Hadoop云计算平台搭建规划方案.docx

Hadoop 云计算平台搭建方案
一、平台搭建概述
总体思路
针对于电网企业在营销服务领域展开的大数据分析处理,搭建Hadoop 云计算平台进行海量数据存储,并作深层次加工、处理,挖掘出无法简单直观便可得到的新的模式,为电力企业
的决策提供指导。平台采用作为海量数据存储和分析工具,将其部署在 4 个物理计算机节点上,搭建 Hadoop 集群,其中 1 个节点作为master 节点,其余 3 个作为 slave 节点。为了获取更好的稳定性,平台搭建在Linux 系统()环境下。
软件列表
软件描述版本
VMware Workstation 虚拟化软件
VMware Workstation 操作系统
JDK Java 的软件开发工具包
开源的云计算基础框架
分布式数据存储系统
可靠协调系统
数据迁移工具
平台搭建总流程和节点信息一览表
在平台搭建前,给出实现的总流程图和节点信息一览表,从而对平台搭建过程和各节点信息有一个全局的认识,平台搭建总流程如下图所示。
创建虚拟机master ,完成 JDK、
Hadoop等应用的安装和配置
对虚拟机master 进行克隆,得到的
虚拟机分别作为slave1 、 slave2 和
完成 Zookeeper 、 HBase等其它分布
式服务的部署,搭建Hadoop 集群
运行并测试Hadoop 集群系统
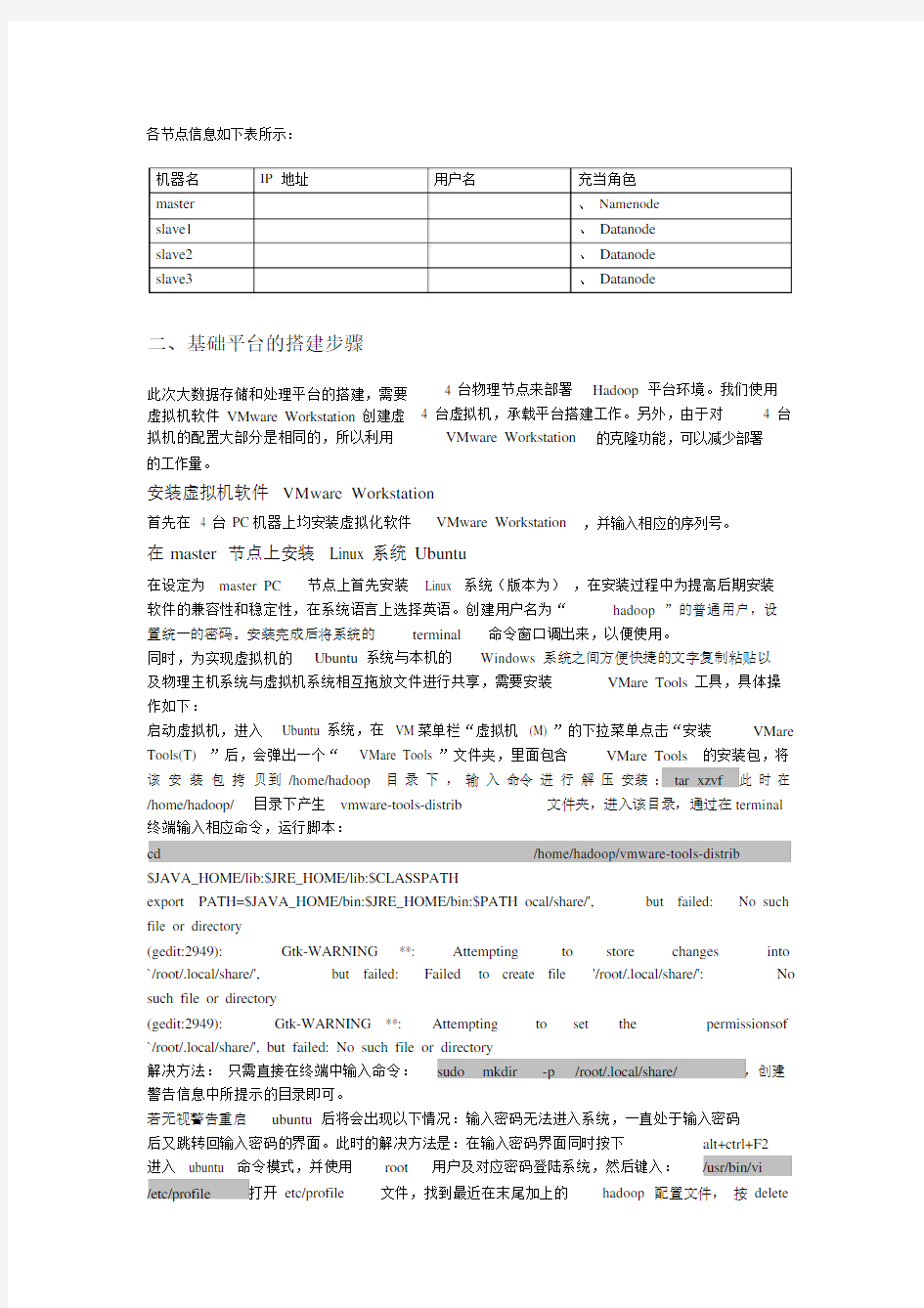
各节点信息如下表所示:
机器名master slave1 slave2 slave3IP地址用户名充当角色
、 Namenode
、 Datanode
、 Datanode
、 Datanode
二、基础平台的搭建步骤
此次大数据存储和处理平台的搭建,需要虚拟机软件 VMware Workstation 创建虚拟机的配置大部分是相同的,所以利用
4 台物理节点来部署Hadoop平台环境。我们使用4 台虚拟机,承载平台搭建工作。另外,由于对 4 台
VMware Workstation的克隆功能,可以减少部署
的工作量。
安装虚拟机软件VMware Workstation
首先在 4 台 PC机器上均安装虚拟化软件VMware Workstation,并输入相应的序列号。
在master 节点上安装 Linux 系统 Ubuntu
在设定为 master PC节点上首先安装 Linux 系统(版本为),在安装过程中为提高后期安装
软件的兼容性和稳定性,在系统语言上选择英语。创建用户名为“hadoop ”的普通用户,设
置统一的密码。安装完成后将系统的terminal命令窗口调出来,以便使用。
同时,为实现虚拟机的Ubuntu 系统与本机的Windows 系统之间方便快捷的文字复制粘贴以
及物理主机系统与虚拟机系统相互拖放文件进行共享,需要安装VMare Tools 工具,具体操作如下:
