人工智能课程习题与部分解答

《人工智能》
课程习题与部分解答
第1章 绪论
什么是人工智能 它的研究目标是什么
什么是图灵测试简述图灵测试的基本过程及其重要特征.
在人工智能的发展过程中,有哪些思想和思潮起了重要作用
在人工智能的发展过程中,有哪些思想和思潮起了重要作用
人工智能的主要研究和应用领域是什么其中,哪些是新的研究热点
第2章 知识表示方法
什么是知识分类情况如何
什么是知识表示不同的知识表示方法各有什么优缺点
人工智能对知识表示有什么要求
用谓词公式表示下列规则性知识:
自然数都是大于零的整数。
任何人都会死的。
[解] 定义谓词如下:
N(x): “x 是自然数”, I(x): “x 是整数”, L(x): “x 大于0”, D(x): “x 会死的”, M(x): “x 是人”,则上述知识可用谓词分别表示为:
)]()()()[(x I x L x N x ∨→?
)]()()[(x D x M x →?
用谓词公式表示下列事实性知识:
小明是计算机系的学生,但他不喜欢编程。
李晓新比他父亲长得高。
产生式系统由哪几个部分组成 它们各自的作用是什么
可以从哪些角度对产生式系统进行分类 阐述各类产生式系统的特点。 简述产生式系统的优缺点。
简述框架表示的基本构成,并给出框架的一般结构
框架表示法有什么特点
试构造一个描述你的卧室的框架系统。
试描述一个具体的大学教师的框架系统。
[解] 一个具体大学教师的框架系统为:
框架名:<教师-1>
类属:<大学教师>
姓名:张宇
性别:男
年龄:32
职业:<教师>
职称:副教授
部门:计算机系
研究方向:计算机软件与理论
工作:参加时间:2000年7月
工龄:当前年份-2000
工资:<工资单>
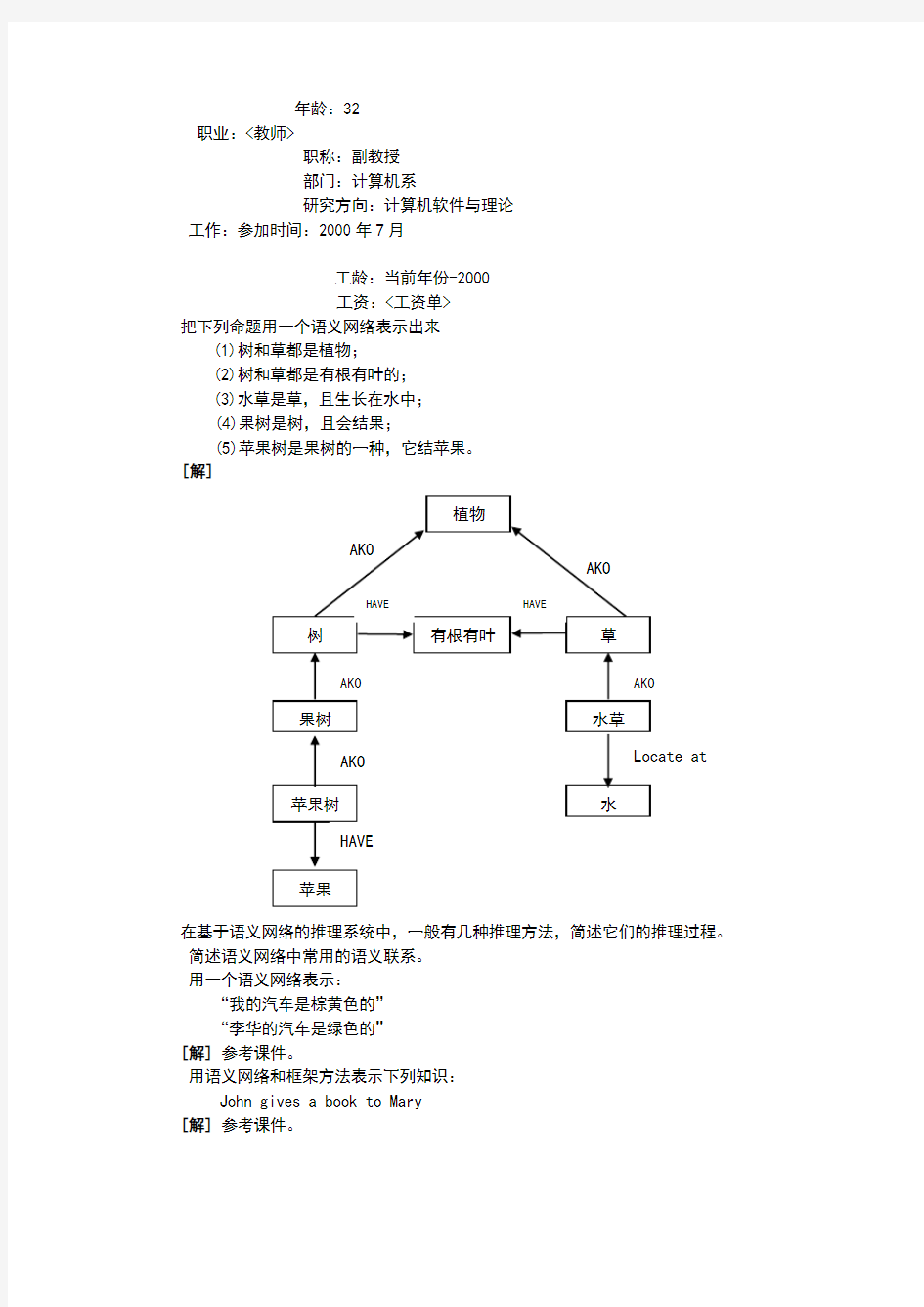
把下列命题用一个语义网络表示出来
(1)树和草都是植物;
(2)树和草都是有根有叶的;
(3)水草是草,且生长在水中;
(4)果树是树,且会结果;
(5)苹果树是果树的一种,它结苹果。
[解]
在基于语义网络的推理系统中,一般有几种推理方法,简述它们的推理过程。
简述语义网络中常用的语义联系。
用一个语义网络表示:
“我的汽车是棕黄色的”
“李华的汽车是绿色的”
[解]参考课件。
用语义网络和框架方法表示下列知识:
John gives a book to Mary
[解]参考课件。
第3章搜索推理技术
在人工智能中,搜索问题一般包括哪两个重要问题
简述搜索策略的评价标准。
比较盲目搜索中各种方法的优缺点。
试用宽度优先搜索策略,画出搜索树、找出最优搜索路线。
[解]
(1)搜索树参考课件。
(2)最优搜索路线:S0→S1→S5→S10.
对于八数码问题,设初始状态和目标状态如图所示:
S 1=
283
S
g
=
123 16484
75765
试给出深度优先(深度限制为5)和宽度优先状态图。
[解]
(1) 深度优先(深度限制为5)状态图为
(2)宽度优先状态图为
什么是启发式搜索其中什么是评估函数其主要作用是什么
最好优先的基本思想是什么有什么优缺点
