工具变量法的Stata命令及实例
工具变量法的Stata命令及实例
●本实例使用数据集“grilic.dta”。
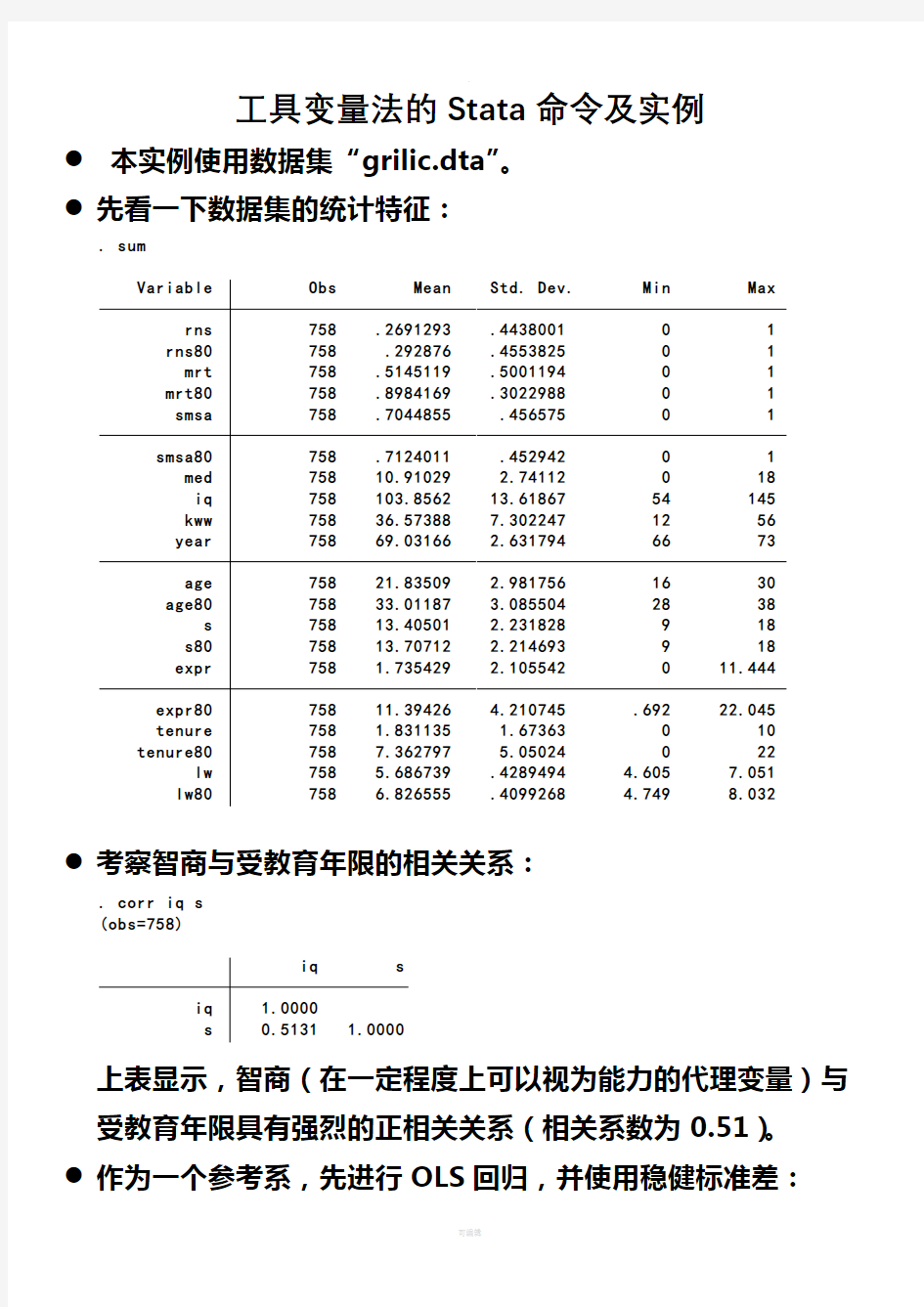
●先看一下数据集的统计特征:
. sum
Variable Obs Mean Std. Dev. Min Max
rns 758 .2691293 .4438001 0 1
rns80 758 .292876 .4553825 0 1
mrt 758 .5145119 .5001194 0 1
mrt80 758 .8984169 .3022988 0 1
smsa 758 .7044855 .456575 0 1
smsa80 758 .7124011 .452942 0 1
med 758 10.91029 2.74112 0 18
iq 758 103.8562 13.61867 54 145
kww 758 36.57388 7.302247 12 56
year 758 69.03166 2.631794 66 73
age 758 21.83509 2.981756 16 30
age80 758 33.01187 3.085504 28 38
s 758 13.40501 2.231828 9 18
s80 758 13.70712 2.214693 9 18
expr 758 1.735429 2.105542 0 11.444
expr80 758 11.39426 4.210745 .692 22.045
tenure 758 1.831135 1.67363 0 10
tenure80 758 7.362797 5.05024 0 22
lw 758 5.686739 .4289494 4.605 7.051
lw80 758 6.826555 .4099268 4.749 8.032
●考察智商与受教育年限的相关关系:
. corr iq s
(obs=758)
iq s
iq 1.0000
s 0.5131 1.0000
上表显示,智商(在一定程度上可以视为能力的代理变量)与受教育年限具有强烈的正相关关系(相关系数为0.51)。
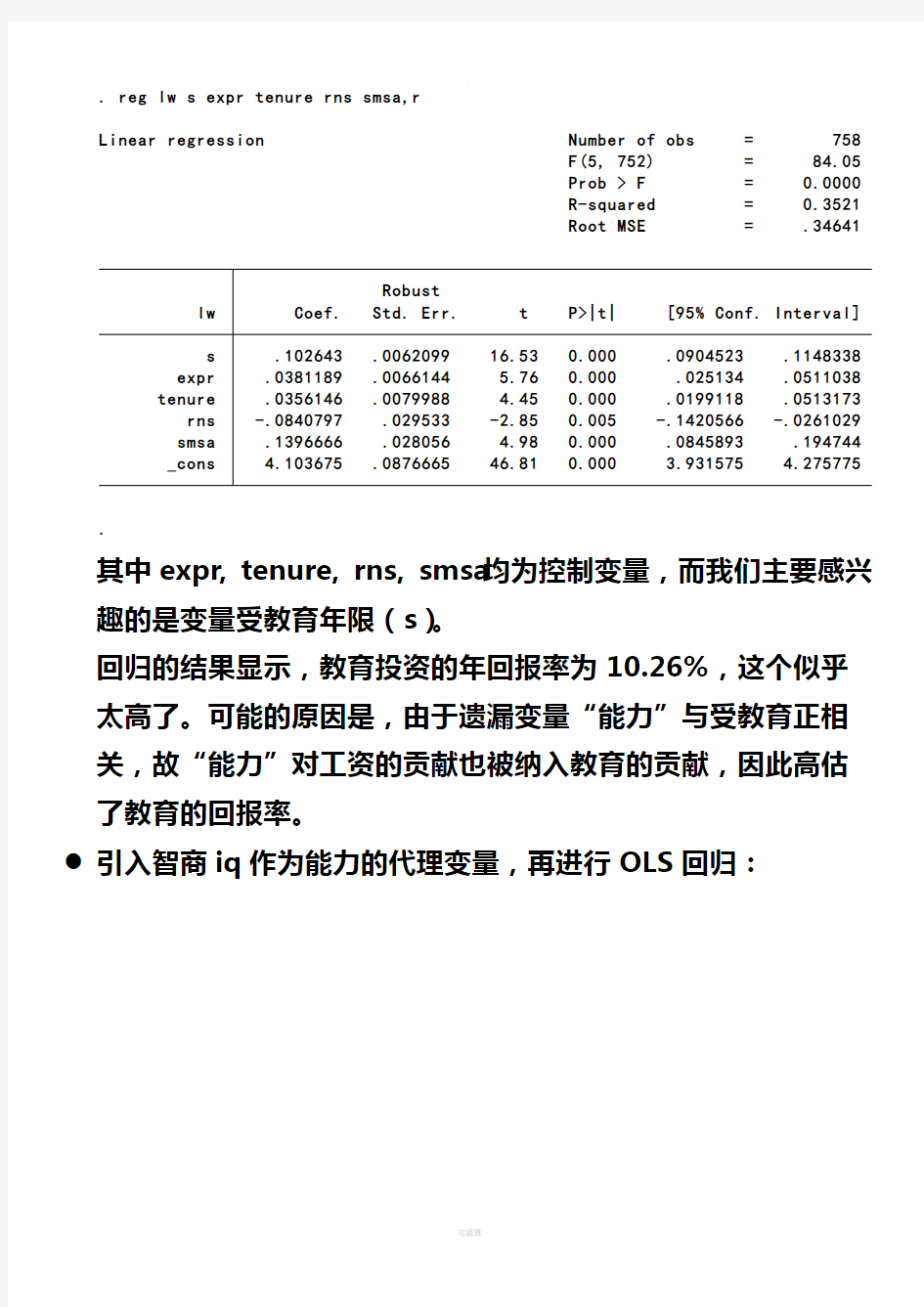
●作为一个参考系,先进行OLS回归,并使用稳健标准差:
. reg lw s expr tenure rns smsa,r
Linear regression Number of obs = 758 F(5, 752) = 84.05 Prob > F = 0.0000 R-squared = 0.3521 Root MSE = .34641
Robust
lw Coef. Std. Err. t P>|t| [95% Conf. Interval]
s .102643 .0062099 16.53 0.000 .0904523 .1148338 expr .0381189 .0066144 5.76 0.000 .025134 .0511038 tenure .0356146 .0079988 4.45 0.000 .0199118 .0513173 rns -.0840797 .029533 -2.85 0.005 -.1420566 -.0261029 smsa .1396666 .028056 4.98 0.000 .0845893 .194744 _cons 4.103675 .0876665 46.81 0.000 3.931575 4.275775
.
其中expr, tenure, rns, smsa均为控制变量,而我们主要感兴趣的是变量受教育年限(s)。
回归的结果显示,教育投资的年回报率为10.26%,这个似乎太高了。可能的原因是,由于遗漏变量“能力”与受教育正相关,故“能力”对工资的贡献也被纳入教育的贡献,因此高估了教育的回报率。
引入智商iq作为能力的代理变量,再进行OLS回归:
. reg lw s iq expr tenure rns smsa,r
Linear regression Number of obs = 758 F(6, 751) = 71.89 Prob > F = 0.0000 R-squared = 0.3600 Root MSE = .34454
Robust
lw Coef. Std. Err. t P>|t| [95% Conf. Interval]
s .0927874 .0069763 13.30 0.000 .0790921 .1064826 iq .0032792 .0011321 2.90 0.004 .0010567 .0055016 expr .0393443 .0066603 5.91 0.000 .0262692 .0524193 tenure .034209 .0078957 4.33 0.000 .0187088 .0497092 rns -.0745325 .0299772 -2.49 0.013 -.1333815 -.0156834 smsa .1367369 .0277712 4.92 0.000 .0822186 .1912553 _cons 3.895172 .1159286 33.60 0.000 3.667589 4.122754
虽然教育的投资回报率有所下降,但是依然很高。
