SPSS软件进行主成分分析的应用例子
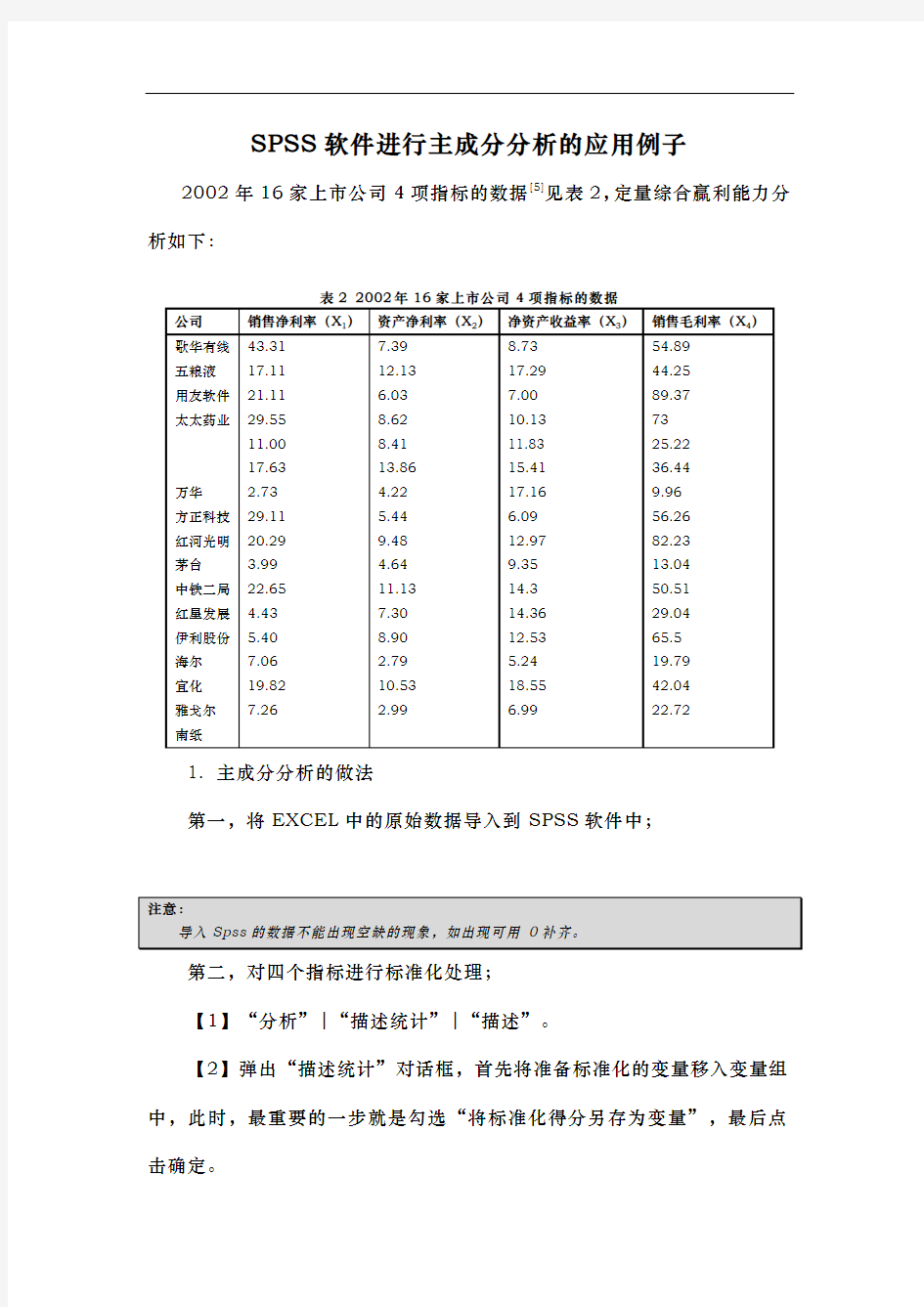

SPSS软件进行主成分分析的应用例子2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下:
1. 主成分分析的做法
第一,将EXCEL中的原始数据导入到SPSS软件中;
第二,对四个指标进行标准化处理;
【1】“分析”|“描述统计”|“描述”。
【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。
【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
所做工作:
a. 原始数据的标准化处理
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。
所的结论:
标准化后的所有指标数据。
注意:
SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。
第三,并把标准化后的数据保存在数据编辑窗口中然后利用SPSS的factor过程对数据进行因子分析(指标之间的相关性判定略)。
【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;
【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框;
【3】设置“抽取”,勾选“碎石图”复选框;
【4】设置“旋转”,勾选“最大方差法”复选框;
【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框;
【6】查看分析结果。
所做工作:
a.查看KMO和Bartlett 的检验
KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;
Bartlett 球度度检验的Sig值越小于显著水平0.05,越说明变量之间存在相关关系。
所的结论:
符合因子分析的条件,可以进行因子分析,并进一步完成主成分分析。
注意:
1.KMO(Kaiser-Meyer-Olkin)
KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因
子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。
Kaiser给出了常用的kmo度量标准: 0.9以上表示非常适合;0.8表示适合;0.7表示一般;
0.6表示不太适合;0.5以下表示极不适合。
2.Bartlett 球度检验:
巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析。
Bartlett 球度检验的原假设为相关系数矩阵为单位矩阵,Sig值为0.001小于显著水平0.05,因此拒绝原假设,说明变量之间存在相关关系,适合做因子分析。
所做工作:
b. 全部解释方差或者解释的总方差(Total Variance Explained)
初始特征根(Initial Eigenvalues)大于1,并且累计百分比达到80%~85%以上。
查看相关系数矩阵的特征根及方差贡献率见表3,由于前2个主成分贡献率≥85%、结合表4中变量不出现丢失,所以提取的主成分个数m=2。
所的结论:
初始特征根:λ1=1.897 λ2=1.550
主成分贡献率:r1=0.47429 r2=0.38740
注意:
主成分的数目可以根据相关系数矩阵的特征根来判定,如前所说,相关系数矩阵的特征根刚好等于主成分的方差,而方差是变量数据蕴涵信息的重要判据之一。根据λ值决定主成分数目的准则有三:
1.只取λ>1的特征根对应的主成分
从Total Variance Explained表中可见,第一、第二和第三个主成分对应的λ值都大于1,这意味着这三个主成分得分的方差都大于1。本例正是根据这条准则提取主成分的。
2.累计百分比达到80%~85%以上的λ值对应的主成分
