时序第五章SAS作业
第五章SAS作业
问题1:1867-1938年英国绵羊数量如下所示:
2203 2360 2254 2165 2024 2078 2214 2292 2207 2119 2119 2137
2132 1955 1785 1747 1818 1909 1958 1892 1919 1853 1868 1991
2111 2119 1991 1859 1856 1924 1892 1916 1968 1928 1898 1850
1841 1824 1823 1843 1880 1968 2029 1996 1933 1805 1713 1726
1752 1795 1717 1648 1512 1338 1383 1344 1384 1484 1597 1686
1707 1640 1611 1632 1775 1850 1809 1653 1648 1665 1627 1791
1、选择恰当模型,拟合该序列的发展;
2、利用拟合模型预测1939-1945年英国绵羊的数量;
3、按照书本相应例题的格式完成问题,并附上SAS程序。
答:
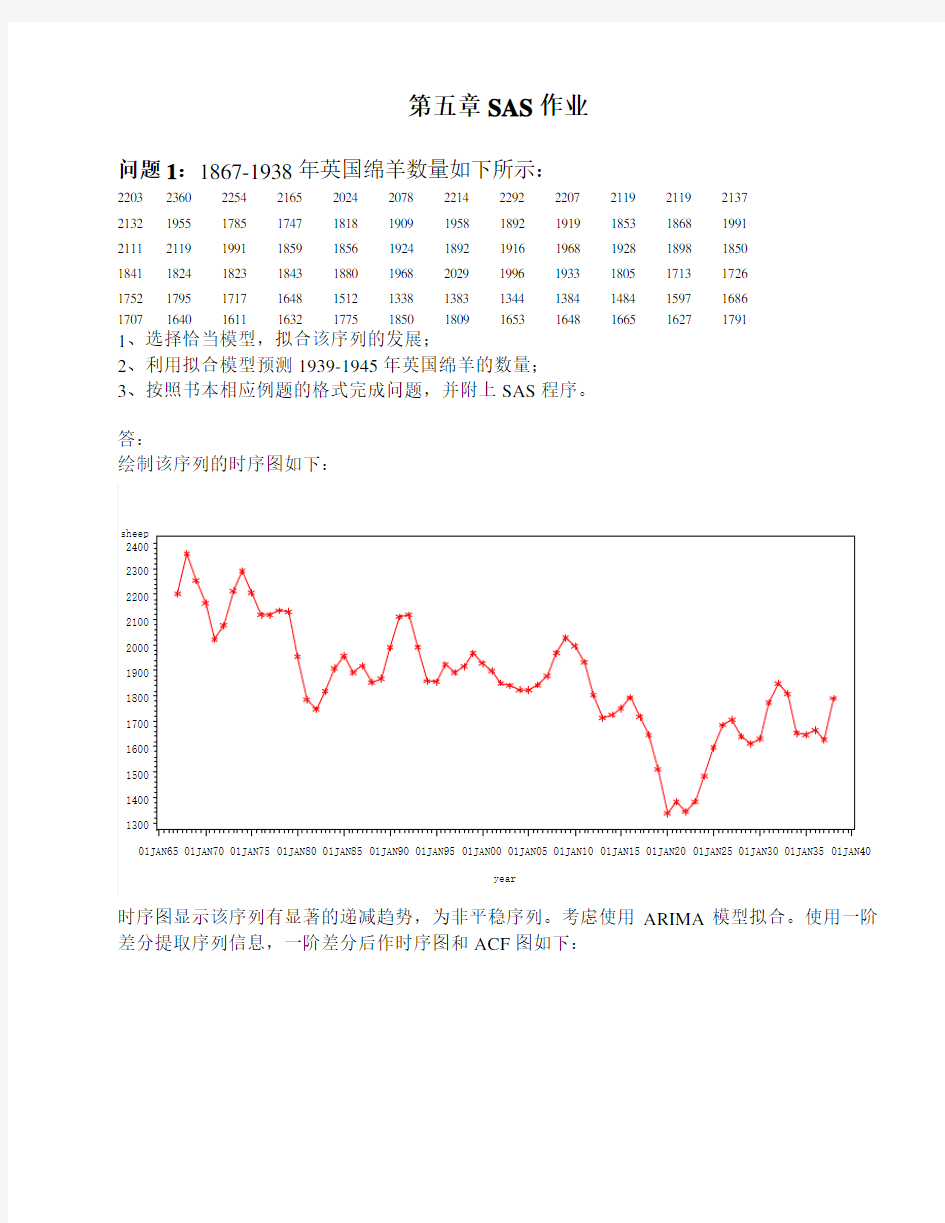
绘制该序列的时序图如下:
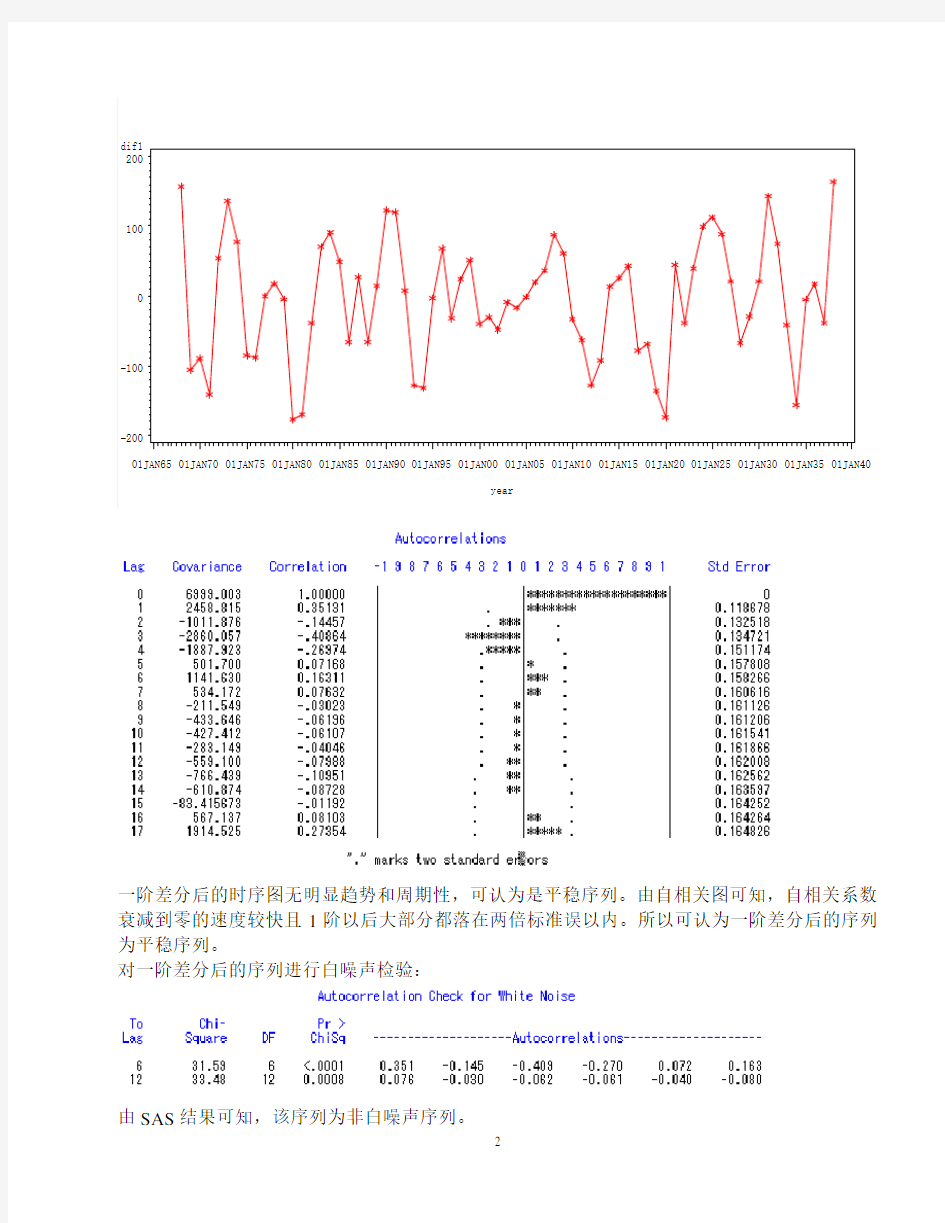
时序图显示该序列有显著的递减趋势,为非平稳序列。考虑使用ARIMA模型拟合。使用一阶差分提取序列信息,一阶差分后作时序图和ACF图如下:
dif1
-200
-100
100
200
year
01JAN6501JAN7001JAN7501JAN8001JAN8501JAN9001JAN9501JAN0001JAN0501JAN1001JAN1501JAN2001JAN2501JAN3001JAN3501JAN40
一阶差分后的时序图无明显趋势和周期性,可认为是平稳序列。由自相关图可知,自相关系数衰减到零的速度较快且1阶以后大部分都落在两倍标准误以内。所以可认为一阶差分后的序列为平稳序列。
对一阶差分后的序列进行白噪声检验:
由SAS结果可知,该序列为非白噪声序列。
一阶差分后序列的PACF图如下:
观察ACF图和PACF图后,可认为ACF图拖尾,PACF图3阶截尾。建立AR(3)模型。SAS输出残差序列及系数检验结果如下:
结果显示AR(3)模型显著,常数项和φ2未通过检验,先剔除常数项,检验结果如下:
φ2仍未通过检验,建立疏系数模型ARIMA((1,3),1,0),检验结果如下:
由上述结果可知,模型ARIMA((1,3),1,0)显著,系数显著。
模型如下:
即▽x t=0.32196▽x t-1-0.37616▽x t-3+εt
(1-B)x t=εt/(1-0.32196B+0.37616B3)
预测7年绵羊数量如下:
预测拟合图如下:
sheep
2600
2500
2400
2300
2200
2100
2000
1900
1800
1700
1600
1500
1400
1300
1200
1100
01JAN6011JAN6021JAN6031JAN6010FEB6020FEB6001MAR6011MAR6021MAR60
year
SAS程序如下:
data homework5_1;
input sheep@@;
dif1=dif(sheep); /*一阶差分*/
year=intnx('year','1jan1867'd,_n_-1);
format year date.;
cards;
2203 2360 2254 2165 2024 2078 2214 2292 2207 2119 2119 2137
2132 1955 1785 1747 1818 1909 1958 1892 1919 1853 1868 1991
2111 2119 1991 1859 1856 1924 1892 1916 1968 1928 1898 1850
1841 1824 1823 1843 1880 1968 2029 1996 1933 1805 1713
1726
1752 1795 1717 1648 1512 1338 1383 1344 1384 1484 1597 1686
1707 1640 1611 1632 1775 1850 1809 1653 1648 1665 1627 1791
;
proc print data=homework5_1;
proc gplot;
plot sheep*year dif1*year;
symbol v=star c=red i=join;
proc arima data=homework5_1;
