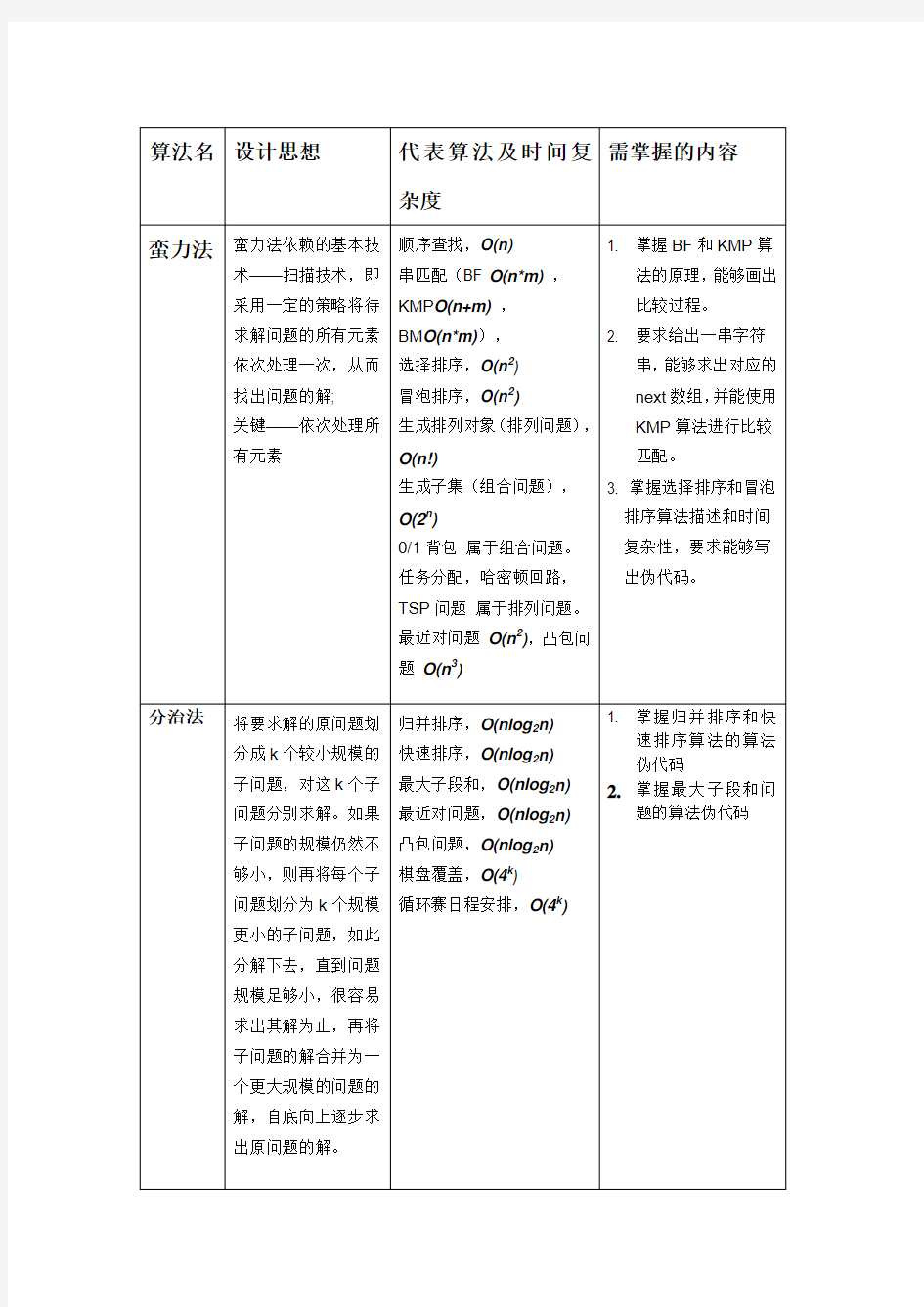
各种算法的归纳

基于FPGA的递归最小二乘算法的研究与实现
摘要 软件测试是保证软件质量和可靠性重要手段,在这方面发挥着其它方法不可替代的作用。然而,软件测试是一个复杂的过程,需要耗费巨大的人力、物力和时间,约占整个软件开发成本的40%~50%。因此,提高软件测试工具的自动化程度对于确保软件开发质量、降低软件开发成本非常重要。而提高测试用例生成的自动化程度又是提高测试工具乃至整个测试过程自动化程度的关键所在,本文主要针对这一问题进行了研究和设计。 本文在分析软件测试和算法基本概念的基础上,提出软件测试用例的设计是软件测试的难点之一。论文提出了基于算法的测试用例生成的内含是应用算法来求解一组优化的测试用例,其框架包括了测试环境构造、算法及测试运行环境三部分,论文给出了基于算法的测试用例生成的模型。最后以三角形分类程序为例应用算法进行测试用例生成的模拟,结果显示,应用算法进行测试用例生成可行。 关键词:软件测试测试用例算法
ABSTRACT Software test is the important means that guarantee software quality and reliability,and in this respect,it plays the role that other method cannot replace. However software test is a complex process , it needs to consume huge manpower,material resources and time,which takes the 40%~50% of entire software development cost approximately . Therefore,raising the automation level of software test tool is very important for ensure software development quality and reduction software development cost . And then,the most important is raising the automation level of the test case generation for raising the automation level of test tool and even entire test process,so this paper study and design mainly according to this problem. Based on the analysis of basic concepts of software testing and genetic algorithm, this article proposes that software test case design is one of the difficulties of software testing. Paper presents the inherent in software test case designing based on genetic algorithm is using genetic algorithm to solve a set of optimization test cases, and the framework includes three parts which are test environment construction, genetic algorithm and the environment for test . Paper presents the model of software test case generation based on genetic algorithm. Finally, we take the triangle categorizer as an example, simulate software test case generation based on genetic algorithm. The results display that software test case generation basing on genetic algorithm is possible. KEY WORDS: software test , test case , genetic algorithm
最小二乘一次完成算法(程序)
