spss应用之聚类分析方法应用举例

物流工程 S11085240007
聚类分析方法应用举例
多元统计,是研究多个随机变量之间相互依赖关系以及内在统计规律性的一门统计学科。多元统计所包括的内容很多.但在实际统计分析中,聚类分析是应用最广泛的方法之一。聚类分析(cluste:Analysis),是研究分类问题的一种多元统计分析方法社会经济统计的分类问题,过去在传统方法上,主要是结合一定的专业知识进行定性分类处理。由于定性分类主要是靠经验完成,因而其结论难免带有较多的主观性和随意性,故不能很好地揭示客观事物内在的本质差别和联系。而聚类分析能带来定量上的分析可以解决这个问题,下面通过一些实例来描述聚类分析方法在应用上的体现;
1 基于聚类分析的安徽省物流需求研究
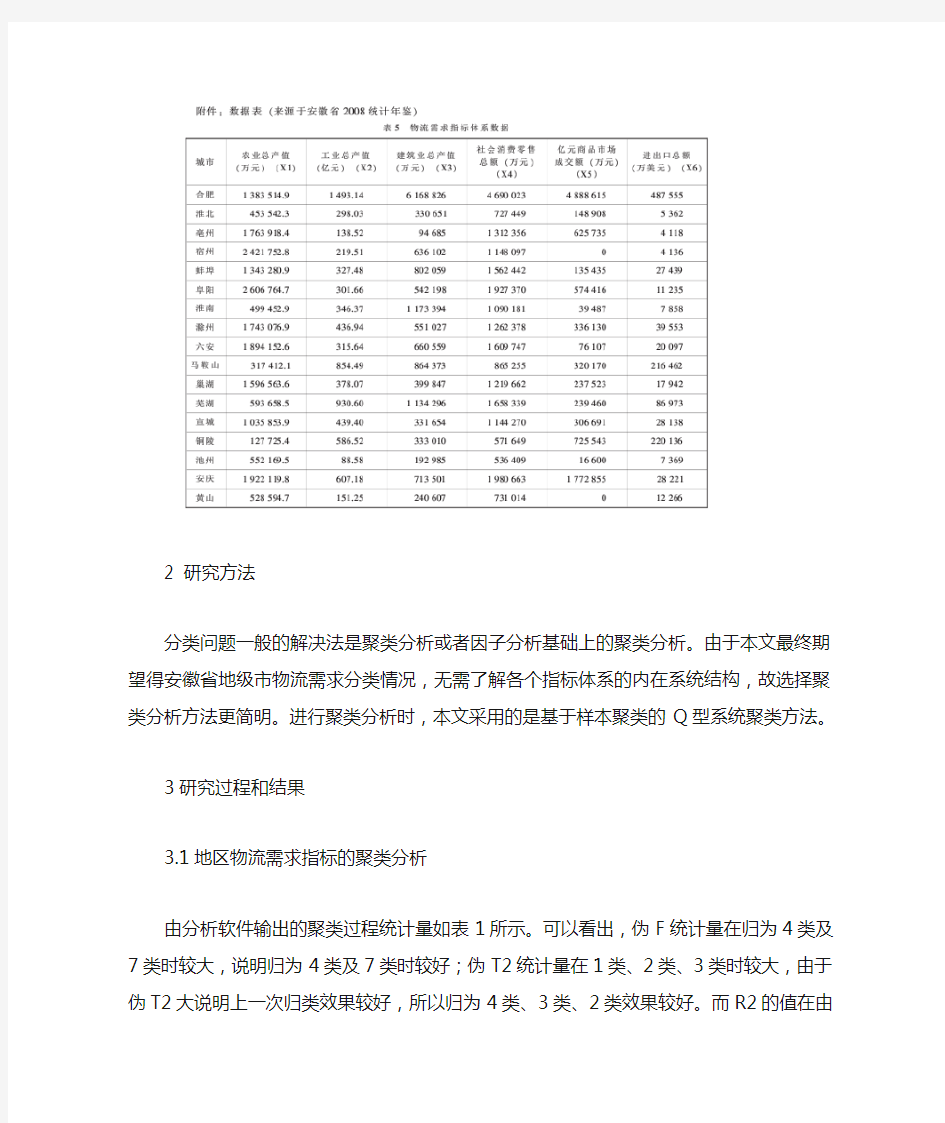
选取了分行业统计的年产值类指标构建物流需求指标体系(X组),具体指标包括:农业总产值(万元)(X1)、工业总产值(亿元)(X2)、建筑业总产值(万元)(X3)、社会消费零售总额(万元)(X4)、亿元商品市场成交额(万元)(X5)、进出口总额(万美元)(X6)。该指标体系通过农业、工业、建筑业、批发业、零售业及国际贸易的发生额较全面地反映了地区的物流需求情况。
2 研究方法
分类问题一般的解决法是聚类分析或者因子分析基础上的聚类分析。由于本文最终期望得安徽省地级市物流需求分类情况,无需了解各个指标体系的内在系统结构,故选择聚类分析方法更简明。进行聚类分析时,本文采用的是基于样本聚类的Q型系统聚类方法。
3研究过程和结果
3.1地区物流需求指标的聚类分析
由分析软件输出的聚类过程统计量如表1所示。可以看出,伪F统计量在归为4类及7类
时较大,说明归为4类及7类时较好;伪T2统计量在1类、2类、3类时较大,由于伪T2大说明上一次归类效果较好,所以归为4类、3类、2类效果较好。而R2的值在由4类归为3类、由3类归为2类以及由2类归为1类时都有较大的减小,说明归类为2类、3类和4类都是比较好的。半偏R2统计量的值越大,则上一步聚类效果更好,所以归为4类、3 类、2类效果都较好。综合考虑四个统计量的值,并考虑分类的实用性,本文认为归为4类比较合适。聚类图见图1。
由软件分析得的聚类过程得到每一类的各个指标的平均值如表2所示。可以看出,四类地区的区分明显,各种产值指标依次递减。依据四类地区物流需求情况可将安徽省的17个地级市分为物流需求旺盛的省会经济圈、需求较大的马铜芜地区;物流需求量小的两淮和皖南山物流需求量小的两淮和皖南山区以及物流需求较小的第三类地区。
2 聚类分析在证券投资基本分析中的应用
有相关数据,聚类分析与结论;
应用SPSS软件对31支股票进行系统聚类分析,由聚类分析的结果将这31支股票大致可以分成6类:第1类:合金投资(18)、四川双马(19),第2类:厦新电子(3)、数源科技(22)、清华同方(1)、皖维高新(15)、哈药集团(14);第3类:乐凯胶片(11)、中原油气(29)、辽河油田(21)、盐田港(23);第4类:王府井(9)、深信泰丰(17)、上海机场(13)、中集集团(24)、西山煤电(26)、中兴通讯(28)、神火股份(30);第5类:波导股份(10)、鞍钢新轧(25)、伊利股份(4)、宝钢股份(12)、燕京啤酒(2)、隆平高科(27);第6类:方正科技(6)、长安汽车(31)、太极集团(5)、青岛啤酒(16)、深康佳(20)、东软股份(7)、中国联通(8)。
3 我国区域可持续发展的聚类分析应用举例1 可持续发展指标体系
2 聚类分析的基本步骤相关公式定理
3 具体应用
应用spss软件,以31个省市、自治区作为样本,部分数据见表1。以各区域的生存支持系统、发展支持系统、环境支持系统、社会支持系统和智力支持系统为指标进行聚类分析。.应用SPSS软件可以得到聚类分析谱系图,如图2。根据树状图,当距离取6时,可将我国各地区的可持续发展水平分为4类,并应用线性加权求平均值法。把4类分别求总指标平均值见表2;
完整word版,SPSS聚类分析实验报告.docx
SPSS 聚类分析实验报告 一.实验目的: 1、理解聚类分析的相关理论与应用 2、熟悉运用聚类分析对经济、社会问题进行分析、 3、熟练 SPSS软件相关操作 4、熟悉实验报告的书写 二.实验要求: 1、生成新变量总消费支出=各变量之和 2、对变量食品支出和居住支出进行配对样本T 检验,并说明检验结果 3、对各省的总消费支出做出条形图(用EXCEL做图也行) 4、利用 K-Mean法把 31 省分成 3 类 5、对聚类分析结果进行解释说明 6、完成实验报告 三.实验方法与步骤 准备工作:把实验所用数据从 Word文档复制到 Excel ,并进一步导入到 SPSS数据文件中。 分析:由于本实验中要对 31 个个案进行分类,数量比较大,用系统聚类法当然也 可以得出结果,但是相比之下在数据量较大时, K 均值聚类法更快速高效,而且准确性更高。 四、实验结果与数据处理: 1.用系统聚类法对所有个案进行聚类:
生成新变量总消费支出 =各变量之和如图所示: 2.对变量食品支出和居住支出进行配对样本 T 检验,如图所示:
得出结论: 3.对各省的总消费支出做出条形图,如图所示: 4.对聚类分析结果进行解释说明: K均值分析将这样的城市分为三类: 第一类北京、上海、广东 第二类除第一类第三类以外的 第三类天津、福建、内蒙古、辽宁、山东 第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。第二类城市位于中西部地区,经济落后,人民消费水平低。第三类城市位于中东部地区,经济发展较好。
