目录结构扫描重组恢复数据简易方法适合小白

目录结构扫描重组恢复数据法
(2012-12-14 00:34:50)
目录结构扫描重组恢复是大多数数据恢复过程要做的事情,不同数据恢复软件有不同的特点和恢复效果。常见软件Easy Recovery、Final Data都是这种软件,而在这里我们推荐效果、速度更好的DiskGenius,同类专业的软件还有R-Studio和数据恢复大师Data Explore 欢迎阅读本文,这是我们的《走进科学--探索发现--硬盘分区信息丢失之谜》三篇文章的第二篇《DiskGenius恢复提示格式化的数据》。在第一篇《寻找丢失的硬盘分区》文章里,我们恢复了客户故障硬盘的分区信息,但仍然有三个分区是未格式化状态,在这篇文章中,我们继续使用硬盘数据恢复软件的新星DiskGenius恢复这三个分区的数据,使用的是扫描重组目录法。我将为大家讲述硬盘分区信息寻找恢复的全过程。第三篇《WinHex应用之奇怪的未格式化》是本案例三篇文章中最绕的一篇,充分认识硬盘数据结构的“CT” WINHEX之后你会觉得,这个可以学,很好很强大。
你可以将本篇教程作为独立的“分区提示格式化”故障类型的数据恢复案例,同样也是适用于文件删除、文件丢失等所有软性故障的数据恢复需求的参考文章。
当我们遇到提示格式化时,一定不要点是,FAT32格式分区格式化后数据恢复效果将会大大打折,如果你不小心已经格式化了,那还可以尽量保护故障分区,避免进一步被覆盖破坏。
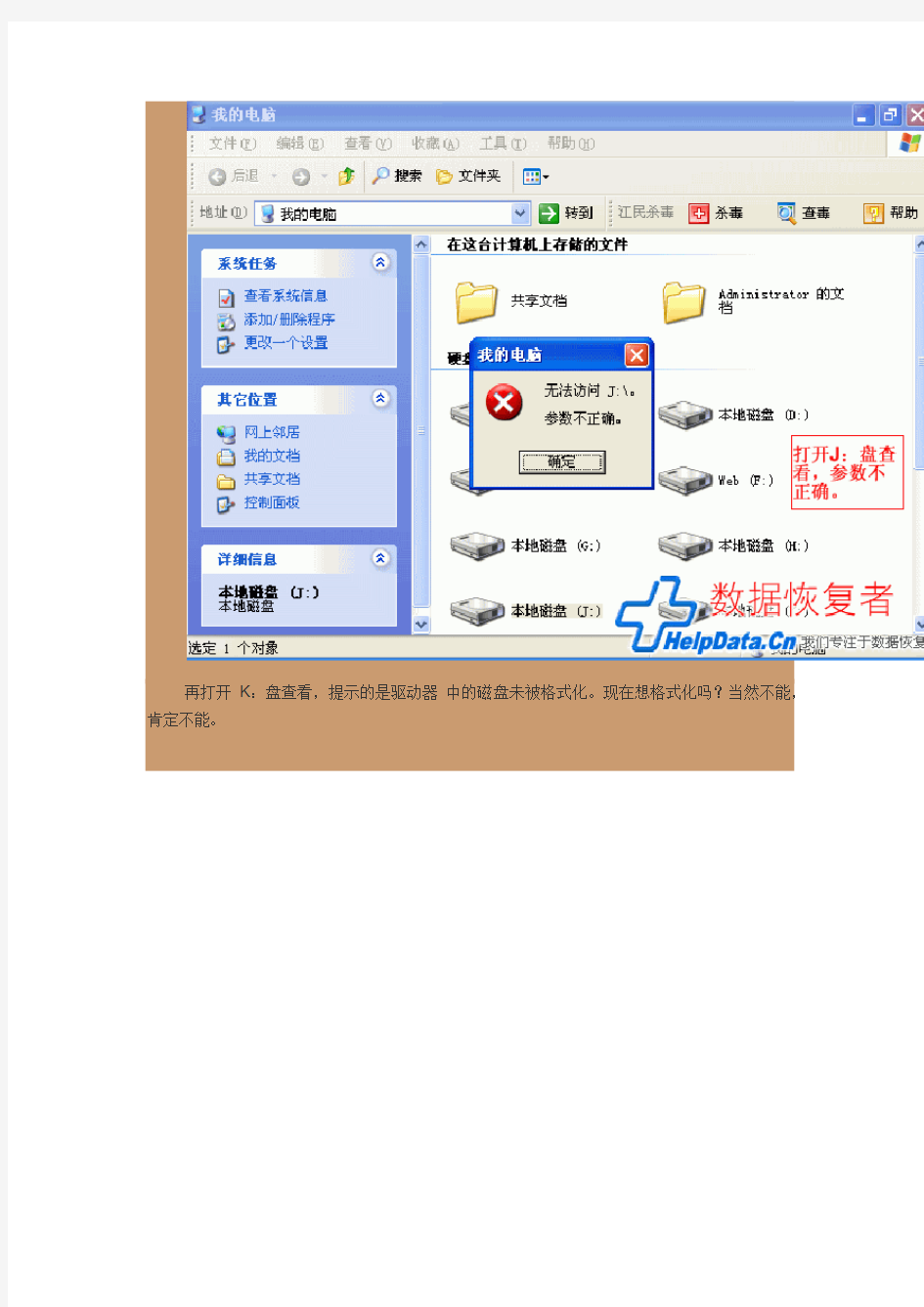
首先我们打开J:盘查看,提示无法访问 J : \ 参数不正确。
再打开K:盘查看,提示的是驱动器中的磁盘未被格式化。现在想格式化吗?当然不能,肯定不能。
DiskGenius软件界面中,这三个区显示未格式化状态。没有任何目录内容。
DiskGenius磁盘精灵直接提供了强大的删除格式化数据恢复功能,我们直接用它来尝试恢复,看看能不能恢复我们未格式化分区内的数据。在第一个未格式化分区上单击右键,选择文件恢复。
由于提示是未格式化,我们就按DiskGenius默认的“误格式化文件恢复”选项。分区格式也默认为NTFS,除非你认为他默认的不正确,否则不用修改。开始。
开始搜索恢复文件,DiskGenius显示搜索进度。
DiskGenius搜索到6291456扇区之后,文件找到文件数出现了,标准Windows的NTFS文件系统的目录是从6291456扇区开始的,只有扫描到这里,才会出现文件。
DiskGenius扫描分析速度很快,扫描结束后,直接返回到文件目录列表界面,分区内的文件内容目录全部出来了。
选择一个文件,复制出来,验证一下,当然你也可以全部选择恢复。
设置DiskGenius复制恢复数据的路径后,复制完成。经验证文件是能够正常打开使用的。
需要注意的是“丢失的文件”文件夹,里面同样包含一些目录索引错误的文件,如果有用,可以选择恢复。
同样方式,继续恢复后面两个分区。使用DiskGenius恢复数据的确直观简单,能拯救出我们的宝贵数据。
至此,未格式化的三个分区数据恢复完毕,我们使用的是DiskGenius及其同类软件扫描分析分区重新组织出来的目录数据。
数据恢复的常用方法
数据恢复的常用方法 硬盘作为计算机中存储数据的载体,往往会因为硬件、软件,恶意与非恶意破坏等因素而出现存储数据完全或部分丢失的现象,特别是在这个随时可能遭受攻击的网络时代,硬盘数据还面临网络方面的破坏。重要数据文件一旦丢失,损失势必难以估量…… 面对这些潜在的危险,再周密和谨慎的数据备份工作都不可能为我们的数据文件提供实时、完整的保护。因此,如何在硬盘数据被破坏后进行妥善而有效的数据拯救,就成为广大用户普遍关心的一件事情。下面本文就硬盘存储数据丢失的原因、恢复技术及相关保护措施方面进行了一些探讨。 一、数据丢失的原因及产生现象 造成数据丢失的原因大致可以分为三大类:软件、硬件和网络。 1.软件方面的起因比较复杂,通常有病毒感染、误格式化、误分区、误克隆、误作等几种,具体表现为无作系统,读盘错误,文件找不到、打不开、乱码,报告无分区等。 2.硬件方面的起因有磁盘划伤、磁组损坏、芯片及其它原器件烧坏、突然断电等。具体表现为硬盘不认,盘体有异常响声或电机不转、通电后无任何声音等现象。 3.网络方面的起因有共享漏洞被探知并利用此漏洞进行的数据破坏、木马病毒等。 上述三种数据的丢失往往都是瞬间发生的事情,能否正确地第一时间判断出数据丢失的原因对于下一步所讲述的数据恢复是很重要的。 二、硬盘数据恢复的可能性与成功率 什么是数据修复呢,数据修复就是把遭受破坏或误作导致丢失的数据找回来的方法。包括硬盘、软盘、可移动磁盘的数据恢复等。数据恢复可以针对不同作系统(DOS、Windows9X/NT/2000、UNIX、NOVELL 等)的数据进行恢复,对于一些比较特殊的数据丢失原因,数据恢复可能会出现完全不能恢复或只能恢复部分数据,如:数据被覆盖(OVERWRITE)、低级格式化(LOWLEVELFORMAT)、磁盘盘片严重损伤等。 1.