数学建模论文(一等奖)

《红色警戒》中兵种战斗力的数字建模与统计研究:以苏联为例
北京二中初一(2)班韩澈
摘要:数学建模是应用知识从实际课题中抽象、提炼出数学模型的过程。本文利用数学建模的方法,对游戏《红色警戒red alert》中的兵力情况进行分析,以苏联的9种兵力为例,,探讨了在如此多的兵种中,哪个兵种的攻击力更有价值问题。研究通过数学建模的思想,运用统计分析方式,发现在此款游戏中,炮兵综合值最高,在战争中最有价值,其次是光凌坦克,最弱的是战斗机。在今后的对比研究中还可继续拓展分析,以便得到更全面的数据。
关键字:数学建模;红色警戒;比较;统计
红色警戒是一款策略游戏,玩家控制苏联或美国来制造军队,配合正确的战略手段,最终将敌人消灭。在这款游戏中,苏联和美国各有9个兵种,每个兵种都有自己的优势和劣势。
[1]
在游戏《红色警戒red alert》当中,苏联共有9种兵力,在如此多的兵种中,究竟哪个更有价值?当玩家在玩“红警”时,总会想到这个问题,只要自己制造的兵力的价值最高,就能在战争中获得胜利。我把这九种兵力按照“制造时间”、“制造金钱”、“生命”、“攻击”、“打击范围”这几个方面进行统计制成下表:
具体分析了每种兵力的特点。如下:
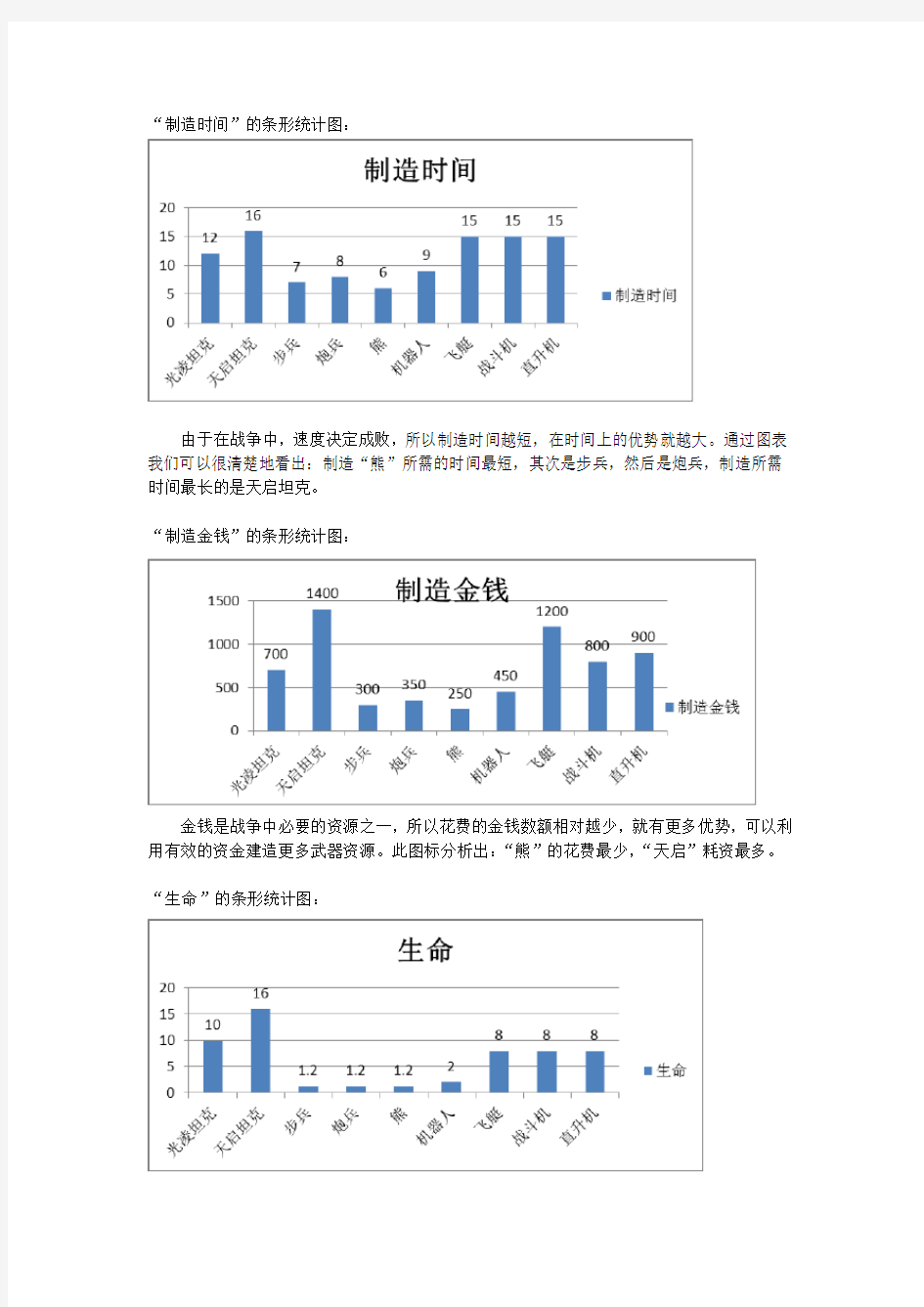
“制造时间”的条形统计图:
由于在战争中,速度决定成败,所以制造时间越短,在时间上的优势就越大。通过图表我们可以很清楚地看出:制造“熊”所需的时间最短,其次是步兵,然后是炮兵,制造所需时间最长的是天启坦克。
“制造金钱”的条形统计图:
金钱是战争中必要的资源之一,所以花费的金钱数额相对越少,就有更多优势,可以利用有效的资金建造更多武器资源。此图标分析出:“熊”的花费最少,“天启”耗资最多。
“生命”的条形统计图:
上图表明:天启坦克的生命值最多,其次是光凌坦克,最低为步兵、炮兵、熊。
“攻击”的条形统计图:
此图研究出攻击力最强的是天启坦克和飞艇,它们的攻击力是2,最弱的是步兵。
“打击范围”的条形统计图:
打击范围是指:此种兵力在空对空、地对地、空对地、地对空的战争中所占的种类。打击范围越大,对战争越有利。有图可知:炮兵和直升机的打击范围最大,在战争中最占优势。
综上所述,经过几个图表的分析研究结果,将各项统计值进行排名汇总,得出最终结论,如下表:
结论:此表中炮兵综合值最高,在战争中最有价值,其次是光凌坦克,最弱的是战斗机。本文只是分析研究了前苏联的9种兵力,当然,还有其他国家的兵力没有进行分析统计。在今后的对比研究中还可继续拓展分析,以便得到更全面的数据。
参考文献:
[1]百度百科.红色警戒[EB/OL]. https://www.360docs.net/doc/9b5494032.html,/view/14410.htm.2011-5-1.
数学建模写论文过程中应该注意的问题
写论文过程中应该注意的问题: (一)问题提出和假设的合理性 (1)论文中的假设要以严格、确切的数学语言来表达,使读者不致产生任何曲解。 (2)所提出的假设确实是建立数学模型所必需的,与建立模型无关的假设只会扰乱读者的思考。 (3)假设应验证其合理性。假设的合理性可以从分析问题过程中得出,例如从问题的性质出发作出合乎常识的假设;或者由观察所给数据的图象,得到变量的函数形式; 也可以参考其他资料由类推得到。对于后者应指出参考文献的相关内容。 (二)模型的建立在作出假设后,我们就可以在论文中引进变量及其记号,抽象而确切地表达它们的关系,通过一定的数学方法,最后顺利地建立方程式或归纳为其他形 式的数学问题,此处,一定要用分析和论证的方法,即说理的方法,让读者清楚地了 解得到模型的过程上下文,之间切忌逻辑推理过程中跃度过大,影响论文的说服力, 需要推理和论证的地方,应该有推导的过程而且应该力求严谨;引用现成定理时,要 先验证满足定理的条件。论文中用到的各种数学符号,必须在第一次出现时加以说明。总之,要把得到数学模型的过程表达清楚,使读者获得判断模型科学性的一个依据。 (三)模型的计算与分析把实际问题归结为一定的数学问题后,就要求解或进行分析。在数值求解时应对计算方法有所说明,并给出所使用软件的名称或者给出计算程序(通常以附录形式给出)。还可以用计算机软件绘制曲线和曲面示意图,来形象地表 达数值计算结果。基于计算结果,可以用由分析方法得到一些对实践有所帮助的结论。有些模型(例如非线性微分方程)需要作稳定性或其他定性分析。这时应该指出所依 据的数学理论,并在推理或计算的基础上得出明确的结论。在模型建立和分析的过程中,带有普遍意义的结论可以用清晰的定理或命题的形式陈述出来。结论使用时要注 意的问题,可以用助记的形式列出。定理和命题必须写清结论成立的条件。 (四)模型的讨论对所作的数学模型,可以作多方面的讨论。例如可以就不同的情景,探索模型将如何变化。或可以根据实际情况,改变文章一开始所作的某些假设,指出 由此数学模型的变化。还可以用不同的数值方法进行计算,并比较所得的结果。有时 不妨拓广思路,考虑由于建模方法的不同选择而引起的变化。通常,应该对所建立模型的优缺点加以讨论比较,并实事求是地指出模型的使用范围。
数学建模美赛o奖论文
