大数据结构实验 - 图地储存与遍历

一、实验目的
掌握图这种复杂的非线性结构的邻接矩阵和邻接表的存储表示,以及在此两种常用存储方式下深度优先遍历(DFS)和广度优先遍历(BFS)操作的实现。
二、实验容与实验步骤
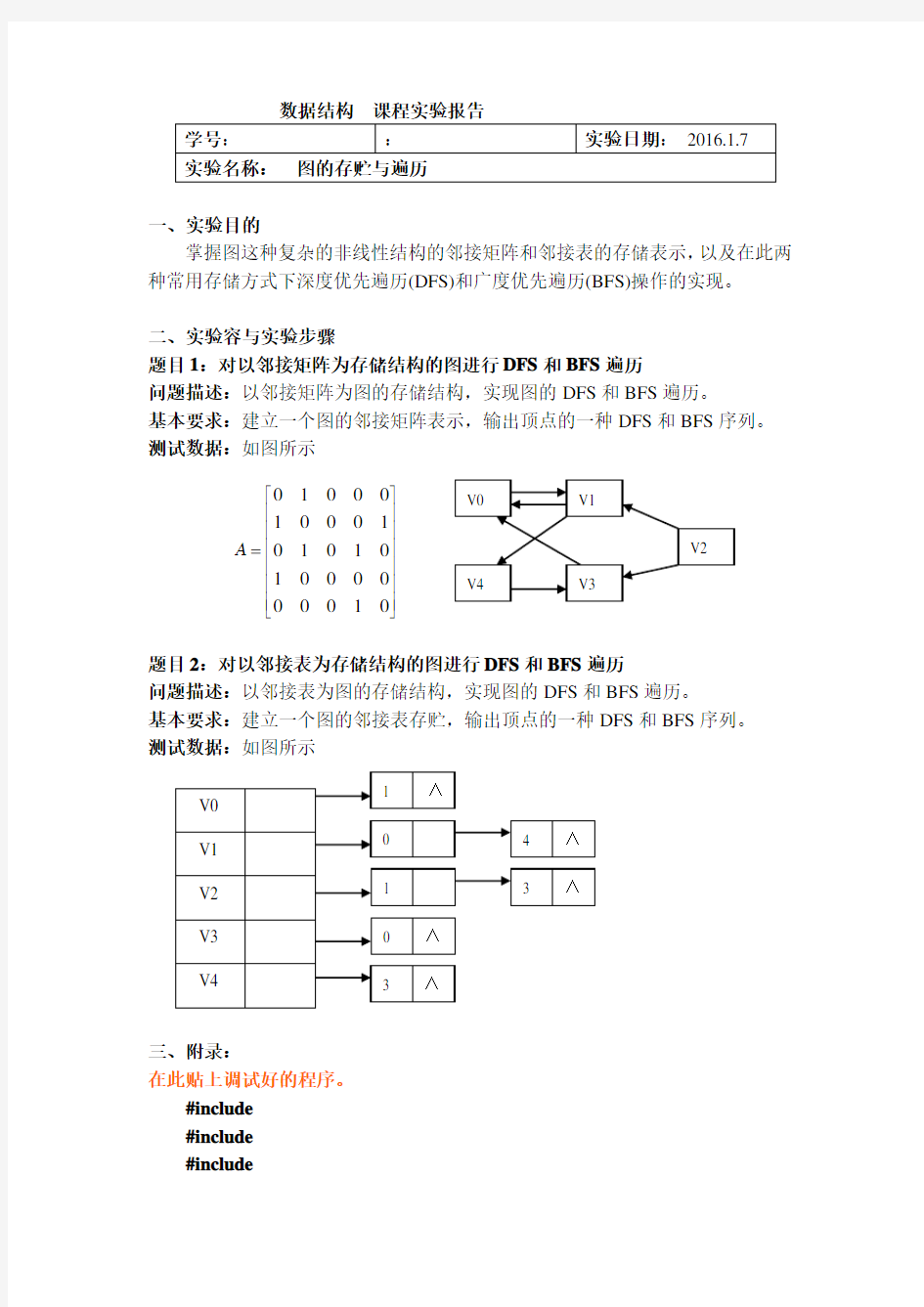
题目1:对以邻接矩阵为存储结构的图进行DFS 和BFS 遍历
问题描述:以邻接矩阵为图的存储结构,实现图的DFS 和BFS 遍历。
基本要求:建立一个图的邻接矩阵表示,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示
题目2:对以邻接表为存储结构的图进行DFS 和BFS 遍历
问题描述:以邻接表为图的存储结构,实现图的DFS 和BFS 遍历。
基本要求:建立一个图的邻接表存贮,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示
三、附录:
在此贴上调试好的程序。
#include
#include
#include
????????????????=010*******
010101000100010A
#define M 100
typedef struct node
{
char vex[M][2];
int edge[M ][ M ];
int n,e;
}Graph;
int visited[M];
Graph *Create_Graph()
{ Graph *GA;
int i,j,k,w;
GA=(Graph*)malloc(sizeof(Graph));
printf ("请输入矩阵的顶点数和边数(用逗号隔开):\n");
scanf("%d,%d",&GA->n,&GA->e);
printf ("请输入矩阵顶点信息:\n");
for(i = 0;i
scanf("%s",&(GA->vex[i][0]),&(GA->vex[i][1]));
for (i = 0;i
for (j = 0;j
GA->edge[i][j] = 0;
for (k = 0;k
{ printf ("请输入第%d条边的顶点位置(i,j)和权值(用逗号隔开):",k+1);
scanf ("%d,%d,%d",&i,&j,&w);
GA->edge[i][j] = w;
}
return(GA);
}
void dfs(Graph *GA, int v)
{ int i;
printf("%c%c\n",GA->vex[v][0],GA->vex[v][1]);
visited[v]=1;
for(i=0; i
if (GA->edge[v][i]==1 && visited[i]==0) dfs(GA, i);
}
void traver(Graph *GA)
{ int i;
for(i=0; i
visited[i]=0;
for(i=0; i
if(visited[i]==0)
dfs(GA, i);
}
void bfs( Graph *GA, int v)
{ int j,k,front=-1,rear=-1;
int Q[M];
printf("%c%c\n",GA->vex[v][0],GA->vex[v][1]); visited[v]=1;
rear=rear+1;
Q[rear]=v;
while (front!=rear)
{ front=front+1;k=Q[front];
for (j=0; j
if (GA->edge[k][j]==1 && visited[j]==0)
{ printf("%c%c\n",GA->vex[j][0],GA->vex[j][1]);
visited[j]=1;
rear=rear+1;
Q[rear]=j;
}
}
}
void traver1(Graph *GA)
{ int i;
for (i=0; i
visited[i]=0;
for (i=0; i
if (visited[i]==0)
bfs(GA, i);
}
typedef struct NODE
{ int adjvex;
struct NODE *next;
}ENode;
typedef struct NODE1
{ char vex[2];
ENode *first;
} VexNode;
typedef struct FS1
{
VexNode GL[M];
int bian,top;
}FS;
FS *CreateGL( )
