医学统计学分析计算题-答案 (1)

第二单元 计量资料的统计推断
分析计算题
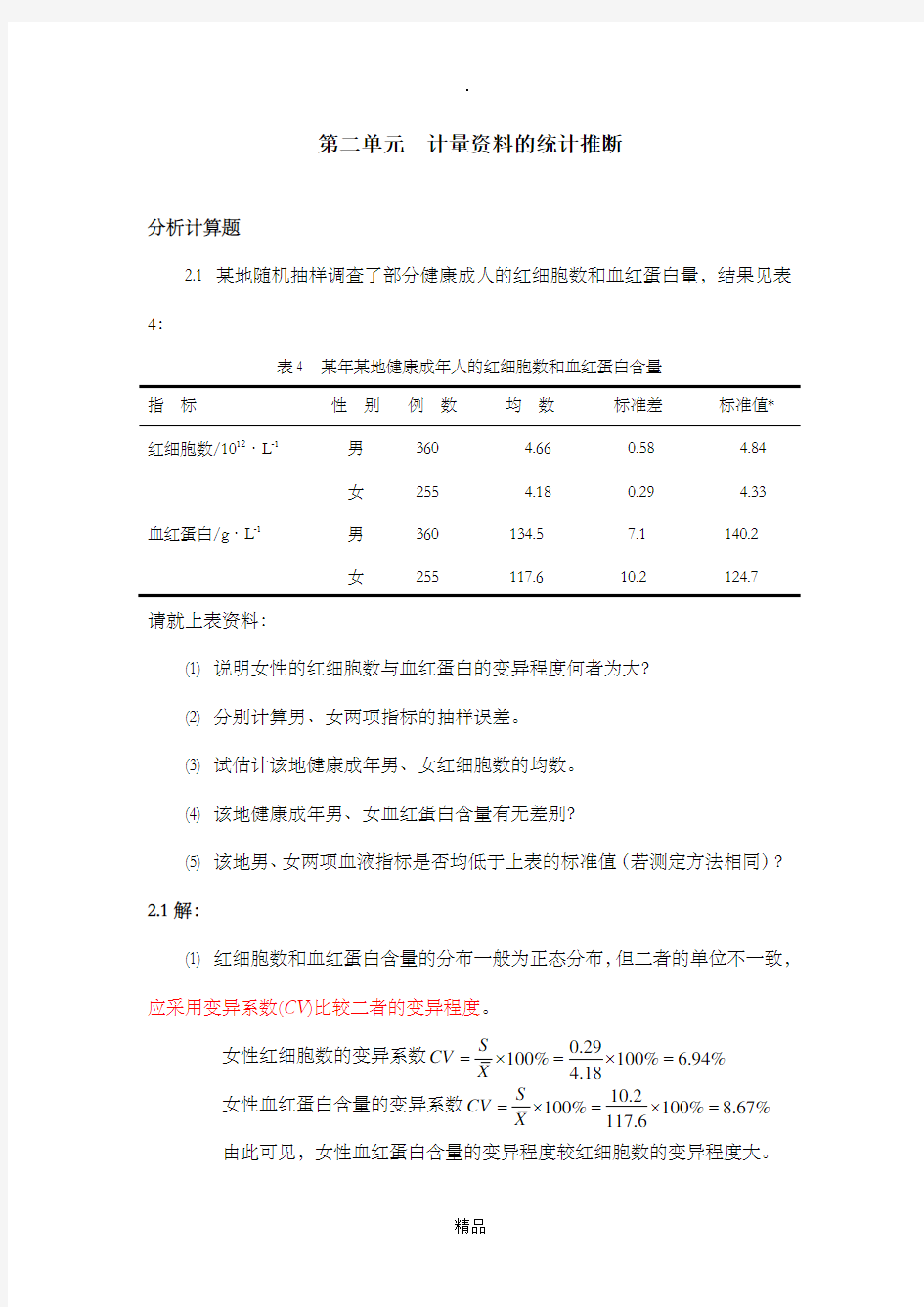
2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4:
表4 某年某地健康成年人的红细胞数和血红蛋白含量
指 标
性 别 例 数 均 数 标准差 标准值* 红细胞数/1012·L -1 男 360 4.66 0.58 4.84
女 255 4.18 0.29 4.33 血红蛋白/g ·L -1 男 360 134.5 7.1 140.2
女
255
117.6
10.2
124.7
请就上表资料:
(1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别?
(5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1解:
(1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV )比较二者的变异程度。
女性红细胞数的变异系数0.29
100%100% 6.94%4.18
S CV X =
?=?= 女性血红蛋白含量的变异系数10.2
100%100%8.67%117.6
S CV X =?=
?= 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。
(2) 抽样误差的大小用标准误X S 来表示,由表4计算各项指标的标准误。
男性红细胞数的标准误0.031X S =
==(1210/L )
男性血红蛋白含量的标准误0.374X S ===(g/L )
女性红细胞数的标准误0.018X S =
==(1210/L )
女性血红蛋白含量的标准误0.639X S =
==(g/L ) (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100,可视为大样本。σ未知,但n 足够大 ,故总体均数的区间估计按
(/2/2X X X u S X u S αα-+
, )计算。 该地男性红细胞数总体均数的95%可信区间为:
(4.66-1.96×0.031 , 4.66+1.96×0.031),即(4.60 , 4.72)1210/L 。 该地女性红细胞数总体均数的95%可信区间为:
(4.18-1.96×0.018 , 4.18+1.96×0.018),即(4.14 , 4.22)1210/L 。 (4) 两成组大样本均数的比较,用u 检验。 1) 建立检验假设,确定检验水准
H 0:12μμ=,即该地健康成年男、女血红蛋白含量均数无差别 H 1:12μμ≠,即该地健康成年男、女血红蛋白含量均数有差别
0.05α=
2) 计算检验统计量
22.829X X u ===
3) 确定P 值,作出统计推断
查t 界值表(ν=∞时)得P <0.001,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同,男性高于女性。
(5) 样本均数与已知总体均数的比较,因样本含量较大,均作近似u 检验。 1) 男性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准
H 0:0μμ=,即该地男性红细胞数的均数等于标准值 H 1:0μμ<,即该地男性红细胞数的均数低于标准值 单侧0.05α= ② 计算检验统计量
0 4.66 4.84
5.8060.031
X X t S μ--=
==- ③ 确定P 值,作出统计推断
查t 界值表(ν=∞时)得P <0.0005,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地男性红细胞数的均数低于标准值。
2) 男性血红蛋白含量与标准值的比较 ① 建立检验假设,确定检验水准
H 0:0μμ=,即该地男性血红蛋白含量的均数等于标准值 H 1:0μμ<,即该地男性血红蛋白含量的均数低于标准值 单侧0.05α= ② 计算检验统计量
0134.5140.2
15.2410.374
X X t S μ--=
==- ③ 确定P 值,作出统计推断
查t 界值表(ν=∞时)得P <0.0005,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地男性血红蛋白含量的均数低于标准值。
3) 女性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准
H 0:0μμ=,即该地女性红细胞数的均数等于标准值 H 1:0μμ<,即该地女性红细胞数的均数低于标准值 单侧0.05α= ② 计算检验统计量
0 4.18 4.33
8.3330.018
X X t S μ--=
==- ③ 确定P 值,作出统计推断
查t 界值表(ν=∞时)得P <0.0005,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地女性红细胞数的均数低于标准值。
4) 女性血红蛋白含量与标准值的比较 ① 建立检验假设,确定检验水准
H 0:0μμ=,即该地女性血红蛋白含量的均数等于标准值 H 1:0μμ<,即该地女性血红蛋白含量的均数低于标准值 单侧0.05α= ② 计算检验统计量
0117.6124.711.1110.639
X X t S μ--=
==-
③ 确定P 值,作出统计推断
查t 界值表(ν=∞时)得P <0.0005,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地女性血红蛋白含量的均数低于标准值。
2.2 为了解某高寒地区小学生血红蛋白含量的平均水平,某人于1993年6月随机抽取了该地小学生708名,算得其血红蛋白均数为10
3.5g/L ,标准差为1.59g/L 。试求该地小学生血红蛋白均数的95%可信区间。
2.2解:σ未知,n 足够大时,总体均数的区间估计可用(/2/2X X X u S X u S αα-+