对于八数码问题,设初始状态和目标状态如图所示。设d (x)表示节点x在搜索树中的深度,评估函数为f (x)=d (x)+w(x),其中w(x)为启发式函数。试按下列要求给出八数码问题的搜索图,并说明满是一种A*算法,找出对应的最优搜索路径。
(1)w (x)=h(x)表示节点x中不在目标状态中相应位置的数码个数;
(2)w (x)=p(x)表示节点x的每一数码与其目标位置之间的距离总和。
(3)w (x)=0,情况又如何
[解] (1) 8数码的搜索过程如图所示:
在上面确定h(x)时,尽管并不知道h*(x)具体为多少,但当采用单位代价时,通过对不在目标状态中相应位置的数码个数的估计,可以得出至少需要移动h(x)步才能够到达目标,显然h(x)≤h*(x)。因此它满足A*算法的要求。
最优搜索路径: 如图粗线所示。
(2) 此时8数码搜索图可表示为:
这时,显然有h(x)≤p(x)≤h*(n),相应的搜索过程也是A*算法。然而,p(x)比h(n)有更强的启发式信息,由w(x)=p(x)构造的启发式搜索树,比w(x)=h(x)构造的启发式搜索树节点数要少。
(3)若w(x)=0,该问题就变为宽度优先搜索问题。
如图所示,是5个城市之间的交通路线图,A城市是出发地,E城市是目的地,两城市之间的交通费用(代价)如图中的数字,求从A到E的最小费用交通路线。
图 旅行交通图
本题是考察代价树搜索的基本概念,了解这种搜索方法与深度优先和宽度优先的不同。首先将旅行交通图转换为代价树如图所示。
图 交通图的代价树
(1) 如果一个节点已经成为某各节点的前驱节点,则它就不能再作为该节点的后继节点。例如节点B 相邻的节点有A 和D ,但由于在代价树中,A 已经作为B 的前驱节点出现,则它就不再作为B 的后继节点。
(2) 除了初始节点A 外,其它节点都有可能在代价树中多次出现,为了区分它们的多次出现,分别用下标1、2、3…标出,但它们都是图中同一节点。例如C1和C2都代表图中节点C 。
对上面所示的代价树做宽度优先搜索,可得到最优解为:
A→C1→D1→E2
代价为8。由此可见,从A 城市到E 城市的最小费用路线为:
A→C→D→E
如果采用代价树的深度优先搜索,也会得到同样的结果:
A→C→D→E
但注意:这只是一种巧合,一般情况下,这两种方法得到的结果不一定相同。再者,代价树的深度优先搜索可能进入无穷分支路径,因此也是不完备的。
对于图所示的状态空间图,假设U 是目标状态,试给出宽度优先搜索与深度优搜索的OPEN 表和CLOSED 表的变化情况。
3 5
A C D E
B 3 4 2 4
图状态空间图
[解] 宽度优先搜索的OPEN表和CLOSED表的变化情况:
1. OPEN=[A]; CLOSED=[ ]
2. OPEN=[B,C,D]; CLOSED=[A]
3. OPEN=[C,D,E,F]; CLOSED=[B,A]
4. OPEN=[D,E,F,G,H]; CLOSED=[C,B, A]
5. OPEN=[E,F,G,H,I,J]; CLOSED=[D,C,B, A]
6. OPEN=[F,G,H,I,J,K,L]; CLOSED=[E,D,C,B,A]