For office use only T1________________ T2________________ T3________________ T4________________ Team Control Number 55069 Problem Chosen A For office use only F1________________ F2________________ F3________________ F4________________ 2017 MCM/ICM Summary Sheet The Rehabilitation of the Kariba Dam Recently, the Institute of Risk Management of South Africa has just warned that the Kariba dam is in desperate need of rehabilitation, otherwise the whole dam would collapse, putting 3.5 million people at risk. Aimed to look for the best strategy with the three options listed to maintain the dam, we employ AHP model to filter factors and determine two most influential criteria, including potential costs and benefits. With the weight of each criterion worked out, our model demonstrates that option 3is the optimal choice. According to our choice, we are required to offer the recommendation as to the number and placement of the new dams. Regarding it as a set covering problem, we develop a multi-objective optimization model to minimize the number of smaller dams while improving the water resources management capacity. Applying TOPSIS evaluation method to get the demand of the electricity and water, we solve this problem with genetic algorithm and get an approximate optimal solution with 12 smaller dams and determine the location of them. Taking the strategy for modulating the water flow into account, we construct a joint operation of dam system to simulate the relationship among the smaller dams with genetic algorithm approach. We define four kinds of year based on the Kariba’s climate data of climate, namely, normal flow year, low flow year, high flow year and differential year. Finally, these statistics could help us simulate the water flow of each month in one year, then we obtain the water resources planning and modulating strategy. The sensitivity analysis of our model has pointed out that small alteration in our constraints (including removing an important city of the countries and changing the measurement of the economic development index etc.) affects the location of some of our dams slightly while the number of dams remains the same. Also we find that the output coefficient is not an important factor for joint operation of the dam system, for the reason that the discharge index and the capacity index would not change a lot with the output coefficient changing.
数学建模国家一等奖优秀论文
2014高教社杯全国大学生数学建模竞赛 承诺书 我们仔细阅读了《全国大学生数学建模竞赛章程》和《全国大学生数学建模竞赛参赛规则》(以下简称为“竞赛章程和参赛规则”,可从全国大学生数学建模竞赛网站下载)。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛章程和参赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛章程和参赛规则,以保证竞赛的公正、公平性。如有违反竞赛章程和参赛规则的行为,我们将受到严肃处理。 我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。 我们参赛选择的题号是(从A/B/C/D中选择一项填写):B 我们的报名参赛队号为(8位数字组成的编号): 所属学校(请填写完整的全名): 参赛队员(打印并签名) :1. 2. 3.
