数据仓库与数据挖掘技术 第八章 人工神经网络

第8章人工神经网络方法8.1人工神经网络的基本概念
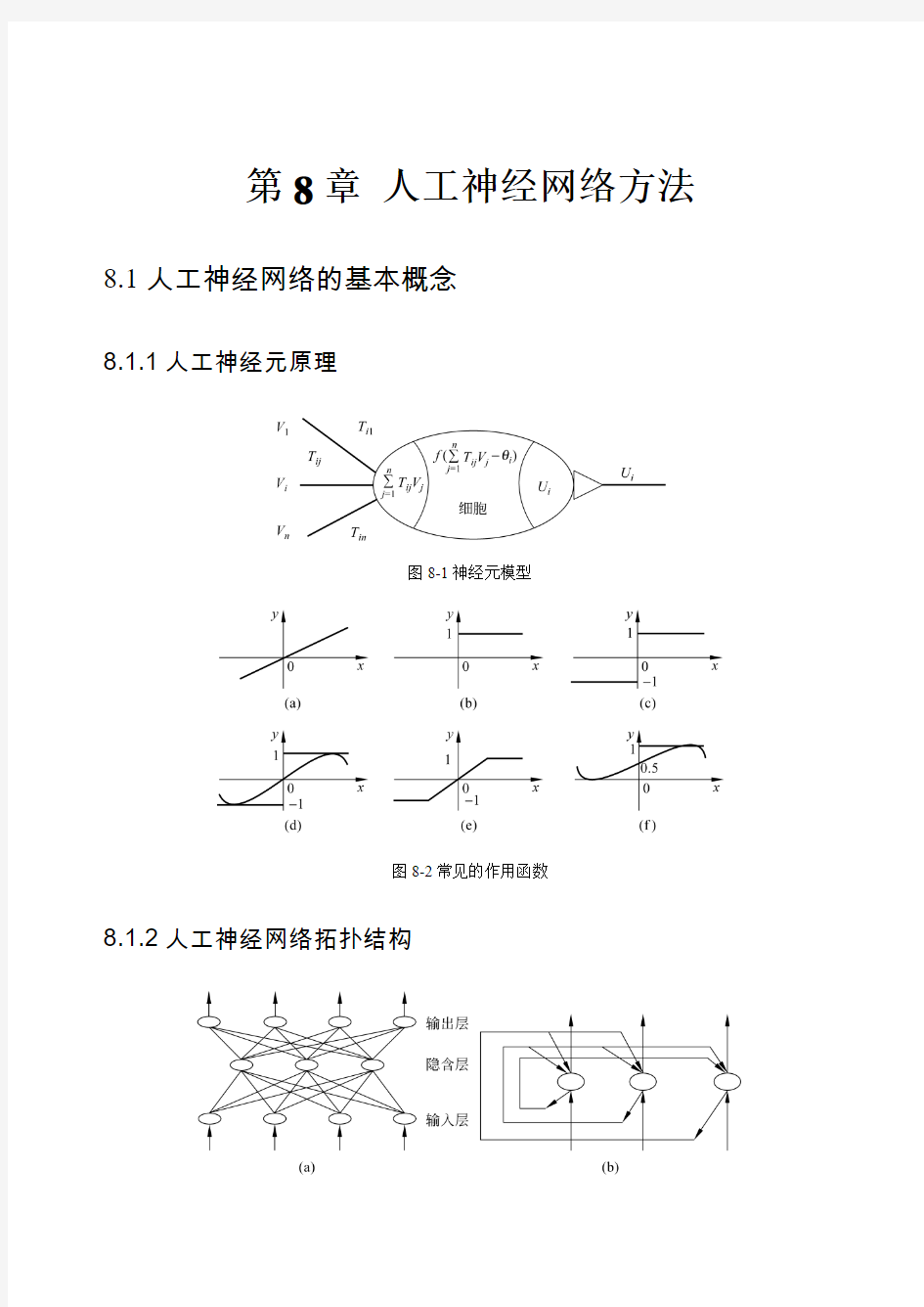
8.1.1人工神经元原理
图8-1神经元模型
图8-2常见的作用函数
8.1.2人工神经网络拓扑结构
数据仓库与数据挖掘技术
图8-3典型的神经网络结构8.1.3人工神经网络学习算法
1. 神经网络的学习方式
2. 神经网络的学习规则
8.1.4人工神经网络泛化
图8-4BP神经网络的拓扑结构
数据仓库与数据挖掘技术8.2误差反向传播(BP)神经网络
8.2.1BP神经网络的拓扑结构
8.2.2BP神经网络学习算法
8.2.3BP神经网络设计
8.3自组织特征映射(SOFM)神经网络8.3.1SOFM神经网络的拓扑结构
图8-5SOFM神经网络的拓扑结构8.3.2SOFM神经网络聚类的基本算法
8.3.3SOFM神经网络学习算法分析
1. 学习率
2. 邻域
数据仓库与数据挖掘技术8.4Elman神经网络
8.4.1Elman神经网络的拓扑结构
图8-6Elman神经网络的拓扑结构8.4.2Elman神经网络权值计算
8.5Hopfield神经网络
8.5.1Hopfield神经网络的拓扑结构
图8-7Hopfield神经网络的拓扑结构
数据仓库与数据挖掘技术
8.5.2Hopfield神经网络学习算法概述
8.5.3离散Hopfield神经网络
8.5.4连续Hopfield神经网络
1. 设置互连权值
2. 未知类别初始化
3. 迭代直到收敛
8.6利用SQL Server 2005神经网络进行数据挖掘8.6.1数据准备
图8-8统计类别个数的实现
数据仓库与数据挖掘技术
图8-9更新表中数据8.6.2挖掘流程
图8-10经处理的tdm数据示意图
数据仓库与数据挖掘技术
图8-11选择数据挖掘技术
图8-12选择数据源视图
图8-13指定表类型
数据仓库与数据挖掘技术
图8-14指定数据类型
图8-15指定列的内容和数据类型
数据仓库与数据挖掘技术
图8-16完成数据挖掘结构的创建
图8-17“次级”提升图
数据仓库与数据挖掘技术
图8-18“次级”分类矩阵图习题8
1. BP神经网络有哪些优缺点?试各列举3条。
2. 人工神经元有哪些性质?