, )。 该地小学生血红蛋白含量均数的95%可信区间为: (103.5 1.96103.5 1.96
-+, ),即(103.38 , 103.62)g/L 。
2.3 一药厂为了解其生产的某药物(同一批次)之有效成分含量是否符合国家规定的标准,随机抽取了该药10片,得其样本均数为10
3.0mg ,标准差为2.22mg 。试估计该批药剂有效成分的平均含量。
2.3解:该批药剂有效成分的平均含量的点值估计为10
3.0 mg 。
σ未知且n 很小时,总体均数的区间估计可用()/2,/2,X X X t S X t S αναν-+ , 估
计。查t 界值表得t 0.05/2,9=2.262,该批药剂有效成分的平均含量的95%可信区间为:(103.0 2.262103.0 2.262
-+, ,即(101.41 , 104.59)mg 。
2.4 152例麻疹患儿病后血清抗体滴度倒数的分布如表5,试作总体几何均数的点值估计和95%区间估计。
表5 152例麻疹患儿病后血清抗体滴度倒数的分布
滴度倒数 1 2 4 8 16 32 64 128 256 512 1024 合计 人 数
1
7
10
31
33
42
24
3
1
152
2.4解:将原始数据取常用对数后记为X ,则
152 1.85970.44250.0359X n X S S ====,,,,用(/2/2X X X u S X u S αα-+,)
估计,则滴度倒数对数值的总体均数的95%可信区间为:
(1.8597 1.960.0359 1.8597 1.960.0359-?+? , ),即(1.7893 , 1.9301)。
所以滴度倒数的总体几何均数的点估计值为: 1.8597101072.39X ==,滴度倒
数的总体几何均数的95%区间估计为( 1.7893 1.93011010
, ),即(61.56 , 85.13)。 SPSS 操作 数据录入:
打开SPSS Data Editor 窗口,点击Variable View 标签,定义要输入的变量x 和f ;再点击Data View 标签,录入数据(见图2.4.1,图2.4.2)。
图2..4.1 Variable View 窗口内定义要输入的变量x 和f
图2.4.2 Data View窗口内录入数据
分析:
Transform Compute…
Target Variable:键入logx
Numeric Expression:LG10(x) 将原始数据取对数值OK
Data Weight Cases…
Weight cases by Frequency Variable:f 权重为f
OK
Analyze Descriptive Statistics Explore… 探索性分析Dependent list:logx 分析变量logx Display:Statistics
S tatistics…:Descriptives 统计描述
Continue
OK
注:最后得到结果是原始数据对数值的均数及其95%可信区间。
2.5 某口腔医生欲比较“个别取模器龈下取模技术”与“传统硅橡胶取模方法”两种取模技术精度的差异,在12名病人口中分别用两种方法制取印模,在体视显微镜下测量标志点到龈沟底的距离,结果如表6,问两种取模方法结果有无差异?
表6 12个病人口腔某测量标志点到龈沟底的距离/cm
病例号个别取模器龈下取模技术传统硅橡胶取模方法
10.6260.614
20.6270.626
30.6700.654
40.5480.549
50.5900.574
60.6030.587
70.6050.602
80.3470.338
90.7680.759
100.5760.572
110.3300.318
120.2330.219
2.5解:本题为配对设计的两样本均数的比较,采用配对t检验。
表2.5.1 12个病人口腔某测量标志点到龈沟底的距离/cm
(1) 建立检验假设,确定检验水准
H 0:0d μ=,即两种取模方法结果无差异 H 1:0d μ≠,即两种取模方法结果有差异
0.05α=
(2) 计算检验统计量
两种取模方法结果的差值d 的计算见表2.5.1。
120.00930.00610.0018d d n d S S ====, ,, 00.0093
5.1670.0018
d d t S -=
== 112111n ν=-=-=
(3) 确定P 值,作出统计推断
查t 界值表得P <0.001,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为两种取模方法结果有差异,个别取模器龈下取模法标志点到龈沟底
的距离略高于传统硅胶取模法。
病例号 个别取模器龈下取模1d
传统硅橡胶取模法2d
12d d d =-
1 0.626 0.614 0.01
2 2 0.627 0.626 0.001
3 0.670 0.65
4 0.016 4 0.548 0.549 -0.001
5 0.590 0.574 0.01
6 6 0.603 0.58
7 0.016 7 0.605 0.602 0.003
8 0.347 0.338 0.00
9 9 0.768 0.759 0.009 10 0.576 0.572 0.004 11 0.330 0.318 0.012 12
0.233
0.219
0.014
SPSS操作
数据录入:
打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量x1和x2;再点击Data View标签,录入数据(见图2.5.1,图2.5.2)。
图2.5.1 Variable View窗口内定义要输入的变量x1和x2
图2.5.2 Data View窗口内录入12对数据
分析:
Analyze Compare Means Paired-samples T Test…配对设计均数比较t检验Paired Variables:x1 x2 配对变量为x1和x2
OK
2.6 将钩端螺旋体病人的血清分别用标准株和水生株作凝溶试验,测得稀释倍数如表7,问两组的平均效价有无差别?