由于用iq作为能力的代理变量有测量误差,故iq是内生变量,考虑使用变量(med(母亲的受教育年限)、kww(在“knowledge of the World of Work”中的成绩)、mrt (婚姻虚拟变量,已婚=1)age(年龄))作为iq的工具变量,进行2SLS回归,并使用稳健的标准差:
Instrumental variables (2SLS) regression Number of obs = 758 Wald chi2(6) = 355.73 Prob > chi2 = 0.0000 R-squared = 0.2002 Root MSE = .38336
Robust
lw Coef. Std. Err. z P>|z| [95% Conf. Interval]
iq -.0115468 .0056376 -2.05 0.041 -.0225962 -.0004974 s .1373477 .0174989 7.85 0.000 .1030506 .1716449 expr .0338041 .0074844 4.52 0.000 .019135 .0484732 tenure .040564 .0095848 4.23 0.000 .0217781 .05935 rns -.1176984 .0359582 -3.27 0.001 -.1881751 -.0472216 smsa .149983 .0322276 4.65 0.000 .0868182 .2131479 _cons 4.837875 .3799432 12.73 0.000 4.0932 5.58255
Instrumented: iq
Instruments: s expr tenure rns smsa med kww mrt age
在此2SLS回归中,教育回报率反而上升到13.73%,而iq对工资的贡献居然为负值。使用工具变量的前提是工具变量的有效性。为此,进行过度识别检验,考察是否所有的工具变量均外生,即与扰动项不相关:
. estat overid
Test of overidentifying restrictions:
Score chi2(3) = 51.5449 (p = 0.0000)
结果强烈拒绝所有工具变量均外生的原假设。
考虑仅使用变量(med, kww)作为iq的工具变量,再次进行2SLS回归,同时显示第一阶段的回归结果:
First-stage regressions
Number of obs = 758 F( 7, 750) = 47.74 Prob > F = 0.0000 R-squared = 0.3066 Adj R-squared = 0.3001 Root MSE = 11.3931
Robust
iq Coef. Std. Err. t P>|t| [95% Conf. Interval]
s 2.467021 .2327755 10.60 0.000 2.010052 2.92399 expr -.4501353 .2391647 -1.88 0.060 -.9196471 .0193766 tenure .2059531 .269562 0.76 0.445 -.3232327 .7351388 rns -2.689831 .8921335 -3.02 0.003 -4.441207 -.938455 smsa .2627416 .9465309 0.28 0.781 -1.595424 2.120907 med .3470133 .1681356 2.06 0.039 .0169409 .6770857 kww .3081811 .0646794 4.76 0.000 .1812068 .4351553 _cons 56.67122 3.076955 18.42 0.000 50.63075 62.71169
Instrumental variables (2SLS) regression Number of obs = 758 Wald chi2(6) = 370.04 Prob > chi2 = 0.0000 R-squared = 0.2775 Root MSE = .36436
Robust
lw Coef. Std. Err. z P>|z| [95% Conf. Interval]
iq .0139284 .0060393 2.31 0.021 .0020916 .0257653 s .0607803 .0189505 3.21 0.001 .023638 .0979227 expr .0433237 .0074118 5.85 0.000 .0287968 .0578505 tenure .0296442 .008317 3.56 0.000 .0133432 .0459452 rns -.0435271 .0344779 -1.26 0.207 -.1111026 .0240483 smsa .1272224 .0297414 4.28 0.000 .0689303 .1855146 _cons 3.218043 .3983683 8.08 0.000 2.437256 3.998831
Instrumented: iq
Instruments: s expr tenure rns smsa med kww
上表显示,教育的回报率为6.08%,较为合理,再次进行过度识别检验:
. estat overid
Test of overidentifying restrictions:
Score chi2(1) = .151451 (p = 0.6972)