恢复数据的几项原则 如果希望在数据恢复时保持最大程度的恢复率,应遵循以下几项原则: 发现问题时:如果可能,应立即停止所有的写作,并进行必要的数据备份,出现明显的硬件故障时,不要尝试修复,应送往专业的数据恢复公司。 恢复数据时:如果可能,则应立即进行必要的数据备份,并优先抢救最关键的数据,在恢复分区时则应优先修复扩展分区,再修复C。 2.数据恢复可能性分析 硬盘数据丢失后,数据还能恢复吗?这是许多电脑用户最关心的问题。根据现有的数据恢复实践和经验表明:大多数情况下,用户找不到的数据往往并没有真正的丢失和被破坏,80%的情况下,数据都是可以复原的。下面是常见的几种数据恢复可能性与成功率分析: ·病毒破坏 破坏硬盘数据信息是电脑病毒主要的设计目的与破坏手段。有些病毒可以篡改、删除用户文件数据,导致文件无法打开,或文件丢失;有些更具破坏力的病毒则修改系统数据,导致计算机无法正常启动和运行。针对病毒导致的硬盘数据丢失,国内各大杀毒软件厂商都掌握了相当成熟的恢复经验,例如江民科技的KV系列杀毒软件就曾将恢复这类数据的过程与方面在软件中设计成了一个模块,即使是初级的用户也只需经过简单的几个步骤就可恢复85~100%的数据。 ·软件破坏 软件破坏通常包括:误删除、误格式化、误分区、误克隆等。目前的硬盘数据恢复技术对于软件破坏而导致的数据丢失恢复成功率相当的高平均90%以上。此类数据恢复技术已经可以对FAT12、FAT16、FAT32、NTFS4.0、NTFS5.0等分区格式,DOS、Windows9X/ME、WindowsNT/2000、WindowsXP、UNIX、Linux 等作系统完全兼容。 ·硬件破坏 硬件原因导致数据丢失,如果是介质设备硬件损坏,电路板有明显的烧毁痕迹或设备(如硬盘)有异响或BIOS不认硬盘参数,这种情况下的数据恢复对于个人用户显得非常困难,所以遇到这种情况,
四种基本的存储结构
四种基本的存储结构 Prepared on 22 November 2020
数据的四种基本存储方法 数据的存储结构可用以下四种基本存储方法得到: (1)顺序存储方法 该方法把逻辑上相邻的结点存储在物理位置上相邻的存储单元里,结点间的逻辑关系由存储单元的邻接关系来体现。 由此得到的存储表示称为顺序存储结构(Sequential Storage Structure),通常借助程序语言的数组描述。 该方法主要应用于线性的数据结构。非线性的数据结构也可通过某种线性化的方法实现顺序存储。 (2)链接存储方法 该方法不要求逻辑上相邻的结点在物理位置上亦相邻,结点间的逻辑关系由附加的指针字段表示。由此得到的存储表示称为链式存储结构(Linked Storage Structure),通常借助于程序语言的指针类型描述。 (3)索引存储方法 该方法通常在储存结点信息的同时,还建立附加的索引表。
索引表由若干索引项组成。若每个结点在索引表中都有一个索引项,则该索引表称之为稠密索引(Dense Index)。若一组结点在索引表中只对应一个索引项,则该索引表称为稀疏索引(Spare Index)。索引项的一般形式是: (关键字、地址) 关键字是能唯一标识一个结点的那些数据项。稠密索引中索引项的地址指示结点所在的存储位置;稀疏索引中索引项的地址指示一组结点的起始存储位置。 (4)散列存储方法 该方法的基本思想是:根据结点的关键字直接计算出该结点的存储地址。 四种基本存储方法,既可单独使用,也可组合起来对数据结构进行存储映像。 同一逻辑结构采用不同的存储方法,可以得到不同的存储结构。选择何种存储结构来表示相应的逻辑结构,视具体要求而定,主要考虑运算方便及算法的时空要求。 数据结构三方面的关系
SQL Server 全文索引查询
SQL Server 全文索引查询T-SQL学习笔记之一(Full-text index) 2009-12-11 11:29 引言 这段时间为了提高海量字符串数据的查询效率,我对字段添加了全文索引。首先全文索引相对于传统的索引是有区别的,这是因为传统的索引主要是以首字母开始建立的索引,处理like 'keword%'这样的查询会很高效,但是如果查询时不限定首字母,而只是包含某个词,比如like '%keyword%'这样的查询,实际操作中无法使用传统索引加速查询效率,而只能一项一项比较了。 而全文索引正是提供了“包含”式查询机制,查询一个长字符串中是否包含给定关键词的功能,这无论是在搜索引擎或是网站的搜索平台都是很有用处的。 首先,推荐一本学习SQL Server全文索引的书籍,这本书详细的讲解了全文索引的方方面面,甚至还阐述许多设计搜索引擎的思想和方法。书名是《Pro Full-Text Search in SQL Server 2008》,是Apress出版的。 这本书的内容是按章划分的,同时由浅入深,从一般的技巧到高级的技巧。我这里就简单分享一下基本的全文查询方法,更多高级的技巧应该在实际应用中按需进行学习。 要实现全文查询,首先安装的SQL Server实例要支持全文查询服务,可以查看windows服务是否有全文索引服务。如果没有,则要重新安装SQL Server并选择添加功能,将Full-Text功能选中,然后再安装或升级。