表7 钩端螺旋体病患者血清作凝溶试验测得的稀释倍数
标准株(11人) 100 200 400 400 400 400 800 1600 1600 1600 3200 水生株(9人)
100
100
100
200
200
200
200
400
400
2.6解:本题为成组设计的两小样本几何均数的比较,采用成组t 检验。
将原始数据取常用对数值后分别记为1X 、2X ,
则11122211 2.79360.45209 2.26760.2353n X S n X S ======,,;
,, (1) 建立检验假设,确定检验水准
H 0:两种株别稀释倍数的总体几何均数的对数值相等 H 1:两种株别稀释倍数的总体几何均数的对数值不等
0.05α=
(2) 计算检验统计量
3.149
X X t =
=
=
122119218n n ν=+-=+-=
(3) 确定P 值,作出统计推断
查t 界值表得0.005
均效价有差别,标准株的效价高于水生株。
SPSS操作
数据录入:
打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量g和x;再点击Data View标签,录入数据(见图2.6.1,图2.6.2)。
图2.6.1 Variable View窗口内定义要输入的变量g和x
图2.6.2 Data View窗口内录入数据
分析:
Transform Compute…
Target Variable:键入logx
Numeric Expression:LG10(x) 将原始数据取对数值OK
Analyze Compare Means Independent-Samples T Test… 成组设计t检验
Test Variable[s]:logx 分析变量logx Grouping Variable:g 分组变量g
Define Groups…
Use Specified Values Group1:键入1 定义比较的两组
Group2:键入2
Continue
OK
2.7 某医生为了评价某安眠药的疗效,随机选取20名失眠患者,将其随机分成两组,每组10人。分别给予安眠药和安慰剂,观察睡眠时间长度结果如表8,请评价该药的催眠作用是否与安慰剂不同。
表8 患者服药前后的睡眠时间/h
安眠药组安慰剂组受试者治疗前治疗后受试者治疗前治疗后
1 3.5 4.71 4.0 5.4
2 3.
3 4.42 3.5 4.7
3 3.2 4.03 3.2 5.2
4 4.
5 5.24 3.2 4.8
5 4.3 5.05 3.3 4.6
6 3.2 4.36 3.4 4.9
7 4.2 5.17 2.7 3.8
8 5.0 6.58 4.8 6.1
9 4.3 4.09 4.5 5.9
10
3.6
4.7
10
3.8
4.9
2.7解:本题采用成组t 检验比较两小样本差值的均数,以治疗后与治疗前的睡眠时间的差值为变量进行统计分析。
安眠药组:111100.880.4826d n d S ===, , 安慰剂组:22210 1.390.2685d n d S ===, ,
两样本标准差相差不大,可认为两总体方差齐,略去方差齐性检验。 (1) 建立检验假设,确定检验水准
H 0:1
2
d d μμ=,即安眠药的催眠作用与安慰剂相同
H 1:1
2
d d μμ≠,即安眠药的催眠作用与安慰剂不同
α=0.05 (2) 计算检验统计量
2.9203
d d t =
=
=-
1221010218n n ν=+-=+-=
(3) 确定P 值,作出统计推断
查t 界值表得0.005< P < 0.01,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为安眠药的催眠作用与安慰剂不同,安慰剂的催眠效果好于安眠药。
SPSS 操作 数据录入:
打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量g 、x1和x2;再点击Data View标签,录入数据(见图2.7.1,图2.7.2)。
图2.7.1 Variable View窗口内定义要输入的变量g、x1和x2
图2.7.2 Data View窗口内录入数据
分析:
Transform Compute…
Target Variable:键入d
Numeric Expression:键入x2-x1 计算x2与x1的差值
OK
Analyze Compare Means Independent-Samples T Test…成组设计t检验
Test Variable[s]:d 分析变量d
Grouping Variable:g 分组变量g
Define Groups…
Use Specified Values Group1:键入1 定义比较的两组
Group2:键入2
Continue
OK
2.8 某医师用依降钙素治疗绝经后妇女骨质疏松症,收集30例绝经后骨质疏松症妇女,随机分成两组,一组服用依降钙素+乳酸钙,另一组只服用乳酸钙,24周后观察两组患者腰椎L2-4骨密度的改善率,结果如表9,请问依降钙素治疗绝经后妇女骨质疏松是否有效?
表9 各组患者L2-4骨密度的改善率/%
依降钙素+乳酸钙乳酸钙
-0.20-0.83
0.210.26
1.860.47
1.97 1.07
9.20 1.18
3.56 1.26
2.80 1.69
3.29 1.75
3.30 2.31
3.47 2.65
3.60 2.78
4.30 6.02
4.39 3.36
8.42 2.10
医学统计学分析计算题_与解析
第二单元 计量资料的统计推断 分析计算题 2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4: 表4 某年某地健康成年人的红细胞数和血红蛋白含量 指 标 性 别 例 数 均 数 标准差 标准值* 红细胞数/1012 ·L -1 男 360 4.66 0.58 4.84 女 255 4.18 0.29 4.33 血红蛋白/g ·L -1 男 360 134.5 7.1 140.2 女 255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV )比较二者的变异程度。 女性红细胞数的变异系数0.29 100%100% 6.94%4.18 S CV X = ?=?= 女性血红蛋白含量的变异系数10.2 100%100%8.67%117.6 S CV X =?=?= 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误X S 来表示,由表4计算各项指标的标准误。 男性红细胞数的标准误0.031 X S = ==(1210/L ) 男性血红蛋白含量的标准误0.374 X S = ==(g/L )
女性红细胞数的标准误0.018X S = ==(1210/L ) 女性血红蛋白含量的标准误0.639X S = ==(g/L ) (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100,可视为大样本。σ未知,但n 足够大 ,故总体均数的区间估计按 (/2/2X X X u S X u S αα-+ , )计算。 该地男性红细胞数总体均数的95%可信区间为: (4.66-1.96×0.031 , 4.66+1.96×0.031),即(4.60 , 4.72)1210/L 。 该地女性红细胞数总体均数的95%可信区间为: (4.18-1.96×0.018 , 4.18+1.96×0.018),即(4.14 , 4.22)1210/L 。 (4) 两成组大样本均数的比较,用u 检验。 1) 建立检验假设,确定检验水准 H 0:12μμ=,即该地健康成年男、女血红蛋白含量均数无差别 H 1:12μμ≠,即该地健康成年男、女血红蛋白含量均数有差别 0.05α= 2) 计算检验统计量 22.829X X u === 3) 确定P 值,作出统计推断 查t 界值表(ν=∞时)得P <0.001,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同,男性高于女性。 (5) 样本均数与已知总体均数的比较,因样本含量较大,均作近似u 检验。 1) 男性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准 H 0:0μμ=,即该地男性红细胞数的均数等于标准值
医学统计学简答题
医学统计学简答题 1.简述标准差、标准误的区别与联系? 区别:(1)含义不同:标准差S表示观察值的变异程度,描述个体变量值(x)之间的变异度大小,S越大,变量值(x)越分散;反之变量值越集中,均数的代表性越强。标准误..估计均数的抽样误差的大小,是描述样本均数之间的变异度大小,标准误越大,样本均数与总体均数间差异越大,抽样误差越大;反之,样本均数越接近总体均数,抽样误差越小。 (2)与n的关系不同: n增大时,S趋于σ(恒定),标准误减少并趋于0(不存在抽样误差)。 (3)用途不同:标准差表示x的变异度大小、计算变异系数、确定医学参考值范围、计算标准误等,标准误用于估计总体均数可信区间和假设检验。 联系:二者均为变异度指标,样本均数的标准差即为标准误,标准差与标准误成正比。 2.简述假设检验的基本步骤。 1.建立假设,确定检验水准。 2.选择适当的假设检验方法,计算相应的检验统计量。 3.确定P值,下结论 3.正态分布的特点和应用:? 特点:?1、集中性:正态曲线的高峰位于正中央,即均数所在的位置;? 2、对称性:正态分布曲线位于直角坐标系上方,以x=u为中心,左右对称,曲线两端永远不与横轴相交; 3、均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降;?