接受原假设,认为(med,kww)外生,与扰动项不相关。 进一步考察有效工具变量的第二个条件,即工具变量与内生变量的相关性。从第一阶段的回归结果可以看出,工具变量对内生变量具有较好的解释力。更正式的检验如下:
. estat firststage,all forcenonrobust
First-stage regression summary statistics
Adjusted Partial Robust
Variable R-sq. R-sq. R-sq. F(2,750) Prob > F iq 0.3066 0.3001 0.0382 13.4028 0.0000
Shea's partial R-squared
Shea's Shea's
Variable Partial R-sq. Adj. Partial R-sq.
iq 0.0382 0.0305
Minimum eigenvalue statistic = 14.9058
Critical Values # of endogenous regressors: 1
Ho: Instruments are weak # of excluded instruments: 2
5% 10% 20% 30%
2SLS relative bias (not available)
10% 15% 20% 25%
2SLS Size of nominal 5% Wald test 19.93 11.59 8.75 7.25
LIML Size of nominal 5% Wald test 8.68 5.33 4.42 3.92
从以上结果可以看出,虽然Shea’s partial R^2不到0.04,但是F统计量为13.40>10。
我们知道,虽然2SLS是一致的,但却是有偏的,故使用2SLS 会带来“显著性水平扭曲”(size distortion),而且这种扭曲随着弱工具变量而增大。上表的最后部分显示,如果在结构方程中对内生解释变量的显著性进行“名义显著性水平”(nominal size)为5%的沃尔德检验,加入可以接受的“真实显著性水平”(true size)不超过15%,则可以拒绝“弱工具变量”的原假设,因为最小特征值统计量为14.91,大于临界值11.59。
总之我们有理由认为不存在弱工具变量。但为了稳健起见,下面使用对弱工具变量更不敏感的有限信息最大似然法(LIML): . ivregress liml lw s expr tenure rns smsa (iq=med kww),r
Instrumental variables (LIML) regression Number of obs = 758 Wald chi2(6) = 369.62 Prob > chi2 = 0.0000 R-squared = 0.2768 Root MSE = .36454
Robust
lw Coef. Std. Err. z P>|z| [95% Conf. Interval]
iq .0139764 .0060681 2.30 0.021 .0020831 .0258697 s .0606362 .019034 3.19 0.001 .0233303 .0979421 expr .0433416 .0074185 5.84 0.000 .0288016 .0578816 tenure .0296237 .008323 3.56 0.000 .0133109 .0459364 rns -.0433875 .034529 -1.26 0.209 -.1110631 .0242881 smsa .1271796 .0297599 4.27 0.000 .0688512 .185508 _cons 3.214994 .4001492 8.03 0.000 2.430716 3.999272
Instrumented: iq
Instruments: s expr tenure rns smsa med kww
结果发现,LIML的系数估计值与2SLS非常接近,这也从侧面印证了“不存在弱工具变量”。
使用工具变量法的前提是存在内生解释变量,为此须进行豪斯
曼检验,其原假设是“所有的解释变量均为外生”:
. qui reg lw iq s expr tenure rns smsa
. estimates store ols
. qui ivregress 2sls lw s expr tenure rns smsa (iq=med kww)
. estimates store iv
. hausman iv ols, constant sigmamore
Note: the rank of the differenced variance matrix (1) does not equal the number of coefficients being tested (7); be sure this is what you expect, or there may be problems computing the test. Examine the output of your estimators for anything unexpected and possibly consider scaling your variables so that the coefficients are on a similar scale.