《系统辨识与建模》(MATLAB编程) 信研0701 孙娅萍2007000694 编程第四次作业 仿真模型参数为:a=[-1.5 0.7];b=[1.0 0.5],由下式递推产生502组数据,并形成如下矩阵: z(k)=1.5z(k–1)-0.7z(k–2)+1.0u(k–1)+0.5u(k–2)+v(k) 试用一次完成最小二乘法辨识系统模型。 程序部分: %************************************************************% % ***** 二阶系统的最小二乘一次完成算法辨识程序*****% % 系统辨识的输入信号u是6阶的M序列,长度是500; L = 500; u = load('u.txt'); u2 = load('u2.txt'); u1 = load('u1.txt'); z = zeros(1,L+1); for k = 3 : (L+1) % 理想输出作为系统观测值 z(k) = 1.5 * z(k-1) - 0.7 * z(k-2) + u(k-1) + 0.5 * u(k-2); end % 绘制输入信号和输出观测值的图形 figure(1) i = 1 : 1 : L; subplot(2,1,1) plot(i,u) k = 1 : 1 : (L+1); subplot(2,1,2) plot(k,z) z = z' z1 = load('z1.txt'); z2 = load('z2.txt'); z3 = load('z3.txt'); Na = 2; Nb = 2; % 定义Na、Nb; for i = 1 : (Na+Nb) if ((i == 1)) H = -1 * z2; end if (i == 2) H = -1 * z1; end if (i == (Na+1)) H = u2; end
推荐系统的架构
本文从互联网收集并整理了推荐系统的架构,其中包括一些大公司的推荐系统框架(数据流存储、计算、模型应用),可以参考这些资料,取长补短,最后根据自己的业务需求,技术选型来设计相应的框架。后续持续更新并收集。。。 图1 界面UI那一块包含3块东西:1) 通过一定方式展示推荐物品(物品标题、缩略图、简介等);2) 给的推荐理由;3) 数据反馈改进个性化推荐;关于用户数据的存放地方:1)数据库/缓存用来实时取数据;2) hdfs文件上面; 抽象出来的三种推荐方式 图2
图3 图3中,推荐引擎的构建来源于不同的数据源(也就是用户的特征有很多种类,例如统计的、行为的、主题的)+不同的推荐模型算法,推荐引擎的架构可以试多样化的(实时推荐的+离线推荐的),然后融合推荐结果(人工规则+模型结果),融合方式多样的,有线性加权的或者切换式的等 图4 图4中,A模块负责用户各类型特征的收集,B模块的相关表是根据图3中的推荐引擎来生成的,B模块的输出推荐结果用来C模块的输入,中间经过过滤模块(用户已经产生行为的物品,非候选物品,业务方提供的物品黑名单等),排名模块也根据预设定的推荐目标来制定,最后推荐解释的生成(这是可能是最容易忽视,但很关键的一环,微信的好友推荐游戏,这一解释已经胜过后台的算法作用了) HULU的推荐系统
总结:这个也就跟图3有点类似了,葫芦的推荐系统,至少在他blog中写的比较简单。更多的是对推荐系统在线部分的一种描述,离线部分我猜想也是通过分布式计算或者不同的计算方式将算法产生的数据存储进入一种介质中,供推荐系统在线部分调用。系统的整个流程是这样的,首先获取用户的行为,包括(watch、subscribe、vote),这样行为会到后台获取show-show对应的推荐数据。同时这些行为也会产生对应的topic,系统也会根据topic 到后台获取topic-show对应的推荐数据。两种数据进行混合,然后经过fliter、explanation、ranking这一系列过程,最后生成用户看到的推荐数据。 淘宝的推荐系统(详细跟简单版)
递推最小二乘法算法
题目: (递推最小二乘法) 考虑如下系统: )()4(5.0)3()2(7.0)1(5.1)(k k u k u k y k y k y ξ+-+-=-+-- 式中,)(k ξ为方差为0.1的白噪声。 取初值I P 610)0(=、00=∧ )(θ。选择方差为1的白噪声作为输入信号)(k u ,采用PLS 法进行参数估计。 Matlab 代码如下: clear all close all L=400; %仿真长度 uk=zeros(4,1); %输入初值:uk(i)表示u(k-i) yk=zeros(2,1); %输出初值 u=randn(L,1); %输入采用白噪声序列 xi=sqrt(0.1)*randn(L,1); %方差为0.1的白噪声序列 theta=[-1.5;0.7;1.0;0.5]; %对象参数真值 thetae_1=zeros(4,1); %()θ初值 P=10^6*eye(4); %题目要求的初值 for k=1:L phi=[-yk;uk(3:4)]; %400×4矩阵phi 第k 行对应的y(k-1),y(k-2),u(k-3), u(k-4) y(k)=phi'*theta+xi(k); %采集输出数据 %递推最小二乘法的递推公式 K=P*phi/(1+phi'*P*phi); thetae(:,k)=thetae_1+K*(y(k)-phi'*thetae_1); P=(eye(4)-K*phi')*P; %更新数据 thetae_1=thetae(:,k); for i=4:-1:2 uk(i)=uk(i-1); end uk(1)=u(k); for i=2:-1:2 yk(i)=yk(i-1);