指导教师或指导教师组负责人(打印并签名): ?(论文纸质版与电子版中的以上信息必须一致,只是电子版中无需签名。以上内容请仔细核对,提交后将不再允许做任何修改。如填写错误,论文可能被取消评奖资格。) 日期: 2014 年 9 月15日 赛区评阅编号(由赛区组委会评阅前进行编号):
2014高教社杯全国大学生数学建模竞赛 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号):赛区评阅记录(可供赛区评阅时使用):
数学建模论文写作—模型假设
数学建模论文写作—模型假设 1.每个交巡警服务平台的职能、警力配备都基本相同 2.事故发生地都近似模拟在各路口节点。 3.每个交巡警服务平台配备一辆警车,一旦遇到突发事件,即刻从平台驶向案 发地,不考虑期间的反应时间。 4.不考虑平台所在节点本身作为案发处的出警情况。 5.相邻两个路口节点之间的道路认为是直线且无其他小道。并且各处的路况都 是相同的,不考虑交通意外(如汽车抛锚、堵塞、路口停顿等)、气候的影响,不考虑转弯时的车速变化等等,这些都是为了保证警车任意时刻在任意路段上的行驶速度均为60km/h。 6.两个不同节点处的发案率是相互独立的,即任意时刻,两互异节点的法案情 况两个不同节点处的案发情况不发生单向或双向的影响 7.不存在越点管辖和交叉管辖的情况。 以下是对上述假设的一些说明,及对在解决问题的过程中,我们发现的题中需要阐述的部分概念、条件与因素的分析: 对于假设一,每个交巡警服务平台的职能、警力配备这两个基本参数都大致相同,这是我们分析整个问题的前提假设,实质就是各平台在我们模型中的权数是相同的。 对于假设二,我们将案发的地点限制在各节点上。其一,在实际生活中,道路上的任何一点都有发案的可能,但通过查阅全国多个大中型城市道路网络案发的资料数据,完全可以得出交通网络中路口节点的案发率远远高于其他路段的结论;其二,考虑到题目给出的该市六区交通网络和平台设置的相关信息数据表(附录二)中只相应地给出了各路口节点的发案率,所以要将非节点处的发案情况计入在内,必须先模拟出道路上各点发案率的函数,这在实际操作中是极为困难的,很难把握其精确度,易造成较大误差。所以可以采用将其离散化的方法,仅选取节点便是最朴素的一种离散化思想的运用。 对于假设三,为何平台所配警车始终以相应平台所在节点为起点驶向案发地,将在下文“模型求解”中详细讨论,这里就不再赘述。不考虑期间的反应时间也是为了简化模型、去除次要因素的影响。 对于假设四,一旦突发事件发生在平台所在节点,那么所需时间一定是零,也就失去了其讨论的价值,所以不考虑平台所在节点本身作为案发处的出警情况。 特别是定量分析的基础。 在假设七中,所谓“越点管辖”是指平台A的管辖区域中存在一部分(甚至全部)与A所在节点间还隔有其他(至少一个)平台(如图2-1中的平台B)。
数学建模国家一等奖优秀论文
2014高教社杯全国大学生数学建模竞赛 承诺书 我们仔细阅读了《全国大学生数学建模竞赛章程》和《全国大学生数学建模竞赛参赛规则》(以下简称为“竞赛章程和参赛规则”,可从全国大学生数学建模竞赛网站下载)。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛章程和参赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛章程和参赛规则,以保证竞赛的公正、公平性。如有违反竞赛章程和参赛规则的行为,我们将受到严肃处理。 我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。
我们参赛选择的题号是(从A/B/C/D中选择一项填写): B 我们的报名参赛队号为(8位数字组成的编号): 所属学校(请填写完整的全名): 参赛队员 (打印并签名) :1. 2. 3. 指导教师或指导教师组负责人 (打印并签名): (论文纸质版与电子版中的以上信息必须一致,只是电子版中无需签名。以 上内容请仔细核对,提交后将不再允许做任何修改。如填写错误,论文可能被取 消评奖资格。) 日期:2014 年9 月 15日 赛区评阅编号(由赛区组委会评阅前进行编号):
2014高教社杯全国大学生数学建模竞赛 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号):赛区评阅记录(可供赛区评阅时使用):
全国大学生数学建模竞赛论文写作要求