Coefficients
(b) (B) (b-B) sqrt(diag(V_b-V_B))
iv ols Difference S.E.
iq .0139284 .0032792 .0106493 .0054318
s .0607803 .0927874 -.032007 .0163254
expr .0433237 .0393443 .0039794 .0020297
tenure .0296442 .034209 -.0045648 .0023283
rns -.0435271 -.0745325 .0310054 .0158145
smsa .1272224 .1367369 -.0095145 .0048529
_cons 3.218043 3.895172 -.6771285 .3453751
b = consistent under Ho and Ha; obtained from ivregress
B = inconsistent under Ha, efficient under Ho; obtained from regress
Test: Ho: difference in coefficients not systematic
chi2(1) = (b-B)'[(V_b-V_B)^(-1)](b-B)
= 3.84
Prob>chi2 = 0.0499
(V_b-V_B is not positive definite)
.
上表显示,可以在5%的显著性水平下拒绝“所有解释变量均外生的原假设”,即认为存在内生解释变量iq。由于传统的豪斯曼检验建立在同方差的前提下,故在上述回归中均没有使用稳健
标准差。
由于传统的豪斯曼检验在异方差的情形下不成立,下面使用异
方差稳健的DWH检验:
. estat endogenous
Tests of endogeneity
Ho: variables are exogenous
Durbin (score) chi2(1) = 3.87962 (p = 0.0489)
Wu-Hausman F(1,750) = 3.85842 (p = 0.0499)
据此可认为iq为内生解释变量。
●如果存在异方差,则GMM比2SLS更有效。为此进行如下的最优GMM估计:
. ivregress gmm lw s expr tenure rns smsa (iq=med kww)
Instrumental variables (GMM) regression Number of obs = 758 Wald chi2(6) = 372.75 Prob > chi2 = 0.0000 R-squared = 0.2750 GMM weight matrix: Robust Root MSE = .36499
Robust
lw Coef. Std. Err. z P>|z| [95% Conf. Interval]
iq .0140888 .0060357 2.33 0.020 .0022591 .0259185 s .0603672 .0189545 3.18 0.001 .0232171 .0975174 expr .0431117 .0074112 5.82 0.000 .0285861 .0576373 tenure .0299764 .0082728 3.62 0.000 .013762 .0461908 rns -.044516 .0344404 -1.29 0.196 -.1120179 .0229859 smsa .1267368 .0297633 4.26 0.000 .0684018 .1850718 _cons 3.207298 .398083 8.06 0.000 2.427069 3.987526
Instrumented: iq
Instruments: s expr tenure rns smsa med kww
.
●进行过度识别检验:
. estat overid
Test of overidentifying restriction:
Hansen's J chi2(1) = .151451 (p = 0.6972)
●由于p值为0.70,故认为所有的工具变量均为外生。考虑迭代
GMM:
. ivregress gmm lw s expr tenure rns smsa (iq=med kww),igmm
Iteration 1: change in beta = 1.753e-05 change in W = 1.100e-02
Iteration 2: change in beta = 4.872e-08 change in W = 7.880e-05
Iteration 3: change in beta = 2.495e-10 change in W = 2.304e-07
Instrumental variables (GMM) regression Number of obs = 758 Wald chi2(6) = 372.73 Prob > chi2 = 0.0000 R-squared = 0.2750 GMM weight matrix: Robust Root MSE = .36499
Robust
lw Coef. Std. Err. z P>|z| [95% Conf. Interval]
iq .0140901 .0060357 2.33 0.020 .0022603 .02592 s .0603629 .0189548 3.18 0.001 .0232122 .0975135 expr .0431101 .0074113 5.82 0.000 .0285841 .057636 tenure .0299752 .0082729 3.62 0.000 .0137606 .0461898 rns -.0445114 .0344408 -1.29 0.196 -.1120142 .0229913 smsa .1267399 .0297637 4.26 0.000 .0684041 .1850757 _cons 3.207224 .3980878 8.06 0.000 2.426986 3.987462
Instrumented: iq
Instruments: s expr tenure rns smsa med kww
如果希望将以上各种估计法的系数估计值及其标准差列在同一张表中,可使用如下命令:
STATA最常用命令大全
stata save命令 FileSave As 例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata格式文件。 STATA数据库的维护 排序 SORT 变量名1 变量名2 …… 变量更名 rename 原变量名新变量名 STATA数据库的维护 删除变量或记录 drop x1 x2 /* 删除变量x1和x2 drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5) drop if x<0 /* 删去x1<0的所有记录 drop in 10/12 /* 删去第10~12个记录 drop if x==. /* 删去x为缺失值的所有记录 drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录 drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录 drop _all /* 删掉数据库中所有变量和数据 STATA的变量赋值 用generate产生新变量 generate 新变量=表达式 generate bh=_n /* 将数据库的内部编号赋给变量bh。 generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个3……。直到数据库结束。 generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。 egen产生新变量 set obs 12 egen a=seq() /*产生1到N的自然数 egen b=seq(),b(3) /*产生一个序列,每个元素重复#次 egen c=seq(),to(4) /*产生多个序列,每个序列从1到# egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2 encode 字符变量名,gen(新数值变量名) 作用:将字符型变量转化为数值变量。 STATA数据库的维护 保留变量或记录 keep in 10/20 /* 保留第10~20个记录,其余记录删除 keep x1-x5 /* 保留数据库中介于x1和x5间的所有变量(包括x1和x5),其余变量删除keep if x>0 /* 保留x>0的所有记录,其余记录删除
Stata命令整理教学内容
Stata 命令语句格式: [by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options] 1、[by varlist:] *如果需要分别知道国产车和进口车的价格和重量,可以采用分类操作来求得, sort foreign //按国产车和进口车排序 . by foreign: sum price weight *更简略的方式是把两个命令用一个组合命令来写。 . by foreign, sort: sum price weight 如果不想从小到大排序,而是从大到小排序,其命令为gsort。 . sort - price //按价格从高到低排序 . sort foreign -price /*先把国产车都排在前,进口车排在后面,然后在国产车内再按价格从大小到排序,在进口车内部,也按从大到小排序*/ 2、[=exp]赋值运算 . gen nprice=price+10 //生成新变量nprice,其值为price+10 /*上面的命令generate(略写为gen) 生成一个新的变量,新变量的变量名为 nprice,新的价格在原价格的基础上均增加了10 元。 . replace nprice=nprice-10 /*命令replace 则直接改变原变量的赋值,nprice 调减后与price 变量取值相等*/ 3、[if exp]条件表达式 . list make price if foreign==0 *只查看价格超过1 万元的进口车(同时满足两个条件),则 . list make price if foreign==1 & price>10000 *查看价格超过1 万元或者进口车(两个条件任满足一个) . list make price if foreign==1 | price>10000 4、[in range]范围筛选 sum price in 1/5 注意“1/5”中,斜杠不是除号,而是从1 到 5 的意思,即1,2,3,4,5。 如果要计算前10 台车中的国产车的平均价格,则可将范围和条件筛选联合使用。 . sum price in 1/10 if foreign==0 5、[weight] 加权 sum score [weight=num] 其中,num为每个成绩所对应的人数 6、[, options]其他可选项 例如,我们不仅要计算平均成绩,还想知道成绩的中值,方差,偏度和峰度等*/ . sum score, detail . sum score, d //d 为detail 的略写,两个命令完全等价 . list price, nohead //不要表头 Stata 数据类型转换 1、字符型转化成数值型 destring, replace //全部转换为数值型,replace 表示将原来的变量(值)更新 destring date, replace ignore(“ ”) 将字符型数据转换为数值型数据:去掉字符间的空格destring price percent, gen(price2 percent2) ignore(“$ ,%”) 与date 变量类似,变量price 前面有美元符号,变量percent 后有百分号,换为数值型时需要忽略这些非数值型字符 2、数值型转化为字符型