identify var=sheep(1);/*如果输入var=dif1,则forecast的结果为差分后的序列的预测值*/ estimate p=(13) noint;
forecast lead=7id=year out=result;
data result2;
set result;
year=_n_;
proc gplot data=result2; /*画图数据集*/
plot sheep*year=1 forecast*year=2 l95*year=3 u95*year=3/overlay;
symbol1v=star c=red i=none;
symbol2v=none c=bule i=join;
symbol3v=none c=black i=join l=32;
run;
问题2,使用Auto-Regressive模型分析例5.9序列。(作业格式参照书“例5.6续”)
答:
绘制该序列时序图如下:
x
11
10
9
8
7
6
5
4
3
2
1
01JAN6201JAN6401JAN6601JAN6801JAN7001JAN7201JAN7401JAN7601JAN7801JAN8001JAN8201JAN8401JAN8601JAN8801JAN9001JAN92
quarter
由上图可以看出该序列既有递增趋势又有周期性。考虑建立如下结构的残差自回归模型:x t=St·(Tt+It)
对Tt和St分别构造如下四个确定性模型:
(1)趋势变量为时间t的幂函数,季节指数为给定的季节指数。
Tt=β0+β1t ,St=St’
S1=1.149585S2=0.932638S3=0.924146S4=0.993631
消除季节效应后的时序图:
x1
10
9
8
7
6
5
4
3
2
1
01JAN6201JAN6401JAN6601JAN6801JAN7001JAN7201JAN7401JAN7601JAN7801JAN8001JAN8201JAN8401JAN8601JAN8801JAN9001JAN92
quarter
然后构造如下确定性趋势模型:T t=β0+β1t
得如下结果:
消除趋势后的时序图如下:
x1
10
9
8
7
6
5
4
3
2
1
-1
0102030405060708090100110120
t
对消除确定性因素后的序列εt=x t/St-Tt做DW检验,结果如下:
DW检验结果p值小于0.05,显示残差序列显著自相关性。
尝试对残差序列{εt}拟合AR(5)模型,确定残差自回归模型的口径:
因为参数没通过检验,去除参数后再次估计模型口径:
所以得到的最终拟合模型为:
x t=St·0.0726t+ut , S1=1.149585S2=0.932638S3=0.924146S4=0.993631 u t=0.9598u t-1+0.6881u t-4-0.7238u t-5+a t
模型解释:德国工人季度失业率有一个长期递增的趋势,每年每季度的增长速度为0.0726St.同时它还受到诸多随机因素的影响,导致随机波动序列具有短期相关性。
拟合图如下:
(2) 趋势变量为历史观测值,季节指数为给定的季节指数。
,S 1=1.149585 S 2=0.932638 S 3=0.924146 S 4=0.993631
消除季节效应后的时序图:
然后构造如下确定性趋势模型:
110-?+=t t x T ββ110-?+=t t x T ββ
得如下结果:
Dh检验结果p值小于0.05,显示残差序列显著自相关性。
尝试对残差序列{εt}拟合AR(2)模型:
确定残差自回归模型的口径:
所有参数均显著。
所以得到的最终拟合模型为:
x t=St·1.0029x t-1+ut , S1=1.149585S2=0.932638S3=0.924146S4=0.993631
u t=0.2812u t-1-0.3151u t-2+a t
拟合图如下:
x
11
10
9
8
7
6
5
4
3
2
1
0102030405060708090100110120
t
(3)趋势变量为历史观测值,季节效应为季节自回归模型。
, ,
构造如下季节自回归模型:S t=α0+α1·x t-12
得如下结果:
参数p值均小于0.05,即参数显著。
所以St=1.5043+0.8006 x t-12.
消除季节效应后的时序图:
x2_
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2.0
2.1
2.2
t
0102030405060708090100110120
然后构造如下确定性趋势模型:
得如下结果:
Dh检验结果p值小于0.05,显示残差序列显著自相关性。
1
1
0-
?
+
=
t
t
x
Tβ
β
1
1
0-
?
