特征选择算法综述20160702

特征选择方法综述
控制与决策2012.2
问题的提出
特征选择框架基于搜索策略划分特征选择方法基于评价准则划分特征选择方法结论
一、问题的提出特征选择是从一组特征中挑选出一些最有效的特征以降低特征空间维数的过程,是模式识别的关键问题之一。对于模式识别系统,一个好的学习样本是训练分类器的关键,样本中是否含有不相关或冗余信息直接影响着分类器的性能。因此研究有效的特征选择方法至关重要。
特征选择算法的目的在于选择全体特征的一个较少特征集合,用以对原始数据进行有效表达按照特征关系度量划分,可分为依赖基尼指数、欧氏距离、信息熵。
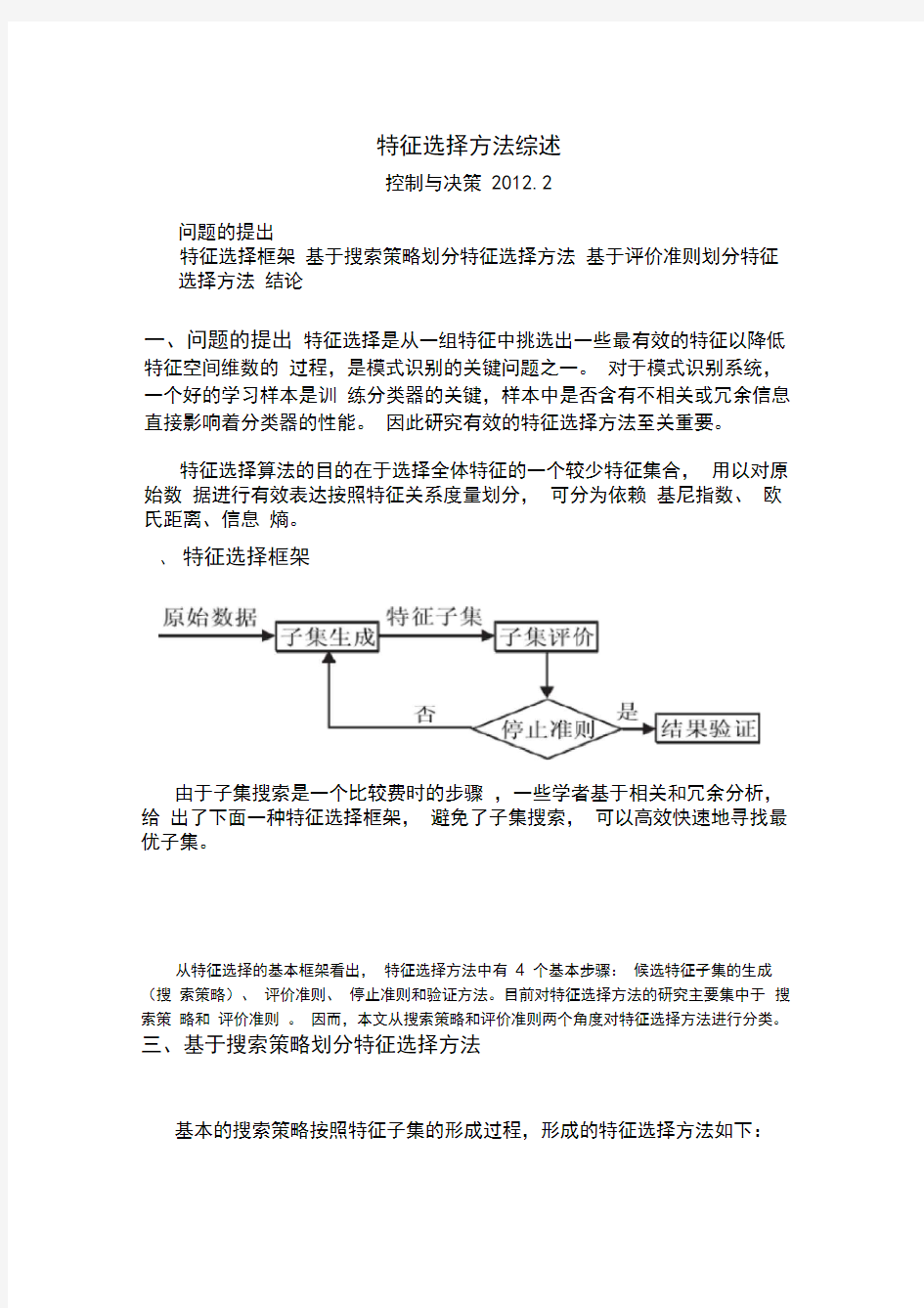
、特征选择框架
由于子集搜索是一个比较费时的步骤,一些学者基于相关和冗余分析,给出了下面一种特征选择框架,避免了子集搜索,可以高效快速地寻找最优子集。
从特征选择的基本框架看出,特征选择方法中有4 个基本步骤:候选特征子集的生成(搜索策略)、评价准则、停止准则和验证方法。目前对特征选择方法的研究主要集中于搜索策略和评价准则。因而,本文从搜索策略和评价准则两个角度对特征选择方法进行分类。
三、基于搜索策略划分特征选择方法
基本的搜索策略按照特征子集的形成过程,形成的特征选择方法如下:
图3 基于搜索策略划分特征选择方法
其中,全局搜索如分支定界法,存在问题:
1)很难确定优化特征子集的数目;
2)满足单调性的可分性判据难以设计;
3)处理高维多类问题时,算法的时间复杂度较高。
随机搜索法如模拟退火、遗传算法、禁忌搜索算法等,存在问题:
1)具有较高的不确定性,只有当总循环次数较大时,才可能找到较好的结果。
2)在随机搜索策略中,可能需对一些参数进行设置,参数选择的合适与否对最终结果的好坏起着很大的作用。
启发式搜索如SFS、SBS、SFFS、SFBS等,存在问题:
1)虽然效率高,但是它以牺牲全局最优为代价。
每种搜索策略都有各自的优缺点,在实际应用过程中,根据具体环境和准则函数来寻找一个最佳的平衡点。例如,特征数较少,可采用全局最优搜索策略;若不要求全局最优,但要求计算速度快,可采用启发式策略;若需要高性能的子集,而不介意计算时间,则可采用随机搜索策略。
四、基于评价准则划分特征选择方法
图4 基于评价准则划分特征选择方法
(一)考虑单个特征对分类的贡献,特征选择方法依据其与分类器的关系分为:Filter 方法、Wrapper 方法和Embedded方法3类。
封装式算法作为一种经典的特征选择算法类型采用学习算法进行特征选择,其选择过程复杂耗时,目前多与过滤式特征选择算法结合,辅助特征选择;嵌入式算法则分多步骤采用不同选择方式,算法繁琐,其代表算法是基于稀疏多项式逻辑回归模型理论的SBMLR算法等;过滤式算法不需其他学习算法,主要考察特征间计量关系,方法简单,时间复杂度相对较低,代表算法包括:基于特征权重的Relief F 、Fisher 、SPEC以及基
于互信息的MRMR算法等。
(1)Filter 方法:通过分析特征子集内部的信息来衡量特征子集的好坏,不依赖于分类器。Filter 实质上属于一种无导师学习算法。
常用:基于特征权重的Relief F、Fisher 、SPEC以及基于互信息的MRMR算法
