myeclipse导出类图教程
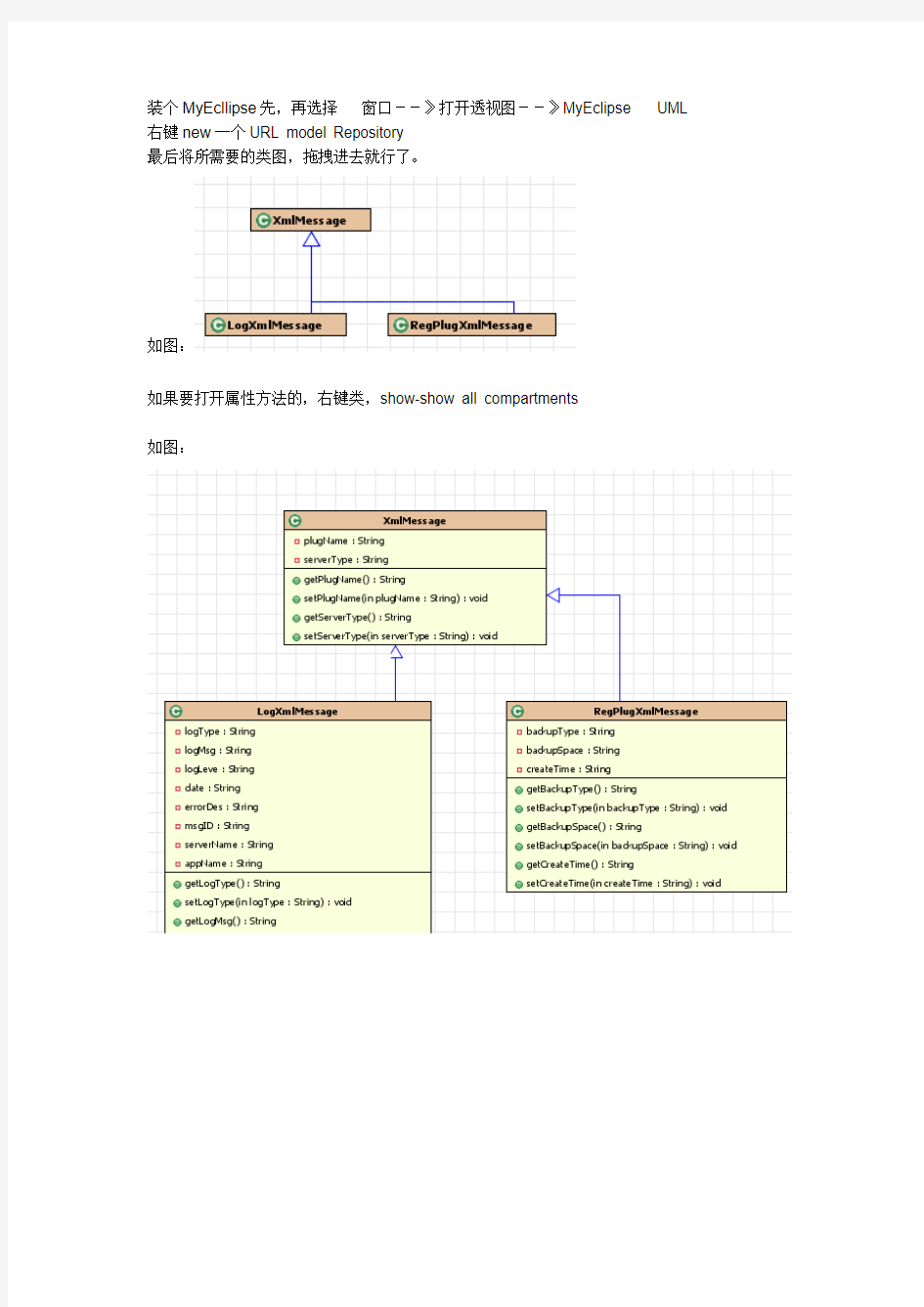
装个MyEcllipse先,再选择窗口--》打开透视图--》MyEclipse UML 右键new一个URL model Repository
最后将所需要的类图,拖拽进去就行了。
如图:
如果要打开属性方法的,右键类,show-show all compartments
如图:
Ku二分图最大权匹配(KM算法)hn
Maigo的KM算法讲解(的确精彩) 顶点Yi的顶标为B[i],顶点Xi与Yj之间的边权为w[i,j]。在算法执行过程中的任一时刻,对于任一条边(i,j),A[i]+B[j]>=w[i,j]始终成立。KM 算法的正确性基于以下定理: * 若由二分图中所有满足A[i]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。 这个定理是显然的。因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配一定是二分图的最大权匹配。 初始时为了使A[i]+B[j]>=w[i,j]恒成立,令A[i]为所有与顶点Xi关联的边的最大权,B[j]=0。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。 我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点全部是X顶点。现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现:
两端都在交错树中的边(i,j),A[i]+B[j]的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。 两端都不在交错树中的边(i,j),A[i]和B[j]都没有变化。也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。 X端不在交错树中,Y端在交错树中的边(i,j),它的A[i]+B[j]的值有所增大。它原来不属于相等子图,现在仍不属于相等子图。 X端在交错树中,Y端不在交错树中的边(i,j),它的A[i]+B[j]的值有所减小。也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。 现在的问题就是求d值了。为了使A[i]+B[j]>=w[i,j]始终成立,且至少有一条边进入相等子图,d应该等于min{A[i]+B[j]-w[i,j]|Xi在交错树中,Yi不在交错树中}。 以上就是KM算法的基本思路。但是朴素的实现方法,时间复杂度为 O(n4)——需要找O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为O(n2)。实际上KM算法的复杂度是可以做到O(n3)的。我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(i,j)时,如果它不在相等子图中,则让slack[j]变成原值与A[i]+B[j]-w[i,j]的较小值。这样,在修改顶标时,取所有不在交错树中的Y顶点的slack值中的最小值作为d值即可。但还要注意一点:修改顶标后,要把所有的slack值都减去d。
从实体关系图生成类图
Generate class diagrams from entity relationship diagrams Written Date : October 30, 2009 Visual Paradigm for UML (VP-UML) supports generating class diagrams from ER diagrams (entity relationship diagram). Entities and relationships are mapped with classes and associations accordingly. This tutorial teaches generating class diagrams from entity relationships diagrams and how to synchronize documentation between classes and entities. To generate class diagrams from entity relationship diagrams: 1.We first create Entity Model in Model Explorer. Right click on the Model Explorer and select Model > New Model. Create entity model in Model Explorer 2.Enter the name as Entity Model. Input "Entity Model" in model specification dialog box