有了全文查询服务,还不能直接进行查询,需要先在想要建立全文索引的字段上建立一个全文索引。方法是打开企业管理器,选择字段所在表格,然后点击右键,选择"Full-text inde”,然后选择"define Full-text index"就能进入设置面板。 需要注意的是,全文索引只能建立在Unique(唯一)字段上,并且每个表最多只能有一个全文索引字段,因此要慎重。然后按照提示建立全文索引即可(可以参见我推荐的那本书,会有一步一步操作的详细说明和注释) 建立好全文索引后,就能够运用T-SQL的全文查询语法进行全文查询了。 主要有两个语法,一个是contains,另一个是freetext Contains contains从字面上就能很好理解,即包含,比如我们在表Sample的一个字段Column里查询包含“世界末日”这个关键词的所有记录,该表一共有60万条记录,传统的查询语法是 select * from Sample where [Column] like '%世界末日%'
硬盘开盘数据恢复教程图解 已开盘的硬盘数据恢复方法
硬盘开盘数据恢复教程图解已开盘的硬盘数据恢复方法 导读:硬盘磁头虽然几乎没有磨损的情况,但小小的振动就可能让磁头受到严重的损坏,当硬盘因为磁头损坏而造成硬盘不读盘的情况下,硬盘就只能使用硬盘开盘数据恢复教程来重新“复活”硬盘。 在开始学习教程前先了解下相关的知识,一般来说数据是以磁记方式存储在盘片上,磁头主要是完成数据的读取和写入。磁头并不是贴在盘片上读取的,由于磁盘的高速旋转,使得磁头利用“温彻斯特/Winchester”技术悬浮在盘片上。这使得硬盘磁头在使用中几乎是不磨损的,数据存储也会非常稳定,硬盘寿命也大大增长。但磁头也是非常脆弱的,在硬盘工作状态下,即使是再小的振动,都有可能使磁头受到严重损坏。由于盘片是工作在无尘环境下,所以,我们在处理磁头故障,也就是更换磁头时,都必须在无尘室内完成,而且还要有扎实的基本功,熟练的技巧,才能使成功率大大提高。 硬盘开盘数据恢复教程图解: 1、首先,开盘需要特定的条件和工具,无尘环境是必不可少的,其次我们可以从图中看到还需要医用手套,美工刀,尖嘴钳,直头和弯头镊子,螺丝刀(一字和t8) 2、这次我们要更换磁头的硬盘是迈拓120g 硬盘,故障情况是工作后不认
盘,电机转,有敲头声。首先,我们用美工刀小心地揭开硬盘上的保修标签。 3、接下来当然是拆除top上的所有螺丝,为了工作效率,外面不是要求很高的螺丝,我们可以用电动起子去卸。
4、我们小心的将螺丝放在培养皿里,打开top,我们就可以一览无遗地看到硬盘的内部结构了,我们可以清楚地看到组成硬盘的各个组件,包括底座base,马达moter,磁盘disc,磁头eblk,和已经打开的顶盖。
R-Studio通用数据恢复方法
R-Studio万能通用数据恢复方法 网上流转的数据恢复方法有很多,今天小编给大家整理了一个图文教程,下面一起来学习下R-Studio万能通用数据恢复方法吧!学会了这个教程对于R-Studio怎么用也就自然学会啦! 我们将故障硬盘连接到电脑上,在我的电脑中可看到共4个分区,格式为FAT32。 在我的电脑上右键单击--管理--然后进入磁盘管理,可以更加直观的了解现在结构,对后面的数据恢复过程很有帮助。
我们首先要了解故障硬盘当前分区的数据量,即对以前数据的覆盖破坏量。在磁盘管理中,在每个盘符上--单击--右键--属性,这是客户硬盘当前第一个分区H盘的属性。剩余空间不多,但客户声明本区为操作系统分区,数据不在这里。因此我们大致了解一下即可。
客户硬盘第3、4个分区K盘和L盘已用空间都基本为空,这些位置的数据恢复效果将会很好。
后并安装运行。 客户需要的是重新分区格式化安装系统以前的数据,并且要求尽可能全部恢复,因为他不记得原来数据放在什么位置,因此需要点击选择扫描恢复整个硬盘而不是分区。选择要恢复的硬盘或分区,点击R-Studio的开始扫描图标。你可以根据硬盘型号、卷标、文件系统、开始位置、分区大小来正确确认。
点击开始扫描后,R-Studio弹出扫描设置窗口,一般采用默认选项即可,也可以去掉我们不需要的文件系统,可加快分析速度。我们要扫描的是整个硬盘,所以从0位置开始,长度149.1G 。 也可以精简R-Studio要分析的文件系统,Windows操作系统只可能是FAT和NTFS格式。
硬盘大约要1小时。 R-Studio扫描完成,OK。
四种基本的存储结构
数据的四种基本存储方法 数据的存储结构可用以下四种基本存储方法得到: (1)顺序存储方法 ???该方法把逻辑上相邻的结点存储在物理位置上相邻的存储单元里,结点间的逻辑关系由存储单元的邻接关系来体现。 ???由此得到的存储表示称为顺序存储结构(SequentialStorageStructure),通常借助程序语言的数组描述。 该方法主要应用于线性的数据结构。非线性的数据结构也可通过某种线性化的方法实现顺序存储。 (2)链接存储方法 ???该方法不要求逻辑上相邻的结点在物理位置上亦相邻,结点间的逻辑关系由附加的指针字段表示。由此得到的存储表示称为链式存储结构(LinkedStorageStructure),通常借助于程序语言的指针类型描述。 (3)索引存储方法 ???该方法通常在储存结点信息的同时,还建立附加的索引表。 ???索引表由若干索引项组成。若每个结点在索引表中都有一个索引项,则该索引表称之为稠密索引(DenseIndex)。若一组结点在索引表中只对应一个索引项,则该索引表称为稀疏索引(SpareIndex)。索引项的一般形式是:
????????????????????(关键字、地址) 关键字是能唯一标识一个结点的那些数据项。稠密索引中索引项的地址指示结点所在的存储位置;稀疏索引中索引项的地址指示一组结点的起始存储位置。(4)散列存储方法 ???该方法的基本思想是:根据结点的关键字直接计算出该结点的存储地址。 四种基本存储方法,既可单独使用,也可组合起来对数据结构进行存储映像。 同一逻辑结构采用不同的存储方法,可以得到不同的存储结构。选择何种存储结构来表示相应的逻辑结构,视具体要求而定,主要考虑运算方便及算法的时空要求。 数据结构三方面的关系 数据的逻辑结构、数据的存储结构及数据的运算这三方面是一个整体。孤立地去理解一个方面,而不注意它们之间的联系是不可取的。 存储结构是数据结构不可缺少的一个方面:同一逻辑结构的不同存储结构可冠以不同的数据结构名称来标识。 【例】线性表是一种逻辑结构,若采用顺序方法的存储表示,可称其为顺序表;若采用链式存储方法,则可称其为链表;若采用散列存储方法,则可称为散列表。
全文检索功能
在应用中加入全文检索功能 ——基于java的全文索引引擎lucene简介 作者:车东 email: https://www.360docs.net/doc/8c1414943.html,/https://www.360docs.net/doc/8c1414943.html, 写于:2002/08 最后更新: 版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明 https://www.360docs.net/doc/8c1414943.html,/tech/lucene.html 关键词:lucene java full-text search engine chinese word segment 内容摘要: lucene是一个基于java的全文索引工具包。 1.基于java的全文索引引擎lucene简介:关于作者和lucene的历史 2.全文检索的实现:luene全文索引和数据库索引的比较 3.中文切分词机制简介:基于词库和自动切分词算法的比较 4.具体的安装和使用简介:系统结构介绍和演示 5.hacking lucene:简化的查询分析器,删除的实现,定制的排序,应用接口的扩展 6.从lucene我们还可以学到什么 基于java的全文索引/检索引擎——lucene lucene不是一个完整的全文索引应用,而是是一个用java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。 lucene的作者:lucene的贡献者doug cutting是一位资深全文索引/检索专家,曾经是v-twin搜索引擎(apple的copland操作系统的成就之一)的主要开发者,后在excite担任高级系统架构设计师,目前从事于一些internet底层架构的研究。他贡献出的lucene的目标是为各种中小型应用程序加入全文检索功能。 lucene的发展历程:早先发布在作者自己的https://www.360docs.net/doc/8c1414943.html,,后来发布在sourceforge,2001年年底成为apache基金会jakarta的一个子项目:https://www.360docs.net/doc/8c1414943.html,/lucene/ 已经有很多java项目都使用了lucene作为其后台的全文索引引擎,比较著名的有: ?jive:web论坛系统; ?eyebrows:邮件列表html归档/浏览/查询系统,本文的主要参考文档“thelucene search engine: powerful, flexible, and free”作者就是eyebrows系统的主要开发者之一,而eyebrows已 经成为目前apache项目的主要邮件列表归档系统。 ?cocoon:基于xml的web发布框架,全文检索部分使用了lucene ?eclipse:基于java的开放开发平台,帮助部分的全文索引使用了lucene
移动硬盘数据恢复方法(入门教程)
