如何做数据挖掘
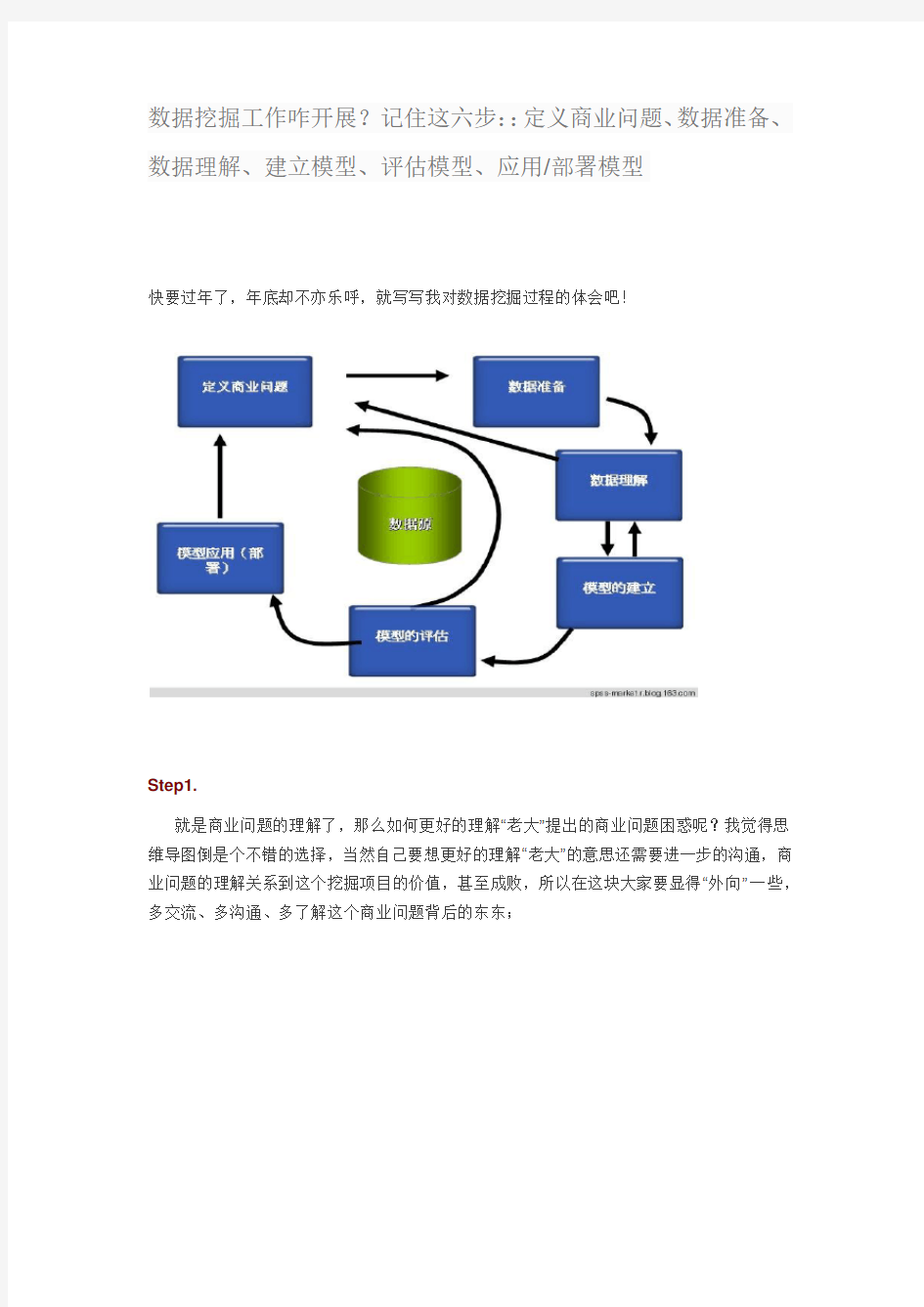
数据挖掘工作咋开展?记住这六步::定义商业问题、数据准备、数据理解、建立模型、评估模型、应用/部署模型
快要过年了,年底却不亦乐呼,就写写我对数据挖掘过程的体会吧!
Step1.
就是商业问题的理解了,那么如何更好的理解“老大”提出的商业问题困惑呢?我觉得思维导图倒是个不错的选择,当然自己要想更好的理解“老大”的意思还需要进一步的沟通,商业问题的理解关系到这个挖掘项目的价值,甚至成败,所以在这块大家要显得“外向”一些,多交流、多沟通、多了解这个商业问题背后的东东;
step2.
接下来就是需要提取的字段,也就是数据挖掘的宽表,这点就要和企业的DBA人员多多交流,看数据库中各个维度的表格都有什么字段,主要关联的主键有那些,那么如何选取字段呢?这就需要自己把自己与“老大”共同讨论的思维导图拿出来看看,这样就有提取那些字段的感觉了,这部分大多数的提取是自己对商业问题的感觉或者一些前辈的经验;
Step3
数据的ETL,这部分一般的时间占数据挖掘项目的70%左右,为什么数据的ETL如此重要呢?万丈高楼平地起,如果连地基都是“豆腐渣工程”的话,那么再华丽的楼房也没人愿意掏腰包;嘿嘿,开个玩笑;数据的ETL主要是一些异常值、空值(miss值)、错误数值的处理,这部分一般需要根据数据自身的分布、简单的统计知识、该字段体现的业务特点、自己的经验进行的,也就是这一部分的处理主要是统计知识+项目经验+业务特点;
Step4
建立模型所需要的变量如何选?当然目标变量(Y)一般都是事前设定好的,那么X如何找呢?大多数都是应用相关分析、特征选择、描述性的统计图表(分箱图、散点图等),这里我只想说一句算法是死的,有时候我们根据算法得出来的X对Y没有影响,但在实际的业务中影响却很大,所以大家不要过于依赖算法、工具,我曾经因为这点,被人批了,555~~~~~
Step5
建立数据挖掘模型,这块是许多同行相当痴迷的地方,我也不例外,记得大学毕业去北京的时候,就在咨询公司研究算法什么的,后来经过leader的几次谈话,自己才慢慢走出了误区;一句话,我们追求的是模型带来的效益,所以没那么多时间去玩模型、搞算法;但是作为数据挖掘从业者,最基本的应该是了解各种算法的原理,还有一些数据挖掘模型参数的意义,比如在spss clementine中就有自定义和专家两个供大家选择,所以掌握一些参数的意义也是有必要的,大家可以上网下一些人大数据挖掘的视频教程,里面讲的比较详细;
Step6
模型评估,大部分都是借助数据挖掘自带的评估模型来做,什么准确度、收益率等,理论上很完美,实际中就一定有疗效吗?非也!有时候模型跑出来的信息很诡异的,建模人员都无法知道这个结果如何去解读,这时我倒是觉得可以从模型中选取一部分人群来做一下简单的调研,或许能获得更多数据背后的东西,也能为自己的片子多几分数据解读的色彩,何乐而不为呢?