3. SOFM神经网络的学习算法步骤?
4. BP神经网络与SOFM神经网络的异同?
5. 人工神经网络常用的学习规则有哪些?
数据仓库与数据挖掘课后习题答案
数据仓库与数据挖掘 第一章课后习题 一:填空题 1)数据库中存储的都是数据,而数据仓库中的数据都是一些历史的、存档的、归纳的、计算的数据。 2)数据仓库中的数据分为四个级别:早起细节级、当前细节级、轻度综合级、高度综合级。3)数据源是数据仓库系统的基础,是整个系统的数据源泉,通常包括业务数据和历史数据。4)元数据是“关于数据的数据”。根据元数据用途的不同将数据仓库的元数据分为技术元数据和业务元数据两类。 5)数据处理通常分为两大类:联机事务处理和联机事务分析 6)Fayyad过程模型主要有数据准备,数据挖掘和结果分析三个主要部分组成。 7)如果从整体上看数据挖掘技术,可以将其分为统计分析类、知识发现类和其他类型的数据挖掘技术三大类。 8)那些与数据的一般行为或模型不一致的数据对象称做孤立点。 9)按照挖掘对象的不同,将Web数据挖掘分为三类:web内容挖掘、web结构挖掘和web 使用挖掘。 10)查询型工具、分析型工具盒挖掘型工具结合在一起构成了数据仓库系统的工具层,它们各自的侧重点不同,因此适用范围和针对的用户也不相同。 二:简答题 1)什么是数据仓库?数据仓库的特点主要有哪些? 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支
持管理决策。 主要特点:面向主题组织的、集成的、稳定的、随时间不断变化的、数据的集合性、支持决策作用 2)简述数据挖掘的技术定义。 从技术角度看,数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程。 3)什么是业务元数据? 业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够读懂数据仓库中的数据 4)简述数据挖掘与传统分析方法的区别。 本质区别是:数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先前未知、有效和实用三个特征。 5)简述数据仓库4种体系结构的异同点及其适用性。 a.虚拟的数据仓库体系结构 b.单独的数据仓库体系结构 c.单独的数据集市体系结构 d.分布式数据仓库结构
大数据仓库与大数据挖掘技术复习资料
数据仓库与数据挖掘技术复习资料 一、单项选择题 1.数据挖掘技术包括三个主要的部分( C ) A.数据、模型、技术 B.算法、技术、领域知识 C.数据、建模能力、算法与技术 D.建模能力、算法与技术、领域知识 2.关于基本数据的元数据是指: ( D ) A.基本元数据与数据源,数据仓库,数据集市和应用程序等结构相关的信息; B.基本元数据包括与企业相关的管理方面的数据和信息; C.基本元数据包括日志文件和简历执行处理的时序调度信息; D.基本元数据包括关于装载和更新处理,分析处理以及管理方面的信息。 3.关于OLAP和OLTP的说法,下列不正确的是: ( A) A.OLAP事务量大,但事务内容比较简单且重复率高 B.OLAP的最终数据来源与OLTP不一样 C.OLTP面对的是决策人员和高层管理人员 D.OLTP以应用为核心,是应用驱动的 4.将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?( C ) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘5.下面哪种不属于数据预处理的方法? ( D ) A.变量代换 B.离散化 C. 聚集 D. 估计遗漏值 6.在ID3 算法中信息增益是指( D ) A.信息的溢出程度 B.信息的增加效益 C.熵增加的程度最大 D.熵减少的程度最大 7.以下哪个算法是基于规则的分类器 ( A ) A. C4.5 B. KNN C. Bayes D. ANN 8.以下哪项关于决策树的说法是错误的( C ) A.冗余属性不会对决策树的准确率造成不利的影响 B.子树可能在决策树中重复多次 C.决策树算法对于噪声的干扰非常敏感 D.寻找最佳决策树是NP完全问题 9.假设收入属性的最小与最大分别是10000和90000,现在想把当前值30000映射到区间[0,1],若采用最大-最小数据规范方法,计算结果是( A )
神经网络在数据挖掘中的应用
神经网络在数据挖掘中的应用
————————————————————————————————作者:————————————————————————————————日期: ?
神经网络在数据挖掘中的应用 摘要:给出了数据挖掘方法的研究现状,通过分析当前一些数据挖掘方法的局限性,介绍一种基于关系数据库的数据挖掘方法——神经网络方法,目前,在数据挖掘中最常用的神经网络是BP网络。在本文最后,也提出了神经网络方法在数据挖掘中存在的一些问题. 关键词:BP算法;神经网络;数据挖掘 1.引言 在“数据爆炸但知识贫乏”的网络时代,人们希望能够对其进行更高层次的分析,以便更好地利用这些数据。数据挖掘技术应运而生。并显示出强大的生命力。和传统的数据分析不同的是数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。所得到的信息具有先未知,有效性和实用性三个特征。它是从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示三个步骤。数据准备是从各种数据源中选取和集成用于数据挖掘的数据;规律寻找是用某种方法将数据中的规律找出来;规律表示是用尽可能符合用户习惯的方式(如可视化)将找出的规律表示出来。数据挖掘在自身发展的过程中,吸收了数理统计、数据库和人工智能中的大量技术。作为近年来来一门处理数据的新兴技术,数据挖掘的目标主要是为了帮助决策者寻找数据间潜在的关联(Relation),特征(Pattern)、趋势(Trend)等,发现被忽略的要素,对预测未来和决策行为十分有用。 数据挖掘技术在商业方面应用较早,目前已经成为电子商务中的关键技术。并且由于数据挖掘在开发信息资源方面的优越性,已逐步推广到保险、医疗、制造业和电信等各个行业的应用。 数据挖掘(Data Mining)是数据库中知识发现的核心,形成了一种全新的应用领域。数据挖掘是从大量的、有噪声的、随机的数据中,识别有效的、新颖的、有潜在应用价值及完全可理解模式的非凡过程。