启动虚拟机,进入 Ubuntu 系统,在 VM菜单栏“虚拟机 (M) ”的下拉菜单点击“安装VMare Tools(T) ”后,会弹出一个“ VMare Tools ”文件夹,里面包含VMare Tools的安装包,将该安装包拷贝到 /home/hadoop目录下,输入命令进行解压安装: tar xzvf此时在/home/hadoop/目录下产生 vmware-tools-distrib文件夹,进入该目录,通过在terminal 终端输入相应命令,运行脚本:
cd/home/hadoop/vmware-tools-distrib $JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH ocal/share/',but failed:No such file or directory
(gedit:2949):Gtk-WARNING**:Attempting to store changes into `/root/.local/share/',but failed:Failed to create file'/root/.local/share/':No such file or directory
(gedit:2949):Gtk-WARNING**:Attempting to set the permissionsof `/root/.local/share/', but failed: No such file or directory
解决方法:只需直接在终端中输入命令:sudo mkdir-p/root/.local/share/,创建警告信息中所提示的目录即可。
若无视警告重启ubuntu 后将会出现以下情况:输入密码无法进入系统,一直处于输入密码
后又跳转回输入密码的界面。此时的解决方法是:在输入密码界面同时按下alt+ctrl+F2
进入 ubuntu 命令模式,并使用root用户及对应密码登陆系统,然后键入:/usr/bin/vi
/etc/profile打开 etc/profile文件,找到最近在末尾加上的hadoop 配置文件,按 delete
键删除这些行,然后键入命令:wq !(注意此处有冒号,不可省略)保存文件。然后同时按下
ctrl+alt+del重启系统即可使系统恢复正常登陆,然后按照上述方法重新配置。
目录设置
在普通用户hadoop 下创建 hadoop 的数据存储目录(若使用root用户创建上述文件夹则会
因权限问题导致无法向这些文件夹中写入并读取数据),可自行选择数据存储的路径,我们
选择在 /home/hadoop/ 文件夹下创建dfs 和 tmp 作为数据存储与交换的目录,并在dfs 文件夹下创建name和 data 两个子文件夹。分别执行命令:
mkdir /home/hadoop/dfs/name
/description>
(4)配置文件,打开该文件,在文件末尾添加以下语句。
文件名打开文件后,在其末尾添加语句:
注意:需要在中配置属性时,属性指定HDFS中文件块复制的份数,其默认值为3,当 datanode 节点少于 3 台便会报错。在一般情况下,当其属性值为 3 的时候, HDFS的部署策略是在本