移动硬盘数据恢复方法(入门教程) 一个完整硬盘的数据应该包括五部分:MBR,DBR,FAT,DIR区和DATA区。其中只有主引导扇区是唯一的,其它的随你的分区数的增加而增加。 1、主引导扇区 主引导扇区位于整个硬盘的0磁道0柱面1扇区,包括硬盘主引导记录MBR(Main Boot Record)和分区表DPT(Disk Partition Table)。 其中主引导记录的作用就是检查分区表是否正确以及确定哪个分区为引导分区,并在程序结束时把该分区的启动程序(也就是操作系统引导扇区)调入内存加以执行。 至于分区表,很多人都知道,以80H或00H为开始标志,以55AAH为结束标志,共64字节,位于本扇区的最末端。 值得一提的是,MBR是由分区程序(例如DOS 的Fdisk.exe)产生的,不同的操作系统可能这个扇区是不尽相同。 如果你有这个意向也可以自己去编写一个,只要它能完成前述的任务即可,这也是为什么能实现多系统启动的原因(说句题外话:正因为这个主引导记录容易编写,所以才出现了很多的引导区病毒)。 2、操作系统引导扇区 OBR(OS Boot Record)即操作系统引导扇区,通常位于硬盘的0磁道1柱面1扇区(这是对于DOS来说的,对于那些以多重引导方式启动的系统则位于相应的主分区/扩展分区的第一个扇区),是操作系统可直接访问的第一个扇区,它也包括一个引导程序和一个被称为BPB(BIOS Parameter Block)的本分区参数记录表。 其实每个逻辑分区都有一个OBR,其参数视分区的大小、操作系统的类别而有所不同。 引导程序的主要任务是判断本分区根目录前两个文件是否为操作系统的引导文件。于是,就把第一个文件读入内存,并把控制权交予该文件。 BPB参数块记录着本分区的起始扇区、结束扇区、文件存储格式、硬盘介质描述符、根目录大小、FAT个数、分配单元(Allocation Unit,以前也称之为簇)的大小等重要参数。OBR由高级格式化程序产生(例如DOS 的https://www.360docs.net/doc/8c1414943.html,)。 3、文件分配表 FAT(File Allocation Table)即文件分配表,是系统的文件寻址系统,为了数据安全起见,FAT一般做两个,第二FAT为第一FAT的备份, FAT区紧接在OBR之后,其大小由本分区的大小及
空间索引结构(学生)分解
第七章空间索引结构 空间索引技术是从空间数据库中获取空间数据的有效方法,是提高空间数据查询和各种空间分析效率的关键技术。建立空间索引是为了缩小空间数据的搜索范围,以便在空间数据查询时不必遍历整个空间数据集,只访问空间索引数据便可快速得到一条特定的空间查询语句所请求的空间数据,或得到包含全部空间查询结果的一个较小的空间数据集。 索引文件中包含的数据称为索引数据,索引结构是索引数据的数据结构及索引创建与维护算法的总称。空间索引结构是按照空间数据在空间分布上的特性来组织和存储索引数据的索引结构。一种良好的空间索引结构应满足下列三个要求: 一、存储效率高:相对于被索引的数据集而言,索引数据的数据量应尽量小。否则,访问索引数据可能成为数据查询与更新的效率瓶颈。 二、查询效率高:空间索引结构需要选择良好的索引数据结构,设计具体的基于索引的空间访问方法(SAM Spatial Access Method),必须能够高效的实现以下几种基于位置的查询: 1、点选择:从数据集中找出包含给定点的所有空间对象。 2、范围查询:查询与给定对象间的距离小于某个给定值的所有空间对象。 3、区域(窗口)查询:查找含在区域内、与区域相交或部分位于区域中的所有空间对象。窗口是一个特殊的区域,窗口查询是GIS中最常用、最基本的查询。 4、K-最邻近查询:给定一个参照对象(点、线或区域),查询距离参照对象最近的K 1个空间对象。 5、空间关系查询:相交、相邻、包含等拓扑关系查询,方位关系和基于距离的各种查询。 6、其他查询:将满足一定空间条件的两个空间对象集合进行空间连接,空间集合运算等也是一种空间访问。 三、更新效率高:许多GIS应用中会涉及海量且不断变化的空间数据集。数据集中数据对象的增加、修改和删除将直接导致索引数据的更新,索引数据与被索引的数据集必须保持一致,才能保证基于索引数据的查询结果的正确性。索引数据的更新操作包括:插入索引项,将新数据对象的索引项添加到索引数据中;删除索引项,把数据对象的索引项从索引数据中删除;修改索引项,在索引数据中先删除再增加该数据对象的索引。数据集经常变化时,要求其索引数据的更新开销不要很大,特别要避免更新时引起的索引重组。因此,需要考虑新增索引项和删除索引项时,索引结构的快速更新能力。 很难设计一种空间索引结构同时能够提供高效的存储、高效的查询和高效的更新,实际应用中总是牺牲某些方面的效率来换取另外方面的效率。 索引结构可分为静态索引和动态索引结构。静态索引结构针对静态不变的数据,索引只建一次,不需要更新,强调索引数据的存储效率和查询效率,不强调索引更新的效率。动态索引结构强调数据在动态更新过程中保证较高的查询效率和索引空间存储效率,往往以牺牲索引更新效率为代价,这种牺牲是有限度的。 索引结构还分为内存索引和外存索引,外存索引需要考虑磁盘页面访问的效率瓶颈问题。这里主要研究面向海量空间数据的、2D空间对象的外存索引结构。 7.1空间索引分类 非空间数据库中存储的数据为结构化数据,通常以主关键字建立索引文件,以非主属性建立倒排文件,索引项按自然数序列或字符顺序排列。空间数据库存储的数据为结构复杂、不能完全结构化的空间数据,为了支持基于位置的各类查询和分析,需要以表示空间对象几何形状的坐标数据为索引字段来建立空间索引。非空间数据库的索引结构不能满足空间数据库的索引需求,必须研究和设计专用的空间索引结构和基于索引的空间访问方法(SAM Spatial Access
数据恢复的概念及注意事项以及恢复方法.