+
=t
t
x
Tβ
β
尝试对残差序列{εt}拟合AR(1)模型,确定残差自回归模型的口径:
所有参数均显著。
所以得到的最终拟合模型为:
x t=(1.5043+0.8006 x t-12)·0.9824x t-1+ut ,
u t=0.3777u t-1+a t
拟合图如下:
x
11
10
9
8
7
6
5
4
3
2
1
0102030405060708090100110120
t
(4)趋势自变量为时间t的幂函数,季节效应为季节自回归模型。
消除季节效应后的时序图:
x2_
2.2
2.1
2.0
1.9
1.8
1.7
1.6
1.5
1.4
1.3
1.2
1.1
1.0
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0102030405060708090100110120
t
然后构造如下确定性趋势模型:T t=β0+β1t
得如下结果:
DW检验结果p值小于0.05,显示残差序列显著自相关性。
尝试对残差序列{εt}拟合AR(5)模型,确定残差自回归模型的口径:
所有参数均显著。
所以得到的最终拟合模型为:
x t=(1.5043+0.8006 x t-12)·0.0130t+ut ,
u t=1.0162u t-1+0.4061u t-4-0.5190u t-5+a t
拟合图如下:
x
11
10
9
8
7
6
5
4
3
2
1
0102030405060708090100110120
t
SAS程序如下:
data homework5_2;
input x@@;
t=_n_;
quarter=intnx('quarter','1jan1962'd,_n_-1);
format quarter date.;
cards;
1.1 0.5 0.4 0.7 1.6 0.6 0.5 0.7
1.3 0.6 0.5 0.7 1.2 0.5 0.4 0.6
0.9 0.5 0.5 1.1 2.9 2.1 1.7 2
2.7 1.3 0.9 1 1.6 0.6 0.5 0.7
1.1 0.5 0.5 0.6 1.2 0.7 0.7 1
1.5 1 0.9 1.1 1.5 1 1 1.6
2.6 2.1 2.3
3.6 5
4.5 4.5 4.9
5.7 4.3 4 4.4 5.2 4.3 4.2 4.5
5.2 4.1 3.9 4.1 4.8 3.5 3.4 3.5
4.2 3.4 3.6 4.3
5.5 4.8 5.4
6.5
8 7 7.4 8.5 10.1 8.9 8.8 9
10 8.7 8.8 8.9 10.4 8.9 8.9 9
10.2 8.6 8.4 8.4 9.9 8.5 8.6 8.7
9.8 8.6 8.4 8.2 8.8 7.6 7.5 7.6
8.1 7.1 6.9 6.6 6.8 6 6.2 6.2
;
proc print data=homework5_2;
proc gplot;
plot x*quarter;
symbol v=star c=red i=join;
data homework5_2a;
merge homework5_2;
input x1@@;
lagx1=lag(x1);
cards;
0.956867025 0.536113411 0.43283208 0.704487179
1.391806582 0.643336093 0.5410401 0.704487179
1.130842848 0.643336093 0.5410401 0.704487179
1.043854936 0.536113411 0.43283208 0.603846154
0.782891202 0.536113411 0.5410401 1.107051282
2.522649429 2.251676325 1.839536341 2.012820513 2.348673606 1.393894868 0.97387218 1.006410256
1.391806582 0.643336093 0.5410401 0.704487179
0.956867025 0.536113411 0.5410401 0.603846154
1.043854936 0.750558775 0.75745614 1.006410256
1.30481867 1.072226821 0.97387218 1.107051282
1.30481867 1.072226821 1.082080201 1.61025641
2.261685695 2.251676325 2.488784461
3.623076923
4.349395567 4.825020695 4.869360902 4.931410256 4.958310947 4.610575331 4.328320802 4.428205128 4.52337139 4.610575331 4.544736842 4.528846154
4.52337139 4.396129967 4.220112782 4.126282051
4.175419745 3.752793874 3.679072682 3.522435897
3.653492277 3.645571192 3.895488722
4.327564103
4.784335124
5.146688742 5.843233083
6.541666667 6.959032908
7.505587748
8.007393484 8.554487179 8.785779046
9.542818709 9.522305764 9.057692308
8.698791135 9.328373344 9.522305764 8.957051282
9.04674278 9.542818709 9.630513784 9.057692308
8.872766958 9.221150662 9.089473684 8.453846154 8.611803224 9.11392798 9.305889724 8.755769231
8.524815312 9.221150662 9.089473684 8.252564103 7.654936199 8.148923841 8.115601504 7.648717949 7.046020819 7.61281043 7.466353383 6.642307692
5.915177972
6.433360927 6.708897243 6.23974359 ;
proc print data=homework5_2a;
run;
proc gplot data=homework5_2a;
plot x1*quarter;
symbol v=star c=red i=join;
run;
proc autoreg data=homework5_2a;
model x1=t/dwprob;
output out=out1 p=xx1 residual=res;
run;
proc print data=out1;
proc gplot data=out1;
plot x1*t=1 xx1*t=2/overlay;
symbol1v=star c=red i=join;
symbol2c=green v=none i=join;
run;
proc autoreg data=homework5_2a;
model x1=t/nlag=5backstep method=ml noint ;
output out=out2 p=xx2;
run;
data homework5_2b;
input st@@;
cards;
1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 1.149585022 0.932638487 0.924145918 0.993630573 ;
data homework5_2c;
merge homework5_2a homework5_2b out2;
x3=xx2*st;
proc gplot data=homework5_2c;;
plot x*t=1 x3*t=2/overlay;
symbol1v=star c=red i=none;
symbol2c=blue v=none i=join;
run;
proc autoreg data=homework5_2a;
model x1=lagx1/lagdep=lagx1 nlag=2noint;
output out=out3 p=xx3;
run;
data homework5_2d;
merge homework5_2a homework5_2b out3;
x4=xx3*st;