Step7
模型可视化展示,可视化一直是一些数据服务公司所追求的东东,也是我们从业人员一种传达信息的方式,对于一个专题的数据挖掘模型,我相信大家都能通过一些图表、表格或者更炫的PPT搞定,打个岔,我常常遇到这样的问题,在对多维度做交叉分析时,因为涉及许多数据维度的钻取而很难展现给决策者,这时可以用水晶易表来做动态的展示,但是遇到更复杂的逻辑呢?大家不难发现现在大部分的数据分析系统或者叫运营体系的分析维度都是作为一个content展现给使用者,从数据从业者的角度来看,这只是从不同维度对数据进行了切割而已,谈不上真正的数据可视化,路漫漫兮修远兮!业务、维度、用户交互三者融合才是王道;
s如何通过线上营销推动线下业务:
数据挖掘试卷一
数据挖掘整理(熊熊整理-----献给梦中的天涯) 单选题 1.下面哪种分类方法是属于神经网络学习算法?() A. 判定树归纳 B. 贝叶斯分类 C. 后向传播分类 D. 基于案例的推理 2.置信度(confidence)是衡量兴趣度度量( A )的指标。 A、简洁性 B、确定性 C.、实用性 D、新颖性 3.用户有一种感兴趣的模式并且希望在数据集中找到相似的模式,属于数据挖掘哪一类任务?(A) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 4.数据归约的目的是() A、填补数据种的空缺值 B、集成多个数据源的数据 C、得到数据集的压缩表示 D、规范化数据 5.下面哪种数据预处理技术可以用来平滑数据,消除数据噪声? A.数据清理 B.数据集成 C.数据变换 D.数据归约 6.假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内?(B) A 第一个 B 第二个 C 第三个 D 第四个 7.下面的数据操作中,()操作不是多维数据模型上的OLAP操作。 A、上卷(roll-up) B、选择(select) C、切片(slice) D、转轴(pivot) 8.关于OLAP和OLTP的区别描述,不正确的是: (C) A. OLAP主要是关于如何理解聚集的大量不同的数据.它与OTAP应用程序不同. B. 与OLAP应用程序不同,OLTP应用程序包含大量相对简单的事务. C. OLAP的特点在于事务量大,但事务内容比较简单且重复率高. D. OLAP是以数据仓库为基础的,但其最终数据来源与OLTP一样均来自底层的数据库系统,两者面对的用户是相同的 9.下列哪个描述是正确的?() A、分类和聚类都是有指导的学习 B、分类和聚类都是无指导的学习
医学数据挖掘
第一章 .填空 1.数据挖掘和知识发现的三大主要技术为:数据库、统计学、机器学习2.数据挖掘获得知识的表现形式主要有 6 种:规则、决策树、 知识基网络权值、公式、案例 3.规则是由前提条件、结论两部分组成 4.基于案例推理的基础是案例库 5.知识发现的基本步骤:数据选择、处理、转换、数据挖掘、解释与评价。数据挖掘是知识发现的关键步骤 6.数据挖掘的核心技术是:人工智能、机器学、统计学 7. 目前数据挖掘在医学领域的应用集中在疾病辅助诊断、药物开发、医院信息系统、遗传学等方面 二.名解 1.数据挖掘:在数据中正规的发现有效的、新颖的、潜在有用的、并且最终可以被读懂的模式的过程 2.案例推理:当要解决一个新问题时,利用相似性检索技术到案例库中搜索与新问题相似的案例,再经过对就案例的修改来解决新问题三.简答 1.数据挖掘的特点 a 挖掘对象是超大型的, b 发现隐含的知识, c 可以用于增进人类认知的知识, d 不是手工完成的 2.案例是解决新问题的一种知识,案例知识表示为三元组 a 问题描述:对求解的问题及周围环境的所有特征的描述, b 解描述:
对问题求解方案的描述,c 效果描述:描述解决方案后的结果情况,是失败还是成功 3.医学数据挖掘存在的关键问题 a 数据预处理, b 信息融合技术, c 快速的鲁棒的书库挖掘算法, d 提供知识的准确性和安全性 4.数据挖掘在遗传学方面的应用 遗传学的研究表明,遗传疾病的发生是由基因决定的,基因数据库搜索技术在基因研究上做出了很多重大发现,其工作主要包括:a 从各种生物体的大量序列中定位出具有某种功能的基因,b 在基因中搜索与某种具有高阶结构或功能的蛋白质相似的高阶结构序列 第二章 一.填空 1.的对象分为:关系型、数据仓库、文本、复杂类型2.从用户角度来看,数据仓库的基本组成包括:数据源、数据存储、应用工具、可视化用户界面 3.数据仓库是最流行的数据模型是多维数据模型,多维数据模型将数据看作是数据立方体的形式,数据立方体是由维和事实来定义 4.常用的多维数据模式包括:星型模式、雪花模式、事实星座模式。星型模式是由事实表和维表构成 5. DM分为:WEB内容挖掘、WEB结构挖掘、WEB使用 挖掘 二.名解 1. 数据仓库:一个面向主题的、集成的、时变的、非易失的数
数据挖掘中分类技术应用
分类技术在很多领域都有应用,例如可以通过客户分类构造一个分类模型来对银行贷款进行风险评估;当前的市场营销中很重要的一个特点是强调客户细分。客户类别分析的功能也在于此,采用数据挖掘中的分类技术,可以将客户分成不同的类别,比如呼叫中心设计时可以分为:呼叫频繁的客户、偶然大量呼叫的客户、稳定呼叫的客户、其他,帮助呼叫中心寻找出这些不同种类客户之间的特征,这样的分类模型可以让用户了解不同行为类别客户的分布特征;其他分类应用如文献检索和搜索引擎中的自动文本分类技术;安全领域有基于分类技术的入侵检测等等。机器学习、专家系统、统计学和神经网络等领域的研究人员已经提出了许多具体的分类预测方法。下面对分类流程作个简要描述: 训练:训练集——>特征选取——>训练——>分类器 分类:新样本——>特征选取——>分类——>判决 最初的数据挖掘分类应用大多都是在这些方法及基于内存基础上所构造的算法。目前数据挖掘方法都要求具有基于外存以处理大规模数据集合能力且具有可扩展能力。 神经网络 神经网络是解决分类问题的一种行之有效的方法。神经网络是一组连接输入/输出单元的系统,每个连接都与一个权值相对应,在将简单的单元连接成较复杂的系统后,通过并行运算实现其功能,其中系统的知识存储于网络结构和各单元之间的连接权中。在学习阶段,通过调整神经网络的权值,达到对输入样本的正确分类。神经网络有对噪声数据的高承受能力和对未经训练数据的模式分类能力。神经网
络概括性强、分类精度高,可以实现有监督和无监督的分类任务,所以神经网络在分类中应用非常广泛。 在结构上,可以把一个神经网络划分为输入层、输出层和隐含层(见图4)。网络的每一个输入节点对应样本一个特征,而输出层节点数可以等于类别数,也可以只有一个,(输入层的每个节点对应一个个的预测变量。输出层的节点对应目标变量,可有多个)。在输入层和输出层之间是隐含层(对神经网络使用者来说不可见),隐含层的层数和每层节点的个数决定了神经网络的复杂度。 除了输入层的节点,神经网络的每个节点都与很多它前面的节点(称为此节点的输入节点)连接在一起,每个连接对应一个权重Wxy,此节点的值就是通过它所有输入节点的值与对应连接权重乘积的和作为一个函数的输入而得到,我们把这个函数称为活动函数或挤压函数。如图5中节点4输出到节点6的值可通过如下计算得到:
数据挖掘常用的方法
数据挖掘常用的方法 在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪 声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知 识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学习,统 计学等。通过对大数据高度自动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、用户调整市场政策、减少风险、理性面对市场,并做出正 确的决策。目前,在很多领域尤其是在商业领域如银行、电信、电商等,数据挖掘可 以解决很多问题,包括市场营销策略制定、背景分析、企业管理危机等。大数据的挖 掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法从不同的角度对数据进行挖掘。 (1)分类。分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。 可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情 况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。 (2)回归分析。回归分析反映了数据库中数据的属性值的特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。它可以应用到对数据序列的预测及相关关系的 研究中去。在市场营销中,回归分析可以被应用到各个方面。如通过对本季度销售的 回归分析,对下一季度的销售趋势作出预测并做出针对性的营销改变。 (3)聚类。聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的 相似性很小,跨类的数据关联性很低。 (4)关联规则。关联规则是隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现。关联规则的挖掘过程主要包括两个阶段:第一阶 段为从海量原始数据中找出所有的高频项目组;第二极端为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各 银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。 (5)神经网络方法。神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的以及那些以模糊、不完整、不严密的知 识或数据为特征的处理问题,它的这一特点十分适合解决数据挖掘的问题。典型的神 经网络模型主要分为三大类:第一类是以用于分类预测和模式识别的前馈式神经网络 模型,其主要代表为函数型网络、感知机;第二类是用于联想记忆和优化算法的反馈式神经网络模型,以Hopfield 的离散模型和连续模型为代表。第三类是用于聚类的自组
数据挖掘论文医学数据论文:医学数据挖掘综述
数据挖掘论文医学数据论文:医学数据挖掘综述 摘要:医学数据挖掘是提高医学信息管理水平,为疾病的诊断和治疗提供科学准确的决策,促进医疗发展的需要。该文主要介绍了医学数据的特点,医学数据挖掘的发展状况和应用的技术方法,同时展望了数据挖掘技术在医学领域的应用前景。 关键词:数据挖掘;医学数据;神经网络;关联规则 summary of medical data mining wang ju-qin (department of computer technology, wuxi institute of technology, wuxi 214121, china) abstract: medical data mining is necessary for improving the management level of medical information, providing scientific decision-making for the diagnosis and treatment of disease, and promoting the development of medicine. this paper mainly introduces the characters of mining medical data, the application and methods used in medicine, and also the application prospect medical field is outlined. key words: data mining; medical data; neural network; association rules
数据挖掘分类实验详细报告概论
《数据挖掘分类实验报告》 信息安全科学与工程学院 1120362066 尹雪蓉数据挖掘分类过程 (1)数据分析介绍 本次实验为典型的分类实验,为了便于说明问题,弄清数据挖掘具体流程,我们小组选择了最经典的决策树算法进行具体挖掘实验。 (2)数据准备与预处理 在进行数据挖掘之前,我们首先要对需要挖掘的样本数据进行预处理,预处理包括以下步骤: 1、数据准备,格式统一。将样本转化为等维的数据特征(特征提取),让所有的样 本具有相同数量的特征,同时兼顾特征的全面性和独立性 2、选择与类别相关的特征(特征选择) 3、建立数据训练集和测试集 4、对数据集进行数据清理 在本次实验中,我们选择了ILPD (Indian Liver Patient Dataset) 这个数据集,该数据集已经具有等维的数据特征,主要包括Age、Gender、TB、DB、Alkphos、Sgpt、Sgot、TP、ALB、A/G、classical,一共11个维度的数据特征,其中与分类类别相关的特征为classical,它的类别有1,2两个值。 详见下表: 本实验的主要思路是将该数据集分成训练集和测试集,对训练集进行训练生成模型,然后再根据模型对测试集进行预测。 数据集处理实验详细过程:
●CSV数据源处理 由于下载的原始数据集文件Indian Liver Patient Dataset (ILPD).csv(见下图)中间并不包含属性项,这不利于之后分类的实验操作,所以要对该文件进行处理,使用Notepad文件,手动将属性行添加到文件首行即可。 ●平台数据集格式转换 在后面数据挖掘的实验过程中,我们需要借助开源数据挖掘平台工具软件weka,该平台使用的数据集格式为arff,因此为了便于实验,在这里我们要对csv文件进行格式转换,转换工具为weka自带工具。转换过程为: 1、打开weka平台,点击”Simple CLI“,进入weka命令行界面,如下图所示: 2、输入命令将csv文件导成arff文件,如下图所示: 3、得到arff文件如下图所示: 内容如下:
数据挖掘分类算法比较
数据挖掘分类算法比较 分类是数据挖掘、机器学习和模式识别中一个重要的研究领域。通过对当前数据挖掘中具有代表性的优秀分类算法进行分析和比较,总结出了各种算法的特性,为使用者选择算法或研究者改进算法提供了依据。 一、决策树(Decision Trees) 决策树的优点: 1、决策树易于理解和解释.人们在通过解释后都有能力去理解决策树所表达的意义。 2、对于决策树,数据的准备往往是简单或者是不必要的.其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。 3、能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。 4、决策树是一个白盒模型。如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。 5、易于通过静态测试来对模型进行评测。表示有可能测量该模型的可信度。 6、在相对短的时间内能够对大型数据源做出可行且效果良好的结果。 7、可以对有许多属性的数据集构造决策树。 8、决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小。 决策树的缺点: 1、对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。 2、决策树处理缺失数据时的困难。 3、过度拟合问题的出现。 4、忽略数据集中属性之间的相关性。 二、人工神经网络 人工神经网络的优点:分类的准确度高,并行分布处理能力强,分布存储及学习能力强,对噪声神经有较强的鲁棒性和容错能力,能充分逼近复杂的非线性关系,具备联想记忆的功能等。 人工神经网络的缺点:神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值;不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;学习时间过长,甚至可能达不到学习的目的。
SAS+8.2+Enterprise+Miner数据挖掘实例
SAS 8.2 Enterprise Miner数据挖掘实例 目录 1.SAS 8.2 Enterprise Miner简介 (2) 2.EM工具具体使用说明 (2) 3.定义商业问题 (3) 4.创建一个工程 (4) 4.1调用EM (4) 4.2新建一个工程 (5) 4.3应用工作空间中的节点 (6) 5.数据挖掘工作流程 (6) 5.1定义数据源 (6) 5.2探索数据 (8) 5.2.1设置Insight节点 (8) 5.2.2察看Insight节点输出结果 (9) 5.3准备建模数据 (11) 5.3.1建立目标变量 (11) 5.3.2设置目标变量 (13) 5.3.3数据分割 (21) 5.3.4替换缺失值 (22) 5.4建模 (23) 5.4.1回归模型 (23) 5.4.2决策树模型 (25) 5.5评估模型 (28) 5.6应用模型 (30) 5.6.1抽取打分程序 (30) 5.6.2引入原始数据源 (31) 5.6.3查看结果 (32) 6.参考文献: (34)
1.SAS 8.2 Enterprise Miner简介 数据挖掘就是对观测到的庞大数据集进行分析,目的是发现未知的关系和以数据拥有者可以理解并对其有价值的新颖方式来总结数据。[1] 一个数据挖掘工程需要足够的软件来完成分析工作,为了计划、实现和成功建立一个数据挖掘工程,需要一个集成了所有分析阶段的软件解决方案,包括从数据抽样到分析和建模,最后公布结果信息。大部分专业统计数据分析软件只实现特定的数据挖掘技术,而SAS 8.2 Enterprise Miner是一个集成的数据挖掘系统,允许使用和比较不同的技术,同时还集成了复杂的数据库管理软件。SAS 8.2 Enterprise Miner把统计分析系统和图形用户界面(GUI)集成在一起,并与SAS协会定义的数据挖掘方法——SEMMA方法,即抽样(Sample)、探索(Explore)、修改(Modify)建模(Model)、评价(Assess)紧密结合,对用户友好、直观、灵活、适用方便,使对统计学无经验的用户也可以理解和使用。 Enterprise Miner简称EM,它的运行方式是通过在一个工作空间(workspace)中按照一定的顺序添加各种可以实现不同功能的节点,然后对不同节点进行相应的设置,最后运行整个工作流程(workflow),便可以得到相应的结果。 2.EM工具具体使用说明 EM中工具分为七类: ?Sample类包含Input Data Source、Sampling、Data Partition ?Explore类包含Distribution Explorer、Multiplot、Insight、 Association、Variable Selection、Link Analysis (Exp.) ?Modify类包含Data Set Attribute、Transform Variable、Filter Outliers、Replacement、Clustering、SOM/Kohonen、 Time Series(Exp.) ?Medel类包括Regression、Tree、Neural Network、 Princomp/Dmneural、User Defined Model、Ensemble、 Memory-Based Reasoning、Two Stage Model ?Assess类包括Assessment、Reporter
医院信息数据挖掘及数据可视化