二分图匹配(匈牙利算法和KM算法)
前言: 高中时候老师讲这个就听得迷迷糊糊,有一晚花了通宵看KM的Pascal代码,大概知道过程了,后来老师说不是重点,所以忘的差不多了。都知道二分图匹配是个难点,我这周花了些时间研究了一下这两个算法,总结一下 1.基本概念 M代表匹配集合 未盖点:不与任何一条属于M的边相连的点 交错轨:属于M的边与不属于M的边交替出现的轨(链) 可增广轨:两端点是未盖点的交错轨 判断M是最大匹配的标准:M中不存在可增广轨 2.最大匹配,匈牙利算法 时间复杂度:O(|V||E|) 原理: 寻找M的可增广轨P,P包含2k+1条边,其中k条属于M,k+1条不属于M。修改M 为M&P。即这条轨进行与M进行对称差分运算。 所谓对称差分运算,就是比如X和Y都是集合,X&Y=(X并Y)-(x交Y) 有一个定理是:M&P的边数是|M|+1,因此对称差分运算扩大了M 实现: 关于这个实现,有DFS和BFS两种方法。先列出DFS的代码,带注释。这段代码来自中山大学的教材
核心部分在dfs(x),来寻找可增广轨。如果找到的话,在Hungarian()中,最大匹配数加一。这是用了刚才提到的定理。大家可以想想初始状态是什么,又是如何变化的 view plaincopy to clipboardprint?
第二种方法BFS,来自我的学长cnhawk 核心步骤还是寻找可增广链,过程是: 1.从左的一个未匹配点开始,把所有她相连的点加入队列 2.如果在右边找到一个未匹配点,则找到可增广链 3.如果在右边找到的是一个匹配的点,则看它是从左边哪个点匹配而来的,将那个点出发的所有右边点加入队列 这么说还是不容易明白,看代码吧
UML软件建模教程课后习题及答案
UML软件建模教程课后习题 习题 1 一、简答题 1. 简述模型的作用。 答:现实系统的复杂性和内隐性,使得人们难于直接认识和把握,为了使得人们能够直观和明了地认识和把握现实系统,就需要借助于模型。 2. 软件模型有什么特征? 答:建模对象特殊,复杂性,多样性 3. 软件建模技术有哪些因素? 答:软件建模方法,软件建模过程,软件建模语言,软件建模工具 4. 软件模型包括哪些方面的内容? 答:从模型所反映的侧面看:功能模型,非功能模型,数据模型,对象模型,过程模型,状态模型,交互模型,架构模型,界面模型等;从软件开发工作看:业务模型,需求模型,分析模型,设计模型,测试模型等。 5. 软件建模工具应该具有哪些基本功能? 答:软件模型的生成和编辑,软件模型的质量保障,软件模型管理等 二、填空题 1、模型是对现实的(抽象)和模拟,是对现实系统(本质)特征的一种抽象、简化和直观的描述。
2、模型具有(反映性)、直观性、(简化性)和抽象性等特征。 3、从抽象程度,可以把模型分为(概念模型)、逻辑模型和(物理模型)三种类型。 4、较之于其他模型,软件模型具有(建模对象特殊)、复杂性和(多样性)等特征。 5、软件模型是软件开发人员交流的(媒介),是软件升级和维护的(依据)。 6、软件建模技术的要素包括软件建模方法、(软件建模过程)、软件建模语言和(软件建模工具)。 7、从开发阶段看,软件建模有业务模型、(需求模型)、分析模型、(设计模型)和测试模型。 8、软件语言有软件需求定义语言、(软件设计语言)、软件建模语言、(软件结构描述语言)、软件程序设计语言等。 9、根据软件建模工具的独立性,把软件建模工具分为(独立软件)建模工具和(插件式软件)建模工具。 10、OMG在( 1997 )年把UML作为软件建模的标准,UML2.0版本是( 200 5 )年颁布的。 三、选择题 1、对软件模型而言,下面说法错误的是( D )。 A.是人员交流的媒介 B.是软件的中间形态 C.是软件升级和维护的依据 D.是软件的标准文档
算法学习:图论之二分图的最优匹配(KM算法)
二分图的最优匹配(KM算法) KM算法用来解决最大权匹配问题:在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连接XiYj有权wij,求一种匹配使得所有wij的和最大。 基本原理 该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。设顶点Xi的顶标为A[ i ],顶点Yj的顶标为B[ j ],顶点Xi与Yj之间的边权为w[i,j]。在算法执行过程中的任一时刻,对于任一条边(i,j),A[ i ]+B[j]>=w[i,j]始终成立。 KM算法的正确性基于以下定理: 若由二分图中所有满足A[ i ]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。 首先解释下什么是完备匹配,所谓的完备匹配就是在二部图中,X点集中的所有点都有对应的匹配或者是 Y点集中所有的点都有对应的匹配,则称该匹配为完备匹配。 这个定理是显然的。