实验二-决策树实验-实验报告

决策树实验
一、实验原理
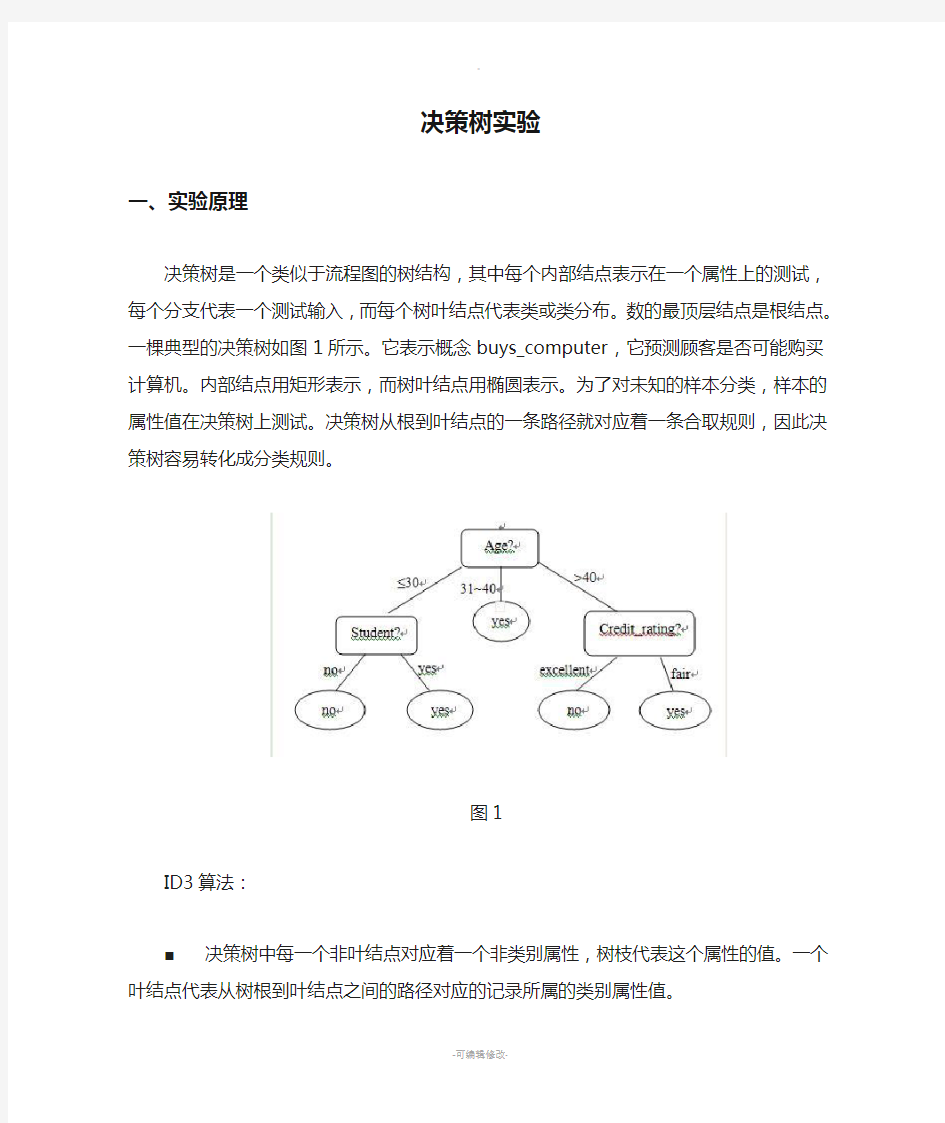
决策树是一个类似于流程图的树结构,其中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输入,而每个树叶结点代表类或类分布。数的最顶层结点是根结点。一棵典型的决策树如图1所示。它表示概念buys_computer,它预测顾客是否可能购买计算机。内部结点用矩形表示,而树叶结点用椭圆表示。为了对未知的样本分类,样本的属性值在决策树上测试。决策树从根到叶结点的一条路径就对应着一条合取规则,因此决策树容易转化成分类规则。
图1
ID3算法:
■决策树中每一个非叶结点对应着一个非类别属性,树枝代表这个属性的值。一个叶结点代表从树根到叶结点之间的路径对应的记录所属的类别属性值。
■每一个非叶结点都将与属性中具有最大信息量的非类别属性相关联。
■采用信息增益来选择能够最好地将样本分类的属性。
信息增益基于信息论中熵的概念。ID3总是选择具有最高信息增益(或最大熵压缩)的属性作为当前结点的测试属性。该属性使得对结果划分中的样本分类所需的信息量最小,并反映划分的最小随机性或“不纯性”。
二、算法伪代码
算法Decision_Tree(data,AttributeName)
输入由离散值属性描述的训练样本集data;
候选属性集合AttributeName。
输出一棵决策树。
(1)创建节点N;
(2)If samples 都在同一类C中then
(3)返回N作为叶节点,以类C标记;
(4)If attribute_list为空then
(5)返回N作为叶节点,以samples 中最普遍的类标记;//多数表决
(6)选择attribute_list 中具有最高信息增益的属性test_attribute;
(7)以test_attribute 标记节点N;
(8)For each test_attribute 的已知值v //划分samples
(9)由节点N分出一个对应test_attribute=v的分支;
(10令S v为samples中test_attribute=v 的样本集合;//一个划分块
(11)If S v为空then
(12)加上一个叶节点,以samples中最普遍的类标记;
(13)Else 加入一个由Decision_Tree(Sv,attribute_list-test_attribute)返回节点值。
三、实验数据预处理
Age:30岁以下标记为“1”;30岁以上50岁以下标记为“2”;50岁以上标记为“3”。Sex:FEMAL----“1”;MALE----“2”
Region:INNER CITY----“1”;TOWN----“2”;RURAL----“3”;SUBURBAN----“4”
Income:5000~2万----“1”;2万~4万----“2”;4万以上----“3”
Married
Children
Car
Mortgage
Pep:以上五个条件,若为“是”标记为“1”,若为“否”标记为“2”。
Age sex region income married children car mortgage pep
1 2 1 1 2 1 1 2 2
1 2 1 1 2 2 2 2 1
2 1 4 1 2 1 2 2 1
2 1 1 1 1 2 2 2 2
1 2 1 1 1 2 2 2 2
1 2 1 1 2 1 2 1 1
2 1 2 1 1 2 1 1 2
2 1 1 1 2 1 1 2 1 2 1
3 1 2 2 1 2 1 2 1 2 2 2 1 2 2 2 2 2 1 2 2 2 2 1 1 2 1 2 2 1 1 2 1 1 2 2 1 2 1 2 2 1 2 1 1 1 2 1 2 2 2 1 3 2 1 2 1 1 1 2 2 1 1 1 2 1 1 1 2 1 1 1 3 2 2 2 1 2 1 3 1 2 2 1 2 2 2 1 3 2 3 3 1 1 1 2 1 3 2 2 3 1 2 1 1 2 3 1 3 3 1 1 2 2 1 3 2 1 3 1 2 1 2 2 3 2 1 3 1 1 1 1 1 3 1 1 3 1 2 1 1 2 3 1 3 3 1 2 2 2 2 3 2
4 3 1 2 2 1 1 3 1 3 3 2 2 1 1 2
四、实验主函数