从而对科学研究、商业决策和企业管理提供帮助。 数据挖掘是一个高级的处理过程,它从数据集中识别出以模式来表示的知识。它的核心技术是人工智能、机器学习、统计等,但一个DM系统不是多项技术的简单组合,而是一个完整的整体,它还需要其它辅助技术的支持,才能完成数据采集、预处理、数据分析、结果表述这一系列的高级处理过程。所谓高级处理过程是指一个多步骤的处理过程,多步骤之间相互影响、反复调整,形成一种螺旋式上升过程。最后将分析结果呈现在用户面前。根据功能,整个DM系统可以大致分为三级结构。 神经网络具有自适应和学习功能,网络不断检验预测结果与实际情况是否相符。把与实际情况不符合的输入输出数据对作为新的样本,神经网络对新样本进行动态学习并动态改变网络结构和参数,这样使网络适应环境或预测对象本身结构和参数的变化,从而使预测网络模型有更强的适应性,从而得到更符合实际情况的知识和规则,辅助决策者进行更好地决策。而在ANN的
数据仓库与数据挖掘试题
武汉大学计算机学院 20XX级研究生“数据仓库和数据挖掘”课程期末考试试题 要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。每张答题纸都要写上姓名和学号。 一、单项选择题(每小题2分,共20分) 1. 下面列出的条目中,()不是数据仓库的基本特征。B A.数据仓库是面向主题的 B.数据仓库是面向事务的 C.数据仓库的数据是相对稳定的 D.数据仓库的数据是反映历史变化的 2. 数据仓库是随着时间变化的,下面的描述不正确的是()。 A.数据仓库随时间的变化不断增加新的数据内容 B.捕捉到的新数据会覆盖原来的快照 C.数据仓库随事件变化不断删去旧的数据内容C D.数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合 3. 以下关于数据仓库设计的说法中()是错误的。A A.数据仓库项目的需求很难把握,所以不可能从用户的需求出发来进行数据仓库的设计,只能从数据出发进行设计 B.在进行数据仓库主题数据模型设计时,应该按面向部门业务应用的方式来设计数据模型 C.在进行数据仓库主题数据模型设计时要强调数据的集成性 D.在进行数据仓库概念模型设计时,需要设计实体关系图,给出数据表的划分,并给出每个属性的定义域 4. 以下关于OLAP的描述中()是错误的。A A.一个多维数组可以表示为(维1,维2,…,维n) B.维的一个取值称为该维的一个维成员 C.OLAP是联机分析处理 D.OLAP是数据仓库进行分析决策的基础 5. 多维数据模型中,下列()模式不属于多维模式。D A.星型模式 B.雪花模式 C.星座模式 D.网型模式 6. 通常频繁项集、频繁闭项集和最大频繁项集之间的关系是()。C A.频繁项集?频繁闭项集?最大频繁项集 B.频繁项集?最大频繁项集?频繁闭项集 C.最大频繁项集?频繁闭项集?频繁项集 D.频繁闭项集?频繁项集?最大频繁项集
数据仓库与数据挖掘-教学大纲
《数据仓库与数据挖掘》教学大纲 一、课程概况 课程名称:数据仓库与数据挖掘 英文名称:Data warehousing and data mining 课程性质:选修 课程学时:32 课程学分:2 授课对象:信息类的大学本科高年级学生 开课时间:三年级下学期 讲课方式:课堂+实验 主讲老师: 二、教学目的 本课程把数据视为基础资源,根据软件工程的思想,总结了数据利用的历程,讲述了数据仓库的基础知识和工具,研究了数据挖掘的任务及其挑战,给出了经典的数据挖掘算法,介绍了数据挖掘的产品,剖析了税务数据挖掘的案例,探索了大数据的管理和应用问题。 三、教学任务 完成《数据仓库与数据挖掘》教材内容,及教学计划中的互动实践内容,另有学生自主选题的大作业、选作的论文报告。32学时:课堂24、实验2、课外2、研讨4学时。 四、教学内容的结构 课程由9个教学单元组成,对应于《数据仓库与数据挖掘》的内容。 第1章数据仓库和数据挖掘概述 1.1概述1 1.2数据中心4 1.2.1关系型数据中心 1.2.2非关系型数据中心
1.2.3混合型数据中心(大数据平台)1.3混合型数据中心参考架构 第2章数据 2.1数据的概念 2.2数据的内容 2.2.1实时数据与历史数据 2.2.2时态数据与事务数据 2.2.3图形数据与图像数据 2.2.4主题数据与全部数据 2.2.5空间数据 2.2.6序列数据和数据流 2.2.7元数据与数据字典 2.3数据属性及数据集 2.4数据特征的统计描述22 2.4.1集中趋势22 2.4.2离散程度23 2.4.3数据的分布形状25 2.5数据的可视化26 2.6数据相似与相异性的度量29 2.7数据质量32 2.8数据预处理32 2.8.1被污染的数据33 2.8.2数据清理35 2.8.3数据集成36 2.8.4数据变换37 2.8.5数据规约38 第3章数据仓库与数据ETL基础39 3.1从数据库到数据仓库39 3.2数据仓库的结构39 3.2.1两层体系结构41 3.2.2三层体系结构41 3.2.3组成元素42 3.3数据仓库的数据模型43 3.3.1概念模型43 3.3.2逻辑模型43 3.3.3物理模型46 3.4 ETL46 3.4.1数据抽取47 3.4.2数据转换48 3.4.3数据加载49 3.5 OLAP49 3.5.1维49 3.5.2 OLAP与OLTP49 3.5.3 OLAP的基本操作50
EDA技术实用教程第五版第13章习题答案
13-1进程有哪几种主要类型?不完全组合进程是 由什么原因引起的?有什么特点?如何避免? 解:两种: (1) begin 顺序语句 end process (2) begin wait 语句; 顺序语句 end process 两个的主要不同就在于敏感信号的不同 13-2比较CASE 语句与WITH_SELECT 语句,叙述它 们的异同点。并用WITH_SELECT_WHEN 语句描述4个16位至1个16位输出的4选1多路选择器。 答:①相同点:CASE 语句中各子句的条件不能有重叠,必须包容所有的条件;WITH_SECLECT 语句也不允许选择值有重叠现象,也不允许选择值涵盖不全的情况。另外,两者对子句各选择值的测试都具有同步性,都依赖于敏感信号的变化。 不同点:CASE 语句只能在进程中使用,至少包含一个条件语句,可以有多个赋值目标;WITH_SECLECT 语句根据满足的条件,对信号进行赋值,其赋值目标只有一个,且必须是信号。 ②LIBRARY IEEE; USE IEEE.STD_LOGIC_1164.ALL; ENTITY mux IS PORT( dina : IN STD_LOGIC_VECTOR(0 to 15); dinb : IN STD_LOGIC_VECTOR(0 to 15); dinc : IN STD_LOGIC_VECTOR(0 to 15); dind : IN STD_LOGIC_VECTOR(0 to 15); sel: IN STD_LOGIC_VECTOR(0 to 1); dout : OUT STD_LOGIC_VECTOR(0 to 15)); END mux; ARCHITECTURE rtl OF mux IS BEGIN with sel select dout<=dina WHEN "00", dinb WHEN "01", dinc WHEN "10", dind WHEN "11", "ZZZZZZZZZZZZZZZZ" when others; END rtl; 13-3 为什么说一条并行赋值语句可以等效为一 个进程?如果是这样的话,该语句咋么实现敏感信号的检测? 解:因为信号赋值语句的共同点是赋值目标必须都是信号,所有赋值语句与其它并行语句一样,在结构体内的执行是同时发生的,与它们的书写顺序没有关系,所以每一信号赋值语句都相当于一条缩写的进程语句。由于这条语句的所有输入信号都被隐性地列入此缩写进程的敏感信号表中,故任何信号的变化都将相关并行语句的赋值操作,这样就实现了敏感信号的检测。 13-4 在STRING,TIME ,REAL,BIT 数据类型中,VHDL 综合器支持哪些类型? 答:VHDL 支持BIT 类型和STRING 类型,其他属于用户定义的数据类型不能综合 13-5 判断下列VHDL 标识符是否合法,如果有误 则指出原因16#0FA#,10#12F#,8#789#,8#356#,2#0101010#,74HC245,\74HC574\,CLR/RESET ,\IN 4/SCLK\, D100%。 答:识符用法规定:(1)只能包含英文字母,数字,下划线(2)标识符的首字符只能是字母。故: (1)16#0FA#错在首字符是数字,且包含非法字符“#“。 10#12F#、8#789#,8#356#,2#0101010#,74HC245也是犯同一错误。 (2)\74HC574\,CLR/RESET,\IN4/SCLK\,D100%都 是非法,包含非法字符…. 13-6 数据类型BIT,INTEGER 和BOOLEAN 分别定义 在那个库中?哪些库和程序包总是可见的? 答:BIT 定义在IEEE 库中,INTEGER 和BOOLEAN 定义在STD 库中,除了STD 库和WORK 库外,IEEE 库面向ASIC 的库和用户自定义的库及其中的包集合 13-7 函数与过程的设计与功能有什么区别? 调用上有什么区别? 1.函数的定义由函数首和函数体两部分组成,在进程或结构体中不必定义函数首,而在程序包中必须定义函数首。 过程也由过程首和过程体构成,在进程或结构体中不必定义过程首,而在过程包中必须定义过程首。 2.函数是串行,过程是串行。 3区别:(1)参数表的区别。函数的参数表是用来定义输出值的,所以不必以显式表示参数的方向;过程的参数表可以对常数、变量和信号三类数据对象目标作出说明,并用关键词IN 、OUT 和INOUT 定
数据仓库与数据挖掘习题
数据仓库与数据挖掘习题 1.1什么是数据挖掘?在你的回答中,强调以下问题: (a) 它是又一个骗局吗? (b) 它是一种从数据库,统计学和机器学习发展的技术的简单转换吗? (c) 解释数据库技术发展如何导致数据挖掘 (d) 当把数据挖掘看作知识发现过程时,描述数据挖掘所涉及的步骤。 1.2 给出一个例子,其中数据挖掘对于一种商务的成功至关重要的。这种商务需要什么数据挖掘功能?他们能够由数据查询处理或简单的统计分析来实现吗? 1.3 假定你是Big-University的软件工程师,任务是设计一个数据挖掘系统,分析学校课程数据库。该数据库包括如下信息:每个学生的姓名,地址和状态(例如,本科生或研究生),所修课程,以及他们累积的GPA(学分平均)。描述你要选取的结构。该结构的每个成分的作用是什么? 1.4 数据仓库和数据库有何不同?它们有那些相似之处? 1.5简述以下高级数据库系统和应用:面向对象数据库,空间数据库,文本数据库,多媒体数据库和WWW。 1.6 定义以下数据挖掘功能:特征化,区分,关联,分类,预测,聚类和演变分析。使用你熟悉的现实生活中的数据库,给出每种数据挖掘的例子。 1.7 区分和分类的差别是什么?特征化和聚类的差别是什么?分类和预测呢?对于每一对任务,它们有何相似之处? 1.8 根据你的观察,描述一种可能的知识类型,它需要由数据挖掘方法发现,但未在本章中列出。它需要一种不同于本章列举的数据挖掘技术吗? 1. 9 描述关于数据挖掘方法和用户交互问题的三个数据挖掘的挑战。 1. 10 描述关于性能问题的两个数据挖掘的挑战。 2.1 试述对于多个异种信息源的集成,为什么许多公司宁愿使用更新驱动的方法(构造使用数据仓库),而不愿使用查询驱动的方法(使用包装程序和集成程序)。描述一些情况,其中查询驱动方法比更新驱动方法更受欢迎。 2.2 简略比较以下概念,可以用例子解释你的观点 (a)雪花模式、事实星座、星型网查询模型 (b)数据清理、数据变换、刷新 (c)发现驱动数据立方体、多特征方、虚拟仓库 2.3 假定数据仓库包含三个维time,doctor和patient,两个度量count 和charge,其中charge 是医生对一位病人的一次诊治的收费。 (a)列举三种流行的数据仓库建模模式。 (b)使用(a)列举的模式之一,画出上面数据仓库的模式图。 (c)由基本方体[day,doctor,patient]开始,为列出2000年每位医生的收费总数,应当执行哪些OLAP操作? (d)为得到同样的结果,写一个SQL查询。假定数据存放在关系数据库中,其模式如下:fee(day,month,year,doctor,hospital,patient,count,charge) 2.4 假定Big_University的数据仓库包含如下4个维student, course, semester和instructor,2个度量count和avg_grade。在最低的概念层(例如对于给定的学生、课程、学期和教师的组合),度量avg_grade存放学生的实际成绩。在较高的概念层,avg_grade存放给定组合的