初始聚类中心 聚类 123 食品支出7776.983052.575790.72衣着支出1794.061205.891281.25居住支出2166.221245.001606.27家庭设备及服务支出1800.19612.59972.24医疗保健支出1005.54774.89617.36交通和通信支出4076.461340.902196.88文化与娱乐服务支出3363.251229.681786.00其它商品和服务支出1217.70331.14499.30总消费支出23200.409792.6614750.02 迭代历史记录a 聚类中心内的更改 迭代123 11250.5921698.8651216.114 2416.86470.786173.731 3138.955 2.94924.819 446.318.123 3.546 5849.114319.1791362.411 6805.00415.199606.915 7161.001.72475.864 832.200.0349.483 9 6.440.002 1.185 10 1.2887.815E-5.148
SPSS因子、聚类案例分析报告
喀什大学实验报告 《多元统计分析SPSS》 实验报告 实验课程:基于SPSS的数据分析 实验地点:现代商贸实训中心实验室名称:经济统计实验室 学院:xxx学院年级专业班:xxx班 学生姓名:xxx 学号:20131808015 完成时间:2016年x月x日 开课时间:2016 至2017 学年第 1 学期 页脚内容1
页脚内容2
实验项目:中国上市银行竞争力分析 (一)实验目的 本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了8个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进行了分析评价。最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比较,提出了提升我国上市商业银行竞争力的一些建议。 (二)实验资料 通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况的因素与上述指标是否有关。 具体数据如下所示: 十家同类型上市商业银行2012年指标 页脚内容3
页脚内容4
中 信银行 1.41 % 0.74 % 93.1 4% 13.4 4% -7.0 4% 15.9 6% 14.5 9% 7.0 2% 民 生银行 1.5 8% 0.76 % 94. 58% 10.7 5% 27. 62% 3.5 3% 2.7 6% 8.4 4% (三)实验步骤 1、选择菜单 2、选择参与因子分析的变量到(变量V)框中 3、选择因子分析的样本 4、在所示窗口中点击(描述D)按钮,指定输出结果,输出基本统计量、图形等 页脚内容5
SPSS软件聚类分析过程的图文解释及结果的全面分析
SPSS聚类分析过程 聚类的主要过程一般可分为如下四个步骤: 1.数据预处理(标准化) 2.构造关系矩阵(亲疏关系的描述) 3.聚类(根据不同方法进行分类) 4.确定最佳分类(类别数) SPSS软件聚类步骤 1. 数据预处理(标准化) →Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可: 标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。);Range 0 to 1(极差正规化变换/ 规格化变换); 2. 构造关系矩阵 在SPSS中如何选择测度(相似性统计量): →Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数; 3. 选择聚类方法 SPSS中如何选择系统聚类法 常用系统聚类方法 a)Between-groups linkage 组间平均距离连接法 方法简述:合并两类的结果使所有的两两项对之间的平均距离最小。(项对的两成员分属不同类)特点:非最大距离,也非最小距离 b)Within-groups linkage 组内平均连接法 方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小 C)Nearest neighbor 最近邻法(最短距离法) 方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法
SPSS因子聚类案例分析报告
S P S S因子聚类案例分析 报告 GE GROUP system office room 【GEIHUA16H-GEIHUA GEIHUA8Q8-
喀什大学实验报告 《多元统计分析SPSS》 实验报告 实验课程:基于SPSS的数据分析 实验地点:现代商贸实训中心实验室名称:经济统计实验室 学院: xxx学院年级专业班: xxx班 学生姓名: xxx 学号: 20131808015 完成时间: 2016年x月x日 开课时间: 2016 至 2017 学年第 1 学期
实验项目:中国上市银行竞争力分析 (一)实验目的 本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了8个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进行了分析评价。最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比较,提出了提升我国上市商业银行竞争力的一些建议。 (二)实验资料 通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况的因素与上述指标是否有关。 具体数据如下所示: 十家同类型上市商业银行2012年指标 (三)实验步骤 1、选择菜单
2、选择参与因子分析的变量到(变量V)框中 3、选择因子分析的样本 4、在所示窗口中点击(描述D)按钮,指定输出结果,输出基本统计量、图形等 5、在所示窗口中点击(抽取E)按钮指定提取因子的方法为:主成分分析法 6、在所示的窗口中点击(旋转T)按钮选择因子旋转方法
SPSS因子、聚类案例分析报告
喀什大学实验报告 《多元统计分析SPSS 实验报告 实验课程:基于SPSS的数据分析 实验地点:现代商贸实训中心实验室名称:经济统计实验室 学院: XXX学院年级专业班:XXX班 学生姓名:XXX 学号:20131808015 完成时间:2016 年X月X日 开课时间:2016 至2017 学年第1 学期