function main
clc;
DataSet=[1 2 1 1 2 1 1 2 2
1 2 1 1 2 2 2 2 1
2 1 4 1 2 1 2 2 1
2 1 1 1 1 2 2 2 2
1 2 1 1 1 2 2 2 2
1 2 1 1 2 1 2 1 1
2 1 2 1 1 2 1 1 2
2 1 1 1 2 1 1 2 1
2 1
3 1 2 2 1 2 1
2 1 2 2 2 1 2 2 2
2 2 1 2 2 2 2 1 1
2 1 2 2 1 1 2 1 1
2 2 1 2 1 2 2 1 2
1 1 1
2 1 2 2 2 1
3 2 1 2 1 1 1 2 2
1 1 1
2 1 1 1 2 1
1 1 3
2 2 2 1 2 1
3 1 2 2 1 2 2 2 1
3 2 3 3 1 1 1 2 1
3 2 2 3 1 2 1 1 2
3 1 3 3 1 1 2 2 1
3 2 1 3 1 2 1 2 2
3 2 1 3 1 1 1 1 1
3 1 1 3 1 2 1 1 2
3 1 3 3 1 2 2 2 2
3 2
4 3 1 2 2 1 1
3 1 3 3 2 2 1 1 2
];
AttributName=[11 12 13 14 15 16 17 18 19];
[Tree RulesMatrix]=DecisionTree(DataSet,AttributName) End
五、实验结果
The Decision Tree:
(The Root):Attribut
|_____1______Attribut
| |_____1______Attribut
| | |_____1______Attribut
| | | |_____1______leaf 1
| | | |_____2______leaf 2
| | |_____2______leaf 2
| | |_____3______Attribut
| | |_____1______Attribut
| | | |_____1______leaf 1 | | | |_____2______leaf 2 | | | |_____3______leaf 1 | | |_____2______leaf 2
| |_____2______Attribut
| |_____1______Attribut
| | |_____1______leaf 2
| | |_____2______leaf 1
| |_____2______leaf 1
|_____2______Attribut
| |_____1______leaf 2
| |_____2______Attribut
| | |_____1______leaf 1
| | |_____2______leaf 2
| |_____3______leaf 2
|_____3______Attribut
| |_____1______leaf 2
| |_____2______Attribut
| |_____1______leaf 1
| |_____2______Attribut
| |_____1______leaf 1
| |_____2______leaf 2
|_____4______leaf 1
Tree =
Attribut: 3
Child: [1x4 struct]
RulesMatrix =
1 1 1 0 1 0 0 0 1
1 2 1 0 1 0 0 0 2
2 0 1 0 1 0 0 0 2
3 0 1 1 1 1 0 0 1
3 0 1 2 1 1 0 0 2
3 0 1 3 1 1 0 0 1
3 0 1 0 1 2 0 0 2
1 0 1 0
2 0 1 0 2
2 0 1 0 2 0 1 0 1
0 0 1 0 2 0 2 0 1
0 0 2 1 0 0 0 0 2
0 0 2 2 1 0 0 0 1
0 0 2 2 2 0 0 0 2
0 0 2 3 0 0 0 0 2
0 0 3 0 0 0 0 1 2
0 0 3 0 0 0 1 2 1
0 0 3 0 0 1 2 2 1
0 0 3 0 0 2 2 2 2
0 0 4 0 0 0 0 0 1
六、实验小结:
通过本次试验,我学习了决策树分类方法,并了解了其他ID3等其它分类方法,应用Matlab软件,学会导入数据文件,并对数据文件进行预处理。
THANKS !!!