中国科技信息2014年第22期·CHINA SCIENCE AND TECHNOLOGY INFORMATION Nov.2014 信息技术推广 -115- 概述 近些年来,信息技术快速发展,现代计算机信息应用 技术在医疗领域发挥了前所未有的作用,大型医院都已经建立了医院信息系统(Hospital Information System,HIS)随着HIS 的广泛使用,数据库中的医院信息不断累积增加。海量数据急剧增加,往往不能得到有效的应用;若没有办法深入理解数据库里面的信息,则将会失去医院信息的价值。所以,当前在医院信息化的建设过程中需要处理的问题之一就是如何充分地利用HIS 数据库中的宝贵信息资源来为临床科研、医院服务质量、医院领导决策、卫生统计等提供科学的依据。 随着各医院的HIS 大范围使用运行之后,其HIS 数据库中存储的数据不断增加,数据库中历史数据日益增多。在这种背景情况下,把数据挖掘技术和数据可视化技术应用到处理医院医疗数据上是一个大趋势。数据挖掘技术对部分医疗数据进行了处理,但所得结果不便于理解因而无法为专业人员提供更好支持,而针对传统数据挖掘技术所得到的各种模式能够提供集成统一的接口及多种形式、多种角度、多种维度的直观的可视化展现方式,可以为专业人员提供更强有力的支持。 国内外研究现状国外研究现状 早在2002年IBM 华生研究中心对以色列的耶路撒冷和哈达萨医院的病人病例,开发了Opal 工具包,对大量的骨髓移植数据进行了可视化显示,这是一个在生物信息学领域的信息可视化技术方面的很好的实用性实例。Brant Chee 等人相继于2008年和2009年提出了健康信息药物治疗方案的可视化和医疗卫生信息的社会可视化。进而实现了信息可视化在医疗领域的应用,并从中发现药物和社会团体之间的关联关系和环境对人的健康状况的影响。美国卡内基梅隆大学的Christopher 等人于2009年提出基于初级保健糖尿病风险的分类和评估的可视化方法。本研究与医学证据、统计降维技术和信息可视化相结合建立一个框架,从而开发信息可视化分类器用于糖尿病风险的评估患者群中。日本岛根大学的Shusaku Tsumoto 等人于2011年。他们提出了包括决策树、聚类分析、MDS 和三维数据挖掘的时空数据挖掘过程。结果表明,大量存储数据的复用为基于医院临床行为的分类表征时间趋势提供有力的工具。葡萄牙的Pedro Pereira Rodrigues 做了预测基于虚拟病人记录的访问日志的生存分析的医院临床报告的可视化的研究。马来西亚的Muhammad Sheraz Arshad Maik 等人从医生的视角研究了电子病历可视化系统在公立医院的使用,用抽象有效的病人数据直观显示, 以获取有效信息进而改善病人的护理。美国NeuroMedical 和Vysis 公司利用数据挖掘可视化技术,通过对其趋势分析进行药物筛选,为药品的研发进行蛋白质的分析,对药物副作用进行了探索,发现了药物间的副作用。Marinovm 等人提出通过数据挖掘可视化技术对糖尿病及并发症流行病学进行了研究。 国内研究现状 在国内,对于医院信息数据挖掘及数据可视化的发展相对较晚。北京大学袁晓如教授带领的北大可视化研究小组在图可视化、轨迹可视化,微博可视化等领域开展了相关的研究工作。浙江大学在医院信息系统的数据挖掘技术、可视化领域开展了相关的研究工作。清华大学的唐泽圣教授是国内较早进行可视化研究的学者之一,其研究领域涵盖了医学、地质学和气象学可视化分析。中科院软件所的田捷教授等在医学可视化领域取得了一些研究成果。浙江大学、北京大学也建立了可视化的国家重点实验室,并在可视化方面做了很多的工作。近几年我国对HIS 进行数据挖掘的研究相对国外较少,我们在银行、移动通信、证券、联通、保险、电信等相关行业虽然已经成功的应用数据挖掘技术,可是当前在HIS 中的应用还处于初始阶段。据报道对HIS 所产生的数据进行挖掘研究的机构,目前在国内有北京协和医院信息中心、解放军福州总医院信息中心等。 数据挖掘概述 数据挖掘及其在医疗研究中的应用 数据挖掘是在1989年提出来的,也称为数据库中的知识发现。挖掘的过程一般由确定挖掘的对象、数据准备、模型建立、数据挖掘、结果分析表述、挖掘应用等阶段组成。 当前的医疗机构的数字化增大了医院数据库医疗数据数量。在疾病的诊断、治疗和医疗研究方面都,这些宝贵的医疗信息提现的非常有价值。因此,怎样自动提升和处理医疗数据库,进而提供全局的、精准的保健措施和诊断决策,已经成为提高医院服务质量和促进医院长远发展而必须解决的新问题。医疗数据挖掘就在这种背景下应运而生。 数据挖掘应用于医疗方面被提出来之后,生物医疗工程领域就将这一领域应用到其中,并取得了相当大的成果。从指定医疗数据中找到医疗模式类是这项技术的主要功能。在文献中指出,在生物工程领域主要有两类典型的研究方向:描述生理规律或现象;预测和诊断疾病发作。可以发现医疗知识模式主要有:孤立点分析、聚类分析、概念/类别描述、关联分析、演变分析、分类和预测等。 所挖掘知识的类型 数据挖掘所挖掘的知识大致有几种:事物各方面的特 DOI:10.3969/j.issn.1001-8972.2014.22.043 医院信息数据挖掘及数据可视化 齐晨虹?高生鹏 兰州交通大学电子与信息工程学院齐晨虹(1989-),女,河南商丘市人,硕士研究生,主要研究方向为医疗数据挖掘及可视化方向。 齐晨虹
大数据在医疗方面有什么作用
数据挖掘随着计算机技术得到了广泛应用,从而提高了数据利用效率,拓展了知识发现的广度与深度。数据挖掘已有较多成熟方法,并在医学大数据挖掘中取得了一定成果。数据挖掘是指从数据库中,提取隐含在其中的人们事先未知、潜在的有用的信息和知识的过程。目前,医院已积累了大量医疗相关数据。 数据挖掘在医学大数据研究中已取得了较多成果,通过文献检索,总结了三方面的应用现状。 疾病早期预警医疗领域往往需要更精确的实时预警工具,而基于数据挖掘的疾病早期预警模型的建立,有助于提高疾病的早期诊断、预警和监护,同时,也有利于医疗机构采取预防和控制措施,减少疾病恶化及并发症的发生。 疾病早期预警,首先要收集与疾病相关的指标数据或危险因素,然后建立模型,从而发现隐含在数据之中的发病机制和病情之间的联系。Forkan等采集日常监测的心率、舒张压、收缩压、平均血压、呼吸率、血氧饱和度等生命体征数据,以J48决策树、随机森林树及序列最小优化算法等建立疾病预警模型,用于远程家庭监测,识别未曾诊断过的疾病发生,并将监测结果发送到医疗急救机构,实现生命体征大数据、病人及医疗机构的完整衔接,以降低突发疾病及死亡的发生率。 Easton等利用贝叶斯分类算法建立了中风后遗症死亡预测模型,认为中风后遗症死亡概率与中风发生后的时间长短成函数关系,有助于中风后遗症患者的后续监护。Tayefi等基于决策树算法建立了冠心病预测模型,该模型发现hs-CRP作为新的冠心病预测标志物,比传统的标志物(如FBG、LDL)更具特异性。 慢性病研究糖尿病、高血压、心血管疾病等慢性病正在影响着人们的健康,识别慢性病危险因素并建立预警模型有助于降低慢性疾病并发症的发生。Alagugowr等建立的心脏病预警系统,从心脏病大数据库中提取特征指标,通过K-means聚类算法识别出心脏病危险因素,又以Apriori算法挖掘高频危险因素与心脏病危险等级之间的关联规则。Ilayaraja等则以高频项集寻找心脏病危险因素并识别病人风险程度,该方法能够回避无意义项集的产生,从而解决了以往研究中项集数量多、所需存储空间大等问题。 CH Jen等对慢性疾病并发症风险识别的研究分三个步骤,首先,选择健康人群体检数据和慢性病患者相关疾病数据,以带有序列前项选择的线性判别分析来寻找相关疾病的特征变量;然后,以K-NN对特征变量进行分类处理;最后,将K-NN算法的分类结果应用于慢性疾病预警模型的建立。Aljumah等先后以回归分析和SVM用于预测和判断糖尿病不同治疗方式与不同年龄组之间的最佳匹配,为患者选择最佳治疗方式提供依据。 Perveen等对糖尿病的预测研究,采用患者人口学数据和临床指标数据,并分别用Adaboost集成算法、Bagging算法及决策树三种算法来建立预测模型,认为Adaboost集成算法的精确性更高。 辅助医学诊断医学数据不仅体量大,而且错综复杂、相互关联。对大量医学数据的分析,挖掘出有价值的诊断规则,将对疾病诊断提供参考。Yang等基于决策树算法和Apriori算法,对肺癌病理报告与临床信息之间的关联性进行了研究,为肺癌病理分期诊断提供依据,从而可回避诊断中需要手术方法获取病理组织。
