基于聚类的复杂网络社团发现算法

PNN神经网络聚类法模式分类思想
目录 摘要 (1) 1概率神经网络 (1) 1.1网络模型 (1) 1.2分类思想 (2) 1.3 PNN分类的优点 (3) 2 PNN网络的构建 (3) 2.1 构建步骤 (3) 2.2 Matlab中的主要代码 (4) 3 Matlab编程及结果分析 (4) 3.1 Matlab中的编程 (4) 3.2 仿真结果分析 (7) 3.3 结论 (10) 4 总结 (11) 参考文献 (12)
PNN神经网络聚类法 摘要 近几年来,对于神经网络的研究越来越普遍,神经网络在我们社会生活中的作用也越来越不可替代,尤其在模式识别的领域里,更是有着举足轻重的作用。 酒是由多种成分按不同的比例构成的,兑酒时需要三种原料(X,Y,Z),现在已测出不同酒中三种原料的含量,本文正是基于PNN神经网络针对酒中X、Y、Z三种含量的不同来对酒进行识别分类。本文首先介绍了PNN神经网络的网络模型以及它对不同的模式进行分类判别的思想,然后针对本文的酒类判别的要求来构建PNN网络,并在Matlab中进行编程仿真,最后对所仿真的结果进行了分析比较,最后找出最优的模式分类。 1概率神经网络 概率神经网络(Probabilistic Neural Networks,PNN)是由D. F. Specht在1990年提出的。主要思想是用贝叶斯决策规则,即错误分类的期望风险最小,在多维输入空间内分离决策空间。它是一种基于统计原理的人工神经网络,它是以Parzen 窗口函数为激活函数的一种前馈网络模型。PNN吸收了径向基神经网络与经典的概率密度估计原理的优点,与传统的前馈神经网络相比,在模式分类方面尤其具有较为显著的优势。 1.1网络模型 PNN的结构如图1所示,共由四层组成。 图1 概率神经网络结构
复杂网络的基础知识
第二章复杂网络的基础知识 2.1 网络的概念 所谓“网络”(networks),实际上就是节点(node)和连边(edge)的集合。如果节点对(i,j)与(j,i)对应为同一条边,那么该网络为无向网络(undirected networks),否则为有向网络(directed networks)。如果给每条边都赋予相应的权值,那么该网络就为加权网络(weighted networks),否则为无权网络(unweighted networks),如图2-1所示。 图2-1 网络类型示例 (a) 无权无向网络(b) 加权网络(c) 无权有向网络 如果节点按照确定的规则连边,所得到的网络就称为“规则网络”(regular networks),如图2-2所示。如果节点按照完全随机的方式连边,所得到的网络就称为“随机网络”(random networks)。如果节点按照某种(自)组织原则的方式连边,将演化成各种不同的网络,称为“复杂网络”(complex networks)。 图2-2 规则网络示例 (a) 一维有限规则网络(b) 二维无限规则网络
2.2 复杂网络的基本特征量 描述复杂网络的基本特征量主要有:平均路径长度(average path length )、簇系数(clustering efficient )、度分布(degree distribution )、介数(betweenness )等,下面介绍它们的定义。 2.2.1 平均路径长度(average path length ) 定义网络中任何两个节点i 和j 之间的距离l ij 为从其中一个节点出发到达另一个节点所要经过的连边的最少数目。定义网络的直径(diameter )为网络中任意两个节点之间距离的最大值。即 }{max ,ij j i l D = (2-1) 定义网络的平均路径长度L 为网络中所有节点对之间距离的平均值。即 ∑∑-=+=-=111)1(2N i N i j ij l N N L (2-2) 其中N 为网络节点数,不考虑节点自身的距离。网络的平均路径长度L 又称为特征路径长度(characteristic path length )。 网络的平均路径长度L 和直径D 主要用来衡量网络的传输效率。 2.2.2 簇系数(clustering efficient ) 假设网络中的一个节点i 有k i 条边将它与其它节点相连,这k i 个节点称为节点i 的邻居节点,在这k i 个邻居节点之间最多可能有k i (k i -1)/2条边。节点i 的k i 个邻居节点之间实际存在的边数N i 和最多可能有的边数k i (k i -1)/2之比就定义为节点i 的簇系数,记为C i 。即 ) 1(2-=i i i i k k N C (2-3) 整个网络的聚类系数定义为网络中所有节点i 的聚类系数C i 的平均值,记
复杂网络聚类系数和平均路径长度计算的MATLAB源代码
复杂网络聚类系数和平均路径长度计算的 MA TLAB 源代码 申明:文章来自百度用户 carrot_hy 复杂网络的代码总共是三个m文件,复制如下: 第一个文件, CCM_ClusteringCoef.m function [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) % CCM_ClusteringCoef calculates clustering coefficients. % Input: % gMatrix adjacency matrix % Types type of graph: 'binary','weighted','directed','all'(default). % Usage: % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) returns % clustering coefficients for all nodes "Cp_Nodal" and average clustering % coefficient of