致力为企业和个人提供合同协议,策划案计划书,学习课件等等
打造全网一站式需求
欢迎您的下载,资料仅供参考
西北工业大学数据库实验报告
1.利用图形用户界面创建,备份,删除和还原数据库和数据表(50分,每小题5分) ●数据库和表的要求(第五版教材第二章习题 6 要求的数据库) 数据库名:SPJ,其中包含四张表:S表, P表, J表, SPJ表 ●完成以下具体操作: (1)创建SPJ数据库,初始大小为 10MB,最大为50MB,数据库自动增长,增长方 式是按5%比例增长;日志文件初始为2MB,最大可增长到5MB,按1MB增长。 数据库的逻辑文件名和物理文件名均采用默认值。 (2)在SPJ数据库中创建如图2.1-图2.4的四张表(只输入一部分数据示意即可)。 S表: P表: J表: SPJ表:
(3)备份数据库SPJ(第一种方法):备份成一个扩展名为bak的文件。(提示: 最好先删除系统默认的备份文件名,然后添加自己指定的备份文件名) (4)备份数据库SPJ(第二种方法):将SPJ数据库定义时使用的文件(扩展名为 mdf,ldf的数据文件、日志文件等)复制到其他文件夹进行备份。 原位置: 新的位置: (5)删除已经创建的工程项目表(J表)。 (6)删除SPJ数据库。(可以在系统默认的数据存储文件夹下查看此时SPJ数据 库对应的mdf,ldf文件是否存在) 删除过后文件不存在 (7)利用备份过的bak备份文件还原刚才删除的SPJ数据库。(还原数据库)
(8)利用备份过的mdf,ldf的备份文件还原刚才删除的SPJ数据库。(附加) (9)将SPJ数据库的文件大小修改为100MB。 (10)修改S表,增加一个联系电话的字段sPhoneNo,数据类型为字符串类 型。 2.利用SQL语言创建和删除数据库和数据表(50分,每小题5分) ●数据库和表的要求 数据库名:Student,其中包含三个表:S:学生基本信息表;C:课程基本信息表;SC:学生选课信息表。 ●完成以下具体操作: (1)用SQL语句创建如图2.5-图2.7要求的数据库Student,初始大小为20MB, 最大为100MB,数据库自动增长,增长方式是按10M兆字节增长;日志文件初
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/9510304757.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/9510304757.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
《农业信息学》实验报告
农业信息技术 实验报告
实验一 L-Studio的使用 一、实验目的及要求 (1)掌握植物拓扑结构的模拟方法 (2)掌握虚拟植物系统Lstudio的使用。 二、实验环境 CPU为酷睿2.4G、内存1G、硬盘为320G的高档微机,L-Studio系统三、实验内容 (1)熟悉L-studio软件的运行环境和使用方法。 (2)根据L-studio的迭代规则和语法实现课本上的实验。 (3)熟悉L-studio中对分支结构的描述。 四、实验步骤 (1)双击L-system\L-studio.bin\LStudio.exe文件,启动L-Studio系统; (2)在project菜单下,单击new菜单项,新建一个工程; (3)在L-System界面下编写程序代码; 完成书上136页的例1至例3; 自行编写一段程序; (4)代码书写完毕后,在cpfg菜单下,单击go菜单项,运行出程序结果,即虚拟植物的形态; (5)通过截图记录程序运行结果。 五、程序代码及实验结果
(1)例1程序代码和运行结果截图 代码:#define STEPS 4 Lsystem: 1 derivation length: STEPS Axiom: A A -->B[+B][-B]A homomorphism A -->, F; B-->,F; Endlsystem 运行结果: 图1(2)例2程序代码和运行结果截图 代码:
#define STEPS 4 Lsystem: 1 derivation length: STEPS Axiom: A A -->B[+A][-A]BA B -->BB homomorphism A -->,(127)F(1),(64)@O(0.8) B -->,(127)F(1) Endlsystem 运行结果: 图2(3)例3程序代码和运行结果截图代码: #define STEPS 4
数据库实验2实验报告 2
数据库第二次试验报告 PB10011020 刘思轶实验内容 本实验有两个可选题目,旅游出行和药品免疫库。本程序即为旅游出行的一个实现。 实验原题摘要如下 数据关系模式: 航班FLIGHTS( String flightNum, int price, int numSeats, int numAvail, String FromCity, StringArivCity); 宾馆房间HOTELS( String location, int price, int numRooms, int numAvail);出租车CARS( String location, int price, int numCars, int numAvail);客户CUSTOMERS( String custName); 预订情况RESERVATIONS( String resvKey, String custName, int resvType) 系统基本功能: 1.航班,出租车,宾馆房间和客户基础数据的入库,更新(表中的属性也可以根据你的需要添加)。 2.预定航班,出租车,宾馆房间。 3.查询航班,出租车,宾馆房间,客户和预订信息。 4.查询某个客户的旅行线路。 5.检查预定线路的完整性。 6.其他任意你愿意加上的功能。 程序功能 本系统由旅行服务提供商运营,发布在支持PHP + MySQL 的服务器上。 系统默认有三个角色,游客、用户和管理员。它们的权限如下 1、游客 查询当前航班、旅馆和出租车的预订情况; 2、注册用户 游客的所用权限; 查询当前预订; 预订航班、旅馆和出租车; 退订航班、旅馆和出租车。 打印旅行路线 检查预定路线的完整性。 检查航班的完备性 3、管理员 注册用户的所用权限
数据库实验报告2
理工大学信息工程与自动化学院学生实验报告 (2011 —2012 学年第 1 学期) 课程名称:数据库系统教程开课实验室:信自楼445 2011 年11月 27日 一、上机目的及容 1.上机容: SQL的数据查询,查询、插入、删除、修改 2.上机目的: 掌握数据查询语句,并能熟练应用 二、实验原理及基本技术路线图(方框原理图或程序流程图) 在SQL server 2008软件中的查询中,输入SQL代码 三、所用仪器、材料(设备名称、型号、规格等或使用软件) 1台PC及SQL server 2008软件 四、实验方法、步骤(或:程序代码或操作过程) 1)select查询 单表查询:查询全体学生的学号及: SELECT SNO,SNAME FROM S;