Filter 特征选择方法一般使用评价准则来增强特征与类的相关性,削减特征之间的相关性。将评价函数分成4 类:
1)距离度量。距离度量通常也认为是分离性、差异性或者辨识能力的度量。最为常用的一些重要距离测度:欧氏距离、S阶Minkowski 测度、Chebychev 距离、平方距离等。
2)信息度量。信息度量通常采用信息增益(IG) 或互信息(MI) 衡量。
信息增益:有无这个特征对分类问题的影响的大小。互信息:描述两
个随机变量之间相互依存关系的强弱。
泛化的信息度量函数标准:
其中,C:类别;f:候选特征;S:已选特征;g(C,f,S):C,f,S之间的信息量;? :调控系数;δ:惩罚因子
① BIF (best individual feature) 是一种最简单最直接的特征选择
方法。评价函数:
类别的相关性,最小化特征之间的冗余。
I():互信息降序排序前k 个
优缺点:这种方法简单快速,适合于高维数据。没有考虑到所选特征间的相关性,会带来较大的冗余。
② MIFS (mutual information feature selection) :互信息特征选择。使用候选特征 f 与
β:调节系数。β在[0.5,1] 时,算法性能较好。
③ mRMR (minimal-redundancy and maximal-relevance) 方法。思想:最大化特
征子集和
④ FCBF (fast correlation-based filter) 。基于相互关系度量给出的一种算法。对于线性随机变量,用相关系数分析特征与类别、特征间的相互关系。对于非线性随机变量,采用对称不确定性(SU)来度量,对于两个非线性随机变量X 和Y,它们的相互关系表示为:
H():信息熵
基本思想:根据所定义的C-相关(特征与类别的相互关系)和F-相关(特征之间的相互关系),从原始特征集合中去除C-相关值小于给定阈值的特征,再对剩余的特征进行冗余分析。
⑤ CMIM (conditional mutual information maximization) 。利用条件互信息来评价特征的重要性程度,即在已知已选特征集S的情况下通过候选特征f 与类别C 的依赖程度来确定
f 的重要性,其中条件互信息I(C; f | S)值越大,f 能提供的新信息越多。
3)依赖性度量。有许多统计相关系数被用来表达特征相对于类别可分离性间的重要性程度。如:Pearson 相关系数、概率误差、Fisher 分数、先行可判定分析、最小平方回归误差、平方关联系数、t-test 、F-Statistic 等。
Hilbert-Schmidt 依赖性准则(HSIC) 可作为一个评价准则度量特征与类别的相关性。核心思想是一个好的特征应该最大化这个相关性。
t: 所选特征个数上限;F:特征集合;S:已选特征集合;J(S):评价准则从式中可知需要解决两个问题:一是评价准则J(S)的选择;二是算法的选择。
4)一致性度量给定两个样本, 若他们特征值均相同, 但所属类别不同, 则称它们是不一致的; 否则, 是一致的。试图保留原始特征的辨识能力, 找到与全集有同样区分类别能力的最小子集。典型算法有Focus、LVF 等。