因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配一定是二分图的最大权匹配。 初始时为了使A[ i ]+B[j]>=w[i,j]恒成立,令A[ i ]为所有与顶点Xi关联的边的最大权,B[j]=0。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。 我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点全部是X顶点。现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现: 1)两端都在交错树中的边(i,j),A[ i ]+B[j]的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。 2)两端都不在交错树中的边(i,j),A[ i ]和B[j]都没有变化。也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。 3)X端不在交错树中,Y端在交错树中的边(i,j),它的A[ i ]+B[j]的值有所增大。它原来不属于相等子图,现在仍不属于相等子图。 4)X端在交错树中,Y端不在交错树中的边(i,j),它的A[ i ]+B[j]的值有所减小。也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。(针对之后例子中x1->y4这条边) 现在的问题就是求d值了。为了使A[ i ]+B[j]>=w[i,j]始终成立,且至少有一条边进入相等子图,d应该等于: Min{A[i]+B[j]-w[i,j] | Xi在交错树中,Yi不在交错树中}。 改进 以上就是KM算法的基本思路。但是朴素的实现方法,时间复杂度为O(n4)——需要找O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为O(n2)。实际上KM算法的复杂度是可以做到O(n3)的。我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(i,j)时,如果它不在相等子图中,则让slack[j]变成原值与A[ i ]+B[j]-w[i,j]的较小值。这样,在修改顶标时,取所有不在交错树中的Y 顶点的slack值中的最小值作为d值即可。但还要注意一点:修改顶标后,要把所有的不在交错树中的Y顶点的slack值都减去d(因为:d的定义为 min{ (x,y)| Lx(x)+ Ly(y)- W(x,y), x∈ S, y? T }
ROSE画图--UML类图关系大全
UML类图关系大全(ROSE画图) 1、关联 双向关联: C1-C2:指双方都知道对方的存在,都可以调用对方的公共属性和方法。 在GOF的设计模式书上是这样描述的:虽然在分析阶段这种关系是适用的,但我们觉得它对于描述设计模式内的类关系来说显得太抽象了,因为在设计阶段关联关系必须被映射为对象引用或指针。对象引用本身就是有向的,更适合表达我们所讨论的那种关系。所以这种关系在设计的时候比较少用到,关联一般都是有向的。 使用ROSE 生成的代码是这样的: class C1 ...{ public: C2* theC2; }; class C2 ...{ public: C1* theC1; };
双向关联在代码的表现为双方都拥有对方的一个指针,当然也可以是引用或者是值。 单向关联: C3->C4:表示相识关系,指C3知道C4,C3可以调用C4的公共属性和方法。没有生命期的依赖。一般是表示为一种引用。 生成代码如下: class C3 ...{ public: C4* theC4; }; class C4 ...{ }; 单向关联的代码就表现为C3有C4的指针,而C4对C3一无所知。
自身关联(反身关联): 自己引用自己,带着一个自己的引用。 代码如下: class C14 ...{ public: C14* theC14; }; 就是在自己的内部有着一个自身的引用。 2、聚合/组合 当类之间有整体-部分关系的时候,我们就可以使用组合或者聚合。 聚合:表示C9聚合C10,但是C10可以离开C9而独立存在(独立存在的意思是在某个应用的问题域中这个类的存在有意义。这句话怎么解,请看下面组合里的解释)。
UML类图-关系数据库之间的映射