地机柜中一个节点放置一个备份,在本地机柜的不同结点再放置一个备份,然后再在另一个
机柜中的一个结点放置一个备份。
(5)配置文件。事实上在进行配置之前,文件默认并不存在,需要首先将该目录下的文件
进行复制,并重命名为,接下来打开,添加以下语句。
文件名打开文件后,在其末尾添加语句:
(6)配置文件,打开该文件,在文件末尾添加以下语句。
文件名打开文件后,在其末尾添加语句:
(7)配置文件,打开该文件,检索“ # export JAVA_HOME=/home/y/libexec/ 语句,在该语句下
一行添加:
export JAVA_HOME=/home/hadoop/通过对上述文件的修改,完成对Hadoop 的配置。事实上,配置过程并不复杂,一般而言,除了规定的端口、IP 地址、文件的存储位置外,其他配置
都不是必须修改的,可以根据需要决定是采用默认配置还是自行修改。还有一点需要注意的是以
上配置都被默认为最终参数,这些参数都不可以在程序中被再次修改。
Hadoop 集群的部署与各节点的通信
安装 SSH服务
通过建立SSH无密码互访,可以实现Hadoop 虚拟机群之间的无密码登录互访。在安装SSH
服之前,首先需要更新件源,并保每台机器上都安装了SSH服器,且都能正常启。
更新件源命令:sudo apt-get update
件源更新完后,在terminal入如下命令开始安装openssh-server:
sudo apt-get install openssh-server
入如下命令,openssh-server是否成功安装:
which ssh
如示/usr/bin/ssh表示ssh 安装成功
which sshd
如示 /usr/bin/sshd表示sshd安装成功
如果以上二者都成功示,表示open-server安装成功
克隆虚机作Slave 点
将上面配置好的虚机作 master ,关作 master 的 ubuntu 系,然后修改虚机的网接置,改
“ 接模式”,即在 master 虚机主界面点“虚机—置—硬件—
网适配器” ,在出的的“网接” 目下“ 接模式 (B) ”此的目的在于使主点和各从点都能上网,从而使各台机器之能互。
接下来 master 行克隆,得到 slave1 、slave2 、slave3 的形,即点 VM菜下的“虚机—管理—克隆” ,入克隆虚机的向界面,根据向提示,在“克隆型”引界
面“ 建完整克隆”,具体置如下所示:
然后入被克隆的虚机名称,先入 slave1 ,点确行克隆,将克隆好的系复制到除 master 之外的三台 PC点上,用虚机 VMware并将其启,并在虚机启界面点“虚机—置——常” 置中,分修改虚机名称 slave1 、 slave2 和 slave3 ,如下所示。
置 IP 地址
在 Hadoop 平台上,各个点之的互是基于 TCP/IP 的,所以要各个点分配 IP 地址。在四个 PC点上,点桌面右上角从左到右的第一个数据接
在下拉菜中最后一“Edit Connections?”