全国大学生数学建模竞赛论文写作要求 题目:明确题目意思 一、摘要:500个字左右,包括模型的主要特点、建模方法和主要结果 二、关键字:3-5个 三.问题重述。略 四.模型假设 根据全国组委会确定的评阅原则,基本假设的合理性很重要。 (1)根据题目中条件作出假设 (2)根据题目中要求作出假设 关键性假设不能缺;假设要切合题意 五.模型的建立 (1)基本模型: 1) 首先要有数学模型:数学公式、方案等 2) 基本模型,要求完整,正确,简明 (2)简化模型 1)要明确说明:简化思想,依据 2)简化后模型,尽可能完整给出 (3)模型要实用,有效,以解决问题有效为原则。 数学建模面临的、要解决的是实际问题, 不追求数学上:高(级)、深(刻)、难(度大)。 u 能用初等方法解决的、就不用高级方法, u 能用简单方法解决的,就不用复杂方法, u 能用被更多人看懂、理解的方法, 就不用只能少数人看懂、理解的方法。 (4)鼓励创新,但要切实,不要离题搞标新立异 数模创新可出现在 ▲建模中,模型本身,简化的好方法、好策略等, ▲模型求解中 ▲结果表示、分析、检验,模型检验 ▲推广部分 (5)在问题分析推导过程中,需要注意的问题: u 分析:中肯、确切 u 术语:专业、内行;; u 原理、依据:正确、明确, u 表述:简明,关键步骤要列出 u 忌:外行话,专业术语不明确,表述混乱,冗长。 六.模型求解 (1)需要建立数学命题时: 命题叙述要符合数学命题的表述规范, 尽可能论证严密。 (2)需要说明计算方法或算法的原理、思想、依据、步骤。
若采用现有软件,说明采用此软件的理由,软件名称 (3)计算过程,中间结果可要可不要的,不要列出。 (4)设法算出合理的数值结果。 5.结果分析、检验;模型检验及模型修正;结果表示 (1)最终数值结果的正确性或合理性是第一位的; (2)对数值结果或模拟结果进行必要的检验。 结果不正确、不合理、或误差大时,分析原因, 对算法、计算方法、或模型进行修正、改进; (3)题目中要求回答的问题,数值结果,结论,须一一列出;(4)列数据问题:考虑是否需要列出多组数据,或额外数据对数据进行比较、分析,为各种方案的提出提供依据; (5)结果表示:要集中,一目了然,直观,便于比较分析 ▲数值结果表示:精心设计表格;可能的话,用图形图表形式▲求解方案,用图示更好 (6)必要时对问题解答,作定性或规律性的讨论。 最后结论要明确。 七.模型评价 优点突出,缺点不回避。 改变原题要求,重新建模可在此做。 推广或改进方向时,不要玩弄新数学术语。 7.参考文献 八.附录 详细的结果,详细的数据表格,可在此列出。 但不要错,错的宁可不列。 主要结果数据,应在正文中列出,不怕重复。 检查答卷的主要三点,把三关: n 模型的正确性、合理性、创新性 n 结果的正确性、合理性 n 文字表述清晰,分析精辟,摘要精彩
美赛:13215---数模英文论文
Team Control Number For office use only 13215 For office use only T1 ________________ F1 ________________ T2 ________________ F2 ________________ T3 ________________ Problem Chosen F3 ________________ T4 ________________ F4 ________________ C 2012 Mathematical Contest in Modeling (MCM) Summary Sheet (Attach a copy of this page to each copy of your solution paper.) Type a summary of your results on this page. Do not include the name of your school, advisor, or team members on this page. Message Network Modeling for Crime Busting Abstract A particularly popular and challenging problem in crime analysis is to identify the conspirators through analysis of message networks. In this paper, using the data of message traffic, we model to prioritize the likelihood of one’s being conspirator, and nominate the probable conspiracy leaders. We note a fact that any conspirator has at least one message communication with other conspirators, and assume that sending or receiving a message has the same effect, and then develop Model 1, 2 and 3 to make a priority list respectively and Model 4 to nominate the conspiracy leader. In Model 1, we take the amount of one’s suspicious messages and one’s all messages with known conspirators into account, and define a simple composite index to measure the likelihood of one’s being conspirator. Then, considering probability relevance of all nodes, we develop Model 2 based on Law of Total Probability . In this model, probability of one’s being