UML类图与关系数据库之间的映射策略 摘要:UML是目前面向对象程序设计中的一种标准的建模技术。在关系数据库系统的设计过程中,我们可先利用UML建立商业模型,然后将其映射成表。本文主要讨论如何将UML 类图中的类映射成表的策略。 关键词:UML 类表关系建模映射 一.概论 在关系数据库设计中,用来创建数据库逻辑模型的标准方法是使用实体关系模型(ER 模型)。ER模型的中心思想是:可以仅通过实体和它们之间的关系合理地体现一个组织的数据模型。但这样做似乎对描述一个组织的信息过于简单化,并且词汇量也远远不足。所以,迫切需要使用更加灵活、健壮的模型来代替ER模型。 标准建模语言UML是由世界著名的面向对象技术专家发起的,在综合了著名的Booch 方法、OMT方法和OOSE方法的基础上而形成的一种建模技术,它通过用例图、类图、交互图、活动图等模型来描述复杂系统的全貌及其相关部件之间的联系。UML可以完成ER 模型的所有建模工作,而且可以描述ER模型所不能表示的关系。 在UML中,类图主要用于描述系统中各种类及其对象之间的静态结构。在关系数据库领域中,类与表相对应。本文主要讨论将UML类图中的类及其对象映射成关系型数据库中的表的策略。 二.UML类图中的类映射成表的策略 UML中的类图主要由类及其关系组成,而类之间的关系又可以细分为: (1)泛化:在UML类图中,如果子类型的接口包括超类型的接口中的每个元素。则超类与子类之间构成泛化关系。泛化通常可以用继承或授权的方式实现。 (2)关联:在UML类图中,关联表示类的实例之间存在的某种关系。它通常可以有1对1、1对多和多对多等情形。 (3)聚集:在UML类图中,聚集描述了部分与整体之间的关系。 (4)组成:在UML类图中,组成由聚集演变而成,它表示一个部分对象仅属于一个整体,并且部分对象通常与整体对象共存亡。 下面结合例子,分别讨论在将类映射成表的过程中这些关系的实现技术。 假设,有一个电脑公司专门从事软件开发,其项目主要由项目开发部门承担,它们之间构成多对多的关联(即一个项目可由多个部门承担,而一个部门又可以承担多个项目的开发工作);项目开发部门由经理及一般职员组成,项目开发部门和组成人员之间构成聚集关系,而人(抽象类)又可以进一步和一般职员及经理两个子类之间构成继承关系;每个项目具有一定的属性,它们之间构成组成关系。 综上所述,其主要关系的UML类图如图1所示。
UML分析题结果图
分析了UML的几个重要图看看是否可以? 第2章用例图 1.一台自动售货机能提供6种不同的饮料,售货机上有6个不同的按钮,分别对应这6种不同的饮料,顾客通过这些按钮选择不同的饮料。售货机有一个硬币槽和找零槽,分别用来收钱和找钱。现在为这个系统设计一个用例图? 顾客 2.现有一个产品销售系统,其总体需求如下: 系统允许管理员生成存货清单报告。 管理员可以更新存货清单。 销售员记录正常的销售情况。 交易可以使用信用卡或支标,系统需要对其进行验证。 每次交易后都需要更新存货清单。 分析其总体需求,并绘制出其用例图? 3.绘制用例图,为如下的每个事件显示酒店管理系统中的用例,并描述各用例的基本操作流程。 客人预订房间。 客人登记。 客人的承担服务费用。 生成最终账单 客人结账 客人支付账单
第3章类图、对象图和包图 1.创建一个类图。下面给出创建类图所需的信息。 ●学生(student)可以是在校生(undergraduate)或者毕业生(graduate)。 ●在校生可以是助教(tutor)。 ●一名助教指导一名学生。 ●教师和教授属于不同级别的教员。 ●一名教师助理可以协助一名教师和一名教授,一名教师只能有一名教师助理,一名 教授可以有5名教师助理。 ●教师助理是毕业生。 创建类图的步骤如下: (1)将学生可以是在校生或者毕业生建模为3个类:Student、UnderGraduate和Graduate,其中,后两个类是Student类的子类。 (2)为“在校生可以是助教的一种”建立模型,即建立UnderGraduate类的另一个超类Tutor。 (3)通过创建从Tutor到Student的关联(名为tutors),建立一名助教指导一名学生的模型。 (4)将“教师和教授属于不同级别的教员”建模为3个类:Instructor、Teacher和Professor,其中,后两个类是Instructor类的子类。 (5)建立“一名教师助理可以协助一名教师和一名教授,一名教师只能有一名教师助理,一名教授可以有5名教师助理”的模型。创建TeacherAssistant类,并使其与Teacher 类和Professor类都建立关联。 (6)将TeacherAssistant类建模为Graduate类的派生类。
用匈牙利算法求二分图的最大匹配
用匈牙利算法求二分图的最大匹配 什么是二分图,什么是二分图的最大匹配,这些定义我就不讲了,网上随便都找得到。二分图的最大匹配有两种求法,第一种是最大流(我在此假设读者已有网络流的知识);第二种就是我现在要讲的匈牙利算法。这个算法说白了就是最大流的算法,但是它跟据二分图匹配这个问题的特点,把最大流算法做了简化,提高了效率。匈牙利算法其实很简单,但是网上搜不到什么说得清楚的文章。所以我决定要写一下。 最大流算法的核心问题就是找增广路径(augment path)。匈牙利算法也不例外,它的基本模式就是: 初始时最大匹配为空 while 找得到增广路径 do 把增广路径加入到最大匹配中去 可见和最大流算法是一样的。但是这里的增广路径就有它一定的特殊性,下面我来分析一下。 (注:匈牙利算法虽然根本上是最大流算法,但是它不需要建网络模型,所以图中不再需要源点和汇点,仅仅是一个二分图。