数据恢复的概念及注意事项以及恢复方法 数据恢复:单纯从字面上的解释也就是恢复数据。 一、什么是数据? 名词解释:进行各种统计、计算、科学研究或技术设计等所依据的数值。 数据的应用领域非常广泛,但在这里我们仅针对计算机领域中部分应用来了解。在计算机科学中,数据是指所有能输入到计算机并被计算机程序处理的符号的介质的总称,是用于输入电子计算机进行处理,具有一定意义的数字、字母、符号和模拟量等的通称。 电子计算机加工处理的对象 早期的计算机主要用于科学计算,故加工的对象主要是表示数值的数字。现代计算机的应用越来越广,能加工处理的对象包括数字、文字、字母、符号、文件、图像等。 二、什么是数据恢复? 当存储介质出现损伤或由于人员误操作、操作系统本身故障所造成的数据看不见、无法读取、丢失。工程师通过特殊的手段读取在正常状态下不可见、不可读、无法读的数据。 数据恢复是指通过技术手段,将保存在台式机硬盘、笔记本硬盘、服务器硬盘、存储磁带库、移动硬盘、U盘、数码存储卡、Mp3等等设备上丢失的电子数据进行抢救和恢复的技术。 三、从哪恢复? 数据记录设备:数据以某种格式记录在计算机内部或外部存储介质上。 存储介质是指存储数据的载体。比如软盘、光盘、DVD、硬盘、闪存、U盘、CF 卡、SD卡、MMC卡、SM卡、记忆棒(Memory Stick)、xD卡等。目前最流行的存储介质是基于闪存(Nand flash)的,比如U盘、CF卡、SD卡、SDHC卡、MMC 卡、SM卡、记忆棒、xD卡等。
四、如何恢复? 针对不同故障的不同问题具体分析、判断。 数据恢复的故障类型 大体上可分为硬故障和软故障两类。 硬故障是指存储介子的物理硬件发生故障、损坏。 如:硬盘物理故障(数据储存装置--主要是磁盘) 大量坏道(启动困难、经常死机、格式化失败、读写困难); 电路板故障:电路板损坏、芯片烧坏、断针断线。(通电后无任何声音、电路板有明显的烧痕等); 盘体故障:磁头损坏、磁头老化、磁头烧坏(常有一种“咔嚓咔嚓”的磁头撞击声);电机损坏(电机不转,通电后无任何声音); 固件信息丢失、固件损坏等。(CMOS不认盘、“磁盘管理”中无法找到该硬盘);盘片划伤。 软故障是相对于硬故障而言的,即存储介子物理硬件没有损坏,通过软件即可解决的故障。包括误删除、误格式化、误分区、误GHOST等。 删除 删除操作却简单的很,当我们需要删除一个文件时,系统只是在文件分配表内在该文件前面写一个删除标志,表示该文件已被删除,他所占用的空间已被"释放", 其他文件可以使用他占用的空间。所以,当我们删除文件又想找回他(数据恢复)时,只需用工具将删除标志去掉,数据被恢复回来了。当然,前提是没有新的文件写入,该文件所占用的空间没有被新内容覆盖。 格式化 格式化操作和删除相似,都只操作文件分配表,不过格式化是将所有文件都加上删除标志,或干脆将文件分配表清空,系统将认为硬盘分区上不存在任何内容。格式化操作并没有对数据区做任何操作,目录空了,内容还在,借助数据恢复知识和相应工具,数据仍然能够被恢复回来。 注意:格式化并不是100%能恢复,有的情况磁盘打不开,需要格式化才能打开。如果数据重要,千万别尝试格式化后再恢复,因为格式化本身就是对磁盘写入的过程,只会破坏残留的信息。 低级格式化 就是将空白的磁盘划分出柱面和磁道,再将磁道划分为若干个扇区,每个扇区又划分出标识部分ID、间隔区GAP和数据区DATA等。可见,低级格式化是高级格式化之前的一件工作,它不仅能在DOS环境来完成,也能在xp甚至vista系统下完成。而且低级格式化只能针对一块硬盘而不能支持单独的某一个分区。每块硬盘在出厂时,已由硬盘生产商进行低级格式化,因此通常使用者无需再进行低级格式化操作。 分区 硬盘存放数据的基本单位为扇区,我们可以理解为一本书的一页。当我们装机或买来一个移动硬盘,第一步便是为了方便管理--分区。无论用何种分区工具,都
基于Java的全文索引引擎
在应用中加入全文检索功能 ——基于Java的全文索引引擎Lucene简介 作者:车东 Email: https://www.360docs.net/doc/8c1414943.html,/https://www.360docs.net/doc/8c1414943.html, 写于:2002/08 最后更新:09/09/2006 17:09:05 Feed Back >> (Read this before you ask question) 版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明 https://www.360docs.net/doc/8c1414943.html,/tech/lucene.html 关键词:Lucene java full-text search engine Chinese word segment 内容摘要: Lucene是一个基于Java的全文索引工具包。 1.基于Java的全文索引引擎Lucene简介:关于作者和Lucene的历史 2.全文检索的实现:Luene全文索引和数据库索引的比较 3.中文切分词机制简介:基于词库和自动切分词算法的比较 4.具体的安装和使用简介:系统结构介绍和演示 5.Hacking Lucene:简化的查询分析器,删除的实现,定制的排序,应用 接口的扩展 6.从Lucene我们还可以学到什么 基于Java的全文索引/检索引擎——Lucene Lucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。 Lucene的作者:Lucene的贡献者Doug Cutting是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些INTERNET底层架构的研究。他贡献出的Lucene的目标是为各种中小型应用程序加入全文检索功能。 Lucene的发展历程:早先发布在作者自己的https://www.360docs.net/doc/8c1414943.html,,后来发布在SourceForge,2001年年底成为APACHE基金会jakarta的一个子项目:https://www.360docs.net/doc/8c1414943.html,/lucene/ 已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有: Jive:WEB论坛系统;
数据恢复精华(图解)