network "Cp_Global". % Example: % G = CCM_TestGraph1('nograph'); % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(G); % Note: % 1) one node have vaule 0, while which only has a neighbour or none. % 2) The dircted network termed triplets that fulfill the follow condition % as non-vacuous: j->i->k and k->i-j,if don't satisfy with that as % vacuous, just like: j->i,k->i and i->j,i->k. and the closed triplets % only j->i->k == j->k and k->i->j == k->j. % 3) 'ALL' type network code from Mika Rubinov's BCT toolkit. % Refer: % [1] Barrat et al. (2004) The architecture of the complex weighted networks. % [2] Wasserman,S.,Faust,K.(1994) Social Network Analysis: Methods and % Applications. % [3] Tore Opsahl and Pietro Panzarasa (2009). "Clustering in Weighted % Networks". Social Networks31(2). % See also CCM_Transitivity % Written by Yong Liu, Oct,2007 % Center for Computational Medicine (CCM), % National Laboratory of Pattern Recognition (NLPR), % Institute of Automation,Chinese Academy of Sciences (IACAS), China. % Revise by Hu Yong, Nov, 2010 % E-mail:
复杂网络模型的matlab实现
function [DeD,aver_DeD]=Degree_Distribution(A) %% 求网络图中各节点的度及度的分布曲线 %% 求解算法:求解每个节点的度,再按发生频率即为概率,求P(k) %A————————网络图的邻接矩阵 %DeD————————网络图各节点的度分布 %aver_DeD———————网络图的平均度 N=size(A,2); DeD=zeros(1,N); for i=1:N % DeD(i)=length(find((A(i,:)==1))); DeD(i)=sum(A(i,:)); end aver_DeD=mean(DeD); if sum(DeD)==0 disp('该网络图只是由一些孤立点组成'); return; else figure; bar([1:N],DeD); xlabel('节点编号n'); ylabel('各节点的度数K'); title('网络图中各节点的度的大小分布图'); end figure; M=max(DeD); for i=1:M+1; %网络图中节点的度数最大为M,但要同时考虑到度为0的节点的存在性 N_DeD(i)=length(find(DeD==i-1)); % DeD=[2 2 2 2 2 2] end P_DeD=zeros(1,M+1); P_DeD(:)=N_DeD(:)./sum(N_DeD); bar([0:M],P_DeD,'r'); xlabel('节点的度 K'); ylabel('节点度为K的概率 P(K)'); title('网络图中节点度的概率分布图'); 平均路径长度 function [D,aver_D]=Aver_Path_Length(A) %% 求复杂网络中两节点的距离以及平均路径长度 %% 求解算法:首先利用Floyd算法求解出任意两节点的距离,再求距离的平均值得平均路
人工神经网络在聚类分析中的运用
摘要:本文采用无导师监督的som网络,对全国31个省市自治区的人民生活质量进行了综合评价,在没有先验信息的条件下,不采用人为主观赋予各指标权重的办法,转而运用自组织神经网络自组织竞争学习的网络方法来进行赋值、计算和评价,消除了主观确定各指标的权重的主观性,得到的结果较为符合各省市自治区的实际结果。 关键词:聚类分析;k-means聚类;系统聚类;自组织神经网络;人民生活质量 一、引言(研究现状) 自改革开放以来,我国生产力极大发展,生活水平总体上得到了提高。但是,地区间的发展不平衡始终存在,而且差距越来越大,不同地区人民的生活水平也存在显著的差异。据此,我们利用自组织人工神经网络方法对全国31个省市自治区的人民生活水平质量进行分析评价。 二、指标选取与预处理 1.指标选取 遵循合理性、全面性、可操作性、可比性的原则,从以下5个层面共11个二级指标构建了人民生活质量综合评价指标体系(如下表所示)。 人民生活质量综合评价指标体系 2.指标预处理 (1)正向指标是指标数据越大,则评价也高,如人均可支配收入,人均公园等。 正向指标的处理规则如下(1): kohonen 自组织神经网络 输入层是一个一维序列,该序列有n个元素,对应于样本向量的维度;竞争层又称为输出层,该层是由m′n=h个神经元组成的二维平面阵列其神经元的个数对应于输出样本空间的维数,可以使一维或者二维点阵。 