在Total Variance Explained表可以看出,前三个主成分对应的λ值累计百分比达到89.584%,这暗示只要选取三个主成分,信息量就够了。
3.根据特征根变化的突变点决定主成分的数量
从特征根分布的折线图(Scree Plot)上可以看到,第4个λ值是一个明显的折点,这暗示选取的主成分数目应有p≤4。那么,究竟是3个还是4个呢?根据前面两条准则,选3个大致合适
(但小有问题)。
第四,计算特征向量矩阵(主成分表达式的系数)
【1】将初始因子载荷矩阵中的两列数据输入( 可用复制粘贴的方法) 到数据编辑窗口( 为变量V1、V2);
F1=V1/SQR(λ1)
【2】然后利用“转换”|“计算变量”, 打开“计算变量”对话框,在“目标变量”文本框中输入“F1”,然后在数字表达式中输入“V1/SQR(λ1)”[注:λ
=1.897], 即可得到特征向量F1;
1
【3】然后利用“转换”|“计算变量”, 打开“计算变量”对话框,在“目标变量”文本框中输入“F2”,然后在数字表达式中输入“V2/SQR(λ2)”[注:λ
=1.550], 即可得到特征向量F2;
1
【4】最后得到特征向量矩阵(主成分表达式的系数)。
所做工作:
a. 成分矩阵或者初始因子载荷矩阵(Component Matrix)
初始因子载荷矩阵见上图,通过初始因子载荷矩阵还不能得出主成分的表达式,还需要把初始因子载荷矩阵中的每列的系数(主成分的载荷)除以其相应主成分的特征根的平方根后才能得到主成分系数向量(主成分的得出系数);
所的结论:
1.用于计算主成分表达式系数的初始因子载荷矩阵中每个指标的载荷。
2.计算后,得到的主成分表达式的系数矩阵。
注意:
1.主成分表达式的系数
提取出来的全部主成分可以基本反映全部指标的信息,但这些新变量(主成分)的表达却不能从输出窗口中直接得到,即:主成分中每个指标所对应的系数不是初始因子载荷矩阵中的对应指标的载荷,因为“Component Matrix ”是指初始因子载荷矩阵, 每一个载荷量表示主成分与对应变量的相关系数。
2.主成分表达式系数的计算方法
初始因子载荷矩阵或主成分载荷矩阵(Component Matrix)中的数据除以主成分相对应的特征根(或特征值)开平方根便得到两个主成分中每个指标所对应的系数。
F 1=V 1/SQR(λ1)
3.主成分的指标划分与命名
初始因子载荷矩阵或主成分载荷矩阵(Component Matrix)中每列表示相应主成分与对应变量的相关系数,每个主成分所反映的原始指标各有不同,为进一步明确每个主成分侧重反应的具体原始指标,需要对原始指标在每个主成分上的载荷进行比较,其中载荷越大,其对应的主成分反映该原始指标的信息量越大,反之亦然;如果某一原始指标在几个主成分的载荷绝对值不相上下,归类比较含混,导致主成分的原始指标划分不清。说明有必要作进一步的因子分析。
从Component Matrix 即主成分载荷表中可以看出,哪一原始指标在哪一主成分上载荷绝对值较大,亦即与该主成分的相关系数较高【注:相关分为正负相关】。
第五,计算主成分得分矩阵(主成分得分)
【1】将得到的特征向量与标准化后....的数据...相乘, 然后就可以得出主成分函数的表达式;
Z 1= F 11*zX 1+ F 12*zX 2+ F 13*zX 3+ F 14*zX 4
Z 2= F 21*zX 1+ F 22*zX 2+ F 23*zX 3+ F 24*zX 4 (其中,zX i 为标准化后的数据)
【2】然后利用“转换”|“计算变量”, 打开“计算变量”对话框,在“目标变量”文本框中输入“Z 1”,然后在数字表达式中输入“0.531* Z (销售净利
率)+0.594*Z (资产净利率)+0.261*Z (净资产收益率)+0.546*Z (销售毛利率)”
[注:F 1=0.531,0.594,0.261,0.546], 即可得到特征向量Z 1;
【3】同理[注:F 2=-0.412,0.404,0.720,-0.383], 可得到特征向量Z 2; 【4】求出16家上市公司的主成分值。