{ FS *kk=(FS *)malloc(sizeof(FS));
int i,j,k;
ENode *s;
printf("请输入顶点数和边数(用逗号隔开):\n");
scanf("%d,%d",&kk->top, &kk->bian);
printf("请输入顶点信息:\n");
for (i=0; i
{ scanf("%s",kk->GL[i].vex);
kk->GL[i].first=NULL; }
printf("请输入边的信息(i,j):\n");
for (k=0;k
{ scanf("\n%d,%d",&i,&j);
s =(ENode*)malloc(sizeof(ENode));
s->adjvex=j;
s->next=kk->GL[i].first;
kk->GL[i].first =s;
}
return kk;
}
void DFS(FS *kk, int v)
{ ENode *w; int i;
printf("%s\n",kk->GL[v].vex); visited[v]=1;
w=kk->GL[v].first ;
while (w!=NULL)
{ i=w->adjvex;
if (visited[i]==0)
DFS(kk,i);
w=w->next;
}
}
void TRAVER(FS *kk)
{ int i;
for(i=0; i
visited[i]=0;
for(i=0; i
if(visited[i]==0)
DFS(kk, i);
}
void BFS(FS *kk, int v)
{ int Q[M], front=-1,rear=-1;
ENode *w;
int i, k;
printf("%s\n",kk->GL[v].vex);
visited[v]=1;
rear=rear+1; Q[rear]=v;
while (front!=rear)
{ front=front+1;
k=Q[front];
w=kk->GL[k].first;
while(w!=NULL)
{ i=w->adjvex;
if( visited[i]==0)
{ visited[i]=1; printf("%s",kk->GL[i].vex);
rear=rear+1; Q[rear]=i;
}
w=w->next;
}
}
}
void TRAVER1(FS *kk)
{ int i;
for(i=0; i
for(i=0; i
if(visited[i]==0)
BFS(kk,i);
}
int main()
{
int i=0;
Graph *p;
FS *q;
while(i=1)
{
/*建立菜单*/
char jz[30]={"1.创建邻接矩阵"};
char jd[30]={"2.邻接矩阵DFS遍历"};
char jb[30]={"3.邻接矩阵BFS遍历"};
char bg[30]={"4.创建邻接表"};
char bd[30]={"5.邻接表DFS遍历"};
char bb[30]={"6.邻接表BFS遍历"};
char tc[30]={"7.退出"};
char mn[30]={"菜单"};
int l=strlen(jd);
int o=strlen(mn);
int m,n;
printf("\n");
for(m=0;m<=(2*l-o)/2;m++)
printf(" ");
数据结构实验十一:图实验
一,实验题目 实验十一:图实验 采用邻接表存储有向图,设计算法判断任意两个顶点间手否存在路径。 二,问题分析 本程序要求采用邻接表存储有向图,设计算法判断任意两个顶点间手否存在路径,完成这些操作需要解决的关键问题是:用邻接表的形式存储有向图并输出该邻接表。用一个函数实现判断任意两点间是否存在路径。 1,数据的输入形式和输入值的范围:输入的图的结点均为整型。 2,结果的输出形式:输出的是两结点间是否存在路径的情况。 3,测试数据:输入的图的结点个数为:4 输入的图的边得个数为:3 边的信息为:1 2,2 3,3 1 三,概要设计 (1)为了实现上述程序的功能,需要: A,用邻接表的方式构建图 B,深度优先遍历该图的结点 C,判断任意两结点间是否存在路径 (2)本程序包含6个函数: a,主函数main() b,用邻接表建立图函数create_adjlistgraph() c,深度优先搜索遍历函数dfs() d,初始化遍历数组并判断有无通路函数dfs_trave() e,输出邻接表函数print() f,释放邻接表结点空间函数freealgraph() 各函数间关系如右图所示: 四,详细设计 (1)邻接表中的结点类型定义:
typedef struct arcnode{ int adjvex; arcnode *nextarc; }arcnode; (2)邻接表中头结点的类型定义: typedef struct{ char vexdata; arcnode *firstarc; }adjlist; (3)邻接表类型定义: typedef struct{ adjlist vextices[max]; int vexnum,arcnum; }algraph; (4)深度优先搜索遍历函数伪代码: int dfs(algraph *alg,int i,int n){ arcnode *p; visited[i]=1; p=alg->vextices[i].firstarc; while(p!=NULL) { if(visited[p->adjvex]==0){ if(p->adjvex==n) {flag=1; } dfs(alg,p->adjvex,n); if(flag==1) return 1; } p=p->nextarc; } return 0; } (5)初始化遍历数组并判断有无通路函数伪代码: void dfs_trave(algraph *alg,int x,int y){ int i; for(i=0;i<=alg->vexnum;i++) visited[i]=0; dfs(alg,x,y); } 五,源代码 #include "stdio.h" #include "stdlib.h" #include "malloc.h" #define max 100 typedef struct arcnode{ //定义邻接表中的结点类型 int adjvex; //定点信息 arcnode *nextarc; //指向下一个结点的指针nextarc }arcnode; typedef struct{ //定义邻接表中头结点的类型 char vexdata; //头结点的序号 arcnode *firstarc; //定义一个arcnode型指针指向头结点所对应的下一个结点}adjlist; typedef struct{ //定义邻接表类型 adjlist vextices[max]; //定义表头结点数组
数据结构实验8实验报告
暨南大学本科实验报告专用纸 课程名称数据结构实验成绩评定 实验项目名称习题6.37 6.38 6.39 指导教师孙世良 实验项目编号实验8 实验项目类型实验地点实验楼三楼机房学生姓名林炜哲学号2013053005 学院电气信息学院系专业软件工程 实验时间年月日午~月日午温度℃湿度(一)实验目的 熟悉和理解二叉树的结构特性; 熟悉二叉树的各种存储结构的特点及适用范围; 掌握遍历二叉树的各种操作及其实现方式。 理解二叉树线索化的实质是建立结点与其在相应序列中的前去或后继之间的直接联系,熟练掌握二叉树的线索化的过程以及在中序线索化树上找给定结点的前驱和后继的方法。 (二)实验内容和要求 6.37试利用栈的基本操作写出先序遍历的非递归形式的算法。 6.38同题6.37条件,写出后序遍历的非递归算法(提示:为分辨后序遍 历时两次进栈的不同返回点需在指针进栈时同时将一个标志进栈)。 6.39假设在二叉链表的结点中增设两个域:双亲域以指示其双亲结点; 标志域以区分在遍历过程中到达该结点时应继续向左或向右或访问该节点。试以此存储结构编写不用栈进行后序遍历的递推形式的算法。(三)主要仪器设备 实验环境:Microsoft Visual Studio 2012 (四)源程序
6.37: #include
数据结构实验
数据结构实验指导书
实验一线性表的顺序存储结构 一、实验学时 4学时 二、背景知识:顺序表的插入、删除及应用。 三、目的要求: 1.掌握顺序存储结构的特点。 2.掌握顺序存储结构的常见算法。 四、实验内容 1.从键盘随机输入一组整型元素序列,建立顺序表。(注意:不可将元素个数和元素值写死在程序中) 2.实现该顺序表的遍历(也即依次打印出每个数据元素的值)。 3.在该顺序表中顺序查找某一元素,如果查找成功返回1,否则返回0。 4.实现把该表中某个数据元素删除。 5.实现在该表中插入某个数据元素。 6.实现两个线性表的归并(仿照课本上P26 算法2.7)。 7. 编写一个主函数,调试上述6个算法。 五、实现提示 1.存储定义 #include