(完整)stata命令总结,推荐文档
stata11 常用命令 注:JB统计量对应的p大于0.05 ,则表明非正态,这点跟sktest 和 swilk 检验刚好相反;dta 为数据文件;gph 为图文件;do 为程序文件;注 意stata 要区别大小写;不得用作用户变量名: _all _n _N _skip _b _coef _cons _pi _pred _rc _weight double float long int in if using with 命令:读入数据一种方式 input x y 14 2 5.5 3 6.2 47.7 58.5 end su/summarise/sum x 或su/summarise/sum x,d 对分组的描述: sort group by group:su x %%%%% tabstat economy,stats(max)%返回变量economy的最大值 %%stats括号里可以是:mean,count(非缺失观测值个数),sum(总 和),max,min,range , %% sd ,var ,cv(变易系数=标准差/ 均值),skewness,kurtosis , median,p1(1 %分位 %% 数,类似地有p10, p25, p50, p75, p95, p99),iqr(interquantile range = p75 –p25) _all %描述全部 _N 数据库中观察值的总个数。 _n 当前观察值的位置。 _pi 圆周率π 的数值。 list gen/generate % 产生数列egen wagemax=max(wage) clear use by(分组变量)
stata命令大全(全)
*********面板数据计量分析与软件实现********* 说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。本人做了一定的修改与筛选。 *----------面板数据模型 * 1.静态面板模型:FE 和RE * 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验 * 4.动态面板模型(DID-GMM,SYS-GMM) * 5.面板随机前沿模型 * 6.面板协整分析(FMOLS,DOLS) *** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。 * 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA) *** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。 * 空间计量分析:SLM模型与SEM模型 *说明:STATA与Matlab结合使用。常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。 * --------------------------------- * --------一、常用的数据处理与作图----------- * --------------------------------- * 指定面板格式 xtset id year (id为截面名称,year为时间名称) xtdes /*数据特征*/ xtsum logy h /*数据统计特征*/ sum logy h /*数据统计特征*/ *添加标签或更改变量名 label var h "人力资本" rename h hum *排序 sort id year /*是以STATA面板数据格式出现*/ sort year id /*是以DEA格式出现*/ *删除个别年份或省份 drop if year<1992 drop if id==2 /*注意用==*/ *如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令) egen year_new=group(year) xtset id year_new **保留变量或保留观测值 keep inv /*删除变量*/ **或 keep if year==2000 **排序 sort id year /*是以STATA面板数据格式出现 sort year id /*是以DEA格式出现 **长数据和宽数据的转换 *长>>>宽数据 reshape wide logy,i(id) j(year)
[推荐] stata基本操作汇总常用命令
[推荐] Stata基本操作汇总——常用命令 help和search都是查找帮助文件的命令,它们之间的 区别在于help用于查找精确的命令名,而search是模糊查找。 如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在stata的命令行窗口中输入help空格加上这个名字。回车后结果屏幕上就会显示出这个命令的帮助文件的全部 内容。如果你想知道在stata下做某个估计或某种计算,而 不知道具体该如何实现,就需要用search命令了。使用的 方法和help类似,只须把准确的命令名改成某个关键词。回车后结果窗口会给出所有和这个关键词相关的帮助文件名 和链接列表。在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。耐心寻找,反复实验,通常可以较快地找到你需要的内容.下面该正式处理数据了。我的处理数据经验是最好能用stata的do文件编辑器记下你做过的工作。因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。能够重复前面的工作是非常重要的。有时因为一些细小的不同,你会发现无法复制原先的结果了。这时如果有记录下以往工作的do文件将把你从地狱带到天堂。因为你不必一遍又一遍地试图重现做过的工作。在stata 窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出
现“bring do-file editor to front”,点击它就会出现do文件编 辑器。 为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。这里给出我使用的“头”和“尾”。capture clear (清空内存中的数据)capture log close (关闭所有 打开的日志文件)set more off (关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。)set matsize 4000 (设置矩阵的最大阶数。我用的是不是太大了?)cd D: (进入数据所在的盘符和文件夹。和dos的命令行很相似。)log using (文件名).log,replace (打开日志文件,并更新。日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。)use (文件名),clear (打开数据文件。)(文件内容)log close (关闭日志文件。)exit,clear (退出并清空内存中的数据。) 实证工作中往往接触的是原始数据。这些数据没有经过整理,有一些错漏和不统一的地方。比如,对某个变量的缺失观察值,有时会用点,有时会用-9,-99等来表示。回归时如果 使用这些观察,往往得出非常错误的结果。还有,在不同的数据文件中,相同变量有时使用的变量名不同,会给合并数
常用到的stata命令
常用到的sta命令 闲话不说了。help和search都是查找帮助文件的命令,它们之间的区别在于help用于查找精确的命令名,而search是模糊查找。如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在sta的命令行窗口中输入help空格加上这个名字。回车后结果屏幕上就会显示出这个命令的帮助文件的全部内容。如果你想知道在sta下做某个估计或某种计算,而不知道具体该如何实现,就需要用search命令了。使用的方法和help类似,只须把准确的命令名改成某个关键词。回车后结果窗口会给出所有和这个关键词相关的帮助文件名和链接列表。在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。耐心寻找,反复实验,通常可以较快地找到你需要的内容。 下面该正式处理数据了。我的处理数据经验是最好能用sta的do文件编辑器记下你做过的工作。因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。能够重复前面的工作是非常重要的。有时因为一些细小的不同,你会发现无法复制原先的结果了。这时如果有记录下以往工作的do文件将把你从地狱带到天堂。因为你不必一遍又一遍地试图重现做过的工作。在sta窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出现“bring do-file editor to front”,点击它就会出现do文件编辑器。 为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。这里给出我使用的“头”和“尾”。 /*(标签。简单记下文件的使命。)*/ capture clear(清空内存中的数据) capture log close(关闭所有打开的日志文件) set mem 128m(设置用于sta使用的内存容量) set more off(关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。) set matsize4000(设置矩阵的最大阶数。我用的是不是太大了?)