生物数据挖掘聚类分析实验报告
实验三 聚类分析 一、实验目的 1. 了解典型聚类算法 2. 熟悉聚类分析算法的思路与步骤 3. 掌握运用Matlab 对数据集做聚类分析的方法 二、实验内容 1. 运用Matlab 对数据集做K 均值聚类分析 2. 运用Matlab 对数据集做基于密度的聚类分析 三、实验步骤 1.写出对聚类算法的理解 聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。聚类(Cluster )分析是由若干模式(Pattern )组成的,通常,模式是一个度量(Measurement )的向量,或者是多维空间中的一个点。聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。在进行聚类分析时,出于不同的目的和要求,可以选择不同的统计量和聚类方法。 2.写出K-means 算法步骤 通过迭代把数据对象划分到不同的簇中,以求目标函数最大化,从而使生成的簇尽可能地紧凑和独立。具体步骤如下: (1)首先,随机选取k 个对象作为初始的k 个簇的质心; (2)然后,将其余对象根据其与各个簇质心的距离分配到最近的簇; (3)再要求形成的簇的质心。 这个迭代重定位过程不断重复,直到目标函数最小化为止。 设p 表示数据对象,i c 表示 簇i C 的均值,通常采用的目标函数形式为平法误差准则函数: 2 1||||∑∑=∈-=k i C p i i c p E (欧几里得距离) 3.写出DBSCAN 算法步骤 与均值漂移聚类类似,DBSCAN 也是基于密度的聚类算法。具体步骤如下: (1)首先确定半径r 和minPoints. 从一个没有被访问过的任意数据点开始,以这个点为
全面解析数据挖掘的分类及各种分析方法
全面解析数据挖掘的分类及各种分析方法 1.数据挖掘能做以下六种不同事情(分析方法): ?分类(Classification) ?估值(Estimation) ?预言(Prediction) ?相关性分组或关联规则(Affinitygroupingorassociationrules) ?聚集(Clustering) ?描述和可视化(DescriptionandVisualization) ?复杂数据类型挖掘(Text,Web,图形图像,视频,音频等) 2.数据挖掘分类 以上六种数据挖掘的分析方法可以分为两类:直接数据挖掘;间接数据挖掘?直接数据挖掘 目标是利用可用的数据建立一个模型,这个模型对剩余的数据,对一个特定的变量(可以理解成数据库中表的属性,即列)进行描述。 ?间接数据挖掘 目标中没有选出某一具体的变量,用模型进行描述;而是在所有的变量中建立起某种关系。 ?分类、估值、预言属于直接数据挖掘;后三种属于间接数据挖掘 3.各种分析方法的简介 ?分类(Classification) 首先从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类。 例子: a.信用卡申请者,分类为低、中、高风险 b.分配客户到预先定义的客户分片 注意:类的个数是确定的,预先定义好的 ?估值(Estimation) 估值与分类类似,不同之处在于,分类描述的是离散型变量的输出,而估值处理连续值的输出;分类的类别是确定数目的,估值的量是不确定的。 例子: a.根据购买模式,估计一个家庭的孩子个数 b.根据购买模式,估计一个家庭的收入 c.估计realestate的价值
医学数据挖掘研究
医学数据挖掘研究 陈彬玫① ①成都市郫县中医医院,610225 摘要当今医疗数据海量增长,利用数据挖掘找出对各类医疗决策有价值的知识迫在眉睫。本文介绍了大数据时代背景下医学数据的内容和特点,并研究了数据仓库构建医疗信息化知识平台的动力、关键技术,最后总结了医学数据挖掘挑战。 关键词医学数据;数据挖掘;数据仓库; 1 引言 以计算机技术为核心的信息与通信技术凭借互联网的飞速发展,大大地促进了医疗卫生行业各个应用领域和行业的发展,形成了包括医院信息系统、公共卫生信息系统、远程医疗、家庭护理和区域协同医疗等数百亿的医疗卫生ICT产业,并得到了学术界和工业界的广泛重视。医疗信息化的发展,也促进了医疗数据的爆炸性增长。 但是,医疗信息化也面临很多问题。在资源利用方面,大病小病都找三甲医院,优质医疗资源紧张,医生的经验与精力也有限,没有充分发挥医生的价值。在医患信息交流方面,信息缺乏,信息不对称。民众医学健康、预防、康复知识匮乏,信息化建设的过程中也缺乏病人的主动参与。对于医疗行业本身,患者个体差异大,医疗疾病种类繁多,复合疾病常见,关系复杂,很难标准化、自动化。在医学认知方面,新的疾病不断产生和变化,医疗发展水平还有未知领域。 人的健康是开展医疗信息化的最终目的,也是国家投入巨资推动医疗信息化的出发点和落脚点。目前,区域医疗信息化是投资的重点,其主要内容是以电子病历和电子档案为基础的数据集成和共享。在这些信息系统的基础上,医疗服务将从传统经验分析和临床试验发展到从海量医疗健康数据中挖掘医疗知识,利用信息化技术创造优质的医疗服务惠及广大民众。 2 医学数据挖掘的研究动力 2.1 伦理需求身体健康是人类社会的本质需求。因此,医疗信息化的根本使命是保证人们身体健康,满足个性化医疗服务,最大限度保证公民的医疗质量和医疗安全。通过信息化建设和数据挖掘平台的建设,可以促进现代医疗模式的应用,大大扩展了医疗服务的活动范围。进而使得社会获得巨大的信息化红利,提高人们的生活水平和生活质量。 2.2 经济效益医疗行业是继电信行业之后最有可能深入广泛开展数据挖掘并从中获得实际效益的行业之一。医疗行业是具有大量现金流的行业,完全有能力通过开展数据挖掘。作为根本的民生举措,国家也在持续加大投入。计世资讯《2013年中国医卫行业信息化建设与IT应用趋势研究报告》的研究结果显示,2012年中国医卫行业IT投入达185.6亿元,较2011年同比增长22.6%;2013年医卫行业信息化建设投入将继续保持理性状态,呈现平稳增长趋势。2013年中国医卫行业的IT投资规模约为225.5亿元人民币,较2012年同比增长21.5%。如下图所示。