proc gplot data=homework5_2d;
plot x*t=1 x4*t=2/overlay;
symbol1v=star c=red i=none;
symbol2c=blue v=none i=join;
run;
data homework5_22;
merge homework5_2;
lag12x=lag12(x);
proc autoreg data=homework5_22; *;
model x=lag12x;
output out=out1_ p=xx_ ;
run;
data homework5_22a;
merge homework5_22 out1_;
x2_=x/xx_;
lag1_12x=lag(x2_);
proc print data=homework5_22a;
run;
proc gplot data=homework5_22a;
plot x2_*t;
symbol v=star c=red i=join;
run;
proc autoreg data=homework5_22a;
model x2_=lag1_12x/lagdep=lag1_12x;
output out=out2_ p=xx1_ ;
run;
proc autoreg data=homework5_22a;
model x2_=lag1_12x/lagdep=lag1_12x nlag=1noint; output out=out3_ p=xx3_;
run;
data homework5_22b;
merge homework5_22a out3_;
x4_=xx3_*xx_;
proc gplot data=homework5_22b;
plot x*t=1 x4_*t=2/overlay;
symbol1v=star c=red i=none;
symbol2c=blue v=none i=join;
run;
proc autoreg data=homework5_22a;
model x2_=t/dwprob noint;
output out=out4_ p=xx4_;
run;
proc autoreg data=homework5_22a;
model x2_=t/nlag=5backstep method=ml noint ; output out=out5_ p=xx5_;
run;
data homework5_22c;
merge homework5_22a out5_;
x5_=xx5_*xx_;
proc gplot data=homework5_22c;
plot x*t=1 x5_*t=2/overlay;
symbol1v=star c=red i=none;
symbol2c=blue v=none i=join;
run;
图书馆管理系统用例图、活动图、类图、时序图
图书馆管理系统 一.图书馆管理系统需求分析 1、系统目标设计 系统开发的总目标是实现内部图书借阅管理的系统化、规范化和自动化。 能够对图书进行注册登记,也就是将图书的基本信息(如:书的编号、书名、作者、价格等)预先存入数据库中,供以后检索。 能够对借阅人进行注册登记,包括记录借阅人的姓名、编号、班级、年龄、性别、地址、电话等信息。 提供方便的查询方法。如:以书名、作者、出版社、出版时间(确切的时间、时间段、某一时间之前、某一时间之后)等信息进行图书检索,并能反映出图书的借阅情况;以借阅人编号对借阅人信息进行检索;以出版社名称查询出版社联系方式信息。 提供对书籍进行的预先预订的功能。 提供旧书销毁功能,对于淘汰、损坏、丢失的书目可及时对数据库进行修改。 能够对使用该管理系统的用户进行管理,按照不同的工作职能提供不同的功能授权。 提供较为完善的差错控制与友好的用户界面,尽量避免误操作。 2、系统功能需求分析 (1) 读者管理:读者信息的制定、输入、修改、查询,包括种类、性别、 借书数量、借书期限、备注等。 (2) 书籍管理:书籍基本信息制定、输入、修改、查询,包括书籍编号、 类别、关键词、备注。 (3) 借阅管理:包括借书,还书,预订书籍,续借,查询书籍,过期处 理和书籍丢失后的处理。
(4)系统管理:包括用户权限管理,数据管理和自动借还书机的管理 满足以上需求的系统主要包含有一下几个子系统 (1)基本业务功能子系统:该系统中主要包含了借书还书和预订等功能。 (2)基本数据录入功能子系统:该子系统主要包含有书籍信息和读者信息录入功能。 (3)信息查询子系统:包含了多功能的查询书籍信息和读者信息。 (4)数据库管理功能子系统:主要包含了借阅信息管理功能,书籍信息管理功能和预订信息管理功能。 (5)帮助功能子系统。 二、系统动态建模 1、用例图、
应用多元统计分析SAS作业审批稿
应用多元统计分析S A S 作业 YKK standardization office【 YKK5AB- YKK08- YKK2C- YKK18】
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为2.95,2.15和1.54,试判断该标本是含矿还是不含矿? 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 2.58 0.9 0.95 1 2.9 1.23 1 1 3.55 1.15 1 1 2.35 1.15 0.79 1 3.54 1.85 0.79 1 2.7 2.23 1.3 1 2.7 1.7 0.48 2 2.25 1.98 1.06 2 2.16 1.8 1.06 2 2.3 3 1.7 4 1.1 2 1.96 1.48 1.04
2 1.94 1.4 1 2 3 1.3 1 2 2.78 1.7 1.48 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=3.19774。还可知两个三元总体均值相等的检验结果:D =3.19774,F =3.10891,p =0.0756<0.10,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值2.95、2.15、1.54分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
图书管理系统用例建模报告(用例图、类图、时序图)
软件系统分析与设计 实验报告 学院:计算机科学与技术学院专业:软件工程 学号:********* 姓名:*** 实验名称:图书管理系统用例建模时间:
一、实验内容与要求 本实验要求学生对学校的图书馆管理系统进行需求分析,对系统功能进行用例建模,画出用例图,类图以及相应的时序图。在使用UML对系统建模时,学会使用UML建模工具,熟悉工具中的功能。 二、用例分析 1、读者“借书还书系统”用例图 (f 还书 (from Use Cases) 1.1、行为者: 主要行为者:读者。 1.2、前置条件: 读者进入图书管理系统。 1.3、事件流: 1.3.1、主要事件流: 1.3.1.1:读者检索所需图书信息,并查看; 1.3.1.2:读者检索到所需图书,登录系统,开始借书; 1.3.1.3:系统查询图书信息,图书数目是否可借; 1.3.1.3.1:图书显示可借,借书成功;
1.3.1.3.2:图书显示不可借,借书失败; 1.3.1.4:进入续借图书界面,续借图书; 1.3.1.5:系统查看预约记录, 1.3.1.5.1:没有冲突,续借成功; 1.3.1.5.2:有冲突,续借失败;1.3.3.1: 1.3.1.6:读者归还图书; 1.3.1.6.1:归还时间没有逾期,归还成功; 1.3.1.5.2:归还时间逾期,逾期处罚,归还成功; 1.3.2、备选事件流: 1.3. 2.1:图书检索信息失败,未检索到图书,重新输入信息检索; 1.3. 2.2:未曾检索到用户检索的图书,系统显示相关联的信息的图书; 1.3. 2.3:用户名或密码输入错误,登录系统失败,重新输入用户名或密码登录; 1.3. 2.4:系统显示图书不可借后,进入图书预约界面,输入信息预约图书; 1.3.3、异常事件流: 1.3.3.1:读者登录系统失败,未曾注册用户; 1.3.3.1.1:返回系统注册用户后,重新登录。 1.4、后置条件:退出系统。 1.5、 1.6、扩展点:无。 2、“图书信息管理系统”用例图 新书信息录入 (f 逾期通知 (from Use Cases) (from Use Cases)
软件工程作业用例图,状态图类图
软件工程作业用例图,状态 图类图 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
软件工程设计方案 学院计算机学院 专业软件工程 班级 2012 级 4 班 学号 86 姓名黎伟杰 指导教师崔洪刚 ( 2015 年 1 月)