实验项目:中国上市银行竞争力分析 (一)实验目的 本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到 对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了8个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进行了分析评价。最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比较,提出了提升我国上市商业银行竞争力的一些建议。 (二)实验资料 通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况的因素与上述指标是否有关。 具体数据如下所示: (三)实验步骤 1、选择菜单
2、选择参与因子分析的变量到(变量V)框中 3、选择因子分析的样本 4、在所示窗口中点击(描述D)按钮,指定输出结果,输出基本统计量、图 5、在所示窗口中点击(抽取E)按钮指定提取因子的方法为: 6在所示的窗口中点击(旋转T)按钮选择因子旋转方法 形等 Vi 93 23% U12K15.&*% 8 3JK. i4 ir% riOM TSO' 開 W05% 3 6?% 12 1] tpSJKr?- 113TM ? 07%W U% 124SS 26 £5%谄01% ?心羽也帕J叽 越雀IB23% 42% U W% ig> 13 DQ% 31%. T6(H% 馬* K.Dfi% fld% 昭卿驚 主成分分析法 1 42% 0 6S% 44 越鴨 1韵飓?的恤站20% 髄 # A#*/#*
聚类分析的案例分析(推荐文档)
《应用多元统计分析》 ——报告 班级: 学号: 姓名:
聚类分析的案例分析 摘要 本文主要用SPSS软件对实验数据运用系统聚类法和K均值聚类法进行聚类分析,从而实现聚类分析及其运用。利用聚类分析研究某化工厂周围的几个地区的 气体浓度的情况,从而判断出这几个地区的污染程度。 经过聚类分析可以得到,样本6这一地区的气体浓度值最高,污染程度是最严重的,样本3和样本4气体浓度较高,污染程度也比较严重,因此要给予及时的控制和改善。 关键词:SPSS软件聚类分析学生成绩
一、数学模型 聚类分析的基本思想是认为各个样本与所选择的指标之间存在着不同程度的相 似性。可以根据这些相似性把相似程度较高的归为一类,从而对其总体进行分析和总结,判断其之间的差距。 系统聚类法的基本思想是在这几个样本之间定义其之间的距离,在多个变量之间定义其相似系数,距离或者相似系数代表着样本或者变量之间的相似程度。根据相似程度的不同大小,将样本进行归类,将关系较为密切的归为一类,关系较为疏远的后归为一类,用不同的方法将所有的样本都聚到合适的类中,这里我们用的是最近距离法,形成一个聚类树形图,可据此清楚的看出样本的分类情况。 K 均值法是将每个样品分配给最近中心的类中,只产生指定类数的聚类结果。 二、数据来源 《应用多元统计分析》第一版164 页第6 题 我国山区有一某大型化工厂,在该厂区的邻近地区中挑选其中最具有代表性的 8 个大气取样点,在固定的时间点每日 4 次抽取6 种大气样本,测定其中包含的8 个取样点中每种气体的平均浓度,数据如下表。试用聚类分析方法对取样点及 大气污染气体进行分类。 三、建立数学模型 一、运行过程
非常好的SPSS软件聚类分析功能介绍(修改稿)
第9章SPSS软件的聚类分析功能介绍 1 SPSS软件简介 1.1当前较为流行的统计分析软件包 SPSS(Statistical Package for Social Science)是由美国SPSS公司于20世纪80年代推出的统计分析软件包,分为SPSS/PC(DOS版)和SPSS for Windows(Windows版),是一个适用于社会科学的统计分析软件包,广泛用于教育、心理、经济及科学等领域,是世界上著名的统计分析软件之一。 SAS—Statistical Analysis System,是一个适用于化学、生物、心理以及农、医等学科领域的统计分析软件。 Statgragh—Statistical Graphics,是一个适用于财政、金融等方面的统计分析软件。 Systal_—System Statistical,是一个广泛用于各种统计分析的软件包。 1.2 SPSS软件功能简介 SPSS软件的功能很强大,可以实现数据的输入与编辑、数据的一般性管理、各种统计分析、图形与输出报告等。其中,统计分析包括常见的统计描述(频次、均值等)、T检验、方差分析、相关分析、回归分析和聚类分析。此外,SPSS与Excel、Word等有很好的兼容性,可以读取Excel表格数据,也可以将SPSS的结果拷贝到Excel和Word。 但是SPSS软件不是一个独立的文献分析软件,因为它进行聚类分析的基础是共现关系矩阵,需要通过其他途径获得,比如Bibexcel等。而且SPSS软件做聚类分析时显示的效果不是很理想,数据量应该控制在100以内,否则软件无法进行处理。 SPSS最早的版本是基于DOS系统的,现在已有多个适用于Windows系统的版本,最新版本是SPSS for Windows 20.0。SPSS for Windows 13.0及以上的版本都可实现聚类分析,本章中采用的是SPSS for Windows 16.0。SPSS可以读取英文和汉语的数据,也有汉化版本专门分析汉语的数据以免处理过程中出现乱码。 2 SPSS软件的下载与安装 2.1 SPSS软件的下载 SPSS for Windows 16.0的下载地址为:https://www.360docs.net/doc/ae1310420.html,:8088/down.asp,,点击“SPSS V16.0”即可下载软件,如图9.1所示。
spss样本聚类案例分析
原数据 1.1样本聚类(Q聚类)