查询全体学生的全部信息: SELECT*FROM S; 2)查询经过计算值 (SELECT子句的<目标列表达式>为表达式,表达式可以是:算术表达式、字符串常量、函数、列别名等) 查全体学生的学号、及其出生年份: SELECT SNO,SNAME,2012-AGE FROM S;
查询全体学生的、出生年份和所属系: SELECT SNO,SNAME,2012-AGE,SDEPT FROM S; 查询选修了课程的学生学号: SELECT SNO FROM SC,C WHERE https://www.360docs.net/doc/9510304757.html,O=https://www.360docs.net/doc/9510304757.html,O; 为了避免这种不合题意的情况,我们用distinct用了去除重复的元组。所以上例中的执行语句为: SELECT DISTINCT SNO FROM SC;
SELECT DISTINCT SNO FROM SC,C WHERE https://www.360docs.net/doc/9510304757.html,O=https://www.360docs.net/doc/9510304757.html,O; 查询选修课程的各种成绩: SELECT CNO,GRADE FROM SC; SELECT DISTINCT CNO,DISTINCT GRADE FROM SC; SELECT CNO,DISTINCT GRADE FROM SC; SELECT DISTINCT CNO,GRADE FROM SC;
实验报告:乳腺肿瘤数据集基于决策树算法的数据挖掘
基于决策树算法的医疗数据挖掘 一、实验目的 利用商业智能分析项目中的数据分析功能,对乳腺癌数据集breast-cancer基于决策树算法进行挖掘,产生相关规则,从而预测女性乳腺癌复发的高发人群。并通过本次实验掌握决策树算法关联规则挖掘的知识及软件操作,以及提高数据分析能力。 二、实验步骤 1、在SQL server 2005中建立breast-cancer数据库,导入breast-cancer数据集; 2、对该数据集进行数据预处理,包括列名的中文翻译、以及node-caps缺失值的填充,即将‘null’填充成‘?’; 3、新建数据分析服务项目,导入数据源、新建数据源视图、新建挖掘结构,其中,将breast-cancer表中的‘序号’作为标识,‘是否复发’作为分类; 4、部署; 5、查看决策树、依赖关系网络等,并根据结果进行分析、预测。 三、实验结果分析 1、如以下三张图片所示,通过调整依赖网络图的依赖强度,可得出,在众多因素中,‘受侵淋巴结数’、‘肿瘤大小’、‘恶心肿瘤程度’这三个因素对于是否复发的影响是较大的,并且影响强度依次递减。
2、从‘全部’节点的挖掘图例可以看到,在breast-cancer数据集中,复发占了29.91%,不复发占了68.32%,说明乳腺肿瘤的复发还是占了相当一部分比例的,因此此挖掘是具备前提意义的。 3、由下两张图可知,‘受侵淋巴数’这一因素对于是否复发是决定程度是最高的。在‘受侵淋巴结数不等于0-2’(即大于0-2)节点中,复发占了50.19%的比例,不复发占了44.44%的比例,而在‘受侵淋巴结数=0-2’的节点中,复发只占了21.71%的比例,不复发占了77.98%的比例。由此可见,当受侵淋巴节点数大于‘0-2’时,复发的几率比较高。
农业信息实验报告
天津农学院 计算机与信息工程学院 《农业信息技术概论》 课程实验报告 题目:基于javaweb的农业信息网站系统 项目名称 . 食用菌农业专家系统 专业班级 11软件4班 指导教师张京京 成绩评定 学期2013-2014第二学期 2014年5月
1.目的 随着农业的不断发展和改进,农业信息技术也不断发展起来,慢慢走进我们的生活,设计一个“食用菌农业专家系统系统”,一方面介绍食用菌的种类,培养技巧和其他的信息,另一方面也为食用菌的发展提供一个可追溯的平台。 2.背景 随着农业迅速发展和农业技术信息的全面进步,随着农产品的大量面世,其管理难度也越来越大,如何优化的管理以及让大家更方便的查询各种农产品的信息就成了一个大众化的问题。本系统的开发就是为了更方便的管理以及让大家更方便的查询食用菌的各种信息。 项目名称:食用菌农业专家系统 项目开发者:马晓波,王竞争,司红蕊,韩昌军,谭鹏成, 钟捷雄 3.要求 (1)系统功能: ①系统首页 ②客户的注册与登录 ③食用菌培养技巧信息详情的查询 ④食用菌的分类管理 ⑤添加删除食用菌信息 (2)系统要求 系统开发人员,可以在自己的权限范围内,查看食用菌及系
统的详细信息及管理、个人信息的修改、系统的维护等。 (3)系统需求 本系统采用VB 与开源的SQL Sever2008数据库进行开发。 系统采用B/S 结构。 4. 模块功能 5数据库设计 5.1 开发背景 根据网站需要,建立了七个表,分别为:Admin 表,bingyi 表,huanggua 表,liuyan 表,xinpin 表,xinwen2表,zhuce 表 5.2流程分析 开始 用户浏览 有无账户 登录 注册 继续浏览并 留言 结束 Y 开始 管理员登 录 增加,修改,删除食用菌信 息 查看用户信息 查看留言 结束 N 添加食用菌新闻
数据库实验报告
课程设计报告题目:数据库实验上机实验报告 专业班级:计算机科学与技术1210班 学号: U9 姓名:候宝峰 指导教师: 报告日期: 2015-06-04 计算机科学与技术学院
目录 一、基本SQL操作(部分选做)............. 错误!未定义书签。 1)数据定义........................... 错误!未定义书签。 2)数据更新........................... 错误!未定义书签。 3)用SQL语句完成下述查询需求:....... 错误!未定义书签。 二、DBMS综合运用(部分选做)............. 错误!未定义书签。 1)学习sqlserver的两种完全备份方式:数据和日志文件的脱机备份、系统的备份功能(选做)。......... 错误!未定义书签。 2)学习系统的身份、权限配置操作....... 错误!未定义书签。 3)了解SQLSERVER的存储过程、触发器、函数实现过程错误!未定义书签。 三、实验总结............................. 错误!未定义书签。 1)实验问题及解决..................... 错误!未定义书签。 2)实验心得........................... 错误!未定义书签。