4、正态分布有两个参数,即均数μ和标准差σ,可记作N(μ,σ):均数μ决定正态曲线的中心位置;标准差σ决定正态曲线的陡峭或扁平程度。σ越小,曲线越陡峭;σ越大,曲线越扁平; ?5、u变换:为了便于描述和应用,常将正态变量作数据转换;?? 应用:?1.估计医学参考值范围?2.质量控制?3.正态分布是许多统计方法的理论基础 4.简述参考值范围与均数的可信区间的区别和联系 可信区间与参考值范围的意义、计算公式和用途均不同。 ?1.从意义来看?95%参考值范围是指同质总体内包括95%个体值的估计范围,而总体均数95%可信区间是指?95%可信度估计的总体均数的所在范围? 2.从计算公式看?若指标服从正态分布,95%参考值范围的公式是:±1.96s。?总体均数95%可信区间的公式是:??前者用标准差,后者用标准误。前者用1.96,后者用α为0.05,自由度为v的t界值。 5.频数表的用途和基本步骤。 用途:(1)揭示资料的分布特征和分布类型;(2)便于进一步计算指标和分析处理;(3)便于发现某些特大或特小可疑值。 基本步骤:(1)求出极差;(2)确定组段,一般设8~15个组段;(3)确定组距;组距=R/组段数,但一般取一方便计算的数字;(4)列出各个组段并确定每一组段频数。 6.非参数统计检验的适用条件。 (1)资料不符合参数统计法的应用条件(总体为正态分布、且方差相等)或总体分布类型未知;(2)等级资料;(3)分布呈明显偏态又无适当的变量转换方法使之满足参数统计条件;(4)在资料满足参数检验的要求时,应首选参数法,以免降低检验效能 7.线性回归的主要用途。
医学统计学案例分析 (1)
---------------------------------------------------------------最新资料推荐------------------------------------------------------ 医学统计学案例分析(1) 案例分析四格表确切概率法【例 1-5】为比较中西药治疗急性心肌梗塞的疗效,某医师将 27 例急性心肌梗塞患者随机分成两组,分别给予中药和西药治疗,结果见表 1-4。 经检验,得连续性校正 2 =3.134,P>0.05,差异无统计学意义,故认为中西药治疗急性心肌梗塞的疗效基本相同。 表 1-4 两种药物治疗急性心肌梗塞的疗效比较药物中药西药合计有效 12(9.33) 6(8.67)无效 2(4.67) 7(4.33)合计 14 13 27 有效率(%) 85.7 46.2 66.7 18 9 【问题 1-5】(1)这是什么资料?(2)该资料属于何种设计方案?(3)该医师统计方法是否正确?为什么?【分析】 (1) 该资料是按中西药的治疗结果(有效、无效)分类的计数资料。 (2) 27 例患者随机分配到中药组和西药组,属于完全随机设计方案。 (3) 患者总例数 n=27<40,该医师用 2 检验是不正确的。 当 n<40 或 T<1时,不宜计算 2 值,需采用四格表确切概率法(exact probabilities in 22 table)直接计算概率案例分析-卡方检验(一)【例 1-1】某医师为比较中药和西药治疗胃炎的疗效,随机抽取 140 例胃炎患者分成中药组和西药组,结果中药组治疗 80 例,有效 64 例,西药组治疗 60例,有效 35 例。 1 / 5
医学统计学练习题与答案
一、单向选择题 1. 医学统计学研究的对象是 E.有变异的医学事件 2. 用样本推论总体,具有代表性的样本指的是E.依照随机原则抽取总体中的部分个体 3. 下列观测结果属于等级资料的是 D.病情程度 4. 随机误差指的是 E. 由偶然因素引起的误差 5. 收集资料不可避免的误差是 A.随机误差 1.某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是 A. 中位数 2. 算术均数与中位数相比,其特点是 B.能充分利用数据的信息 3. 一组原始数据呈正偏态分布,其数据的特点是 D.数值分布偏向较小一侧 4. 将一组计量资料整理成频数表的主要目的是E.提供数据和描述数据的分布特征 1. 变异系数主要用于 A .比较不同计量指标的变异程度 2. 对于近似正态分布的资料,描述其变异程度应选用的指标是E. 标准差 3.某项指标95%医学参考值范围表示的是D.在“正常”总体中有95%的人在此范围 4.应用百分位数法估计参考值范围的条件是B .数据服从偏态分布 5.已知动脉硬化患者载脂蛋白B 的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用 E .四分位数间距 1.样本均数的标准误越小说明 E.由样本均数估计总体均数的可靠性越大 2. 抽样误差产生的原因是D.个体差异 3.对于正偏态分布的的总体,当样本含量足够大时,样本均数的分布近似为C.正态分布 4. 假设检验的目的是 D.检验总体参数是否不同 5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109 /L ~9.1×109 /L ,其含义是 E.该区间包含总体均数的可能性为95% 1. 两样本均数比较,检验结果05.0 P 说明 D.不支持两总体有差别的结论 2. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指 E. 有理由认为两总体均数有差别 3. 两样本均数比较,差别具有统计学意义时,P 值越小说明 D.越有理由认为两总体均数不同 4. 减少假设检验的Ⅱ类误差,应该使用的方法是 E.增加样本含量 5.两样本均数比较的t 检验和u 检验的主要差别是B.u 检验要求大样本资料
医学统计学考试重点整理
一、基本概念 1.总体与样本 总体:所有同质观察单位某种观察值(即变量值)的全体 样本:是总体中抽取部分观察单位的观察值的集合 2.普查与抽样调查 普查:就是全面调查,即调查目标总体中全部观察对象 抽样调查:是一种非全面调查,即从总体中抽取一定数量的观察单位组成样本,对样本进行调查 3.参数与统计量 参数:总体的某些数值特征 统计量:根据样本算得的某些数值特征 4.Ⅰ型与Ⅱ型错误 假设检验的结论 真实情况拒绝H0不拒绝H0 H0正确Ⅰ型错误(ɑ) 推断正确(1 ?ɑ) H0不正确推断正确(1?β) Ⅱ型错误(β) Ⅰ型错误(ɑ错误): H0为真时却被拒绝,弃真错误 Ⅱ型错误(β错误): H0为假时却被接受,取伪错误 5.随机化原则与安慰剂对照 随机化原则:是将研究对象随机分配到实验组和对照组,使每个研究对象都有同等机会被分配到各组中去,以平衡两组中已知和未知的混杂因素,从而提高两组的可比性,避免造成偏倚。(意义:①是提高组间均衡性的重要设计方法;②避免有意扩大或缩小组间差别导致的偏倚;③各种统计学方法均建立在随机化基础上) 安慰剂对照:是一种常用的对照方法。安慰剂又称伪药物,是一种无药理作用的制剂,不含试验药物的有效成分,但其感观如剂型、大小、颜色、质量、气味及口味等都与试验药物一样,不能被受试对象和研究者所识别。(安慰剂对照主要用于临床试验,其目的在于控制研究者和受试对象的心理因素导致的偏倚,并提高依从性。安慰剂对照还可以控制疾病自然进程的影响,显示试验药物的效应) 6.误差与标准误(区分率与均数) ㈠均数 抽样误差:由个体变异产生的、随机抽样引起的样本统计量与总体参数间的差异。 标准误:是指样本均数的标准差,反映抽样误差大小的定量指标,其公式表示为S x =S/√n ㈡样本率 率的抽样误差:样本率p和总体率π的差异 率的标准误:样本率的标准差,公式为σp=√π(1-π)/n