聚类表 阶 群集组合 系数首次出现阶群 集 下一阶 群集 1群集 2群集 1群集 2 157.855003 21112 1.379007 325 1.772015
41014 1.776007 526 2.451308 6813 2.7720010 71011 4.3224212 812 4.5570512 934 4.8950013 10815 5.5006011 11897.74010013 121108.3148714 133812.79091114 141316.65012130通过系数做出其散点图 群集成员 案例 5 群集 4 群集 3 群集
1:Case 1 111 2:Case 2 111 3:Case 3 222 4:Case 4 222 5:Case 5 111 6:Case 6 111 7:Case 7 111 8:Case 8 333 9:Case 9 433 541 10:Case 10 541 11:Case 11 12:Case 541 12 333 13:Case 13 14:Case 541 14 15:Case 333 15
1.2变量聚类(R聚类) 近似矩阵 案例矩阵文件输入 总人口从业人 员 土地面 积 耕地面 积 财政收 入 粮食产 量 总人口 1.000.857.698.714.512.043从业人 员 .857 1.000.597.570.643.277 土地面 积 .698.597 1.000.856.044-.147 耕地面 积 .714.570.856 1.000-.001-.335
聚类分析的SPSS实现
§7.5聚类分析的SPSS实现 一、系统聚类法的SPSS实现 例7.5.1利用全国30个省市自治区经济发展基本情况的八项指标数据(见数据集wyzb6_5.),用系统聚类法对这30个省市自治区作一初步的分类,并说明各类地区经济发展的特点。 操作 分析(Analyze)?分类(Classify)?系统聚类(Hierarchical Cluster)打开系统聚类分析(Hierarchical Cluster Analysis)对话框 1.变量(V ariable(s))列表框设置分析变量。 2.标志个案(Label Cases by)框设置分析对象的标志变量。3.分群(Cluster)单选择框设置聚类分析的类型。 4.输出(Display)复选择框设置聚类分析的输出结果,统计量和图都是默认选项。 5.统计量(Statistics)按钮设置输出的统计量。 合并进程表(Agglomeration schedule)默认选项,输出聚类分析的凝聚状态表; 相似性矩阵(Proximitymatrix)为复选项,输出各样品的距离矩阵。 聚类成员(Cluster Menbership)选择框: 无(None)选项:不显示类的样品构成; 单一方案(Single solution)选项:选择此项,并输入一个确定的分类数n,并输出聚成n个类时各个类的样品构成 情况。 方案范围(Range of solutions):选择此项,并输入两个数n1,n2,将显示指定聚成n1类到n2类时各个类的样品构成 情况。
6.Plots按钮设置输出图形:树状图冰状图 7.Method按钮设置聚类分析的具体方法。 聚类方法: 组间连接:类间平均法 组内连接:类内平均法 最近临元素:最短距离法 最远临元素:最长距离法 质心聚类法:重心法 中位数聚类法:中位数法 Ward法:离差平方和法 度量方法选择框:选择计算样品距离的方法转换值选择框:选择原始数据标准化的方法Z得分,最常用的方法
spss软件聚类分析怎么用
spss软件聚类分析怎么用,从输入数据到结果,树状图结果。整个操作怎么进行。需要基本思路。 excel表:整理一份excel数据表,第一列为材料或数据的名称,后几列为各项数值 导入数据:打开SPSS,点击File——Open——DATA, 选择已经编辑好的excel表 点击analyze——Classify——Hierarchical cluster analysis——数据导入variables,表头项导入label case by; 选择Method 项,根据需要选择方法,点击Plots选择dendrogram(打对勾),其余各项根据自己需要选择要计算的统计量,点击ok即可。 于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法) 层次聚类法和迭代聚类法的主要区别在于:层次聚类法的聚类结果受奇异值的影响非常大,且聚类过程是单方向的,一旦某个样本进入某一类,就不可能从该类出来,再归入其他的类;迭代聚类法的聚类结果受奇异值和不合适的聚类变量的影响较小,对于不合适的初始聚类可以进行反复调整,但其缺点是聚类结果对初始聚类非常敏感,而且它也只能得到局部最优解. (一)层次聚类 Analyze--> C1assify-->Hierachical Cluster 在“C1uster”组中选择聚类类型:要进行变量聚类选择指定“Vanables”;要进行观测量聚类指定“Cases”。 指定参与分析的变量,将选定的变量通过按钮箭头转移到箭头按钮右侧的“Variable[s]:”矩形框中;将标识变量通过下面一个箭头按钮转移到按钮右侧的“Label Cases by:”下面的矩形框中。 如果不使用系统默认值,或由于参与分析的变量量纲不一致需要指定选择项,则应该根据需要有选择性地执行下述某些步骤。 1.确定聚类方法 在主对话框中,点击“Methed”按钮,展开分层聚类分析的方法选择对话框,即“Hierachical Cluster Analysis:Method”。
SPSS教程-聚类分析-附实例操作