在出的“ Network Connections ”框中“ Edit ?”,示“ Editing Ethernet 框,点“ IPv4Settings”将出的Method 框置Manual,然后添加connection1
IP 地址。
”
添加同一网关内的IP 地址、子网掩、默网关,目的是各个点机器能互。需要
注意的是在置IP 地址,需要首先在DNS servers入相的IP 地址,否无法填写
“Addresses ” 内容。
因此,我将DNS服器( DNS servers )地址置:,接下来将master 点的IP 地址
(Address )置:,子网掩 (Netmask) 置:,默网关( Gateway)置:。
用同的方法,将虚机 salve1 的 IP 地址置:( DNS服器);( IP 地址);(子网掩);
(网关),将 slave2的IP地址置:(DNS服器);(IP地址);(子网掩);(网关),将slave3 的 IP 地址置:( DNS服器);( IP 地址);(子网掩);(网关)。修改机器名
通克隆得到的ubuntu 系有相同的机器名,所以要修改加在各虚机中的系名称,
来区分不同的节点,以便后期操作。
在master 机器上打开 etc/hostname 文件,命令为:
sudo gedit /etc/hostname
将etc/hostname 文件内容修改为 master
用同样的方法分别在刚刚克隆得到的slave1 、 slave2 和 slave3 上,修改其机器名:
将slave1 的机器名修改为 slave1
将slave2 的机器名修改为 slave2
将slave3 的机器名修改为 slave3
修改 hosts 文件
通过修改hosts文件可以实现机器名和IP 地址之间的映射,在master 节点上,打开文件/etc/hosts,命令为:
sudo gedit /etc/hosts
将/etc/hosts文件修改为
master
slave1
slave2
slave3
用同样的方法,在 slave1 、slave2和slave3机器上修改如上hosts 文件,映射配置与master 一致。配置完成后重启master 和 slave1 、 slave2和slave3使其生效。
建立 SSH无密码互访
通过建立SSH无密码互访,可以实现Hadoop 虚拟机集群之间的无密码登陆互访。首先在4台机器上均生成秘钥对,并将 slave1 、slave2 和 slave3 分别所生成的公钥进行重命名后发
送到 master 机器上,由 master 将自身所生成的公钥与其它三台slave 节点发送过来的公钥
合并到一个文件中,重新分发给三台slave 节点。对于不同的机器执行对应的操作如下:
(1) master 生成密钥对
ssh-keygen -t rsa sh/( 隐藏的文件夹 ) 下生成两个文件id_rsa和
(2) slave1 生成密钥对,重命名公钥,并将其发送到 maser 在终
端 terminal 输入如下命令:
ssh-keygen -t rsa sh/(隐藏的文件夹)下生成两个文件id_rsa和,并重命名公钥为,执行命令:
scp ~/.ssh/
将重命名后的文件都复制到master 机,命令如下:
scp ~/.ssh/ hadoop@master:/home/hadoop/.ssh/
(3) slave2 生成密钥对,重命名公钥,并将其发送到 maser
slave2 执行与 slave1 类似的命令:
ssh-keygen -t rsa sh/ hadoop@master:/home/hadoop/.ssh/
(4) slave3 生成密钥对,重命名公钥,并将其发送到 maser
slave3 也执行与 slave1 类似的操作:
ssh-keygen -t rsa sh/ hadoop@master:/home/hadoop/.ssh/
(5) master 合并公钥,重新分发给各slave 节点
在master 机器的 /home/hadoop/.ssh/ 文件夹中重命名秘钥文件,命令如下:
mv authorized_keys
然后把每台slave机器发过来的文件合并到authorized_keys,命令如下:
cat >> authorized_keys
cat >> authorized_keys
cat >> authorized_keys
最后把合成的authorized_keys发给每台slave 机器:
scp authorized_keys hadoop@slave1:/home/hadoop/.ssh/authorized_keys
scp authorized_keys hadoop@slave2:/home/hadoop/.ssh/authorized_keys
scp authorized_keys hadoop@slave3:/home/hadoop/.ssh/authorized_keys
(6)节点间无密码互访测试
在任意机器上输入命令访问另一台机器,命令如下:
ssh slave1
如果返回” Agent admitted failure to sign using the key“,不能连接到slave1,此时可输入命令:
ssh-agent
使ssh-agent 处于运行状态。再将 id_rsa 添加到 ssh-agent 中,命令为:
ssh-add id_rsa
启动 Hadoop
启动 HDFS
(1)初始化 namenode
在运行 Hadoop 平台之前,要在 master 上格式化文件系统,建立HDFS。切换至hadoop用户,进入 /home/hadoop/ ,初始化Namenode,执行命令如下:
cd/home/hadoop/namenode– format Storage directory
/home/hadoop/hdfs/name has been successfully formatted 初始化完成之后会自动的在/home/hdoop/ 创建 dfs/name/
,则说明格式化
目录。
HDFS成功,
(2)测试启动 HDFS
在 hadoop 用户下,启动 namenode,执行命令: start namenode ;启动 datanode ,执行命令:start datanode 。当 namenode与 datanode 均启动之后,可使用 jps 命令查看进程,命令如下:
jps
当同时看到下列进程时,标明hadoop 正常运行:
3588 NameNode
3692 DataNode
3757 Jps
如上述进程启动过程正常,则可启动HFS。在hadoop 用户下,切换至 /home/hadoop/目录下,执行命令:
cd /home/hadoop/执行脚本./,启动HDFS
在上述目录下执行脚本文件,命令为:./ ,使用 jps 命令查看进程,终端显示:
4177 SecondaryNameNode
3588 NameNode
3692 DataNode
4285 Jps
其中 master 产生 SecondaryNameNode和 NameNode进程, slave节点产生DataNode进程。启动 YARN
在hadoop 用户下,切换至 /home/hadoop/ 目录下,执行命令:
cd /home/hadoop/执行脚本./,启动YARN
在 terminal终端输入命令:./ ,执行脚本文件,使用jps命令查看master 节点进程时,终
端显示:
4177 SecondaryNameNode
4660 Jps
3588 NameNode
4411 ResourceManager
3692 DataNode
其中 master 产生 ResourceManager 、 NameNode和 SecondaryNameNode进程,同时输入 jps 命令在 slave 节点进行进程查看时终端显示:
3329 DataNode
3670 Jps
3484 NodeManager
可知 slave 节点上产生DataNode 和 NodeManager 进程。
异常处理2:
问题: Hadoop启动发生异常,有些进程不能被启动。
解决方法:执行命令 ./ 、 ./ 或直接执行 ./ 命令关闭进程后,清空 /home/hadoop/dfs 和
/home/hadoop/dfs 文件夹中的数据,并重新执行格式化,命令如下:
rm -rf /home/hadoop/dfs/
rm -rf /home/hadoop/tmp
hdfs namenode–format
异常处理3:
问题: slave节点DataNode无法启动。
解决方法:
a、系统防火墙没有关闭:执行命令sudo ufw disable关闭防火墙;
b、所有节点 hosts 链表不统一,或有错误:重新检查IP地址与机器名之间的对应关系,
检查 hadoop 的配置文件中是否发生IP 地址的书写错误;
c、多次 format namenode造成 namenode 和 datanode的 clusterID不一致:更改slave Cluster ID 使其与 master相同,修改每一个 datanode 上面的 CID( 位于home/hadoop/dfs/data/current/VERSION文件夹中 ) 使两者一致;删除所有节点/home/hadoop/dfs/data/下 curren目录,重新运行脚本即可。
Hadoop 平台测试
在 Hadoop平台搭建完成后,我们要对 Hadoop平台进行测试。在 Hadoop 的安装目录下,提供了
一个单词统计程序— WordCount。WordCount 程序运行于 Hadoop计算平台之上,充分利用了MapReduce和 HDFS。它可以对文件中单词出现次数进行统计,然后给出统计结果。我们通过运
行 WordCount 程序,可以检测 Hadoop 平台是否能够正常运行。
(1)在 HDFS上建立相应的目录和相应的文本文件
在/home/hadoop/ 目录下建立文件夹 input ,并进入文件夹 input ,执行命令如下:
mkdir /home/hadoop/input
cd /home/hadoop/input
建立文件file01和file02,并分别写入要统计的内容,命令如下:
echo "hello world bye world" > file01
ar,${}/lib,${}/lib/*.jar,${}/../lib/*.jar,/usr/lib/hadoop/*.jar,/home/hadoop/
(2)配置文件
打开 /home/hadoop/ 下的文件,在文件中检索文本“,将等号“=”后的目录修改为:
/home/hadoop/ ,即配置:
此处的配置文件中不能用环境变量(比如$HADOOP_HOME),必须用全路径。
jar包的拷贝与替换
(1)拷入需要用到的Oracle 的 jdbc 包到相关目录
由于从 Oracle 等数据库向HBase、 HDFS等 Hadoop 存储系统导入数据时,需要建立Oracle 与Sqoop 的连接,这就需要用到一个 Oracle 驱动程序 jdbc 的 jar 包,因此将下载好的包拷贝到
以下两个 Sqoop 文件目录下:
/home/hadoop/到此,正常启动。