数据仓库与数据挖掘学习心得
数据仓库与数据挖掘学习心得 通过数据仓库与数据挖掘的这门课的学习,掌握了数据仓库与数据挖掘的一些基础知识和基本概念,了解了数据仓库与数据库的区别。下面谈谈我对数据仓库与数据挖掘学习心得以及阅读相关方面的论文的学习体会。 《浅谈数据仓库与数据挖掘》这篇论文主要是介绍数据仓库与数据挖掘的的一些基本概念。数据仓库是支持管理决策过程的、面向主题的、集成的、稳定的、不同时间的数据集合。主题是数据数据归类的标准,每个主题对应一个客观分析的领域,他可为辅助决策集成多个部门不同系统的大量数据。数据仓库包含了大量的历史数据,经集成后进入数据仓库的数据极少更新的。数据仓库内的数据时间一般为5年至10年,主要用于进行时间趋势分析。数据仓库的数据量很大。 数据仓库的特点如下: 1、数据仓库是面向主题的; 2、数据仓库是集成的,数据仓库的数据有来自于分散的操作型数据,将所需数据从原来的数据中抽取出来,进行加工与集成,统一与综合之后才能进入数据仓库; 3、数据仓库是不可更新的,数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询; 4、数据仓库是随时间而变化的,传统的关系数据库系统比较适合处理格式化的数据,能够较好的满足商业商务处理的需求,它在商业领域取得了巨大的成功。
作为一个系统,数据仓库至少包括3个基本的功能部分:数据获取:数据存储和管理;信息访问。 数据挖掘的定义:数据挖掘从技术上来说是从大量的、不完全的、有噪音的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在的有用的信息和知识的过程。 数据开采技术的目标是从大量数据中,发现隐藏于其后的规律或数据间的的关系,从而服务于决策。数据挖掘的主要任务有广义知识;分类和预测;关联分析;聚类。 《数据仓库与数据挖掘技术在金融信息化中的应用》论文主要通过介绍数据额仓库与数据挖掘的起源、定义以及特征的等方面的介绍引出其在金融信息化中的应用。在金融信息化的应用方面,金融机构利用信息技术从过去积累的、海量的、以不同形式存储的数据资料里提取隐藏着的许多重要信息,并对它们进行高层次的分析,发现和挖掘出这些数据间的整体特征描述及发展趋势预测,找出对决策有价值的信息,以防范银行的经营风险、实现银行科技管理及银行科学决策。 现在银行信息化正在以业务为中心向客户为中心转变6银行信息化不仅是数据的集中整合,而且要在数据集中和整合的基础上向以客为中心的方向转变。银行信息化要适应竞争环境客户需求的变化,创造性地用信息技术对传统过程进行集成和优化,实现信息共享、资源整合综合利用,把银行的各项作用统一起来,优势互补统一调配各种资源,为银行的客户开发、服务、综理财、管理、风险防范创立坚实的基础,从而适应日益发展的数据技术需要,全面提高银行竞争力,为金融创新和提高市场反映能力
数据仓库技术简介13页
数据仓库技术简介 数据仓库是近年来兴起的一种新的数据库应用。在各大数据库厂商纷纷宣布产品支持数据仓库并提出一整套用以建立和使用数据仓库的产品是,业界掀起了数据库热。比如INFORMIXGONGSIDE公司的数据仓库解决方案;ORACLE公司的数据仓库解决方案;Sybase公司的交互式数据仓库解决方案等等。这同时也引起了学术界的极大兴趣,国际上许多重要的学术会议,如超大型数据库国际会议(VLDB),数据工程国际会议(Data Engineering)等,都出现了专门研究数据仓库(Data Warehousing,简记为DW)、联机分析处理(On-Line Analytical Processing,简记为OLAP)、数据挖掘(Data Mining, 简记为DM)的论文。对我国许多企业而言,在建立或发展自己的信息系统常常困扰于这样的问题:为什么要在原有的数据库上建立数据仓库?数据仓库能否代替传统的数据库?怎样建立数据仓库?等等。本章将简要介绍一下用到的数据仓库技术背景,并在下一章结合数据清理系统设计实例,更深一步阐述数据仓库技术在现实中的重大意义 一.从数据库到数据仓库 传统的数据库技术是以单一的数据资源,即数据库为中心,进行事务处理、批处理、决策分析等各种数据处理工作,主要的划分为两大类:操作型处理和分析型处理(或信息型处理)。操作型处理也叫事务处理,是指对数据库联机的日常操作,通常是对一个或一组纪录的查询和修改,主要为企业的特定应用服务的,注重响应时间,数据的安全性和完整性;分析型处理则用于管理人员的决策分析,经常要访问大量的历史数据。而传
统数据库系统优于企业的日常事务处理工作,而难于实现对数据分析处理要求,已经无法满足数据处理多样化的要求。操作型处理和分析型处理的分离成为必然。 近年来,随着数据库技术的应用和发展,人们尝试对DB中的数据进行再加工,形成一个综合的,面向分析的环境,以更好支持决策分析,从而形成了数据仓库技术(Data Warehousing,简称DW)。作为决策支持系统(Decision-making Support System,简称DSS),数据仓库系统包括: ①数据仓库技术; ②联机分析处理技术(On-Line Analytical Processing,简称OLAP); ③数据挖掘技术(Data Mining,简称DM); 数据仓库弥补了原有的数据库的缺点,将原来的以单一数据库为中心的数据环境发展为一种新环境:体系化环境。 1.什么是数据仓库 业界公认的数据仓库概念创始人W.H.Inmon在《建立数据仓库》一书中对数据仓库的定义是:数据仓库就是面向主题的、集成的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程 数据仓库中的数据面向主题,与传统数据库面向应用相对应。主题是一个在较高层次上将数据归类的标准,每一个主题对应一个宏观的分析领域:数据仓库的集成特性是指在数据进入数据仓库之前,必须经过数据加工和集成,这是建立数据仓库的关键步骤,首先要统一原始数据中的矛盾之处,还要将原始数据结构做一个从面向应用向面向主题的转变;数据仓
数据库第13章 数据库恢复技术