conspirator is the weight sum of probabilities of others directly linking to it. And we develop Algorithm 1 to calculate probabilities of all the network nodes as direct calculation is infeasible. Besides, in order to better quantify one’s relationship to the known conspirators, we develop Model 3, which brings in the concept “shortest path” of graph theory to create an indicator evaluating the likelihood of one’s being conspirator which can be calculated through Algorithm 2. As a result, we compare three priority lists and conclude that the overall rankings are similar but quite changes appear in some nodes. Additionally, when altering the given information, we find that the priority list just changes slightly except for a few nodes, so that we validate the models’ stability. Afterwards, by using Freeman’s centrality method, we develop Model 4 to nominate three most probable leaders: Paul, Elsie, Dolores (senior manager). What’s more, we make some remarks about the models and discuss what could be done to enhance them in the future work. In addition, we further explain Investigation EZ through text and semantic network analysis, so to illustrate the models’ capacity of applying to more complicated cases. Finally, we briefly state the application of our models in other disciplines.
全国大学生数学建模竞赛论文格式规范
全国大学生数学建模竞赛论文格式规范 (全国大学生数学建模竞赛组委会,2019年修订稿) 为了保证竞赛的公平、公正性,便于竞赛活动的标准化管理,根据评阅工作的实际需要,竞赛要求参赛队分别提交纸质版和电子版论文,特制定本规范。 一、纸质版论文格式规范 第一条,论文用白色A4纸打印(单面、双面均可);上下左右各留出至少2.5厘米的页边距;从左侧装订。 第二条,论文第一页为承诺书,第二页为编号专用页,具体内容见本规范第3、4页。 第三条,论文第三页为摘要专用页(含标题和关键词,但不需要翻译成英文),从此页开始编写页码;页码必须位于每页页脚中部,用阿拉伯数字从“1”开始连续编号。摘要专用页必须单独一页,且篇幅不能超过一页。 第四条,从第四页开始是论文正文(不要目录,尽量控制在20页以内);正文之后是论文附录(页数不限)。 第五条,论文附录至少应包括参赛论文的所有源程序代码,如实际使用的软件名称、命令和编写的全部可运行的源程序(含EXCEL、SPSS等软件的交互命令);通常还应包括自主查阅使用的数据等资料。赛题中提供的数据不要放在附录。如果缺少必要的源程序或程序不能运行(或者运行结果与正文不符),可能会被取消评奖资格。论文附录必须打印装订在论文纸质版中。如果确实没有源程序,也应在论文附录中明确说明“本论文没有源程序”。 第六条,论文正文和附录不能有任何可能显示答题人身份和所在学校及赛区的信息。 第七条,引用别人的成果或其他公开的资料(包括网上资料)必须按照科技论文写作的规范格式列出参考文献,并在正文引用处予以标注。 第八条,本规范中未作规定的,如排版格式(字号、字体、行距、颜色等)不做统一要求,可由赛区自行决定。在不违反本规范的前提下,各赛区可以对论文增加其他要求。 二、电子版论文格式规范 第九条,参赛队应按照《全国大学生数学建模竞赛报名和参赛须知》的要求提交以
2019数学建模美赛论文