Stata常用15条命令
【命令1】:导入数据 一般做实证分析使用的是excel中的数据,其后缀名为.xls,需要将其修改为.csv insheet using name.csv, clear 【命令2】:删除重复变量 sort var1 var2 duplicatesdrop var1 var2, force 【命令3】:合并数据 use data1, clear merge m:m var1 var2 using data2 drop if _merge==2 drop if _merge==1 drop _merge 【命令4】:描述性统计分析 tabstat var1var2, stat(n min mean median p25 p75 max sd), if groupvar==0 or 1 输出到word中: logout, save(name) word replace: tabstat var, stat(n min mean p50 max sd) col(stat)f(%9.2g) 【命令5】:结果输出 安装 ssc install estout, replace 单个回归 reg y x esttab using name.rtf, compress nogap r2 ar2 star(* 0.1 ** 0.05 *** 0.01) 多个回归一起 reg y x1 est store m1 reg y x2 est store m2 esttab m1 m2 using name.rtf, compress nogap r2 ar2 star(* 0.1 ** 0.05 *** 0.01)
(完整)stata命令总结,推荐文档
stata11常用命令 注:JB统计量对应的p大于0.05,则表明非正态,这点跟sktest和swilk 检验刚好相反; dta为数据文件; gph为图文件; do为程序文件; 注意stata要区别大小写; 不得用作用户变量名: _all _n _N _skip _b _coef _cons _pi _pred _rc _weight double float long int in if using with 命令: 读入数据一种方式 input x y 1 4 2 5.5 3 6.2 4 7.7 5 8.5 end su/summarise/sum x 或 su/summarise/sum x,d 对分组的描述: sort group by group:su x %%%%% tabstat economy,stats(max) %返回变量economy的最大值 %%stats括号里可以是:mean,count(非缺失观测值个数),sum(总和),max,min,range, %% sd,var,cv(变易系数=标准差/均值),skewness,kurtosis,median,p1(1%分位 %% 数,类似地有p10, p25, p50, p75, p95, p99),iqr(interquantile range = p75 – p25) _all %描述全部 _N 数据库中观察值的总个数。 _n 当前观察值的位置。 _pi 圆周率π的数值。 list gen/generate %产生数列 egen wagemax=max(wage) clear use by(分组变量)
常用到的stata命令
安装estat: ssc install estout,replace\ 2010-10-14 11:38:15来自: 杨囡囡(all a woman lack is a wife) (转自人大论坛) 调整变量格式: format x1 %10.3f ——将x1的列宽固定为10,小数点后取三位 format x1 %10.3g ——将x1的列宽固定为10,有效数字取三位 format x1 %10.3e ——将x1的列宽固定为10,采用科学计数法 format x1 %10.3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符 format x1 %10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符 format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐 合并数据: use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge using "C:\Documents and Settings\xks\桌面\1999.dta" ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来 use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge id using "C:\Documents and Settings\xks\桌面\1999.dta" ,unique sort ——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort) 建议采用第一种方法。 对样本进行随机筛选: sample 50 在观测案例中随机选取50%的样本,其余删除 sample 50,count 在观测案例中随机选取50个样本,其余删除 查看与编辑数据:
stata常用命令
面板数据估计 首先对面板数据进行声明: 前面是截面单元,后面是时间标识: tsset company year tsset industry year 产生新的变量:gen newvar=human*lnrd 产生滞后变量Gen fiscal(2)=L2.fiscal 产生差分变量Gen fiscal(D)=D.fiscal 描述性统计: xtdes :对Panel Data截面个数、时间跨度的整体描述 Xtsum:分组内、组间和样本整体计算各个变量的基本统计量 xttab 采用列表的方式显示某个变量的分布 Stata中用于估计面板模型的主要命令:xtreg xtreg depvar [varlist] [if exp] , model_type [level(#) ] Model type 模型 be Between-effects estimator fe Fixed-effects estimator re GLS Random-effects estimator pa GEE population-averaged estimator mle Maximum-likelihood Random-effects estimator 主要估计方法: xtreg: Fixed-, between- and random-effects, and population-averaged linear models xtregar:Fixed- and random-effects linear models with an AR(1) disturbance xtpcse :OLS or Prais-Winsten models with panel-corrected standard errors xtrchh :Hildreth-Houck random coefficients models
stata常用命令
stata常用命令 stata save命令 FileSave As 例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata格式文件。STATA数据库的维护 排序 SORT 变量名1 变量名2 …… 变量更名 rename 原变量名新变量名 STATA数据库的维护 删除变量或记录 drop x1 x2 /* 删除变量x1和x2 drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5) drop if x<0 /* 删去x1<0的所有记录 drop in 10/12 /* 删去第10~12个记录 drop if x==. /* 删去x为缺失值的所有记录 drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录 drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录 drop _all /* 删掉数据库中所有变量和数据 STATA的变量赋值 用generate产生新变量 generate 新变量=表达式 generate bh=_n /* 将数据库的内部编号赋给变量bh。 generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个3……。直到数据库结束。 generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。 egen产生新变量 set obs 12 egen a=seq() /*产生1到N的自然数 egen b=seq(),b(3) /*产生一个序列,每个元素重复#次 egen c=seq(),to(4) /*产生多个序列,每个序列从1到# egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2
常用stata命令-好用