竞争层之间的神经元与输入层之间的神经元是全连接的,在输入层神经元之间没有权连接,在竞争层的神经元之间有局部的权连接,表明竞争层神经元之间的侧反馈作用。训练之后的竞争层神经元代表者不同的分类样本。 自组织特征映射神经网络的目标:从样本的数据中找出数据所具有的特征,达到能够自动对样本进行分类的目的。 2.网络反馈算法 自组织网络的学习过程可分为以下两步: (1)神经元竞争学习过程 对于每一个样本向量,该向量会与和它相连的竞争层中的神经元的连接权进行竞争比较(相似性的比较),这就是神经元竞争的过程。相似性程度最大的神经元就被称为获胜神经元,将获胜神经元称为该样本在竞争层的像,相同的样本具有相同的像。 (2)侧反馈过程 竞争层中竞争获胜的神经元会对周围的神经元产生侧反馈作用,其侧反馈机制遵循以下原则:以获胜神经元为中心,对临近邻域的神经元表现为兴奋性侧反馈。以获胜神经元为中心,对邻域外的神经元表现为抑制性侧反馈。 对于竞争获胜的那个神经元j,其邻域内的神经元在不同程度程度上得到兴奋的侧反馈,而在nj(t)外的神经元都得到了抑制的侧反馈。nj(t)是时间t的函数,随着时间的增加,nj(t)围城的面积越来越小,最后只剩下一个神经元,而这个神经元,则反映着一个类的特征或者一个类的属性。 3.评价流程 (1)对n个输入层输入神经元到竞争层输出神经元j的连接权值为(6)式:
复杂网络聚类系数和平均路径长度计算的MATLAB源代码上课讲义
复杂网络聚类系数和平均路径长度计算的M A T L A B源代码
复杂网络聚类系数和平均路径长度计算的MATLAB源代码 申明:文章来自百度用户carrot_hy 复杂网络的代码总共是三个m文件,复制如下: 第一个文件,CCM_ClusteringCoef.m function [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) % CCM_ClusteringCoef calculates clustering coefficients. % Input: % gMatrix adjacency matrix % Types type of graph: 'binary','weighted','directed','all'(default). % Usage: % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) returns % clustering coefficients for all nodes "Cp_Nodal" and average clustering % coefficient of network "Cp_Global". % Example: % G = CCM_TestGraph1('nograph'); % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(G); % Note: % 1) one node have vaule 0, while which only has a neighbour or none. % 2) The dircted network termed triplets that fulfill the follow condition % as non-vacuous: j->i->k and k->i-j,if don't satisfy with that as % vacuous, just like: j->i,k->i and i->j,i->k. and the closed triplets % only j->i->k == j->k and k->i->j == k->j.
复杂网络聚类系数和平均路径长度计算的MATLAB源代码(知识浅析)
复杂网络聚类系数和平均路径长度计算的MA TLAB源代码 申明:文章来自百度用户carrot_hy 复杂网络的代码总共是三个m文件,复制如下: 第一个文件,CCM_ClusteringCoef.m function [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) % CCM_ClusteringCoef calculates clustering coefficients. % Input: % gMatrix adjacency matrix % Types type of graph: 'binary','weighted','directed','all'(default). % Usage: % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) returns % clustering coefficients for all nodes "Cp_Nodal" and average clustering % coefficient of network "Cp_Global". % Example: % G = CCM_TestGraph1('nograph'); % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(G); % Note: % 1) one node have vaule 0, while which only has a neighbour or none. % 2) The dircted network termed triplets that fulfill the follow condition % as non-vacuous: j->i->k and k->i-j,if don't satisfy with that as % vacuous, just like: j->i,k->i and i->j,i->k. and the closed triplets % only j->i->k == j->k and k->i->j == k->j. % 3) 'ALL' type network code from Mika Rubinov's BCT toolkit. % Refer: % [1] Barrat et al. (2004) The architecture of the complex weighted networks. % [2] Wasserman,S.,Faust,K.