计算机学院软件工程专业12级4班班学号:86 姓名:黎伟杰协作者:________ 教师评定: 问题定义:为实现一个功能强大的学生宿舍管理信息系统,它主要实现对入住人员的管理及对宿舍的其它管理,如新生、老生的基本信息处理,毕业生退宿,水、电费的超额处理。该系统功能齐全,操作简便,实用性强,主要包括三个模块:资料管理模块、宿舍管理模块、收费管理模块最后还给出实现的设计思想和关键技术。 系统名称:学生宿舍管理系统 作者名称:广东工业大学计算机学院软件工程12(4)班86 黎伟杰 系统功能描述:随着计算机的应用与普及,现在越来越多的学校学生宿舍都是利用计算机来控制和管理的,学校的不断发展,人数的不断增长,生活水平的提高,要求也越来越高。为了改善学校的宿舍管理,为此开发了学生宿舍管理信息系统软件。本系统要学生用户对它进行查询,管理员有效地对它进行管理用户,即随时可以对它进行添加与删除,在没有旁人指导的情况下,用户也可以进入这个系统并且知道该如何使用它,比如,用户点击进入后就会出现一个系统登陆对话框,根据用户的用户名和密码,点击“登陆”按钮,就可进入系统。这个系统可以适用于各大院校,具有管理权限的用户可以对系统进行修改,没有此权限的用户只能对系统进行查询。 用例图:
数据流图:
SAS作业(1)详解
SAS作业(1)详解 By 乔兴龙P57 13.下表分别给出两个文学家马克吐温(Mark Twain)的8篇小品文以及斯诺特格拉斯(Snodgrass)的10篇小品文中由3个字母组成的词的比例: 马克 0.225 0.262 0.217 0.240 0.230 0.229 0.235 0.217 吐温 斯诺 0.209 0.205 0.196 0.210 0.202 0.207 0.224 0.223 0.220 0.201 特格 拉斯 设两组数据分别来自正态总体,且两个总体方差相等,两个样本相互独立。问两个作家所写的小品文中包含由3个字母组成的词的比例是否有显著的差异(取α=)? 0.05 分析:检验是否有差异,即检验u1-u2=0,方差相等且未知,因此要用t检验法,置信区间a=0.05 操作: 在program editor 中输入 Data P59Q13; input x y @@; card; 0.225 0.209 0.262 0.205 0.217 0.196 0.240 0.210 0.230 0.202 0.229 0.207 0.235 0.224 0.217 0.223 . 0.220 . 0.201 proc print; run; 点击运行一次。 Solutions—analysis—analyst File—open by sas name—work—p59q13—OK Statistics—hypothesis tests—two sample t test for means 选中two variables,x—group 1,y—group 2,mean1-mean2=0,alternative选择第一个,test—confidence intervals选择interval,95.0% OK—OK 所得结果: Two Sample t-test for the Means of x and y 8 09:29 Wednesday, October 7, 2011 Sample Statistics
图书馆管理系统用例图活动图类图时序图
图书馆管理系统 一、图书馆管理系统需求分析 1、系统目标设计 系统开发的总目标就是实现内部图书借阅管理的系统化、规范化与自动化。 能够对图书进行注册登记,也就就是将图书的基本信息(如:书的编号、书名、作者、价格等)预先存入数据库中,供以后检索。 能够对借阅人进行注册登记,包括记录借阅人的姓名、编号、班级、年龄、性别、地址、电话等信息。 提供方便的查询方法。如:以书名、作者、出版社、出版时间(确切的时间、时间段、某一时间之前、某一时间之后)等信息进行图书检索,并能反映出图书的借阅情况;以借阅人编号对借阅人信息进行检索;以出版社名称查询出版社联系方式信息。 提供对书籍进行的预先预订的功能。 提供旧书销毁功能,对于淘汰、损坏、丢失的书目可及时对数据库进行修改。 能够对使用该管理系统的用户进行管理,按照不同的工作职能提供不同的功能授权。 提供较为完善的差错控制与友好的用户界面,尽量避免误操作。 2、系统功能需求分析 (1) 读者管理:读者信息的制定、输入、修改、查询,包括种类、性别、借书数量、借书期限、备注等。 (2) 书籍管理:书籍基本信息制定、输入、修改、查询,包括书籍编号、 类别、关键词、备注。 (3) 借阅管理:包括借书,还书,预订书籍,续借,查询书籍,过期处理与 书籍丢失后的处理。 (4)系统管理:包括用户权限管理,数据管理与自动借还书机的管理
满足以上需求的系统主要包含有一下几个子系统 (1)基本业务功能子系统:该系统中主要包含了借书还书与预订等功能。 (2)基本数据录入功能子系统:该子系统主要包含有书籍信息与读者信息录入功能。 (3)信息查询子系统:包含了多功能的查询书籍信息与读者信息。 (4)数据库管理功能子系统:主要包含了借阅信息管理功能,书籍信息管理功能与预订信息管理功能。 (5)帮助功能子系统。 二、系统动态建模 1、用例图、
应用多元统计分析SAS作业
应用多元统计分析S A S作 业 Prepared on 22 November 2020
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为,和,试判断该标本是含矿还是不含矿 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 1 1 1 1 1 1 1 1 2 2
2 2 2 1 2 3 1 2 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=。还可知两个三元总体均值相等的检验结果:D =,F =,p =<,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值、、分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
网上购物系统详细精炼版(UML-类图-时序图-数据流图)
附件一 说明书编号:XXXXXX-01 网上商城购物系统需求说明 书 某某软件学院毕业论文精炼版 2011 年7 月20 日
目录 目录 (2) 1引言 (1) 1.1项目背景 (1) 1.2项目意义 (1) 1.3文档目的 (2) 1.4定义 (3) 2任务概述 (4) 2.1系统目标 (4) 2.2用户特点 (4) 2.3应用范围 (4) 2.4假定和约束 (4) 2.5关键性技术 (4) 3需求分析 (4) 3.1业务描述 (6) 3.2用例分析 (9) 3.3系统功能概述 . (15) 5 运行环境规定 (15) 5.1 设备 (23) 5.2支持软件 (23) 5.3控制 (24) 用户确认函 (25)
1引言 1.1项目背景 信息化是当今世界发展的大趋势,是推动经济社会发展和变革的重要力量。随着信息化时代的到来,信息传播发生了深刻的变革,人们的工作方式、生活方式乃至思维方式都发生了前所未有的改变,各行各业都在顺应这一时代变革加强信息化建设。谁能在信息化变革时期先人一步,就能获得先机,抢占鳌头。传统的销售方式是商家把商品放在店铺里供顾客挑选,店铺的规模、位置等客观因素影响着商店的客流量,并且商品的存放与销售需要人力进行管理,雇员的工资、店面的租金等又增加了成本,顾客也不能迅速找到所需要的商品,而开一个网上商店只需要一个可以存放商品的仓库,比租一个店面能节省很多,也不需要太多的人力来管理,不会因为商店的面积影响客流量,客户足不出户就能买东西,并且很容易就能找到所需要的商品。 近年来,随着Internet 的迅速崛起,互联网已日益成为收集提供信息的最 佳渠道并逐步进入传统的流通领域。于是电子商务开始流行起来,越来越多的商家在网上建起在线商店,向消费者展示出一种新颖的购物理念。 网上购物系统作为B2B,B2C(Business to Customer ,即企业对消费者),C2C(Customer to Customer ,即消费者对消费者)电子商务的前端商务平台,在其商务活动全过程中起着举足轻重的作用。本文主要考虑的是如何建设B2C 的网上购物系统。 网上购物是一种具有交互功能的商业信息系统,它向用户提供静态和动态两类信息资源。所谓静态信息是指那些比经常变动或更新的资源,如公司简介、管理规范和公司制度等等;动态信息是指随时变化的信息,如商品报价,会议安排和培训信息等。网上购物系统具有强大的交互功能,可使商家和用户方便的传递信息,完成电子贸易或EDI 交易,这种全新的交易方式实现了公司间文档与资 金的无纸化交换【1】。 可行性研究 建设Web平台系统的必要性取决于需求的迫切性和实现的可能性。可行性并不