2019 MCM/ICM Summary Sheet (Your team's summary should be included as the first page of your electronic submission.) Type a summary of your results on this page. Do not include the name of your school, advisor , or team members on this page. Ecosystems provide many natural processes to maintain a healthy and sustainable environment after human life. However, over the past decades, rapid industrial development and other anthropogenic activities have been limiting or removing ecosystem services. It is necessary to access the impact of human activities on biodiversity and environmental degradation. The main purpose of this work is to understand the true economic costs of land use projects when ecosystem services are considered. To this end, we propose an ecological service assessment model to perform a cost benefit analysis of land use development projects of varying sites, from small-scale community projects to large national projects. We mainly focus on the treatment cost of environmental pollution in land use from three aspects: air pollution, solid waste and water pollution. We collect pollution data nationwide from 2010 to 2015 to estimate economic costs. We visually analyze the change in economic costs over time via some charts. We also analyze how the economic cost changes with time by using linear regression method. We divide the data into small community projects data (living pollution data) and large natural data (industrial pollution data). Our results indicate that the economic costs of restoring economical services for different scales of land use are different. For small-scale land, according to our analysis, the treatment cost of living pollution is about 30 million every year in China. With the rapid development of technology, the cost is lower than past years. For large-scale land, according to our analysis, the treatment cost of industrial pollution is about 8 million, which is lower than cost of living pollution. Meanwhile the cost is trending down due to technology development. The theory developed here provides a sound foundation for effective decision making policies on land use projects. Key words: economic cost , ecosystem service, ecological service assesment model, pollution. Team Control Number For office use only For office use only T1 ________________ F1 ________________ T2 ________________ F2 ________________ T3 ________________ Problem Chosen F3 ________________ T4 ________________ F4 ________________ E
数学建模优秀论文模板(全国一等奖模板)
Haozl觉得数学建模论文格式这么样设置 版权归郝竹林所有,材料仅学习参考 版权:郝竹林 备注☆ ※§等等字符都可以作为问题重述左边的。。。。。一级标题 所有段落一级标题设置成段落前后间距13磅 图和表的标题采用插入题注方式题注样式在样式表中设置居中五号字体 Excel中画出的折线表字体采用默认格式宋体正文10号 图标题在图上方段落间距前0.25行后0行 表标题在表下方段落间距前0行后0.25行 行距均使用单倍行距 所有段落均把4个勾去掉 注意Excel表格插入到word的方式在Excel中复制后,粘贴,word2010粘贴选用使用目标主题嵌入当前 Dsffaf 所有软件名字第一个字母大写比如E xcel 所有公式和字母均使用MathType编写 公式编号采用MathType编号格式自己定义