第13章数据库恢复技术 计算机同其他任何设备一样,都有可能发生故障。故障的原因有多种多样,包括磁盘故障、电源故障、软件故障、灾害故障、人为破坏等。这些情况一旦发生,就有可能造成数据的丢失。因此,数据库管理系统必须采取必要的措施,以保证即使发生故障,也不会造成数据丢失,或尽可能减少数据的丢失。 数据库恢复作为数据库管理系统必须提供的一种功能,保证了数据库的可靠性,并保证在故障发生时,数据库总是处于一致的状态。这里的可靠性指的是数据库管理系统对各种故障的适应能力,也就是从故障中进行恢复的能力。 本章讨论各种故障的类型以及针对不同类型的故障采用的数据库恢复技术。 13.1恢复的基本概念 数据库恢复是指当数据库发生故障时,将数据库恢复到正确(一致性)状态的过程。换句话说,它是将数据库恢复到发生系统故障之前最近的一致性状态的过程。故障可能是软、硬件错误引起的系统崩溃,例如存储介质故障,或者是数据库访问程序的逻辑错误等应用软件错误。恢复是将数据库从一个给定状态(通常是不一致的)恢复到先前的一致性状态。 数据库恢复是基于事务的原子性特性。事务是一个完整的工作单元,它所包含的操作必须都被应用,并且产生一个一致的数据库状态。如果因为某种原因,事务中的某个操作不能执行,则必须终止该事务并回滚(撤销)其对数据库的所有修改。因此,事务恢复是在事务终止前撤销事务对数据库的所有修改。 数据库恢复过程通常遵循一个可预测的方案。首先它确定所需恢复的类型和程度。如果整个数据库都需要恢复到一致性状态,则将使用最近的一次处于一致性状态的数据库的备份进行恢复。通过使用事务日志信息,向前回滚备份以恢复所有的后续事务。如果数据库需要恢复,但数据库已提交的部分仍然不稳定,则恢复过程将通过事务日志撤销所有未提交的事务。 恢复机制有两个关键的问题:第一,如何建立备份数据;第二,如何利用备份数据进行恢复。 数据转储(也称为数据库备份)是数据库恢复中采用的基本技术。所谓转储就是数据库管理员定期地将整个数据库复制到辅助存储设备上,比如磁带、磁盘。当数据库遭到破坏后可以利用转储的数据库进行恢复,但这种方法只能将数据库恢复到转储时的状态。如果想恢复到故障发生时的状态,则必须利用转储之后的事务日志,并重新执行日志中的事务。 转储是一项非常耗费资源的活动,因此不能频繁地进行。数据库管理员应该根据实际情况制定合适的转储周期。 转储可分为静态转储和动态转储两种。 静态转储是在系统中无运行事务时进行转储操作。即在转储操作开始时数据库处于一致性状态,而在转储期间不允许对数据库进行任何操作。因此,静态转储得到的一定是数据库的一个一致性副本。 静态转储实现起来比较简单,但转储必须要等到正在运行的所有事务结束才能开始,而且在转储时也不允许有新的事务运行,因此,这种转储方式会降低数据库的可用性。
数据仓库与数据挖掘课后习题答案
数据仓库与数据挖掘课后习 题答案 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
数据仓库与数据挖掘 第一章课后习题 一:填空题 1)数据库中存储的都是数据,而数据仓库中的数据都是一些历史的、存档的、归纳的、计算的数据。 2)数据仓库中的数据分为四个级别:早起细节级、当前细节级、轻度综合级、高度综合级。 3)数据源是数据仓库系统的基础,是整个系统的数据源泉,通常包括业务数据和历史数据。 4)元数据是“关于数据的数据”。根据元数据用途的不同将数据仓库的元数据分为技术元数据和业务元数据两类。 5)数据处理通常分为两大类:联机事务处理和联机事务分析 6)Fayyad过程模型主要有数据准备,数据挖掘和结果分析三个主要部分组成。 7)如果从整体上看数据挖掘技术,可以将其分为统计分析类、知识发现类和其他类型的数据挖掘技术三大类。 8)那些与数据的一般行为或模型不一致的数据对象称做孤立点。 9)按照挖掘对象的不同,将Web数据挖掘分为三类:web内容挖掘、web结构挖掘和web使用挖掘。 10)查询型工具、分析型工具盒挖掘型工具结合在一起构成了数据仓库系统的工具层,它们各自的侧重点不同,因此适用范围和针对的用户也不相同。 二:简答题 1)什么是数据仓库数据仓库的特点主要有哪些 2) 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。 主要特点:面向主题组织的、集成的、稳定的、随时间不断变化的、数据的集合性、支持决策作用 3)简述数据挖掘的技术定义。 从技术角度看,数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程。 4)什么是业务元数据? 业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够读懂数据仓库中的数据 5)简述数据挖掘与传统分析方法的区别。 本质区别是:数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先前未知、有效和实用三个特征。 6)简述数据仓库4种体系结构的异同点及其适用性。 a.虚拟的数据仓库体系结构 b.单独的数据仓库体系结构
数据仓库技术及实施
数据库与信息管理 电脑知识与技术 1引言 传统的数据库技术是以单一的数据资源,即数据库为中心,进行事务处理、批处理、决策分析等各种数据处理工作,数据处理可划分为两大类:操作型处理(OLTP)和分析型处理(统计分析)。操作型处理也叫事务处理,是指对数据库联机的日常操作,通常是对一个或一组纪录的查询和修改,主要为企业的特定应用服务的,注重响应时间,数据的安全性和完整性;分析型处理则用于管理人员的决策分析,经常要访问大量的历史数据。而传统数据库系统利于应用的日常事务处理工作,而难于实现对数据分析处理要求,更无法满足数据处理多样化的要求。因此,专门为业务的统计分析建立一个数据中心,它是一个联机的系统,专门为分析统计和决策支持应用服务的,通过它可以满足决策支持和联机分析应用所要求的一切。这个数据中心就叫做数据仓库。 2数据仓库概念及发展 2.1什么是数据仓库 数据仓库就是面向主题的、集成的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程。数据仓库最根本的特点是物理地存放数据,而且这些数据并不是最新的、专有的,而是来源于其它数据库的。数据仓库的建立并不是要取代数据库,它要建立在一个较全面和完善的信息应用的基础上,用于支持高层决策分析,而事务处理数据库在企业的信息环境中承担的是日常操作性的任务。 2.2相关基本概念 2.2.1元数据 元数据(metadata):是“关于数据的数据”,相当于数据库系统 中的数据字典,指明了数据仓库中信息的内容和位置,刻画了数据的抽取和转换规则,存储了与数据仓库主题有关的各种信息,而且整个数据仓库的运行都是基于元数据的,如修改跟踪数据、抽取调度数据、同步捕获历史数据等。 