typedef int ElemType;//元素类型 typedef struct list{ ElemType *elem;//静态线性表 int length; //表的实际长度 int listsize; //表的存储容量 }SqList;//顺序表的类型名 2.建立顺序表时可利用随机函数自动产生数据。 3.为每个算法功能建立相应的函数分别调试,最后在主函数中调用它们。 六、注意问题 插入、删除元素时对于元素合法位置的判断。 七、测试过程 1.先从键盘输入元素个数,假设为6。 2.从键盘依次输入6个元素的值(注意:最好给出输入每个元素的提示,否则除了你自己知道之外,别人只见光标在闪却不知道要干什么),假设是:10,3,8,39,48,2。 3.遍历该顺序表。 4.输入待查元素的值例如39(而不是待查元素的位置)进行查找,因为它在表中所以返回1。假如要查找15,因为它不存在,所以返回0。 5.输入待删元素的位置将其从表中删掉。此处需要注意判断删位置是否合法,若表中有n个元素,则合法的删除位
数据结构实验报告图实验
图实验一,邻接矩阵的实现 1.实验目的 (1)掌握图的逻辑结构 (2)掌握图的邻接矩阵的存储结构 (3)验证图的邻接矩阵存储及其遍历操作的实现 2.实验内容 (1)建立无向图的邻接矩阵存储 (2)进行深度优先遍历 (3)进行广度优先遍历 3.设计与编码 MGraph.h #ifndef MGraph_H #define MGraph_H const int MaxSize = 10;
template
#include
数据结构实验五-查找与排序的实现
实验报告 课程名称数据结构实验名称查找与排序的实现 系别专业班级指导教师11 学号实验日期实验成绩 一、实验目的 (1)掌握交换排序算法(冒泡排序)的基本思想; (2)掌握交换排序算法(冒泡排序)的实现方法; (3)掌握折半查找算法的基本思想; (4)掌握折半查找算法的实现方法; 二、实验内容 1.对同一组数据分别进行冒泡排序,输出排序结果。要求: 1)设计三种输入数据序列:正序、反序、无序 2)修改程序: a)将序列采用手工输入的方式输入 b)增加记录比较次数、移动次数的变量并输出其值,分析三种序列状态的算法时间复杂 性 2.对给定的有序查找集合,通过折半查找与给定值k相等的元素。 3.在冒泡算法中若设置一个变量lastExchangeIndex来标记每趟排序时经过交换的最后位置, 算法如何改进? 三、设计与编码 1.本实验用到的理论知识 2.算法设计
3.编码 package sort_search; import java.util.Scanner; public class Sort_Search { //冒泡排序算法 public void BubbleSort(int r[]){ int temp; int count=0,move=0; boolean flag=true; for(int i=1;i 实验报告 实验六图的应用及其实现 一、实验目的 1.进一步功固图常用的存储结构。 2.熟练掌握在图的邻接表实现图的基本操作。 3.理解掌握AOV网、AOE网在邻接表上的实现以及解决简单的应用问题。 二、实验内容 一>.基础题目:(本类题目属于验证性的,要求学生独立完成) [题目一]:从键盘上输入AOV网的顶点和有向边的信息,建立其邻接表存储结构,然后对该图拓扑排序,并输出拓扑序列. 试设计程序实现上述AOV网 的类型定义和基本操作,完成上述功能。 [题目二]:从键盘上输入AOE网的顶点和有向边的信息,建立其邻接表存储结构,输出其关键路径和关键路径长度。试设计程序实现上述AOE网类型定义和基本操作,完成上述功能。 测试数据:教材图7.29 【题目五】连通OR 不连通 描述:给定一个无向图,一共n个点,请编写一个程序实现两种操作: D x y 从原图中删除连接x,y节点的边。 Q x y 询问x,y节点是否连通 输入 第一行两个数n,m(5<=n<=40000,1<=m<=100000) 接下来m行,每行一对整数 x y (x,y<=n),表示x,y之间有边相连。保证没有重复的边。 接下来一行一个整数 q(q<=100000) 以下q行每行一种操作,保证不会有非法删除。 