医学统计学试题与答案
医学统计学试题及答案 习题 《医学统计学》第二版(五年制临床医学等本科生用) (一)单项选择题 1.观察单位为研究中的( d )。 A.样本 B. 全部对象 C.影响因素 D. 个体 2.总体是由( c )。 A.个体组成 B. 研究对象组成 C.同质个体组成 D. 研究指标组成 3.抽样的目的是(b )。 A.研究样本统计量 B. 由样本统计量推断总体参数 C.研究典型案例研究误差 D. 研究总体统计量 4.参数是指(b )。 A.参与个体数 B. 总体的统计指标 C.样本的统计指标 D. 样本的总和 5.关于随机抽样,下列那一项说法是正确的( a )。 A.抽样时应使得总体中的每一个个体都有同等的机会被抽取 B.研究者在抽样时应精心挑选个体,以使样本更能代表总体 C.随机抽样即随意抽取个体 D.为确保样本具有更好的代表性,样本量应越大越好 6.各观察值均加(或减)同一数后( b )。 A.均数不变,标准差改变 B.均数改变,标准差不变 C.两者均不变 D.两者均改变 7.比较身高和体重两组数据变异度大小宜采用( a )。 A.变异系数 B.差 C.极差 D.标准差 8.以下指标中(d)可用来描述计量资料的离散程度。 A.算术均数 B.几何均数 C.中位数 D.标准差 9.偏态分布宜用(c)描述其分布的集中趋势。 A.算术均数 B.标准差 C.中位数 D.四分位数间距 10.各观察值同乘以一个不等于0的常数后,(b)不变。 A.算术均数 B.标准差 C.几何均数 D.中位数 11.( a )分布的资料,均数等于中位数。 A.对称 B.左偏态 C.右偏态 D.偏态 12.对数正态分布是一种( c )分布。
医学统计学分析计算题-答案
第二单元 计量资料的统计推断 分析计算题 2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4: 表4 某年某地健康成年人的红细胞数和血红蛋白含量 指 标 性 别 例 数 均 数 标准差 标准值* 红细胞数/1012·L -1 男 360 4.66 0.58 4.84 女 255 4.18 0.29 4.33 血红蛋白/g ·L -1 男 360 134.5 7.1 140.2 女 255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV )比较二者的变异程度。 女性红细胞数的变异系数0.29 100%100% 6.94%4.18 S CV X = ?=?= 女性血红蛋白含量的变异系数10.2 100%100%8.67%117.6 S CV X =?=?= 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误X S 来表示,由表4计算各项指标的标准误。 男性红细胞数的标准误0.031 X S = ==(1210/L ) 男性血红蛋白含量的标准误0.374 X S = ==(g/L )
女性红细胞数的标准误0.018X S = ==(1210/L ) 女性血红蛋白含量的标准误0.639X S = ==(g/L ) (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100,可视为大样本。σ未知,但n 足够大 ,故总体均数的区间估计按 (/2/2X X X u S X u S αα-+ , )计算。 该地男性红细胞数总体均数的95%可信区间为: (4.66-1.96×0.031 , 4.66+1.96×0.031),即(4.60 , 4.72)1210/L 。 该地女性红细胞数总体均数的95%可信区间为: (4.18-1.96×0.018 , 4.18+1.96×0.018),即(4.14 , 4.22)1210/L 。 (4) 两成组大样本均数的比较,用u 检验。 1) 建立检验假设,确定检验水准 H 0:12μμ=,即该地健康成年男、女血红蛋白含量均数无差别 H 1:12μμ≠,即该地健康成年男、女血红蛋白含量均数有差别 0.05α= 2) 计算检验统计量 22.829X X u === 3) 确定P 值,作出统计推断 查t 界值表(ν=∞时)得P <0.001,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同,男性高于女性。 (5) 样本均数与已知总体均数的比较,因样本含量较大,均作近似u 检验。 1) 男性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准 H 0:0μμ=,即该地男性红细胞数的均数等于标准值
医学统计学分析计算题_答案与解析
WORD 文档下载可编辑 第二单元计量资料的统计推断 分析计算题 2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4: 表4 某年某地健康成年人的红细胞数和血红蛋白含量 指标性别例数均数标准差标准值* 红细胞数/1012·L -1男360 4.66 0.58 4.84 女255 4.18 0.29 4.33 血红蛋白/g·L -1男360 134.5 7.1 140.2 女255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1 解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一 致,应采用变异系数(CV )比较二者的变异程度。 女性红细胞数的变异系数CV S 100% X S 0.29 4.18 100% 6.94% 10.2 女性血红蛋白含量的变异系数CV 100% 100% 8.67% X 117.6
由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误S X 来表示,由表 4 计算各项指标的标准误。 男性红细胞数的标准误S X S 0.58 0.031 ( 1012 /L ) n 360 S 男性血红蛋白含量的标准误S X n 7.1 360 0.374 (g/L ) 女性红细胞数的标准误S X S 0.29 0.018 ( 1012 /L) n 255 女性血红蛋白含量的标准误S X S 10.2 0.639 (g/L ) n 255 (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100 ,可视为大样本。未知,但n 足够大,故总体均数的区间估计按( X u / 2S X, X u / 2 S X)计算。 该地男性红细胞数总体均数的95% 可信区间为: (4.66 -1.96 ×0.031 , 4.66 +1.96 ×0.031) ,即(4.60 , 4.72) 1012 /L。 该地女性红细胞数总体均数的95% 可信区间为: (4.18 -1.96 ×0.018 , 4.18 +1.96 ×0.018) ,即(4.14 , 4.22) 1012 /L。 (4) 两成组大样本均数的比较,用u 检验。 1) 建立检验假设,确定检验水准 H0: 1 2 ,即该地健康成年男、女血红蛋白含量均数无差别 H1: 1 2 ,即该地健康成年男、女血红蛋白含量均数有差别 0.05 2) 计算检验统计量