【精品】高中数学 必修3_算法案例_知识点讲解+巩固练习(含答案)_提高
算法案例 【学习目标】 1.理解辗转相除法与更相减损术中蕴含的数学原理,并能根据这些原理进行算法分析; 2.基本能根据算法语句与程序框图的知识设计完整的程序框图并写出算法程序; 3.了解秦九韶算法的计算过程,并理解利用秦九韶算法可以减少计算次数提高计算效率的实质; 4.了解各种进位制与十进制之间转换的规律,会利用各种进位制与十进制之间的联系进行各种进位制之间的转换. 【要点梳理】 要点一、辗转相除法 也叫欧几里德算法,它是由欧几里德在公元前300年左右首先提出的.利用辗转相除法求最大公约数的步骤如下: 第一步:用较大的数m除以较小的数n得到一个商q 0和一个余数r ; 第二步:若r 0=0,则n为m,n的最大公约数;若r ≠0,则用除数n除以余数r 得到一个 商q 1和一个余数r 1 ; 第三步:若r 1=0,则r 为m,n的最大公约数;若r 1 ≠0,则用除数r 除以余数r 1 得到一个 商q 2和一个余数r 2 ; …… 依次计算直至r n =0,此时所得到的r n-1 即为所求的最大公约数. 用辗转相除法求最大公约数的程序框图为:
程序: INPUT “m=”;m INPUT “n=”;n IF m
WEND PRINT n END 要点诠释: 辗转相除法的基本步骤是用较大的数除以较小的数,考虑到算法中的赋值语句可以对同一变量多次赋值,我们可以把较大的数用变量m 表示,把较小的数用变量n 表示,这样式子 )0(n r r q n m <≤+?=就是一个反复执行的步骤,因此可以用循环结构实现算法. 要点二、更相减损术 我国早期也有解决求最大公约数问题的算法,就是更相减损术. 更相减损术求最大公约数的步骤如下:可半者半之,不可半者,副置分母、子之数,以少减多,更相减损,求其等也.以等数约之. 翻译出来为: 第一步:任意给出两个正整数;判断它们是否都是偶数.若是,用2约简;若不是,执行第二步. 第二步:以较大的数减去较小的数,接着把较小的数与所得的差比较,并以大数减小数.继续这个操作,直到所得的数相等为止,则这个数(等数)就是所求的最大公约数. 理论依据: 由r b a r b a +=→=-,得b a ,与r b ,有相同的公约数 更相减损术一般算法: 第一步,输入两个正整数)(,b a b a >; 第二步,如果b a ≠,则执行3S ,否则转到5S ; 第三步,将b a -的值赋予r ; 第四步,若r b >,则把b 赋予a ,把r 赋予b ,否则把r 赋予a ,重新执行2S ; 第五步,输出最大公约数b . 程序: INPUT “a=”,a INPUT “b=”,b WHILE a<>b
算法设计及分析递归算法典型例题
算法递归典型例题 实验一:递归策略运用练习 三、实验项目 1.运用递归策略设计算法实现下述题目的求解过程。 题目列表如下: (1)运动会开了N天,一共发出金牌M枚。第一天发金牌1枚加剩下的七分之一枚,第二天发金牌2枚加剩下的七分之一枚,第3天发金牌3枚加剩下的七分之一枚,以后每天都照此办理。到了第N天刚好还有金牌N枚,到此金牌全部发完。编程求N和M。 (2)国王分财产。某国王临终前给儿子们分财产。他把财产分为若干份,然后给第一个儿子一份,再加上剩余财产的1/10;给第二个儿子两份,再加上剩余财产的1/10;……;给第i 个儿子i份,再加上剩余财产的1/10。每个儿子都窃窃自喜。以为得到了父王的偏爱,孰不知国王是“一碗水端平”的。请用程序回答,老国王共有几个儿子?财产共分成了多少份? 源程序: (3)出售金鱼问题:第一次卖出全部金鱼的一半加二分之一条金鱼;第二次卖出乘余金鱼的三分之一加三分之一条金鱼;第三次卖出剩余金鱼的四分之一加四分之一条金鱼;第四次卖出剩余金鱼的五分之一加五分之一条金鱼;现在还剩下11条金鱼,在出售金鱼时不能把金鱼切开或者有任何破损的。问这鱼缸里原有多少条金鱼? (4)某路公共汽车,总共有八站,从一号站发轩时车上已有n位乘客,到了第二站先下一半乘客,再上来了六位乘客;到了第三站也先下一半乘客,再上来了五位乘客,以后每到一站都先下车上已有的一半乘客,再上来了乘客比前一站少一个……,到了终点站车上还有乘客六人,问发车时车上的乘客有多少? (5)猴子吃桃。有一群猴子摘来了一批桃子,猴王规定每天只准吃一半加一只(即第二天吃剩下的一半加一只,以此类推),第九天正好吃完,问猴子们摘来了多少桃子? (6)小华读书。第一天读了全书的一半加二页,第二天读了剩下的一半加二页,以后天天如此……,第六天读完了最后的三页,问全书有多少页? (7)日本著名数学游戏专家中村义作教授提出这样一个问题:父亲将2520个桔子分给六个儿子。分完后父亲说:“老大将分给你的桔子的1/8给老二;老二拿到后连同原先的桔子分1/7给老三;老三拿到后连同原先的桔子分1/6给老四;老四拿到后连同原先的桔子分1/5给老五;老五拿到后连同原先的桔子分1/4给老六;老六拿到后连同原先的桔子分1/3给老大”。结果大家手中的桔子正好一样多。问六兄弟原来手中各有多少桔子? 四、实验过程 (一)题目一:…… 1.题目分析 由已知可得,运动会最后一天剩余的金牌数gold等于运动会举行的天数由此可倒推每一 天的金牌剩余数,且每天的金牌数应为6的倍数。 2.算法构造 设运动会举行了N天, If(i==N)Gold[i]=N; Else gold[i]=gold[i+1]*7/6+i;