7. OPEN=[G,H,I,J,K,L,M](由于L已在OPEN中);
CLOSED=[F,E,D,C,B,A]
8. OPEN=[H,I,J,K,L,M,N]; CLOSED=[G,F,E,D,C,B,A]
9. 以此类推,直到找到了U或OPEN=[ ]。
深度优先搜索的OPEN表和CLOSED表的变化情况:
1. OPEN=[A]; CLOSED=[ ]
2. OPEN=[B,C,D]; CLOSED=[A]
3. OPEN=[E,F,C,D]; CLOSED=[B,A]
4. OPEN=[K,L,F,C,D]; CLOSED=[E,B, A]
5. OPEN=[S,L,F,C,D]; CLOSED=[K,E,B, A]
6. OPEN=[L,F,C,D]; CLOSED=[S,K,E,B,A]
7. OPEN=[T,F,C,D]; CLOSED=[L,S,K,E,B,A]
8. OPEN=[F,C,D]; CLOSED=[T,L,S,K,E,B,A]
9. OPEN=[M,C,D](由于L已经在CLOSED中;
CLOSED=[F,T,L,S,K,E,B,A]
10. OPEN=[C,D]; CLOSED=[M,F,T,L,S,K,E,B,A]
11. OPEN=[G,H,D]; CLOSED=[C,M,F,T,L,S,K,E,B,A]
12. 以此类推,直到找到了U或OPEN=[ ]。
第4章自动推理
什么是推理的控制策略有哪几种主要的推理驱动模式
自然演绎推理的基本概念与基本的推理规则。
什么是合取范式 什么是析取范式 什么是Skolem 标准化 如何将一个公式化为这些形式 将下列公式化为Skolem 标准型:
),,,,,(w v u z y x wP v u z y x ??????
[解] 在公式中,)(x ?的前面没有全称量词,)(u ?的前面有全称量词)(y ?和)(z ?, 在)(w ?的前面有全称量词)(y ?,)(z ?和)(v ?。所以,在),,,,,(w v u z y x P 中,用常数a 代替x, 用二元函数f(y,z)代替u, 用三元函数g(y,z,v)代替w,去掉前缀中的所有存在量词之后得出Skolem 标准型:
)),,(,),,(,,,(v z y g v z y f z y a vP z y ???
化为子句形有哪些步骤
[解]
(1)利用等价谓词关系消去谓词公式中的蕴涵符“→ ”和双条件符“←→ ”。
(2)利用等价关系把否定符号“┐”移到紧靠谓词的位置上。
(3)重新命名变元名,使不同量词约束的变元有不同的名字。
(4)消去存在量词。
(5)将公式化为前束形。
(6)把公式化为Skolem 标准形。
(7)消去全称量词。
(8)消去合取词。
(9)对变元更名,使不同子句中的变元不同名。
将下列谓词公式化为子句集:
(1) (?x)[~P(x)∨~Q(x)]→(?y)[S(x,y)∧Q(x)]∧(?x)[P(x)∨B(x)]
(2))]]](),([~))],(()([[)([y P y x Q y y x f P y P y x P x →?∧→?→?