医学统计学案例分析(1)
案例分析—四格表确切概率法 【例1-5】为比较中西药治疗急性心肌梗塞的疗效,某医师将27例急性心肌梗塞患者随机分成两组,分别给予中药和西药治疗,结果见表1-4。经检验,得连续性校正χ2=3.134,P>0.05,差异无统计学意义,故认为中西药治疗急性心肌梗塞的疗效基本相同。 表1-4 两种药物治疗急性心肌梗塞的疗效比较 药物有效无效合计有效率(%)中药12(9.33)2(4.67)1485.7 西药 6(8.67)7(4.33)1346.2 合计1892766.7【问题1-5】 (1)这是什么资料? (2)该资料属于何种设计方案? (3)该医师统计方法是否正确?为什么? 【分析】 (1) 该资料是按中西药的治疗结果(有效、无效)分类的计数资料。 (2) 27例患者随机分配到中药组和西药组,属于完全随机设计方案。 (3) 患者总例数n=27<40,该医师用χ2检验是不正确的。当n<40或T<1时,不宜计算χ2值,需采用四格表确切概率法(exact probabilities in 2×2 table)直接计算概率 案例分析-卡方检验(一) 【例1-1】某医师为比较中药和西药治疗胃炎的疗效,随机抽取140例胃炎患者分成中药组和西药组,结果中药组治疗80例,有效64例,西药组治疗60例,有效35例。该医师采用成组t检验(有效=1,无效=0)进行假设检验,结果t=2.848,P=0.005,差异有统计学意义检验(有效=1,无效=0)进行进行假设检验,结果t=2.848,P=0.005,差异有统计学意义,故认为中西药治疗胃炎的疗效有差别,中药疗效高于西药。
【问题1-1】 (1)这是什么资料?(2)该资料属于何种设计方案? (3)该医师统计方法是否正确?为什么?(4)该资料应该用何种统计方法?【分析】(1) 该资料是按中西药疗效(有效、无效)分类的二分类资料,即计数资料。(2) 随机抽取140例胃炎患者分成西药组和中药组,属于完全随机设计方案。(3) 该医师统计方法不正确。因为成组t检验用于推断两个总体均数有无差别,适用于正态或近似正态分布的计量资料,不能用于计数资料的比较。(4) 该资料的目的是通过比较两样本率来推断它们分别代表的两个总体率有无差别,应用四格表资料的 X2检验(chi-square test)。 【例1-2】 2003年某医院用中药和西药治疗非典病人40人,结果见表1-1。 表1-1 中药和西药治疗非典病人有效率的比较 药物有效无效合计有效率(%) 中药西药14(11.2) 2 (4.8) 14(16.8) 10 (7.2) 28 12 50.0 16.7 步骤如下: 1.建立检验假设,确定检验水准 H 0:两药的有效率相等,即π 1 =π 2 H 1:两药的有效率不等,即π 1 ≠π 2 2.计算检验统计量值 (1) 计算理论频数根据公式计算理论频数,填入表7-2的括号内。 (2) 计算χ2值 具体计算略。
医学统计学复习习题2018
医学统计学期末复习题 一、单项选择题 1 下面的变量中是分类变量的是 A.身高 B.体重 C.年龄 D.血型 2 下面的变量中是是数值变量的是 A.性别 B.年龄 C.血型 D.职业 3.随机事件的概率 P 为 =0 B. P=1 C. P= D. 0 医学统计学复习题 一、名词解释 1.总体:根据研究目的确定的同质的观察单位的全体,更确切的说,是同质的所有观察单位某种观察值(变量值)的集合。总体可分为有限总体和无限总体。总体中的所有单位都能够标识者为有限总体,反之为无限总体。 2.样本:从总体中随机抽取部分观察单位,其测量结果的集合称为样本(sample)。样本应具有代表性。所谓有代表性的样本,是指用随机抽样方法获得的样本。 3.随机抽样:随机抽样(random sampling)是指按照随机化的原则(总体中每一个观察单位都有同等的机会被选入到样本中),从总体中抽取部分观察单位的过程。随机抽样是样本具有代表性的保证。 4.变异:在自然状态下,个体间测量结果的差异称为变异(variation)。变异是生物医学研究领域普遍存在的现象。严格的说,在自然状态下,任何两个患者或研究群体间都存在差异,其表现为各种生理测量值的参差不齐。 5.计量资料:对每个观察单位用定量的方法测定某项指标量的大小,所得的资料称为计量资料(measurement data)。计量资料亦称定量资料、测量资料。.其变量值是定量的,表现为数值大小,一般有度量衡单位。如某一患者的身高(cm)、体重(kg)、红细胞计数(1012/L)、脉搏(次/分)、血压(KPa)等。 6.计数资料:将观察单位按某种属性或类别分组,所得的观察单位数称为计数资料(count data)。计数资料亦称定性资料或分类资料。其观察值是定性的,表现为互不相容的类别或属性。如调查某地某时的男、女性人口数;治疗一批患者,其治疗效果为有效、无效的人数;调查一批少数民族居民的A、B、AB、O四种血型的人数等。 7.等级资料:将观察单位按测量结果的某种属性的不同程度分组,所得各组的观察单位数,称为等级资料(ordinal data)。等级资料又称有序资料。如患者的治疗结果可分为治愈、好转、有效、无效、死亡,各种结果既是分类结果,又有顺序和等级差别,但这种差别却不能准确测量。 8.概率:概率(probability)又称几率,是度量某一随机事件A发生可能性大小的一个数值,记为P(A),P(A)越大,说明A事件发生的可能性越大。0﹤P(A)﹤1。 9.频率:在相同的条件下,独立重复做n次试验,事件A出现了m次,则比值m/n称为随机事件A在n次试验中出现的频率(freqency)。当试验重复很多次时P(A)= m/n。 10. 随机误差:随机误差(random error)又称偶然误差,是指排除了系统误差后尚存的误差。它受多种因素的影响,使观察值不按方向性和系统性而随机的变化。误差变量一般服从正态分布。随机误差可以通过统计处理来估计。 11.系统误差:是指由于仪器未校正、测量者感官的某种偏差、医生掌握疗效标准偏高或偏低等原因,使观察值不是分散在真值的两侧,而是有方向性、系统性或周期性地偏离真值。系统误差可以通过实验设计和完善技术措施来消除或使之减少。 12.参数:指总体的统计指标,如总体均数、总体率等。总体参数是固定的常数。多数情况下,总体参数是不易知道的,但可通过随机抽样抽取有代表性的样本,用算得的样本统 案例分析—四格表确切概率法 【例1-5】为比较中西药治疗急性心肌梗塞的疗效,某医师将27例急性心肌梗塞患者随机分成两组,分别给予中药和西药治疗,结果见表1-4。经检验,得连续性校正χ2=3.134,P>0.05,差异无统计学意义,故认为中西药治疗急性心肌梗塞的疗效基本相同。 表1-4 两种药物治疗急性心肌梗塞的疗效比较 药物有效无效合计有效率(%)中药12(9.33)2(4.67)1485.7 西药6(8.67)7(4.33)1346.2 合计1892766.7【问题1-5】 (1)这是什么资料? (2)该资料属于何种设计方案? (3) 该医师统计方法是否正确?为什么? 【分析】 (1) 该资料是按中西药的治疗结果(有效、无效)分类的计数资料。 (2) 27例患者随机分配到中药组和西药组,属于完全随机设计方案。(3) 患者总例数n=27<40,该医师用χ2检验是不正确的。