(1994) Social Network Analysis: Methods and % Applications. % [3] Tore Opsahl and Pietro Panzarasa (2009). "Clustering in Weighted % Networks". Social Networks31(2). % See also CCM_Transitivity % Written by Yong Liu, Oct,2007 % Center for Computational Medicine (CCM), % National Laboratory of Pattern Recognition (NLPR), % Institute of Automation,Chinese Academy of Sciences (IACAS), China. % Revise by Hu Yong, Nov, 2010 % E-mail: % based on Matlab 2006a % $Revision: 1.0, Copywrite (c) 2007
聚类与网络__总结
1、什么是聚类(clustering)? ●一种将具有相似性(similarity)的数据样本组合在一起的方法---根据选择的某种准则●一种非监督性学习(unsupervised learning)方法---通常并没有例子阐明如何让将数据 聚集在一起 ●一种数据探索(data exploration)的方法---在感兴趣的数据中寻找模式或结构的方法 2、聚类中关键的一步---选择(非)相似性度量值((dis)similarity measures),通常比聚类算法更重要 ——欧氏距离(Euclidean distance) ——Pearson相关系数(Pearson Linear Correlation) 3、聚类算法——凝聚层次聚类(Hierarchical agglomerative clustering) ——K-means聚类(K-means clustering)和品质衡量 补充:聚类算法有两类:hierarchical和partitioning methods,其中partitioning methods包括self-organizing maps (SOP)和K-means 4、欧氏距离:n是数据向量的维数,例如 ——样本中时间点/状态的数量(聚类基因的时候) ——基因的数量(聚类样本的时候) 5、相关性:我们常常更关注表达谱的形状而不是实际量级差异,也就是说我们常常认为同时上调或下调的基因是相似的。 补充:在理想情况下,表达谱中数据中的距离度量应该能够和表达差异的生理学相关性成正比。几乎可以肯定的是,不同系统的敏感性会有很复杂的波动,这些波动不仅可能由基因或者蛋白质的不同造成,也可能由某种状态的相对表达水平的不同所造成,还可能由系统本身所处的状态造成。 6、Pearson相关系数:我们将表达谱降低(减去平均值)并通过标准差缩放比例(如使数据平均值为0,标准差为1)。 Pearson linear correlation (PLC)是形状(”shape”)相似性的度量
基于复杂网络的制造服务建模及聚类分析
目录 目录 摘要...........................................................................................................................................I Abstract....................................................................................................................................III 1 绪论. (1) 1.1 研究背景与意义 (1) 1.1.1 制造业的挑战及“云制造”的提出 (1) 1.1.2 研究目的及复杂网络的引入 (2) 1.2 国内外研究现状 (3) 1.2.1 云制造现状 (3) 1.2.2 制造服务建模的研究现状 (5) 1.2.3 复杂网络研究现状 (7) 1.2.4 聚类分析研究现状 (8) 1.3 研究内容与章节安排 (9) 2 基于复杂网络的制造服务研究体系框架 (11) 2.1 制造服务研究体系框架 (11) 2.2 制造服务关联网络的复杂性分析 (12) 2.2.1 节点复杂特性分析 (12) 2.2.2 网络结构的动态变化特性分析 (13) 2.3 相关理论基础 (15) 2.3.1 复杂网络的概念与表示 (15) 2.3.2 复杂网络的特征参量 (17) 2.3.3 复杂网络中的社团聚类 (19) 2.4 本章小结 (22) 3 基于复杂网络的制造服务建模 (23) 3.1 服务节点的选取 (23) 3.1.1 云制造服务定义及描述 (23) 3.1.2 企业级制造服务 (27) 3.1.3 业务级制造服务 (28) 3.1.4 资源级制造服务 (29) 3.2 关联关系挖掘 (30) 3.2.1 可组合关系 (30) 3.2.2 服务关系的数值化计算 (32) 3.3 制造服务建模 (33) 3.3.1 形式化描述及数据库设计 (33) I
复杂网络聚类系数和平均路径长度计算的MATLAB源代码