SAS作业
1. Homework1数据集是我国农产品进口排名前10的国家,请对进口额进行描述性统计分析(要求计算均值,标准差,最大,最小,中位数)。 程序及运行结果: /*读入数据文件*/ procimport datafile='C:\Users\Administer\Desktop\SAS\第一次作业 \Homework1.csv'out=homework1; run; procprint data=homework1; run; 上述读取数据的运行结果如下: /*描述性统计*/ procmeans data=homework1 meanstdmaxminmedian ; var VAR3; outputout=result; run; means过程指定输出平均值,标准差,最大值,最小值和中位数的描述性统计结果如下图。
2. Homework2 数据集是对成人每天摄入蛋白质含量的调查数据,利用univariate 过程对调查数据进行描述分析,进一步按照性别分组分析。 (1)读入数据 procimport datafile='C:\Users\Administer\Desktop\SAS\第一次作业 \Homework2.txt'out=homework2; run; procprint data=homework2; run; 打印数据: (2)利用univariate过程对调查数据进行描述分析 procunivariate data=homework2; var VAR3 VAR4 ; run; VAR3变量运行结果(VAR4同理,结果不再列出)如下。其中位置检验表明t检验,符号检验和符号秩和检验都显著,即拒绝原假设。
时间序列分析,sas各种模型,作业神器
实验一分析太阳黑子数序列 一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。 二、实验内容:分析太阳黑子数序列。 三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。 四、实验时间:2小时。 五、实验软件:SAS系统。 六、实验步骤 1、开机进入SAS系统。 2、创建名为exp1的SAS数据集,即在窗中输入下列语句: 3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问 后就可以把这段程序保存下来即可)。 4、绘数据与时间的关系图,初步识别序列,输入下列程序: ods html; ods listing close; 5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。 7、提交程序,观察输出结果。初步识别序列为AR(2)模型。 8、估计和诊断。输入如下程序: 9、提交程序,观察输出结果。假设通过了白噪声检验,且模型合理,则进行预测。 10、进行预测,输入如下程序: 11、提交程序,观察输出结果。
12、退出SAS系统,关闭计算机。总程序: data exp1; infile "D:\"; input a1 @@;
year=intnx('year','1jan1742'd,_n_-1); format year year4.; ; proc print;run; ods html; ods listing close; proc gplot data=exp1 ; symbol i=spline v=dot h=1 cv=red ci=green w=1; plot a1*year/autovref lvref=2 cframe=yellow cvref=black ; title "太阳黑子数序列"; run; proc arima data=exp1; identify var=a1 nlag=24 minic p=(0:5) q=(0:5); estimate p=3; forecast lead=6 interval=year id=year out=out; run; proc print data=out; run; 选取拟合模型的规则: 1.模型显著有效(残差检验为白噪声)
自动分拣系统 配送中心的作业流程包括
自动分拣系统配送中心的作业流程包括“入库-保管-捡货-分拣-暂存-出库”等作业,其中分拣作业是一项非常繁重的工作。尤其是面对零售业多品种、少批量的订货,配送中心的劳动量大大增加,若无新技术的支撑将会导致作业效率下降。与此同时,对物流服务和质量的要求也越来越高,致使一些大型连锁商业公司把拣货和分拣视为两大难题。随着科学技术日新月异的进步,特别是感测技术(激光扫描)、条码及计算机控制技术等的导入使用,自动分拣机已被广泛用于配送中心。我国的邮政等系统也已多年使用自动分拣设备。由于我国商品包装箱(指运输包装)上基本没有印刷条码,故商业系统至今尚没有认真研究过运用自动分拣机。应该看到,自动分拣机的分拣效率极高,通常每小时可分拣商品6000-12000箱;在日本和欧洲自动分拣机的使用很普遍。特别是在日本的连锁商业(如西友、日生协、高岛屋等)和宅急便中(大和、西浓、佐川等)自动分拣机的应用更是普遍。可以肯定,随着物流大环境的逐步改善,自动分拣机在我国流通领域大有用武之地。自动分拣机种类很多,而其主要组成部分相似。基本上由下列各部分组成: 1.输入装置:被拣商品由输送机送入分拣系统。 2.货架信号设定装置:被拣商品在进入分拣机前,先由信号设定装置(键盘输入、激光扫描条码等)把分拣信息(如配送目的地、客户户名等)输入计算机中央控制器。 3.进货装置:或称喂料器,它把被拣商品依次均衡地进入分拣传送带,与此同时,还使商品逐步加速到分拣传送带的速度。 4.分拣装置:它是自动分拣机的主体,包括传送装置和分拣装置两部分。前者的作用是把被拣商品送到设定的分拣道口位置上;后者的作用是把被拣商品送入分拣道口。 5.分拣道口:是从分拣传送带上接纳被拣商品的设施。可暂时存放未被取走的商品,当分拣道口满载时,由光电管控制阻止分拣商品不再进入分拣道口。 6.计算机控制器:是传递处理和控制整个分拣系统的指挥中心。自动分拣的实施主要靠它把分拣信号传送到相应的分拣道口,并指示启动分拣装置,把被拣商品送入道口。分拣机控制方式主要是脉冲信号跟踪法。
UML类图和时序图简述
目录 目录 (1) 1类图基本元素符号: (2) 1.1 类(Classes) (2) 1.2 包(Package) (2) 1.3 接口(Interface) (3) 2类图关系: (3) 2.1. 依赖(Dependency) (3) 2.2 关联(Association) (4) 2.3 聚合(Aggregation) (4) 2.4 合成(Composition) (5) 2.5 泛化(Generalization) (5) 2.6 实现(Realization) (5) 3 UML建模之时序图(Sequence Diagram) (6) 3.1. 时序图简介(Brief introduction) (6) 3.2. 时序图元素(Sequence Diagram Elements) (6) 3.2.1 角色(Actor) (6) 3.2.2 对象(Object) (6) 3.2.3 生命线(Lifeline) (7) 3.2.4 控制焦点(Focus of Control) (7) 3.2.5 消息(Message) (8) 3.2.6 自关联消息(Self-Message) (9) 3.2.7 Combined Fragments (10) 3.3. 时序图实例分析(Sequece Diagram Example Analysis) (10) 3.3.1 时序图场景 (10) 3.3.2 时序图实例 (11) 3.3.3 时序图实例分析 (11) 3.4. 总结(Summary) (11)
1类图基本元素符号: 1.1 类(Classes) 类包含3个组成部分。第一个是Java中定义的类名。第二个是属性(attributes)。第三个是该类提供的方法。 属性和操作之前可附加一个可见性修饰符。加号(+)表示具有公共可见性。减号(-)表示私有可见性。#号表示受保护的可见性。省略这些修饰符表示具有package(包)级别的可见性。如果属性或操作具有下划线,表明它是静态的。在操作中,可同时列出它接受的参数,以及返回类型,如下图所示: 1.2 包(Package) 包是一种常规用途的组合机制。UML中的一个包直接对应于Java中的一个包。在Java中,一个包可能含有其他包、类或者同时含有这两者。进行建模时,你通常拥有逻辑性的包,它主要用于对你的模型进行组织。你还会拥有物理性的包,它直接转换成系统中的Java包。每个包的名称对这个包进行了惟一性的标识。