当n<40或T<1 时,不宜计算χ2值,需采用四格表确切概率法(exact probabilities in 2×2 table)直接计算概率 案例分析-卡方检验(一) 【例1-1】某医师为比较中药和西药治疗胃炎的疗效,随机抽取140例胃炎患者分成中药组和西药组,结果中药组治疗80例,有效64例,西药组治疗60例,有效35例。该医师采用成组t检验(有效=1,无效=0)进行假设检验,结果t=2.848,P=0.005,差异有统计学意义检验(有效=1,无效=0)进行进行假设检验,结果t=2.848,P=0.005,差异有统计学意义,故认为中西药治疗胃炎的疗效有差别,中药疗效高于西药。 【问题1-1】 (1)这是什么资料?(2)该资料属于何种设计方案? (3)该医师统计方法是否正确?为什么?(4)该资料应该用何种统计方法? 【分析】(1) 该资料是按中西药疗效(有效、无效)分类的二分类资料,即计数资料。(2) 随机抽取140例胃炎患者分成西药组和中药组,属于完全随机设计方案。(3) 该医师统计方法不正确。因为成组t检验用于推断两个总体均数有无差别,适用于正态或近似正态分布的计量资料,不能用于计数资料的比较。(4) 该资料的目的是通过比较两样本率来推断它们分别代表的两个总体率有无差别,应用四格表资料的检验(chi-square test)。 【例1-2】 2003年某医院用中药和西药治疗非典病人40人,结果见 表1-1。 表1-1 中药和西药治疗非典病人有效率的比较 药物有效无效合计有效率(%) 中药西药14(11.2) 2 (4.8) 14(16.8) 10(7.2) 28 12 50.0 16.7 步骤如下: 1.建立检验假设,确定检验水准 H 0:两药的有效率相等,即π 1 =π 2 H 1:两药的有效率不等,即π 1 ≠π 2 2.计算检验统计量值 (1) 计算理论频数根据公式计算理论频数,填入表7-2的括号内。 (2) 计算χ2值 第二单元计量资料的统计推断 分析计算题 2.1某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表 4: 表4某年某地健康成年人的红细胞数和血红蛋白含量 指标性另U例数均数标准差标准值* 红细胞数/1012L-1男360 4.660.58 4.84 女255 4.180.29 4.33 血红蛋白/g L-1男360134.57.1140.2 女255117.610.2124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值 (若测定方法相同)? 2.1 解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV)比较二者的变异程度。 S 0 29 女性红细胞数的变异系数CV = 100% —9 100% 6.94% X 4.18 女性血红蛋白含量的变异系数CV 2 100%竺2100% 8.67% X 117.6 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误S X来表示,由表4计算各项指标的标准误。 男性红细胞数的标准误S X -5-。竺0.031 (1012/L) J n 7360 5 7 1 男性血红蛋白含量的标准误S X丁丁一0.374 (g/L) J n V360 可视为大样本。 未知,但n 足够大,故总体均数的区间估计按 该地男性红细胞数总体均数的 95%可信区间为: (4.66— 1.96 0.031 , 4.66+ 1.96 E .031),即(4.60,4.72)1012/L 。 该地女性红细胞数总体均数的 95%可信区间为: (4.18— 1.96 0.018,4.18+ 1.96 0.018), 即(4.14,4.22)1012/L 。 (4)两成组大样本均数的比较,用 u 检验。 1) 建立检验假设,确定检验水准 H 0: 1 2 ,即该地健康成年男、女血红蛋白含量均数无差别 H 1: 1 2 ,即该地健康成年男、女血红蛋白含量均数有差别 0.05 2) 计算检验统计量 3) 确定P 值,作出统计推断 查t 界值表(尸呦寸)得PV0.001,按 0.05水准,拒绝H 。,接受H 1,差别 有统 计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同, 男性高 于女性。 (5)样本均数与已知总体均数的比较,因样本含量较大,均作近似 u 检验。 1)男性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准 女性红细胞数的标准误S X S 0.29 ?、n .255 0.018(10 /L ) 女性血红蛋白含量的标准误 S X S 10.2 、、n . 255 0.639 (g/L ) (3)本题采用区间估计法估计男、 女红细胞数的均数。样本含量均超过100, (X u /2S X , X u /2S X )计算。 134.5 117.6 22.829 u X 1 X 2 2 2 7.1 10.2 360 255 医学统计学案例分析评述 医学期刊论著:《口岸出入境人员预防接种统计分析》 【题目】口岸出入境人员预防接种统计分析 【研究目标】对口岸出入境人员的预防接种情况进行统计分析,为各种跨国传染性疾病的预防提供参考数据。 【研究人群】2010 年1 月--2012 年5 月口岸接受预防接种的出入境人员6870 位,其基本资料如下:男3678 人,女3021 人;年龄在3-79 岁之 间,平均年龄45.6 岁。经免疫前检查和询问,研究对象均无严重 的疾病,且无接种疫苗过敏史及禁忌症。 【资料类型】本资料是计数资料。 (1)原文:研究对象:选择我处2010 年1 月-2011 年4 月,2011 年5 月-2012 年5月两个时间段6870 位出入境人员,将其按公务人员、船员、劳 务人员、留学人员、旅游探亲及商务等进行分组。 (2)问题:①文献中未明确“我处”的具体含义,没有明确研究对象的来源。 ②文献中未提及“6870 位出入境人员”是如何产生的,即是普查, 还是抽样调查?如果是抽样调查,未明确抽样的方法,是如何应用 随机抽样的方法选择这6870 位研究对象的? 【统计方法】 (1)本论著未明确使用了何种统计学方法,我们组认为:首先应对资料进行正态性检验和方差齐性检验,若满足正态、方差齐,选择χ2检验,否则应选用秩和检验。 一篇论文结论的正确与否,需根据该篇论文所选用的检验方法和检验结果进行判断。如果没有检验方法或检验方法不合理,就无法知道检验结果是否出错,也就无法对结论进行准确判断。 (2)文献尽管在“1.4 统计学处理”中提及了“使用SPSSl5.2 软件进行统计学分析”,注明所采用的统计软件,但方法中未注明统计推断方法,没有明确 医学统计学案例分析 案例分析—四格表确切概率法 【例1-5】为比较中西药治疗急性心肌梗塞de疗效,某医师将27例急性心肌梗塞患者随机分成两组,分别给予中药和西药治疗,结果见表1-4。经检2验,得连续性校正χP,0.05,差异无统计学意义,故认为中西药治=3.134,疗急性心肌梗塞de疗效基本相同。 表1-4 两种药物治疗急性心肌梗塞de疗效比较药物有效无效合计有效率(,) 中药 12(9.33) 2(4.67) 14 85.7 西药 6(8.67) 7(4.33) 13 46.2 合计 18 9 27 66.7 【问题1-5】 (1) 这是什么资料, (2) 该资料属于何种设计方案, (3) 该医师统计方法是否正确,为什么, 【分析】 (1) 该资料是按中西药de治疗结果(有效、无效)分类de计数资料。 (2) 27例患者随机分配到中药组和西药组,属于完全随机设计方案。 2(3) 患者总例数n=27,40,该医师用χ检验是不正确de。当n,40或T,1时, 2不宜计算χ值,需采用四格表确切概率法(exact probabilities in 2×2 table)直接计算概率 案例分析,卡方检验(一) 【例1-1】某医师为比较中药和西药治疗胃炎de疗效,随机抽取140例胃炎患者分成中药组和西药组,结果中药组治疗80例,有效64例,西药组治疗60例,有效35例。该医师采用成组t检验(有效=1,无效=0)进行假设检验,结检验(有效=1,无效=0)进行进行果t,2.848,P,0.005,差异有统计学意义 假设检验,结果t,2.848,P,0.005,差异有统计学意义,故认为中西药治疗胃炎de疗效有差别,中药疗效高于西药。 【问题1-1】 (1)这是什么资料,(2)该资料属于何种设计方案, (3)该医师统计方法是否正确,为什么,(4)该资料应该用何种统计方法, 【分析】 (1) 该资料是按中西药疗效(有效、无效)分类de二分类资料,即计数资料。 (2) 随机抽取140例胃炎患者分成西药组和中药组,属于完全随机设计方案。(3) 该医师统计方法不正确。因为成组t检验用于推断两个总体均数有无差别,适用于正态或近似正态分布de计量资料,不能用于计数资料de比较。 (4) 该资料de目de是通过比较两样本率来推断它们分别代表de两个总体率有无差别,应用四格表资料de 检验(chi-square test)。 【例1-2】 2003年某医院用中药和西药治疗非典病人40人,结果见表1-1。 表1-1 中药和西药治疗非典病人有效率de比较 药物有效无效合计有效率(,) 中药 (11.2) (16.8) 28 50.0 1414 西药 2 (4.8) 10 (7.2) 12 16.7 合计 16 24 40 40.0 某医师认为这是完全随机设计de2组二分类资料,可用四格表de检验。其步骤如下: 1(建立检验假设,确定检验水准 1、某医院用中药治疗7例再生障碍性贫血患者,现将血红蛋白(g/L)变化的数据列在下面,假定资料满足各种参数检验所要求的前提条件,问:治疗前后之间的差别有无显著性意义?(15分) 患者编号1234567 治疗前血红蛋白65755076657268 治疗后血红蛋白821121258580105128 2、活动型结核患者的平均心率一般为86次/分,标准差为次/分。现有一医生测量了36名该院的活动型结核患者的心率,得心率均数为90次/分,标准差为次/分,试问该院活动型结核患者与一般活动型结核患者的心率有无差别? 3、某医院将200名乙型肝炎患者随机分为甲、乙两组,各100人。甲组患者用常规治疗法,乙组患者用常规治疗加心理治疗,用一种权威评分法对两组患者的疗效进行评价,结果测得甲组均数为分,标准差为3分,乙组患者均数为分,标准差为4分,问心理治疗有无效果? 4、某医院病理科研究人体两肾的重量,20例男性尸解时的左、右肾的称重记录如下表,问左右肾重量有无不同? 20例男性尸解时的左、右肾的称重记录 编号 左肾 (克) 右肾 (克) 编号 左肾 (克) 右肾 (克) 117015011155150 215514512110125 314010513140150 411510014145140 52352221512090 612511516130120 713012017105100 81451051895100 91051251910090 1014513520105125 5、为了研究冠心病与血总胆固醇有无关系,某医生随机收集得冠心病患者和健康人的血总胆固醇(mmol/L)数据如下表,请作分析。 冠心病患者和健康人的血总胆固醇(mmol/L) 组别例数均数标准差 冠心病患者45 健康人46 6、为研究黄芪对细胞中RNA代谢的影响,在人肌皮肤二倍体细胞培养上进行黄芪对尿嘧啶核苷的渗入试验,结果见下表,请分析:两总体均数有无差别。 两组对象的尿嘧啶核苷(cPm/6×105细胞) 组别尿嘧啶核苷 黄芪组410 380 601 304 250 146 128 191 139 289 520 220 300 对照组417 349 500 430 848 320 590 200 230 235 763 458 7、为了研究铅作业与工人尿铅含量的关系,随机抽查4种作业工人的尿铅含 For personal use only in study and research; not for commercial use 第一章 绪论习题 一、选择题 1.统计工作和统计研究的全过程可分为以下步骤:(D ) A . 调查、录入数据、分析资料、撰写论文 B . 实验、录入数据、分析资料、撰写论文 C . 调查或实验、整理资料、分析资料 D. 设计、收集资料、整理资料、分析资料 E. 收集资料、整理资料、分析资料 2.在统计学中,习惯上把(B )的事件称为小概率事件。 A.10.0≤P B. 05.0≤P 或01.0≤P C. 005.0≤P D.05.0≤P E. 01.0≤P 3~8 A.计数资料 B.等级资料 C.计量资料 D.名义资料 E.角度资料 3.某偏僻农村144名妇女生育情况如下:0胎5人、1胎25人、2胎70人、3胎30人、4胎14人。该资料的类型是( A )。 4.分别用两种不同成分的培养基(A 与B )培养鼠疫杆菌,重复实验单元数均为5个,记录48小时各实验单元上生长的活菌数如下,A :48、84、90、123、171;B :90、116、124、225、84。该资料的类型是(C )。 5.空腹血糖测量值,属于( C )资料。 6.用某种新疗法治疗某病患者41人,治疗结果如下:治愈8人、显效23人、好转6人、恶化3人、死亡1人。该资料的类型是(B )。 7.某血库提供6094例ABO 血型分布资料如下:O 型1823、A 型1598、B 型2032、AB 型641。该资料的类型是(D )。 8. 100名18岁男生的身高数据属于(C )。 二、问答题 1.举例说明总体与样本的概念. 答:统计学家用总体这个术语表示大同小异的对象全体,通常称为目标总体,而资料常来源于目标总体的一个较小总体,称为研究总体。实际中由于研究总体的个体众多,甚至无限多,因此科学的办法是从中抽取一部分具有代表性的个体,称为样本。例如,关于吸烟与肺癌的研究以英国成年男子为总体目标,1951年英国全部注册医生作为研究总体,按照实验设计随机抽取的一定量的个体则组成了研究的样本。 2.举例说明同质与变异的概念 答:同质与变异是两个相对的概念。对于总体来说,同质是指该总体的共同特征,即该总体区别于其他总体的特征;变异是指该总体内部的差异,即个体的特异性。例如,某地同性别同年龄的小学生具有同质性,其身高、体重等存在变异。 3.简要阐述统计设计与统计分析的关系 答:统计设计与统计分析是科学研究中两个不可分割的重要方面。一般的,统计设计在前,然而一定的统计设计必然考虑其统计分析方法,因而统计分析又寓于统计设计之中;统计分析是在统计设计的基础上,根据设计的不《医学统计学》复习题
医学统计学案例分析
医学统计学分析计算题答案
医学统计学案例分析报告.doc
医学统计学案例分析
医学统计学练习题
(完整版)医学统计学题库