各地区各行业工资水平的分析(2009年数据) 小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍 1.研究背景及意义 1.1 研究背景 工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。 1.2 研究意义 1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。 2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。 2.数据来源与描述 2.1 数据来源——《中国劳动统计年鉴─2010》 (URL:https://www.360docs.net/doc/ae1310420.html,/Navi/YearBook.aspx?id=N2011010069&floor=1###) 主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司 出版社:中国统计出版社 简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。 2.2 数据描述 本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-0 3.分析方法及原理 3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高 描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。 在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。 3.2 通过聚类分析方法,判断哪些地区平均工资水平较高 聚类分析是依据研究对象的个体特征,对其进行分类的方法,分类在经济、管理、社会学、医学等领域,都有广泛的应用。聚类分析能够将一批样本(或变量)数据根据其诸多特征,按照在性质上的亲疏程度在没有先验知识的情况下进行自动分类,产生多个分类结果。类内部个体特征之间具有相似性,不同类间个体特征的差异性较大。 在本案例中,我们将采用两种方法进行聚类分析:一种是系统聚类法,另一种是K-均值法(快速聚类法)。 3.2.1系统聚类法 系统聚类法的基本原理:首先将一定数量的样本或指标各自看成一类,然后根据样本(或指标)的亲疏程度,将亲疏程度最高的两类进行合并,然后考虑合并后的类与其他类之间的亲疏程度,再进行合并。重复这一过程,直到将所有的样本(或指标)合并为一类。 系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就可以在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数、降低变量维度的目的。 在本例中进行的是Q型聚类。 类与类之间距离的计算方法主要有以下几种: (1)最短距离法(Nearest Neighbor),是指两类之间每个个体距离的最小值; (2)最长距离法(Farthest Neighbor),是指两类之间每个个体距离的最大值; (3)组间联接法(Between-groups Linkage),是指两类之间个体之间距离的平均值;
SPSS因子、聚类案例分析报告.doc
《多元统计分析SPSS》 实验报告 实验课程:基于 SPSS的数据分析 实验地点:现代商贸实训中心实验室名称:经济统计实验室学院: xxx 学院年级专业班: xxx 班 学生姓名:xxx 学号: 015 完成时间:2016 年 x 月 x 日 开课时间:2016 至 2017 学年第 1 学期 成绩 教师签名 批阅日期
实验项目:中国上市银行竞争力分析 (一)实验目的 本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到 对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012 年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了 8 个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞 争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进 行了分析评价。最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比 较,提出了提升我国上市商业银行竞争力的一些建议。 (二)实验资料 通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进 行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况 的因素与上述指标是否有关。 具体数据如下所示: 十家同类型上市商业银行2012 年指标 盈利能力安全能力发展能力 资产利润资产负债资本充足每股收益贷款增长存款增长总资产增 率不良贷款率 率率增长率率率长率 平安银行% % % % % % % % 浦发银行% % % % % % % % 建设银行% % % % % % % % 中国银行% % % % % % % % 农业银行% % % % % % % % 工商银行% % % % % % % 10% 交通银行% % % % % % % % 招商银行% % % % % % % % 中信银行% % % % % % % % 民生银行% % % % % % % % (三)实验步骤 1、选择菜单
多元统计分析聚类分析的各种方法spss
多元统计分析 (第一次作业) 学院:信息与计算科学学院 专业: ____________ 指导老师: ____________ 小组成员:罗健水(20080560) 许志欢(20080574) 庄娜(20080595) 卓玛(20080561)
2011年4月10日