[解] (1) 转换过程遵照下列9个步骤依此为:
A. 消去蕴涵符符号:
)]()()[()]}(),()[()](~)([~){~(x B x P x x Q y x S y x Q x p x ∨?∧∧?∨∨?
B.减少否定符号的辖域:
)]()()[()]}(),()[()]()(){[(x B x P x x Q y x S y x Q x p x ∨?∧∧?∨∧?
C. 变量标准化:
)]()()[()]}(),()[()]()(){[(w B w P w x Q y x S y x Q x p x ∨?∧∧?∨∧?
D. 消去存在量词:
)]()()[()]}())(,([)]()(){[(w B w P w x Q x f x S x Q x p x ∨?∧∧∨∧?
E. 化为前束型:
)]()([)]}())(,([)]()(){[)((w B w P x Q x f x S x Q x p w x ∨∧∧∨∧??
F. 把母式化为合取范式:
)]}()([)())](,()(){[)((w B w P x Q x f x S x p w x ∨∧∧∨??
G. 消去全称量词:
)]()([)())](,()([w B w P x Q x f x S x p ∨∧∧∨
H. 消去合取词:
))(,()(x f x S x p ∨
)(x Q
)()(w B w P ∨
I. 子句变量标准化后, 最终的子句集为:
))(,()(x f x S x p ∨
)(y Q
)()(w B w P ∨
(2) 参见课本P122
A. 消去蕴涵符符号:
)]]](),([~~))],(()([~[)()[~(y P y x Q y y x f P y P y x P x ∨?∧∨?∨?
B. 减少否定符号的辖域:
)]]](~),([))],(()([~[)()[~(y P y x Q y y x f P y P y x P x ∧?∧∨?∨?
C. 变量标准化:
)]]](~),([))],(()([~[)()[~(w P w x Q w y x f P y P y x P x ∧?∧∨?∨?
D. 消去存在量词:
))]]]((~))(,([))],(()([~[)()[~(x g P x g x Q y x f P y P y x P x ∧∧∨?∨?
E. 化为前束型:
))]]]((~))(,([))],(()([[~)()[~)((x g P x g x Q y x f P y P x P y x ∧∧∨∨??
F. 把母式化为合取范式:
))],(()(~)()[~)((y x f P y P x P y x ∨∨??))]]((~)([~))](,()([~x g P x P x g x Q x P ∨∧∨∧
G. 消去全称量词:
))]]((~)([~))](,()([~))],(()(~)([~x g P x P x g x Q x P y x f P y P x P ∨∧∨∧∨∨
H. 消去合取词:)),(()(~)(~y x f P y P x P ∨∨
))(,()(~x g x Q x P ∨
))((~)(~x g P x P ∨
I. 更改变量名:
)),(()(~)(~11y x f P y P x P ∨∨
))(,()(~222x g x Q x P ∨
))((~)(~33x g P x P ∨
把下面的表达式转化成子句形式
(1))]()()[()]()[()]()[((x Q x P x x Q x x p x ∨?→?∨?
(2))]],,()[()],()[)[(()]()[(z y x R z z x Q z x x P x ?∨??→?
(3))]]],()[(~)],()[)[(()()[(x y R z y x Q z y x P x ?→??→?
[解]
(1) ))()()(())()()()((x Q x P x x Q x x P x ∨?→?∨?
))()()(())()()()((x Q x P x x Q x x P x ∨?∨?∨??
))()()(())()()()((x Q x P x x Q x x P x ∨?∨??∧??
))()()(())()()()((x Q x P x x Q x x P x ∨?∨??∧??
))()()(())()()()((z Q z P z x Q x x P x ∨?∨??∧??
))()(())()()()((a Q a P y Q y x P x ∨∨??∧??
)))()(())()()()((a Q a P y Q x P y x ∨∨?∧???
))()(())()((a Q a P y Q x P ∨∨?∧?
))()(())())()()((a Q a P y Q a Q a P x P ∨∨?∧∨∨?
则子句集为
)}()(())()),()()({a Q a P y Q a Q a P x P S ∨∨?∨∨?=
(2) )],,()(),())[(()()(z y x R z z x Q z x x P x ?∨??→?