我常用到的stata命令 最重要的两个命令莫过于help和search了。即使是经常使用stata的人也很难,也没必要记住常用命令的每一个细节,更不用说那些不常用到的了。所以,在遇到困难又没有免费专家咨询时,使用stata自带的帮助文件就是最佳选择。stata的帮助文件十分详尽,面面俱到,这既是好处也是麻烦。当你看到长长的帮助文件时,是不是对迅速找到相关信息感到没有信心? 闲话不说了。help和search都是查找帮助文件的命令,它们之间的区别在于help用于查找精确的命令名,而search是模糊查找。如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在stata的命令行窗口中输入help空格加上这个名字。回车后结果屏幕上就会显示出这个命令的帮助文件的全部内容。如果你想知道在stata下做某个估计或某种计算,而不知道具体该如何实现,就需要用search命令了。使用的方法和help类似,只须把准确的命令名改成某个关键词。回车后结果窗口会给出所有和这个关键词相关的帮助文件名和链接列表。在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。耐心寻找,反复实验,通常可以较快地找到你需要的内容。 下面该正式处理数据了。我的处理数据经验是最好能用stata的do文件编辑器记下你做过的工作。因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。能够重复前面的工作是非常重要的。有时因为一些细小的不同,你会发现无法复制原先的结果了。这时如果有记录下以往工作的do文件将把你从地狱带到天堂。因为你不必一遍又一遍地试图重现做过的工作。在stata窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出现“bring do-file editor to front”,点击它就会出现do文件编辑器。 为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。这里给出我使用的“头”和“尾”。 /*(标签。简单记下文件的使命。)*/ capture clear (清空内存中的数据) capture log close (关闭所有打开的日志文件) set mem 128m (设置用于stata使用的内存容量) set more off (关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。)set matsize 4000 (设置矩阵的最大阶数。我用的是不是太大了?) cd D: (进入数据所在的盘符和文件夹。和dos的命令行很相似。) log using (文件名).log,replace (打开日志文件,并更新。日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。) use (文件名),clear (打开数据文件。) (文件内容)
stata常用命令
调整变量格式: format x1 % ——将x1的列宽固定为10,小数点后取三位 format x1 % ——将x1的列宽固定为10,有效数字取三位 format x1 % ——将x1的列宽固定为10,采用科学计数法 format x1 % ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符 format x1 % ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符 format x1 % ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐合并数据: use "C:\Documents and Settings\xks\桌面\", clear merge using "C:\Documents and Settings\xks\桌面\" ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来 use "C:\Documents and Settings\xks\桌面\", clear merge id using "C:\Documents and Settings\xks\桌面\" ,unique sort ——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。 对样本进行随机筛选: sample 50 在观测案例中随机选取50%的样本,其余删除 sample 50,count 在观测案例中随机选取50个样本,其余删除 查看与编辑数据: browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器) edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器) 数据合并(merge)与扩展(append) merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。one-to-one merge: 数据源自stata tutorial中的exampw1和exampw2 第一步:将exampw1按v001~v003这三个编码排序,并建立临时数据库tempw1 clear use "t:\statatut\" su ——summarize的简写 sort v001 v002 v003 save tempw1 第二步:对exampw2做同样的处理 clear use "t:\statatut\" su sort v001 v002 v003 save tempw2 第三步:使用tempw1数据库,将其与tempw2合并: clear use tempw1 merge v001 v002 v003 using tempw2 第四步:查看合并后的数据状况:
Stata统计分析命令
Stata统计分析常用命令汇总 一、winsorize极端值处理 范围:一般在1%和99%分位做极端值处理,对于小于1%的数用1%的值赋值,对于大于99%的数用99%的值赋值。 1、Stata中的单变量极端值处理: stata 11.0,在命令窗口输入“findit winsor”后,系统弹出一个窗口,安装winsor模块 安装好模块之后,就可以调用winsor命令,命令格式:winsor var1, gen(new var) p(0.01) 或者在命令窗口中输入:ssc install winsor安装winsor命令。winsor命令不能进行批量处理。 2、批量进行winsorize极端值处理: 打开链接:.edu/judson.caskey/data.html,找到winsorizeJ,点击右键,另存为到stata中的ado/plus/目录下即可。命令格式:winsorizeJ var1var2var3,suffix(w)即可,这样会生成三个新变量,var1w var2w var3w,而且默认的是上下1%winsorize。如果要修改分位点,则写成如下格式:winsorizeJ var 1 var2 var3,suffix(w) cuts(5 95)。 3、Excel中的极端值处理:(略) winsor2 命令使用说明 简介:winsor2 winsorize or trim (if trim option is specified) the variables in varlist at particular percentiles specified by option cuts(# #). In defult, new variables will be generated with a suffix "_w" or "_tr", which can be changed by specifying suffix() option. The replace option replaces the variables with their winsorized or trimmed ones. 相比于winsor命令的改进: (1) 可以批量处理多个变量; (2) 不仅可以winsor,也可以trimming; (3) 附加了by() 选项,可以分组winsor 或trimming; (4) 增加了replace 选项,可以不必生成新变量,直接替换原变量。 范例: *- winsor at (p1 p99), get new variable "wage_w" . sysuse nlsw88, clear . winsor2 wage *- left-trimming at 2th percentile . winsor2 wage, cuts(2 100) trim *- winsor variables by (industry south), overwrite the old variables . winsor2 wage hours, replace by(industry south) 使用方法: 1. 请将winsor 2.ado 和winsor2.sthlp 放置于stata12\ado\base\w 文件夹下; 2. 输入help winsor2 可以查看帮助文件; 二、描述性统计 1、summarize 命令格式:su、sum或者summarize [varlist] [if] [in] [weight] [,options] 如果summarize或sum后不加任何变量,则默认对数据中的所有变量进行描述统计options 选项:detail 表示产生更加详细的统计变量