winhex教程 winhex 数据恢复分类:硬恢复和软恢复。所谓硬恢复就是硬盘出现物理性损伤,比如有盘体坏道、电路板芯片烧毁、盘体异响,等故障,由此所导致的普通用户不容易取出里面数据,那么我们将它修好,同时又保留里面的数据或后来恢复里面的数据,这些都叫数据恢复,只不过这些故障有容易的和困难的之分;所谓软恢复,就是硬盘本身没有物理损伤,而是由于人为或者病毒破坏所造成的数据丢失(比如误格式化,误分区),那么这样的数据恢复就叫软恢复。 这里呢,我们主要介绍软恢复,因为硬恢复还需要购买一些工具设备(比如 pc3000,电烙铁,各种芯片、电路板),而且还需要懂一点点电路基础,我们这里所讲到的所有的知识,涉及面广,层次深,既有数据结构原理,为我们手工准确恢复数据提供依据,又有各种数据恢复软件的使用方法及技巧,为我们快速恢复数据提供便利,而且所有软件均为网上下载,不需要我们投资一分钱。 数据恢复的前提:数据不能被二次破坏、覆盖! 关于数码与码制: 关于二进制、十六进制、八进制它们之间的转换我不想多说,因为他对我们数据恢复来说帮助不大,而且很容易把我们绕晕。如果你感兴趣想多了解一些,可以到百度里面去搜一下,这方面资料已经很多了,就不需要我再多说了。 数据恢复我们主要用十六进制编辑器:Winhex (数据恢复首选软件) 我们先了解一下数据结构: 下面是一个分了三个区的整个硬盘的数据结构 MBR C盘EBR D盘EBR E盘 MBR,即主引导纪录,位于整个硬盘的0柱面0磁道1扇区,共占用了63个扇区,但实际只使用了1个扇区(512字节)。在总共512字节的主引导记录中,MBR 又可分为三部分:第一部分:引导代码,占用了446个字节;第二部分:分区表,占用了64字节;第三部分:55AA,结束标志,占用了两个字节。后面我们要说的用winhex软件来恢复误分区,主要就是恢复第二部分:分区表。 引导代码的作用:就是让硬盘具备可以引导的功能。如果引导代码丢失,分区表还在,那么这个硬盘作为从盘所有分区数据都还在,只是这个硬盘自己不能够用来启动进系统了。如果要恢复引导代码,可以用DOS下的命令:FDISK /MBR;这
数据库的存储结构(文件、记录的组织和索引技术)
数据库的存储结构(文件、记录的组织和索引技术) by 沈燕然0124141 利用课余时间自学了第6章《数据库存储结构》,对于数据 库不同层次的存储结构,文件记录组织和索引技术有了一定的 了解,在这篇札记中将会结合一些具体应用中涉及到的数据存 储和索引知识,以及通过与过去学习过的一些数据结构比较来 记录自己学习的心得体会。这些实例涉及不同的数据库系统, 如Oracle, DB2和Mysql等等,它们之间会有一些差异。不过 本文旨在探讨数据存储方面的问题,因而兼容并包地将其一并收入,凡是可能需要说明之处都会加上相应的注解。:) 1、数据库(DBS)由什么组成?——逻辑、物理和性能特征 1、什么是数据库系统(DBS)——DBS用文件系统实现 在关系模型中,我们把DBS看成关系的汇集。DBS存在的目的就是为了使用户能够简单、方便、容易地存取数据库中的数据。因此在用户的眼中,数据库也就是以某种方式相关的表的集合。用户并不需要去关心表之间关系,更不需要了解这些表是怎样存储的。但是我们现在从DBA(数据库管理员)的角度来看,情况就比那稍稍复杂一点。 实际的数据库包含许多下面列出的物理和逻辑对象: ?表、视图、索引和模式(确定数据如何组织) ?锁、触发器、存储过程和包(引用数据库的物理实现) ?缓冲池、日志文件和表空间(仅处理如何管理数据库性能) 2、什么是表空间?——表空间相当于文件系统中的文件夹。 表空间被用作数据库和包含实际表数据的容器对象之间的一层,表空间可以包含多个不同的表。用户处理的实际数据位于表中,他们并不知道数据的物理表示,这种情况有时被称为数据的物理无关性。
上图描述了一个ORACLE数据库大致的表空间组织,USER中存放主要的数据表,TEMP存放临时数据表,INDX存放索引,TOOLS存放回退段(RBS). 表空间在DB2数据库系统中是比较典型的说法,在Mysql等系统中也直接使用文件系统中文件夹的概念。新建一个表的时候可以指定它所在的表空间,至于用文件具体存储数据时如何存储这可能就是各个数据库系统的商业机密了,至少DB2是这样。另外值得关注的一点是不同于oracles对表空间的严格要求,Mysql的数据库形式相对比较简单,以文件夹的形式存放在安装目录的/data/下面,该数据库的每一个表对应两个文件,一个存放表中数据,另一个存放元数据信息,也就是建表时指明的列属性等等信息。 3、文件中的记录在物理上如何实现?——文件组织形式 在外存中,DB以文件形式组织,而文件由记录组成。文件结构由OS的文件系统提供和管理。文件组织有两种方式——定长记录格式和变长记录格式。 那种格式更好? 定长记录格式——优点是插入操作较简单。 缺点是对记录长度有硬性要求,而且有的记录可能横跨多个快,降低读写效率。 变长记录格式——优点是记录长度自由方便 缺点是记录长度差异导致删除后产生大量“碎片”,记录很难伸长,尤其“被拴记录”移动代价相当大。 中庸之道——预留空间和指针方式 记录长度大多相近——采用预留空间方法,取最大记录长为统一标准,在短记录多于空间处填特定空值或记录尾标志符。 记录长度相差很大——采用指针形式(每纪录后的指针字段把相同属性值记录链接起来)。文件中使用两种块——固定块(存放每条链中第一条记录)和溢出块(存放其 余纪录)。 3、记录在文件中怎样组织?
数据恢复软件FinalData的详细使用方法
数据恢复软件FinalData的详细使用方法 首先我们打开FinalData的主程序可以见到一下窗口(图1)。程序的组成 非常简洁,由菜单栏、工具栏、目录示图和目录内容示图组成。一、打开丢失数据的盘符选择界面左上角的“文件”、“打开”,从“选择驱动器对话框”(图2)中选择想要恢复的文件所在的驱动器。这里我们选择“驱动器G”然后单击“确定”。 二、扫描驱动器在选择好驱动器以后FinalData会马上开始扫描驱动器上已经存在的文件与目录(图3)。扫描完毕以后出现一个“选择查找的扇区范围”对话框,由于我们并不知道被删除的文件所在的扇区具体位置所以我们不做修改。这里有“完整扫描”与“快速扫描”两种方式让我们选择,这里我们选择“快速扫描”(图4)。如果选择“完整扫描”FinalData将会扫描硬盘分区的每一个簇,所以速度也会慢很多(图5)。两者产生效果的具体区别本文后面会指出。 图4 其实当文件被删除时,实际上只有文件或者目录名称的第一个字符会被删掉。FinalData通过扫描子目录入口或者数据区来查找被删除的文件。扫描完成后将生成删除的文件和目录的列表在目录示图和目录内容示图。图5 当目录扫描完成后,在窗口的左边区域将会出现七个项目,而目录和文件信息将会显示在右边窗口(图6)。这七个项目的含义如下:1、“根目录”:正常根目录2、“删除的目录”:从根目录删除的目录集合(只在“快速扫描”后可用)3、“删除的文件”:从根目录删除的文件集合(只在“快速扫描”后可用)4、“丢失的目录”:只有在“完整扫描”后找到的目录将会被显示在这里。由于已经被部分覆盖或者破坏,所以“快速扫描”不能发现这些目录。如果根目录由于格式化或者病毒等引起破坏,FinalData 就会把发现和恢复的信息放到“丢失的目录”中。(只在“完整扫描”后可用)5、“丢失的文件”:被严重破坏的文件,如果数据部分依然完好,可以从“丢失的文件”中恢复。在“快速扫描”过后,FinalData将执行“完整扫描”以查找被破坏的文件并将列表显示在“丢失的文件”中。(只在“完整扫描”后可用)6、“最近删除的文件”:当FinalData安装后,“文件删除管理器”功能自动将被删除文件的信息加入到“最近删除的文件”中。因为FinalData将这些文件信息保存在一个特殊的硬盘位置,大多数情况下可以完整地恢复出现(安装程序时会指定一定的硬盘空间用来存放这些信息)。7、“找到的文件”:这些就是所有硬盘上面被删除的文件,以后可以按照文件名、簇号和日期对扫描到的文件进行查找。