)]),,()(),())[(()())(((z y x R z z x Q z x x P x y ?∨??→??
)]),,()(),())[(()()()((z y x R z z x Q z x x P x y ?∨??∨???
)]),,()(),())[(()())(((z y x R z z x Q z x x P x y ?∨??∨???
)]),,()(),())[(()())(((u y t R u z t Q z t x P x y ?∨??∨???
)),),(()()),(()())(()((221u y y f R u z y f Q z y f P y ?∨?∨??
)),),(()),(())(()()()((221u y y f R z y f Q y f P u z y ∨∨????
)),),(()),(())(((221u y y f R z y f Q y f P ∨∨?
则子句集为
)},),(()),(())(({221u y y f R z y f Q y f P S ∨∨?=
(3) )]],()()],()[)[(()()[(x y R z y x Q z y x P x ??→??→?
)]],()()],()[()[()()[(x y R z y x Q z y x P x ??∨???∨??
)]],()()],()[)[(()()[(x y R z y x Q z y x P x ?∨???∨??
)]],()()],()[)[(()()[(x y R u y x Q z y x P x ?∨???∨??
)]],(),()[()()[(x y R y x Q y x P x ∨??∨??
)],(),()()[)((x y R y x Q x P y x ∨?∨???
),(),()(x y R y x Q x P ∨?∨?
则子句集为
)},(),()({x y R y x Q x P S ∨?∨?=
求证G 是F1和F2的逻辑结论。
))),()()(()()((:1y x L y Q y x P x F ?→?→?
))),()()(()()((:2y x L y R y x P x F →?∧?
))()()((:x Q x R x G ?→?
[证明] 首先将21,F F 和G ?化为子句集:
F 1: ))),()()(()()((y x L y Q y x P x ?→?→?
))),()()(()()((y x L y Q y x P x ?∨??∨???
))),()(()()()((y x L y Q x P y x ?∨?∨????
所以))},()(()({1y x L y Q x P S ?∨?∨?=
F 2:))),()()(()()((y x L y R y x P x →?∧?
))),()(()()()((y x L y R x P y x ∨?∧???
))),()(()()((y a L y R a P y ∨?∧??
所以)},()(),({2y a L y R a P S ∨?=
:G ? ))()()((x Q x R x ?→?
))()()((x Q x R x ?∨???
))()()((x Q x R x ∧??
))()((b Q b R ∧?
所以)}(),({3b Q b R S =
下面进行归结:
① ),()(()(y x L y Q x P ?∨?∨?
② )(a P
③ ),()(y a L y R ∨?
④ R(b)
⑤ Q(b)
⑥ L(a,b) ③和④
⑦ ),()(y a L y Q ?∨? ①和②
⑧ ),(b a L ? ⑤和⑦
⑨ Nil ⑥和⑧
所以,G 是F 1,F 2的逻辑结论。
利用归结原理证明:“有些患者喜欢任一医生。没有任一患者喜欢任一庸医。所以没有庸医的医生”。
[解] 定义谓词为: P(x): “x 是患者”, D(x): “x 是医生”, Q(x): “x 是庸医”, L(x,y): “x 喜欢y ”, 则前提与结论可以符号化为:
A1: ))),()()(()()((y x L y D y x P x →?∧?
A2: ))),()()(()()((y x L y Q y x P x ?→?→?
G: ))()()((x Q x D x ?→?
目前是证明G 是A1和A2的逻辑结论, 即证明G A A ?∧∧21是不可满足的. 首先, 求出子句集合:
A1: ))),()()(()()((y x L y D y x P x →?∧?
))),()(()()()((y x L y D x P y x ∨?∧???
))),()(()()((y a L y D a P y ∨?∧??
A2: ))),()()(()()((y x L y Q y x P x ?→?→?
))),()()(()()((y x L y Q y x P x ?∨??∨???
))),()(()()()((y x L y Q x P y x ?∨?∨????
G ~: ))()()((x Q x D x ?→??
))()()((x Q x D x ∧??
))()((b Q b D ∧?