常用到的STATA命令
年0606月月0101日,日,日,200820082008年第年第年第44期,总第期,总第6 6期编者按:Stata 的数据管理能力非常powerful ,而我们EpiMan 论坛上有很多优秀的帖子,我们会不定期对其进行整理,以期使得大家可以更好地掌握Stata 软件,提高工作和学习的效率和乐趣。毕竟,Stata 是一款巨有特色的统计软件包,推荐使用。 我常用到的Stata命令 by 无为而治的西瓜与西瓜老死不相往来 Special Issue Fundamental of Data Manipulation Using Stata https://www.360docs.net/doc/aa17332051.html,
EpiMan Cluster特刊:我常用到的Stata命令 https://www.360docs.net/doc/aa17332051.html, Special Issue 我常用到的Stata命令 文章作者:无为而治的西瓜与西瓜老死不相往来 本期主编:epiman 本期审校:epiman 本期排版:epiman 2008年06月01日 2008年第4期 总第6期 邮箱:epiman@https://www.360docs.net/doc/aa17332051.html, 网址:https://www.360docs.net/doc/aa17332051.html, 目录 第一讲,do文件的穿靴戴帽 第二讲,原始数据→分析数据 第三讲,批量生成虚拟变量 第四讲,改变数据结构 第五讲,复杂数据处理技巧--迂回 第六讲,本期声明和好汉招募
第一讲,help和search的区别以及do文件的穿靴戴帽第一讲,help和search的区别以及do文件的穿靴戴帽 作者:无为而治的西瓜与西瓜老死不相往来@https://www.360docs.net/doc/aa17332051.html, 最重要的两个命令莫过于help和search了。即使是经常使用stata的人也很难,也没必要记住常用命令的每一个细节,更不用说那些不常用到的了。所以,在遇到困难又没有免费专家咨询时,使用stata自带的帮助文件就是最佳选择。stata的帮助文件十分详尽,面面俱到,这既是好处也是麻烦。当你看到长长的帮助文件时,是不是对迅速找到相关信息感到没有信心?闲话不说了。help和search都是查找帮助文件的命令,它们之间的区别在于help用于查找精确的命令名,而search是模糊查找。如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在stata的命令行窗口中输入help空格加上这个名字。回车后结果屏幕上就会显示出这个命令的帮助文件的全部内容。如果你想知道在stata下做某个估计或某种计算,而不知道具体该如何实现,就需要用search命令了。使用的方法和help类似,只须把准确的命令名改成某个关键词。回车后结果窗口会给出所有和这个关键词相关的帮助文件名和链接列表。在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。耐心寻找,反复实验,通常可以较快地找到你需要的内容。 下面该正式处理数据了。我的处理数据经验是最好能用stata的do文件编辑器记下你做过的工作。因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。能够重复前面的工作是非常重要的。有时因为一些细小的不同,你会发现无法复制原先的结果了。这时如果有记录下以往工作的do文件将把你从地狱带到天堂。因为你不必一遍又一遍地试图重现做过的工作。在stata窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出现“bring do-file editor to front”,点击它就会出现do文件编辑器。 为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。这里给出我使用的“头”和“尾”。 capture clear(清空内存中的数据) capture log close(关闭所有打开的日志文件) set mem128m(设置用于stata使用的内存容量) set more off(关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。)set matsiz e4000(设置矩阵的最大阶数。我用的是不是太大了?) cd D:(进入数据所在的盘符和文件夹。和dos的命令行很相似。) log using(文件名).log,replace(打开日志文件,并更新。日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。)use(文件名),clear(打开数据文件。) (文件内容) log close(关闭日志文件。) exit,clear(退出并清空内存中的数据。) 这个do文件的“头尾”并非我的发明,而是从沈明高老师那里学到的。版权归沈明高老师。
stata常用命令
stata 常用命令 (2012-07-29 17:22:25) 转载▼ 分类:stata 标签: 杂谈 save命令 FileSave As 例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata格式文件。STATA数据库的维护 排序 SORT 变量名1 变量名2 …… 变量更名 rename 原变量名新变量名 STATA数据库的维护 删除变量或记录 drop x1 x2 /* 删除变量x1和x2 drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5) drop if x<0 /* 删去x1<0的所有记录 drop in 10/12 /* 删去第10~12个记录 drop if x==. /* 删去x为缺失值的所有记录 drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录 drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录 drop _all /* 删掉数据库中所有变量和数据 STATA的变量赋值 用generate产生新变量 generate 新变量=表达式 generate bh=_n /* 将数据库的内部编号赋给变量bh。 generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个 3……。直到数据库结束。 generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。 egen产生新变量 set obs 12 egen a=seq() /*产生1到N的自然数 egen b=seq(),b(3) /*产生一个序列,每个元素重复#次 egen c=seq(),to(4) /*产生多个序列,每个序列从1到# egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2 encode 字符变量名,gen(新数值变量名) 作用:将字符型变量转化为数值变量。
STATA简单命令
STATA 的简单命令 Stata 中最重要的命令莫过于help 和search 了。 help 用于查找精确的命令,而search 是模糊查找。例如:help regress 又如:我们记不清regress命令的全名,只记得regress 的前半部分reg,那么可以输入search reg 用户获得信息最有效的另一个途径是使用Statalist 在线论坛,该论坛提供Stata 用户交流的一个良好的平台。要加入Statalist,我们可以给以下地址发个邮件: majordomo@https://www.360docs.net/doc/aa17332051.html, 邮件的内容为:subscribe Statalist 变量的命名: 1. 变量名可达32 个字符。 2. 字符组成部分为A~Z 、a~z、0~9与下划线“ _”,这些字符以外的其他符号不可以出现在 变量名中。 3. 变量名不能以数字开头。 4. 变量名区分大小写。 5. 倘若遵循以上原则依然无法正常命名变量,那么这个变量可能与Stata 自身保留的供系 统使用的变量重复了。 创建数据文件的方法: 1. 手动输入。 2. 从excel 等文件中复制粘贴到stata 数据表中。 3. 运用stata 软件导入。 查看数据的概貌: summarize x codebook x 如果上面两个命令后面不加内容,那么显示的结果是所有变量的概貌。 对数据进行排序的命令:sort 标准 1 标准 2 标准3 生成数据的命令:gen 1. 如果要得到一阶差分,可以用以下命令:gen Difference_invest(新变量的名称是任意 的)=d.invest ( d.是运算符号,不得改变;invest 是变量名称) 2. 要想产生一个新的变量Lag_invest ,也就是invest 的一阶滞后,那么我们可以采用如下 命令:gen Lag_invest = l.invest 3. 生成对数的命令:gen Ln_invest=ln(invest) 作散点图的命令:scatter 1. scatter x1 x2:scatter 后的第一个变量是纵轴的变量,第二个变量是横轴的变量。 2. scatter x1 x2, connect(1) :以直线的方式连接相邻的两个点。