属性选择
分类模型中的属性选择算法研究 1引言 20世纪六、七十年代以来,计算机科学技术的飞速发展使得存储或获得海量数据成为可能,数据存储成本的不断降低则加速了这一过程的发展。因为数据生成和积聚的量超过了分析人员所能分析的数量,建立一套方法来从数据库中自动分析数据和进行知识发现将是一种必然性选择。对这一问题,人们进行了有益的探索,其结果是导致了处理大型或海量数据的数据挖掘技术的产生和发展。 数据挖掘从机器学习、统计学、数据库等多学科领域汲取营养,发展了一套适合自身特点的数据挖掘方法和数据处理手段,用于知识学习、信息提取和结果可视化展现。数据挖掘任务建模过程中,在考虑模型拟合效果、任务系统运行时间和数据存储空间限制的前提下,对某些数据集而言,包含所有或更多的属性/变量的模型并不一定是最适合、最满意的(或最优的)模型。这是因为数据集中存在和学习任务不相关的属性/变量,或者是高度相关而冗余属性/变量,它们会导致无效的归纳和降低学习的效率。最近的研究表明【1】,简单最近邻算法(KNN)对不相关属性非常敏感——它的样本复杂度(达到给定精度所需最低样本量)与冗余属性呈指数性增长。决策树算法,如C4.5,有时可能过度拟合数据,从而获得较大的树,在许多情形下,去掉不相关或冗余的信息可使得C4.5产生更小的树。朴素贝叶斯分类算法由于其给定类的属性独立性假设,冗余属性的存在也可能影响其分类表现。 大量的实证研究结果表明,属性选择在提高学习任务的效率、任务预测的精度和增强、获得规则的可理解性等方面是较有成效的。由此,可知在数据挖掘任务建模过程中,通过一定的方式和方法去掉不相关或冗余属性,进行属性变量选择往往可以获得更令人满意的知识学习模型。这也就引发并促进了有关属性选择问题的研究和讨论。 2属性选择概述 2.1属性选择的定义 在过去的十多年,属性选择己经在机器学习、模式识别中关于数据的预处理部分变得非常重要,特别是对于一些高维的数据,如基因数据、代谢数据、质谱数据等。从理论上讲,属性数目越多,越有利于目标的分类,但实际情况并非如此。在样本数目有限的情况下,利用很多属性进行分类器设计,无论是从计算的复杂程度考虑,还是分类器性能都是不适宜的。同时样本的属性通常可分为4种类型,即有效属性,噪音属性,问题无关属性和冗余属性。其中有效属性是指对学习算法有积极效果的属性,噪音属性会对学习算法造成不良影响,问题无关属性指与学习算法无关的属性,而冗余属性指包含分类有关的信息,但在己有的属性集中添加或删除该属性并不会影响学习算法性能的属性。 对于特定的任务来说,噪音属性的存在容易使分类算法得出错误的结果,导致错误分类;冗余和问题无关属性的存在会降低算法的性能。人们通常通过属性选择或提取来去掉冗余和噪音属性,这是降低复杂度和提高分类精度的有效途径。属性选择在减少冗余不相关属性的同时,往往也可以:(1)减少获取数据的成本;(2)获得更易理解和解释的模型;(3)提高数据挖掘归纳学习的速度和效率;(4)提高分类的精度;(5)降低或避免维度灾难;(6)更好地形成结构化知识。
几种最小二乘法递推算法的小结
一、 递推最小二乘法 递推最小二乘法的一般步骤: 1. 根据输入输出序列列出最小二乘法估计的观测矩阵?: ] )(u ... )1( )( ... )1([)(T b q n k k u n k y k y k ------=? 没有给出输出序列的还要先算出输出序列。 本例中, 2)]-u(k 1),-u(k 2),-1),-y(k -[-y(k )(T =k ?。 2. 给辨识参数θ和协方差阵P 赋初值。一般取0θ=0或者极小的数,取σσ,20I P =特别大,本例中取σ=100。 3. 按照下式计算增益矩阵G : ) ()1()(1)()1()(k k P k k k P k G T ???-+-= 4. 按照下式计算要辨识的参数θ: )]1(?)()()[()1(?)(?--+-=k k k y k G k k T θ?θθ 5. 按照下式计算新的协方差阵P : )1()()()1()(---=k P k k G k P k P T ? 6. 计算辨识参数的相对变化量,看是否满足停机准则。如满足,则不再递推;如不满足, 则从第三步开始进行下一次地推,直至满足要求为止。 停机准则:ε???<--) (?)1(?)(?max k k k i i i i 本例中由于递推次数只有三十次,故不需要停机准则。 7. 分离参数:将a 1….a na b 1….b nb 从辨识参数θ中分离出来。 8. 画出被辨识参数θ的各次递推估计值图形。 