.4 6.2283.9 4.9679.7 5.7673.6 5.2389.3 5.0286.1 4.8373.2 6.2573.7 5.8870.3 6.4173.7 6.3585.9 5.3478.1 6.2473.2 5.8575.7 6.4783.3 4.9869.7 6.4786.1 5.4178.8 5.6973.6 6.3967.6 5.4681 6.2473.7 5.5679.2 6.2286.5 5.1176.4 6.280.2 6.4188.1 5.187.6 5.0476.6 5.4869.9 5.5464.5 6.4984.2 5.0882.2 6.1469.1 6.4784.1 4.8675.2 5.8682.1 5.3783.8 4.9491.2 5.184.7 4.8968.6 6.4584.3 6.1671.8 5.9873.7 5.6876.5 5.3566 5.9380.6 5.0282.2 5.7380.3 5.2284.3 5.273.1 5.0874.2 5.1170.7 5.8979.5 5.6281 5.2375.4 5.7175 5.2180.2 5.2873.7 6.0281.3 5.45 75 6.05 81.2 5.83 69 6.33 其中,sales 表示在某城市的月销售收入,以千美元为单位;price 表示在该城市的价格,以美元为单位。 假设表1中的月销售收入数据满足假设SR1—SR5。即,假设Big Andy 店的月销售收入的期望值是产品价格水平的线性函数,误差项额的均值为零,销售收入的方差和误差项e 的方差相同,随机误差项e 在统计上不相关,且选取的价格的值是非随机的。 这样,在上面的基础之上,建立Big Andy 的食品销售收入(sales )与食品价格(price )之间的线性模型方程: e price sales ++=10ββ根据最小二乘估计的思想估计模型参数,(此过程参见附B )结果如下图: Coefficient Std.Error t-Statistic Prob.C 121.9002 6.52629118.678320.0000PRICE -7.829074 1.142865 -6.850394 0.0000R-squared 0.391301Mean dependent var 77.37467Adjusted R-squared 0.382963 S.D.dependent var 6.488537
用excel进行方差分析的实验报告
实验四:用excel进行方差分析的实验报告 实验目的:学会在计算机上利用excel进行单因素方差分析和有交互的双因素分析以及无交互的双因素分析, 实验背景:方差分析是从观测变量的方差入手,研究诸多控制变量中哪些变量是对观测变量有显著影响的变量。一个复杂的事物,其中往往有许多因素互相制约又互相依存。方差分析的目的是通过数据分析找出对该事物有显著影响的因素,各因素之间的交互作用,以及显著影响因素的最佳水平等。方差分析是在可比较的数组中,把数据间的总的“变差”按各指定的变差来源进行分解的一种技术。对变差的度量,采用离差平方和。 实验内容: 实验(1):单因素方差分析 条件:单因素方差分析是对成组设计的多个样本均数比较,所以对数据格式有特殊要求,因素的不同水平作为表格的列(或行),在不同水平下的重复次数作为行(或列)。 例1:以下数据来自2009年中国统计年鉴,各地区农村居民家庭平均每人生活消费支出,按不同项目分组的不同地区: 其中,1代表生活消费支出合计,2代表食品,3代表衣着,4代表居住, 5代表家庭设施及服务, 6代表交通和通讯, 7代表文教娱乐用品及服务,8代表医疗保健, 9代表其他商品及服务 各地区农村居民家庭平均每人生活消费支出 (2009年) 单位:元 地区项目 地区生活消 费食品衣着居住 家庭设 备交通和 文教娱 乐 医疗保 健 其他 品支出合 计 及服 务通讯 用品及 服务 及 务 地区 1 2 3 4 5 6 7 8 北京8897.59 2808.92 654.36 1798.88 528 1132.09 960.41 867.87 14天津4273.15 1848.11 324.63 674.67 187.83 481.27 371.85 299.79 8河北3349.74 1195.65 217.82 796.62 170.4 350.92 263.53 289.27 6山西3304.76 1224.6 283.2 584.07 156.27 324.89 416.94 240.94 7内蒙古3968.42 1578.57 271.88 609.29 148.03 466.34 390.85 416.87 8辽宁4254.03 1563.33 335.93 793.91 185.5 416.41 437.79 409.64 11吉林3902.9 1371.12 286.97 737.07 168.36 355.99 376.76 511.5 9黑龙江4241.27 1331.07 345.69 946.84 161.03 427.35 496.42 434.25 9上海9804.37 3639.14 496.14 2102.96 480.62 1212.38 942.76 738.94 19江苏5804.45 2275.28 306.62 969.76 286.37 691.56 818.45 322.99 13浙江7731.7 2812.39 473.11 1488.95 374.31 968.17 843.34 609.07 16安徽3655.02 1494.19 203.37 813.12 229.66 302.23 312.05 227.1 福建5015.72 2304.14 291.72 821.21 260.68 570.24 421.69 219.02 12江西3532.66 1609.2 162.58 725.11 181.91 295.76 254.77 232.78 7
EViews计量经济学实验报告异方差的诊断及修正
姓名学号实验题目异方差的诊断与修正 一、实验目的与要求: 要求目的:1、用图示法初步判断是否存在异方差,再用White检验异方差; 2、用加权最小二乘法修正异方差。