数据挖掘期末大作业
数据挖掘期末大作业 1.数据挖掘的发展趋势是什么?大数据环境下如何进行数据挖掘。 对于数据挖掘的发展趋势,可以从以下几个方面进行阐述: (1)数据挖掘语言的标准化描述:标准的数据 挖掘语言将有助于数据挖掘的系统化开发。改进多个数据挖掘系统和功能间的互操作,促进其在企业和社会中的使用。 (2)寻求数据挖掘过程中的可视化方法:可视 化要求已经成为数据挖掘系统中必不可少的技术。可以在发现知识的过程中进行很好的人机交互。数据的可视化起到了推动人们主动进行知识发现的作用。 (3)与特定数据存储类型的适应问题:根据不 同的数据存储类型的特点,进行针对性的研究是目前流行以及将来一段时间必须面对的问题。 (4)网络与分布式环境下的KDD问题:随着 Internet的不断发展,网络资源日渐丰富,这就需要分散的技术人员各自独立地处理分离数据库的工作方式应是可协作的。因此,考虑适应分布式与网络环境的工具、技术及系统将是数据挖掘中一个最为重要和繁荣的子领域。 (5)应用的探索:随着数据挖掘的日益普遍,其应用范围也日益扩大,如生物医学、电信业、零售业等 领域。由于数据挖掘在处理特定应用问题时存在局限性,因此,目前的研究趋势是开发针对于特定应用的数据挖掘系统。 (6)数据挖掘与数据库系统和Web数据库系统的集成:数据库系统和Web数据库已经成为信息处理 系统的主流。 2. 从一个3输入、2输出的系统中获取了10条历史数据,另外,最后条数据是系统的输入, 不知道其对应的输出。请使用SQL SERVER 2005的神经网络功能预测最后两条数据的输出。 首先,打开SQL SERVER 2005数据库软件,然后在界面上右键单击树形图中的“数据库”标签,在弹出的快捷菜单中选择“新建数据库”命令,并命名数据库的名称为YxqDatabase,单击确定,如下图所示。 然后,在新建的数据库YxqDatabas中,根据题目要求新建表,相应的表属性见下图所示。
SAS数据挖掘流程
SAS数据挖掘的流程 一、数据挖掘的一般流程 数据挖掘是指一个完整的过程,该过程从大型数据库中挖掘先前未知的,有效的,可实用的信息,并使用这些信息做出决策或丰富知识. 数据挖掘过程图如下所示,它描述了数据挖掘的基本过程和主要步骤 图1.数据挖掘过程图 数据挖掘过程中各步骤的大体内容如下 1. 确定业务对象 清晰地定义出业务问题,认清数据挖掘的目的是数据挖掘的重要一步.挖掘的最后结构是不可预测的,但要探索的问题应是有预见的,为了数据挖掘而数据挖掘则带有盲目性,是不会成功的. 2. 数据准备 1) 数据的选择 搜索所有与业务对象有关的内部和外部数据信息,并从中选择出适用于数据挖掘应用的数据. 2) 数据的预处理 研究数据的质量,为进一步的分析作准备.并确定将要进行的挖掘操作的类型. 3) 数据的转换 将数据转换成一个分析模型.这个分析模型是针对挖掘算法建立的.建立一个真正适合挖掘算法的分析模型是数据挖掘成功的关键. 3. 数据挖掘 对所得到的经过转换的数据进行挖掘.除了完善从选择合适的挖掘算法外,其余一切工作都能自动地完成. 4. 结果分析 解释并评估结果.其使用的分析方法一般应作数据挖掘操作而定,通常会用到可视化技术. 5. 知识的同化 将分析所得到的知识集成到业务信息系统的组织结构中去. 二、SAS数据挖掘的方法(SEMMA) 作为智能型的数据挖掘集成工具,SAS/EM的图形化界面、可视化操作可引导用户(即使是数理统计经验不太多的用户)按SEMMA原则成功地进行数据挖掘,用户只要将数据输入,经过SAS/EM运行,即可得到一些分析结果。有经验的专家还可通过修改数据调整分析处理过程。 SAS/EM可实现同数据仓库和数据集市、商务智能及报表工具的无缝集成,它内含完整的数据获取工具、数据取样工具、数据筛选工具、数据变量转换工具、数据挖掘数据库、数据挖掘过程以及数据挖掘评价工具。
医学信息数据库的建立与数据挖掘
医学信息数据库的建立与数据挖掘 【关键词】医学信息 关键词: 医学信息;数据仓库;数据挖掘;数据组织 0 引言 计算机和信息技术在医学领域中的应用,形成了现代医学中一个新的边缘学科医学信息学或医药信息学(medical informatics),进而成为生物医学工程学的重要支柱.医学信息涵盖了医学活动中产生的文字、图像、声音以及电磁波、光波、压力、温度等多媒体物理数据,这些数据在计算机和数据库技术的支持下,已成为医学技术领域实施科学管理和科学研究的重要资源.数据仓库(data warehouse,DW)与数据挖掘(data mining,DM)技术的出现[1],为医务管理人员、科研工作者分析、利用这些数据资源进行科学管理、决策和开展大规模、高水平医学研究提供了有力的技术工具.数据仓库与数据挖掘技术已在国外一些大型企业中得到了成功应用,国内一些企业也已开始着手这方面的投资,有的并得到了可喜的回报.由于医学技术具有很强的实践性、实验性、统计性,是一门验证科学,浩瀚的医学资源要用现代技术去组织、去分析、去利用,因此,探索数据仓库与数据挖掘技术在医学信息方面的应用就具有更重要的实用价值和广阔的发展前景. 1 问题的提出 目前,医学信息的处理大多停留在基于数据库技术支持的操作型事务处理的水平上,如数据的查询、修改等,是为特定的应用服务的.而建立在数据库技术之上的分析型信息处理最典型的应用是一些医学诊断方面的专家系统(expert system,ES),其数据资源仅仅是 某一方面的专家知识,涉及的数据量很小,覆盖面也很窄.那么,摆在我们面前这个巨大的医学资源宝库究竟能为我们做些什么呢?例如,医院信息系统(hospital information system,HIS),它是医学信息学的一个分支,分为管理信息系统(management informa-tion system,MIS)和临床信息系统(clinical information sys-tem,CIS).前者主要处理医院内部管理方面的信息如人事、财务和设备管理等,而后者是以处理患者为中心的信息系统,如患者入院、住院、治疗、检查、病历、出院等一系列与患者有关的信息.那么,这两类系统能否满足下列要求呢?①如果医院明年利润目标要增长5%,哪些前提条件变化才能达到这一目标?此外还需采取哪些措施来实现这些变化?②未来某段时间内哪些药品使用的频度最高或最低?以 及与治疗疾病间的关系?③未来某段时间内哪些疾病是常发病或发病率最高?使用的药物主 要有哪些?如何组织急需药品的供应?④环境、气候、地理位置与流行病间的关系?利用现有信息系统要回答这些问题是困难的,有些甚至是不可能的.然而,利用数据仓库与数据挖掘技术就可以轻而易举地找到问题的答案.因此,建立数据仓库与利用数据挖掘技术对于开展科学研究,提高医学技术水平是很有必要的.