输出 按询问次序输出所有Q操作的回答,连通的回答C,不连通的回答D 样例输入 3 3 1 2 1 3 2 3 5 Q 1 2 D 1 2 Q 1 2 D 3 2 Q 1 2 样例输出 C C D 【题目六】 Sort Problem An ascending sorted sequence of distinct values is one in which some form of a less-than operator is used to order the elements from smallest to largest. For example, the sorted sequence A, B, C, D implies that A < B, B < C and C < D. in this problem, we will give you a set of relations of the form A < B and ask you to determine whether a sorted order has been specified or not. 【Input】 Input consists of multiple problem instances. Each instance starts with a line containing two positive integers n and m. the first value indicated the number of objects to sort, where 2 <= n<= 26. The objects to be sorted will be the first n characters of the uppercase alphabet. The second value m indicates the number of relations of the form A < B which will be given in this problem instance. 1 <= m <= 100. Next will be m lines, each containing one such relation consisting of three characters: an uppercase letter, the character "<" and a second uppercase letter. No letter will be outside the range of the first n letters of the alphabet. Values of n = m = 0 indicate end of input. 【Output】 For each problem instance, output consists of one line. This line should be one of the following three: Sorted sequence determined: y y y… y. Sorted sequence cannot be determined. Inconsistency found. 邻接矩阵的实现 1. 实验目的 (1)掌握图的逻辑结构 (2)掌握图的邻接矩阵的存储结构 (3)验证图的邻接矩阵存储及其遍历操作的实现2. 实验内容 (1)建立无向图的邻接矩阵存储 (2)进行深度优先遍历 (3)进行广度优先遍历3.设计与编码MGraph.h #ifndef MGraph_H #define MGraph_H const int MaxSize = 10; template int vertexNum, arcNum; }; #endif MGraph.cpp #include 数据结构实验报告 一.题目要求 1)编程实现二叉排序树,包括生成、插入,删除; 2)对二叉排序树进行先根、中根、和后根非递归遍历; 3)每次对树的修改操作和遍历操作的显示结果都需要在屏幕上用树的形状表示出来。 4)分别用二叉排序树和数组去存储一个班(50人以上)的成员信息(至少包括学号、姓名、成绩3项),对比查找效率,并说明在什么情况下二叉排序树效率高,为什么? 二.解决方案 对于前三个题目要求,我们用一个程序实现代码如下 #include 实验1 (C语言补充实验) 有顺序表A和B,其元素值均按从小到大的升序排列,要求将它们合并成一 个顺序表C,且C的元素也是从小到大的升序排列。 #include 求A QB #include 1. 