估计结果为: i Y ? = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670) 2R =0.854696 R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353 这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。 2R =0.854696 , 拟合程度较好。在给定 =0.0时,t=12.36670 > )26(025.0t =2.056 ,拒 绝原假设,说明销售收入对销售利润有显著性影响。F=152.9353 > )6,21(F 05.0= 4.23 ,
表明方程整体显著。 (三) 检验模型的异方差 ※(一)图形法 6、判断 由图3可以看出,被解释变量Y 随着解释变量X 的增大而逐渐分散,离散程度越来越大; 同样,由图4可以看出,残差平方2 i e 对解释变量X 的散点图主要分布在图形中的下三角部分,大致看出残差平方2 i e 随i X 的变动呈增大趋势。因此,模型很可能存在异方差。但是否确实存在异方差还应该通过更近一步的检验。
※ (二)White 检验 White 检验结果 White Heteroskedasticity Test: F-statistic 3.607218 Probability 0.042036 Obs*R-squared 6.270612 Probability 0.043486 Test Equation: t 界值5.002 χ (2) =5.99147。比较计算的2χ统计量与临界值,因为n 2R = 6.270612 > 5 .002 χ(2)=5.99147 ,所以拒绝原假设,不拒绝备择假设,这表明模型存在异方差。 (四) 异方差的修正 在运用加权最小二乘法估计过程中,分别选用了权数t 1ω=1/t X ,t 2ω=1/2 t X ,t 3ω=1/t X 。 用权数t 1ω的结果
异方差加权最小二乘法修正(精)资料
第五章 案例分析 一、问题的提出和模型设定 根据本章引子提出的问题,为了给制定医疗机构的规划提供依据,分析比较医疗机构与人口数量的关系,建立卫生医疗机构数与人口数的回归模型。假定医疗机构数与人口数之间满足线性约束,则理论模型设定为 i i i u X Y ++=21ββ (5.31) 其中i Y 表示卫生医疗机构数,i X 表示人口数。由2001年《四川统计年鉴》得到如下数据。 表5.1 四川省2000年各地区医疗机构数与人口数 地区 人口数(万人) X 医疗机构数(个) Y 地区 人口数(万人) X 医疗机构数(个) Y 成都 1013.3 6304 眉山 339.9 827 自贡 315 911 宜宾 508.5 1530 攀枝花 103 934 广安 438.6 1589 泸州 463.7 1297 达州 620.1 2403 德阳 379.3 1085 雅安 149.8 866 绵阳 518.4 1616 巴中 346.7 1223 广元 302.6 1021 资阳 488.4 1361 遂宁 371 1375 阿坝 82.9 536 内江 419.9 1212 甘孜 88.9 594 乐山 345.9 1132 凉山 402.4 1471 南充 709.2 4064 二、参数估计 进入EViews 软件包,确定时间范围;编辑输入数据;选择估计方程菜单,估计样本回归函数如下 表5.2
估计结果为 56.69,2665.508..,7855.0) 3403.8() 9311.1(3735.50548.563?2===-+-=F e s R X Y i i (5.32) 括号内为t 统计量值。 三、检验模型的异方差 本例用的是四川省2000年各地市州的医疗机构数和人口数,由于地区之间存在的不同人口数,因此,对各种医疗机构的设置数量会存在不同的需求,这种差异使得模型很容易产生异方差,从而影响模型的估计和运用。为此,必须对该模型是否存在异方差进行检验。 (一)图形法 1、EViews 软件操作。 由路径:Quick/Qstimate Equation ,进入Equation Specification 窗口,键入“y c x ”,确认并“ok ”,得样本回归估计结果,见表5.2。 (1)生成残差平方序列。在得到表5.2估计结果后,立即用生成命令建立序列2 i e ,记 为e2。生成过程如下,先按路径:Procs/Generate Series ,进入Generate Series by Equation 对话框,即
4方差分析实验报告
方差分析实验报告 姓名:班级:学号(后3位): 一.实验名称:方差分析 二.实验性质:综合性实验 三.实验目的及要求: 1.掌握【方差分析:单因素方差分析】的使用方法. 2.掌握【方差分析:无重复双因素分析】的使用方法. 3.掌握【方差分析:可重复双因素分析】的使用方法. 4.掌握方差分析的基本方法,并能对统计结果进行正确的分析. 四.实验内容、实验操作关键步骤及实验主要结果 1.用5种不同的施肥方案分别得到某种农作物的收获量(kg)如下: 施肥方案 1 2 3 4 5 67 98 60 79 90 67 96 69 64 70 收获量 55 91 50 81 79 42 66 35 70 88 α0.05下,检验施肥方案对农作物的收获量是否有显著影响. 在显著性水平= 实验操作关键步骤及实验主要结果 在EXCEL中选用【 】工具模块,得到如下表的实验结果.由于检验的P-value=,所以,施肥方案对农作物的收获量的影响 .
2.某粮食加工厂试验三种储藏方法对粮食含水率有无显著影响,现取一批粮食分成若干份,分别用三种不同的方法储藏,过段时间后测得的含水率如下表: 储藏方法 含水率数据 A7.3 8.3 7.6 8.4 8.3 1 A 5.4 7.4 7.1 6.8 5.3 2 A7.9 9.5 10 9.8 8.4 3 α0.05下,检验储藏方法对含水率有无显著的影响. 在显著性水平= 实验操作关键步骤及实验主要结果 在EXCEL中选用【 】工具模块,得到如下表的实验结果.由于检验的P-value=,所以,储藏方法对含水率的影响 .
3.进行农业实验,选择四个不同品种的小麦其三块试验田,每块试验田分成四块面积相等的小块,各种植一个品种的小麦,收获(kg)如下: 试验田 品种 1B 2B 3B 1A 26 25 24 2A 30 23 25 3A 22 21 20 4A 20 21 19 在显著性水平=α0.05下,检验小麦品种及实验田对收获量是否有显著影响. 实验操作关键步骤及实验主要结果 在EXCEL 中选用【 】工具模块,得到如下表的实验结果. (1)由于检验的 P-value=,所以,小麦品种对收获量的影响 . (2)由于检验的 P-value=,所以,实验田对收获量的影响 .