sas第一次作业
SAS 第二次作业 光科1201 梁修业 7-4-2一种合金在某种添加剂的不同浓度之下,各做三次实验,得数据如下表: 浓度x 10.0 15.0 20.0 25.0 30.0 抗压强度y 25.2 27.3 28.7 29.8 31.1 27.8 31.2 32.6 29.7 31.7 30.1 32.3 29.4 30.8 32.8 (1)作散点图; (2)以模型y=b 0+b1x+b2x+ ε ,2~0N εσ(,),拟合数据,其中b0,b1,b2,2σ与x 无 关,求回归方程2012????y b b x b x =++。 解:(1) (2)将x 看成x1,x^2 看成x2,在表格中增加变量x2,此题即转化为多元线性回归 所以2?19.0333 1.00860.0204y x x =+-。
7-4-3对§7.4例3的钢包容积y和使用次数x的数据,假定 b x y ae-=。 (1)画散点图; (2)试分别作变量替换,化非线性回归模型为线性回归模型并讨论回归方程的显著性。 解: (1) (2)利用Insight模块求解。增加两个变量,u=lny,v=-1/x, 说明:方程为 1 ? ln 4.71410.0903() y x =+-,方差分析表中p-值小于0.0001,说明 了回归方程高度显著。
7-4-4槲寄生是一种寄生在大树上部树枝上的寄生植物,它喜欢寄生在年轻的大树上,下表给出在一定条件下完成的实验中采集的数据。 x 3 4 9 15 40 y 28 33 22 10 36 24 15 22 10 6 14 9 1 1 (1)作出(x i ,y i )的散点图, (2)令z i =lny i ,作出(x i ,z i )的散点图 (3)以模型2 ,ln~(0,) bx y ae N εεσ =拟合数据,其中a,b,2σ与x无关,试求曲线回归方程?bx ? ?y=ae。 解:(1) (2)Insight模块。增加变量z=lny
SAS作业
使用SAS软件完成下列任务: 1.对数据集sashelp.class中的身高和体重进行描述性统计分析,计算基本统计量,并给出分析结论。 身高: 结论:身高数据共19个,最大值为72,最小值为51.3,相差20.7。55-65之间的数据最多。中位数为62.8,平均数为62.3。数据的标准差为5.1271,方差为26.2869
体重: 结论:体重数据共19个,最大值为150,最小值为50,相差99.5。中位数为99.5,平均数为100.026。数据的标准差为22.7739,方差为518.652 2.对数据集中的男生和女生分别进行问题1中的基本统计量的计算,并写出结论 身高:
结论:男生身高数据共10个,平均数为63.91。数据的标准差为4.9379,方差为24.3832,对男生身高95%的可能集中于60.3776到67.4424之间。 女生身高数据共9个,平均数为60.5889。数据的标准差为5.0183,方差为25.1836,对女生身高预测95%的可能集中于56.7315到64.4463之间。 男生的身高相较于女生而言更集中。男生身高也普遍比女生高一些。 体重: 结论:男生体重数据共10个,平均数为108.95。数据的标准差为22.7272,方差为516.525,对男生身高95%的可能集中于92.692到125.208之间。 女生体重数据共9个,平均数为90.1111。数据的标准差为19.3839,方差为375.7361,对女生身高预测95%的可能集中于75.2113到105.0109之间。 女生的体重相较于男生而言更集中。女生体重也普遍比男生轻一些。
分拣中心分拣作业流程
分拣中心分拣作业流程 第一节航空出港中转操作 一、航空到件交接: 1机场提货: 1)、发货操作员在货到达提货方前,将完整的提货信息传真给提货方。 2) 、提货方按照发货方传真信息,至机场、客运站、铁路提货处提取货物,核对到件数量是否一致,用把枪在提货处直接做提货扫描。 3)、对出现的破损件、短缺件等问题,要当场与提货处人员进行核对登记,并要求其开具 破损证明(有条件可当场拍照),并通知发货方. 4)、保存好提货费发票,以备对账。 2、主干线网络车: 1) 、主干线网络车到达,操作人员检查封车锁情况并填写相关清单. 2)、按照规定时间要求,先卸下航空出港件,再卸下汽运线快件。 3、支线网络车: 1)、操作人员要求所有到达的支线车进行打卡。 2)、对未按照规定时间到达的支线车除要进行处罚外, 优先安排整点到达车辆的卸车入库. 3)、支线车晚点到达的,不能延误主干线网络车、航空发货车的时间,晚点的支线车尽可能将文件类物品中转发出。 4、收入计费: 1)、对货车或支线车快件全部做卸车扫描,将单件分别放到电子秤上做卸车扫描,文件包扫描包签时,不需放至电子秤上. 2)、在E3操作系统上输入始发地与目的地,以便计算中转费用。 3)、分别做解包操作,与卸车操作一样,分别将包内件进行逐票扫描称重计费. 4)、所有交接快件扫描完毕后,按货签数据进行收发对比. 二、中转分拣: 1快件入库后按文件与大货进行分类分拣. 2、文件类在文件操作区分拣;大货直接上传输带,由分拣人员卸至固定分拣区。 3、在分拣过程中,如遇大头笔标注错误或未标注、地址不详、违禁品、包装不良及破损件 等,要由专人负责登记并拍照。到分拣中心直接交接的营业部,当场通知随车人员;不是直 接交接的,在内网上报,在不违反操作规定的情况下,能当班次中转的,尽量发出;不能当班次发出的,要放在问题件区,由客服人员按规定程序处理. 4、由建包操作人员将文件及小物品,按建包(笼)规定操作,并填写完整货签。 5、单件发出的,要用大于面单的白纸将面单除单号外的内容覆盖,并在白纸上写明始发地、目的地、提货电话和提货人等各项内容. 6、将文件包与单件一起做装车扫描,扫一件(包)上一件,确保实际发货件数与扫描数一致。 三、中转发出: 1做发车操作,同时手工输入车牌号码。 2、按不同目的地进行整批称重,并做好记录,以便与货代核对、结算。 3、操作人员与随车人员做好交接,由发货人员至机场发货。 4、发货员与承运方(机场或货代、大巴客运站,铁路行包房)当场清点发货数量及称重。 5、按事先确定下的结算方式付费,带回承运方开具的运输凭证,如航空发货单(配载成功 后,由承运方返回传真件),返回公司后交与操作人员, 对交接过程中出现的异常情况要及
软件工程学期项目Osric用例图类图时序图
学期项目用例图 分配任务 更新客户信息 更新客户优先级 打印报表 增加客户 查找客户 估算服务等待时间 增加服务请求 更新服务请求 完成服务 技师 维护技师信息 助手 删除服务请求 顾客 Osric 项目的初始用例图
打印任务分配情况 打印杰出工作报表 打印报表 助手 打印请求列表 打印统计报表 打印账单 <
学期项目用例描述和类图、时序图 Osric电信公司管理系统的增加客户用例描述 简要描述 增加客户用例使助手能够根据情况增加新客户 按步骤描述 1、判断是否允许新公司申请服务 1.1.若是在白天,如果等候列表上的顾客数超过了白天工作的技师数的两倍, 则软件认为不允许增加新客户 1.2.偶尔情况下,允许增加某个新公司 2、若允许申请,则助手输入新客户信息 3、添加结束后,返回一个成功添加的信息确认 增加客户用例的类图
: 助手 : UserInterface : Maintain_Customer : Request : Technician : Customer 1:助手登录系统 2:传送增加客户申请 3:申请等候列表上的顾客数 4:返回等候列表上的顾客数 5:申请白天工作的技师数 6:返回白天工作的技师数 7:判断是否允许增加该客户 8:如果允许,则将该客户加入顾客列表 9:发送成功添加的信息 10:发送成功添加的信息 11:发送成功添加的信息 增加客户用例的时序图 Osric电信公司管理系统的查找客户用例描述 简要描述 查找客户用例使助手能够根据顾客提供的信息查找顾客相关信息 按步骤描述 1.助手询问顾客编号。助手根据顾客编号查找该顾客信息 2.如果顾客不知道顾客编号,助手询问公司名称。助手根据公司名称查找顾客信 息 3.查找结束后,返回顾客信息,以后查找成功的确认信息
应用多元统计分析SAS作业第三章
3-8假定人体尺寸有这样的一般规律,身高(X 1),胸围(X 2)和上半臂围(X 3)的平均尺寸比例是6:4:1,假设()()1,,X n αα=L 为来自总体()123=,,X X X X '的随机样本,并设()~,X N μ∑。试利用表3.4中男婴这一数据来检验其身高、胸围和上半臂围这三个尺寸变量是否符合这一规律(写出假设H 0,并导出检验统计量)。 解:设32,~(,),~(,)Y CX X N Y N C C C μμ'=∑∑。 121231233106,,,,,014C X X X μμμμμμμ??-?? ? == ? ?-?? ? ??其中,分别为 的样本均值。则检验三个变量是否符合规律的假设为 0212:,:H C O H C O μμ=≠。 检验统计量为 2 1(1)1~(1,1) (3,6)(1)(1) n p F T F p n p p n n p ---+= --+==--, 由样本值计算得:=(82,60.2,14.5)X ',及 15840.2 2.5=40.215.86 6.552.5 6.559.5A ?? ? ? ??? , 2-1(1)()()()=47.1434T n n CX CAC CX ''=-,