一、基本SQL操作(部分选做) 1)数据定义 参照下面的内容建立自己实验所需的关系数据 创建三个关系: 商品表【商品名称、商品类型】 GOODS【GNAME char(20),GTYPE char(10)】 主关键字为(商品名称)。商品类型为(电器、文具、服装。。。) 商场【商场名称,所在地区】 PLAZA【PNAME char(20),PAREA char(20)】 主关键字为商场名称。所在地区为(洪山、汉口、汉阳、武昌。。。) 销售价格表【商品名称、商场名称、当前销售价格、目前举办活动类型】 SALE【GNAME char(20),PNAME char(20),PRICE FLOAT,ATYPE char(10)】主关键字为(商品名称、商场名称)。举办活动类型为(送券、打折),也可为空值,表示当前未举办任何活动。表中记录如(‘哈森皮靴’,‘亚贸广场’,200,‘打折’),同一商场针对不同的商品可能采取不同的促销活动。 create table goods(gname char(20) primary key,gtype char(10)); create table plaza(pname char(20) primary key,parea char(20)); create table sale (gname char(20), pname char(20), price FLOAT, atype char(10)check (atype in('送券','打折','')), primary key(gname,pname), foreign key(gname)references goods(gname), foreign key(pname)references plaza(pname)); 图1 goods表 图2 plaza表 图3 sale表 2)数据更新 (1)向上述表格中用sql语句完成增、删、个、改的操作;
数据库原理实验报告二.pdf
LIAOCHENG UNIVERSITY 计算机学院实验报告 【2015 ~2016 学年第 2 学期】 【一、基本信息】 【实验课程】数据库原理与应用 【设课形式】独立□非独立【课程学分】 【实验项目】实验二、SQL数据操作及查询 【项目类型】基础综合□设计□研究创新□其它[ ]【项目学时】4【学生姓名】傅雪晨【学号】59 【系别专业】电子商务 【实验班组】 【同组学生】 【实验室名】综合实验楼 【实验日期】【报告日期】 【二、实验教师对报告的最终评价及处理意见】 实验成绩:(涂改无效) 指导教师签名:年月日注:要将实验项目、实验课程的成绩评定及课程考核办法明确告知学生,并报实验管理中心备案
【三、实验预习】 实验条件(实验设备、软件、材料等): 实验2 SQL数据操作及查询 实验目的: 1. 向实验1建立的表中添加数据(元组), 掌握INSERT语句的用法; 2. 修改基本表中的数据, 掌握UPDATE语句的用法; 3. 删除基本表中的数据,掌握DELETE语句的用法; 4. 体会数据完整性约束的作用, 加深对数据完整性及其约束的理解。 5. 熟练掌握SELECT语句,能够运用该语句完成各种查询。 实验内容: 1.使用INSERT语句将教材P82表中的数据添加到数据库STUDENTDB中. 2. Insert into student59 select'1','李勇','男','20','CS','',''union select'2','刘晨','女','19','CS','',''union select'3','王敏','女','18','MA','',''union select'5','张立','男','19','IS','','' select*from student59 select*from course59 select*from sc59 alter table course59NOCHECK Constraint fk_cpno Insert into course59 select'1','数据库','5','4'union select'2','数学','','2'union select'3','信息系统','1','4'union select'4','操作系统','6','3'union select'5','数据结构','7','4'union select'6','数据处理','','2'union select'7','PASCAL语言','6','4' alter table course59CHECK Constraint FK_course59_course59 Insert into sc59 select'1','1',92 union select'1','2',85 union select'1','3',88 union select'2','2',90 union select'2','3',80 alter table sc59CHECK Constraint fk_S_c alter table sc59NOCHECKConstraint fk_S_c
实验三决策树算法实验实验报告
实验三决策树算法实验 一、实验目的:熟悉和掌握决策树的分类原理、实质和过程;掌握典型的学习算法和实现技术。 二、实验原理: 决策树学习和分类. 三、实验条件: 四、实验内容: 1 根据现实生活中的原型自己创建一个简单的决策树。 2 要求用这个决策树能解决实际分类决策问题。 五、实验步骤: 1、验证性实验: (1)算法伪代码 算法Decision_Tree(data,AttributeName) 输入由离散值属性描述的训练样本集data; 候选属性集合AttributeName。 输出一棵决策树。(1)创建节点N; 资料.
(2)If samples 都在同一类C中then (3)返回N作为叶节点,以类C标记;(4)If attribute_list为空then (5)返回N作为叶节点,以samples 中最普遍的类标记;//多数表决(6)选择attribute_list 中具有最高信息增益的属性test_attribute; (7)以test_attribute 标记节点N; (8)For each test_attribute 的已知值v //划分samples ; (9)由节点N分出一个对应test_attribute=v的分支; (10令Sv为samples中test_attribute=v 的样本集合;//一个划分块(11)If Sv为空then (12)加上一个叶节点,以samples中最普遍的类标记; (13)Else 加入一个由Decision_Tree(Sv,attribute_list-test_attribute)返回节点值。 (2)实验数据预处理 Age:30岁以下标记为“1”;30岁以上50岁以下标记为“2”;50岁以上标记为“3”。 Sex:FEMAL----“1”;MALE----“2” Region:INNER CITY----“1”;TOWN----“2”; RURAL----“3”; SUBURBAN----“4” Income:5000~2万----“1”;2万~4万----“2”;4万以上----“3” Married Children Car Mortgage 资料.