每条边也不需要有方向。) 图1是我给出的二分图中的一个匹配:[1,5]和[2,6]。图2就是在这个匹配的基础上找到的一条增广路径:3->6->2->5->1->4。我们借由它来描述一下二分图中的增广路径的性质: (1)有奇数条边。 (2)起点在二分图的左半边,终点在右半边。 (3)路径上的点一定是一个在左半边,一个在右半边,交替出现。(其实二分图的性质就决定了这一点,因为二分图同一边的点之间没有边相连,不要忘记哦。) (4)整条路径上没有重复的点。 (5)起点和终点都是目前还没有配对的点,而其它所有点都是已经配好对的。(如图1、图2所示,[1,5]和[2,6]在图1中是两对已经配好对的点;而起点3和终点4目前还没有与其它点配对。) (6)路径上的所有第奇数条边都不在原匹配中,所有第偶数条边都出现在原匹配中。(如图1、图2所示,原有的匹配是[1,5]和[2,6],这两条配匹的边在图2给出的增广路径中分边是第2和第4条边。而增广路径的第1、3、5条边都没有出现在图1给出的匹配中。) (7)最后,也是最重要的一条,把增广路径上的所有第奇数条边加入到原匹配中
UML类图关系
UML类图关系(泛化、继承、实现、依赖、关联、聚合、组合) 继承、实现、依赖、关联、聚合、组合的联系与区别 分别介绍这几种关系: 继承 指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java 中此类关系通过关键字extends明确标识,在设计时一般没有争议性; 实现 指的是一个class类实现interface接口(可以是多个)的功能;实现是类与接口之间最常见的关系;在Java中此类关系通过关键字implements明确标识,在设计时一般没有争议性; 依赖 可以简单的理解,就是一个类A使用到了另一个类B,而这种使用关系是具有偶然性的、、临时性的、非常弱的,但是B类的变化会影响到A;比如某人要过河,需要借用一条船,此时人与船之间的关系就是依赖;表现在代码层面,为类B作为参数被类A在某个method
方法中使用; 关联 他体现的是两个类、或者类与接口之间语义级别的一种强依赖关系,比如我和我的朋友;这种关系比依赖更强、不存在依赖关系的偶然性、关系也不是临时性的,一般是长期性的,而且双方的关系一般是平等的、关联可以是单向、双向的;表现在代码层面,为被关联类B 以类属性的形式出现在关联类A中,也可能是关联类A引用了一个类型为被关联类B的全局变量; 聚合 聚合是关联关系的一种特例,他体现的是整体与部分、拥有的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分; 组合 组合也是关联关系的一种特例,他体现的是一种contains-a的关系,这种关系比聚合更强,也称为强聚合;他同样体现整体与部分间的关系,但此时整体与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束;比如你和你的大脑;表现在代码层面,和关联
图论二分图最大匹配算法
二分图最大匹配算法 令G = (X,*,Y)是一个二分图,其中,X = {x1,x2,...xm}, Y = {y1,y2,...yn}。令M为G中的任一个匹配。 1)讲X的所有不与M的边关联的顶点标上(@),并称所有的顶点为未被扫描的。转到2)。2)如果在上一步没有新的标记加到X的顶点上,则停止。否则转到3)。 3)当存在X被标记但未被扫描的顶点时,选择一个被标记但未被扫描的X的顶点,比如,xi,用(xi)标记Y的所有顶点,这些顶点被不属于M且尚未标记的边连到xi .现在,顶点xi 是被扫描的。如果不存在被标记但未被扫描的顶点,则转到4)。 4)如果在步骤3)没有新的标记被标到Y的顶点上,则停止。否则,转到5)。 5)当存在Y被标记但未被扫描的顶点时,选择Y的一个被标记但未被扫描的顶点,比如yi,用(yi)标记X的顶点,这些顶点被属于M且尚未标记的边连到yi.现在,顶点yi是被扫描的。如果不存在被标记但未被扫描的顶点,则转到2)。 也可以叙述为: [ZZ]匈牙利算法 关键在于匈牙利算法的递归过程中有很多重复计算的节点,而且这种重复无法避免,他不能向动态规划一样找到一个“序”将递归改为递推。 算法中的几个术语说明: 1。二部图: 如果图G=(V,E)的顶点集何V可分为两个集合X,Y,且满足X∪Y = V, X∩Y=Φ,则G称为二 部图; 图G的边集用E(G)表示,点集用V(G)表示。 2。匹配: 设M是E(G)的一个子集,如果M中任意两条边在G中均不邻接,则称M是G的一个匹配。M中的 —条边的两个端点叫做在M是配对的。 3。饱和与非饱和: 若匹配M的某条边与顶点v关联,则称M饱和顶点v,并且称v是M-饱和的,否则称v 是M-不 饱和的。 4。交互道: 若M是二分图G=(V,E)的一个匹配。设从图G中的一个顶点到另一个顶点存在一条道路,这条道路是由属于M的边和不属于M的边交替出现组成的,则称这条道路为交互道。 5。可增广道路: 若一交互道的两端点为关于M非饱和顶点时,则称这条交互道是可增广道路。显然,一条边的两端点非饱和,则这条边也是可增广道路。 6。最大匹配: 如果M是一匹配,而不存在其它匹配M',使得|M'|>|M|,则称M是最大匹配。其中|M|表