为了说明噪声对递推最小二乘法结果的影响,程序5-7-2在计算模拟观测值时不加噪 声, 辨识结果为a1 =1.6417,a2 = 0.7148,b1 = 0.3900,b2 =0.3499,与真实值a1 =1.642, a2 = 0.715, b1 = 0.3900,b2 =0.35相差无几。 程序5-7-2-1在计算模拟观测值时加入了均值为0,方差为0.1的白噪声序列,由于噪 声的影响,此时的结果为变值,但变化范围较小,现任取一组结果作为辨识结果。辨识结果为a1 =1.5371, a2 = 0.6874, b1 = 0.3756,b2 =0.3378。 程序5-7-2-2在计算模拟观测值时加入了有色噪声,有色噪声为 E(k)+1.642E(k-1)+0.715E(k-2),E(k)是均值为0,方差为0.1的白噪声序列,由于有色噪声的影响,此时的辨识结果变动范围远比白噪声时大,任取一组结果作为辨识结果。辨识结果为a1 =1.6676, a2 = 0.7479, b1 = 0.4254,b2 =0.3965。 可以看出,基本的最小二乘法不适用于有色噪声的场合。
个性化推荐系统研究综述
个性化推荐系统研究综述 【摘要】个性化推荐系统不仅在社会经济中具有重要的应用价值,而且也是一个非常值得研究的科学问题。给出个性化推荐系统的定义,国内外研究现状,同时阐述了推荐系统的推荐算法。最后对个性化推系统做出总结与展望。 【关键词】推荐系统;推荐算法;个性化 1.个性化推荐系统 1.1个性化推荐系统的概论 推荐系统是一种特殊形式的信息过滤系统(Information Filtering),推荐系统通过分析用户的历史兴趣和偏好信息,可以在项目空间中确定用户现在和将来可能会喜欢的项目,进而主动向用户提供相应的项目推荐服务[1]。传统推荐系统认为推荐系统通过获得用户个人兴趣,根据推荐算法,并对用户进行产品推荐。事实上,推荐系统不仅局限于单向的信息传递,还可以同时实现面向终端客户和面向企业的双向信息传递。 一个完整的推荐系统由3个部分组成:收集用户信息的行为记录模块,分析用户喜好的模型分析模块和推荐算法模块,其中推荐算法模块是推荐系统中最为核心的部分。推荐系统把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。 1.2国内外研究现状 推荐系统的研宄开始于上世纪90年代初期,推荐系统大量借鉴了相关领域的研宄成果,在推荐系统的研宄中广泛应用了认知科学、近似理论、信息检索、预测理论、管理科学以及市场建模等多个领域的知识。随着互联网的普及和电子商务的发展,推荐系统逐渐成为电子商务IT技术的一个重要研究内容,得到了越来越多研究者的关注。ACM从1999年开始每年召开一次电子商务的研讨会,其中关于电子商务推荐系统的研究文章占据了很大比重。个性化推荐研究直到20世纪90年代才被作为一个独立的概念提出来。最近的迅猛发展,来源于Web210技术的成熟。有了这个技术,用户不再是被动的网页浏览者,而是成为主动参与者[2]。 个性化推荐系统的研究内容和研究方向主要包括:(1)推荐系统的推荐精度和实时性是一对矛盾的研究;(2)推荐质量研究,例如在客户评价数据的极端稀疏性使得推荐系统无法产生有效的推荐,推荐系统的推荐质量难以保证;(3)多种数据多种技术集成性研究;(4)数据挖掘技术在个性化推荐系统中的应用问题,基于Web挖掘的推荐系统得到了越来越多研究者的关注;(5)由于推荐系统需要分析用户购买习惯和兴趣爱好,涉及到用户隐私问题,如何在提供推荐服务的
递归算法的优缺点
○1优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。 ○2缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。 边界条件与递归方程是递归函数的二个要素 应用分治法的两个前提是问题的可分性和解的可归并性 以比较为基础的排序算法的最坏倩况时间复杂性下界为0(n·log2n)。 回溯法以深度优先的方式搜索解空间树T,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T。 舍伍德算法设计的基本思想: 设A是一个确定性算法,当它的输入实例为x时所需的计算时间记为tA(x)。设Xn是算法A的输入规模为n的实例的全体,则当问题的输入规模为n时,算法A所需的平均时间为 这显然不能排除存在x∈Xn使得的可能性。希望获得一个随机化算法B,使得对问题的输入规模为n的每一个实例均有 拉斯维加斯( Las Vegas )算法的基本思想: 设p(x)是对输入x调用拉斯维加斯算法获得问题的一个解的概率。一个正确的拉斯维加斯算法应该对所有输入x均有p(x)>0。 设t(x)是算法obstinate找到具体实例x的一个解所需的平均时间 ,s(x)和e(x)分别是算法对于具体实例x求解成功或求解失败所需的平均时间,则有: 解此方程可得:
蒙特卡罗(Monte Carlo)算法的基本思想: 设p是一个实数,且1/2 第32卷 第7期 2018年7月中文信息学报JOU RNAL OF CHINESE INFORM A TION PROCESSING Vol .32,No .7July ,2018文章编号:1003-0077(2018)07-0091-08 融合K 均值聚类和低秩约束的属性选择算法 杨常清 (西安航空学院材料工程学院,陕西西安710077) 摘 要:针对无监督属性选择算法无类别信息和未考虑属性低秩等问题,该文提出了一种融合K 均值聚类和低秩约束的属性选择算法。算法在线性回归的模型框架中有效地嵌入自表达方法,同时利用K 均值聚类产生伪类标签最大化类间距以更好地稀疏结构,并使用l 2,p -范数代替传统的l 2,1-范数,通过参数p 来灵活调节结果的稀疏性,最后证明了该文算法具有执行线性判别分析的特点和收敛性。经实验验证,该文提出的属性算法与NFS 算法、LDA 算法、RFS 算法、RSR 算法相比分类准确率平均提高了17.04%、13.95%、3.6%和9.39%,分类准确率方差 也是最小的,分类结果稳定。关键词:属性选择;自表达方法;K 均值聚类;低秩约束;稀疏学习 中图分类号:T P 181 文献标识码:A Attribute Selection Algorithm Based on K -Means Clustering and Low Rank Constraint YANG Changqing (School of Materials Engineering ,Xi ’an Aeronautical University ,Xi ’an ,Shaanxi 710077,China ) Abstract :T he unsupervised attribute selection algorithm does not consider the classification information and the low rank of attributes .To address this issue ,this paper proposes an attribute selection algorithm combining K -means clustering and low -rank constraint .The algorithm embeds the self -expression method into the framework of the line -ar regression model .At the same time ,the K -means clustering is used to generate the pseudo -class label to maxi -mize the class spacing to better sparse the structure .The algorithm uses l 2,p -norm instead of the traditional l 2,1-norm ,which can adjust the sparsity of the result flexibly by parameter p .It is also proved that the algorithm has the characteristics and convergence of linear discriminant analysis .The experimental results show that the accuracy of the proposed algorithm is 17.04%,13.95%,3.6%and 9.39%higher than that of the NFS algorithm 、the LDA al - g orithm 、the RFS algorithm 、the RSR algorithm ,respectively ,with the lowest classification accuracy variance .Key words :attribute selection ;self -expression method ;K -means clustering ;low rank constraints ;sparse learning 收稿日期:2017-09-04 定稿日期:2017-11-07 基金项目:陕西省教育厅项目(15BY 117)0 引言 高维特征虽然可以准确多样化地表现物体特 性,但使用高维数据不仅增大存储空间,还增加运算 复杂度。对高维数据进行属性约简,降低数据维度, 挖掘数据内部具有代表性的低维属性,已成为机器 学习的一个研究热点[1-2]。属性约简的优点包括能降低处理时间和得到更具有泛化能力和更坚实的学习模型等 [3-4]。常见的属性约简方法包含子空间学习和属性选择两种方法。子空间学习是把高维属性从高维空间投影到低维空间,并保持数据间的关联结构,而属性选择是从原始属性集中选择最能代表整个属性集的属性。利用多方向理论,学者们提出了各种属性选择算法。文献[5]将知觉理论赫姆霍兹原理作为特征选择的度量,用于文本分类的特征选择中,取得了较好的效果。