《作物营养与施肥》教学大纲
《作物营养与施肥》教学大纲 第一部分大纲说明 课程编号: 开课学期:5 本课程课内总学时数:36 本课程实验课时数:9 学分:2 一、课程的性质与任务 《作物营养与施肥》课程是根据石河子大学农学专业本科培养目标和课程设置的规定为农学类各专业开设的一门重要专业基础课。通过本课程的学习,使学生获得作物营养与作物营养诊断的基本知识,掌握基本理论与操作技能,对学生从事农业教学、科研、推广奠定知识基础。 二、教学对象 本教学大纲适用于农业资源与环境、农学专业本科学生。 三、课程教学基本要求 要求学生掌握施肥的基本原理、基本理论与基本技术,掌握养分平衡法、肥料效应函数法施肥理论和技术,施肥技术、轮作施肥技术、保护地施肥技术、计算机施肥专家系统的基本理论和应用、农化服务与施肥、大田作物营养与施肥、蔬菜营养与施肥、果树营养与施肥、保护地栽培作物营养与施肥等知识。 四、课程教学要求的层次 课程按“了解”、“掌握”、“重点掌握”三个层次对学生的学习进行要求。 考核难度及题量的梯度对应于教学要求的三个层次。 未作具体教学要求的内容不作考核要求。 第二部分学时分配与教学要求 一、学时分配
课内总学时30,实验学时6,2学分。 序号内容课内学时 1 绪论1 2 施肥的基本原理3 3 施肥的基本原则1 4 养分平衡法2 5 肥料效应函数法4 6 作物营养诊断5 7 常规施肥技术2 8 轮作施肥技术2 9 保护地施肥技术2 10 计算机施肥专家系统的建立与应用4 11 农化服务与施肥1 12 大田作物营养与施肥1 13 蔬菜作物营养与施肥1 14 果树营养与施肥1 合计36 二、教材 1、主教材为《作物施肥原理与技术》。谭金芳主编,张自立、邱慧珍副主编,中国农业大学出版社,实验教材是《土壤农化实验指导书》,土壤农化教研室编写,石河子大学教材科编印 辅助教材《作物营养与施肥》,浙江大学主编,农业出版社。 第三部分教学内容与教学要求 第一章绪论 教学内容: 一、施肥的作用、施肥科学的发展概况 二、施肥科学的体系、研究内容与研究方法 教学要求:
数据库实验报告2
数据库原理实验报告 姓名:学号:班级: 实验日期:03/30/2017 实验名称:数据库创建与管理 实验二数据库创建与管理 一、实验目的 1.熟练掌握界面方式创建和管理数据库。 2.熟练掌握查询编辑器T-SQL语句创建和管理数据库。 3.熟练掌握备份和还原数据库。 二、实验器材 1、接入Internet的计算机主机; 三、实验内容 1、界面方式创建和管理数据库 (1)创建数据库 (2)修改数据库
(3)删除数据库(使用右键) 2、利用企业管理器备份和还原数据库(1)备份数据库 (2)还原数据库(操作->右键)
(1)创建SPJ数据库:“新建查询”,输入以下语句并运行 CREATE DATABASE SPJ ON (NAME=’SPJ_Data’,FELENAME='C:\Program Files\Microsoft SQL Server\MSSQL\data\SPJ_Data.MDF' , SIZE = 3, MAXSIZE = 10, FILEGROWTH = 10%) LOG ON (NAME = 'SPJ_Log', FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL\data\SPJ_Log.LDF' ,
SIZE = 1, FILEGROWTH = 10%) (2)修改SPJ数据库:在查询分析器中输入以下语句并运行 ALTER DATABASE SPJ MODIFY FILE (NAME='SPJ_Data', SIZE=4, MAXSIZE=UNLIMITED) ALTER DATABASE SPJ ADD FILE (NAME='SPJ_Data_2', FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL\Data\SPJ_Date_2.ndf',SIZE=1, MAXSIZE=10, FILEGROWTH=10%) (3)删除SPJ数据库:DROP DA TABASE SPJ
(完整版)生物数据挖掘-决策树实验报告
实验四决策树 一、实验目的 1.了解典型决策树算法 2.熟悉决策树算法的思路与步骤 3.掌握运用Matlab对数据集做决策树分析的方法 二、实验内容 1.运用Matlab对数据集做决策树分析 三、实验步骤 1.写出对决策树算法的理解 决策树方法是数据挖掘的重要方法之一,它是利用树形结构的特性来对数据进行分类的一种方法。决策树学习从一组无规则、无次序的事例中推理出有用的分类规则,是一种实例为基础的归纳学习算法。决策树首先利用训练数据集合生成一个测试函数,根据不同的权值建立树的分支,即叶子结点,在每个叶子节点下又建立层次结点和分支,如此重利生成决策树,然后对决策树进行剪树处理,最后把决策树转换成规则。决策树的最大优点是直观,以树状图的形式表现预测结果,而且这个结果可以进行解释。决策树主要用于聚类和分类方面的应用。 决策树是一树状结构,它的每一个叶子节点对应着一个分类,非叶子节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。构造决策树的核心问题是在每一步如何选择适当的属性对样本进行拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下分而治之的过程。 2.启动Matlab,运用Matlab对数据集进行决策树分析,写出算法名称、数据集名称、关键代码,记录实验过程,实验结果,并分析实验结果 (1)算法名称: ID3算法 ID3算法是最经典的决策树分类算法。ID3算法基于信息熵来选择最佳的测试属性,它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少个不同的取值就将样本集划分为多少个子样本集,同时决策树上相应于该样本集的节点长出新的叶子节点。ID3算法根据信息论的理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不确定性越小。因此,ID3算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯的划分,从而得到较小的决策树。 ID3算法的具体流程如下: 1)对当前样本集合,计算所有属性的信息增益; 2)选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集; 3)若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。 (2)数据集名称:鸢尾花卉Iris数据集 选择了部分数据集来区分Iris Setosa(山鸢尾)及Iris Versicolour(杂色鸢尾)两个种类。