第4章 类图实战
第4章类图实战 4.1从分析到设计 首先,我们先来简单归纳一下在分析阶段生成的文件,如下: 1. 类图。类图描述系统内部的静态结构,以领域概念为参考对象。如果应用BCE 模式的话,原先的类图会是实体类图,而在序列图生成后,会额外生成边界类图和控制类图。 2. 用例图。用例图描述系统的外部行为,也就是描述参与者如何与系统交互,以便获取服务的使用过程。 3. 序列图。序列图描述系统的内部行为,针对每一个用例,至少会有一张描述主要流程的序列图。在应用BCE 模式之后,序列图内部的一群对象,将由边界对象、控制对象和实体对象所组成。换言之,序列图的一群对象必须来自于类图,而对象之间的交互过程,则来自于用例描述。 分析阶段与设计阶段最大的差别在于,分析阶段所关注的重点在领域概念、业务流程等,并未考虑并涉及实际工作平台。所以,到了设计阶段,不再需要花费太多时间在业务概念上,取而代之的是,必须把精力放在实际工作平台上,承接分析阶段的类图、用例图、序列图再加上实际工作平台或者是开发人员的观点,生成可以交付给程序员的设计文件。因此,在本书的开发流程规划中,我们会让设计师直接承接分析师的生成文件,进行下述的加工: 1. 类图。分析师所生成的类图通常跟实际工作平台有些差别,所以设计师要补上一些实际工作平台的概念,让设计出来的类图可以真正交付给程序员实际工作。 2. 用例图。之前我们没有教给分析师用例之间的包含关系和扩展关系如何处理,只是让用例图保持单纯化,以便将焦点聚焦在业务流程上。此处,我们会教设计师如何加入开发人员的观点,使用包含关系和扩展关系,罗列出可以共享的部分,并且让用例图更为细致化。 3. 序列图。在分析阶段的序列图并没有太重视消息上的参数,在设计阶段,每张序列图都要拿出来再检查一次,加上所需要的参数。由于,有些分析师已经太久没摸过程序代码了,所以生成的序列图偏离实际工作情况太大,需要设计师来补上这一块,否则程序员是很难直接参考分析文件编写程序代码。 好了,接下来,我们要再来多谈一些类图中的元素,这些元素可能对分析师意义不大,但是对设计师而言,会是非常实用的概念。 4.2设计师必学元素 4.2.1依赖关系 之前,我们学到了类之间的关联或组合关系,它们都是一种需要长期保存在数据库中的静态关系。相较之下,“依赖关系(dependency relationship)”是一种暂时的、动态的关系,它不需要被长期保存,可以在使用的瞬间建立,如果不用了就回收。 因此,当两个对象之间可以互传消息时,意味着两个对象之间存在需要长期保管的静态关系,或者是暂时性的动态关系。例如,在图4-1 中,边界对象与实体对象之间可以通过动态的依赖关系交互,用完就丢,不需要将这个动态关系保存在数据库中。而房型和景观图片两者之间由于存在组合关系,所以它们可以通过静态关系交互。
UML基础与Rose建模实用教程课后习题及答案
UML基础与Rose建模实用教程课后习题及答案 第1章面向对象概述 1. 填空题 (1)软件对象可以这样定义:所谓软件对象,是一种将状态和行为有机结合起来形成的软件构造模型,它可以用来描述现实世界中的一个对象。 (2)类是具有相同属性和操作的一组对象的组合,即抽象模型中的“类”描述了一组相似对象的共同特征,为属于该类的全部对象提供了统一的抽象描述。 (3)面向对象程序的基本特征是抽象、封装、继承和多态。 2. 选择题 (1)可以认为对象是ABC。 (A)某种可被人感知的事物 (B)思维、感觉或动作所能作用的物质 (C)思维、感觉或动作所能作用的精神体 (D)不能被思维、感觉或动作作用的精神体 (2)类的定义要包含以下的要素ABD。 (A)类的属性(B)类所要执行的操作 (C)类的编号(D)属性的类型 (3)面向对象程序的基本特征不包括B。 (A)封装(B)多样性 (C)抽象(D)继承 (4)下列关于类与对象的关系的说法不正确的是A。 (A)有些对象是不能被抽象成类的 (B)类给出了属于该类的全部对象的抽象定义 (C)类是对象集合的再抽象 (D)类用来在内存中开辟一个数据区,并存储新对象的属性 3. 简答题 (1)什么是对象?试着列举三个现实中的例子。 对象是某种可被人感知的事物,也可是思维、感觉或动作所能作用的物质或精神体,例如桌子.椅子.汽车等。 (2)什么是抽象? 抽象是对现实世界信息的简化。能够通过抽象将需要的事物进行简化、将事物特征进行概括、将抽象模型组织为层次结构、使软件重用得以保证。 (3)什么是封装?它有哪些好处? 封装就是把对象的状态和行为绑在一起的机制,使对象形成一个独立的整体,并且尽可能地隐藏对象的内部细节。封装有两个含义;一是把对象的全部状态和行为结合在一起,形成一个不可分割的整体。对象的私有属性只能够由对象的行为来修改和读取。