Lucene:基于Java的全文检索引擎简介
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明。 https://www.360docs.net/doc/8c1414943.html,/tech/lucene.html -------------------------------------------------------------------------------- Lucene是一个基于Java的全文索引工具包。 基于Java的全文索引引擎Lucene简介:关于作者和Lucene的历史 全文检索的实现:Luene全文索引和数据库索引的比较 中文切分词机制简介:基于词库和自动切分词算法的比较 具体的安装和使用简介:系统结构介绍和演示 Hacking Lucene:简化的查询分析器,删除的实现,定制的排序,应用接口的扩展 从Lucene我们还可以学到什么 基于Java的全文索引/检索引擎——Lucene Lucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。 Lucene的作者:Lucene的贡献者Doug Cutting是一位资深全文索引/检索专家,曾经是V-Twin 搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些INTERNET底层架构的研究。他贡献出的Lucene的目标是为各种中小型应用程序加入全文检索功能。 Lucene的发展历程:早先发布在作者自己的https://www.360docs.net/doc/8c1414943.html,,后来发布在SourceForge,2001年年底成为APACHE基金会jakarta的一个子项目:https://www.360docs.net/doc/8c1414943.html,/lucene/ 已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有: Jive:WEB论坛系统; Eyebrows:邮件列表HTML归档/浏览/查询系统,本文的主要参考文档“TheLucene search engine: Powerful, flexible, and free”作者就是EyeBrows系统的主要开发者之一,而EyeBrows已经成为目前APACHE项目的主要邮件列表归档系统。 Cocoon:基于XML的web发布框架,全文检索部分使用了Lucene Eclipse:基于Java的开放开发平台,帮助部分的全文索引使用了Lucene 对于中文用户来说,最关心的问题是其是否支持中文的全文检索。但通过后面对于Lucene 的结构的介绍,你会了解到由于Lucene良好架构设计,对中文的支持只需对其语言词法分析接口进行扩展就能实现对中文检索的支持。 全文检索的实现机制 Lucene的API接口设计的比较通用,输入输出结构都很像数据库的表==>记录==>字段,所以很多传统的应用的文件、数据库等都可以比较方便的映射到Lucene的存储结构/接口中。总体上看:可以先把Lucene当成一个支持全文索引的数据库系统。
电脑硬盘恢复数据恢复,数据恢复如此简单
电脑硬盘恢复数据恢复,数据恢复如此简单 对于移动硬盘来说,相信大家也都并不陌生,不管是上班族,还是开公司的老板或者学生,往往也都会有一个属于自己的硬盘或者U盘,用来存储一些重要的数据文件。虽然移动硬 盘在目前生活中比较常见,使用的时候也都是比较方便的,但是很多人往往也都认为移动 硬盘存储数据比较安全,认为存储在里面也都可以确保万无一失,但是在日常使用时,往 往也都会由于一些外界因素的影响,而导致它内部数据出现丢失或者误删除的现象,并且 此时所删除的文件也都将直接被系统所隐藏。那么对于这种现象来说,当数据误删除后, 我们又该如何恢复呢?下面就为大家介绍一种常见的数据文件恢复技巧,主要分为以下几点: 硬盘打不开的原因: 1、硬盘系统驱动出现问题,如果是驱动出现问题的话,在插入硬盘时会有所提示,此时 也就需要重新安装对应的 USB3.0 驱动程序。 2、硬盘内部设备供电不足,导致硬盘无法打开。
3、人为因素导致接口出现问题,很多人在使用 USB 设备时,往往没有对硬盘进行定期的保养和维护,导致它内部的 USB 接口出现断针的现象。 4、文件或目录损坏,如果将硬盘插入电脑中,界面提示是否需要对硬盘进行格式化,此时也就说明硬盘的目录文件有损坏的现象, 以上就是移动硬盘打不开的几种原因介绍,相信大家也都有了一定的了解,为了能够找回我们所丢失的文件,当硬盘数据丢失后,也就需要结合丢失文件类型选择不同的方法进行数据的修复。以”嗨格式数据恢复大师“为例,可修复误删除,误清空,误格式化等多种情景下丢失的文件,在操作过程中也都比较简单方便。 希望以上内容对大家有所帮助,不管是哪种原因造成数据丢失或损坏,首先也就需要及时停止对都是数据的硬盘进行扫描和读写,避免文件出现覆盖丢失的现象。
数据存储结构
LCU vs. Sub-CU 所有的CU都是按照TComDataCU*的指针进行处理 对于每个LCU(largest CU),要么分为多个Sub-CU,要么不分。如果分为多个Sub-CU,则每个Sub-CU都是按照z-scan的扫描方式递归进行处理。 TComDataCU class has all information we need 数据存储在LCU层,也就是按照LCU的结构进行存储,大小是4x4的单元 在Sub-CU中,数据存储指向LCU存储结构中的适当位置 CU中所有的信息都通过索引index获得,该索引也是CU存储单元的序列号,这里称为地址吧。 在顺序编码中,AbsPartIdx表示当前CU的绝对地址,也就是当前CU中,每个4x4的块存储的地址,从0开始 How to obtain absolute index in LCU?如何获取LCU中CU的绝对地址呢?
每个TcomDataCU的类中有个成员变量m_uiAbsIdxInLCU,它表示当前CU在LCU层中z-scan的绝对地址 CU的绝对地址有利于其得到领域CU的地址 Z-scan和raster(z扫描和光栅扫描)相互转化 两个数组g_auiZscanToRaster 和g_auiRasterToZscan转化的地址 g_auiZscanToRaster[ z-scan index ] = raster scan index g_auiRasterToZscan[ raster index ] = z-scan index 光栅扫描有利于得到领域CU的地址。 转换系数的结构 一维数组m_pcTrCoeffY, m_pcTrCoeffCb和m_pcTrCoeffCr保存了LCU的系数 对于每个CU,getCoeffY, getCoeffCb和getCoeffCr都得到指向相应系数的指针,这些系数按照光栅扫描存储