文献[6]将类特定变换的新型语义平滑核融入 支持向量机模型中,提出了一种使用语义分类方法 来构建高性能的半监督文本分类算法。文献[7]将万方数据 【高中必修3数学算法案例总结】高中数学必修1 在高中数学必修3算法教学中,为帮助学生理解案例的数学本质,安排了算法案例一节内容,下面是小编给大家带来的高中必修3数学算法案例总结,希望对你有帮助。 高中必修3数学算法案例 高中数学学习方法 抓好基础是关键 数学习题无非就是数学概念和数学思想的组合应用,弄清数学基本概念、基本定理、基本方法是判断题目类型、知识范围的前提,是正确把握解题方法的依据。只有概念清楚,方法全面,遇到题目时,就能很快的得到解题方法,或者面对一个新的习题,就能联想到我们平时做过的习题的方法,达到迅速解答。弄清基本定理是正确、快速解答习题的前提条件,特别是在立体几何等章节的复习中,对基本定理熟悉和灵活掌握能使习题解答条理清楚、逻辑推理严密。反之,会使解题速度慢,逻辑混乱、叙述不清。 严防题海战术 做习题是为了巩固知识、提高应变能力、思维能力、计算能力。学数学要做一定量的习题,但学数学并不等于做题,在各种考试题中,有相当的习题是靠简单的知识点的堆积,利用公理化知识体系的演绎而就能解决的,这些习题是要通过做一定量的习题达到对解题方法的展移而实现的,但,随着高考的改革,高考已把考查的重点放在创造型、能力型的考查上。因此要精做习题,注意知识的理解和灵活应用,当你做完一道习题后不访自问:本题考查了什么知识点?什么方法?我们从中得到了解题的什么方法?这一类习题中有什么解题的通性?实现问题的完全解决我应用了怎样的解题策略?只有这样才会培养自己的悟性与创造性,开发其创造力。也将在遇到即将来临的期末考试和未来的高考题目中那些综合性强的题目时可以有一个科学的方法解决它。 归纳数学大思维 递归算法的优缺点: ○ 1优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。 ○2缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。 边界条件与递归方程是递归函数的二个要素 应用分治法的两个前提是问题的可分性和解的可归并性 以比较为基础的排序算法的最坏倩况时间复杂性下界为0(n·log2n)。 回溯法以深度优先的方式搜索解空间树T ,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T 。 舍伍德算法设计的基本思想: 设A 是一个确定性算法,当它的输入实例为x 时所需的计算时间记为tA(x)。设Xn 是算法A 的输入规模为n 的实例的全体,则当问题的输入规模为n 时,算法A 所需的平均时间为 这显然不能排除存在x ∈Xn B ,使得对问题的输入规模为n 拉斯维加斯( Las Vegas )算法的基本思想: 设p(x) 是对输入x 调用拉斯维加斯算法获得问题的一个解的概率。一个正确的拉斯维加斯算法应该对所有输入x 均有p(x)>0。 设t(x)是算法obstinate 找到具体实例x 的一个解所需的平均时间 ,s(x)和e(x)分别是算法对于具体实例x 蒙特卡罗(Monte Carlo)算法的基本思想: 设p 是一个实数,且1/2 Xiaol v2009-Relevance is more significant than correlation: Information filtering on sparse data 本文提出了在针对数据稀疏时,使用相关性信息比关联性信息效果更好,因为在关联性信息中,会用到更多的数据, Recommendation System 推荐系统存在的主要挑战: 1.Data sparsity. 2.Scalability 解决该问题的一般方法(28-30) a)有必要考虑计算成本问题和需找推荐算法,这些算法要么是小点的要求 或易于并行化(或两者) b)使用基于增量的算法,随着数据的增加,不重新计算所有的数据,而是 微调的进行 3.Cold start 解决该问题的方法一般有 a)使用混合推荐技术,结合content和collaborative数据,或者需 要基础信息的使用比如用户年龄、位置、喜好genres(31、32) b)识别不同web服务上的单独用户。比如Baifendian开发了一个可以 跟踪到单独用户在几个电子商务网站上的活动,所以对于在网站A的一 个冷启动用户,我们可以根据他在B,C,D网站上的记录来解决其冷启 动问题。 4.Diversity vs. Accuracy(多样性和精确性) 将一些很受欢迎的且高评分的商品推荐给一个用户时,推荐非常高效,但是这种推荐不起多少作用,因为这些商品可以很容易的找到。因此一个好的推荐商 品的列表应该包含一些不明显的不容易被该用户自己搜索到的商品。解决该问题 的方法主要是提高推荐列表的多样性,以及使用混合推荐方法。(34-37) 5.Vulnerability to attacks 6.The value of time. 7.Evaluation of recommendations 8.er interface. 