二是尽可能隐蔽对象的内部细节,与外界的联系只能够通过外部接口来实现。通过公共访问控制器来限制对象的私有属性,使用封装具有以下好处:避免对封装数据的未授权访问、帮助保护数据的完整性、当类的私有方法必须修改时,限制了在整个应用程序内的影响。 (4)什么是继承?它有哪些好处? 继承是指特出类的对象拥有其一般类的属性和行为。继承意味着“自动地拥有”,即在特殊类中不必重新对已经在一般类中定义过的属性和行为进行定义,而是特殊类自动地、隐含地拥有其一般类的属性和行为。通过继承可使派生类能够比不使用继承直接进行描述的类更加简洁、能够重用和扩展现有类库资源、使软件易于维护和修改。 (5)面向对象分析的过程有哪些? 面向对象的分析的过程包括:获取需求内容陈述、建立系统的对象模型结构、建立对象的动态
二分图最大匹配算法的应用及Matlab实现+++
一共有RecuCal.m LockMap.m BuildMatrix.m Edmonds.m GUI1.m 这几个文件,我把它们合到一块粘上去了,你再把他们分开保存就可以了. 其中前三个文件都是为建立邻接矩阵服务的,Edmonds.m是匈牙利算法的主文件,GUI1.m只是调用Edmonds.m做个界面而已。 调用关系是GUI1.m调用Edmonds.m;Edmonds.m调用BuildMatrix.m和LockMap.m ;LockMap.m调用RecuCal.m 最后运行GUI1.m就ok了 #LockMap.m function [LMA, LMB] = LockMap(n, m) % LOCKMAP - 求解满足条件锁并设置相应的映射 % 输入参数:n 表槽数,m 表高度数。 % 输出参数:LMA,LMB 分别为二维矩阵表示自然数到满足条件锁之间的映射。 global jiA ouB ary A B mm N N = n; mm = m; jiA=0; ouB=0; A=[]; B=[]; ary = zeros(1, n); RecuCal(n); LMA=A; LMB=B; [lena, n] = size(LMA); [lenb, n] =size(LMB); if lena>lenb temp = LMA; LMA=LMB;LMB=temp; temp = lena;lena=lenb;lenb=temp; end #RecuCal.m function RecuCal(n) % RECUCAL - 递归函数 global jiA ouB ary A B mm N if n ==1 for k=1:mm % 调用递归函数时要用到的变量所以 % 设为全局 ary(1) = k; Max = max(ary); Min = min(ary); num = 0; neighbor = 0; for i=1:N num = num + (Max-ary(i))*(ary(i)-Min);
UML从需求到实现(三)----类图
UML从需求到实现(三)----类图 作者: 李守宏发布时间: 2011-04-02 09:51 按照UML中图的出现顺序.当做完包图以后.我们下一步要做的当然是类图,类图也是UML中的三大核心图之一. 看到很多文章在描述类图的时候.总是大部分在叙述类之间的关系:关联,依赖,继承,组合,聚合呀这些.很少有人说明类是怎么来的.没有了类,你拿什么来画类图.那些关系其实没有多大意义.就像是象棋的马走日,象飞 天一样.只是一个规定.你知道了这些就是一个象棋高手吗? 类图是UML中的一种静态图.他是体现面向对象编程的基础.类图就像是软件设计的细胞.是基本元素.没有了类图.也就没有了接下来的设计.但是类不可能是凭空产生的.类是我们凭借自己的经验和智慧去抽象,提取出来的. 所以说,对于一个良好的系统.如何去提取出类来.才是最关键的.下面我介绍一下面向对象开发过程中.利用三层架构的方式.分析典型MIS系统的类图从提出类.到类图的生成的过程. 一:根据用例确定数据库,确定表,创建实体类 第一个也是最关键的一个.我们要做的第一步就是要根据用户对数据的要求,去确定数据库中的表.去设计数据库(如何去设计数据库中的表,这里不在叙述). 因为我们在信息管理系统中.所有的操作可以说都是对数据的操作.你首先要确定的是数据.确定了数据,你才知道怎么操作(这个仅仅是我的个人体会).就像是你要谈恋爱.你首先要确定你要追求的目标.才能制定追
求的方法.如果你连个目标也没有.整天和别人说你要谈恋爱.别人会怎么想你? 然后根据设计好的数据库,一一对应的方式设计成实体类.实体类可以说就是数据库的映射.把数据库的每一个表影射成一个类,每一个字段设计成一个属性.这样保证你的操作是面向对象的.对于一条记录,你可以整体去操作它.如下图: PS:这里我要补充一点.很多人不理解实体类是干什么的.不知道该把它放在三层架构的那一层.其实实体类不属于三层的任何一层.其实它就是一个自定义的变量.你这么理解他就行了. 就像是你的string,int型变量一样.你用它来存放数据就对了.不同地方就是它可以放多个不同类型的变量而已.