复习思考题
《农业推广学》复习思考题 第一章导论 一、名词解释题 1.农业推广 2.推广服务系统 3.目标团体系统 二、填空题 1.农业推广的框架模型中包含( )和( )两个子系统。 2.美国的合作农业推广法《史密斯—利弗法》最早是于( )年通过的。 三、简答题 1.当代世界农业推广模式主要有哪些类型? 2.现代农业推广的主要特征有哪些? 3.农业推广的社会功能有哪些? 4.根据农业推广的框架模型理论,怎样提高推广服务的工作效率? 5.农业推广学的相关学科主要有哪些? 第二章农业推广 一、名词解释题 1.人的行为 2.需要 3.动机 二、单项选择题 1.一个人对某个目标能够实现的可能性(概率)的估计,称为( )。 A. 动机 B. 目标价值 C.期望概率 D.激励力量 2.同一群体的成员由于经常相处、相互认识和了解,即使成员之间某时有不合意的语言或行为,彼此也能宽容待之,此种现象是( )。
A. 从众 B. 模仿 C感染 D.相容 三、简答题 1.人的行为主要有哪些特征? 2.需要层次论主要有哪些内容? 3.群体成员的行为规律主要表现在哪些方面? 4.简述改变农民行为的基本策略。 5.改变农民行为的方法主要有哪些? 第三章农业推广沟通 一、名词解释题 1.沟通 2.正式沟通 二、单项选择题 1.信息在传播过程中所受到的干扰可称之为。 A. 杂音 B.噪声 C.反馈 D.趋异 2.一个人把信息同时传递给若干人,若干人再反馈给这个传送信息的人,这种沟通形式可称之为。 A.链式沟通 B. 轮式沟通 C. 扩散型沟通 D.全通道型沟通 3.一个人把信息同时传递给若干人,再由这些人将信息分别传送给更多的人,使信息接收者越来越多,这种沟通形式可称之为。 A.单串型且车轮型 C. 扩散型 D.全通道型 4.在一定的组织体系中,通过明文规定的渠道所进行的沟通称为。 A.单向沟通 B.双向沟通 C. 正式沟通 D.非正式沟通 三、简答题 1.简述沟通的分类依据及其类型。 2.农业推广沟通由哪些要素组成? 3.简述农业推广沟通的特点。 4.简述单向沟通和双向沟通的含义与区别。
数据库实验报告二
《数据库原理》实验报告 实验三: 数据库完整性与安全性控 制 实验四: 视图与索引 学号姓名 班级日期 2013302534 杨添文10011303 2015.10.1 7 实验三:数据完整性与安全性控制 一、实验内容 1.利用图形用户界面对实验一中所创建的Student库的S表中,增加以下的约束和索引。 (18分,每小题3分) (1)非空约束:为出生日期添加非空约束。 (2)主键约束:将学号(sno)设置为主键,主键名为pk_sno。 (3)唯一约束:为姓名(sname)添加唯一约束(唯一键),约束名为uk_sname。 (4)缺省约束:为性别(ssex)添加默认值,其值为“男”。 (5)CHECK约束:为SC表的成绩(grade)添加CHECK约束,约束名为ck_grade,其检查 条件为:成绩应该在0-100之间。
(6)外键约束:为SC表添加外键约束,将sno,cno设置为外键,其引用表为分别是S 表和C表,外键名称分别为fk_sno,fk_cno。 2.在图形用户界面中删除上小题中已经创建的各种约束,用SQL语言分别重新创建第1小题中的(2)-(6)小题。(15分,每小题3分,提示:alter table add constraint)(2)alter table s add constraint pk_sno primary key(sno) (3)alter table s add constraint uk_sname unique(sname) (4)alter table s add constraint a default('男')for ssex (5) alter table sc add constraint ck_grade check(grade between 0 and 100) (6) alter table sc add constraint fk_sno foreign key(sno)references s(sno) alter table sc add constraint fk_cno foreign key(cno)references c(cno)
机器学习实验报告
决策树算法 一、决策树算法简介: 决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。决策树方法的基本思想是:利用训练集数据自动地构造决策树,然后根据这个决策树对任意实例进行判定。其中决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。 决策树算法构造决策树来发现数据中蕴涵的分类规则.如何构造精度高、规模小的决策树是决策树算法的核心内容。决策树构造可以分两步进行。第一步,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是根据实际需要有历史的、有一定综合程度的,用于数据分析处理的数据集。第二步,决策树的剪技:决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修下的过程,主要是用新的样本数扼集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除、决策树方法最早产生于上世纪60年代,到70年代末。由J Ross Quinlan 提出了ID3算法,此算法的目的在于减少树的深度。但是忽略了叶子数目的研究。C4.5算法在ID3算法的基础上进行了改进,对于预测变量的缺值处理、剪枝技术、派生规则等方面作了较大改进,既适合于分类问题,又适合于回归问题。 本节将就ID3算法展开分析和实现。 ID3算法: ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。 在ID3算法中,决策节点属性的选择运用了信息论中的熵概念作为启发式函数。
数据库原理实验报告(2)
南京晓庄学院 《数据库原理与应用》 课程实验报告 实验二数据库的创建、管理、备份及还原实验 所在院(系):数学与信息技术学院 班级:11软工转本2 学号: 1130708 11130710 姓名:马琦乔凌杰