实验步骤: 先定义顺序表的结点: typedef struct { KeyType key; InfoType otherinfo; }ElemType; typedef struct { ElemType *R; int length; }SqList; 然后定义一个随机取数的函数,存到顺序表中: void CreateList(SqList &L,int n) 然后定义一个显示顺序表的函数,将顺序表中的数据显示出来: void ListTraverse(SqList L) 然后通过排序函数,将所有的数据按照从大到小的顺序排列: void BubbleSort(SqList &L) 实验结果: 测试数据: 38 86 9 88 29 18 58 27 排序后: 9 18 27 29 38 58 86 88 BubbleSort排序方法中数据的比较次数为:27 疑难小结: 这个程序的难点在于排序函数,总是把从第几个数开始排序以及怎样循环弄错。 源代码: #include #include 《数据结构与算法分析》 实验报告书 学期:2014 - 2015 学年第 2 学期 班级:信息管理与信息系统2班 学号: 1310030217 姓名:田洪斌 实验类别:(★)基础型()设计型 实验时间: 成绩: 信息管理系 一、实验内容 实现程序,按满二叉树给元素编号并输入的方式构造二叉树。 二、实验目的 1、掌握二叉树的静态及操作特点; 2、掌握二叉树的各种遍历方法; 3、掌握二叉树的存储、线索化等在C语言环境中的实现方法; 4、掌握哈夫曼树的构造方法及编码方法。 三、需求分析 用二叉树结构表示来完成输入、编辑、调试、运行的全过程。并规定: a.手动输入数字建立二叉树 b.程序可以输入、调试、运行、显示、遍历 c.测试数据:用户手动输入的数据 四、系统设计 1.数据结构设计 在本程序中对二叉树的存储主要用的是顺序存储结构,将二叉树存储在一个一维数组中。数据的输入输出都是采用整型数据进行。在主函数中只是定义数据类型,程序的实现功能化主要是在主函数中通过给要调用的函数参数来实现程序要求的功能。 2.程序结构设计 (1)程序中主要函数功能: main()/////////////////////////////////////////////主函数 menu()/////////////////////////////////////////////菜单 BiTree CreateBiTree()///////////////////////先序建立二叉树 (2)函数调用关系 见图4-1。 图4-1 函数关系图 五、 调试分析 1.算法和函数中出现了一些系统无法识别的变量,照成程序出现了错 误。原因是没有注意算法与源程序的区别。算法是简单的对源程序进行描述 的,是给人阅读的,所以有些变量没有定义我们就能看懂。而程序中的变量一定要先定义才能够被引用,才能被计算机识别。 2.在调试过程中遇到问题是利用C++程序进行调试的,找出错误并改正。 3.数据输出函数运行不正常,经检查程序,发现是定义错误,更改后错误排除; 六、 测试结果 1.运行时输入正确密码进入主界面,系统根据输入的数字选项来调用相应的函数。主要实现“功能选择”的界面,在这个界面里有显示系统的五大功能,根据每个功能前面的序号进行选择。以下为该界面: main BiTree CreateB iTree() meun() 数据结构与算法课程实验报告实验五:图的相关算法应用 姓名:cll 班级: 学号: 【程序运行效果】 一、实验内容: 求有向网络中任意两点之间的最短路 实验目的: 掌握图和网络的定义,掌握图的邻接矩阵、邻接表和十字链表等存储表示。掌握图的深度和广度遍历算法,掌握求网络的最短路的标号法和floyd算法。 二、问题描述: 对于下面一张若干个城市以及城市间距离的地图,从地图中所有可能的路径中求出任意两个城市间的最短距离及路径,给出任意两个城市间的最短距离值及途径的各个城市。 三、问题的实现: 3.1数据类型的定义 #define MAXVEX 50 //最大的顶点个数 #define MAX 100000 typedef struct{ char name[5]; //城市的名称 }DataType; //数据结构类型 typedef struct{ int arcs[MAXVEX][MAXVEX]; //临接矩阵 DataType data[MAXVEX]; //顶点信息 int vexs; //顶点数 }MGraph,*AdjMetrix; //邻接矩阵表示图 3.2主要的实现思路: 用邻接矩阵的方法表示各城市直接路线的图,之后用Floyd算法求解两点直接的最短距离,并用递归的方法求出途经的城市。 