复杂网络聚类系数和平均路径长度计算的MATLAB源代码 申明:文章来自百度用户carrot_hy 复杂网络的代码总共是三个m文件,复制如下: 第一个文件,CCM_ClusteringCoef.m function [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) % CCM_ClusteringCoef calculates clustering coefficients. % Input: % gMatrix adjacency matrix % Types type of graph: 'binary','weighted','directed','all'(default). % Usage: % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) returns % clustering coefficients for all nodes "Cp_Nodal" and average clustering % coefficient of network "Cp_Global". % Example: % G = CCM_TestGraph1('nograph'); % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(G); % Note: % 1) one node have vaule 0, while which only has a neighbour or none. % 2) The dircted network termed triplets that fulfill the follow condition % as non-vacuous: j->i->k and k->i-j,if don't satisfy with that as % vacuous, just like: j->i,k->i and i->j,i->k. and the closed triplets % only j->i->k == j->k and k->i->j == k->j. % 3) 'ALL' type network code from Mika Rubinov's BCT toolkit. % Refer: % [1] Barrat et al. (2004) The architecture of the complex weighted networks. % [2] Wasserman,S.,Faust,K.(1994) Social Network Analysis: Methods and % Applications. % [3] Tore Opsahl and Pietro Panzarasa (2009). "Clustering in Weighted % Networks". Social Networks31(2). % See also CCM_Transitivity % Written by Yong Liu, Oct,2007 % Center for Computational Medicine (CCM), % National Laboratory of Pattern Recognition (NLPR), % Institute of Automation,Chinese Academy of Sciences (IACAS), China. % Revise by Hu Yong, Nov, 2010 % E-mail: % based on Matlab 2006a % $Revision: 1.0, Copywrite (c) 2007
复杂网络聚类系数和平均路径长度计算的MATLAB源代码
申明:文章来自百度用户carrot_hy 复杂网络的代码总共是三个m文件,复制如下: 第一个文件, function [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) % CCM_ClusteringCoef calculates clustering coefficients. % Input: % gMatrix adjacency matrix % Types type of graph: 'binary','weighted','directed','all'(default). % Usage: % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(gMatrix, Types) returns % clustering coefficients for all nodes "Cp_Nodal" and average clustering % coefficient of network "Cp_Global". % Example: % G = CCM_TestGraph1('nograph'); % [Cp_Global, Cp_Nodal] = CCM_ClusteringCoef(G); % Note: % 1) one node have vaule 0, while which only has a neighbour or none. % 2) The dircted network termed triplets that fulfill the follow condition % as non-vacuous: j->i->k and k->i-j,if don't satisfy with that as % vacuous, just like: j->i,k->i and i->j,i->k. and the closed triplets % only j->i->k == j->k and k->i->j == k->j. % 3) 'ALL' type network code from Mika Rubinov's BCT toolkit. % Refer: % [1] Barrat et al. (2004) The architecture of the complex weighted networks. % [2] Wasserman,S.,Faust,K.