1.实验目的 (1)掌握分别使用SQL Server Management Studio图形界面和Transact-SQL语句创建和修改 数据库的基本方法; (2)学习使用SQL Server查询分析窗口接收Transact-SQL语句和进行结果分析。 (3)了解SQL Server的数据库备份和恢复机制,掌握SQL Server中数据库备份与还原的方 法。 2.实验要求 (1)使用SQL Server Management Studio创建“教学管理”数据库。 (2)使用SQL Server Management Studio修改和删除“教学管理”数据库。 (3)使用Transact-SQL语句创建“教学管理”数据库。 (4)使用Transact-SQL语句修改和删除“教学管理”数据库。 (5)使用SQL Server Management Studio创建“备份设备”;使用SQL Server Management Studio对数据库“教学管理”进行备份和还原。 (6)SQL Server 2005数据库文件的分离与附加。 (7)按要求完成实验报告 3.实验步骤、结果和总结实验步骤/结果 (1) 总结使用SQL Server Management Studio创建、修改和册除“TM”(教学管理)数据库的过程。 新建数据库如下图所示: 进入sql server management studio 主界面,选择数据库右击新建数据库。 如何修改数据库 进入sql server management studio 主界面,选择数据库右击属性即可看到数据库信息,可更改数据库基本信息。
《农业推广学》期末考试复习题及参考答案
农业推广学复习题 (课程代码312029) 一、名词简释题 1.农业推广信息 2.项目可行性报告 3.多因素试验 4.创新 5.大众传播法 6.沟通 7.农业推广组织 8.项目验收 9.农业科技成果 10. 绿色证书 12.创新的采用 13.科技实验报告 14.现代农业推广 15.成果示范 16.方法示范 二、单项选择题 1.美国的合作农业推广《史密斯-利弗法》最早通过于【C 】。 A.1866年 B.1924年 C.1914年 D.1851年 2.狭隘的农业推广对“推广”理解为【B 】。 A.农村教育与咨询服务 B.农业技术推广 C.科技成果推广 D.农村家政推广 3.农业推广学的相关学科不包括【D 】。 A.心理学 B.传播学 C.社会学 D.物理学 4.同一群体成员由于经常相处、相互认识和了解,即使成员之间时有不合意的语言或行为,彼此也能宽容待之,此种现象是【D】 A.从众 B.模仿 C.感染 D.相容 5.“需要层次论”由美国心理学家马斯诺提出于【A】。 A.1943 B.1953 C.1843 D.1853 6.“大家干我就干”的行为规律属于【C】。 A.服从 B.相容 C.从众 D.感染与模仿
7.一个人对某个目标能够实现的可能性(概率)的估计,称为【C 】。 A.动机 B.目标价值 C.期望概率 D.激励力量 8.在一定的组织体系中,通过明文规定的渠道所进行的沟通称为【C 】。 A.单向沟通 B.双向沟通 C.正式沟通 D.非正式沟通 9.一个人把信息同时传递给若干人,再由这些人分别将信息传递给更多的人,使信息接收者越来越多,这种沟通形式可称为【C 】。 A.单串型 B.车轮型 C.扩散型 D.全通道型 10.一个人同时传递给若干人,若干人再反馈给这个传送信息的人,这种沟通形式可称为【B 】。 A.链式沟通 B.轮式沟通 C.扩散型沟通 D.全通道型沟通 11.在S—M—C—R沟通模式中,R代表的含义是【C 】。 A.传播者(信息源) B.媒介(传播渠道) C.接受者 D.信息 12.扩散曲线是横坐标为【B 】。 A扩散规模 B.时间 C.采用者的数量 D.百分比率 13.下列选项不属于创新的是【D 】。 A.新的技术 B.新的产品 C.新的设备 D.空想主义 14.创新早期采用者所占的百分率为【B 】。 A.2.5% B.13.5% C.34% D.16% 15.集体指导法的基本形式不包括【C 】。 A.小组讨论 B. 示范 C. 农户访问 D. 实地参观 16.个别指导法的特点不包括【A 】。 A.信息反馈及时 B. 针对性强 C. 沟通的双向性 D. 信息的发送量的有限性 17.用来申请科研课题立项、策划科研开展的文件称为【C】。 A.可行性报告 B. 调查报告 C.项目申请报告 D.科技实验报告 18.科技简报的写作格式,一般为【C 】。 A. 报头、正文、报尾、密级 B. 期号、报头、正文、报尾 C. 报头、正文、报尾 D. 报头、正文、报尾、签名 19.农业推广合同的写作格式一般为【A 】。 A.标题合同当事人合同正文结尾 B. 合同当事人标题合同正文结尾 C. 标题合同正文合同当事人结尾 D. 标题合同正文结尾合同当事人 20.以科学研究为目的和农业推广探索性试验一般采用【D 】。 A.大区对比试验 B. 多因素试验 C.综合性试验D小区试验 21.一次正规的试验一般要求的重复数【D 】
数据库实验报告实验二
湘潭大学 数据库实验报告 实验名称SQL操作 班级软件工程一班 指导老师郭云飞(老师)学生姓名汤能武 系(院)信息工程学院实验时间2011年12月
SQL操作 一、实验目的 1.了解和掌握MS SQL Server 工具的使用; 2.熟悉掌握SQL' 3.训练学生设计与编写过程,函数与触发器的能力; 二、实验环境 1. 硬件:数据库服务器,客户机,局域网; 2.软件:MS SQL Server 2008 ,建模软件; 三、实验内容 根据给定的问题建立数据库模型,在MS SQL Management Studio 中建立该数据库,并利用SQL语句建立表格与视图,录入数据,进行查询,插入,删除,修改等操作,编写过程,函数,触发器等; 给定问题如下: 1.一个学校有若干教学楼和若干班; 2.一个教室有若干教室和若干管理人员; 3.一间教室只有一个管理人员,但一个管理人员可以管理若干个教室; 4.每周7天,每周上午,下午,晚上都可以安排上课,每周的课表都不变; 5.一间教室或班在一段时间内只能安排一堂课,但可以是合班上课;
四、实验准备 1.理论知识预习及要求 ①使用SQL语句建立数据库; ②使用SQL语句进行查询,修改等操作; ③使用SQL语句建立过程,函数,触发器等; ④使用SQL创建数据表; 2.实验指导书预习及要求 上机前先预习数据库原理指导书的实验,理解和掌握SQL语言的常用操作。 五、实验原理或操作要点简介 注意服务器要先启动,才能与服务器建立连接。 使用SQL命令,完成预定功能。 六、实验步骤 1. 分析给定问题,设计E-R 模型;
2.根据E-R图设计出该问题的关系数据模型,分析数据模型并规范之;关系模型