主要源程序代码: #include 实验六图的应用及其实现 一、实验目的 1.进一步功固图常用的存储结构。 2.熟练掌握在图的邻接表实现图的基本操作。 3.理解掌握AOE网在邻接表上的实现及解决简单的应用问题。 二、实验内容 [题目]:从键盘上输入AOE网的顶点和有向边的信息,建立其邻接表存储结构,输出其关键路径和关键路径长度。试设计程序实现上述AOE网类型定义和基本操作,完成上述功能。 三、实验步骤 (一)、数据结构与核心算法的设计描述 本实验题目是基于图的基本操作以及邻接表的存储结构之上,着重拓扑排序算法的应用,做好本实验的关键在于理解拓扑排序算法的实质及其代码的实现。 (二)、函数调用及主函数设计 以下是头文件中数据结构的设计和相关函数的声明: typedef struct ArcNode // 弧结点 { int adjvex; struct ArcNode *nextarc; InfoType info; }ArcNode; typedef struct VNode //表头结点 { VertexType vexdata; ArcNode *firstarc; }VNode,AdjList[MAX_VERTEX_NUM]; typedef struct //图的定义 { AdjList vertices; int vexnum,arcnum; int kind; }MGraph; typedef struct SqStack //栈的定义 { SElemType *base; SElemType *top; int stacksize; }SqStack; int CreateGraph(MGraph &G);//AOE网的创建 int CriticalPath(MGraph &G);//输出关键路径 (三)、程序调试及运行结果分析 (四)、实验总结 在做本实验的过程中,拓扑排具体代码的实现起着很重要的作用,反复的调试和测试占据着实验大量的时间,每次对错误的修改都加深了对实验和具体算法的理解,自己的查错能力以及其他各方面的能力也都得到了很好的提高。最终实验结果也符合实验的预期效果。 四、主要算法流程图及程序清单 1、主要算法流程图: 2、程序清单: 创建AOE网模块: int CreateGraph(MGraph &G) //创建有向网 { int i,j,k,Vi,Vj; ArcNode *p; cout<<"\n请输入顶点的数目、边的数目"< 附录A 实验报告 课程:数据结构(c语言)实验名称:图的建立、基本操作以及遍历系别:数字媒体技术实验日期: 12月13号 12月20号 专业班级:媒体161 组别:无 姓名:学号: 实验报告内容 验证性实验 一、预习准备: 实验目的: 1、熟练掌握图的结构特性,熟悉图的各种存储结构的特点及适用范围; 2、熟练掌握几种常见图的遍历方法及遍历算法; 实验环境:Widows操作系统、VC6.0 实验原理: 1.定义: 基本定义和术语 图(Graph)——图G是由两个集合V(G)和E(G)组成的,记为G=(V,E),其中:V(G)是顶点(V ertex)的非空有限集E(G)是边(Edge)的有限集合,边是顶点的无序对(即:无方向的,(v0,v2))或有序对(即:有方向的, 无向图中顶点V i的度TD(V i)是邻接矩阵A中第i行元素之和有向图中, 顶点V i的出度是A中第i行元素之和 顶点V i的入度是A中第i列元素之和 邻接表 实现:为图中每个顶点建立一个单链表,第i个单链表中的结点表示依附于顶点Vi的边(有向图中指以Vi为尾的弧) 特点: 无向图中顶点Vi的度为第i个单链表中的结点数有向图中 顶点Vi的出度为第i个单链表中的结点个数 顶点Vi的入度为整个单链表中邻接点域值是i的结点个数 逆邻接表:有向图中对每个结点建立以Vi为头的弧的单链表。 图的遍历 从图中某个顶点出发访遍图中其余顶点,并且使图中的每个顶点仅被访问一次过程.。遍历图的过程实质上是通过边或弧对每个顶点查找其邻接点的过程,其耗费的时间取决于所采用的存储结构。图的遍历有两条路径:深度优先搜索和广度优先搜索。当用邻接矩阵作图的存储结构时,查找每个顶点的邻接点所需要时间为O(n2),n为图中顶点数;而当以邻接表作图的存储结构时,找邻接点所需时间为O(e),e 为无向图中边的数或有向图中弧的数。 实验内容和要求: 选用任一种图的存储结构,建立如下图所示的带权有向图: 要求:1、建立边的条数为零的图; 数据结构课程实验报告-实验5 HUNAN UNIVERSITY 课程实习报告 题目:四则运算表达式求值 学生姓名康小雪 学生学号 20090810310 专业班级计科三班 指导老师李晓鸿 完成日期2010-10-24 一、需求分析 1.