农业化肥公司的生产与销售优化方案 摘 要 要求总分总 本文针对储油罐的变位识别与罐容表标定的计算方法问题,运用二重积分法和最小二乘法建立了储油罐的变位识别与罐容表标定的计算模型,分别对三种不同变位情况推导出的油位计所测油位高度与实际罐容量的数学模型,运用matlab 软件编程得出合理的结论,最终对模型的结果做出了误差分析。 针对问题一要求依据图4及附表1建立积分数学模型研究罐体变位后对罐容表的影响,并给出罐体变位后油位高度间隔为1cm 的罐容表标定值。我们作图分析出实验储油罐出现纵向倾斜 14.时存在三种不同的可能情况,即储油罐中储油量较少、储油量一般、储油量较多的情况。针对于每种情况我们都利用了高等数学求容积的知识,以倾斜变位后油位计所测实际油位高度为积分变量,进行两次积分运算,运用MATLAB 软件推导出了所测油位高度与实际罐容量的关系式。并且给出了罐体倾斜变位后油位高度间隔为1cm 的罐容标定值(见表1),最后我们对倾斜变位前后的罐容标定值残差进行分析,得到样本方差为4103878.2-?,这充分说明残差波动不大。我们得出结论:罐体倾斜变位后,在同一油位条件下倾斜变位后罐容量比变位前罐容量少L 243。 表 1.1 针对问题二要求对于图1所示的实际储油罐,试建立罐体变位后标定罐容表的数学模型,即罐内储油量与油位高度及变位参数(纵向倾斜角度α和横向偏转角度β)之间的一般关系。利用罐体变位后在进/出油过程中的实际检测数据(附件2),根据所建立的数学模型确定变位参数,并给出罐体变位后油位高度间隔为10cm 的罐容表标定值。进一步利用附件2中的实际检测数据来分析检验你们模型的正确性与方法的可靠性。我们根据实际储油罐的特殊构造将实际储油罐分为三部分,左、右球冠状体与中间的圆柱体。运用积分的知识,按照实际储油罐的纵向变位后油位的三种不同情况。利用MATLAB 编程进行两次积分求得仅纵向变位时油量与油位、倾斜角α的容积表达式。然后我们通过作图分析油罐体的变位情况,将双向变位后的油位h 与仅纵向变位时的油位0h 建立关系表达式01.5(1.5)cos h h β=--,从而得到双向变位油量与油位、倾斜角α、偏转角β的容积表达式。利用附件二的数据,采用最小二乘法来确定倾斜角α、偏转角β的值,用matlab 软件求出03.3=α、04=β α=3.30,β=时总的平均相对误差达到最小,其最小值为0.0594。由此得到双向变位后油量与油位的容积表达式V ,从而确定了双向变位后的罐容表(见表2)。 本文主要应用MATLAB 软件对相关的模型进行编程求解,计算方便、快捷、准确,整篇文章采取图文并茂的效果。文章最后根据所建立的模型用附件2中的实际检测数据进行了误差分析,结果可靠,使得模型具有现实意义。 关键词:罐容表标定;积分求解;最小二乘法;MATLAB ;误差分
数学建模论文格式
(论文题目,3 摘要(4号黑体居中、加粗,两个字之间空3个英文空格) 离散化为光线,直接用光线密度来描述光强度。 对于问题1,我们采用追迹法求解模型,其主要思想是:追踪点光源发向空间中的每一条光线的行迹,确定其在测试屏上的落点,从而确定B、C处的光强度比值。然后以此计算出所有满足设计要求的灯丝长度,最后衡量线光源功率,求得最优解。模型求解得:最佳灯丝长为4 = L mm。当灯丝长度确定后,代入模型中,问题2得解,亮区见图5。 作为追迹法的改进,提出简化算法。我们证明了如下定理: 到达B、C点连线的光线,来自于且仅来自于由B、C和焦点这三点确定的水平面。因此,只需追踪光源沿水平方向发出光线的行迹,即可确定B、C处的光强度。 对于问题2,为了更真实地反应实际情况,我们建立柱面光源模型,同时提出了“追源法”求解模型。其主要思想是:利用光路是可逆的原理,先后在B、C点放置点光源,用试探法求解发自B、C的光线照射在灯丝表面的范围,以此确定能够照射到B、C的灯丝表面的发光区域,再求解该区域照在B、C点的光强度比值,进而求解灯丝长度。模型求解得:最佳灯丝长为98 .3 = L mm。 对于问题3,参考实际需求,利用光照图的方法,重新分配测试点,以测出实际需要检测处的指标。求解得,只需在中轴线下方0.2m和0.3m处各添加一测试点即可。 针对论文的实际情况,对论文的优缺点做了评价,文章最后还给出了其他的改进方 注:摘要内容不超过一页。主要包括用什么方法,解决了什么问题,主要结果是什么,有什么特色。在完成基本问题的基础上,还做了哪些有意义的工作等。 摘要中不要出现公式和表格。篇幅A4纸大半页,不超过1页。
数学建模美赛论文格式中文版