题目:某行政系统所属独立核算工业企业16个行业经济实力强弱的聚类分析 独立核算:独立核算是指对本单位的业务经营活动过程及其成果进行全面、系统的会计核算。独立核算单位的特点是:在管理上有独立的组织形式,具有一定数量的资金,在当地银行开户;独立进行经营活动,能同其他单位订立经济合同;独立计算盈亏,单独设置会计机构并配备会计人员,并有完整的会计工作组织体系。 非独立核算又称报帐制,是把本单位的业务经营活动有关的日常业务资料,逐日或定期报送上级单位,由上级单位进行核算。非独立核算单位的特点是:一般由上级拔给一定数额的周转金,从事业务活动,一切收入全面上缴,所有支出向上级报销,本身不单独计算盈亏,只记录和计算几个主要指标,进行简易核算 数据来源:上海市青浦区统计局数据链接:数据5?11.sav 固定资产原价:指企业在建造、改置、安装、改建、扩建、技固定资产计量术改造固定资产时实际支出的全部货币总额。该指标根据企业会计"资产负债表"中"固定资产原价"项的期末数填列。 固定资产净值平均余额:每月逐步减少。有部分企业单位,是按季度计提折旧,那么在没有提折旧的月 份,比如10月份,和9月份比较,固定资产净值平均余额就没有变化,也就是说,还是等于9月份的 固定资产净值平均余额 例:如09年底的固定资产净值余额为5000万元,2010年元月份完成固定资产投资1000万元,那么元月份的固定资产净值平均余额是多少?2月份又完成投资500万元,那2月份的固定资产净值平均余额是多少?(计算公式是怎样) 解:平均余额等于期初的加期末的除以2 所以一月份=(5000+6000-当月折旧)/2 二月份的=(6000+6500-两个月的折旧)/2 所有者权益(Owne' s Equities:资产扣除负债后由所有者应享的剩余利益。即一个会计主体在一定时期所拥有或可控制的具有未来经济利益资源的净额。 营业税金及附加:主营业务税金及附加”科目改名为“营业税金及附加”, “营业税金及附加”科目用法如下: 一、本科目核算企业经营活动发生的营业税、消费税、城市维护建设税、资源税和教育费附加等相关税费。 房产税、车船使用税、土地使用税、印花税在“管理费用”等科目核算,不在本科目核算。 二、企业按规定计算确定的与经营活动相关的税费,借记本科目,贷记“应交税费”等科目。企业收到的返还的消费税、营业税等原记入本科目的各种税金,应按实际收到的金额,借记“银行存款”科目,贷记本科目。
SPSS聚类分析实验报告
SPSS聚类分析实验报告 一.实验目的: 1、理解聚类分析的相关理论与应用 2、熟悉运用聚类分析对经济、社会问题进行分析、 3、熟练SPSS软件相关操作 4、熟悉实验报告的书写 二.实验要求: 1、生成新变量总消费支出=各变量之和 2、对变量食品支出和居住支出进行配对样本T检验,并说明检验结果 3、对各省的总消费支出做出条形图(用EXCEL做图也行) 4、利用K-Mean法把31省分成3类 5、对聚类分析结果进行解释说明 6、完成实验报告 三.实验方法与步骤 准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS数据文件中。 分析:由于本实验中要对31个个案进行分类,数量比较大,用系统聚类法当然也可以得出结果,但是相比之下在数据量较大时,K均值聚类法更快速高效,而且准确性更高。 四、实验结果与数据处理: 1.用系统聚类法对所有个案进行聚类:
生成新变量总消费支出=各变量之和如图所示: 2. 对变量食品支出和居住支出进行配对样本T检验,如图所示:
得出结论: 3. 对各省的总消费支出做出条形图,如图所示: 4.对聚类分析结果进行解释说明: K均值分析将这样的城市分为三类: 第一类北京、上海、广东 第二类除第一类第三类以外的 第三类天津、福建、内蒙古、辽宁、山东 第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。第二类城市位于中西部地区,经济落后,人民消费水平低。第三类城市位于中东部地区,经济发展较好。
迭代历史记录a 迭代 聚类中心内的更改 1 2 3 1 1250.592 1698.865 1216.114 2 416.864 70.786 173.731 3 138.955 2.949 24.819 4 46.318 .123 3.546 5 849.114 319.179 1362.411 6 805.004 15.199 606.915 7 161.001 .724 75.864 8 32.200 .034 9.483 9 6.440 .002 1.185 10 1.288 7.815E-5 .148 初始聚类中心 聚类 1 2 3 食品支出 7776.98 3052.57 5790.72 衣着支出 1794.06 1205.89 1281.25 居住支出 2166.22 1245.00 1606.27 家庭设备及服务支出 1800.19 612.59 972.24 医疗保健支出 1005.54 774.89 617.36 交通和通信支出 4076.46 1340.90 2196.88 文化与娱乐服务支出 3363.25 1229.68 1786.00 其它商品和服务支出 1217.70 331.14 499.30 总消费支出 23200.40 9792.66 14750.02
SPSS因子聚类案例分析报告
S P S S因子聚类案例分 析报告 集团标准化工作小组 [Q8QX9QT-X8QQB8Q8-NQ8QJ8-M8QMN]
喀什大学实验报告《多元统计分析SPSS》 实验报告 实验课程:基于SPSS的数据分析 实验地点:现代商贸实训中心实验室名称:经济统计实验室 学院: xxx学院年级专业班: xxx班 学生姓名: xxx 学号:5 完成时间: 2016年x月x日 开课时间: 2016 至 2017 学年第 1 学期
实验项目:中国上市银行竞争力分析 (一)实验目的 本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了8个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进行了分析评价。最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比较,提出了提升我国上市商业银行竞争力的一些建议。 (二)实验资料 通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况的因素与上述指标是否有关。 具体数据如下所示: 十家同类型上市商业银行2012年指标 (三)实验步骤 1、选择菜单 2、选择参与因子分析的变量到(变量V)框中 3、选择因子分析的样本 4、在所示窗口中点击(描述D)按钮,指定输出结果,输出基本统计量、图形等