数据挖掘流程模型CRISP-DM
CRISP-DM 1.0 数据挖掘方法论指南 Pete Chapman (NCR), Julian Clinton (SPSS), Randy Kerber (NCR), Thomas Khabaza (SPSS), Thomas Reinartz (DaimlerChrysler), Colin Shearer (SPSS) and Rüdiger Wirth (DaimlerChrysler)
该手册描述了CRISP-DM(跨行业数据挖掘标准流程)过程模型,包括CRISP-DM的方法论、相关模型、用户指南、报告介绍,以及一个含有其他相关信息的附录。 本手册和此处的信息均为CRISP-DM协会以下成员的专利:NCR Systems Engineering Copenhagen (USA and Denmark), DaimlerChrysler AG (Germany), SPSS Inc. (USA) and OHRA Verzekeringen en Bank Groep B.V (The Netherlands)。 著作权? 1999, 2000 本手册中所有商标和服务标记均为它们各自所有者的标记,并且为CRISP-DM协会的成员所公认。
前言 1996年下半年,数据挖掘市场尚处于萌芽状态,CRISP-DM率先由三家资深公司共同提出。DaimlerChrysler (即后来的Daimler-Benz) 在其商业运营中运用数据挖掘的经验颇为丰富,远远领先于其他大多数商业组织。SPSS(即后来的ISL)自1990年以来一直致力于提供基于数据挖掘的服务,并于1994年推出了第一个商业数据挖掘平台——Clementine。至于NCR,作为对其Teradata数据仓库客户增值目标的一部分,它已经建立了数据挖掘顾问和技术专家队伍以满足其客户的需要。 当时,数据挖掘所引起的市场关注开始表明其进入爆炸式增长和广泛应用的迹象。这既令人兴奋又使人害怕。随着我们在这条路上不断走下去,所有人都不断研究和发展数据挖掘方法。可是我们做的是否正确?是否每一个数据挖掘的新使用者都必须像我们当初一样经历反复试验和学习?此外,从供应商的角度来看,我们怎样向潜在客户证明数据挖掘技术已足够成熟到可以作为它们商业流程的一个关键部分? 在这种情况下,我们认为急需一个标准的流程模型——非私人所有并可以免费获取——向我们和所有的从业者很好的回答这些问题。 一年后我们组建了联盟,名字CRISP-DM取自CRoss-Industry Standard Process for Data Mining的缩写,由欧洲委员会提供资助,开始实施我们最初的想法。因为CRISP-DM的定位是面向行业、工具导向和面向应用的,所以我们明白必须“海纳百川,博采众家之长”,必须在一个尽可能宽的范围内吸引人们的兴趣(比如数据仓库制造商和管理咨询顾问)。于是我们决定成立CRISP-DM 专门兴趣小组(即大家所知道的“The SIG”)。我们邀请所有感兴趣的团体和个人到阿姆斯特丹参加为期一天的工作会议,讨论并正式成立SIG组织:我们观念共享,鼓励与会者畅所欲言,为发展CRISP-DM共商大计。 当天每个协会成员都心怀惴惴,会不会没有人对CRISP-DM有足够的兴趣?即使有,那他们是否认为实际上并未看到一种对标准化流程的迫切需求?或者我们的想法迄今为止与别人的步调不一致,任何标准化的念头只是不切实际的白日梦? 事实上,讨论的结果大大超出了我们的期望。下面三点最为突出: 当天的与会人数是我们原先期望的两倍 行业需要而且现在就需要一个标准化流程——大家压倒性的一致同意 每个出席者从他们的项目经验出发陈述了自己关于数据挖掘的看法,这使我们越来越清晰地看到:尽管表述上有些区别——主要是在阶段的划分和术语方面,但在如何看待数据挖掘流程上大家具有极大的相似之处。 在工作组结束的时候,我们充满了自信,受SIG的启发和批评,我们能够建成一个标准化流程模型,为数据挖掘事业作出贡献。 接下来的两年半里,我们努力工作来完善和提炼CRISP-DM。我们不断地在Mercedes-Benz、保险部门的伙伴及OHRA的实际大型数据挖掘项目中进行尝试。同时也运用商业数据挖掘工具来整合CRISP-DM。SIG证明了是无价的,其成员增长到200多,并且在伦敦、纽约和布鲁塞尔都拥有工作组。 到该项目的欧洲委员会支持基金部分结束时——1999年年中,我们提出了自己觉得质量优良的流程模型草案。熟悉这一草案的人将会发现,一年以来,尽管现在的CRISP-DM1.0更完整更好,但从根本上讲并没有什么本质不同。我们强烈地意识到:在整个项目中,流程模型仍然是一个持续进行的工作;CRISP-DM还只是在一系列有限的项目中得到证实。过去的一年里,DaimlerChrysler有机会把CRISP-DM运用于更为广阔的范围。SPSS和NCR的专业服务团体采纳了CRISP-DM,而且用之成功地完成了无数客户委托,包括许多工业和商业的问题。这段时间以来,我们看到协会外部的服务供应商也采用了CRISP-DM;分析家不断重复地提及CRISP-DM