Filter 方法选择合适的准则函数将会得到较好的分类结果。优点:可以很快地排除很大数量的非关键性的噪声特征, 缩小优化特征子集搜索的规模,计算效率高,通用性好,可用作特征的预筛选器。
缺点:它并不能保证选择出一个优化特征子集, 尤其是当特征和分类器息息相关时。因而, 即使能找到一个满足条件的优化子集,它的规模也会比较庞大,会包含一些明显的噪声特征。
2 )Wrapper 法:评价函数是一个分类器,采用特定特征子集对样本集进行分类,
根据分类的结果来衡量该特征子集的好坏。Wrapper 实质上是一种有导师学习算法。
训练集测试集
优点:准确率高
缺点:1)为选择出性能最好的特征子集,Wrapper 算法需要的计算量巨大;
2 )该方法所选择的特征子集依赖于具体学习机;
3 )容易产生“过适应”问题,推广性能较差
(3)Embedded方法。将特征选择集成在学习机训练过程中,通过优化一个目标函数在训练分类器的过程中实现特征选择。
优点:相对于Wrapper 方法,不用将训练数据集分成训练集和测试集两部分,避免了为评估每一个特征子集对学习机所进行的从头开始的训练,
可以快速地得到最佳特征子集,是一种高效的特征选择方法。
缺点:构造一个合适的函数优化模型是该方法的难点。
通常,将Filter 方法的高效与Wrapper 方法的高准确率进行结合,可得到更优的特征子集。混合特征选择过程一般由两个阶段组成:1)使用Filter 方法初步剔除大部分无关或噪声特征,只保留少量特征, 从而有效地减小后续搜索过程的规模。
2)将剩余的特征连同样本数据作为输入参数传递给Wrapper 选择方法, 以进一步优化选择重要的特征。
(二)依据特征之间的联合作用对分类的贡献,分为:CFS (Correltion based Feature Selector )、CFSPabs(CFSb ased on the absolute of Perons 's correlation coefficient)、DFS (Discernibility of Feature Subset s)。
(1)CFS:基于关联特征的特征选择。CFS计算整个特征子集的类间区分能力实现特征选择,使得被选特征子集中的特征之间尽可能不相
关,而与类标高度相关。
Ms:度量了包含k个特征的特征子集S 的类别辨识能力。
:特征f(f )与类别C 的相关系数的均值
:特征之间相关系数的均值
分子:特征子集S的类预测能力
分母:特征子集S中特征的冗余程度
适合于二分类
(2)CFSPabs:基于皮尔森相关系数的绝对值的相关特征选择。
3)DFS:特征子集区分度量。
:当前i 个特征的特征子集在整个数据集上的均值向量
:当前i 个特征的特征子集在第j类数据集上的均值向量
:第j类中第k 个样本对应当前i 个特征的特征值向量
分子:l个类别中各类别对应包含当前i个特征的特征子集的样本中心向量与整个样本集对应当前i个特征的中心向量的距离平方和,其值越大,类间越疏分母:各个类别对应包含当前i个特征的特征子集的类内方差。方差越小,类内越聚
五、结论
现有特征选择研究主要着眼于选择最优特征子集所需要的两个主要步骤:特征子集搜索策略和特征子集性能评价准则。将Filter方法和Wrapper 方法两者结合,根据特定的环境选择所需要的度量准则和分类器是一个值得研究的方向。