除了这些问题外,还有其他的。随着相关学科分支的出现,特别是网络分析工具,科学家考虑网络结构对推荐的效果影响,以及如何有效使用已知的结构属性来提 高推荐。比如,(45)分析了消费者-商品网络并提出了一个基于喜好边(preferring edges)改进的推荐算法,该算法提高了局部聚类属性。(46)设计并提高了算法,该算法充分利用了社区结构(community structure)。随之而来的挑战主要有:带有GPS移动手机成为主流,并且可以访问网络,因此,基于位置的推荐更需要精确的推荐,其需要对人的移动有一个高效预测能力(47、48)并且高质量的定义位置和人之间的相似性的方法。(49、50)。智能推荐系统需考虑不同人的不同行为模式。比如新用户比较喜欢访问popular商品并且选择相似的商品,而老的用户有更不同的喜好(51,52)用户行为在低风险商品和高风险商品之间更加的不同。(53,54) 推荐系统的一些概念 网络 网络分析对于复杂系统的组织原则的发现是一个万能的工具(5-9)。网络是 由一些元素点和连接点的边组成的。点即为个人或者组织,边为他们之间的交互。 网络G可用(V,E)表示,V(vertice)为节点的集合,E为边(edge)的 集合。在无向网络中,边无方向。在有向网络中,边有向。我们假设网络中不存 在回路以及两个节点之间不存在多条边。G(V,E)图中,一些参数表示是指与节点x连接的节点(即x的邻居)的集合。 即为x节点的度。 人教版高中数学必修三 知识点梳理 重点题型(常考知识点)巩固练习 算法案例 【学习目标】 1.理解辗转相除法与更相减损术中蕴含的数学原理,并能根据这些原理进行算法分析; 2.基本能根据算法语句与程序框图的知识设计完整的程序框图并写出算法程序; 3.了解秦九韶算法的计算过程,并理解利用秦九韶算法可以减少计算次数提高计算效率的实质; 4.了解各种进位制与十进制之间转换的规律,会利用各种进位制与十进制之间的联系进行各种进位制之间的转换. 【要点梳理】 要点一、辗转相除法 也叫欧几里德算法,它是由欧几里德在公元前300年左右首先提出的.利用辗转相除法求最大公约数的步骤如下: 第一步:用较大的数m除以较小的数n得到一个商q0和一个余数r0; 第二步:若r0=0,则n为m,n的最大公约数;若r0≠0,则用除数n除以余数r0得到一个商q1和一个余数r1; 第三步:若r1=0,则r0为m,n的最大公约数;若r1≠0,则用除数r0除以余数r1得到一个商q2和一个余数r2; …… 依次计算直至r n=0,此时所得到的r n-1即为所求的最大公约数. 用辗转相除法求最大公约数的程序框图为: 程序: INPUT “m=”;m INPUT “n=”;n IF m 算法分析 1.TOPSIS(逼近理想解法):(TOPSIS方法属于经典的多属性决策方法之一,由H.wang.C.L和Yoon,K.S.1981提出). 基本原理:根据评价指标的标准化值与指标的权重共同构成规范化矩阵来确定评价指标的正、负理想解。然后,建立评价指标综合向量与正、负理想解之间距离的二维数据空间。在此基础上对评价方案与最优理想参照点之间的距离进行模糊评判。最后,依据该距离的大小对评价方案进行优劣排序.若某方案为最优方案则此方案最接近最优解,同时又远离最劣解. TOPSIS法最大的优点是:无严格限制数据分布及样本含量指标的多少,小样本资料、多评价单元、多指标的大系统资料都同样适用,同时也不受参考序列选择的干扰。既可用于多单位之间进行对比,也可用于不同年度之间对比分析,该法运用灵活,计算简便同时结果量化也客观[1]。 缺点:(1)规范决策矩阵的求解比较复杂,故不易求出理想解和负理想解;(2)评价缺少稳定性,当评判的环境及自身条件发生变化时,指标值也相应会发生变化,就有可能引起理想解和负理想解向量的改变,使排出的顺序随之变化,评判结果就不具有唯一性;(3)属性权重是事先确定的,其主观性较强。[2] 基本步骤: ○1建立多属性决策问题的决策矩阵 ○2决策矩阵的规范化处理 常见的标准化处理方法有:模糊数学法、标准差标准化法、极差标准化法、极大值标准化法和百分比标准法等. ○3构建加权规范化矩阵 确定权重的方法有主观赋权法和客观赋权法。主观赋权法包括层次分析法、Delphi法等。主观权重法土要根据专家判断打分,主观性 太强,其结果对多因素非线性定量关系的反映有一定影响:客观权重法人为因素干扰较小,可以较为客观地确定权重,但该方法也受样本数据数量和质量的制约。权重确定的方法:主成分分析法、变异系数法。 ○4确定正理想点和负理想点 所谓正理想点是设想得到的最好的解,它的各个指标值都达到各候选方案中最好的值。而负理想点是另一设想的最坏的解,它的各个指标都达到各候选方案中最坏的值。 ○5计算各方案到正负理想点的距离 ○6计算各方案与理想点的相对贴近度,相对贴近度的取值越大则表示该方案越优。贴近度的计算公式为:[3]融合K均值聚类和低秩约束的属性选择算法
【高中必修3数学算法案例总结】高中数学必修1
递归算法的优缺点
推荐系统总结
人教版高中数学【必修三】[知识点整理及重点题型梳理]_算法案例_基础
多属性决策算法对比分析