221(1)12 =18.8574(1)(1)5 n p F T T n p ---+= ?=--, 对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值: p =P {F ≥18.8574}=0.0091948。 因为p 值=0.0091948<0.05,故否定0H ,即认为这组男婴数据与人类的一般规律不一致。在这种情况下,可能犯第一类错误·且犯第一类错误的概率为0.05。 SAS 程序及结果如下: prociml ; n=6;p=3; x={7860.616.5, 7658.112.5, 9263.214.5, 815914, 8160.815.5, 8459.514 }; m0={00,00}; c={10 -6,01 -4}; ln={[6]1}; x0=(ln*x)`/n; print x0; mm=i(6)-j(6,6,1)/n; a=x`*mm*x; a1=inv(c*a*c`); a2=c*x0; dd=a2`*a1*a2; d2=dd*(n-1); t2=n*d2; f=(n+1-p)*t2/((n-1)*(p-1)); print x0 a d2 t2 f; p0=1-probf(f,p-1,n-p+1); fa=finv(0.95,2,4); print p0; run ;
网上购物系统详细精炼版(UML,类图,时序图,数据流图)
附件一 说明书编号:XXXXXX-01网上商城购物系统需求说明书 某某软件学院毕业论文精炼版 2011年7月20日
目录 (2) 1 引言 (1) 1.1 项目背景 (1) 1.2 项目意义 (1) 1.3 文档目的 (2) 1.4 定义 (3) 2 任务概述 (4) 2.1 系统目标 (4) 2.2 用户特点 (4) 2.3 应用范围 (4) 2.4 假定和约束 (4) 2.5 关键性技术 (4) 3 需求分析 (4) 3.1 业务描述 (6) 3.2 用例分析 (9) 3.3 系统功能概述 (15) 5 运行环境规定 (15) 5.1 设备 (23) 5.2 支持软件 (23) 5.3 控制 (24) 用户确认函 (25)
1.1 项目背景 信息化是当今世界发展的大趋势,是推动经济社会发展和变革的重要力量。随着信息化时代的到来,信息传播发生了深刻的变革,人们的工作方式、生活方式乃至思维方式都发生了前所未有的改变,各行各业都在顺应这一时代变革加强信息化建设。谁能在信息化变革时期先人一步,就能获得先机,抢占鳌头。传统的销售方式是商家把商品放在店铺里供顾客挑选,店铺的规模、位置等客观因素影响着商店的客流量,并且商品的存放与销售需要人力进行管理,雇员的工资、店面的租金等又增加了成本,顾客也不能迅速找到所需要的商品,而开一个网上商店只需要一个可以存放商品的仓库,比租一个店面能节省很多,也不需要太多的人力来管理,不会因为商店的面积影响客流量,客户足不出户就能买东西,并且很容易就能找到所需要的商品。 近年来,随着Internet的迅速崛起,互联网已日益成为收集提供信息的最佳渠道并逐步进入传统的流通领域。于是电子商务开始流行起来,越来越多的商家在网上建起在线商店,向消费者展示出一种新颖的购物理念。 网上购物系统作为B2B,B2C(Business to Customer,即企业对消费者),C2C(Customer to Customer,即消费者对消费者)电子商务的前端商务平台,在其商务活动全过程中起着举足轻重的作用。本文主要考虑的是如何建设B2C 的网上购物系统。 网上购物是一种具有交互功能的商业信息系统,它向用户提供静态和动态两类信息资源。所谓静态信息是指那些比经常变动或更新的资源,如公司简介、管理规范和公司制度等等;动态信息是指随时变化的信息,如商品报价,会议安排和培训信息等。网上购物系统具有强大的交互功能,可使商家和用户方便的传递信息,完成电子贸易或EDI交易,这种全新的交易方式实现了公司间文档与资金的无纸化交换【1】。
SAS入门教程
第一章SAS系统概况 SAS(Statistic Analysis System)系统是世界领先的信息系统,它由最初的用于统计分析经不断发展和完善而成为大型集成应用软件系统;具有完备的数据存取、管理、分析和显示功能。在数据处理和统计分析领域,SAS系统被誉为国际上的标准软件系统。 SAS系统是一个模块化的集成软件系统。SAS系统提供的二十多个模块(产品)可完成各方面的实际问题,功能非常齐全,用户根据需要可灵活的选择使用。 ●Base SAS Base SAS软件是SAS系统的核心。主要功能是数据管理和数据加工处理,并有报表生成和描述统计的功能。Base SAS软件可以单独使用,也可以同其他软件产品一起组成一个用户化的SAS系统。 ●SAS/AF 这是一个应用开发工具。利用SAS/AF的屏幕设计能力及SCL语言的处理能力可快速开发各种功能强大的应用系统。SAS/AF采用先进的OOP(面向对象编程)的技术,是用户可方便快速的实现各类具有图形用户界面(GUI)的应用系统。 ●SAS/EIS 该软件是SAS系统种采用OOP(面向对象编程)技术的又一个开发工具。该产品也称为行政信息系统或每个人的信息系统。利用该软件可以创建多维数据库(MDDB),并能生成多维报表和图形。 ●SAS/INTRNET ●SAS/ACCESS 该软件是对目前许多流行数据库的接口组成的接口集,它提供的与外部数据库的接口是透明和动态的。 第二章Base SAS软件 第一节SAS编程基础 SAS语言的编程规则与其它过程语言基本相同。 SAS语句 一个SAS语句是有SAS关键词、SAS名字、特殊字符和运算符组成的字符串,并以分号(;)结尾。 注释语句的形式为:/*注释内容*/ 或*注释内容。 二、SAS程序 一序列SAS语句组成一个SAS程序。SAS程序中的语句可分为两类步骤:DA TA步和
SAS 作业
课程作业报告 课程名称:数据统计分析软件 班级:环科1401 学号:A03140377 姓名:沈晶晶 教师:郭微 成绩: P61 例5.1.1(1) data eg51;
input name $ sex $ age salary educa $; label name="姓名" sex="性别" age="年龄"; label salary="工资"educa="受教育情况"; cards ; 李斯 男 20 1200 初 王老五 女 25 1260 初 赵柳 女 28 1350 中 史奇 男 27 1350 高 朱巴 男 30 1290 中 刘久 男 35 1400 中 康实 女 32 1410 高 申山 男 31 1410 高 ;; proc gchart data =eg51; vbar sex; run ; P61 例5.1.1(2) data eg51; input name $ sex $ age salary educa $; label name="姓名" sex="性别" age="年龄"; label salary="工资"educa="受教育情况"; cards ; 李斯 男 20 1200 初 王老五 女 25 1260 初 赵柳 女 28 1350 中 史奇 男 27 1350 高 朱巴 男 30 1290 中
P100 例6.1 title'6种施肥法的小麦植株含氮量的方差分析'; data mp97; input treat nitrogen @@; cards; 1 2.9 2 4.0 3 2.6 4 0. 5 5 4. 6 6 4.0 1 2.3 2 3.8 3 3.2 4 0.8 5 4. 6 6 3.3 1 2. 2 2 3.8 3 3. 4 4 0.7 5 4.4 6 3.7 1 2.5 2 3.6 3 3. 4 4 0.8 5 4.4 6 3.5 1 2.7 2 3.6 3 3.0 4 0. 5 5 4.4 6 3.7 ; proc anova; class treat; model nitrogen=treat; means treat/duncan; run; 6种施肥法的小麦植株含氮量的方差分析 The ANOVA Procedure Class Level Information Class Levels Values treat 6 1 2 3 4 5 6