你的论文需要从此开始 请居中 使用Arial14字体 第一作者,第二作者和其他(使用Arial14字体) 1.第一作者的详细地址,包括国籍和email(使用Arial11) 2.第二作者的详细地址,包括国籍和email(使用Arial11) 3.将所有的详细信息标记为相同格式 关键词 列出文章的关键词。这些关键词会被出版方用作关键词索引(使用Arial11字体) 论文正文使用Times New Roman12字体 摘要 这一部分阐述说明了如何为TransTechPublications.准备手稿。最好阅读这些用法说明并且整篇论文都是遵照这个提纲。手稿的正文部分应该是17cm*25cm(宽*高)的格式(或者是6.7*9.8英尺)。请不要在这个区域以外书写。请使用21*29厘米或8*11英尺的质量较好的白纸。你的手稿可能会被出版商缩减20%。在制图和绘表格时候请特别注意这些准则。 引言 所有的语言都应该是英语。请备份你的手稿(以防在邮寄过程中丢失)我们收到手稿即默认为原作者允许我们在期刊和书报出版。如果作者在论文中使用了其他刊物中的图表,他们需要联系原作者,获取使用权。将单词或词组倾斜以示强调。除了每一部分的标题(标记部分的标题),不要加粗正文或大写首字母。使用激光打印机,而不是点阵打印机 正文的组织: 小标题 小标题应该加粗并注意字母的大小写。第二等级的小标题被视为后面段落的一部分(就像这一大段的一小部分的开头) 页码 不要打印页码。请用淡蓝色铅笔在每一张纸的左下角(在打印区域以外)标注数字。 脚注 脚注应该单独放置并且和正文分开理想地情况下,脚注应该出现在参考文献页,并且放在文章的末尾,和正文用分割线分开。 表格 表格(如表一,表二,...)应该放在正文当中,是正文的一部分,但是,要避免文本混乱。一个描述性的表格标题要放在图表的下方。标题应该独立的放在表格的下方或旁边。 表中的单位应放在中括号中[兆伏]如果中括号不可用,需使用大括号{兆}或小括号(兆)。1.这就是脚注
数学建模个人经验谈:论文写作
数学建模个人经验谈:论文写作 、论文是建模中最后的一环也是最关键的一环,这环做好了那就圆满了,做砸了全功尽弃了。关于怎么写论文已经有很多文章介绍了,这就足以可见写论文的重要性了。 先介绍下写论文的工具,或许很多朋友要纳闷了,写论文什么工具,不就是电脑呗,还有朋友会进一步说用word呗,两者都对,当然用电脑的这个说法绝对正确,如果说是用手那更对了,呵呵,其实偶指的工具是软件。很多人用word,对于word就不重点介绍了,要重点介绍的是tex,它是一个功能强大的特别适合排版科技文献和书籍的格式化排版程序。它是由著名计算机专家和数学家斯坦福大学D.E.Knuth教授研制的。20世纪60年代,knuth准备出系列专著《计算机程序设计技巧》(The Arts of Computer Programming),前三册已经出版,当他正在撰写第四册时,出版社拿来第二册的第二版给他过目,结果令他大失所望,因为当时出版社的印刷技术没有使他的书稿更好看,反而变糟了,尤其是在数学公式和字体上面的缺陷更令他无法接受。于是他就打算自己写一个既能供科学家编排手稿又符合出版社印刷要求的高质量的计算机排版系统。这就是TeX排版系统的由来。 TeX系统是由Pascal语言编写的,程序的源代码也是公开的。它包含300条基本命令和600条扩展命令,几乎可以排版任何格式的文献,如一般文章、报告、书刊和诗集等,对数学公式的排版也被公认是最好的。TeX系统的优点之一是它还支持命令宏,这使得使用TeX成为一种乐趣,用户可以自己编写红包来定义更多、更方便的新命令,这也是TeX 能得以迅速发展的原因。而且TeX是一个可移植性系统,可以运行于所有类型的计算机(如苹果机、IBM PC机及大型工作站)和各种操作系统(如DOS、Windows、Unix等),它的排版结果dvi文件于输出设备无关,可以在不同的操作系统上显示和打印。TeX源文件是ASCII码文件,可以方便地在网络上传播。目前,大多数学术部分和校园网上都安装有TeX 系统。国际上许多出版机构也采用TeX系统来排版书刊,不少出版社还要求作者提供手稿的TeX源文件。
数学建模全国赛07年A题一等奖论文
关于中国人口增长趋势的研究 【摘要】 本文从中国的实际情况和人口增长的特点出发,针对中国未来人口的老龄化、出生人口性别比以及乡村人口城镇化等,提出了Logistic、灰色预测、动态模拟等方法进行建模预测。 首先,本文建立了Logistic阻滞增长模型,在最简单的假设下,依照中国人口的历史数据,运用线形最小二乘法对其进行拟合,对2007至2020年的人口数目进行了预测,得出在2015年时,中国人口有13.59亿。在此模型中,由于并没有考虑人口的年龄、出生人数男女比例等因素,只是粗略的进行了预测,所以只对中短期人口做了预测,理论上很好,实用性不强,有一定的局限性。 然后,为了减少人口的出生和死亡这些随机事件对预测的影响,本文建立了GM(1,1) 灰色预测模型,对2007至2050年的人口数目进行了预测,同时还用1990至2005年的人口数据对模型进行了误差检验,结果表明,此模型的精度较高,适合中长期的预测,得出2030年时,中国人口有14.135亿。与阻滞增长模型相同,本模型也没有考虑年龄一类的因素,只是做出了人口总数的预测,没有进一步深入。 为了对人口结构、男女比例、人口老龄化等作深入研究,本文利用动态模拟的方法建立模型三,并对数据作了如下处理:取平均消除异常值、对死亡率拟合、求出2001年市镇乡男女各年龄人口数目、城镇化水平拟合。在此基础上,预测出人口的峰值,适婚年龄的男女数量的差值,人口老龄化程度,城镇化水平,人口抚养比以及我国“人口红利”时期。在模型求解的过程中,还对政府部门提出了一些有针对性的建议。此模型可以对未来人口做出细致的预测,但是需要处理的数据量较大,并且对初始数据的准确性要求较高。接着,我们对对模型三进行了改进,考虑人为因素的作用,加入控制因子,使得所预测的结果更具有实际意义。 在灵敏度分析中,首先针对死亡率发展因子θ进行了灵敏度分析,发现人口数量对于θ的灵敏度并不高,然后对男女出生比例进行灵敏度分析得出其灵敏度系数为0.8850,最后对妇女生育率进行了灵敏度分析,发现在生育率在由低到高的变化过程中,其灵敏度在不断增大。 最后,本文对模型进行了评价,特别指出了各个模型的优缺点,同时也对模型进行了合理性分析,针对我国的人口情况给政府提出了建议。 关键字:Logistic模型灰色预测动态模拟 Compertz函数