该程序可以从通过从键盘输入一个中缀表达式,判断该表达式是否合法,若合法将 其转化为后缀表达式,并计算其结果,否则说明该表达式错误 2..输入的表达式包含数字和运算符及括号,之间用空格隔开 3.数字可以为整数和小数 4.运算结果保留两位小数 输入输出举例 输入:21+23*(12-6) 输出:21 23 12 6 -*+ 二、概要设计 在表达式中每个运算符应对应两个操作数,与二叉树中非叶子结点和叶子结点之间的关系刚好相同,于是,本题可采用二叉树来将中缀表达式变为后缀表达式。 最后用堆栈来实现后缀表达式的计算。 抽象数据类型 二叉树 ADT BiTree { 数据对象D:D是具有相同特性的数据元素集合 数据关系R: 若D为空集,则R为空集,则称BinaryTree 为空二叉树; 若D不为空集,否则R={H},H是如下二元关系: (1)在D中存在唯一的称为根的数据元素root,它在关系H下无前驱; (2)若D-{root}≠空集,则存在D-{root}的一个划分{D1,Dr} 且D1∩Dr=空集; (3)若D1≠空集,则D1中存在唯一元素x1, 数据结构教程 上机实验报告 实验七、图算法上机实现 一、实验目的: 1.了解熟知图的定义和图的基本术语,掌握图的几种存储结构。 2.掌握邻接矩阵和邻接表定义及特点,并通过实例解析掌握邻接矩阵和邻接表的类型定义。 3.掌握图的遍历的定义、复杂性分析及应用,并掌握图的遍历方法及其基本思想。 二、实验内容: 1.建立无向图的邻接矩阵 2.图的xx优先搜索 3.图的xx优先搜索 三、实验步骤及结果: 1.建立无向图的邻接矩阵: 1)源代码: #include "stdio.h" #include "stdlib.h" #define MAXSIZE 30 typedefstruct{charvertex[MAXSIZE];//顶点为字符型且顶点表的长度小于MAXSIZE intedges[MAXSIZE][MAXSIZE];//边为整形且edges为邻近矩阵 }MGraph;//MGraph为采用邻近矩阵存储的图类型 voidCreatMGraph(MGraph *g,inte,int n) {//建立无向图的邻近矩阵g->egdes,n为顶点个数,e为边数inti,j,k; printf("Input data of vertexs(0~n-1): \n"); for(i=0;i 合肥师范学院实验报告册 2013 / 2014 学年第2 学期 系别计算机科学与技术系 实验课程数据库原理 专业计算机软件 班级软件一班 姓名周锦 学号1210431081 指导教师潘洁珠 实验一——数据库基本操作 一、实验目的 1.熟悉MS SQL SERVER运行界面,掌握服务器的基本操作。 2.掌握界面操作方法完成用户数据库建立、备份和还原。 3.建立两个实验用的数据库,使用企业管理器和查询分析器对数据库和表进行基本操作。 二、实验预习内容 在认真阅读教材及实验指导书的基础上,上机前请预习以下内容,并在空白处填写相应的步骤或命令。 1.熟悉SQL SERVER 2000 的运行环境,练习服务器基本操作:打开、停止、关闭。 2.使用SQL SERVER 2000 中的企业管理器完成以下任务。 数据库名称:STC 表:STU(sno char(9), sname varchar(50), ssex char(2) , sage int, sdept char(2) ); COUTSES(cno char(3), cname varchar(50), cpno char(3), credit int ); SC(sno char(9), cno char(3), grade int ); 说明:以上为表结构,以sno char(9)为例,说明sno属性设置为字符类型,宽度为9,int指整型数据。 1)建立数据库STC,分别建立以上三张表,并完成数据录入。(表结构及数据参见教材) 建立数据库:数据库→右击鼠标→新建数据库,出现如上图所示的框,然后填上所建数据库的名称。数据结构_实验六_报告
数据结构实验报告图实验
数据结构实验报告
数据结构实验
数据结构实验五
数据结构第六章实验
数据结构实验五A
数据结构-实验五-图
数据结构实验六 图的应用及其实现
数据结构实验报告(图)
数据结构课程实验报告-实验5
数据结构图实验报告
数据结构实验报告3543435