2.2.2OLAP(联机分析处理On-lineAnalyticalProcessing)数据仓库用于存储和管理面向决策主题的数据,OLAP对数据仓库中的数据分析,并将其转换成辅助决策信息。OLAP的一个 重要特点是多维数据分析,这与数据仓库的多维数据组织正好形 成相互结合、相互补充的关系。OLAP技术中比较典型的应用是对多维数据的切片和切块、钻取、旋转等,它便于使用者从不同角度提取有关数据,其基本思想是:企业的决策者应能灵活地操纵企业的数据,以多维的形式从多方面和多角度来观察企业的状态、了解企业的变化。对OLAP进行分类,按照存储方式的不同,可将 OLAP分成ROLAP、MOLAP和HOLAP;ROLAP没有大小限制;现 有的关系数据库的技术可以沿用;可以通过SQL实现详细数据与概要数据的储存;现有关系型数据库已经对OLAP做了很多优 化,包括并行存储、并行查询、并行数据管理、基于成本的查询优化、位图索引、SQl的OLAP扩展等大大提高了ROALP的速度;可以针对SMP或MPP的结构进行查询优化。 一般比MDD响应 速度慢;只读、不支持有关预算的读写操作;SQL无法完成部分计算,主要是无法完成多行的计算,无法完成维之间的计算。 MOLAP性能好、 响应速度快;专为OLAP所设计;支持高性能的决策支持计算;复杂的跨维计算;多用户的读写操作;行级的计算。增加系统复杂度,增加系统培训与维护费用;受操作系统平台中文件大小的限制,难以达到TB级;需要进行预计算,可能导致数据爆炸;无法支持维的动态变化;缺乏数据模型和数据访问的标准。 HOLAP综合了ROLAP和MOLAP的优点。它将常用的数据存储为MOLAP,不常用或临时的数据存储为ROLAP,这样就兼顾 了ROLAP的伸缩性和MOLAP的灵活、纯粹的特点。 收稿日期:2006-03-24 作者简介:赵方(1979-),女,浙江杭州人,浙江树人大学助教,硕士在读,主要从事教学、科研工作,以数据库应用、信息管理为主要研究方向。 数据仓库技术及实施 赵 方 (浙江树人大学,浙江杭州310015) 摘要:介绍了数据仓库的基本概念,针对数据仓库建立对创建数据仓库的过程进行了分析,对实现数据抽取、数据仓库的存储和管理等进行分析和比较。 关键词:数据仓库;联机分析处理;数据抽取;数据存储中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2006)17-0032-02 ResearchofDataWarehouseTechnology ZHAOFang (ZhejiangShurenUniversity,Hangzhou310015,China) Abstract:Inthispaper,theinternalcharacteristicsofDataWarehouseareintroduced.AnalyzedtheprocedureofintegratedDataWarehouseandbuildingthedatawarehouse,DataExtract,DataWarehouseStorageandhowtomanagetheDataWarehouse. Keywords:DataWarehouse;OLAP(On-lineAnalyticalProcessing);DataExtractTransformLoad;DataStorage 32
数据挖掘与数据仓库课程简介
数据挖掘与数据仓库课程简介 英文名:Data Mining and Data Warehouse 开课单位:计算机学院 课程编码:203086 学分学时:学分,学时32(含实验10) 授课对象:计算机科学与技术专业方向选修课 先修课程:数据库 课程目的和主要内容: 通过本课程的学习,学生应能理解数据库技术的发展为何导致需要数据挖掘,以及数据挖掘潜在应用的重要性;掌握数据仓库和多维数据结构,OLAP(联机分析处理)的实现以及数据仓库与数据挖掘的关系;熟悉数据挖掘之前的数据预处理技术;了解定义数据挖掘任务说明的数据挖掘原语;掌握数据挖掘技术的基本算法,为将来从事数据仓库的规划和实施以及数据挖掘技术的研究工作打下一定的基础。 主要内容包括数据仓库和数据挖掘的基本知识;数据清理、数据集成和变换、数据归约以及离散化和概念分层等数据预处理技术;DMQL数据挖掘查询语言;用于挖掘特征化和比较知识的面向属性的概化技术、用于挖掘关联规则知识的基本Apriori算法和它的变形、用于挖掘分类和预测知识的判定树分类算法和贝叶斯分类算法以及基于划分的聚类分析算法等;了解先进的数据库系统中的数据挖掘方法,以及对数据挖掘和数据仓库的实际应用问题展开讨论。 参考教材: 《数据挖掘概念与技术》,机械工业出版社,JiaWei Han,Micheline Kamber著,范明等译 参考和阅读书目: 《Data Mining: Concepts and Techniques》Jiawei Han and Micheline Kamber, Morgan Kaufmann, 2000 《机器学习》,Tom Mitchell著,曾华军等译 《SQLServer2000数据挖掘技术指南》,机械工业出版社,Claude Seidman著,刘艺等译 数据挖掘与数据仓库教学大纲 一、课程概况 英文名:Data Mining and Data Warehouse 开课单位:计算机学院 课程编码:203086 学分学时:学分,学时32(含实验10) 授课对象: 先修课程:数据库 课程目的和主要内容: 通过本课程的学习,学生应能理解数据库技术的发展为何导致需要数据挖掘,以及数据
(数据仓)数据仓库与数据挖掘分析