Ku二分图最大权匹配(KM算法)hn
Kuhn-Munkres 算法
Maigo 的 KM 算法讲解(的确精彩)
KM 算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转 化为求完备匹配的问题的。设顶点 Xi 的顶标为 A[i],
顶点 Yi 的顶标为 B[i],顶点 Xi 与 Yj 之间的边权为 w[i,j]。在算法执行过程中 的任一时刻,对于任一条边(i,j), A[i]+B[j]>=w[i,j]始终成立。KM 算法的正确 性基于以下定理: * 若由二分图中所有满足 A[i]+B[j]=w[i,j]的边(i,j)构成的子图 (称做相等子 图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。 这个定理是显然的。因为对于二分图的任意一个匹配,如果它包含于相 等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相 等子图,那么它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配 一定是二分图的最大权匹配。 初始时为了使 A[i]+B[j]>=w[i,j]恒成立,令 A[i]为所有与顶点 Xi 关联的边 的最大权,B[j]=0。如果当前的相等子图没有完备匹配,就按下面的方法修改 顶标以使扩大相等子图,直到相等子图具有完备匹配为止。 我们求当前相等子图的完备匹配失败了,是因为对于某个 X 顶点,我们 找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点 全部是 X 顶点。现在我们把交错树中 X 顶点的顶标全都减小某个值 d,Y 顶 点的顶标全都增加同一个值 d,那么我们会发现:
两端都在交错树中的边(i,j),A[i]+B[j]的值没有变化。也就是说,它原来属于 相等子图,现在仍属于相等子图。 两端都不在交错树中的边(i,j),A[i]和 B[j]都没有变化。也就是说,它原来属于 (或不属于)相等子图,现在仍属于(或不属于)相等子图。 X 端不在交错树中,Y 端在交错树中的边(i,j),它的 A[i]+B[j]的值有所增大。 它原来不属于相等子图,现在仍不属于相等子图。 X 端在交错树中,Y 端不在交错树中的边(i,j),它的 A[i]+B[j]的值有所减小。 也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子 图得到了扩大。 现在的问题就是求 d 值了。为了使 A[i]+B[j]>=w[i,j]始终成立,且至少有 一条边进入相等子图,d 应该等于 min{A[i]+B[j]-w[i,j]|Xi 在交错树中,Yi 不在 交错树中}。 以上就是 KM 算法的基本思路。但是朴素的实现方法,时间复杂度为 O(n4)——需要找 O(n)次增广路,每次增广最多需要修改 O(n)次顶标,每次 修改顶标时由于要枚举边来求 d 值,复杂度为 O(n2)。实际上 KM 算法的复 杂度是可以做到 O(n3)的。我们给每个 Y 顶点一个“松弛量”函数 slack,每次 开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(i,j)时,如 果它不在相等子图中, 则让 slack[j]变成原值与 A[i]+B[j]-w[i,j]的较小值。 这样, 在修改顶标时,取所有不在交错树中的 Y 顶点的 slack 值中的最小值作为 d 值即可。但还要注意一点:修改顶标后,要把所有的 slack 值都减去 d。
ER图,对象联系图和类图的特征与比较
ER 图、对象联系图和类图的特征与比较 第一部分:简述 ER 图,对象联系图和类图的基本概念和特点 ER 图: ER 图是用来表示实体联系模型( Entity Relationship Model )的方式,这个模型可以直 接从现实世界中抽象出实体类型和实体间的联系。举个例子来说。 ER 图的约定表示方法。 矩形框,表示实体类型(即考虑问题的对象) 菱形框,表示联系类型(即实体间的联系) 椭圆形框,表示实体类型和联系类型的属性(对于键的属性,在属性下面划一 条横线) 直线,联系类型与其涉及的实体类型之间用直线相连,用来表示他们之间的联 系,在直线 端部标注联系的种类(1:1,1:N,M:N ) 再通过一个例子来说明用 ER 图表示现实世界的特点: 1)考虑零件和工程的关系,零件可以服务于不同的工程,一个工程也需要各种不 同的零 件,因此,建模的时候零件和工程是一个多对多的联系。 a) b) c) d) J#、项目名称JNAME 、项目开工日期 DATE ;而part 的属性有零件号 P#、 零件名PNAME 、零件颜色 COLOR 以及零件重量 WEIGHT 。联系类型 从上面的可以看出,ER 图作为对现实世界的抽象,可以很方便的表示出现实 中实体以及实体间的联系, 不同形状的框代表不同的概念, 让读者一目了然哪些是 实体,哪些是联系,哪些是属性。实体间的数量对应关系也通过连线两端的数字记 号体现出来了。可以说, ER 图是一种简洁的模拟现实世界的符号方法。 对象联系图: 使用类型构造图的思想, 可以把ER 图扩充成为对象联系图。 对象联系图可以完整地揭 示数据间的联系。 对象联系图有一下几个基本成分: F 面对上述例子做一个说明,同时给出 (1) (2) (3) (4) 首先确定实体类型,这个例子 中, 再确定联系类型,正如前面所述, 把实体类型和联系类型组合成 确定实体类型和联系类型的 实体只有两个,就是工程和零件 工程和零件的关系是 M:N 的关系 ER 图(见图1) 在这个例子中,Project 的属性有项目号
二分图及二分图匹配
9.1 二 分 图 9.1.1 二分图的基本概念 定义9.1 无向图G =
证 先证必要性。 设G为二分图