因此G A A ?∧∧21的子句集合S 为:
)}(),(),,()()(),,()(),({b Q b D y x L y Q x P y a L y D a P S ?∨?∨?∨?=
归结证明S 是不可满足的:
)
()5()
()4(),()()()3()
,()()2()
()1(b Q b D y x L y Q x P y a L y D a P ?∨?∨?∨? S
),()6(b a L (2)(4)
),()()7(b a L y Q ?∨? (1)(3)
),()8(b a L ? (5)(7)
(9) Nil (6)(8)
已知:能阅读的都是有文化的;
海豚是没有文化的;
某些海豚是有智能的;
用归结反演法证明:某些有智能的并不能阅读。
[证明] 首先定义谓词:
R(x): x 能阅读, L(x): x 有文化
D(x): x 是海豚, I(x): x 有智能
将前提形式化地表示为:
A1: ))()()((x L x R x →?
A2: ))()()((y L y D y ?→?
A3: ))()()((z I z D z ∧?
将结论形式化地表示为:
G: ))()()((w R w I w ?∧?
即要证明G A A A →∧∧321为真. 即证明G A A A ?∧∧∧321是不可满足的. 把它化为子句集为:
)}()(),(),(),()(),()({w R w I A I A D y L y D x L x R S ∨??∨?∨?=
现在用归结证明S 是不可满足的:
)
()()5()
()4()()3()
()()2()
()()1(w R w I A I A D y L y D x L x R ∨??∨?∨? S
)()6(A R (4)(5)
)()7(A L (1)(6)
)()8(A D ? (2)(7)
(9) Nil (3)(8)
某人被盗,公安局派出所派出5个侦察员去调查。研究案情时:
侦察员A 说:“赵与钱中至少有一人作案”;
侦察员B 说:“钱与孙中至少有一人作案”;
侦察员C 说:“孙与李中至少有一人作案”;
侦察员D 说:“赵与孙中至少有一人与此案无关”;
侦察员E 说:“钱与李中至少有一人与此案无关”。
如果这5个侦察员的话都是可信的,试问谁是盗窃犯呢
[解]
第一步: 设谓词P(x)表示x 是作案者,所以根据题意:
A: P(zhao)∨P(qian) B: P(qian)∨P(sun) C: P(sun)∨P(li) D: ~P(zhao)∨~P(sun) E: ~P(qian)∨~P(li) 以上每个侦查员的话都是一个子句。
第二步:将待求解的问题表示成谓词。设y 是盗窃犯,则问题的谓词公式为P(y),将其否定并与ANS(y)做析取得: ~P(y)∨ANS(y)第三步:求前提条件及~P(y)∨ANS(y)的子句集,并将各子句列表如下:
(1) P(zhao)∨P(qian)
(2) P(qian)∨P(sun)
(3) P(sun)∨P(li)
(4) ~P(zhao)∨~P(sun)
(5) ~P(qian)∨~P(li)
(6) ~P(y)∨ANS(y)
第四步:应用归结原理进行推理。
(7) P(qian)∨~P(sun) (1) 与 (4) 归结
(8) P(zhao)∨~P(li) (1) 与 (5) 归结
(9) P(qian)∨~P(zhao) (2) 与 (4) 归结
(10) P(sun)∨~P(li) (2) 与 (5) 归结
(11) ~P(zhao)∨P(li) (3) 与 (4) 归结
(12) P(sun)∨~P(qian) (3) 与 (5) 归结
(13) P(qian) (2) 与 (7) 归结
(14) P(sun) (2) 与 (12) 归结
(15) ANS(qian) (6) 与 (13) 归结
(16) ANS(sun) (6) 与 (14) 归结
所以,本题的盗窃犯是两个人:钱和孙。
已知:张和李是同班同学,如果x 和y 是同班同学,则x 的教室也是y 的教室。现在张在J1-3上课,问李在哪里上课
[解] 首先定义谓词:
C(x,y): x 和y 是同学At(x,u): x 在u 教室上课
则已知前提可表示为
C(Zhang, Li)
)).(),(),((u y At u x At y x C u y x →∧???
At(Zhang, J1-3)
将目标表示成谓词:典At(Li, v),采用重言式,得到子句集合S 为:
),,(),(),(),,({u y At u x At y x C Li Zhang C S ∨?∨?=
)},(),(),31,(v Li At v Li At J Zhang At ∨?-
归结过程如下:
S v Li At v Li At J Zhang At u y At u x At y x C Li Zhang C ???
????