(1994) Social Network Analysis: Methods and % Applications. % [3] Tore Opsahl and Pietro Panzarasa (2009). "Clustering in Weighted % Networks". Social Networks31(2). % See also CCM_Transitivity % Written by Yong Liu, Oct,2007 % Center for Computational Medicine (CCM), % National Laboratory of Pattern Recognition (NLPR), % Institute of Automation,Chinese Academy of Sciences (IACAS), China. % Revise by Hu Yong, Nov, 2010 % E-mail: % based on Matlab 2006a % $Revision: , Copywrite (c) 2007
复杂网络理论及其研究现状
复杂网络理论及其研究现状 复杂网络理论及其研究现状 【摘要】简单介绍了蓬勃发展的复杂网络研究新领域,特别是其中最具代表性的是随机网络、小世界网络和无尺度网络模型;从复杂网络的统计特性、复杂网络的演化模型及复杂网络在社会关系研究中的应用三个方面对其研究现状进行了阐述。 【关键词】复杂网络无标度小世界统计特性演化模型 一、引言 20世纪末,以互联网为代表的信息技术的迅速发展使人类社会步入了网络时代。从大型的电力网络到全球交通网络,从Internet 到WWW,从人类大脑神经到各种新陈代谢网络,从科研合作网络到国际贸易网络等,可以说,人类生活在一个充满着各种各样的复杂网络世界中。 在现实社会中,许多真实的系统都可以用网络的来表示。如万维网(WWW网路)可以看作是网页之间通过超级链接构成的网络;网络可以看成由不同的PC通过光缆或双绞线连接构成的网络;基因调控网络可以看作是不同的基因通过调控与被调控关系构成的网络;科学家合作网络可以看成是由不同科学家的合作关系构成的网络。复杂网络研究正渗透到数理科学、生物科学和工程科学等不同的领域,对复杂网络的定性与定量特征的科学理解,已成为网络时代研究中一个极其重要的挑战性课题,甚至被称为“网络的新科学”。 二、复杂网络的研究现状 复杂网络是近年来国内外学者研究的一个热点问题。传统的对网络的研究最早可以追溯到18世纪伟大数学家欧拉提出的著名的“Konigsberg七桥问题”。随后两百多年中,各国的数学家们一直致力于对简单的规则网络和随机网络进行抽象的数学研究。规则网络过于理想化而无法表示现实中网络的复杂性,在20世纪60年代由Erdos和Renyi(1960)提出了随机网络。进入20世纪90年代,人们发现现实世界中绝大多数的网络既不是完全规则,也不是完全随机
基于信号传递与层次聚类的社团发现算法
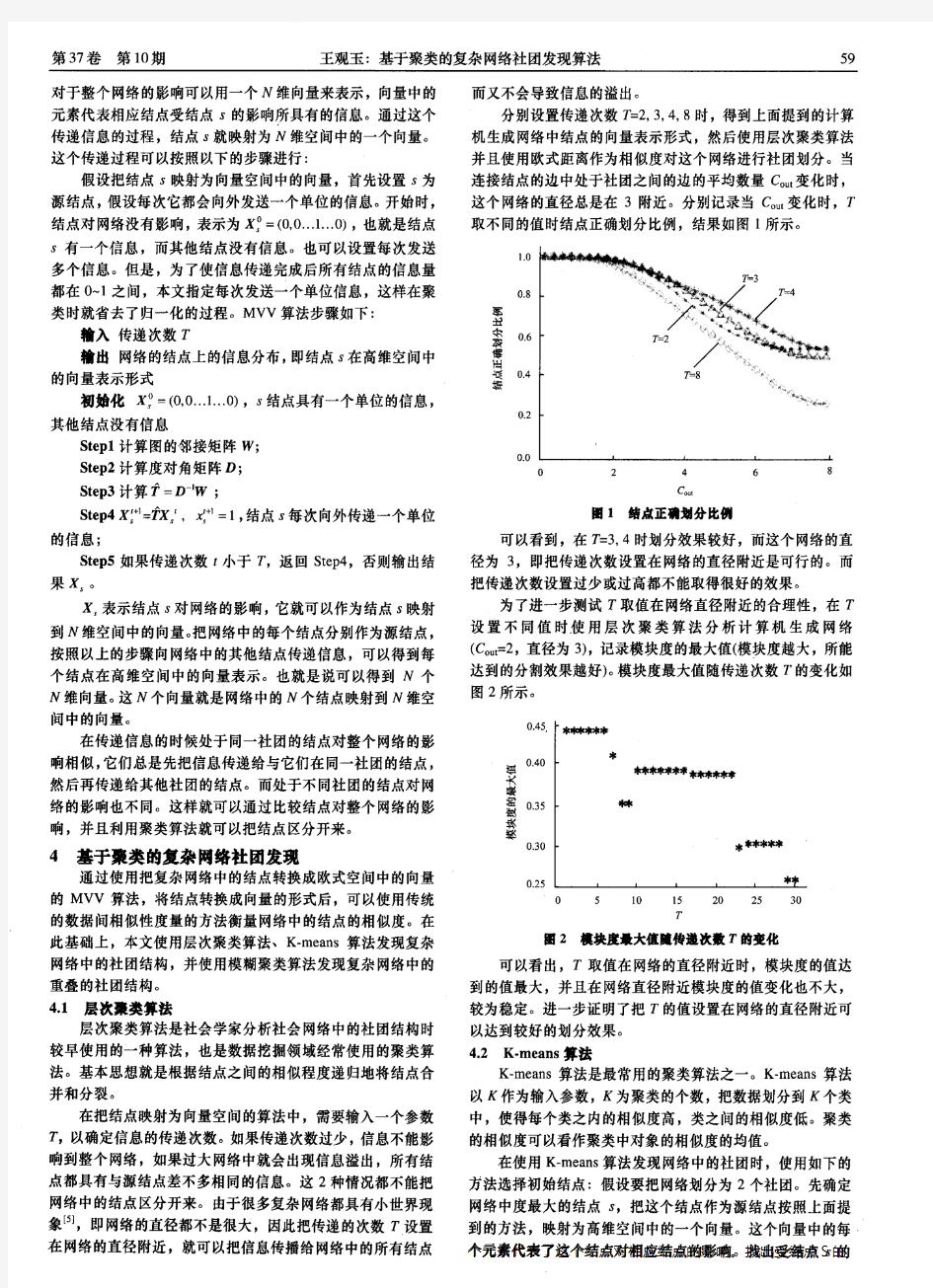
ComputerEngineeringandApplications计算机工程与应用2010,46(9)51 基于信号传递与层次聚类的社团发现算法 黄浩英,马英红 HUANGHao-ying,MAYing-hong 山东师范大学管理与经济学院,济南250014 SchoolofManagement&Economy,ShandongNormalUllive玛ity,Jinan250014,China E—mail:huanghaoyin92000@126.com HUANGHao-ying。MAYing-hong.DetectingcommunityalgorttlunbasedOnagualprocessandhierarchicalclustering.ComputerEngineertngandApplications.2010。46(9):51-54. Abstract:Communityisoneofimportantcharactersinsocialnetworksandcommunitydetectingisalsoafashionablestatementrecently.Inthispaper,basedonsignalingprocessoncomplexnetworks,influencevectorsofeachnodeategot,topologicalStltllC--tureofeachnodeistranslatedintogeometricalrelationshipsofvector8inalgebraspaces.andbytheaidofhierarchicalch吼e卜ingmodularityhietlIod,communitiesaredetectedeffectively.WithdatasimulationsontheZacharyKarateClubnetwork,CoHegeFootballnetworkandDolphinsocialnetwork,itshowsthatthepropo窨edalgorithminthistopicismoleaccuratethanNewman’8.Keywords:communitystructure;signalprocess;hierarchicalclustering;modularity 摘要:社团是社会网络的一个重要特征,社团发现是近年来研究的热点问题之一。