SPSS因子、聚类案例分析报告
时磊忖呎I I 喀什大学实验报告 《多元统计分析SPSS 实验报告 实验课程:基于SPSS的数据分析 实验地点:现代商贸实训中心实验室名称:经济统计实验室 学院:XXX学院年级专业班:XXX班 学生姓名:XXX 学号:20131808015 完成时间:2016 年X月X日 开课时间:2016 至2017 学年第1 学期
时需Sr彳 实验项目:中国上市银行竞争力分析 (一)实验目的 本实验目的围绕上市商业银行竞争力这一主线,遵循一般理论、具体分析到对策建议的研究思路,以我国国内上市的十家商业银行为研究对象,采用其2012 年度财务报告的数据,从盈利能力、安全能力和发展能力三方面共选取了8个重要指标,试图通过这些指标量化影响竞争力的因素,构建我国上市商业银行的竞争力评价指标体系,并运用因子分析方法,对我国上市商业银行的竞争力状况进行了分析评价。最后针对分析的结果,通过对我国上市银行竞争力进行优劣势比较,提出了提升我国上市商业银行竞争力的一些建议。 (二)实验资料 通过对资产利润率、不良贷款率、资产负债率、资本充足率、每股收益增长率、贷款增长率、存款增长率、总资产增长率等指标的选择分析不同指标在进行因子分析时所考虑的因素是否存在差异,影响我国上市商业银行的竞争力状况的因素与上述指标是否有关。 具体数据如下所示: (三)实验步骤 1、选择菜单
附磊册说 2、选择参与因子分析的变量到(变量V )框中 箱c±% *6 W% 3M% 3、选择因子分析的样本 4、在所示窗口中点击(描述D )按钮,指定输出结果,输出基本统计量、图 6在所示的窗口中点击(旋转 T )按钮选择因子旋转方法 5、在所示窗口中点击(抽取E )按钮指定提取因子的方法为: 主成分分析法 即竭 14 10% ■j L.*v Ttt'-% 3 51% 1 ?w ■1 1鼠典 11 3TM 12 M 2JW P-3% ?aw 形等 0 99% S314A2K 13 54% ■V 何粘 2%
spss 聚类分析例题
1.打开数据文件后,在数据编辑窗口中,从菜单栏中选择“分析”—“分类”—“k-均值 聚类”命令。 2.在该对话框中选择变量城市进入“个案标记依据”文本框,作为标签变量。把聚类数标 记为4次。 3.选择变量一至十二月份的日照时数进入“变量”列表框作为观测变量。 4.单击“迭代”按钮,迭代次数为10次,收敛性标准为0. 5.单击“保存”按钮,选择“聚类成员”。 6.单击“选项”按钮,选择“初始聚类中心”和“ANOVA表”,要求输出方差分析表,单 击“继续”。 7.单击“确定”按钮,执行快速聚类分析。 [数据集1] C:\Documents and Settings\Administrator\桌面\ch9\主要城市日照时数.sav 初始聚类中心 聚类 1 2 3 4 一月日照时数89.10 9.00 230.10 121.70 二月日照时数145.40 45.00 215.30 104.40 三月日照时数153.20 49.20 234.20 55.30 四月日照时数258.50 150.50 207.10 83.40 五月日照时数284.00 99.60 196.80 125.00 六月日照时数309.70 99.10 122.60 176.50 七月日照时数320.80 190.90 151.10 155.80 八月日照时数292.80 175.40 151.30 167.10 九月日照时数266.10 80.20 127.10 185.00 十月日照时数223.70 33.00 146.70 246.50 十一月日照时数95.00 38.50 148.70 165.10 十二月日照时数57.30 4.30 173.10 181.60
:聚类分析SPSS操作方法09
:聚类分析SPSS操作方法09 实验指导之一 聚类分析的SPSS操作方法 系统聚类法 实验例城镇居民消费水平通常用下表中的八项指标来描述。八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。 实验数据表 2001年30个省。市,自治区城镇居民月平均消费数据 x1人均粮食支出(元/人) x5人均衣着商品支出(元/人) x2人均副食支出(元/人) x6人均日用品支出(元/人) x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人) x4人均其他副食支出(元/人) x8人均非商品支出(元/人) x1x2x3x4x5x6x7x8 北京7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61 天津10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57 河北9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65
系统聚类法的SPSS操作:
1. 从数据编辑窗口点击Analyze →Classify →Hierachical Cluster , (见图1) 图1 系统聚类法 打开层次聚类法对话如图2。 图2 系统聚类法对话框 选择需要进行聚类分析的变量进入Variable框内后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法: Cases 对样品聚类(Q型;系统默认), Variable 对指标变量聚类(R型),本例选择。 在Display栏中选择默认的输出项。 2. 点击Statistics按钮,打开对话框如图 3.