Adventure Works分销商销售数据分析 ---Women’s Tights 一、概述 Women’s Tights型号共三种产品,分别为“Women’s Tights,L”、“omen’s Tights,M”和“omen’s Tights,S”。这三种商品在拿大、法国和英国均有销售。 在Adventure WorksDW数据库中查询得知三种产品的总销售额如下: 表 1 三种商品销量对比 English Product Name Sales Amount Women's Tights, L$93,554.46 Women's Tights, M$17,727.64 Women's Tights, S$90,550.91 总计$201,833.01 查询命令为: SELECT DimProduct.EnglishProductName AS产品, SUM(FactResellerSales.SalesAmount)AS销售额 FROM DimProduct INNER JOIN FactResellerSales ON DimProduct.ProductKey = FactResellerSales.ProductKey GROUP BY DimProduct.EnglishProductName, DimProduct.ModelName HAVING(DimProduct.ModelName ='Women''s Tights') 从上表可以看出,[Women's Tights, L]与[Women's Tights, S]的销量相当,而[Women's Tights, M]的销量明显低于另两种,其销量只占总销量的9%。会有如此大的差距呢?下面运用OLAP技术进行分析。 为叙述方便,下文用“M”简称[Women's Tights, M],用“L”表示[Women's Tights, L],用“S”表示[Women's Tights, S]。 二、多维数据集的设计
人工神经网络在数据挖掘中的潜在应用
人工神经网络在数据挖掘中的潜在应用 摘要:随着存储在文件,数据库,和其他的库中的数据量巨大,数据正在变得越来越重要,开发用于分析或解释这些数据和用于提取有趣的知识的强有力的手段可以帮助决策。数据挖掘,也普遍被称为数据库中的知识发现(KDD),是指从数据库中的数据中提取隐含的,先前未知的,潜在地有用的信息。因此,数据挖掘的过程就是从大型数据库中自动提取隐藏的,预测的信息。数据挖掘,包括:提取,转换和加载到数据仓库系统的数据。神经网络已经成功地广泛的应用在监督和无监督的学习应用当中。神经网络方法不常用于数据挖掘任务当中,因为它们可能会结构复杂,训练时间长,结果的表示不易理解并且经常产生不可理解的模型。然而,神经网络对嘈杂的高精度的数据具有高度的接受能力在数据挖掘中的应用是可取的。在本论文中,调查探索人工神经网络在数据挖掘技术的应用,关键技术和实现基于神经网络的数据挖掘研究方法。鉴于目前的行业状态,神经网络作为一个工具盒在数据挖掘领域是非常有价值的一点。 关键词:数据挖掘;KDD;SOM;数据挖掘的过程 一、引言 数据挖掘,从大型数据库中提取隐藏的预测性信息,是一个功能强大的具有巨大潜力的新技术在帮助公司集中重要的信息在他们的数据仓库中。数据挖掘工具预测未来的趋势和行为,允许企业作出主动的,知识驱动的决策。所提供的数据挖掘超越过去的事件进行回顾性工具的典型的决策支持系统提供了自动、前瞻性的分析。数据挖掘工具可以回答那些,传统上耗费太多的时间来解决的业务问题。他们寻找隐藏的模式数据库,寻找专家们可能由于超出在他们期望之外而错过的预测信息。不同类型的数据挖掘工具,在市场上是可用的,每个都有自己的长处和弱点。内部审计人员需要了解数据挖掘工具的不同种类和推荐的工具,满足组织电流检测的需要。这应该在项目的生命周期中尽早考虑,甚至可行性研究。 数据挖掘通常包括四类任务。 分类:把这些数据整理到组。例如一个电子邮件程序会试图将一封电子邮件分类为合法的或垃圾邮件。常见的算法包括决策树学习,最近邻,朴素贝叶斯分类和神经网络算法。 聚类:就像分类但这些组却没有被预定义,因此该算法会尝试将类似的物品放在一起进行分组。 回归:试图找到一个以最小的误差的数据函数模型。 关联规则的学习:变量之间的关系搜索。例如,超市会对将消费者的购买习惯的数据集合起来。利用关联规则的学习,超市可以决定哪些产品经常一起购买和利用此信息实现营销的目的。有时将这种方法称为“市场分析”。 人工神经网络是一个基于人类大脑的松散的系统建模。现场有许多名字,如联结,并行分布处理,神经计算,自然智能系统,机器学习算法,人工神经网络。它必须考虑任何功能的依赖性。网络发现(学习,模型)无需提示的依赖性。最初的数据挖掘应用中神经网络不被使用是由于其结构复杂,训练时间长,且操作性较差。而神经网络是解决许多现实世界的问题的一个有力的技术。他们从经验中学习,以提高其性能和适应变化的能力环境。此外,他们能够处理不完备信息或嘈杂的数据,特别是在无法定义的规则或步骤导致一个问题的解决方案的情况下是非常有效的。
数据仓库与数据挖掘
数据仓库与数据挖掘 摘要 数据挖掘是一新兴的技术,近年对其研究正在蓬勃开展。本文阐述了数据仓库及数据挖掘的相关概念.做了相应的分析,同时共同探讨了两者共同发展的关系,并对数据仓库与挖掘技术结合应用的发展做了展望。用Data Miner作为对数据挖掘的工具,给出了应用于医院的数据仓库实例。指出了数据挖掘技术在医疗费用管理、医疗诊断管理、医院资源管理中具有的广泛应用性,为支持医院管理者的分析决策作出了积极探索。 Abstract The Data Mine is a burgeoning technology,the research about it is developing flourishing.In this paper,it expatiates and analyses the concepts of Data Warehouse and Data Mine Together,discussing the connections of how to expand the two technologies,and combining the two technologies with prospect.The data warehouse supports the mass data on the further handling and recycling.The paper points out the use of data mining in patient charge control,medical quality control, hospital resources allocation management. It helps the hospital to make decisions positively 关键字:数据仓库;数据挖掘;医院信息系统 Key words:Data Warehouse;Data Mine;Hospital information system