通过在复杂网络上传递信号,获得各节点对网络的影响向量,从而把网络中节点的拓扑性质转化为代数空间上向量的几何关系,然后用结合模块度的层次聚类挖掘社会网络中的社团结构。该算法优点是不需要预先知道社团的数量或社团内节点的数量,用Zachary空手道俱乐部网络、大学足球赛网络以及海豚关系网络的数据进行验证,该算法划分的社团准确性超过了Newman的结论。 关键词:社团结构;信号传递;层次聚类;模块度 I)OI:10.3778/j.issn.1002-8331.2010.09.016文章编号:l002_833l(20lO)09-005l—04文献标识码:A中图分类号:N94;TP393 1引言 复杂网络是复杂系统的抽象,网络中的节点代表复杂系统中的个体,节点之间的边则代表系统中个体之问某一种关系。现实世界中复杂网络无处不在,如人际关系网、科学家合作网络、万维网、食物链网络等等。大量的研究表明,许多实际网络都呈现具有社团的性质,即整个网络是由若干个社团构成,在每个社团内部节点之间的连接相对紧密,而在各个社团之间却相对稀疏111。例如,在以人为主体的社交网络模型中,网络中的连线是根据兴趣或某种关系而形成的,—个人连接线越多,则表示他拥有的关系越多、影响也越大,并且可以控制的资源也越多,此时他与所连接的人就构成了—个社团。在科学引文网络中的社团代表针对同一主题的相关论文,而生物化学网络中的社团则代表具有相近功能的单元嘲,发现网络中的社团有助于更加有效地理解网络结构以及网络特性。 社团的研究中—个重要的课题是网络社团的划分,与此相关的理论包括图论以及模式识别等。社团的发现最早起源于社会学研究工作,较早的算法是在社会学研究中的分级聚类算法,它与计算机科学中的图形分割研究有着密切的关系嗍,其中分级聚类中最著名的是GN算i去fu,Kemighart—Lin算法哪谱平分嗣法是图形分割在处理社团划分中最具代表性的方法。此外,还有许多有效的算法如Radicchi算法、极值优化算法、Newman快速算法等M。在所有的社团的搜索算法中时间复杂度和查找的准确性是最为关键的两个问题。 基于上述问题,用在复杂网络传递信号的方法,得到网络中每个节点对网络的影响向量,通过每个节点的影响向量把网络的拓扑关系转换到n维代数空问上,将GN算法中提出的模块度函数与层次聚类方法结合进行社团结构的探测,用Zachary空手道俱乐部网络、大学足球赛网络以及海豚关系网络的数据进行验证,该算法划分的社团准确性超过了Newman的结论研。该算法优点是不需要预先知道社团的数量或社团内节点的数量,算法较好地改善了运行时间,提高了社团搜索的准确率。 2算法准备 HuYanqing等人提出了在复杂网络中传递信号的方j去I嘲,是将—个具有n个节点的网络视为—个系统,系统中的每个节点被认为具有发送、接受和记录信号的功能。信号传递基本思 基金项目:国家自然科学基金(theNationalNaturalScienceFoundationofChinaunderGrantNo.60673047);山东省自然科学基金(theNaturalScienceFoundationofShandongProvinceofChina);山东省教育厅科技项目(NoJ07YJ02)。 作者筒介:黄浩英(1983一)。女。研究生。主要研究方向:复杂网络与复杂系统;马英红(1971一),女,副教授,主要研究方向:复杂网络与复杂系统,图论,粗糙集应用等。 收稽日期:2009一lo-12修回日期:2010-01-08 万方数据
广义神经网络的聚类算法-网络入侵聚类
%% 清空环境文件 clear all; clc; %% 提取攻击数据 %攻击样本数据 load netattack; P1=netattack; T1=P1(:,39)'; P1(:,39)=[]; %数据大小 [R1,C1]=size(P1); csum=20; %提取训练数据多少 %% 模糊聚类 data=P1; [center,U,obj_fcn] = fcm(data,5); for i=1:R1 [value,idx]=max(U(:,i)); a1(i)=idx; end %% 模糊聚类结果分析Confusion_Matrix_FCM=zeros(6,6); Confusion_Matrix_FCM(1,:)=[0:5]; Confusion_Matrix_FCM(:,1)=[0:5]'; for nf=1:5 for nc=1:5
Confusion_Matrix_FCM(nf+1,nc+1)=length(find(a1(find(T1==nf))==nc)); end end %% 网络训练样本提取 cent1=P1(find(a1==1),:);cent1=mean(cent1); cent2=P1(find(a1==2),:);cent2=mean(cent2); cent3=P1(find(a1==3),:);cent3=mean(cent3); cent4=P1(find(a1==4),:);cent4=mean(cent4); cent5=P1(find(a1==5),:);cent5=mean(cent5); %提取范数最小为训练样本 for n=1:R1; ecent1(n)=norm(P1(n,:)-cent1); ecent2(n)=norm(P1(n,:)-cent2); ecent3(n)=norm(P1(n,:)-cent3); ecent4(n)=norm(P1(n,:)-cent4); ecent5(n)=norm(P1(n,:)-cent5); end for n=1:csum [va me1]=min(ecent1); [va me2]=min(ecent2); [va me3]=min(ecent3); [va me4]=min(ecent4); [va me5]=min(ecent5); ecnt1(n,:)=P1(me1(1),:);ecent1(me1(1))=[];tcl(n)=1; ecnt2(n,:)=P1(me2(1),:);ecent2(me2(1))=[];tc2(n)=2; ecnt3(n,:)=P1(me3(1),:);ecent3(me3(1))=[];tc3(n)=3; ecnt4(n,:)=P1(me4(1),:);ecent4(me4(1))=[];tc4(n)=4; ecnt5(n,:)=P1(me5(1),:);ecent5(me5(1))=[];tc5(n)=5;