使用SPSS软件进行因子分析和聚类分析的方法
使用SPSS软件进行因子分析和聚类分析的方法 一、方法原理 1.因子分析(FactorAnalysis) 因子分析是从多个变量指标中选择出少数几个综合变量指标的一种降维的多元统计方法。 我们在多元分析中处理的是多指标的问题,观察指标的增加是为了使研究过程趋于完整,但由于指标太多,使得分析的复杂性增加;同时在实际工作中,指标间经常具备一定的相关性,使得观测数据所放映的信息有重叠,故人们希望用较少的指标代替原来较多的指标,但依然能放映原有的全部信息,于是就产生了因子分析方法。 2.聚类分析(ClusterAnlysis) 聚类分析是根据事物本身特性来研究个体分类的统计方法,是按照物以类聚的原则来研究的事物分类。 3.市场细分方法的流程图
二、实证分析
已调查35个城市的总人口、生产总值、消费总额、人均年工资、年度储蓄总额、年度财政总收入等数据,试对上述城市进行分类研究。 1.因子分析: ·选用Analyze→DataReduction→Factor…… ·引入因子分析的6个变量(总人口、生产总值、消费总额、人均年工资、年度总储蓄额、年度财政总收入) ·提取公因子的方法(Method):主成分分析法 ·提取(Extract)可选:提取特征值大于1的因子 ·旋转(Rotation)的方法:方差最大正交旋转 ·因子得分(FactorScores):作为新变量存入 表 1 方差解释表(Total Variance Explained) 表 2 旋转后的因子负荷矩阵(Rotated Component Matrix)
2.聚类分析: ·选用Analyze→Classify→K-MeansCluster…… ·引入聚类分析的2个变量(即上面的2个公因子) ·聚类的数目(NumberofClusters):3类 ·聚类方法(Method):仅分类 ·储存新变量(SaveNewVariables):聚类成员 表 3 各类数量分布表(Number of Cases in each Cluster)
8.利用Matlab和SPSS软件实现聚类分析
§8.利用Matlab和SPSS软件实现聚类分析 1. 用Matlab编程实现 运用Matlab中的一些基本矩阵计算方法,通过自己编程实现聚类算法,在此只讨论根据最短距离规则聚类的方法。 调用函数: min1.m——求矩阵最小值,返回最小值所在行和列以及值的大小 min2.m——比较两数大小,返回较小值 std1.m——用极差标准化法标准化矩阵 ds1.m——用绝对值距离法求距离矩阵 cluster.m——应用最短距离聚类法进行聚类分析 print1.m——调用各子函数,显示聚类结果 聚类分析算法 假设距离矩阵为vector,a阶,矩阵中最大值为max,令矩阵上三角元素等于max 聚类次数=a-1,以下步骤作a-1次循环: 求改变后矩阵的阶数,计作c 求矩阵最小值,返回最小值所在行e和列f以及值的大小g for l=1:c,为vector(c+1,l)赋值,产生新类
令第c+1列元素,第e行和第f行所有元素为,第e列和第f列所有元素为max 源程序如下: %std1.m,用极差标准化法标准化矩阵 function std=std1(vector) max=max(vector); %对列求最大值 min=min(vector); [a,b]=size(vector); %矩阵大小,a为行数,b为列数 for i=1:a for j=1:b std(i,j)= (vector(i,j)-min(j))/(max(j)-min(j)); end end %ds1.m,用绝对值法求距离 function d=ds1(vector); [a,b]=size(vector); d=zeros(a); for i=1:a for j=1:a for k=1:b d(i,j)=d(i,j)+abs(vector(i,k)-vector(j,k)); end end end fprintf('绝对值距离矩阵如下:\n'); disp(d) %min1.m,求矩阵中最小值,并返回行列数及其值 function [v1,v2,v3]=min1(vector);%v1为行数,v2为列数,v3为其值 [v,v2]=min(min(vector')); [v,v1]=min(min(vector)); v3=min(min(vector)); %min2.m,比较两数大小,返回较小的值 function v1=min(v2,v3); if v2>v3 v1=v3; else