∨?-∨?∨?),(),()4()31,()3(),(),(),()2()
,()1( (5)),(),(),(v x At Li x C v Li At ?∨?∨ (2)(4)归结 {Li|y, v|u} (6)),(),(v Zhang At v Li At ?∨ (1)(5)归结 {Zhang|x}
(7))31,(-J Li At (3)(6)归结 {J1-3|v}
最后就是所得到的答案:李在J1-3上课。
第5章 不确定性推理
什么是不确定性推理不确定性推理的基本问题是什么
在主观Bayes 方法中,如何引入规则的强度的似然率来计算条件概率这种方法优点是什么主观Bayes 方法有什么问题试说明LS 和LN 的意义。
设有规则:
R1: IF E1 THEN (20, 1) H
R2: IF E2 THEN (300, 1) H
已知证据E1和E2必然发生,并且P(H)=,求H 的后验概率。
[解] 因为P(H)=, 则O(H)==
根据R1有
O(H|E1)=LS1×O(H)=20×=
根据R2有
O(H|E2)=LS2×O(H)=300×=
那么
)()
()|()()|()|(2121H O H O E H O H O E H O E E H O ??= 55.185030927.0030927
.02781.9030927.06185.0=??= 所以H 的后验概率为
99464.055
.185155.185)|(1)|()|(212121=+=+=E E H O E E H O E E H P 设有规则:
R1: IF E1 THEN (65, H
R2: IF E2 THEN (300, H
已知:P(E1|S1)=, P(E2|S2)=,
P(H)=, P(E1)=, P(E2)=
求:P(H|S1S2)
[解] 根据R1,因为P(E1|S1)=>P(E1)=,则有
3963414.01
01.06401.0651)()1()()|(1=+??=+-?=H P LS H P LS E H P .18170)]()|([)
(1)()|()()|(111111=-?--+=E P S E P E P H P E H p H P S H P 根据R2,因为P(E2|S2)= 000001.01 01.09999.001.00001.01)()1()()|(2=+?-?=+-?=?H P LN H P LN E H P .0066670)|() ()|()()|()|(222222=??-+?=S E P E P E H P H p E H P S H P 根据上面的计算,因为: 010101.00.01 -10.01P(H)-1P(H)O(H)=== 222.00.1817-10.1817)S |P(H -1)S |P(H )S |O(H 111=== 006712.00.006667 -10.006667)S |P(H -1)S |P(H )S |O(H 222=== 则有 1475.0O(H)O(H) )S |O(H O(H))S |O(H )S S |O(H 2121=??= 12854.0)S S |O(H 1)S S |O(H )S S |P(H 212121=+= 何谓可信度简述可信度模型及其各部分含义。 设有如下规则: R1: IF E1 THEN H R2: IF E2 THEN H R3: IF E3 THEN H R4: IF E4 AND (E5 OR E6) THEN E1 已知CF(E2)=, CF(E3)=, CF(E4)=, CF(E5)=, CF(E6)=, 求CF(H)= [解] 由R4得到: CF(E 1)=×max{0,CF(E 4 AND (E 5 OR E 6))=×max{0,min{CF(E 4),CF(E 5 OR E 6)}} =×max{0,min{CF(E 4),max{CF(E 5),CF(E 6)}}=×max{0,min{,}} =×max{0,}= 由R 1得到: CF 1(H)=CF(H,E 1)×max{0,CF(E 1)}=×max{0,}= 由R 2得到: CF 2(H)=CF(H,E 2)×max{0,CF(E 2)}=×max{0,}= 由R 3得到: CF 3(H)=CF(H,E 3)×max{0,CF(E 3)}=×max{0,}= 根据结论不确定性的合成算法得到: CF 1,2(H)=CF 1(H)+CF 2(H)-CF 1(H)×CF 2(H)=+或者 53.0} 3.0,67.0min{13.067.0|})(||,)(min{|1)()()(32,13123,2,1=--=-+=H CF H CF H CF H CF H CF 设有如下规则: R1: IF E1 THEN H R2: IF E2 THEN H R3: IF E3 THEN H R4: IF E4 AND (E5 OR E6) THEN E1 R5: IF E7 AND E8 THEN E3 在系统运行中已从用户处得CF(E2)=, CF(E4)=, CF(E5)=, CF(E6)=, CF(E7)=, CF(E8)=, 求H 的综合可信度CF(H)。 [解] (1)求证据E4,E5,E6逻辑组合的可信度 )}} (),(max{),(min{))((654654E CF E CF E CF E OR E AND E CF =5.0}}7.0,6.0max{,5.0min{== (2)根据规则R4,求CF(E1) ))}((,0max{7.0)(6541E OR E AND E CF E CF ?= )}}(),(min{,0max{7.0654E OR E CF E CF ?= )}}}(),(max{),(min{,0max{7.0654E CF E CF E CF ?= }}}7.0,6.0max{,5.0min{,0max{7.0?= }5.0,0max{7.0?= 35.05.07.0=?=(3)求证据E7,E8逻辑组合的可信度 6.0}9.0,6.0min{)}(),(min{)(8787===E CF E CF E AND E CF (4)根据规则R5, 求CF(E3) 54.06.09.0)}(,0max{9.0)(873=?=?=E AND E CF E CF (5)根据规则R1, 求CF1(H) 28.035.08.0)}(,0max{8.0)(11=?=?=E CF H CF (6)根据规则R2, 求CF2(H) 48.08.06.0)}(,0max{6.0)(22=?=?=E CF H CF (7)根据规则R3, 求CF3(H) 27.054.05.0)}(,0max{5.0)(33-=?-=?-=E CF H CF (8)组合由独立证据导出的假设H 的可信度CF1(H),CF2(H)和CF3(H),得到H 的综合可信度: )()()()()(21212,1H CF H CF H CF H CF H CF ?-+= 63.048.028.048.028.0=?-+= 36.027.063.0)()()(32,13,2,1=-=+=H CF H CF H CF 或者 49.0} 27.0,63.0min{127.063.0|})(||,)(min{|1)()()(32,13123,2,1=--=-+=H CF H CF H CF H CF H CF 设有如下规则: R1: A1→B1 CF(B1,A1)= R2: A2→B1 CF(B1,A2)= R3: B1∧A3→B2 CF(B2,B1∧A3)= 初始证据A1,A2,A3的CF 值均设为1,而初始未知证据B1,B2的CF 值均为0,即对B1,B2一无所知。求CF(B1),CF(B2)的更新值。 [解] (1) 对知识R1,R2,分别计算CF(B1)。 CF1(B1)=CF(B1,A1)×max{0,CF(A1)}=×1= CF2(B1)=CF(B1,A2)×max{0,CF(A2)}=×1= (2) 计算B1的综合可信度。 CF 1,2(B 1)=CF 1(B 1)+CF 2(B 1)-CF 1(B 1)×CF 2(B 1) + 计算B2的可信度CF(B2)。这时,B1作为B2的证据,其可信度已有前面计算出来,而A3的可信度为初始指定的1。 由规则R3得到 CF(B2)=CF(B2, B1∧A3)×max{0,CF(B1∧A3)} = CF(B2, B1∧A3)×max{0,min{CF(B1),CF(A3)} =×max{0,}= 所以,所求得的B1,B2的可信度的更新值分别为 CF(B1)=, CF(B2)= 什么是概率分配函数、信任函数、似然函数与类概率函数 如何用证据理论描述假设、规则和证据的不确定性,并实现不确定的传递与组合 已知f1(E1)=, f1(E2)=, |U|=20, E1∧E2→H={h1,h2} (c1,c2)=, ,计算f1(H)。 [解] 先计算f1(E1∧E2): f1(E1∧E2)=min{f1(E1),f1(E2)}=min{,}= 再计算m({h1},{h2}): m({h1},{h2})=×, ×=, 于是 Bel(H)=m(φ)+m({h1})+m({h2})+m({h1,h2}) =0+++0= Pl(H)==1-Bel(~H)=1-0=1 最后得 f1(H)=Bel(H)+|H|/|U|(Pl(B)-Bel(B)=+2/20=. 考生考试成绩的论域为{A,B,C,D,E},小王成绩为A 、为B 、为A 或B 的基本概率分别分配为、、。Bel({C,D,E})=。请给出Bel({A,B})、Pl({A,B})和f1({A,B})。 [解] 由题意知道: M({A})=, M({B})=, M({A,B})= 则 Bel({A,B})=M({A,B})+M({A})+M({B})+M(Φ)= Pl({A,B})=1-Bel(?{A,B})=1-Bel({C,D,E})= F({A,B})=Bel({A,B})+| ||},{|ΩB A (Pl({A,B})-Bel({A,B}) =+2/5第6章 机器学习(了解) 简单的学习模型由哪几部分组成各部分的功能是什么 可以从哪几个角度来分类机器学习方法按各类方式阐述主要的机器学习类型。 何谓归纳学习何谓变型空间学习 画出归纳学习的双空间模型,并简述各部分功能。