复杂网络聚类及其在神经网络中的应用
Network World ? 网络天地Electronic Technology & Software Engineering 电子技术与软件工程? 9【关键词】复杂网络聚类 神经网络 算法 聚 类分析 计算机网络技术的出现,推动了人类社 会文明的快速发展,大数据时代以指数增长的 速度创造着越来越多的数据。在以数据库为核 心的信息技术背景下,聚类分析在数据挖掘中 的使用,能够有效加快对信息的定位,并且, 结合神经网络的发展需要,聚类分析法的应用 范围更加广阔。 1 复杂网络研究概述 所谓复杂网络,是指具有一定组织性、吸 引子、小世界、无标度中部分或全部性质的网 络,并在结构与形式方面存在较高的自相似性。 这一概念早在上个世纪90年代就已经得到广 泛认同,计算机网络技术的发展,验证了复杂 网络中的节点度分布服从幂律分布的特点,并 在此基础上建立了无标度网络模型。自此,关 于复杂网络结构的研究进入到新的技术领域。 关于复杂网络的研究,我国虽然起步较 晚,但是,凭借众多研究人员的努力,我国复 杂网络研究的进展速度惊人,在相关领域的渗 透速度令世界各国瞩目。经过长期的研究发现, 复杂网络普遍具有的社团结构特征,以及与之 相对应的社团结构算法,为复杂网络聚类分析 法的提出奠定了基础。 2 人工神经网络的研究现状 互联网技术的出现,重新定义了人类所 了解的世界,与现实世界相似,互联网创造了 一个虚拟的世界,并且,在这一虚拟世界中, 也要严格遵守相关“生存规则”。随着互联网 技术在生物技术、人工智能等领域的不断渗透, 关于人工神经网络的研究逐渐浮出水面。复杂网络聚类及其在神经网络中的应用 文/高超 早期人工神经网络的发展受技术条件的限制,多停留在理论研究阶段,直至1957年,ERosenblat 所提出的感知器模型,为人工神经网络技术的工程化应用创造了可能。在此之后,关于人工神经网络的研究进入到了“黄金时期”,各种具有创新性的理论研究成果,为人工神经网络的实践应用提供了理论支撑,实验室中的相关研究结果,同样证明了这一技术的可行性。3 几种常见的复杂网络聚类分析方法在神经网络技术实现过程中,所使用到的复杂网络聚类分析法主要包括K-Lin 算法、传统谱平分法、分裂算法。3.1 K-Lin算法基于对贪婪算法的研究,B.W.kernighan 和S.Lin 提出了一个新的聚类算法“K-Lin 算法”,该算法将已知网络进行社团划分,利用增益函数表达两个大小已知社团内部变数与连接两个社团变数的差值Q 。通过对比Q 值,其中Q 值最大的划分网络就是最佳的社团结构,在不断的试探过程中,得到最佳算法。然而,K-Lin 算法也存在的一定的缺陷,这就是必须事先知道两个社团的大小,否则,计算结果将存在不确定性。正因为此,K-Lin 算法不能够应用于位置网络大小的实际网络之中。3.2 传统谱平分法在计算机图形分割的实现过程中,基于Laplace 矩阵特征值的谱平分法得到了较为广泛的应用,这是由于传统谱平分法能够严格执行数学理论的各项要求。基于Laplace 矩阵特征值的谱平分法根据无向量图G 对应的对称矩阵L 的不同特征值与特征向量进行网络区分,其复杂程度较高,其中主要运算内容是对特征矩阵向量的求解。由于传统谱平分法在使用过程中需要将网络进行一定比例的划分,因此,对复杂网络的首次二分结果,将直接影响到今后网络划分的正确性,所以,采用传统谱平分法存在一定的算法冗余情况,其效果也并不理想。3.3 分裂算法在实际使用过程中,分列算法则依据网络节点对的相似程度对节点对的边进行删除,在这一行为的不断重复过程中,整个复杂网络也就被划分成了多个社团。研究人员可以根据社团划分的情况,随时终止算法进程,以避免复杂网络过度分割后的情况出现。如图1所示,在水平虚线逐渐下移的过程中,复杂网络中的社团个数不断增加,当水平虚线移至最底端时,也就达到了这一复杂网络的最小社团划分单位。4 基于CNM聚类优化的RBF神经网络算法由于RBF 网络中隐含基层函数的中心选取会对整体网络的收敛特性造成一定的影响,同时也会降低网络精度,这导致了RBF 神经网络所具有的优势得不到有效发挥。然而,研究人员发现,在使用了CNM 聚类算法的情况下,RBF 神经网络原本存在的问题得到了明显改善,网络质量、稳定性、精度均得到了不同程度的提高。基于CNM 聚类优化下的RBF 神经网络算法思想如图2所示。5 总结在计算机网络信息技术快速发展的今天,大数据技术的应用范围不断扩大,为实现对数据的有效管理和使用,则需要采用科学的复杂网络聚类分析方法,对神经网络进行优化,使其在实际应用中的范围更加广阔。参考文献 [1]孙丹,万里明,孙延风,梁艳春.一种改进的RBF 神经网络混合学习算法[J].吉林大学学报(理学版),2010(05).[2]安娜,谢福鼎,张永,刘绍海.一种基于GN 算法的文本概念聚类新方法[J].计算机工程与应用,2008(14).[3]杨博, 刘大有,金弟,马海宾.复杂网络聚类方法[J].软件学报,2009(01).作者单位中国地质大学(武汉)计算机学院 湖北省武 汉市 430074 图1:基于树状图记录算法的复杂网络社团分割结果图2:CNM 聚类优化下的RBF 神经网络算法思想流程示意图